在本书的最后一章,我们打算讨论几个独立的话题,主要内容包括:
□模块加载机制;
□异步编程模式下的控制流;
□Node.js应用部署;
□Node.js的一些劣势。
6.1 模块加载机制
Node.js的模块加载对用户来说十分简单,只需调用require即可,但其内部机制较为复杂。我们通过这一节简要介绍一下Node.js模块加载的一些细节,帮你减少开发中可能遇到的问题。
6.1.1 模块的类型
Node.js的模块可以分为两大类,一类是核心模块,另一类是文件模块。核心模块就是Node.js标准API中提供的模块,如fs、http、net、vm等,这些都是由Node.js官方提供的模块,编译成了二进制代码。我们可以直接通过require获取核心模块,例如require('fs')。核心模块拥有最高的加载优先级,换言之如果有模块与其命名冲突,Node.js总是会加载核心模块。
文件模块则是存储为单独的文件(或文件夹)的模块,可能是JavaScript代码、JSON或编译好的C/C++代码。文件模块的加载方法相对复杂,但十分灵活,尤其是和npm结合使用时。在不显式指定文件模块扩展名的时候,Node.js会分别试图加上.js、.json和.node扩展名。.js是JavaScript代码,.json是JSON格式的文本,.node是编译好的C/C++代码。
表6-1总结了Node.js模块的类型,从上到下加载优先级由高到低。
表6-1 Node.js模块的类别和加载顺序

6.1.2 按路径加载模块
文件模块的加载有两种方式,一种是按路径加载,一种是查找node_modules文件夹。
如果require参数以“/”开头,那么就以绝对路径的方式查找模块名称,例如require('/home/byvoid/module')将会按照优先级依次尝试加载/home/byvoid/module.js、/home/byvoid/module.json和/home/byvoid/module.node。
如果require参数以“./”或“../”开头,那么则以相对路径的方式来查找模块,这种方式在应用中是最常见的。例如前面的例子中我们用了require('./hello')来加载同一文件夹下的hello.js。
6.1.3 通过查找node_modules目录加载模块
如果require参数不以“/”、“./”或“../”开头,而该模块又不是核心模块,那么就要通过查找node_modules加载模块了。我们使用npm获取的包通常就是以这种方式加载的。
在某个目录下执行命令npm install express,你会发现出现了一个叫做node_modules的目录,里面的结构大概如图6-1所示。
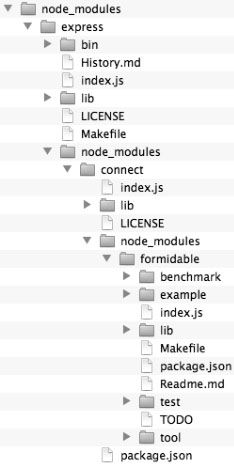
图6-1 node_modules目录结构
在node_modules目录的外面一层,我们可以直接使用require('express')来代替require('./node_modules/express')。这是Node.js模块加载的一个重要特性:通过查找node_modules目录来加载模块。
当require遇到一个既不是核心模块,又不是以路径形式表示的模块名称时,会试图在当前目录下的node_modules目录中来查找是不是有这样一个模块。如果没有找到,则会在当前目录的上一层中的node_modules目录中继续查找,反复执行这一过程,直到遇到根目录为止。举个例子,我们要在/home/byvoid/develop/foo.js中使用require('bar.js')命令,Node.js会依次查找:
□/home/byvoid/develop/node_modules/bar.js
□/home/byvoid/node_modules/bar.js
□/home/node_modules/bar.js
□/node_modules/bar.js
为什么要这样做呢?因为通常一个工程内会有一些子目录,当子目录内的文件需要访问到工程共同依赖的模块时,就需要向父目录上溯了。比如说工程的目录结构如下:

我们不仅要在project目录下的app.js中使用require('express'),而且可能要在controllers子目录下的index_controller.js中也使用require('express'),这时就需要向父目录上溯一层才能找到node_modules中的express了。
6.1.4 加载缓存
我们在前面提到过,Node.js模块不会被重复加载,这是因为Node.js通过文件名缓存所有加载过的文件模块,所以以后再访问到时就不会重新加载了。注意,Node.js是根据实际文件名缓存的,而不是require()提供的参数缓存的,也就是说即使你分别通过require('express')和require('./node_modules/express')加载两次,也不会重复加载,因为尽管两次参数不同,解析到的文件却是同一个。
6.1.5 加载顺序
下面总结一下使用require(some_module)时的加载顺序。
(1)如果some_module是一个核心模块,直接加载,结束。
(2)如果some_module以“/”、“./”或“../”开头,按路径加载some_module,结束。
(3)假设当前目录为current_dir,按路径加载current_dir/node_modules/some_module。
□如果加载成功,结束。
□如果加载失败,令current_dir为其父目录。
□重复这一过程,直到遇到根目录,抛出异常,结束。
6.2 控制流
基于异步I/O的事件式编程容易将程序的逻辑拆得七零八落,给控制流的疏理制造障碍。让我们通过下面的例子来说明这个问题。
6.2.1 循环的陷阱
Node.js的异步机制由事件和回调函数实现,一开始接触可能会感觉违反常规,但习惯以后就会发现还是很简单的。然而这之中其实暗藏了不少陷阱,一个很容易遇到的问题就是循环中的回调函数,初学者经常容易陷入这个圈套。让我们从一个例子开始说明这个问题。

这段代码的功能很直观,就是依次读取文件a.txt、b.txt、c.txt,并输出文件名和内容。假设这三个文件的内容分别是AAA、BBB和CCC,那么我们期望的输出结果就是:

可是我们运行这段代码的结果是怎样的呢?竟然是这样的结果:

这个结果说明文件内容正确输出了,而文件名却不对,也就意味着,contents的结果是正确的,但files[i]的值是undefined。这怎么可能呢,文件名不正确却能读取文件内容?既然难以直观地理解,我们就把files[i]分解并打印出来看看,在读取文件的回调函数中分别输出files、i和files[i]。

运行修改后的代码,结果如下:

看到这里是不是有点启发了呢?三次输出的i的值都是3,超出了files数组的下标范围,因此files[i]的值就是undefined了。这种情况通常会在for循环结束时发生,例如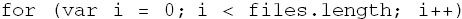 ,退出循环时i的值就是files.length的值。既然i的值是3,那么说明了事实上fs.readFile的回调函数中访问到的i值都是循环退出以后的,因此不能分辨。而files[i]作为fs.readFile的第一个参数在循环中就传递了,所以文件可以被定位到,而且可以显示出文件的内容。
,退出循环时i的值就是files.length的值。既然i的值是3,那么说明了事实上fs.readFile的回调函数中访问到的i值都是循环退出以后的,因此不能分辨。而files[i]作为fs.readFile的第一个参数在循环中就传递了,所以文件可以被定位到,而且可以显示出文件的内容。
现在问题就明朗了:原因是3次读取文件的回调函数事实上是同一个实例,其中引用到的i值是上面循环执行结束后的值,因此不能分辨。如何解决这个问题呢?我们可以利用JavaScript函数式编程的特性,手动建立一个闭包:

上面代码在for循环体中建立了一个匿名函数,将循环迭代变量i作为函数的参数传递并调用。由于运行时闭包的存在,该匿名函数中定义的变量(包括参数表)在它内部的函数(fs.readFile的回调函数)执行完毕之前都不会释放,因此我们在其中访问到的i就分别是不同的闭包实例,这个实例是在循环体执行的过程中创建的,保留了不同的值。
事实上以上这种写法并不常见,因为它降低了程序的可读性,故不推荐使用。大多数情况下我们可以用数组的forEach方法解决这个问题:

6.2.2 解决控制流难题
除了循环的陷阱,Node.js异步式编程还有一个显著的问题,即深层的回调函数嵌套。在这种情况下,我们很难像看基本控制流结构一样一眼看清回调函数之间的关系,因此当程序规模扩大时必须采取手段降低耦合度,以实现更加优美、可读的代码。这个问题本身没有立竿见影的解决方法,只能通过改变设计模式,时刻注意降低逻辑之间的耦合关系来解决。
除此之外,还有许多项目试图解决这一难题。async是一个控制流解耦模块,它提供了async.series、async.parallel、async.waterfall等函数,在实现复杂的逻辑时使用这些函数代替回调函数嵌套可以让程序变得更清晰可读且易于维护,但你必须遵循它的编程风格。
streamlinejs和jscex则采用了更高级的手段,它的思想是“变同步为异步”,实现了一个JavaScript到JavaScript的编译器,使用户可以用同步编程的模式写代码,编译后执行时却是异步的。
eventproxy的思路与前面两者区别更大,它实现了对事件发射器的深度封装,采用一种完全基于事件松散耦合的方式来实现控制流的梳理。
无论是以上哪种解决手段,都不是“非侵入性的”,也就是说它对你编程模式的影响是非常大的,你几乎不可能无代价地在使用了一种模式很久以后从容地换成另一种模式,或者直接糅合使用两种模式。而且它们都是在解决了深层嵌套的回调函数可读性问题的同时,引入了其他复杂的语法,带来了另一种可读性的降低。所以,是否使用,使用哪种方案,在决定之前是需要仔细斟酌研究的。
这些库的具体使用方法,乃至实现的原理以及更深一步的讨论已经超出了本书的范围,欢迎有兴趣的读者到Node.js中文社区(http://club.cnodejs.org/)交流。
6.3 Node.js应用部署
在第5章我们已经使用Express实现了一个微博网站,在开发的过程中,通过node app.js命令运行服务器即可。但它不适合在产品环境下使用,为什么呢?因为到目前为止这个服务器还有几个重大缺陷。
□不支持故障恢复
不知你是否在调试的过程中注意,当程序有错误发生时,整个进程就会结束,需要重新在终端中启动服务器。这一点在开发中无可厚非,但在产品环境下就是严重的问题了,因为一旦用户访问时触发了程序中某个隐含的bug,整个服务器就崩溃了,将无法继续为所有用户提供服务。在部署Node.js应用的时候一定要考虑到故障恢复,提高系统的可靠性。
□没有日志
对于开发者来说,日志,尤其是错误日志是及其重要的,经常查看它可以发现测试时没有注意到的程序错误。然而这个服务器运行时没有产生任何日志,包括访问日志和错误日志,所以有必要实现它的日志功能。
□无法利用多核提高性能
由于Node.js是单线程的,一个进程只能利用一个CPU核心。当请求大量到来时,单线程就成为了提高吞吐量的瓶颈。随着多核乃至众核时代的到来,只能利用一个核心所带来的浪费是十分严重的,我们需要使用多进程来提高系统的性能。
□独占端口
假如整个服务器只有一个网站,或者可以给每个网站分配一个独立的IP地址,不会有端口冲突的问题。而很多时候为了充分利用服务器的资源,我们会在同一个服务器上建立多个网站,而且这些网站可能有的是PHP,有的是Rails,有的是Node.js。不能每个进程都独占80端口,所以我们有必要通过反向代理来实现基于域名的端口共享。
□需要手动启动
先前每次启动服务器都是通过在命令行中直接键入命令来实现的,但在产品环境中,特别是在服务器重启以后,全部靠手动启动是不现实的。因此,我们应该制作一个自动启动服务器的脚本,并且通过该脚本可以实现停止服务器等功能。
6.3.1 日志功能
下面我们开始在第5章的代码的基础上,介绍如何实现服务器的日志功能。Express支持两种运行模式:开发模式和产品模式,前者的目的是利于调试,后者则是利于部署。使用产品模式运行服务器的方式很简单,只需设置NODE_ENV环境变量。通过NODE_ENV=production node app.js命令运行服务器可以看到:
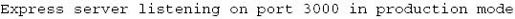
接下来让我们实现访问日志和错误日志功能。访问日志就是记录用户对服务器的每个请求,包括客户端IP地址,访问时间,访问路径,服务器响应以及客户端代理字符串。而错误日志则记录程序发生错误时的信息,由于调试中需要即时查看错误信息,将所有错误直接显示到终端即可,而在产品模式中,需要写入错误日志文件。
Express提供了一个访问日志中间件,只需指定stream参数为一个输出流即可将访问日志写入文件。打开app.js,在最上方加入以下代码:

然后在app.configure函数第一行加入:
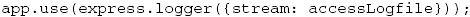
至于错误日志,需要单独实现错误响应,修改如下:

这段代码的功能是通过app.error注册错误响应函数,在其中将错误写入错误日志流。
现在重新运行服务器,在浏览器中访问http://127.0.0.1:3000/,即可在app.js同一目录下的access.log文件中看到与以下类似的内容:
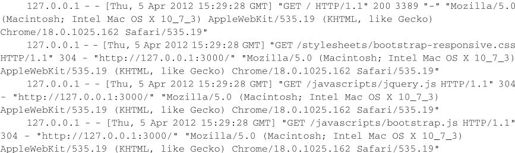

为了产生一个错误,我们修改routes/index.js中“/”的响应函数,加入以下代码:
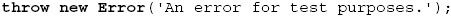
再次访问http://127.0.0.1:3000/,可以看到error.log输出了完整的错误内容,如下所示:
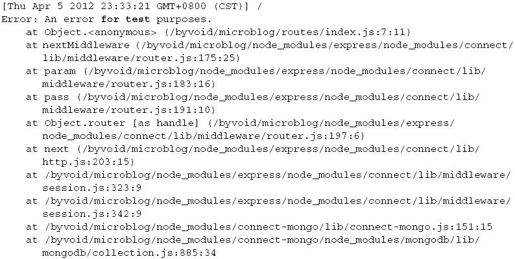
这样,一个简单有效的日志功能就这样实现了。
6.3.2 使用cluster模块
从0.6版本开始,Node.js提供了一个核心模块:cluster。cluster的功能是生成与当前进程相同的子进程,并且允许父进程和子进程之间共享端口。Node.js的另一个核心模块child_process也提供了相似的进程生成功能,但最大的区别在于cluster允许跨进程端口复用,给我们的网络服务器开发带来了很大的方便。
为了在外部模块调用app.js,首先需要禁止服务器自动启动。修改app.js,在app.listen(3000);前后加上判断语句:

这个语句的功能是判断当前模块是不是由其他模块调用的,如果不是,说明它是直接启动的,此时启动调试服务器;如果是,则不自动启动服务器。经过这样的修改,以后直接调用node app.js服务器会直接运行,但在其他模块中调用require('./app')则不会自动启动,需要再显式地调用listen()函数。
接下来就让我们通过cluster调用app.js。创建cluster.js,内容如下所示:

cluster.js的功能是创建与CPU核心个数相同的服务器进程,以确保充分利用多核CPU的资源。主进程生成若干个工作进程,并监听工作进程结束事件,当工作进程结束时,重新启动一个工作进程。分支进程产生时会自顶向下重新执行当前程序,并通过分支判断进入工作进程分支,在其中读取模块并启动服务器。通过cluster启动的工作进程可以直接实现端口复用,因此所有工作进程只需监听同一端口。当主进程终止时,还要主动关闭所有工作进程。
在终端中执行node cluster.js命令,可以看到进程列表中启动了多个node进程(8核CPU):
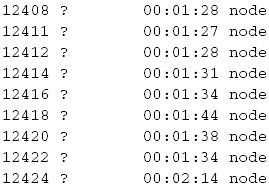
终止工作进程,新的工作进程会立即启动,终止主进程,所有工作进程也会同时结束。这样,一个既能利用多核资源,又有实现故障恢复功能的服务器就诞生了。
6.3.3 启动脚本
接下来,我们还需要一个启动脚本来简化维护工作。如果你维护过Linux服务器,会对/etc/init.d/下面的脚本有印象。例如使用/etc/init.d/nginx start和/etc/init.d/nginx stop可以启动和关闭Nginx服务器。我们通过bash脚本也来实现一个类似的功能,创建microblog并使用chmod +x microblog赋予其执行权限,脚本内容为:

它的功能是通过nohup启动服务器,使进程不会因为退出终端而关闭,同时将主进程的pid写入microblog.pid文件。当调用结束命令时,从microblog.pid读取pid的值,终止主进程以关闭服务器。
运行./microblog start,结果如下:

在该目录下生成了microblog.pid文件,查看进程表可以发现服务器已经启动。关闭服务器时只需执行./microblog stop,即可结束所有工作进程。
有了这个启动脚本,我们就可以实现服务器的开机自动启动了,根据不同的操作系统,将其加入启动运行项即可,唯一需要修改的地方是DAEMON和PIDFILE应该写成绝对路径,以便在不同的目录下运行。

这段脚本只支持POSIX操作系统,如Linux、MacOS等,在Windows下不可用。
6.3.4 共享80端口
到目前为止,网站都是运行在3000端口下的,也就是说用户必须在网址中加入:3000才能访问网站。默认的HTTP端口是80,因此必须监听80端口才能使网址更加简洁。如果整个服务器只有一个网站,那么只需让app.js监听80端口即可。但很多时候一个服务器上运行着不止一个网站,尤其是还有用其他语言(如PHP)写成的网站,这该怎么办呢?此时虚拟主机可以粉墨登场了。
虚拟主机,就是让多个网站共享使用同一服务器同一IP地址,通过域名的不同来划分请求。主流的HTTP服务器都提供了虚拟主机支持,如Nginx、Apache、IIS等。我们以Nginx为例,介绍如何通过反向代理实现Node.js虚拟主机。
在Nginx中设置反向代理和虚拟主机非常简单,下面是配置文件的一个示例:

这个配置文件的功能是监听访问mysite.com 80端口的请求,并将所有的请求转发给http://localhost:3000,即我们的Node.js服务器。现在访问http://mysite.com/,就相当于服务器访问http://localhost:3000了。
在添加了虚拟主机以后,还可以在Nginx配置文件中添加访问静态文件的规则(具体请参考Nginx文档),删去app.js中的app.use(express.static(__dirname+'/public'));。这样可以直接让Nginx来处理静态文件,减少反向代理以及Node.js的开销。
6.4 Node.js不是银弹
在本书正文的最后一节,我们打算讨论一下Node.js不适合做什么,涉及它的不足之处和一些弊端。
在西方古老的传说里,有一种叫做“狼人”的可怕生物。这种生物平时和人类没有什么不同之处,但每到月圆之夜,他们就会变成狼身。当他们变成狼以后,兽性会不能控制,开始袭击普通的人类。狼人给人类带来了巨大的恐惧,因为他们是无法被一般的手段杀死的,只有用赐福过的银弹(Silver Bullet)才能杀死狼人。“银弹”因此成为了“任何能够带来极大效果的直接解决方案”的代名词。
Fred Brooks【1】在1987年发表了一篇关于软件工程的经典文章——“No Silver Bullet”(没有银弹)。所谓的“没有银弹”指的就是没有任何一项技术或方法可使软件工程的生产力能像摩尔定律一样在十年内提高超过十倍,不仅当时没有,现在也没有,今后也不会有。这篇文章收录在《人月神话》(The Mythical Man-Month)一书中,被誉为软件工程领域的基本定律之一。
Node.js也不例外,它不是什么能够大幅度提高软件开发效率和质量的灵丹妙药。无论使用什么语言、工具,所能改变的仅仅是开发的舒适程度和方便程度,而最终软件的好坏所能改变的范围相当有限。任何试图以限制程序员犯错来提高软件质量的方式最终都已经以失败告终。真正优秀的软件是靠优秀的程序员开发出来的,优秀的语言、平台、工具只有在优秀的程序员的手中才能显现出它的威力。
Node.js不适合做什么
Node.js是一个优秀的平台,吸引大量开发者关注。它有许多传统架构不具备的优点,以至于我们情不自禁地愿意用它来做开发。Node.js和任何东西一样,都有它擅长的和不擅长的事情,如果你非要用它来做它不擅长的事情,那么你将会陷入僵局之中。尽管你可以以喜欢、它很新潮、性能高为借口,却不得不写出难看的代码。
和大多数新技术的本质一样,Node.js也只是旧瓶盛新酒。大多数人事实上并不知道为什么使用Node.js,只是因为你了解它,所以使用它,进而觉得它好,觉得它是最合适的。这是一个必须跳出的误区,否则你就像是得了强迫症,不管三七二十一,遇到什么问题都用Node.js解决。
所以现在就让我们来谈谈Node.js不适合做的事情吧。
1.计算密集型的程序
在Node.js 0.8版本之前,Node.js不支持多线程。当然,这是一种设计哲学问题,因为Node.js的开发者和支持者坚信单线程和事件驱动的异步式编程比传统的多线程编程运行效率更高。但事实上多线程可以达到同样的吞吐量,尽管可能开销不小,但不必为多核环境进行特殊的配置。相比之下,Node.js由于其单线程性的特性,必须通过多进程的方法才能充分利用多核资源。
理想情况下,Node.js单线程在执行的过程中会将一个CPU核心完全占满,所有的请求必须等待当前请求处理完毕以后进入事件循环才能响应。如果一个应用是计算密集型的,那么除非你手动将它拆散,否则请求响应延迟将会相当大。例如,某个事件的回调函数中要进行复杂的计算,占用CPU 200毫秒,那么事件循环中所有的请求都要等待200毫秒。为了提高响应速度,你唯一的办法就是把这个计算密集的部分拆成若干个逻辑,这给编程带来了额外的复杂性。即使这样,系统的总吞吐量和总响应延迟也不会降低,只是调度稍微公平了一些。
不过好在真正的Web服务器中,很少会有计算密集的部分,如果真的有,那么它不应该被实现为即时的响应。正确的方式是给用户一个提示,说服务器正在处理中,完成后会通知用户,然后交给服务器的其他进程甚至其他专职的服务器来做这件事。
2.单用户多任务型应用
前面我们讨论的通常都是服务器端编程,其中一个假设就是用户数量很多。但如果面对的是单用户,譬如本地的命令行工具或者图形界面,那么所谓的大量并发请求就不存在了。于是另一个恐怖的问题出现了,尽管是单用户,却不一定是单任务。例如给用户提供界面的同时后台在进行某个计算,为了让用户界面不出现阻塞状态,你不得不开启多线程或多进程。而Node.js线程或进程之间的通信到目前为止还很不便,因为它根本没有锁,因而号称不会死锁。Node.js的多进程往往是在执行同一任务,通过多进程利用多处理器的资源,但遇到多进程相互协作时,就显得捉襟见肘了。
3.逻辑十分复杂的事务
Node.js的控制流不是线性的,它被一个个事件拆散,但人的思维却是线性的,当你试图转换思维来迎合语言或编译器时,就不得不作出牺牲。举例来说,你要实现一个这样的逻辑:从银行取钱,拿钱去购买某个虚拟商品,买完以后加入库存数据库,这中间的任何一步都可能会涉及数十次的I/O操作,而且任何一次操作失败以后都要进行回滚操作。这个过程是线性的,已经很复杂了,如果要拆分为非线性的逻辑,那么其复杂程度很可能就达到无法维护的地步了。
Node.js更善于处理那些逻辑简单但访问频繁的任务,而不适合完成逻辑十分复杂的工作。
4.Unicode与国际化
Node.js不支持完整的Unicode,很多字符无法用string表示。公平地说这不是Node.js的缺陷,而是JavaScript标准的问题。目前JavaScript支持的字符集还是双字节的UCS2,即用两个字节来表示一个Unicode字符,这样能表示的字符数量是65536。显然,仅仅是汉字就不止这个数目,很多生僻汉字,以及一些较为罕见语言的文字都无法表示。这其实是一个历史遗留问题,像2000年问题(俗称千年虫)一样,都起源于当时人们的主观判断。最早的Unicode设计者认为65536个字符足以囊括全世界所有的文字了,因此那个时候盲目兼容Unicode的系统或平台(如Windows、Java和JavaScript)在后来都遇到了问题。
Unicode随后意识到2个字节是不够的,因此推出了UCS4,即用4个字节来表示一个Unicode字符。很多原先用定长编码的UCS2的系统都升级为了变长编码的UTF-16,因为只有它向下兼容UCS2。UTF-16对UCS2以内的字符采用定长的双字节编码,而对它以外的部分使用多字节的变长编码。这种方式的好处是在绝大多数情况下它都是定长的编码,有利于提高运算效率,而且兼容了UCS2,但缺点是它本质还是变长编码,程序中处理多少有些不便。
许多号称支持UTF-16的平台仍然只支持它的子集UCS2,而不支持它的变长编码部分。相比之下,UTF-8完全是变长编码,有利于传输,而UTF-32或UCS4则是4字节的定长编码,有利于计算。
当下的JavaScript内部支持的仍是定长的UCS2而不是变长的UTF-16,因此对于处理UCS4的字符它无能为力。所有的JavaScript引擎都被迫保留了这个缺陷,包括V8在内,因此你无法使用Node.js处理罕见的字符。想用Node.js实现一个多语言的字典工具?还是算了吧,除非你放弃使用string数据类型,把所有的字符当作二进制的Buffer数据来处理。
6.5 参考资料
□“深入浅出Node.js(三):深入Node.js的模块机制”: http://www.infoq.com/cn/articles/nodejs-module-mechanism。
□《Node Web开发》David Herron著,人民邮电出版社出版。
□“遭遇回调函数产生的陷阱”: http://club.cnodejs.org/topic/4f6f057f8a04d82a3d0d230a。
□What Is Node? JavaScript Breaks Out of the Browser: http://shop.oreilly.com/product/06369 20021506.do。
□“Node.js究竟是什么?一个“编码就绪”服务器”: http://www.ibm.com/developerworks/cn/opensource/os-nodejs/。
□“Node.js is Cancer”: http://teddziuba.com/2011/10/node-js-is-cancer.html。
□“Node.js is Candy”: http://xentac.net/2011/10/05/1-nodejs-is-candy.html。
□“V8 does not support UCS 4 characters”: http://code.google.com/p/v8/issues/detail?id=1697。
注 释
【1】IBM大型计算机之父,曾经开发过OS/360等大型计算机的操作系统。
