- 创建一个D6
- 掷几次骰子,并将结果存储在一个列表中
- 掷几次骰子,并将结果存储在一个列表中
- 分析结果
- 分析结果
- 对结果进行可视化
- 创建两个D6骰子
- 掷骰子多次,并将结果存储到一个列表中
- 分析结果
- 可视化结果
- 创建一个D6和一个D10
- 掷骰子多次,并将结果存储在一个列表中
- 分析结果
- 可视化结果
- 从文件中获取最高气温
- 从文件中获取最高气温
- 根据数据绘制图形
- 设置图形的格式
- 从文件中获取日期和最高气温
- 根据数据绘制图形
- 设置图形的格式
- 从文件中获取日期和最高气温
- 设置图形的格式
- 从文件中获取日期、最高气温和最低气温
- 根据数据绘制图形
- 设置图形的格式
- 根据数据绘制图形
- 从文件中获取日期、最高气温和最低气温
- 从文件中获取日期、最高气温和最低气温
- 根据数据绘制图形
- 设置图形的格式
- 将数据加载到一个列表中
- 打印每个国家2010年的人口数量
- 如果没有找到指定的国家,就返回None
- 打印每个国家2010年的人口数量
- 将数据加载到列表中
- 创建一个包含人口数量的字典
- 创建一个包含人口数据的字典
- 根据人口数量将所有的国家分成三组
- 看看每组分别包含多少个国家
- 根据人口数量将所有的国家分成三组
- 执行API调用并存储响应
- 将API响应存储在一个变量中
- 处理结果
- 执行API调用并存储响应
- 将API响应存储在一个变量中
- 探索有关仓库的信息
- 研究第一个仓库
- 研究有关仓库的信息
- 研究第一个仓库
- 研究有关仓库的信息
- 执行API调用并存储响应
- 将API响应存储在一个变量中
- 研究有关仓库的信息
- 可视化
- 可视化
- 研究有关仓库的信息
- 可视化
- 执行API调用并存储响应
- 处理有关每篇文章的信息
- 对于每篇文章,都执行一个API调用
- 在这里创建模型
- 我的应用程序
- 在这里注册你的模型
中随机地选择距离。请修改这些列表中的值,看看对随机漫步路径有何影响。尝试使用更长的距离选择列表,如0~8;或者将-1从 x 或 y 方向列表中删除。
15-5 重构 :方法fill_walk() 很长。请新建一个名为get_step() 的方法,用于确定每次漫步的距离和方向,并计算这次漫步将如何移动。然后,
在fill_walk() 中调用get_step() 两次:
x_step = get_step()
y_step = get_step()
通过这样的重构,可缩小fill_walk() 的规模,让这个方法阅读和理解起来更容易。
15.4 使用Pygal 模拟掷骰子
在本节中,我们将使用Python可视化包Pygal来生成可缩放的矢量图形文件。对于需要在尺寸不同的屏幕上显示的图表,这很有用,因为它们将自动缩放,以适合观看者的屏幕。
如果你打算以在线方式使用图表,请考虑使用Pygal来生成它们,这样它们在任何设备上显示时都会很美观。
在这个项目中,我们将对掷骰子的结果进行分析。掷6面的常规骰子时,可能出现的结果为1~6点,且出现每种结果的可能性相同。然而,如果同时掷两个骰子,某些点数出现的
可能性将比其他点数大。为确定哪些点数出现的可能性最大,我们将生成一个表示掷骰子结果的数据集,并根据结果绘制出一个图形。
在数学领域,常常利用掷骰子来解释各种数据分析,但它在赌场和其他博弈场景中也得到了实际应用,在游戏《大富翁》以及众多角色扮演游戏中亦如此。
15.4.1 安装Pygal
请使用pip 来安装Pygal(如果还未使用过pip ,请参阅12.2.1节)。
在Linux和OS X系统中,应执行的命令类似于下面这样:
pip install —user pygal
在Windows系统中,命令类似于下面这样:
python -m pip install —user pygal
注意 你可能需要使用命令pip3 而不是pip ,如果这还是不管用,你可能需要删除标志—user 。
15.4.2 Pygal 画廊
要了解使用Pygal可创建什么样的图表,请查看图表类型画廊:访问http://www.pygal.org/ ,单击Documentation,再单击Chart types。每个示例都包含源代码,让你知道这些图表是如何
生成的。
15.4.3 创建Die 类
下面的类模拟掷一个骰子:
die.py
from random import randint
class Die():
"""表示一个骰子的类"""
❶ def init(self, num_sides=6):
"""骰子默认为6面"""
self.num_sides = num_sides
def roll(self):
""""返回一个位于1和骰子面数之间的随机值"""
❷ return randint(1, self.num_sides)
方法init() 接受一个可选参数。创建这个类的实例时,如果没有指定任何实参,面数默认为6;如果指定了实参,这个值将用于设置骰子的面数(见❶)。骰子是根据面
数命名的,6面的骰子名为D6,8面的骰子名为D8,以此类推。
方法roll() 使用函数randint() 来返回一个1和面数之间的随机数(见❷)。这个函数可能返回起始值1、终止值num_sides 或这两个值之间的任何整数。
15.4.4 掷骰子
使用这个类来创建图表前,先来掷D6骰子,将结果打印出来,并检查结果是否合理:
die_visual.py
from die import Die
创建一个D6
❶ die = Die()
掷几次骰子,并将结果存储在一个列表中
results = []
❷ for roll_num in range(100):
result = die.roll()
results.append(result)
print(results)
在❶处,我们创建了一个Die 实例,其面数为默认值6。在❷处,我们掷骰子100次,并将每次的结果都存储在列表results 中。下面是一个示例结果集:
[4, 6, 5, 6, 1, 5, 6, 3, 5, 3, 5, 3, 2, 2, 1, 3, 1, 5, 3, 6, 3, 6, 5, 4, 1, 1, 4, 2, 3, 6, 4, 2, 6, 4, 1, 3, 2, 5, 6, 3, 6, 2, 1, 1, 3, 4, 1, 4, 3, 5, 1, 4, 5, 5, 2, 3, 3, 1, 2, 3, 5, 6, 2, 5, 6, 1, 3, 2, 1, 1, 1, 6, 5, 5, 2, 2, 6, 4, 1, 4, 5, 1, 1, 1, 4, 5, 3, 3, 1, 3, 5, 4, 5, 6, 5, 4, 1, 5, 1, 2]
通过快速扫描这些结果可知,Die 类看起来没有问题。我们见到了值1和6,这表明返回了最大和最小的可能值;我们没有见到0或7,这表明结果都在正确的范围内。我们还看到
了1~6的所有数字,这表明所有可能的结果都出现了。
15.4.5 分析结果
为分析掷一个D6骰子的结果,我们计算每个点数出现的次数:
die_visual.py
—snip—
掷几次骰子,并将结果存储在一个列表中
results = []
❶ for roll_num in range(1000):
result = die.roll()
results.append(result)
分析结果
frequencies = []
❷ for value in range(1, die.num_sides+1):
❸ frequency = results.count(value)
❹ frequencies.append(frequency)
print(frequencies)
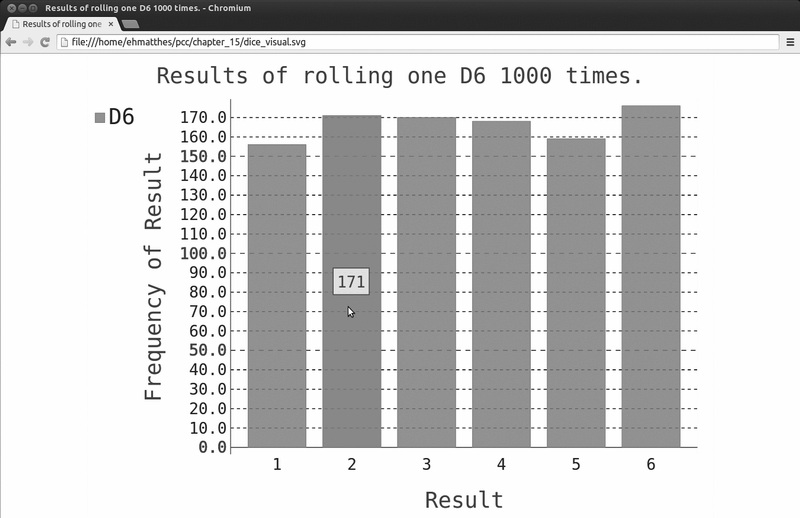
由于我们将使用Pygal来进行分析,而不是将结果打印出来,因此可以将模拟掷骰子的次数增加到1000(见❶)。为分析结果,我们创建了空列表frequencies ,用于存储每种
点数出现的次数。在❷处,我们遍历可能的点数(这里为1~6),计算每种点数在results 中出现了多少次(见❸),并将这个值附加到列表frequencies 的末尾(见❹)。
接下来,我们在可视化之前将这个列表打印出来:
[155, 167, 168, 170, 159, 181]
结果看起来是合理的:我们看到了6个值——掷D6骰子时可能出现的每个点数对应一个;我们还发现,没有任何点数出现的频率比其他点数高很多。下面来可视化这些结果。
15.4.6 绘制直方图
有了频率列表后,我们就可以绘制一个表示结果的直方图。直方图 是一种条形图,指出了各种结果出现的频率。创建这种直方图的代码如下:
die_visual.py
import pygal
—snip—
分析结果
frequencies = []
for value in range(1, die.num_sides+1):
frequency = results.count(value)
frequencies.append(frequency)
对结果进行可视化
❶ hist = pygal.Bar()
hist.title = "Results of rolling one D6 1000 times."
❷ hist.x_labels = ['1', '2', '3', '4', '5', '6']
hist.x_title = "Result"
hist.y_title = "Frequency of Result"
❸ hist.add('D6', frequencies)
hist.render_to_file('die_visual.svg')
为创建条形图,我们创建了一个pygal.Bar() 实例,并将其存储在hist 中(见❶)。接下来,我们设置hist 的属性title (用于标示直方图的字符串),将掷D6骰子的可
能结果用作 x 轴的标签(见❷),并给每个轴都添加了标题。在❸处,我们使用add() 将一系列值添加到图表中(向它传递要给添加的值指定的标签,还有一个列表,其中包含
将出现在图表中的值)。最后,我们将这个图表渲染为一个SVG文件,这种文件的扩展名必须为.svg。
要查看生成的直方图,最简单的方式是使用Web浏览器。为此,在任何Web浏览器中新建一个标签页,再在其中打开文件die_visual.svg(它位于die_visual.py所在的文件夹中)。你
将看到一个类似于图15-11所示的图表(为方便印刷,我稍微修改了这个图表;默认情况下,Pygal生成的图表的背景比你在图15-11中看到的要暗)。
图15-11 使用Pygal 创建的简单条形图
注意,Pygal让这个图表具有交互性:如果你将鼠标指向该图表中的任何条形,将看到与之相关联的数据。在同一个图表中绘制多个数据集时,这项功能显得特别有用。
15.4.7 同时掷两个骰子
同时掷两个骰子时,得到的点数更多,结果分布情况也不同。下面来修改前面的代码,创建两个D6骰子,以模拟同时掷两个骰子的情况。每次掷两个骰子时,我们都将两个骰子
的点数相加,并将结果存储在results 中。请复制die_visual.py并将其保存为dice_visual.py,再做如下修改:
dice_visual.py
import pygal
from die import Die
创建两个D6骰子
die_1 = Die()
die_2 = Die()
掷骰子多次,并将结果存储到一个列表中
results = []
for roll_num in range(1000):
❶ result = die_1.roll() + die_2.roll()
results.append(result)
分析结果
frequencies = []
❷ max_result = die_1.num_sides + die_2.num_sides
❸ for value in range(2, max_result+1):
frequency = results.count(value)
frequencies.append(frequency)
可视化结果
hist = pygal.Bar()
❹ hist.title = "Results of rolling two D6 dice 1000 times."
hist.x_labels = ['2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12']
hist.x_title = "Result"
hist.y_title = "Frequency of Result"
hist.add('D6 + D6', frequencies)
hist.render_to_file('dice_visual.svg')
创建两个Die 实例后,我们掷骰子多次,并计算每次的总点数(见❶)。可能出现的最大点数12为两个骰子的最大可能点数之和,我们将这个值存储在了max_result 中(见
❷)。可能出现的最小总点数2为两个骰子的最小可能点数之和。分析结果时,我们计算2到max_result 的各种点数出现的次数(见❸)。我们原本可以使用range(2, 13) ,但这只适用于两个D6骰子。模拟现实世界的情形时,最好编写可轻松地模拟各种情形的代码。前面的代码让我们能够模拟掷任何两个骰子的情形,而不管这些骰子有多少面。
创建图表时,我们修改了标题、 x 轴标签和数据系列(见❹)。(如果列表x_labels 比这里所示的长得多,那么编写一个循环来自动生成它将更合适。)
运行这些代码后,在浏览器中刷新显示图表的标签页,你将看到如图15-12所示的图表。
图15-12 模拟同时掷两个6 面骰子1000 次的结果
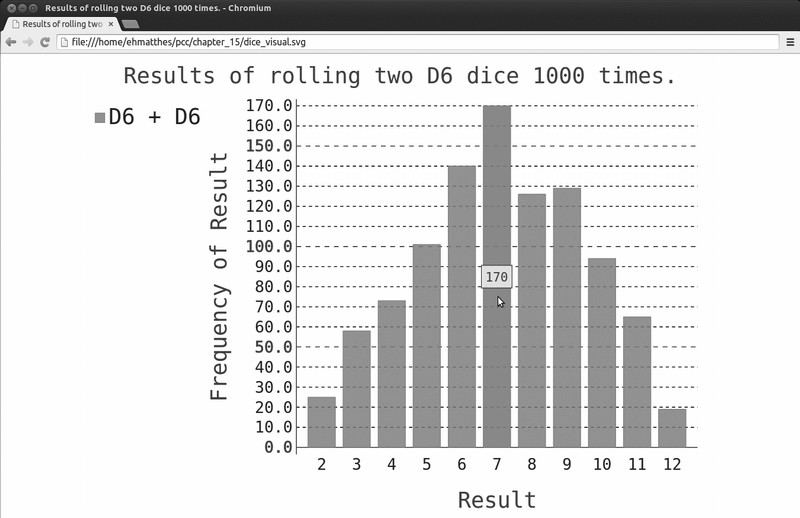
这个图表显示了掷两个D6骰子时得到的大致结果。正如你看到的,总点数为2或12的可能性最小,而总点数为7的可能性最大,这是因为在6种情况下得到的总点数都为7。这6种
情况如下:1和6、2和5、3和4、4和3、5和2、6和1。
15.4.8 同时掷两个面数不同的骰子
下面来创建一个6面骰子和一个10面骰子,看看同时掷这两个骰子50 000次的结果如何:
different_dice.py
from die import Die
import pygal
创建一个D6和一个D10
die_1 = Die()
❶ die_2 = Die(10)
掷骰子多次,并将结果存储在一个列表中
results = []
for roll_num in range(50000):
result = die_1.roll() + die_2.roll()
results.append(result)
分析结果
—snip—
可视化结果
hist = pygal.Bar()
❷ hist.title = "Results of rolling a D6 and a D10 50,000 times."
hist.x_labels = ['2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16']
hist.x_title = "Result"
hist.y_title = "Frequency of Result"
hist.add('D6 + D10', frequencies)
hist.render_to_file('dice_visual.svg')
为创建D10骰子,我们在创建第二个Die 实例时传递了实参10 (见❶)。我们还修改了第一个循环,以模拟掷骰子50 000次而不是1000次。可能出现的最小总点数依然是2,但现
在可能出现的最大总点数为16,因此我们相应地调整了标题、 x 轴标签和数据系列标签(见❷)。
图15-13显示了最终的图表。可能性最大的点数不是一个,而是5个,这是因为导致出现最小点数和最大点数的组合都只有一种(1和1以及6和10),但面数较小的骰子限制了得到
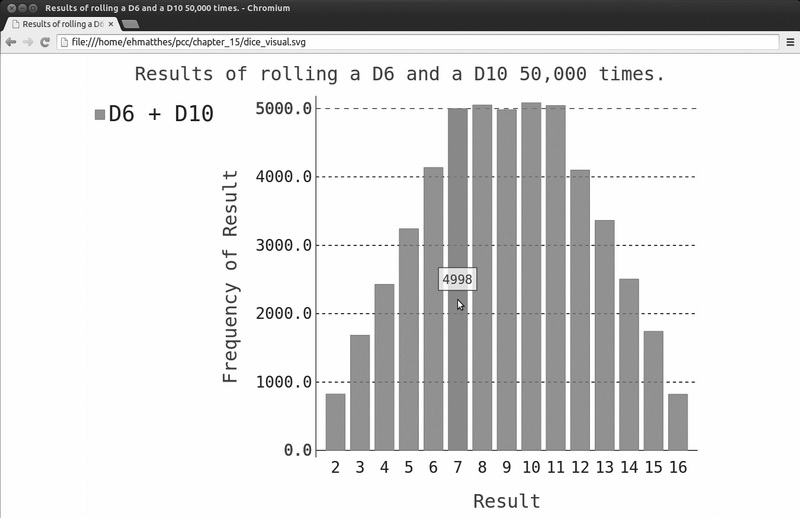
中间点数的组合数:得到总点数7、8、9、10和11的组合数都是6种。因此,这些总点数是最常见的结果,它们出现的可能性相同。
图15-13 同时掷6 面骰子和10 面骰子50 000 次的结果
通过使用Pygal来模拟掷骰子的结果,能够非常自由地探索这种现象。只需几分钟,就可以掷各种骰子很多次。
动手试一试
15-6 自动生成标签 :请修改die.py和dice_visual.py,将用来设置hist.x_labels 值的列表替换为一个自动生成这种列表的循环。如果你熟悉列表解析,可尝试将
die_visual.py和dice_visual.py中的其他for 循环也替换为列表解析。
15-7 两个D8 骰子: 请模拟同时掷两个8面骰子1000次的结果。逐渐增加掷骰子的次数,直到系统不堪重负为止。
15-8 同时掷三个骰子 :如果你同时掷三个D6骰子,可能得到的最小点数为3,而最大点数为18。请通过可视化展示同时掷三个D6骰子的结果。
15-9 将点数相乘 :同时掷两个骰子时,通常将它们的点数相加。请通过可视化展示将两个骰子的点数相乘的结果。
15-10 练习使用本章介绍的两个库 :尝试使用matplotlib通过可视化来模拟掷骰子的情况,并尝试使用Pygal通过可视化来模拟随机漫步的情况。
15.5 小结
在本章中,你学习了:如何生成数据集以及如何对其进行可视化;如何使用matplotlib创建简单的图表,以及如何使用散点图来探索随机漫步过程;如何使用Pygal来创建直方图,
以及如何使用直方图来探索同时掷两个面数不同的骰子的结果。
使用代码生成数据集是一种有趣而强大的方式,可用于模拟和探索现实世界的各种情形。完成后面的数据可视化项目时,请注意可使用代码模拟哪些情形。请研究新闻媒体中的
可视化,看看其中是否有图表是以你在这些项目中学到的类似方式生成的。
在第16章中,我们将从网上下载数据,并继续使用matplotlib和Pygal来探索这些数据。
第 16 章 下载数据

在本章中,你将从网上下载数据,并对这些数据进行可视化。网上的数据多得难以置信,且大多未经过仔细检查。如果能够对这些数据进行分析,你就能发现别人没
有发现的规律和关联。
我们将访问并可视化以两种常见格式存储的数据:CSV 和JSON。我们将使用Python模块csv 来处理以CSV(逗号分隔的值)格式存储的天气数据,找出两个不同地区
在一段时间内的最高温度和最低温度。然后,我们将使用matplotlib根据下载的数据创建一个图表,展示两个不同地区的气温变化:阿拉斯加锡特卡和加利福尼亚死亡
谷。在本章的后面,我们将使用模块json 来访问以JSON格式存储的人口数据,并使用Pygal绘制一幅按国别划分的人口地图。
阅读本章后,你将能够处理各种类型和格式的数据集,并对如何创建复杂的图表有更深入的认识。要处理各种真实世界的数据集,必须能够访问并可视化各种类型和
格式的在线数据。
16.1 CSV 文件格式
要在文本文件中存储数据,最简单的方式是将数据作为一系列以逗号分隔的值 (CSV)写入文件。这样的文件称为CSV文件。例如,下面是一行CSV格式的天气数据:
2014-1-5,61,44,26,18,7,-1,56,30,9,30.34,30.27,30.15,,,,10,4,,0.00,0,,195
这是阿拉斯加锡特卡2014年1月5日的天气数据,其中包含当天的最高气温和最低气温,还有众多其他数据。CSV文件对人来说阅读起来比较麻烦,但程序可轻松地提取并处理其
中的值,这有助于加快数据分析过程。
我们将首先处理少量锡特卡的CSV格式的天气数据,这些数据可在本书的配套资源(https://www.nostarch.com/pythoncrashcourse/ )中找到。请将文件sitka_weather_07-2014.csv复制到
存储本章程序的文件夹中(下载本书的配套资源后,你就有了这个项目所需的所有文件)。
注意 这个项目使用的天气数据是从http://www.wunderground.com/history/ 下载而来的。
16.1.1 分析CSV 文件头
csv 模块包含在Python标准库中,可用于分析CSV文件中的数据行,让我们能够快速提取感兴趣的值。下面先来查看这个文件的第一行,其中包含一系列有关数据的描述:
highs_lows.py
import csv
filename = 'sitka_weather_07-2014.csv'
❶ with open(filename) as f:
❷ reader = csv.reader(f)
❸ header_row = next(reader)
print(header_row)
导入模块csv 后,我们将要使用的文件的名称存储在filename 中。接下来,我们打开这个文件,并将结果文件对象存储在f 中(见❶)。然后,我们调用csv.reader() ,
并将前面存储的文件对象作为实参传递给它,从而创建一个与该文件相关联的阅读器(reader )对象(见❷)。我们将这个阅读器对象存储在reader 中。
模块csv 包含函数next() ,调用它并将阅读器对象传递给它时,它将返回文件中的下一行。在前面的代码中,我们只调用了next() 一次,因此得到的是文件的第一行,其中
包含文件头(见❸)。我们将返回的数据存储在header_row 中。正如你看到的,header_row 包含与天气相关的文件头,指出了每行都包含哪些数据:
['AKDT', 'Max TemperatureF', 'Mean TemperatureF', 'Min TemperatureF',
'Max Dew PointF', 'MeanDew PointF', 'Min DewpointF', 'Max Humidity',
' Mean Humidity', ' Min Humidity', ' Max Sea Level PressureIn',
' Mean Sea Level PressureIn', ' Min Sea Level PressureIn',
' Max VisibilityMiles', ' Mean VisibilityMiles', ' Min VisibilityMiles', ' Max Wind SpeedMPH', ' Mean Wind SpeedMPH', ' Max Gust SpeedMPH', 'PrecipitationIn', ' CloudCover', ' Events', ' WindDirDegrees']
reader处理文件中以逗号分隔的第一行数据,并将每项数据都作为一个元素存储在列表中。文件头AKDT 表示阿拉斯加时间(Alaska Daylight Time),其位置表明每行的第一个值都
是日期或时间。文件头Max TemperatureF 指出每行的第二个值都是当天的最高华氏温度。可通过阅读其他的文件头来确定文件包含的信息类型。
注意 文件头的格式并非总是一致的,空格和单位可能出现在奇怪的地方。这在原始数据文件中很常见,但不会带来任何问题。
16.1.2 打印文件头及其位置
为让文件头数据更容易理解,将列表中的每个文件头及其位置打印出来:
highs_lows.py
—snip—
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
❶ for index, column_header in enumerate(header_row):
print(index, column_header)
我们对列表调用了enumerate() (见❶)来获取每个元素的索引及其值。(请注意,我们删除了代码行print(header_row) ,转而显示这个更详细的版本。)
输出如下,其中指出了每个文件头的索引:
0 AKDT
1 Max TemperatureF
2 Mean TemperatureF
3 Min TemperatureF
—snip—
20 CloudCover
21 Events
22 WindDirDegrees
从中可知,日期和最高气温分别存储在第0列和第1列。为研究这些数据,我们将处理sitka_weather_07-2014.csv中的每行数据,并提取其中索引为0和1的值。
16.1.3 提取并读取数据
知道需要哪些列中的数据后,我们来读取一些数据。首先读取每天的最高气温:
highs_lows.py
import csv
从文件中获取最高气温
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
❶ highs = []
❷ for row in reader:
❸ highs.append(row[1])
print(highs)
我们创建了一个名为highs 的空列表(见❶),再遍历文件中余下的各行(见❷)。阅读器对象从其停留的地方继续往下读取CSV文件,每次都自动返回当前所处位置的下一
行。由于我们已经读取了文件头行,这个循环将从第二行开始——从这行开始包含的是实际数据。每次执行该循环时,我们都将索引1处(第2列)的数据附加到highs 末尾(见
❸)。
下面显示了highs 现在存储的数据:
['64', '71', '64', '59', '69', '62', '61', '55', '57', '61', '57', '59', '57', '61', '64', '61', '59', '63', '60', '57', '69', '63', '62', '59', '57', '57', '61', '59', '61', '61', '66']
我们提取了每天的最高气温,并将它们作为字符串整洁地存储在一个列表中。
下面使用int() 将这些字符串转换为数字,让matplotlib能够读取它们:
highs_lows.py
—snip—
highs = []
for row in reader:
❶ high = int(row[1])
highs.append(high)
print(highs)
在❶处,我们将表示气温的字符串转换成了数字,再将其附加到列表末尾。这样,最终的列表将包含以数字表示的每日最高气温:
[64, 71, 64, 59, 69, 62, 61, 55, 57, 61, 57, 59, 57, 61, 64, 61, 59, 63, 60, 57, 69, 63, 62, 59, 57, 57, 61, 59, 61, 61, 66]
下面来对这些数据进行可视化。
16.1.4 绘制气温图表
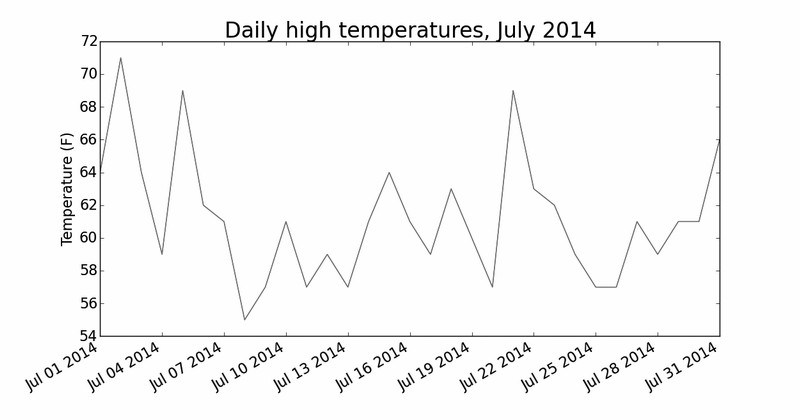
为可视化这些气温数据,我们首先使用matplotlib创建一个显示每日最高气温的简单图形,如下所示:
highs_lows.py
import csv
from matplotlib import pyplot as plt
从文件中获取最高气温
—snip—
根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
❶ plt.plot(highs, c='red')
设置图形的格式
❷ plt.title("Daily high temperatures, July 2014", fontsize=24)
❸ plt.xlabel('', fontsize=16)
plt.ylabel("Temperature (F)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()
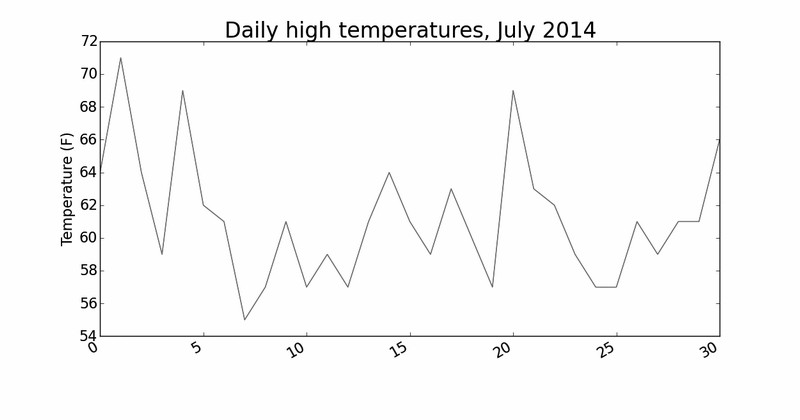
我们将最高气温列表传给plot() (见❶),并传递c='red' 以便将数据点绘制为红色(红色显示最高气温,蓝色显示最低气温)。接下来,我们设置了一些其他的格式,如字
体大小和标签(见❷),这些都在第15章介绍过。鉴于我们还没有添加日期,因此没有给 x 轴添加标签,但plt.xlabel() 确实修改了字体大小,让默认标签更容易看清。图
16-1显示了绘制的图表:一个简单的折线图,显示了阿拉斯加锡特卡2014年7月每天的最高气温。
图16-1 阿拉斯加锡特卡2014 年7 月每日最高气温折线图
16.1.5 模块datetime
下面在图表中添加日期,使其更有用。在天气数据文件中,第一个日期在第二行:
2014-7-1,64,56,50,53,51,48,96,83,58,30.19,—snip—
读取该数据时,获得的是一个字符串,因为我们需要想办法将字符串'2014-7-1' 转换为一个表示相应日期的对象。为创建一个表示2014年7月1日的对象,可使用模
块datetime 中的方法strptime() 。我们在终端会话中看看strptime() 的工作原理:
>>> from datetime import datetime
>>> first_date = datetime.strptime('2014-7-1', '%Y-%m-%d')
>>> print(first_date)
2014-07-01 00:00:00
我们首先导入了模块datetime 中的datetime 类,然后调用方法strptime() ,并将包含所需日期的字符串作为第一个实参。第二个实参告诉Python如何设置日期的格式。在
这个示例中,'%Y-' 让Python将字符串中第一个连字符前面的部分视为四位的年份;'%m-' 让Python将第二个连字符前面的部分视为表示月份的数字;而'%d' 让Python将字符串
的最后一部分视为月份中的一天(1~31)。
方法strptime() 可接受各种实参,并根据它们来决定如何解读日期。表16-1列出了其中一些这样的实参。
表16-1 模块datetime 中设置日期和时间格式的实参
实参
含义
%A
星期的名称,如Monday
%B
月份名,如January
%m
用数字表示的月份(01~12)
%d
用数字表示月份中的一天(01~31)
%Y
四位的年份,如2015
实参
含义
%y
两位的年份,如15
%H
24小时制的小时数(00~23)
%I
12小时制的小时数(01~12)
%p
am或pm
%M
分钟数(00~59)
%S
秒数(00~61)
16.1.6 在图表中添加日期
知道如何处理CSV文件中的日期后,就可对气温图形进行改进了,即提取日期和最高气温,并将它们传递给plot() ,如下所示:
highs_lows.py
import csv
from datetime import datetime
from matplotlib import pyplot as plt
从文件中获取日期和最高气温
filename = 'sitka_weather_07-2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
❶ dates, highs = [], []
for row in reader:
❷ current_date = datetime.strptime(row[0], "%Y-%m-%d")
dates.append(current_date)
high = int(row[1])
highs.append(high)
根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
❸ plt.plot(dates, highs, c='red')
设置图形的格式
plt.title("Daily high temperatures, July 2014", fontsize=24)
plt.xlabel('', fontsize=16)
❹ fig.autofmt_xdate()
plt.ylabel("Temperature (F)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()
我们创建了两个空列表,用于存储从文件中提取的日期和最高气温(见❶)。然后,我们将包含日期信息的数据(row[0] )转换为datetime 对象(见❷),并将其附加到列
表dates 末尾。在❸处,我们将日期和最高气温值传递给plot() 。在❹处,我们调用了fig.autofmt_xdate() 来绘制斜的日期标签,以免它们彼此重叠。图16-2显示了改
进后的图表。
图16-2 现在图表的 x 轴上有日期,含义更丰富
16.1.7 涵盖更长的时间
设置好图表后,我们来添加更多的数据,以成一幅更复杂的锡特卡天气图。请将文件sitka_weather_2014.csv复制到存储本章程序的文件夹中,该文件包含Weather Underground提供
的整年的锡特卡天气数据。
现在可以创建覆盖整年的天气图了:
highs_lows.py
—snip—
从文件中获取日期和最高气温
❶ filename = 'sitka_weather_2014.csv'
with open(filename) as f:
—snip—
设置图形的格式
❷ plt.title("Daily high temperatures - 2014", fontsize=24)
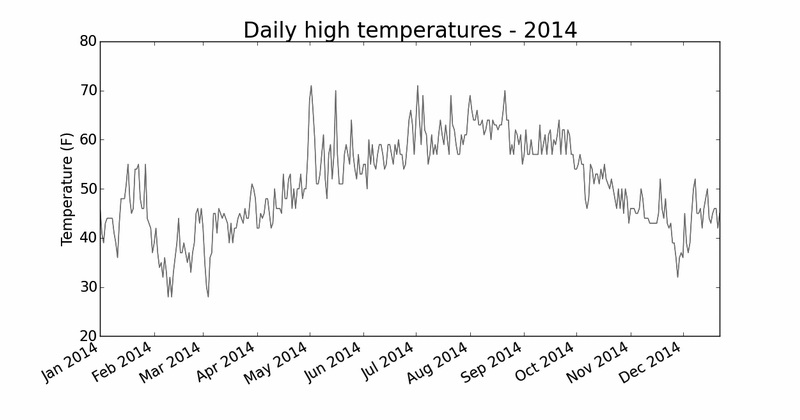
plt.xlabel('', fontsize=16)
—snip—
我们修改了文件名,以使用新的数据文件sitka_weather_2014.csv(见❶);我们还修改了图表的标题,以反映其内容的变化(见❷)。图16-3显示了生成的图形。
图16-3 一年的天气数据
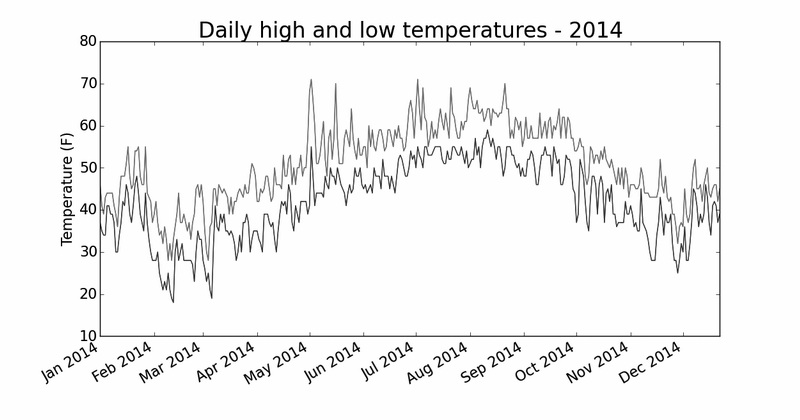
16.1.8 再绘制一个数据系列
图16-3所示的改进后的图表显示了大量意义深远的数据,但我们可以在其中再添加最低气温数据,使其更有用。为此,需要从数据文件中提取最低气温,并将它们添加到图表
中,如下所示:
highs_lows.py
—snip—
从文件中获取日期、最高气温和最低气温
filename = 'sitka_weather_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
❶ dates, highs, lows = [], [], []
for row in reader:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
dates.append(current_date)
high = int(row[1])
highs.append(high)
❷ low = int(row[3])
lows.append(low)
根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates, highs, c='red')
❸ plt.plot(dates, lows, c='blue')
设置图形的格式
❹ plt.title("Daily high and low temperatures - 2014", fontsize=24)
—snip—
在❶处,我们添加了空列表lows ,用于存储最低气温。接下来,我们从每行的第4列(row[3] )提取每天的最低气温,并存储它们(见❷)。在❸处,我们添加了一个
对plot() 的调用,以使用蓝色绘制最低气温。最后,我们修改了标题(见❹)。图16-4显示了这样绘制出来的图表。
图16-4 在一个图表中包含两个数据系列
16.1.9 给图表区域着色
添加两个数据系列后,我们就可以了解每天的气温范围了。下面来给这个图表做最后的修饰,通过着色来呈现每天的气温范围。为此,我们将使用方法fill_between() ,它
接受一个 x 值系列和两个 y 值系列,并填充两个 y 值系列之间的空间:
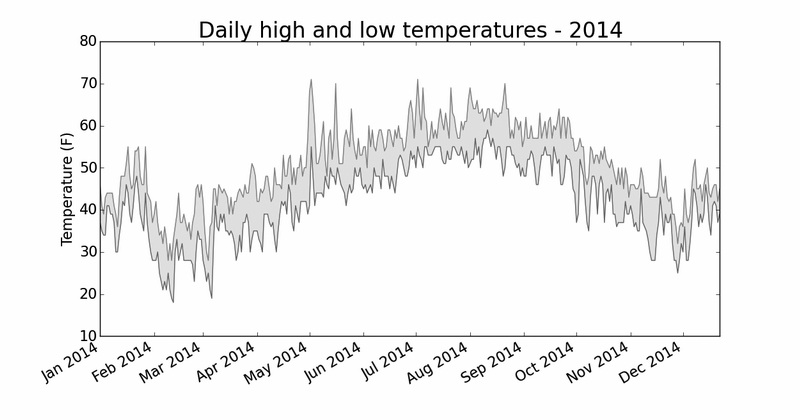
highs_lows.py
—snip—
根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
❶ plt.plot(dates, highs, c='red', alpha=0.5)
plt.plot(dates, lows, c='blue', alpha=0.5)
❷ plt.fill_between(dates, highs, lows, facecolor='blue', alpha=0.1)
—snip—
❶处的实参alpha 指定颜色的透明度。Alpha 值为0表示完全透明,1(默认设置)表示完全不透明。通过将alpha 设置为0.5,可让红色和蓝色折线的颜色看起来更浅。
在❷处,我们向fill_between() 传递了一个 x 值系列:列表dates ,还传递了两个 y 值系列:highs 和lows 。实参facecolor 指定了填充区域的颜色,我们还将alpha 设置成了较小的值0.1,让填充区域将两个数据系列连接起来的同时不分散观察者的注意力。图16-5显示了最高气温和最低气温之间的区域被填充的图表。
图16-5 给两个数据集之间的区域着色
通过着色,让两个数据集之间的区域显而易见。
16.1.10 错误检查
我们应该能够使用有关任何地方的天气数据来运行highs_lows.py中的代码,但有些气象站会偶尔出现故障,未能收集部分或全部其应该收集的数据。缺失数据可能会引发异常,如
果不妥善地处理,还可能导致程序崩溃。
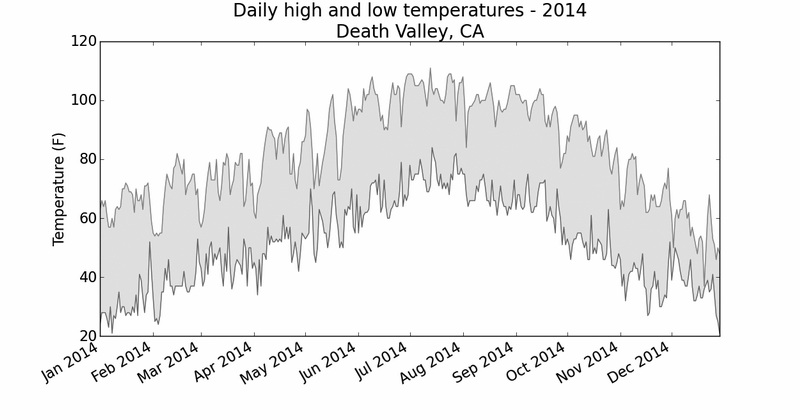
例如,我们来看看生成加利福尼亚死亡谷的气温图时出现的情况。将文件death_valey_2014.csv复制到本章程序所在的文件夹,再修改highs_lows.py,使其生成死亡谷的气温图:
highs_lows.py
—snip—
从文件中获取日期、最高气温和最低气温
filename = 'death_valley_2014.csv'
with open(filename) as f:
—snip—
运行这个程序时,出现了一个错误,如下述输出的最后一行所示:
Traceback (most recent call last):
File "highs_lows.py", line 17, in <module>
high = int(row[1])
ValueError: invalid literal for int() with base 10: ''
该traceback指出,Python无法处理其中一天的最高气温,因为它无法将空字符串(' ' )转换为整数。只要看一下death_valey_2014.csv,就能发现其中的问题:
2014-2-16,,,,,,,,,,,,,,,,,,,0.00,,,-1
其中好像没有记录2014年2月16日的数据,表示最高温度的字符串为空。为解决这种问题,我们在从CSV文件中读取值时执行错误检查代码,对分析数据集时可能出现的异常进行
处理,如下所示:
highs_lows.py
—snip—
从文件中获取日期、最高气温和最低气温
filename = 'death_valley_2014.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
dates, highs, lows = [], [], []
for row in reader:
❶ try:
current_date = datetime.strptime(row[0], "%Y-%m-%d")
high = int(row[1])
low = int(row[3])
except ValueError:
❷ print(current_date, 'missing data')
else:
❸ dates.append(current_date)
highs.append(high)
lows.append(low)
根据数据绘制图形
—snip—
设置图形的格式
❹ title = "Daily high and low temperatures - 2014\nDeath Valley, CA"
plt.title(title, fontsize=20)
—snip—
对于每一行,我们都尝试从中提取日期、最高气温和最低气温(见❶)。只要缺失其中一项数据,Python就会引发ValueError 异常,而我们可这样处理:打印一条错误消息,
指出缺失数据的日期(见❷)。打印错误消息后,循环将接着处理下一行。如果获取特定日期的所有数据时没有发生错误,将运行else 代码块,并将数据附加到相应列表的末
尾(见❸)。鉴于我们绘图时使用的是有关另一个地方的信息,我们修改了标题,在图表中指出了这个地方(见❹)。
如果你现在运行highs_lows.py ,将发现缺失数据的日期只有一个:
2014-02-16 missing data
图16-6显示了绘制出的图形。
图16-6 死亡谷每日高气温和最低气温
将这个图表与锡特卡的图表对比可知,总体而言,死亡谷比阿拉斯加东南部暖和,这可能符合预期,但这个沙漠中每天的温差也更大,从着色区域的高度可以明显看出这一点。
使用的很多数据集都可能缺失数据、数据格式不正确或数据本身不正确。对于这样的情形,可使用本书前半部分介绍的工具来处理。在这里,我们使用了一个try-except-else 代码块来处理数据缺失的问题。在有些情况下,需要使用continue 来跳过一些数据,或者使用remove() 或del 将已提取的数据删除。可采用任何管用的方法,只要能
进行精确而有意义的可视化就好。
动手试一试
16-1 旧金山 :旧金山的气温更接近于锡特卡还是死亡谷呢?请绘制一个显示旧金山最高气温和最低气温的图表,并进行比较。可从http://www.wunderground.com/history/
下载几乎任何地方的天气数据。为此,请输入相应的地方和日期范围,滚动到页面底部,找到名为Comma-Delimited File的链接,再单击该链接,将数据存储为CSV文
件。
16-2 比较锡特卡和死亡谷的气温 :在有关锡特卡和死亡谷的图表中,气温刻度反映了数据范围的不同。为准确地比较锡特卡和死亡谷的气温范围,需要在 y 轴上使
用相同的刻度。为此,请修改图16-5和图16-6所示图表的 y 轴设置,对锡特卡和死亡谷的气温范围进行直接比较(你也可以对任何两个地方的气温范围进行比较)。你
还可以尝试在一个图表中呈现这两个数据集。
16-3 降雨量 :选择你感兴趣的任何地方,通过可视化将其降雨量呈现出来。为此,可先只涵盖一个月的数据,确定代码正确无误后,再使用一整年的数据来运行它。
16-4 探索 :生成一些图表,对你好奇的任何地方的其他天气数据进行研究。
16.2 制作世界人口地图:JSON 格式
在本节中,你将下载JSON格式的人口数据,并使用json 模块来处理它们。Pygal提供了一个适合初学者使用的地图创建工具,你将使用它来对人口数据进行可视化,以探索全球
人口的分布情况。
16.2.1 下载世界人口数据
将文件population_data.json复制到本章程序所在的文件夹中,这个文件包含全球大部分国家1960~2010年的人口数据。Open Knowledge Foundation(http://data.okfn.org/ )提供了大量可
以免费使用的数据集,这些数据就来自其中一个数据集。
16.2.2 提取相关的数据
我们来研究一下population_data.json,看看如何着手处理这个文件中的数据:
population_data.json
[
{
"Country Name": "Arab World",
"Country Code": "ARB",
"Year": "1960",
"Value": "96388069"
},
{
"Country Name": "Arab World",
"Country Code": "ARB",
"Year": "1961",
"Value": "98882541.4"
},
—snip—
]
这个文件实际上就是一个很长的Python列表,其中每个元素都是一个包含四个键的字典:国家名、国别码、年份以及表示人口数量的值。我们只关心每个国家2010年的人口数量,
因此我们首先编写一个打印这些信息的程序:
world_population.py
import json
将数据加载到一个列表中
filename = 'population_data.json'
with open(filename) as f:
❶ pop_data = json.load(f)
打印每个国家2010年的人口数量
❷ for pop_dict in pop_data:
❸ if pop_dict['Year'] == '2010':
❹ country_name = pop_dict['Country Name']
population = pop_dict['Value']
print(country_name + ": " + population)
我们首先导入了模块json ,以便能够正确地加载文件中的数据,然后,我们将数据存储在pop_data 中(见❶)。函数json.load() 将数据转换为Python能够处理的格式,
这里是一个列表。在❷处,我们遍历pop_data 中的每个元素。每个元素都是一个字典,包含四个键—值对,我们将每个字典依次存储在pop_dict 中。
在❸处,我们检查字典的'Year' 键对应的值是否是2010(由于population_data.json中的值都是用引号括起的,因此我们执行的是字符串比较)。如果年份为2010,我们就将
与'Country Name' 相关联的值存储到country_name 中,并将与'Value' 相关联的值存储在population 中(见❹)。接下来,我们打印每个国家的名称和人口数量。
输出为一系列国家的名称和人口数量:
Arab World: 357868000
Caribbean small states: 6880000
East Asia & Pacific (all income levels): 2201536674
—snip—
Zimbabwe: 12571000
我们捕获的数据并非都包含准确的国家名,但这开了一个好头。现在,我们需要将数据转换为Pygal能够处理的格式。
16.2.3 将字符串转换为数字值
population_data.json中的每个键和值都是字符串。为处理这些人口数据,我们需要将表示人口数量的字符串转换为数字值,为此我们使用函数int() :
world_population.py
—snip—
for pop_dict in pop_data:
if pop_dict['Year'] == '2010':
country_name = pop_dict['Country Name']
❶ population = int(pop_dict['Value'])
❷ print(country_name + ": " + str(population))
在❶处,我们将每个人口数量值都存储为数字格式。打印人口数量值时,需要将其转换为字符串(见❷)。
然而,对于有些值,这种转换会导致错误,如下所示:
Arab World: 357868000
Caribbean small states: 6880000
East Asia & Pacific (all income levels): 2201536674
—snip—
Traceback (most recent call last):
File "print_populations.py", line 12, in <module>
population = int(pop_dict['Value'])
❶ ValueError: invalid literal for int() with base 10: '1127437398.85751'
原始数据的格式常常不统一,因此经常会出现错误。导致上述错误的原因是,Python不能直接将包含小数点的字符串'1127437398.85751' 转换为整数(这个小数值可能是人
口数据缺失时通过插值得到的)。为消除这种错误,我们先将字符串转换为浮点数,再将浮点数转换为整数:
world_population.py
—snip—
for pop_dict in pop_data:
if pop_dict['Year'] == '2010':
country = pop_dict['Country Name']
population = int(float(pop_dict['Value']))
print(country + ": " + str(population))
函数float() 将字符串转换为小数,而函数int() 丢弃小数部分,返回一个整数。现在,我们可以打印2010年的完整人口数据,不会导致错误了:
Arab World: 357868000
Caribbean small states: 6880000
East Asia & Pacific (all income levels): 2201536674
—snip—
Zimbabwe: 12571000
每个字符串都成功地转换成了浮点数,再转换为整数。以数字格式存储人口数量值后,就可以使用它们来制作世界人口地图了。
16.2.4 获取两个字母的国别码
制作地图前,还需要解决数据存在的最后一个问题。Pygal中的地图制作工具要求数据为特定的格式:用国别码表示国家,以及用数字表示人口数量。处理地理政治数据时,经常
需要用到几个标准化国别码集。population_data.json中包含的是三个字母的国别码,但Pygal使用两个字母的国别码。我们需要想办法根据国家名获取两个字母的国别码。
Pygal使用的国别码存储在模块i18n (internationalization的缩写)中。字典COUNTRIES 包含的键和值分别为两个字母的国别码和国家名。要查看这些国别码,可从模块i18n 中导
入这个字典,并打印其键和值:
countries.py
from pygal.i18n import COUNTRIES
❶ for country_code in sorted(COUNTRIES.keys()):
print(country_code, COUNTRIES[country_code])
在上面的for 循环中,我们让Python将键按字母顺序排序(见❶),然后打印每个国别码及其对应的国家:
ad Andorra
ae United Arab Emirates
af Afghanistan
—snip—
zw Zimbabwe
为获取国别码,我们将编写一个函数,它在COUNTRIES 中查找并返回国别码。我们将这个函数放在一个名为country_codes 的模块中,以便能够在可视化程序中导入它:
country_codes.py
from pygal.i18n import COUNTRIES
❶ def get_country_code(country_name):
"""根据指定的国家,返回Pygal使用的两个字母的国别码"""
❷ for code, name in COUNTRIES.items():
❸ if name == country_name:
return code
如果没有找到指定的国家,就返回None
❹ return None
print(get_country_code('Andorra'))
print(get_country_code('United Arab Emirates'))
print(get_country_code('Afghanistan'))
get_country_code() 接受国家名,并将其存储在形参country_name 中(见❶)。接下来,我们遍历COUNTRIES 中的国家名—国别码对(见❷);如果找到指定的国家
名,就返回相应的国别码(见❸)。在循环后面,我们在没有找到指定的国家名时返回None (见❹)。最后,我们使用了三个国家名来调用这个函数,以核实它能否正确地工
作。与预期的一样,这个程序输出了三个由两个字母组成的国别码:
ad
ae
af
使用这个函数前,先将country_codes.py中的print 语句删除。
接下来,在world_population.py中导入get_country_code :
world_population.py
import json
from country_codes import get_country_code
—snip—
打印每个国家2010年的人口数量
for pop_dict in pop_data:
if pop_dict['Year'] == '2010':
country_name = pop_dict['Country Name']
population = int(float(pop_dict['Value']))
❶ code = get_country_code(country_name)
if code:
❷ print(code + ": "+ str(population))
❸ else:
print('ERROR - ' + country_name)
提取国家名和人口数量后,我们将国别码存储在code 中,如果没有国别码,就在其中存储None (见❶)。如果返回了国别码,就打印国别码和相应国家的人口数量(见❷)。
如果没有找到国别码,就显示一条错误消息,其中包含无法找到国别码的国家的名称(见❸)。如果你运行这个程序,将看到一些国别码和相应国家的人口数量,还有一些错误
消息:
ERROR - Arab World
ERROR - Caribbean small states
ERROR - East Asia & Pacific (all income levels)
—snip—
af: 34385000
al: 3205000
dz: 35468000
—snip—
ERROR - Yemen, Rep.
zm: 12927000
zw: 12571000
导致显示错误消息的原因有两个。首先,并非所有人口数量对应的都是国家,有些人口数量对应的是地区(阿拉伯世界)和经济类群(所有收入水平)。其次,有些统计数据使
用了不同的完整国家名(如Yemen, Rep.,而不是Yemen)。当前,我们将忽略导致错误的数据,看看根据成功恢复了的数据制作出的地图是什么样的。
16.2.5 制作世界地图
有了国别码后,制作世界地图易如反掌。Pygal提供了图表类型Worldmap ,可帮助你制作呈现各国数据的世界地图。为演示如何使用Worldmap ,我们来创建一个突出北美、中
美和南美的简单地图:
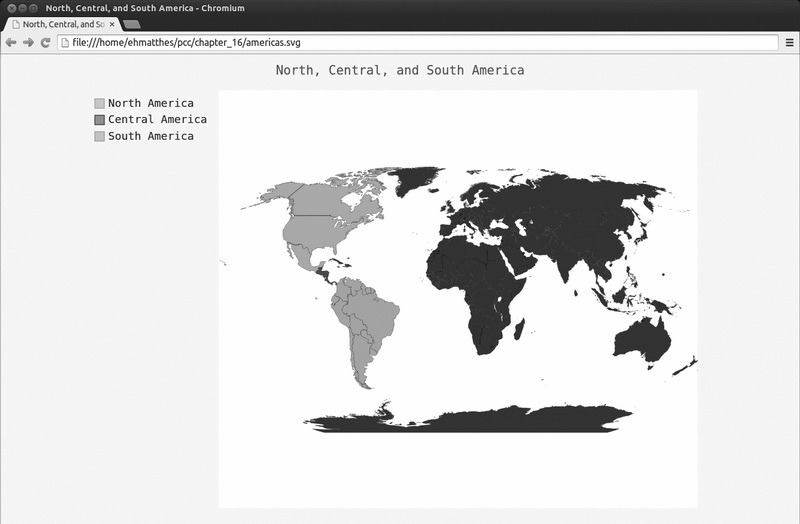
americas.py
import pygal
❶ wm = pygal.Worldmap()
wm.title = 'North, Central, and South America'
❷ wm.add('North America', ['ca', 'mx', 'us'])
wm.add('Central America', ['bz', 'cr', 'gt', 'hn', 'ni', 'pa', 'sv'])
wm.add('South America', ['ar', 'bo', 'br', 'cl', 'co', 'ec', 'gf',
'gy', 'pe', 'py', 'sr', 'uy', 've'])
❸ wm.render_to_file('americas.svg')
在❶处,我们创建了一个Worldmap 实例,并设置了该地图的的title 属性。在❷处,我们使用了方法add() ,它接受一个标签和一个列表,其中后者包含我们要突出的国家
的国别码。每次调用add() 都将为指定的国家选择一种新颜色,并在图表左边显示该颜色和指定的标签。我们要以同一种颜色显示整个北美地区,因此第一次调用add() 时,
在传递给它的列表中包含'ca' 、'mx' 和'us' ,以同时突出加拿大、墨西哥和美国。接下来,对中美和南美国家做同样的处理。
❸处的方法render_to_file() 创建一个包含该图表的.svg文件,你可以在浏览器中打开它。输出是一幅以不同颜色突出北美、中美和南美的地图,如图16-7所示。
图16-7 图表类型Worldmap 的一个简单实例
知道如何创建包含彩色区域、颜色标示和标签的地图后,我们在地图中添加数据,以显示有关国家的信息。
16.2.6 在世界地图上呈现数字数据
为练习在地图上呈现数字数据,我们来创建一幅地图,显示三个北美国家的人口数量:
na_populations.py
import pygal
wm = pygal.Worldmap()
wm.title = 'Populations of Countries in North America'
❶ wm.add('North America', {'ca': 34126000, 'us': 309349000, 'mx': 113423000}) wm.render_to_file('na_populations.svg') 首先,创建了一个Worldmap 实例并设置了标题。接下来,使用了方法add() ,但这次通过第二个实参传递了一个字典而不是列表(见❶)。这个字典将两个字母的Pygal国别
码作为键,将人口数量作为值。Pygal根据这些数字自动给不同国家着以深浅不一的颜色(人口最少的国家颜色最浅,人口最多的国家颜色最深),如图16-8所示。
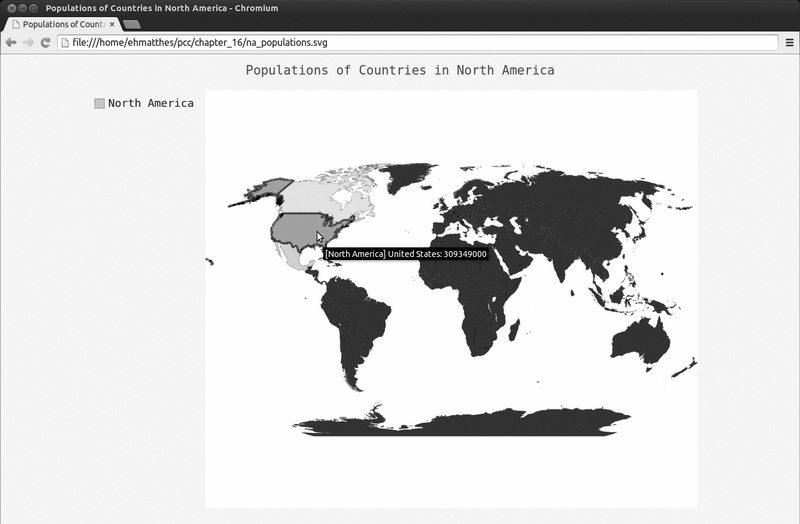
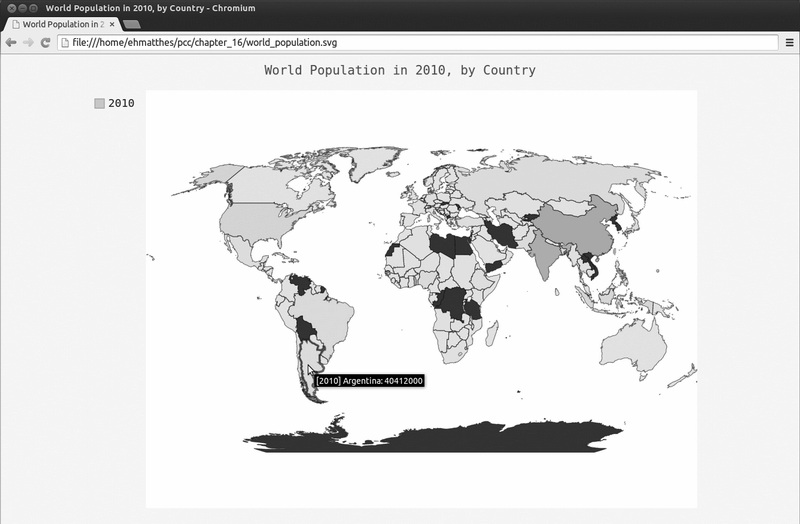
图16-8 北美国家的人口数量
这幅地图具有交互性:如果你将鼠标指向某个国家,将看到其人口数量。下面在这个地图中添加更多的数据。
16.2.7 绘制完整的世界人口地图
要呈现其他国家的人口数量,需要将前面处理的数据转换为Pygal要求的字典格式:键为两个字母的国别码,值为人口数量。为此,在world_population.py中添加如下代码:
world_population.py
import json
import pygal
from country_codes import get_country_code
将数据加载到列表中
—snip—
创建一个包含人口数量的字典
❶ cc_populations = {}
for pop_dict in pop_data:
if pop_dict['Year'] == '2010':
country = pop_dict['Country Name']
population = int(float(pop_dict['Value']))
code = get_country_code(country)
if code:
❷ cc_populations[code] = population
❸ wm = pygal.Worldmap()
wm.title = 'World Population in 2010, by Country'
❹ wm.add('2010', cc_populations)
wm.render_to_file('world_population.svg')
我们首先导入了pygal 。在❶处,我们创建了一个空字典,用于以Pygal要求的格式存储国别码和人口数量。在❷处,如果返回了国别码,就将国别码和人口数量分别作为键和值
填充字典cc_populations 。我们还删除了所有的print 语句。
在❸处,我们创建了一个Worldmap 实例,并设置其title 属性。在❹处,我们调用了add() ,并向它传递由国别码和人口数量组成的字典。图16-9显示了生成的地图。
图16-9 2010 年的世界人口数量
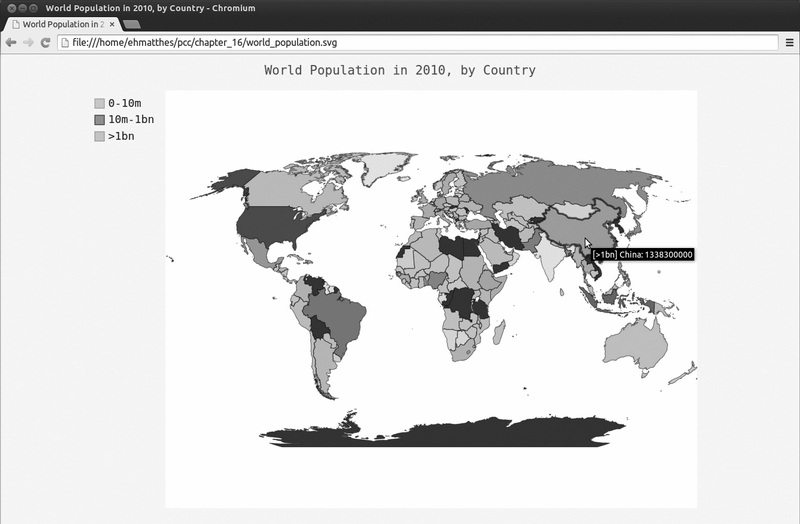
有几个国家没有相关的数据,我们将其显示为黑色,但对于大多数国家,都根据其人口数量进行了着色。本章后面将处理数据缺失的问题,这里先来修改着色,以更准确地反映
各国的人口数量。在当前的地图中,很多国家都是浅色的,只有两个国家是深色的。对大多数国家而言,颜色深浅的差别不足以反映其人口数量的差别。为修复这种问题,我们
将根据人口数量将国家分组,再分别给每个组着色。
16.2.8 根据人口数量将国家分组
印度和中国的人口比其他国家多得多,但在当前的地图中,它们的颜色与其他国家差别较小。中国和印度的人口都超过了10亿,接下来人口最多的国家是美国,但只有大约3亿。
下面不将所有国家都作为一个编组,而是根据人口数量分成三组——少于1000万的、介于1000万和10亿之间的以及超过10亿的:
world_population.py
—snip—
创建一个包含人口数据的字典
cc_populations = {}
for pop_dict in pop_data:
if pop_dict['Year'] == '2010':
—snip—
if code:
cc_populations[code] = population
根据人口数量将所有的国家分成三组
❶ cc_pops_1, cc_pops_2, cc_pops_3 = {}, {}, {}
❷ for cc, pop in cc_populations.items():
if pop < 10000000:
cc_pops_1[cc] = pop
elif pop < 1000000000:
cc_pops_2[cc] = pop
else:
cc_pops_3[cc] = pop
看看每组分别包含多少个国家
❸ print(len(cc_pops_1), len(cc_pops_2), len(cc_pops_3))
wm = pygal.Worldmap()
wm.title = 'World Population in 2010, by Country'
❹ wm.add('0-10m', cc_pops_1)
wm.add('10m-1bn', cc_pops_2)
wm.add('>1bn', cc_pops_3)
wm.render_to_file('world_population.svg')
为将国家分组,我们创建了三个空字典(见❶)。接下来,遍历cc_populations ,检查每个国家的人口数量(见❷)。if-elif-else 代码块将每个国别码-人口数量对加
入到合适的字典(cc_pops_1 、cc_pops_2 或cc_pops_3 )中。
在❸处,我们打印这些字典的长度,以获悉每个分组的规模。绘制地图时,我们将全部三个分组都添加到Worldmap 中(见❹)。如果你现在运行这个程序,首先看到的将是每
个分组的规模:
85 69 2
上述输出表明,人口少于1000万的国家有85个,人口介于1000万和10亿之间的国家有69个,还有两个国家比较特殊,其人口都超过了10亿。这样的分组看起来足够了,让地图包
含丰富的信息。图16-10显示了生成的地图。
图16-10 分三组显示的世界各国人口
现在使用了三种不同的颜色,让我们能够看出人口数量上的差别。在每组中,各个国家都按人口从少到多着以从浅到深的颜色。
16.2.9 使用Pygal 设置世界地图的样式
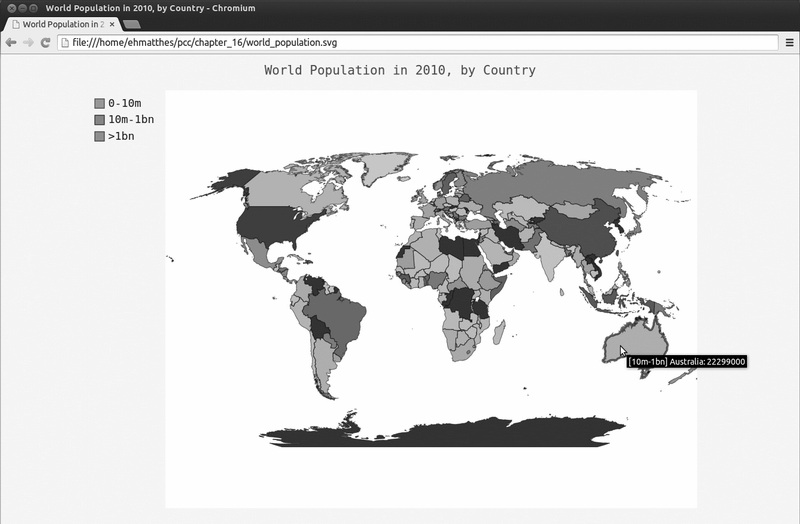
在这个地图中,根据人口将国家分组虽然很有效,但默认的颜色设置很难看。例如,在这里,Pygal选择了鲜艳的粉色和绿色基色。下面使用Pygal样式设置指令来调整颜色。
我们也让Pygal使用一种基色,但将指定该基色,并让三个分组的颜色差别更大:
world_population.py
import json
import pygal
❶ from pygal.style import RotateStyle
—snip—
根据人口数量将所有的国家分成三组
cc_pops_1, cc_pops_2, cc_pops_3 = {}, {}, {}
for cc, pop in cc_populations.items():
if pop < 10000000:
—snip—
❷ wm_style = RotateStyle('#336699')
❸ wm = pygal.Worldmap(style=wm_style)
wm.title = 'World Population in 2010, by Country'
—snip—
Pygal样式存储在模块style 中,我们从这个模块中导入了样式RotateStyle (见❶)。创建这个类的实例时,需要提供一个实参——十六进制的RGB颜色(见❷);Pygal将根
据指定的颜色为每组选择颜色。十六进制格式 的RGB颜色是一个以井号(#)打头的字符串,后面跟着6个字符,其中前两个字符表示红色分量,接下来的两个表示绿色分量,最
后两个表示蓝色分量。每个分量的取值范围为00 (没有相应的颜色)~FF (包含最多的相应颜色)。如果你在线搜索hex color chooser(十六进制颜色选择器 ),可找到让你能
够尝试选择不同的颜色并显示其RGB值的工具。这里使用的颜色值(#336699)混合了少量的红色(33)、多一些的绿色(66)和更多一些的蓝色(99),它为RotateStyle 提
供了一种淡蓝色基色。
RotateStyle 返回一个样式对象,我们将其存储在wm_style 中。为使用这个样式对象,我们在创建Worldmap 实例时以关键字实参的方式传递它(见❸)。更新后的地图如
图16-11所示。
图16-11 按人口划分的三个国家编组了统一的颜色主题
前面的样式设置让地图的颜色更一致,也更容易区分不同的编组。
16.2.10 加亮颜色主题
Pygal通常默认使用较暗的颜色主题。为方便印刷,我使用LightColorizedStyle 加亮了地图的颜色。这个类修改整个图表的主题,包括背景色、标签以及各个国家的颜色。
要使用这个样式,先导入它:
from pygal.style import LightColorizedStyle
然后就可独立地使用LightColorizedStyle 了,例如:
wm_style = LightColorizedStyle
然而使用这个类时,你不能直接控制使用的颜色,Pygal将选择默认的基色。要设置颜色,可使用RotateStyle ,并将LightColorizedStyle 作为基本样式。为此,导
入LightColorizedStyle 和RotateStyle :
from pygal.style import LightColorizedStyle, RotateStyle
再使用RotateStyle 创建一种样式,并传入另一个实参base_style :
wm_style = RotateStyle('#336699', base_style=LightColorizedStyle)
这设置了较亮的主题,同时根据通过实参传递的颜色给各个国家着色。使用这种样式时,生成的图表与本书的屏幕截图更一致。
尝试为不同的可视化选择合适的样式设置指令时,在import 语句中指定别名会有所帮助:
from pygal.style import LightColorizedStyle as LCS, RotateStyle as RS

这样,样式定义将更短:
wm_style = RS('#336699', base_style=LCS)
通过使用几个样式设置指令,就能很好地控制图表和地图的外观。
动手试一试
16-5 涵盖所有国家 :本节制作人口地图时,对于大约12个国家,程序不能自动确定其两个字母的国别码。请找出这些国家,在字典COUNTRIES 中找到它们的国别
码;然后,对于每个这样的国家,都在get_country_code() 中添加一个if-elif 代码块,以返回其国别码:
if country_name == 'Yemen, Rep.'
return 'ye'
elif —snip—
将这些代码放在遍历COUNTRIES 的循环和语句return None 之间。完成这样的修改后,你看到的地图将更完整。
16-6 国内生产总值 :Open Knowledge Foundation提供了一个数据集,其中包含全球各国的国内生产总值(GDP),可在http://data.okfn.org/data/core/gdp/ 找到这个数据
集。请下载这个数据集的JSON版本,并绘制一个图表,将全球各国最近一年的GDP呈现出来。
16-7 选择你自己的数据 :世界银行(The World Bank)提供了很多数据集,其中包含有关全球各国的信息。请访问http://data.worldbank.org/indicator/ ,并找到一个你感
兴趣的数据集。单击该数据集,再单击链接Download Data并选择CSV。你将收到三个CSV文件,其中两个包含字样Metadata,你应使用第三个CSV文件。编写一个程
序,生成一个字典,它将两个字母的Pygal国别码作为键,并将你从这个文件中选择的数据作为值。使用Worldmap 制作一个地图,在其中呈现这些数据,并根据你的
喜好设置这个地图的样式。
16-8 测试模块country_codes :我们编写模块country_codes 时,使用了print 语句来核实get_country_code() 能否按预期那样工作。请利用你在第11
章学到的知识,为这个函数编写合适的测试。
16.3 小结
在本章中,你学习了:如何使用网上的数据集;如何处理CSV和JSON文件,以及如何提取你感兴趣的数据;如何使用matplotlib来处理以往的天气数据,包括如何使用模
块datetime ,以及如何在同一个图表中绘制多个数据系列;如何使用Pygal绘制呈现各国数据的世界地图,以及如何设置Pygal地图和图表的样式。
有了使用CSV和JSON文件的经验后,你将能够处理几乎任何要分析的数据。大多数在线数据集都可以以这两种格式中的一种或两种下载。学习使用这两种格式为学习使用其他格
式的数据做好了准备。
在下一章,你将编写自动从网上采集数据并对其进行可视化的程序。如果你只是将编程作为业余爱好,学会这些技能可以增加乐趣;如果你有志于成为专业程序员,就必须掌握
这些技能。
第 17 章 使用API
在本章中,你将学习如何编写一个独立的程序,并对其获取的数据进行可视化。这个程序将使用Web 应用编程接口 (API)自动请求网站的特定信息而不是整个网
页,再对这些信息进行可视化。由于这样编写的程序始终使用最新的数据来生成可视化,因此即便数据瞬息万变,它呈现的信息也都是最新的。
17.1 使用Web API
Web API是网站的一部分,用于与使用非常具体的URL请求特定信息的程序交互。这种请求称为API调用。请求的数据将以易于处理的格式(如JSON或CSV)返回。依赖于外部数
据源的大多数应用程序都依赖于API调用,如集成社交媒体网站的应用程序。
17.1.1 Git 和GitHub 本章的可视化将基于来自GitHub的信息,这是一个让程序员能够协作开发项目的网站。我们将使用GitHub的API来请求有关该网站中Python项目的信息,然后使用Pygal生成交互式
可视化,以呈现这些项目的受欢迎程度。
GitHub(https://github.com/ )的名字源自Git,Git是一个分布式版本控制系统,让程序员团队能够协作开发项目。Git帮助大家管理为项目所做的工作,避免一个人所做的修改影响其
他人所做的修改。你在项目中实现新功能时,Git将跟踪你对每个文件所做的修改。确定代码可行后,你提交所做的修改,而Git将记录项目最新的状态。如果你犯了错,想撤销所
做的修改,可轻松地返回以前的任何可行状态(要更深入地了解如何使用Git进行版本控制,请参阅附录D)。GitHub上的项目都存储在仓库中,后者包含与项目相关联的一切:代
码、项目参与者的信息、问题或bug报告等。
对于喜欢的项目,GitHub用户可给它加星(star)以表示支持,用户还可跟踪他可能想使用的项目。在本章中,我们将编写一个程序,它自动下载GitHub上星级最高的Python项目的
信息,并对这些信息进行可视化。
17.1.2 使用API 调用请求数据
GitHub的API让你能够通过API调用来请求各种信息。要知道API调用是什么样的,请在浏览器的地址栏中输入如下地址并按回车键:
https://api.github.com/search/repositories?q=language:python&sort=stars 这个调用返回GitHub当前托管了多少个Python项目,还有有关最受欢迎的Python仓库的信息。下面来仔细研究这个调用。第一部分(https://api.github.com/ )将请求发送
到GitHub网站中响应API调用的部分;接下来的一部分(search/repositories )让API搜索GitHub上的所有仓库。
repositories 后面的问号指出我们要传递一个实参。q 表示查询,而等号让我们能够开始指定查询(q= )。通过使用language:python ,我们指出只想获取主要语言为
Python的仓库的信息。最后一部分(&sort=stars )指定将项目按其获得的星级进行排序。
下面显示了响应的前几行。从响应可知,该URL并不适合人工输入。
{
"total_count": 713062,
"incomplete_results": false,
"items": [
{
"id": 3544424,
"name": "httpie",
"full_name": "jkbrzt/httpie",
—snip—
从第二行输出可知,编写本书时,GitHub总共有713 062个Python项目。"incomplete_results" 的值为false ,据此我们知道请求是成功的(它并非不完整的)。倘若GitHub 无法全面处理该API,它返回的这个值将为true 。接下来的列表中显示了返回的"items" ,其中包含GitHub上最受欢迎的Python项目的详细信息。
17.1.3 安装requests
requests包让Python程序能够轻松地向网站请求信,息以及检查返回的响应。要安装requests,请执行类似于下面的命令:
$ pip install —user requests
如果你还没有使用过pip,请参阅12.2.1节(根据系统的设置,你可能需要使用这个命令的稍微不同的版本)。
17.1.4 处理API 响应
下面来编写一个程序,它执行API调用并处理结果,找出GitHub上星级最高的Python项目:
python_repos.py
❶ import requests
执行API调用并存储响应
❷ url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
❸ r = requests.get(url)
❹ print("Status code:", r.status_code)
将API响应存储在一个变量中
❺ response_dict = r.json()
处理结果
print(response_dict.keys())
在❶处,我们导入了模块requests 。在❷处,我们存储API调用的URL,然后使用requests 来执行调用(见❸)。我们调用get() 并将URL传递给它,再将响应对象存储在
变量r 中。响应对象包含一个名为status_code 的属性,它让我们知道请求是否成功了(状态码200表示请求成功)。在❹处,我们打印status_code ,核实调用是否成功
了。
这个API返回JSON格式的信息,因此我们使用方法json() 将这些信息转换为一个Python字典(见❺)。我们将转换得到的字典存储在response_dict 中。
最后,我们打印response_dict 中的键。输出如下:
Status code: 200
dict_keys(['items', 'total_count', 'incomplete_results'])
状态码为200,因此我们知道请求成功了。响应字典只包含三个键:'items' 、'total_count' 和'incomplete_results' 。
注意 像这样简单的调用应该会返回完整的结果集,因此完全可以忽略与'incomplete_results' 相关联的值。但执行更复杂的API调用时,程序应检查这个
值。
17.1.5 处理响应字典
将API调用返回的信息存储到字典中后,就可以处理这个字典中的数据了。下面来生成一些概述这些信息的输出。这是一种不错的方式,可确认收到了期望的信息,进而可以开始
研究感兴趣的信息:
python_repos.py
import requests
执行API调用并存储响应
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
r = requests.get(url)
print("Status code:", r.status_code)
将API响应存储在一个变量中
response_dict = r.json()
❶ print("Total repositories:", response_dict['total_count'])
探索有关仓库的信息
❷ repo_dicts = response_dict['items']
print("Repositories returned:", len(repo_dicts))
研究第一个仓库
❸ repo_dict = repo_dicts[0]
❹ print("\nKeys:", len(repo_dict))
❺ for key in sorted(repo_dict.keys()):
print(key)
在❶处,我们打印了与'total_count' 相关联的值,它指出了GitHub总共包含多少个Python仓库。
与'items' 相关联的值是一个列表,其中包含很多字典,而每个字典都包含有关一个Python仓库的信息。在❷处,我们将这个字典列表存储在repo_dicts 中。接下来,我们
打印repo_dicts 的长度,以获悉我们获得了多少个仓库的信息。
为更深入地了解返回的有关每个仓库的信息,我们提取了repo_dicts 中的第一个字典,并将其存储在repo_dict 中(见❸)。接下来,我们打印这个字典包含的键数,看看
其中有多少信息(见❹)。在❺处,我们打印这个字典的所有键,看看其中包含哪些信息。
输出让我们对实际包含的数据有了更清晰的认识:
Status code: 200
Total repositories: 713062
Repositories returned: 30
❶ Keys: 68
archive_url
assignees_url
blobs_url
—snip—
url
watchers
watchers_count
GitHub的API返回有关每个仓库的大量信息:repo_dict 包含68个键(见❶)。通过仔细查看这些键,可大致知道可提取有关项目的哪些信息(要准确地获悉API将返回哪些信
息,要么阅读文档,要么像此处这样使用代码来查看这些信息)。
下面来提取repo_dict 中与一些键相关联的值:
python_repos.py
—snip—
研究有关仓库的信息
repo_dicts = response_dict['items']
print("Repositories returned:", len(repo_dicts))
研究第一个仓库
repo_dict = repo_dicts[0]
print("\nSelected information about first repository:")
❶ print('Name:', repo_dict['name'])
❷ print('Owner:', repo_dict['owner']['login'])
❸ print('Stars:', repo_dict['stargazers_count'])
print('Repository:', repo_dict['html_url'])
❹ print('Created:', repo_dict['created_at'])
❺ print('Updated:', repo_dict['updated_at'])
print('Description:', repo_dict['description'])
在这里,我们打印了表示第一个仓库的字典中与很多键相关联的值。在❶处,我们打印了项目的名称。项目所有者是用一个字典表示的,因此在❷处,我们使用键owner 来访问
表示所有者的字典,再使用键key 来获取所有者的登录名。在❸处,我们打印项目获得了多少个星的评级,以及项目在GitHub仓库的URL。接下来,我们显示项目的创建时间
(见❹)和最后一次更新的时间(见❺)。最后,我们打印仓库的描述。输出类似于下面这样:
Status code: 200
Total repositories: 713065
Repositories returned: 30
Selected information about first repository:
Name: httpie
Owner: jkbrzt
Stars: 16101
Repository: https://github.com/jkbrzt/httpie
Created: 2012-02-25T12:39:13Z
Updated: 2015-07-13T14:56:41Z
Description: CLI HTTP client; user-friendly cURL replacement featuring intuitive UI, JSON support, syntax highlighting, wget-like downloads, extensions, etc.
从上述输出可知,编写本书时,GitHub上星级最高的Python项目为HTTPie,其所有者为用户jkbrzt,有16 000多个GitHub用户给这个项目加星。我们可以看到这个项目的仓库的
URL,其创建时间为2012年2月,且最近更新了。最后,描述指出HTTPie用于帮助从终端执行HTTP调用(CLI是命令行界面 的缩写)。
17.1.6 概述最受欢迎的仓库
对这些数据进行可视化时,我们需要涵盖多个仓库。下面就来编写一个循环,打印API调用返回的每个仓库的特定信息,以便能够在可视化中包含所有这些信息:
python_repos.py
—snip—
研究有关仓库的信息
repo_dicts = response_dict['items']
print("Repositories returned:", len(repo_dicts))
❶ print("\nSelected information about each repository:")
❷ for repo_dict in repo_dicts:
print('\nName:', repo_dict['name'])
print('Owner:', repo_dict['owner']['login'])
print('Stars:', repo_dict['stargazers_count'])
print('Repository:', repo_dict['html_url'])
print('Description:', repo_dict['description'])
在❶处,我们打印了一条说明性消息。在❷处,我们遍历repo_dicts 中的所有字典。在这个循环中,我们打印每个项目的名称、所有者、星级、在GitHub上的URL以及描述:
Status code: 200
Total repositories: 713067
Repositories returned: 30
Selected information about each repository:
Name: httpie
Owner: jkbrzt
Stars: 16101
Repository: https://github.com/jkbrzt/httpie
Description: CLI HTTP client; user-friendly cURL replacement featuring intuitive UI, JSON support, syntax highlighting, wget-like downloads, extensions, etc.
Name: django
Owner: django
Stars: 15028
Repository: https://github.com/django/django
Description: The Web framework for perfectionists with deadlines.
—snip—
Name: powerline
Owner: powerline
Stars: 4315
Repository: https://github.com/powerline/powerline
Description: Powerline is a statusline plugin for vim, and provides statuslines and prompts for several other applications, including zsh, bash, tmux, IPython, Awesome and Qtile.
上述输出中有一些有趣的项目,可能值得再看一眼。但不要在这上面花费太多时间,因为我们即将创建的可视化可让你更容易地看清结果。
17.1.7 监视API 的速率限制
大多数API都存在速率限制,即你在特定时间内可执行的请求数存在限制。要获悉你是否接近了GitHub的限制,请在浏览器中输入https://api.github.com/rate_limit ,你将看到类似于下
面的响应:
{
"resources": {
"core": {
"limit": 60,
"remaining": 58,
"reset": 1426082320
},
❶ "search": {
❷ "limit": 10,
❸ "remaining": 8,
❹ "reset": 1426078803
}
},
"rate": {
"limit": 60,
"remaining": 58,
"reset": 1426082320
}
}
我们关心的信息是搜索API的速率限制(见❶)。从❷处可知,极限为每分钟10个请求,而在当前这一分钟内,我们还可执行8个请求(见❸)。reset 值指的是配额将重置的
Unix时间或新纪元时间 (1970年1月1日午夜后多少秒)(见❹)。用完配额后,你将收到一条简单的响应,由此知道已到达API极限。到达极限后,你必须等待配额重置。
注意 很多API都要求你注册获得API密钥后才能执行API调用。编写本书时,GitHub没有这样的要求,但获得API密钥后,配额将高得多。
17.2 使用Pygal 可视化仓库
有了一些有趣的数据后,我们来进行可视化,呈现GitHub上Python项目的受欢迎程度。我们将创建一个交互式条形图:条形的高度表示项目获得了多少颗星。单击条形将带你进入
项目在GitHub上的主页。下面是首次尝试这样做:
python_repos.py
import requests
import pygal
from pygal.style import LightColorizedStyle as LCS, LightenStyle as LS
执行API调用并存储响应
URL = 'https://api.github.com/search/repositories?q=language:python&sort=star'
r = requests.get(URL)
print("Status code:", r.status_code)
将API响应存储在一个变量中
response_dict = r.json()
print("Total repositories:", response_dict['total_count'])
研究有关仓库的信息
repo_dicts = response_dict['items']
❶ names, stars = [], []
for repo_dict in repo_dicts:
❷ names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
可视化
❸ my_style = LS('#333366', base_style=LCS)
❹ chart = pygal.Bar(style=my_style, x_label_rotation=45, show_legend=False) chart.title = 'Most-Starred Python Projects on GitHub'
chart.x_labels = names
❺ chart.add('', stars)
chart.render_to_file('python_repos.svg')
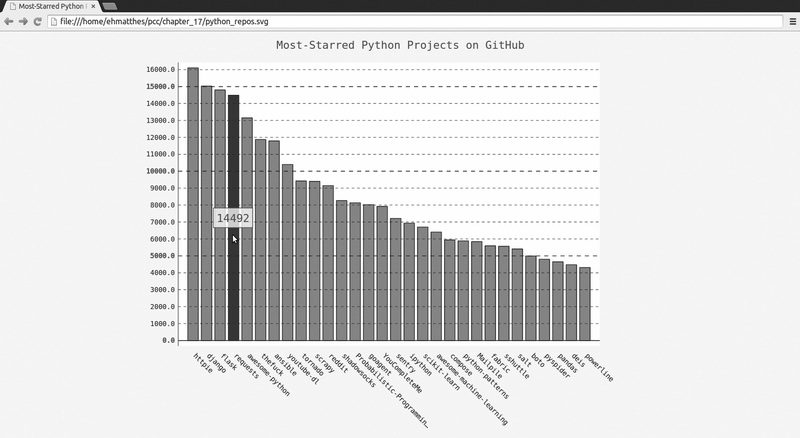
我们首先导入了pygal 以及要应用于图表的Pygal样式。接下来,打印API调用响应的状态以及找到的仓库总数,以便获悉API调用是否出现了问题。我们不再打印返回的有关项目
的信息,因为将通过可视化来呈现这些信息。
在❶处,我们创建了两个空列表,用于存储将包含在图表中的信息。我们需要每个项目的名称,用于给条形加上标签,我们还需要知道项目获得了多少个星,用于确定条形的高
度。在循环中,我们将项目的名称和获得的星数附加到这些列表的末尾❷。
接下来,我们使用LightenStyle 类(别名LS )定义了一种样式,并将其基色设置为深蓝色(见❸)。我们还传递了实参base_style ,以使用LightColorizedStyle 类(别名LCS )。然后,我们使用Bar() 创建一个简单的条形图,并向它传递了my_style (见❹)。我们还传递了另外两个样式实参:让标签绕 x 轴旋转45度
(x_label_rotation=45 ),并隐藏了图例(show_legend=False ),因为我们只在图表中绘制一个数据系列。接下来,我们给图表指定了标题,并将属性x_labels 设置为列表names 。
由于我们不需要给这个数据系列添加标签,因此在❺处添加数据时,将标签设置成了空字符串。生成的图表如图17-1所示。从中可知,前几个项目的受欢迎程度比其他项目高得
多,但所有这些项目在Python生态系统中都很重要。
图17-1 GitHub 上受欢迎程度最高的Python 项目
17.2.1 改进Pygal 图表
下面来改进这个图表的样式。我们将进行多个方面的定制,因此先来稍微调整代码的结构,创建一个配置对象,在其中包含要传递给Bar() 的所有定制:
python_repos.py
—snip—
可视化
my_style = LS('#333366', base_style=LCS)
❶ my_config = pygal.Config()
❷ my_config.x_label_rotation = 45
my_config.show_legend = False
❸ my_config.title_font_size = 24
my_config.label_font_size = 14
my_config.major_label_font_size = 18
❹ my_config.truncate_label = 15
❺ my_config.show_y_guides = False
❻ my_config.width = 1000
❼ chart = pygal.Bar(my_config, style=my_style)
chart.title = 'Most-Starred Python Projects on GitHub'
chart.x_labels = names
chart.add('', stars)
chart.render_to_file('python_repos.svg')
在❶处,我们创建了一个Pygal类Config 的实例,并将其命名为my_config 。通过修改my_config 的属性,可定制图表的外观。在❷处,我们设置了两个属性
——x_label_rotation 和show_legend ,它们原来是在创建Bar 实例时以关键字实参的方式传递的。在❸处,我们设置了图表标题、副标签和主标签的字体大小。在这个
图表中,副标签是 x 轴上的项目名以及 y 轴上的大部分数字。主标签是 y 轴上为5000整数倍的刻度;这些标签应更大,以与副标签区分开来。在❹处,我们使
用truncate_label 将较长的项目名缩短为15个字符(如果你将鼠标指向屏幕上被截短的项目名,将显示完整的项目名)。接下来,我们将show_y_guides 设置为False ,以隐藏图表中的水平线(见❺)。最后,在❻处设置了自定义宽度,让图表更充分地利用浏览器中的可用空间。
在❼处创建Bar 实例时,我们将my_config 作为第一个实参,从而通过一个实参传递了所有的配置设置。我们可以通过my_config 做任意数量的样式和配置修改,而❼处的
代码行将保持不变。图17-2显示了重新设置样式后的图表。
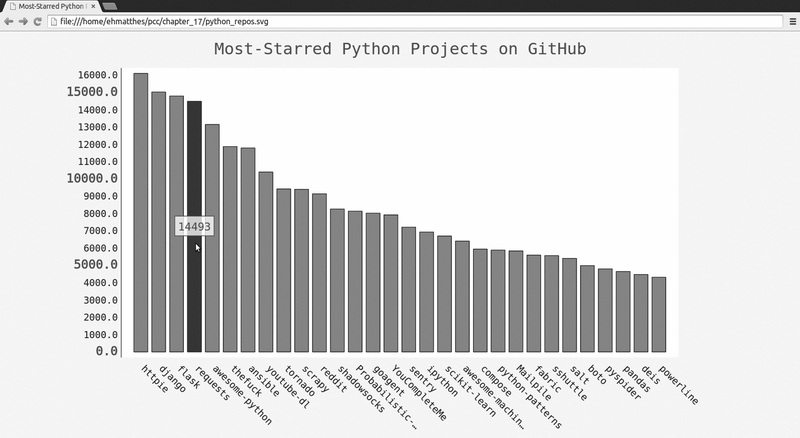
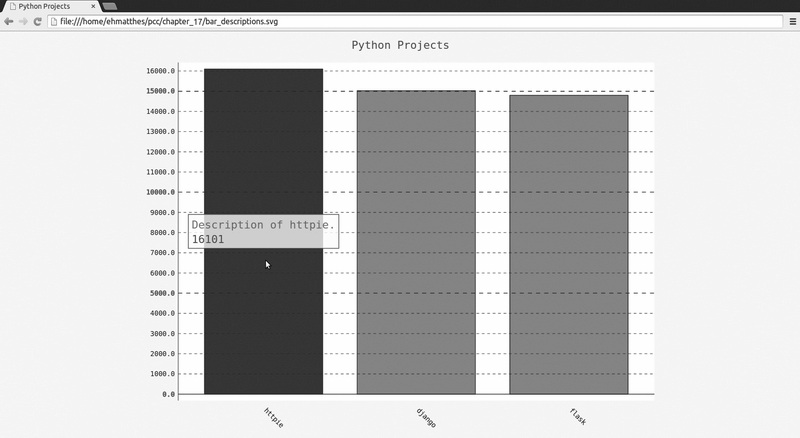
图17-2 改进了图表的样式
17.2.2 添加自定义工具提示
在Pygal中,将鼠标指向条形将显示它表示的信息,这通常称为工具提示 。在这个示例中,当前显示的是项目获得了多少个星。下面来创建一个自定义工具提示,以同时显示项目
的描述。
来看一个简单的示例,它可视化前三个项目,并给每个项目对应的条形都指定自定义标签。为此,我们向add() 传递一个字典列表,而不是值列表:
bar_descriptions.py
import pygal
from pygal.style import LightColorizedStyle as LCS, LightenStyle as LS
my_style = LS('#333366', base_style=LCS)
chart = pygal.Bar(style=my_style, x_label_rotation=45, show_legend=False) chart.title = 'Python Projects'
chart.x_labels = ['httpie', 'django', 'flask']
❶ plot_dicts = [
❷ {'value': 16101, 'label': 'Description of httpie.'},
{'value': 15028, 'label': 'Description of django.'},
{'value': 14798, 'label': 'Description of flask.'},
]
❸ chart.add('', plot_dicts)
chart.render_to_file('bar_descriptions.svg')
在❶处,我们定义了一个名为plot_dicts 的列表,其中包含三个字典,分别针对项目HTTPie、Django和Flask。每个字典都包含两个键:'value' 和'label' 。Pygal根据与
键'value' 相关联的数字来确定条形的高度,并使用与'label' 相关联的字符串给条形创建工具提示。例如,❷处的第一个字典将创建一个条形,用于表示一个获得了16 101
颗星、工具提示为Description of httpie的项目。
方法add() 接受一个字符串和一个列表。这里调用add() 时,我们传入了一个由表示条形的字典组成的列表(plot_dicts )(见❸)。图17-3显示了一个工具提示:除默认
工具提示(获得的星数)外,Pygal还显示了我们传入的自定义提示。
图17-3 每个条形都有自定义的工具提示标签
17.2.3 根据数据绘图
为根据数据绘图,我们将自动生成plot_dicts ,其中包含API调用返回的30个项目的信息。
完成这种工作的代码如下:
python_repos.py
—snip—
研究有关仓库的信息
repo_dicts = response_dict['items']
print("Number of items:", len(repo_dicts))
❶ names, plot_dicts = [], []
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
❷ plot_dict = {
'value': repo_dict['stargazers_count'],
'label': repo_dict['description'],
}
❸ plot_dicts.append(plot_dict)
可视化
my_style = LS('#333366', base_style=LCS)
—snip—
❹ chart.add('', plot_dicts)
chart.render_to_file('python_repos.svg')
在❶处,我们创建了两个空列表names 和plot_dicts 。为生成 x 轴上的标签,我们依然需要列表names 。
在循环内部,对于每个项目,我们都创建了字典plot_dict (见❷)。在这个字典中,我们使用键'value' 存储了星数,并使用键'label' 存储了项目描述。接下来,我们
将字典plot_dict 附加到plot_dicts 末尾(见❸)。在❹处,我们将列表plot_dicts 传递给了add() 。图17-4显示了生成的图表。
图17-4 将鼠标指向条形将显示项目的描述
17.2.4 在图表中添加可单击的链接
Pygal还允许你将图表中的每个条形用作网站的链接。为此,只需添加一行代码,在为每个项目创建的字典中,添加一个键为'xlink' 的键—值对:
python_repos.py
—snip—
names, plot_dicts = [], []
for repo_dict in repo_dicts:
names.append(repo_dict['name'])
plot_dict = {
'value': repo_dict['stargazers_count'],
'label': repo_dict['description'],
'xlink': repo_dict['html_url'],
}
plot_dicts.append(plot_dict)
—snip—
Pygal根据与键'xlink' 相关联的URL将每个条形都转换为活跃的链接。单击图表中的任何条形时,都将在浏览器中打开一个新的标签页,并在其中显示相应项目的GitHub页面。
至此,你对API获取的数据进行了可视化,它是交互性的,包含丰富的信息!
17.3 Hacker News API
为探索如何使用其他网站的API调用,我们来看看Hacker News(http://news.ycombinator.com/ )。在Hacker News网站,用户分享编程和技术方面的文章,并就这些文章展开积极的讨
论。Hacker News的API让你能够访问有关该网站所有文章和评论的信息,且不要求你通过注册获得密钥。
下面的调用返回本书编写时最热门的文章的信息:
https://hacker-news.firebaseio.com/v0/item/9884165.json
响应是一个字典,包含ID为9884165的文章的信息:
{
❶ 'url': 'http://www.bbc.co.uk/news/science-environment-33524589',
'type': 'story',
❷ 'title': 'New Horizons: Nasa spacecraft speeds past Pluto',
❸ 'descendants': 141,
'score': 230,
'time': 1436875181,
'text': '',
'by': 'nns',
'id': 9884165,
❹ 'kids': [9884723, 9885099, 9884789, 9885604, 9885844]
}
这个字典包含很多键,如'url' (见❶)和'title' (见❷)。与键'descendants' 相关联的值是文章被评论的次数(见❸)。与键'kids' 相关联的值包含对文章所做的
所有评论的ID(见❹)。每个评论自己也可能有kid,因此文章的后代(descendant)数量可能比其kid数量多。
下面来执行一个API调用,返回Hacker News上当前热门文章的ID,再查看每篇排名靠前的文章:
hn_submissions.py
import requests
from operator import itemgetter
执行API调用并存储响应
❶ url = 'https://hacker-news.firebaseio.com/v0/topstories.json'
r = requests.get(url)
print("Status code:", r.status_code)
处理有关每篇文章的信息
❷ submission_ids = r.json()
❸ submission_dicts = []
for submission_id in submission_ids[:30]:
对于每篇文章,都执行一个API调用
❹ url = ('https://hacker-news.firebaseio.com/v0/item/' +
str(submission_id) + '.json')
submission_r = requests.get(url)
print(submission_r.status_code)
response_dict = submission_r.json()
❺ submission_dict = {
'title': response_dict['title'],
'link': 'http://news.ycombinator.com/item?id=' + str(submission_id),
❻ 'comments': response_dict.get('descendants', 0)
}
submission_dicts.append(submission_dict)
❼ submission_dicts = sorted(submission_dicts, key=itemgetter('comments'), reverse=True) ❽ for submission_dict in submission_dicts:
print("\nTitle:", submission_dict['title'])
print("Discussion link:", submission_dict['link'])
print("Comments:", submission_dict['comments'])
首先,我们执行了一个API调用,并打印了响应的状态(见❶)。这个API调用返回一个列表,其中包含Hacker News上当前最热门的500篇文章的ID。接下来,我们将响应文本转
换为一个Python列表(见❷),并将其存储在submission_ids 中。我们将使用这些ID来创建一系列字典,其中每个字典都存储了一篇文章的信息。
在❸处,我们创建了一个名为submission_dicts 的空列表,用于存储前面所说的字典。接下来,我们遍历前30篇文章的ID。对于每篇文章,我们都执行一个API调用,其中
的URL包含submission_id 的当前值(见❹)。我们打印每次请求的状态,以便知道请求是否成功了。
在❺处,我们为当前处理的文章创建一个字典,并在其中存储文章的标题以及到其讨论页面的链接。在❻处,我们在这个字典中存储了评论数。如果文章还没有评论,响应字典
中将没有键'descendants' 。不确定某个键是否包含在字典中时,可使用方法dict.get() ,它在指定的键存在时返回与之相关联的值,并在指定的键不存在时返回你指定
的值(这里是0)。最后,我们将submission_dict 附加到submission_dicts 末尾。
Hacker News上的文章是根据总体得分排名的,而总体得分取决于很多因素,其中包含被推荐的次数、评论数以及发表的时间。我们要根据评论数对字典列
表submission_dicts 进行排序,为此,使用了模块operator 中的函数itemgetter() (见❼)。我们向这个函数传递了键'comments' ,因此它将从这个列表的每个
字典中提取与键'comments' 相关联的值。这样,函数sorted() 将根据这种值对列表进行排序。我们将列表按降序排列,即评论最多的文章位于最前面。
对列表排序后,我们遍历这个列表(见❽),对于每篇热门文章,都打印其三项信息:标题、到讨论页面的链接以及文章现有的评论数:
Status code: 200
200
200
200
—snip—
Title: Firefox deactivates Flash by default
Discussion link: http://news.ycombinator.com/item?id=9883246
Comments: 231
Title: New Horizons: Nasa spacecraft speeds past Pluto
Discussion link: http://news.ycombinator.com/item?id=9884165
Comments: 142
Title: Iran Nuclear Deal Is Reached With World Powers
Discussion link: http://news.ycombinator.com/item?id=9884005
Comments: 141
Title: Match Group Buys PlentyOfFish for $575M
Discussion link: http://news.ycombinator.com/item?id=9884417
Comments: 75
Title: Our Nexus 4 devices are about to explode
Discussion link: http://news.ycombinator.com/item?id=9885625
Comments: 14
—snip—
使用任何API来访问和分析信息时,流程都与此类似。有了这些数据后,你就可以进行可视化,指出最近哪些文章引发了最激烈的讨论。
动手试一试
17-1 其他语言 :修改python_repos.py中的API调用,使其在生成的图表中显示使用其他语言编写的最受欢迎的项目。请尝试语言JavaScript、Ruby、C、Java、Perl、
Haskel和Go等。
17-2 最活跃的讨论 :使用hn_submissions.py中的数据,创建一个条形图,显示Hacker News上当前最活跃的讨论。条形的高度应对应于文章得到的评论数量,条形的标
签应包含文章的标题,而每个条形应是到该文章讨论页面的链接。
17-3 测试python_repos.py :在python_repos.py中,打印status_code 的值,以核实API调用是否成功了。请编写一个名为test_python_repos.py的程序,它使用单元测试
来断言status_code 的值为200。想想你还可做出哪些断言,如返回的条目数符合预期,仓库总数超过特定的值等。

17.4 小结
在本章中,你学习了:如何使用API来编写独立的程序,它们自动采集所需的数据并对其进行可视化;使用GitHub API来探索GitHub上星级最高的Python项目,还大致地了解了
Hacker News API;如何使用requests包来自动执行GitHub API调用,以及如何处理调用的结果。我们还简要地介绍了一些Pygal设置,使用它们可进一步定制生成的图表的外观。
在本书的最后一个项目中,我们将使用Django来创建一个Web应用程序。
项目3 Web 应用程序
第 18 章 Django 入门
当今的网站实际上都是富应用程序(rich application),就像成熟的桌面应用程序一样。Python提供了一组开发Web应用程序的卓越工具。在本章中,你将学习如何使用
Django(http://djangoproject.com/ )来开发一个名为“学习笔记”(Learning Log)的项目,这是一个在线日志系统,让你能够记录所学习的有关特定主题的知识。
我们将为这个项目制定规范,然后为应用程序使用的数据定义模型。我们将使用Django的管理系统来输入一些初始数据,再学习编写视图和模板,让Django能够为我们
的网站创建网页。
Django是一个Web 框架 ——一套用于帮助开发交互式网站的工具。Django能够响应网页请求,还能让你更轻松地读写数据库、管理用户等。在第19章和第20章,我们
将改进“学习笔记”项目,再将其部署到活动的服务器,让你和你的朋友能够使用它。
18.1 建立项目
建立项目时,首先需要以规范的方式对项目进行描述,再建立虚拟环境,以便在其中创建项目。
18.1.1 制定规范
完整的规范详细说明了项目的目标,阐述了项目的功能,并讨论了项目的外观和用户界面。与任何良好的项目规划和商业计划书一样,规范应突出重点,帮助避免项目偏离轨
道。这里不会制定完整的项目规划,而只列出一些明确的目标,以突出开发的重点。我们制定的规范如下:
我们要编写一个名为“学习笔记”的Web应用程序,让用户能够记录感兴趣的主题,并在学习每个主题的过程中添加日志条目。“学习笔记”的主页对这个网站进行描述,
并邀请用户注册或登录。用户登录后,就可创建新主题、添加新条目以及阅读既有的条目。
学习新的主题时,记录学到的知识可帮助跟踪和复习这些知识。优秀的应用程序让这个记录过程简单易行。
18.1.2 建立虚拟环境
要使用Django,首先需要建立一个虚拟工作环境。虚拟环境 是系统的一个位置,你可以在其中安装包,并将其与其他Python包隔离。将项目的库与其他项目分离是有益的,且为
了在第20章将“学习笔记”部署到服务器,这也是必须的。
为项目新建一个目录,将其命名为learning_log,再在终端中切换到这个目录,并创建一个虚拟环境。如果你使用的是Python 3,可使用如下命令来创建虚拟环境:
learning_log$ python -m venv ll_env
learning_log$
这里运行了模块venv ,并使用它来创建一个名为l_env的虚拟环境。如果这样做管用,请跳到后面的18.1.4节;如果不管用,请阅读18.1.3节。
18.1.3 安装virtualenv
如果你使用的是较早的Python版本,或者系统没有正确地设置,不能使用模块venv ,可安装virtualenv包。为此,可执行如下命令:
$ pip install —user virtualenv
别忘了,对于这个命令,你可能需要使用稍微不同的版本(如果你没有使用过pip,请参阅12.2.1节)。
注意 如果你使用的是Linux系统,且上面的做法不管用,可使用系统的包管理器来安装virtualenv。例如,要在Ubuntu系统中安装virtualenv,可使用命令sudo apt-get install python-virtualenv 。
在终端中切换到目录learning_log,并像下面这样创建一个虚拟环境:
learning_log$ virtualenv ll_env
New python executable in ll_env/bin/python
Installing setuptools, pip…done.
learning_log$
注意 如果你的系统安装了多个Python版本,需要指定virtualenv使用的版本。例如,命令virtualenv ll_env —python=python3 创建一个使用Python 3的虚拟
环境。
18.1.4 激活虚拟环境
建立虚拟环境后,需要使用下面的命令激活它:
learning_log$ source ll_env/bin/activate
❶ (ll_env)learning_log$
这个命令运行l_env/bin中的脚本activate。环境处于活动状态时,环境名将包含在括号内,如❶处所示。在这种情况下,你可以在环境中安装包,并使用已安装的包。你在l_env中安
装的包仅在该环境处于活动状态时才可用。
注意 如果你使用的是Windows系统,请使用命令ll_env\Scripts\activate (不包含source )来激活这个虚拟环境。
要停止使用虚拟环境,可执行命令deactivate :
(ll_env)learning_log$ deactivate
learning_log$
如果关闭运行虚拟环境的终端,虚拟环境也将不再处于活动状态。
18.1.5 安装Django
创建并激活虚拟环境后,就可安装Django了:
(ll_env)learning_log$ pip install Django
Installing collected packages: Django
Successfully installed Django
Cleaning up…
(ll_env)learning_log$
由于我们是在虚拟环境中工作,因此在所有的系统中,安装Django的命令都相同:不需要指定标志—user ,也无需使用python -m pip install package_name 这样较
长的命令。
别忘了,Django仅在虚拟环境处于活动状态时才可用。
18.1.6 在Django 中创建项目
在依然处于活动的虚拟环境的情况下(l_env包含在括号内),执行如下命令来新建一个项目:
❶ (ll_env)learning_log$ django-admin.py startproject learning_log .
❷ (ll_env)learning_log$ ls
learning_log ll_env manage.py
❸ (ll_env)learning_log$ ls learning_log
init.py settings.py urls.py wsgi.py
❶处的命令让Django新建一个名为learning_log的项目。这个命令末尾的句点让新项目使用合适的目录结构,这样开发完成后可轻松地将应用程序部署到服务器。
注意 千万别忘了这个句点,否则部署应用程序时将遭遇一些配置问题。如果忘记了这个句点,就将创建的文件和文件夹删除(l_env除外),再重新运行这个命令。
在❸处,运行了命令ls (在Windows系统上应为dir ),结果表明Django新建了一个名为learning_log的目录。它还创建了一个名为manage.py的文件,这是一个简单的程序,它接受
命令并将其交给Django的相关部分去运行。我们将使用这些命令来管理诸如使用数据库和运行服务器等任务。
目录learning_log包含4个文件(见❸),其中最重要的是settings.py、urls.py和wsgi.py。文件settings.py指定Django如何与你的系统交互以及如何管理项目。在开发项目的过程中,我们
将修改其中一些设置,并添加一些设置。文件urls.py告诉Django应创建哪些网页来响应浏览器请求。文件wsgi.py帮助Django提供它创建的文件,这个文件名是web server gateway interface(Web 服务器网关接口 )的首字母缩写。
18.1.7 创建数据库
Django将大部分与项目相关的信息都存储在数据库中,因此我们需要创建一个供Django使用的数据库。为给项目“学习笔记”创建数据库,请在处于活动虚拟环境中的情况下执行下
面的命令:
(ll_env)learning_log$ python manage.py migrate
❶ Operations to perform:
Synchronize unmigrated apps: messages, staticfiles
Apply all migrations: contenttypes, sessions, auth, admin
—snip—
Applying sessions.0001_initial… OK
❷ (ll_env)learning_log$ ls
db.sqlite3 learning_log ll_env manage.py
我们将修改数据库称为迁移 数据库。首次执行命令migrate 时,将让Django确保数据库与项目的当前状态匹配。在使用SQLite(后面将更详细地介绍)的新项目中首次执行这个
命令时,Django将新建一个数据库。在❶处,Django指出它将创建必要的数据库表,用于存储我们将在这个项目(Synchronize unmigrated apps,同步未迁移的应用程序 )中使用的
信息,再确保数据库结构与当前代码(Apply al migrations,应用所有的迁移 )匹配。
在❷处,我们运行了命令ls ,其输出表明Django又创建了一个文件——db.sqlite3。SQLite是一种使用单个文件的数据库,是编写简单应用程序的理想选择,因为它让你不用太关
注数据库管理的问题。
18.1.8 查看项目
下面来核实Django是否正确地创建了项目。为此,可执行命令runserver ,如下所示:
(ll_env)learning_log$ python manage.py runserver
Performing system checks…
❶ System check identified no issues (0 silenced).
July 15, 2015 - 06:23:51
❷ Django version 1.8.4, using settings 'learning_log.settings'
❸ Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
Django启动一个服务器,让你能够查看系统中的项目,了解它们的工作情况。当你在浏览器中输入URL以请求网页时,该Django服务器将进行响应:生成合适的网页,并将其发送
给浏览器。
在❶处,Django通过检查确认正确地创建了项目;在❷处,它指出了使用的Django版本以及当前使用的设置文件的名称;在❸处,它指出了项目的URL。URL http://127.0.0.1:8000/
表明项目将在你的计算机(即localhost)的端口8000上侦听请求。localhost是一种只处理当前系统发出的请求,而不允许其他任何人查看你正在开发的网页的服务器。
现在打开一款Web浏览器,并输入URL:http://localhost:8000/;如果这不管用,请输入http://127.0.0.1:8000/。你将看到类似于图18-1所示的页面,这个页面是Django创建的,让你知道
到目前为止一切正常。现在暂时不要关闭这个服务器。若要关闭这个服务器,按Ctrl + C即可。
图18-1 到目前为止一切正常
注意 如果出现错误消息“That port is already in use”(指定端口已被占用),请执行命令python manage.py runserver 8001 ,让Diango使用另一个端口;如果
这个端口也不可用,请不断执行上述命令,并逐渐增大其中的端口号,直到找到可用的端口。
动手试一试
18-1 新项目 :为更深入地了解Django做了些什么,可创建两个空项目,看看Django创建了什么。新建一个文件夹,并给它指定简单的名称,如InstaBook或
FaceGram(不要在目录learning_log中新建该文件夹),在终端中切换到该文件夹,并创建一个虚拟环境。在这个虚拟环境中安装Django,并执行命令django-admin.py startproject instabook. (千万不要忘了这个命令末尾的句点)。
看看这个命令创建了哪些文件和文件夹,并与项目“学习笔记”包含的文件和文件夹进行比较。这样多做几次,直到对Django新建项目时创建的东西了如指掌。然后,将
项目目录删除——如果你想这样做的话。
18.2 创建应用程序
Django 项目 由一系列应用程序组成,它们协同工作,让项目成为一个整体。我们暂时只创建一个应用程序,它将完成项目的大部分工作。在第19章,我们将再添加一个管理用户
账户的应用程序。
当前,在前面打开的终端窗口中应该还运行着runserver 。请再打开一个终端窗口(或标签页),并切换到manage.py所在的目录。激活该虚拟环境,再执行命令startapp :
learning_log$ source ll_env/bin/activate
(ll_env)learning_log$ python manage.py startapp learning_logs
❶ (ll_env)learning_log$ ls
db.sqlite3 learning_log learning_logs ll_env manage.py
❷ (ll_env)learning_log$ ls learning_logs/
admin.py init.py migrations models.py tests.py views.py
命令startapp appname 让Django建立创建应用程序所需的基础设施。如果现在查看项目目录,将看到其中新增了一个文件夹learning_logs(见❶)。打开这个文件夹,看看
Django都创建了什么(见❷)。其中最重要的文件是models.py、admin.py和views.py。我们将使用models.py来定义我们要在应用程序中管理的数据。admin.py和views.py将在稍后介
绍。
18.2.1 定义模型
我们来想想涉及的数据。每位用户都需要在学习笔记中创建很多主题。用户输入的每个条目都与特定主题相关联,这些条目将以文本的方式显示。我们还需要存储每个条目的时
间戳,以便能够告诉用户各个条目都是什么时候创建的。
打开文件models.py,看看它当前包含哪些内容:
models.py
from django.db import models
在这里创建模型
这为我们导入了模块models,还让我们创建自己的模型。模型告诉Django如何处理应用程序中存储的数据。在代码层面,模型就是一个类,就像前面讨论的每个类一样,包含属性
和方法。下面是表示用户将要存储的主题的模型:
from django.db import models
class Topic(models.Model):
"""用户学习的主题"""
❶ text = models.CharField(max_length=200)
❷ date_added = models.DateTimeField(auto_now_add=True)
❸ def str(self):
"""返回模型的字符串表示"""
return self.text
我们创建了一个名为Topic 的类,它继承了Model ——Django中一个定义了模型基本功能的类。Topic 类只有两个属性:text 和date_added 。
属性text是一个CharField——由字符或文本组成的数据(见❶)。需要存储少量的文本,如名称、标题或城市时,可使用CharField 。定义CharField 属性时,必须告诉Django 该在数据库中预留多少空间。在这里,我们将max_length 设置成了200(即200个字符),这对存储大多数主题名来说足够了。
属性date_added 是一个DateTimeField ——记录日期和时间的数据(见❷)。我们传递了实参auto_add_now=True ,每当用户创建新主题时,这都让Django将这个属性
自动设置成当前日期和时间。
注意 要获悉可在模型中使用的各种字段,请参阅Django Model Field Reference(Django模型字段参考),其网址为https://docs.djangoproject.com/en/1.8/ref/models/fields/ 。
就当前而言,你无需全面了解其中的所有内容,但自己开发应用程序时,这些内容会提供极大的帮助。
我们需要告诉Django,默认应使用哪个属性来显示有关主题的信息。Django调用方法str() 来显示模型的简单表示。在这里,我们编写了方法str() ,它返回存储在
属性text 中的字符串(见❸)。
注意 如果你使用的是Python 2.7,应调用方法unicode() ,而不是str() ,但其中的代码相同。
18.2.2 激活模型
要使用模型,必须让Django将应用程序包含到项目中。为此,打开settings.py(它位于目录learning_log/learning_log中),你将看到一个这样的片段,即告诉Django哪些应用程序安装
在项目中:
settings.py
—snip—
INSTALLED_APPS = (
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
)
—snip—
这是一个元组,告诉Django项目是由哪些应用程序组成的。请将INSTALLED_APPS 修改成下面这样,将前面的应用程序添加到这个元组中:
—snip—
INSTALLED_APPS = (
—snip—
'django.contrib.staticfiles',
我的应用程序
'learning_logs',
)
—snip—
通过将应用程序编组,在项目不断增大,包含更多的应用程序时,有助于对应用程序进行跟踪。这里新建了一个名为My apps的片段,当前它只包含应用程序learning_logs。
接下来,需要让Django修改数据库,使其能够存储与模型Topic 相关的信息。为此,在终端窗口中执行下面的命令:
(ll_env)learning_log$ python manage.py makemigrations learning_logs
Migrations for 'learning_logs':
0001_initial.py:
- Create model Topic
(ll_env)learning_log$
命令makemigrations 让Django确定该如何修改数据库,使其能够存储与我们定义的新模型相关联的数据。输出表明Django创建了一个名为0001_initial.py的迁移文件,这个文件
将在数据库中为模型Topic 创建一个表。
下面来应用这种迁移,让Django替我们修改数据库:
(ll_env)learning_log$ python manage.py migrate
—snip—
Running migrations:
Rendering model states… DONE
❶ Applying learning_logs.0001_initial… OK
这个命令的大部分输出都与我们首次执行命令migrate的输出相同。我们需要检查的是❶处的输出行,在这里,Django确认为learning_logs 应用迁移时一切正常(OK )。
每当需要修改“学习笔记”管理的数据时,都采取如下三个步骤:修改models.py;对learning_logs 调用makemigrations ;让Django迁移项目。
18.2.3 Django 管理网站
为应用程序定义模型时,Django提供的管理网站(admin site)让你能够轻松地处理模型。网站的管理员可使用管理网站,但普通用户不能使用。在本节中,我们将建立管理网站,
并通过它使用模型Topic 来添加一些主题。
- 创建超级用户
Django允许你创建具备所有权限的用户——超级用户。权限决定了用户可执行的操作。最严格的权限设置只允许用户阅读网站的公开信息;注册了的用户通常可阅读自己的私有
数据,还可查看一些只有会员才能查看的信息。为有效地管理Web应用程序,网站所有者通常需要访问网站存储的所有信息。优秀的管理员会小心对待用户的敏感信息,因为用
户对其访问的应用程序有极大的信任。
为在Django中创建超级用户,请执行下面的命令并按提示做:
(ll_env)learning_log$ python manage.py createsuperuser
❶ Username (leave blank to use 'ehmatthes'): ll_admin
❷ Email address:
❸ Password:
Password (again):
Superuser created successfully.
(ll_env)learning_log$
你执行命令createsuperuser 时,Django提示你输入超级用户的用户名(见❶)。这里我们输入的是l_admin,但你可以输入任何用户名,比如电子邮件地址,也可让这个字段
为空(见❷)。你需要输入密码两次(见❸)。
注意 可能会对网站管理员隐藏有些敏感信息。例如,Django并不存储你输入的密码,而存储从该密码派生出来的一个字符串——散列值。每当你输入密码
时,Django都计算其散列值,并将结果与存储的散列值进行比较。如果这两个散列值相同,就通过了身份验证。通过存储散列值,即便黑客获得了网站数据库的访问
权,也只能获取其中存储的散列值,而无法获得密码。在网站配置正确的情况下,几乎无法根据散列值推导出原始密码。
- 向管理网站注册模型
Django自动在管理网站中添加了一些模型,如User 和Group ,但对于我们创建的模型,必须手工进行注册。
我们创建应用程序learning_logs 时,Django在models.py所在的目录中创建了一个名为admin.py的文件:
admin.py
from django.contrib import admin
在这里注册你的模型
为向管理网站注册Topic ,请输入下面的代码:
from django.contrib import admin
❶ from learning_logs.models import Topic
❷ admin.site.register(Topic)
这些代码导入我们要注册的模型Topic (见❶),再使用admin.site.register() (见❷)让Django通过管理网站管理我们的模型。
现在,使用超级用户账户访问管理网站:访问http://localhost:8000/admin/ ,并输入你刚创建的超级用户的用户名和密码,你将看到类似于图18-2所示的屏幕。这个网页让你能够添加
和修改用户和用户组,还可以管理与刚才定义的模型Topic 相关的数据。
图18-2 包含模型Topic 的管理网站
注意 如果你在浏览器中看到一条消息,指出访问的网页不可用,请确认你在终端窗口中运行着Django服务器。如果没有,请激活虚拟环境,并执行命令python manage.py runserver 。
- 添加主题
向管理网站注册Topic 后,我们来添加第一个主题。为此,单击Topics进入主题网页,它几乎是空的,这是因为我们还没有添加任何主题。单击Add,你将看到一个用于添加新主
题的表单。在第一个方框中输入Chess ,再单击Save,这将返回到主题管理页面,其中包含刚创建的主题。
下面再创建一个主题,以便有更多的数据可供使用。再次单击Add,并创建另一个主题Rock Climbing 。当你单击Save时,将重新回到主题管理页面,其中包含主题Chess和
Rock Climbing。
18.2.4 定义模型Entry
要记录学到的国际象棋和攀岩知识,需要为用户可在学习笔记中添加的条目定义模型。每个条目都与特定主题相关联,这种关系被称为多对一关系,即多个条目可关联到同一个
主题。
下面是模型Entry 的代码:
models.py
from django.db import models
class Topic(models.Model):
—snip—
❶ class Entry(models.Model):
"""学到的有关某个主题的具体知识"""
❷ topic = models.ForeignKey(Topic)
❸ text = models.TextField()
date_added = models.DateTimeField(auto_now_add=True)
❹ class Meta:
verbose_name_plural = 'entries'
def str(self):
"""返回模型的字符串表示"""
❺ return self.text[:50] + "…"
像Topic 一样,Entry 也继承了Django基类Model (见❶)。第一个属性topic 是一个ForeignKey 实例(见❷)。外键是一个数据库术语,它引用了数据库中的另一条记
录;这些代码将每个条目关联到特定的主题。每个主题创建时,都给它分配了一个键(或ID)。需要在两项数据之间建立联系时,Django使用与每项信息相关联的键。稍后我们
将根据这些联系获取与特定主题相关联的所有条目。
接下来是属性text ,它是一个TextField 实例(见❸)。这种字段不需要长度限制,因为我们不想限制条目的长度。属性date_added 让我们能够按创建顺序呈现条目,并
在每个条目旁边放置时间戳。
在❹处,我们在Entry 类中嵌套了Meta 类。Meta 存储用于管理模型的额外信息,在这里,它让我们能够设置一个特殊属性,让Django在需要时使用Entries 来表示多个条
目。如果没有这个类, Django将使用Entrys来表示多个条目。最后,方法str() 告诉Django,呈现条目时应显示哪些信息。由于条目包含的文本可能很长,我们让Django只
显示text 的前50个字符(见❺)。我们还添加了一个省略号,指出显示的并非整个条目。
18.2.5 迁移模型Entry
由于我们添加了一个新模型,因此需要再次迁移数据库。你将慢慢地对这个过程了如指掌:修改models.py,执行命令python manage.py makemigrations app_name ,
再执行命令python manage.py migrate 。
下面来迁移数据库并查看输出:
(ll_env)learning_log$ python manage.py makemigrations learning_logs
Migrations for 'learning_logs':
❶ 0002_entry.py:
- Create model Entry
(ll_env)learning_log$ python manage.py migrate
Operations to perform:
—snip—
❷ Applying learning_logs.0002_entry… OK
生成了一个新的迁移文件——0002_entry.py,它告诉Django如何修改数据库,使其能够存储与模型Entry 相关的信息(见❶)。执行命令migrate ,我们发现Django应用了这种
迁移且一切顺利(见❷)。
18.2.6 向管理网站注册Entry
我们还需要注册模型Entry 。为此,需要将admin.py修改成类似于下面这样:
admin.py
from django.contrib import admin
from learning_logs.models import Topic, Entry
admin.site.register(Topic)
admin.site.register(Entry)
返回到http://localhost/admin/ ,你将看到learning_logs下列出了Entries。单击Entries的Add链接,或者单击Entries再选择Add entry。你将看到一个下拉列表,让你能够选择要为哪个主题创
建条目,还有一个用于输入条目的文本框。从下拉列表中选择Chess,并添加一个条目。下面是我添加的第一个条目。
The opening is the first part of the game, roughly the first ten moves or so. In the opening, it's a good idea to do three things— bring out your bishops and knights, try to control the center of the board, and castle your king.(国际象棋的第一个阶段是开局,大致是前10步左右。在开局阶段,最好做三件事情:将象和马调出来;努力控制棋盘的中间区域;用车将王
护住。)
Of course, these are just guidelines. It wil be important to learn when to folow these guidelines and when to disregard these suggestions.(当然,这些只是指导原则。学习什么情况下遵
守这些原则、什么情况下不用遵守很重要。)
当你单击Save时,将返回到主条目管理页面。在这里,你将发现使用text[:50] 作为条目的字符串表示的好处:管理界面中,只显示了条目的开头部分而不是其所有文本,这
使得管理多个条目容易得多。
再来创建一个国际象棋条目,并创建一个攀岩条目,以提供一些初始数据。下面是第二个国际象棋条目。
In the opening phase of the game, it's important to bring out your bishops and knights. These pieces are powerful and maneuverable enough to play a significant role in the beginning moves of a game.(在国际象棋的开局阶段,将象和马调出来很重要。这些棋子威力大,机动性强,在开局阶段扮演着重要角色。)
下面是第一个攀岩条目:
One of the most important concepts in climbing is to keep your weight on your feet as much as possible. There's a myth that climbers can hang al day on their arms. In reality, good climbers have practiced specific ways of keeping their weight over their feet whenever possible.(最重要的攀岩概念之一是尽可能让双脚承受体重。有谬误认为攀岩者能依靠手臂的力量坚持一
整天。实际上,优秀的攀岩者都经过专门训练,能够尽可能让双脚承受体重。)
继续往下开发“学习笔记”时,这三个条目可为我们提供使用的数据。
18.2.7 Django shell
输入一些数据后,就可通过交互式终端会话以编程方式查看这些数据了。这种交互式环境称为Django shel,是测试项目和排除其故障的理想之地。下面是一个交互式shel会话示
例:
(ll_env)learning_log$ python manage.py shell
❶ >>> from learning_logs.models import Topic
>>> Topic.objects.all()
[<Topic: Chess>, <Topic: Rock Climbing>]
在活动的虚拟环境中执行时,命令python manage.py shell 启动一个Python解释器,可使用它来探索存储在项目数据库中的数据。在这里,我们导入了模
块learning_logs.models 中的模型Topic (见❶),然后使用方法Topic.objects.all() 来获取模型Topic 的所有实例;它返回的是一个列表,称为查询集
(queryset)。
我们可以像遍历列表一样遍历查询集。下面演示了如何查看分配给每个主题对象的ID:
>>> topics = Topic.objects.all()
>>> for topic in topics:
… print(topic.id, topic)
…
1 Chess
2 Rock Climbing
我们将返回的查询集存储在topics 中,然后打印每个主题的id 属性和字符串表示。从输出可知,主题Chess的ID为1,而Rock Climbing的ID为2。
知道对象的ID后,就可获取该对象并查看其任何属性。下面来看看主题Chess的属性text 和date_added 的值:
>>> t = Topic.objects.get(id=1)
>>> t.text
'Chess'
>>> t.date_added
datetime.datetime(2015, 5, 28, 4, 39, 11, 989446, tzinfo=<UTC>)
我们还可以查看与主题相关联的条目。前面我们给模型Entry 定义了属性topic ,这是一个ForeignKey ,将条目与主题关联起来。利用这种关联,Django能够获取与特定主
题相关联的所有条目,如下所示:
❶ >>> t.entry_set.all()
[<Entry: The opening is the first part of the game, roughly…>, <Entry: In the opening phase of the game, it's important t…>]
为通过外键关系获取数据,可使用相关模型的小写名称、下划线和单词set(见❶)。例如,假设你有模型Pizza 和Topping ,而Topping通过一个外键关联到Pizza ;如果你有
一个名为my_pizza 的对象,表示一张比萨,就可使用代码my_pizza.topping_set.all() 来获取这张比萨的所有配料。
编写用户可请求的网页时,我们将使用这种语法。确认代码能获取所需的数据时,shel很有帮助。如果代码在shel中的行为符合预期,那么它们在项目文件中也能正确地工作。如
果代码引发了错误或获取的数据不符合预期,那么在简单的shel环境中排除故障要比在生成网页的文件中排除故障容易得多。我们不会太多地使用shel,但应继续使用它来熟悉对
存储在项目中的数据进行访问的Django语法。
注意 每次修改模型后,你都需要重启shel,这样才能看到修改的效果。要退出shel会话,可按Ctr + D;如果你使用的是Windows系统,应按Ctr + Z,再按回车键。
动手试一试
18-2 简短的条目 :当前,Django在管理网站或shel中显示Entry 实例时,模型Entry 的方法str() 都在它的末尾加上省略号。请在方法str() 中添加一
条if 语句,以便仅在条目长度超过50字符时才添加省略号。使用管理网站来添加一个长度少于50字符的条目,并核实显示它时没有省略号。
18-3 Django API :编写访问项目中的数据的代码时,你编写的是查询。请浏览有关如何查询数据的文档,其网址为https://docs.djangoproject.com/en/7.8/topics/db/queries/
。其中大部分内容都是你不熟悉的,但等你自己开发项目时,这些内容会很有用。
18-4 比萨店 :新建一个名为pizzeria 的项目,并在其中添加一个名为pizzas 的应用程序。定义一个名为Pizza 的模型,它包含字段name ,用于存储比萨名
称,如Hawaian和Meat Lovers。定义一个名为Topping 的模型,它包含字段pizza 和name ,其中字段pizza 是一个关联到Pizza 的外键,而字段name 用于存储配
料,如pineapple 、Canadian bacon 和sausage 。
向管理网站注册这两个模型,并使用管理网站输入一些比萨名和配料。使用shel来查看你输入的数据。
18.3 创建网页:学习笔记主页
使用Django创建网页的过程通常分三个阶段:定义URL、编写视图和编写模板。首先,你必须定义URL模式。URL模式描述了URL是如何设计的,让Django知道如何将浏览器请求
与网站URL匹配,以确定返回哪个网页。
每个URL都被映射到特定的视图 ——视图函数获取并处理网页所需的数据。视图函数通常调用一个模板,后者生成浏览器能够理解的网页。为明白其中的工作原理,我们来创建
学习笔记的主页。我们将定义该主页的URL、编写其视图函数并创建一个简单的模板。
鉴于我们只是要确保“学习笔记”按要求的那样工作,我们将暂时让这个网页尽可能简单。Web应用程序能够正常运行后,设置样式可使其更有趣,但中看不中用的应用程序毫无意
