第6章 特殊的索引和集合
本章介绍MongoDB中一些特殊的集合和索引类型,包括:
- 用于类队列数据的固定集合(capped collection);
- 用于缓存的TTL索引;
- 用于简单字符串搜索的全文本索引;
- 用于二维平面和球体空间的地理空间索引;
- 用于存储大文件的GridFS。
6.1 固定集合
MongoDB中的“普通”集合是动态创建的,而且可以自动增长以容纳更多的数据。MongoDB中还有另一种不同类型的集合,叫做固定集合,固定集合需要事先创建好,而且它的大小是固定的(如图6-1所示)。说到固定大小的集合,有一个很有趣的问题:向一个已经满了的固定集合中插入数据会怎么样?答案是,固定集合的行为类似于循环队列。如果已经没有空间了,最老的文档会被删除以释放空间,新插入的文档会占据这块空间(如图6-2所示)。也就是说,当固定集合被占满时,如果再插入新文档,固定集合会自动将最老的文档从集合中删除。
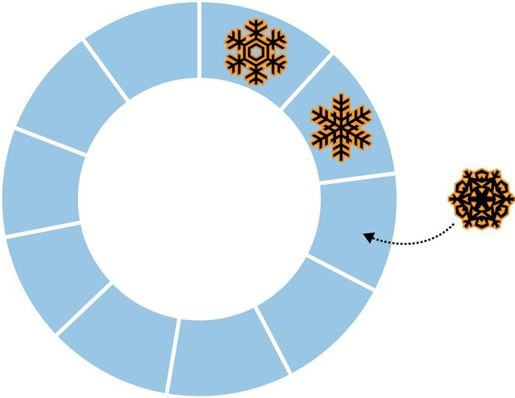
图6-1 新文档被插入到队列末尾
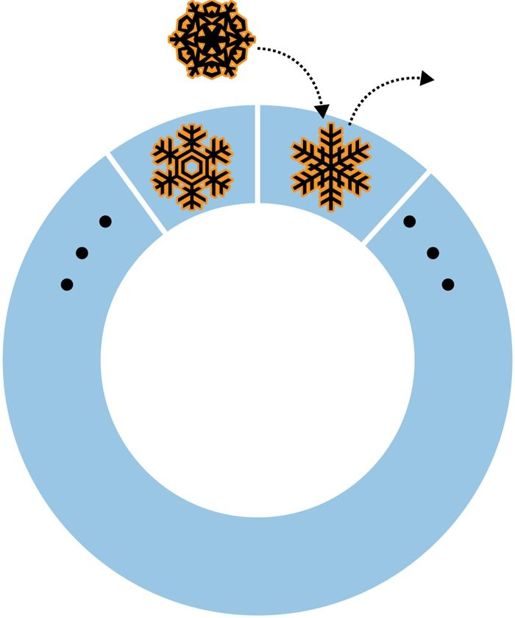
图6-2 如果队列已经被占满,那么最老的文档会被之后插入的新文档覆盖
固定集合的访问模式与MongoDB中的大部分集合不同:数据被顺序写入磁盘上的固定空间。因此它们在碟式磁盘(spinning disk)上的写入速度非常快,尤其是集合拥有专用磁盘时(这样就不会因为其他集合的一些随机性的写操作而“中断”)。
固定集合不能被分片。
固定集合可以用于记录日志,尽管它们不够灵活。虽然可以在创建时指定集合大小,但无法控制什么时候数据会被覆盖。
6.1.1 创建固定集合
不同于普通集合,固定集合必须在使用之前先显式创建。可以使用create命令创建固定集合。在shell中,可以使用createCollection函数:
> db.createCollection("my_collection", {"capped" : true, "size" : 100000});{ "ok" : true }
上面的命令创建了一个名为my_collection大小为100 000字节的固定集合。
除了大小,createCollection还能够指定固定集合中文档的数量:
> db.createCollection("my_collection2",... {"capped" : true, "size" : 100000, "max" : 100});{ "ok" : true }
可以使用这种方式来保存最新的10则新闻,或者是将每个用户的文档数量限制为1000。
固定集合创建之后,就不能改变了(如果需要修改固定集合的属性,只能将它删除之后再重建)。因此,在创建大的固定集合之前应该仔细想清楚它的大小。
为固定集合指定文档数量限制时,必须同时指定固定集合的大小。不管先达到哪一个限制,之后插入的新文档就会把最老的文档挤出集合:固定集合的文档数量不能超过文档数量限制,固定集合的大小也不能超过大小限制。
创建固定集合时还有另一个选项,可以将已有的某个常规集合转换为固定集合,可以使用convertToCapped命令实现。下面的例子将test集合转换为一个大小为10 000字节的固定集合:
> db.runCommand({"convertToCapped" : "test", "size" : 10000});{ "ok" : true }
无法将固定集合转换为非固定集合(只能将其删除)。
6.1.2 自然排序
对固定集合可以进行一种特殊的排序,称为自然排序(natural sort)。自然排序返回结果集中文档的顺序就是文档在磁盘上的顺序(如图6-3所示)。
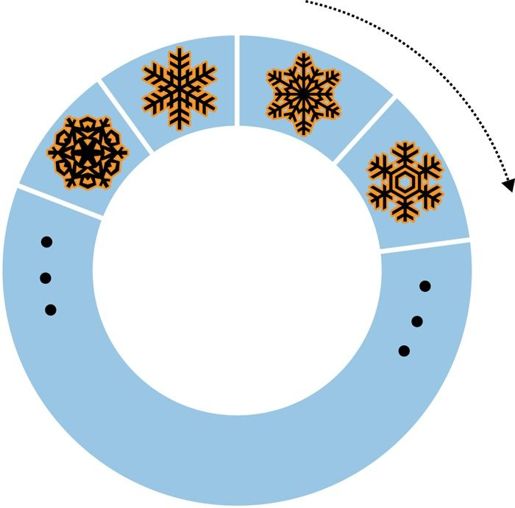
图6-3 使用{"$natural" : 1}进行排序
对大多数集合来说,自然排序的意义不大,因为文档的位置经常变动。但是,固定集合中的文档是按照文档被插入的顺序保存的,自然顺序就是文档的插入顺序。因此,自然排序得到的文档是从旧到新排列的。当然也可以按照从新到旧的顺序排列(如图6-4所示)。
> db.my_collection.find().sort({"$natural" : -1})
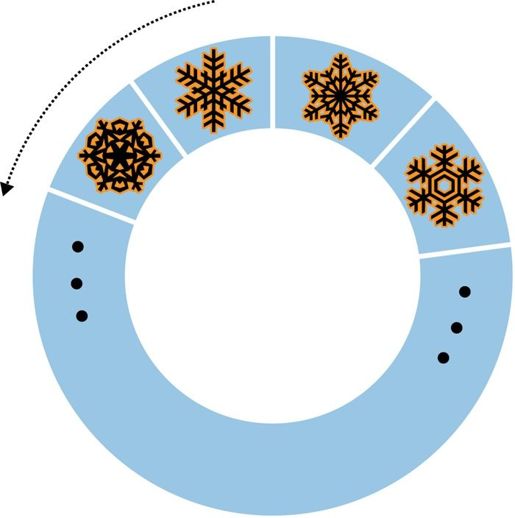
图6-4 使用{"$natural" : -1}进行排序
6.1.3 循环游标
循环游标(tailable cursor)是一种特殊的游标,当循环游标的结果集被取光后,游标不会被关闭。循环游标的灵感来自tail -f命令(循环游标跟这个命令有点儿相似),会尽可能久地持续提取输出结果。由于循环游标在结果集取光之后不会被关闭,因此,当有新文档插入到集合中时,循环游标会继续取到结果。由于普通集合并不维护文档的插入顺序,所以循环游标只能用在固定集合上。
循环游标通常用于当文档被插入到“工作队列”(其实就是个固定集合)时对新插入的文档进行处理。如果超过10分钟没有新的结果,循环游标就会被释放,因此,当游标被关闭时自动重新执行查询是非常重要的。下面是一个在PHP中使用循环游标的例子(不能在mongo shell中使用循环游标):
$cursor = $collection->find()->tailable();while (true) {if (!$cursor->hasNext()) {if ($cursor->dead()) {break;}sleep(1);}else {while ($cursor->hasNext()) {do_stuff($cursor->getNext());}}}
这个游标会不断对查询结果进行处理,或者是等待新的查询结果,直到游标被关闭(超过10分钟没有新的结果或者人为中止查询操作)。
6.1.4 没有_id索引的集合
默认情况下,每个集合都有一个"_id"索引。但是,如果在调用createCollection创建集合时指定autoIndexId选项为false,创建集合时就不会自动在"_id"上创建索引。实践中不建议这么使用,但是对于只有插入操作的集合来说,这确实可以带来速度的稍许提升。
如果创建了一个没有
"_id"索引的集合,那就永远都不能复制它所在的mongod了。复制操作要求每个集合上都要有"_id"索引(对于复制操作,能够唯一标识集合中的每一个文档是非常重要的)。
在2.2版本之前,固定集合默认是没有"_id"索引的,除非显式地将autoIndexId置为true。如果正在使用旧版的固定集合,要确保你的应用程序能够填充"_id"字段(大多数驱动程序会自动填充"_id"字段),然后使用ensureIndex命令创建"_id"索引。
记住,"_id"索引必须是唯一索引。不同于其他索引,"_id"索引一经创建就无法删除了,因此在生产环境中创建索引之前先自己实践一下是非常重要的。所以创建"_id"索引必须一次成功!如果创建的"_id"索引不合规范,就只能删除集合再重建了。
6.2 TTL索引
上一节已经讲过,对于固定集合中的内容何时被覆盖,你只拥有非常有限的控制权限。如果需要更加灵活的老化移出系统(age-out system),可以使用TTL索引(time-to-live index,具有生命周期的索引),这种索引允许为每一个文档设置一个超时时间。一个文档到达预设置的老化程度之后就会被删除。这种类型的索引对于缓存问题(比如会话的保存)非常有用。
在ensureIndex中指定expireAfterSecs选项就可以创建一个TTL索引:
> // 超时时间为24小时> db.foo.ensureIndex({"lastUpdated" : 1}, {"expireAfterSecs" : 60*60*24})
这样就在"lastUpdated"字段上建立了一个TTL索引。如果一个文档的"lastUpdated"字段存在并且它的值是日期类型,当服务器时间比文档的"lastUpdated"字段的时间晚expireAfterSecs秒时,文档就会被删除。
为了防止活跃的会话被删除,可以在会话上有活动发生时将"lastUpdated"字段的值更新为当前时间。只要"lastUpdated"的时间距离当前时间达到24小时,相应的文档就会被删除。
MongoDB每分钟对TTL索引进行一次清理,所以不应该依赖以秒为单位的时间保证索引的存活状态。可以使用collMod命令修改expireAfterSecs的值:
> db.runCommand({"collMod" : "someapp.cache", "expireAfterSecs" : 3600})
在一个给定的集合上可以有多个TTL索引。TTL索引不能是复合索引,但是可以像“普通”索引一样用来优化排序和查询。
6.3 全文本索引
MongoDB有一个特殊类型的索引用于在文档中搜索文本。前面几章都是使用精确匹配和正则表达式来查询字符串,但是这些技术有一些限制。使用正则表达式搜索大块文本的速度非常慢,而且无法处理语言的理解问题(比如entry与entries应该算是匹配的)。使用全文本索引可以非常快地进行文本搜索,就如同内置了多种语言分词机制的支持一样。
创建任何一种索引的开销都比较大,而创建全文本索引的成本更高。在一个操作频繁的集合上创建全文本索引可能会导致MongoDB过载,所以应该是离线状态下创建全文本索引,或者是在对性能没要求时。创建全文本索引时要特别小心谨慎,内存可能会不够用(除非你有SSD)。第18章会介绍如何在创建索引时将对应用程序的影响降至最低。
全文本索引也会导致比“普通”索引更严重的性能问题,因为所有字符串都需要被分解、分词,并且保存到一些地方。因此,可能会发现拥有全文本索引的集合的写入性能比其他集合要差。全文本索引也会降低分片时的数据迁移速度:将数据迁移到其他分片时,所有文本都需要重新进行索引。
写作本书时,全文本索引仍然只是一个处于“试验阶段”的功能,所以需要专门启用这个功能才能进行使用。启动MongoDB时指定--setParameter textSearch Enabled=true选项,或者在运行时执行setParameter命令,都可以启用全文本索引:
> db.adminCommand({"setParameter" : 1, "textSearchEnabled" : true})
假如我们使用这个非官方的Hacker News JSON API(http://api.ihackernews.com)将最近的一些文章加载到了MongoDB中。
为了进行文本搜索,首先需要创建一个"text"索引:
> db.hn.ensureIndex({"title" : "text"})
现在,必须通过text命令才能使用这个索引(写作本书时,全文本索引还不能用在“普通”查询中):
test> db.runCommand({"text" : "hn", "search" : "ask hn"}){"queryDebugString" : "ask|hn||||||","language" : "english","results" : [{"score" : 2.25,"obj" : {"_id" : ObjectId("50dcab296803fa7e4f000011"),"title" : "Ask HN: Most valuable skills you have?","url" : "/comments/4974230","id" : 4974230,"commentCount" : 37,"points" : 31,"postedAgo" : "2 hours ago","postedBy" : "bavidar"}},{"score" : 0.5625,"obj" : {"_id" : ObjectId("50dcab296803fa7e4f000001"),"title" : "Show HN: How I turned an old book...","url" : "http://www.howacarworks.com/about","id" : 4974055,"commentCount" : 44,"points" : 95,"postedAgo" : "2 hours ago","postedBy" : "AlexMuir"}},{"score" : 0.5555555555555556,"obj" : {"_id" : ObjectId("50dcab296803fa7e4f000010"),"title" : "Show HN: ShotBlocker - iOS Screenshot detector...","url" : "https://github.com/clayallsopp/ShotBlocker","id" : 4973909,"commentCount" : 10,"points" : 17,"postedAgo" : "3 hours ago","postedBy" : "10char"}}],"stats" : {"nscanned" : 4,"nscannedObjects" : 0,"n" : 3,"timeMicros" : 89},
"ok" : 1 } 匹配到的文档是按照相关性降序排列的:"Ask HN"位于第一位,然后是两个部分匹配的文档。每个对象前面的"score"字段描述了每个结果与查询的匹配程度。
如你所见,这个搜索是不区分大小写不的,至少对于[a-zA-Z]这些字符是这样。全文本索引会使用toLower将单词变为小写,但这是与本地化相关的,所以某些语言的用户可能会发现MongoDB会不可预测性地变得区分大小写,这取决于toLower在不同字符集上的行为。MongoDB一直在努力提高对不同字符集的支持。
全文本索引只会对字符串数据进行索引:其他的数据类型会被忽略,不会包含在索引中。一个集合上最多只能有一个全文本索引,但是全文本索引可以包含多个字段:
> db.blobs.ensureIndex({"title" : "text", "desc" : "text", "author" : "text"})
与“普通”的多键索引不同,全文本索引中的字段顺序不重要:每个字段都被同等对待。可以为每个字段指定不同的权重来控制不同字段的相对重要性:
> db.hn.ensureIndex({"title" : "text", "desc" : "text", "author" : "text"},... {"weights" : {"title" : 3, "author" : 2}})
默认的权重是1,权重的范围可以是1~1 000 000 000。使用上面的代码设置权重之后,"title"字段成为其中最重要的字段,"author"其次,最后是"desc"(没有指定,因此它的权重是默认值1)。
索引一经创建,就不能改变字段的权重了(除非删除索引再重建),所以在生产环境中创建索引之前应该先在测试数据集上实际操作一下。
对于某些集合,我们可能并不知道每个文档所包含的字段。可以使用"$**"在文档的所有字符串字段上创建全文本索引:这不仅会对顶级的字符串字段建立索引,也会搜索嵌套文档和数组中的字符串字段:
> db.blobs.ensureIndex({"$**" : "text"})
也可以为"$**"设置权重:
> db.hn.ensureIndex({"whatever" : "text"},... {"weights" : {"title" : 3, "author" : 1, "$**" : 2}})
"whatever"可以指代任何东西。在设置权重时指明了是对所有字段进行索引,因此MongoDB并不要求你明确给出字段列表。
6.3.1 搜索语法
默认情况下,MongoDB会使用OR连接查询中的每个词:“ask OR hn”。这是执行全文本查询最有效的方式,但是也可以进行短语的精确匹配,以及使用NOT。为了精确查询“ask hn”这个短语,可以用双引号将查询内容括起来:
> db.runCommand({text: "hn", search: "\"ask hn\""}){"queryDebugString" : "ask|hn||||ask hn||","language" : "english","results" : [{"score" : 2.25,"obj" : {"_id" : ObjectId("50dcab296803fa7e4f000011"),"title" : "Ask HN: Most valuable skills you have?","url" : "/comments/4974230","id" : 4974230,"commentCount" : 37,"points" : 31,"postedAgo" : "2 hours ago","postedBy" : "bavidar"}}],"stats" : {"nscanned" : 4,"nscannedObjects" : 0,"n" : 1,"nfound" : 1,"timeMicros" : 20392},"ok" : 1}
这比使用OR的匹配慢一些,因为MongoDB首先要执行一个OR匹配,然后再对匹配结果进行AND匹配。
可以将查询字符串的一部分指定为字面量匹配,另一部分仍然是普通匹配:
> db.runCommand({text: "hn", search: "\"ask hn\" ipod"})
这会精确搜索"ask hn"这个短语,也会可选地搜索"ipod"。
也可以使用"-"字符指定特定的词不要出现在搜索结果中:
> db.runCommand({text: "hn", search: "-startup vc"})
这样就会返回匹配“vc”但是不包含“startup”这个词的文档。
6.3.2 优化全文本搜索
有几种方式可以优化全文本搜索。如果能够使用某些查询条件将搜索结果的范围变小,可以创建一个由其他查询条件前缀和全文本字段组成的复合索引:
> db.blog.ensureIndex({"date" : 1, "post" : "text"})
这就是局部的全文本索引,MongoDB会基于上面例子中的"date"先将搜索范围分散为多个比较小的树。这样,对于特定日期的文档进行全文本查询就会快很多了。
也可以使用其他查询条件后缀,使索引能够覆盖查询。例如,如果要返回"author"和"post"字段,可以基于这两个字段创建一个复合索引:
> db.blog.ensureIndex({"post" : "text", "author" : 1})
前缀和后缀形式也可以组合在一起使用:
> db.blog.ensureIndex({"date" : 1, "post" : "text", "author" : 1})
这里的前缀索引字段和后缀索引字段都不可以是多键字段。
创建全文本索引会自动在集合上启用usePowerOf2Sizes选项,这个选项可以控制空间的分配方式。这个选项能够提高写入速度,所以不要禁用它。
6.3.3 在其他语言中搜索
当一个文档被插入之后(或者索引第一次被创建之后),MongoDB会查找索引字段,对字符串进行分词,将其减小为一个基本单元(essential unit)。然后,不同语言的分词机制是不同的,所以必须指定索引或者文档使用的语言。文本类型的索引允许指定"default_language"选项,它的默认值是"english",可以被设置为多种其他语言(MongoDB的在线文档提供了最新的支持语言列表)。
例如,要创建一个法语的索引,可以这么做:
> db.users.ensureIndex({"profil" : "text", "intérêts" : "text"},... {"default_language" : "french"})
这样,这个索引就会默认使用法语的分词机制,除非指定了其他的分词机制。如果在插入文档时指定"language"字段,就可以为每个文档分别指定分词时使用的语言:
> db.users.insert({"username" : "swedishChef",... "profile" : "Bork de bork", language : "swedish"})
6.4 地理空间索引
MongoDB支持几种类型的地理空间索引。其中最常用的是2dsphere索引(用于地球表面类型的地图)和2d索引(用于平面地图和时间连续的数据)。
2dsphere允许使用GeoJSON格式(http://www.geojson.org)指定点、线和多边形。点可以用形如[longitude, latitude]([经度,纬度])的两个元素的数组表示:
{"name" : "New York City","loc" : {"type" : "Point","coordinates" : [50, 2]}}
线可以用一个由点组成的数组来表示:
{"name" : "Hudson River","loc" : {"type" : "Line","coordinates" : [[0,1], [0,2], [1,2]]}}
多边形的表示方式与线一样(都是一个由点组成的数组),但是"type"不同:
{"name" : "New England","loc" : {"type" : "Polygon","coordinates" : [[0,1], [0,2], [1,2]]}}
"loc"字段的名字可以是任意的,但是其中的子对象是由GeoJSON指定的,不能改变。
在ensureIndex中使用"2dsphere"选项就可以创建一个地理空间索引:
> db.world.ensureIndex({"loc" : "2dsphere"})
6.4.1 地理空间查询的类型
可以使用多种不同类型的地理空间查询:交集(intersection)、包含(within)以及接近(nearness)。查询时,需要将希望查找的内容指定为形如{"$geometry" : geoJsonDesc}的GeoJSON对象。
例如,可以使用"$geoIntersects"操作符找出与查询位置相交的文档:
> var eastVillage = {... "type" : "Polygon",... "coordinates" : [... [-73.9917900, 40.7264100],... [-73.9917900, 40.7321400],... [-73.9829300, 40.7321400],... [-73.9829300, 40.7264100]... ]}> db.open.street.map.find(... {"loc" : {"$geoIntersects" : {"$geometry" : eastVillage}}})
这样就会找到所有与East Village区域有交集的文档。
可以使用"$within"查询完全包含在某个区域的文档,例如:“East Village有哪些餐馆?”
> db.open.street.map.find({"loc" : {"$within" : {"$geometry" : eastVillage}}})
与第一个查询不同,这次不会返回那些只是经过East Village(比如街道)或者部分重叠(比如用于表示曼哈顿的多边形)的文档。
最后,可以使用"$near"查询附近的位置:
> db.open.street.map.find({"loc" : {"$near" : {"$geometry" : eastVillage}}})
注意,"$near"是唯一一个会对查询结果进行自动排序的地理空间操作符:"$near"的返回结果是按照距离由近及远排序的。
地理位置查询有一点非常有趣:不需要地理空间索引就可以使用"$geoIntersects"或者"$within"("$near"需要使用索引)。但是,建议在用于表示地理位置的字段上建立地理空间索引,这样可以显著提高查询速度。
6.4.2 复合地理空间索引
如果有其他类型的索引,可以将地理空间索引与其他字段组合在一起使用,以便对更复杂的查询进行优化。上面提到过一种可能的查询:“East Village有哪些餐馆?”。如果仅仅使用地理空间索引,我们只能查找到East Village内的所有东西,但是如果要将“restaurants”或者是“pizza”单独查询出来,就需要使用其他索引中的字段了:
> db.open.street.map.ensureIndex({"tags" : 1, "location" : "2dsphere"})
然后就能够很快地找到East Village内的披萨店了:
> db.open.street.map.find({"loc" : {"$within" : {"$geometry" : eastVillage}},... "tags" : "pizza"})
其他索引字段可以放在"2dsphere"字段前面也可以放在后面,这取决于我们希望首先使用其他索引的字段进行过滤还是首先使用位置进行过滤。应该将那个能够过滤掉尽可能多的结果的字段放在前面。
6.4.3 2D索引
对于非球面地图(游戏地图、时间连续的数据等),可以使用"2d"索引代替"2dsphere":
> db.hyrule.ensureIndex({"tile" : "2d"})
"2d"索引用于扁平表面,而不是球体表面。"2d"索引不应该用在球体表面上,否则极点附近会出现大量的扭曲变形。
文档中应该使用包含两个元素的数组表示2d索引字段(写作本书时,这个字段还不是GeoJSON文档)。示例如下:
{"name" : "Water Temple","tile" : [ 32, 22 ]}
"2d"索引只能对点进行索引。可以保存一个由点组成的数组,但是它只会被保存为由点组成的数组,不会被当成线。特别是对于"$within"查询来说,这是一项重要的区别。如果将街道保存为由点组成的数组,那么如果其中的某个点位于给定的形状之内,这个文档就会与$within相匹配。但是,由这些点组成的线并不一定完全包含在这个形状之内。
默认情况下,地理空间索引是假设你的值都介于-180~180。可以根据需要在ensureIndex中设置更大或者更小的索引边界值:
> db.star.trek.ensureIndex({"light-years" : "2d"}, {"min" : -1000, "max" : 1000})
这会创建一个2000×2000大小的空间索引。
使用"2d"索引进行查询比使用"2dsphere"要简单许多。可以直接使用"$near"或者"$within",而不必带有"$geometry"子对象。可以直接指定坐标:
> db.hyrule.find({"tile" : {"$near" : [20, 21]}})
这样会返回hyrule集合内的全部文档,按照距离(20,21)这个点的距离排序。如果没有指定文档数量限制,默认最多返回100个文档。如果不需要这么多结果,应该根据需要设置返回文档的数量以节省服务器资源。例如,下面的代码只会返回距离(20,21)最近的10个文档:
> db.hyrule.find({"tile" : {"$near" : [20, 21]}}).limit(10)
"$within"可以查询出某个形状(矩形、圆形或者是多边形)范围内的所有文档。如果要使用矩形,可以指定"$box"选项:
> db.hyrule.find({"tile" : {"$within" : {"$box" : [[10, 20], [15, 30]]}}})
"$box"接受一个两元素的数组:第一个元素指定左下角的坐标,第二个元素指定右上角的坐标。
类似地,可以使用"$center"选项返回圆形范围内的所有文档,这个选项也是接受一个两元素数组作为参数:第一个元素是一个点,用于指定圆心;第二个参数用于指定半径:
> db.hyrule.find({"tile" : {"$within" : {"$center" : [[12, 25], 5]}}})
还可以使用多个点组成的数组来指定多边形:
> db.hyrule.find(... {"tile" : {"$within" : {"$polygon" : [[0, 20], [10, 0], [-10, 0]]}}})
这个例子会查询出包含给定三角形内的点的所有文档。列表中的最后一个点会被连接到第一个点,以便组成多边形。
6.5 使用GridFS存储文件
GridFS是MongoDB的一种存储机制,用来存储大型二进制文件。下面列出了使用GridFS作为文件存储的理由。
- 使用GridFS能够简化你的栈。如果已经在使用MongoDB,那么可以使用GridFS来代替独立的文件存储工具。
- GridFS会自动平衡已有的复制或者为MongoDB设置的自动分片,所以对文件存储做故障转移或者横向扩展会更容易。
- 当用于存储用户上传的文件时,GridFS可以比较从容地解决其他一些文件系统可能会遇到的问题。例如,在GridFS文件系统中,如果在同一个目录下存储大量的文件,没有任何问题。
- 在GridFS中,文件存储的集中度会比较高,因为MongoDB是以2 GB为单位来分配数据文件的。
GridFS也有一些缺点。
- GridFS的性能比较低:从MongoDB中访问文件,不如直接从文件系统中访问文件速度快。
- 如果要修改GridFS上的文档,只能先将已有文档删除,然后再将整个文档重新保存。MongoDB将文件作为多个文档进行存储,所以它无法在同一时间对文件中的所有块加锁。
通常来说,如果你有一些不常改变但是经常需要连续访问的大文件,那么使用GridFS再合适不过了。
6.5.1 GridFS入门
使用GridFS最简单的方式是使用mongofiles工具。所有的MongoDB发行版中都包含了mongofiles,可以用它在GridFS中上传文件、下载文件、查看文件列表、搜索文件,以及删除文件。
与其他的命令行工具一样,运行mongofiles --help就可以查看它的可用选项了。
在下面这个会话中,首先用mongofiles从文件系统中上传一个文件到GridFS,然后列出GridFS中的所有文件,最后再将之前上传过的文件从GridFS中下载下来:
$ echo "Hello, world" > foo.txt$ ./mongofiles put foo.txtconnected to: 127.0.0.1added file: { _id: ObjectId('4c0d2a6c3052c25545139b88'),filename: "foo.txt", length: 13, chunkSize: 262144,uploadDate: new Date(1275931244818),md5: "a7966bf58e23583c9a5a4059383ff850" }done!$ ./mongofiles listconnected to: 127.0.0.1foo.txt 13$ rm foo.txt$ ./mongofiles get foo.txtconnected to: 127.0.0.1done write to: foo.txt$ cat foo.txtHello,world
在上面的例子中,使用mongofiles执行了三种基本操作:put、list和get。put操作可以将文件系统中选定的文件上传到GridFS;list操作可以列出GridFS中的文件;get操作与put相反,用于将GridFS中的文件下载到文件系统中。mongofiles还支持另外两种操作:用于在GridFS中搜索文件的search操作和用于从GridFS中删除文件的delete操作。
6.5.2 在MongoDB驱动程序中使用GridFS
所有客户端驱动程序都提供了GridFS API。例如,可以用PyMongo(MongoDB的Python驱动程序)执行与上面直接使用mongofiles一样的操作:
>>> from pymongo import Connection>>> import gridfs>>> db = Connection().test>>> fs = gridfs.GridFS(db)>>> file_id = fs.put("Hello, world", filename="foo.txt")>>> fs.list()[u'foo.txt']>>> fs.get(file_id).read()'Hello, world'
PyMongo中用于操作GridFS的API与mongofiles非常像:可以很方便地执行put、get和list操作。几乎所有MongoDB驱动程序都遵循这种基本模式对GridFS进行操作,当然通常也会提供一些更高级的功能。关于特定驱动程序对GridFS的操作,可以查询相关驱动程序的文件。
6.5.3 揭开GridFS的面纱
GridFS是一种轻量级的文件存储规范,用于存储MongoDB中的普通文档。MongoDB服务器几乎不会对GridFS请求做“特殊”处理,所有处理都由客户端的驱动程序和工具负责。
GridFS背后的理念是:可以将大文件分割为多个比较大的块,将每个块作为独立的文档进行存储。由于MongoDB支持在文档中存储二进制数据,所以可以将块存储的开销降到非常低。除了将文件的每一个块单独存储之外,还有一个文档用于将这些块组织在一起并存储该文件的元信息。
GridFS中的块会被存储到专用的集合中。块默认使用的集合是fs.chunks,不过可以修改为其他集合。在块集合内部,各个文档的结构非常简单:
{"_id" : ObjectId("..."),"n" : 0,"data" : BinData("..."),"files_id" : ObjectId("...")}
与其他的MongoDB文档一样,块也都拥有一个唯一的"_id"。另外,还有如下几个键。
"files_id"
块所属文件的元信息。
"n"
块在文件中的相对位置。
"data"
块所包含的二进制数据。
每个文件的元信息被保存在一个单独的集合中,默认情况下这个集合是fs.files。这个文件集合中的每一个文档表示GridFS中的一个文件,文档中可以包含与这个文件相关的任意用户自定义元信息。除用户自定义的键之外,还有几个键是GridFS规范规定必须要有的。
"_id"
文件的唯一id,这个值就是文件的每个块文档中"files_id"的值。
"length"
文件所包含的字节数。
"chunkSize"
组成文件的每个块的大小,单位是字节。这个值默认是256 KB,可以在需要时进行调整。
"uploadDate"
文件被上传到GridFS的日期。
"md5"
文件内容的md5校验值,这个值由服务器端计算得到。
这些必须字段中最有意思(或者说能够见名知意)的一个可能是"md5"。"md5"字段的值是由MongoDB服务器使用filemd5命令得到的,这个命令可以用来计算上传到GridFS的块的md5校验值。这意味着,用户可以通过检查文件的md5校验值来确保文件上传正确。
如上面所说,在fs.files中,除了这些必须字段外,可以使用任何自定义的字段来保存必需的文件元信息。可能你希望在文件元信息中保存文件的下载次数、MIME类型或者用户评分。
只要理解了GridFS底层的规范,自己就可以很容易地实现一些驱动程序没有提供的辅助功能。例如,可以使用distinct命令得到GridFS中保存文件的文件名集合(集合中的每个文件名都是唯一的)。
> db.fs.files.distinct("filename")[ "foo.txt" , "bar.txt" , "baz.txt" ]
这样,在加载或者收集文件相关信息时,应用程序可以拥有非常大的灵活性。
