第13章 分片
本章介绍如果扩展MongoDB:
- 分片和集群组件;
- 如何配置分片;
- 分片与应用程序的交互 。
13.1 分片简介
分片(sharding)是指将数据拆分,将其分散存放在不同的机器上的过程。有时也用分区(partitioning)来表示这个概念。将数据分散到不同的机器上,不需要功能强大的大型计算机就可以储存更多的数据,处理更大的负载。
几乎所有数据库软件都能进行手动分片(manual sharding)。应用需要维护与若干不同数据库服务器的连接,每个连接还是完全独立的。应用程序管理不同服务器上不同数据的存储,还管理在合适的数据库上查询数据的工作。这种方法可以很好地工作,但是非常难以维护,比如向集群添加节点或从集群删除节点都很困难,调整数据分布和负载模式也不轻松。
MongoDB支持自动分片(autosharding),可以使数据库架构对应用程序不可见,也可以简化系统管理。对应用程序而言,好像始终在使用一个单机的MongoDB服务器一样。另一方面,MongoDB自动处理数据在分片上的分布,也更容易添加和删除分片。
不管从开发角度还是运营角度来说,分片都是最困难最复杂的MongoDB配置方式。有很多组件可以用于自动配置、监控和数据转移。在尝试部署或使用分片集群之前,你需要先熟悉前面章节中讲过的单机服务器和副本集。
13.2 理解集群的组件
MongoDB的分片机制允许你创建一个包含许多台机器(分片)的集群,将数据子集分散在集群中,每个分片维护着一个数据集合的子集。与单机服务器和副本集相比,使用集群架构可以使应用程序具有更大的数据处理能力。
许多人可能会混淆复制和分片的概念。记住,复制是让多台服务器都拥有同样的数据副本,每一台服务器都是其他服务器的镜像,而每一个分片都有其他分片拥有不同的数据子集。
分片的目标之一是创建一个拥有5台、10台甚至1000台机器的集群,整个集群对应用程序来说就像是一台单机服务器。为了对应用程序隐藏数据库架构的细节,在分片之前要先执行mongos进行一次路由过程。这个路由服务器维护着一个“内容列表”,指明了每个分片包含什么数据内容。应用程序只需要连接到路由服务器,就可以像使用单机服务器一样进行正常的请求了,如图13-1所示。路由服务器知道哪些数据位于哪个分片,可以将请求转发给相应的分片。每个分片对请求的响应都会发送给路由服务器,路由服务器将所有响应合并在一起,返回给应用程序。对应用程序来说,它只知道自己是连接到了一台单机mongod服务器,如图13-2所示。
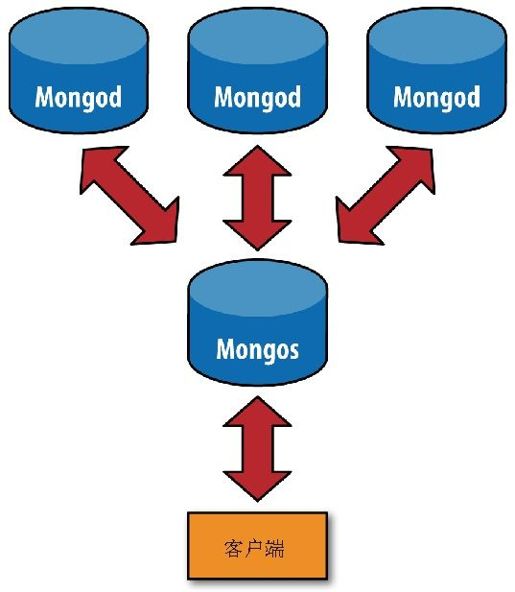
图13-1 使用分片的连接
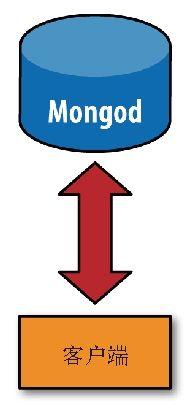
图13-2 不使用分片的连接
13.3 快速建立一个简单的集群
如前面介绍复制时一样,本节会在单台服务器上快速建立一个集群。首先,使用--nodb选项启动mongo shell:
$ mongo --nodb
使用ShardingTest类创建集群:
> cluster = new ShardingTest({"shards" : 3, "chunksize" : 1})
第16章会详细介绍chunksize选项,目前来说可以简单将其设置为1。
运行这个命令就会创建一个包含3个分片(mongod进程)的集群,分别运行在30000、30001、30002端口。默认情况下,ShardingTest会在30999端口启动mongos。接下来就连接到这个mongos开始使用集群。
集群会将日志输出到当前shell中,所以再打开一个shell用来连接到集群的mongos:
> db = (new Mongo("localhost:30999")).getDB("test")
现在的情况如图13-1所示:客户端(shell)连接到了一个mongos。现在就可以将请求发送给mongos了,它会自动将请求路由到合适的分片。客户端不需要知道分片的任何信息,比如分片数量和分片地址。只要有分片存在,就可以向mongos发送请求,它会自动将请求转发到合适的分片上。
首先插入一些数据:
> for (var i=0; i<100000; i++) {... db.users.insert({"username" : "user"+i, "created_at" : new Date()});... }> db.users.count()100000
可以看到,与mongos进行交互与使用单机服务器完全一样,如图13-2所示。
运行sh.status()可以看到集群的状态:分片摘要信息、数据库摘要信息、集合摘要信息:
> sh.status()--- Sharding Status ---sharding version: { "_id" : 1, "version" : 3 }shards:{ "_id" : "shard0000", "host" : "localhost:30000" }{ "_id" : "shard0001", "host" : "localhost:30001" }{ "_id" : "shard0002", "host" : "localhost:30002" }databases:{ "_id" : "admin", "partitioned" : false, "primary" : "config" }{ "_id" : "test", "partitioned" : false, "primary" : "shard0001" }
sh命令与rs命令很像,除了它是用于分片的:rs是一个全局变量,其中定义了许多分片操作的辅助函数。可以运行sh.help()查看可以使用的辅助函数。如sh.stats()的输出所示,当前拥有3个分片,2个数据库(其中admin数据库是自动创建的)。
与上面sh.stats()的输出信息不同,test数据库可能有一个不同的主分片(primary shard)。主分片是为每个数据库随机选择的,所有数据都会位于主分片上。MongoDB现在还不能自动将数据分发到不同的分片上,因为它不知道你希望如何分发数据。必须要明确指定,对于每一个集合,应该如何分发数据。
主分片与副本集中的主节点不同。主分片指的是组成分片的整个副本集。而副本集中的主节点是指副本集中能够处理写请求的单台服务器。
要对一个集合分片,首先要对这个集合的数据库启用分片,执行如下命令:
> sh.enableSharding("test")
现在就可以对test数据库内的集合进行分片了。
对集合分片时,要选择一个片键(shard key)。片键是集合的一个键,MongoDB根据这个键拆分数据。例如,如果选择基于"username"进行分片,MongoDB会根据不同的用户名进行分片:"a1-steak-sauce"到"defcon"位于第一片,"defcon1"到"howie1998"位于第二片,以此类推。选择片键可以认为是选择集合中数据的顺序。它与索引是个相似的概念:随着集合的不断增长,片键就会成为集合上最重要的索引。只有被索引过的键才能够作为片键。
在启用分片之前,先在希望作为片键的键上创建索引:
> db.users.ensureIndex({"username" : 1})
现在就可以依据"username"对集合分片了:
> sh.shardCollection("test.users", {"username" : 1})
尽管我们这里选择片键时并没有作太多考虑,但是在实际中应该仔细斟酌。第15章会详细介绍如何选择片键。
几分钟之后再次运行sh.status(),可以看到,这次的输出信息比较多:
--- Sharding Status ---sharding version: { "_id" : 1, "version" : 3 }shards:{ "_id" : "shard0000", "host" : "localhost:30000" }{ "_id" : "shard0001", "host" : "localhost:30001" }{ "_id" : "shard0002", "host" : "localhost:30002" }databases:{ "_id" : "admin", "partitioned" : false, "primary" : "config" }{ "_id" : "test", "partitioned" : true, "primary" : "shard0000" }test.users chunks:shard0001 4shard0002 4shard0000 5{ "username" : { $minKey : 1 } } -->> { "username" : "user1704" }on : shard0001{ "username" : "user1704" } -->> { "username" : "user24083" }on : shard0002{ "username" : "user24083" } -->> { "username" : "user31126" }on : shard0001{ "username" : "user31126" } -->> { "username" : "user38170" }on : shard0002{ "username" : "user38170" } -->> { "username" : "user45213" }on : shard0001{ "username" : "user45213" } -->> { "username" : "user52257" }on : shard0002{ "username" : "user52257" } -->> { "username" : "user59300" }on : shard0001{ "username" : "user59300" } -->> { "username" : "user66344" }on : shard0002{ "username" : "user66344" } -->> { "username" : "user73388" }on : shard0000{ "username" : "user73388" } -->> { "username" : "user80430" }on : shard0000{ "username" : "user80430" } -->> { "username" : "user87475" }on : shard0000{ "username" : "user87475" } -->> { "username" : "user94518" }on : shard0000{ "username" : "user94518" } -->> { "username" : { $maxKey : 1 } }on : shard0000
集合被分为了多个数据块,每一个数据块都是集合的一个数据子集。这些是按照片键的范围排列的({"username" : minValue} -->> {"username" : maxValue}指出了每个数据块的数据范围)。通过查看输出信息中的"on" : shard部分,可以发现集合数据比较均匀地分布在不同分片上。
将集合拆分为多个数据块的过程如图13-3到图13-5所示。在分片之前,集合实际上是一个单一的数据块。分片依据片键将集合拆分为多个数据块,如图13-4所示。这块数据块被分布在集群中的每个分片上,如图13-5所示。

图13-3 在分片之前,可以认为集合是一个单一的数据块,从片键的最小值一直到片键的最大值都位于这个块
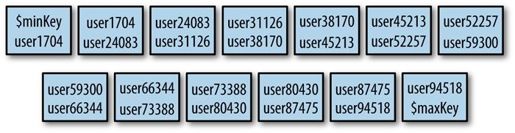
图13-4 分片依据片键范围将集合拆分为多个数据块
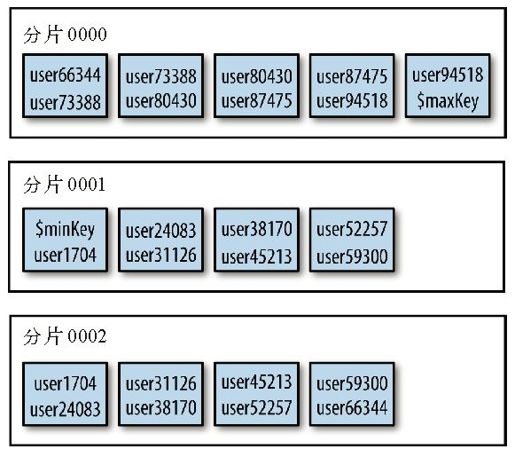
图13-5 数据块均衡地分布在不同分片上
注意,数据块列表开始的键值和结束的键值:$minkKey和$maxKey。可以将$minKey认为是“负无穷”,它比MongoDB中的任何值都要小。类似地,可以将$maxKey认为是“正无穷”,它比MongoDB中的任何值都要大。因此,经常会见到这两个“端值”出现在数据块范围中。片键值的范围始终位于$minKey和$maxKey之间。这些值实际上是BSON类型,只是用于内部使用,不应该被用在应用程序中。如果希望在shell中使用的话,可以用MinKey和MaxKey常量代替。
现在数据已经分布在多个分片上了,接下来做一些查询操作。首先,做一个基于指定的用户名的查询:
> db.users.find({username: "user12345"}){"_id" : ObjectId("50b0451951d30ac5782499e6"),"username" : "user12345","created_at" : ISODate("2012-11-24T03:55:05.636Z")}
可以看到,查询可以正常工作。现在运行explain()来看看MongoDB到底是如何处理这次查询的:
> db.users.find({username: "user12345"}}).explain(){"clusteredType" : "ParallelSort","shards" : {"localhost:30001" : [{"cursor" : "BtreeCursor username_1","nscanned" : 1,"nscannedObjects" : 1,"n" : 1,"millis" : 0,"nYields" : 0,"nChunkSkips" : 0,"isMultiKey" : false,"indexOnly" : false,"indexBounds" : {"username" : [["user12345","user12345"]]}}]},"n" : 1,"nChunkSkips" : 0,"nYields" : 0,"nscanned" : 1,"nscannedObjects" : 1,"millisTotal" : 0,"millisAvg" : 0,"numQueries" : 1,"numShards" : 1}
输出信息包含两个部分:一个看起来比较普通的explain()输出嵌套在另一个explain()输出中。外层的explain()输出来自mongos:描述了为了处理这个查询,mongos所做的工作。内层的explain()输出来自查询所使用的分片,在本例中是localhost:30001。
由于"username"是片键,所以mongos能够直接将查询发送到正确的分片上。作为对比,来看一下查询所有数据的过程:
> db.users.find().explain(){"clusteredType" : "ParallelSort","shards" : {"localhost:30000" : [{"cursor" : "BasicCursor","nscanned" : 37393,"nscannedObjects" : 37393,"n" : 37393,"millis" : 38,"nYields" : 0,"nChunkSkips" : 0,"isMultiKey" : false,"indexOnly" : false,"indexBounds" : {}}],"localhost:30001" : [{"cursor" : "BasicCursor","nscanned" : 31303,"nscannedObjects" : 31303,"n" : 31303,"millis" : 37,"nYields" : 0,"nChunkSkips" : 0,"isMultiKey" : false,"indexOnly" : false,"indexBounds" : {}}],"localhost:30002" : [{"cursor" : "BasicCursor","nscanned" : 31304,"nscannedObjects" : 31304,"n" : 31304,"millis" : 36,"nYields" : 0,"nChunkSkips" : 0,"isMultiKey" : false,"indexOnly" : false,"indexBounds" : {}}]},"n" : 100000,"nChunkSkips" : 0,"nYields" : 0,"nscanned" : 100000,"nscannedObjects" : 100000,"millisTotal" : 111,"millisAvg" : 37,"numQueries" : 3,"numShards" : 3}
可以看到,这次查询不得不访问所有3个分片,查询出所有数据。通常来说,如果没有在查询中使用片键,mongos就不得不将查询发送到每个分片。
包含片键的查询能够直接被发送到目标分片或者是集群分片的一个子集,这样的查询叫做定向查询(targeted query)。有些查询必须被发送到所有分片,这样的查询叫做分散-聚集查询(scatter-gather query):mongos将查询分散到所有分片上,然后将各个分片的查询结果聚集起来。
完成这个实验之后,关闭数据集。切换回最初的shell,按几次Enter键以回到命令行。然后运行cluster.stop()就可以关闭整个集群了。
> cluster.stop()
如果不确定某个操作的作用,可以使用ShardingTest快速创建一个本地集群然后做一些尝试。
