第八章 图形界面与中文处理
主要内容
1.X-Window与Linux
2.Linux与中文处理 8.1 X-Window与Linux 一、X-Window简介 要想成为一套优秀的操作系统,除了性能稳定、功能齐全之外,还应该拥有一个友好的操作系统,否则只会待在研究室里,难以普及。
在UNIX系统下,大多都是采用X-Window做为图形界面的。1984年,麻省理工学院与DEC制订了Athena计划,这就是X-Window第一个版本。1988年1月成立了一个非营利性的X联盟,负责制定X-Window的标准。在Linux出现后,XFree86 Project Inc.基于Linux实现了一个开源的X-Window系统:XFree86。
X Window与其他的图形界面系统相比,有几个特点:
良好的网络支持:X-Window采用了C/S网络结构,程序间可以通过网络来通信,而且有良好的网络透明性,也就是说用户不需知道程序在使用远端主机资源。
个性化的窗口界面:X-Window并未对窗口界面作统一性的规范,程序员可以根据需求自行设计,其中最有名的就是后面要介绍的GNOME与KDE。
不内嵌于操作系统:X-Window只定义了一个标准,而不属于某个操作系统,因此可在不同的操作系统上运行相同的X-Window软件。
整个X-Window由三个部分组成:
X Server:主要是控制输出及输入设备的程序,并维护相关资源,它接收输入设备的信息,并将其传给X Client,而将X Client传来的信息输出到屏幕上。所以不同的显卡就需要选择不同的X Server,在配置X-Window时最主要的就是配置X Server。
X Client:它才是应用程序的核心部分,它是与硬件无关的,每个应用程序就是一个X Client。
X protocol:X Client与X Server之间的通信语言就是X protocol。
为了使得X Window更加易于使用,各个不同的公司与组织都针对其做了许多集成桌面环境。如AIX上的CDE,SUN上的OpenServer,而在Linux下则主要是GNOME与KDE的双雄会。下面我们就一起来了解一下它们。 二、GNOME简介 GNOME最初是由墨西哥的程序设计师MiguelDeIcazq发起的,它受到了Red Hat公司的大力支持。它现在属于GNU(GNU is Not UNIX)计划的一部分,主要目的是希望能够为用户提供一个完整、易学、易用的桌面环境,并为程序设计师提供强大的应用程序开发环境。
1997年8月,为了克服KDE所遇到的QT许可协议和单一C++依赖的困难,以墨西哥的MigueldeIcaza为首的250程序员就开始了一个新项目,完全从头开始,这就是GNOME。经过14个月的共同努力,终于完成了这个工程。现在GNOME已得到了占Linux市场份额最大发行商Red Hat的支持,拥有了大量应用软件,包括文字处理软件Go,电子表格软件Gnumeric,日历程序GNOMEcal,堪与Photoshop媲美的图形图像处理软件Gimp等。
现在GNOME与KDE成为了两大竞争阵营,必将使得Linux更加易于使用。
GNOME中还提供了大量的应用软件,它们都放在GNOME的“开始”(一个小脚丫)Programs中,包括了许许多多的应用软件,下面就是其中的一些:
1.Applications:应用软件
(1)Dia:一个工程图编辑器,适用于绘制电路图。
(2)Calendar:一个集日历与日程表于一身的好工具。
(3)Address Book:一个通讯录。
(4)GEdit:一个功能类似于Windows下的记事本的文本编辑器。
(5)Gnumeric:Linux下的一个类似于Excel的电子表格软件。
(6)Timetrackingtools:一个用于提醒时间的小工具。
2.Games:游戏软件
(1)Gnome Milnes:GNOME下的扫雷。
(2)Gnibbles:贪吃蛇游戏。
(3)Freecell:Windows下的空当接龙游戏。
3.Graphics:图形处理软件
(1)Electric Eyes:一个十分优秀的图形处理软件,可谓GNOME下的AcdSee呀!
(2)XPDF:一个在Linux阅读PDF文档的工具。
(3)TheGimp:一个十分优秀的绘图软件,与Photoshop很像!
4.Internet:Internet应用软件
(1)Dialup Configuration Tool:一个界面十分友好的拨号上网设置工具。
(2)gFTP:一个FTP客户端。
(3)pine:一个E-mail客户端软件。
(4)Netscape:大名鼎鼎的浏览器软件,被微软从Windows平台挤下来的。
(5)RHNetworkmonitor:网络流量显示。
5.Multimedia:多媒体软件
(1)Audio Mixer:声音控制器。
(2)CDPlayer:CD播放器。
(3)XMMS:与Winamp是一个模子里出来的。 三、KDE简介 KDE项目在1996年10月发起,其目的是在X-Window上建立一个完整易用的桌面环境。KDE现在除了拥有KFM(类似于IE4.0)、KPresenter(类似PowerPoint)、KIllustrator(类似CorelDraw或Illustrator)等重量级软件,还有体贴用户的GUI配置软件可以帮助用户配置UNIX/Linux,使其深受使用者欢迎。
但由于KDE是基于由TrollTech公司开发的Qt程序库的,所以也受到了许多批评。虽然Qt本身作为一个基于C++的跨平台开发工具是非常优秀,但可惜的是它不是自由软件。Qt的License允许任何人使用Qt编写免费软件及免费拷贝给其他用户使用,但如果利用Qt编写非免费软件则需要购买他们的License。更重要的是任何人都不可以随意修改Qt源代码。如果TrollTech公司更改QtLicense、公司倒闭或给人收购等都会令KDE前功尽弃。
在KDE中,也有许许多的应用软件,它们被分组放在“开始”(一个K字)菜单中,说实在的,我感觉KDE的软件应用比GNOME更多,图形界面也更好。
1.Office:办公软件
这就是大名鼎鼎的Koffice套件。
(1)Kword:字处理软件
(2)Kspread:像Excel的电子表格处理软件
(3)Kpresenter:一个类似于PowerPoint的演示软件
(4)Kchart:一个电子图表软件
(5)Kiiiustrator:一个电子出版软件
2.Develop:开发工具
(1)Kdevelop:一个KDE下的集成开发环境
3.Applications:应用软件
(1)AdvancedEditor:一个增强型的文本编辑软件
(2)Emacs:这是一个功能强大的编辑软件,在GNOME中也有,它的原形是字符终端下的Emacs
(3)Organizer:一个日程安排软件
4.Internet:Internet软件
(1)Kppp:一个十分友好的拨号上网配置工具
(2)Kmail:一个十分漂亮的E-mail客户端,有点像Outlook
(3)ChatClient:一个IRC客户端
(4)KPPPLoad:一个网络流量工具
(5)Netscape:大名鼎鼎的Web浏览器,在GNOME中也有集成 四、使用窗口管理器 Red Hat/Fedora默认安装后,X-Window将使用GNOME做为窗口管理器,除非你在安装时将GNOME去掉,而选择了KDE包。通常我们可以将这两个包都安装上,到使用的时候再选择。
(1)在字符终端下执行以下命令,则以后X-Window的窗口管理器都成了KDE:
#switchdeskKDE
(2)如果你又不想使用KDE了,则可以使用以下命令转回GNOME:
#switchdeskGNOME 8.2 Linux与中文处理 在信息处理日益国际化的今天,计算机软件的国际化与本地化工作显得越来越重要。可以想象,一个不能处理多国语言文字的软件,将很难在国际上推广。另外,一个国外的软件,如果不能很好地做好本地化工作,那么满屏的外文,也很难让国内的用户接受。
众所周知,计算机的“母语”是英语,计算机一开始就只认识英文。但是,全世界的语言文字有上百种,这还不包括一些罕用的语言与文字。为了让计算机能够处理这些语言与文字,也为了让使用非英语的人能够方便地使用计算机,就需要做大量的国际化与本地化工作。本文将针对在这个过程中常见的问题加以分析并给出解决方法。
国际化与本地化
国际化,即Internationalization。这个单词很长,因第一个字母与最后一个字母之间有18个字母,故常简写为i18n。国际化指的是一个软件所处理的信息应当是包含各国语言和文字的,而不能仅局限于英文。
本地化,即Localization,因第一个字母与最后一个字母之间有10个字母,故常简写为l10n。本地化指的是将本来是其他国家语言和文字的软件,翻译成本国语言和文字,以方便本国用户使用。
国际化与本地化是两个技术,但他们都面临着相同的问题,即如果处理世界上众多的语言与文字。这个问题是与字符集编码有着密切的关系。
常见字符集编码 一、字符与编码 字符在计算机内以编码的形式存储。所谓编码,是以固定的顺序排列字符,并以此作为记录、存贮、传递、交换的统一内部特征,这个字符排列顺序被称为“编码”。 二、英文数字编码 最初计算机只能处理英文,英文、数字和标点符号,采用的是美国的国家标准ASCII(American Standard Code for Information Interchange)。ASCII编码进一步成为世界性的编码标准:ISO646(全名为7-bit coded character set for information interchange)。时至今日,虽然一个字节(byte)的长度已经从7位(bit)增加为8位,ASCII和ISO646仍然是电脑与网络世界里重要的奠基标准。
ASCII码编码长度为7位,可以提供128个编码位置(0~127)。分为两个部分:94个图形字符和34个控制字符。图形字符编码范围从33~126。控制字符则编码为0~32及127。ASCII开始时采用7位编码,高位(bit-8)用于在网络传输中做奇偶校验。后来,为了表示一些常见的欧洲字符,对高位(bit-8)为1的128个码位也进行了扩展编码。
8位字符集只能容纳256个字符,比如Latin-1(ISO 646)包括了英语、数字、常用标点和常见的一些欧洲字符。但是它们无法很好地承担在世界范围内进行信息交换的重任,因为它们没有足够的空间来容纳其他语言上万的字符。后来,很多国家为了表示本国文字,使用2或多字节来编码,如日语(JIS)、汉语(GB、BIG5)、韩语(KS)、印度语(ISCII)等等。 三、早期的汉字编码 1980年我国颁布了第一个汉字编码字符集标准,即GB2312-1980《信息交换用汉字编码字符集基本集》。该标准共收了6763个汉字及常用符号,奠定了中文信息处理的基础。GB2312-1980全称是《信息交换用汉字编码字符集基本集》,1980年发布,是中文信息处理的国家标准,在大陆及海外使用简体中文的地区(如新加坡等)是强制使用的唯一中文编码。P-Windows3.2和苹果OS就是以GB2312为基本汉字编码,Windows 95/98则以GBK为基本汉字编码,但兼容支持GB2312。
GB2312编码的码长为2个字节。在这个方案中,每个字符都有一个区位码。区位码由区码和位码组成,区码:01~94,位码:01~94。其中01区~15区:符号区。16区~88区:汉字区。区码+160(0xA0)=国标码高位,位码+160(0xA0)=国标码低位。GB2312编码体系中,机内存储的是国标码,范围:A1A1~FEFE,其中高位A1-A9:符号区,包含682个符号。B0-F7:汉字区,包含6 763个汉字。GB码共收录6 763个简体汉字、682个符号,其中汉字部分:一级字3 755个,以拼音排序,二级字3008,以偏旁排序。该标准的制定和应用为规范、推动中文信息化进程起了很大作用。
在同时期,在我国台湾地区、香港地区等使用繁体字的地方,通行的是BIG5编码,这是一种繁体汉字的编码标准,包括440个符号,一级汉字5 401个、二级汉字7 652个,共计13060个汉字。另外,日本、韩国等国家,因为其语言中包括“汉字”,所以各自也有对汉字的编码。
上述这些编码都是在计算机刚刚从科学计算领域走向信息处理领域,并从美国等西方少数国家走向全世界的时候诞生的。为了处理成千上万的汉字,中、日、韩等国家大都采用双字节编码体系。这些编码在早期处理汉字等非英语字符时起到了重要的作用。但是发展到现在,也暴露出很多问题:
(1)字符集太小。双字节编码体系(DBCS)理论上能容纳65 536个字符,但是实际上为了预防多字节字符编码被电脑或网络设备“吃掉”其中的某些字节,在编码时就必须避开每个字节的0~32和127这34个控制码(0~31叫做C0控制码区,128~159叫做C1控制码区),这样就会严重浪费编码空间。GB2312-1980所包含的汉字只有6 763个,BIG5也只有13060个。相对康熙大字典、中华大字典所收录的五六万的汉字,这些编码只能包含其中常用的一部分汉字。这样,没有被收录的汉字计算机就没有办法处理。我们经常在输入一些人名、地名时遇到这样的问题。
(2)由于国家、厂商和组织众多,缺乏共识,往往是你编你的码,我编我的码,其后果则是引发万“码”奔腾的现象。同样的一个编码,在不同的编码体系中代表不同的字。这样对于信息的识别和交换带来很大的麻烦。 四、国际统一编码 1.ISO10646
为容纳全世界各种语言的字符,ISO于1984年发起制定新的国际字符集编码标准。新标准由工作小组ISO/IEC JTC1/SC2/WG2(以下简称WG2)负责拟定,标准最后定名为“Universal Multiple-Octet Coded Character Set”(简称UCS),其编号则定为ISO/ IEC 10646。
ISO 10646字符集的正规形式为32位,即4个字节,简记为USC-4。4个字节分别代表编码结构中的组(group)、面(plane)、列(row)和格(cell)。WG2规定b32必须为0,且每个平面的最后二个编码位置,即FFFE和FFFF,保留不用。所以ISO10646共有128256=32768个面,每个面有256256-2=65 534个编码位置,共计2 147 418 112个编码位置。
ISO10646中第0组第0面称为“基本多语言文字面”即“Basic Multi-lingual Plane,BMP”。当只使用BMP字符码时,可以省略群八位和面八位,因而将字符码由32位缩短为16位,称为ISO10646字符码的基本面形式(可简称为UCS-2)。1993年国际标准化组织发布了ISO/IEC 10646-1《信息技术通用多八位编码字符集第一部分体系结构与基本多文种平面》。我国等同采用此标准制定了GB 13000.1-1993。该标准共收录了中、日、韩20 902个汉字。ISO10646的编码空间足以容纳古今人类使用过的所有文字和符号。但目前真正被使用的文字或符号,绝大多数都已经编入BMP,它们的使用频率可以超过99%。
WG2依语言特性把各种文字区分为表意文字和非表意文字两类。WG2截至目前为止所收集、整理的非表意文字和符号部分,扣除已编入BMP者,其余全部编入第1字面。而表意文字部分扣除已编入BMP者,其余全部编入第二字面。ISO10646所有字面中,目前仅有第0、第1和第2字面真正收容编码字符。
2.Unicode
与ISO制定10646的同时,以Universal,Unique和Uniform为主旨的Unicode组织也开始开发一个16位字符标准,为避免两种16位编码的竞争,1991年10月两组织达成协议,采用同一编码字集。这就是今天的UCS-2(BMP,Basic Multilingual Plane,16bit)和Unicode,但它们仍然是不同的方案。
目前Unicode是采用16位编码体系,其字符集内容与ISO10646的BMP(Basic Multilingual Plane)相同。Unicode于1992年6月通过DIS(Draft International Stand-ard),版本V2.0于1996年公布,内容包含符号6 811个,汉字20 902个,韩文拼音11 172个,造字区6 400个,保留20249个,共计65 534个。
但是,在Unicode世界中,遇到必须使用ISO10646中第1、第2字面甚至更后方字面的字符时,怎么办?Unicode协会提出的解决方式称为UTF-16或代理法(surro-gates)。UTF为“UCS(or Unicode)Transformation Format”的缩写。UTF-16意即把原为32位的ISO10646字符码转换为两个或多个16位的Unicode。目前的做法是组合两个Unicode字符码来代表一个ISO10646字符,所以又称为代表法。UTF-16总计可提供16个字面。对BMP而言,当然无需使用UTF-16转码,所以UTF-16主要应用于ISO10646的第1~14字面(因为第15字面为专用字面,WG2不予编码)。
由于Unicode编码是16位编码,因此它和很多只能使用US-ASCII编码的应用程序不兼容,因此产生了对Unicode进行各种转换的编码,以满足不同场合的需要。常见的编码为UTF-8。很多应用程序不能直接处理Unicode或UCS-4/UCS-2中的16(32)位字符。如Unicode中含有的\x0等字符将不能直接用于文件名或C字符串等等。利用UTF-8转码规则可将一个Unicode或ISO10646字符码转换成1~4个字节的编码。其中与ASCII码对应的字符转换成1个字节,与ASCII码相同,汉字等其他文字转成2~4个字节。
3.GBK和GB180130-2000
GBK编码是中国大陆制定的、等同于UCS的新的中文编码扩展国家标准。GBK工作小组于1995年12月完成GBK规范。该编码标准兼容GB2312,共收录汉字21003个、符号883个,并提供1 894个造字码位,简、繁体字融于一库。Windows95/98简体中文版的字库表层编码就采用的是GBK,通过GBK与UCS之间一一对应的码表与底层字库联系。
GBK的英文名:Chinese Internal Code Specification。中文名:汉字内码扩展规范1.0版。GBK采用双字节编码,GB2312-80的扩充,在码位上和GB2312-80兼容。范围:8140~FEFE(剔除xx7F)共23 940个码位,包含21003个汉字,包含了ISO/IEC 10646-1中的全部中日韩汉字。
信息产业部和原国家质量技术监督局于2000年3月17日联合发布了GB18030-2000《信息技术信息交换用汉字编码字符集基本集的扩充》。该方案与GB2312信息处理交换码所对应的事实上的内码标准兼容,在字汇上支持GB13000.1的全部中、日、韩(CJK)统一汉字字符和全部CJK扩充A的字符,并且确定了编码体系和27 484个汉字,兼容性、扩展性、前瞻性兼备。该标准作为国家强制性标准自发布之日起实施,过渡期到2001年8月31日止。GB18030是国家标准,在技术上是GBK的超集,并与其兼容,因此,GBK将结束其历史使命。
GB18030的英文名:Chinese Internal Code Specification。中文名:信息技术信息交换用汉字编码字符集。它是GB2312-1980基本集的扩充(2000-03-17发布和实施)。GB18030-2000采用单字节、双字节、四字节编码,向下与国家标准GB2312信息处理交换码所对应的事实上的内码标准兼容。在字汇上支持GB13000.1的全部中、日、韩(CJK)统一汉字字符和全部CJK统一汉字扩充A的字符。双字节部分收录内容主要包括GB13000.1全部CJK汉字20 902个,有关标点符号、表意文字描述符13个,增补的汉字和部首/构件80个,双字节编码的欧元符号等。四字节部分收录了上述双字节字符之外的,包括CJK统一汉字扩充A在内的GB13000.1中的全部字符。GB18030编码空间约为160万码位,目前已编码的字符约2.6万。随着我国汉字整理和编码研究工作的不断深入,以及国际标准ISO/IEC10646的不断发展,GB18030所收录的字符将在新版本中增加。
GB18030在体系结构上延续GB2311-1990《信息处理七位和八位编码字符集代码扩充技术》体系,采用单/双/四字节混合编码。GB18030-2000码位范围分配图见图8.1,码位总体结构图见图8.2。该标准与现有的绝大多数操作系统、中文平台在计算机内码一级兼容,能够支持现有的应用系统,在字汇上与GB13000.1-1993《信息技术通用多八位编码字符集(UCS)第一部分:体系结构与基本多文种平面》兼容,从而为中文信息在国际互联网上的传输与交换提供了保障。
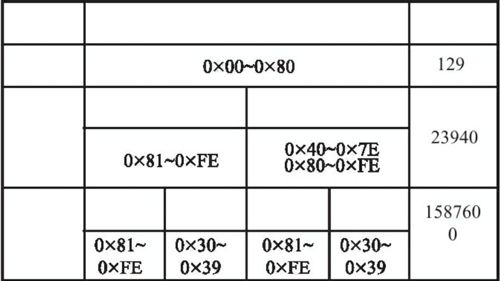
图8.1 GB18030-2000码位范围分配图
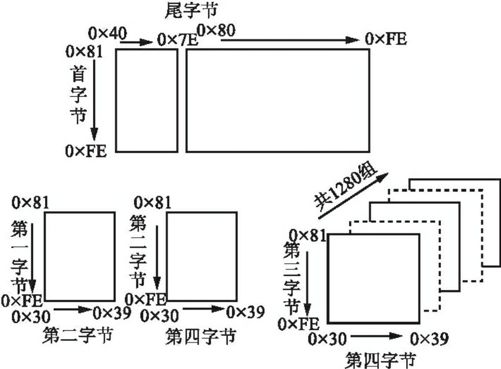
图8.2 GB18030-2000码位总体结构图
国家标准GB18030-2000《信息交换用汉字编码字符集基本集的扩充》是我国继GB2312-1980和GB13000-1993之后最重要的汉字编码标准,是未来我国计算机系统必须遵循的基础性标准之一。凡是在2001年8月31日后正式发布或出厂的产品,必须符合GB18030相关要求。凡不符合该标准的产品,视为不合格产品。GB18030收录了27 484个汉字,总编码空间超过150万个码位,为解决人名、地名用字问题提供了方案,为汉字研究、古籍整理等领域提供了统一的信息平台基础。该标准同时收录了藏文、蒙文、维吾尔文等主要的少数民族文字,为推进少数民族的信息化奠定了坚实的基础。 五、操作系统中处理汉字的方法 现在微机上用的操作系统主要有两类,一类是微软的Windows系列;一类是Unix/Linux。Windows从Windows 2000开始支持GB18030-2000,但需要安装GB18030支持包。Windows 2000为了能够处理多国文字,在内核中使用Unicode编码体系,但为了符合中国相关规定,在上层增加了对GB18030的支持,之间使用了一套映射机制,这套机制对用户是透明的,这样可以最大程度上保护已有的GB2312、GBK编码的文档的使用。Linux也是采用了类似的机制。
图形界面、X-Window、中文、i18n、l10 n
1.X-Window与Linux内核是什么关系?
2.X-Window分为几部分?它们之间是什么关系?
3.如何启动Linux的图形界面?
4.常见的中文字符编码有哪些?
5.Linux在处理中文方面有哪些面临的问题?
