图16-2
明珠暗投
分形几何学与财富分配、城市规模、金融市场收益、战争死亡率或行星大小有什么关系呢?下面让我们把点连成线。
这里的关键是分形的数字或统计方法(在某种程度上)对不同的尺度都适用,比率是不变的,与高斯分布不同。图16-3演示了另一种自相似关系。我们在第十五章看到,巨富与一般富人是相似的,前者只是更富而已。财富是独立于尺度的,或者更精确地说,财富对尺度的依赖性是未知的。
20世纪60年代,曼德尔布罗特向经济学界提出了关于商品和金融证券价格的观点,所有的金融经济学家都无比兴奋。1963年,芝加哥商学院当时的院长乔治·舒尔茨邀请他担任教授。乔治·舒尔茨后来成为罗纳德·里根政府的国务卿。
舒尔茨一天晚上又打电话来取消了邀请。
在我写这本书时,已经过了44年,经济学和社会科学统计学领域什么大事也没有发生,只有一些微不足道的粉饰文章把世界当成只受温和随机性的影响,但诺贝尔奖照发不误。一些不懂曼德尔布罗特中心思想的人写了一些文章“证明”曼德尔布罗特的错误,你总是可以找到“确证”相关过程为高斯随机过程的数据,因为总有不发生稀有事件的时期,就像你总能找到一个谁也没有杀谁的下午用来“证明”人们的无辜。我要重申,由于归纳的不对称性,就像人们更容易否定无罪而不是承认无罪一样,人们更容易抛弃钟形曲线而不是接受它;反过来,人们更难以抛弃分形理论而不是接受它。为什么?因为一个事件就能否定高斯钟形曲线的论断。
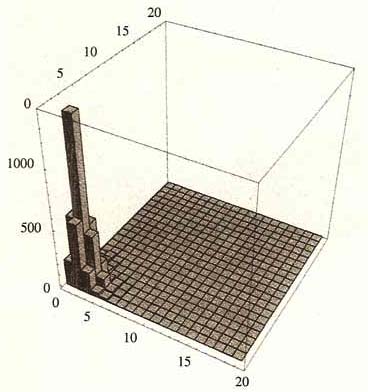
图中全部16个小部分的不均等性是相同的。在高斯世界,当你从更高的的角度看时,财富(或任何其他变量)的不均等会下降,亿万富翁之间的均等性高于百万富翁,百万富翁之间的均等性高于中产阶级。简而言之,这种不同财富水平之间的不均等性是一种统计自相似。
图16-3 纯粹的分形统计
简而言之,40年前,曼德尔布罗特把珍珠交给经济学家和喜欢造简历的市侩,却被他们抛弃了,因为这些观点好得让他们无法接受。这真可谓明珠暗投。
在本章余下的部分,我将解释为什么我能用曼德尔布罗特分形理论描述大量的随机性,却不必承认它的精确应用的原因。分形能够充当默认环境、近似和框架。它不能解决黑天鹅问题,也不能把所有的黑天鹅现象变为可预测事件,但它极大地淡化了黑天鹅问题,因为它使这些大事件更易于理解。(分形理论把它们变成灰色。为什么是灰色?因为只有高斯现象能给你确定性。之后会更详细地解释这一点。)
分形随机性(警告)①
我在第十五章的财富数据表中已经演示了分形分布:如果财富从100万翻倍变为200万,至少拥有这一财富的人数被除以4,是2的指数倍。如果指数是1,那么至少拥有这一财富的人数会被除以2。指数被称为“幕”(所以有“幂律”这一术语)。我们把某事件高于某一水平的发生次数称为“超过数”,200万的超过数是财富超过200万的人数。分形分布的一个特点(另一个特点是突破性)是两个超过数的比率等于两个相应水平的比率的负幂指数次方。我们来演示这一点。假设你“认为”每年只有96种书能够卖出超过25万册(去年的实际情况就是如此),并且你“认为”指数大约为1.5。你可以推测大约34种书能够卖出超过50万册,只要用96乘以(500000/250000)我们可以继续计算,大约8种书能够卖出超过100万册,也就是96乘以(1000000/250000)^(-1.5)。
表16-1 不同现象的假设指数
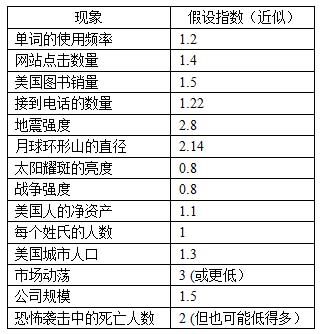
来源:M·E·J·纽曼
我们来看看不同现象观察到的指数。
我要先说明这些指数没有很高的精确度。一会儿我们就知道为什么,但现在,让我们暂时记住我们并不是观测这些参数,而只是猜测,或者为了统计的目的推测。有时我们很难知道真正的参数,假如它真的存在的话。我们先来看看指数的实际影响。
表16-2 指数的意义

*显然,对于有限样本不可能出现100%。
表16-2显示了发生概率极低的事件的影响。它列出了样本中最高的1%和20%的观测值对整体的贡献。指数越小,它们的贡献越大。但看看这个过程有多么敏感:在1.1~1.3之间,贡献率能够从66%下降到34%。指数变化0.2能使结果产生巨大的变化,而一个简单的计算错误就能产生这样的差异。这个差异绝不是微不足道:想一想,我们根本不知道精确的指数是什么,因为我们无法直接计算它。我们能做的只是从历史数据中估计它,或者依赖能让我们有点概念的模型理论,但这些模型可能有潜在缺陷,使我们无法盲目地将它们应用于现实。
所以请记住,1.5的指数只是近似,它本身是很难计算的,它不是天上掉下来的,至少来之不易,而且计算时很可能存在巨大的样本误差。你会发现销售超过100万册的图书并不一定是8种,可能是20种,也可能是2种。
更重要的是,指数从某个“临界值”开始起作用,对大于这个临界值的数产生影响。它可能从20万册书开始,也可能从40万册开始。同样,财富在比如6亿美元以上时开始出现不均衡的加剧,而在低于这个数字时呈现不同的特征。你怎么知道临界值在哪里?这是一个问题。我跟我的同事分析了大约2000万条金融数据。我们都有同样的数据集,但我们从来没能在指数上达成一致。我们知道这些数据符合分形幂律,但明白不可能得出精确的数字。不过知道分布是具有突破性的而且是分形的,这已足够我们做决策。
上限问题
有些人做过研究,并认同分形直到“某个上限”。他们认为,财富、图书销量和市场回报率都存在一个临界点,使得它们不再是分形的。他们提出了“截面”的说法。我同意,可能存在一个分形终止的点,但它在哪里呢?在实践中,说存在一个上限但我不知道它在哪里,与说没有上限是同一回事。提出任何上限都极有可能是错的。你可以说,我们把1500亿美元作为分析的上限吧。然后另一个人说,为什么不是1510亿美元?或者为什么不是1520亿美元?所以我们把变量当做无上限也是一样。
当心精确的东西
我从经验中总结了一些诀窍:不论我想计算什么指数,最终都可能高估它(请注意较高的指数意味着大离差的影响更小),也就是说,你看到的比你没有看到的较不具有黑天鹅的特征。我称之为化装舞会问题。
假设我生成了一个指数为1.7的随机过程。你看不到生成的机制,只能看到产生的数据。如果我问指数是多少,你很可能算出2.4之类的结果。即使你有100万个数据点,仍可能算错,原因在于有些分形过程要过很久才会显露出特征,于是你低估了这种冲击的严重性。
有时一个分形过程会让你以为它是高斯过程,尤其当采样点很高的时候。在分形分布中,极端离差出现的概率极低,足以迷惑你:你根本没有意识到它是分形分布。
再说一摊水
读者已经看到,不论我们假设世界符合怎样的模型,我们都难以知道模型的参数。所以,对于极端斯坦,归纳问题再次出现,这一次比本书之前提到的更为严重。简而言之,如果某个机制是分形的,它就能够产生很大的值,因此有可能出现大的离差,但可能性有多大,频率有多高,很难准确知道。这与一摊水问题很相似:很多种形状的冰块融化后都可能形成一摊水。作为一个从现实寻找可能的解释模型的人,我与那些做相反事情的人面临截然不同的问题。
我刚刚读了三本“大众科学”书,它们总结了对复杂系统的研究:马克·布坎南的《改变世界的简单法则》、菲利普·鲍尔的《临界点》和保罗·奥默罗德的《为何多数事情归于失败》。这三位作者展现了一个充满幂律的世界,这是一个我相当赞同的视角。他们还指出,许多幂律现象具有普遍性,在各种自然过程和社会群体的行为中有一种奇妙的相似性,这一点我也赞同。他们提出各种关于网络的理论支持他们的研究,并显示了自然科学中的所谓临界现象与社会群体的自我组织之间的联系。他们把产生崩塌事件的过程、社会传染病和信息瀑布效益联系在一起,我还是赞同。
普遍性正是物理学家对有临界点的幂律问题感兴趣的原因之一。在许多情况下——既包括动态系统理论也包括统计学模型,变量在临界点附近的许多特征独立于相关动态系统。临界点处的指数对于同一群体内的许多系统可能是相同的,即使系统的其他方面各不相同。我几乎同意这种普遍性观点。最后,三位作者都建议我们使用统计物理学的方法,并要像躲瘟疫那样避免使用计量经济学方法和高斯式的非突破性分布,我对此再赞同不过了。
但三位作者要么得出精确的结论,要么鼓吹对精确的追求,因此落入了混淆正向过程与反向过程(问题与反向问题)的陷阱。对我而言,这是最大的科学和认知错误。他们并不是唯一的:几乎每一个与数据打交道但并不基于这些数据做决策的人都会犯同样的错误,这是又一种叙述谬误。在缺乏反馈过程的情况下,你会认为模型证实了现实。我同意这三本书中的观点,但不同意它们的应用方式,当然也不同意作者赋予它们的精确性。实际上,复杂性理论应该让我们对现实的精确模型持更加怀疑的态度。它不会让所有天鹅变白,这是可以预料的:它把它们变灰,而且只变灰。
我在前面已经提到,从认知上讲,世界对于自下而上的经验主义者来说是另一个世界。我们享受不起坐下来研究主宰宇宙的方程的奢侈;我们只是观察数据,对产生数据的真实过程做出假设,根据进一步信息对方程进行“校准”。随着事件的逐步展开,我们把看到的与曾期望看到的做比较。发现历史是向前发展而不是向后发展的,通常是一个低调的过程,对知道叙述谬误的人来说尤其如此。虽然人们以为商务人士都很自大,但其实这些人在决策与结果、精确模型与现实的差距面前经常感到卑微。
我所说的是现实的迷雾,信息的不完整性,世界推动者的不可见性。历史不会向我们透露它的想法,我们必须猜测。
从表象到现实
上面的观点把本书的各个部分连接在一起。许多人学习心理学、数学或进化论,并试图把它们应用到商务中。我的建议正好相反:研究市场中大量存在的、未知的、强大的不确定性,从而理解对心理学、概率论、数学、决策理论甚至统计物理学都适用的随机性的本质。我们将看到叙述谬误、游戏谬误和伟大的柏拉图化谬误的各种狡猾表现,看到怎样从表象进入现实。
第一次遇见曼德尔布罗特时,我问他,为什么像他这样本来有许多有价值的事可做的、有地位的科学家会对金融这样的庸俗课题感兴趣。我认为从事金融和经济学的人只不过是学到各种各样的经验现实,在他们的银行账户里存上大笔现金,然后就去追求更大更好的东西。曼德尔布罗特的回答是:“数据,数据的金库。”实际上,所有人都忘了他最先从事的是经济学,然后才转入物理学和自然几何学。与如此浩繁的数据打交道令我们感到卑微;它会导致我们犯错误——在表象与现实之间的路上走反了方向。
下面探讨统计循环问题(或称统计回归问题)。假设你需要用历史数据发现某个概率分布是高斯的、分形的还是什么别的。你需要确定你是否有足够的数据支持你的论断。我们如何知道数据是否充分呢?根据概率分布来判断,概率分布确实能够告诉你是否有足够的数据对你的推论提出“置信”。如果是高斯钟形曲线,只需要几个数据点就够了(大数定理再次起作用)。而你如何知道相关分布是不是高斯分布呢?好吧,通过数据知道。于是,我们需要数据告诉我们概率分布是什么,又需要概率分布告诉我们需要多少数据。这是一个突出的循环问题。
假如你事前就假定分布是高斯分布,这种循环问题就不会出现。出于某种原因,高斯分布很容易表现出特点。极端斯坦的概率分布不会这样。所以选择高斯分布从而可以借用某种通用法则是一件很方便的事。正是由于这个原因,高斯分布被选为默认分布。我一直反复强调,事前假定高斯分布对少数领域是可行的,比如犯罪统计学、死亡率等平均斯坦问题,但对特性不明的历史数据和极端斯坦问题行不通。
那么,为什么与历史数据打交道的统计学家不明白这一点呢?首先,他们不喜欢听到他们的整个事业被循环问题取消了。其次,他们没有在严格意义上面对他们的预测结果。我们在马克利达基斯竞争实验中已经看到,他们深陷于叙述谬误中,不愿意听这些。
再次强调,当心预测者
让我把问题再拔高一点。我之前提过,人们试图用许多时髦的模型解释极端斯坦的起源。实际上,他们主要分为两类,偶尔也有别的方法。第一类包括类似富者更富(或强者更强)的简单模型,人们用它们解释人口在城市的聚集、微软和家用录像系统对市场的统治、学术声望的产生,等等。第二类主要是“渗流模型”,它们不考虑个人的行为,而是个人行为作用的环境。当你向一个多孔的表面泼水时,表面的结构比液体更重要。当一粒沙子击中一堆沙子时,沙堆表面的组织结构才是是否会出现崩塌的决定因素。
当然,大部分模型都试图达到精准预测,而不仅限于描述,这令我感到生气。它们是描述极端斯坦起源的不错工具,但我坚持认为现实的“创造者”对它们的符合程度似乎不足以使它们对精确预测有帮助,至少对你目前在关于极端斯坦的文献中看到的问题都不行。我们再一次面临严重的校准问题,所以我们应该避免在对非线性过程进行校准的过程中经常犯的错误。回忆一下,非线性过程比线性过程有更高的自由度(我们在第十一章讨论过),也就是说你更有可能用错模型。你也会不时读到一本书或者一些文章,提倡使用统计物理学模型描述现实。菲利普·鲍尔的书具有启发性和知识性,但那样的书不会得出准确的量化模型,不要只看它们的表面价值。
但让我们看看能够从这些模型中获得什么。
又一个令人愉快的解决方案
首先,由于假设分布是突破性的,我认为任意大的数字都是可能出现的。也就是说,不均等性不会在某个已知的上限上消失。
假设《达·芬奇密码》卖出了大约6000万册。(《圣经》卖出了10亿册,但让我们忽略它,把分析局限在由单个作者完成的通俗书上。)虽然我们从没见过卖出2亿册的通俗书,但我们可以认为其可能性并不为零。每三种《达·芬奇密码》这样的畅销书里,可能有一种超级畅销书,虽然还没有真的出现过,但我们不能排除它的可能性。而且,每15种《达·芬奇密码》这样的畅销书中,可能有一种超级畅销书能够卖出比如5亿册。
把同样的逻辑应用于财富。假设地球上最富的人身家500亿美元。一种不可忽略的可能就是下一年一个身家1000亿美元或更多的人会横空出世。每三个身家超过500亿美元的人当中就可能有一个身家超过1000亿美元的人。身家超过2000亿美元的人出现的概率更小,是前一种可能性的1/3,但也不是零。甚至出现身家超过5000亿美元的人也存在微小的可能性,而不是零可能性。
这说明:我可以推断在历史数据中没有看到的事情,但这些事情应该仍然属于概率王国。有一本看不见的畅销书没有在过去的数据中出现过,但你必须考虑它。回忆我在第十三章的观点:它使对一本书或一种药品的投资可能得到比历史统计数据显示的更好的回报,但它也可能使股票市场发生比历史上更严重的损失。
战争的本质是分形的。有可能发生死亡人数超过第二次世界大战的战争,这可能性不大,但不是零,尽管这样的战争在历史上没有发生过。
其次,我将用自然界的例子帮助说明准确预测的问题。山在某种程度上与石头相似:它与石头有亲缘关系,这是一种家族相似性,但并非完全相同。这种相似性被称为“自仿”(self-affine),不是精确的“自相似”(self-similar),但曼德尔布罗特没能让人们记住“自仿”的概念,表示精确相似性而非家族相似性的“自相似”一词却流传开来。与山和石头一样,10亿美元以上的财富分布与10亿美元以下的财富分布也不完全相同,但两种分布有“亲缘关系”。
第三,我之前说过,世界上有大量以校准为目的的经济物理学(把统计物理学应用于社会和经济现象)论文,旨在从现象中剥离出数字,许多试图预测未来。可惜,我们无法从“变迁”中预测危机或传染病。我的朋友迪迪尔·索尼特试图建立预测模型,我很喜欢,只是我不能用它们进行预测,但请别告诉他,否则他可能会停止造模型。我不能像他希望的那样使用它们,这并不否定他的工作,只是要求人们有开放的思维,这种思维与有根本缺陷的传统经济学模型不同。索尼特的有些模型可能很不错,但不是全部。
灰天鹅在哪里
我整本书都在写黑天鹅。这并不是因为我爱上了黑天鹅,作为人道主义者,我恨它。我恨它造成的大部分不公平和对人类的伤害。因此我希望消除许多黑天鹅现象,或者至少缓和它们的影响,保护人们不受伤害。分形随机性是减少意外事件的一种方式,它使有些黑天鹅变得更明显,使我们意识到它们的影响,把它们变成灰色。但分形随机性不能产生准确的答案,它的好处在于如下几点:如果你知道股市可能崩盘,像美国1987年那样,那么这一事件就不是黑天鹅;如果你使用指数为3的分形分布,1987年的崩盘就不是意外;如果你知道生物科技公司能够研制出一种超级轰动的药物,比历史上的所有药物都轰动,那么它就不是黑天鹅,假如这一药物真的出现,你也不会感到意外。
因此,曼德尔布罗特的分形理论使我们能够考虑到一些黑天鹅,但不是全部。我之前说过,有些黑天鹅现象发生是因为我们忽视了随机性的来源,有的是因为我们高估了分形指数。灰天鹅是可以模型化的极端事件,黑天鹅则是未知的未知。
我曾与这个伟大的人坐下来讨论这个问题,同往常一样,我们的谈话变成了一种语言游戏。在第九章我提过经济学家对奈特不确定性(不可计算)与奈特风险(可计算)的区分,这一区分不可能新到在我们的词汇表中还没有收录,所以我们在法语中寻找。曼德尔布罗特提到他的一位朋友兼英雄,贵族数学家马塞尔-保罗·舒森伯格(Marcel-Paul Schutzenberger)。他是一个优雅博学的人,很容易对事物感到乏味(与本作者一样),无法对出现收益递减的问题继续研究。舒森伯格认为上述区分在法语中就是hasard和fortuit的区别。hasard源自阿拉伯语az-zahr,意思是骰子一样的偶然性,也就是可理解的随机性;fortuit是我的黑天鹅,具有纯粹的意外性和不可预测性。我们求助于佩蒂特·罗伯特(Petit Robert)编写的法语字典,发现确实存在这样的区别。fortuit似乎与我的认知迷雾相对应,表示意外而不可量化的事物;hasard更像游戏类随机性,由法国著名赌徒查瓦利埃·德梅瑞(Chevalier de Mere)在早期的赌博文献中提出。令人惊讶的是,阿拉伯人为不确定性引入了另一个词:rizk,意思是特性。
我再次重申:曼德尔布罗特研究灰天鹅,我研究黑天鹅。所以曼德尔布罗特驯服了我的许多黑天鹅,但不是全部,不是完全驯服。但他用他的方法为我们展现了一线希望,一种思考不确定性问题的方式。如果你知道那些野生动物在哪里,你真的会安全许多。
①非专业读者可以跳过此节直到本章末。
