7.3 数据库
你已经看到如何使用文件来储存数据,那么为什么还要用数据库呢?非常简单,因为在有些情况下,数据库的特性提供了解决问题的更好方法。与使用文件来存储数据相比,使用数据库有如下两方面的优势。
❑ 你可以存储长度可变的数据记录,这对平面的、非结构化的文件来说实现起来有点困难。
❑ 数据库使用索引来有效地存储和检索数据。这样做的一个显著优点是这个索引不必非得是一个简单的记录号——这在平面文件中很容易实现,它可以是一个任意的字符串。
7.3.1 dbm数据库
所有版本的Linux以及大多数的UNIX版本都随系统带有一个基本的、但却非常高效的数据存储例程集,它被称为dbm数据库。dbm数据库适合于存储相对比较静态的索引化数据。一些数据库纯粹主义者可能会认为dbm根本算不上是一个数据库,充其量就是一个索引化的文件存储系统。但X/Open规范把dbm看作是一个数据库,因此在本书里我们也会这么称呼它。
1.dbm简介
尽管一些免费的关系型数据库,如MySQL和PostgreSQL使用越来越广泛,dbm数据库仍然在Linux中扮演着一个重要的角色。那些使用RPM的Linux发行版本,如RedHat和SUSE,就是用dbm来储存已安装软件包的信息。LDAP的开源实现OpenLDAP也可以使用dbm作为它的储存机制。与更加完整的数据库产品如MySQL相比,dbm的优势在于它是一个很轻量级的软件,而且它非常容易被编译进一个可发布的二进制文件中,因为它无需安装独立的数据库服务器。在写作本书的时候,Sendmail和Apache都在使用dbm数据库。
dbm数据库可以使用索引来存储可变长的数据结构,然后通过索引或顺序扫描数据库来检索结构。dbm数据库适用于处理那些被频繁访问但却很少被更新的数据,因为它创建数据项时非常慢,而检索时非常快。
讲到这里,我们遇到了一个小问题:多年以来,dbm数据库存在着各种不同的版本,它们的API接口和特性都有一些细微的差别。既有最初的dbm集,又有“新”的被称为ndbm的dbm集,还有GNU的dbm实现gdbm。GNU的实现版本虽然可以模拟旧版本的dbm和ndbm接口,但其本身的接口和其他实现版本相比,还是有着显著的不同。不同的Linux发行版本自带的dbm库也不一样,虽然最常见的选择是带有gdbm库,因为它可以模拟其他两种接口类型。
在这里,我们将重点介绍ndbm接口,因为它已由X/Open组织标准化,并且它的使用要比原始的gdbm实现简单一些。
2.获得dbm
大多数主流的Linux发行版都会默认安装gdbm,但在一些发行版中,你可能需要使用软件包管理器来安装相应的开发库。例如,在Ubuntu中,你可能需要使用Synaptic软件包管理器来安装libgdbm-dev软件包,因为它一般不会被默认安装。
如果想要查看gdbm开发包的源代码,或者使用的Linux发行版没有提供预编译的gdbm开发包,你可以在网址www.gnu.org/software/gdbm/gdbm.html上找到dbm的GNU实现gdbm。
3.故障解决和重装dbm
本章假设你已安装了dbm的GNU实现gdbm和ndbm兼容库。Linux发行版通常都已这么做了,但如前所述,你可能必须明确安装开发库软件包以编译使用ndbm例程的文件。
遗憾的是,对于不同的Linux发行版,编译使用ndbm库的源文件所需的包含库和链接库略有不同,所以,虽然你已安装了gdbm和ndbm兼容库,但你可能还需要经过实验来发现如何编译这些源文件。最常见的情况是,系统已安装了gdbm,并且它在默认情况下就支持了ndbm兼容模式,Red Hat发行版就是这样的。在这种情况下,你需要执行如下操作。
(1)在C源文件中包含头文件ndbm.h。
(2)使用编译行选项-I/usr/include/gdbm包含头文件目录/usr/include/gdbm。
(3)使用编译行选项-lgdbm链接gdbm库。
如果这不起作用,一种常见的选择(也是最近的Ubuntu和SUSE发行版使用的方法)是:系统已安装了gdbm,但在需要ndbm兼容模式时,你必须明确地指定它,并且你可能需要在链接主函数库之前链接兼容库。你需要做的具体操作如下所示。
(1)在C源文件中包含头文件gdbm-ndbm.h而不是ndbm.h。
(2)使用编译行选项-I/usr/include/gdbm包含头文件目录/usr/include/gdbm。
(3)使用编译行选项-lgdbm_compat -lgdbm链接其他的gdbm兼容库。
可下载的Makefile文件和dbm C源文件都被默认设置为使用第一种选择,但它们都包含注释以说明如何可以通过编辑方便地切换到使用第二种选择。在本章的剩余部分,我们将假设你的系统默认就支持ndbm兼容模式。
7.3.2 dbm例程
和我们在第6章中讨论的curses函数库一样,dbm也是由头文件和库文件组成,而且库文件必须在程序被编译时链接进来。库文件被简称为dbm,但因为我们通常在Linux中使用的是GNU的dbm实现,所以我们需要在编译行中使用选项-lgdbm来链接这个实现。其头文件是ndbm.h。
在开始解释每个dbm函数之前,你必须明白dbm数据库能够做什么,这一点很重要。一旦明白了这个,你就能更好地理解该如何使用dbm函数。
dbm数据库的基本元素是需要储存的数据块以及与它关联的在检索数据时用作关键字的数据块。每个dbm数据库必须针对每个要存储的数据块有一个唯一的关键字。关键字的取值被用作存储数据的索引。dbm对于关键字和数据没有限制,对使用超长关键字和数据的情况也未定义任何错误。规范允许具体实现把关键字/数据对的长度限制为1023个字节,但具体实现通常不会进行限制,这是因为具体实现往往要比技术规范所要求的更灵活。
为了操纵这些数据块,头文件ndbm.h定义了一个名为datum的新数据类型。该类型确切的内容依赖于具体实现,但它至少包含下面两个成员:
void *dptr;
size_t dsize
datum是一个用typedef语句定义的类型。在ndbm.h文件中还为dbm声明了一个类型定义,它是一个用来访问数据库的结构,其作用和用来访问文件的FILE结构很相似。dbm类型定义的内部结构依赖于具体实现,它决不允许被直接使用。
在使用dbm库时,如果要引用一个数据块,你必须声明一个datum类型的变量,将成员dptr指向数据的起始点,并把成员dsize设为包含数据的长度。无论是待存储的数据或是用来访问它的索引都总是通过这个datum类型来引用。
你最好将dbm类型看作为类似于FILE的类型。当打开一个dbm数据库时,通常会创建两个物理文件,它们的后缀分别是.pag和.dir,并返回一个dbm指针,它被用来访问这两个文件。这两个文件决不应该被直接读写,对它们的访问只能通过dbm例程来进行。
在一些实现中,这两个文件被合并到一起,打开数据库只会创建一个文件。
如果对SQL数据库很熟悉,你会发现dbm数据库没有与之关联的表格或列结构。这些结构对于dbm数据库来说并不是必需的,因为dbm不仅对待存储的每个数据项没有固定长度的要求,而且对数据的内部结构也无要求。dbm数据库工作在非结构化的二进制数据块基础上。
7.3.3 dbm访问函数
现在我们已介绍了dbm库工作的基础,下面我们可以来具体看看它提供的函数。主要的dbm函数的原型如下所示:

1.dbm_open函数
这个函数用来打开已有的数据库,也可以用来创建新数据库。filename参数是一个基本文件名,它不包含.dir或.pag后缀。
其余的参数和第3章中的open函数的第二个和第三个参数一样。你可以使用相同的#define定义。第二个参数控制数据库的读、写或读/写权限。如果要创建一个新的数据库,这个标志必须与O_CREAT进行二进制或才允许文件被创建。第三个参数指定将被创建的文件的初始权限。
dbm_open返回一个指向DBM类型的指针。它被用于所有后续对数据库的访问。如果失败,它将返回(DBM *)0。
2.dbm_store函数
你用这个函数把数据存储到数据库中。如前所述,所有数据在存储时都必须有一个唯一的索引。为了定义你想要存储的数据和用来引用它的索引,你必须设置两个datum类型的参数:一个用于引用索引,一个用于实际数据。最后一个参数store_mode用于控制当试图以一个已有的关键字来存储数据时会发生的情况。如果它被设置为dbm_insert,存储操作将失败并且dbm_store返回1。如果它被设置为dbm_replace,则新数据将覆盖已有数据并且dbm_store返回0。当发生其他错误时,dbm_store将返回一个负值。
3.dbm_fetch函数
dbm_fetch函数用于从数据库中检索数据。它使用一个先前dbm_open调用返回的指针和一个指向关键字的datum类型结构作为其参数。它返回一个datum类型的结构。如果在数据库中找到与这个关键字关联的数据,返回的datum结构的dptr和dsize成员的值将被设为相应数据的值。如果没有找到关键字,dptr将被设置为null。
要记住的是,dbm_fetch返回的datum类型结构中仅仅包含一个指向数据的指针。实际数据依然保存在dbm库的本地存储空间中。你在继续调用dbm函数前,必须把数据复制到程序的变量中才行。
4.dbm_close函数
这个函数关闭用dbm_open打开的数据库。它的参数是先前dbm_open调用返回的dbm指针。
实 验 一个简单的dbm数据库
在学习了dbm数据库的基本函数之后,你可以开始编写第一个dbm程序dbm1.c了。在这个程序中,你将使用一个名为test_data的结构。
(1)程序的开始部分是#include语句、#define定义、main函数和test_data结构的声明:

(2)在main函数中,设置了items_to_store和items_received两个结构,还设置了关键字字符串和datum结构:
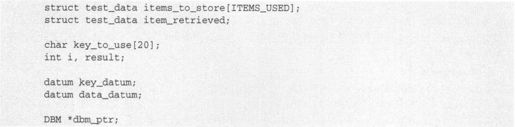
(3)在声明了一个指向dbm类型结构的指针后,现在打开测试数据库用来读写,如果需要就创建它:

(4)现在添加一些数据到items_to_store结构中:
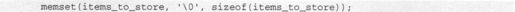

(5)你需要为每个数据项建立一个供以后引用的关键字。它被设为每个字符串的头一个字母加上整数。这个关键字由key_datum标识,而data_datum则指向items_to_store数据项。然后将数据存储到数据库中:

(6)接下来,查看是否可以检索这个新存入的数据。最后,关闭数据库:

编译并运行这个程序,它的输出如下所示:

如果gdbm是以兼容模式安装的,这就是你将获得的输出结果。如果编译失败,你可能需要修改源文件中的#include语句,按照源文件中注释说明的方法,用gdbm-ndbm.h文件替换ndbm.h,并在编译源文件时,在链接主函数库之前先链接兼容库,如下所示:
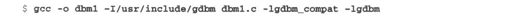
实验解析
首先,打开数据库,如果需要就创建它。接着,填充作为测试数据的items_to_store的3个成员。针对每个成员,你分别创建一个索引关键字。为简单起见,你使用两个字符串的头一个字符再加上整数来构成关键字。
然后,设置两个datum结构,一个用于关键字,另一个用于存储的数据。在把3个数据项存储到数据库中之后,你构建一个新的关键字并设置一个datum结构来指向它。然后,使用这个关键字来从数据库中检索数据。通过检查返回的datum结构中的dptr成员是否为null,来判断检索是否成功。假设它不是null,你就可以把检索到的数据(它可能储存在dbm库的内部空间中)复制到你自己的结构中。注意,要使用dbm_fetch返回的长度值(如果不这样做,并且使用的是可变长数据,你可能就会复制根本不存在的数据)。最后,打印检索到的数据来验证是否正确获取了数据。
7.3.4 其他dbm函数
现在你已知道了主要的dbm函数,本节我们将介绍用于dbm数据库的一些其他函数:

1.dbm_delete函数
dbm_delete函数用于从数据库中删除数据项。与dbm_fetch一样,它也使用一个指向关键字的datum类型结构作为其参数,但不同的是,它是用于删除数据而不是用于检索数据。它在成功时返回0。
2.dbm_error函数
dbm_error函数只是用于测试数据库中是否有错误发生,如果没有就返回0。
3.dbm_clearerr函数
dbm_clearerr函数用于清除数据库中所有已被置位的错误条件标志。
4.dbm_firstkey和dbm_nextkey函数
这两个函数一般成对使用来对数据库中的所有关键字进行扫描。它们需要的循环结构如下所示:

实 验 检索和删除
在本例中,使用上面介绍的新函数对dbm1.c做一些改进。下面是dbm2.c的源代码:
(1)复制一份dbm1.c,打开它进行编辑。修改#define TEST_DB_FILE一行:

(2)然后只需要修改检索数据的部分:
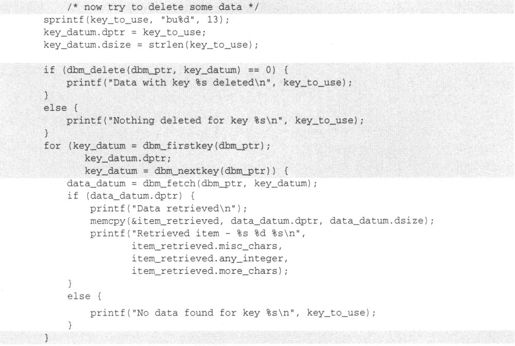
其输出为:

实验解析
这个程序的第一部分同前面的例子完全一样,只是往数据库里储存一些数据。然后构建一个关键字来匹配第二个数据项,并把它从数据库中删除。
接下来,这个程序使用dbm_firstkey和dbm_nextkey依次访问数据库中的每个关键字,并检索数据。注意,数据的获取并不是按序的:按关键字的顺序检索数据并不意味着获取的数据是有序的,它只是一种扫描所有数据项的方式。
