13.4 pipe调用
在看过高级的popen函数之后,我们再来看看底层的pipe函数。通过这个函数在两个程序之间传递数据不需要启动一个shell来解释请求的命令。它同时还提供了对读写数据的更多控制。
pipe函数的原型如下所示:

pipe函数的参数是一个由两个整数类型的文件描述符组成的数组的指针。该函数在数组中填上两个新的文件描述符后返回0,如果失败则返回-1并设置errno来表明失败的原因。在Linux手册页(手册的第二部分)中定义了下面一些错误。
❑ EMFILE:进程使用的文件描述符过多。
❑ ENFILE:系统的文件表已满。
❑ EFAULT:文件描述符无效。
两个返回的文件描述符以一种特殊的方式连接起来。写到file_descriptor[1]的所有数据都可以从file_descriptor[0]读回来。数据基于先进先出的原则(通常简写为FIFO)进行处理,这意味着如果你把字节1,2,3写到file_descriptor[1],从file_descriptor[0]读取到的数据也会是1,2,3。这与栈的处理方式不同,栈采用后进先出的原则,通常简写为LIFO。
特别要注意,这里使用的是文件描述符而不是文件流,所以我们必须用底层的read和write调用来访问数据,而不是用文件流库函数fread和fwrite。
下面的程序pipe1.c用pipe函数来创建一个管道。
实 验 pipe函数
注意file_pipes数组的用法,它的地址被当作参数传递给pipe函数。

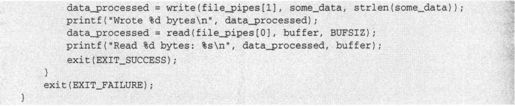
运行这个程序时,输出结果如下所示:

实验解析
这个程序用数组file_pipes[]中的两个文件描述符创建一个管道。然后它用文件描述符file_pipes[1]向管道中写数据,再从file_pipes[0]读回数据。注意,管道有一些内置的缓存区,它在write和read调用之间保存数据。
如果你尝试用file_descriptor[0]写数据或用file_descriptor[1]读数据,其后果并未在文档中明确定义,所以其行为可能会非常奇怪,并且随着系统的不同,其行为可能会发生变化。在我的系统上,这样的调用将失败并返回-1,这至少能够说明这种错误比较容易发现。
乍看起来,这个使用管道的例子并无特别之处,它做的工作也可以用一个简单的文件完成。管道的真正优势体现在,当你想在两个进程之间传递数据的时候。我们在第12章讲过,当程序用fork调用创建新进程时,原先打开的文件描述符仍将保持打开状态。如果在原先的进程中创建一个管道,然后再调用fork创建新进程,我们即可通过管道在两个进程之间传递数据。
实 验 跨越fork调用的管道
(1)下面这个程序pipe2.c的开始部分(在调用fork之前的部分)和第一个例子非常相似。
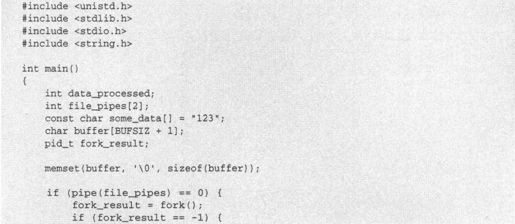
(2)在确认fork调用成功后,如果fork_result等于零,就说明我们是在子进程中,如下所示:

(3)否则,我们肯定是在父进程中,如下所示:

运行这个程序时,输出结果和前例一样:

你可能会在实际运行这个程序的时候发现,命令提示符在输出结果的最后一行之前出现,为了便于阅读,我们在这里对输出结果进行了调整。
实验解析
这个程序首先用pipe调用创建一个管道,接着用fork调用创建一个新进程。如果fork调用成功,父进程就写数据到管道中,而子进程从管道中读取数据。父子进程都在只调用了一次write或read之后就退出。如果父进程在子进程之前退出,你就会在两部分输出内容之间看到shell提示符。
虽然从表面上看,这个程序和第一个使用管道的例子很相似,但实际上在这个例子中我们往前跨出了一大步,我们可以在不同的进程之间进行读写操作了,如图13-2所示。

图 13-2
