10.2 常用调试技巧
目前有几种典型的调试和测试Linux程序的方法。一般做法是先运行程序并观察其输出结果,如果不能正常工作,我们就需要决定应该釆取哪些措施。可以修改程序然后重新尝试(代码检查-试运行-出错法),也可以在程序中增加一些语句来获得更多关于程序内部运行情况的信息(取样法),还可以直接检查程序的执行情况(受控执行法)。程序调试可以分为如下5个阶段。
❑ 测试:找出程序中存在的缺陷或错误。
❑ 固化:让程序的错误可重现。
❑ 定位:确定相关的代码行。
❑ 纠正:修改代码纠正错误。
❑ 验证:确定修改解决了问题。
10.2.1 有漏洞的程序
我们先来看一个有漏洞的示例程序。在本章中,我们将对其进行调试。这个程序是在某大型软件系统的开发过程中编写的,其作用是测试函数sort,该函数的功能是通过冒泡排序算法对一个类型为item的结构数组进行排序,具体的排序方法为基于结构中的成员key以升序排列数组成员。程序用一个样本数组来测试函数sort。在现实中,我们可能永远也不会使用这个算法,因为它的执行效率实在太低了。在这里使用这个算法的原因在于它比较短小,相对来说简单易懂,而且也更容易出错。事实上,在标准的C函数库中已经有一个完成同样功能的函数qsort了。
糟糕的是,这个程序的可读性比较差,里面没有任何注释,也不知道最初的程序员是哪一位,所以一切只能靠我们自己了。先从基本的例程debug1.c开始,下面是该文件的内容:


我们来编译这个程序:

编译过程很顺利,既无出错信息也无警告信息。
运行这个程序之前,我们需要在程序中添加一些代码来打印出结果,否则就不会知道这个程序是否正常工作了。这些代码的作用是显示排序后的数组。我们将这个新版本的文件命名为debug2.c,如下所示:

严格来说,这些额外的代码并不属于程序员的职责范围,加上它完全是因为测试工作的需要。添加这些代码时,我们必须非常小心以避免在测试代码中引入新的漏洞。现在,再次编译,然后运行程序:

这样做产生的输出结果取决于你所使用的Linux(或UNIX)版本及其具体设置情况。在我的系统上运行它时,得到的输出结果是:


但它在本书另一位作者的系统(运行的是另一个版本的Linux内核)上运行时,给出的输出却是这样:

在你的Linux系统中运行这个程序时,你可能会看到其中一种输出结果,或者完全不同的另外一个输出结果。而我们希望看到的输出是:

很明显,这段代码存在着很严重的问题。即使它能运行,给出的排序结果也是错误的。如果它的运行产生段错误(segmentation fault)而被终止,就说明操作系统向程序发送了一个信号,告诉程序操作系统检测到了非法的内存访问,为防止内存空间被破坏,操作系统提前终止了该程序的运行。
操作系统检测非法内存访问的能力,取决于它的硬件配置和它在内存管理实现方面的一些具体做法。在大多数系统中,操作系统分配给程序的内存一般都会比程序实际需要使用的大一些。如果非法内存访问出现在这部分内存区域内,硬件就可能检测不到,这就是并非所有版本的Linux和UNIX系统都会产生段错误的原因。
有的库函数(比如printf)在某些特殊情况下(比如使用了一个空指针)也会阻止非法访问操作的发生。
如果想捕捉到数组访问方面的错误,最好增加数组元素的大小,因为这样同时也增加了错误的大小。如果只是在数组的结尾之后读取一个字节,我们很可能会看不到有错误发生,因为分配给程序的内存大小会取整到操作系统的特定边界,一般分配的内存大小以8K为单位递增。
如果增加数组元素的大小,比如在此例中将item结构中的成员data扩大为一个可以容纳4096个字符的数组,对不存在的数组元素进行访问时,内存地址就有可能落在分配给这个程序的内存之外的地方。因为数组的每个元素大小为4K,所以我们错误使用的内存将落在数组结尾之后的0K~4K范围内。
如果这样做,并将修改后的程序命名为debug3.c,它将在两位作者的Linux系统上都产生段错误。如下所示:

但还是存在着这样的可能性,即某些Linux或UNIX版本仍然不会产生段错误。当C语言的ANSI标准将某种行为定义为“未定义”时,实际上它还是允许程序运行的。现在看来,我们所写的这个C语言程序是不合规范的,而且这个不合规范的C语言程序可能会表现出非常奇怪的行为!我们将看到这个错误确实就属于刚才所说的“未定义”行为的范畴。
10.2.2 代码检查
先前已经提到过,当程序的运行情况和预期不同时,最好重新阅读程序。根据本章的学习目的,我们假设程序代码已经被检查过,那些比较明显的错误也都已经被排除了。
代码检查这一术语还用于一种更加正式的场合:一组开发人员逐字逐句的检查数百行的代码。但代码本身的规模大小其实并不重要,它仍然是代码检查并且是一个非常有用的技巧。
有些工具可以帮助你完成代码检查工作,编译器就是其中比较明显的一个。如果程序有语法错误,它就会告诉你。
有些编译器还有用来针对可疑行为产生报警的选项,比如未对变量进行初始化、在条件判断里使用赋值操作等。举例来说,GNU编译器在运行时可以使用下面这些选项。

这些选项将启用许多警告和其他检查来检验程序是否符合C语言标准。我们建议大家养成使用这些选项的习惯,特别是-Wall选项。在追踪程序的错误时,它可以产生非常有用的信息。
我们将在稍后介绍lint和splint等工具。与编译器一样,它们对源代码进行分析并报告可能不正确的代码。
10.2.3 取样法
取样法是指在程序中添加一些代码以收集更多与程序运行时的行为相关的信息的方法。取样法的常见做法是,在程序中添加printf函数调用以打印出变量在程序运行的不同阶段的值,如同我们在上面的例子中所做的那样。我们可以添加多个printf函数调用,但需要注意,无论何时程序发生了改动,这一过程都将带来更多的编辑和编译次数,而且,在程序错误被修复后,我们还要把这些额外的代码删除掉。
在这里可以使用两种取样法的技巧。第一种技巧是用C语言的预处理器有选择地包括取样代码,这样只需重新编译程序就可以包含或去除调试代码。实现方法非常简单,只需使用如下的语句结构:
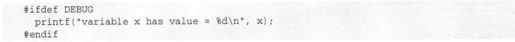
在编译程序时可以加上编译器标志-DDEBUG。如果加上这个标志,就定义了DEBUG符号,从而可以在程序中包含额外的调试代码;如果未加上该标志,这些调试代码将被删除。我们还可以用数值调试宏来完成更复杂的调试应用,如下所示:

在这种情况下,我们必须总是定义DEBUG宏,但我们可以设置它为代表一组调试信息或代表一个调试级别。比如编译器标志-DDEBUG=5将启用BASIC_DEBUG和SUPER_DEBUG,但不包括EXTRA_DEBUG。标志-DDEBUG=0将禁用所有的调试信息。另外,也可以在程序中添加如下语句。这样,当不需要调试时,就不必在命令行上定义DEBUG宏:

C语言预处理器定义的一些宏可以帮助我们进行调试。这些宏在扩展后会提供当前编译操作的相关信息,如表10-1所示。
表 10-1

注意,这些符号的前后各有两个下划线,这是标准的预处理器符号通常的做法,你应该注意避免选择可能会与它们冲突的符号。上面说明中的术语当前指的是预处理操作正在执行的那一时刻,即正在运行编译器对文件进行处理时的时间和日期。
实 验 调试信息
请看下面这个程序cinfo.c,如果在编译它时启用了调试,就会打印出编译时的日期和时间:

编译这个程序时启用调试(用-DDEBUG),我们将看到如下所示的编译信息:

实验解析
作为编译器的一部分的C语言预处理器跟踪记录正在编译的当前文件和文件中的当前行。当它在代码中遇到符号LINE和FILE时,就将它们替换为这些变量的当前值(编译时刻),对编译日期和时间的处理也与此相同。因为DATE和TIME都是字符串,所以我们可以用printf函数的格式字符串把它们连在一起,ANSI C标准定义相邻的字符串可以被看作为一个字符串。
无需重新编译的调试技巧
在继续学习新的内容之前,我们先介绍一个使用printf函数帮助调试的技巧,它的好处是无需使用#ifdef DEBUG语句,后者还需要重新编译才能开始对程序进行调试。
方法是在程序中增加一个作为调试标志的全局变量,这使得用户可以在命令行上通过-d选项切换是否启用调试模式,即使程序已经发布了,仍然可以这样做,该方法同时还会在程序中增加一个用于记录调试信息的函数。现在我们可以把如下的内容加入到程序代码中:

你应该将调试信息输出到标准错误输出stderr,或者,如果因为程序的原因不能这样做,你还可以使用syslog函数提供的日志功能。
如果用这种调试方法来解决程序开发过程中的问题,你可以将这些代码一直留在程序中。只要你比较谨慎在意,这样做将是相当安全的。它的好处体现在:当程序发布之后,如果用户遇到了问题,他们自己就可以在运行程序时打开调试功能,自己完成诊断错误的工作。在出现问题时除了报告段错误外,它们还可以报告出当时程序正在做什么,而不仅是用户本人正在做什么。这两者之间的区别还是很明显的。
当然,这样做也有一个明显的不足,就是程序的长度会有所增加。但在大多数情况下,它只是一个表面问题,算不上是实际意义上的问题。程序的长度可能会增加20%或30%,但往往并不会对程序的性能造成真正的影响。只有在程序的长度提高几个数量级时,才会造成程序性能的降低。
10.2.4 程序的受控执行
现在回到示例程序,该程序有一个漏洞,我们可以修改程序,增加一些代码把变量在程序运行时的值打印出来,或者还可以用调试器来控制程序的执行,随时查看这些变量的状态。
商业UNIX系统中有许多可用的调试器,能用哪些调试器取决于厂商。常见的有adb、sdb、idebug和dbx。较复杂的调试器可以在源代码级别查看程序的比较详细的状态信息。GNU的调试器gdb(可以在Linux和许多类UNIX系统中使用)就可以做到这一点。目前有一些针对gdb的“前端”程序,它们提供非常友好的用户界面,xxgdb、KDbg和ddd都是这样的程序。一些IDE,比如我们在第9章介绍的,也提供了调试功能或一个用于gdb的前端。Emacs编辑器甚至还提供了一个功能(gdb-mode),允许用户在程序上运行gdb,设置断点并查看现在执行到源代码中的哪一行。
为了能够调试程序,我们需要在编译它时加上一个或多个特殊的编译器选项。这些选项的作用是让编译器在程序中添加额外的调试信息。这些信息包括各种符号和源代码行号,调试器将利用这些信息向用户显示程序已经执行到源代码的位置。
-g标志是对程序进行调试性编译时常用的一个选项。我们必须在编译每个需要调试的源文件时都加上这个选项,对链接器也要这样做(编译器会把这个标志自动传递给链接器),它将使用特殊版本的C语言标准库以提供库函数中的调试支持。对那些在编译时没有加上调试功能的函数库,虽然调试工作也能够进行,但灵活性就要差些。
调试信息的加入将使可执行程序的长度成倍增加(最高可达到10倍)。尽管可执行程序的容量可能增加了(并且占用了更多的磁盘空间),但程序运行时所需要的内存数量还是和原来一样。程序调试结束后,最好还是将调试信息从程序的发行版本中删除。
你可以用命令strip <file>将可执行文件中的调试信息删除而不需要重新编译程序。
