第16章 string类和标准模板库
本章内容包括:
● 标准C++string类。
● auto_ptr模板。
● 标准模板库(STL)。
● 容器类。
● 迭代器。
● 函数对象(functors)。
● STL算法。
至此已经熟悉了C++可重用代码的目标,这样做的一个很大的回报是可以重用别人编写的代码,这正是类库的用武之地。有很多商业C++类库,也有一些库是C++程序包自带的。例如,曾使用过的头文件ostream支持的输入/输出类。本章介绍一些其他可重用代码,它们将给编程工作带来快乐。
本书前面介绍过string类,本章将更深入地讨论它;然后介绍auto_ptr,它是一个“智能指针”模板类,使得管理动态内存更容易;最后介绍标准模板库(STL),它是一组用于处理各种容器对象的模板。STL例解了一种新出现的编程模式——通用编程技术(generic programming)。
16.1 string类
很多应用程序都需要处理字符串。C语言在string.h(在C++中,为cstring)中提供了一系列的字符串函数,很多早期的C++实现为处理字符串提供了自己的类。第4章介绍了ANSI/ISO C++ string类;而第12章创建了一个不大的String类,以说明设计表示字符串的类的某些方面。
string类是由头文件string支持的(注意,头文件string.h和cstring支持对C-风格字符串进行操纵的C库字符串函数,但不支持string类)。要使用类,关键在于知道它的公有接口,而string类包含大量的方法,其中包括了若干构造函数,用于将字符串赋给变量、合并字符串、比较字符串和访问各个元素的重载操作符以及用于在字符串中查找字符和子字符串的工具等。简而言之,string类包含的内容很多。
16.1.1 构造字符串
先来看string的构造函数。毕竟,对于类而言,最重要的内容之一是,有哪些方法可用于创建其对象。程序清单16.1使用了string的全部6个构造函数(标有ctor,这是传统C++中构造函数的缩写)。表16.1按照程序中使用的顺序简要描述了这些构造函数。使用构造函数时都进行了简化,即隐藏了这样一个事实:string实际上是模板规范basic_string<char>的一个typedef,同时省略了与内存管理相关的参数(这将在本章后面和附录F中讨论)。size_type是一个依赖于实现的整型,是在头文件string中定义的。string类将string::npos定义为字符串的最大长度,通常为无符号int的最大值。另外,表格中使用缩写NBTS (null-byte-terminated string)来表示以空字符结束的字符串——传统的C字符串。
程序清单16.1 str1.cpp

表16.1 string类的构造函数

程序清单16.1中程序还使用了重载+=操作符,它将一个字符串附加到另一个字符串的后面;重载的=操作符用于将一个字符串赋给另一个字符串;重载的<<操作符用于显示string对象;重载的[]操作符用于访问字符串中的各个字符。
注意:有些老式string实现不支持程序清单16.1中的ctor #6(在C++中,ctor指的是构造函数)。
下面是程序清单16.1中程序的输出:


程序说明
程序清单16.1中的程序首先演示了可以将string对象初始化为常规的C-风格字符串,然后使用重载的<<操作符来显示它:

接下来的构造函数将string对象two初始化为由20个$字符组成的字符串:
string two (20, '$'); // ctor #2
复制构造函数将string对象three初始化为string对象one:
string three (one); // ctor #3
重载的+=操作符将字符串“Oops!”附加到字符串one的后面:
one += "Oops!"; // overloaded +=
这里是将一个C-风格字符串附加到一个string对象的后面。不过+=操作符被多次重载,以便能够附加string对象和单个字符:

同样,=操作符也被重载,以便可以将string对象、C-风格字符串或char值赋给string对象:

重载[]操作符(就像第12章的String范例那样)使得可以使用数组表示法来访问string对象中的各个字符:
three[0] = 'P';
默认构造函数创建一个以后可对其进行赋值的空字符串:

第2行使用重载的+操作符创建了一个临时string对象,然后使用重载的=操作符将它赋给对象four。正如所预料的,+操作符将其两个操作数组合成一个string对象。该操作符被多次重载,以便第二个操作数可以是string对象、C-风格字符串或char值。
第5个构造函数将一个C-风格字符串和一个整数作为参数,其中的整数参数表示要复制多少个字符:

从输出可知,这里只使用前20个字符(“All's well that ends”)来初始化five对象。正如表16.1指出的,如果字符数超过了C-风格字符串的长度,仍将复制请求数目的字符。所以在上面的例子中,如果用40代替20,将导致15个无用字符被复制到five的结尾处(即构造函数将内存中位于字符串“All's well that ends well”后面的内容作为字符)。
第6个构造函数有一个模板参数:
template<class Iter> string (Iter begin, Iter end);
begin和end将像指针那样,指向内存中两个位置(通常,begin和end可以是迭代器——广泛用于STL中的广义化指针)。构造函数将使用begin和end指向的位置之间的值,对string对象进行初始化。[begin,end)来自数学中,意味着包括begin,但不包括end在内的区间。也就是说,end指向被使用的最后一个值后面的一个位置。请看下面的语句:
string six (alls+6, alls + 10); // ctor #6
由于数组名相当于指针,所以alls+6和alls+10的类型都是char,因此使用模板时,将用类型char替换Iter。第一个参数指向数组alls中的第一个w,第二个参数指向第一个well后面的空格。因此,six将被初始化为字符串“well”。图16.1说明了该构造函数的工作原理。
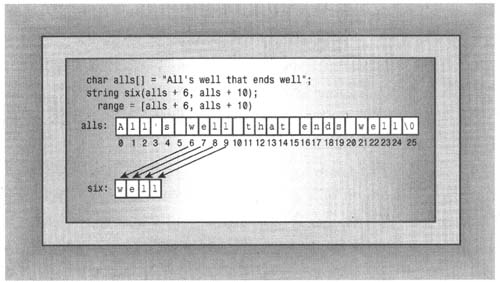
图16.1 使用区间的string构造函数
现在假设要用这个构造函数将对象初始化为另一个string对象(假设为five)的一部分内容,则下面的语句不管用:
string seven (five + 6, five + 10);
原因在于,对象名(不同于数组名)不会被看作是对象的地址,因此five不是指针,所以five+6是没有意义的。不过,five[6]是一个char值,所以&five[6]是一个地址,因此可被用作该构造函数的一个参数。
string seven (&five[6], &five[10]); // ctor #6 again
16.1.2 string类输入
对于类,很有帮助的另一点是,知道有哪些输入方式可用。对于C-风格字符串,有3种方式:

对于string对象,有两种方式:

两个版本的getline()都有一个可选参数,用于指定使用哪个字符来确定输入的边界:
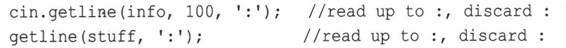
在功能上,它们之间的主要区别在于,string版本的getline()将自动调整目标string对象的大小,使之刚好能够存储输入的字符:

自动调整大小的功能让string版本的getline()不需要指定读取多少个字符的数值参数。
在设计方面的一个区别是,读取C-风格字符串的函数是istream类的方法,而string版本是独立的函数。这就是对于C-风格字符串输入,cin是调用对象;而对于string对象输入,cin是一个函数参数的原因。这种规则也适用于>>形式,如果使用函数形式来编写代码,这一点将显而易见:
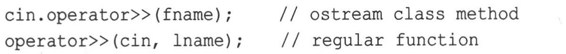
下面更深入地探讨一下string输入函数。正如前面指出的,这两个函数都自动调整目标string的大小,使之与输入匹配。但也存在一些限制。第一个限制因素是string对象的最大允许长度,由常量string::npos指定。这通常是最大的unsigned int值,因此对于普通的交互式输入,这不会带来实际的限制;但如果您试图将整个文件的内容读取到单个string对象中,这可能成为限制因素。第二个限制因素是程序可以使用的内存量。
string版本的getline()函数从输入中读取字符,并将其存储到目标string中,直到发生下列3种情况之一:
● 到达文件尾,在这种情况下,输入流的eofbit将被设置,这意味着方法fail()和eof()都将返回true。
● 遇到分界字符(默认为\n),在这种情况下,将把分界字符从输入流中删除,但不存储它。
● 读取的字符数达到最大允许值(string::npos和可供分配的内存字节数中较小的一个),在这种情况下,将设置输入流的failbit,这意味着方法fail()将返回true。
输入流对象有一个统计系统,用于跟踪流的错误状态。在这个系统中,检测到文件尾后将设置eofbit寄存器,检测到输入错误时将设置failbit寄存器,出现无法识别的故障(如硬盘故障)时将设置badbit寄存器,一切顺利时将设置goodbit寄存器。第17章将更深入地讨论这一点。
string版本的operator>>()函数的行为与此类似,只是它不断读取,直到遇到空白字符并将其留在输入队列中,而不是不断读取,直到遇到分界字符并将其丢弃。空白字符指的是空格、换行符和制表符,更普遍地说,是任何将其作为参数来调用isspace()时,该函数返回ture的字符。
本书前面有多个控制台string输入范例。由于用于string对象的输入函数使用输入流,能够识别文件尾,因此也可以使用它们来从文件中读取输入。程序清单16.2是一个从文件中读取字符串的简短范例,它假设文件中包含用冒号字符分隔的字符串,并使用指定分界符的getline()方法。然后,显示字符串并给它们编号,每个字符串占一行。
程序清单 16.2 strfile.cpp

下面是文件tobuy.txt的内容:

通常,对于程序要查找的文本文件,应将其放在可执行程序或工程文件所在的目录中;否则必须提供完整的路径名。在Windows/DOS系统中,C-风格字符串中的转义序列\表示一个斜杠:
fin.open("C:\CPP\Progs\tobuy.txt"); // file = C:\CPP\Progs\tobuy.txt

注意,将:指定为分界字符后,换行符将被视为常规字符。因此文件tobuy.txt中第一行末尾的换行符将称为包含“cottage cheese”的字符串中的第一个字符。同样,第二行末尾的换行符是第9个输入字符串中惟一的内容。
16.1.3 使用字符串
现在,已经知道可以使用不同方式来创建string对象、显示string对象的内容、将数据读取和附加到string对象中、给string对象赋值以及将两个string对象连接起来。除此之外,还能做些什么呢?
可以比较字符串。String对象对全部6个关系操作符都进行了重载。如果在机器排列序列中,一个对象位于另一个对象的前面,则前者被视为小于后者。如果机器排列序列为ASCII码,则数字将小于大写字符,而大写字符小于小写字符。对于每个关系操作符,都以三种方式被重载,以便能够将string对象与另一个string对象、C-风格字符串进行比较,并能够将C-风格字符串与string对象进行比较:

可以确定字符串的长度。size()和length()成员函数都返回字符串中的字符数:

为什么这两个函数完成相同的任务呢?length()成员来自较早版本的string类,而size()则是为提供STL兼容性而添加的。
可以以多种不同的方式在字符串中搜索给定的子字符串或字符。表16.2简要地描述了find()方法的4个版本。如前所述,string::npos是字符串可存储的最大字符数,通常是无符号int或无符号long的最大取值。
表16.2 重载的find()方法

string库还提供了相关的方法:rfind()、find_first_of()、find_last_of()、find_first_not_of()和find_last_not_of(),它们的重载函数特征标都与find()方法相同。rfind()方法查找子字符串或字符最后一次出现的位置;find_first_of()方法在字符串中查找参数中任何一个字符首次出现的位置。例如,语句:
int where = snakel.find_first_of ("hark");
将返回r在“cobra”中的位置(即索引3),因为这是“hark”中各个字母在“cobra”首次出现的位置。find_last_of()方法的功能与此相同,只是它查找的是最后一次出现的位置。因此,语句:
int where = snakel.last_first_of ("hark");
将返回a在“cobra”中的位置。find_first_not_of()方法在字符串中查找第一个不被包含在参数中的字符,因此:
int where = snakel.find_first_not_of ("hark");
将返回c在“cobra”中的位置,因为“hark”中没有c。在本章最后的练习中,读者将了解find_last_not_of()。
还有很多其他的方法,这些方法足以创建一个非图形版本的Hangman拼字游戏。该游戏将一系列的单词存储在一个string对象数组中,然后随机选择一个单词,让人猜测单词的字母。如果猜错6次,玩家就输了。该程序使用find()函数来检查玩家的猜测,使用+=操作符创建一个string对象来记录玩家的错误猜测。为记录玩家猜对的情况,程序创建了一个单词,其长度与被猜的单词相同,但包含的是连字符。玩家猜对字符时,将用该字符替换相应的连字符。程序清单16.3列出了该程序的代码。
程序清单 16.3 hangman.cpp


程序清单16.3中程序的运行情况如下:


程序说明
在程序清单16.3中,由于关系操作符被重载,因此可以像对待数值变量那样对待字符串:
while (guesses > 0 && attempt != target)
与对C-风格字符串使用strcmp()相比,这样简单些。
该程序使用find()来检查玩家以前是否猜过某个字符。如果是,则它要么位于badchars字符串(猜错)中,要么位于attempt字符串(猜对)中:

npos变量是string类的静态成员,它的值是string对象能存储的最大字符数。由于索引从0开始,所以它比最大的索引值大1,因此可以使用它来表示没有查找到字符或字符串。
该程序利用了这样一个事实:+=操作符的某个重载版本使得能够将一个字符附加到字符串中:
badchars += letter; // append a char to a string object
该程序的核心是从检查玩家选择的字符是否位于被猜测的单词中开始的:
int loc = target.find (letter);
如果loc是一个有效的值,则可以将该字母放置在答案字符串的相应位置:
attempt[loc]=letter;
不过,由于字母在被猜测的单词中可能出现多次,所以程序必须一直进行检查。该程序使用了find()的第二个可选参数,该参数可以指定从字符串什么位置开始搜索。因为字母是在位置loc找到的,所以下一次搜索应从loc+1开始。while循环使搜索一直进行下去,直到找不到该字符为止。如果loc位于字符串尾,则表明find()没有找到该字符。
// check if letter appears again

16.1.4 string还提供了哪些功能
string库提供了许多其他的工具,包括完成下述功能的函数:删除字符串的部分或全部内容、用一个字符串的部分或全部内容替换另一个字符串的部分或全部内容、将数据插入到字符串中或删除字符串中的数据、将一个字符串的部分或全部内容与另一个字符串的部分或全部内容进行比较、从字符串中提取子字符串、将一个字符串中的内容复制到另一个字符串中、交换两个字符串的内容。这些函数中的大多数都被重载,以便能够同时处理C-风格字符串和string对象。附录F简要地介绍了string库中的函数。
首先来看自动调整大小的功能。在程序清单16.3中,每当程序将一个字母附加到字符串末尾时将发生什么呢?不能仅仅将已有的字符串加大,因为相邻的内存可能被占用了。因此,可能需要分配一个新的内存块,并将原来的内容复制到新的内存单元中。如果执行大量这样的操作,效率将非常低,因此很多C++实现分配一个比实际字符串大的内存块,为字符串提供了增大空间。然而,如果字符串不断增大,超过了内存块的大小,程序将分配一个大小为原来两倍的新内存块,以提供足够的增大空间,避免不断地分配新的内存块。方法capacity()返回当前分配给字符串的内存块的大小,而reserve()方法让您能够请求内存块的最小长度。程序清单16.4是一个使用这些方法的范例。
程序清单16.4 str2.cpp

下面是使用某种C++实现时,程序清单16.4中程序的输出:

注意,该实现使用的最小容量为15个字符,这比标准容量选择(16的倍数)小1。其他实现可能做出不同的选择。
如果您有string对象,但需要C-风格字符串,该如何办呢?例如,您可能想打开一个其名称存储在string对象中的文件:

不幸的是,open()方法要求使用一个C-风格字符串作为参数;幸运的是,c_str()方法返回一个指向C-风格字符串的指针,该C-风格字符串的内容与用于调用c_str()方法的string对象相同。因此可以这样做:
fout.open(filename.c_str());
重载C函数以使用string对象
可以使用重载的= =操作符来比较string对象。不过,在某些情况下,==操作符执行相等比较时的区分大小写特征会带来问题。通常,比较两个字符串是否相等时不区分大小写。例如,程序可能将用户的输入与常数值进行比较,而用户输入时的大小写可能与常量不完全相同。程序清单16.3将所有输入都转换为小写来避免这种问题。可能还有另一种选择。很多C库都提供了stricmp()或_stricmp()函数,能够执行不区分大小写的比较(不过,该函数不属于C标准,因此不一定普遍适用)。通过创建该函数的重载版本,可以避免上述问题。

使用简化句法,现在可以对两个字符串进行相等与否的比较。更普遍地说,c_str()方法提供了一条将C-风格字符串函数转换为string对象函数的路径。
本节将string类看作是基于char类型的。事实上,正如前面指出的,string库实际上是基于一个模板类的:

这个类中包含下面两个typedef:

这使得能够使用基于类型wchar_t和char的字符串。甚至可以开发某种类似字符的类,并对它使用basic_string类模板(只要它满足某些要求)。traits类描述关于被选择的字符类型的特定情况,如何对值进行比较。对于char和wchar_t类型的、有预定义的char_traits模板规范,它们都是traits的默认值。Allocator是一个管理内存分配的类。对于char和wchar_t类型,有预定义的allocator模板规范,它们都是默认的。它们按通常的方式使用new和delete,但编程者可以保留一部分内存,并提供自己的分配方法。
16.2 auto_ptr类
auto_ptr是一个模板类,用于管理动态内存分配的用法。我们来看需要哪些功能,及这些功能是如何实现的。请看下面的函数:

可能会发现其中的缺陷。每当调用时,该函数都将分配堆中的内存,但从来不收回,从而导致内存泄漏。您可能也知道解决之道——只要别忘了在return语句前添加下面的语句,以释放分配的内存即可:
delete ps;
不过,大凡涉及到“别忘了”的解决方法,都不会是最佳的。因为编程者有时可能忘了,有时可能记住了,但可能在不经意间删除或注释掉了这些代码。即使确实没有忘记,也可能有问题。请看下面的变体:

当出现异常时,delete将不被执行,因此也将导致内存泄漏。
可以按第14章介绍的方式修复这种问题,但如果有更灵巧的解决方法就好了。我们来看一下需要些什么。当remodel()这样的函数终止(不管是正常终止,还是由于出现了异常而终止),本地变量都将被从堆内存中删除——因此指针ps占据的内存将被释放。如果ps指向的内存也被释放,那该有多好啊。这就意味着希望程序在ps过期时采取另一项额外的措施。对于基本类型,并没有提供这种额外服务;但对于类,则可以通过析构函数机制来提供。因此,ps的问题在于:它只是一个常规指针,不是类对象。如果它是对象,则可以在对象过期时,让它的析构函数删除被指向的内存。这正是auto_ptr背后的思想。
16.2.1 使用auto_ptr
auto_ptr模板定义了类似指针的对象,可以将new获得(直接或间接)的地址赋给这种对象。当auto_ptr对象过期时,其析构函数将使用delete来释放内存。因此,如果将new返回的地址赋给auto_ptr对象时,无须记住稍后释放这些内存。在auto_ptr对象过期时,这些内存将自动被释放。图16.2说明了auto_ptr和常规指针在行为方面的差别。
要创建auto_ptr对象,必须包含头文件memory,该文件包括auto_ptr模板。然后使用通常的模板句法来实例化所需类型的指针。模板中包括:


图16.2 常规指针与auto_ptr
(由前所述,throw()意味着构造函数不引发异常)因此,请求X类型的auto_ptr将获得一个指向X类型的auto_ptr:

new double是new返回的指针,指向新分配的内存块。它是auto_ptr<double>构造函数的参数,即它是对应于原型中形参p的实参。同样,new string也是构造函数的实参。
因此,要转换remodel()函数,应按下面的3个步骤进行:
1.包含头文件memory。
2.将指向string的指针替换为指向string的auto_ptr对象。
3.删除delete语句。
下面是该函数被修改后的情况:


注意,auto_ptr的构造函数是显式的,这意味着不存在从指针到auto_ptr对象的隐式类型转换:

模板让您能够通过构造函数将auto_ptr对象初始化为一个常规指针。
auto_ptr是一种智能指针(smart pointer)——类似于指针,但特性比指针更多。auto_ptr类被定义为在很多方面与常规指针类似。例如,如果ps是一个auto_ptr,则可以对它执行解除引用操作(* ps)和递增操作(++ps),用它来访问结构成员(ps->puffIndex),将它赋给指向相同类型的常规指针。还可以将auto_ptr赋给另一个同类型的auto_ptr,但将引起一个问题,这将在下一节进行讨论。
16.2.2 有关auto_ptr的注意事项
auto_ptr并不是万灵丹。例如,请看下面的代码:
auto_ptr<int> pi (new int [200]); // NO!
别忘了,对于new和new[],必须相应地使用delete和delete[ ]。auto_ptr模板使用的是delete,而不是delete[],因此它只能与new一起使用,而不能与new[]一起使用。没有适用于动态数组的auto_ptr等同物。可以复制头文件memory中的auto_ptr模板,将它重命名为auto_arr_ptr,然后对其进行修改,使之使用delete[],而不是delete。在这种情况下,可能希望添加对[]操作符的支持。
下述代码将如何呢?

这将把delete操作符用于非堆内存,这是错误的。
警告:只能对new分配的内存使用auto_ptr对象,而不要对由new[]分配的或通过声明变量分配的内存使用它。
现在来看赋值情况:

上述赋值语句将完成什么工作呢?如果ps和vocation是常规指针,则两个指针将指向同一个string对象,其中的一个是另一个的拷贝。这是不可接受的,因为ps和vocation都过期时,程序将试图删除同一个对象两次。要避免这种问题,方法有多种:
● 定义赋值操作符,使之执行深复制。这样两个指针将指向不同的对象,其中的一个对象是另一个对象的拷贝。
● 建立所有权(ownership)概念,对于特定的对象,只能有一个智能指针可拥有它。智能指针的构造函数只能删除该智能指针拥有的对象。并使赋值操作转让所有权。这就是用于auto_ptr的策略。
● 创建智能更高的指针,跟踪引用特定对象的智能指针数。这被称为引用计数(reference counting)。例如,赋值时,计数将加1;指针过期时,计数将减1。仅当最后一个指针过期时,delete才被调用。
当然,同样的策略也适用于复制构造函数。
每种方法都有自己的用途。例如,下面这种情况就不适合使用auto_ptr对象:
auto_ptr<string> films[5] =

问题在于,将所有权从films[2]转让给pwin时,可能导致films[2]不再引用该字符串。也就是说,在auto_ptr对象放弃所有权之后,将可能不再可用。它是否可用取决于实现。
智能指针
C++库中auto_ptr对象是一种智能指针(smart pointer)。智能指针是这样一种类,即其对象的特征类似于指针。例如,智能指针可以存储new分配的内存地址,也可以被解除引用。因为智能指针是一个类对象,因此它可以修改和扩充简单指针的行为。例如,智能指针可以建立引用计数,这样多个对象可共享由智能指针跟踪的同一个值。当使用该值的对象数为0时,智能指针将删除这个值。智能指针可以提高内存的使用效率,帮助防止内存泄漏,但并不要求用户熟悉新的编程技术。
16.3 STL
STL提供了一组表示容器、迭代器、函数对象和算法的模板。容器是一个与数组类似的单元,可以存储若干个值。STL容器是同质的,即存储的值的类型相同;算法是完成特定任务(如对数组进行排序或在链表中查找特定值)的处方;迭代器能够用来遍历容器的对象,与能够遍历数组的指针类似,是广义指针;函数对象是类似于函数的对象,可以是类对象或函数指针(包括函数名,因为函数名被用作指针)。STL使得能够构造各种容器(包括数组、队列和链表)和执行各种操作(包括搜索、排序和随机排列)。
Alex Stepanov和Meng Lee在Hewlett-Packard实验室开发了STL,并于1994年发布其实现。ISO/ANSI C++委员会投票同意将其作为C++标准的组成部分。STL不是面向对象的编程,而是一种不同的编程模式——通用编程技术(generic programming)。这使得STL在功能和方法方面都很有趣。关于STL的信息很多,无法用一章的篇幅全部介绍,所以这里将介绍一些有代表性的例子,并领会通用编程方法的精神。先来看几个具体的例子,让读者对容器、迭代器和算法有一些感性的认识,然后再介绍底层的设计理念,并简要地介绍STL。附录G对各种STL方法和函数进行了总结。
16.3.1 vector模板类
在计算中,矢量(vector)对应数组,而不是第11章介绍的数学矢量(在数学中,可以使用N个分量来表示N维数学矢量,因此从这方面讲,数学矢量类似一个N维数组。不过,数学矢量还有一些计算机矢量不具备的其他特征,如内乘积和外乘积)。计算矢量存储了一组可随机访问的值,即可以使用索引来直接访问矢量的第10个元素,而不必首先访问前面第9个元素。所以vector类提供了与第14章介绍的valarray和ArrayTP类似的操作,即可以创建vector对象,将一个vector对象赋给另一个对象,使用[]操作符来访问vector元素。要使类成为通用的,应将它设计为模板类。这正是STL所做的工作——在头文件vector(以前为vector.h)中定义了一个vector模板。
要创建vector模板对象,可使用通常的<type>表示法来指出要使用的类型。另外,vector模板使用动态内存分配,因此可以用初始化参数来指出需要多少矢量:

由于操作符[]被重载,因此创建vector对象后,可以使用通常的数组表示法来访问各个元素:

分配器
与string类相似,各种STL容器模板都接受一个可选的模板参数,该参数指定使用哪个分配器对象来管理内存。例如,vector模板的开头与下面类似:

如果省略该模板参数的值,则容器模板将默认使用allocator<T>类。这个类以标准方式使用new和delete。
程序清单16.5是一个要求不高的应用程序,它使用了这个类。该程序创建了两个vector对象——一个是int规范,另一个是string规范,它们都包含5个元素。
程序清单 16.5 vectl.cpp


注意:老式STL实现使用的头文件为vector.h,而不是vector。尽管包含文件的顺序无关紧要,但有些旧版本g++要求先包含string头文件,然后包含STL头文件。老版本的Microsoft Visual C++的getline()存在错误,导致输入和输出同步出现混乱。
程序清单16.5中程序的运行情况如下:

该程序使用vector模板只是为方便创建动态分配的数组。下一节将介绍一个使用更多类方法的例子。
16.3.2 可对矢量执行的操作
除分配存储空间外,vector模板还可以完成哪些任务呢?所有的STL容器都提供了一些基本方法,其中包括size()——返回容器中元素数目、swap()——交换两个容器的内容、begin()——返回一个指向容器中第一个元素的迭代器、end()——返回一个表示超过容器尾的迭代器。
什么是迭代器?它是一个广义指针。事实上,它可以是指针,也可以是一个可对其执行类似指针的操作——如解除引用(如operator*())和递增(如operator++())——的对象。稍后将知道,对指向迭代器的指针进行广义化使得STL能够为各种不同的容器类(包括那些简单指针无法处理的类)提供统一的接口。每个容器类都定义了一个合适的迭代器,该迭代器的类型是一个名为iterator的typedef,其作用域为整个类。例如,要为vector的double类型规范声明一个迭代器,可以这样做:
vector<double>::iterator pd; // pd an iterator
假设scores是一个vector<double>对象:
vector<double> scores;
则可以使用迭代器pd执行这样的操作:

正如所看到的,迭代器的行为就像指针。
什么是超过结尾(past-the-end)呢?它是一种迭代器,指向容器最后一个元素后面的那个元素。这与C-风格字符串最后一个字符后面的空字符类似,只是空字符是一个值,而“超过结尾”是一个指向元素的指针(迭代器)。end()成员函数标识超过结尾的位置。如果将迭代器设置为容器的第一个元素,并不断地递增,则最终它将到达容器结尾,从而遍历整个容器的内容。因此,如果scores和pd的定义与前面的范例中相同,则可以用下面的代码来显示容器的内容:

所有容器都包含刚才讨论的那些方法。vector模板类也包含一些只有某些STL容器才有的方法。push_back()是一个方便的方法,它将元素添加到矢量末尾。这样做时,它将负责内存管理,增加矢量的长度,使之能够容纳新的成员。这意味着可以编写这样的代码:

每次循环都给scores矢量增加一个元素。在编写或运行程序时,无须了解元素的数目。只要能够取得足够的内存,程序就可以根据需要增加scores的长度。
erase()方法删除矢量中给定区间的元素。它接受两个迭代器参数,这些参数定义了要删除的区间。了解STL如何使用两个迭代器来定义区间至关重要。第一个迭代器指向区间的起始处,第二个迭代器位于区间终止处的后一个位置。例如下述代码:
scores.erase (scores.begin(), scores.begin()+ 2);
将删除第一个和第二个元素,即删除begin()和begin()+1指向的元素(由于vector提供了随机访问功能,因此vector类迭代器定义了诸如begin()+2等操作)。如果it1和it2是迭代器,则STL文档使用(pl,p2)来表示从p1到p2(不包括p2)的区间。因此,区间[begin(),end()]将包括集合的所有内容(参见图16.3),而区间[p1,pl])为空。[]表示法并不是C++的组成部分,因此不能在代码中使用,而只能出现在文档中。
记住:区间[it1,it2]由迭代器it1和it2指定,其范围为it1到it2(不包括it2)。
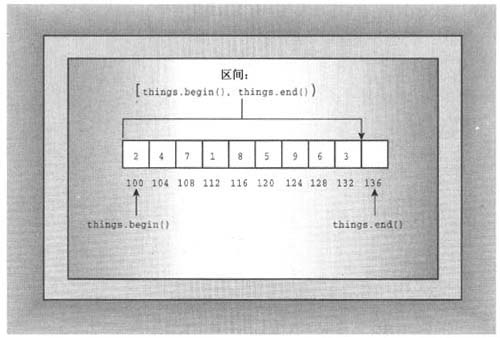
图16.3 STL的区间概念
insert()方法的功能与erase()相反。它接受3个迭代器参数,第一个参数指定了新元素的插入位置,第二个和第三个迭代器参数定义了被插入区间,该区间通常是另一个容器对象的一部分。例如,下面的代码:

将矢量new中除第一个元素以外的所有元素插入到old矢量的第一个元素的前面。顺便说一句,对于这种情况,拥有超尾元素是非常方便的,因为这使得在矢量尾部附加元素非常简单:
old.insert (old.end(), new.begin()+ 1, new.end());
上述代码将新元素插入到old.end()前面,即矢量最后一个元素的后面。
程序清单16.6演示了size()、begin()、end()、push_back()、erase()和insert()的用法。为简化数据处理,程序清单16.5将rating和title组合为一个Review结构,并使用FillReview()和ShowReview()函数来输入和输出Review对象。
程序清单 16.6 vect2.cpp


注意:老式C++实现使用的头文件是vector.h,而不是vector。虽然包含文件的顺序无关紧要,但是有些旧的g++版本要求string头文件出现在STL头文件前面。老式Microsoft Visual C++版本的getline()实现中存在错误,例如下面的输出在再次输入一些内容之前不会出现(在这个例子中,由于存在错误,要求在输入标题之后敲击Enter键两次)。
程序清单16.6中程序的运行情况如下:

16.3.3 对矢量可执行的其他操作
程序员通常要对数组执行很多操作,如搜索、排序、随机排序等。矢量模板类包含了执行这些常见的操作的方法吗?没有!STL从更广泛的角度定义了非成员(non-member)函数来执行这些操作,即不是为每个容器类定义find()成员函数,而是定义了一个适用于所有容器类的非成员函数find()。这种设计理念省去了大量重复的工作。例如,假设有8个容器类,需要支持10种操作。如果每个类都有自己的成员函数,则需要定义80 (8*10)个成员函数。但采用STL方式时,只需要定义10个非成员函数即可。在定义新的容器类时,只要遵循正确的指导思想,则它也可以使用已有的10个非成员函数来执行查找、排序等操作。
下面来看3个具有代表性的STL函数:for_each()、random_shuffle()和sort()。for_each()函数可用于许多容器类,它接受3个参数。前两个是定义容器中区间的迭代器,最后一个是指向函数的指针(更普遍地说,最后一个参数是一个函数对象,函数对象将稍后介绍)。for_each()函数将被指向的函数应用于容器区间中的各个元素。被指向的函数不能修改容器元素的值。可以用for_each()函数来代替for循环。例如,可以将代码:

替换为:
for_each (books.begin(), books.end(), ShowReview);
这样可避免显式地使用迭代器变量。
Random_shuffle()函数接受两个指定区间的迭代器参数,并随机排列该区间中的元素。例如,语句
random_shuffle (books.begin(), books.end());
将随机排列books矢量中所有元素。与可用于任何容器类的for_each不同,该函数要求容器类允许随机访问,vector类可以做到这一点。
sort()函数也要求容器支持随机访问。该函数有两个版本,第一个版本接受两个定义区间的迭代器参数,并使用为存储在容器中的类型元素定义的<操作符,对区间中的元素进行操作。例如:

将按升序对coolstuff的内容进行排序,排序时使用内置的<操作符对值进行比较。
如果容器元素是用户定义的对象,则要使用sort(),必须定义能够处理该类型对象的operator<()函数。例如,如果为Review提供了成员或非成员函数operator<(),则可以对包含Review对象的矢量进行排序。由于Review是一个结构,因此其成员是公有的,这样的非成员函数将为:

有了这样的函数后,就可以对包含Review对象(如books)的矢量进行排序了:
sort (books.begin(), books.end());
上述版本的operator<()函数按title成员的字母顺序排序。如果title成员相同,则按照rating排序。不过,如果想按降序或是按rating(而不是title)排序,该如何办呢?可以使用另一种格式的sort()。它接受3个参数,前两个参数也是指定区间的迭代器,最后一个参数是指向要使用的函数的指针(函数对象),而不是用于比较的operator<()。返回值可转换为bool,false表示两个参数的顺序不正确。下面是一个例子:


有了这个函数后,就可以使用下面的语句将包含Review对象的books矢量按rating升序排列:
sort (books.begin(), books.end(), WorseThan);
注意,与operator<()相比,WorseThan()函数执行的对Review对象进行排序的工作不那么完整。如果两个对象的title成员相同,operator<()函数将按rating进行排序,而WorseThan()将它们视为相同。第一种排序称为全排序(total ordering),第二种排序称为完整弱排序(strict weak ordering)。在全排序中,如果a<b和b<a都不成立,则a和b必定相同。在完整弱排序中,情况就不是这样了。它们可能相同,也可能只是在某方面相同,如WorseThan()范例中的rating成员。所以在完整弱排序中,只能说它们等价,而不是相同。
程序清单16.7演示了这些STL函数的用法。
程序清单 16.7 vect3.cpp


注意:老式C++实现使用头文件vector.h和algo.h,而不是vector和algorithm。尽管包含文件的顺序无关紧要,但g++2.7.1要求先包含头文件string,然后包含STL头文件;在最新的版本中,不存在这样的问题。老式版本的Microsoft Visual C++的getline()存在错误,使下一行输出仅在再次输入后才出现。另外,老式版本的Microsoft Visual C++要求除了定义operator<()之外,还必须定义operator= =()。Borland C++ BuilderX要求将下述语句加入到全局名称空间中:
using std::rand;
程序清单16.7中程序的运行情况如下:

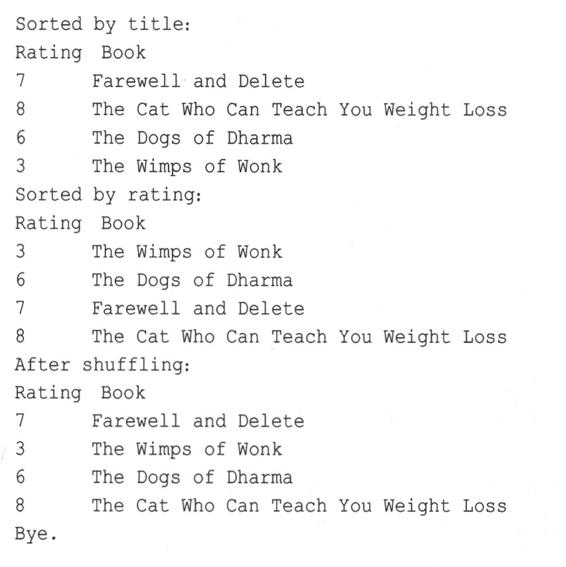
16.4 通用编程技术
有了一些使用STL的经验后,来看一看底层理念。STL是一种通用编程技术(generic programming)。面向对象编程关注的是编程的数据方面,而通用编程技术关注的是算法。它们之间的共同点是抽象和创建可重用代码,但它们的理念绝然不同。
通用编程技术旨在编写独立于数据类型的代码。在C++中,完成通用程序的工具是模板。当然,模板使得能够按通用类型定义函数或类,而STL通过通用算法更进了一步。模板让这一切成为可能,但必须对元素进行仔细地设计。为了解模板和设计是如何协同工作的,我们来看一看需要迭代器的原因。
16.4.1 为何使用迭代器
理解迭代器是理解STL的关键所在。模板使得算法独立于存储的数据类型,而迭代器使算法独立于使用的容器类型。因此,它们都是STL通用方法的重要组成部分。
为了解为何需要迭代器,我们来看如何为两种不同数据表示实现find函数,然后来看如何推广这种方法。首先看一个在double数组中搜索特定值的函数,可以这样编写该函数:

如果函数在数组中找到这样的值,则返回该值在数组中的地址,否则返回一个空指针。该函数使用下标来遍历数组。可以用模板将这种算法推广到包含==操作符的、任意类型的数组。尽管如此,这种算法仍然与一种特定的数据结构(数组)关联在一起。
下面来看搜索另一种数据结构——链表的情况(第12章使用链表实现了Queue类)。链表由被链接在一起的Node结构组成:

假设有一个指向链表的第一个节点的指针,每个节点的p_next指针都指向下一个节点,链表最后一个节点的p_next指针被设置为0,则可以这样编写find_ll()函数:

同样,也可以使用模板将这种算法推广到支持==操作符的任何数据类型的链表。不过,这种算法也是与特定的数据结构——链表关联在一起。
从实现细节上看,这两个find函数的算法是不同的:一个使用数组索引来遍历元素,另一个则将start重置为start->p_next。不过从广义上说,这两种算法是相同的:将值依次与容器中的每个值进行比较,直到找到匹配的为止。
通用编程技术旨在使用同一个find函数来处理数组、链表或任何其他容器类型。即函数不仅独立于容器中存储的数据类型,而且独立于容器本身的数据结构。模板提供了存储在容器中的数据类型的通用表示,因此还需要遍历容器中的值的通用表示,迭代器正是这样的通用表示。
要实现find函数,迭代器应具备哪些特征呢?下面是一个简短的特征列表:
● 应能够对迭代器执行解除引用的操作,以便能够访问它引用的值。即如果p是一个迭代器,则应对*p进行定义。
● 应能够将一个迭代器赋给另一个。即如果p和q都是迭代器,则应对表达式p=q进行定义。
● 应能够将一个迭代器与另一个进行比较,看它们是否相等。即如果p和q都是迭代器,则应对p= =q和p!=q进行定义。
● 应能够使用迭代器遍历容器中的所有元素,这可以通过为迭代器p定义++p和p++来实现。
迭代器也可以完成其他的操作,但有上述功能就足够了,至少对于find函数是如此。实际上,STL按功能的强弱定义了多种级别的迭代器,这将在后面介绍。顺便说一句,常规指针就能满足迭代器的要求,因此,可以这样重新编写find_arr()函数:

然后可以修改函数参数,使之接受两个指示区间的指针参数,其中的一个指向数组的起始位置,另一个指向数组的超尾(程序清单7.8与此类似);同时函数可以通过返回尾指针,来指出没有找到要找的值。下面的find_ar()版本完成了这些修改:

对于find_ll()函数,可以定义一个迭代器类,其中定义了操作符*和++:


为区分++操作符的前缀版本和后缀版本,C++将operator++()作为前缀版本,将operator++(int)作为后缀版本;其中的参数永远也不会被用到,所以不必指定其名称。
这里重点不是如何定义iterator类,而是有了这样的类后,第二个find函数就可以这样编写:

这和find_ar()几乎相同,差别在于如何断言已到达最后一个值。find_ar()函数使用超尾迭代器,而find_ll()使用存储在最后一个节点中的空值。除了这种差别外,这两个函数完全相同。例如,可以要求链表的最后一个元素后面还有一个额外的元素,即让数组和链表都有超尾元素,并在迭代器到达超尾位置时结束搜索。这样,find_ar()和find_ll()检测数据尾的方式将相同,从而成为相同的算法。注意,增加超尾元素后,对迭代器的要求变成了对容器类的要求。
STL遵循上面介绍的方法。首先,每个容器类(vector、list、deque等)定义了相应的迭代器类型。对于其中的某个类,迭代器可能是指针;而对于另一个类,则可能是对象。不管实现方式如何,迭代器都将提供所需的操作,如*和++(有些类需要的操作可能比其他类多)。其次,每个容器类都有一个超尾标记,当迭代器递增到超越容器的最后一个值后,这个值将被赋给迭代器。每个容器类都有begin()和end()方法,它们分别返回一个指向容器的第一个元素和超尾位置的迭代器。每个容器类都使用++操作,让迭代器从指向第一个元素逐步指向超尾位置,从而遍历容器中的每一个元素。
使用容器类时,无须知道其迭代器是如何实现的,也无须知道超尾是如何实现的,而只需知道它有迭代器,其begin()返回一个指向第一个元素的迭代器,end()返回一个指向超尾位置的迭代器即可。例如,假设要打印vector<double>对象中的值,则可以这样做:

其中代码行:
vector<double>::iterator pr;
将pr的类型声明为vector<double>类的迭代器。如果要使用list<double>类模板来存储分数,则代码如下:
list<double>::iterator pr;

惟一不同的是pr的类型。因此,STL通过为每个类定义适当的迭代器,并以统一的风格设计类,能够对内部表示绝然不同的容器,编写相同的代码。
实际上,就风格方面而言,最好避免直接使用迭代器,而应尽可能使用STL函数(如for_each())来处理细节。
来总结一下STL方法。首先是处理容器的算法,应尽可能用通用的术语来表达算法,使之独立于数据类型和容器类型。为使通用算法能够适用于具体情况,应定义能够满足算法需求的迭代器,并把要求加到容器设计上。即基于算法的要求,设计基本迭代器的特征和容器特征。
16.4.2 迭代器类型
不同的算法对迭代器的要求也不同。例如,查找算法需要定义++操作符,以便迭代器能够遍历整个容器;它要求能够读取数据,但不要求能够写数据(它只是查看数据,而并不修改数据)。而排序算法要求能够随机访问,以便能够交换两个不相邻的元素。如果iter是一个迭代器,则可以通过定义+操作符来实现随机访问,这样就可以使用像iter+10这样的表达式了。另外,排序算法要求能够读写数据。
STL定义了5种迭代器,并根据所需的迭代器类型对算法进行了描述。这5种迭代器分别是输入迭代器、输出迭代器、正向迭代器、双向迭代器和随机访问迭代器。例如,find()的原型与下面类似:

这指出,这种算法需要一个输入迭代器。而原型:

指出排序算法需要一个随机访问迭代器。
对于这5种迭代器,都可以执行解除引用操作(即为它们定义了*操作符),也可进行比较,看其是相等(使用==操作符,可能被重载了)还是不相等(使用!=操作符,可能被重载了)。如果两个迭代器相同,则对它们执行解除引用操作得到的值将相同。即如果表达式iterl==iter2为真,则下述表达式也为真:
iterl == iter2
当然,对于内置操作符和指针来说,情况也是如此。因此,这些要求将指导您如何对迭代器类重载这些操作符。下面来看迭代器的其他特征。
1.输入迭代器
术语“输入”是从程序的角度说的,即来自容器的信息被视为输入,就像来自键盘的信息对程序来说是输入一样。因此,输入迭代器可被程序用来读取容器中的信息。具体地说,对输入迭代器解除引用将使程序能够读取容器中的值,但不一定能让程序修改值。因此,需要输入迭代器的算法将不会修改容器中的值。
输入迭代器必须能够访问容器中所有的值,这是通过支持++操作符(前缀格式和后缀格式)来实现的。如果将输入迭代器设置为指向容器中的第一个元素,并不断将其递增,直到到达超尾位置,则它将依次指向容器中的每一个元素。顺便说一句,并不能保证输入迭代器第二次遍历容器时,顺序不变。另外,输入迭代器被递增后,也不能保证其先前的值仍然可以被解除引用。基于输入迭代器的任何算法都应当是单通行(single-pass)的,不依赖于前一次遍历时的迭代器值,也不依赖于本次遍历中前面的迭代器值。
注意,输入迭代器是单向迭代器,可以递增,但不能倒退。
2.输出迭代器
STL使用术语“输出”来指用于将信息从程序传输给容器的迭代器,因此程序的输出就是容器的输入。输出迭代器与输入迭代器相似,只是解除引用让程序能修改容器值,而不能读取。也许您会感到奇怪,能够写,却不能读。发送到显示器上的输出就是如此,cout可以修改发送到显示器的字符流,却不能读取屏幕上的内容。STL足够通用,其容器可以表示输出设备,因此容器也可能如此。另外,如果算法不用读取容器的内容就可以修改它(如通过生成要存储的新值),则没有理由要求它使用能够读取内容的迭代器。
简而言之,对于单通行、只读算法,可以使用输入迭代器;而对于单通行、只写算法,则可以使用输出迭代器。
3.正向迭代器
与输入迭代器和输出迭代器相似,正向迭代器只使用++操作符来遍历容器,所以它每次沿容器向前移动一个元素;不过,与输入和输出迭代器不同的是,它总是按相同的顺序遍历一系列值。另外,将正向迭代器递增后,仍然可以对前面的迭代器值解除引用(如果保存了它),并可以得到相同的值。这些特征使得多次通行算法成为可能。
正向迭代器既可以使得能够读取和修改数据,也可以使得只能读取数据:

4.双向迭代器
假设算法需要能够双向遍历容器,情况将如何呢?例如,reverse函数可以交换第一个元素和最后一个元素、将指向第一个元素的指针加1、将指向第二个元素的指针减1,并重复这种处理过程。双向迭代器具有正向迭代器的所有特性,同时支持两种(前缀和后缀)递减操作符。
5.随机访问迭代器
有些算法(如标准排序和二分检索)要求能够直接跳到容器中的任何一个元素,这叫作随机访问,需要随机访问迭代器。随机访问迭代器具有双向迭代器的所有特性,同时添加了支持随机访问的操作(如指针增加运算)和用于对元素进行排序的关系操作符。表16.3列出了除双向迭代器的操作外,随机访问迭代器还支持的操作。其中,X表示随机迭代器类型,T表示被指向的类型,a和b都是迭代器值,n为整数,r为随机迭代器变量或引用。
表16.3 随机访问迭代器操作

像a+n这样的表达式仅当a和a+n都位于容器区间(包括超尾)内时才合法。
16.4.3 迭代器层次结构
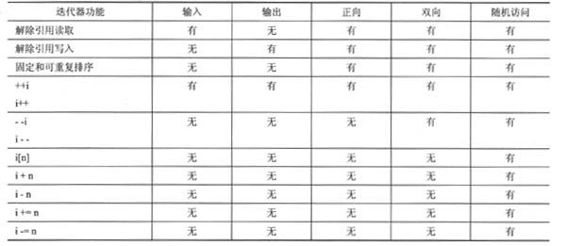
读者可能已经注意到,迭代器类型形成了一个层次结构。正向迭代器具有输入迭代器和输出迭代器的全部功能,同时还有自己的功能;双向迭代器具有正向迭代器的全部功能,同时还有自己的功能;随机访问迭代器具有正向迭代器的全部功能,同时还有自己的功能。表16.4总结了主要的迭代器功能。其中,i为迭代器,n为整数。
根据特定迭代器类型编写的算法可以使用该种迭代器,也可以使用具有所需功能的任何其他迭代器。所以具有随机访问迭代器的容器可以使用为输入迭代器编写的算法。
为何需要这么多迭代器呢?目的是为了在编写算法时尽可能使用要求最低的迭代器,并让它适用于容器的最大区间。这样,通过使用级别最低的输入迭代器,find()函数便可用于任何包含可读取值的容器。而sort()函数由于需要随机访问迭代器,所以只能用于支持这种迭代器的容器。
注意,各种迭代器的类型并不是确定的,而只是一种概念性描述。正如前面指出的,每个容器类都定义了一个类级typedef名称——iterator,因此vector<int>类的迭代器类型为vector<int>::interator。但是,该类的文档将指出,矢量迭代器是随机访问迭代器,它允许使用基于任何迭代器类型的算法,因为随机访问迭代器具有所有迭代器的功能。同样,list<int>类的迭代器类型为list<int>::iterator。STL实现了一个双向链表,它使用双向迭代器,因此不能使用基于随机访问迭代器的算法,但可以使用基于要求较低的迭代器的算法。
表16.4 迭代器性能
16.4.4 概念、改进和模型
STL有若干个用C++语言无法表达的特性,如迭代器种类。因此,虽然可以设计具有正向迭代器特征的类,但不能让编译器将算法限制为只使用这个类。原因在于,正向迭代器是一系列要求,而不是类型。所设计的迭代器类可以满足这种要求,常规指针也能满足这种要求。STL算法可以使用任何满足其要求的迭代器实现。STL文献使用术语概念(concept)来描述一系列的要求。因此,存在输入迭代器概念、正向迭代器概念,等等。顺便说一句,如果所设计的容器类需要迭代器,可考虑STL,它包含用于标准种类的迭代器模板。
概念可以具有类似继承的关系。例如,双向迭代器继承了正向迭代器的功能。不过,不能将C++继承机制用于迭代器。例如,可以将正向迭代器实现为一个类,而将双向迭代器实现为一个常规指针。因此,对C++而言,这种双向迭代器是一种内置类型,不能从类派生而来。不过,从概念上看,它确实能够继承。有些STL文献使用术语改进(refinement)来表示这种概念上的继承,因此,双向迭代器是对正向迭代器概念的一种改进。
概念的具体实现被称为模型(model)。因此,指向int的常规指针是一个随机访问迭代器模型,也是一个正向迭代器模型,因为它满足该概念的所有要求。
1.将指针用作迭代器
迭代器是广义指针,而指针满足所有的迭代器要求。迭代器是STL算法的接口,而指针是迭代器,因此STL算法可以使用指针来对基于指针的非STL容器进行操作。例如,可将STL算法用于数组。假设Receipts是一个double数组,希望按照升序对它进行排序:

STL sort()函数接受指向容器第一个元素的迭代器和指向超尾的迭代器作为参数。&Receipts0是第一个元素的地址,&Receipts[SIZE](或Receipts + SIZE)是数组最后一个元素后面的元素的地址。因此,函数调用:
sort (Receipts, Receipts + SIZE);
对数组进行排序。C++确保了表达式Receipts+n是被定义的,只要该表达式的结果位于数组中。因此,C++支持将超尾概念用于数组,使得可以将STL算法用于常规数组。由于指针是迭代器,而算法是基于迭代器的,这使得可将STL算法用于常规数组。同样,可以将STL算法用于自己设计的数组形式,只要提供适当的迭代器(可以是指针,也可以是对象)和超尾指示器即可。
copy()、ostream_iterator和istream_iterator
STL提供了一些预定义迭代器。为了解其中的原因,这里先介绍一些背景知识。有一种算法(名为copy())可以将数据从一个容器复制到另一个容器中。这种算法是以迭代器方式实现的,所以它可以从一种容器到另一种容器进行复制,甚至可以在数组之间复制,因为可以将指向数组的指针用作迭代器。例如,下面的代码将一个数组复制到一个矢量中:

copy()的前两个迭代器参数表示要复制的范围,最后一个迭代器参数表示要将第一个元素复制到什么位置。前两个参数必须是(或最好是)输入迭代器,最后一个参数必须是(或最好是)输出迭代器。Copy()函数将覆盖目标容器中已有的数据,同时目标容器必须足够大,以便能够容纳被复制的元素。因此,不能使用copy()将数据放到空矢量中——至少,如果不采用本章后面将介绍的技巧,则不能这样做。
现在,假设要将信息复制到显示器上。如果有一个表示输出流的迭代器,则可以使用copy()。STL为这种迭代器提供了ostream_iterator模板。用STL的话说,该模板是输出迭代器概念的一个模型,它也是一个适配器(adapter)——一个类或函数,可以将一些其他接口转换为STL使用的接口。可以通过包含头文件iterator(以前为iterator.h)并作下面的声明来创建这种迭代器:
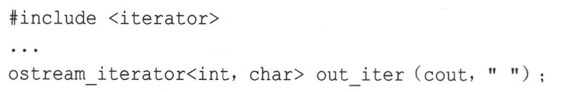
out_iter迭代器现在是一个接口,让您能够使用cout来显示信息。第一个模板参数(这里为int)指出了被发送给输出流的数据类型;第二个模板参数(这里为char)指出了输出流使用的字符类型(另一个可能的值是wcharj)。构造函数的第一个参数(这里为cout)指出了要使用的输出流,它也可以是用于文件输出的流(参见第17章);最后一个字符串参数是在发送给输出流的每个数据项后显示的分隔符。
警告:在老式C++实现中,只使用了ostream_iterator的第一个模板参数:
ostream_iterator<int> out_iter (cout, " "); // older implementation
可以这样使用迭代器:
*out_iter++ = 15; // works like cout << 15 << " ";
对于常规指针,这意味着将15赋给指针指向的位置,然后将指针加1。但对于该ostream_iterator,这意味着将15和由空格组成的字符串发送到cout管理的输出流中,并为下一个输出操作做好了准备。可以将copy()用于迭代器,如下所示:
copy (dice.begin(), dice.end(), out_iter); // copy vector to output stream
这意味着将dice容器的整个区间复制到输出流中,即显示容器的内容。
也可以不创建命名的迭代器,而直接构建一个匿名迭代器。即可以这样使用适配器:
copy (dice.begin(), dice.end(), ostream_iterator<int, char> (cout, " "));
iterator头文件还定义了一个istream_iterator模板,使istream输入可用作迭代器接口。它是一个输入迭代器概念的模型,可以使用两个istream_iterator对象来定义copy()的输入范围:

与ostream_iterator相似,istream_iterator也使用两个模板参数。第一个参数指出要读取的数据类型,第二个参数指出输入流使用的字符类型。使用构造函数参数cin意味着使用由cin管理的输入流,省略构造函数参数表示输入失败,因此上述代码从输入流中读取,直到文件结尾、类型不匹配或出现其他输入故障为止。
除了ostream_iterator和istream_iterator之外,头文件iterator还提供了其他一些专用的预定义迭代器类型。它们是reverse_iterator、back_insert_iterator、front_insert_iterator和insert_iterator。
我们先来看reverse -iterator的功能。对reverse_iterator执行递增操作将导致它被递减。为什么不直接对常规迭代器进行递减呢?主要原因是为了简化对已有的函数的使用。假设要显示dice容器的内容,正如刚才介绍的,可以使用copy()和ostream_iterator来将内容复制到输出流中:

现在假设要反向打印容器的内容(可能您正在从事时间反演研究)。有很多方法都不管用,不过与其在这里耽误工夫,不如来看看能够完成这种任务的方法。vector类有一个名为rbegin()的成员函数和一个名为rend()的成员函数,前者返回一个指向超尾的反向迭代器,后者返回一个指向第一个元素的反向迭代器。因为对迭代器执行递增操作将导致它被递减,所以可以使用下面的语句来反向显示内容:
copy (dice.rbegin(), dice.rend(), out_iter); // display in reverse order
甚至不必声明反向迭代器。
记住:rbegin()和end()返回相同的值(超尾),但类型不同(reverse_iterator和iterator)。同样,rend()和begin()也返回相同的值(指向第一个元素的迭代器),但类型不同。
必须对反向指针做一种特殊补偿。假设rp是一个被初始化为dice.rbegin()的反转指针。那么*rp是什么呢?因为rbegin()返回超尾,因此不能对该地址进行解除引用。同样,如果rend()是第一个元素的位置,则copy()必须提早一个位置停止,因为区间的结尾处不包括在区间中。
反向指针通过先递减,再解除引用解决了这两个问题。即rp将在rp的当前值之前对迭代器执行解除引用。也就是说,如果rp指向位置6,则*rp将是位置5的值,依次类推。程序清单16.8演示了如何使用copy()、istream迭代器和反向迭代器。
程序清单 16.8 copyit.cpp


注意:老式C++实现可能需要使用头文件iterator.h和vector.h而不是iterator和vector。另外,有些实现不使用ostream_iterator<int, char>,而使用ostream_iterator<int>。
程序清单16.8中程序的输出如下:

如果可以在显式声明迭代器和使用STL函数来处理内部问题(如通过将rbegin()返回值传递给函数)之间选择,请采用后者。后一种方法要做的工作较少,人为出错的机会也较少。
另外3种迭代器(back_insert_iterator、front_insert_iterator和insert_iterator)也将提高STL算法的通用性。很多STL函数都与copy()相似,将结果发送到输出迭代器指示的位置。由前所述,下面的语句:
copy (casts, casts + 10, dice.begin());
将值复制到从dice.begin()开始的位置。这些值将覆盖dice中以前的内容,且该函数假设dice有足够的空间,能够容纳这些值,即copy()不能自动根据发送值调整目标容器的长度。程序清单16.8考虑到了这种情况,将dice声明为包含10个元素。但是,如果预先并不知道dice的长度,该如何办呢?或者要将元素添加到dice中,而不是覆盖已有的内容,又该如何办呢?
3种插入迭代器通过将复制转换为插入解决了这些问题。插入将添加新的元素,而不会覆盖已有的数据,并使用自动内存分配来确保能够容纳新的信息。back_insert_iterator将元素插入到容器尾部,而front_insert_iterator将元素插入到容器的前端。最后,insert_iterator将元素插入到insert_iterator构造函数的参数指定的位置前面。这3个插入迭代器都是输出容器概念的模型。
这里存在一些限制。back_insert_iterator只能用于允许在尾部快速插入的容器(快速插入指的是一个时间固定的算法,将在本章后面的“容器概念”一节做进一步讨论),vector类符合这种要求。front_insert_iterator只能用于允许在起始位置做时间固定插入的容器类型,vector类不能满足这种要求,但queue满足。insert_iterator没有这些限制,因此可以用它把信息插入到矢量的前端。不过,front_insert_iterator对于那些支持它的容器来说,完成任务的速度更快。
提示:可以用insert_iterator将复制数据的算法转换为插入数据的算法。
这些迭代器将容器类型作为模板参数,将实际的容器标识符作为构造函数参数。也就是说,要为名为dice的vector<int>容器创建一个back_insert_iterator,可以这样做:
back_insert_iterator<vector<int> > back_iter (dice);
必须声明容器类型的原因是,迭代器必须使用合适的容器方法。back_insert_iterator的构造函数将假设传递给它的类型有一个push_back()方法。copy()是一个独立的函数,没有重新调整容器大小的权限。但前面的声明让back_iter能够使用方法vector<int>::push_back(),该方法有这样的权限。
声明front_insert_iterator的方式与此相同。对于insert_iterator声明,还需一个指示插入位置的构造函数参数:
insert_iterator<vector<int> > insert_iter (dice, dice.begin());
程序清单16.9演示了这两种迭代器的用法。
程序清单 16.9 inserts.cpp


注意:老式编译器可能使用list.h和iterator.h。另外,有些编译器可能使用ostream_iterator<int>,而不是ostream_iterator<int, char>。
程序清单16.9中程序的输出如下:

第一个copy()从s1中复制4个字符串到words中。这之所以可行,在某种程度上说是由于words被声明为能够存储4个字符串,这等于被复制的字符串数目。然后,back_insert_iterator将s2中的字符串插入到words数组的末尾,将words的长度增加到6个元素。最后,insert_iterator将s3中的两个字符串插入到words的第一个元素的前面,将words的长度增加到8个元素。如果程序试图使用words.end()和words.begin()作为迭代器,将s2和s3复制到words中,words将没有空间来存储新数据,程序可能会由于内存违规而异常终止。
如果您被这些迭代器搞晕,则请记住,只要使用就会熟悉它们。另外还请记住,这些预定义迭代器提高了STL算法的通用性。因此,copy()不仅可以将信息从一个容器复制到另一个容器,还可以将信息从容器复制到输出流,从输入流复制到容器中。还可以使用copy()将信息插入到另一个容器中。因此使用同一个函数可以完成很多工作。copy()只是是使用输出迭代器的若干STL函数之一,因此这些预定义迭代器也增加了这些函数的功能。
16.4.5 容器种类
STL具有容器概念和容器类型。概念是具有名称(如容器、序列容器、联合容器等)的通用类别;容器类型是可用于创建具体容器对象的模板。11个容器类型分别是deque、list、queue、priority_queue、stack、vector、map、multimap、set、multiset和bitset(本章不讨论bitset,它是在比特级处理数据的容器)。因为概念对类型进行了分类,我们先讨论它们。
1.容器概念
没有与基本容器概念对应的类型,但概念描述了所有容器类都通用的元素。它是一个概念化的抽象基类——说它概念化,是因为容器类并不真正使用继承机制。换句话说,容器概念指定了所有STL容器类都必须满足的一系列要求。
容器是存储其他对象的对象。被存储的对象必须是同一种类型的,它们可以是OOP意义上的对象,也可以是内置类型值。被存储在容器中的数据为容器所有,这意味着当容器过期时,存储在容器中的数据也将过期(不过,如果数据是指针的话,则它指向的数据并不一定过期)。
不能将任何类型的对象存储在容器中,具体地说,类型必须是可复制构造的和可赋值的。基本类型满足这些要求;只要类定义没有将复制构造函数和赋值操作符声明为私有或保护的,则类也满足这种要求。
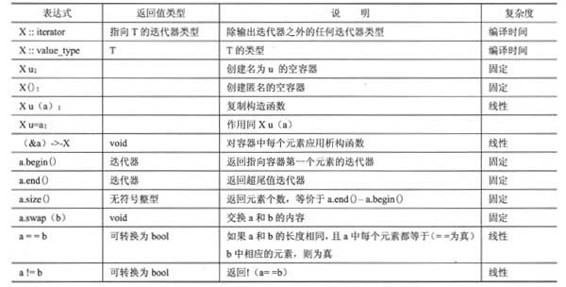
基本容器不能保证其元素都按特定的顺序存储,也不能保证元素的顺序不变,但对概念进行改进后,则可以增加这样的保证。所有的容器都提供某些特性和操作。表16.5对一些通用的特性进行了总结。其中,X表示容器类型,例如vector;T表示存储在容器中的对象类型;a和b表示类型X的值;u表示类型X的标识符。
表16.5中的“复杂度”一列描述了执行操作所需的时间。这个表列出了3种可能性,从快到慢依次为:
● 编译时间。
● 固定时间。
● 线性时间。
如果复杂度为编译时间,则操作将在编译时执行,执行时间为0。固定复杂度意味着操作发生在运行阶段,但是独立于对象中的元素数目。线性复杂度意味着时间与元素数目成正比。即如果a和b都是容器,则a = = b具有线性复杂度,因为==操作必须用于容器中的每个元素。实际上,这是最糟糕的情况。如果两个容器的长度不同,则不需要作任何的单独比较。
表16.5 一些基本的容器特征
固定时间和线性时间复杂度
假设有一个装满大包裹的狭长盒子,包裹一字排开,而盒子只有一端是打开的。假设任务是从打开的一端取出一个包裹,则这将是一项固定时间任务。不管在打开的一端后面有10个还是1000个包裹,都没有区别。
现在假设任务是取出盒子中没有打开的一端的那个包裹,则这将是线性时间任务。如果盒子里有10个包裹,则必须取出10个包裹才能拿到封口端的那个包裹;如果有100个包裹,则必须取出100个包裹。假设是一个不知疲倦的工人来做,每次只能取出1个包裹,则需要取10次或者更多。
现在假设任务是取出任意一个包裹,则可能取出第一个包裹。不过,通常必须移动的包裹数目仍旧与容器中包裹的数目成正比,所以这种任务依然是线性时间复杂度。
如果盒子各边都可打开,而不是狭长的,则这种任务的复杂度将是固定时间的,因为可以直接取出想要的包裹,而不用移动其他的包裹。
时间复杂度概念描述了容器长度对执行时间的影响,而忽略了其他因素。如果超人从一端打开的盒子中取出包裹的速度比普通人快100倍,则他完成任务时,复杂度仍然是线性时间的。在这种情况下,他取出封闭盒子中包裹(一端打开,复杂度为线性时间)的速度将比普通人取出开放盒子中包裹(复杂度为固定时间)要快,条件是盒子里没有太多的包裹。
复杂度要求是STL特征,虽然实现细节可以隐藏,但性能规格应公开,以便编程者能够知道完成特定操作的计算成本。
2.序列
可以通过添加要求来改进基本的容器概念。序列(sequence)是一种重要的改进,因为6种STL容器类型(deque、list、queue、priority_queue、stack和vector)都是序列(队列能够在队尾添加元素,在队首删除元素。Deque表示的双端队列允许在两端添加和删除元素)。序列概念增加了迭代器至少是正向迭代器这样的要求。这保证了元素将按特定的顺序排列,不会在两次迭代之间发生变化。
序列还要求其元素按严格的线性顺序排列,即存在第一个元素、最后一个元素,除第一个元素和最后一个元素外,每个元素前后都分别有一个元素。数组和链表都是序列,但分支结构(其中每个节点都指向两个子节点)不是序列。
因为序列中的元素具有确定的顺序,因此可以执行诸如将值插入到特定位置、删除特定区间等操作。表16.6列出了这些操作以及序列必须完成的其他操作。该表格使用的表示法与表16.5相同,此外,t表示T类型(存储在容器中的值的类型)的值,n表示整数,p、q、i和j表示迭代器。
表16.6 序列的要求
| 表达式 | 返回值类型 | 说 明 |
| X a (n, t); | 声明一个名为a的、由n个t值组成的序列 | |
| X (n,t) | 创建一个由n个t值组成的匿名序列 | |
| Xa (i, j) | 声明一个名为a的序列,并将其初始化为区间[i,j)的内容 | |
| X (i,j) | 创建一个匿名序列,并将其初始化为区间[i,j)的内容 | |
| a. insert (p,t) | 迭代器 | 将t插入到p的前面 |
| a.insert (p, n, t) | void | 将n个t插入到p的前面 |
| a.insert (p,i, j) | void | 将区间[i,j)中的元素插入到p的前面 |
| a.erase (p) | 迭代器 | 删除p指向的元素 |
| a.erase (p, q) | 迭代器 | 删除区间[p,q]中的元素 |
| a.clear() | void | 等价于erase (begin(),end()) |
因为deque、list、queue、priority_queue、stack和vector模板类都是序列概念的模型,所以它们都支持表16.6中的操作符。除此之外,这6个模型中的一些还可使用其他操作。在允许的情况下,它们的复杂度为固定时间。表16.7列出了其他操作。
表16.7 序列的可选要求

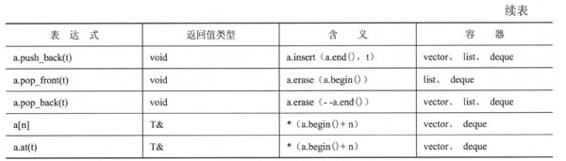
表16.7有些需要说明的地方。首先,a[n]和a.at(n)都返回一个指向容器中第n个元素(从0开始编号)的引用。它们之间的差别在于,如果n落在容器的有效区间之外,则a.at(n)将执行边界检查,并引发out_of_range异常。其次,可能有人会问,为何为list和deque定义了push_front(),而没有为vector定义?假设要将一个新值插入到包含100个元素的矢量的最前面。要腾出空间,必须将第99个元素移到位置100,然后把第98个元素移动到位置99,依此类推。这种操作的复杂度为线性时间,因为移动100个元素所需的时间为移动单个元素的100倍。但表16.7的操作被假设为仅当它们的复杂度为固定时间时才被实现。链表和双端队列的设计允许将元素添加到前端,而不用移动其他元素,所以它们可以以固定时间的复杂度来实现push_front()。图16.4说明了push_front()和push_back()。
下面详细介绍6种序列容器类型。
(1) vector
前面介绍了多个使用vector模板的例子,该模板是在vector头文件中声明的。简单地说,vector是数组的一种类表示,它提供了自动内存管理功能,可以动态地改变vector对象的长度,并随着元素的添加和删除而增大和缩小。它提供了对元素的随机访问。在尾部添加和删除元素的时间是固定的,但在头部或中间插入和删除元素的复杂度为线性时间。

图16.4 push_front()和push_back()
除了序列外,vector还是可反转容器(reversible container)概念的模型。这增加了两个类方法:rbegin()和rend(),前者返回一个指向反转序列的第一个元素的迭代器,后者返回反转序列的超尾迭代器。因此,如果dice是一个vector<int>容器,而Show (int)是显示一个整数的函数,则下面的代码将首先正向显示dice的内容,然后反向显示:

这两种方法返回的迭代器都是类级类型reverse_iterator。对这样的迭代器进行递增,将导致它反向遍历可反转容器。
vector模板类是最简单的序列类型,除非其他类型的特殊优点能够更好地满足程序的要求,否则应默认使用这种类型。
(2) deque
deque模板类(在deque头文件中声明)表示双端队列(double-ended queue),通常被简称为deque。在STL中,其实现类似于vector容器,支持随机访问。主要区别在于,从deque对象的开始位置插入和删除元素的时间是固定的,而不像vector中那样是线性时间的。所以,如果多数操作发生在序列的起始和结尾处,则应考虑使用deque数据结构。
为实现在deque两端执行插入和删除操作的时间为固定的这一目的,deque对象的设计比vector对象更为复杂。因此,尽管二者都提供对元素的随机访问和在序列中部执行线性时间的插入和删除操作,但vector容器执行这些操作时速度要快些。
(3) list
list模板类(在list头文件中声明)表示双向链表。除了第一个和最后一个元素外,每个元素都与前后的元素相链接,这意味着可以双向遍历链表。list和vector之间关键的区别在于,list在链表中任一位置进行插入和删除的时间都是固定的(vector模板提供了除结尾处外的线性时间的插入和删除,在结尾处,它提供了固定时间的插入和删除)。因此,vector强调的是通过随机访问进行快速访问,而list强调的是元素的快速插入和删除。
与vector相似,list也是可反转容器。与vector不同的是,list不支持数组表示法和随机访问。与矢量迭代器不同,从容器中插入或删除元素之后,链表迭代器指向元素将不变。我们来解释一下这句话。例如,假设有一个指向vector容器第5个元素的迭代器,并在容器的起始处插入一个元素。此时,必须移动其他所有元素,以便腾出位置,因此插入后,第5个元素包含的值将是以前第4个元素的值。因此,迭代器指向的位置不变,但数据不同。然后,在链表中插入新元素并不会移动已有的元素,而只是修改链接信息。指向某个元素的迭代器仍然指向该元素,但它链接的元素可能与以前不同。
除了序列和可反转容器的函数外,list模板类还包含了链表专用的成员函数。表16.8列出了其中一些(有关STL方法和函数的完整列表,请参见附录G)。通常不必担心Alloc模板参数,因为它有默认值。
表16.8 list成员函数
| 函 数 | 说 明 |
| void merge (list<T, Alloc>& x) | 将链表x与调用链表合并。两个链表必须已经排序。合并后的、经过排序的链表 保存在调用链表中,x为空。这个函数的复杂度为线性时间 |
| void remove (const T & val) | 从链表中删除val的所有实例。这个函数的复杂度为线性时间 |
| void sort() | 使用<操作符对链表进行排序;N个元素的复杂度为NlogN |
| void splice (iterator pos, list<T, Alloc>x) | 将链表x的内容插入到pos的前面,x将为空。这个函数的的复杂度为固定时间 |
| void unique() | 将连续的相同元素压缩为单个元素。这个函数的复杂度为线性时间 |
程序清单16.10演示了这些方法和insert()方法(所有模拟序列的STL类都有这种方法)的用法。
程序清单 16.10 list.cpp


注意:老式STL版本可能使用list.h和iterator.h。另外,老式版本还可能使用ostream_iterator<int>,而不是ostream_iterator<int, char>。
下面是程序清单16.10中程序的输出:

(4)程序说明
程序清单16.10中程序使用前面讨论的技术(即通用的STL copy()函数)和ostream_iterator对象来显示容器的内容。
insert()和splice()之间的主要区别在于:insert()将原始区间的副本插入到目标地址,而splice()则将原始区间移到目标地址。因此,在one的内容与three合并后,one为空(splice()方法还有其他原型,用于移动单个元素和元素区间)。splice()方法执行后,迭代器仍有效。也就是说,如果将迭代器设置为指向one中的元素,则在splice()将它重新定位到元素three后,该迭代器仍然指向相同的元素。
注意,unique()只能将相邻的相同值压缩为单个值。程序执行three.unique()后,three中仍包含不相邻的两个4和两个6。但应用sort()后再应用unique()时,每个值将只占一个位置。
还有非成员sort()函数(程序清单16.7),但它需要随机访问迭代器。因为快速插入的代价是放弃随机访问功能,所以不能将非成员函数sort()用于链表。因此,这个类中包括了一个只能在类中使用的成员版本。
(5) list工具箱
list方法组成了一个方便的工具箱。例如,假设有两个邮件列表要整理,则可以对每个列表进行排序,合并它们,然后使用unique()来删除重复的元素。
sort()、merge()和unique()方法还各自拥有接受另一个参数的版本,该参数用于指定用来比较元素的函数。同样,remove()方法也有一个接受另一个参数的版本,该参数用于指定用来确定是否删除元素的函数。这些参数都是判定函数,将在稍后介绍。
(6) queue
queue模板类(在头文件queue(以前为queue.h)中声明)是一个适配器类。由前所述,ostream_iterator模板就是一个适配器,让输出流能够使用迭代器接口。同样,queue模板让底层类(默认为deque)展示典型的队列接口。
queue模板的限制比deque更多。它不仅不允许随机访问队列元素,甚至不允许遍历队列。它把使用限制在定义队列的基本操作上,可以将元素添加到队尾、从队首删除元素、查看队首和队尾的值、检查元素数目和测试队列是否为空。表16.9列出了这些操作。
表16.9 queue的操作
| 方 法 | 说 明 |
| bool empty()const | 如果队列为空,则返回true;否则返回false |
| size_type size()const | 返回队列中元素的数目 |
| T& front() | 返回指向队首元素的引用 |
| T& back() | 返回指向队尾元素的引用 |
| void push (const T& x) | 在队尾插入x |
| void pop() | 删除队首元素 |
注意,pop()是一个删除数据的方法,而不是检索数据的方法。如果要使用队列中的值,应首先使用front()来检索这个值,然后使用pop()将它从队列中删除。
(7) priority_queue
priority_queue模板类(在queue头文件中声明)是另一个适配器类,它支持的操作与queue相同。两者之间的主要区别在于,在priority_queue中,最大的元素被移到队首(生活不总是公平的,队列也一样)。内部区别在于,默认的底层类是vector。可以修改用于确定哪个元素放到队首的比较方式,方法是提供一个可选的构造函数参数:
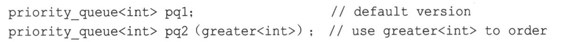
greater<>()函数是一个预定义的函数对象,本章稍后将讨论它。
(8) stack
与queue相似,stack(在头文件stack——以前为stack.h——中声明)也是一个适配器类,它给底层类(默认情况下为vector)提供了典型的堆栈接口。
Stack模板的限制比vector更多。它不仅不允许随机访问堆栈元素,甚至不允许遍历堆栈。它把使用限制在定义堆栈的基本操作上,即可以将压入推到栈顶、从栈顶弹出元素、查看栈顶的值、检查元素数目和测试堆栈是否为空。表16.10列出了这些操作。
表16.10 stack的操作
| 方 法 | 说 明 |
| bool empty()const | 如果堆栈为空,则返回true;否则返回false |
| size_type size () const | 返回堆栈中的元素数目 |
| T& top() | 返回指向栈顶元素的引用 |
| void push (const T&x) | 在堆栈顶部插入x |
| void pop() | 删除栈顶元素 |
与queue相似,如果要使用堆栈中的值,必须首先使用top()来检索这个值,然后使用pop()将它从堆栈中删除。
16.4.6 联合容器
联合容器(associative container)是对容器概念的另一个改进。联合容器将值与关键字关联在一起,使用关键字来查找值。例如,值可以是表示雇员信息(如姓名、地址、办公室号码、家庭电话和工作电话、健康计划等)的结构,关键字可以是具有惟一性的员工编号。为了获取雇员信息,程序将使用关键字查找雇员结构。由前所述,对于容器X,表达式X:: value_type通常指出了存储在容器中的值的类型。对于联合容器来说,表达式X:: key_type指出了用作关键字的类型。
联合容器的长处在于,它提供了对元素的快速访问。与序列相似,联合容器也允许插入新元素,不过不能指定元素的插入位置。原因是联合容器通常包含用于确定数据放置位置的算法,以便能够很快检索信息。
STL提供了4种联合容器:set、multiset、map和multimap。前两种是在set头文件中(以前分别为set.h和multiset.h)定义的,后两种是在map头文件(以前分别为map.h和multimap.h)中定义的。
最简单的簇(bunch)是set,其值的类型与关键字相同,关键字是惟一的——集合中不会有多个相同的关键字。确实,对于set来说,值就是关键字。multiset类型类似于set,只是前者可能有多个值的关键字相同。例如,如果关键字和值的类型为int,则multiset对象包含的内容可以是1、2、2、2、3、5、7、7。
对于map类型来说,值的类型与关键字不同,关键字是惟一的,每个关键字只对应一个值。multimap类型与map相似,只是一个关键字可以与多个值关联。
有关这些类型的信息很多,无法在本章全部列出(不过附录G列出了方法),这里只介绍一个使用set的简单例子和一个使用multimap的简单例子。
1.set范例
STL set是多个概念的模型,它是一个联合集合,可反转,可排序,关键字是惟一的,所以它只能存储同一种类型的值。与vector和list相似,set也使用模板参数来提供要存储的值的类型:
set<string> A; // a set of string objects
可选的第二个模板参数可以用于指示用来对关键字进行排序的比较函数或对象。在默认情况下,将使用less<>模板(稍后将讨论)。老式C++实现可能没有提供默认值,因此必须显式指定模板参数:
set<string, less<string> > A; // older implementation
考虑下面的代码:

与其他容器相似,set也有一个将迭代器的区间作为参数的构造函数(参见表16.6)。这样提供了一种将集合初始化为数组内容的简单方法。记住,区间的最后一个元素是超尾,s1+N指向数组s1尾部后面的一个位置。上述代码片段的输出表明,关键字是惟一的(字符串“for”在数组中出现了2次,但在集合中只出现1次),集合被排序:
buffoon can for heavy thinkers
数学为集合定义了一些标准操作,例如,并集包含两个集合合并后的内容。如果两个集合中包含相同的值,则这个值将在并集中只出现一次,这是因为关键字是惟一的。交集包含两个集合公有的元素。两个集合的差是第一个集合减去两个集合公有的元素。
STL提供了支持这些操作的算法。它们是通用函数,而不是方法,因此它们不是只能够用于set对象。不过,所有的set对象都自动满足使用这些算法的先决条件,即容器是经过排序的。set_union()函数接受5个迭代器参数。前两个迭代器定义了一个集合的区间,接下来的两个定义了第二个集合的区间,最后一个迭代器是输出迭代器,指出将结果集合复制到什么位置。例如,要显示集合A和B的并集,可以这样做:

假设要将结果放到集合C中,而不是显示它,则最后一个参数应是一个指向C的迭代器。显而易见的选择是C.begin(),但它不管用,原因有两个。首先,联合集合将关键字看作是常量,所以C.begin()返回的迭代器是一个固定迭代器,不能用作输出迭代器。不直接使用C.begin()的第二个原因是,与copy()相似,set_union()将覆盖容器中已有的数据,并要求容器有足够的空间来容纳新信息。C是空的,不能满足这种要求。但是前面讨论的insert_iterator模板可以解决这两个问题。此前已经看到,它可以将复制转换为插入。另外,它还模拟了输出迭代器概念,所以可以用它来将信息写入容器。因此,可以创建一个匿名insert_iterator,将信息复制给C。由前所述,构造函数将容器名称和迭代器作为参数:
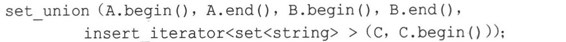
set_intersection()和set_difference()函数查找交集和获得两个集合的差,它们的接口与set_union()相同。
两个有用的set方法分别是lower_bound()和upper_bound ()。lower_bound()方法将关键字作为参数并返回一个迭代器,该迭代器指向集合中第一个不小于关键字参数的成员。同样,upper_bound()方法将关键字作为参数,并返回一个迭代器,该迭代器指向集合中第一个大于关键字参数的成员。例如,如果有一个字符串集合,则可以用这些方法来获得一个区间,该区间包含集合中从“b”到“f”的所有字符串。
因为排序决定了插入的位置,所以这种类包含只指定要插入的信息,而不指定位置的插入方法。例如,如果A和B是字符串集合,则可以这样做:
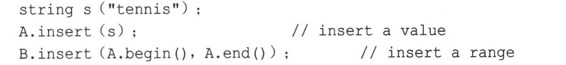
程序清单16.11演示了集合的这些用途。
程序清单 16.11 setops.cpp


注意:老式STL实现可能使用set.h、iterator.h和algo.h,且可能要求将less<string>作为set的第二个模板参数。另外,旧版本可能并不使用ostream_iterator<string,char>,而是使用ostream_iterator<string>。
下面是程序清单16.11中程序的输出:

和本章中大多数范例一样,程序清单16.11在处理名称空间std时采取了偷懒的方式:
这样做旨在简化表示方式。这些范例使用了名称空间std中非常多的元素,如果使用using声明或作用于解析操作符,代码将变得混乱:

2.multimap范例
与set相似,multimap也是可反转的、经过排序的联合容器,但在multimap中,关键字的类型与值类型不同,在multimap对象中,特定的关键字可能与多个值相关联。
基本的multimap声明使用模板参数指定了关键字的类型和所存储的值的类型。例如,下面的声明将创建一个multimap对象,其中关键字的类型为int,所存储的值的类型为string:
multimap<int, string> codes;
可选的第3个模板参数可以用于指出用于对关键字进行排序的比较函数或对象。在默认情况下,将使用less<>模板(稍后将讨论),该模板将关键字类型作为参数。老式C++实现可能要求显式指定该模板参数。
为将信息结合在一起,实际的值类型将关键字类型和数据类型结合为一对。为此,STL使用pair<class T,class U>模板类将这两种值存储到一个对象中。如果keytype是关键字类型,而datatype是被存储的数据类型,则值类型为pair<const keytype, datatype>。例如,前面声明的codes对象的值类型为pair<const int,string>。
例如,假设要用区号作为关键字来存储城市名。这恰好与codes声明一致,它将关键字的类型声明为int,数据类型声明为string。一种方法是创建一个pair,然后将它插入:

也可以使用一条语句创建一个匿名pair对象,并将它插入:
codes.insert (pair<const int, string> (213, "Los Angeles"));
因为数据项是按关键字排序的,所以不需要指出插入位置。
有了pair对象后,便可以使用first和second成员来访问其两个部分了:

如何获得有关multimap对象的信息呢?count()成员函数用关键字作为参数,并返回具有该关键字的元素的数目。成员函数lower_bound()和upper_bound()将关键字作为参数,它们的工作方式与处理set的方式相同。equal_range()成员函数用关键字作为参数,并返回表示与该关键字匹配的区间的迭代器。为返回两个值,该方法将这两个值封装在一个pair对象中,此时两个模板参数是迭代器类型。例如,下面的代码打印codes对象中区号为718的所有城市:

程序清单16.12演示了上述大部分技术,它也使用typedef来简化代码:
程序清单 16.12 multimap.cpp


注意:老式STL实现可能使用multimap.h和algo.h,且还可能要求将less<pair>作为multimap的第3个模板参数。另外,老式实现还使用ostream_iterator<string>,而不是ostream_iterator<string, char>。Borland's C++Builder 1.0希望在Pair typedef中省略const。
下面是程序清单16.12中程序的输出:
16.5 函数对象
很多STL算法都使用函数对象——也叫函数符(functor)。函数符是可以以函数方式与()结合使用的任意对象。这包括函数名、指向函数的指针和重载了()操作符的类对象(即定义了函数operator()()的类)。例如,可以像这样定义一个类:

这样,重载的()操作符将使得能够像函数那样使用Linear对象:

其中y1将使用表达式0 + 1 12.5来计算,y2将使用表达式10.0 + 2.5 0.4来计算。在表达式y0 + slope *x中,y0和slope的值来自对象的构造函数,而x的值来自operator() ()的参数。
还记得函数for_each吗?它将指定的函数用于区间中的每个成员:
for_each (books.begin(), books.end(), ShowReview);
通常,第3个参数可以是常规函数,也可以是函数符。实际上,这提出了一个问题:如何声明第3个参数呢?不能把它声明为函数指针,因为函数指针指定了参数类型。由于容器可以包含任意类型,所以预先无法知道应使用哪种参数类型。STL通过使用模板解决了这个问题。for_each的原型看上去就像这样:

ShowReview()的原型如下:
void ShowReview (const Review &);
这样,标识符ShowReview的类型将为void(*)(const Review &),这也是赋给模板参数Function的类型。对于不同的函数调用,Function参数可以表示具有重载的()操作符的类类型。最终,for_each()代码将具有一个使用f(…)的表达式。在ShowReview()范例中,f是指向函数的指针,而f(…)调用该函数。如果最后的for_each()参数是一个对象,则f(…)将是调用其重载的()操作符的对象。
16.5.1 函数符概念
正如STL定义了容器和迭代器的概念一样,它也定义了函数符概念:
● 生成器(generator)是不用参数就可以调用的函数符。
● 一元函数(unary function)是用一个参数可以调用的函数符。
● 二元函数(binary function)是用两个参数可以调用的函数符。
例如,提供给for_each()的函数符应当是一元函数,因为它每次用于一个容器元素。
当然,这些概念都有相应的改进版:
● 返回bool值的一元函数是断言(predicate)。
● 返回bool值的二元函数是二元断言(binary predicate)。
一些STL函数需要断言参数或二元断言参数。例如,程序清单16.7使用了sort()的这样一个版本,即将二元断言作为其第3个参数:

list模板有一个将断言作为参数的remove_if()成员,该函数将断言应用于区间中的每个元素,如果断言返回true,则删除这些元素。例如,下面的代码删除链表three中所有大于100的元素:

scores.remove_if (tooBig);
最后这个例子演示了类函数符适用的地方。假设要删除另一个链表中所有大于200的值。如果能将取舍值作为第二个参数传递给tooBig(),则可以使用不同的值调用该函数,但断言只能有一个参数。不过,如果设计一个TooBig类,则可以使用类成员而不是函数参数,来传递额外的信息:

这里,一个值(V)作为函数参数传递,而第二个参数(cutoff)是由类构造函数设置的。有了该定义后,就可以将不同的TooBig对象初始化为不同的取舍值,供调用remove_if()时使用。程序清单16.13演示了这种技术。
程序清单 16.13 functor.cpp


一个函数符(fl00)是一个声明的对象,而另一个函数符(TooBig<int>(200))是一个匿名对象,它是由构造函数调用创建的。下面是程序清单16.13中程序的输出:

注意:remove_if()方法是模板类的一个模板方法。模板方法是最近对C++模板工具的扩展,因此老式编译器可能不支持该方法。不过,还有一个非成员函数remove_if(),它使用区间(两个迭代器)和断言作为参数。
假设已经有了一个接受两个参数的模板函数:

则可以使用类将它转换为单个参数的函数对象:

即可以这样做:

因此,调用tB100 (x)相当于调用tooBig (x, 100),不过两个参数的函数被转换为单参数的函数对象,其中第二个参数被用于构建函数对象。简而言之,类函数符TooBig2是一个函数适配器,使函数能够满足不同的接口。
16.5.2 预定义的函数符
STL定义了多个基本函数符,它们执行诸如将两个值相加、比较两个值是否相等操作。提供这些函数对象是为了支持将函数作为参数的STL函数。例如,考虑函数transform()。它有两个版本。第一个版本接受4个参数,前两个参数是指定容器区间的迭代器(现在读者应该已熟悉了这种方法),第3个参数是指定将结果复制到哪里的迭代器,最后一个参数是一个函数符,它被应用于区间中的每个元素,生成结果中的新元素。例如,请看下面的代码:

上述代码计算每个元素的平方根,并将结果发送到输出流。目标迭代器可以位于原始区间中。例如,将上述范例中的out替换为gr8.begin()后,新值将覆盖原来的值。很明显,使用的函数符必须是接受单个参数的函数符。
第2种版本使用一个接受两个参数的函数,并将该函数用于两个区间中元素。它用另一个参数(即第3个)标识第二个区间的起始位置。例如,如果m8是另一个vector<double>对象,mean (double,double)返回两个值的平均值,则下面的的代码将输出来自gr8和m8的值的平均值:
transform (gr8.begin(), gr8.end(), m8.begin(), out, mean);
现在假设要将两个数组相加。不能将+作为参数,因为对于类型double来说,+是内置的操作符,而不是函数。可以定义一个将两个数相加的函数,然后使用它:

不过,这样必须为每种类型单独定义一个函数。更好的办法是定义一个模板(除非STL已经有一个模板了,这样就不必定义)。头文件functional(以前为function.h)定义了多个模板类函数对象,其中包括plus<>()。
可以用plus<>类来完成常规的相加运算:

它使得将函数对象作为参数很方便:
transform (gr8.begin(), gr8.end(), m8.begin(), out, plus<double>());
这里,代码没有创建命名的对象,而是用plus<double>构造函数构造了一个函数符,以完成相加运算(括号表示调用默认的构造函数,传递给transform()的是构造出来的函数对象)。
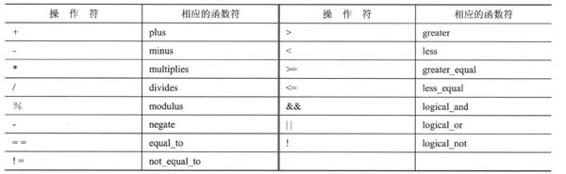
对于所有内置的算术操作符、关系操作符和逻辑操作符,STL都提供了等价的函数符。表16.11列出了这些函数符的名称。它们可以用于处理C++内置类型或任何用户定义类型(如果重载了相应的操作符)。
警告:老式C++实现使用名称times,而不是multiplies。
表16.11 操作符和相应的函数符
16.5.3 自适应函数符和函数适配器
表16.11列出的预定义函数符都是自适应的。实际上STL有5个相关的概念:自适应生成器(adaptable generator)、自适应一元函数(adaptable unary function)、自适应二元函数(adaptable binary function)、自适应断言(adaptable predicate)和自适应二元断言(adaptable binary predicate)。
使函数符成为自适应的原因是,它携带了标识参数类型和返回值类型的typedef成员。这些成员分别是result_type、first_argument_type和second_argument_type,它们的作用是不言自明的。例如,plus<int>对象的返回值类型被标识为plus<int>::result_type,这是int的typedef。
函数符自适应性的意义在于:函数适配器对象可以使用函数对象,并认为存在这些typedef成员。例如,接受一个自适应函数符参数的函数可以使用result_type成员来声明一个与函数的返回值类型匹配的变量。
STL提供了使用这些工具的函数适配器类。例如,假设要将矢量gr8的每个元素都增加2.5倍,则需要使用接受一个一元函数参数的transform()版本,就像前面的例子那样:
transform (gr8.begin(), gr8.end(), out, sqrt);
multiplies()函数符可以执行乘法运行,但它是二元函数。因此需要一个函数适配器,将接受两个参数的函数符转换为接受1个参数的函数符。前面的TooBig2范例提供了一种方法,但STL使用binderlst和binder2nd类自动完成这一过程,它们将自适应二元函数转换为自适应一元函数。
我们来看binderlst。假设有一个自适应二元函数对象f2(),则可以创建一个binderlst对象,该对象与一个将被用作f2()的第一个参数的特定值(val)相关联:
binderlst (f2, val) f1;
这样,使用单个参数调用f1(x)时,返回的值与将val作为第一参数、将f1()的参数作为第二参数调用f2()返回的值相同。即f1(x)等价于f2(val, x),只是前者是一元函数,而不是二元函数。f2()函数被适配。同样,仅当f2()是一个自适应函数时,这才能实现。
看上去有点麻烦。不过,STL提供了函数bind1st(),以简化binderlst类的使用。可以问其提供用于构建binderlst对象的函数名称和值,它将返回一个这种类型的对象。例如,要将二元函数multiplies()转换为将参数乘以2.5的一元函数,则可以这样做:
bindlst (multiplies<double>(), 2.5)
因此,将gr8中的每个元素与2.5相乘,并显示结果的代码如下:

binder2nd类与此类似,只是将常数赋给第二个参数,而不是第一个参数。它有一个名为bind2nd的助手函数,该函数的工作方式类似于bind1st。
提示:如果STL函数需要一个一元函数,而现有一个能完成相应工作的自适应二元函数,则可以使用bindlst()或bind2nd()使该二元函数适应于一元接口。
程序清单16.14将一些最近的范例合并成了一个小程序。
程序清单 16.14 funadap.cpp


注意:老式STL实现可能使用vector.h、iterator.h、algo.h和function.h,且可能使用times,而不是multiplies。
程序清单16.14中程序的输出如下:
16.6 算法
STL包含了很多处理容器的非成员函数,前面已经介绍过其中的一些:sort()、copy()、find()、random_shuffle()、set union()、set_intersection()、set_difference()和transform()。可能已经注意到,它们的总体设计是相同的,都使用迭代器来标识要处理的数据区间和结果的放置位置。有些函数还接受一个函数对象参数,并使用它来处理数据。
对于算法函数设计,有两个主要的通用部分。首先,它们都使用模板来提供通用类型;其次,它们都使用迭代器来提供访问容器中数据的通用表示。因此,copy()函数可用于将double值存储在数组中的容器、将string值存储在链表中的容器,也可用于将用户定义的对象存储在树结构中(如set所使用的)的容器。因为指针是一种特殊的迭代器,因此诸如copy()等STL函数可用于常规数组。
统一的容器设计使得不同类型的容器之间具有明显关系。例如,可以使用copy()将常规数组中的值复制到vector对象中,将vector对象中的值复制到list对象中,将list对象中的值复制到set对象中。可以用==来比较不同类型的容器,如deque和vector。之所以能够这样做,是因为容器重载的==操作符使用迭代器来比较内容,因此如果deque对象和vector对象的内容相同,并且排列顺序也相同,则它们是相等的。
16.6.1 算法组
STL将算法库分成4组:
● 非修改式序列操作。
● 修改式序列操作。
● 通用数字运算。
前3组在algorithm(以前为algo.h)头文件中描述,第4组是专用于数值数据的,有自己的头文件,称为numeric(以前它们也位于algol.h中)。
非修改式序列操作对区间中的每个元素进行操作。这些操作不修改容器的内容。例如,find()和for_each()就属于这一类。
修改式序列操作也对区间中的每个元素进行操作。不过,顾名思义,它们可以修改容器的内容。可以修改值,也可以修改值的排列顺序。例如,transform()、random_shuffle()和copy()就属于这一类。
排序和相关操作包括多个排序函数(包括sort())和其他各种函数,包括集合操作。
数字操作包括将区间的内容累积、计算两个容器的内部乘积、计算小计、计算相邻对象差的函数。通常,这些都是数组的操作特性,因此vector是最有可能使用这些操作的容器。
16.6.2 算法的通用特征
正如读者多次看到的,STL函数使用迭代器和迭代器区间。从函数原型可知有关迭代器的假设。例如,copy()函数的原型如下:

因为标识符Inputlterator和Outputlterator都是模板参数,所以它们就像T和U一样。不过,STL文档使用模板参数名称来表示参数模型的概念。因此上述声明告诉我们,区间参数必须是输入迭代器或更高级别的迭代器,而指示结果存储位置的迭代器必须是输出迭代器或更高级别的迭代器。
对算法进行分类的方式之一是按结果放置的位置进行分类。有些算法就地完成工作,有些则创建拷贝。例如,在sort()函数完成时,结果被存放在原始数据的位置上,因此,sort()是就地算法(in-place algorithm);而copy()函数将结果发送到另一个位置,所以它是复制算法(copying algorithm)。transform()函数可以以这两种方式完成工作。与copy()相似,它使用输出迭代器指示结果的存储位置;与copy()不同的是,transform()允许输出迭代器指向输入区间,因此它可以用计算结果覆盖原来的值。
有些算法有两个版本:就地版本和复制版本。STL的约定是,复制版本的名称将以_copy结尾。复制版本将接受一个额外的输出迭代器参数,该参数指定结果的放置位置。例如,函数replace()的原型如下:

它将所有的old_value替换为new_value,这是就地发生的。由于这种算法同时读写容器元素,因此迭代器类型必须是Forwardlterator或更高级别的。复制版本的原型如下:

此时,结果被复制到result指定的新位置,因此对于指定区间而言,只读输入迭代器足够了。
注意,replace_copy()的返回值类型为Outputlterator。对于复制算法,统一的约定是:返回一个迭代器,该迭代器指向复制的最后一个值后面的一个位置。
另一个常见的变体是:有些函数有这样的版本,即根据将函数应用于容器元素得到的结果来执行操作。这些版本的名称通常以_if结尾。例如,如果将函数用于旧值时,返回的值为true,则replace_if()将把旧值替换为新的值。下面是该函数的原型:

如前所述,断言是返回bool值的一元函数。还有一个replace_copy_if()版本,读者不难知道其作用和原型。
与Inputlterator一样,Predicate也是模板参数名称,可以为T或U。不过,STL选择用Predicate来提醒用户,实参应是Predicate概念的一个模型。同样,STL使用诸如Generator和BinaryPredicate等术语来
指示必须是其他函数对象概念模型的参数。
16.6.3 STL和string类
string类虽然不是STL的组成部分,但设计它时考虑到了STL。例如,它包含begin()、end()、rbegin()和rend()等成员,因此可以使用STL接口。程序清单16.15用STL显示了使用一个词的字母可以得到的所有排列组合。排列组合就是重新安排容器中元素的顺序。next_permutation()算法将区间内容转换为下一种排列方式。对于字符串,排列按照字母递增的顺序进行。如果成功,该算法返回true;如果区间已经处于最后的序列中,则该算法返回false。要得到区间内容的所有排列组合,应从最初的顺序开始,为此程序使用了STL sort()算法。
程序清单 16.15 strgst1.cpp

程序清单16.15中程序的运行情况如下:

注意,next_permutation()算法自动提供惟一的排列组合,这就是输出中“wed”一词的排列组合比“wee”(它有重复的字母)的排列组合要多的原因。
16.6.4 函数和容器方法
有时,可以选择使用STL方法还是使用STL函数。通常方法是更好的选择。首先,它更适合于特定的容器;其次,作为成员函数,它可以使用模板类的内存管理工具,从而在需要时调整容器的长度。
例如,假设有一个由数字组成的链表,并要删除链表中某个特定值(例如4)的所有实例。如果la是一个list<int>对象,则可以使用链表的remove()方法:
la.remove (4); // remove all 4s from the list
调用该方法后,链表中所有值为4的元素都将被删除,同时链表的长度将被自动调整。
还有一个名为remove()的STL算法(见附录G),它不是由对象调用,而是接受区间参数。因此,如果1b是一个list<int>对象,则调用该函数的代码如下:
remove (lb.begin(), lb.end(), 4);
但是,由于该remove()函数不是成员,因此不能调整链表的长度。它将没被删除的元素放在链表的开始位置,并返回一个指向新的超尾值的迭代器。这样,便可以用该迭代器来修改容器的长度。例如,可以使用链表的erase()方法来删除一个区间,该区间描述了链表中不再需要的部分。程序清单16.16演示了这是如何进行的。
程序清单 16.16 listrmv.cpp

下面是程序清单16.16中程序的输出:

从中可知,remove()方法将链表1a从10个元素减少到6个元素。但对链表lb应用remove()后,它仍然包含10个元素。最后4个元素可任意处理,因为其中每个元素要么为4,要么与已经移到链表开头的值相同。
尽管方法通常更适合,但非方法函数更通用。正如读者看到的,可以将它们用于数组、string对象、STL容器,还可以用它们来处理混合的容器类型,例如,将矢量容器中的数据存储到链表或集合中。
16.6.5 使用STL
STL是一个库,其组成部分被设计成协同工作。STL组件是工具,但也是创建其他工具的基本部件。我们用一个例子说明。假设要编写一个程序,让用户输入单词。希望最后得到一个按输入顺序排列的单词列表、一个按字母顺序排列的单词列表(忽略大小写),并记录每个单词被输入的次数。出于简化的目的,假设输入中不包含数字和标点符号。
输入和保存单词列表很简单。可以按程序清单16.5和16.6那样创建一个vector<string>对象,并用push_back()将输入的单词添加到矢量中:

如何得到按字母顺序排列的单词列表呢?可以使用sort(),然后使用unique(),但这种方法将覆盖原始数据,因为sort()是就地算法。有一种更简单的方法,可以避免这种问题:创建一个set<string>对象,然后将矢量中的单词复制(使用插入迭代器)到集合中。集合自动对其内容进行排序,因此无须调用sort();集合只允许同一个关键字出现一次,因此无须调用unique()。这里要求忽略大小写,处理这种情况的方法之一是使用transform()而不是copy(),将矢量中的数据复制到集合中。使用一个转换函数将字符串转换成小写形式。

ToLower()函数很容易编写,只需使用transform()将tolower()函数应用于字符串中的各个元素,并将字符串用作源和目标。记住,string对象也可以使用STL函数。将字符串按引用传递和返回意味着算法不必复制字符串,而可以直接操作原始字符串。下面是函数ToLower()的代码:

一个可能出现的问题是:tolower()函数被定义为int tolower (int),而一些编译器希望函数与元素类型(即char)匹配。一种解决方法是,使用toLower代替tolower,并提供下面的定义:
char toLower (char ch) { return tolower (ch); }
要获得每个单词在输入中出现的次数,可以使用count()函数。它将一个区间和一个值作为参数,并返回这个值在区间中出现的次数。可以使用vector对象来提供区间,并使用set对象来提供要计算其出现次数的单词列表。即对于集合中的每个词,都计算它在矢量中出现的次数。要将单词与其出现的次数关联起来,可将单词和计数作为pair<const string, int>对象存储在map对象中。单词将作为关键字(只出现一次),计数作为值。这可以通过一个循环来完成:

警告:老式STL实现将count()的类型声明为void。不使用返回值,而是提供按引用传递的第4个参数,元素数目将被加入到该参数中:
map类有一个有趣的特性:可以用数组表示法(将关键字用作索引)来访问所存储的值。例如,wordmap[“the”]表示与关键字“the”相关联的值,这里是字符串“the”出现的次数。因为wordset容器保存了wordmap使用的全部关键字,所以可以用下面的代码来存储结果,这是一种更具吸引力的方法:

因为si指向wordset容器中的一个字符串,所以*si是一个字符串,可以用作wordmap的关键字。上述代码将关键字和值都放到wordmap映象中。
同样,也可以使用数组表示法来报告结果:

如果关键字无效,则对应的值将为0。
程序清单16.17把这些想法组合在一起,同时包含了用于显示3个容器(包含输入内容的矢量、包含单词列表的集合和包含单词计数的映象)内容的代码。
程序清单 16.17 usealgo.cpp


注意:老式C++实现可能使用vector.h、map.h、iterator.h和ctype.h,且可能要求set和map模板使用另一个less<string>模板参数。旧版本使用前面提到的void count()函数。
程序清单16.17中程序的运行情况如下:

这里的精神就在于,使用STL时应尽可能减少要编写的代码。STL通用、灵活的设计将节省大量工作。另外,STL设计者就是非常关心效率的算法人员,算法是经过仔细选择的,并且是内联的。
16.7 其他库
C++还提供了其他一些类库,它们比本章讨论前面的例子更为专用。Complex头文件为复数提供了一个complex类模板,专用于float、long和long double。这个类提供了标准的复数运算及能够处理复数的标准函数。
第14章介绍了头文件valarray提供的模板类valarray。这个类模板被设计成用于表示数值数组,支持各种数值数组操作,例如将两个数组的内容相加、对数组的每个元素应用数学函数以及对数组进行线性代数运算。
vector和valarray
读者可能会问,C++为何提供了两个数组模板:vector和valarray。这些类是由不同的小组开发的,用于不同的目的。vector模板类是一个容器类和算法系统的一部分,它支持面向容器的操作,如排序、插入、重新排列、搜索、将数据转移到其他容器中等。而valarray类模板是面向数值计算的,不是STL的一部分。例如,它没有push_back()和insert()方法,但为很多数学运算提供一个简单、直观的接口。
例如,假设有如下声明:
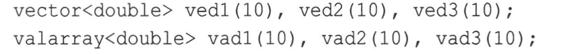
同时,假设ved1、ved2、vadl和vad2都有合适的值。要将两个数组中第一个元素的和赋给第三个数组的第一个元素,使用vector类时,可以这样做:

然而,valarray类重载了所有算术操作符,使其能够用于valarray对象,因此您可以这样做:
vad3 = vadl + vad2; //+ overloaded
同样,下面的语句将使vad3中每个元素都是vadl和vad2中相应元素的乘积:
vad3 = vadl vad2; // overloaded
要将数组中每个元素的值扩大2.5倍,STL方法如下:

valarray类重载了将valarray对象乘以一个值的操作符,还重载了各种组合赋值操作符,因此可以采取下列两种方法之一:
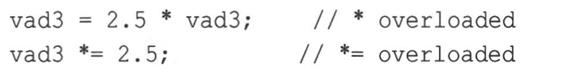
假设您要计算数组中每个元素的自然对象,并将计算结果存储到另一个数组的相应元素中,STL方法如下:

valarray类重载了这种数学函数,使之接受一个valarray参数,并返回一个valarray对象,因此您可以这样做:
vad3 = log(vadl); // log() overloaded
也可以使用apply()方法,该方法也适用于非重载函数:
vad3 = vadl.apply(log);
apply()方法不修改调用对象,而是返回一个包含结果的新对象。
执行多步计算时,valarray接口的简单性将更为明显:
vad3 = 10.0 ((vadl + vad2) / 2.0 + vadl cos(vad2));
有关使用STL vector来完成上述计算的代码留给读者去完成。
valarray类还提供了sum()方法——计算valarray对象中所有元素的和、size()方法——返回元素数、max()方法一返回最大的元素值和min()方法——返回最小的元素值。
正如读者看到的,对于数学运算而言,valarray类提供了比vector更清晰的表示方式,但通用性更低。valarray类确实有一个resize()方法,但不能像使用vector的push_back时那样自动调整大小。没有支持插入、排序、搜索等操作的方法。总之,与vector类相比,valarray类关注的东西更少,但这使得它的接口更简单。
valarray的接口更简单是否意味着性能更高呢?在大多数情况下,答案是否定的。简单表示法通常是使用类似于您处理常规数组时使用的循环实现的。然而,有些硬件设计允许在执行矢量操作时,同时将一个数组中的值加载到一组寄存器中,然后并行地进行处理。从原则上说,valarray操作也可以实现成利用这样的设计。
可以将STL功能用于valarray对象吗?通过回答这个问题,可以快速地复习一些STL原理。假设有一个包含10个元素的valarray<double>对象:
valarray<double> vad(10);
使用数字填充该数组后,能够将STL sort()函数用于该数组呢?valarray类没有begin()和end()方法,因此不能将它们用作指定区间的参数:
sort(vad.begin(), vad.end()); // NO, no begin(), end()
不能像处理常规数组那样,使用vad和vad+10作为区间参数,因为vad不是数组名。它是一个对象名,因此没有地址。因此,下面的代码不可行:
sort(vad, vad + 10); // NO, vad an object, not an address
也许可以使用地址操作符:
sort(&vad[0], &vad[10]); // maybe?
这看起来可行。vad的类型为valarray<double>, vad[0]的类型为double, &vad[0]的类型为double ,因此可以将其值赋给类型为double 的指针,后者可用作迭代器。接下来,看看该指针(我们将其称为pt)是否满足STL对随机存取迭代器的要求。首先,它能够被解除引用:*pt为vad[0]——数组中第一个元素的值。pt++又如何呢?显然指针可以被递增,但递增后是否指向数组中第二个元素呢?类描述指出,&a[i+j]和&a[i] +j等价。具体地说,&[i] + 1等于&a[i+l],也就是说,将地址加1结果为下一个元素的地址,因此将pt递增确实会使其指向下一个元素。上述等价规则也意味着随机存取是可行的。到目前为止,一切顺利。
但涉及&vad[10]时存在两个问题。规则“&a[i+j]与&[i]+j”存在这样的限制,即i+j必须比数组长度小1。因此,在这个例子中,该规则只适用于&vad[0]到&vad[9]。另外,使用大于或等于数组长度的下标的结果是不确定的,因此使用vad[10]的结果是不确定的。这并不意味着使用sort()不可行,事实上,使用6种编译器来测试上述代码时,都是可行的;但这确实意味着可能不可行。为使上述代码不可行,需要一个不太可能出现的条件,如让数组与预留给堆的内存块相邻。然而,如果3亿5千万美元的交易命悬于您的代码,您可能不想冒代码出现问题的风险。
为避开这种超尾问题,可以将valarray对象声明为比所需元素数多1,但这样做将给sum()、max()和size()方法带来麻烦。
程序清单16.18演示了vector和valarray类各自的优势。它使用vector的push_back()方法和自动调整大小的功能来收集数据,然后对数字进行排序后,将它们从vector对象复制到一个同样大小的valarray对象中,再执行一些数学运算。
程序清单 16.18 valvect.cpp


下面是程序清单16.18中程序的运行情况:

注意:编写本书时,Borlan C++BuilderX默认库在实现valarray数学函数方面存在一个bug。解决方式之一是在命令行上使用下面的选项,让编译器使用老版本的STL:
-D_USE_OLD_RW_STL
在IDE模式下,可以选择菜单Project/Build Options Explorer,然后单击bcc32,再将选项_USE_OLD_RW_STL加入到文本框Conditional Defines中。
除前面讨论的外,valarray类还有很多其他特性。例如,如果numbers是一个valarray<double>对象,则下面的语句将创建一个bool值数组,其中vbool[i]被设置为numbers[i]>9的值,即true或false。
valarray<bool>vbool=numbers>9
还有扩展的下标指定版本。来看其中的一个——slice类。slice类对象可用作数组索引,在这种情况下,它代表的不是一个值而是一组值。slice对象被初始化为三个整数值:起始索引、索引数和跨距。起始索引是第一个被选中的元素的索引,索引数指出要选择多少个元素,跨距表示元素之间的间隔。例如,slice(l,4,3)创建的对象表示选择4个元素,它们的索引分别是1、4、7和10。也就是说,从起始索引开始,加上跨距得到下一个元素的索引,依此类推,直到选择了4个元素。如果varint是一个valarray<int>对象,则下面的语句将把第1、4、7、10个元素都设置为10:
varint[slice(1,4,3)] = 10; // set selected elements to 10
这种特殊的下标指定功能让您能够使用一个一维valarray对象来表示二维数据。例如,假设要表示一个4行3列的数组,可以将信息存储在一个包含12个元素的valarray对象中,然后使用一个slice(0,3,1)对象作为下标,来表示元素0、1和2,即第1行。同样,下标slice(0,4,3)表示元素0、3、6和9,即第一列。程序清单16.19演示了slice的一些特性。
程序清单 16.19 vslice.cpp

对于valarray对象(如valint)和单个int元素,+操作符已经被定义;但正如程序清单16.19中指出的,对于使用slice下标指定的valarray单元,如valint[slice(1,4,3),并没有定义+操作符。因此程序使用slice指定的元素创建一个完整的valint对象,以便能够执行加法运算:
vint(valint[slice(1,4,3)]) // calls a slice-based constructor
valarray类提供了用于这种目的的构造函数。
下面是程序清单16.19中程序的运行情况:

由于元素值是使用rand()设置的,因此不同的rand()实现将设置不同的值。
另外,使用gslice类可以表示多维下标,但上述内容应该足以让读者对valarray有一定的了解。
16.8 总结
C++提供了一组功能强大的库,这些库提供了很多常见编程问题的解决方案以及简化其他问题的工具。string类为将字符串作为对象来处理提供了一种方便的方法。string类提供了自动内存管理功能以及众多处理字符串的方法和函数。例如,这些方法和函数让您能够合并字符串、将一个字符串插入到另一个字符串中、反转字符串、在字符串中搜索字符或子字符串以及执行输入和输出操作。
auto_ptr模板使得管理由new分配的内存更为容易。如果使用auto_ptr对象,而不是常规指针来保存new返回的地址,则不必在以后使用删除操作符。当auto_ptr对象过期时,其析构函数将自动调用删除操作符。
STL是一个容器类模板、迭代器类模板、函数对象模板和算法函数模板的集合,它们的设计是一致的,都是基于通用编程技术原则的。算法通过使用模板,从而独立于所存储的对象的类型;通过使用迭代器接口,从而独立于容器的类型。迭代器是广义指针。
STL使用术语“概念”来描述一组要求。例如,正向迭代器的概念包含这样的要求,即正向迭代器能够被解除引用,以便读写,同时能够被递增。概念真正的实现方式被称为概念的“模型”。例如,正向迭代器概念可以是常规指针或导航链表的对象。基于其他概念的概念叫作“改进”。例如,双向迭代器是正向迭代器概念的改进。
诸如vector和set等容器类是容器概念(如容器、序列和联合容器)的模型。STL定义了多种容器类模板:vector、deque、list、set、multiset、map、multimap和bitset;还定义了适配器类模板queue、priority_queue和stack;这些类让底层容器类能够提供适配器类模板名称所建议的特性接口。因此,stack虽然在默认情况下是基于vector的,但仍只允许在栈顶进行插入和删除。
有些算法被表示为容器类方法,但大量算法都被表示为通用的、非成员函数,这是通过将迭代器作为容器和算法之间的接口得以实现的。这种方法的一个优点是:只需一个诸如for_each()或copy()这样的函数,而不必为每种容器提供一个版本;另一个优点是:STL算法可用于非STL容器,如常规数组、string对象和所设计的、秉承STL迭代器和容器规则的任何类。
容器和算法都是由其提供或需要的迭代器类型表征的。应当检查容器是否具备支持算法要求的迭代器概念。例如,for_each()算法使用一个输入迭代器,所有的STL容器类型都满足其最低要求;而sort()则要求随机访问迭代器,并非所有的容器类都支持这种迭代器。如果容器类不能满足特定算法的要求,则可能提供一个专用的方法。例如,list类包含一个基于双向迭代器的sort()方法,因此它可以使用该方法,而不是通用函数。
STL还提供了函数对象(函数符),函数对象是重载了()操作符(即定义了operator()()方法)的类。可以使用函数表示法来调用这种类的对象,同时可以携带额外的信息。自适应函数符有typedef语句,这种语句标识了函数符的参数类型和返回值类型。这些信息可供其他组件(如函数适配器)使用。
通过表示常用的容器类型,并提供各种使用高效算法实现的常用操作(全部是通用的方式实现的),STL提供了一个非常好的可重用代码源。可以直接使用STL工具来解决编程问题,也可以把它们作为基本部件,来构建所需的解决方案。
模板类complex和valarray支持复数和数组的数值运算。
16.9 复习题
1.考虑下面的类声明:

将它转换为使用string对象的声明。哪些方法不再需要显式定义?
2.在易于使用方面,指出string对象至少有两个优于C-风格字符串的地方。
3.编写一个函数,用string对象作为参数,将string对象转换为全部大写。
4.从概念上或句法上说,下面哪个不是正确使用auto_ptr的方法(假设已经包含了所需的头文件)?

5.如果可以生成一个存储高尔夫球棍(而不是数字)的堆栈,为何它(从概念上说)是一个坏的高尔夫袋子?
6.为什么说对于逐洞记录高尔夫成绩来说,set容器是糟糕的选择?
7.既然指针是一个迭代器,为什么STL设计人员没有简单地使用指针来代替迭代器呢?
8.为什么STL设计人员仅定义了迭代器基类,而使用继承来派生其他迭代器类型的类,并根据这些迭代器类来表示算法?
9.给出vector对象比常规数组方便的3个例子。
10.如果程序清单16.7是使用list(而不是vector)实现的,则该程序的哪些部分将是非法的?非法部分能够轻松修复吗?如果可以,如何修复呢?
16.10 编程练习
1.回文指的是顺读和逆读都一样的字符串。例如,“tot”和“otto”都是简短的回文。编写一个程序,让用户输入字符串,并将字符串引用传递给一个bool函数。如果字符串是回文,该函数将返回true,否则返回false。此时,不要担心诸如大小写、空格和标点符号这些复杂的问题。即这个简单的版本将拒绝“Otto”和“Madam, I'm Adam”。请查看附录F中的字符串方法列表,以简化这项任务。
2.与编程练习1中给出的问题相同,不过要考虑诸如大小写、空格和标点符号这样的复杂问题。即“Madam, I'm Adam”将作为回文来测试。例如,测试函数可能会将字符串缩略为“madamimadam”,然后测试倒过来是否一样。不要忘了有用的cctype库,您可能从中找到几个有用的STL函数,尽管不一定非要使用它们。
3.修改程序清单16.3,使之从文件中读取单词。一种方案是,使用vector<string>对象而不是string数组。这样便可以使用push_back()将数据文件中的单词复制到vector<string>对象中,并使用size()来确定单词列表的长度。由于程序应该每次从文件中读取一个单词,因此应使用操作符>>而不是getline()。文件中包含的单词应该用空格、制表符或换行符分隔。
4.编写一个具有老式风格接口的函数,其原型如下:
int reduce (long ar[], int n);
实参应是数组名和数组中的元素个数。该函数对数组进行排序,删除重复的值,返回缩减后数组中的元素数目。请使用STL函数编写该函数(如果决定使用通用的unique()函数,请注意它将返回结果区间的结尾)。使用一个小程序测试该函数。
5.问题与编程练习4相同,不过要编写一个模板函数:

在一个使用long实例和string实例的小程序中测试该函数。
6.使用STL queue模板类而不是第12章的Queue类,重新编写程序清单12.15所示的范例。
7.彩票卡是一个常见的游戏。卡片上是带编号的圆点,其中一些圆点被随机选中。编写一个lotto()函数,它接受两个参数。第一个参数是彩票卡上圆点的个数,第二个参数是随机选择的圆点个数。该函数返回一个vector<int>对象,其中包含(按排列后的顺序)随机选择的号码。例如,可以这样使用该函数:

这样将把一个矢量赋给winner,该矢量包含从1~51中随机选定的6个数字。注意,仅仅使用rand()无法完成这项任务,因它会生成重复的值。提示:让函数创建一个包含所有可能值的矢量,使用random_shuffle(),然后通过打乱后的矢量的第一个值来获取值。编写一个小程序来测试这个函数。
8.Mat和Pat希望邀请他们的朋友来参加派对。他们要编写一个程序完成下面的任务:
● 让Mat输入他朋友的姓名列表。姓名存储在一个容器中,然后按排列后的顺序显示出来。
● 让Pat输入她朋友的姓名列表。姓名存储在另一个容器中,然后按排列后的顺序显示出来。
● 创建第三个容器,将两个列表合并,删除重复的部分,并显示这个容器的内容。
