附录G STL方法和函数
标准模板库(STL)旨在提供通用算法的高效实现,它通过通用函数(可用于满足特定算法要求的任何容器)和方法(可用于特定容器类实例)来表达这些算法。本附录假设读者对STL有一定的了解(如通过阅读第16章)。例如,本章假设读者了解迭代器和构造函数。
G.1 所有容器都有的成员
所有容器都定义了表G.1列出的类型。在这个表中,x为容器类型,如vector<int>;T为存储在容器中的类型,如int。表G.1中的范例阐明了含义
表G.1 为所有容器定义的类型
| 类 型 | 值 |
| x::value-type | T,元素类型 |
| x::reference | T& |
| x::const_reference | const T& |
| x::iterator | 指向T的迭代器类型,行为与T相似 |
| x::const_iterator | 指向const T的迭代器类型,行为与const T相似 |
| x::different_type | 用于表示两个迭代器之间距离的符号整型,如两个指针的差 |
| x::size_type | 无符号整型size_type可以表示数据对象的长度、元素数目和下标 |
类定义使用typedef定义这些成员。可以使用这些类型来声明适当的变量。例如,下面的代码使用迂回的方式,将由string对象组成的矢量中的第一个“bonus”替换为“bogus”,以演示如何使用成员类型来声明变量。

上述代码使r成为一个指向(want指向的)input中元素的引用。同样,继续前面的例子,可以编写下面这样的代码:

这将导致s1为一个新string对象,它是input[0]的拷贝;而s2为指向input[1]的引用。在这个例子中,由于已经知道模板是基于string类型的,因此编写下面的等效代码将更简单:

然而,还可以在更通用的代码中使用表G.1中较精致(其中容器和元素的类型是通用的)的类型。例如,假设希望min()函数将一个指向容器的引用作为参数,并返回容器中最小的项目。这假设为用于实例化模板的值类型定义了<操作符,而不想使用STL min_element()算法,这种算法使用迭代器接口。由于参数可能是vector<int>、list<strint>或deque<double>,因此需要使用带模板参数(如Bag)的模板来表示容器(也就是说,Bag是一个模板类型,可能被实例化为vector<int>、list<string>或其他一些容器类型)。因此,函数的参数类型应为const Bag & b。返回类型是什么呢?应为容器的值类型,即Bag::value_type。不过,在这种情况下,Bag只是一个模板参数,编译器无法知道value_type成员实际上是一种类型。但可以使用typename关键字来指出,类成员是typedef:
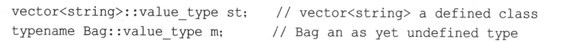
对于上述第一个定义,编译器能够访问vector模板定义,该定义指出,value_type是一个typedef;对于第二个定义,typename关键字指出,无论Bag将会是什么,Bag::value-type都将是类型的名称。这些考虑因素导致了下面的定义:

这样,便可以这样使用该模板函数:

temperatures参数将使得Bag被断言为 vector<int>,而 typename Bag::value-type被断言为vector<int>::value_type,进而为int。
所有的容器都还可以包含表G.2中列出的成员函数或操作。其中,X是容器类型,如vector<int>;而T是存储在容器中的类型,如int。另外,a和b是类型为X的值。
表G.2 为所有容器定义的方法
| 方法/操作 | 描 述 |
| begin() | 返回一个指向第一个元素的迭代器 |
| end() | 返回一个指向超尾的迭代器 |
| rbegin() | 返回一个指向超尾的反向迭代器 |
| rend() | 返回一个指向第一个元素的反向迭代器 |
| size() | 返回元素数目 |
| maxsize() | 返回容器的最大长度 |
| empty() | 如果容器为空,则返回true |
| swap()交换2个容器的内容 | |
| == | 如果2个容器的长度相同,包含的元素相同,并且元素排列的顺序相同,则返回true |
| != | a!=b返回!(a= =b) |
| < | 如果a按词典顺序排在6之前,则a<b返回true |
| > | a>b返回b<a |
| <= | a<=b返回!(a>b) |
| >= | a>=b返回!(a<b) |
容器的>操作符假设已经为值类型定义了>操作符。词典比较是一种广义的按字母顺序排序,它逐元素地比较两个容器,直到两个容器中对应的元素相同时为止。在这种情况下,元素对的顺序将决定容器的顺序。例如,如果两个容器的前10个元素都相同,但第一个容器的第11个元素比第二个容器的第11个元素小,则第一个容器将排在第二个容器之前。如果两个容器中的元素一直相同,直到其中一个容器中的元素用完,则较短的容器将排在较长的容器之前。
G.2 矢量、链表和双端队列的其他成员
矢量、链表和双端队列都是序列,它们都拥有表G.3列出的方法。其中,x是容器类型,如vector<int>: T是存储在容器中的类型,如int;a是类型为X的值;t是type x::value_type值;i和j是输入迭代器;q2和p是迭代器;q和q1是可被解除引用的迭代器(可以对它们使用*操作符);n是x::size_type类型的整数。
表G.3 为矢量、链表和双端队列定义的方法
| 方 法 | 描 述 |
| a.insert (p, t) | 在p之前插入t;返回指向插入的t的迭代器。T的默认值是T(),即在没有显式初始化时,用于T 类型的值 |
| a.insert (p, n, t) | 在p之前插入n个t,没有返回值 |
| a.insert (p, i, j) | 在p之前插入[i,j]区间内的元素,没有返回值 |
| a.resize (n, t) | 如果n>a.size(),则在a.end()之前插入n-a.size()个t;t的默认值为T(),即在没有显式初始化时, 用于T类型的值。如果n<a.size(),将删除第n个元素之后的所有元素 |
| a.ssign (i,j) | 使用区间[i,j]内的元素替换a当前的内容 |
| a.ssign (n,t) | 使用n个t替换a当前的内容。t的默认值为T(),即在没有显式初始化时,用于T类型的值 |
| a.erase (q) | 删除q指向的元素;返回一个指向q后面的元素的迭代器 |
| a.erase (q1,q2) | 删除[q1,q2]区间内的元素;返回一个迭代器,该迭代器指向q2原来指向的元素 |
| a.clear() | 与erase (a.begin(),a.end())等效 |
| a.front() | 返回a.begin()(第一个元素) |
| a.back() | 返回—a.end()(最后一个元素) |
| a.push_back (t) | 将t插入到a.end()的前面 |
| a.pop_back() | 删除最后一个元素 |
表G.4列出了这3种序列类(vector、list和deque)中的两种都有通用的两个方法。
表G.4 为某些序列定义的方法
| 方 法 | 描 述 | 容 器 |
| a.push_front (t) | 将t插入到第一个元素的前面 | 链表、队列 |
| a.pop_front() | 删除第一个元素 | 链表、队列 |
| a[n] | 返回 (a.begin() + n) | 矢量、队列 |
| a.at (n) | 返回 (a.begin() + n);如果n>a.size,则引发out_of_range异常 | 矢量、队列 |
vector模板还包含表G.5列出的方法。其中,a是vector容器,n是x::size_type型整数。
表G.5 矢量的其他方法
| 方 法 | 说 明 |
| a.capacity() | 返回矢量在不要求重新分配内存的情况下,所能存储的元素总量 |
| a.reserve (n) | 提醒a对象:至少需要存储n个元素的内存。该方法被调用后,容量至少为n个元素。如果n大于当前的 容量,则需要重新分配内存。如果n大于a.max_size(),该方法将引发length_error异常 |
list模板还包含表G.6列出的方法。其中,a和b是list容器;T是存储在链表中的类型,如int;t是类型为T的值;i和j是输入迭代器;q2和p是迭代器;q和q1是可解除引用的迭代器;n是x::size_type型整数。该表使用了标准的STL表示法[i,j),它指的是从i到j(不包括j)的区间。
表G.6 List的其他方法
| 方 法 | 描 述 |
| a.splice (p, b) | 将链表b的内容移到链表a中,并将它们插在p之前 |
| a.splice (p, b, i) | 将i指向的链表b中的元素移到链表a的p位置之前 |
| a.splice (p, b, i, j) | 将链表b中[i,j]区间内的元素移到链表a的p位置之前 |
| a.remove (const T& t) | 删除链表a中值为t的所有元素 |
| a.remove_if (Predicate pred) | 如果i是指向链表a中元素的迭代器,则删除pred(i)为true的所有值(Predicate是 布尔值函数或函数对象,参见第15章) |
| a.unique() | 删除连续的相同元素组中除第一个元素之外的所有元素 |
| a.unique (BinaryPredicate bin_pred) | 删除连续的bin_pred(i,*(i-1))为true的元素组中除第一个元素之外的所有元素(BinaryPredicate是布尔值函数或函数对象,参见第15章) |
| a.merge (b) | 使用为值类型定义的<操作符,将链表b与链表a的内容合并。如果链表a的某个元素 与链表b的某个元素相同,则a中的元素将放在前面。合并后,链表b为空 |
| a.merge (b, Compare comp) | 使用comp函数或函数对象将链表b与链表a的内容合并。如果链表a的某个元素与链 表b的某个元素相同,则链表a中的元素将放在前面。合并后,链表b为空 |
| a.sort() | 使用<操作符对链表a进行排序 |
| a.sort (Compare comp) | 使用comp函数或函数对象对链表a进行排序 |
| a.reverse() | 将链表a中的元素顺序反转 |
G.3 set和map的其他成员
联合容器(集合和映象是这种容器的模型)带有模板参数Key和Compare,这两个参数分别表示用来对内容进行排序的关键字的类型和用于对关键字值进行比较的函数对象(被称为比较对象)。对于set’和multiset容器,存储的关键字为存储的值,因此关键字类型与值类型相同。对于map和multimap容器,一种类型(模板参数T)的存储值与关键字类型(模板参数Key)相关联,值类型为pair<const Key, T>。联合容器新增了其他成员来描述这些特性,如表G.7所示。
表G.7 为联合容器定义的类型
联合容器提供了表G.8列出的方法。通常,比较对象不要求关键字相同的值是相同的;等价关键字(equivalent key)意味着两个值(可能相同,也可能不同)的关键字相同。在上表中,X为容器类,a是类型为X的对象。如果X使用惟一性的关键字(即为set或map),则a_uniq将是类型为X的对象。如果x使用多个关键字(即为multiset或multimap),则a_eq将是类型为X的对象。和前面一样,i和j也是引用value_type元素的输入迭代器,[i,j]是一个有效的区间,p和q2是指向a的迭代器,q和q1是指向a的、可解除引用的迭代器,[q1,q2]是一个有效的区间,t是一个X::value_type值(可能是一对),而k是一个X::key_type值。
表G.8 为Set、Multiset、Map和Multimap定义的方法
G.4 STL函数
STL算法库(由头文件algorithm和numeric支持)提供了大量基于迭代器的非成员模板函数。正如第16章介绍的,选择的模板参数名指出了特定参数应模拟的概念。例如,ForwardIterator用于指出,参数至少应模拟正向迭代器的要求;Predicate用于指出,参数应是一个接受一个参数并返回bool值的函数对象。C++标准将算法分成4组:非修改式序列操作、修改式序列操作、排序和相关操作符以及数值操作。序列操作(sequence operation)表明,函数将接受两个迭代器作为参数,它们定义了要操作的区间或序列。修改式(mutating)意味着函数可以修改容器的内容。
G.4.1 非修改式序列操作
表G.9对非修改式序列操作进行了总结。这里没有列出参数,而重载函数只列出了一次。表后做了更详细的说明,其中包括原型。因此,可以浏览该表,以了解函数的功能,如果对某个函数非常感兴趣,则可以了解其细节。
表G.9 非修改式序列操作
| 函 数 | 说 明 |
| for-each() | 将一个非修改式函数对象用于区间中的每个成员 |
| find() | 在区间中查找某个值首次出现的位置 |
| find_if() | 在区间中查找第一个满足断言测试条件的值 |
| find_end() | 在序列中查找最后一个与另一个序列匹配的值。匹配时可以使用等式或二元断言 |
| find_first_of() | 在第二个序列中查找第一个与第一个序列的值匹配的元素。匹配时可以使用等式或二元断言 |
| adjacent_find() | 查找第一个与其后面的元素匹配的元素。匹配时可以使用等式或二元断言 |
| count() | 返回特定值在区间中出现的次数 |
| count_if() | 返回特定值与区间中的值匹配的次数,匹配时使用二元断言 |
| mismatch() | 查找区间中第一个与另一个区间中对应元素不匹配的元素,并返回指向这两个元素的迭代器。匹配时 可以使用等式或二元断言 |
| equal() | 如果一个区间中的每个元素都与另一个区间中的相应元素匹配,则返回true。匹配时可以使用等式或二 元断言 |
| search() | 在序列中查找第一个与另一个序列的值匹配的值。匹配时可以使用等式或二元断言 |
| search_n() | 查找第一个由n个元素组成的序列,其中每个元素都与给定值匹配。匹配时可以使用等式或二元断言 |
下面更详细地讨论这些非修改型序列操作。对于每个函数,首先列出其原型,然后做简要地描述。和前面一样,迭代器对指出了区间,而选择的模板参数名指出了迭代器的类型。通常,[first, last]区间指的是从first到last(不包括last)。有些函数接受两个区间,这两个区间的容器类型可以不同。例如,可以使用equal()来对链表和矢量进行比较。作为参数传递的函数是函数对象,这些函数对象可以是指针(如函数名),也可以是定义了()操作的对象。正如第16章介绍的,断言是接受一个参数的布尔函数,二元断言是接受2个参数的布尔函数(函数可以不是bool类型,只要它对于false返回0,对于true返回非0值)。
1.copy()

for_each()函数将函数对象f用于[first, last]区间中的每个元素,它也返回f。
2.find()
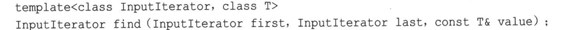
find()函数返回一个迭代器,该迭代器指向区间[first, last]中第一个值为value的元素;如果没有找到这样的元素,则返回last。
3.find_if()

find_if()函数返一个迭代器,该迭代器指向[first, last)区间中第一个对其调用函数对象pred (*i)时结果为true的元素;如果没有找到这样的元素,则返回last。
4.find_end()

find_end()函数返回一个迭代器,该迭代器指向[first1, last1)区间中最后一个与[first2,last2)区间的内容匹配的序列的第一个元素。第一个版本使用值类型的==操作符来比较元素;第二个版本使用二元断言函数对象pred来比较元素。也就是说,如果pred(it1, it2)为true,则it1和it2指向的元素相匹配。如果没有找到这样的元素,则它们都返回last1。
5.find_first_of()

find_first_of()函数返回一个迭代器,该迭代器指向区间[first1,last1)中第一个与[first2,last2)区间中的任何元素匹配的元素。第一个版本使用值类型的==操作符对元素进行比较;第二个版本使用二元断言函数对象pred来比较元素。也就是说,如果pred(it1,it2)为true,则it1和it2指向的元素是匹配的。如果没有找到这样的元素,则它们都将返回last1。
6.adjacent_find()

adjacent_find()函数返回一个迭代器,该迭代器指向[first1,last1)区间中第一个与其后面的元素匹配的元素。如果没有找到这样的元素,则返回last。第一个版本使用值类型的==操作符来对元素进行比较;第二个版本使用二元断言函数对象pred来比较元素。也就是说,如果pred(it1, it2)为true,则it1和it2指向的元素是匹配的。
7.count()

count()函数返回[first, last)区间中与值value匹配的元素数目。对值进行比较时,将使用值类型的==操作符。返回值类型为整型,它足以存储容器所能存储的最大元素数。
8.count_if()

count if()函数返回[first, last)区间中这样的元素数目,即将其作为参数传递给函数对象pred时,后者的返回值为true。
9.mismatch()

每个mismatch()函数都在[first1,last1)区间中查找第一个与从first2开始的区间中相应元素不匹配的元素,并返回两个迭代器,它们指向不匹配的两个元素。如果没有发现不匹配的情况,则返回值为pair<last1,first2+(last1-first1) >。第一个版本使用==操作符来测试匹配情况;第二个版本使用二元断言函数对象pred来比较元素。也就是说,如果pred(it1,it2)为false,则it1和it2指向的元素不匹配。
- equal()

如果[first1,last1)区间中每个元素都与以first2开始的序列中相应元素匹配,则equal()函数返回true,否则返回false。第一个版本使用值类型的==操作符来对元素进行比较;第二个版本使用二元断言函数对象pred来比较元素。也就是说,如果pred(it1,it2)为true,则it1和it2指向的元素是匹配的。
- search()

search()函数在[first1, last1)区间中搜索第一个与[first2, last2)区间中相应的序列匹配的序列;如果没有找到这样的序列,则返回last1。第一个版本使用值类型的==操作符来对元素进行比较;第二个版本使用二元断言函数对象pred来比较元素。也就是说,如果pred(it1, it2)为true,则it1和it2指向的元素是匹配的。
12.search n()

search_n()函数在[first1, last1)区间中查找第一个与count个value组成的序列匹配的序列;如果没有找到这样的序列,则返回last1。第一个版本使用值类型的==操作符来对元素进行比较;第二个版本使用二元断言函数对象pred来比较元素。也就是说,如果pred(it1, it2)为true,则it1和it2指向的元素是匹配的。
G.4.2 修改式序列操作
表G.10对修改式序列操作进行了总结。其中没有列出参数,而重载函数也只列出了一次。表后做了更详细的说明,其中包括原型。因此,可以浏览该表,以了解函数的功能,如果对某个函数非常感兴趣,则可以了解其细节。
| 函 数 | 描 述 |
| copy() | 将一个区间中的元素复制到迭代器指定的位置 |
| copy_backward() | 将一个区间中的元素复制到迭代器指定的位置。复制时从区间结尾开始,由后向前进行 |
| swap() | 交换引用指定的位置中存储的值 |
| swap_ranges() | 对两个区间中对应的值进行交换 |
| iter_swap() | 交换迭代器指定的位置中存储的值 |
| transform() | 将函数对象用于区间中的每一个元素(或区间对中的每对元素),并将返回的值复制到另一个区间 的相应位置 |
| replace() | 用另外一个值替换区间中某个值的每个实例 |
| replace_if() | 如果用于原始值的断言函数对象返回true,则使用另一个值来替换区间中某个值的所有实例 |
| replace_copy() | 将一个区间复制到另一个区间中,使用另外一个值替换指定值的每个实例 |
| replace_copy_if() | 将一个区间复制到另一个区间,使用指定值替换断言函数对象为true的每个值 |
| fill() | 将区间中的每一个值设置为指定的值 |
| fill_n() | 将n个连续元素设置为一个值 |
| generate() | 将区间中的每个值设置为生成器的返回值,生成器是一个不接受任何参数的函数对象 |
| generate_n() | 将区间中的前n个值设置为生成器的返回值,生成器是一个不接受任何参数的函数对象 |
| remove() | 删除区间中指定值的所有实例,并返回一个迭代器,该迭代器指向得到的区间的超尾 |
| remove_if() | 将断言对象返回true的值从区间中删除,并返回一个迭代器,该迭代器指向得到的区间的超尾 |
| remove_copy() | 将一个区间中的元素复制到另一个区间中,复制时忽略与指定值相同的元素 |
| remove_copy_if() | 将一个区间中的元素复制到另一个区间中,复制时忽略断言函数对象返回true的元素 |
| unique() | 将区间内两个或多个相同元素组成的序列压缩为一个元素 |
| unique_copy() | 将一个区间中的元素复制到另一个区间中,并将两个或多个相同元素组成的序列压缩为一个元素 |
| reverse() | 反转区间中的元素的排列顺序 |
| reverse_copy() | 按相反的顺序将一个区间中的元素复制到另一个区间中 |
| rotate() | 将区间中的元素循环排列,并将元素左转 |
| rotate_copy() | 以旋转顺序将区间中的元素复制到另一个区间中 |
| random_shuffle() | 随机重新排列区间中的元素 |
| partition() | 将满足断言函数对象的所有元素放在不满足断言函数对象的元素之前 |
| stable_partition() | 将满足断言函数对象的所有元素放置在不满足断言函数对象的元素之前,每组中元素的相对顺序保 持不变 |
下面详细地介绍这些修改型序列操作。对于每个函数,首先列出其原型,然后做简要的描述。正如前面介绍的,迭代器对指出了区间,而选择的模板参数名指出了迭代器的类型。通常,[first, last)区间指的是从first到last(不包括last)。作为参数传递的函数是函数对象,这些函数对象可以是指针,也可以是定义了()操作的对象。正如第16章介绍的,断言是接受一个参数的布尔函数,二元断言是接受两个参数的布尔函数(函数可以不是bool类型,只要它对于false返回0,对于true返回非0值)。另外,正如第16章介绍的,一元函数对象接受一个参数,而二元函数对象接受两个参数。
1.copy()

copy()函数将[first, last)区间中的元素复制到区间[result, result + (last - first)]中,并返回result + (last-first),即指向被复制到的最后一个位置后面的迭代器。该函数要求result不位于[first,last)区间中,也就是说,目标不能与源重叠。

copy_backward()函数将[first, last)区间中的元素复制到区间[result - (last - first), result)中。复制从last-1开始,该元素被复制到位置result-1,然后由后向前处理,直到first。该函数返回result -(last - first),即指向被复制到的最后一个位置后面的迭代器。
函数要求result不位于[first, last)区间中。不过,由于复制是从后向前进行的,因此目标和源可能重叠。
3.swap()
template<class T> void swap (T& a, T& b);
swap()函数对引用指定的两个位置中存储的值进行交换。
4.swap_ranges()

swap_ranges()函数将[first1, last1)区间中的值与从first2开始的区间中对应的值交换。这两个区间不能重叠。
5.iter_swap()

iter_swap()函数将迭代器指定的两个位置中存储的值进行交换。
6.transform()

第一个版本的transform()将一元函数对象op应用到[first, last)区间中每个元素,并将返回值赋给从result开始的区间中对应的元素。因此,result被设置为op(first),依此类推。该函数返回result + (last - first),即目标区间的超尾值。
第二个版本的transform()将二元函数对象op应用到[first1, last1)区间和[first2, last2)区间中的每个元素,并将返回值赋给从result开始的区间中对应的元素。因此,result被设置成op (first1, *first2),依此类推。该函数返回result + (last - first),即目标区间的超尾值。
7.replace()

replace()函数将[first, last)中的所有old_value替换为new_value。
8.replace_if()

replace_if()函数使用new_value值替换[first, last)区间中pred (old)为true的每个old值。
9.replace_copy()

replace_copy()函数将[first, last)区间中的元素复制到从result开始的区间中,不过它使用new_value代替所有的old_value。该函数返回result + (last - first),即目标区间的超尾值。
10.replace_copy_if()

replace_copy_if()函数将[first, last)区间中的元素复制到从result开始的区间中,不过它使用new_value代替pred (old)为true的所有old值。该函数返回result+ (last- first),即目标区间的超尾值。
11.fill()

fill()函数将[first, last)区间中的每个元素都设置为value。
12.fill_n()

fill_n()函数将从first位置开始的前n个元素都设置为value。
13.generate()

generator()函数将[first, last]区间中的每个元素都设置为gen(),其中gen是一个生成器函数对象,即不接受任何参数。例如,gen可以是一个指向rand()的指针。
14.generator_n()

generator_n()函数将从first开始的区间中前n个元素都设置为gen(),其中,gen是一个生成器函数对象,即不接受任何参数。例如,gen可以是一个指向rand()的指针。
15.remove()

remove()函数删除[first, last)区间中所有值为value的元素,并返回得到的区间的超尾迭代器。该函数是稳定的,这意味着未删除的元素的顺序将保持不变。
注意:由于所有的remove()和unique()函数都不是成员函数,同时这些函数并没有限制为只能用于STL容器,因此它们不能重新设置容器的长度。相反,它们返回一个指示新超尾位置的迭代器。通常,被删除的元素只是被移到容器尾部。不过,对于STL容器,可以使用返回的迭代器和erase()方法来重新设置end()。
16.remove if()

remove_if()函数将pred (val)为true的所有val值从[first, last)区间删除,并返回得到的区间的超尾迭代器。该函数是稳定的,这意味着未删除的元素的顺序将保持不变。
17.remove_copy()

remove_copy()函数将[first, last]区间中的值复制到从result开始的区间中,复制时将忽略value。该函数返回得到的区间的超尾迭代器。该函数是稳定的,这意味着没有被删除的元素的顺序将保持不变。
18.remove_copy_if()

OutputIterator result, Predicate pred);
remove_copy_if()函数将[first, last)区间中的值复制到从result开始的区间,但复制时忽略pred (val)为true的val。该函数返回得到的区间的超尾迭代器。该函数是稳定的,这意味着没有删除的元素的顺序将保持不变。
19.unique()

unique()函数将[first,last)区间中由两个或更多相同元素构成的序列压缩为一个元素,并返回新区间的超尾迭代器。第一个版本使用值类型的==操作符对元素进行比较;第二个版本使用二元断言函数对象pred来比较元素。也就是说,如果pred (it1, it2)为true,则it1和it2指向的元素是匹配的。
20.unique_copy()

unique_copy()函数将[first, last)区间中的元素复制到从result开始的区间中,并将由两个或更多个相同元素组成的序列压缩为一个元素。该函数返回新区间的超尾迭代器。第一个版本使用值类型的==操作符,对元素进行比较;第二个版本使用二元断言函数对象pred来比较元素。也就是说,如果pred(it1, it2)为true,则it1和it2指向的元素是匹配的。
21.reverse()

reverse()函数通过调用swap (first, last-1)等来反转[first, last)区间中的元素。
22.reverse_copy

reverse_copy()函数按相反的顺序将[first, last)区间中的元素复制到从result开始的区间中。这两个区间不能重叠。
23.rotate()

rotate()函数将[first,last)区间中的元素左旋。middle处的元素被移到first处,middle + 1处的元素被移到first + 1处,依此类推。middle前的元素绕回到容器尾部,以便first处的元素可以紧接着last - 1处的元素。
24.rotate_copy()

rotate_copy()函数使用为rotate()函数描述的旋转序列,将[first, last)区间中的元素复制到从result开始的区间中。
25.replace()

这个版本的random_shuffle()函数将[first, last)区间中的元素打乱。分布是一致的,即原始顺序的每种可能的排列方式出现的概率相同。
26.random_shuffle()

这个版本的random_shuffle()函数将[first,last)区间中的元素打乱。函数对象random确定分布。假设有n个元素,表达式random(n)将返回[0,n)区间中的一个值。
27.partition()

partition()函数将满足pred (val)为true的元素放在不满足该测试条件的所有元素之前。这个函数返回一个迭代器,该迭代器指向最后一个断言对象函数为true的值的后面。
28.stable_partition()

stable_partition()函数将满足pred (val)为true的元素放在不满足该测试条件的所有元素之前,这两组中元素的相对顺序保持不变。这个函数返回一个迭代器,该迭代器指向最后一个断言对象函数为true的值的后面。
G.4.3 排序和相关操作
表G.11对排序和相关操作进行了总结。其中没有列出参数,而重载函数也只列出了一次。每一个函数都有一个使用<对元素进行排序的版本和一个使用比较函数对象对元素进行排序的版本。表后做了更详细的说明,其中包括原型。因此,可以浏览该表,以了解函数的功能,如果对某个函数非常感兴趣,则可以了解其细节。
表G.11 排序和相关操作
本节中的函数使用为元素定义的<操作符或模板类型Compare指定的比较对象来确定两个元素的顺序。如果comp是一个Compare类型的对象,则comp(a,b)就是a<b的统称,如果在排序机制中,a在b之前,则返回true。如果a<b返回fasle,同时b<a也返回false,则说明a和b相等。比较对象必须至少提供严格弱排序功能(strict weak ordering)。这意味着:
● 表达式comp (a,a)一定为false,这是“值不能比其本身小”的统称(这是严格部分)。
● 如果comp (a,b)为true,且comp (b,c)也为true,则comp(a, c)为true(也就是说,比较是一种可传递的关系)。
● 如果a与b等价,且b与c也等价,则a与c等价(也就是说,等价也是一种可传递的关系)。
如果想将<操作符用于整数,则等价就意味着相等,但这一结论不能推而广之。例如,可以用几个描述邮件地址的成员来定义一个结构,同时定义一个根据邮政编码对结构进行排序的comp对象。则邮政编码相同的地址是等价的,但它们并不相等。
下面更详细地介绍排序及相关操作。对于每个函数,首先列出其原型,然后做简要的说明。我们将这一节分成几个小节。正如前面介绍的,迭代器对指出了区间,而选择的模板参数名指出了迭代器的类型。通常,[first,last]区间指的是从first到last(不包括last)。作为参数传递的函数是函数对象,这些函数对象可以是指针,也可以是定义了()操作的对象。正如第16章介绍的,断言是接受一个参数的布尔函数,二元断言是接受2个参数的布尔函数(函数可以不是bool类型,只要它对于false返回0,对于true返回非0值)。另外,正如第16章介绍的,一元函数对象接受一个参数,而二元函数对象接受两个参数。
1.排序
首先来看看排序算法。
(1) sort()

sort()函数将[first,last)区间按升序进行排序,排序时使用值类型的<操作符进行比较。第一个版本使用<来确定顺序,而第二个版本使用比较对象comp。
(2) stable_sort()

stable_sort()函数对[first,last)区间进行排序,并保持等价元素的相对顺序不变。第一个版本使用<来确定顺序,而第二个版本使用比较对象comp。
(3) partial_sort()

partial_sort()函数对[first,last)区间进行部分排序。将排序后的区间的前middle-first个元素置于[first,last]区间内,其余元素没有排序。第一个版本使用<来确定顺序,而第二个版本使用比较对象comp。
(4) partial_sort_copy()

partial_sort_copy()函数将排序后的区间[first, last)中的前n个元素复制到区间[result_first, result_first + n)中。n的值是last-first和result_last-result_first中较小的一个。该函数返回result-first + n。第一个版本使用<来确定顺序,第二个版本使用比较对象comp。
(5) nth element()

nth_element()函数找到将[first, last)区间排序后的第n个元素,并将该元素置于第n个位置。第一个版本使用<来确定顺序,而第二个版本使用比较对象comp。
2.二分法搜索
二分法搜索组中的算法假设区间是排序后的。这些算法只要求正向迭代器,但使用随机迭代器时,效率最高。
(1) lower bound()

lower_bound()函数在排序后的区间[first, last)中找到第一个这样的位置,即将value插入到它前面时不会破坏顺序。它返回一个指向这个位置的迭代器。第一个版本使用<来确定顺序,而第二个版本使用比较对象compo
(2) upper_bound()

upper_bound()函数在排序后的区间[first,last)中最后一个这样的位置,即将value插入到它前面时不会破坏顺序。它返回一个指向这个位置的迭代器。第一个版本使用<来确定顺序,而第二个版本使用比较对象comp。
(3) equal_range()

equal_range()函数在排序后的区间[first, last]区间中找到这样一个最大的子区间[it1,it2),即将value插入到该区间的任何位置都不会破坏顺序。该函数返回一个由it1和it2组成的pair。第一个版本使用<来确定顺序,第二个版本使用比较对象comp。
(4) binary_search()

如果在排序后的区间[first,last)中找到与value等价的值,则binary_search()函数返回true,否则返回false。第一个版本使用<来确定顺序,而第二个版本使用比较对象comp。
注意:由前所述,使用<进行排序时,如果a<b和b<a都为false,则a和b等价。对于常规数字来说,等价意味着相等;但对于只根据一个成员进行排序的结构来说,情况并非如此。因此,在确保顺序不被破坏的情况下,可插入新值的位置可能不止一个。同样,如果使用比较对象comp进行排序,等价意味着comp(a,b)和comp (b,a)都为false(这是“如果a不小于b,b也不小于a,则a与b等价”的统称)。
3.合并
合并函数假设区间是经过排序的。
(1) merge()

merge()函数将排序后的区间[first1, last1)中的元素与排序后的区间[first2, last2)中的元素进行合并,并将结果放到从result开始的区间中。目标区间不能与被合并的任何一个区间重叠。在两个区间中发现了等价元素时,第一个区间中的元素将位于第二个区间中的元素前面。返回值是合并的区间的超尾迭代器。第一个版本使用<来确定顺序,第二个版本使用比较对象comp。
(2) inplace_merge()

inplace_merge()函数将两个连续的、排序后的区间——[first, middle)和[middle,last)——合并为一个
经过排序后的序列,并将其存储在[first,last)区间中。第一个区间中的元素将位于第二个区间中的等价元素之前。第一个版本使用<来确定顺序,而第二个版本使用比较对象comp。
4.使用集合
集合操作可用于所有排序后的序列,包括集合(set)和多集合(multiset)。对于存储一个值的多个实例的容器(如multiset)来说,定义是广义的。对于两个多集合的并集,将包含较大数目的元素实例,而交集将包含较小数目的元素实例。例如,假设多集合A包含了字符串“apple”7次,多集合B包含该字符串4次。则A和B的并集将包含7个“apple”实例,它们的交集将包含4个实例。
(1) includes()

如果[first2, last2)区间中的每一个元素在[first1,last1)区间中都可以找到,则includes()函数返回true,否则返回false。第一个版本使用<来确定顺序,而第二个版本使用比较对象comp。
(2) set_union()

set_union()函数构造一个由[first1, last1)区间和[first2, last2)区间组合而成的集合,并将结果复制到result指定的位置。得到的区间不能与原来的任何一个区间重叠。该函数返回构造的区间的超尾迭代器。并集包含在任何一个集合(或两个集合)中出现的所有元素。第一个版本使用<来确定顺序,而第二个版本使用比较对象comp。
(3) set_intersection()

set_intersection()函数构造[first1,last1)区间和[first2, last2)区间的交集,并将结果复制到result指定的位置。得到的区间不能与原来的任何一个区间重叠。该函数返回构造的区间的超尾迭代器。交集包含两个集合中共有的元素。第一个版本使用<来确定顺序,而第二个版本使用比较对象comp。
(4) set_difference()


set_difference()函数构造[first1, last1)区间与[first2,last2)区间的差集,并将结果复制到result指定的位置。得到的区间不能与原来的任何一个区间重叠。该函数返回构造的区间的超尾迭代器。差集包含出现在第一个集合中,但不出现在第二个集合中的所有元素。第一个版本使用<来确定顺序,而第二个版本使用比较对象comp。
(5) set_symmetric_difference()

set_symmetric_difference()函数构造[first1, last1)区间和[first2, last2)区间的对称(symmetric)差集,并将结果复制到result指定的位置。得到的区间不能与原来的任何一个区间重叠。该函数返回构造的区间的超尾迭代器。对称差集包含出现在第一个集合中,但不出现在第二个集合中,或者出现在第二个集合中,但不出现在第一个集合中的所有元素。第一个版本使用<来确定顺序,第二个版本使用比较对象comp。
5.使用堆
堆(heap)是一种常用的数据形式,具有这样特征:第一个元素是最大的。每当第一个元素被删除或添加了新元素时,堆都可能需要重新排列,以确保这一特征。设计堆是为了提高两种操作的效率。
(1) make_heap()

make_heap()函数将[first, last)区间构造成一个堆。第一个版本使用<来确定顺序,而第二个版本使用comp比较对象。
(2) push_heap()

push_heap()函数假设[first,last - 1)区间是一个有效的堆,并将last-1位置(即被假设为有效堆的区间后面的一个位置)上的值添加到堆中,使[first, last)区间成为一个有效堆。第一个版本使用<来确定顺序,而第二个版本使用comp比较对象。
(3) pop_heap()

pop_heap()函数假设[first,last)区间是一个有效堆,并将位置last - 1处的值与first处的值进行交换,使[first,last-1)区间成为一个有效堆。第一个版本使用<来确定顺序,而第二个版本使用comp比较对象。
(4) sort_heap()

sort_heap()函数假设[first, last)区间是一个有效堆,并对其进行排序。第一个版本使用<来确定顺序,而第二个版本使用comp比较对象。
6.查找最小和最大值
最小函数和最大函数返回两个值或值序列中的最小值和最大值。
(1) min()

min()函数返回两个值中较小一个;如果这两个值相等,则返回第一个值。第一个版本使用<来确定顺序,而第二个版本使用comp比较对象。
(2) max()

max()函数返回这两个值中较大的一个;如果这两个值相等,则返回第一个值。第一个版本使用<来确定顺序,而第二个版本使用comp比较对象。
(3) min_element()

min_element()函数返回这样一个迭代器,该迭代器指向[first, last)区间中第一个最小的元素。第一个版本使用<来确定顺序,而第二个版本使用comp比较对象。
(4) max_element()

max_element()函数返回这样一个迭代器,该迭代器指向[first, last)区间中第一个最大的元素。第一个版本使用<来确定顺序,而第二个版本使用comp比较对象。
(5) lexicographical_compare()

如果[first1, last1)区间中的元素序列按字典顺序小于[first2, last2)区间中的元素序列,则lexico-graphical_compare()函数返回true,否则返回false。字典比较将两个序列的第一个元素进行比较,即对first1和first2进行比较。如果first1小于first2,则该函数返回true;如果first2小于first1,则返回fasle;如果相等,则继续比较两个序列中的下一个元素。直到对应的元素不相等或到达了某个序列的结尾,比较才停止。如果在到达某个序列的结尾时,这两个序列仍然是等价的,则较短的序列较小。如果两个序列等价,且长度相等,则任何一个序列都不小于另一个序列,因此函数将返回false。第一个版本使用<来比较元素,而第二个版本使用comp比较对象。字典比较是按字母顺序比较的统称。
7.排列组合
序列的排列组合(Permutation)是对元素重新排序。例如,由3个元素组成的序列有6种可能的排列方式,因为对于第一个位置,有3种选择;给第一个位置选定元素后,第二个位置有两种选择;第三个位置有1种选择。例如,数字1、2和3的6种排列如下:
123 132 213 231 312 321
通常,由n个元素组成的序列有n(n-1) …1或n!种排列。
排列函数假设按字典顺序排列各种可能的排列组合,就像前一个例子中的6种排列那样。这意味着,通常,在每个排列之前和之后都有一个特定的排列。例如,213在231之前,312在231之后。不过,第一个排列(如范例中的123)前面没有其他排列,而最后一个排列(321)后面没有其他排列。
(1) next_permutation()

next_permutation()函数将[first, last)区间中的序列转换为字典顺序的下一个排列。如果下一个排列存在,则该函数返回true;如果下一个排列不存在(即区间中包含的是字典顺序的最后一个排列),则该函数返回false,并将区间转换为字典顺序的第一个排列。第一个版本使用<来确定顺序,而第二个版本则使用comp比较对象。
(2) prev_permutation()

previous_permutation()函数将[first, last)区间中的序列转换为字典顺序的前一个序列。如果前一个排列存在,则该函数返回true;如果前一个序列不存在(即区间包含的是字典顺序的第一个排列),则该函数返回false,并将该区间转换为字典顺序的最后一个排列。第一个版本使用<来确定顺序,而第二个版本则使用comp比较对象。
G.4.4 数字操作
表G.12对数字操作进行了总结,这些操作是由头文件numeric描述的。其中没有列出参数,而重载函数也只列出了一次。每一个函数都有一个使用<对元素进行排序的版本和一个使用比较函数对象对元素进行排序的版本。表后做了更详细的说明,其中包括原型。因此,可以浏览该表,以了解函数的功能;如果对某个函数非常感兴趣,则可以了解其细节。
表G.12 数字操作
| 函 数 | 描 述 |
| accumulate() | 计算区间中的值的总和 |
| inner_product() | 计算两个区间的内部乘积 |
| partial_sum() | 将使用一个区间计算得到的小计复制到另一个区间中 |
| adjacent_different() | 将使用一个区间的元素计算得到的相邻差集复制到另一个区间中 |
下面详细地介绍这些数字操作。对每个函数,首先列出其原型,然后做简要的描述。
1.accumulate()

accumulate()函数将acc的值初始化为init,然后按顺序对[first, last)区间中的每一个迭代器i执行acc = acc + i(第一个版本)或acc = binary_op (acc, i)(第二个版本)。然后返回acc的值。
2.inner_product()

inner_product()函数将acc的值初始化为init,然后按顺序对[first1, last1)区间中的每一个迭代器i和[first2, first2 + (last1 - first1))区间中对应的迭代器j执行acc = i**j(第一个版本)或 acc = binary_op(i, *j)(第二个版本)。也就是说,该函数对每个序列的第一个元素进行计算,得到一个值,然后对每个序列中的第二个元素进行计算,得到另一个值,依此类推,直到到达第一个序列的结尾(因此,第二个序列至少应同第一个序列一样长)。然后,函数返回acc的值。
3.partial_sum()

partial_sum()函数将first赋给result,将first+ (first+1)赋给 (result + 1)(第一个版本),或者将binary_op (first, (first + 1))赋给 (result+1)(第二个版本),依此类推。也就是说,从result开始的序列的第n个元素将包含从first开始的序列的前n个元素的总和(或binary_op的等价物)。该函数返回结果的超尾迭代器。该算法允许result等于first,也就是说,如果需要,该算法允许使用结果覆盖原来的序列。
4.djacent_difference()

adjacent_difference()函数将first赋给result (result = first)。目标区间中随后的位置将被赋值为源区间中相邻位置的差集(或binary_op等价物)。也就是说,目标区间的下一个位置(result+1)将被赋值为 (first + 1) - first(第一个版本)或binary_op( (first+1), * first)(第二个版本),依此类推。该函数返回结果的超尾迭代器。该算法允许result等于first,也就是说,如果需要,该算法允许结果覆盖原来的序列。
