第4章 视频编码标准简介
4.1 视频编码发展简史
1984年CCITT第15研究组发布了数字基群电视会议编码标准H.120建议。1988年CCITT通过了“p×64kbit/s(p=1,2,3,4,5,…,30)”视像编码标准H.261建议,被称为视频压缩编码的一个里程碑。从此,ITU-T、ISO等公布的基于波形的一系列视频编码标准的编码方法都是基于H.261中的混合编码方法。
1986年,ISO和CCITT成立了联合图像专家组(JPEG,Joint Photographic Experts Group),研究连续色调静止图像压缩算法国际标准,1992年7月通过了JPEG标准。
1988年ISO/IEC信息技术联合委员会成立了活动图像专家组(MPEG,Moving Picture Expert Group)。1991年公布了MPEG-1视频编码标准,码率为1.5Mbit/s,主要应用于家用VCD的视频压缩;1994年11月,公布了MPEG-2标准,用于数字视频广播(DVB)、家用DVD的视频压缩及高清晰度电视(HDTV)。码率从4Mbit/s、15Mbit/s直至100Mbit/s,分别用于不同档次和不同级别的视频压缩中。
1995年,ITU-T推出H.263标准,用于低于64kbit/s的低码率视频传输,如PSTN信道中可视会议、多媒体通信等。1984年和2000年又分别公布了H.263+、H.263++等标准。
1998年11月,ISO/IEC通过了“视听对象的编码标准”——MPEG-4,它除了定义视频压缩编码标准外,还强调了多媒体通信的交互性和灵活性。
2000年3月,联合图像专家组JPEG推出了JPEG2000标准。JPEG2000是基于小波变换的图像压缩标准,JPEG2000通常被认为是未来取代JPEG的下一代静止图像压缩标准。JPEG2000文件的扩展名通常为“.jp2”。
2003年3月,ITU-T和ISO/IEC正式公布了H.264视频压缩标准,不仅显著提高了压缩比,而且具有良好的网络亲和性,加强了对IP网、移动网的误码和丢包的处理。有人将H.264称为新一代的视频编码标准。本书也将重点介绍该标准。
2002年,我国成立数字音视频编解码技术标准AVS专家组,先后完成AVS标准的第一部分(系统)和第二部分(视频)的草案最终稿。2006年3月正式获颁为国家标准并开始实施。
4.2 H.261标准
由于会议电视和可视电话的需要,CCITT发布了码率为p×64kbit/s(p=1,2,3,4,5,…,30)的H.261建议,这个视频编码方案对以后各种视频编码标准产生了深远影响,直至今天。
4.2.1 图像格式
H.261用于视频通信,仍面临多个国家之间的互通问题,不同国家采用不同的彩电制式,不可能直接互通。H.261采用一种公共中间格式(CIF,Common Intermediate Format),不论何种彩色格式,发送方先把自己国家的彩电制式转换成CIF格式,经H.261编码后再由CIF格式转换到接收方彩电制式,见表4.1。
表4.1 CIF图像格式
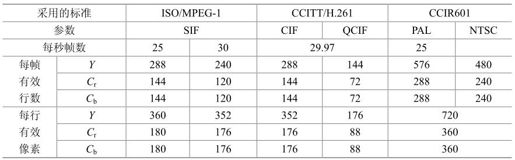
为了便于比较,表4.1中列出了CCIR601规定的两种常用PAL和NTSC彩电制式的图像格式,它并不属于CIF格式。表中SIF(Source Input Format)格式用于MPEG-1。
采用CIF及QCIF格式时,视频信号的结构采用如图4.1所示的图像、块组(GOB,Group Of Block)、宏块(MB,MacroBlock)、块(B,Block)四级结构。每帧CIF图像由2个GOB组成,每个GOB由33个MB组成,每个MB由4个亮度块和1个Cr块及1个Cb块组成,每个块(B)又由8×8像素构成。每帧QCIF图像由3个GOB组成。
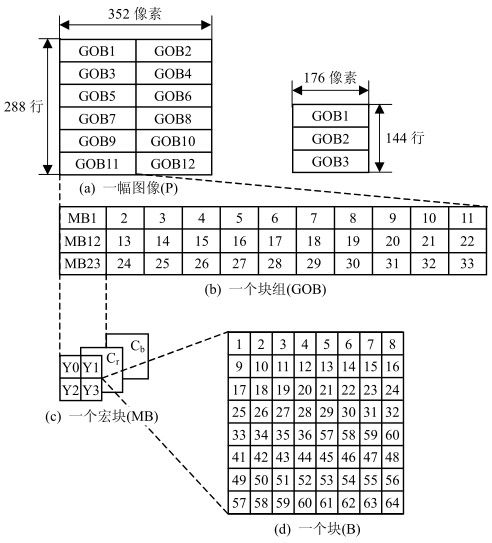
图4.1 CIF及QCIF结构
不论CIF还是QCIF格式帧都为29.97帧/秒≈30帧/秒,如果每像素的量化取8bit,彩色格式取4∶2∶0,码率分别为:
CIF:352×288×8×30×1.5=36.5(Mbit/s)
QCIF:176×144×8×30×1.5=9.1(Mbit/s)
显然,这样高的码率如果不经过视频压缩编码,要通过ISDN的64kbit/s~2.048Mbit/s信道是不可能的。
4.2.2 H.261视频编解码器
1.H.261编解码器系统
H.261视频编解码器结构如图4.2所示。其中,视频信源编码器用于视频信号的码率压缩,主要采用混合编码方法;视频复合编码器将每帧图像数据编排成四层结构,并通过熵编码对视频数据进一步压缩输出;传输缓冲器和码率控制器用于保证输出码流尽可能稳定;传输编码器则用于视频数据的误码检测和纠正。解码器各部分功能与编码器相反。
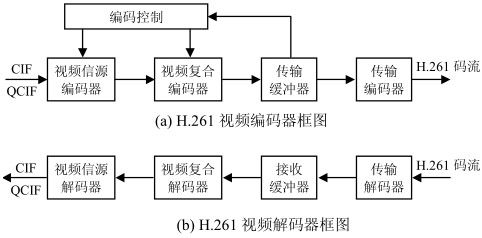
图4.2 H.261视频编解码器框图
2.视频信源编码器
视频信源编码器结构框图如图4.3所示,输入以MB为单位。
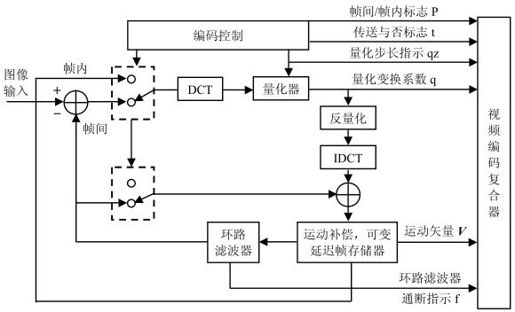
图4.3 H.261信源编码器
(1)帧间编码和帧内编码自动判决准则
一般可根据帧间相关性判定,相关性大则采用帧间编码,否则用帧内编码。帧间相关性可用当前帧与过去帧的对应像素差的均方值表示:
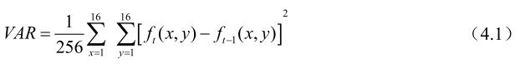
VAR越小相关性越大。当VAR≤64时,采用帧间模式;VAR>64时,一般可采用帧内模式。但如果帧内运动小,而过去帧的方差大(部分像素值变化大),也会导致残差较大,这时可以采用帧间编码处理,即当VAR>64,但σt+12≥VAR时采用帧间编码。
其中,有
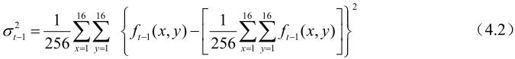
在H.261中对此并未作出规定。
(2)帧间编码与运动估计
如按上述判决规则采用帧间编码,则需引入以宏块为基础的运动补偿预测编码。当过去帧与当前帧的宏块匹配时,求出该亮度宏块的运动矢量Vx和Vy,分别表示过去帧的最佳匹配宏块比当前帧的宏块右移Vx个像素及下移Vy个像素,构成当前帧的亮度预测帧;色度块则作Vx/2和Vy/2位移,组成当前色度预测帧。接着将相应的当前帧块和预测帧块相减,得到帧误差信号(残差信号),再对此帧误差信号进行DCT变换、量化后传送到复合编码器。
量化后信号经过反量化的残差图像,如不计量化失真,与预测图像相加得到恢复的原始图像,存入帧存储器。每个宏块的原始图像都存入帧存储器,直到一帧中所有宏块残差都发完。于是当前帧存满ft(x, y),并作为下一帧ft+1(x, y)的参考图像。
(3)帧内编码
如上述判决准则,采用帧内编码,帧内/帧间开关向上。ft(x, y)直接经DCT,变换系数经过量化送入视频复合编码器。
(4)环路滤波器
由于利用运动补偿方法得出预测图像,宏块匹配可能不准确,导致宏块的运动矢量不准确及方块效应出现,最终产生伪轮廓等高频成分,大大影响了图像质量。为此需设置环路滤波器保证图像质量。环路滤波器实质上是一个FIR低通滤波器,把一些不必要的高频虑去。
3.视频复合编码器
针对图4.1中四层的视频数据结构,视频复合编码器对量化后的视频数据进行变长编码(直流系数用定长编码),并插入一些辅助数据(如帧首、块组首、宏块首等),得到复合编码图像数据结构,如图4.4所示。
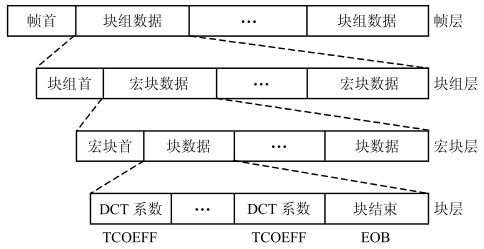
图4.4 图像复合编码数据结构
各层数据简要说明如下:
(1)帧层,帧首包括帧起始码(PSC)、帧计数码(TR)、帧类型信息码(PTYPE)及备用插入信息码等;
(2)块组层,块组首包括块组起始码(GBSC)、块组编号码(GN)、块组量化步长(GQOANT)、备用插入信息等;
(3)宏块层,由6个块组成,包括4个亮度块和两个色度块,宏块首包括宏块地址码(MBA)、宏块类型码(MTYPE)、宏块量化步长码(MQUANT)、运动矢量数据(MVD)、编码模式(CBP)等,CBP说明各块中数据数;
(4)块层,各块(8×8)的DCT系数按图4.5所示的Zig-Zag(之字形)扫描,将像素排成一维序列并进行熵编码(变长编码),每块结束时用EoB结束符作为块结束。
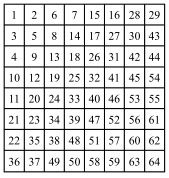
图4.5 之字形扫描
4.传输缓冲器
为使输出码率基本恒定,可采用缓冲器控制并调整帧亚速率、改变量化步长等。
在H.261中,建议缓存器容量B应满足下式:

其中,R为信道速率,fF为帧频。
例:在会议电视中,如R=2.048Mbit/s,fF=30帧/秒,则B≥(4×2048/30+256)kbit=529kbit=66.1KB,实际取96KB为缓存容量。
5.传输编码器
H.261中规定使用BCH码纠正信道中的误码,其码长n=511bit,其中信息码493bit,即采用BCH(511,493)纠错码。
由于:

将n=511,k=493代入,得m=9,t=2,即可以纠正2bit误码。
如图4.6所示为纠错数据帧结构,每个数据帧由R=483bit信息码,再加1bit同步码构成。一个数据帧共有512bit。8个数据帧构成一个帧群,帧首中同步码为1bit,规定S1S2S3…S8=00011011。
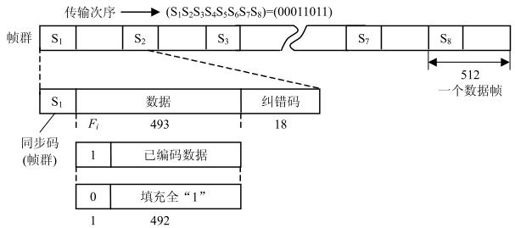
图4.6 纠错数据帧结构
解码器结构如图4.7所示,其原理与编码器相反,这里不再重述。
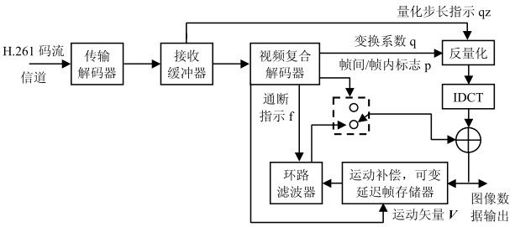
图4.7 解码器框图
4.3 H.263标准
4.3.1 H.263标准图像格式
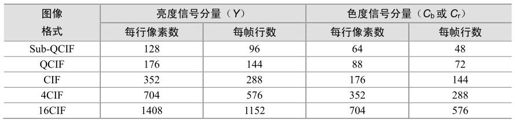
H.263共有五种图像格式,见表4.2。
表4.2 H.263标准图像格式
彩色格式取4∶2∶0,亮度、色度取样位置如图4.8所示。
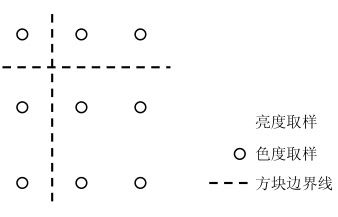
图4.8 亮度、色度取样位置
对于Sub-QCIF、QCIF、CIF格式,每个块组(GOB)均为16行。4CIF每一块组32行,16CIF每一块组64行。Sub-QCIF、QCIF、CIF、4CIF、16CIF含有的块组数分别为6、9、18、18、18。
QCIF图像得GOB如图4.9所示。每个宏块由4个8×8亮度块和2个8×8色度块组成。对于Sub-QCIF、QCIF、CIF格式,每个GOB垂直方向有一个宏块行,水平方向分别有8、11、22个宏块;对于4CIF和16CIF,垂直方向分别有2个及4个宏块行,水平方向分别有44个和88个宏块。

图4.9 QCIF图像GOB编号
4.3.2 H.263视频信源编码算法
H.263的视频信源编码框图与H.261相同,信源编码方法也类似,不同的是H.263的输入有多种格式,输出为H.263码流。传输码率最初定为低于64kbit/s,但实际上其应用范围已远远超出低码率图像编码范围,也适于高速率图像编码。
为了适应低码率传输要求,并进一步提高图像质量,H.263+、H.263++做了不少改进,增加了若干选项,现选择主要技术介绍。
(1)运动矢量。H.263中1个MB可以使用1个运动矢量表示,也可以4个8×8块各使用1个运动矢量表示,以提高运动估计精确性和压缩比(H.261规定每个MB使用1个运动矢量)。
(2)半像素预测。H.263为了进一步提高压缩比,采用半像素预测,而H.261采用整像素预测,预测精度明显低于H.263。
(3)二维预测。H.263采用二维预测,H.261采用一维预测。
(4)非限制的运动矢量模式(选项)。H.263的运动矢量范围允许指向图像帧之外。
(5)基于句法的算术编码(选项)。显著降低了码率,但复杂度比哈夫曼编码高。
(6)高级预测模式(选项)。H.263除可以采用每个8×8块1个运动矢量,每个16×16宏块4个运动矢量外,还采用OBMC运动补偿方式,以减少方块效应。
(7)PB帧模式(选项)。PB帧由1个P帧和1个B帧组成,P帧由前一帧预测而得,B帧由双向(前向和后向)预测而得,分别用前向MV、后向MV、前后向MV平均进行运动补偿得到3个预测误差,取其最小者作为B帧的预测误差进行编码。
4.4 MPEG-1标准
4.4.1 功能
其功能主要有:
①视频压缩编码,压缩后码率为1.5Mbit/s,可用于视频传输和视频存储,编码前必须将视频图像转换成逐行扫描图像;
②录像机的正放、图像冻结、快进、快退和慢放功能以及随机存储功能。
4.4.2 图像类型和编码结构
1.MPEG-1的图像类型
MPEG-1定义了3种图像类型:I、P、B图像。I图像即帧内(Intra)图像,采用帧内编码,不参考其他图像,但可作为其他类型图像的参考帧。P图像即预测(Predicted)图像,采用帧间编码,参考前一幅I或P图像,用作运动估计。B图像即双向预测(Bi-predicted)图像,参考前后两个方向图像。I、P、B图像之间的显示顺序如图4.10所示,其编码顺序为1、4、2、3、7、5、6。
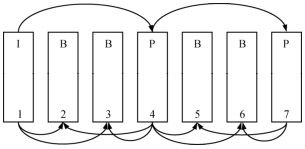
图4.10 I、P、B图像显示顺序
双向预测编码可解决“暴露”问题,即某物体在前一帧未显示出来,但在后一帧却先“暴露”出来,双向预测能更准确地找出运动矢量,并只有在视频存储、VOD等非实时通信及数字广播电视中才应用。会议电视、可视电话等实时通信中不宜应用B图像,因为实时通信后一帧处在当前帧之后,当前帧编码时它尚未出现,若应用B图像势必会引入较大的编解码时延。
2.MPEG-1编码结构
MPEG-1编码结构类似H.261,也采用分层结构,但有所不同,如图4.11所示。MPEG-1多出片层(切片或Slice层),用于防止误码在一帧内扩散。
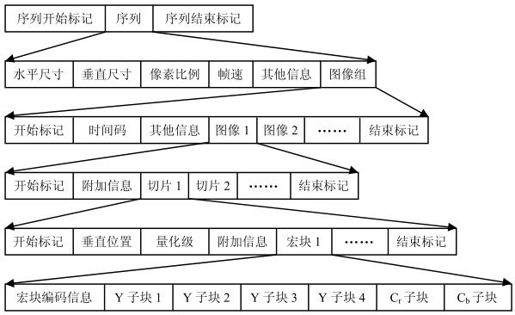
图4.11 MPEG-1编码层次结构
3.视频编码器
和H.261并无多大区别,但需考虑双向预测编码和解码。解码时先将恢复的图像存在缓存中,在显示时按顺序显示。
4.5 MPEG-2标准
MPEG-2标准包括系统、视频、音频及符合性(检验和测试视音频及系统码流)4个文件。
4.5.1 MPEG-2编码复用系统
MPEG-2码流分为三层,即基本比特流(ES,Elementary Bit Stream)、分组基本码流(PES,Packet Elementary Stream)和复用后的传送码流(TS,Transport Stream)、节目码流(PS,Program Stream)。其编码复用系统结构如图4.12所示。
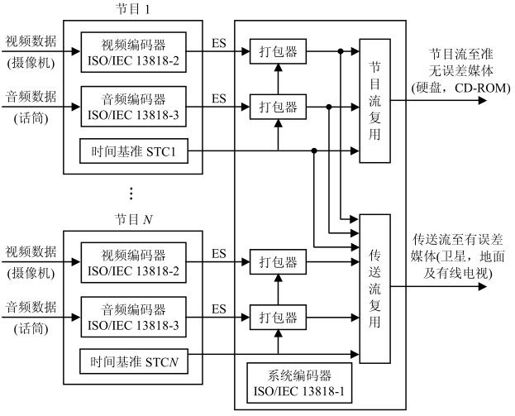
图4.12 MPEG-2编码复用系统
ES:由视频压缩编码后的视频基本码流(Video ES)和音频压缩编码后的音频基本码流(Audio ES)组成。
PES:把视音频ES分别打包,长度可变,最长为216字节。
TS、PS:若干个节目的PES复用后输出为传输流TS和节目流PS,分别用于传输和存储。
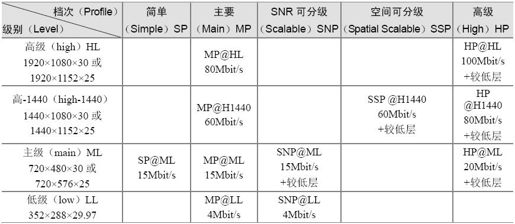
4.5.2 MPEG-2档次和级别
MPEG-2按不同的压缩比分成五个档次,按视频清晰度分为四个级别,如表4.3所示。共有20种组合,最常用的有11种组合,分别用于标准数字电视、高清晰度电视,码率为4~100Mbit/s。
表4.3 MPEG-2档次和级别
4.5.3 MPEG-2视频编码器
1.框图
MPEG-2编、解码器结构与H.261区别不大,如图4.13和图4.14所示。
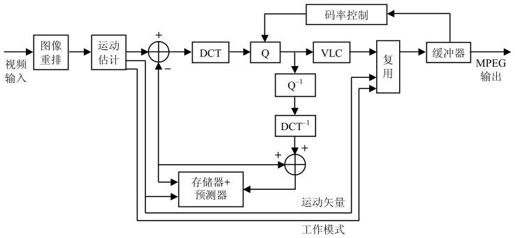
图4.13 MPEG-2编码器
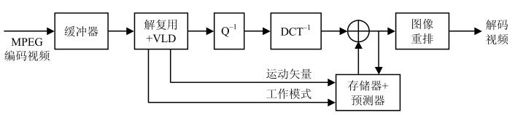
图4.14 MPEG-2解码器
2.ES码流结构
ES码流采用图像序列(PS)、图像组(GOP)、图像(P)、片(Slice)、宏块(MB)、块(B)六层结构,具体结构如图4.15所示。
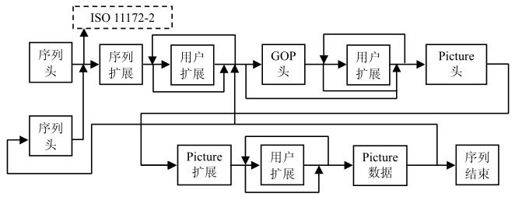
图4.15 ES码流结构
(1)图像序列层。图像序列包括若干GOP,序列头包含起始码和序列参数,如档次、级别、彩色图像格式、帧场选择等。
(2)图像组层。图像组包含若干幅图像,组头包含起始码、GOP标志等,如视频磁带记录器时间、控制码、B帧处理码等。
(3)图像层。一幅图像包含若干片,头信息中有起始码、P标志,如时间、参考帧号、图像类型、MV、分级等。
(4)片层。片是最小的同步单位,包含若干宏块,片头中有起始码、片地址、量化步长等。
(5)宏块层。宏块由4个8×8亮度块和2个色度块组成,宏块头包括宏块地址、宏块类型、运动矢量等。
3.基于帧或场的DCT编码
MPEG-2可用于逐行扫描图像,也可用于隔行扫描图像。对逐行扫描图像,可按行分割成块,基于块进行DCT变换;对逐行扫描图像,一帧由两场组成,于是就有基于帧的分割和基于场的分割两种宏块结构,如图4.16所示。
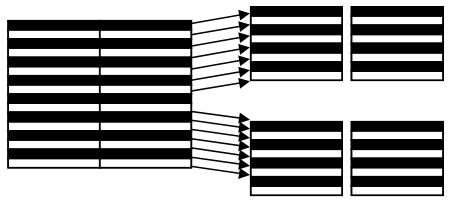
图4.16 按帧分割进行DCT变换的亮度宏块结构
同一帧内各邻近行之间的空间相关性比同一场内各邻近行之间的空间相关性要强。因此,基于帧的DCT编码适用于相对静止或慢运动的景物。
同一场内各邻近行之间的时间相关性比同一帧内各邻近行之间的时间相关性要强(因为同一帧内当前行的下一行要等到一场扫描完后才出现在当前行之下,时间相关性弱),基于场的DCT编码适用于运动快的景物。
根据帧的行间相关系数和场的行间相关系数,可判定采用帧分割还是场分割进行编码。
4.分层服务
为了适应信道的变化和扩大应用范围,MPEG-2采用三种分级编码:空间域分级、时间域分级和信噪比分级。
以空间域分级为例,用户接收HDTV信号时,丢弃一部分解码中的SDTV信号,也可再丢弃一部分解出CIF甚至QCIF信号。这种分级可为不同用户提供不同质量的服务。
4.6 MPEG-4标准
MPEG-4于1998年11月被ISO/IEC批准为国际标准,其正式标准编号是ISO/IEC 14496。与MPEG-1和MPEG-2标准相比,MPEG-4更加注重多媒体系统的交互性和灵活性,主要应用于可视电话、视频会议等。
MPEG-4的主要特点如下:
(1)对于不同的对象可采用不同的编码算法,从而进一步提高压缩效率;
(2)对象各自相对独立,提高了多媒体数据的可重用性;
(3)允许用户对单个的对象操作,提供前所未有的交互性;
(4)允许在不同的对象之间灵活分配码率,对重要的对象可分配较多的字节,对次要的对象可分配较少的字节,从而能在低码率下获得较好的效果;
(5)可以方便地集成自然音视频对象和合成音视频对象。
4.6.1 MPEG-4标准构成
MPEG-4标准由一系列的子标准组成,即由若干部分组成。主要包括6个部分,如表4.4所示。此外,MPEG-4标准还包括MPEG-4的参考软件、基于IP架构的MPEG-4参考硬件以及高级视频编码标准(AVC,Advanced Video Coding)等,AVC就是H.264视频编码标准。
表4.4 MPEG-4的6部分
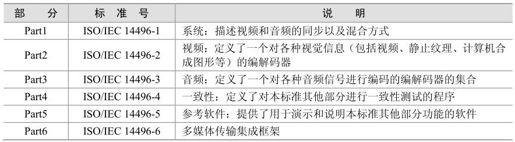
MPEG-4码流主要包括基本码流和系统流。基本码流包括音视频和场景描述的编码流表示,每个基本码流只包含一种数据类型,并通过各自的解码器解码;系统流则指定了根据编码视听信息和相关场景描述信息产生交互方式的方法,并描述其交互通信系统。
1.系统
MPEG-4系统把音视频对象及其组合复用成一个场景,提供与场景互相作用的工具,使用户具有交互能力。MPEG-4的数据在3个层中进行传输,这3层分别是压缩层、同步层和传输层。其中,压缩层是执行媒体解码的系统组件,接收从同步层传来的压缩数据,并完成解码操作。同步层负责各个压缩媒体的同步和缓冲,一方面接收来自传输层的同步层数据包(SL),从流中提取同步数据,为以后的同步解码和基本流解码的合成做准备;另一方面,实现压缩的数据流和同步信息封装层的同步数据包,并将它们传输到传输层。传输层完成各种传输协议的描述,使用DMIF应用接口,通过接口定义数据流的传输接口,并定义信道建立和断开的信号。MPEG-4的系统终端模型如图4.17所示。
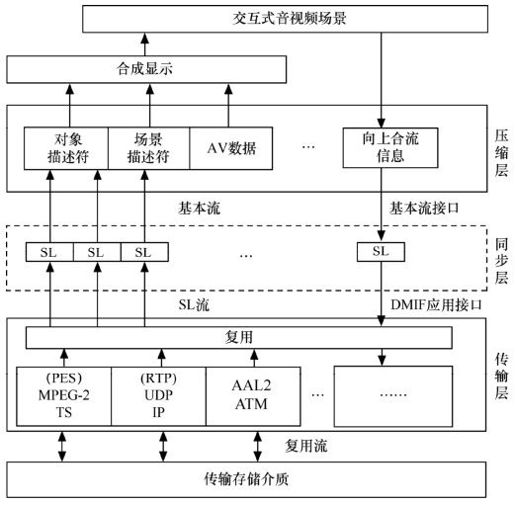
图4.17 MPEG-4终端模型
2.音频
与MPEG-1、MPEG-2相比,MPEG-4不仅支持自然声音(如语音和音乐),还支持合成声音(如MIDI)。MPEG-4音频部分将音频的合成编码和自然声音的编码相结合,并支持音频的对象特征。
MPEG-4研究比较了现有的各种音频编码算法,支持2~64kbit/s的自然声音编码。如8kHz采样频率的2~4kbit/s的语音编码,以及8kHz或16kHz采样频率4~16kbit/s的语音编码,一般采用参数编码;而6~24kbit/s的语音编码,一般采用码激励线性预测(CELP,Code Excited Linear Predictive)编码技术;而16kbit/s以上码率的编码,则采用视频变换编码技术。这些技术实质上借鉴了G.723、G.728以及MPEG-1和MPEG-2等。图4.18给出了MPEG-4音频支持2~64kbit/s信道语音编码范围。
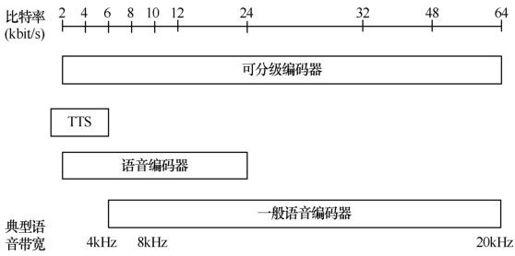
图4.18 MPEG-4音频支持语音编码范围
MPEG-4引入两个有力的编码技术:文本到语音编码(TTS,Text-to-Speech)和乐谱驱动合成语音编码。事实上,合成语音编码技术是一种基于知识库的参数编码技术。乐谱驱动合成技术中,解码器由一种特殊的合成语言——结构化音频管弦乐团语言(SAQL,Structured Audio Orchestra Language)驱动。“管弦乐团”由不同“乐器”组成,解码器不具有某“乐器”时,MPEG-4还允许解码器从编码器下载该“乐器”,以恢复合成声音。
3.视频
MPEG-4支持对自然和合成视觉对象的编码。合成的视觉对象包括2D、3D动画和人面部表情动画等。对于静止图像,MPEG-4采用零树小波算法(Zerotree Wavelet Algorithm),以提高压缩比,同时还提供多达11级的空间分辨率和质量的可伸缩性。对于运动视频对象的编码,MPEG-4的编码结构如图4.19所示,包括:形状编码、运动补偿和纹理编码。其中的主要技术是运动估计补偿、DCT变换(标准的8×8DCT或自适应DCT)和混合DPCM(差分脉冲编码)等。
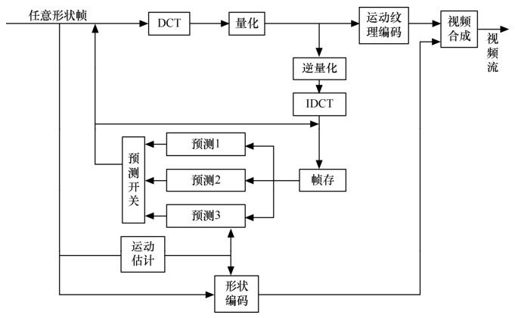
图4.19 MPEG-4视频编码框架
4.6.2 基于VOP的视频编码
与基于块的传统视频编码标准(如H.26x、MPEG-1/MPEG-2)不同,MPEG-4标准通过分析图像信息的本质,从轮廓、纹理的思路出发,支持基于视觉内容的交互。MPEG-4创新地提出了基于视频对象(VO,Video Object)的思想。为此,MPEG-4引入了视频对象平面(VOP,Video Object Plane)的概念,在这一概念中,根据人眼感兴趣的一些方面,如形状、运动和纹理等,将图像序列中每个时刻的场景,也就是每一帧,看成由不同VOP所组成。而同一对象连续的VOP称为视频对象(VO)。VO可以表示矩形帧(以兼容传统的标准),也可以是场景中某一物体或某一层面,即画面中被分割出来的不同物体。每个VO由3类信息来描述:运动信息、形状信息和纹理信息。
图4.20为MPEG-4基于内容视频编码方法的简化原理图。编解码都是针对VOP进行的,编码时,输入的图像序列首先进行图像对象分割形成各个VOP,然后针对每个VOP分别进行编码,最后将所有的VOP编码合成一个视频数据流进行传输。解码是编码的逆过程。

图4.20 VOP视频编码框图
图4.21和图4.22分别为VOP的编码结构图和解码结构图。VOP编解码器主要由两部分组成:形状编解码和传统运动纹理编解码。重构的VOP由形状、纹理和运动信息正确组合而成。
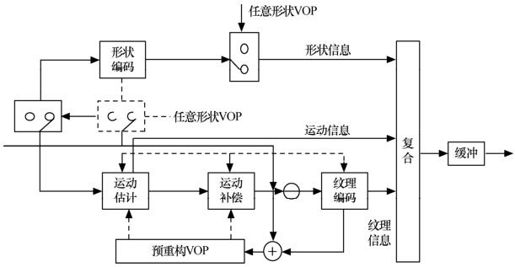
图4.21 VOP编码结构
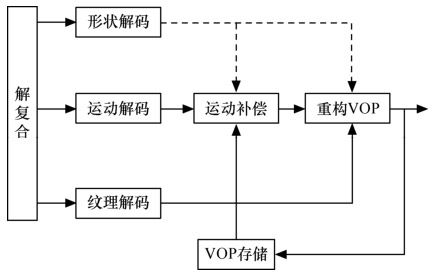
图4.22 VOP解码结构
1.MPEG-4的层次结构
MPEG-4通过层次结构进行管理,层次结构分别由视频对象面、视频对象组、视频对象层、视频对象和视频场景组成。层次逻辑结构如图4.23所示。
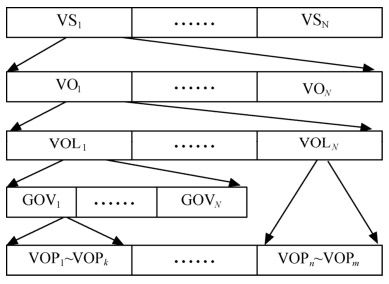
图4.23 MPEG-4视频数据流结构
其中,视频对象(VO,Video Object)如前所述,为场景中的某个物体,有生命期,由时间上连续的许多帧构成;视频对象平面(VOP,Video Object Plane)可看作VO在某一时刻的表示,即某一帧;视频对象平面组(GOV,Group of VOP)提供视频流的标记点,标记VOP单独解码的时域位置,也就是对视频流任意访问的标记;视频对象层(VOL,Video Object Layer)用于扩展VO的时域和空域分辨率,包含VO的3种属性信息;几个视频场景(VS,Video Session)组成一个完整的视频序列。
2.VOP的编码技术
(1)形状编码
编码的形状信息有两类:二值形状信息和灰度级形状信息。二值形状信息用0和1表示编码VOP形状的信息,0表示非VOP区域,1表示VOP区域;灰度级形状信息可取值0~255,0表示非VOP区域(即透明区域),1~255表示透明度不同的区域,255表示完全不透明。灰度级形状信息的引入主要为了使前景物体叠加到背景上时,边界不至于太明显、生硬,进行“模糊”处理。灰度形状信息的编码采用基于块的运动补偿DCT方法,属于有损编码。MPEG-4采用位图法表示这两种形状信息。VOP被一个“边框”框住,如图4.24所示,边框长和宽均为16的整数倍,同时保证边框最小。
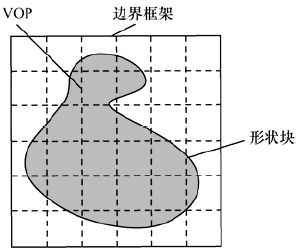
图4.24 VOP形状编码
(2)运动估计和运动补偿
与以前的视频编码标准类似,MPEG-4仍采用运动预测和运动补偿技术消除图像信息的时间冗余度。MPEG-4的VOP也有3种帧格式:I-VOP、P-VOP、B-VOP,如图4.25所示。在MPEG-4中运动预测和运动补偿可以基于16×16宏块或8×8块。MPEG-4运动估计与补偿与H.263类似,采用了“重叠运动补偿”。为了适应任意形状的VOP,还引入了图像填充(Image Padding)技术和多边形匹配(Polygon Matching)技术。此外,MPEG-4还采用8参数运动模型来进行全局运动补偿。
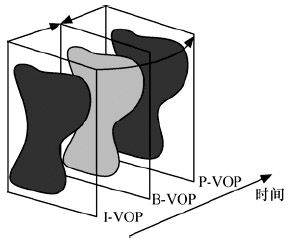
图4.25 VOP帧编码类型
(3)纹理编码
纹理信息编码对象既可以是帧内编码模式I-VOP,也可以是帧间编码模式P-VOP或B-VOP的运动补偿后的预测误差。编码方法上基本采用分块的的DCT方法。
DCT变换基于8×8,有3种情况:VOP外和边框内的块不编码;VOP内的块采用传统DCT方法编码;部分在VOP内、部分在VOP外的块先进行重复填充,再进行DCT编码。这样增加了块内数据的空间相关性,有利于DCT变换和量化去除块内的空间冗余。
DCT系数要经量化、Z扫描、游程及哈夫曼熵编码。量化有两种选择:类似于H.263用一个量化参数表征块内所有AC系数,这个值可根据质量要求和目标码率的变化而变化;或类似于MPEG-2用量化矩阵。
(4)分级扩展编码
MPEG-4的一个重要功能是能够利用VOL结构来实现空域和时域的分级扩展。当一个位流中至少存在一个子集能够产生一种有用的表示,则认为这个位流可分级。而视频分级扩展编码就是指可以产生一种编码表示,可支持多于一种的分辨率和质量。每一种分级编码至少都有两个VOL:一个是基本层,一个是增强层。一般来讲。空域分级就是用增强层来增加基本层的空域分辨率;时域分级就是由增强层来增加基本层中感兴趣区域的时域分辨率,即帧率。
4.6.3 MPEG-4档次和级别
MPEG-4 Visual通过工具、对象和档次的联合提供其编码函数。工具是一些支持某一特定特征(如基本视频编码、编码对象形状等)的编码函数集合。对象是利用工具编码的视频元素(如矩形帧、静态图像等)。举个例子来说,一个简单视频对象用针对矩形视频帧序列的工具编码,而一核心视频对象用针对任意形状对象的工具编码等。档次则是对象类型的集合,是相应编解码器必须支持的。
MPEG-4 Visual档次中针对自然视频场景编码部分见表4.5,其档次范围从针对矩形视频帧编码的Simple档次到了针对任意形状及扩展对象、工作室级视频编码的档次。表4.6列出了人工合成视频和混合视频编码的档次。
表4.5 MPEG-4 Visual自然视频档次

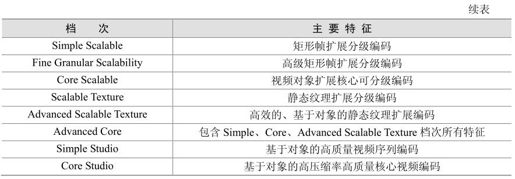
表4.6 MPEG-4 Visual合成视频档次

4.7 JPEG标准
1991年3月ISO/IEC正式通过了静止图像压缩编码标准,该标准称为JPEG建议。JPEG标准分为基本系统、扩展系统和信息保持系统三个部分。
基本系统提供对顺序扫描静止图像的高效有损编码,输入图像精度为8bit/像素。
(1)图4.26为JPEG基本系统的编解码器方框图,输入的彩色图像为Y、U、V三个分量,JPEG对它们分别进行编码。
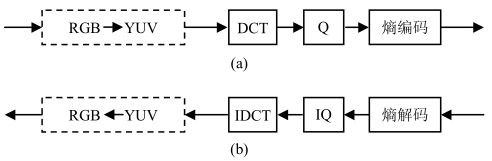
图4.26 JPEG基本系统编解码器结构
(2)编码时,先将一帧图像分为互不重叠的8×8像素块,接着对各块进行DCT变换,然后对各变换系数进行线性量化。
量化步长Q的选择应结合人眼视觉敏感性,亮度和色差信号的量化步长矩阵见表4.7和表4.8。
表4.7 亮度量化步长矩阵


表4.8 色差量化步长矩阵

量化后系数为:

反量化后DCT系数为:

(3)熵编码,一般采用哈夫曼VLC编码。AC系数量化后为少数稀疏的值,大部分为零,采用锯齿形(Zig-Zag)扫描,然后以游程编码表示方式进行变长的哈夫曼编码。对于DC系数则采用本块与上一块DC系数之差进行VLC编码(可查表)。
(4)数据交换格式。熵编码后得到变长度的码流。为便于数据的交换,JPEG规定了统一的压缩后数据交换格式,如图4.27所示。
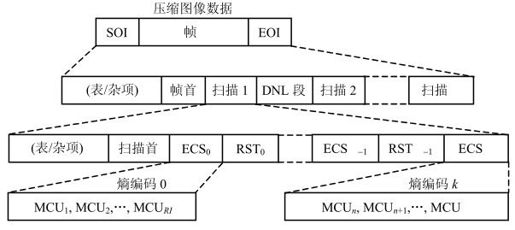
图4.27 数据交换格式
第一行:SOI表示图像数据开始,EOI为一帧图像结束,各占两个字节。
第二行:表/杂项中放置量化表、哈夫曼表,帧首包括编码方法、取样精度、量化系数、源图像行数、每行取样数等,DNL重新定义帧内的行数。
第三行:扫描首说明扫描起始信息、分量图像号码、参数、熵编码表选择(ECS),RST为重新开始标志。
第四行:为熵编码区,MCU为最小编码单元,包括4个亮度块、1个Cr块和1个Cb块。
4.8 JPEG2000标准
从1997年3月开始,JPEG委员会一直致力于制定一个具有更高压缩效率和更多新功能的新一代静止图像压缩标准——JPEG2000。2000年年底,基于小波变换的JPEG2000被推出,它统一了二值图像编码标准JBIG、无损压缩编码标准JPEG-LS以及原来的JPEG编码标准,支持更多的颜色分量和更大的颜色深度,具有多分辨率表示和渐进传输功能,同时支持有损和无损压缩,比JPEG标准的压缩率更高、性能更优秀。JPEG2000可广泛应用于互联网、彩色传真、图像文件、医学图像、数字图书馆、遥感等领域。
4.8.1 JPEG2000标准的组成和特点
JPEG2000标准的制定分为14个部分,其中第7部分已经被取消。表4.9列出了第1部分至第6部分。剩下的第8~14部分包括了安全性(JPSEC)、交互性、传输协议、三维数据扩展、无线应用、ISO基本媒体文件格式、初级编码器以及XML结构表示与参考。
表4.9 JPEG2000标准的部分组成

JPEG2000具有以下特点。
(1)良好的低比特率压缩性能。JPEG2000格式的图片压缩比可在JPEG标准的基础上再提高10%~30%,并呈现更好的图像质量,具有良好的率失真性能,适合移动通信等带宽受限的应用需求。
(2)支持多分辨表示。利用小波变换的多分辨特性,可在JPEG2000码流中,包含各个分辨率的信息。因此,一个单一的JPEG2000码流,可以同时满足不同分辨率应用的需要,如高分辨率的打印机、中分辨率的显示器和低分辨率的手持设备等。
(3)压缩域的图像处理与编辑。利用JPEG2000的多分辨特性,可以直接从JPEG2000码流中抽取新的低分辨率的JPEG2000码流,也可在压缩域中直接对图像进行剪切、旋转、镜像和翻转等操作,而不需经历解压缩/再压缩过程。
(4)渐进性。JPEG2000支持多种类型的渐进传送,可从轮廓到细节渐进传输,适用于窄带通信和低速网络。JPEG2000支持四维渐进传送:质量(改善)、分辨率(提高)、空间位置(顺序/免缓冲)和分量(逐个)。
(5)连续色调和二值图像压缩。与JPEG只支持灰度图和真彩图不同,JPEG2000支持黑白二值图和伪彩图的无损压缩,相当于JBIG和JPEG-LS。
(6)感兴趣区(ROI,Region of Interest)编码。在压缩编码时可对图片上感兴趣区域指定压缩质量,在显示解码时还可以指定新的兴趣区来指导传输方的编码。
4.8.2 JPEG2000核心编解码器
JPEG2000核心编解码系统是指JPEG2000标准的第一部,规定了实现JPEG2000功能的基本的编解码方案。核心编解码器的原理框图如图4.28(a)、(b)所示。在编码器中,原始图像经过预处理后,进行离散小波变换,变换后的系数经过量化、熵编码,然后组成JPEG2000码流格式。解码器是编码器的逆过程,也就是对编码码流进行熵解码、反量化,然后进行逆向离散小波变换,再进行后处理得到重构图像数据。
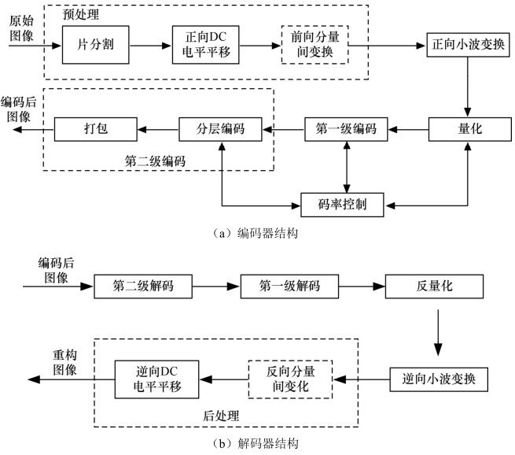
图4.28 JPEG2000核心编解码器的原理框图
1.预处理
将图像数据进行小波变换前,对原始图像进行的工作可归为预处理。这个阶段包括片分割、DC电平平移和分量间变换。
片分割是指将图像分割成不重叠的矩形块(即片,Tile)。这些片可以单独进行压缩编码,所有编码器的后续操作,包括分量间变换、小波变换、量化和熵编码,都是针对每个分片独立进行。在某些场合下,例如原始图像数据大小比编码器系统提供的内存大时,进行图像的片分割后单独处理就显得很有意义了。片可以任意大小,最大可以为整个图像。
DC电平平移是指将图像片的所有无符号分量的样本值进行直流电平平移,即减去一个相同的数2P-1,这里的P就是分量的比特精度。直流电平平移只是针对无符号分量的样本,它只是将无符号数转换为有符号数,使原本无符号样本值的动态范围基本关于零对称,使得在进行离散小波变换后的系数动态范围不会太大,有利于后续编码。在解码端,如果某个分量在编码时采用了直流电平平移,则需要在逆分量变换后,再进行逆向DC电平平移。
分量间变换的目的是尽量去除分量间的相关性,达到提高压缩编码效率的作用。分量间变换在整个系统中不是必须的,所以图4.28中用虚线框表示。JPEG2000标准中定义了两种分量间变换:一种是适用于有损或无损编码的可逆分量变换(RCT),另一种是只适用于有损编码的不可逆分量变换(ICT)。需要指出的是,这里的可逆和不可逆不是指逆变换存在不存在,而是针对有无精度损失。可逆分量变换是整数到整数的有限精度计算,不会损失精度;而不可逆分量变换是实数到实数的变换,在运算中有精度损失。
2.小波变换
JPEG2000中采用的离散小波变换是对每个分片的每个分量进行的。每个分片的分量(Tile Component)独立进行变换产生一系列的二维子带,这些子带中的系数描述了原图像在水平、垂直的空间频率特性。图4.29给出了二维小波变换的典型结构图。
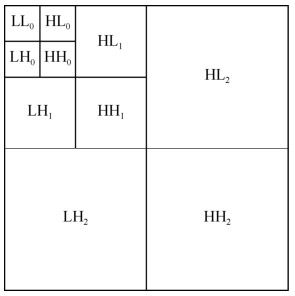
图4.29 二维小波变换的示意图
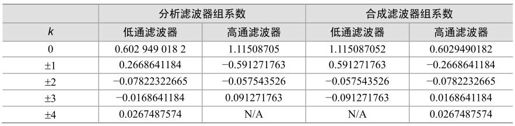
JPEG2000标准提供了两组默认的小波变换基。默认的不可逆小波变换使用Daubechies 9/7滤波器组,表4.10给出了其分析和合成滤波器组的系数。从表中可以看出,Daubechies 9/7滤波器组的系数不是整数,在进行小波变换中,用有限精度存储时,会有精度损失,因而重构系数与原系数必然存在差异,因此这个滤波器组只能用于有损压缩编码。
表4.10 Daubechies 9/7分析和合成滤波器组系数
默认的可逆小波变换使用Le Gall 5/3分析和合成滤波器组,表4.11给出了其分析和合成滤波器组的系数,由于是有限精度的运算,Le Gall 5/3分析和合成滤波器组既可用于有损压缩,也可用于无损压缩编码。
表4.11 Le Gall 5/3分析和合成滤波器组系数

3.量化
JPEG2000标准采用了标量量化。量化降低了系数的精度,量化操作一般是有损的。既要保证在解码端能够恢复出预期的图像质量,同时又能获得更高的压缩率,必须选择合适的步长。考虑到各个子带的动态范围都不一样,因此不同子带可使用不同的量化步长。
4.编码算法
如何有效地组织量化后的小波系数并编码成JPEG2000的压缩码流,这就是编码算法的工作。JPEG2000编码器采用的是EBCOT算法。编码过程是整个编码器中复杂度最高的部分,也是耗时最多的部分。编码过程分为两级:第一级编码是以基于上下文的二进制算术编码,包括位平面编码算法,生成嵌入式压缩码流,这一级实质上对各种编码元素进行了熵编码;第二级编码过程实际上是分层和打包形成规定格式码流的过程。
4.9 AVS标准
数字音视频编解码技术标准工作组由原信息产业部科学技术司于2002年6月批准成立。工作组的任务是:面向我国的信息产业需求,联合国内企业和科研机构,制(修)订数字音视频的压缩、解压缩、处理和表示等共性技术标准,为数字音视频设备与系统提供高效经济的编解码技术,服务于高分辨率数字广播、高密度激光数字存储媒体、无线宽带多媒体通讯、互联网宽带流媒体等重大信息产业应用。
4.9.1 AVS标准进展情况
AVS(Audio Video coding Standard)为中国具备自主知识产权的第二代信源编码标准,此编码技术主要解决数字音视频海量数据(即初始数据、信源)的编码压缩问题,故也称数字音视频编解码技术。
AVS标准是《信息技术——先进音视频编码》系列标准的简称,是基于我国创新技术和部分公开技术的自主标准,编码效率比MPEG-2高2~3倍,与AVC相当,而且技术方案简洁,芯片实现复杂度低,达到了第二代标准的最高水平;AVS通过简洁的一站式许可政策,解决了AVC专利许可问题死结,是开放式制订的国家、国际标准,易于推广;此外,AVC仅是一个视频编码标准,而AVS是一套包含系统、视频、音频、媒体版权管理在内的完整标准体系,为数字音视频产业提供更全面的解决方案。综上所述,AVS可称第二代信源标准的上选。
AVS标准包括系统、视频、音频、数字版权管理等四个主要技术标准和一致性测试等支撑标准。在2003年12月18~19日举行第7次会议上,工作组完成了AVS标准的第一部分(系统)和第二部分(视频)的草案最终稿,和报批稿配套的验证软件也已完成。2004年12月29日,全国信息技术标准化技术委员会组织评审并通过了AVS标准视频草案。2005年1月,AVS工作组将草案报送原信息产业部。2005年3月30日,原信产部初审认可,标准草案视频部分进入公示期。2004年度第一季度(第8次全体会议)正式开始“数字版权管理与保护”标准的制定。2005年年初(第12次全体会议)完成了第三部分(音频)草案。经过四年的努力,2006年2月22日,国家标准化管理委员会颁布通知:《信息技术——先进音视频编码》第二部分已经批准,国家标准号GB/T 20090.2—2006,于2006年3月1日起开始实施。
4.9.2 AVS视频编码及关键技术
AVS视频与MPEG标准都采用混合编码框架,如图4.30所示,包括变换、量化、熵编码、帧内预测、帧间预测、环路滤波等技术模块,这是当前主流的技术路线。AVS的主要创新在于提出了一批具体的优化技术,在较低的复杂度下实现了与国际标准相当的技术性能,但并未使用国际标准背后的大量复杂的专利。
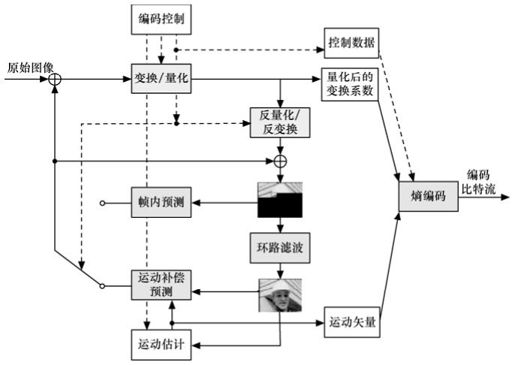
图4.30 AVS视频标准编码框架
AVS视频编码当中具有特征性的核心技术包括:8×8整数变换、量化、帧内预测、1/4精度像素插值、特殊的帧间预测运动补偿、二维熵编码、环路滤波等。
1.变换量化
AVS的8×8变换与量化可以在16位处理器上无失配地实现,从而克服了H.264之前所有视频压缩编码国际标准中采用的8×8 DCT变换存在失配的固有问题。而H.264所采用的4×4整数变换在高分辨率的视频图像上的去相关性能不及8×8的变换有效。AVS采用了64级量化,可以完全适应不同的应用和业务对码率和质量的要求。在解决了16位实现的问题后,目前AVS所采用的8×8变换与量化方案,既适合于16位DSP或其他软件方式的快速实现,也适合于ASIC的优化实现。
2.帧内预测
AVS的帧内预测技术沿袭了H.264帧内预测的思路,用相邻块的像素预测当前块,采用代表空间域纹理方向的多种预测模式。但AVS亮度和色度帧内预测都是以8×8块为单位的。亮度块采用5种预测模式,而色度块采用4种预测模式,而这4种模式中又有3种和亮度块的预测模式相同。在编码质量相当的前提下,AVS采用较少的预测模式,使方案更加简洁、实现的复杂度大为降低。
3.帧间预测
帧间运动补偿编码是混合编码技术框架中最重要的部分之一。AVS标准采用了16×16、16×8、8×16和8×8的块模式进行运动补偿,而去除了H.264标准中的8×4、4×8、4×4的块模式,目的是为了能够更好地刻画物体运动,提高运动搜索的准确性。实验表明,对于高分辨率视频,AVS选用的块模式已经能足够精细地表达物体的运动。较少的块模式,能降低运动矢量和块模式传输的开销,从而提高压缩效率、降低编解码实现的复杂度。
AVS和H.264都采用了1/4像素精度的运动补偿技术。H.264采用6抽头滤波器进行半像素插值并采用双线性滤波器进行1/4像素插值。而AVS采用了不同的4抽头滤波器进行半像素插值和1/4像素插值,在不降低性能的情况下减少插值所需要的参考像素点,减小了数据存取带宽需求,这在高分辨率视频压缩应用中是非常有意义的。
多参考帧预测允许当前块从前面几帧图像中寻找更好的匹配,因此能够提高编码效率。但一般来讲,2~3个参考帧基本上能达到最高的性能,更多的参考图像对性能提升影响甚微,但复杂度却会成倍增加。H.264最多可采用16个参考帧,并且为了支持灵活的参考图像引用,采用了复杂的参考图像缓冲区管理机制,实现较复杂;而AVS视频标准限定最多采用两个参考帧,其优点在于在没有增大缓冲区的前提下提高了P帧的编码效率,因为B帧图像的解码本身也需要能存放两个参考图像的缓冲区。
H.264的B帧宏块编码模式中,时域直接模式(Temporal Direct Mode)与空域直接模式(Spatial Direct Mode),是相互独立的;而AVS视频标准采用了更加高效的空域/时域相结合的直接模式,并在此基础上结合使用了运动矢量舍入控制技术,使得AVS视频标准中B帧的性能比H.264中B帧的性能有所提高。此外,AVS标准还提出了对称模式(Symmetric Mode),即只编码一个前向运动矢量,后向运动矢量通过前向运动矢量导出,从而实现双向预测。此方案与编码双向运动矢量效率相当。
4.熵编码
AVS熵编码基于上下文的自适应变长编码技术。对变换量化后预测残差进行编码。其具体策略为:系数经过“Z”字形扫描后,形成(Run,Level)对,其中,Run表示非零系数前连续值为零的系数个数,Level表示一个非零系数;之后采用多个变长码表对这些(Run,Level)对于进行编码,编码过程中进行码表的自适应切换来匹配(Run,Level)的局部概率分布,从而提高编码效率;编码顺序为逆向扫描顺序,这样易于局部概率分布变化的识别;变长码采用指数哥伦布码,这样可以降低多码表的存储空间。此方法与H.264用于编码4×4变换系数的CAVLC具有相当的编码效率。相比于H.264的算术编码方案,AVS的熵编码方法编码效率低0.5dB。
5.环路滤波
基于块的编码有一个显著特性就是重建图像存在块效应。采用环路滤波去除块效应,可以提高图像的主观质量和压缩效率。
AVS采用自适应环路滤波,即根据块边界两侧的块类型先确定块边界强度Bs值,然后对不同的Bs值采取不同滤波策略。帧内块滤波最强,非连续运动补偿的帧间滤波较弱,而连续性较好的块之间不滤波。由于AVS变换和最小预测块大小都是8×8,因此环路滤波的块大小也是8×8。与H.264的4×4相比,AVS块边界数量大大减少。另外,Bs值和改变的像素的数量也有所减少。
总的来说,AVS视频标准对每项技术都进行了复杂性与效率的权衡,努力降低复杂度,并保证高的编码效率,为所面向的应用提供了很好的解决方案。H.264的编码器大概比MPEG-2的复杂9倍,而AVS视频标准由于编码模块中的各项技术复杂度都有所降低,其编码器复杂度大致为MPEG-2的6倍。在高分辨率视频序列上,AVS视频标准保持了与H.264相近的编码效率。
参考文献
[1]许志祥.数字电视与图像通信.上海:上海大学出版社,2000.
[2]余兆明.数字电视和高清晰度电视.北京:人民邮电出版社,1997.5.
[3]朱秀昌.图像通信应用系统.北京:北京邮电大学出版社,2003.6.
[4]毕厚杰.图像通信工程.北京:人民邮电出版社,1995.10.
[5]Yao Wang, Jorn Ostermann, Ya-Qin Zhang.Video Processing and Communication. Pearson Education, 2002.
[6]Iain E.G.Richardon.H.264 and MPEG-4 Video Compression Video Coding for Next Generation Multimedia. Wiley Press, 2003.
[7]毕厚杰.多媒体信息的传输与处理.北京:人民邮电出版社,1999.
[8]玉琢,等.基于对象的多媒体数据压缩编码国际标准——MPEG-4及其校验模型.北京:科学出版社,2000.
[9]何小海,王正勇.数字图像通信及其应用.四川:四川大学出版社,2006.
[10]虞露.AVS-视频技术概述.中国多媒体视讯,2003.
