第10章 H.264的可伸缩编码SVC
10.1 概述
随着视频会议、可视电话、视频点播、视频监控等面向网络应用的视频服务的迅速增长,视频编码的目标由单纯的追求高压缩率转向了使视频流能够更好地适应各种不同的网络环境和用户终端。然而,实际系统中网络环境和用户终端设备均存在异构性。网络的异构性体现在带宽的不同,终端设备的异构性则是指处理能力和显示能力的差异。这些对视频编码提出了新的挑战,编码器无法预知传输网络和客户设备的条件,因此,视频服务器需要对视频传输请求有自适应性,以使得码流可以被灵活地组织适应不同的应用需求。为了获得这种自适应性,可以采用的视频编码技术主要有自适应编码、转码、联播、多描述编码和可伸缩编码等。
(1)自适应编码(Adaptive Coding)。根据网络的状况,编码器可以使用码率控制技术,改变量化参数或编码帧率来生成所需速率的码流。这对网络带宽变化有一定的适应性。但只能应用于码率调整范围受限的实时视频传输场合,对于离线编码系统(编码和传输相独立)并不适用。
(2)转码技术(Transcoding)。在服务器上保持一个质量足够好的压缩视频流,根据网络传输和用户端情况,对高质量视频流进行解码和编码,丢弃压缩数据中不会严重影响视频质量的部分,以获得较低码率/分辨率/帧率的视频流。由于引入了额外解码和编码操作,当大量用户点播时,会加重服务器开销。
(3)联播(Simulcast),也就是多码流切换。将视频信息进行多次编码,在服务器上保存不同分辨率、帧率和码率的码流。当网络带宽发生变化时,服务器会选择合适的码流进行传送。本方案能提供一定的网络带宽自适应性,但同时也增加了编码的时间、流媒体服务器的存储空间和操作的复杂度。
(4)多描述编码(Multiple Description Coding)。将原始视频编码分解为多个相关码流(描述),其中任何一个码流都可以独立解码成满足基本接收质量的视频。接收端接收到的码流越多,恢复的视频质量越好。多描述编码作为一种典型的容错编码方案,在多径传输和多播中具有优势。
(5)可伸缩编码(Scalable Video Coding)。可伸缩编码实质上是将视频信息按照重要性分解,对分解的各个部分按照其自身的统计特性进行编码。一般它会将视频编码成一个基本层和一组增强层。基本层中包含满足最小需求的基本信息,可以独立解码。增强层依赖于基本层,因此基本层在码流中最为重要。增强层是对基本层信息的增强,接收到的增强层越多,视频信息的恢复质量也就越高。
和其他编码方案相比,可伸缩编码允许一次压缩后的视频能以不同的码率、帧率、空间分辨率和视频质量解码。因此可伸缩编码为IP网络和移动无线网络视频传输提供了一套简单、灵活的解决方案。可伸缩性编码的相关研究已经进行了十几年了,一直是编码领域研究的热点之一。一个成功的可伸缩视频编码,应该具有以下特性:
(1)支持时间、空间和SNR可分级;
(2)支持简单的比特流自适应;
(3)与现在的单层编码相比,解码复杂度仅略有增加;
(4)解码复杂度随所需解码的时空分辨率和比特率不同而相应变化;
(5)与非可伸缩编码器相比,编码效率没有明显的损失。
因此,基于以上的考虑,2004年4月MPEG组织征集SVC技术草案,旨在开发出一个全新的可伸缩视频编码的标准。2004年10月,JVT最终确定采用德国HHI研究所提出的基于H.264扩展的架构作为SVC标准的实现框架和研究起点。从2005年1月开始MPEG和VCEG的联合组织JVT正式开始SVC项目的标准化工作,2007年6月,确定了最终的SVC标准草案(ISO/IEC 14496-10/Amd.3)。
10.2 SVC的基本原理
传统的通信系统中,编码器将视频信号压缩到一个特定的比特率,使此比特率小于或接近信道容量(带宽),解码器利用收到的全部数据重建视频信号。但是在目前的流媒体应用环境下,编码器无法预知传输网络状态和终端设备能力,因此要求视频编码器能够实现特定使用环境下的最优编码,使得编码后的码流可以灵活地适应不同网络用户的需求。
率失真理论表明率失真曲线是编码器性能能够达到的最佳曲线。图10.1给出了面向传输的可伸缩编码方法与传统非可伸缩编码方法的比较。图中,横轴表示信道的比特率(信道带宽),纵轴表示视频解码重建质量。率失真曲线表示了在特定码率上各种编码方法所能达到的质量上限,阶梯线表示了非可伸缩编码技术所能达到的性能。一旦选定了一个特定的比特率,非可伸缩编码就尽量使编码质量达到最好,即阶梯线尽可能接近率失真曲线。当信道带宽恰好与编码比特率相同时,解码端的视频质量最优;当信道带宽小于编码比特率时,解码端的质量会变得很差。相反,如果信道带宽比编码比特率高,解码器的视频质量也不能提高。为了适应网络带宽的变化,面向传输的编码技术应尽可能逼近率失真曲线,具有在任意位置截断的特性,而且解码端的视频质量随着网络带宽的增加而不断提高。
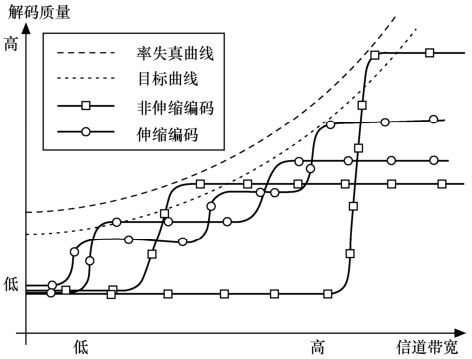
图10.1 可伸缩编码方法和非可伸缩编码方法的比较
视频编码的可伸缩性包括时域可伸缩性、空域可伸缩性、质量可伸缩性等。时域可伸缩性是指将视频流分解成表示不同帧率的信息,其中基本层保留最低帧率的信息,随着层数的增加帧率也随之增加,从而用户能够观赏到更为连贯流畅的画面。空域可伸缩性是指将视频流分解成表示不同分辨率的信息,其中基本层保留最低分辨率的信息,随着层数的增加分辨率也随之增加,从而用户能够观赏到更为细腻的画面。质量可伸缩性是指将像素值分解成不同级别,在基本层每个像素只拥有很小的比特率,因此画面质量粗糙;随着层数的增加,每个像素的比特率也随之增加,从而能够展现出更为丰富的图像内容。
根据可伸缩性粒度大小的不同,可伸缩性又可分为精细粒度的可伸缩性(FGS,Fine Grain Scalability)、中等粒度的可伸缩性(MGS,Medium Grain Scalability)和粗粒度可伸缩性(CGS,Coarse Grain Scalability)。增强层的数目越多,可伸缩性的粒度就越小,反之则越大。
根据可伸缩编码的压缩编码架构的不同,可以分为基于DCT变换的视频编码和基于小波变换的可伸缩视频编码。前者的代表性技术包括基于H.264/AVC扩展的可伸缩编码架构和MPEG-4的FGS编码方案,后者的代表性技术包括杠铃式三维提升子带视频编码器(3D-DWT Video Compression System)和运动补偿嵌入式零树块编码器(MC-EZBC)。
下面列出了可伸缩性编码的基本类型。
(1)传统可伸缩性编码(Layered Scalability Coding),又细分为3种基本类型:时域可伸缩性编码(Temporal Scalability Coding)、空域可伸缩性编码(Spatial Scalability Coding)和质量可伸缩性编码(SNR Scalability Coding)。
(2)精细粒度可伸缩性编码(FGS,Fine Granular Scalable Coding)。
(3)渐进精细粒度可伸缩性编码(PFGS,Progressive FGS)。
10.2.1 传统可伸缩编码
传统编码可伸缩编码在MPEG-2标准中就已有应用。可伸缩性编码的核心思想是将视频流在编码时分为两个或更多个码流,这些码流也称为层。这些层中至少有一个是基本层(BL,Base Layer),其余的为增强层(EL,Enhancement Layer)。基本层包含视频信号基本的也是最重要的信息,接收端接收到基本层就可重建基本质量的图像;增强层包含视频信号的细节信息,接收端将增强层和基本层一起解码,可以重建出更高质量的图像。传输时可以根据基本层和增强层的不同重要性,赋予不同的优先级和保护机制。解码器可在多个图像质量级别上进行解码,用户可根据需要进行解码,即使增强层的数据丢失或者被抛弃,也能够使恢复的图像质量达到一个可以接受的水平。传统可伸缩性视频编码框架如图10.2所示。
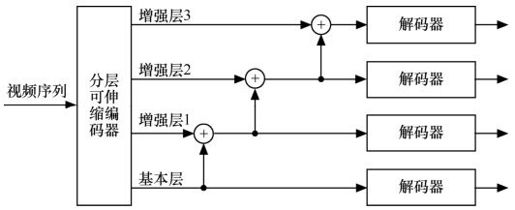
图10.2 传统可伸缩性视频编码框架
可伸缩性编码有3种基本类型:时域可伸缩性(Temporal Scalability)、空域可伸缩性(Spatial Scalability)和SNR可伸缩性(SNR Scalability)。这3种可伸缩性分别对应了视频的帧率、分辨率、PSNR等基本参数,它们都能在基本层外提供一个或几个增强层,实现码流的可伸缩性。
1.时域可伸缩编码
时域可伸缩编码是通过调节图像的帧率,在基本层帧率和最高帧率之间提供帧率的可伸缩性。当网络带宽较窄时,接收端只须接收到基本层帧率fBL帧图像就可恢复出基本视频;当网络带宽较宽时,则可接收到fBL+fEL帧图像,解码后的视频更加流畅。将各个码流层定义为同一视频的不同的时间分辨率下的表示。对不同内容的层使用不同的帧率,利用较低层的时间上采样图像作为较高层的预测。时间下采样可通过简单的丢帧来实现,而时间上采样可通过增强层的预测帧来实现。时域可伸缩编码如图10.3所示。增强层预测帧的引入可以使压缩性能得到改善,加大了编解码器的复杂度和预测参考帧的存储开销。

图10.3 时域可伸缩编码示意图
2.空域可伸缩性
空域可伸缩性是通过为视频中每帧图像都提供多个分辨率表示来实现的。其主要思想是先对原始视频中的每帧图像进行下采样获得低分辨率图像,编码得到空域基本层码流;然后编码原始图像和低分辨率图像上采样恢复图像的差值信息,生成空域增强层码流。当接收端接收到基本层后,即可解码恢复出低分辨率的基本图像;当接收端还能接收到增强层数据时,重建的图像的分辨率提升,如果接收到图像的所有增强层数据,即可恢复出原始图像。
作为一个视频流服务器,其发送视频信息的目标可能是不同种类的终端设备,对每种设备都单独编码显然是不合理的。空域可伸缩性的设计满足了接收端设备显示屏幕分辨率不同的场合,提供统一的可伸缩性视频码流就成为一种有效的解决方案。
3.SNR可伸缩性
SNR可伸缩性主要利用了视频的峰值信噪比来提供可伸缩性。视频图像帧在编码过程中存在量化这一步骤,量化是一种有损压缩方法,通过改变量化步长,可以得到不同质量和压缩比的图像。若量化步长较小,则视频图像丢失的信息比较少,视频质量的损失就比较少,但压缩率就会偏低;若量化步长较大,则视频图像丢失的信息比较多,视频压缩率较高,但图像质量损失比较大。SNR可伸缩性就是利用视频编码过程中的量化这一步骤实现的。其实现办法有两种:一是先对原始视频图像进行粗量化,得到质量较差的图像,进行编码后形成基本层,然后对原始图像与基本层的残差进行细量化,得到增强层;二是将原始图像进行DCT变换到频域后,对低频部分进行量化得到基本层,对高频部分量化得到增强层。其编码示意图如图10.5所示。SNR可伸缩性编码和空域可伸缩性编码很相似,只是SNR可伸缩编码提供的增强层码流和基本层码流的分辨率是相同的。
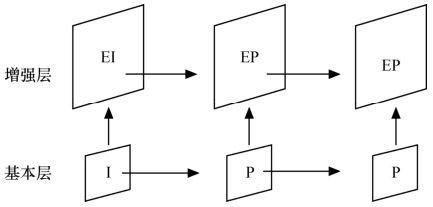
图10.4 空域可伸缩编码示意图
图10.5 SNR可伸缩编码示意图
10.2.2 精细粒度可伸缩编码
精细粒度可伸缩视频编码(FGS,Fine Granular Scalable Coding)是在MPEG-4上提出的,主要解决了网络上视频流的带宽适应性的问题。其基本思想是将视频编码成为一个可以单独解码的基本层码流和一个可以在任意点截断的增强层码流。通常,基本层的码率很低,要求所有的接收端都具备接收并解码基本层的码流的能力。当然基本层的码率很低,仅仅解码基本层码流重建的视频质量也不高。如果接收端有额外的带宽和处理能力可以接收解码更多的数据,那么它可以从发送端接收并解码增强层的码流来提升重建的视频质量。由于位平面编码技术提供了精细可伸缩的特性,码流可任意地被截断,因此该码流可以根据可用的网络带宽进行任意码率的传输,接收端的终端用户根据接收到的增强层码流来增强基本层的视频质量,接收到的增强层码流越多,终端用户重建的视频质量就越高。FGS编码技术可以在一个很大的码率范围内调整数据传输,适应各种复杂的网络带宽变化。
FGS编码虽然具有优良的可伸缩特性,但它也有致命的弱点,即效率太低。在同等码率下,FGS的质量要比MPEG-4中的非可伸缩性编码低2~3dB,这显然是难以接受的,FGS的基本层和所有增强层都以参考帧的基本层图像为参考进行运动补偿,如图10.6所示。
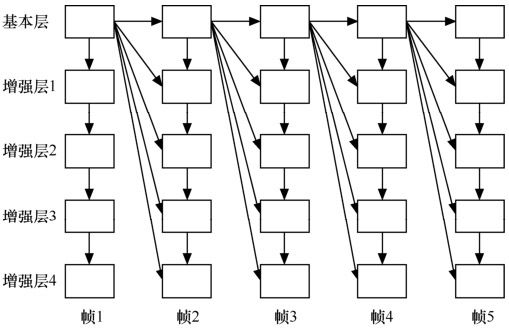
图10.6 FGS的体系结构
10.2.3 渐进精细粒度可伸缩编码
PFGS(PFGS,Progressive Fine Granular Scalability)编码技术是在FGS编码技术的基础上进行改进,具有更高的编码效率。PFGS的编码结构如图10.7所示。其基本思想是在编码增强层用一些高质量的增强层重构图像作为参考,使得运动补偿更有效,从而提高了精细可伸缩编码的编码效率。当然,这种编码效率的改进必须以牺牲其精细可伸缩性的特性为前提条件,因此在设计渐进精细可伸缩性编码框架时有两个关键点:其一是在编码增强层时尽量采用高质量的增强层为参考来提高编码效率;其二是必须保留一些从基本层到最高质量的增强层之间完整的预测路径,以使生成的码流具有可伸缩性。渐进精细粒度可伸缩性的视频编码方案PFGS,在保持了FGS所具有的网路带宽自适应和错误恢复能力的同时,提高了将近1dB的编码效率。
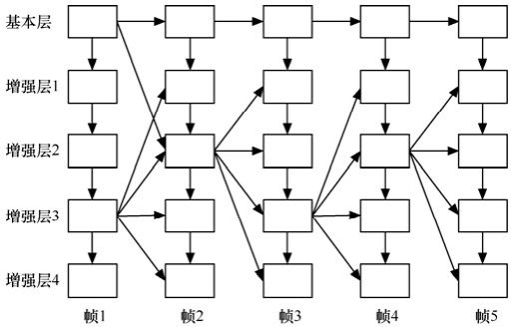
图10.7 PFGS的体系结构
10.3 H.264的SVC
JVT最终确定采用德国HHI研究所提出的基于H.264扩展的架构作为SVC新标准。基于H.264扩展的SVC编码架构和目前的H.264视频标准显然存在着很大的联系,SVC作为H.264的扩展被开发的,继承了后者的核心编码工具,其架构中有许多的编码模块都沿用了H.264标准的功能,如帧间运动估计方法、多参考帧运动估计、帧内预测、可变大小块等。SVC通过考虑添加了那些必需并且高效地支持所需类型的可伸缩性的编码工具。在本节中,将进一步对H.264 SVC的技术细节作简要的说明,分别介绍实现空域、时域和质量可伸缩性的关键技术。
图10.8显示了H.264扩展和H.264的关系,它们是扩展和基础的关系,前者是后者的功能扩展,后者是前者的基础。
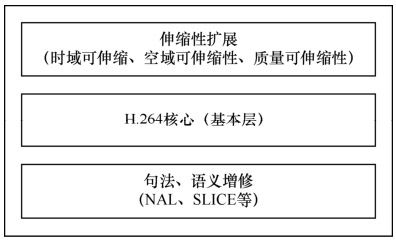
图10.8 H.264扩展和H.264的关系
H.264扩展的SVC架构规定了3种主要档次,每个档次支持一类特定的应用,规定了相应的编码功能。
(1)伸缩性基本档次(Scalable Baseline Profile)。基本层的码流符合H.264标准的基本档次(Baseline Profile),增强层支持H.264主要档次的许多编码技术,例如B片的帧间编码、加权预测帧间编码、基于上下文的自适应的算术编码CABAC、8×8亮度变换等。主要用于移动广播、交互会话业务和视频监控等应用。
(2)伸缩性高级档次(Scalable High profile)。基本层的码流符合H.264标准的高清档次(High Profile),还支持任意分辨率的空域可伸缩编码等。主要用于广播、流和存储等业务应用。
(3)伸缩性高级帧内档次(Scalable High Intra Profile)。码流中只包含IDR帧,支持H.264标准的高清档次(High Profile)的编码技术。
图10.9是H.264 SVC的编码原理框图。空间可伸缩性通过空域分解下采样来生成多个不同空间分辨率的信号。每个空域层再经过层次B帧预测编码结构来提供时域可伸缩性。低空域层的运动信息和纹理信息可以用于高空域层相关信息的预测。H.264 SVC的视频编码也是基于宏块的,每个宏块除了可以进行帧内预测编码和帧间预测编码之外,高空间层的图像还可以进行层间预测编码。对于每个空间分层中的任意时间级图像,都采用质量可伸缩性编码。
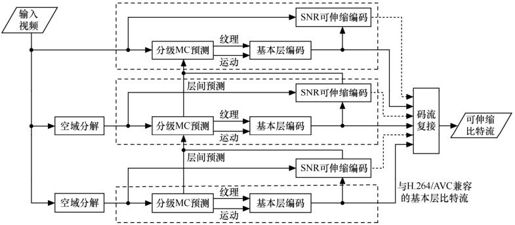
图10.9 基于H.264扩展的可伸缩编码示意图
10.3.1 空域可伸缩性
为了支持空域可伸缩编码,SVC沿袭了传统的多层编码方案。每一个空间层对应于一个空间分辨率,假设标识为D(D=0,1,2,…),其中基础层标识为0,其他空间层逐次递增。在每一个空间层,跟非伸缩编码一样,使用帧间预测和帧内编码。此时,为了改善编码效率引入了层间预测(Inter-Layer Prediction)机制,如图10.10所示。
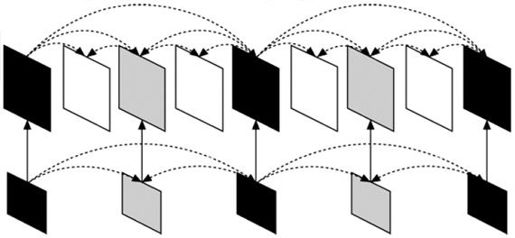
图10.10 含层间预测的空间可伸缩编码的多层结构
层间预测通常还会引入额外的计算复杂度,SVC包含了能同时改善编码效率和降低解码复杂度的工具。为了限制存储空间的需求和解码器的复杂度,SVC要求基础层和增强层的编码顺序是一致的。但是低层的图片不需要在所有的访问单元显示,这样是为了能将时间和空间分级结合起来。
1.层间预测
在分层编码的概念下,不同层间的预测算法是改善编码效率的关键。层间预测算法的设计原则是尽量多地利用基础层的信息来改善增强层的率失真性能。基本层的重建信号具有基本层的完整信息,但是不一定能被用来作层间预测的参考。当加入层间预测算法后,SVC的编码性能将明显改善,甚至有可能高于非伸缩编码。编码器可以根据输入视频信号的特性,自动选择层间或者层内预测编码。层间预测机制只能在访问单元(Access Unit)内部进行,且被预测的帧,其空间层级应该高于参考帧。SVC的层间预测技术主要分为3种:层间运动预测、层间残差预测和层间帧内预测。下面分别进行介绍。
(1)层间运动预测
在空间增强层,SVC设计包含了被称作B1Skip的新宏块模式。当增强层的宏块采用这个新的预测模式时,其对应基本层宏块采用帧间编码模式,就可以使用层间运动预测模式。具体来说,此时增强层待编码宏块的分割模式、运动矢量和参考帧序号都将直接继承其对应的基本层宏块的值或尺度伸缩之后的值,所以实际上只需要传递残差信息,从而节省了编码比特数。
宏块分割模式是通过低分辨率层的同一位置的8×8块上采样得到的。当基础层的8×8块没有被分割成更小的子块时,那么增强层的宏块也不用分割;否则每个基础层的A×B子宏块分割对应于增强层的一个(2A)×(2B)子宏块。如果宏块或者其子宏块是直接模式编码,其分割模式依赖于得到的运动向量。
对于这种新的宏块类型,SVC可以使用成比例的运动向量作为传统的运动补偿宏块模式的运动向量预测。SVC新增一个标志位用来区别这个运动向量预测是来自传统的空间预测还是相应的基础层运动向量乘以相应比例得到的。
(2)层间残差预测
当使用B1Skip模式进行层间运动预测时,基本层的运动信息可以被同一位置的增强层使用。为了进一步提升压缩性能,SVC还设计了层间的残差预测。
不管B1skip模式还是传统的宏块类型,层间残差预测可以应用到所有的帧间预测编码的宏块。SVC将一个标志位加到空间增强层的宏块语法中,标记是否使用了层间残差预测。当这个标志位为真的时候,相应的8×8的基础层子宏块的残差信号,在经过双线性滤波器上采样后,可以用来作为增强层宏块的预测残差信号。
(3)层间帧内预测
当一个增强层的宏块采用B1Skip预测模式编码,并且其对应的基本层的8×8子宏块采用帧内编码模式时,就必须采用层间帧内预测模式。亮度信号的上采样分别在水平和垂直方向使用6抽头FIR滤波器滤波,而对于色度信号的上采样就是使用简单的双线性滤波器。这个滤波器总是作用在子宏块的边缘。如果基本层相邻块不是帧内编码的,则原始像素还要通过特别的边缘延拓算法来得到所需样本。
2.空间可伸缩扩展
与MPEG-2、MPEG-4等编码器类似,H.264 SVC支持任意分辨率的空间可伸缩编码。唯一的限制是水平和垂直的分辨率从基本层到增强层不能减小。SVC的设计也可以使增强层只重现基本层中一个选定的矩形区域,把此区域编码成更高的或者指定的空间分辨率,或者在增强层中添加超过基本层边缘的部分。SVC还包含了隔行扫描视频源的空间可分级编码。任意空间分辨率、剪切和隔行扫描视频源的空间可分级编码,都可以通过三种基本的层间预测方法来实现。
10.3.2 时域可伸缩性
运动补偿时域滤波器技术(MCTF,Motion Compensated Temporal Filter)在SVC标准初期被认为是一种有效的提供时间可分级功能的工具。MCTF是一种时域分级技术,沿着运动轨迹自适应地对图像做离散小波变换,并可采用高效的小波提升结构,利用预测和更新算子实现高质量视频重建。MCTF采用开环预测结构,原始帧被用作后续帧的参考,从而具有较高的预测质量。但MCTF的开环结构在实际应用中很容易造成编解码两端的匹配错误,更新算子也大大增加了算法和内存的开销。随着层次B帧预测技术的提出,其在大多数情况下的性能要超过MCTF,JVT最终确定采用层次B帧预测技术作为实现时域可伸缩的标准方式。
一个提供时域可伸缩性的比特流可以分割成具有以下特性的一个基本层和一个或多个增强层:这些时间层通过时间级来标志,基本层以时间级0表示,其它的时间层依次递增;对于一个自然数k,可以通过移除比特流中所有时间级大于k的时间增强层,得到一个通过给定解码器解码的子比特流。在混合视频编解码器中,一般情况下时间分级可以通过将当前被预测帧的运动补偿预测参考帧限制在低于等于当前帧的时间层中来实现。
图10.10给出了实现时间伸缩的层次B帧预测编码结构,包括4个时间增强层。图10.11和图10.12中下部的序号代表编码顺序,符号TX代表相应的第X时域级别。基本层T0采用全I帧或者IPPP的结构,而除T0层以外的其他增强层通常编为B帧。两个连续T0层之间的所有增强层图像帧加上后一个T0图像帧组成了一组图像GOP。每个时间层集合{T0,…,Tx}可以独立于所有时间级Y(大于X)的增强层被解码。一般情况下完成时间分级的分层预测结构可以与H.264/MPEG-4的多参考帧方法相结合。参考帧列表可以使用多个参考帧,而且可以包含与被预测帧相同时间级的图片。图10.11给出了2个时间增强层的分层编码结构。针对要求低延时的应用,SVC提出一种零延迟的时域伸缩预测编码,如图10.12所示。
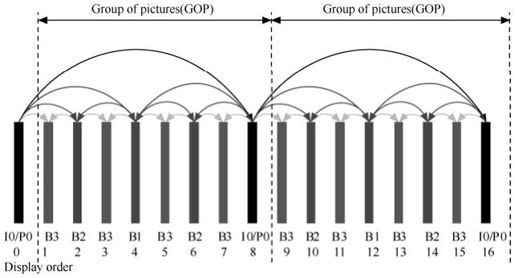
图10.11 实现时间伸缩的层次B帧预测编码结构
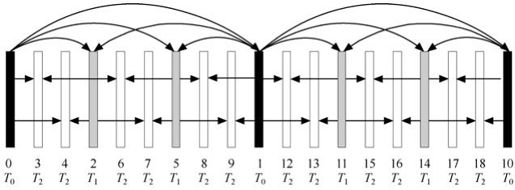
图10.12 非二阶分层预测编码结构
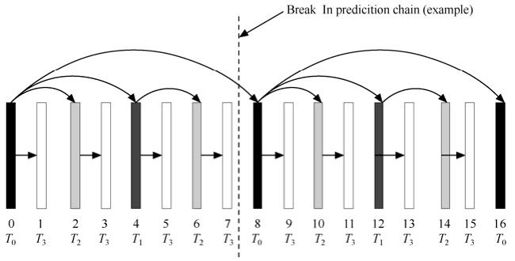
图10.13 零延时的时域伸缩预测编码结构
除了时间上的预测,一个编码器总是要应用率失真优化策略来优化和控制压缩性能。在分层预测结构下,可以使用以下几点来进一步改善编码效率。
(1)多分级量化参数
在分层预测结构的编码过程中,一个重要的问题是如何针对不同的时间层来选择量化参数。基本层编码必须有最高的保真度,它是其他层级图像运动预测的参考。其他时间层的量化参数数值可以逐层增加,时间层越高,重建图像的质量影响越小。最优量化参数的选择可以依照传统方式,依靠率失真最优的策略来实现,然而在可伸缩编码中,率失真优化的计算量会比非伸缩编码显著增加。为了降低计算复杂度,可充分利用不同层次视频码流之间的相关性,假设基本层的量化参数是QP0,对于时间层级为k>0的增强层量化参数可以选择为QPk=QP0+3+k。
(2)时间直接模式(Temporal Direct Mode)
在H.264解码过程中,时间直接模式的运动向量由List0和List1中第1帧图像对应的宏块计算得来。当使用层次B帧预测超过两个时间层级时,大约超过一半的B帧运动向量不适合用于产生直接模式的运动向量。此时即使修改参考帧列表相应图像序号,也不能避免这个问题。因此,对于层次B帧预测通常使用时间直接模式。
(3)运动搜索
JM模型指出双预测块的运动向量是由两个参考列表的独立运动搜索决定的。因此,在运动搜索的时候,综合考虑参考列表的预测信息也可以改善B片的编码效率。
10.3.3 质量可伸缩性
质量可伸缩是空间可伸缩的一个特例,此时基本层和增强层的空间尺寸是相同的。因此,可以运用一种显而易见的方案来实现质量可分级,这种方法被称作粗粒度质量可伸缩编码(CGS,Coarse-Grain quality Scalability)。当在SVC中采用层间预测技术来实现CGS时,一般通过采用比前一个CGS层更小的量化步长来重新量化残差信息的方法来获得更精细一级的纹理信息。CGS具有很大的局限性,它只支持固定个码率点的质量分级,也就是粗略地在几个固定码率上调节视频质量。在不同CGS层之间的切换也只能在比特流中的固定位置才可以实现。为了增加比特流码率自适应的灵活性,增加可支持的码率点个数,SVC的设计中包括了一种称之为精细粒度质量可伸缩编码的技术(FGS,Fine-Grain quality Scalability)。从理论上来说,FGS支持在任意位置截断码流,码流中的每一位比特都可以对质量做出贡献。但由于FGS实现复杂度过高,JVT提出了一种替代方案:中等粒度质量可伸缩方案(MGS,Medium-Grain quality Scalability)。
MGS的基本实现原理和CGS相似,也是采取逐层减小量化步长的策略。所不同的是,通过对高层语法元素的指示,MGS支持在任意访问单元进行不同层之间切换,并运用关键帧的概念来控制误差传播和质量增强层编码效率两者之间的折衷。MGS还支持将质量增强层的变换系数分布到不同的分片中。
1.漂移控制
在视频编解码过程中,运动补偿预测是一种提高编码压缩效率的常用措施。编码端和解码端必须使得运动补偿预测操作所需的参考图像信息同步一致,否则解码端的重建图像与编码端的图像就会出现差异,这就是漂移。对于可伸缩编码而言,运动补偿预测的参考图像信息中包含SNR增强层,使得参考图像更具保真度,从而获得更高的视频编码效率;但比特流的截断或丢弃引起可伸缩解码端的重建图像漂移。因此,需要综合考虑运动补偿预测和参考图像,以达到编码效率和漂移控制的平衡。下面就图10.14给出了4种漂移控制方式进行对比分析。
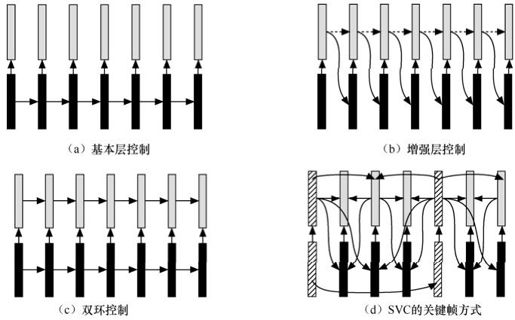
图10.14 漂移控制方式
按图10.14(a)所示,运动补偿预测只选用基本层参考,图像的增强层不能被用于后一帧图像的编码,显然可以完全避免漂移问题;这种方法的不足是与单层编码相比,明显地降低了视频编码效率。第二种情况如图10.14(b)所示,可伸缩编码的增强层图像被用于运动补偿预测参考,这可以获得很高的编码效率,但任何的SNR增强层的丢失或截断处理都会造成漂移。第三种情况如图10.14(c)所示,引入一种双运动补偿环的方法,基本层不会被增强层的任何修改所影响,但是任何增强层信息的丢失会在增强层的重建中仍引起漂移。在SVC的MGS设计中,运动补偿预测所需的参考图像被称为关键帧,如果将关键帧和可伸缩编码的多层结构综合考虑,可以获得编码效率和漂移的平衡。可以看出,引入关键帧的层级越低,引起漂移问题越小,理想情况是只把基本层作为关键帧;与此相反,如果引入关键的层级越高,运动预测补偿的参考图像质量越好,视频编码效率也越高。关键帧在编码器和解码器之间饰演了一个重新对称的角色,漂移的扩散被局限于GOP的内部。编码效率和漂移之间的调节取决于GOP的大小和分层的数目。
2.渐进精细片
质量可伸缩性通过反复的降低量化步长,从最小质量层开始通过逐步增加图像细节,这个编码方式称之为渐进精细(Progressive Refinement),也为此新增加了一个Slice类型,称之为渐进精细片(Progressive Refinement Slice)。渐进精细片可以更有效地表示SNR增强层的NAL单元。通常情况下,某一层量化步长大小是下一层的一半。但是SVC的SNR可伸缩编码与比特平面编码有所不同的,SVC允许编码器在决定变换系数方面有更大的自由度。对于特定变换系数,SVC的SNR可伸缩编码可以任意调整SNR增强层的变换系数,这会对于编码效率有很大的影响。
对于渐进精细片,SNR增强层表现为从粗到精的方式。整个宏块的变化系数需要被传输,每个4×4变换块允许只有一些变换系数被编码。进一步而言,不仅能截断包含渐进精细片的NAL单元,而且还可以分配一个渐进精细片的数据到多个NAL单元。
3.比特流提取
从一个给定的SNR可分级的比特流中,几乎可以任意比例来提取一个子流。这一般会通过截断和丢弃SNR精细包的方法来调节。但是与比特率相关的编码效率依赖于比特流提取的方法。
比特流提取的主要任务就是对编码码流进行分析,并根据解码端用户的需求对原始码流进行切割。由于SVC在编码时可以嵌入SEI信息标识时间、空间和质量分级,比特流提取只需丢弃那些高于要求的NAL数据。对于要求截取具体比特率的码流,情况则稍微复杂一些,需要逐层检查比特数是否已经满足要求,并根据质量分级是由CGS还是MGS实现的不同,对最后一层的NAL数据作不同策略的截取或保留。
10.3.4 H.264的扩展
H.264扩展继承了H.264标准的大部分特性和句法元素,但是为了适应空域、时域和质量可伸缩编码的要求,在H.264标准的基础上修改或增加了一些语法结构或语义,包含层、Slice、参数集、宏块、块等众多语法和语义修改,以及H.264标准未曾明确定义的一些保留参数的重新定义。考虑到NAL语法和Slice语法是H.264标准最重要的组成部分,而且SVC标准在也对这两部进行了重要调整,可以说是可伸缩编码最重要的组成部分。因此,下面主要分析一下NAL语法的扩展和Slice语法的扩展。
1.NAL扩展
在H.264标准中,视频编码层VCL用来有效的表示视频数据内容,而网络抽象层NAL用来为传输层或存储介质格式化数据,并为传输提供合适的头信息。所有数据都包含在NAL单元中,每个单元都包含整数个字节。根据前面章节7.2.1中NAL单元结构介绍看出,NRI可以表示当前NAL单元的相对重要性,因此如果使用它来表示可伸缩编码的层次结构,由于NRI占2位,因此只能区分4个可伸缩级,这显然是不够的。因此,需要对H.264标准的1个字节的NAL Header进行扩展。新的结构是在原NALU的头部增加3个字节专门用于表示可伸缩级,如图10.15所示。
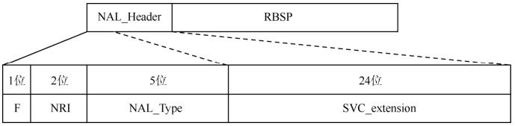
图10.15 NALU扩展的结构
在H.264标准保留的NAL单元类型中,有2个用于表示可伸缩扩展。当nal_unit_type等于14或nal_unit_type等于20时,解码器识别到该NAL单元属于可伸缩扩展类型,它将分析NAL头的后三个字节,这三个字节新增的句法元素包括idr_flag、priority_id、no_inter_layer_pred_flag、dependency_id、quality_id、temporal_id、use_ref_base_pic_flag、discardable_flag和output_flag,详见表10.1所示。本节将对新增句法元素作详细解释。
表10.1 SVC扩展中NAL 单元头信息句法元素
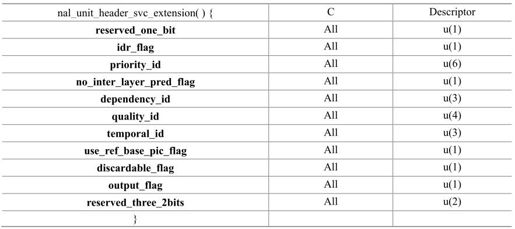
idr_flag 等于1表示当访问单元(access units)是IDR帧。
priority_id 用于标识NAL单元的优先级。
no_inter_layer_pred_flag 用于标识层间预测是否用于解码片数据。当no_inter_layer_pred_flag等于1时,层间预测不被用于解码片数据;当no_inter_layer_pred_flag等于0时,层间预测有可能被用于解码片数据。
dependency_id 用于空域可伸缩性扩展。当nal_type等于14时,dependency_id等于0。
quality_id 用于质量可伸缩性扩展。变量DQId可以如下获取:
DQId=(dependency_id << 4)+quality_id
temporal_id用于时域可伸缩性扩展。当访问单元内的NAL单元nal_unit_type等于5或idr_flag等于1时,temporal_id应等于0。
use_ref_base_pic_flag 标识基本层图像是否用于帧间预测参考。
discardable_flag 表示当前NAL单元是否用于当前访问单元的解码。等于0表示用于解码。
output_flag 影响解码图像过程的输出。
2.SLICE扩展
如前所述,基于H.264扩展的SVC架构继承了H.264的大部分语法,由于Slice主要参数都集中在头部,因此只需要分析这部分的语法结构就大致可以看出伸缩性的特点。H.264 SVC标准扩展了几种Slice类型。当NAL单元类型等于20时,Slice类型如表10.2所示。SVC扩展的Slice语法结构详见本章参考文献[1]中的G.7.3.3.4 Slice header in scalable extension syntax。
表10.2 NAL类型等于20时的Slice类型

10.4 性能与分析
图10.16给出了基于H.264扩展的SVC标准和H.264/AVC标准的压缩性能比较。其中,图10.14(a)、(b)分别讨论了SVC的质量可伸缩性和空域可伸缩性。测试结果表明:与单层H.264/AVC相比,基于H.264扩展的SVC标准只以10%码率的代价,提供了合适的可伸缩性能。H.264 SVC设计提供了许多改善分级编码效率的工具。基于H.264扩展的SVC的技术要点如下。
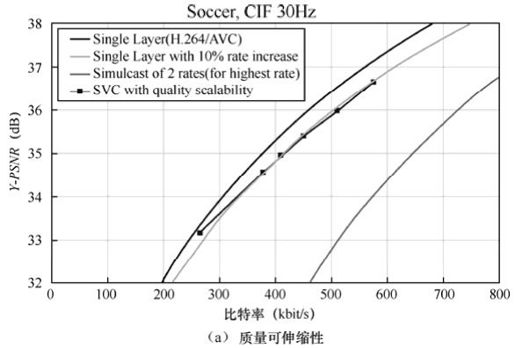
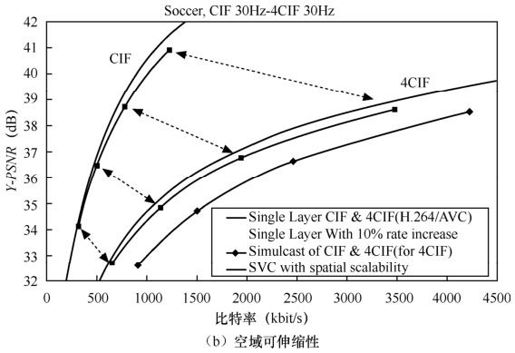
图10.16 基于H.264扩展的SVC和单层H.264/AVC的性能比较
(1)时域可伸缩预测结构。
(2)用于空域可伸缩性的层间预测机制。
(3)基本层与H.264/AVC兼容。
(4)用渐进细化片实现精细颗粒的质量可伸缩性。
(5)NAL单元概念的使用和扩展。
参考文献
[1]Joint Draft ITU-T Rec. H.264 | ISO/IEC 14496-10 / Amd.3 Scalable video coding, Doc: JVT-X201,24th Meeting: Geneva, Switzerland, 29 June–5 July, 2007.
[2]Heiko Schwarz,Mathias Wien.The Scalable Video Coding Extension of the H.264/AVC Standard IEEE Signal Processing Magazine, Vol. 25, No. 2, pp. 135-141, Mar. 2008.
[3]Heiko Schwarz, Detlev Marpe, Thomas Wiegand.Overview of the Scalable Video Coding Extension of the H.264/AVC Standard IEEE Transactions on Circuits and Systems for Video Technology, Special Issue on Scalable Video Coding, Vol. 17, No. 9, pp. 1103-1120, September 2007.
[4]Mathias Wien, Heiko Schwarz, Tobias Oelbaum.Performance Analysis of SVC IEEE Transactions on Circuits and Systems for Video Technology, Special Issue on Scalable Video Coding, Vol. 17, No. 9, pp. 1194-1203, September 2007.
[5]Stephan Wenger, Ye-Kui Wang, Thomas Schierl.Transport and Signaling of SVC in IP Networks IEEE Transactions on Circuits and Systems for Video Technology, Special Issue on Scalable Video Coding, Vol. 17, No. 9, pp. 1164-1173, September 2007.
[6]Thomas Schierl, Thomas Stockhammer, Thomas Wiegand.Mobile Video Transmission Using Scalable Video Coding IEEE Transactions on Circuits and Systems for Video Technology, Special Issue on Scalable Video Coding, Vol. 17, No. 9, pp. 1204-1217, September 2007.
[7]Heiner Kirchhoffer, Detlev Marpe, Heiko Schwarz, Thomas Wiegand.A low-complexity approach for increasing the granularity of packet-based fidelity scalability in Scalable Video Coding.Picture Coding Symposium(PCS'07), Lisboa, Portugal, November 2007.
[8]Thomas Wiegand, Heiko Schwarz, Detlev Marpe.Overview of the Scalable Video Coding Extension of H.264/AVC.Proceedings of 12. Dortmunder Fernsehseminar, ITG/FKTG-Fachtagung, Dortmund, Germany, March 20-21, 2007.
[9]Heiko Schwarz, Detlev Marpe, Thomas Wiegand.Overview of the Scalable H.264/MPEG4-AVC Extension IEEE International Conference on Image Processing(ICIP'06), Atlanta, GA, USA, October 2006.
[10]Heiko Schwarz, Detlev Marpe, Thomas Wiegand.Analysis of hierarchical B pictures and MCTF IEEE International Conference on Multimedia and Expo(ICME'06), Toronto, Ontario, Canada, July 2006.
[11]Heiko Schwarz, Detlev Marpe, Thomas Wiegand. SVC.The future Scalable Video Coding Standard.2nd International Mobile Multimedia Communications Conference(MobiMedia'06), Aleghero, Sardinia, Italy, September 2006, Invited Paper.
[12]Thomas Wiegand, Thomas Schierl, Karsten Grüneberg.Skalierbare Video Codierung.22. Jahrestagung der Fernseh-und Kinotechnischen Gesellschaft(FKTG), Potsdam, Germany, May 2006.
[13]Heiko Schwarz, Tobias Hinz, Detlev Marpe, Thomas Wiegand.Constrained Inter-Layer Prediction for Single-Loop Decoding in Spatial Scalability IEEE International Conference on Image Processing(ICIP'05), Genova, Italy, September 2005.
[14]Ralf Schäfer, Heiko Schwarz, Detlev Marpe, Thomas Schierl, Thomas Wiegand.MCTF and Scalability Extension of H.264/AVC and its Application to Video Transmission, Storage, and Surveillance. IS&T/SPIE Symposium on Visual Communications and Image Processing(VCIP'05), Bejing, China, July 2005.
[15]Heiko Schwarz, Detlev Marpe, Thomas Wiegand.Basic concepts for supporting spatial and SNR scalability in the scalable H.264/MPEG4 AVC extension IEEE International Workshop on Systems, Signals, and Image Processing(IWSSIP'05), Chalkida, Greece, Sep. 2005.
[16]Heiko Schwarz, Detlev Marpe, Thomas Wiegand.MCTF and Scalability Extension of H.264/AVC.Picture Coding Symposium(PCS'04), San Francisco.CA, USA, December 2004.
[17]Heiko Schwarz, Detlev Marpe, Thomas Wiegand.SNR-Scalable Extension of H.264/AVC IEEE International Conference on Image Processing(ICIP'04), Singapore, October 2004.
[18]Heiko Schwarz, Detlev Marpe, Thomas Wiegand.SNR-Scalable Video Coding Based on H.264/AVC IEEE International Workshop on Systems, Signals and Image Processing(IWSSIP 2004), Poznan, Poland, September 2004.
[19]苏曙光.基于H.264扩展架构的可伸缩视频编码关键技术研究[D].武汉:华中科技大学,2006.
[20]谈永敏.可伸缩视频编码的率失真分析及其码率控制[D].上海:上海交通大学,2008.
[21]赵增华.无线网络视频传输技术与可伸缩视频编码[D].天津:天津大学,2006.
[22]J. Xu, R. Xion, B. Fend et al. 3D subband video coding using Barbell lifting. ISO/IEC JTC1/SC29/ WG11 MPEG 68th meeting, M10569/s05, Mar. 2004, Munich, German.
[23]M. Wien, T. Rusert, K. Hanke. RWTH proposal for scalable video coding technology. ISO/IEC JTC1/SC29/ WG11 MPEG 68th meeting, Mar. 2004, Munich, Germany.
[24]Heiko Schwarz, Detlev Marpe, Thomas Wiegand.Scalable Extension of H.264/AVC. ISO/IEC JTC1/SC29/WG11, Munich, Germany, MPEG04/M10569/S03, March 2004.
[25]W. Li. Streaming video profile in MPEG-4. IEEE trans. on Circuits and Systems for Video Technology, Mar. 2001, 11(3): 301-317.
[26]W. Li. Overview of fine granularity scalability in MPEG-4 video standard. IEEE Trans. Circuits and Systems for Video Technology,Mar 2001, 11(3).
[27]朱江.基于DCT的可伸缩视频编码的研究[D].北京:北京邮电大学,2007.
[28]F.Wu,S. P. Li, Y. Q. Zhang. DCT-prediction based progressive fine granularity scalable coding. Proc. International Conference on Image Processing,2000. Vancouver. 566-569.
