第5章 H.264/AVC编码器原理
5.1 概述
MPEG(Moving Picture Experts Group)和VCEG(Video Coding Experts Group)已经联合开发了一个比早期研发的MPEG和H.263性能更好的视频压缩编码标准,这就是被命名为AVC(Advanced Video Coding),也被称为ITU-T H.264建议和MPEG-4的第10部分的标准,在这里就简称它为H.264/AVC或H.264。这个国际标准已于2003年3月正式被ITU-T所通过并在国际上正式颁布。为适应高清视频压缩的需求,2004年又增加了FRExt部分;为适应不同码率及质量的需求,2006年又增加了可伸缩编码SVC。
应该说,H.264的颁布是视频压缩编码学科发展中的一件大事,它优异的压缩性能也将在数字电视广播、视频实时通信、网络视频流媒体传递以及多媒体短信等各个方面发挥重要作用。
数字电视的优越性已是公认的,但它的广泛应用还有赖于高效的压缩技术。例如利用MPEG-2压缩的一路高清晰度电视(HDTV),约需20Mbit/s的带宽,有人作过初步试验,如利用H.264进行一路HDTV的压缩,大概只需5Mbit/s的带宽。众所周知,美国已公布在2010年(我国约在2015年)停止模拟电视广播,全部采用数字电视广播,如果那时HDTV要获得迅猛发展,必须要降低成本。以传输费用而言,采用H.264,可使传输费用降为原来的1/4,这是一个十分诱人的前景。2008年,北京奥运会的成功举办,为中国数字电视,尤其是高清数字电视带来了难得的历史发展机遇,北京、上海、天津等8个奥运城市的观众都切身体验到了高清赛场画面所带来的震撼。一个高质量的压缩性能优异的H.264视频编码技术和设备的市场前景是可以想象的!
视频通信是H.264的又一个重要应用,20世纪90年代初以来,会议电视在我国获得了迅速发展,主要是用于召开行政会议,其优点是节约大量旅途出差时间,节约出差费用,争取了时间并能及时作出重大决策。短短几年,全国从中央到省,到地市甚至县,建立了几千个会议电视室,在国民经济的发展中发挥了重要作用。其不足之处为:一是不方便,必须到电信局专门的电视会议室才能参加会议,这对一些领导同志更是十分不便;二是价格昂贵,当时采用H.261作为视频压缩编码标准,压缩比不高,而且图像质量也不够好,设备价格昂贵,传输费用也昂贵。可视电话是视频通信的另一个重要应用,人们一直把它作为实现古人的“千里眼、顺风耳”理想的通信工具,可是直到今天,尚未很好地广泛地被应用,其中一个重要原因是视频质量不理想,这与视频压缩技术有密切关系。特别是,由于互联网在20世纪90年代的迅猛发展,人们希望利用IP技术传输视频。现在人们已可看到,在网络流量不大时,人们看到的可视电话尽管质量不是很好,但尚能接受;由于IP数据流的突发性,当流量大时,网络会发生拥塞,这时经常发生丢包、误码,看到图像中带有不少方块,这样的视频质量是无法让人们接受的。于是对视频编码的要求,不仅仅要高压缩比,而且应在恶劣的传输条件下(诸如IP网的拥塞和移动网络的衰落)具有抗阻塞、抗误码的健壮性。
H.264不仅具有优异的压缩性能,而且具有良好的网络亲和性,这对实时的视频通信是十分重要的。现在已有基于DSP的采用H.264编码的可视电话出现在市场上,进一步说明了H.264在视频通信中的重要应用价值。
H.264还有一个重要应用,即网络流媒体。众所周知,应用流媒体技术的电视点播(VOD)最近有了迅速发展,韩国的宽带上网的应用中VOD占据了第二位。截至2008年年底,我国宽带上网用户已达2.7亿户以上,网络视频用户达到2.02亿户。
和MPEG-4中的重点是灵活性不同,H.264着重于解决压缩的高效率和传输的高可靠性,因而其应用面十分广泛。具体说来,H.264的基本部分支持3个不同档次的应用。
(1)基本档次:主要用于“视频会话”,如会议电视、可视电话、远程医疗、远程教学等。
(2)扩展档次:主要用于网络的视频流,如视频点播。
(3)主要档次:主要用于消费电子应用,如数字电视广播、数字视频存储等。
5.2 H.264/AVC编解码器
5.2.1 H.264编解码器特点
H.264并不明确地规定一个编解码器如何实现,而是规定了一个编码后的视频比特流的句法,和该比特流的解码方法,各个厂商的编码器和解码器在此框架下应能够互通,在实现上具有较大灵活性,而且有利于相互竞争。
H.264编码器和解码器的功能组成分别如图5.1和图5.2所示。

图5.1 H.264编码器
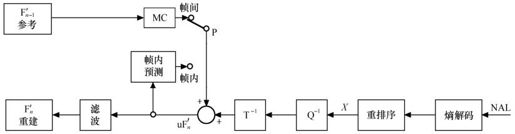
图5.2 H.264解码器
从图5.1和图5.2中可见,H.264和基于以前的标准(如H.261、H.263、MPEG-1、MPEG-4)的编解码器功能块的组成并没有什么区别,主要的不同在于各功能块的细节。由于视频内容时刻在变化,有时空间细节很多,有时大面积的平坦,这种内容的多变性就必须采用相应的自适应的技术措施;由于信道在环境恶劣下也是多变的,例如互联网,有时畅通,有时不畅,有时阻塞,又如无线网络,有时发生严重衰落,有时衰耗很小,这就要求采取相应的自适应方法来对抗这种信道畸变带来的不良影响。这两方面的多变带来了自适应压缩技术的复杂性。H.264就是利用实现的复杂性获得压缩性能的明显改善。由于大规模集成电路技术和工艺的迅猛进步,今天已完全具备了实现的可能性。
在描述各个功能块的细节前,我们还是先对H.264编码器、解码器的主要功能描述,以便对编码器有一个总的了解。
5.2.2 H.264编码器
编码器采用的仍是变换和预测的混合编码法。在图5.1中,输入的帧或场Fn以宏块为单位被编码器处理。首先,按帧内或帧间预测编码的方法进行处理。
如果采用帧间预测编码,其预测值PRED(图中用P表示)是由当前片中前面已编码的参考图像经运动补偿(MC)后得出,其中参考图像用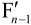 表示。为了提高预测精度,从而提高压缩比,实际的参考图像可在过去或未来(指显示次序上)已编码解码重建和滤波的帧中进行选择。
表示。为了提高预测精度,从而提高压缩比,实际的参考图像可在过去或未来(指显示次序上)已编码解码重建和滤波的帧中进行选择。
预测值PRED和当前块相减后,产生一个残差块Dn,经块变换、量化后产生一组量化后的变换系数X,再经熵编码,与解码所需的一些头信息(如预测模式量化参数、运动矢量等)一起组成一个压缩后的码流,经NAL(网络自适应层)供传输和存储用。
正如上述,为了提供进一步预测用的参考图像,编码器必须有重建图像的功能。因此必须使残差图像经反量化、反变换后得到的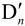 与预测值P相加,得到
与预测值P相加,得到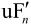 (未经滤波的帧)。为了去除编解码环路中产生的噪声,提高参考帧的图像质量,从而提高压缩图像性能,设置了一个环路滤波器,滤波后的输出
(未经滤波的帧)。为了去除编解码环路中产生的噪声,提高参考帧的图像质量,从而提高压缩图像性能,设置了一个环路滤波器,滤波后的输出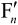 即重建图像,可用作参考图像。
即重建图像,可用作参考图像。
5.2.3 H.264解码器
由图5.1可知,由编码器的NAL输出一个压缩后的H.264压缩比特流。在图5.2中,经熵解码得到量化后的一组变换系数X,再经反量化、反变换,得到残差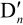 。利用从该比特流中解码出的头信息,解码器就产生一个预测块PRED,它和编码器中的原始PRED是相同的。当该解码器产生的PRED与残差
。利用从该比特流中解码出的头信息,解码器就产生一个预测块PRED,它和编码器中的原始PRED是相同的。当该解码器产生的PRED与残差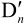 相加后,就产生
相加后,就产生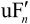 ,再经滤波后,最后就得到滤波后的
,再经滤波后,最后就得到滤波后的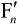 ,这个
,这个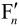 就是最后的解码输出图像。
就是最后的解码输出图像。
5.3 H.264/AVC的结构
5.3.1 名词解释
为了弄清H.264编解码器的细节,必须先对以下名词的定义有清楚的理解。
1.场和帧
视频的一场或一帧可用来产生一个编码图像。通常,视频帧可分成两种类型:连续或隔行视频帧。在电视中,为减少大面积闪烁现象,把一帧分成两个隔行的场。显然,这时场内邻行之间的时间相关性较强,而帧内邻近行空间相关性强,因此活动量较小或静止的图像宜采用帧编码方式,对活动量较大的运动图像则宜采用场编码方式。
2.宏块、片
一个编码图像通常划分成若干宏块组成,一个宏块由一个16×16亮度像素和附加的一个8×8 Cb和一个8×8 Cr彩色像素块组成。每个图像中,若干宏块被排列成片的形式。
I片只包含I宏块,P片可包含P和I宏块,而B片可包含B和I宏块。
I宏块利用从当前片中已解码的像素作为参考进行帧内预测,不能取其他片中的已解码像素作为参考进行帧内预测。
P宏块利用前面已编码的图像作为参考图像进行帧间预测,一个帧内编码的宏块可进一步作宏块的分割,即分成16×16、16×8、8×16或8×8亮度像素块(以及附带的彩色像素)。如果选了8×8的子宏块,则可再分割成各种子宏块,其尺寸为8×8、8×4、4×8或4×4亮度像素块(以及附带的彩色像素)。
B宏块则利用双向的参考图像(当前和未来的已编码的图像帧)进行帧间预测。
5.3.2 档次和级
H.264的基本部分规定了三种主要档次,每个档次支持一组特定的编码功能,并支持一类特定的应用。
(1)基本档次:利用I片和P片支持帧内和帧间编码,支持利用基于上下文的自适应的变长编码进行的熵编码(CAVLC)。主要用于可视电话、会议电视、无线通信等实时视频通信。
(2)主要档次:支持隔行视频,采用B片的帧间编码和采用加权预测的帧间编码;支持利用基于上下文的自适应的算术编码(CABAC)。主要用于数字广播电视与数字视频存储。
(3)扩展档次:支持码流之间有效的切换(SP和SI片)、改进误码性能(数据分割),但不支持隔行视频和CABAC。
图5.3所示为H.264的档次以及各个档次具有的不同功能。可见扩展档次包括了基本档次的所有功能,而不能包括主要档次的。每一档次设置不同参数(如取样速率、图像尺寸、编码比特率等),得到编解码器性能不同的级。
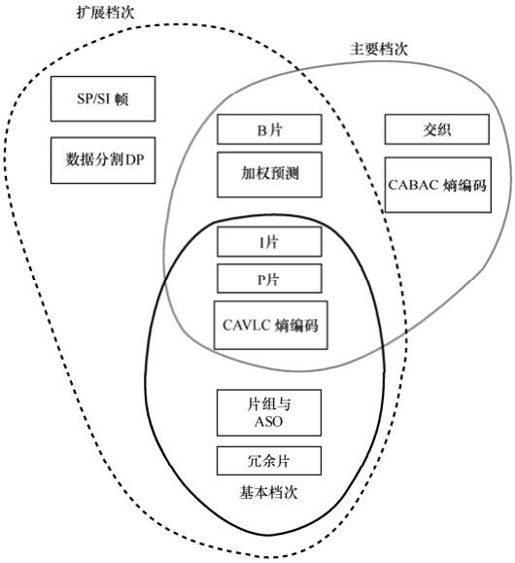
图5.3 H.264档次
5.3.3 编码数据格式
1.H.264的视频格式
H.264支持4∶2∶0的连续或隔行视频的编码和解码,缺省的4∶2∶0的取样格式如图5.4和图5.5所示。
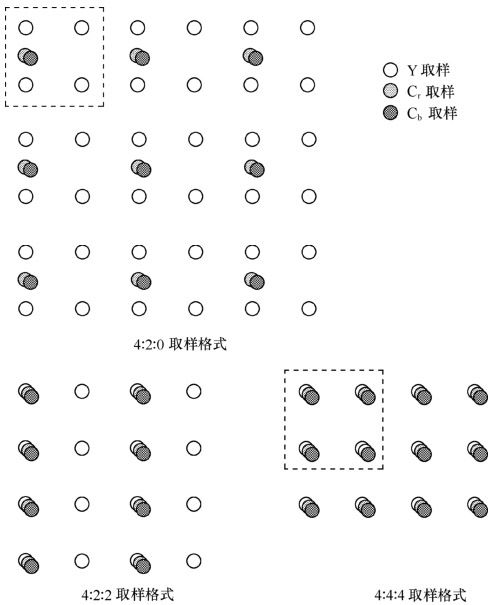
图5.4 连续视频取样格式

图5.5 隔行视频取样格式
2.H.264的编码格式
制订H.264的主要目标有两个。
(1)得到高的视频压缩比。与H.263、MPEG-4相比,视频压缩比提高一倍。
(2)具有良好的网络亲和性,即可适用于各种传输网络。
为此,H.264的功能分为两层:视频编码层(VCL,Video Coding Layer)和网络提取层(NAL,Network Abstraction Layer)。VCL数据即编码处理的输出,它表示被压缩编码后的视频数据序列。在VCL数据传输或存储之前,这些编码的VCL数据,先被映射或封装进NAL单元中。
每个NAL单元包括一个原始字节序列负荷(RBSP,Raw Byte Sequence Payload)、一组对应于视频编码数据的NAL头信息。NAL单元序列的结构如图5.6所示。

图5.6 NAL单元序列
5.3.4 参数图像
为了提高预测精度,H.264编码器可从一组前面或后面已编码图像中选出一个或两个与当前最匹配的图像作为帧间编码间的参数图像,这样一来,复杂度大为增加,但多次比较的结果,使匹配后的预测精度显著改善。H.264中最多可从15个参数图像中进行选择,选出最佳的匹配图像。
对于P片中帧间编码宏块和宏块分割的预测可从表“0”中选择参数图像;对于B片中的帧间编码宏块和宏块分割的预测,可从表“0”和“1”中选择参考图像(表“0”和表“1”的详见第6章)。
5.3.5 片和片组
1.片
一个视频图像可编码成一个或更多个片,每片包含整数个宏块(MB),即每片至少包含一个宏块,最多时可包含整个图像的宏块。总之,一幅图像中每片的宏块数不一定固定。
编码片相互间是独立的,这样做可以限制误码的扩散和传输。某一片的预测不能以其他片中的宏块为参考图像,这样该片中的预测误差才不会传播到其他片中去。
编码片共有5种不同的类型,除了前面已介绍的I片、P片、B片外,还有SP片和SI片。其中SP(切换P)用于不同编码流之间的切换,它包含P宏块和/或I宏块,是扩展档次中的必备功能。SI片包含了一种特殊类型的编码宏块,叫做SI宏块,SI片也是扩展档次中的必备功能。
片的句法结构如图5.7所示。其中,片头规定了片的类型、该片属于哪个图像、有关的参考图像等;片的数据包含一系列的编码宏块(MB),和/或跳编码(不编码)数据。每个MB包含头单元和残差数据,头单元见表5.1。
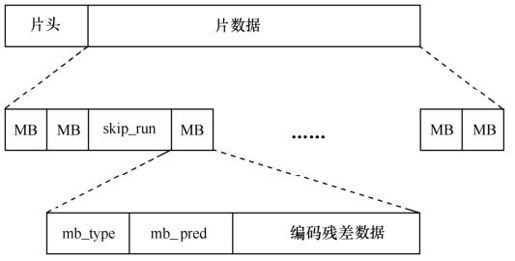
图5.7 片的句法结构
表5.1 宏块的句法单元
2.片组
片组是一个编码图像中若干MB的一个子集,它可包含一个或若干个片,如图5.8至图5.11所示。
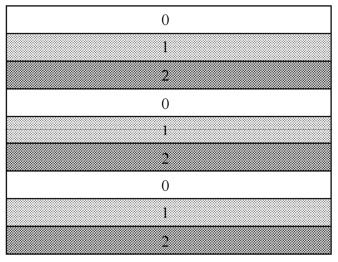
图5.8 交错型片组

图5.9 散乱型片组
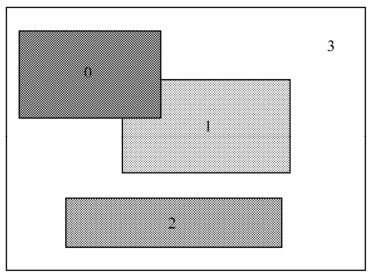
图5.10 前景和背景型片组
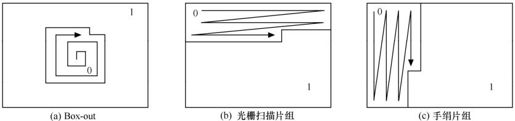
图5.11 片组
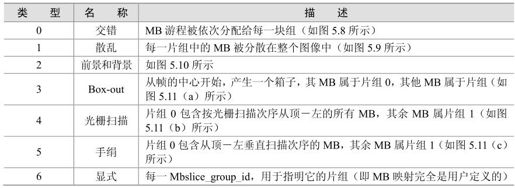
在一个片组中,每片的MB按光栅扫描次序被编码,如果每幅图像仅取一个片组,则该图像中所有的MB均按光栅扫描次序被编码(除非使用任意的片次序(ASO),即一个编码帧中的片之后可跟随任一解码程序的片)。
还有一种片组,叫灵活宏块次序(FMO,Flexible Macroblock Ordering),它可用灵活的方法,把编码MB序列映射到解码图像中MB的分配用MB到片组之间的映射来确定,它表示每一个MB属于哪个片组。MB到片组的各种映射类型见表5.2。
表5.2 MB到片组的映射
5.4 帧内预测
在帧内预测模式中,预测块P是基于已编码重建块和当前块形成的。对亮度像素而言,P块用于4×4子块或者16×16宏块的相关操作。4×4亮度子块有9种可选预测模式,独立预测每一个4×4亮度子块,适用于带有大量细节的图像编码;16×16亮度块有4种预测模式,预测整个16×16亮度块,适用于平坦区域图像编码;色度块也有4种预测模式,类似于16×16亮度块预测模式。编码器通常选择使P块和编码块之间差异最小的预测模式。
此外,H.264还有一种帧内编码模式I_PCM,该模式允许编码器直接传输图像的像素值,而不经过预测和变换。在一些特殊的情况下,特别是图像内容不规则或者量化参数非常低时,该模式比起“常规操作”(帧内预测—变换—量化—熵编码)效率更高。I_PCM模式用于以下目的:
(1)允许编码器精确地表示像素值;
(2)提供表示不规则图像内容的准确值,而不引起重大的数据量增加;
(3)严格限制宏块解码比特数,但不损害编码效率。
在以往H.263+、MPEG-4等视频压缩编码标准中,帧内编码被引入变换域;H.264帧内编码则是参考预测块左方或者上方的已编码块的邻近像素点被引入空间域。但是,如果参考预测块是帧间编码宏块,该预测会因参考块的运动补偿而引起误码扩散,所以参考块通常选取帧内编码的邻近块。
图5.12所示的是采用帧内模式编码的QCIF视频帧,其块或者宏块是通过邻近已编码像素预测而得。图5.13所示的是根据最佳模式而得的预测亮度P帧,该模式使得编码信息量最小。

图5.12 QCIF帧(帧内预测)

图5.13 预测帧
5.4.1 4×4亮度预测模式
如图5.14所示,4×4亮度块的上方和左方像素A~Q为已编码并进行重构的像素,用作编解码器中的预测参考像素。a~p为待预测像素,利用A~Q值和9种模式实现。其中模式2(DC预测)根据A~Q中已编码像素预测,而其余模式只有在所需预测像素全部提供后才能使用。图5.15中的箭头表明了每种模式的预测方向。对模式3~8,预测像素由A~Q加权平均而得。例如,模式4中,d=round(B/4+C/2+D/4)。表5.3给出了这9种模式的描述。
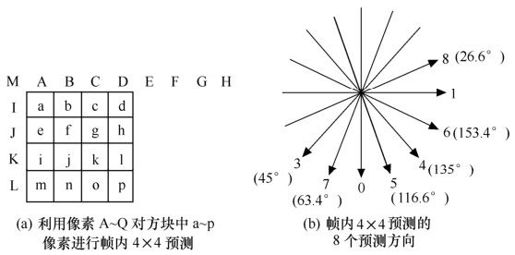
图5.14 4×4亮度预测
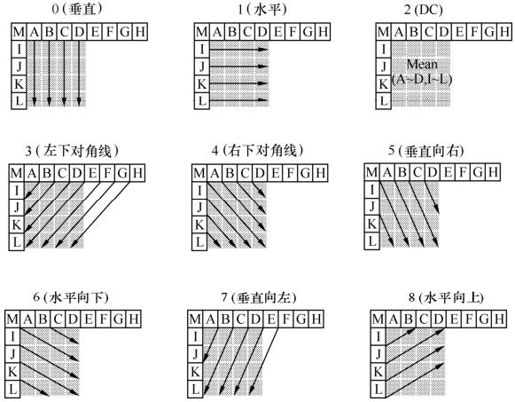
图5.15 4×4亮度块预测模式
表5.3 预测模式描述

举例:图5.15所示的4×4块的9种预测模式计算所产生的相应预测块如图5.16所示(SAE定义了每种预测的预测误差)。其中,与当前块的最匹配的模型为模式8,因为该模式SAE最小且最接近于原始4×4块。

图5.16 预测块(亮度4×4)

图5.16 预测块(亮度4×4)(续)
5.4.2 16×16亮度预测模式
宏块的全部16×16亮度成分可以整体预测,有4种预测模式,如图5.17所示,其描述见表5.4。
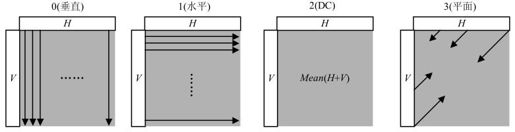
图5.17 16×16预测模式
表5.4 16×16预测模式

举例:图5.18为一个左上方像素已编码的亮度宏块。图5.19为4种预测模式的预测结果。其中模式3与原始宏块最匹配。帧内16×16模式适用于图像平坦区域的预测。

图5.18 16×16宏块

图5.19 帧内16×16预测块
5.4.3 8×8色度块预测模式
每个帧内编码宏块的8×8色度成分由已编码左上方色度像素预测而得,两种色度成分常用同一种预测模式。4种预测模式类似于帧内16×16预测的4种预测模式,只是模式编号不同。其中DC为模式0,水平为模式1,垂直为模式2,平面为模式3。
5.4.4 帧内预测模式的选择和编码
1.帧内预测模式的选择
H.264采用拉格朗日率失真优化(RDO,Rate Distortion Optimization)策略进行最优化编码模式选择,通过遍历所有可能的编码模式,最后选择最小率失真代价模式作为最佳帧内预测模式。具体的编码模式选择过程如下。
(1)计算当前4×4块和重建的4×4块之间的差值平方和(SSD,Sum of Squared Difference)以及编码的比特率。
(2)分别按公式(5.1)计算9种帧内模式的率失真值
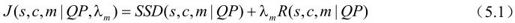
式中,QP是宏块的量化参数,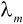 是拉格朗日乘数,与QP有关,SSD(
是拉格朗日乘数,与QP有关,SSD( )是原始亮度块s与重建块c之间的差值平方和,R(
)是原始亮度块s与重建块c之间的差值平方和,R( )是利用模式m进行编码的比特数。
)是利用模式m进行编码的比特数。
(3)选择具有最小率失真值的模式作为最佳4×4帧内预测模式。
(4)对宏块内16个4×4块重复以上步骤(1)~(3),获得每一个4×4块的最佳预测模式和相应的最小率失真值。
(5)累加计算得出的16个块的最小率失真值,得到当前宏块的4×4帧内预测率失真值。
(6)按类似的方法,分别计算当前宏块在4种帧16×16模式下的宏块率失真值,选择宏块率失真值最小的模式为最佳帧内16×16预测模式。
(7)根据步骤(5)和步骤(6)中最小的率失真值,选择亮度宏块采用4×4或16×16帧内预测模式。
(8)8×8色度宏块的帧内预测模式,方法与亮度类似。
在基本档次下,以色度模式为外循环,依次扫描亮度模式,搜索的总数为4×(9×16+4)=592次,获得最优的帧内预测模式的计算量非常大。
2.帧内预测模式的编码
每个4×4块帧内预测模式必须转变成信号传给解码器。该信息可能需大量比特表示,但邻近块的帧内模式通常是相关的。例如,A、B、E分别为左边、上边和当前块,如果A和B预测模式为模式1,当前块E的最佳预测模式很可能也为模式1。通常利用这种相关性来表征4×4帧内模式。
对每个当前块E,编码器和解码器需要计算最可能的预测模式和A、B预测模式的较小者。如果这些相邻块不存在(当前片外或者非帧内4×4模式),相应值A或B置2(DC预测模式)。
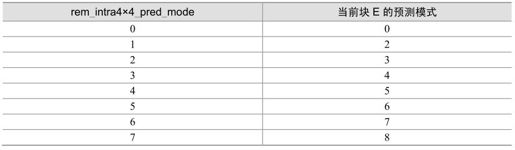
编码器分配每个4×4块一个标志prev_intra4×4_pred_mode。该标志置1时,使用最可能预测模式;置0时,使用参数rem_intra4×4_pred_mode来指明模式变化。rem_intra4×4_pred_mode小于当前最可能模式时,预测模式选rem_intra4×4_pred_mode;否则预测模式为rem_intra4×4_pred_mode+1。rem_intra4×4_pred_mode值为0~7。
举例:块A和B分别用模式3和模式1预测。当前块E的最可能的预测模式则为1,prev_intra4×4_pred_mode置0,rem_intra4×4_pred_mode被传送。块E的预测模式取决于rem_intra4×4_pred_mode的值,表5.5所示的是8种可选的预测模式。
表5.5 预测模式选择(最可能模式为1)
帧内16×16亮度和色度预测模式在宏块头中指明。
这里需说明的是,包括帧内预测的所有预测都不能跨片边界预测,每片必须独立编解码。
5.5 帧间预测
H.264帧间预测在继承了以往标准中成熟的编码框架的同时,得到了进一步的增强和改善,同时还增加了一些新的技术和方法,包括可变尺寸块运动补偿、1/4像素精度的运动估计以及多参考帧等。
下文将重点讨论基本(Baseline)档次支持的P片帧间预测工具及主要(Main)和扩展(Extended)档次支持的B片和加权预测等帧间预测工具。SP/SI的内容将在后面的章节中有详细的阐述。
5.5.1 可变尺寸块运动补偿
每个宏块(16×16像素)可以按4种方式进行分割:1个16×16,2个16×8,2个8×16,4个8×8。其运动补偿也相应有四种。而8×8模式的每个子宏块还可以进一步用4种方式再进行分割:1个8×8,2个4×8或两个8×4及4个4×4。这些分割和子宏块大大地提高了各宏块之间的关联性。这种分割下的运动补偿称为树状结构运动补偿,如图5.20所示。
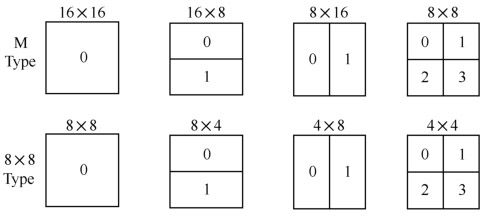
图5.20 宏块及子宏块分割
每个分割或子宏块都有一个独立的运动补偿。每个运动矢量MV必须被编码和传输,分割的选择也需编码到压缩比特流中。对大的分割尺寸而言,MV选择和分割类型只需少量的比特来表征,但运动补偿残差在多细节区域能量将非常高。小尺寸分割运动补偿残差能量低,但需要较多的比特来表征MV和分割选择,分割尺寸的选择影响了压缩性能。整体而言,大的分割尺寸适合平坦区域,而小尺寸适合多细节区域。
宏块的色度成分(Cr和Cb)则为相应亮度的一半(水平和垂直各一半)。色度块采用和亮度块同样的分割模式,只是尺寸减半(水平和垂直方向都减半)。例如,8×16的亮度块相应的色度块尺寸为4×8,8×4亮度块相应的色度块尺寸为4×2等。色度块的MV也是通过相应亮度MV水平和垂直分量减半而得。
举例:图5.21显示了一个残差帧(没有进行运动补偿)。H.264编码器为帧的每个部分选择了最佳分割尺寸,使传输信息量最小,并将选择的分割加到残差帧上。在帧变化小的区域(残差显示灰色),选择16×16分割;多运动区域(残差显示黑色或白色),选择更有效的小尺寸分割。
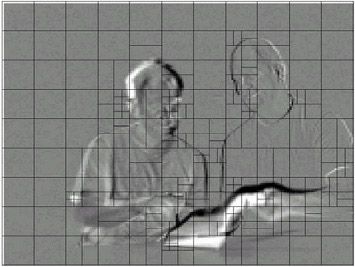
图5.21 残差帧
5.5.2 运动矢量
帧间编码宏块的每个分割或者子宏块都是从参考图像的某一相同尺寸区域预测而得。两者之间的差异(MV)对亮度成分采用1/4像素精度,色度成分采用1/8像素精度。亚像素位置的亮度和色度像素并不存在于参考图像中,需利用邻近已编码点进行内插而得。如果MV的垂直和水平分量为整数,则参考块相应像素实际存在。如果其中一个或两个为分数,预测像素则要通过参考帧中相应像素内插获得。
图5.22描述了亮度半像素内插方法。图中A、B、C、D、E、F、G、H等为整像素点,b、h、m、s、aa、bb、cc、dd等为半像素点。
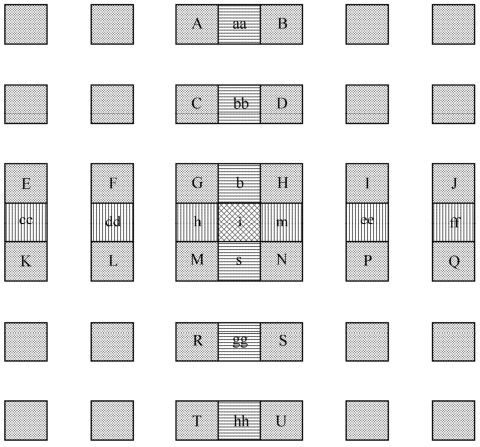
图5.22 亮度半像素位置内插
首先生成参考图像亮度成分半像素位置像素。半像素点(如b、h、m、s)通过对相应整像素点进行6抽头FIR滤波器滤波得出,权重为(1/32, -5/32, 5/8, 5/8, -5/32, 1/32)。b的计算公式如下:
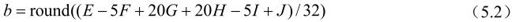
式中,round()为取整函数,输出值取输入最接近的整数。
类似的,h由A、C、G、M、R、T滤波得出。只要邻近(垂直或水平方向)整像素点的所有像素都计算出,剩余的半像素点便可以通过对6个垂直或水平方向的半像素点滤波而得。例如,j由cc、dd、h、m、ee、ff滤波得出。这里需要说明的是,6抽头FIR滤波器尽管比较复杂,但可明显改善运动补偿性能。
半像素点计算出来以后,1/4像素点就可通过线性内插得出,如图5.23所示。1/4像素点(如a、c、i、k、d、f、n、q)由邻近像素内插而得,如
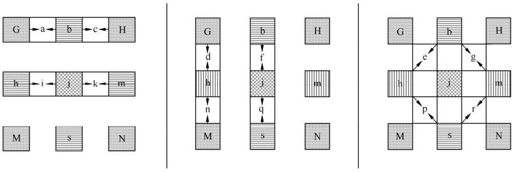
图5.23 亮度1/4像素内插

剩余1/4像素点(p, r)由两个对角半像素点线性内插得出。如e由b和h获得。
相应地,色度像素需要1/8精度的MV,也同样通过整像素的线性内插得出,如图5.24所示。
图5.24 色度1/8像素内插
其中,有
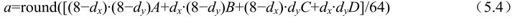
当dx=2,dy=3时,
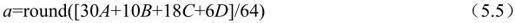
5.5.3 MV预测
每个分割MV的编码需要相当数目的比特,特别是使用小的分割尺寸时。为减少传输比特数,利用邻近分割的MV较强的相关性,MV可由邻近已编码分割的MV预测而得。预测矢量MVp基于已计算MV和MVD(预测与当前的差异),并被编码和传送。MVp取决于运动补偿尺寸和邻近MV的有无。
E为当前宏块或宏块分割子宏块。A、B、C分别为E的左、上、右上方的三个相对应块。如果E的左边不止一个分割,取其中最上的一个为A;上方不止一个分割时,取最左边一个为B。图5.25显示了所有分割有相同尺寸时的邻近分割选择。图5.26给出了不同尺寸时临近分割的选择。
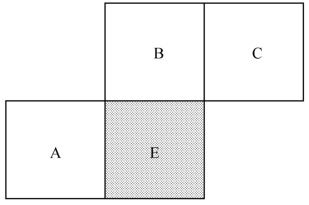
图5.25 当前和邻近分割(相同尺寸)
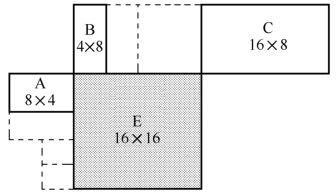
图5.26 当前和邻近分割(不同尺寸)
其中:
(1)传输分割不包括16×8和8×16时,MVp为A、B、C分割MV的中值;
(2)16×8分割,上面部分MVp由B预测,下面部分MVp由A预测;
(3)8×16分割,左面部分MVp由A预测,右面部分MVp由C预测;
(4)Skipped宏块,MVp为A、B、C分割MV的中值。
如果图5.26所示的已传送块不存在时(如在当前片外),MVp选择需重新调整。在解码端,MVp以相同的方式形成并加到MVD上。对跳跃宏块来说,不存在MVD,运动补偿宏块也由MV直接生成。
5.5.4 B片预测
B片中的帧间编码宏块的每个子块都是由一个或两个参考图像预测而得。该参考图像在当前图像的前面或者后面。参考图像存储于编解码器中,其选择有多种方式。图5.27显示了三种方式:一个前向和一个后向的(类似于MPEG的B图像预测)、两个前向、两个后向。
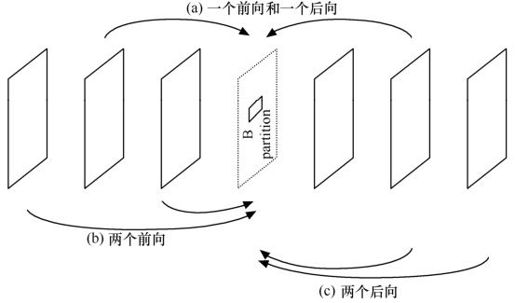
图5.27 分割预测举例
1.参考图像
B片用到了两个已编码图像列表:list0和list1,包括短期和长期图像两种。这两个列表都可包含前向和后向的已编码图像,图像的显示顺序排列采用图像顺序号POC表示。其中,
list0:最近前向图像标为index0,接着是其余前向图像(POC递减顺序)及后向图像(POC递增顺序)。
list1:最近后向图像标为index0,接着是其余后向图像(POC递增顺序)及前向图像(POC递减顺序)。
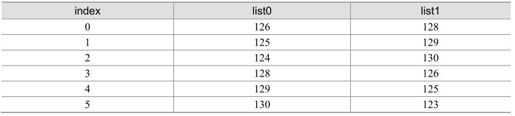
举例:一个H.264解码器存储了6幅短期参考图像,其POC分别为:123,125,126,128,129和130,当前图像为127。所有6幅短期参考图像在list0和list1中都标为“用作参考”,如表5.6所示。
表5.6 短期缓冲索引
选择的缓冲索引采用指数哥伦布(Exp-Golomb)的统一变长编码发送。最有效的参考索引(codeword最小)便是index0(例如:前向编码图像在list0中,后向编码图像在list1中)。
2.预测模式选择
B片的预测方式包括:宏块分割方式、双向选择方式、参考列表选择方式等等。具体说,B片中宏块分割可由多种预测方式中的一种实现,如直接模式、利用list0的运动补偿模式、利用list1的运动补偿模式或者利用list0和list1的双向运动补偿模式等。表5.7给出了不同分割模式下各自可选择的预测模式。如果8×8分割被使用,每个8×8分割所选择的模式适用于分割中的所有亚分割。图5.28给出了例子,左边的两个16×8分割分别使用list0和双向预测模式,而右边的4个8×8分割分别采用了直接、list0、list1和双向预测四种模式。
表5.7 B片宏块预测选择

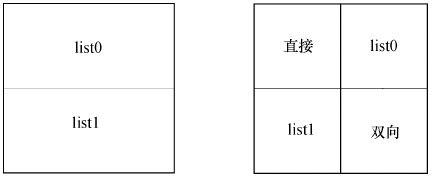
图5.28 B片中分割预测模式举例
3.双向预测
双向预测中,参考块(与当前分割或亚分割同尺寸)是由list0和list1的参考图像得出的。从list0和list1分别得出两个运动补偿参考区域(需要两个MV),而预测块的像素取list0和list1相应像素的平均值。当不用加权预测时,用下列等式:
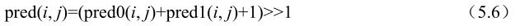
其中,pred0(i, j)和pred1(i, j)为由list0和list1参考帧推出的预测像素,pred(i, j)为双向预测像素。计算出每个预测像素后,运动补偿残差通过当前宏块像素减pred(i, j)而得。
举例:一宏块用B_Bi_16×16模式预测。图5.29和图5.30分别给出了基于list0和list1参考图像的运动补偿参考区域。图5.31给出了根据这两个参考区域的双向预测。

图5.29 参考区域(list0)

图5.30 参考区域(list1)

图5.31 双向预测(无加权)
双向预测宏块或块中的list0和list1矢量根据邻近相同方向的MV预测而得。
4.直接预测
直接预测模式编码的B片宏块或宏块分割不传送MV。而是由解码器计算list0和list1中已编码MV,得出直接模式的双向预测运动补偿。B片中的skipped宏块就是由解码器采用直接模式重建而得。
直接预测模式具体可分为空域和时域两种模式,由片头指明。空域和时域均采用共同位置(co-located)宏块的运动矢量和参考索引。
在空域直接预测模式中,list0和list1预测矢量计算如下:
如果第一幅list1参考图像的co-located MB或分割有一个MV幅度上小于±1/2亮度像素,其一个或两个预测矢量置为0;否则预测list0和list1矢量用以计算双向运动补偿。
在时域直接预测模式中,计算步骤如下:
(1)找出list0图像co-located MB或相应的分割作为参考;
(2)找出list1图像co-located MB或相应的分割作为参考;
(3)计算当前图像和list1图像的MV,作为新的list1 MV1;
(4)计算当前图像和list0图像的MV,作为新的list0 MV0。
当然,这些模式在预测参考宏块、分割不存在或帧内编码等情况下需作出调整。
举例:当前宏块list1参考在当前帧两幅图像后出现,如图5.32所示。list1参考co-located MB有MV(+2.5,+5),指向list0参考图像(出现于当前图像的3幅图像前)。解码器分别计算指向list1和list0的MV1(-1,-2)和MV0(+1.5,+3)。
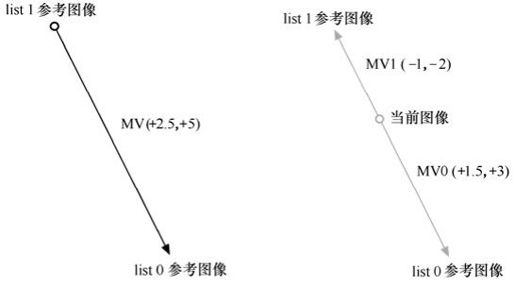
图5.32 时间直接运动矢量举例
5.5.5 加权预测
加权预测是一种用来修正P片或B片中运动补偿预测像素方法。H.264中有3种加权预测类型:
(1)P片宏块“explicit”加权预测;
(2)B片宏块“explicit”加权预测;
(3)B片宏块“implicit”加权预测。
每个预测像素pred0(i, j)和pred1(i, j)在运动补偿之前通过加权系数ω0和ω1修正。在“explicit”类型中,加权系数由编码器决定并在片头中传输。在“implicit”类型中,系数ω0和ω1由相应list0和list1参考图像的时间位置推出。大的系数用于时间上接近当前图像的情况,小的则用于时间上远离当前图像的情况。
可见,H.264采用树状结构的运动补偿技术,提高了预测能力。特别是,小块预测提高了模型处理的运动描述能力,产生更好的图像质量。H.264运动向量的精度提高到1/4像素(亮度分量),运动补偿算法的预测能力得到进一步提高。H.264还提供多参考帧可选模式,这将产生更好的视频质量和效率更高的视频编码。相对于1帧参考,5个参考帧可以节约5%~10%的比特率,且有助于比特流的恢复。当然,并不是说参考帧越多越好,经实验,考虑到缓冲区的能力和编码器的效率,目前一般都选取3~5个参考帧。
5.6 H.264的SP/SI帧技术
当前视频编码标准主要包括3种的帧类型:I帧、P帧和B帧。H.264/AVC为了顺应视频流的带宽自适应性和抗误码性能的要求,又定义了两种新的帧类型:SP帧和SI帧。
SP帧编码的基本原理同P帧类似,仍是基于帧间预测的运动补偿预测编码,两者之间的差异在于SP帧能够参照不同参考帧重构出相同的图像帧。充分利用这一特性,SP帧可取代I帧,广泛应用于流间切换(bitstream switching)、拼接(splicing)、随机接入(random access)、快进快退(fast forward、fast backward)以及错误恢复(error recovery)等应用中,同时大大降低了码率的开销。与SP帧相对应,SI帧则是基于帧内预测的编码技术,其重构图像的方法SP完全相同。
SP帧的编码效率尽管略低于P帧,但却远远高于I帧,大大改善了H.264的网络亲和性,支持灵活的流媒体服务应用,具有很强的抗误码性能,适合在噪声干扰大、丢包率高的无线信道中传输。
5.6.1 SP/SI帧的应用
视频流传输已经成为了“尽力而为”的因特网和无线网络的基本应用,而网络传输条件是时变的。正是为了满足视频流切换的需求,H.264提出了SP/SI帧技术,从而解决了视频流应用中终端用户可用带宽不断变化、不同内容节目拼接时数据量的激增、快进快退以及错误恢复等问题。
1.流间切换
视频服务器应该可以根据网络条件,调整编码码率,实现带宽的自适应性。这涉及会话业务和流业务两种应用场合。其中会话业务的特点是实时编解码、点对点传输,一般根据解码端的反馈信息,调整码率或帧率;而流业务的特点是非实时编解码,这往往采用预先编码得到不同质量和带宽要求的视频码流。
下面主要以流业务的应用为例进行介绍。众所周知,实现带宽自适应的最好方法是设置多组不同的信源编码参数对同一视频序列分别进行压缩,从而生成适应不同质量和带宽要求的多组相互独立的码流。这样,视频服务器只需在不同的码流间切换,以适应网络有效带宽的不断变化。
设{P1,n-1,P1,n,P1,n+1}和{P2,n-1,P2,n,P2,n+1}分别是同一视频序列采用了不同的信源编码参数编码所得到的两个视频流。由于编码参数不同,两个码流中同一时刻的帧,如P1,n-1和P2,n-1,并不完全一样。假设服务器首先发送视频流P1,到时刻n再发送视频流P2,则解码端接收到的视频流为{P1,n-2,P1,n-1,P2,n,P2,n+1,P2,n+2}。在这种情况下,由于接收的P2,n应使用的参考帧应该是P2,n-1而不是P1,n-1,所以P2,n帧就不能完全正确地解码。在以往的视频压缩标准中,实现码流间的切换功能时,确保完全正确解码的前提条件是切换帧不得使用当前帧之前的帧信息,即只使用I帧。在实际的流业务码流切换中,往往通过周期性地放置I帧确实能实现流间切换等功能,但I帧的插入势必造成视频流数据量增大,增加传输带宽的要求。
从SP帧的特性可知,使用不同的参考帧作预测,也可以得到完全相同的解码帧。这一特点正好适用于流间切换。如图5.33所示,视频流明确的切换点处放置主SP帧(Primary SP-frames)——S1,n帧和S2,n帧。在不同编码参数的视频流间进行切换时,发送与主SP帧相对应的辅SP帧(Secondary SP-frames)——S12,n。当然,信源编码部分根据需要插入SP/SI帧,也适当增加了编码的复杂度。
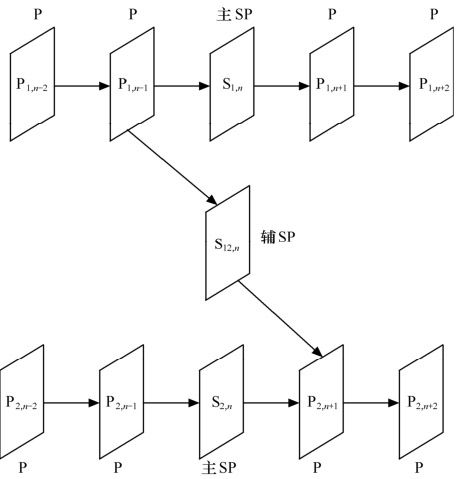
图5.33 SP帧进行流间切换
2.拼接(Splicing)与随机接入(Random Access)
上述流间切换的例子讨论了同一图像序列、不同编码参数压缩编码的流间切换。然而,实际的流间切换的应用并不单单如此。例如,关注同一事件而处于不同视角的多台摄像机的输出码流间的切换和电视节目中插入广告等,这就涉及拼接不同图像序列生成码流的问题。如图5.34所示,由于各个码流来自于不同的信源,帧间缺乏相关性,切换点处的辅帧如果仍采用帧间预测的辅SP帧,编码就不会那么有效,而应采用空间预测的SI帧——SI2,n帧。
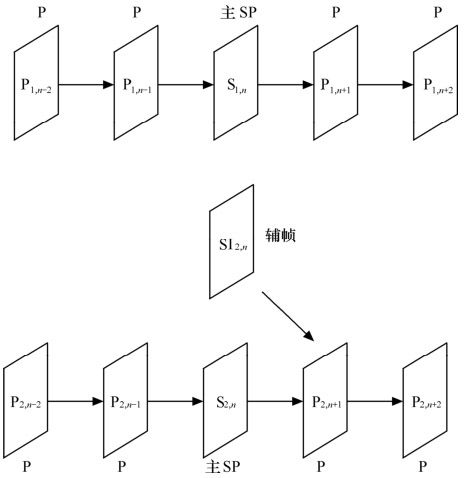
图5.34 SI帧进行拼接和随机接入
综上所述,SP帧与SI帧均可用于流间切换。当视频流的内容相同,编码参数不同时,采用SP帧;而当视频流的内容相差很大时,采用SI帧将更加有效。
3.错误恢复
采用不同的参考帧预测,可以获得同一帧的多个SP帧,利用这种特性可以增强错误恢复的能力。例如,如图5.35所示,正在进行视频流传输的比特流中的一个帧P1,n-1无法正确解码,得到用户端反馈的错误报告后,服务器就可以发送其后最邻近主SP帧的一个辅SP帧——S12,n,以避免错误影响更多后续帧,S12,n帧的参考帧是已经正确解码的帧。当然,用户端也可以使用辅SI帧——SI1,n来实现相同的功能。
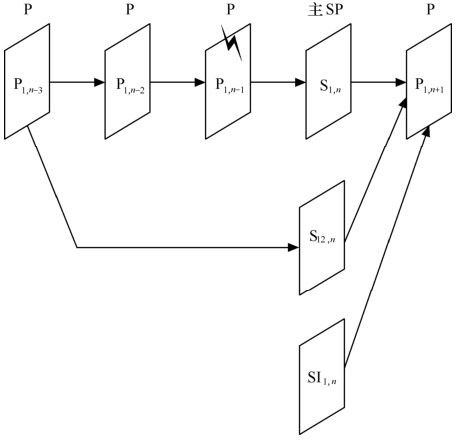
图5.35 SP帧进行错误恢复
5.6.2 SP/SI帧的基本原理
从上述的应用可知,SP帧分为主SP帧(Primary SP-Frame)和辅SP帧(Secondary SP-Frame)。其中,前者的参考帧和当前编码帧属于同一个码流,而后者则不属于同一个码流。与此同时,如图5.36所示,主SP帧作为切换插入点,不切换时,码流进行正常的编码传输;而切换时,辅SP帧取代主SP帧进行传输。其中,△:编码器的输入。〇:解码器的输出。
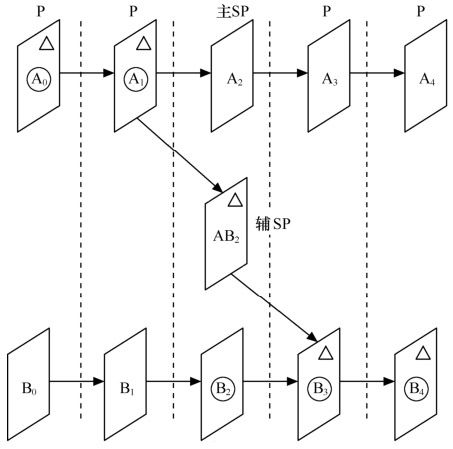
图5.36 流间切换中SP帧编码顺序图
下面描述SP帧实现的功能原理。SI帧的功能实现与SP帧相类似,都能恢复出相同的解码图像帧,只是前者利用的是帧间预测,而后者利用的则是帧内预测。
1.主SP帧的编码过程
主SP帧的编码过程如图5.37所示。从结构上看,与传统P帧编码的不同之处在于:变换处理提到了求差值,即前者的预测残差是变换系数的差值。改进的目的在于使得主辅两种SP帧的编码器能相结合。主SP帧的编码的具体过程如下:预测块P(x,y)是利用原始图像和已重建帧进行运动补偿预测得到的。对预测块P(x,y)和原始图像中相对应的块分别进行正向变换,然后用量化参数SPQP对预测块P(x,y)的变换系数进行量化和反量化,得到系数dpred。将原始图像中相对应的变换系数减去dpred就得到预测残差cerr,然后将cerr用量化参数PQP进行量化,其结果lerr和运动矢量一起传送到多路复用器。
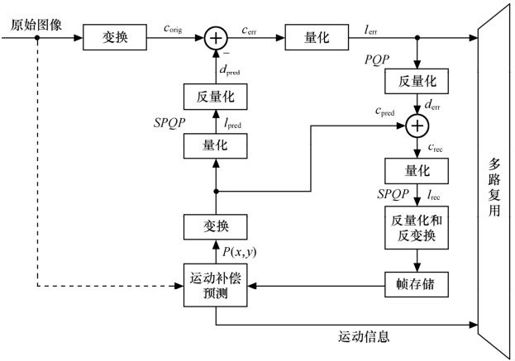
图5.37 SP帧的编码原理图
在这个编码器中,用于对crec也就是对预测重构块系数进行量化的量化参数SPQP与对预测残差系数cerr进行量化的量化参数PQP没有必要相同。因此,对预测块系数可采用不同于对预测残差系数的量化参数,以使产生的重建误差更小。
以主SP帧A2的编码过程为例,如图5.38所示。与P帧编码过程相比,主SP帧的编解码过程有所不同。视频序列中帧A2和帧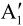 (帧A2参考帧A1的重建图像)分别经过变换处理,得到的变换系数计算出变换系数差值,再进行量化和熵编码,最终得到主SP帧的编码。
(帧A2参考帧A1的重建图像)分别经过变换处理,得到的变换系数计算出变换系数差值,再进行量化和熵编码,最终得到主SP帧的编码。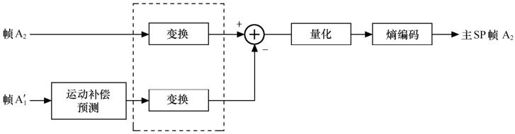
图5.38 主SP帧A2的编码过程示意图
2.主SP帧的解码
图5.39描述了主SP帧的解码原理图。获得预测块P(x,y),后进行正变换,变换后得到的系数记为cpred,将编码端输出的已经量化的预测残差系数lerr采用量化参数PQP进行反量化,得到的系数记为derr。derr与cpred的和记为crec,重建系数crec采用量化参数SPQP进行量化和反量化,并对反量化后获得的drec进行反变换和滤波,即得重建图像。
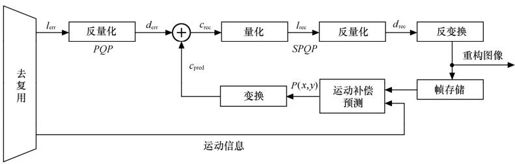
图5.39 主SP帧解码原理图
以主SP帧A2的解码过程为例,如图5.40所示。主SP帧A2经过熵解码和反量化,和帧 ′(帧A2参考帧A1的重建图像)分别经过运动补偿预测和变换处理的结果相加,得到重建图像的变换系数值,再进行反变换,最终得到主SP帧的重构图像帧
′(帧A2参考帧A1的重建图像)分别经过运动补偿预测和变换处理的结果相加,得到重建图像的变换系数值,再进行反变换,最终得到主SP帧的重构图像帧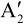 。
。
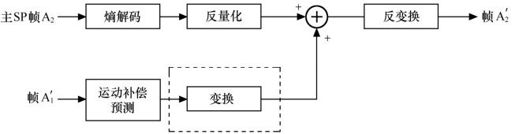
图5.40 主SP帧A2的解码过程示意图
3.辅SP/SI帧编码过程
设以P1(x, y)作为预测帧时,主SP帧的重建图像为Ic(x, y),Ic(x, y)由重建系数lrec做反量化和反变换得到。假设另一预测帧为P2(x, y),若要得到与主SP帧具有相同重建图像Ic(x, y)的辅SP帧,所要做的就是找到新的预测残差系数lrec,2,使得利用P2(x, y)而不是P1(x, y)也能准确地重建图像Ic(x, y)。对P2(x, y)进行变换并量化,量化后的系数记为lpred,2,则辅SP帧的预测残差系数lerr,2可按下式计算得到
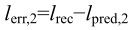
然后把计算所得的预测残差系数lerr,2进行无损的熵编码。解码端生成P2(x, y)后,对P2(x, y)进行变换和量化,得到lpred,2,其值与编码器端的值相同。lpred,2与接收到的预测残差系数lerr,2相加,所得和为lrec,对lrec进行反量化和反变换,就得到了重建图像Ic(x, y),其与以P1(x, y)作为预测帧得主SP帧所重建得图像完全相同。辅SP帧的编码过程也如图5.37所示。
以辅SP帧AB2的编码过程为例,如图5.41所示。
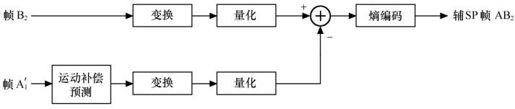
图5.41 辅SP帧AB2的编码过程示意图
4.辅SP/SI帧的解码
图5.42是辅SP/SI帧的解码原理图。首先获得预测块P(x, y),对于SP帧,P(x, y)是利用编码端输出的运动矢量和参考帧号等信息经过运动补偿预测得到。对于SI帧,P(x, y)则是利用编码端输出的帧内预测模式信息通过空间预测得到。然后,对P(x, y)进行正向变换,并将获得的变换系数量化,其结果记为lpred。lpred和量化后的预测残差系数lerr相加得到已经量化的重建系数lrec,lrec量化得到drec,drec反变换并加以滤波即得重建图像。
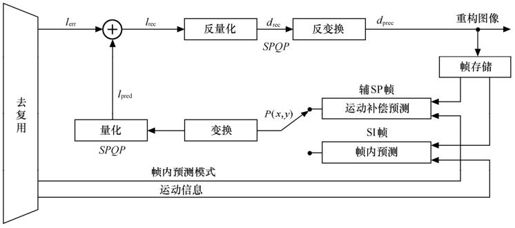
图5.42 辅SP/SI帧的解码原理图
以辅SP帧AB2的编码过程为例,如图5.43所示。

图5.43 辅SP帧AB2的解码过程示意图
5.6.3 实验结果和性能分析
在TML8.7参考测试模型基础上,采用5个参考帧的UVLC模式,并选用率失真优化选项。仿真选用的JVT测试序列,帧率为10帧/秒。针对SP帧的编码效率和序列周期性插入SP帧的编码效率分别进行了测试,实验结果参考本章的参考文献[1]。
1.SP帧的编码效率
图5.44给出了SP帧、I帧和P帧编码效率的比较。序列的起始帧均按I帧编码处理,其余帧分别按SP帧、I帧和P帧进行编码。图中SP帧编码又给出了3种不同的SPQP值:SPQP=PQP、SPQP=3、SPQP=PQP-6。可以看出,SP帧的编码效率低于P帧,但远远高于I帧。选择恰当的SPQP值,可以改善SP帧的编码效率。其中,SPQP的值相对于PQP的下降,SP帧的编码效率逐渐提高。当SPQP=3时,SP帧的编码效率非常接近P帧的编码效率。
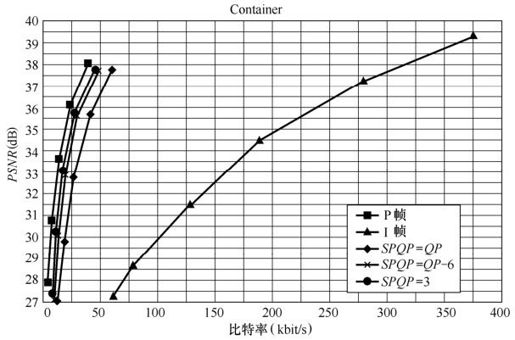
图5.44 SP帧、I帧、P帧编码效率的比较
2.序列周期性插入SP帧的编码性能
如上所述,在流间切换或随机接入等应用中,往往需要在序列中周期性地插入SP帧或I帧。设定序列的起始帧为I帧,每隔一个固定周期(1s)插入一个SP帧或I帧,其余帧则仍采用P帧。当然只是周期性插入SP帧和I帧,还不能实现上述功能,但可以给出序列插入I帧和SP帧后编码性能的比较。由图5.45中可以看出,在实现同样功能的情况下,SP帧的编码效率比I帧高得多,而通过降低SPQP值,SP帧的编码效率将获得进一步改善,逐步逼近P帧的编码效率。
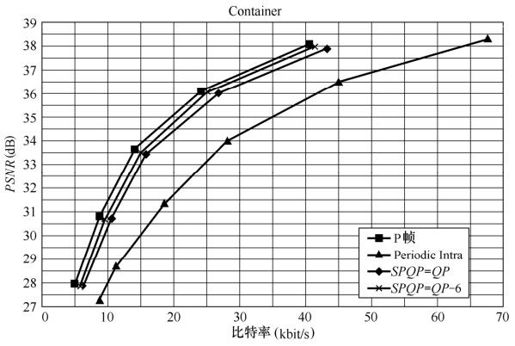
图5.45 序列周期性插入SP帧、I帧的比较
5.7 整数变换与量化
为了进一步节省图像传输码率,需要对图像信号进行压缩,通常采用变换编码及量化来消除图像信号中的相关性及减小图像编码的动态范围。变换编码将图像时域信号变换成频域信号,在频域中,图像信号能量大部分集中在低频区域,相对时域信号,码率有较大的下降。H.264对图像或预测残差采用了4×4整数离散余弦变换技术,避免了以往标准中使用的通用8×8离散余弦变换、逆变换经常出现的失配问题。量化过程根据图像的动态范围大小确定来量化参数,既保留了图像必要的细节,又可减少码流。
在图像编码中,变换编码和量化从原理上讲是两个独立的过程。但在H.264中,将两个过程中的乘法合二为一,并进一步采用整数运算,减少编解码的运算量,提高图像压缩的实时性,这些措施对峰值信噪比(PSNR)的影响很小,一般低于0.02dB,可忽略不计。H.264中整数变换及量化的具体过程如图5.46所示。其中,如果输入块是色度块或帧内16×16预测模式的亮度块,则将宏块中各4×4块的整数余弦变换的直流分量组合起来再进行Hadamard变换,进一步压缩码率。
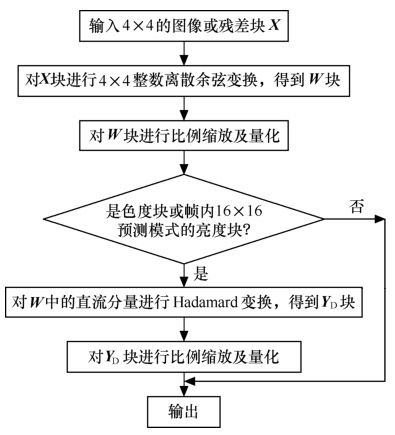
图5.46 编码器中变换编码及量化过程
图5.46和图5.47给出了编码器中变换编码及量化过程的流程。
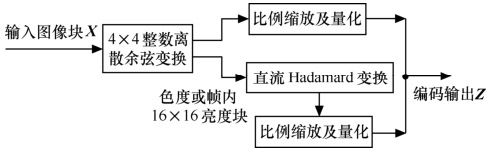
图5.47 编码变换及量化过程流程图
5.7.1 整数变换
一维N点离散余弦余弦变换(DCT)可以表示为:

其中,xn是输入时域序列中第n项,yk是输出频域序列中第k项,系数Ck定义如下:
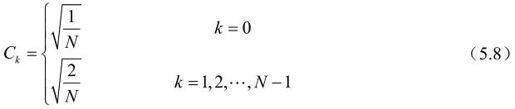
每个DCT系数yk确定信号xn在相应频率点上的贡献。最低的系数(即k=0)为DC系数,代表信号的平均值,也称为直流分量。其他系数称为AC系数,与递增的较高频率相联系。
一维N点离散余弦逆变换(IDCT)可以表示为:

二维N×N图像块的DCT可以理解为先对图像块的每行进行一维DCT,然后对经行变换的块的每列再应用一维DCT。可以表示为:
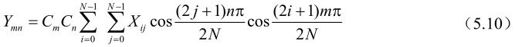
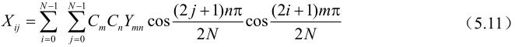
其中,Xij是图像块X中第i行第j列图像或残差值,Ymn是变换结果矩阵Y相应频率点上的DCT系数。可以用矩阵表示:

其中N×N变换矩阵A中的系数为:

H.264对4×4的图像块(亮度块或Cr、Cb色度块)进行操作,则相应的4×4 DCT变换矩阵A为:

设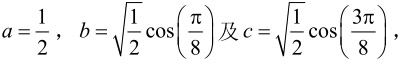 则:
则:

A中的a、b和c是实数,而图像块X中的元素是整数。对实数的DCT,由于在解码端的浮点运算精度问题,会造成解码后的数据的失配,进而引起漂移。H.264较其他图像编码使用了更多的预测过程,甚至内部编码模式也依赖于空间预测。因此,H.264对预测漂移是十分敏感的。为此,H.264对4×4 DCT中的A进行了改造,采用整数DCT技术,有效地减少计算量,同时不损失图像准确度。式(5.12)可以等效为:
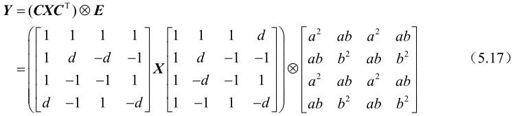
其中,d=c/b(≈0.414)。符号“⊗”表示(CXCT)结果中的每个元素乘以矩阵E中对应位置上的系数值的运算。为了简化计算,取d为0.5。同时又要保持变换的正交性,对b进行修正,取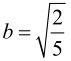 。对矩阵C中的第2行和第4行,以及矩阵CT中的第2列和第4列元素乘以2,相应地改造矩阵E为Ef,以保持式(5.17)成立,得到:
。对矩阵C中的第2行和第4行,以及矩阵CT中的第2列和第4列元素乘以2,相应地改造矩阵E为Ef,以保持式(5.17)成立,得到:
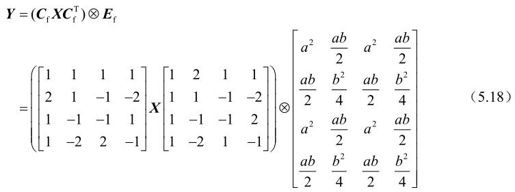
其中,运算“⊗”对每个矩阵元素只进行一次乘法,同时它将被归纳到量化运算中。这样,(CfXCfT)中只剩下整数的加法、减法和移位(乘以2)运算。被称为整数DCT的式(5.18)与通常DCT运算结果近似,但因为b和d的值有所变化,所以两者结果有差别。例如:输入图像或残差块X为:
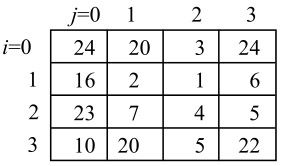
其4×4 DCT输出为:

而式(5.18)对应的整数DCT变换结果为:

两者之差为:
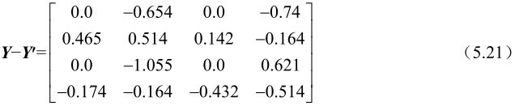
H.264将DCT中“⊗Ef”运算的乘法融合到后面的量化过程中,实际的DCT输出为:

如上所述,可以将式(5.18)的矩阵乘法运算改造成两次一维整数DCT变换,例如先对图像或其残差块的每行进行一维整数DCT,然后对经行变换的块的每列再应用一维整数DCT。而每次一维整数DCT可以采用蝶形快速算法,节省计算时间,如图5.48所示。
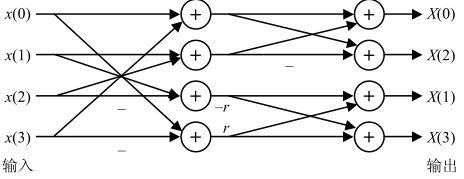
其中,r=2是整数DCT变换,r=1是Hadamard变换
图5.48 一维快速变换算法
5.7.2 量化
量化过程在不降低视觉效果的前提下应尽量减少图像编码长度,减少视觉恢复中不必要的信息。H.264采用标量量化技术,它将每个图像样点编码映射成较小的数值。一般标量量化器的原理为:

其中,y为输入样本点编码,Qstep为量化步长,FQ为y的量化值,round()为取整函数(其输出为与输入实数最近的整数)。其相反过程,即反量化为:

在量化和反量化过程中,量化步长Qstep决定量化器的编码压缩率及图像精度。如果Qstep比较大,则量化值FQ动态范围较小,其相应的编码长度较小,但反量化时损失较多的图像细节信息;如果Qstep比较小,则FQ动态范围较大,相应的编码长度也较大,但图像细节信息损失较少。编码器根据图像值实际动态范围自动改变Qstep值,在编码长度和图像精度之间折衷,达到整体最佳效果。
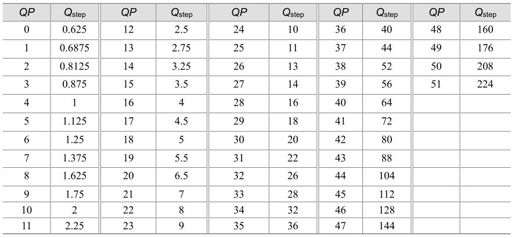
在H.264中,量化步长Qstep共有52个值,如表5.8所示。其中QP是量化参数,是量化步长的序号。当QP取最小值0时代表最精细的量化,当QP取最大值51时代表最粗糙的量化。QP每增加6,Qstep增加一倍。应用时可以在这个较宽的量化步长范围内根据实际需要灵活选择。对于色度编码,一般使用与亮度编码同样的量化步长。为了避免在较高量化步长时的出现颜色量化人工效应,现在的H.264草案把色度的QP最大值大约限制在亮度QP最大值的80%范围内。最终的H.264标准草案规定,亮度QP的最大值是51,而色度QP的最大值是39。
表5.8 H.264中编解码器的量化步长
在H.264中,量化过程是对前面式(5.18)的DCT结果进行操作:

其中,Yij是矩阵Y中的转换系数,Zij是输出的量化系数,Qstep是量化步长。
H.264量化过程还要同时完成DCT变换中“⊗Ef”乘法运算,它可以表述为:

其中,Wij是矩阵W中的转换系数,PF是矩阵Ef中的元素,根据样本点在图像块中的位置(i, j)取值:

利用量化步长随量化参数每增加6而增加一倍的性质,可以进一步简化计算。设:

令

其中,floor()为取整函数(其输出为不大于输入实数的最大整数)。则式(5.26)可以写成:

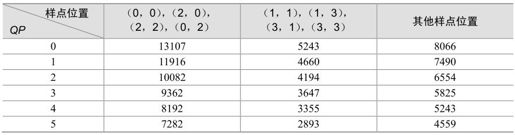
这样,MF可以取整数,如表5.9所示的量化表。表5.9只列出了对应QP值为0~5的MF值,对于QP值大于5的情况,只是qbits值随QP值每增加6而增加1,而对应的MF值不变。这样,量化过程则为整数运算,并且可以避免使用除法,并且确保用16位算法来处理数据,在没有PSNR性能恶化的情况下实现最小的运算复杂度。
表5.9 H.264中MF值
具体量化过程的运算为:

其中,“>>”为右移运算,右移一次完成整数除以2;sign()为符号函数;f为偏移量,它的作用是改善恢复图像的视觉效果。例如,对帧内预测图像块f取2qbits/3,对帧间预测图像块f取2qbits/6。
5.7.3 DCT直流系数的变换量化
如果当前处理的图像宏块是色度块或帧内16×16预测模式的亮度块,则需要将其中各图像块的DCT变换系数矩阵W中的直流分量或直流系数W00按对应图像块顺序排序,组成新的矩阵WD,再对WD进行Hadamard变换及量化。对这种情况,在5.7.2节中介绍的量化过程就不需要对各图像块中的W00单独进行量化。
1.帧内16×16预测模式亮度块的直流系数变换量化
16×16的图像宏块中有4×4个4×4图像亮度块,所以亮度块的WD为4×4矩阵,其组成元素为各图像块DCT的直流系数W00,这些W00在WD中的排列顺序为对应图像块在宏块的位置。宏块中亮度块序号与其在宏块中位置的对应关系如图5.49所示。其中,16个大方块代表宏块中16个图像亮度块,大方块中的数字为对应图像亮度块在宏块中的序号,大方块左上方的小方块中两个数字代表该图像亮度块在宏块中的行和列。
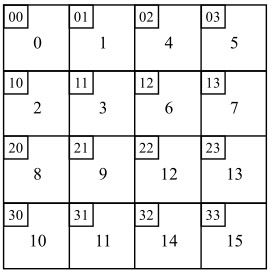
图5.49 宏块中亮度块序号与其在宏块中位置的对应关系
对亮度块WD的Hadamard变换为:
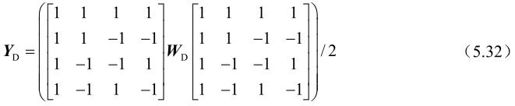
其中,YD是Hadamard变换结果。接着要对YD再进行量化输出:
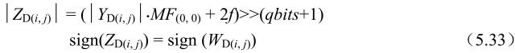
其中,MF(0,0)是位置为(0,0)的MF系数值,其他参数见上节。4×4 Hadamard变换也可以采用快速算法。
2.色度块的直流系数变换量化
16×16的图像宏块中包含图像色度Cr及Cb块各2×2个,所以色度Cr或Cb块的WD为2×2矩阵,其组成元素为各对应图像块色度信号DCT的直流系数W00,这些W00在WD中的排列顺序为对应图像块在宏块的位置。宏块中色度块序号与其在宏块中位置的对应关系如图5.50所示。其中,4个大方块代表宏块中4个图像色度块,大方块中的数字为对应图像色度块在宏块中的序号,大方块左上方的小方块中两个数字代表该图像色度块在宏块中的行和列。可以看出,这四个方块的对应关系与图5.49中亮度块前四个序号的对应关系一致,有利于软件开发时减少程序代码。
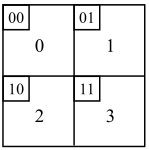
图5.50 宏块中色度块序号与其在宏块中位置的对应关系
对各色度块WD的Hadamard变换为:

其中,YD是Hadamard变换结果。接着要对YD再进行量化输出:
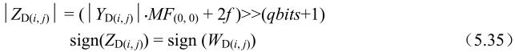
其中,MF(0,0)、f、qbits等的定义同亮度块部分。
5.8 CAVLC(基于上下文自适应的可变长编码)
5.8.1 熵编码的基本原理
熵编码是无损压缩编码方法,它生成的码流可以经解码无失真地恢复出原数据。熵编码是建立在随机过程的统计特性基础上的。
设信息源X可发出的消息符号集合为A={ai|i=1,2,…,m}|,并设X发出符号ai的概率为P(ai),则定义符号ai出现的自信息量为:

通常,上式中的对数取2为底,这时定义的信息量单位为“比特”(bit)。
如果各符号a的出现是独立的,那么X发出一符号序列的概率等于各符号的概率之积,因而该序列出现的信息量等于相继出现的各符号的自信息量之和。这类信源称为无记忆信源。
对信息源X的各符号的自信息量取统计平均,可得平均信息量:

称H(X)为信息源X的熵,单位为bit/符号,通常也称为X的一阶熵,它可以理解为信息源X发任意一个符号的平均信息量。由信息论的基本概念可以知道,一阶熵是无记忆信息源(在无失真编码时)所需数码率的下界。
熵的大小与信源的概率模型有着密切的关系,各个符号出现的概率不同,信源的熵也不同。当信源中各事件是等概率分布时,熵具有极大值。信源的熵与其可能达到的最大值之间的差值反映了该信源所含有的冗余度。信源的冗余度越小,即每个符号所独立携带的信息量越大,那么传送相同的信息量所需要的序列长度也就越短,符号位也越少。因此,数据压缩的一个基本的途径是去除信源的符号之间的相关性,尽可能地使序列成为无记忆的,即前一符号的出现不影响以后任何一个符号出现的概率。
5.8.2 CAVLC的基本原理
在H.264的CAVLC(基于上下文自适应的可变长编码)中,通过根据已编码句法元素的情况,动态调整编码中使用的码表,取得了极高的压缩比。
CAVLC用于亮度和色度残差数据的编码。残差经过变换量化后的数据表现出如下特性:4×4块数据经过预测、变换、量化后,非零系数主要集中在低频部分,而高频系数大部分是零;量化后的数据经过Zig-Zag扫描,DC系数附近的非零系数值较大,而高频位置上的非零系数值大部分是+1和-1;相邻的4×4的非零系数的数目是相关的。CAVLC充分利用残差经过整数变换、量化后数据的特性进行压缩,进一步减少数据中的冗余信息,为H.264的编码效率的提升奠定了基础。
5.8.3 CAVLC的上下文模型
利用相邻已编码符号所提供的相关性,为所要编码的符号选择合适的上下文模型。利用合适的上下文模型,就可以大大降低符号间的冗余度。在CAVLC中上下文模型的选择主要体现在两个方面:非零系数编码所需表格的选择以及拖尾系数后缀长度的更新。
5.8.4 CAVLC的编码过程
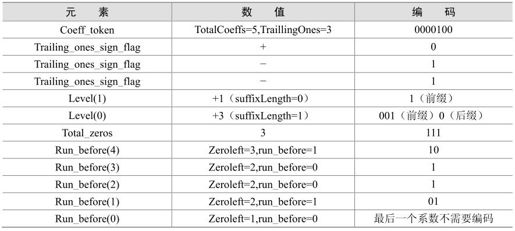
1.对非零系数的数目(TotalCoeffs)以及拖尾系数的数目(TrailingOnes)进行编码
非零系数数目的范围是从0到16,拖尾系数数目的范围是从0到3。如果±1的个数大于3个,只有最后3个被视为拖尾系数,其余的被视为普通的非零系数。对非零系数数目和拖尾系数数目的编码是通过查表的方式,共有4个变长表格和1个定长表格可供选择。其中的定长表格的码字是6个比特长,高4位表示非零系数的个数(TotalCoeffs),最低两位表示拖尾系数的个数(TrailingOnes)。
表格的选择是根据变量NC(Number Current,当前块值)的值来选择的,在求变量NC值的过程中,体现了基于上下文的思想。除了色度的直流系数外,其他系数类型的NC值是根据当前块左边4×4块的非零系数数目(NA)和当前块上面4×4块的非零系数数目(NB)求得的。当输入的系数是色度的直流系数时,NC=-1。求NC的过程见表5.10,X表示与当前块同属于一个片并可用。选择非零系数数目和拖尾系数数目的编码表格的过程见表5.11。CAVLC的码表见本书附录。
表5.10 计算NC的值

表5.11 选择非零系数数目和拖尾系数数目的编码表格

2.对每个拖尾系数的符号进行编码
对于每个拖尾系数(±1)只需要指明其符号,其符号用一个比特表示(0表示+,1表示-)。编码的顺序是按照反向扫描的顺序,从高频数据开始。
3.对除了拖尾系数之外的非零系数的幅值(Levels)进行编码
非零系数的幅值(Levels)按照反向扫描顺序进行编码,即从高频向低频顺序编码。非零系数的幅值的组成分为两个部分:前缀(level_prefix)和后缀(level_suffix)。levelSuffixsSize和suffixLength是编码过程中需要使用的两个变量。后缀是长度为LevelSuffixsSize位的无符号整数。通常情况下变量levelSuffixsSize的值等于变量suffixLength的值,有两种情况例外:
(1)当level_prefix等于14且suffixLength等于0时,levelSuffixsSize等于4;
(2)当level_prefix大于等于15时,levelSuffixsSize等于level_prefix-3。
变量suffixLength是基于上下文模式自适应更新的,suffixLength的更新与当前的suffixLength的值以及已经解码好的非零系数的值(Level)有关。suffixLength数值的初始化以及更新过程如下所示:
(1)普通情况下suffixLength初始化为0,但是当块中有多于10个非零系数并且其中拖尾系数的数目少于3个时,suffixLength初始化为1;
(2)对最高频率位置上的非零系数进行编码;
(3)如果当前已经解码好的非零系数值大于预先定义好的阈值,变量suffixLength加1。
决定是否要将变量suffixLength的值加1的阈值如表5.12所示。第一个阈值是0,表示在第一个非零系数被编码后,suffixLength的值总是加1。
表5.12 决定增加suffixLength的阈值

4.对最后一个非零系数前零的数目(TotalZeros)进行编码
TotalZeros指的是在最后一个非零系数前零的数目,此非零系数指的是按照正向扫描的最后一个非零系数。例如:已知一串系数0 0 5 0 3 0 0 0 1 0 0 -1 0 0 0 0,最后一个非零系数是-1,TotalZeros的值等于2+3+1+2=8。因为非零系数数目(TotalCoeffs)是已知,这就决定了TotalZeros可能的最大值。根据这一特性,CAVLC在编排TotalZeros的码表时做了进一步的优化。
5.对每个非零系数前零的个数(RunBefore)进行编码
每个非零系数前零的个数(RunBefore)是按照反序来进行编码的,从最高频的非零系数开始。RunBefore在以下两种情况下是不需要编码的:
(1)最后一个非零系数(在低频位置上)前零的个数不需要进行RunBefore编码;
(2)如果没有剩余的零需要编码(Σ[RunBefore]=TotalZeros)时,没有必要再进行RunBefore的编码。
在CAVLC中,对每个非零系数前零的个数的编码是依赖于ZerosLeft的值,ZerosLeft表示当前非零系数左边的所有零的个数,ZerosLeft的初始值等于TotalZeros,在每个非零系数的RunBefore值编码后进行更新。用这种编码方法,有助于进一步压缩编码的比特数目。例如:如果当前ZerosLeft等于1,就是只剩下一个零没有编码,下一个非零系数前零的数目只可能是0或1,编码只需要一个比特。
5.8.5 CAVLC的解码过程
CAVLC解码过程可参考图5.51至图5.53所示的程序流程图。其中,CAVLC解码程序的流程图如图5.51所示,解析除了拖尾系数之外的非零系数幅值的子程序流程图如图5.52所示,解析每个非零系数前零的个数(Run_Before[i])的子程序流程图如图5.53所示。
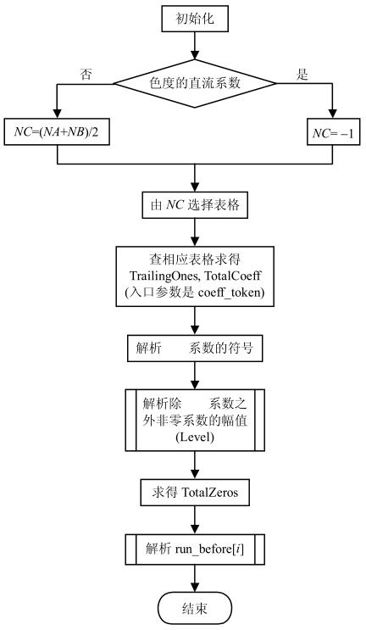
图5.51 解码程序流程图
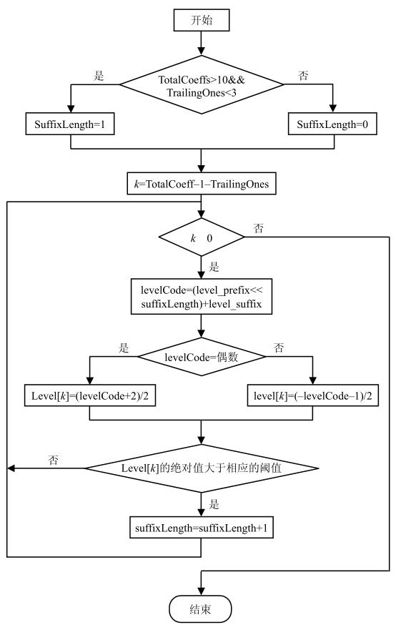
图5.52 解析除拖尾系数之外的非零系数的幅值子程序流程图
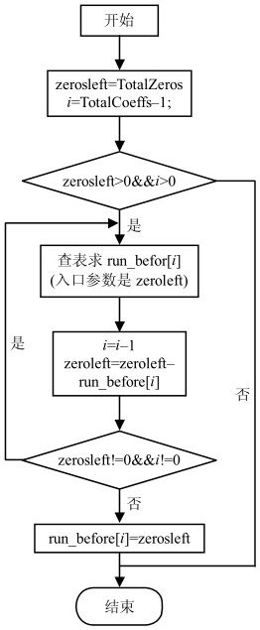
图5.53 解析每个非零系数前零的数(Run_Before[i])的子程序流程图
在图5.51中,第一步根据输入的参数求得输入数据的块类型、输入数据的个数等参数,这是初始化的工作。随后求变量NC,并根据变量NC的值来选择所要查的表格,其中变量NA表示与当前块相邻的左边块中非零系数的个数,变量NB表示与当前块相邻的上面块中非零系数的个数。Coeff_token是一个句法元素,以这个句法元素为入口参数,可查表求得非零系数的个数(TotalCoeffs)、拖尾系数的个数(TrailingOnes)。TotalZeros值的编码方式是查表,用TotalCoeff作为入口参数。
图5.52是解析除拖尾系数之外的非零系数幅值的子程序流程。首先根据条件初始化变量suffixLength的值,随后进入循环求解非零系数幅值的过程中。因为拖尾系数已经在前面的过程中解析好了,此时的非零系数不包括拖尾系数,所以求解的循环次数是TotalCoeff-TrailingOnes。在循环中,levelCode是求解过程中所要使用的中间变量,判断levelCode的奇偶性,使用不同的公式求解非零系数幅值。循环中最后的步骤是变量suffixLength的更新,如果已经解码好的非零系数的幅值大于相应的预先设定好的阈值,变量suffixLength的值加1;否则suffixLength的值不变。决定suffixLength是否需要增加的阈值见表5.12。
在图5.53解析每个非零系数前零的个数(Run_Before[i])的子程序流程图中,Run_before的值是查表求得的,表格的入口参数是Zeroleft,表示当前非零系数之前0的个数。查表解析Run_before的值到Zeroleft等于零或者已经解码到最后一个非零系数(低频位置)时结束。
5.8.6 CAVLC编解码过程实例
设有一个4×4块数据(假定NC=0):
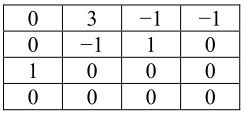
数据重排序:
0,3,0,1,-1,-1,0,1…
非零系数的数目(TotalCoeffs)=5
以及拖尾系数的数目(TrailingOnes)=3
最后一个非零系数前零的数目(Total_zeros)=3
编码过程见表5.13。
表5.13 编码过程
CAVLC编码输出的码流:000010001110010111101101。
解码过程见表5.14。
表5.14 解码过程

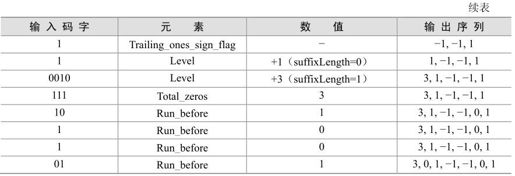
解码后输出序列:0,3,0,1,-1,-1,0,1…
5.8.7 CAVLC与UVLC比较
H.264中需要进行熵编码的语法元素中,图像序列、图像层及片层上的语法元素均采用定长或变长的二进制编码,片及片以下的语法元素根据编码模式选择两类熵编码:变长编码(Variable Length Coding)和算术编码(Arithmetic Coding)。对于变长比编码,当熵编码模式为0时,残差数据采用基于上下文的变长编码(CAVLC),其他的元素采用基于指数哥伦布的统一变长编码(UVLC,Universal Variable Length Coding)。
基于指数哥伦布的统一变长编码实现简单,不需浪费空间来存储映射码表。数字0~8的指数哥伦布编码结果见表5.15。
表5.15 指数哥伦布码字
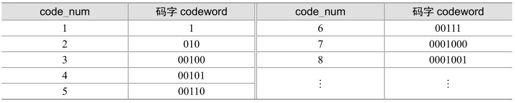
可以看出,指数哥伦布编码的码字codeword由三部分组成:
code_num=[M个0]+[1]+[Info]
其中,Info是一个携带信息的M位数据,每个指数哥伦布码的长度为(2M+1)位,每个码字都可由code_num产生,其编码过程和解码过程如下。
(1)编码过程
对于每个待编码的code_num,根据下面公式计算M和Info,实现编码码字codeword:
M=floor(log2code_num+1)
Info=code_num+1-2M
codeword=[M个0]+[1]+[Info]
(2)解码过程
首先读入M位以“1”为结尾的0;
接着根据得到的M,读入接下的M位Info数据;
最后根据下式还原code_num:
code_num=Info-1+2M
对于一个待编码的语法元素,可以采用3种方式映射到指数哥伦布码字的code_num。
(1)无符号直接映射。这种映射方式的语法元素包括宏块类型、参数帧索引等。
code_num=v
(2)有符号映射。这种映射方式的语法元素主要包括运动矢量差值、量化因子增量等。
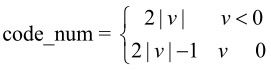
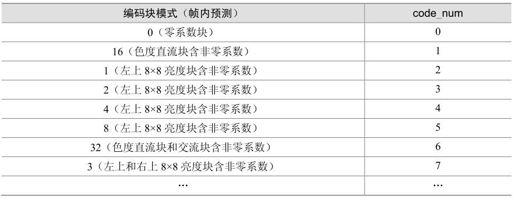
(3)映射符号。这种映射方式中,标准给出一个映射表规定语法元素到code_num的映射关系,主要用于块编码模式参数的映射。表5.16列出了部分帧内预测宏块编码模式的映射关系。
表5.16 帧内预测宏块编码模式的映射关系
从前面的分析可以看出,对于H.264标准中使用了两种可变长编码方法。基于指数哥伦布的统一的可变长编码实现简单有效,而基于上下文的变长编码CAVLC具有更好的熵编码效率。H.264对于残差数据仍采用CAVLC。
CAVLC与UVLC相比在编码方法上有如下的改进。
(1)量化后的数据经过(Zig-Zag)扫描,高频位置上的非零系数值只可能是+1或-1,这些值为+1或-1的非零系数被称为拖尾系数(TrailingOnes)。在CAVLC拖尾系数的编码中,只对拖尾系数的数目以及各个系数的符号进行编码。
(2)除拖尾系数外,其他的非零系数(Level)是一维参数,使用的是结构化的VLC编码,不需要查表。
(3)在编码零行程(Run)时,输入系数的总数目和其中非零系数的数目是已知的,这限制了零行程的范围。CAVLC利用了此特性将零行程分为最后一个非零系数前零的数目(TotalZeros)和每个非零系数前零的个数(RunBefore),并在码表的安排上进行了进一步的优化。
下面对CAVLC和UVLC分别做测试。测试序列是Silent(15fps,QCIF),测试软件是JVT的标准测试软件,测试结果如图5.54和图5.55所示。可以看出来,CAVLC相对于UVLC在编码性能上占有优势。在相同码率的情况下,用CAVLC编码的PSNR的值高于用UVLC编码的PSNR的值,并且随着比特率的增加CAVLC的优势更加明显。
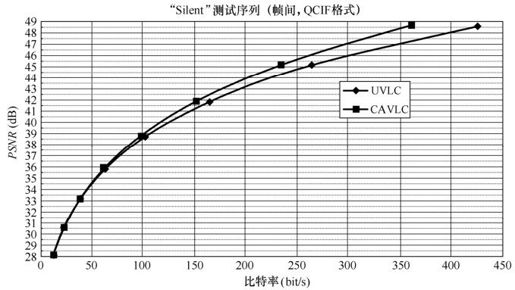
图5.54 实验结果(1)
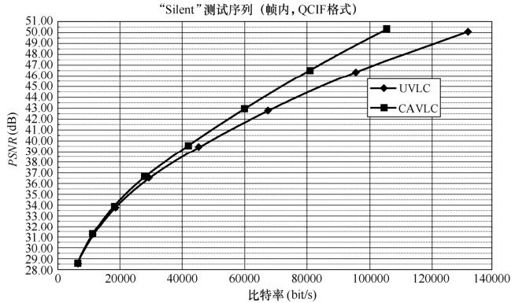
图5.55 实验结果(2)
5.9 CABAC(基于上下文的自适应二进制算术熵编码)
5.9.1 自适应算术编码
算术编码的思想是用0到1的区间上的一个数来表示一个字符输入流,它的本质是为整个输入流分配一个码字,而不是给输入流中的每个字符分别指定码字。算术编码是用区间递进的方法来为输入流寻找这个码字的,它从第一个符号确定的初始区间(0, 1)开始,逐个字符地读入输入流,在每一个新的字符出现后递归地划分当前区间,划分的根据就是各个字符的概率,将当前区间按照各个字符的概率划分成若干子区间,将当前字符对应的子区间取出,作为处理下一个字符时的当前区间。当处理完最后一个字符后,得到了最终区间,在最终区间中任意挑选一个数作为输出。解码器按照和编码相同的方法和步骤工作,不同的是,作为逆过程,解码器每划分一个子区间就得到输入流中的一个字符。
1.算法流程
在算术编码的递进计算过程中,编码器必须保存以下变量的记录状态:
(1)当前区间的下限L;
(2)当前区间的大小R;
(3)当前字符Binval;
(4)各字符的概率Px。
L和R用来确定当前区间;Px则是当前区间的划分根据,在二进制编码中,只有1和0两个字符,所以只需记录P1或P0即可;最后确定Binval所在的子区间作为下一个递进中的当前区间。R的递进关系如下:

2.自适应
在实际过程中,输入流中字符的概率分布是动态改变的,这需要维护一个概率表去记录概率变化的信息。在作递进计算时,通过对概率表中的值估计当前字符的概率,当前字符处理后,需要重新刷新概率表。这个过程表现为对输入流字符的自适应。编码器和解码器按照同样的方法估计和刷新概率表,从而保证编码后的码流能够顺利解码。
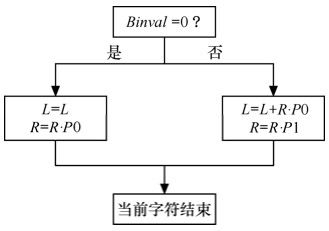
图5.56 算术编码流程
3.码流输出
在实际操作过程中,编码器并不是等递进到最终区间才输出码字的,这里有两方面的原因:一是在编码器的递进计算过程中,如果没有输出,信道会出现空闲,形成浪费;二是如果输入流较长,最终得到的区间非常小,必须以极高的精度来记录L和R。幸运的是,在二进制编码中,区间的上下限以二进制形式表示,每当下限的最高有效位与上限的最高有效位一样时,就可以移出这个比特。这样的方法可以保证编码器在递进计算的同时不断地输出码流。序列出现的可能性越大,区间就越长,确定该区间所需要的比特数就越少。
4.算术编码与哈夫曼性能比较
下面通过对比哈夫曼编码来评价算术编码的优势。算术编码的比特率由下式限制:
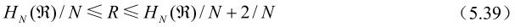
其中,N是编码序列中的符号数,HN(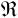 )是序列的N阶熵。参照矢量哈夫曼编码的情况:
)是序列的N阶熵。参照矢量哈夫曼编码的情况:
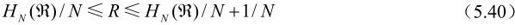
可以看到,当N足够大时,都有:

也就是说当输入流足够长时可使比特率接近于信源熵率。从这点看,这两者都是优秀的熵编码算法。然而,用哈夫曼编码,必须为所有可能的长度为N的序列设计和存储码书,这样做的复杂度随N呈指数增长。用算术编码则不需要预先为每个可能的信源序列指定码书。而是每当所确定区间的下限和上限有公共最高有效位时,就可以连续地得到比特。编码序列的长度可以和信源的长度一样长。因此,实际上,算术编码可以更接近熵率。
算术编码的另一个优点是可以简单地通过更新符号概率表来实现对信源统计特性的自适应。通过对不同上下文用不同的概率表也可以容易地实现条件编码。对于哈夫曼编码,则不得不基于更新概率表重新设计码表,或对不同的上下文设计多个码表。
由于算术编码具有较高的编码效率和自适应性,只要所涉及的计算量是能接受的,无疑算术编码是比哈夫曼编码更好的选择。
5.自适应算术编码的计算复杂度及优化
从上文可以看到,算术编码的计算复杂度主要体现在两个方面:概率的估计和更新。
划分子区间时的乘法运算:R=R×Px。
(1)CABAC的概率模型
假设输入流为T,当前字符为Binval,在Binval之前的字符流为z,z∈T,条件概率P(Binval|z)就是当前字符的概率估计值。随着条件因子z的增长,带来的计算量急剧增大,而且每处理一个字符,需要作两次类似的计算,必须找到一种更好的法则来解决这个问题。
首先来研究如果当前字符的概率估计值Px不是取自P(Binval|z)会有什么影响。首先,毫无疑问这会影响编码效率,P(Binval|z)是取自一个较严格的统计模型,对应于它的输出流的码率能取得对信源熵率的最大逼近;其次,从解码的可行性上讲,只要保证编码和解码双方在划分当前区间时能得到同样的Px,也就是通过同样的法则估计和更新Px,就能顺利解码。
CABAC在计算的复杂度和编码效率之间作了折中,建立了一个基于查表的概率模型,将从0到0.5范围内的概率量化为64个值,这些概率对应于最小概率符号LPS,则最大概率符号MPS的概率为1-Plps。字符的概率估计值被限制在表内,概率的刷新也不是去计算P(Binval|z),而是按照某种法则在表中查找。
如图5.57所示,列出了LPS被量化后的概率值,这些值以σ为编号,实线和虚线指示了概率的刷新值。在处理当前字符Binval时,概率的刷新有两个方向:一是如果当前字符是LPS,则Plps变大,在图上顺着虚线往左寻找;二是如果当前字符是MPS,则Plps变小,在图上顺着实线往右寻找。可以看到,在CABAC建立的这个概率模型中,出现MPS时的刷新值都只是简单地指向当前值的下一位,即σ→σ+1,这一点可以被利用来降低计算量。
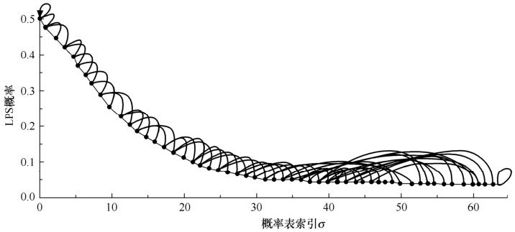
图5.57 CABAC概率估计与刷新模型
在CABAC建立的概率模型中,有3个值是较特殊的:σ=0时,LPS的概率已经达到了最大值0.5,如果下一个出现的字符仍是LPS,则此时LPS和MPS的字符交换位置;σ=63对应着LPS的最小概率值,但它并没有被纳入CABAC的概率估计和更新的范围,这个值被用作特殊的场合,传达特殊的信息,比如,当解码器检测到当前区间的划分依据是这个概率值时,认为这表示当前流的结束;σ=62,这是表中可用的最小值,它对应的刷新值是它自身,当MPS连续出现,LPS的概率持续减小,直到σ=62,保持不变。
(2)乘法优化
CABAC的概率模型很有效地降低了概率估计和刷新中的计算量,而对于在算术编码频繁使用的乘法运算R=R×Px,CABAC也应用了类似的思想。
CABAC首先建立一个4×64的二维表格,存储预先计算好的乘法结果。表格的入口参数毫无疑问一个来自Px,另一个来自R。Px可以直接以σ作为参数,下面的式子给出R的量化方法:

每次在需要做乘法运算时,携带ρ和σ进行查表操作就可得到结果。
建立了概率模型和乘法模型后,在递进计算过程中CABAC必须保存以下变量的记录状态:
(1)当前区间的下限L;
(2)当前区间的大小R;
(3)当前MPS字符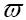 ;
;
(4)LPS的概率编号σ。
算法流程如图5.58所示。
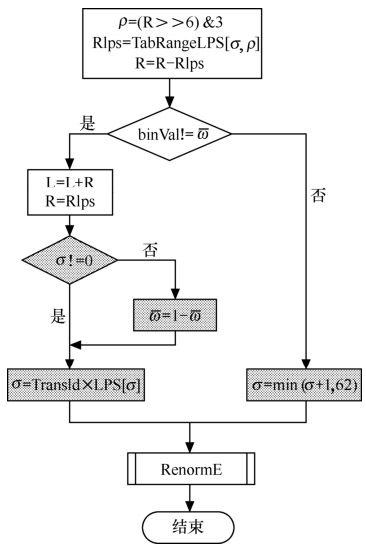
图5.58 CABAC做算术编码时流程图
图中,灰色部分是概率的刷新部分。表TabRangeLPS存储预先计算好的乘法结果,表TransIdxLPS是图5.57对应的概率表。
5.9.2 上下文模型
1.算术编码的生命期
算术编码是对整个流分配码字,但考虑到如果有某个比特丢失,编码和解码将错位。为了将差错控制在一定范围内,CABAC将片(Slice)作为算术编码的生命期,在每个片开始时,CABAC进行初始化,按照一定的法则为编码器指定初始、σ,并初始化[0,1)为当前区间。
2.CABAC的上下文模型
即使对片内的数据,CABAC也不是将它们作为整体来处理的,而是继续分割为若干个子部分,分别编码。除了上文提到的差错控制的原因外,也是由于如果输入流过长,则要求L和R必须有足够的精度和长度来保存中间数据,这对于编码器是个不小的负担。
H.264将一个片内可能出现的数据划分为399个上下文模型,每个模型以ctxIdx标识,在每个模型内部进行概率的查找和更新。H.264共要建立399个概率表,每个上下文模型都独立地使用对应的表维护概率状态。这些模型的划分精确到比特,几乎大多数的比特和它们邻近的比特处于不同的上下文模型中。
解码器对于输入的每一个比特首先要做的工作是查找它属于哪个上下文模型,然后查找该上下文模型对应的概率表以及递进区间。查找某个比特对应的上下文模型一般有以下两个步骤。
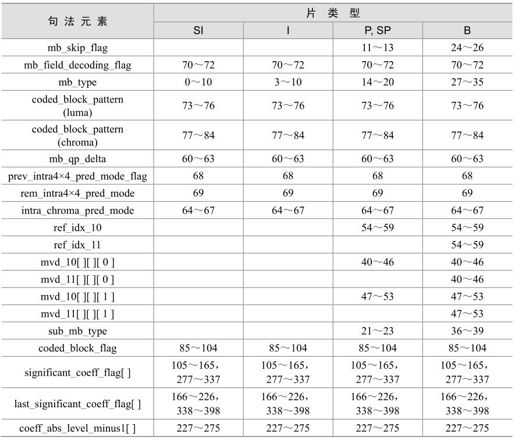
(1)确定该比特所属的句法元素,H.264对每个句法元素都分配了一个上下文模型的区间,该句法元素中的每个比特的上下文模型的ctxIdx都在这一区间。表5.17描述了用CABAC编码的各句法元素所在上下文模型区间的起始ctxIdx。句法元素的具体含义在第7章句法与语义中详细介绍。
表5.17 句法元素与上下文模型区间
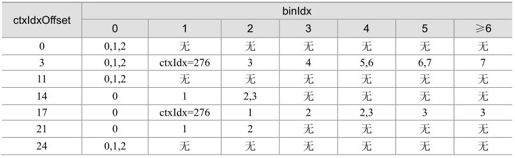
(2)按照某个法则在当前比特在(1)中得到的区间中找到所对应的ctxIdx。该法则对于每个句法元素都不同。这个法则一般是用表来定义的,表5.18描述了大多数句法元素为所属各比特查找ctxIdx的法则。在这个表中,binIdx是各比特在对应句法元素中的序号。ctsOffset是表5.17中各句法元素对应上下文模式区间的起始偏移。我们看到,在表5.18中某些比特对应多个上下文模型,这一般是在解码中需要根据前后宏块在空间上的相关性再作进一步确定。
表5.18 句法元素中各比特的ctxIdx
5.9.3 对输入流预编码
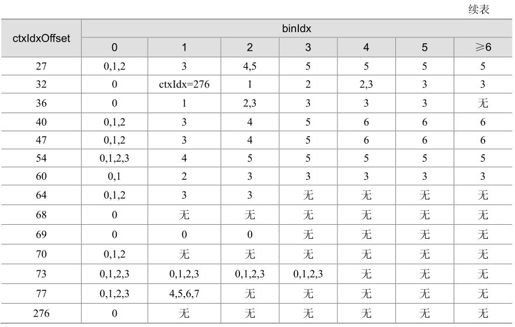
CABAC围绕算术编码的特性作了许多优化,其中也包括从统计角度对输入流作的一套预编码方法。由图5.58可以看到,当前处理的字符为MPS时,区间递进只是子区间的长度发生改变,而作为影响实际输出值的L却并没有变化。这个现象意味着如果输入流中连续出现大量MPS,或者MPS 对LPS的概率比非常高时,可以达到极高的压缩效果。算术编码对这种输入流的压缩性能达到最优,编码输出的码率也更能接近信源熵率。由此CABAC体系包含了一个预编码过程,将输入流重新编码后再进行算术编码。这个预编码过程叫做输入流的二进制化,经它编码输出的是MPS概率极高的比特流。
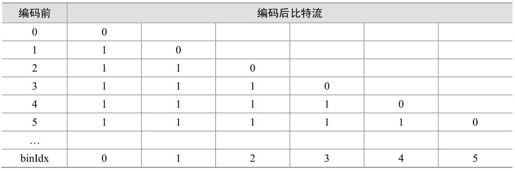
CABAC中对不同的句法元素一共应用了4种二进制化方法:U,TU,UEGK,FL。
表5.19是其中U变换的码表,其他二进制化编码方法与之类似。binIdx是编码后各比特的序号。
表5.19 U二进制化码表
5.9.4 初始化
前文提到,CABAC的生命期是片,每个片开始时,要对399种上下文模型全部进行初始化工作。初始化的步骤如下。
(1)将递进区间复位到[0,1)。
(2)为每个上下文模型指定一个初始的、σ。这又由以下几步得到:
①H.264为每个上下文模型定义了初始化常量m、n,通过查表获得上下文模型相对应的m、n。
②按照如下算法计算、σ:
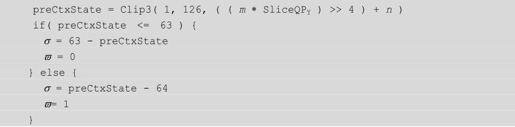
式中,函数Clip3(a,b,c)表示将c的值限制在[a,b]。preCtxState是一个中间变量。
5.9.5 结论
CABAC中内建了由大量实验统计而得到的概率模型。在编码过程中,CABAC根据当前所要编码的内容以及先前已编码好的内容,动态地选择概率模型来进行编码,并实时更新相对应的概率模型。并且,CABAC在计算量和编码速度上进行了优化,用了量化查表、移位、逻辑运算等方法代替复杂的概率估计和乘法运算。在实际应用中,CABAC与其他主流的熵编码方式相比有更高的编码效率,用一组质量在28~40dB的视频图像做测试,应用CABAC可使比特率进一步提高9%~14%。图5.59描述了图像质量在各信噪比时CABAC节省码率的性能。
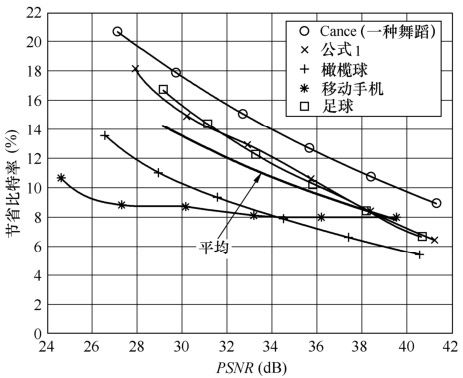
图5.59 各测试序列中CABAC节省码率的性能
5.10 码率控制
在H.264视频编码标准中仅仅规定了编码后比特流的句法结构和解码器的结构,而对于编码器的结构和实现模式没有具体的规定。然而无论编码器的结构如何,相应的视频编码的控制都是编码器实现的核心问题。在对数字视频信号进行压缩编码时,编码器通过相应的编码控制算法以确定各种编码模式,如宏块的划分类型、运动矢量以及量化参数等,已选定的各种编码模式进一步确定了编码器输出比特流的比特率和失真度。
H.264编码器采用了基于Lagrangian优化算法的编码控制模型,其编码性能相较于以往的所有编码标准有了重大提高。
5.10.1 基于Lagrangian优化算法的H.264编码控制模型
视频编码的控制都是编码器实现的核心问题。由于视频序列中的图像内容随着空间与时间的不同而变化很大,需要为图像的不同部分选择不同的编码参数进行压缩编码,而编码控制的目的就是确定一组编码参数。H.264编码器采用基于Lagrangian优化算法的率失真优化模型实现视频编码的控制,其实现简单而且效率高。下面将分析Lagrangian优化算法及其在H.264视频编码控制中的应用。
1.Lagrangian优化算法
考虑K个信源样本值的集合S=(S1,…,SK),其中SK可以是矢量或标量。每一个样本值SK可以通过选取编码模式集Ok=(Ok1,…,OkN)中的某些编码模式Ik(Ik∈Ok)进行压缩编码。因此,对应于样本值集合S,存在相应的编码模式集合I=(I1,…,IK)。在给定的限定码率Rc下,对于给定信源样本序列所选的编码模式,应使编码后的失真度最小,如式(5.43)所示。

式(5.43)中,D(S,I)与R(S,I)分别表示输出比特流的失真度和码率,其中比特流由采用编码模式I对样本S进行编码并进行量化后输出。
在实际应用中,通常采用下式来选取编码模式。

其中,J(S , I|λ)=D(S , I)+λ×R(S , I),式(5.44)中λ是Lagrange参数。对于样本S及其选定的编码模式I,当其编码后得到的比特率和失真度的线性组合J(S, I|λ)(Lagrangian代价函数)最小时,此时的编码模式是最优的。
考虑某一样本Sk,可认为其编码后的比特率和失真度仅与相应的编码模式Ik有关,因此有下面两式成立。

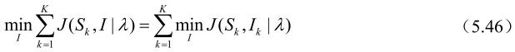
因此,只要分别对每一个样本Sk∈S选择最优的编码模式,便可以很容易地得到J(S,I|λ)的最小值,从而实现相应的编码控制。
2.编码控制模型
由于编码后比特流的比特率和失真度与时间和空间的关系密切,基于Lagrangian优化算法的编码控制不可能在混合视频编码器中简单的实现。假设图像序列s被分割为K个不同的块Ak,相应的像素用Sk表示。编码Sk所选择的编码模式Ok分为帧内模式和帧间模式两类。每种模式均包括预测编码的模式以及相应的编码参数,其中编码参数为变换系数和量化参数等,对于帧间模式,编码参数还应包括一个或多个运动矢量。在对图像序列s进行基于块的混合视频编码时,对于每块Sk所选定的编码模式应当使编码后的Lagrangian代价函数J(S,I|λ)达到最小,当且仅当此时认为基于块的混合视频编码器达到最优化。
对帧间模式的选择,通常通过搜索使得编码后Lagrangian代价函数J(S, I|λ)最小化的运动矢量实现,相应的运动矢量作为编码参数被编码传输。因此在编码控制模型中,宏块分割模式的判决与帧间模式运动估计的最佳比特分配这两个问题将会被分别处理。
在Lagrange参数λMODE与量化参数Q选定后,H.264的编码器通过最小化Lagrangian代价函数实现对每一个宏块的编码模式的选定。宏块Sk的Lagrangian代价函数如式(5.47)所示。

其中Ik为相应宏块的编码模式。
在不同编码模式下,编码后比特流的比特率RREC与失真度DREC的计算并不完全相同。在帧内模式下,RREC(Sk,INTRA|Q)为熵编码后比特流的比特率,失真度DREC(Sk,INTRA|Q)则由宏块的原始像素和重建像素决定,共有2种计算方式,分别如式(5.48)、式(5.49)所示。
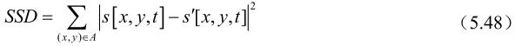
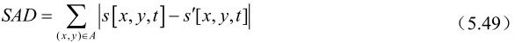
其中A为当前的宏块。
对于SKIP模式,由于无需残差信号,因此比特率RREC(Sk,INTRA|Q)与失真度DREC(Sk,INTRA|Q)与量化参数无关。其中失真度DREC(Sk,INTRA|Q)由宏块的原始像素值和预测像素值决定,而比特率RREC(Sk,INTRA|Q)则在H.264中被近似为1bit/MB。
在帧间模式下,由于采用了基于块的运动估计,Lagrangian代价函数的计算比帧内模式与SKIP模式要复杂。对于采用帧间编码模式的A×B大小的块Si,在给定的Lagrange 参数λMOTION和参考图像s′的情况下,通过最小化Lagrangian代价函数来实现块Si的运动估计,如式(5.50)所示。
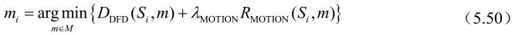
其中M为可能的编码模式的集合,RDFD(Si,m)为传输运动矢量(mx,my,mt)所需的比特数,失真度DDFD由式(5.51)或式(5.52)得到。
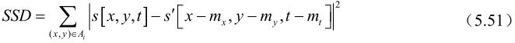
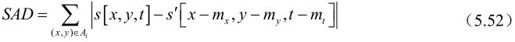
在进行运动估计时,水平与垂直方向的搜索范围为±32个整像素,并采用一帧或多帧参考图像。
为寻找满足式(5.50)要求的运动矢量mt,首先在整像素位置进行运动估计的运算,求得满足式(5.50)要求的运动矢量后,需进一步确定周围半像素位置的运动矢量是否可使Lagrangian代价函数进一步降低。由于在H.264中采用了1/4像素的运动估计精度,之前确定的半像素周围1/4像素位置的运动矢量被进一步考察,以确定当采用此1/4像素精度的运动矢量后Lagrangian代价函数是否获得进一步的降低。通过以上分析可知,最终选定使得Lagrangian代价函数最小的运动矢量具有1/4像素精度。
与帧内模式相同,在帧间模式下,比特率RREC(Sk,INTER|Q)为熵编码后比特流的比特率,失真度DREC(Sk,INTER|Q)则由宏块的原始像素和重建像素决定,由式(5.47)或式(5.48)得到。
在H.264视频编码控制模型中,λMODE由量化参数确定,如式(5.53)所示。

另一个Lagrange参数λMOTION与λMODE有关,由式(5.54)或式(5.55)确定。其中式(5.54)对应于式(5.48)与式(5.51),式(5.55)对应于式(5.49)与式(5.52)。


在H.264中,通常通过速率控制相关算法选择合适的量化参数,并通过相应的Lagrange参数进行视频编码控制。
由上所述,H.264视频编码器中的基于Lagrangian优化算法的编码控制模型可由图5.60表示。

图5.60 H.264视频编码控制模型
5.10.2 实验结果和性能分析
实验分别针对H.264在流媒体与视频会议中的应用进行。视频会议与流媒体应用的主要区别在于,视频会议需要满足低时延和实时的要求,而流媒体的相关应用则侧重于图像细节的处理。因此,基于H.264编码标准的视频会议与流媒体应用所实现的编码器的构成区别很大。在合理地为两种编码器选择编码工具的基础上,实现了基于Lagrangian优化算法的编码控制模型,并与其他编码标准MPEG-2、MPEG-4、H.263的编码器的编码性能进行比较。
1.流媒体应用中的实验结果和性能分析
针对于流媒体应用,基于H.264测试模型JM-61e所实现的主要档次编码器的构成特性见表5.20,并在此基础上实现了基于Lagrangian优化算法的编码控制模型。考虑到流媒体应用的特点,选取4∶2∶0 CIF格式标准测试序列Mobile&Calendar进行测试,输入帧频为30F/s,长度为8.33s。该视频序列具有复杂的运动和较高的空间色彩细节,适于测试流媒体应用中编码器的性能。
表5.20 编码器的构成特性

在实验中,设定编码后帧率为30F/s,实验结果如图5.61所示。其中,在编码码率分别为512kbit/s、1024kbit/s的条件下,得到相应输出比特率的码率和亮度色度分量的信噪比,如表5.21所示。为公平比较编码性能,在同样条件下对基于H.263 HLP、MPEG-2、MPEG-4 ASP编码标准的编码器也进行了测试,相应的测试模型分别为TMN-10、TM-5、VM-18。
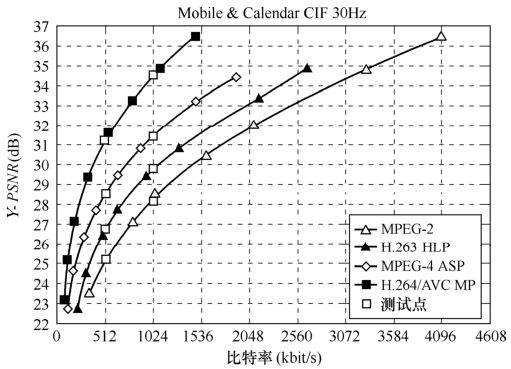
图5.61 流媒体应用中各编码器的性能比较
表5.21 流媒体应用中各编码器的实验结果
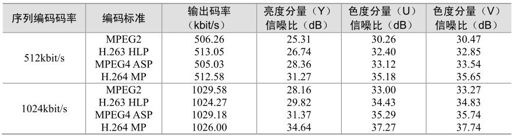
由表5.19可知,实现了基于Lagrangian优化算法的编码控制模型的H.264编码器,其编码性能(即输出亮度色度分量的信噪比)相较于MPEG-4 ASP提高了1~3dB,相较于H.263 HLP提高了1~5dB,相较于MPEG-2提高了3~6dB。
2.视频会议应用中的实验结果和性能分析
针对于视频会议应用,基于H.264测试模型JM-61e所实现的基本档次(Baseline)编码器的构成特性如表5.22所示,并在此基础上实现了基于Lagrangian优化算法的编码控制模型。考虑到视频会议应用的特点,选取4∶2∶0 CIF格式标准测试序列Paris进行测试,输入帧频为30F/s,长度为10s。该视频序列中的物体几乎处于静止状态,适于测试视频会议应用中编码器的性能。
表5.22 编码器的构成特性

在实验中,设定编码后帧率为15F/s,实验结果如图5.62所示。在设定编码码率为128kbit/s的条件下,得到相应输出码率和亮度色度分量的信噪比。为公平比较编码性能,在同样条件下对基于H.263 Baseline、H.263 CHC、MPEG-4 SP编码标准的编码器也进行了测试,相应的测试模型分别为TMN-10、TMN-10、VM-18。
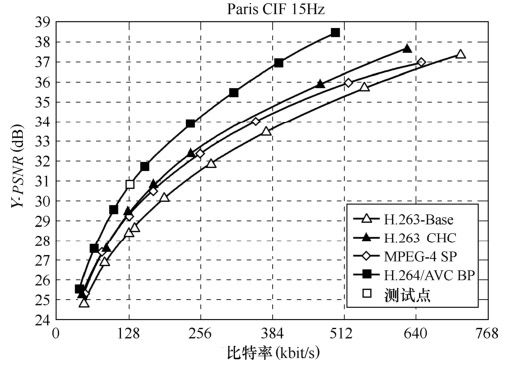
图5.62 视频会议应用中各编码器的性能比较
通过表5.23可知,实现了基于Lagrangian优化算法的编码控制模型的H.264编码器,其编码性能(即输出亮度色度分量的信噪比)相较于MPEG-4提高了1~2dB,相较于H.263 Baseline提高了1~3dB。
表5.23 视频会议应用中各编码器的实验结果

以上两个实验结果证实:实现了基于Lagrangian优化算法的编码控制模型的H.264编码器,其编码性能相较于以往的所有编码标准都有了重大提高,并在流媒体及视频会议等视频应用中显示出了巨大的潜力。
5.11 去方块滤波
H.264/MPEG-4 AVC视频编码标准中,在编解码器反变换量化后,图像会出现方块效应。其产生的原因有两个。最重要的一个原因是基于块的帧内和帧间预测残差的DCT变换,变换系数的量化过程相对粗糙,因而反量化过程恢复的变换系数带有误差,会造成在图像块边界上的视觉不连续。第二个原因来自于运动补偿预测。运动补偿块可能是从不是同一帧的不同位置上的内插样点数据复制而来。因为运动补偿块的匹配不可能是绝对准确的,所以就会在复制块的边界上产生数据不连续。当然,参考帧中存在的边界不连续也被复制到需要补偿的图像块内。尽管H.264/MPEG-4 AVC采用较小的4×4变换尺寸可以降低这种不连续现象,但仍需要一个去方块滤波器,以最大程度提高编码性能。
在视频编解码器中加入去方块滤波器的方法有两种:后置滤波器和环路滤波器。后置滤波器只处理编码环路外的显示缓冲器中的数据,所以它不是标准化过程中的规范内容,在标准中只是可选项。相反,环路滤波器处理编码环路中的数据。在编码器中,被滤波的图像帧作为后续编码帧运动补偿的参考帧;在解码器中,滤波后的图像输出显示。这要求所有与本标准一致的解码器采用同一个滤波器以与编码器同步。当然,如果有必要,解码器也还可以在使用环路滤波器的同时使用后置滤波器。
在编码环路中使用滤波器比后置滤波有几点优点:首先,环路滤波器可以保证不同水平的图像质量;其次,在解码器端没有必要再为滤波器准备额外的帧缓存;第三,试验已显示环路滤波比后置滤波更能增强视频流的主客观水平,同时有效降低了解码器的复杂度。
尽管有以上这些优点,环路滤波器的复杂度还是较高的。即使经过很大努力进行滤波算法的时间优化,去除其中的乘除法,环路滤波器所带来的计算复杂度也相当解码器计算复杂度的1/3左右。
高复杂度的主要原因是滤波器的高度自适应性,它需要对方块边界及样点量化值进行条件判断和处理。这样,在算法的主要内部循环中不可避免地出现条件分支,众所周知,这是很耗时的。另一个高复杂度的原因是H.264中编码算法中残差编码的尺寸。对于4×4的方块大小及平均在每个方向上滤波2个点,几乎图像中每个点都要被调入到内存中,要么被修正,要么用来判断边界点是否要被修正。而对H.263环路滤波器或任何MPEG-4/H.263后置滤波器来说不是这样的,因为它们对8×8方块进行操作。
下面介绍的自适应去方块滤波器利用简单的算法可靠地提高图像的主客观评价质量。其较好的性能是因为可靠地区分了真实的和人为的图像边界,并有效地滤除后者。在相同的PSNR下可以节省码流超过9%,并同时明显地提高了图像视觉质量。因为去方块滤波在H.264编码器和解码器中的作法是一致的,所以在第7章解码器中就不再赘述。
5.11.1 去方块滤波基本概念
图5.63(a)显示不采用去方块滤波器的编解码器的效果图。基于上述原因,图中在DCT变换边界上有明显的痕迹,呈现出方块形状。图5.63(b)则是采用去方块滤波器的编解码器对同一幅图像的处理效果图,图5.63(a)中的方块已不明显了。
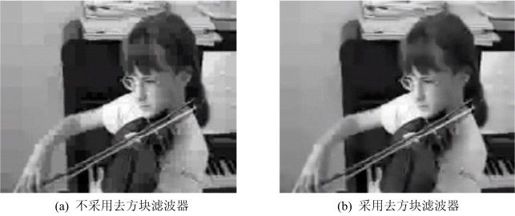
图5.63 不采用和采用去方块滤波器的H.264编解码器的效果
显然,去方块滤波器的作用是去除H.264编解码算法带来的方块效应。但是,如果在DCT边界上正好是图像的边界,如家具边等,若不加以判断而误认为是方块效应,则可能造成新的误差。因此,在滤波方块效应时,应该先判断该边界是图像真实边界还是方块效应所形成的“伪边界”。对真实边界不进行滤波处理,而对伪边界则要根据周围图像块的性质和编码方法采用不同强度的滤波。
5.11.2 边界分析
1.4×4方块的误差分析
当对残差用方块变换进行编码时,方块边界比内部的编码误差大。对这个现象的合理解释是内部点的重建是对周围点进行加权平均得到的。而边界点所用到的加权平均点较少,所以重建效果较差。这个误差分布不均匀的后果是需要方块边界滤波以提高图像客观质量。
H.264/MPEG-4 AVC去方块滤波器能适应以下不同水平的需要:
(1)片级,全局滤波强度能根据视频序列个体特征进行调节;
(2)图像块边界级,滤波强度依赖于边界两边图像块的帧间/帧内预测、运动矢量差别及变换量化是否是对残差编码的。特别强的滤波应用于非常平坦的图像宏块以去除“马赛克效应”;
(3)图像样点级,样点值及与量化参数相关的阈值可以决定是否对每个样点进行滤波。
下面将讨论H.264/MPEG-4 AVC去方块滤波器如何根据这些自适应性设计的细节。
2.自适应边界级滤波器
边界强度(Bs)决定去方块滤波器选择的滤波参数,控制去除方块效应的程度。对所有4×4亮度块间的边界,边界强度参数值在0~4之间,它与边界的性质有关。表5.24列出了Bs与相邻图像块的模式及编码条件的关系。表中的条件是从表的上部至下部进行判断的,直到某一条件满足,给Bs相应赋值。
表5.24 滤波器强度参数与编码模式的关系
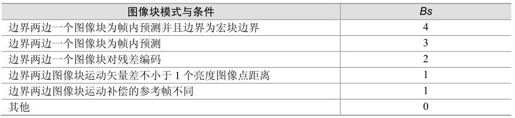
在实际滤波算法中,Bs决定对边界的滤波强度,包括对两个主要滤波模式的选择。当其值为4时表示要用特定最强的滤波模式,而其值为0表示不需要对边界进行滤波。对其值为1~3的标准滤波模式,Bs值影响滤波器对样点的最大修正程度。Bs值的下降趋势说明最强的方块效应主要来自于帧内预测模式及对预测残差编码,而在较小程度上与图像的运动补偿有关。
色度块边界滤波的Bs值不另外单独计算,而是从相应亮度块边界的Bs值复制而来。
在帧场自适应宏块中,表5.22中的条件相对复杂些,因为相邻两图像块中的一个可能来自帧编码宏块或来自场编码宏块。滤波强度变化的原则不变。为了避免将图像过度模糊化,对于来自场编码宏块的水平边界需要特别考虑,以避免过强的滤波强度,这是因为这种宏块的垂直滤波的空间扩展范围是其他情况的两倍。
3.自适应样点级滤波器
在去方块滤波中,非常重要的是要区分图像中的真实边界和由DCT变换系数量化而造成的假边界。为了保持图像的逼真度,应该尽量在滤除假边界以不致被看出的同时保持图像真实边界不被滤波。
为了区分这两种情况,要分析每个需要被滤波的边界两边的样点值。这里,定义两个相邻4×4块中一条直线上的样点为p3、p2、p1、p0、q0、q1、q2、q3,实际的图像边界在p0和q0之间,如图5.64所示。

图5.64 典型的不需要去方块滤波的图像边界
如上小节所述,当Bs值为0时,滤波器对边界不起作用。对于Bs值为非0的边界,为了区分上述真假两种边界,定义一对与量化有关的参数,为α和β,用来检查图像内容,以决定每个样本点集是否要被滤波。只有下述三个条件同时满足,直线上的样点才会被滤波:



α和β值根据边界两边的平均量化参数查表得到,α和β的查表指数根据下式计算:
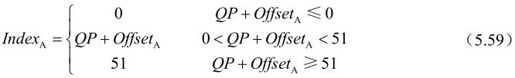
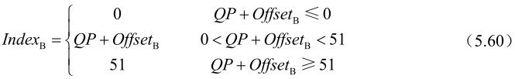
其中,0~51为QP的范围。OffsetA和OffsetB为在编码器中选择的偏移值,用来在片级上控制去方块滤波的性能。
α和β值满足下面近似经验关系:


这个关系式中的变量是根据测试进行选择的,让不同的内容得到满意的视觉效果。一般来说,β(x)比α(x)小。为了节省计算量,α和β值通过查找与上式关系一致的表格得到,见表5.25。特别地,在表格低端,取值被限为0,这样对IndexA<16或IndexB<16,α和β中的一个或两个全部为0,相应地不进行滤波。
表5.25 阈值变量α和β与变量indexA和indexB的关系
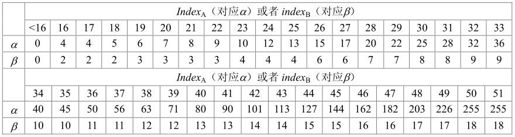
α和β与QP的关系将滤波强度与滤波前重建的图像一般质量联系起来。因为阈值随QP增加,当QP较大时,含有较多内容活性的边界需要被滤波,这是由于编码误差随QP增加。α中的指数特性中反映期望的方块效应与α的关系,因为QP每增加6则量化步长增加一倍。
4.自适应片级滤波器
在片级上,编码器可以选择偏移(OffsetA和OffsetB)来调整滤波器中的α和β值,相对于0偏移增加或减少滤波强度。偏移值在图像片头通过句法元素传输,应用于根据QP值查表求α和β值,或按式(5.61)和式(5.62)来计算。
利用传递非0偏移控制去方块滤波性能,使解码器设计者可以优化解码视频质量,获得比默认表(当偏移为0时)效果好的图像。例如,通过传递负的偏移以减少滤波强度,可以有助于小的空间细节的逼真度,特别是高分辨率的视频内容,因为这时小的方块效应不容易被觉察。相反,采用正的偏移以增加滤波强度,可以去除默认表所不能滤除的方块效应,增加图像主观质量。这有助于平滑过渡的低分辨率内容的亮度块情况,去除可能由次优的运动估计、模式选择或残差编码引起的额外方块。
5.11.3 滤波过程
1.滤波运算概述
为了保证编码器和解码器中的滤波过程完全一致,对每个编码图像的滤波运算必需按规定顺序进行。滤波应该在适当位置上进行,这样边界两边直线上修改过的样点值作为后续运算的输入值就不会引入误差。
滤波是基于宏块基础上的,先对垂直边界进行水平滤波,再对水平边界进行垂直滤波。对宏块的两个方向滤波都完成后才能进行后面宏块的滤波。对图像中宏块的滤波按raster扫描方式进行。对帧场自适应编码帧,它们在垂直方向上相邻的宏块对放在一起,则滤波顺序按宏块对进行,即在帧中对宏块对进行raster扫描,对每个宏块对先进行顶部宏块的滤波。
对每个亮度宏块,先滤波宏块最左边的边界(如图5.65中的a),然后依次滤波从左到右宏块内的3个垂直边界(如图5.65中的b~d)。类似的,对水平边界先滤波宏块顶部的边界(如图5.65中的e),然后依次滤波从上到下宏块内的三个水平边界(如图5.65中的f~h)。色度滤波次序类似,对8×8的色度宏块,在每个方向上,先滤波宏块外部边界再滤波一个内部边界(如图5.65所示,水平方向先滤波i,再滤波j;垂直方向上先滤波k,再滤波l)。
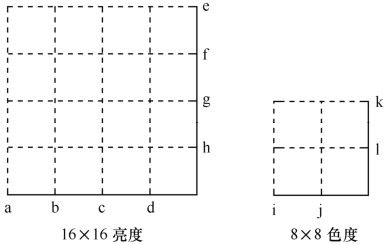
图5.65 宏块中边界滤波顺序
根据样点集的Bs值有两种滤波方式可选择:特定滤波方式是针对Bs为4的强滤波,普通滤波方式应用于其他情况(Bs=1,2,3)。
对每种方式,用β阈值估计另外两个空间变化的条件,以决定亮度点的滤波范围。


当上述条件成立,说明边界变化强度不大,滤波强度的设定值相对实际滤波来说偏大。
2.Bs值从1到3的边界滤波
滤波运算可以分为基本滤波运算和限幅两个阶段。
(1)基本滤波运算
先讨论对亮度点的滤波。对这种模式的滤波,滤波后的0p′和0q′值按下式计算:


其中,△0分两步计算,先计算它的初始值△0i,再对这个初始值进行限幅后代入上式。
初始值△0i根据边界两边的样点值计算:
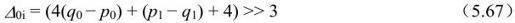
计算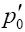 的脉冲响应运算为(1,4,4,-1)/8。
的脉冲响应运算为(1,4,4,-1)/8。
只有式(5.63)或式(5.64)成立,才修正对应p1或q1值。即如果式(5.63)成立,滤波后的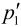 值按下式计算:
值按下式计算:

同样,如果式(5.64)成立,滤波后的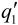 值按下式计算:
值按下式计算:

这些同样要经过两步计算。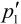 的初始值△按下式计算:
的初始值△按下式计算:
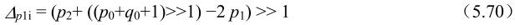
△q1i按同样关系式计算,用q2和q1分别代替p2和p1。上式相应的脉冲响应为(1,0,0.5,-0.5)/2,具有很强的低通特性。
(2)限幅
如果上述初始值△0i、△p1i和△q1i直接应用在滤波计算中,则可能导致滤波频率过低,出现图像模糊。自适应滤波器的一个重要部分是限制△的值,这个过程称为限幅。对于内部和边界上的样点,限幅过程不同。
对于内部样点,用于滤波的△值被限制在-c1到c1范围内,c1是从二维表(表5.26)中查找的参数,它是根据用于计算α的IndexA和Bs查找。IndexA和Bs越大,则c1也越大,允许更强的滤波。最终对p1和q1滤波的限幅值为:
表5.26 滤波限幅变量c值与index和Bs的关系
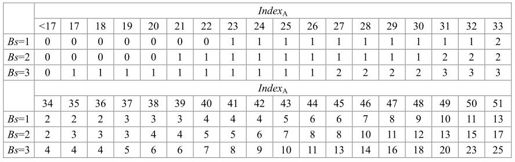
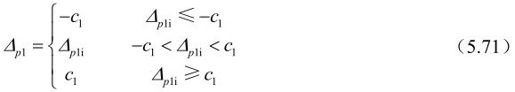
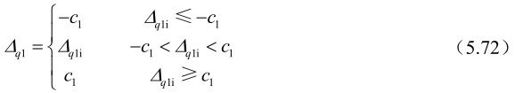
对于滤波边界p0和q0样点,△0i的限幅值由c1和式(5.63)或式(5.64)决定。先将它的限幅值c0定为c1。如果式(5.63)或式(5.64)都成立,说明边界两边内部的变化强度小于β阈值,需要对边界进行更强的滤波(同时如上述,需要对p1和/或q1样点进行修正),c0将增加1。这样对边界样点的修正值为:
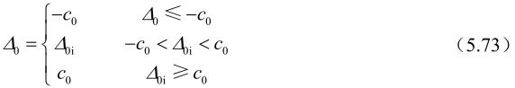
对色度点滤波,只有p0和q0才被修正。滤波方法与亮度点一样,只是限幅值c0为c1加1。这样对Bs小于4的边界没有必要对色度的式(5.63)或式(5.64)进行估计,也不必存取变量p2和q2值。
3.Bs值为4的边界滤波
H.264/MPEG-4 AVC的帧内编码在对同一图像区域编码时,倾向采用16×16亮度预测模式,这会在宏块边界引起小幅度的方块效应。但是由于Mach band效应,在这种情况下,即使是很小的强度值差别在视觉上的感觉也会是陡峭的阶梯。为了消除这种马赛克效应,需要在图像内容平滑的两个宏块边界采用较强的滤波器。
对亮度滤波,根据图像内容判断是选择较强的4拍或5拍滤波器,还是较弱的3拍滤波器。4拍或5拍滤波器对边界两边的边界点及两个内部点进行修正,而3拍滤波器仅改变边界点。只有下面的跨边界差异的约束条件成立时才使用较强的滤波器:

注意,式(5.74)与式(5.56)很相似,只是它跨边界的最大样点值差异的约束更加严格。
对亮度滤波来说,当式(5.63)和式(5.74)都成立时,根据下式计算滤波后的样点值:
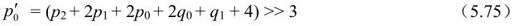
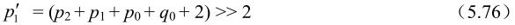
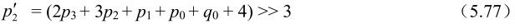
否则,对色度点或当式(5.63)和式(5.74)中只要有一个不成立的亮度点,只根据下式修正p0:

q点值的修正方法相同,只是在选择亮度滤波器时用式(5.64)代替式(5.63)。
5.12 其余特征
5.12.1 参考图像的管理
H.264中,已编码图像存储在编码器和解码器的参考缓冲区,即解码图像缓冲区(DPB,Decoded Picture Buffer),并有相应的参考图像列表list0,以供帧间宏块的运动补偿预测使用。对B片预测而言,list0包含当前图像的前面和后面两个方向的图像,并以显示次序排列;也可同时包含短期和长期参考图像。这里,已编码图像由编码器重建的短期参考图像或刚刚编码的图像,并由其帧号标定;长期参考图像是较早的图像,由LongTermPicNum标定,保存在DPB中,直到被代替或删除。
当一幅图像在编码器被编码重建或在解码器被解码时,它存放在DPB并标定为以下各种图像中的一种:(1)“非参考”,不用于进一步的预测,(2)短期参考图像,(3)长期参考图像,(4)直接输出显示。list0中短期参考图像是按PicNum(由帧号推出的变量)从高到低的顺序排列,长期参考图像按LongTermPicNum从低到高的顺序排列。当新图像加在短期列表的位置0时,剩余的短期图像索引号依次增加。当短期和长期图像号达到参考帧最大数时,最高索引号的图像被移出缓冲区,即实行滑动窗内存控制。该操作使得编码器和解码器保持N幅短期参考图像,包括一幅当前图像和N-1幅已编码图像。
由编码器发送的自适应内存控制命令用来管理短期和长期参考图像索引。这样,短期图像才可能被指定长期帧索引,短期或长期图像才可能标定为“非参考”。编码器从list0中选择参考图像,进行帧间宏块编码。而该参考图像的选择由索引号标志,索引0对应于短期部分的第一帧,长期帧索引开始于最后一个短期帧。
参考图像缓冲区通常由编码器发送的即时解码刷新图像(IDR,Instantaneous Decoding Refresh)编码图像刷新,IDR图像一般为I片或SI片。当接受到IDR图像时,解码器立即将缓冲区中的图像标为“非参考”。后继的片进行无图像参考编码。通常,编码视频序列的第一幅图像都是IDR图像。
5.12.2 重排序
在编码器中,每个已量化的4×4块的变换系数以图5.66所示的Zig-Zag顺序映射为一个16元素的矩阵。在16×16帧内模式编码的宏块中,每个4×4亮度块的DC系数首先以图5.66所示的顺序扫描。剩余的15个AC系数从第二个位置开始扫描。类似的,色度的2×2DC系数以光栅顺序首先扫描,剩余的15个AC系数从第二个位置开始扫描。

图5.66 Zig-Zag扫描(帧模式)
5.12.3 隔行视频
效率高的隔行视频编码工具应该能优化场宏块的压缩。如果支持场模式,图像的类型(场或帧)应在片头中表示。H.264采用宏块自适应帧场编码(MB-AFF)模式中,帧场编码的选择在宏块级中指定,且当前片通常是16亮度像素宽和32亮度像素高的单元组成,并以宏块对的形式编码,如图5.67所示。编码器可按两个帧宏块或者两个场宏块来编码每个宏块对,也可根据图像每个区域选择最佳编码模式。
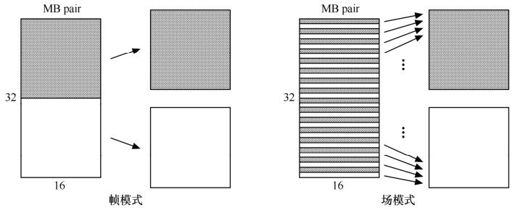
图5.67 宏块自适应帧场编码
显然,以场模式编码片或宏块对须对编解码的一些步骤进行调整。比如,P片和B片预测中,每个编码场作为一个独立的参考图像;帧内宏块编码模式和帧间宏块MV的预测需根据宏块类型(帧还是场)进行调整;图5.67所示的重排序扫描也须按图5.68所示的顺序进行。
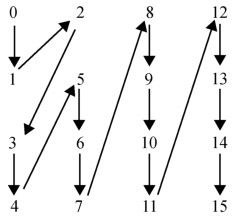
图5.68 Zig-Zag扫描(场模式)
5.12.4 数据分割片
组成片的编码数据存放在3个独立的DP(数据分割,A、B、C)中,各自包含一个编码片的子集。分割A包含片头和片中每个宏块头数据。分割B包含帧内和SI片宏块的编码残差数据。分割C包含帧间宏块的编码残差数据。每个分割可放在独立的NAL单元并独立传输。
如果分割A数据丢失,便很难或者不能重建片,因此分割A对传输误差很敏感。解码器可根据要求只解A和B或者A和C,以降低在一定传输条件下的复杂度。
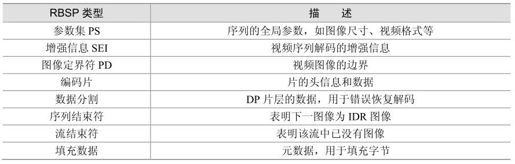
5.12.5 H.264传输
H.264的编码视频序列包括一系列的NAL单元,每个NAL单元包含一个RBSP,见表5.27。编码片(包括数据分割片和IDR片)和序列RBSP结束符被定义为VCL NAL单元,其余的为NAL单元。典型的RBSP单元序列如图5.69所示。每个单元都按独立的NAL单元传送。NAL单元的头信息(一个字节)定义了RBSP单元的类型,NAL单元的其余部分则为RBSP数据。

图5.69 RBSP序列举例
表5.27 RBSP描述
1.参数集
H.264引入了参数集的概念,每个参数集包含了相应的编码图像的信息。序列参数集(SPS)包含的是针对一连续编码视频序列的参数,如标识符seq_parameter_set_id、帧数及POC的约束、参考帧数目、解码图像尺寸和帧场编码模式选择标识等。图像参数集(PPS)对应的是一个序列中某一幅图像或者某几幅图像,其参数如标识符pic_parameter_set_id、可选的seq_parameter_set_id、熵编码模式选择标识、片组数目、初始量化参数和去方块滤波系数调整标识等。
通常,SPS和PPS在片的头信息和数据解码前传送至解码器。每个片的头信息对应一个pic_parameter_set_id,PPS被其激活后一直有效到下一个PPS被激活;类似的,每个PPS对应一个seq_parameter_set_id,SPS被其激活以后将一直有效到下一个SPS被激活。
参数集机制将一些重要的、改变少的序列参数和图像参数与编码片分离,并在编码片之前传送至解码端,或者通过其他机制传输。
2.NAL单元传输和存储
H.264标准并未定义NAL单元的传输方式,但实际中根据不同的传输环境其传输方式还是存在一定的差异。如在分组传输网络中,每个NAL单元以独立的包传输,在解码之前进行重新排序;在电路交换传输环境中,传输之前须在每个NAL单元之前加上起始前缀码,使解码器能够找出NAL单元的起始位置。
在一些应用中,编码视频需要和音频及相关信息一起传输存储,这就需要一些机制来实现,目前通常用的是RTP/UDP协议协同实现。MPEG-2 System部分的一个改进版本规定了H.264视频传输机制,ITU-T H.241定义了用H.264连接H.32*多媒体终端。对要求视频、音频及其他信息一起存储的流媒体回放、DVD回放等应用,将推出的MPEG-4 System改进版本定义了H.264编码数据和相关媒体流如何以ISO的媒体文件格式存储。
H.264提供了许多优化视频编码压缩的机制,并希望能够满足多种媒体通信应用。相对MPEG-4来说,H.264编码工具有一定的限制,但仍可选择多种编码参数和档次。H.264实际应用是否成功取决于编解码器的设计和编码参数的选择。
参考文献
[1]T. Wiegand, G. J. Sullivan, G. Bjøntegaard, A. Luthra. Overview of the H.264/AVC Video Coding Standard. IEEE Trans. Circuits Syst. Video Technol., vol. 13, pp. 560–576, July 2003.
[2]S. Wenger. H.264/AVC over IP. IEEE Trans. Circuits Syst. Video Technol., vol. 13, pp. 645–656, July 2003.
[3]T. Stockhammer, M. M. Hannuksela, T. Wiegand. H.264/AVC in wireless environments. IEEE Trans. Circuits Syst. Video Technol., vol. 13, pp. 657–673, July 2003.
[4]T. Wedi. Motion compensation in H.264/AVC. IEEE Trans. Circuits Syst. Video Technol., vol. 13, pp. 577–586, July 2003.
[5]M. Flierl, B. Girod. Generalized B pictures and the draft JVT/H.264 video compression standard. IEEE Trans. Circuits Syst. Video Technol.,vol. 13, pp. 587–597, July 2003.
[6]T. Wiegand, H. Schwarz, A. Joch, F. Kossentini, G. J. Sullivan. Rate-constrained coder control and comparison of video coding standards. IEEE Trans. Circuits Syst. Video Technol., vol. 13, pp. 688–703, July 2003.
[7]Schafer Ralf, Wiegand Thomas, Schwarz Heiko. The emerging H.264/AVC Standard EBU Technical Review. Jan.2003.
[8]M. Karczewicz, R. Kurçeren. The SP and SI frames design for H.264/AVC. IEEE Trans. Circuits Syst. Video Technol., vol. 13, pp. 637–644, July 2003.
[9]H. Malvar, A. Hallapuro, M. Karczewicz, L. Kerofsky. Low-Complexity transform and quantization in H.264/AVC. IEEE Trans. Circuits Syst. Video Technol., vol. 13, pp. 598–603, July 2003.
[10]P. List, A. Joch, J. Lainema, G. Bjøntegaard, M. Karczewicz. Adaptive deblocking filter. IEEE Trans. Circuits Syst. Video Technol., vol. 13, pp. 614–619, July 2003.
[11]J. Ribas-Corbera, P. A. Chou, S. Regunathan. A generalized hypothetical reference decoder for H.264/AVC. IEEE Trans. Circuits Syst. Video Technol., vol. 13, pp. 674–687, July 2003.
[12]Mathias Wien. Variable Block-Size Transforms for H.264/AVC. IEEE Trans. Circuits Syst. Video Technol., vol. 13, pp. 604 –613, July 2003.
[13]Michael Horowitz, Anthony Joch, Faouzi Kossentini. H.264/AVC Baseline Profile Decoder Complexity Analysis IEEE Trans. Circuits Syst. Video Technol., vol. 13, pp. 704 –716, July 2003.
[14]T. Wiegand, G. J. Sullivan. Draft ITU-T Recommendation H.264 and Final Draft International Standard of Joint Video Specification(ITU-T Recommendation H.264 | ISO/IEC 14496-10 AVC). Joint Video Team of ISO/IEC JTC1/SC29/WG11 and ITU-T SG16/Q.6 Doc. JVT-G050, Pattaya, Thailand, Mar. 2003.
[15]G .Bjontegarrd, K.Lillevold. Context –adaptive VLC Coding of Coefficients. JVT Document JVT-C028, Fairfax , VA, MAY 2002.
[16]Yao Wang, Jorn Ostermann, Ya-qin Zhang . 视频处理与通信.北京:电子工业出版社,2003.
[17]X. L. Ce Zhu, Lap-Pui Chau. Hexagon-Based Search Pattern for Fast Block Motion Estimation. IEEE Trans. on CSVT, vol.12, 2002: 349-355.
[18]Ghanbari, M. The cross-search algorithm for motion estimation, Communications. IEEE Transactions on, Volume: 38 Issue:7, July 1990: 950-953.
[19]Chang, Y.-C., D. G. Messerschmitt, T. Carney, S. A. Klein. Delay cognizant video coding: architecture, applications, and quality evaluations. Forthcoming in IEEE Trans, Image Processing.
[20]Iain E. G. Richarson. H.264 and MPEG-4 Video Compression. Aberdeen, UK. 2003.
[21]Joint Model for Non-normative Aspects of Advanced Video Coding. Study of ISO/IEC 14496-6 / PDAM6: 2003(E).
[22]陈志波.H.264运动估值与网络视频传输关键问题研究.北京:清华大学,毕业论文,2002.
[23]王汇源.数字图像通信原理与技术.北京:国防工业出版社,2000.
[24]丁贵广,计文平,郭宝龙.Visual C++6.0 数字图像编码.北京:机械工业出版社,2004.
[25]朱秀昌,刘峰,胡栋.数字图像处理与图像通信.北京:北京邮电大学出版社,2002.
[26]Marta Karczewicz The. SP- and SI- Frames Design for H.264/AVC. IEEE Trans. Circuits and Systems for Video Technology, vol. 13, No.7, July 2003.
[27]TML 8.7 Software. ftp://standard.pictel.com/video/h26l/.
[28]万萍,陈仁雷,王海婴.H.264/AVC中的SP/SI帧技术.电视技术,2004.1, pp.22-25.
