9.3 遥测数据的分类与处理
业界将系统输出的数据总结为三种独立的类型,它们的含义与区别如下:
指标(metric):量化系统性能和状态的“数据点”,每个数据点包含度量对象(如接口请求数)、度量值(如 100 次/秒)和发生的时间,多个时间上连续的数据点便可以分析系统性能的趋势和变化规律。指标是发现问题的起点,例如你半夜收到一条告警:“12 点 22 分,接口请求成功率下降到 10%”,这表明系统出现了问题。接着,你挣扎起床,分析链路追踪和日志数据,找到问题的根本原因并进行修复。
日志(log):系统运行过程中,记录离散事件的文本数据。每条日志详细描述了事件操作对象、操作结果、操作时间等信息。例如下面的日志示例,包含了时间、日志级别(ERROR)以及事件描述。
[2024-12-27 14:35:22] ERROR: Failed to connect to database. Retry attempts exceeded.
日志为问题诊断提供了精准的上下文信息,与指标形成互补。当系统故障时,“指标”告诉你应用程序出现了问题,“日志”则解释了问题出现的原因。
链路追踪(trace):记录请求在多个服务之间的“调用链路”(Trace),以“追踪树”(Trace Tree)的形式呈现请求的“调用”(span)、耗时分布等信息。
// 追踪树Trace ID: 12345└── Span ID: 1 - API Gateway (Duration: 50ms)└── Span ID: 2 - User Service (Duration: 30ms)└── Span ID: 3 - Database Service (Duration: 20ms)
上述 3 类数据各自侧重不同,但并非孤立存在,它们之间有着天然的交集与互补。比如指标监控(告警)帮助发现问题,日志和链路追踪则帮助定位根本原因。这三者之间的关系如图 9-2 的韦恩图所示。
:::center
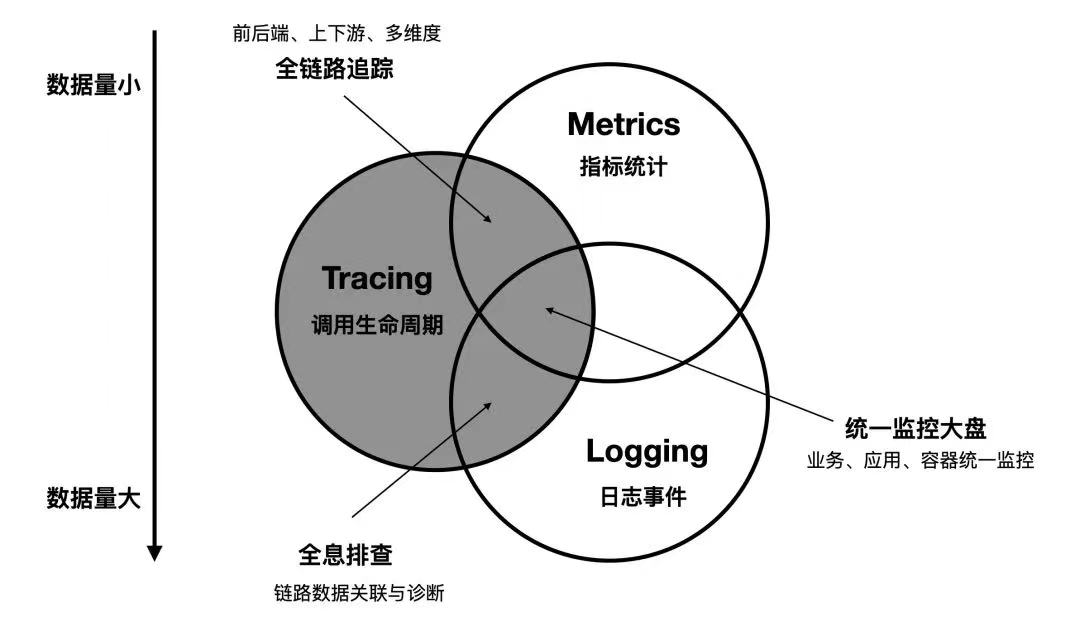
图 9-2 指标、链路追踪、日志三者之间的关系 图片来源
:::
2021 年,CNCF 发布了可观测性白皮书[^1],里面新增了性能剖析(Profiling)和核心转储(Core dump)2 种数据类型。接下来,笔者将详细介绍这 5 类遥测数据的采集、存储和分析原理。
[^1]: 参见 https://github.com/cncf/tag-observability/blob/main/whitepaper.md
