第15章 脚本化文档
客户端JavaScript的存在使得静态的HTML文档变成了交互式的Web应用。脚本化Web页面内容是JavaScript的核心目标。本章——本书中最重要的章节之一——阐述了它是如何做到的。
第13章和第14章解释了每一个Web浏览器窗口、标签页和框架由一个Window对象所表示。每个Window对象有一个document属性引用了Document对象。Document对象表示窗口的内容,它就是本章的主题。尽管如此,Document对象并非独立的,它是一个巨大的API中的核心对象,叫做文档对象模型(Document Object Model,DOM),它代表和操作文档的内容。
本章开始部分解释DOM的基本架构,然后进一步解释以下内容:
·如何在文档中查询或选取单独的元素。
·如何将文档作为节点树来遍历,如何找到任何文档元素的祖先、兄弟和后代元素。
·如何查询和设置文档元素的属性。
·如何查询、设置和修改文档内容。
·如何通过创建、插入和删除节点来修改文档结构。
·如何与HTML表单一起工作。
本章最后一节涵盖其他各种文档特性,包含referrer属性、write()方法和查询当前文档中选取的文档文本的技术等。
15.1 DOM概览
文档对象模型(DOM)是表示和操作HTML和XML文档内容的基础API。API不是特别复杂,但是需要理解大量的架构细节。首先,应该理解HTML或XML文档的嵌套元素在DOM树对象中的表示。HTML文档的树状结构包含表示HTML标签或元素(如<body>、<p>)和表示文本字符串的节点,它也可能包含表示HTML注释的节点。考虑以下简单的HTML文档:
<html>
<head>
<title>Sample Document</title>
</head>
<body>
<h1>An HTML Document</h1>
<p>This is a<i>simple</i>document.
</html>
图15-1是此文档DOM表示的树状图。
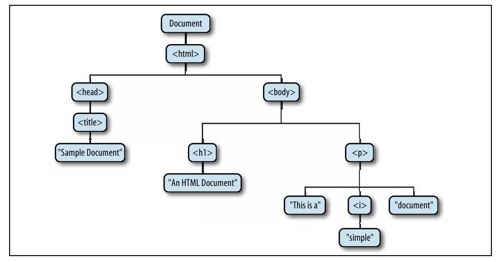
图 15-1 HTML文档的树状表示
如果还未熟悉计算机编程中的树状结构,借用家谱图来形容是比较有用的方法。在一个节点之上的直接节点是其父节点,在其下一层的直接节点是其子节点。在同一层上具有相同父节点的节点是兄弟节点。在一个节点之下的所有层级的一组节点是其后代节点。一个节点的任何父节点、祖父节点和其上层的所有节点是祖先节点。
图15-1中的每个方框是文档的一个节点,它表示一个Node对象。我们将在后续几节中讨论Node的属性和方法,并且可以在第四部分查找这些属性和方法。注意,图15-1包含3种不同类型的节点。树形的根部是Document节点,它代表整个文档。代表HTML元素的节点是Element节点,代表文本的节点是Text节点。Document、Element和Text是Node的子类,在第四部分中它们有自己的条目。Document和Element是两个重要的DOM类,本章大部分内容将阐述它们的属性和方法。
图15-2展示了Node及其在类型层次结构中的子类型。注意,通用的Document和Element类型与HTMLDocument和HTMLElement类型之间是有严格的区别的。Document类型代表一个HTML或XML文档,Element类型代表该文档中的一个元素。HTMLDocument和HTMLElement子类只是针对于HTML文档和元素。此书中,我们经常使用通用类名Document和Element,甚至在指代HTML文档时也不例外。在第四部分中也是如此:HTMLDocument和HTMLElement类型的属性和方法记录于Document和Element参考页中。
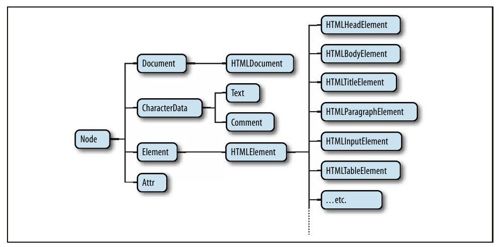
图 15-2 文档节点的部分层次结构
值得注意的是,在图15-2中有HTMLElement的很多子类型代表HTML元素的具体类型。每个类型定义多个JavaScript属性,它们对应具体的元素或元素组(参照15.4.1节)的HTML属性。有些具体元素类也定义额外的属性和方法,它们并不是简单地映射HTML语法。第四部分涵盖这些类型及其额外的特性。
最后,请注意图15-2也展示了到目前为止还未提及的一些节点类型。Comment节点代表HTML或XML的注释。由于注释基本上是文本字符串,因此它们很像表示文档中显示文本的Text节点。CharacterData通常是Text和Comment的祖先,它定义这两种节点所共享的方法。Attr节点类型代表XML或HTML属性,但它几乎从不使用,因为和文档节点不同,Element类型定义了将属性当做“名/值”对使用的方法。DocumentFragment类(未在图15-2上显示)在实际文档中并不存在的一种节点:它代表一系列没有常规父节点的节点。对一些文档操作来说DocumentFragment非常有用,15.6.4节涵盖这部分内容。DOM也定义了一些不经常使用的类型,如像代表doctype声明和XML处理指令等类型。
15.2 选取文档元素
大多数客户端JavaScript程序运行时总是在操作一个或多个文档元素。当这些程序启动时,可以使用全局变量document来引用Document对象。但是,为了操作文档中的元素,必须通过某种方式获得或选取这些引用文档元素的Element对象。DOM定义许多方式来选取元素,查询文档的一个或多个元素有如下方法:
·用指定的id属性;
·用指定的name属性;
·用指定的标签名字;
·用指定的CSS类;
·匹配指定的CSS选择器。
随后几节解释每一种元素选取技术。
15.2.1 通过ID选取元素
任何HTML元素可以有一个id属性,在文档中该值必须唯一,即同一个文档中的两个元素不能有相同的ID。可以用Document对象的getElementById()方法选取一个基于唯一ID的元素。此方法我们在第13章和第14章都已经使用过了:
var section1=document.getElementById("section1");
这是最简单和常用的选取元素的方法。如果想要操作某一组指定的文档元素,提供这些元素的id属性值,并使用ID查找这些Element对象。如果需要通过ID查找多个元素,会发现例15-1中的getElements()函数非常有用:
例15-1:通过ID查找多个元素
/**
*函数接受任意多的字符串参数
*每个参数将当做元素的id传给document.getElementById()
*返回一个对象,它把这些id映射到对应Element对象
*如任何一个id对应的元素未定义,则抛出一个Error对象
*/
function getElements(/ids…/){
var elements={};//开始是一个空map映射对象
for(var i=0;i<arguments.length;i++){//循环每个参数
var id=arguments[i];//参数是元素的id
var elt=document.getElementById(id);//查找元素
if(elt==null)//如果未定义
throw new Error("No element with id:"+id);//抛出异常
elements[id]=elt;//id和元素之间映射
}
return elements;//对于元素映射返回id
}
在低于IE 8版本的浏览器中,getElementById()对匹配元素的ID不区分大小写,而且也返回匹配name属性的元素。
15.2.2 通过名字选取元素
HTML的name属性最初打算为表单元素分配名字,在表单数据提交到服务器时使用该属性的值。类似id属性,name是给元素分配名字,但是区别于id,name属性的值不是必须唯一:多个元素可能有同样的名字,在表单中,单选和复选按钮通常是这种情况。而且,和id不一样的是name属性只在少数HTML元素中有效,包括表单、表单元素、<iframe>和<img>元素。
基于name属性的值选取HTML元素,可以使用Document对象的getElementsByName()方法。
var radiobuttons=document.getElementsByName("favorite_color");
getElementsByName()定义在HTMLDocument类中,而不在Document类中,所以它只针对HTML文档可用,在XML文档中不可用。它返回一个NodeList对象,后者的行为类似一个包含若干Element对象的只读数组。在IE中,getElementsByName()也返回id属性匹配指定值的元素。为了兼容,应该小心谨慎,不要将同样的字符串同时用做名字和ID。
在14.7节中我们看到,为某些HTML元素设置name属性值将自动为Window对象中创建对应的属性,对Document对象也类似。为<form>、<img>、<iframe>、<applet>、<embed>或<object>元素(其中只有<object>元素没有后备对象)设置name属性值,即在Document对象中创建以此name属性值为名字的属性(当然,假设此文档还没有该名字的属性)。
如果给定的名字只有一个元素,自动创建的文档属性对应的该值是元素本身。如果有多个元素,该文档属性的值是一个NodeList对象,它表现为一个包含这些元素的数组。如14.7节所示,为若干命名<iframe>元素所创建的文档属性比较特殊:它们指代这些框架的Window对象而不是Element对象。
这就意味着有些元素可以作为Document属性仅通过名字来选取:
//针对<form name="shipping_address">元素,得到Element对象
var form=document.shipping_address;
在14.7节介绍了为什么不要用为窗口对象自动创建的属性,这同样适用于为文档对象自动创建的属性。如果需要查找命名的元素,最好显式地调用getElementsByName()来查找它们。
15.2.3 通过标签名选取元素
Document对象的getElementsByTagName()方法可用来选取指定类型(标签名)的所有HTML或XML元素。例如,如下代码,在文档中获得包含所有<span>元素的只读的类数组对象:
var spans=document.getElementsByTagName("span");
类似于getElementsByName(),getElementsByTagName()返回一个NodeList对象(关于NodeList类,见本节的补充信息)。在NodeList中返回的元素按照在文档中的顺序排序的,所以可用如下代码选取文档中的第一个<p>元素:
var firstpara=document.getElementsByTagName("p")[0];
HTML标签是不区分大小写的,当在HTML文档中使用getElementsByTagName()时,它进行不区分大小写的标签名比较。例如,上述的变量span将包含所有写成<SPAN>的span标签。
给getElementsByTagName()传递通配符参数“*”将获得一个代表文档中所有元素的NodeList对象。
Element类也定义getElementsByTagName()方法,其原理和Document版本的一样,但是它只选取调用该方法的元素的后代元素。因此,要查找文档中第一个<p>元素里面的所有<span>元素,代码如下:
var firstpara=document.getElementsByTagName("p")[0];
var firstParaSpans=firstpara.getElementsByTagName("span");
由于历史的原因,HTMLDocument类定义一些快捷属性来访问各种各样的节点。例如,images、forms和links等属性指向行为类似只读数组的<img>、<form>和<a>(但只包含那些有href属性的<a>标签)元素集合。这些属性指代HTMLCollection对象,它们很像NodeList对象,但是除此之外它们可以用元素的ID或名字来索引。早些时候,我们已经看到用如下的表达式来引用一个命名的<form>元素:
document.shipping_address
用document.forms属性也可以更具体地引用命名(或有ID的)表单,如下:
document.forms.shipping_address;
HTMLDocument也定义embeds和plugins属性,它们是同义词,都是HTMLCollection类型的<embed>元素的集合。anchors是非标准属性,它指代有一个name属性的<a>元素而并不是一个href属性。scripts在HTML5中是标准属性,它是HTMLCollection类型的<script>元素的集合,但是在写本书的时候,它还未普遍实现。
HTMLDocument对象还定义两个属性,它们指代特殊的单个元素而不是元素的集合。document.body是一个HTML文档的<body>元素,document.head是<head>元素。这些属性总是会定义:如果文档源代码未显式地包含<head>和<body>元素,浏览器将隐式地创建它们。Document类的documentElement属性指代文档的根元素。在HTML文档中,它总是指代<html>元素。
节点列表和HTML集合
getElementsByName()和getElementsByTagName()都返回NodeList对象,而类似document.images和document.forms的属性为HTMLCollection对象。
这些对象都是只读的类数组对象(见7.11节)。它们有length属性,也可以像真正的数组一样索引(只是读而不是写)。可以对一个NodeList或HTMLCollection的内容用如下标准的循环进行迭代:
for(var i=0;i<document.images.length;i++)//循环所有的图片
document.images[i].style.display="none";//……隐藏它们
不能直接在NodeList和HTML集合上调用Array的方法,但可以间接地使用:
var content=Array.prototype.map.call(document.getElementsByTagName("p"),
function(e){return e.innerHTML;});
HTMLCollection对象也有额外的命名属性,也可以通过数字和字符串来索引。
由于历史的原因,NodeList和HTMLCollection对象也都能当做函数:以数字或字符串为参数调用它就如同使用数字或字符串索引它们一般。不鼓励使用这种怪异的方式。
NodeList和HTMLCollection接口都不是为像JavaScript这样的动态语言设计的。它们都定义了item()方法,期望输入一个整数,并返回此索引处的元素。在JavaScript中根本没有必要调用此方法,因为简单地使用数组索引就能替代。类似地,HTMLCollection定义了namedItem()方法,它返回指定属性名的值,但在JavaScript程序中可以用数组索引或常规属性来访问。
NodeList和HTMLCollection对象不是历史文档状态的一个静态快照,而通常是实时的,并且当文档变化时它们所包含的元素列表能随之改变,这是其中一个最重要和令人惊讶的特性。假设在一个没有<div>元素的文档中调用getElementsByTagName('div'),此时返回值是一个length为0的NodeList对象。如果再在文档中插入一个新的<div>元素,此元素将自动成为NodeList的一个成员,并且它的length属性变成1。
通常,NodeList和HTMLCollection的实时性非常有用。但是,如果要在迭代一个NodeList对象时在文档中添加或删除的元素,首先会需要对NodeList对象生成一个静态的副本:
var snapshot=Array.prototype.slice.call(nodelist,0);
15.2.4 通过CSS类选取元素
HTML元素的class属性值是一个以空格隔开的列表,可以为空或包含多个标识符。它描述一种方法来定义多组相关的文档元素:在它们的class属性中有相同标识符的任何元素属于该组的一部分。在JavaScript中class是保留字,所以客户端JavaScript使用className属性来保存HTML的class属性值。class属性通常与CSS样式表一起使用,对某组内的所有元素应用相同的样式,在第16章中将再次看到它。尽管如此,HTML定义了getElementsByClassName()方法,它基于其class属性值中的标识符来选取成组的文档元素。
类似getElementsByTagName(),在HTML文档和HTML元素上都可以调用getElementsByClassName(),它的返回值是一个实时的NodeList对象,包含文档或元素所有匹配的后代节点。getElementsByClassName()只需要一个字符串参数,但是该字符串可以由多个空格隔开的标识符组成。只有当元素的class属性值包含所有指定的标识符时才匹配,但是标识符的顺序是无关紧要的。注意,class属性和getElementsByClassName()方法的类标识符之间都是用空格隔开的,而不是逗号。如下是使用getElementsByClassName()的一些例子:
//查找其class属性值中包含"warning"的所有元素
var warnings=document.getElementsByClassName("warning");//查找以"log"命名并且有"error"和"fatal"类的元素的所有后代
var log=document.getElementById("log");
var fatal=log.getElementsByClassName("fatal error");
如今的Web浏览器依赖于文档开头处对<!DOCTYPE>声明的严格程度来选择“怪异模式”或“标准模式”方式显示HTML文档。怪异模式是为了向后兼容性而存在的,其中一个怪异行为就是在class属性中和CSS样式表中的类标识符不区分大小写。getElementsByClassName()方法使用样式表的匹配算法。如果文档以怪异模式渲染,该方法将执行不区分大小写的字符串比较;否则,该比较区分大小写。
在写本书这段时间内,除了IE 8及其较低的版本,getElementsByClassName()在所有当前的浏览器中都实现了。IE 8确实支持querySelectorAll()方法,下一节会介绍它,而getElementsByClassName()方法是可以在其之上实现的。
15.2.5 通过CSS选择器选取元素
CSS样式表有一种非常强大的语法,那就是选择器,它用来描述文档中的若干或多组元素。CSS选择器语法的全部细节介绍超出了本书的范围[1],但是这里有一些例子来说明基本的语法。元素可以用ID、标签名或类来描述:
#nav//id="nav"的元素
div//所有<div>元素
.warning//所有在class属性值中包含了"warning"的元素
更一般地,元素可以基于属性值来选取:
p[lang="fr"]//所有使用法语的段落,如:<p lang="fr">
*[name="x"]//所有包含name="x"属性的元素
这些基本的选择器可以组合使用:
span.fatal.error//其class中包含"fatal"和"error"的所有<span>元素
span[lang="fr"].warning//所有使用法语的且其class中包含"warning"的<span>元素
选择器可以指定文档结构:
#log span//id="log"元素的后代元素中的所有<span>元素
#log>span//id="log"元素的子元素中的所有<span>元素
body>h1:first-child//<body>的子元素中的第一个<h1>元素
选择器可以组合起来选取多个或多组元素:
div,#log//所有<div>元素,以及id="log"的元素
如你所见,CSS选择器可以使用上述所有方法选取元素:通过ID、名字、标签名和类名。与CSS3选择器的标准化一起的另一个称做“选择器API”的W3C标准定义了获取匹配一个给定选择器的元素的JavaScript方法[2]。该API的关键是Document方法querySelectorAll()。它接受包含一个CSS选择器的字符串参数,返回一个表示文档中匹配选择器的所有元素的NodeList对象。与前面描述的选取元素的方法不同,querySelectorAll()返回的NodeList对象并不是实时的:它包含在调用时刻选择器所匹配的元素,但它并不更新后续文档的变化。如果没有匹配的元素,querySelectorAll()将返回一个空的NodeList对象。如果选择器字符串非法,querySelectorAll()将抛出一个异常。
除了querySelectorAll(),文档对象还定义了querySelector()方法。与querySelectorAll()的工作原理类似,但它只是返回第一个匹配的元素(以文档顺序)或者如果没有匹配的元素就返回null。
这两个方法在Element节点中也有定义(并且也在DocumentFragment节点中,见15.6.4节)。在元素上调用时,指定的选择器仍然在整个文档中进行匹配,然后过滤出结果集以便它只包含指定元素的后代元素。这看起来是违反常规的,因为它意味着选择器字符串能包含元素的祖先而不仅仅是上述所匹配的元素。
注意,CSS定义了":first-line"和":first-letter"等伪元素。在CSS中,它们匹配文本节点的一部分而不是实际元素。如果和querySelectorAll()或querySelector()一起使用它们是不匹配的。而且,很多浏览器会拒绝返回":link"和":visited"等伪类的匹配结果,因为这会泄露用户的浏览历史记录。
所有当前的浏览器都支持querySelector()和querySelectorAll()方法。但是注意,这些方法的规范并不要求支持CSS3选择器:鼓励浏览器支持和在样式表中一样的选择器集合。当前的浏览器除了IE都支持CSS3选择器。IE 7和8支持CSS2选择器。(期望IE 9能支持CSS3选择器。)
querySelectorAll()是终极的选取元素的方法:它是一种非常强大的技术,通过它客户端JavaScript程序能够选择它们想要操作的元素。幸运的是,甚至在没有querySelectorAll()的原生支持的浏览器中也可以使用CSS选择器。jQuery库(见第19章)使用这种基于CSS选择器的查询作为它的核心编程范式。基于jQuery的Web应用程序使用一个轻便的、跨浏览器的、和querySelectorAll()等效的方法,命名为$()。
jQuery的CS S选择器匹配代码已经作为一个独立的标准库提出来并发布了,命名为Sizzle。它已经被Dojo和其他一些客户端库所采纳[3]。使用一个类似Sizzle的库(或一个包含Sizzle的库)的好处就是在老式浏览器中选取元素也能正常工作,并保证一个基准的选择器集合在所有的浏览器中都能运行。
15.2.6 document.all[]
在DOM标准化之前,IE 4引入了document.all[]集合来表示所有文档中的元素(除了Text节点)。document.all[]已经被标准的方法(如getElementById()和getElementsByTagName())等所取代,现在已经废弃不应该再使用了。但是,在引入之时它是革命性的,它在以各种方式使用的已有代码中仍然可以看到:
document.all[0]//文档中第一个元素
document.all["navbar"]//id或name为"navbar"的元素(或多个元素)
document.all.navbar//同上
document.all.tags("div")//文档中所有的<div>元素
document.all.tags("p")[0]//文档中第一个<p>元素
15.3 文档结构和遍历
一旦从文档中选取了一个元素,有时需要查找文档中与之在结构上相关的部分(父亲、兄弟和子女)。文档从概念上可以看做是一棵节点对象树,如图15-1所示。节点类型定义了遍历该树所需的属性,我们将在节15.3.1中介绍。另一个API允许文档作为元素对象树来遍历。15.3.2节介绍这个新的(通常也更容易使用的)API。
15.3.1 作为节点树的文档
Document对象、它的Element对象和文档中表示文本的Text对象都是Node对象。Node定义了以下重要的属性:
parentNode
该节点的父节点,或者针对类似Document对象应该是null,因为它没有父节点。
childNodes
只读的类数组对象(NodeList对象),它是该节点的子节点的实时表示。
firstChild、lastChild
该节点的子节点中的第一个和最后一个,如果该节点没有子节点则为null。
nextSibling、previoursSibling
该节点的兄弟节点中的前一个和下一个。具有相同父节点的两个节点为兄弟节点。节点的顺序反映了它们在文档中出现的顺序。这两个属性将节点之间以双向链表的形式连接起来。
nodeType
该节点的类型。9代表Document节点,1代表Element节点,3代表Text节点,8代表Comment节点,11代表DocumentFragment节点。
nodeValue
Text节点或Comment节点的文本内容。
nodeName
元素的标签名,以大写形式表示。
使用这些Node属性,可以用以下类似的表达式得到文档的第一个子节点下面的第二个子节点的引用:
document.childNodes[0].childNodes[1]
document.firstChild.firstChild.nextSibling
假设上述提到的文档代码如下:
<html><head><title>Test</title></head><body>Hello World!</body></html>
那么第一个子节点下面的第二个子节点就是<body>元素,它的nodeType为1,nodeName为"BODY"。
但请注意,该API对文档文本的变化及其敏感。例如,如果修改了文档,在<html>和<head>标签之间插入一个新行,那么表示该新行的Text节点就是文档的第一个子节点下面的第一个子节点,并且<head>元素就是第二个子节点而不是<body>元素了。
15.3.2 作为元素树的文档
当将主要的兴趣点集中在文档中的元素上而非它们之间的文本(和它们之间的空白)上时,我们可以使用另外一个更有用的API。它将文档看做是Element对象树,忽略部分文档:Text和Comment节点。
该API的第一部分是Element对象的children属性。类似ChildNodes,它也是一个NodeList对象,但不同的是children列表只包含Element对象。children并非标准属性,但是它在所有当前的浏览器中都能工作。IE已经实现有一段很长的时间了,其他大多数浏览器也已如法炮制。最后采纳它的主流浏览器是Firefox 3.5。
注意,Text和Comment节点没有children属性,它意味着上述Node.parentNode属性不可能返回Text或Comment节点。任何Element的parentNode总是另一个Element,或者,追溯到树根的Document或DocumentFragment节点。
基于元素的文档遍历API的第二部分是Element属性,后者类似Node对象的子属性和兄弟属性:
firstElementChild,lastElementChild
类似firstChild和lastChild,但只代表子Element。
nextElementSibling,previousElementSibling
类似nextSibling和previousSibling,但只代表兄弟Element。
childElementCount
子元素的数量。返回的值和children.length值相等。
子元素和兄弟元素的属性是标准属性,并在除了IE[4]之外的浏览器中都已实现。
由于逐个元素的文档遍历的API并未完全标准化,我们仍然可以通过像例15-2中可移植的遍历函数那样来实现这种功能:
例15-2:可移植的文档遍历函数
/**
*返回元素e的第n层祖先元素,如果不存在此类祖先或祖先不是Element,
*(例如Document或者DocumentFragment)则返回null
*如果n为0,则返回e本身。如果n为1(或省略),则返回其父元素
*如果n为2,则返回其祖父元素,依次类推
*/
function parent(e,n){
if(n===undefined)n=1;
while(n—&&e)e=e.parentNode;
if(!e||e.nodeType!==1)return null;
return e;
}/**
*返回元素e的第n个兄弟元素
*如果n为正,返回后续的第n个兄弟元素
*如果n为负,返回前面的第n个兄弟元素
*如果n为零,返回e本身
*/
function sibling(e,n){
while(e&&n!==0){//如果e未定义,即刻返回它
if(n>0){//查找后续的兄弟元素
if(e.nextElementSibling)e=e.nextElementSibling;
else{
for(e=e.nextSibling;e&&e.nodeType!==1;e=e.nextSibling)/空循环/;
}
n—;
}
else{//查找前面的兄弟元素
if(e.previousElementSibing)e=e.previousElementSibling;
else{
for(e=e.previousSibling;e&&e.nodeType!==1;e=e.previousSibling)/空循环/;
}
n++;
}
}
return e;
}/**
*返回元素e的第n代子元素,如果不存在则为null
*负值n代表从后往前计数。0表示第一个子元素,而-1代表最后一个,-2代表倒数第二个,依次类推
*/
function child(e,n){
if(e.children){//如果children数组存在
if(n<0)n+=e.children.length;//转换负的n为数组索引
if(n<0)return null;//如果它仍然为负,说明没有子元素
return e.children[n];//返回指定的子元素
}
//如果e没有children数组,找到第一个子元素并向前数,或找到最后一个子元素并往回数
if(n>=0){//n非负:从第一个子元素向前数
//找到元素e的第一个子元素
if(e.firstElementChild)e=e.firstElementChild;
else{
for(e=e.firstChild;e&&e.nodeType!==1;e=e.nextSibling)/空循环/;
}
return sibling(e,n);//返回第一个子元素的第n个兄弟元素
}
else{//n为负:从最后一个子元素往回数
if(e.lastElementChild)e=e.lastElementChild;
else{
for(e=e.lastChild;e&&e.nodeType!==1;e=e.previousSibling)/空循环/;
}
return sibling(e,n+1);//+1来转化最后1个子元素为最后1个兄弟元素
}
}
自定义Element的方法
所有当前的浏览器(包含IE 8,除了IE 7及其更早的版本)都实现了DOM,故类似Element和HTMLDocument[5]等类型都像String和Array一样是类。它们不是构造函数(将在本章后面看到如何创建新的Element对象),但它们有原型对象,可以用自定义方法扩展它:
Element.prototype.next=function(){
if(this.nextElementSibling)return this.nextElementSibling;var sib=this.nextSibling;
while(sib&&sib.nodeType!==1)sib=sib.nextSibling;return sib;
};
例15-2中的函数并没有定义为Element的方法是因为这种技术在IE 7中不支持。
尽管如此,如果希望将IE专有的特性在除了IE之外的其他浏览器中得以实现,这种扩展DOM类型的能力是非常有用的。从上面注意到,Element的非标准children属性由IE首先引入,并已经被其他浏览器所采纳。类似Firefox 3.0不支持它的浏览器中可以使用以下代码模拟此属性:
//在不包含此属性的非IE浏览器中模拟Element.children属性
//注意,返回值为静态数组,而不是实时的NodeList对象
if(!document.documentElement.children){
Element.prototype.defineGetter("children",function(){
var kids=[];
for(var c=this.firstChild;c!=null;c=c.nextSibling)
if(c.nodeType===1)kids.push(c);
return kids;
});
}
defineGetter方法(在6.7.1节中介绍)完全是非标准的,但它用来移植类似的代码非常完美。
15.4 属性
HTML元素由一个标签和一组称为属性(attribute)的名/值对组成。例如,<a>元素定义了一个超链接,它的href属性值作为链接的目的地址。HTML元素的属性值在代表这些元素的HTMLElement对象的属性(property)中是可用的。DOM还定义了另外的API来获取或设置XML属性值和非标准的HTML属性。详细信息见以下各节。
15.4.1 HTML属性作为Element的属性
表示HTML文档元素的HTMLElement对象定义了读/写属性,它们映射了元素的HTML属性。HTMLElement定义了通用的HTTP属性(如id、标题lang和dir)的属性,以及事件处理程序属性(如onclick)。特定的Element子类型为其元素定义了特定的属性。例如,查询一张图片的URL,可以使用表示<img>元素的HTMLElement对象的src属性:
var image=document.getElementById("myimage");
var imgurl=image.src;//src属性是图片的URL
image.id==="myimage"//判定要查找图片的id
同样地,可以为一个<form>元素设置表单提交的属性,代码如下:
var f=document.forms[0];//文档中第一个<form>
f.action="http://www.example.com/submit.php";//设置提交至的URL
f.method="POST";//HTTP请求类型
HTML属性名不区分大小写,但JavaScript属性名则大小写敏感。从HTML属性名转换到JavaScript属性名应该采用小写。但是,如果属性名包含不止一个单词,则将除了第一个单词以外的单词的首字母大写,例如:defaultChecked和tabIndex。
有些HTML属性名在JavaScript中是保留字。对于这些属性,一般的规则是为属性名加前缀"html"。例如,HTML的for属性(<lable>元素)在JavaScript中变为htmlFor属性。"class"在JavaScript中是保留字(但还未使用),它是HTML非常重要的class属性,是上面规则的一个例外:在JavaScript代码中它变为className。我们将在第16章中再次见到className属性。
表示HTML属性的值通常是字符串。当属性为布尔值或数值(例如,<input>元素的defaultChecked和maxLength属性),属性也是布尔值或数值,而不是字符串。事件处理程序属性值总是为Function对象(或null)。HTML5规范定义了一个新的属性(如<input>和相关元素的form属性)用以将元素ID转换为实际的Element对象。最后,任何HTML元素的style属性值是CSSStyleDeclaration对象,而不是字符串。我们将在第16章中看到关于这个重要属性的更多信息。
注意,这个基于属性的API用来获取和设置属性值,但没有定义任何从元素中删除属性的方法。奇怪的是,delete操作符也无法完成此目的。下一节描述一种可以实现此目的的方法。
15.4.2 获取和设置非标准HTML属性
如上所述,HTMLElement和其子类型定义了一些属性,它们对应于元素的标准HTML属性。Element类型还定义了getAttribute()和setAttribute()方法来查询和设置非标准的HTML属性,也可用来查询和设置XML文档中元素上的属性。
var image=document.images[0];
var width=parseInt(image.getAttribute("WIDTH"));
image.setAttribute("class","thumbnail");
上述代码给出了这些方法和前面的基于属性的API之间两个重要的区别。首先,属性值都被看做是字符串。getAttribute()不返回数值、布尔值或对象。其次,方法使用标准属性名,甚至当这些名称为JavaScript保留字时也不例外。对HTML元素来说,属性名不区分大小写。
Element类型还定义了两个相关的方法,hasAttribute()和removeAttribute(),它们用来检测命名属性是否存在和完全删除属性。当属性为布尔值时这些方法特别有用:有些属性(如HTML的表单元素的disabled属性)在一个元素中是否存在是重点关键,而其值却无关紧要。
如果操作包含来自其他命名空间中属性的XML文档,可以使用这4个方法的命名空间版本:getAttributeNS()、setAttributeNS()、hasAttributeNS()和removeAttributeNS()。这些方法需要两个属性名字符串作为参数,而不是一个。第一个是标识命名空间的URI,第二个通常是属性的本地名字,在命名空间中是无效的。但特别地,setAttributeNS()的第二个参数应该是属性的有效名字,它包含命名空间的前缀。可以在本书的第四部分中阅读更多关于命名空间识别的属性的方法。
15.4.3 数据集属性
有时候在HTML元素上绑定一些额外的信息也是很有帮助的,当JavaScript选取这些元素并以某种方式操纵这些信息时就是很典型的情况。有时可以通过给class属性添加特殊的标识符来完成。其他时候针对更复杂的数据,客户端程序员会借助使用非标准的属性。如上所述,可以使用getAttribute()和setAttribute()来读和写非标准属性的值。但为此而付出的代价是文档将不再是合法有效的HTML。
HTML5提供了一个解决方案。在HTML5文档中,任意以"data-"为前缀的小写的属性名字都是合法的。这些“数据集属性”将不会对其元素的表现产生影响,它们定义了一种标准的、附加额外数据的方法,并不是在文档合法性上做出让步。
HTML5还在Element对象上定义了dataset属性。该属性指代一个对象,它的各个属性对应于去掉前缀的data-属性。因此dataset.x应该保存data-x属性的值。带连字符的属性对应于驼峰命名法属性名:data-jquery-test属性就变成dataset.jqueryTest属性。
看一个更具体的例子,假设文档包含如下标记:
<span class="sparkline"data-ymin="0"data-ymax="10">
1 1 1 2 2 3 4 5 5 4 3 5 6 7 7 4 2 1
</span>
火花线(sparkline)是个小图案——通常是一条线——设计用来在文本流中显示。为了生成一条火花线,也许可以同如下代码提取上述dataset属性的值:
//假设ES5的Array.map()方法(或类似能工作的方法)有定义
var sparklines=document.getElementsByClassName("sparkline");
for(var i=0;i<sparklines.length;i++){
var dataset=sparklines[i].dataset;
var ymin=parseFloat(dataset.ymin);
var ymax=parseFloat(dataset.ymax);
var data=sparklines[i].textContent.split("").map(parseFloat);
drawSparkline(sparklines[i],ymin,ymax,data);//该方法未实现
}
在写本书的这段时间中,dataset属性还没有在当前的浏览器中实现,上述代码应该写成这样:
var sparklines=document.getElementsByClassName("sparkline");
for(var i=0;i<sparklines.length;i++){
var elt=sparklines[i];
var ymin=parseFloat(elt.getAttribute("data-ymin"));
var ymin=parseFloat(elt.getAttribute("data-ymax"));
var points=elt.getAttribute("data-points");
var data=elt.textContent.split("").map(parseFloat);
drawSparkline(elt,ymin,ymax,data);//该方法未实现
}
注意,dataset属性是(或将是,当实现以后)元素的data-属性的实时、双向接口。设置或删除dataset的一个属性就等同于设置或移除对应元素的data-属性。
上述例子中的drawSparkline()函数是虚构的,但例21-13给出了用<canvas>元素绘制类似火花线的标记代码。
15.4.4 作为Attr节点的属性
还有一种使用Element的属性的方法。Node类型定义了attributes属性。针对非Element对象的任何节点,该属性为null。对于Element对象,attributes属性是只读的类数组对象,它代表元素的所有属性。类似NodeLists,attributes对象也是实时的。它可以用数字索引访问,这意味着可以枚举元素的所有属性。并且,它也可以用属性名索引:
document.body.attributes[0]//<body>元素的第一个属性
document.body.attributes.bgcolor//<body>元素的bgcolor属性
document.body.attributes["ONLOAD"]//<body>元素的onload属性
当索引attributes对象时得到的值是Attr对象。Attr对象一类特殊的Node,但从来不会像Node一样去用。Attr的name和value属性返回该属性的名字和值。
15.5 元素的内容
再看一下图15-1,并问自己一个问题:<p>元素的“内容”是什么?回答这个问题也许有3个方法:
·内容是HTML字符串"This is a<i>simple</i>document"。
·内容是纯文本字符串"This is a simple document"。
·内容是一个Text节点、一个包含了一个Text子节点的Element节点和另外一个Text节点。
每一种回答都有效,并且各有千秋。后面几节解释如何使用HTML表示、纯文本表示和元素内容的树状表示。
15.5.1 作为HTML的元素内容
读取Element的innerHTML属性作为字符串标记返回那个元素的内容。在元素上设置该属性调用了Web浏览器的解析器,用新字符串内容的解析展现形式替换元素当前内容。(不要管它的名字,除了在HTML元素上,innerHTML也可以在XML元素上使用。)
Web浏览器很擅长解析HTML,通常设置innerHTML效率非常高,甚至在指定的值需要解析时效率也是相当不错。但注意,对innerHTML属性用“+=”操作符重复追加一小段文本通常效率低下,因为它既要序列化又要解析。
innerHTML是在IE 4中引入的。虽然所有的浏览器都支持它已经有很长一段时间了,但随着HTML5的到来它才变得标准化。HTML5说innerHTML应该在Document节点以及Element节点上工作正常,但这还未被普遍地支持。
HTML5还标准化了outerHTML属性。当查询outerHTML时,返回的HTML或XML标记的字符串包含被查询元素的开头和结尾标签。当设置元素的outerHTML时,元素本身被新的内容所替换。只有Element节点定义了outerHTML属性,Document节点则无。在写本书的这段时间里,outerHTML在除了Firefox的所有当前浏览器中都支持。(见本章后面的例15-5,基于innerHTML实现outerHTML。)
IE引入的另一个特性是insertAdjacentHTML()方法,它将在HTML5中标准化,它将任意的HTML标记字符串插入到指定的元素“相邻”的位置。标记是该方法的第二个参数,并且“相邻”的精确含义依赖于第一个参数的值。第一个参数为具有以下值之一的字符串:"beforebegin"、"afterbegin"、"beforeend"和"afterend"。这些值对应的插入点如图15-3所示。

图 15-3 insertAdjacentHTML()的插入点
insertAdjacentHTML()在当前版本的Firefox中不支持。本章后面的内容,例15-6展示了如何用innerHTML属性实现insertAdjacentHTML(),也展示了如何写出不需要一个字符串参数来指定插入点的HTML插入方法。
15.5.2 作为纯文本的元素内容
有时需要查询纯文本形式的元素内容,或者在文档中插入纯文本(不必转义HTML标记中使用的尖括号和&符号)。标准的方法是用Node的textContent属性来实现:
var para=document.getElementsByTagName("p")[0];//文档中第一个<p>
var text=para.textContent;//文本是"This is a simple document."
para.textContent="Hello World!";//修改段落内容
textContent属性在除了IE的所有当前的浏览器中都支持。在IE中,可以用Element的innerText属性来代替。微软在IE 4中引入了innerText属性,它在除了Firefox的所有当前浏览器中都支持。
textContent和innerText属性非常相似,通常可以互相替换使用。不过要小心空元素(在JavaScript中字符串""是假值)和未定义的属性之间的区别:
/**
*一个参数,返回元素的textContent或innerText
*两个参数,用value参数的值设置元素的textContent或innerText
*/
function textContent(element,value){
var content=element.textContent;//检测textContent是否有定义
if(value===undefined){//没传递value,因此返回当前文本
if(content!==undefined)return content;
else return element.innerText;
}
else{//传递了value,因此设置文本
if(content!==undefined)element.textContent=value;
else element.innerText=value;
}
}
textContent属性就是将指定元素的所有后代Text节点简单地串联在一起。innerText没有一个明确指定的行为,但是和textContent有一些不同。innerText不返回<script>元素的内容。它忽略多余的空白,并试图保留表格格式。同时,innerText针对某些表格元素(如<table>、<tbody>和<tr>)是只读的属性。
<script>元素中的文本
内联的<script>元素(也就是那些没有src属性的)有一个text属性用来获取它们的文本。浏览器不显示<script>元素的内容,并且HTML解析器忽略脚本中的尖括号和星号。这使得<script>元素成为应用程序用来嵌入任意文本内容的一个理想的地方。简单地将元素的type属性设置为某些值(如"text/x-custom-data"),就标明了脚本为不可执行的JavaScript代码。如果这样做,JavaScript解释器将忽略该脚本,但该元素将仍然存在于文档树中,它的text属性还将返回数据给你。
15.5.3 作为Text节点的元素内容
另一种方法处理元素的内容来是当做一个子节点列表,每个子节点可能有它自己的一组子节点。当考虑元素的内容时,通常感兴趣的是它的Text节点。在XML文档中,你也必须准备好处理CDATASection节点——它是Text的子类型,代表了CDATA段的内容。
例15-3展示了一个textContent()函数,它递归地遍历元素的子节点,然后连接后代节点中所有的Text节点的文本。为了理解代码,回想一下nodeValue属性(定义在Node类型中),它保存Text节点的内容。
例15-3:查找元素的后代中节点中的所有Text节点
//返回元素e的纯文本内容,递归进入其子元素
//该方法的效果类似于textContent属性
function textContent(e){
var child,type,s="";//s保存所有子节点的文本
for(child=e.firstChild;child!=null;child=child.nextSibling){
type=child.nodeType;
if(type===3||type===4)//Text和CDATASection节点
s+=child.nodeValue;
else if(type===1)//递归Element节点
s+=textContent(child);
}
return s;
}
nodeValue属性可以读/写,设置它可以改变Text或CDATASection节点所显示的内容。Text和CDATASection都是CharacterData的子类型,可以在第四部分查看相关信息。CharacterData定义了data属性,它和nodeValue的文本相同。以下函数通过设置data属性将Text节点的内容转换成大写形式:
//递归地把n的后代子节点中的所有Text节点内容转换为大写形式
function upcase(n){
if(n.nodeType==3||n.nodeTyep==4)//如果n是Text或CDATA节点
n.data=n.data.toUpperCase();//……转换为大写
else//否则,递归进入其子节点
for(var i=0;i<n.childNodes.length;i++)
upcase(n.childNodes[i]);
}
CharacterData还定义了一些在Text或CDATASection节点中不太常用的方法来添加、删除、插入和替换文本。除了修改已存在Text节点的内容,还可以在Element中插入全新的Text节点或用新Text节点来替换已有节点。创建、插入和删除节点就是下一节的主题。
15.6 创建、插入和删除节点
我们已经看到用HTML和纯文本字符串如何来查询和修改文档内容,也已经看到我们能够遍历Document来检查组成Document的每个Element和Text节点。在每个节点级别修改文档也是有可能的。Document类型定义了创建Element和Text对象的方法,Node类型定义了在节点树中插入、删除和替换的方法。例13-4展示了节点的创建和插入,这里复制了这个简短的示例:
//从指定的URL,异步加载和执行脚本
function loadasync(url){
var head=document.getElementsByTagName("head")[0];//查找文档的<head>标签
var s=document.createElement("script");//创建一个<script>元素
s.src=url;//设置它的src属性值
head.appendChild(s);//将该<script>插入到head中
}
以下小节包含了节点创建、插入和删除的更多细节和具体例子,也包含在操作多个节点时的一种捷径:使用DocumentFragment。
15.6.1 创建节点
如以上代码所示,创建新的Element节点可以使用Document对象的createElement()方法。给方法传递元素的标签名:对HTML文档来说该名字不区分大小写,对XML文档则区分大小写。
Text节点用类似的方法创建:
var newnode=document.createTextNode("text node content");
Document也定义了一些其他的工厂方法,如不经常使用的createComment()。在15.6.4节中使用了createDocumentFragment()方法。在使用了XML命名空间的文档中,可以使用createElementNS()来同时指定命名空间的URI和待创建的Element的标签名字。
另一种创建新文档节点的方法是复制已存在的节点。每个节点有一个cloneNode()方法来返回该节点的一个全新副本。给方法传递参数true也能够递归地复制所有的后代节点,或传递参数false只是执行一个浅复制。在除了IE的其他浏览器中,Document对象还定义了一个类似的方法叫importNode()。如果给它传递另一个文档的一个节点,它将返回一个适合本文档插入的节点的副本。传递true作为第二个参数,该方法将递归地导入所有的后代节点。
15.6.2 插入节点
一旦有了一个新节点,就可以用Node的方法appendChild()或insertBefore()将它插入到文档中。appendChild()是在需要插入的Element节点上调用的,它插入指定的节点使其成为那个节点的最后一个子节点。
insertBefore()就像appendChild()一样,除了它接受两个参数。第一个参数就是待插入的节点,第二个参数是已存在的节点,新节点将插入该节点的前面。该方法应该是在新节点的父节点上调用,方法的第二个参数必须是该父节点的子节点。如果传递null作为第二个参数,insertBefore()的行为类似appendChild(),它将节点插入在最后。
这是一个在数字索引的位置插入节点的简单函数。它同时展示了appendChild()和insertBefore()方法:
//将child节点插入到parent中,使其成为第n个子节点
function insertAt(parent,child,n){
if(n<0||n>parent.childNodes.length)throw new Error("invalid index");
else if(n==parent.childNodes.length)parent.appendChild(child);
else parent.insertBefore(child,parent.childNodes[n]);
}
如果调用appendChild()或insertBefore()将已存在文档中的一个节点再次插入,那个节点将自动从它当前的位置删除并在新的位置重新插入:没有必要显式删除该节点。例15-4展示了一个函数,基于表格指定列中单元格的值来进行行排序。它没有创建任何新的节点,只是用appendChild()来改变已存在节点的顺序罢了。
例15-4:表格的行排序
//根据指定表格每行第n个单元格的值,对第一个<tbody>中的行进行排序
//如果存在comparator函数则使用它,否则按字母表顺序比较
function sortrows(table,n,comparator){
var tbody=table.tBodies[0];//第一个<tbody>,可能是隐式创建的
var rows=tbody.getElementsByTagName("tr");//tbody中的所有行
rows=Array.prototype.slice.call(rows,0);//真实数组中的快照
//基于第n个<td>元素的值对行排序
rows.sort(function(row1,row2){
var cell1=row1.getElementsByTagName("td")[n];//获得第n个单元格
var cell2=row2.getElementsByTagName("td")[n];//两行都是
var val1=cell1.textContent||cell1.innerText;//获得文本内容
var val2=cell2.textContent||cell2.innerText;//两单元格都是
if(comparator)return comparator(val1,val2);//进行比较
if(val1<val2)return-1;
else if(val1>val2)return 1;
else return 0;
});//在tbody中按它们的顺序把行添加到最后
//这将自动把它们从当前位置移走,故没必要预先删除它们
//如果<tbody>还包含了除了<tr>的任何其他元素,这些节点将会悬浮到顶部位置
for(var i=0;i<rows.length;i++)tbody.appendChild(rows[i]);
}
//查找表格的<th>元素(假设只有一行),让它们可单击,
//以便单击列标题,按该列对行排序
function makeSortable(table){
var headers=table.getElementsByTagName("th");
for(var i=0;i<headers.length;i++){
(function(n){//嵌套函数来创建本地作用域
headers[i].onclick=function(){sortrows(table,n);};
}(i));//将i的值赋给局部变量n
}
}
15.6.3 删除和替换节点
removeChild()方法是从文档树中删除一个节点。但是请小心:该方法不是在待删除的节点上调用,而是(就像其名字的一部分"child"所暗示的一样)在其父节点上调用。在父节点上调用该方法,并将需要删除的子节点作为方法参数传递给它。在文档中删除n节点,代码可以这样写:
n.parentNode.removeChild(n);
replaceChild()方法删除一个子节点并用一个新的节点取而代之。在父节点上调用该方法,第一个参数是新节点,第二个参数是需要代替的节点。例如,用一个文本字符串来替换节点n,代码可以这样写:
n.parentNode.replaceChild(document.createTextNode("[REDACTED]"),n);
以下函数展示了replaceChild()的另一种用法:
//用一个新的<b>元素替换n节点,并使n成为该元素的子节点
function embolden(n){//假如参数为字符串而不是节点,将其当做元素的id
if(typeof n=="string")n=document.getElementById(n);
var parent=n.parentNode;//获得n的父节点
var b=document.createElement("b");//创建一个<b>元素
parent.replaceChild(b,n);//用该<b>元素替换节点n
b.appendChild(n);//使n成为<b>元素的子节点
}
15.5.1 节介绍过元素的outerHTML属性,也解释过在当前版本的Firefox中还未实现它。例15-5展示了在Firefox中(和其他任何支持innerHTML的浏览器,要有一个可扩展的Element.prototype对象,还要有一些方法来定义属性的getter和setter)如何来实现该属性。同时代码也展示了removeChild()和cloneNode()方法的实际用法。
例15-5:使用innerHTML实现outerHTML属性
//为那些不支持它的浏览器实现outerHTML属性
//假设浏览器确实支持innerHTML,并有个可扩展的Element.prototype,
//并且可以定义getter和setter
(function(){//如果outerHTML存在,则直接返回
if(document.createElement("div").outerHTML)return;//返回this所引用元素的外部HTML
function outerHTMLGetter(){
var container=document.createElement("div");//虚拟元素
container.appendChild(this.cloneNode(true));//复制到该虚拟节点
return container.innerHTML;//返回虚拟节点的innerHTML
}
//用指定的值设置元素的外部HTML
function outerHTMLSetter(value){//创建一个虚拟元素,设置其内容为指定的值
var container=document.createElement("div");
container.innerHTML=value;//将虚拟元素中的节点全部移动到文档中
while(container.firstChild)//循环,直到container没有子节点为止
this.parentNode.insertBefore(container.firstChild,this);//删除所被取代的节点
this.parentNode.removeChild(this);
}
//现在使用这两个函数作为所有Element对象的outerHTML属性的getter和setter
//如果它存在则使用ES5的Object.defineProperty()方法,
//否则,退而求其次,使用defineGetter()和defineSetter()
if(Object.defineProperty){
Object.defineProperty(Element.prototype,"outerHTML",{
get:outerHTMLGetter,
set:outerHTMLSetter,
enumerable:false,configurable:true
});
}
else{
Element.prototype.defineGetter("outerHTML",outerHTMLGetter);
Element.prototype.defineSetter("outerHTML",outerHTMLSetter);
}
}());
15.6.4 使用DocumentFragment
DocumentFragment是一种特殊的Node,它作为其他节点的一个临时的容器。像这样创建一个DocumentFragment:
var frag=document.createDocumentFragment();
像Document节点一样,DocumentFragment是独立的,而不是任何其他文档的一部分。它的parentNode总是为null。但类似Element,它可以有任意多的子节点,可以用appendChild()、insertBefore()等方法来操作它们。
DocumentFragment的特殊之处在于它使得一组节点被当做一个节点看待:如果给appendChild()、insertBefore()或replaceChild()传递一个DocumentFragment,其实是将该文档片段的所有子节点插入到文档中,而非片段本身。(文档片段的子节点从片段移动到文档中,文档片段清空以便重用。)以下函数使用DocumentFragment来倒序排列一个节点的子节点:
//倒序排列节点n的子节点
function reverse(n){//创建一个DocumentFragment作为临时容器
var f=document.createDocumentFragment();//从后至前循环子节点,将每一个子节点移动到文档片段中
//n的最后一个节点变成f的第一个节点,反之亦然
//注意,给f添加一个节点,该节点自动地会从n中删除
while(n.lastChild)f.appendChild(n.lastChild);//最后,把f的所有子节点一次性全部移回n中
n.appendChild(f);
}
例15-6使用innerHTML属性和DocumentFragment实现insertAdjacentHTML()方法(见15.5.1节)。它还定义一些名字更符合逻辑的HTML插入函数,可以替换让人迷惑的insertAdjacentHTML()API。内部工具函数fragment()可能是代码中最有用的部分:它返回一个对指定HTML字符串文本进行解析后的DocumentFragment。
例15-6:使用innerHTML实现insertAdjacentHTML()
//本模块为不支持它的浏览器定义了Element.insertAdjacentHTML
//还定义了一些可移植的HTML插入函数,它们的名字比insertAdjacentHTML更符合逻辑:
//Insert.before()、Insert.after()、Insert.atStart()和Insert.atEnd()
var Insert=(function(){//如果元素有原生的insertAdjacentHTML,
//在4个函数名更明了的HTML插入函数中使用它
if(document.createElement("div").insertAdjacentHTML){
return{
before:function(e,h){e.insertAdjacentHTML("beforebegin",h);},
after:function(e,h){e.insertAdjacentHTML("afterend",h);},
atStart:function(e,h){e.insertAdjacentHTML("afterbegin",h);},
atEnd:function(e,h){e.insertAdjacentHTML("beforeend",h);}
};
}
//否则,无原生的insertAdjacentHTML
//实现同样的4个插入函数,并使用它们来定义insertAdjacentHTML
//首先,定义一个工具函数,传入HTML字符串,返回一个DocumentFragment,
//它包含了解析后的HTML的表示
function fragment(html){
var elt=document.createElement("div");//创建空元素
var frag=document.createDocumentFragment();//创建空文档片段
elt.innerHTML=html;//设置元素内容
while(elt.firstChild)//移动所有的节点
frag.appendChild(elt.firstChild);//从elt到frag
return frag;//然后返回frag
}
var Insert={
before:function(elt,html){
elt.parentNode.insertBefore(fragment(html),elt);
},
after:function(elt,html){
elt.parentNode.insertBefore(fragment(html),elt.nextSibling);
},
atStart:function(elt,html){
elt.insertBefore(fragment(html),elt.firstChild);
},
atEnd:function(elt,html){elt.appendChild(fragment(html));}
};//基于以上函数实现insertAdjacentHTML
Element.prototype.insertAdjacentHTML=function(pos,html){
switch(pos.toLowerCase()){
case"beforebegin":return Insert.before(this,html);
case"afterend":return Insert.after(this,html);
case"afterbegin":return Insert.atStart(this,html);
case"beforeend":return Insert.atEnd(this,html);
}
};
return Insert;//最后返回4个插入函数
}());
15.7 例子:生成目录表
例15-7说明了如何为文档动态地创建一个目录表。它展示了上一节所描述的文档脚本化的很多概念:元素选取、文档遍历、元素属性设置、innerHTML属性设置和在文档中创建与插入新节点等。本例注释详尽,理解代码应该不会有问题。
例15-7:一个自动生成的目录表
/**
*
*这个模块注册一个可在页面加载完成后自动运行的匿名函数。当执行这个函数时会去文档中查找
*id为"TOC"的元素。如果这个元素不存在,就创建一个元素
*
*生成的TOC目录应当具有自己的CSS样式。整个目录区域的样式className设置为"TOCEntry"
*同样我们为不同层级的目录标题定义不同的样式。<h1>标签生成的标题
*className为"TOCLevel1",<h2>标签生成的标题className为"TOCLevel2",以此类推
*段编号的样式为"TOCSectNum"
*
*完整的CSS样式代码如下:
*
*#TOC{border:solid black 1px;margin:10px;padding:10px;}
*.TOCEntry{font-family:sans-serif;}
*.TOCEntry a{text-decoration:none;}
*.TOCLevel1{font-size:16pt;font-weight:bold;}
*.TOCLevel2{font-size:12pt;margin-left:.5in;}
*.TOCSectNum:after{content:":";}
*
*这段代码的最后一行表示每个段编号之后都有一个冒号和空格符。要想隐藏段编号,
*请使用这行代码:
*.TOCSectNum{display:none}
*
*这个模块需要onLoad()工具函数
**/
onLoad(function(){//匿名函数定义了一个局部作用域
//查找TOC容器元素
//如果不存在,则在文档开头处创建一个
var toc=document.getElementById("TOC");
if(!toc){
toc=document.createElement("div");
toc.id="TOC";
document.body.insertBefore(toc,document.body.firstChild);
}
//查找所有的标题元素
var headings;
if(document.querySelectorAll)//我们是否能用这个简单的方法?
headings=document.querySelectorAll("h1,h2,h3,h4,h5,h6");
else//否则,查找方法稍微麻烦一些
headings=findHeadings(document.body,[]);//递归遍历document的body,查找标题元素
function findHeadings(root,sects){
for(var c=root.firstChild;c!=null;c=c.nextSibling){
if(c.nodeType!==1)continue;
if(c.tagName.length==2&&c.tagName.charAt(0)=="H")
sects.push(c);
else
findHeadings(c,sects);
}
return sects;
}
//初始化一个数组来保持跟踪章节号
var sectionNumbers=[0,0,0,0,0,0];//现在,循环已找到的标题元素
for(var h=0;h<headings.length;h++){
var heading=headings[h];//跳过在TOC容器中的标题元素
if(heading.parentNode==toc)continue;//判定标题的级别
var level=parseInt(heading.tagName.charAt(1));
if(isNaN(level)||level<1||level>6)continue;//对于该标题级别增加sectionNumbers对应的数字
//重置所有标题比它级别低的数字为零
sectionNumbers[level-1]++;
for(var i=level;i<6;i++)sectionNumbers[i]=0;//现在,将所有标题级别的章节号组合产生一个章节号,如2.3.1
var sectionNumber=sectionNumbers.slice(0,level).join(".")//为标题级别增加章节号
//把数字放在<span>中,使得其可以用样式修饰
var span=document.createElement("span");
span.className="TOCSectNum";
span.innerHTML=sectionNumber;
heading.insertBefore(span,heading.firstChild);//用命名的锚点将标题包起来,以便为它增加链接
var anchor=document.createElement("a");
anchor.name="TOC"+sectionNumber;
heading.parentNode.insertBefore(anchor,heading);
anchor.appendChild(heading);//现在为该节创建一个链接
var link=document.createElement("a");
link.href="#TOC"+sectionNumber;//链接的目标地址
link.innerHTML=heading.innerHTML;//链接文本与实际标题一致
//将链接放在一个div中,div用基于级别名字的样式修饰
var entry=document.createElement("div");
entry.className="TOCEntry TOCLevel"+level;
entry.appendChild(link);//该div添加到TOC容器中
toc.appendChild(entry);
}
});
15.8 文档和元素的几何形状和滚动
在本章中,到目前为止我们考虑的文档被看做是元素和文本节点的抽象树。但是当浏览器在窗口中渲染文档时,它创建文档的一个视觉表现层,在那里每个元素有自己的位置和尺寸。通常,Web应用程序可以将文档看做是元素的树,并且不用关心在屏幕上这些元素是如何渲染的。但有时,判定一个元素精确的几个形状也是非常有必要的。例如,将在第16章中看到利用CSS为元素指定位置。如果想用CSS动态定位一个元素(如工具提示或插图)到某个已经由浏览器定位后的普通元素的旁边,首先需要判定那个元素的当前位置。
本节阐述了在浏览器窗口中完成文档的布局以后,怎样才能在抽象的基于树的文档模型与几何形状的基于坐标的视图之间来回变换。本节描述的属性和方法已经在浏览器中实现了有相当长的一段时间了(虽然有些是IE特有的,有些直到IE 9才实现)。在写本书的这段时间里,它们通过了W3C的标准化流程,作为CSSOM-View模块(参见http://www.w3.org/TR/cssom-view/)。
15.8.1 文档坐标和视口坐标
元素的位置是以像素来度量的,向右代表X坐标的增加,向下代表Y坐标的增加。但是,有两个不同的点作为坐标系的原点:元素的X和Y坐标可以相对于文档的左上角或者相对于在其中显示文档的视口的左上角。在顶级窗口和标签页中,“视口”只是实际显示文档内容的浏览器的一部分:它不包括浏览器“外壳”(如菜单、工具条和标签页)。针对框架页中显示的文档,视口是定义了框架页的<iframe>元素。无论在何种情况下,当讨论元素的位置时,必须弄清楚所使用的坐标是文档坐标还是视口坐标。(注意,视口坐标有时也叫做窗口坐标。)
如果文档比视口要小,或者说它还未出现滚动,则文档的左上角就是视口的左上角,文档和视口坐标系统是同一个。但是,一般来说,要在两种坐标系之间互相转换,必须加上或减去滚动的偏移量(scrol l offset)。例如,在文档坐标中如果一个元素的Y坐标是200像素,并且用户已经把浏览器向下滚动75像素,那么视口坐标中元素的Y坐标是125像素。同样,在视口坐标中如果一个元素的X坐标是400像素,并且用户已经水平滚动了视口200像素,那么文档坐标中元素的X坐标是600像素。
文档坐标比视口坐标更加基础,并且在用户滚动时它们不会发生变化。不过,在客户端编程中使用视口坐标是非常常见的。当使用CSS指定元素的位置时运用了文档坐标(见第16章)。但是,最简单的查询元素位置的方法(见15.8.2节)返回视口坐标中的位置。类似地,当为鼠标事件注册事件处理程序函数时,报告的鼠标指针的坐标是在视口坐标系中的。
为了在坐标系之间互相转换,我们需要判定浏览器窗口的滚动条的位置。Window对象的pageXOffset和pageYOffset属性在所有的浏览器中提供这些值,除了IE 8及更早的版本以外。IE(和所有现代浏览器)也可以通过scrollLeft和scrollTop属性来获得滚动条的位置。令人迷惑的是,正常情况下通过查询文档的根节点(document.documentElement)来获取这些属性值,但在怪异模式下(见13.4.4节),必须在文档的<body>元素(document.body)上查询它们。例15-8显示了如何简便地查询滚动条的位置。
例15-8:查询窗口滚动条的位置
//以一个对象的x和y属性的方式返回滚动条的偏移量
function getScrollOffsets(w){//使用指定的窗口,如果不带参数则使用当前窗口
w=w||window;//除了IE 8及更早的版本以外,其他浏览器都能用
if(w.pageXOffset!=null)return{x:w.pageXOffset,y:w.pageYOffset};//对标准模式下的IE(或任何浏览器)
var d=w.document;
if(document.compatMode=="CSS1Compat")
return{x:d.documentElement.scrollLeft,y:d.documentElement.scrollTop};//对怪异模式下的浏览器
return{x:d.body.scrollLeft,y:d.body.scrollTop};
}
有时能够判定视口的尺寸也是非常有用的——例如,为了确定文档的哪些部分是当前可见的。利用滚动偏移量查询视口尺寸的简单方法在IE 8及更早的版本中无法工作,而且该技术在IE中的运行方式还要取决于浏览器是处于怪异模式还是标准模式。例15-9介绍了如何简便地查询视口尺寸。注意,它和例15-8的代码是如此相似。
例15-9:查询窗口的视口尺寸
//作为一个对象的w和h属性返回视口的尺寸
function getViewportSize(w){//使用指定的窗口,如果不带参数则使用当前窗口
w=w||window;//除了IE 8及更早的版本以外,其他浏览器都能用
if(w.innerWidth!=null)return{w:w.innerWidth,h:w.innerHeight};//对标准模式下的IE(或任何浏览器)
var d=w.document;
if(document.compatMode=="CSS1Compat")
return{w:d.documentElement.clientWidth,
h:d.documentElement.clientHeight};//对怪异模式下的浏览器
return{w:d.body.clientWidth,h:d.body.clientWidth};
}
上述两个例子已经用到了scrollLeft、scrollTop、clientWidth和clientHeight属性。我们将在15.8.5节中再次遇到这些属性。
15.8.2 查询元素的几何尺寸
判定一个元素的尺寸和位置最简单的方法是调用它的getBoundingClientRect()方法。该方法是在IE 5中引入的,而现在当前的所有浏览器都实现了。它不需要参数,返回一个有left、right、top和bottom属性的对象。left和top属性表示元素的左上角的X和Y坐标,right和bottom属性表示元素的右下角的X和Y坐标。
这个方法返回元素在视口坐标中的位置。(getBoundingClientRect()方法名中的"Client"是一种间接指代,它就是Web浏览器客户端——专指它定义的窗口或视口。)为了转化为甚至用户滚动浏览器窗口以后仍然有效的文档坐标,需要加上滚动的偏移量:
var box=e.getBoundingClientRect();//获得在视口坐标中的位置
var offsets=getScrollOffsets();//上面定义的工具函数
var x=box.left+offsets.x;//转化为文档坐标
var y=box.top+offsets.y;
在很多浏览器(和W3C标准)中,getBoundingClientRect()返回的对象还包含width和height属性,但是在原始的IE中未实现。为了简便起见,可以这样计算元素的width和height:
var box=e.getBoundingClientRect();
var w=box.width||(box.right-box.left);
var h=box.height||(box.bottom-box.top);
在第1 6章中将学到元素内容被一块可选的空白区域所包围,叫做内边距。内边距被边框所包围,边框被外边距所包围。内边距、边框和外边距都是可选的。getBoundingClientRect()所返回的坐标包含元素的边框和内边距,但不包含元素的外边距。
如果getBoundingClientRect()方法名中的"Client"指定了返回的矩形的坐标系,那么方法名中的"Bounding"做何解释呢?浏览器在布局时块状元素(如图片、段落和<div>元素等)总是为矩形。但是,内联元素(如<span>、<code>和<b>等)可能跨了多行,因此可能由多个矩形组成。想象一下,例如,一些被断成两行的斜体文本(用<i>和</i>标签标记的)。它的形状是由第一行的右边部分和第二行的左边部分两个矩形组成的(假设文本顺序是从左向右)。如果在内联元素上调用getBoundingClientRect(),它返回“边界矩形”。对于如上描述的<i>元素,边界矩形会包含整整两行的宽度。
如果想查询内联元素每个独立的矩形,调用getClientRects()方法来获得一个只读的类数组对象,它的每个元素类似于getBoundingClientRect()返回的矩形对象。
我们已经见过如getElementsByTagName()这样的DOM方法返回的结果是“实时的”,当文档变化时这些结果能自动更新。但getBoundingClientRect()和getClientRects()所返回的矩形对象(和矩形对象列表)并不是实时的。它们只是调用方法时文档视觉状态的静态快照,在用户滚动或改变浏览器窗口大小时不会更新它们。
15.8.3 判定元素在某点
getBoundingClientRect()方法使我们能在视口中判定元素的位置。但有时我们想反过来,判定在视口中的指定位置上有什么元素。这可以用Document对象的elementFromPoint()方法来判定。传递X和Y坐标(使用视口坐标而非文档坐标),该方法返回在指定位置的一个元素。在写本书的这段时间里,选取元素的算法还未详细指定,但是该方法的意图就是它返回在那个点的最里面的和最上面的(见16.2.1节中CSS的z-index属性)元素。如果指定的点在视口以外,elementFromPoint()返回null,即使该点在转换为文档坐标后是完美有效的,返回值也一样。
elementFromPoint()方法看上去很有用,典型的案例是将鼠标指针的坐标传递给它来判定鼠标在哪个元素上。但是,我们将在第17章学到,鼠标事件对象已经在target属性中包含了这些信息。因此,实际上elementFromPoint()不经常使用。
15.8.4 滚动
例15-8展示了如何在浏览器窗口中查询滚动条的位置。该例子中的scrollLeft和scrollTop属性可以用来设置让浏览器滚动,但有一种更简单的方法从JavaScript最早的时期开始就支持的。Window对象的scrollTop()方法(和其同义词scroll())接受一个点的X和Y坐标(文档坐标),并作为滚动条的偏移量设置它们。也就是,窗口滚动到指定的点出现在视口的左上角。如果指定的点太接近于文档的下边缘或右边缘,浏览器将尽量保证它和视口的左上角之间最近,但是无法达到一致。以下代码滚动浏览器到文档最下面的页面可见:
//获得文档和视口的高度,offsetHeight会在下面解释
var documentHeight=document.documentElement.offsetHeight;
var viewportHeight=window.innerHeight;//或使用上面的getViewportSize()
//然后,滚动让最后一页在视口中可见
window.scrollTo(0,documentHeight-viewportHeight);
Window的scrollBy()方法和scroll()和scrollTo()类似,但是它的参数是相对的,并在当前滚动条的偏移量上增加。例如,快速阅读者可能会喜欢这样的书签(见13.2.5节):
//每200毫秒向下滚动10像素。注意,它无法关闭
javascript:void setInterval(function(){scrollBy(0,10)},200);
通常,除了滚动到文档中用数字表示的位置,我们只是想它滚动使得文档中的某个元素可见。可以利用getBoundingClientRect()计算元素的位置,并转换为文档坐标,然后用scrollTo()方法达到目的。但是在需要显示的HTML元素上调用scrollIntoView()方法更加方便。该方法保证了元素能在视口中可见。默认情况下,它试图将元素的上边缘放在或尽量接近视口的上边缘。如果只传递false作为参数,它将试图将元素的下边缘放在或尽量接近视口的下边缘。只要有助于元素在视口内可见,浏览器也会水平滚动视口。
scrollIntoView()的行为与设置window.location.hash为一个命名锚点(<a name="">元素)的名字后浏览器产生的行为类似。
15.8.5 关于元素尺寸、位置和溢出的更多信息
getBoundingClientRect()方法在所有当前的浏览器上都有定义,但如果需要支持老式浏览器,不能依靠此方法而必须使用更老的技术来判定元素的尺寸和位置。元素的尺寸比较简单:任何HTML元素的只读属性offsetWidth和offsetHeight以CSS像素返回它的屏幕尺寸。返回的尺寸包含元素的边框和内边距,除去了外边距。
所有HTML元素拥有offsetLeft和offsetTop属性来返回元素的X和Y坐标。对于很多元素,这些值是文档坐标,并直接指定元素的位置。但对于已定位元素的后代元素和一些其他元素(如表格单元),这些属性返回的坐标是相对于祖先元素的而非文档。offsetParent属性指定这些属性所相对的父元素。如果offsetParent为null,这些属性都是文档坐标,因此,一般来说,用offsetLeft和offsetTop来计算元素e的位置需要一个循环:
function getElementPosition(e){
var x=0,y=0;
while(e!=null){
x+=e.offsetLeft;
y+=e.offsetTop;
e=e.offsetParent;
}
return{x:x,y:y};
}
通过循环offsetParent对象链来累加偏移量,该函数计算指定元素的文档坐标。(回想一下getBoundingClientRect()返回的是视口坐标。)这里不能对元素的位置就一锤定音,尽管如此——这个getElementPosition()函数也不总是计算正确的值,下面看看如何来修复它。
除了这些名字以offset开头的属性以外,所有的文档元素定义了其他两组属性,其名称一组以client开头,另一组以scroll开头。即,每个HTML元素都有以下这些属性:

为了理解这些client和scroll属性,你需要知道HTML元素的实际内容有可能比分配用来容纳内容的盒子更大,因此单个元素可能有滚动条(见16.2.6节中CSS的overflow属性)。内容区域是视口,就像浏览器的窗口,当实际内容比视口更大时,需要把元素的滚动条位置考虑进去。
clientWidth和clientHeight类似offsetWidth和offsetHeight,不同的是它们不包含边框大小,只包含内容和它的内边距。同时,如果浏览器在内边距和边框之间添加了滚动条,clientWidth和clientHeight在其返回值中也不包含滚动条。注意,对于类似<i>、<code>和<span>这些内联元素,clientWidth和clientHeight总是返回0。
在例15-9的getViewportSize()方法中使用了clientWidth和clientHeight。有一个特殊的案例,在文档的根元素上查询这些属性时,它们的返回值和窗口的innerWidth和innerHeight属性值相等。
clientLeft和clientTop属性没什么用:它们返回元素的内边距的外边缘和它的边框的外边缘之间的水平距离和垂直距离,通常这些值就等于左边和上边的边框宽度。但是如果元素有滚动条,并且浏览器将这些滚动条放置在左侧或顶部(可这不太常见),clientLeft和clientTop也就包含了滚动条的宽度。对于内联元素,clientLeft和clientTop总是为0。
scrollWidth和scrollHeight是元素的内容区域加上它的内边距再加上任何溢出内容的尺寸。当内容正好和内容区域匹配而没有溢出时,这些属性与clientWidth和clientHeight是相等的。但当溢出时,它们就包含溢出的内容,返回值比clientWidth和clientHeight要大。
最后,scrollLeft和scrollTop指定元素的滚动条的位置。在getScrollOffsets()方法(例15-8)中在文档的根元素上我们查询过它们。注意,scrollLeft和scrollTop是可写的属性,通过设置它们来让元素中的内容滚动。(HTML元素并没有类似Window对象的scrollTo()方法。)
当文档包含可滚动的且有溢出内容的元素时,上述定义的getElementPosition()方法就不能正常工作了,因为它没有把滚动条考虑进去。这里有一个修改版,它从累计的偏移量中减去了滚动条的位置,这样一来,将返回的位置从文档坐标转换为视口坐标。
function getElementPos(elt){
var x=0,y=0;//循环以累加偏移量
for(var e=elt;e!=null;e=e.offsetParent){
x+=e.offsetLeft;
y+=e.offsetTop;
}
//再次循环所有的祖先元素,减去滚动的偏移量
//这也减去了主滚动条,并转换为视口坐标
for(var e=elt.parentNode;e!=null&&e.nodeType==1;e=e.parentNode){
x-=e.scrollLeft;
y-=e.scrollTop;
}
return{x:x,y:y};
}
在现代浏览器中,getElementPos()方法的返回值和getBoundingClientRect()的返回值一样(但是更低效)。理论上,如getElementPos()这样的函数可以在不支持getBoundingClientRect()的浏览器中使用。但实际上,不支持getBoundingClientRect()的浏览器在元素位置方面有很多的不兼容性,像这样如此简陋的函数无法可靠地工作。
实际类似jQuery这样的客户端类库包含了一些函数来计算元素的位置,它们扩充了这个基本的位置计算算法,修复了一系列浏览器特定的bug。如果需要代码在所有不支持getBoundingClientRect()的浏览器中正确计算元素的位置,你很可能需要像jQuery这样的类库。
15.9 HTML表单
HTML的<form>元素和各种各样的表单输入元素(如<input>、<select>和<button>)在客户端编程中有着重要的地位。这些HTML元素可以追溯到Web的最开始,比JavaScript本身更早。HTML表单就是第一代We b应用程序背后的运作机制,它根本就不需要JavaScript。用户的输入从表单元素来收集;表单将这些输入递交给服务器;服务器处理输入并生成一个新的HTML页面(通常有一个新的表单元素)显示在客户端。
即使当整个表单数据都是由客户端JavaScript来处理并不会提交到服务器时,HTML表单元素仍然是收集用户数据很好的方法。在服务端程序中,表单必须要有一个“提交”按钮,否则它就没有用处。另一方面,在客户端编程中,“提交”按钮不是必须的(虽然它可能仍然有用)。服务端程序是基于表单提交动作的——它们按表单大小的块处理数据——这限制了它们的交互性。客户端程序是基于事件的——它们可以对单独的表单元素上的事件做出响应——这使得它们有更好的响应度。例如,在用户打字时客户端程序就能校验输入的有效性。或者通过单击一个复选框来启用一组选项,也就是说当复选框被选中时那组选项才有意义。
以下小节阐述了用HTML表单如何做到这些事情。表单由HTML元素组成,就像HTML文档的其他部分一样,并且可以用本章中介绍过的DOM技术来操作它们。但是表单是第一批脚本化的元素,在最早的客户端编程中它们还支持比DOM更早的一些其他的API。
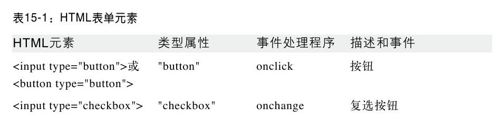
请注意,本节是关于脚本化HTML表单,而不是HTML本身。假设你已经对用于定义表单的HTML元素(<input>、<textarea>、<select>等)有一定的了解。尽管如此,表15-1列出了最常使用的表单元素。更详细的内容请参考第四部分中的表单和表单元素API,在Form、Input、Option、Select和TextArea下面。

15.9.1 选取表单和表单元素
表单和它们所包含的元素可以用如getElementById()和getElementsByTagName()等标准的方法从文档中来选取:
var fields=document.getElementById("address").getElementsByTagName("input");
在支持querySelectorAll()的浏览器中,从一个表单中选取所有的单选按钮或所有同名的元素的代码如下:
//id为"shipping"的表单中所有的单选按钮
document.querySelectorAll('#shipping input[type="radio"]');//id为"shipping"的表单中所有名字为"method"的单选按钮
document.querySelectorAll('#shipping input[type="radio"][name="method"]');
尽管如此,如同在14.7节、15.2.2节和15.2.3节所描述的,有name或id属性的<form>元素能够通过很多方法来选取。name="address"属性的<form>可以用以下任何方法来选取:
window.address//不可靠:不要使用
document.address//仅当表单有name属性时可用
document.forms.address//显式访问有name或id的表单
document.forms[n]//不可靠:n是表单的序号
15.2.3 节阐述了document.forms是一个HTMLCollection对象,可以通过数字序号或id或name来选取表单元素。Form对象本身的行为类似于多个表单元素组成的HTMLCollection集合,也可以通过name或数字序号来索引。如果名为"address"的表单的第一个元素的name是"street",可以使用以下任何一种表达式来引用该元素:
document.forms.address[0]
document.forms.address.street
document.address.street//当有name="address",而不是只有id="address"
如果要明确地选取一个表单元素,可以索引表单对象的elements属性:
document.forms.address.elements[0]
document.forms.address.elements.street
一般来说指定文档元素的方法用id属性要比name属性更佳。但是,name属性在HTML表单提交中有特殊的目的,它在表单中较为常用,在其他元素较少使用。它应用于相关的复选按钮组和强制共享name属性值的、互斥的单选按钮组。请记住,当用name来索引一个HTMLCollection对象并且它包含多个元素来共享name时,返回值是一个类数组对象,它包含所有匹配的元素。考虑以下表单,它包含多个单选按钮来选择运输方式:
<form name="shipping">
<fieldset><legend>Shipping Method</legend>
<label><input type="radio"name="method"value="1st">First-class</label>
<label><input type="radio"name="method"value="2day">2-day Air</label>
<label><input type="radio"name="method"value="overnite">Overnight</label>
</fieldset>
</form>
对于该表单,用如下代码来引用单选按钮元素数组:
var methods=document.forms.shipping.elements.method;
注意,<form>元素本身有一个HTML属性和对应的JavaScript属性叫"method",所以在此案例中,必须要用该表单的elements属性而非直接访问method属性。为了判定用户选取哪种运输方式,需要遍历数组中的表单元素并检测它们的checked属性:
var shipping_method;
for(var i=0;i<methods.length;i++)
if(methods[i].checked)shipping_method=methods[i].value;
在下一节中可以看到更多表单元素的属性,如checked和value。
15.9.2 表单和元素的属性
上面描述的elements[]数组是Form对象中最有趣的属性。Form对象中的其他属性相对没有如此重要。action、encoding、method和target属性(property)直接对应于<form>元素的action、encoding、method和target等HTML属性(attribute)。这些属性都控制了表单是如何来提交数据到Web服务器并如何显示的。客户端JavaScript能够设置这些属性值,不过仅当表单真的会将数据提交到一个服务端程序时它们才有用。
在JavaScript产生之前,要用一个专用的“提交”按钮来提交表单,用一个专用的“重置”按钮来重置各表单元素的值。JavaScript的Form对象支持两个方法:submit()和reset(),它们完成同样的目的。调用Form对象的submit()方法来提交表单,调用reset()方法来重置表单元素的值。
所有(或多数)表单元素通常都有以下属性。如果一些元素有其他专用的属性,会在后面单独考虑各种类型的表单元素时描述它们:
type
标识表单元素类型的只读的字符串。针对用<input>标签定义的表单元素而言,就是其type属性的值。其他表单元素(如<textarea>和<select>)定义type属性是为了轻松地标识它们,与<input>元素在类型检测时互相区别。表15-1的第二列给出了各个表单元素此属性的值。
form
对包含元素的Form对象的只读引用,或者如果元素没有包含在一个<form>元素中则其值为null。
name
只读的字符串,由HTML属性name指定。
value
可读/写的字符串,指定了表单元素包含或代表的“值”。它就是当提交表单时发送到Web服务器的字符串,也是JavaScript程序有时候会感兴趣的内容。针对Text和Textarea元素,该属性值包含了用户输入的文本。针对用<input>标签创建的按钮元素(除了用<button>标签创建的按钮),该属性值指定了按钮显示的文本。但是,针对单选和复选按钮元素,该属性用户不可见也不能编辑。它仅是用HTML的value属性来设置的一个字符串。它在表单提交时使用,但在关联表单元素的额外数据时也很有用。在本章后面关于不同类目的表单元素小节中将深入讨论value属性。
15.9.3 表单和元素的事件处理程序
每个Form元素都有一个onsubmit事件处理程序来侦测表单提交,还有一个onreset事件处理程序来侦测表单重置。表单提交前调用onsubmit程序;它通过返回false能够取消提交动作。这给JavaScript程序一个机会来检查用户的输入错误,目的是为了避免不完整或无效的数据通过网络提交到服务端程序。注意,onsubmit事件处理程序只能通过单击“提交”按钮来触发。直接调用表单的submit()方法不触发onsubmit事件处理程序。
onreset事件处理程序和onsubmit是类似的。它在表单重置之前调用,通过返回false能够阻止表单元素被重置。在表单中很少需要“重置”按钮,但如果有,你可能需要提醒用户来确认是否重置:
<form…
onreset="return confirm('Really erase ALL input and start over?')">
…
<button type="reset">Clear and Start Over</button>
</form>
类似onsubmit事件处理程序,onreset只能通过单击“重置”按钮来触发。直接调用表单的reset()方法不触发onreset事件处理程序。
当用户与表单元素交互时它们往往会触发click或change事件,通过定义onclick或onchange事件处理程序可以处理这些事件。表15-1的第三列给出了各个表单元素主要的事件处理程序。一般来说,当按钮表单元素激活(甚至当通过键盘而不是实际的鼠标单击发生激活)时它们会触发click事件。当用户改变其他表单元素所代表的值时它们会触发change事件。当用户在一个文本域输入文本或从下拉列表中选择了一个选项后就发生这样的改变。注意,在一个文本域中该事件不是每次用户输入一个键值时都会触发。它仅当用户改变了元素的值然后将焦点移到其他元素上时才会触发。也就是说,调用该事件处理程序就意味着一个完整的改变。单选按钮和复选框都有一个状态标识,它们的click和change事件都会触发;两个之中change事件更加有用。
表单元素在收到键盘的焦点时也会触发focus事件,失去焦点时会触发blur事件。
关于事件处理程序有一点非常重要,在事件处理程序代码中关键字this是触发该事件的文档元素的一个引用(我们将在第17章中再次讨论)。既然在<form>元素中的元素都有一个form属性引用了该包含的表单,这些元素的事件处理程序总是能够通过this.form来得到Form对象的引用。更进一步,这意味着某个表单元素的事件处理程序能够通过this.form.x得到该表单中以x命名的元素。
15.9.4 按钮
按钮是最常用的表单元素之一,因为它们是一种视觉上明确让用户触发某种脚本动作的方法。按钮元素本身没有默认的行为,除非它有onclick事件处理程序,否则它并没有什么用处。以<input>元素定义的按钮会将value属性值以纯文本显示。以<button>元素定义的按钮会将元素的一切内容显示出来。
注意,超级链接与按钮一样提供了onclick事件处理程序。当onclick事件所触发的动作可以概念化为“跟随此链接”时就用一个链接;否则,用按钮。
提交和重置元素本就是按钮,不同的是它们有与之相关联的默认动作(表单的提交和重置)。如果onclick事件处理程序返回false,这些按钮的默认动作就不再执行了。可以使用提交元素的onclick事件处理程序来执行表单校验,但是更为常用的是使用Form对象本身的onsubmit事件处理程序来执行表单校验。
本书第四部分未包含按钮。关于所有按钮表单元素的详细内容请参看input项,它包含了用<button>元素创建的按钮。
15.9.5 开关按钮
复选框和单选元素是开关按钮,或称有两种视觉状态的按钮:选中或未选中。通过对其单击用户可以改变它的开关状态。单选元素为整组有相关性的元素而设计的,组内所有按钮的HTML属性name的值都相同。按这种方式创建的单选按钮是互斥的:选中其一,之前选中的即变成未选中。复选框通常也整组使用并共享name属性,必须注意的是当利用做为表单属性的名字来选中这些元素时,它返回一个类数组对象而不是单个元素。
单选和复选框元素都定义了checked属性。该属性是可读/写的布尔值,它指定了元素当前是否选中。defaultChecked属性也是布尔值,它是HTML属性checked的值;它指定了元素在第一次加载页面时是否选中。
单选和复选框元素本身不显示任何文本,它们通常和相邻的HTML文本一起显示(或与<label>元素相关联)。这意味着设置复选框或单选元素的value属性不改变元素的视觉表现。设置value只改变提交表单时发送到Web服务器的字符串。
当用户单击单选或复选开关按钮,单选或复选框元素触发onclick事件。如果由于单击开关按钮改变了它的状态,它也触发onchange事件。(但注意,当用户单击其他单选按钮而导致这个单选按钮状态的改变,后者不触发onchange事件。)
15.9.6 文本域
文本输入域在HTML表单和JavaScript程序中可能是最常用的元素。用户可以输入单行简短的文本字符串。value属性表示用户输入的文本。通过设置该属性值可以显式地指定应该在输入域中显示的文本。
在HTML5中,placeholder属性指定了用户输入前在输入域中显示的提示信息:
Arrival Date:<input type="text"name="arrival"placeholder="yyyy-mm-dd">
文本输入域的onchange事件处理程序是在用户输入新的文本或编辑已存在的文本时触发,它表明用户完成了编辑并将焦点移出了文本域。
Textarea元素类似文本输入域元素,不同的是它允许用户输入(和JavaScript程序显示)多行文本。Textarea元素用<textarea>标签来创建,与用<input>标签创建的文本域在语法上有显著的区别。(见第四部分的TextArea。)尽管如此,两种元素的行为非常类似。如同针对Text元素一样,可以用Textarea元素的value属性和onchange事件处理程序。
<input type="password">元素在用户输入时显示为星号,它修改了输入的文本。其名字表明,用户输入密码时不用担心他背后的人能看到,这很有用。注意,密码输入元素只能防止眼睛窥视,但在提交表单时输入未经任何加密(除非通过安全的HTTPS连接提交它),当在网络上传输时它可能被看见。
最后,<input type="file">元素将用户输入待上传到Web服务器的文件的名称。它由一个文本域和一个单击打开文件选择对话框的按钮所组成。该文件选取元素拥有onchange事件处理程序,就像普通的输入域一样。但不同的是它的value属性是只读的。这个防止恶意的JavaScript程序欺骗用户上传本意不想共享的文件。
不同的文本输入元素定义onkeypress、onkeydown和onkeyup事件处理程序。可以从onkeypress或onkeydown事件处理程序返回false,防止记录用户的按键。这很有用,例如,如果希望强制用户在特定文本输入域中仅输入数字。该技术的说明参见例17-6。
15.9.7 选择框和选项元素
Select元素表示用户可以做出选择的一组选项(用Option元素表示)。浏览器通常将其渲染为下拉菜单的形式,但当指定其s iz e属性值大于1时,它将显示为列表中的选项(可能有滚动)。Select元素能以两种不同的方式运作,这取决于它的type属性值是如何设置的。如果<select>元素有multiple属性,也就是Select对象的type属性值为"select-multiple",那就允许用户选取多个选项。否则,如果没有多选属性,那只能选取单个选项,它的type属性值为"select-one"。
某种程度上"select-multiple"元素与一组复选框元素类似,"select-one"元素和一组单选元素类似。但是,由Select元素显示的选项并不是开关按钮:它们由<option>元素定义。Select元素定义了options属性,它是一个包含了多个Option元素的类数组对象。
当用户选取或取消选取一个选项时,Select元素触发onchange事件处理程序。针对"select-one"Select元素,它的可读/写属性selectedIndex指定了哪个选项当前被选中。针对"select-multiple"元素,单个selectedIndex属性不足以表示被选中的一组选项。在这种情况下,要判定哪些选项被选中,就必须遍历options[]数组的元素,并检测每个Option对象的selected属性值。
除了其selected属性,每个Option对象有一个text属性,它指定了在Select元素中的选项所显示的纯文本字符串。设置该属性可以改变显示给用户的文本。value属性指定了在提交表单时发送到Web服务器的文本字符串,它也是可读/写的。甚至在写纯客户端程序并且不可能有表单提交时,value属性(或它所对应的HTML属性value)是用来保存任何数据的好地方,在用户选取特定的选项时可以使用这些数据。注意,Option元素并没有与表单相关的事件处理程序:用包含Select元素的onchange事件处理程序来代替。
除了设置Option对象的text属性以外,使用options属性的特殊功能可以动态改变显示在Select元素中的选项,这些功能可以追溯到最早期的客户端编程。通过设置options.length为一个希望的值可以截断Option元素数组,而设置options.length为0可以从Select元素中移除所有的选项。设置options[]数组中某点的值为null可以从Select元素中移除单个Option对象。这将删除该Option对象,options[]数组中高端的元素自动移下来填补空缺。
为Select元素增加一个新的选项,首先用Option()构造函数创建一个Option对象,然后将其添加到options[]属性中,代码如下:
//创建一个新的选项
var zaire=new Option("Zaire",//text属性
"zaire",//value属性
false,//defaultSelected属性
false);//selected属性
//通过添加到options数组中,在Select元素中显示该选项
var countries=document.address.country;//得到Select对象
countries.options[countries.options.length]=zaire;
请牢记一点,这些专用的Select元素的API已经很老了。可以用那些标准的调用更明确地插入和移除选项元素:Document.createElement()、Node.insertBefore()、Node.removeChild()等。
15.10 其他文档特性
本章在一开始就声明了它是本书中最重要的一章。由其必要性,它也是最长的一章之一。本章最后一节涵盖了Document对象的若干混杂的特性。
15.10.1 Document的属性
本章已经介绍的Document的属性有body、documentElement和forms等这些特殊的文档元素。文档还定义了一些其他有趣的属性:
cookie
允许JavaScript程序读、写HTTP cookie的特殊的属性。第20章涵盖该属性。
domain
该属性允许当Web页面之间交互时,相同域名下互相信任的Web服务器之间协作放宽同源策略安全限制(见13.6.2节)。
lastModified
包含文档修改时间的字符串。
location
与Window对象的location属性引用同一个Location对象。
referrer
如果有,它表示浏览器导航到当前链接的上一个文档。该属性值和HTTP的Referer头信息的内容相同,只是拼写上有两个r。
title
文档的<title>和</title>标签之间的内容。
URL
文档的URL,只读字符串而不是Location对象。该属性值与location.href的初始值相同,只是不包含Location对象的动态变化。例如,如果用户在文档中导向到一个新的片段,location.href会发生变化,但是document.URL则不会。
referrer是这些属性中最有趣的属性之一:它包含用户链接到当前文档的上一个文档的URL。可以用如下代码来使用该属性:
if(document.referrer.indexOf("http://www.google.com/search?")==0){
var args=document.referrer.substring(ref.indexOf("?")+1).split("&");
for(var i=0;i<args.length;i++){
if(args[i].substring(0,2)=="q="){
document.write("<p>Welcome Google User.");
document.write("You searched for:"+
unescape(args[i].substring(2)).replace('+','');
break;
}
}
}
上述代码中使用的document.write()方法将是下一节的主题。
15.10.2 document.write()方法
document.write()方法是其中一个由Netscape 2浏览器实现的非常早期的脚本化API。它曾在DOM之前就被很好地引入了,也曾是在文档中显示计算后的文本的唯一方法。新代码中已经不再需要它了,但在已有的代码中你还能不时地看到该方法。
document.write()会将其字符串参数连接起来,然后将结果字符串插入到文档中调用它的脚本元素的位置。当脚本执行结束,浏览器解析生成的输出并显示它。例如,以下代码使用write()动态把信息输出到一个静态的HTML文档中:
<script>
document.write("<p>Document title:"+document.title);
document.write("<br>URL:"+document.URL);
document.write("<br>Referred by:"+document.referrer);
document.write("<br>Modified on:"+document.lastModified);
document.write("<br>Accessed on:"+new Date());
</script>
只有在解析文档时才能使用write()方法输出HTML到当前文档中,理解这点非常重要。也就是说能够在<script>元素中的顶层代码中调用document.write(),就是因为这些脚本的执行是文档解析流程的一部分。如果将document.write()放在一个函数的定义中,而该函数的调用是从一个事件处理程序中发起的,产生的结果未必是你想要的——事实上,它会擦除当前文档和它包含的脚本!(马上你将看到为什么。)同理,在设置了defer或async属性的脚本中不要使用document.write()。
第13章中的例13-3以这种方式使用了document.write()来产生更加复杂的输出。
还可以使用write()方法在其他的窗口或框架页中来创建整个全新文档。(但是,当有多个窗口或框架页时,必须注意不要违反同源策略。)第一次调用其他文档的write()方法即会擦除该文档的所有内容。可以多次调用write()来逐步建立新文档的内容。传递给write()的内容可能缓存起来(并且不会显示)直到调用文档对象的close()方法来结束该写序列。本质上这告诉HTML解析器文档已经达到了文件的末尾,应该结束解析并显示新文档。
值得一提的是Document对象还支持writeln()方法,除了在其参数的输出之后追加一个换行符以外它和write()方法完全一样。例如,在<pre>元素内输出预格式化的文本时这非常有用。
在当今的代码中document.write()方法并不常用:innerHTML属性和其他DOM技术提供了更好的方法来为文档增加内容。另一方面,某些算法的确使得它们本身成为很好的流式I/O API,如同write()方法提供的API一样。如果你正在书写在运行时计算和输出文本的代码,可能会对例15-10感兴趣,它利用指定元素的innerHTML属性包装了简单的write()和close()方法。
例15-10:针对innerHTML属性的流式API
//为设置元素的innerHTML定义简单的"流式"API
function ElementStream(elt){
if(typeof elt==="string")elt=document.getElementById(elt);
this.elt=elt;
this.buffer="";
}
//连接所有的参数,添加到缓存中
ElementStream.prototype.write=function(){
this.buffer+=Array.prototype.join.call(arguments,"");
};//类似write(),只是多增加了换行符
ElementStream.prototype.writeln=function(){
this.buffer+=Array.prototype.join.call(arguments,"")+"\n";
};//从缓存设置元素的内容,然后清空缓存
ElementStream.prototype.close=function(){
this.elt.innerHTML=this.buffer;
this.buffer="";
};
15.10.3 查询选取的文本
有时判定用户在文档中选取了哪些文本非常有用。可以用类似如下的函数达到目的:
function getSelectedText(){
if(window.getSelection)//HTML5标准API
return window.getSelection().toString();
else if(document.selection)//IE特有的技术
return document.selection.createRange().text;
}
标准的window.getSelection()方法返回一个Selection对象,后者描述了当前选取的一系列一个或多个Range对象。Selection和Range定义了一个不太常用的较为复杂的API,本书中并没有文档记录。toString()方法是Selection对象中最重要的也广泛实现了(除了IE)的特性,它返回选取的纯文本内容。
IE定义了一个不同的API,它在本书中也没有文档记录。document.selection对象代表了用户的选择。该对象的createRange()方法返回IE特有的TextRange对象,它的text属性包含了选取的文本。
如上的代码在书签工具(见13.2.5节)中特别有用,它操作选取的文本,然后利用搜索引擎或参考站点查找某个单词。例如,如下HTML链接在Wikipedia上查找当前选取的文本。收藏书签后,该链接和它包含的JavaScript URL就变成了一个书签工具:
<a href="javascript:var q;
if(window.getSelection)q=window.getSelection().toString();
else if(document.selection)q=document.selection.createRange().text;
void window.open('http://en.wikipedia.org/wiki/'+q);">
Look Up Selected Text In Wikipedia
</a>
上述展示的查询选取代码的兼容性不佳:Window对象的getSelection()方法无法返回那些表单元素<input>或<textarea>内部选中的文本,它只返回在文档主体本身中选取的文本。另一方面,IE的document.selection属性可以返回文档中任意地方选取的文本。
从文本输入域或<textarea>元素中获取选取的文本可使用以下代码:
elt.value.substring(elt.selectionStart,elt.selectionEnd);
IE 8以及更早版本的浏览器不支持selectionStart和selectionEnd属性。
15.10.4 可编辑的内容
我们已经知道HTML表单元素包含了文本字段和文本域元素,用户可以输入并编辑纯文本。跟随IE的脚步,所有当今的Web浏览器也支持简单的HTML编辑功能:你也许已经看到过这在页面上使用了(如博客评论页),它嵌入了一个富文本编辑器,包含了一个有一系列按钮的工具栏来设置排版样式(粗体、斜体)、对齐和插入图片与链接。
有两种方法来启用编辑功能。其一,设置任何标签的HTML contenteditable属性;其二,设置对应元素的JavaScript contenteditable属性;这都将使得元素的内容变成可编辑。当用户单击该元素的内容时就会出现插入光标,用户敲击键盘就可以插入其中。如以下代码,一个HTML元素创建了一个可编辑的区域:
<div id="editor"contenteditable>
Click to edit
</div>
浏览器可能为表单字段和contenteditable元素支持自动拼写检查。在支持该功能的浏览器中,检查可能默认开启或关闭。为元素添加spellcheck属性来显式开启拼写检查,而使用spellcheck=false来显式关闭该功能(例如,当一个<textarea>将显示源代码或其他内容包含了字典里找不到的标识符时)。
将Document对象的designMode属性设置为字符串"on"使得整个文档可编辑。(设置为"off"将恢复为只读文档。)designMode属性并没有对应的HTML属性。如下代码使得<iframe>内部的文档可编辑(注意,这里用了例13-5中的onLoad()函数):
<iframe id="editor"src="about:blank"></iframe>//空iframe
<script>
onLoad(function(){//document加载后,
var editor=document.getElementById("editor");//获得iframe中的文档对象,
editor.contentDocument.designMode="on";//开启编辑
});
</script>
所有当今的浏览器都支持contenteditable和designMode属性。但是,当谈到它们实际的可编辑行为时,它们是不太兼容的。所有的浏览器都允许插入与删除文本并用鼠标与键盘移动光标。在所有的浏览器中,Enter键另起一行,但不同的浏览器生成了不同的标记。有些开始了新的段落,而其他的只是插入一个<br/>元素。
有些浏览器允许键盘快捷键(如Ctrl+B)来加粗当前选中的文本。在其他浏览器(如Firefox)中,标准的字处理快捷键(如Ctrl+B和Ctrl+I)被绑定到浏览器相关的其他功能上了而无法应用到文本编辑器上。
浏览器定义了多项文本编辑命令,大部分没有键盘快捷键。为了执行这些命令,应该使用Document对象的execCommand()方法。(注意,这是Document的方法,而不是设置了contenteditable属性的元素的方法。如果文档中有多个可编辑的元素,命令将自动应用到选区或插入光标所在那个元素上。)用execCommand()执行的命令名字都是如"bold"、"subscript"、"justifycenter"或"insertimage"之类的字符串。命令名是execCommand()的第一个参数。有些命令还需要一个值参数——例如,"createlink"需要一个超级链接URL。理论上,如果execCommand()的第二个参数为true,浏览器会自动提示用户输入所需值。但为了提高可移植性,你应该提示用户输入,并传递false作为第二参数,传递用户输入的值作为第三个参数。
function bold(){document.execCommand("bold",false,url);}
function link(){
var url=prompt("Enter link destination");
if(url)document.execCommand("createlink",false,url);
}
execCommand()所支持的命令通常是由工具栏上的按钮触发的。当要触发的命令不可用时,良好的UI会使对应的按钮无效。可以给document.queryCommandSupport()传递命令名来查询浏览器是否支持该命令。调用document.queryCommandEnabled()来查询当前所使用的命令。(例如,一条需要文本选择区域的命令在无选区的情况下有可能是无效的。)有一些命令如"bold"和"italic"有一个布尔值状态,开或关取决于当前选区或光标的位置。这些命令通常用工具栏上的开关按钮表示。要判定这些命令的当前状态可以使用document.queryCommandState()。最后,有些命令(如"fontname")有一个相关联的值(字体系列名)。用document.queryCommandValue()查询该值。如果当前选取的文本使用了两种不同的字体,"fontname"的查询结果是不确定的。使用document.queryCommandIndeterm()来检测这种情况。
不同的浏览器实现了不同的编辑命令组合。只有一少部分命令得到了很好的支持,如"bold"、"italic"、"createlink"、"undo"和"redo"等[6]。在写本书这段时间里HTML5草案定义了以下命令。但由于它们并没有被普遍地支持,这里就不做详细的文档记录:

如果Web应用程序需要富文本编辑器功能,很可能需要采纳一个预先构建的解决浏览器之间的各种差异的解决方案。在网上可以找到很多这样的编辑器组件[7]。值得注意的是,浏览器内置的编辑功能对用户输入少量的富文本来说是足够强大了,但要解决所有种类的文档的编辑来说还是过于简陋了。特别要注意,这些编辑器生成的HTML标记很可能是杂乱无章的。
一旦用户编辑了某元素的内容,该元素设置了conteneditable属性,就可以使用innerHTML属性得到已编辑内容的HTML标记。如何处理该富文本由你自己决定。可以把它存储在隐藏的表单字段中,并通过提交该表单把它发送到服务器。可以使用第18章描述的技术直接把已编辑文本发送到服务器。或者使用第20章的技术在本地保存用户的编辑文本。
[1]CSS3选择器规范:http://www.w3.org/TR/css3-selectors/。
[2]选择器API标准不是HTML5的一部分,但与之有紧密的关联。见http://www.w3.org/TR/selectors-api/。
[3]Sizzle独立版本参见http://sizzlejs.com。
[4]http://www.w3.org/TR/ElementTraversal。
[5]IE8支持Element、HTMLDocument和Text的可扩展属性,但不支持Node、Document、HTMLElement或HTMLElement更具体的子类型的可扩展的属性。
[6]互操作命令列表,请参见http://www.quirksmode.org/dom/execCommand.html。
[7]YUI和Dojo框架包含了编辑器组件。这里也有一些其他的可选方案http://en.wikipedia.org/wiki/Online_rich-text_editor。
