第22章 HTML5 API
HTML5不仅仅指的是最新版的HTML标准,它还指代目前一整套的Web应用技术,其中包括HTML相关技术。这里所谓的Web应用技术更正规的术语其实是开放的Web平台。然而,在实际开发过程中,"HTML5"更像一个方便的简写,本章就是以这种方式使用它的。一些新的HTML5 API在本书的如下其他章节做了介绍:
·第15章介绍了g etElementsByClassName()方法和querySelectorAll()方法以及文档元素的dataset属性。
·第16章介绍了元素的classList属性。
·第18章介绍了XMLHttpRequest Level 2、跨域HTTP请求,以及在服务端发送事件标准中定义的EventSource API。
·第20章介绍了Web存储API和用于离线Web应用的应用缓存。
·第21章介绍了<audio>、<video>和<canvas>元素以及SVG图形。
本章将介绍其他的一些HTML5 API,如下所示:
·22.1节将介绍地理位置API,它能够允许浏览器(用户允许的情况)检测用户的物理位置。
·22.2节将介绍历史管理API,它允许Web应用保存和更新它们的状态,以便当用户单击浏览器的“后退”和“前进”按钮的时候,无须刷新立即做出响应。
·22.3节将介绍在非同源文档间传递消息的一个简单的API。该API提供了同源安全策略下(参见13.6.2节)解决跨域问题安全性的方案。
·22.4节将介绍HTML5中一个主要的新特性:能在一个独立的后台线程中运行JavaScript代码,并且能够让这些worker线程[1]之间能够进行安全的通信。
·22.5节将介绍一些与字节数组和数字数组相关的专用高效内存类型。
·22.6节将介绍Blob:不透明的数据块,作为中心数据交换格式,用于一些新的二进制数据API。该节还将介绍一些与Blob相关的类型和API:File和FileReader对象、BlobBuilder类型以及Blob URL。
·22.7节将介绍文件系统API,它允许Web应用对一个私有沙箱文件系统中的文件进行读/写操作。该API还不稳定,因此在第四部分中也没有对其做介绍。
·22.8节将介绍IndexedDB API,它用于在一个简单的数据库中存储和获取对象。和Filesytem API一样,该API也还不稳定,因此在第四部分中也没有对其做介绍。
·最后22.9节将介绍Web套接字API:它允许Web应用使用基于流的双向通信网络连接到服务器,而不是利用XMLHttpRequest支持的无状态的请求/响应的网络模型。
本章要介绍的这些特性要么是不适合将它们放在前面章节中介绍,要么就是由于它们还不够稳定和成熟,无法将它们放在本书主要的章节中介绍。其中有些API看似已经足够稳定可以在第四部分中介绍,然而它们在其他一些场景下,还是会出问题,因此没有在本书第四部分中介绍。此外,这里要说明的是,在本书出版之时,本章中除了例22-9外,其他的例子都至少可以在一个浏览器中运行。因为这里介绍到的HTML5标准一直都在不断完善中,也就是说,当你正在阅读本章的时候,其中有些例子可能都已经根本无法运行了。
22.1 地理位置
支持地理位置API的浏览器会定义navigator.geolocation。此属性指代一个拥有如下这三个方法的对象:
navigator.geolocation.getCurrentPosition()
获取用户当前位置。
navigator.geolocation.watchPosition()
获取当前位置,同时不断地监视当前位置,一旦用户位置发生更改,就会调用指定的回调函数。
navigator.geolocation.clearWatch()
停止监视用户位置。传递给此方法的参数应当是调用watchPosition()方法获得的返回值。
在包含GPS硬件的设备上,通过GPS单元可以获取精确的位置信息。不过,绝大多数情况下,位置信息都是通过Web获取的。当浏览器提交Internet IP地址给一个Web服务的时候,该服务通常能够知道(基于ISP记录)该IP属于哪个城市(通常广告商会在服务器端这么做)。浏览器还可以通过请求操作系统获取附近无线网络的列表和它们的信号强度,来得到更加精确的位置信息。当将这些信息提交给高级的Web服务的时候,允许非常精确地计算位置(通常在一个城市范围中)。
这些地理位置相关的技术都包含通过网络的数据交换或者和多个卫星之间的通信,因此地理位置API是异步的:getCurrentPosition()方法和watchPosition()方法需要接受一个回调函数作为参数,在判断用户的位置信息(或者当位置改变信息)时,浏览器会调用该函数。如下代码展示了一个获取位置的简单例子:
navigator.geolocation.getCurrentPosition(function(pos){
var latitude=pos.coords.latitude;
var longitude=pos.coords.longitude;
alert("Your position:"+latitude+","+longitude);
});
除了经度和纬度外,凡是成功获取到的地理位置信息还包括一个精度值(米为单位),该值表示获取到的位置信息精度是多少。如例22-1所示:它调用getCurrentPosition()方法来获取当前位置,并用获取到的位置信息,在一张地图中(来自Google地图)中显示当前位置,并且当前位置是根据位置精度进行过适当的缩放。
例22-1:通过获取地理位置信息在地图上显示当前位置
//返回一个新创建的<img>元素,该元素用于在获取到地理位置信息后,显示一张Google地图,
//该地图上显示了当前的位置。要注意的是,此函数的调用者必须要将返回的元素
//插入到文档中,以使它可见
//如果当前浏览器不支持地理位置API,则抛出一个错误
function getmap(){//检查是否支持地理位置API
if(!navigator.geolocation)throw"Geolocation not supported";//创建一个新的<img>元素,并开始请求地理位置信息,
//img元素显示包含当前位置的地图,然后再将返回该图片
var image=document.createElement("img");
navigator.geolocation.getCurrentPosition(setMapURL);
return image;//当(如果)成功获取到地理位置信息后,会在返回image对象后调用此方法
function setMapURL(pos){//从参数对象(pos)中获取位置信息
var latitude=pos.coords.latitude;//经度
var longitude=pos.coords.longitude;//纬度
var accuracy=pos.coords.accuracy;//米
//构造一个URL,用于请求一张显示当前位置的静态Google地图
var url="http://maps.google.com/maps/api/staticmap"+
"?center="+latitude+","+longitude+"&size=640x640&sensor=true";//设置一个大致的缩放级别
var zoomlevel=20;//以各种方式开始缩放
if(accuracy>80)//在低精度情况下进行放大
zoomlevel-=Math.round(Math.log(accuracy/50)/Math.LN2);
url+="&zoom="+zoomlevel;//将缩放级别添加到URL中
//现在在image对象中显示该地图。感谢Google
image.src=url;
}
}
地理位置API还有如下一些特性,例子22-1中没有体现:
·除了第一个回调函数的参数之外,getCurrentPosition()方法和watchPosition()方法还接受第二个可选的回调函数,当获取地理位置信息失败的时候,会调用该回调函数。
·除了成功和失败情况下的回调函数这两个参数之外,这两个方法还接受一个配置对象作为可选的第三个参数。该对象的属性指定了是否需要高精度的位置信息,该位置信息的过期时间,以及允许系统在多长时间内获取位置信息。
·作为参数传递给成功情况下的回调函数的对象,还包含一个时间戳,也有可能(在某些设备上)包含诸如海拔、速度和航向之类的额外信息。
例22-2展示了如何使用这些额外的特性。
例22-2:展示如何使用所有地理位置特性
//异步的获取我的位置,并在指定的元素中展示出来
function whereami(elt){//将此对象作为第三个参数传递给getCurrentPosition()方法
var options={//设置为true,表示如果可以的话
//获取高精度的位置信息(例如,通过GPS获取)
//但是,要注意的是,这会影响电池寿命
enableHighAccuracy:false,//可以近似:这是默认值
//如果获取缓存过的位置信息就足够的话,可以设置此属性
//默认值为0,表示强制检查新的位置信息
maximumAge:300000,//5分钟左后
//愿意等待多长时间来获取位置信息?
//默认值为无限长[2],getCurrentPosition()方法永不超时
timeout:15000//不要超过15秒
};
if(navigator.geolocation)//如果支持的话,就获取位置信息
navigator.geolocation.getCurrentPosition(success,error,options);
else
elt.innerHTMl="Geolocation not supported in this browser";//当获取位置信息失败的时候,会调用此函数
function error(e){//error对象包含一些数字编码和文本消息,如下所示:
//1:用户不允许分享他/她的位置信息
//2:浏览器无法确定位置
//3:发生超时
elt.innerHTML="Geolocation error"+e.code+":"+e.message;
}
//当获取位置信息成功的时候,会调用此函数
function success(pos){//总是可以获取如下这些字段
//但是要注意的是时间戳信息在outer对象中,而不在inner、coords对象中
var msg="At"+
new Date(pos.timestamp).toLocaleString()+"you were within"+
pos.coords.accuracy+"meters of latitude"+
pos.coords.latitude+"longitude"+
pos.coords.longitude+".";//如果设备还返回了海拔信息,则将其添加进去
if(pos.coords.altitude){
msg+="You are"+pos.coords.altitude+"±"+
pos.coords.altitudeAccuracy+"meters above sea level.";
}
//如果设备还返回了速度和航向信息,也将它们添加进去
if(pos.coords.speed){
msg+="You are travelling at"+
pos.coords.speed+"m/s on heading"+
pos.coords.heading+".";
}
elt.innerHTML=msg;//显示所有的位置信息
}
}
22.2 历史记录管理
Web浏览器会记录在一个窗口中载入的所有文档,同时提供了“后退”和“前进”按钮,允许用户在这些文档之间切换浏览。这种浏览器历史记录模型最早在“文档都是被动的,所有的计算都在服务器上完成”那个时期就已经存在了。如今,Web应用通常都是动态地生成或载入页面内容,并在无须刷新页面的情况下就显示新的应用状态。如果想要提供用户能够通过浏览器的“后退”和“前进”按钮,直观地切换应用状态,像这类应用就必须自己处理应用的历史记录管理。HTML5定义了两种用于历史记录管理的机制。
其中比较简单的历史记录管理技术就是利用location.hash和hashchange事件。截至撰写本书时,这种技术一直也是比较广泛实现的:浏览器甚至在HTML5标准化之前就已经开始实现该技术了。在绝大多数浏览器中(IE早期版本除外),设置location.hash属性会更新显示在地址栏中的URL,同时会在浏览器的历史记录中添加一条记录。hash属性设置URL的片段标识符,通常是用于指定要滚动到的文档中某一部分的ID。但是location.hash不一定非要设置为一个元素的ID:它可以设置成任何的字符串。如果能够将应用状态编码成一个字符串,就可以使用该字符串作为片段标识符。
设置了location.hash属性后,接下来要实现允许用户通过“后退”和“前进”按钮来切换不同的文档状态。这个时候,应用必须要想办法检测状态变化,以便它能够读取出存储在片段标识符中的状态并相应地更新自己的状态。支持HTML5的浏览器一旦发现片段标识符发生了改变,就会在Window对象上触发一个hashchange事件。这样,在支持hashchange事件的浏览器中,就可以通过设置window.onhashchange为一个处理程序函数,使得每次由于切换历史记录导致片段标识符变化的时候,都会调用该处理程序函数。当调用该处理程序函数的时候,就可以对location.hash的值进行解析,然后使用该值包含的状态信息来重新显示应用。
HTML5还定义了一个相对更加复杂和强健的历史记录管理方法,该方法包含history.pushState()方法和popstate事件。当一个Web应用进入一个新的状态的时候,它会调用history.pushState()方法将该状态添加到浏览器的浏览历史记录中。该方法的第一个参数是一个对象,该对象包含用于恢复当前文档状态所需的所有信息。该对象可以是任何能够通过JSON.stringify()方法转换成相应字符串形式的对象,也可以是其他类似Date和RegExp这样特定的本地类型(参见下面的补充内容)。该方法的第二个可选参数是一个可选的标题(普通的文本字符串),浏览器可以使用它(比如,在一个<Back>菜单中)来标识浏览历史记录中保存的状态。该方法的第三个参数是一个可选的URL,表示当前状态的位置。相对的URL都是以文档的当前位置为参照,通常该URL只是简单地指定URL(诸如#state)这样的hash(或者“片段标识符”)部分。将一个URL和状态关联,可以允许用户将应用的内部状态作为书签添加到浏览器中,并当在URL中包含足够信息的时候,应用可以在从书签中载入的时候就恢复它的状态。
结构性复制
正如上面所提到的,pushState()方法接受一个状态对象并为该对象创建一份私有副本。这是对一个对象进行深拷贝或者深复制:它会递归地复制所有嵌套对象或者数组的内容。HTML5标准将这类复制称为“结构性复制”(structured clone)。创建一个结构性复制的过程就好比是将一个对象传递给JSON.stringify()方法,然后再将结果字符串传递给JSON.parse()方法(参见6.9节)。但是JSON只支持JavaScript的基础类型和对象以及数组。在HTML5标准中提到,结构性复制算法必须还能够复制Date对象、RegExp对象、ImageData对象(来自<canvas>元素:参见21.4.14节)、FileList对象、File对象以及Blob对象(在22.6节介绍)。但是在结构性复制算法中会显式排除JavaScript中的函数和错误以及绝大部分诸如窗口、文档、元素等这类宿主对象。或许还不会存储文件或者图片数据作为历史状态的一部分,但是结构性复制还被其他一些HTML5相关的标准用到,在本章其他地方,还会对其做相应的介绍。
除了pushState()方法之外,History对象还定义了replaceState()方法,该方法和pushState()方法接受同样的参数,但是不同的是,它不是将新的状态添加到浏览历史记录中,而是用新的状态代替当前的历史状态。
当用户通过“后退”和“前进”按钮浏览保存的历史状态时,浏览器会在Window对象上触发一个popstate事件。与该事件相关联的事件对象有一个state属性,该属性包含传递给pushState()方法的状态对象的副本(另一个结构性复制)。
例22-3是一个简单的Web应用——如图22-1所示的一个猜数字的游戏——它使用这些HTML5技术来保存应用记录,允许用户通过“后退”来回顾或者撤销对数字的猜测。
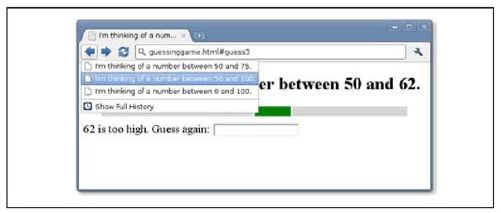
图 22-1 一个猜数字游戏
在本书出版时,Firefox 4对历史记录AP做了两点修改,其他的浏览器可能也会跟着进行这两点修改。第一,Firefox 4使得History对象自身可以通过state属性获取当前状态,这就意味着新载入的页面无须等待一个popstate事件。第二,对于没有任何保存状态的新载入的页面,Firefox 4不再出发popstate事件。第二点修改意味着下面这个例子在Firefox 4将无法工作。
例22-3:使用pushState()方法进行历史记录管理
<!DOCTYPE html><html><head><title>I'm thinking of a number...</title><script>window.onload=newgame;//页面载入的时候就开始一个新的游戏window.onpopstate=popState;//处理历史记录相关事件var state,ui;//全局变量,在newgame()方法中会对其初始化function newgame(playagain){//开始一个新的猜数字游戏//初始化一个包含需要的文档元素的对象ui={heading:null,//文档最上面的<h1>元素prompt:null,//要求用户输入一个猜测数字input:null,//用户输入猜测数字的地方low:null,//可视化的三个表格单元格mid:null,//猜测的数字范围high:null};//查询这些元素中每个元素的idfor(var id in ui)ui[id]=document.getElementById(id);//给input字段定义一个事件处理程序函数ui.input.onchange=handleGuess;//生成一个随机的数字并初始化游戏状态state={n:Math.floor(99*Math.random())+1,//整数:0<n<100low:0,//可猜测数字范围的下限high:100,//可猜测数字范围的上限guessnum:0,//猜测的次数guess:undefined//最后一次猜测};//修改文档内容来显示该初始状态display(state);//此函数会作为onload事件处理程序调用,//同时当单击显示在游戏最后的"再玩一次"按钮时候,也会调用它//在第二种调用情况下,playagain参数值为true//如果playagain为true,则保存新的游戏状态//但是如果是作为onload事件处理程序调用的情况下,则不保存状态//这是因为,当通过浏览器历史记录从其他文档状态回退到当前的游戏状态时,//也会触发load事件。如果这种情况下,也保存状态的话,//会将真正的游戏历史状态记录覆盖掉//在支持pushState()方法的浏览器中,load事件之后总是有一个popstate事件//因此,这里的处理方式是,等待popstate事件而不是直接进行状态保存//如果该事件提供一个状态对象,则直接使用该对象即可//如果该事件没有状态对象,就表示这实际上是一个新的游戏,//则使用replaceState来保存最新的游戏状态if(playagain===true)save(state);}//如果支持的话,就使用pushState()方法将游戏状态保存到浏览器历史记录中function save(state){if(!history.pushState)return;//如果pushState()方法没有定义的话,则什么也不做//这里会将一个保存的状态和URL关联起来//该URL显示猜测的数字,但是不对游戏状态进行编码,//因此,这对于书签是没有用的//不能简单地将游戏状态写到URL中,因为这会将游戏一些机密数字暴露在地址栏中var url="#guess"+state.guessnum;//保存状态对象和URLhistory.pushState(state,//要保存的状态对象"",//状态标题:当前浏览器会忽略它url);//状态URL:对书签是没有用的}//这是onpopstate的事件处理程序,用于恢复历史状态function popState(event){if(event.state){//如果事件有一个状态对象,则恢复该状态//要注意的是,event.state是对已保存状态对象的一个深拷贝//因此无须改变保存的值就可以修改该对象state=event.state;//恢复历史状态display(state);//显示恢复的状态}else{//当第一次载入页面时,会触发一个没有状态的popstate事件//用真实的状态将null状态替换掉:参见newgame()方法中的注释//这里不需要调用display()方法history.replaceState(state,"","#guess"+state.guessnum);}};//每次用户猜测一个数字的时候,都会调用此事件处理程序//此处理程序用于更新游戏的状态、保存游戏状态并显示游戏状态function handleGuess(){//从input字段中获取用户猜测的数字var g=parseInt(this.value);//如果该值是限定范围中的一个数字if((g>state.low)&&(g<state.high)){//对应地更新状态对象if(g<state.n)state.low=g;else if(g>state.n)state.high=g;state.guess=g;state.guessnum++;//在浏览器历史记录中保存新的状态save(state);//根据用户猜测情况来修改文档display(state);}else{//无效的猜测:不保存状态alert("Please enter a number greater than"+state.low+"and less than"+state.high);}}//修改文档来显示游戏当前状态function display(state){//显示文档的导航和标题ui.heading.innerHTML=document.title="I'm thinking of a number between"+state.low+"and"+state.high+".";//使用一个表格来显示数字的取值范围ui.low.style.width=state.low+"%";ui.mid.style.width=(state.high-state.low)+"%";ui.high.style.width=(100-state.high)+"%";//确保input字段是可见的、空的并且是聚焦的ui.input.style.visibility="visible";ui.input.value="";ui.input.focus();//根据用户最近的猜测,设置提示if(state.guess===undefined)ui.prompt.innerHTML="Type your guess and hit Enter:";else if(state.guess<state.n)ui.prompt.innerHTML=state.guess+"is too low.Guess again:";else if(state.guess>state.n)ui.prompt.innerHTML=state.guess+"is too high.Guess again:";else{//当猜对了的时候,就隐藏input字段并显示"再玩一次"按钮ui.input.style.visibility="hidden";//不需要再猜了ui.heading.innerHTML=document.title=state.guess+"is correct!";ui.prompt.innerHTML="You Win!<button onclick='newgame(true)'>Play Again</button>";}}</script><style>/*通过CSS样式美化游戏界面*/#prompt{font-size:16pt;}table{width:90%;margin:10px;margin-left:5%;}#low,#high{background-color:lightgray;height:1em;}#mid{background-color:green;}</style></head><body><!--下面的HTML元素是游戏的UI--><!--游戏标题和数字猜测范围的文本表示--><h1 id="heading">I'm thinking of a number...</h1><!--用于确保猜测的数字在有效范围内--><table><tr><td id="low"></td><td id="mid"></td><td id="high"></td></tr></table><!--用户输入猜测数字的地方--><label id="prompt"></label><input id="input"type="text"></body></html>
22.3 跨域消息传递
正如14.8节提到的,一些浏览器窗口和标签之间都是完全相互独立的,在其中一个窗口或者标签中运行的代码在其他窗口或标签中完全无法识别。但是,在其他的一些场景下,当脚本显式打开一个新窗口或者在嵌套的窗体中运行的时候,多个窗口或者窗体之间是互相可识别的。如果它们包含的文档是来自同一台Web服务器,则再这些窗口和窗体中的脚本可以互相之间进行交互和操作对方的文档。
然而,有的时候,尽管脚本可以引用其他的Window对象,但是由于那个窗口中的内容是来自于不同的源,Web浏览器(遵循同源策略)不会允许访问其他窗口中的文档内容。大部分情况下,浏览器还不允许脚本读取其他窗口的属性或调用其他窗口方法。不过有个window方法,是允许来自非同源脚本调用的:postMessage()方法,该方法允许有限的通信——通过异步消息传递的方式——在来自不同源的脚本之间。这类通信机制是在HTML5标准中定义的,所有主流的浏览器(包括IE8和更新版本)都已经实现了该通信机制。这项技术称为“跨文档消息传递”,而由于该API是定义在Window对象上的,而不是文档对象上的,因此,它又称为“窗口间消息传递”或者“跨域消息传递”。
postMessage()方法接受两个参数。其中第一个参数是要传递的消息。HTML5标准提到,该参数可以是任意基本类型值或者可以复制的对象(参见22.2节的“结构性复制”),但是,有些当前浏览器(包括Firefox 4 beta版本)的实现只支持字符串,因此,如果想要作为消息传递对象或者数组,首先应当使用JSON.stringify()方法(参见6.9节)对其序列化。
其中第二个参数是一个字符串,指定目标窗口的源。其中包括协议、主机名以及URL(可选的)端口部分(可以传递一个完整的URL,但是除了协议、主机名和端口号之外的任何信息都会忽略)。这是一个安全特性:由于恶意代码或普通用户都可以在窗口中浏览新的未知文档,因此postMessage()只会将消息传递给指定的窗口,而不会传递给包含非同源文档的窗口。当然,如果传递的消息不包含任何敏感信息的话,并且愿意将其传递给任何窗口,就可以直接将该参数设置成“*”通配符即可。如果要指定和当前窗口同源的话,那么也可以简单地使用“/”。
如果指定的源匹配的话,那么当调用postMessage()方法的时候,在目标窗口的Window对象上就会触发一个message事件。在目标窗口中的脚本则可以定义通知message事件的处理程序函数。调用该事件处理程序的时候会传递给它一个拥有如下属性的事件对象:
data
作为第一个参数传递给postMessage()方法的消息内容副本。
source
消息源自的Window对象。
origin
一个字符串,指定消息来源(URL形式)。
通常,onmessage()事件处理程序应当首先检测其中的origin属性,忽略来自未知源的消息。
当想要在We b页面中嵌入一个来自其他站点的模块或者"gadget"的时候,利用postMessage()和message事件实现的跨域消息传递是很有用的。当然,如果gadget本身就很简单并且又是自包含的,就可以直接简单地将它放在<iframe>中实现隔离即可。然而,假设gadget本身比较复杂,它自身还定义了一些API,同时Web页面需要利用这些API和它进行交互。这个时候,用<iframe>就不行了,而如果将它嵌入在<script>元素中,它可以提供一个正常的JavaScript API,但是同时它也可以完全操控页面和页面内容了。目前在Web上通常不会这样去做(尤其是Web广告),哪怕信任第三方站点,这也不是个好的方案。
跨域消息传递提供了另外一种实现方案:首先gadget的开发者可以将gadget内容定义在一个HTML页面中,它负责监听message事件,并将它们分发给对应的JavaScript函数去处理。然后,嵌入gadget的Web页面就可以通过postMessage()方法传递消息来和gadget进行交互了。例22-4和例22-5展示了如何使用该方案。例22-4是一个简单的gadget,放置在<iframe>中,它搜索Twitter并将匹配指定搜索项的tweet显示出来。要让它实现真正的搜索功能,包含的页面只需要简单地作为消息传递搜索项给它即可。
例22-4:Twitter搜索gadget,由postMessage()来控制
<!DOCTYPE html><!--这是一个Twitter搜索gadget。将它通过iframe的形式内嵌在任何Web页面中,通过postMessage()方法将查询字符串传递给它来搜索tweet。由于它是内嵌在<iframe>中而不是<script>中,因此它无法对内嵌它的页面造成破坏--><html><head><style>body{font:9pt sans-serif;}</style><!--使用jQuery的jQuery.getJSON()工具函数--><script src="http://code.jquery.com/jquery-1.4.4.min.js"/></script><script>//原本只要能够使用window.onmessage就可以了,但是考虑到早期的浏览器(比如:Firefox 3)不支持它,因此,采用如下兼容方式实现if(window.addEventListener)window.addEventListener("message",handleMessage,false);elsewindow.attachEvent("onmessage",handleMessage);//For IE8function handleMessage(e){//不在意消息来源:愿意接受任何来源的Twitter搜索请求//但是,希望消息源自内嵌gadget的窗口if(e.source!==window.parent)return;var searchterm=e.data;//获取搜索内容//使用jQuery Ajax工具函数以及Twitter的搜索API来查找匹配消息的tweetjQuery.getJSON("http://search.twitter.com/search.json?callback=?",{q:searchterm},function(data){//使用请求结果调用var tweets=data.results;//构造一个HTML文档来显示搜索结果var escaped=searchterm.replace("<","&lt;");var html="<h2>"+escaped+"</h2>";if(tweets.length==0){html+="No tweets found";}else{html+="<dl>";//以<dl>列表形式呈现结果for(var i=0;i<tweets.length;i++){var tweet=tweets[i];var text=tweet.text;var from=tweet.from_user;var tweeturl="http://twitter.com/#!/"+from+"/status/"+tweet.id_str;html+="<dt><a target='_blank'href='"+tweeturl+"'>"+tweet.from_user+"</a></dt><dd>"+tweet.text+"</dd>";}html+="</dl>";}//设置<iframe>文档document.body.innerHTML=html;});}$(function(){//通知内嵌gadget的页面<sup class="calibre5">[[3]](part0031.html#ch3-back)</sup>,//我们(gadget)已经准备就绪//容器在没有收到这条消息前,它不能发送任何消息//因为我们还没有准备好接收消息//通常,容器只需要等待onload事件的触发,以此来得知所有的<iframe>都已载入完毕//我们发送消息告诉容器已经准备就绪,甚至有可能在容器获得onload事件之前//我们并不知道容器的源,所以采用"*"来让浏览器把消息发送给任何窗口window.parent.postMessage("Twitter Search v0.1","*");});</script></head><body></body></html>
例22-5是一个简单的JavaScript文件,可以将它引入到任何想要使用Twitter搜索gadget的Web页面中。它将gadget插入到文档中,然后为文档中所有的链接都添加一个事件处理程序,以便当鼠标指针划过一个链接的时候,就会调用postMessage()方法,让gadget去搜索链接上的URL指定的内容。这可以允许用户在发一条包含网站内容的tweet时,在未访问该站点前就能够先看到网站内容。
例22-5:通过postMessage()来使用Twitter搜索gadget
//如下JS代码实现将Twitter搜索gadget添加到文档中
//然后为文档中所有的链接都添加一个事件处理程序
//实现当鼠标指针划过一个链接的时候,就会调用postMessage()方法
//让gadget去搜索链接上的URL指定的内容。这可以允许用户要发一条包含网站内容的tweet时
//在未访问该站点前就能够先看到网站内容
window.addEventListener("load",function(){//在IE9以下的版本无效
var origin="http://davidflanagan.com";//gadget源
var gadget="/demos/TwitterSearch.html";//gadget路径
var iframe=document.createElement("iframe");//创建iframe
iframe.src=origin+gadget;//设置它的URL
iframe.width="250";//250个像素宽
iframe.height="100%";//整个文档高度
iframe.style.cssFloat="right";//右浮动
//将该iframe插入到文档的最开始
document.body.insertBefore(iframe,document.body.firstChild);//查找所有的链接,并把它们绑定到gadget上
var links=document.getElementsByTagName("a");
for(var i=0;i<links.length;i++){//addEventListener在IE8及其早期版本无效
links[i].addEventListener("mouseover",function(){//作为查询内容传递url
//只当iframe仍然显示来自davidflanagan.com文档的时候传递它
iframe.contentWindow.postMessage(this.href,origin);
},false);
}
},false);
22.4 Web Worker
客户端JavaScript其中一个基本的特性就是单线程:比如,浏览器无法同时运行两个事件处理程序,它也无法在一个事件处理程序运行的时候触发一个计时器。并行更新应用状态和文档状态根本是不可能的,客户端的程序员也不需要理解或者关心并行编程。之所以设计成单线程的理论就是,客户端的JavaScript函数必须不能运行太长时间:否则会导致循环事件,Web浏览器无法对用户输入作出响应。这也是为什么Ajax的API都是异步的,以及为什么客户端JavaScript不能使用一个简单的异步load()函数或者require()函数来加载JavaScript库。
在Web Workers标准[4]中,定义了解决客户端JavaScript无法多线程的问题。其中定义的"Worker"是指执行代码的并行线程。不过,Web Workers处在一个自包含的执行环境中,无法访问Window对象和Document对象,和主线程之间的通信也只能通过异步消息传递机制来实现。这就意味着,并行地修改DOM是不可能的,不过,它提供了一种使用异步API的方式,同时允许书写需要长时间运行的函数而不会带来循环事件和导致浏览器崩溃的问题。创建一个新的Worker并不像打开一个新的浏览器窗口那样属于重量级的操作,不过,Worker本身也不是轻量级的线程,因此创建一些新的Worker去处理次要的操作是不划算的。这里不建议创建太多的Worker(比如成百上千个),一个复杂的Web应用一般包含几十个Worker。
和任何线程API一样,Web Workers标准包含两部分。第一部分是Worker对象:该对象是暴露给创建该线程的线程的。第二部分是WorkerGlobalScope:这是一个用来表示新创建的Worker的全局对象,也是Worker线程内部使用的对象。下面几节会结合例子对这两者一一做介绍。
22.4.1 Worker对象
要创建一个新的Worker,只须使用Worker()构造函数,并将指定在Worker中运行的JavaScript脚本的URL传递给该构造函数即可,如下所示:
var loader=new Worker("utils/loader.js");
如果URL采用的是相对路径,那么是以包含调用Worker()构造函数脚本的文档的URL为参照的。而如果指定的URL采用的是绝对路径,那么必须和包含该脚本的文档是同源的(同样的协议、主机名和端口)。
一旦获取到Worker对象后,就可以通过postMessage()方法来传递参数了。传递给postMessage()方法的值会复制(参见22.2节的“结构性复制”),最终的副本会通过message事件传递给Worker。
loader.postMessage("file.txt");
要注意的是,Worker的postMessage()方法是没有参数的,而Window对象的postMessage()方法是有的(参见22.3节)。还有,Worker的postMessage()方法在主流浏览器中都会正确地复制消息,不像Window.postMessage(),在一些重要的浏览器中,对字符串消息仍然是有限制的。
可以通过监听Worker对象上的message事件来接收来自Worker的消息:
worker.onmessage=function(e){
var message=e.data;//从事件对象中获取消息
console.log("URL contents:"+message);//用它进行一些操作
}
如果Worker抛出了异常,并且它自己没有对其进行捕获和处理,可以作为监听的一个error事件来传递该异常:
worker.onerror=function(e){//记录错误消息日志:包括Worker的文件名和行数
console.log("Error at"+e.filename+":"+e.lineno+":"+
e.message);
}
和所有的事件目标一样,Worker对象也定义了标准的addEventListener()方法和removeEventListener()方法,如果想要管理多个事件处理程序,可以使用这些方法来代替onmessage和onerror属性。
Worker对象还有另一个方法:terminate()。该方法强制一个Worker线程结束运行。
22.4.2 Worker作用域
在通过Worker()构造函数创建一个新Worker的时候,指定了包含JavaScript代码文件的URL。该代码会运行在一个全新的JavaScript运行环境中,完全和创建Worker的脚本隔离开来。WorkerGlobalScope全局对象表示了该新的运行环境。WorkerGlobalScope对象在某种程度上来说是大于核心的JavaScript全局对象,但又小于整个客户端的Window对象。
和Worker对象一样,WorkerGlobalScope对象也有一个postMessage()方法和一个onmessage事件处理程序的属性,不过使用方法恰好相反:在Worker中调用postMessage()方法会触发Worker外部的一个message事件,而Worker外部传递的消息会转换成一个事件,并传递给onmessage事件处理程序。要注意的是,WorkerGlobalScope是一个供Worker使用的全局对象,因此该对象上的postMessage()方法和onmessage属性在Worker代码中使用的时候,看起来就像是全局函数和全局变量。
close()函数允许Worker将自己终止,它从效果上来说和Worker对象的terminate()方法类似。但是,要注意的是,在Worker对象上没有定义任何API用于检测是否Worker已经将自己关闭了,也没有类似onclose这样的事件处理程序属性。如果在一个已经关闭的Worker上调用postMessage()方法,那么消息会被无声无息地丢弃,而且也不会有任何错误抛出。因此,如果一个Worker想要使用close()方法将自己关闭,那么最好是先传递诸如“关闭”这样的消息。
WorkerGlobalScope对象上定义的最有意思的全局函数是importScripts():Worker使用此方法来加载任何需要的库代码。如下所示:
//在开始工作前,先载入需要的类、工具函数
importScripts("collections/Set.js","collections/Map.js","utils/base64.js");
importScripts()方法接受一个或者多个URL参数,每个URL都需指向一个JavaScript代码文件。相对地址的URL以传递给Worker()构造函数的URL为参照。它会按照指定的顺序依次载入并运行这些JavaScript文件。如果载入脚本的时候抛出了网络错误,或者在执行的时候抛出了错误,那么剩下的脚本都不会载入和运行。通过importScripts()方法载入的脚本自身还可以调用importScripts()方法载入它需要的文件。但是,要注意的是,importScripts()方法不会试图去跟踪哪些脚本已经载入了,也不会去防止循环依赖的问题。
importScripts()是一个同步的方法:它直到所有的脚本都已经载入并运行完成才会返回。一旦importScripts()方法返回就可以开始使用载入的脚本了:这里不需要回调函数或者事件处理程序。一旦对客户端JavaScript异步的特性根深蒂固之后,再回到简单的同步编程方式会感觉很不适应。但是,这就是线程之美:可以在一个Worker中使用阻塞式函数,而不会导致主线程中的事件循环,也不会阻塞在其他Worker中并行执行的计算。
Worker执行模型
Worker线程从上到下同步运行它们的代码(以及所有导入的脚本),然后进入一个异步阶段,来对事件以及计时器做出响应。如果Worker注册了onmessage事件处理程序,那么只要message事件有可能触发,那么它将永远不会退出。但是,如果Worker没有监听消息,那么一直到所有任务相关的回调函数都调用以及再也没有挂起的任务(比如下载和计时器)之后,它就会退出。一旦所有注册的回调函数都已经调用之后,Worker也不再创建新任务了,这个时候线程就可以安全退出了。想象这样一个Worker,它通过XMLHttpRequest下载一个文件,但是没有任何onmessage事件处理程序。如果该下载任务的onload处理程序开始一个新的下载任务或者通过setTimeout()方法注册一个超时的程序,那么线程有了新的任务并保持运行状态;否则,线程就会退出。
因为WorkerGlobalScope是Worker的全局对象,所以它有所有核心JavaScript全局对象拥有的那些属性,诸如JSON对象、isNaN()函数和Date()构造函数。(请通过在第三部分中查询Global来获得完整的列表。)然而,除此之外,WorkerGlobalScope对象还有客户端Window对象拥有的一些如下属性:
·self是对全局对象自身的引用。但是,要注意的是,WorkerGlobalScope对象的self和Window对象的self意义不同。
·计时器方法:setTimeout()、clearTimeout()、setInterval()以及clearInterval()。
·location属性,描述传递给Worker()构造函数的URL。和Window对象的location属性一样,此属性指向一个Location对象。该对象有href、protocol、host、hostname、port、pathname、search以及hash属性。在Worker中,这些属性都是只读的。
·navigator属性,指向一个对象,该对象拥有的属性和Window的Navigator对象拥有的那些属性类似。Worker的navigator对象有appName、appVersion、platform、userAgent以及onLine属性。
·常用的事件目标方法:addEventListener()和removeEventListener()。
·onerror属性,可以将它设置为一个错误事件处理程序,就像在14.6节中介绍的Window.onerror处理程序那样。如果注册了错误处理程序,那么错误的消息、URL以及行号会作为三个字符串参数传递给该处理程序。如果该处理程序返回false,则表示错误已经处理,不应该再将其当成一个Worker对象上的error事件传播了。(不过,截至撰写本书时,不是所有的浏览器都实现了在Worker中的错误处理。)
最后,WorkerGlobalScope对象还包含客户端JavaScript一些重要的构造函数对象。其中包括XMLHttpRequest(),以便Worker可以通过它进行脚本化的HTTP请求(参见第18章),以及Worker()构造函数,Worker可以通过它创建它们自己的Worker线程。(然而,截至撰写本书时,Chrome和Safari还不支持在Worker中使用Worker()构造函数。)
本章后续将要介绍的一些HTML 5 API,在普通的Window对象和Worker的WorkerGlobalScope对象上都定义了一些新特性。通常,Window对象会定义一个异步的API,同时,WorkerGlobalScope会添加一个相同基本API的异步版本。这些“启用Worker的”API会在本章后续部分做相应介绍。
Worker高级特性
本节介绍的Worker线程都是专用Worker线程:它们和单独的父线程相关联。Web Workers标准还定义了另外一类Worker线程:共享Worker线程。截至撰写本书时,浏览器还未实现此类线程。但是这里仍然对其做相应介绍,原因是,共享Worker线程是一种命名资源,为任何与之相连接的线程提供计算服务,和共享Worker之间的交互就好比是通过网络套接字和服务器进行通信。
对于共享Worker线程而言,“套接字”又叫MessagePort。MessagePorts定义了一个消息传递API,和为专用Worker线程和跨文档消息传递统一的API类似:它们有一个postMessage()方法以及一个onmessage事件处理程序属性。HTML5标准允许通过MessageChannel()构造函数,创建一对相互连接的MessagePort对象。可以将MessagePorts(作为postMessage()方法的特殊参数)传递给其他窗口或者其他Worker,并将它们作为专用的通信频道。MessagePorts和MessageChannels是高级API,目前大多数浏览器都还未实现,因此这里将不做介绍。
22.4.3 Web Worker的例子
本节将以两个Web Worker的例子结束。第一个例子展示了如何在一个Worker线程中执行长时间计算,同时又不影响主线程进行UI响应。第二个例子展示了Worker线程如何使用更加简单的同步API。
例22-6定义了一个smear()函数,它接受一个<img>元素作为参数。该函数用于在图片上产生向右的动态模糊效果。它使用了第21章介绍的技术,将图片复制到一个屏幕外的<canvas>元素中,然后再将图片的像素提取到一个ImageData对象中。不能通过postMessage()方法将<img>元素或者<canvas>元素传递给Worker,但是可以传递ImageData对象(具体细节参见22.2节的“结构性复制”)。例22-6创建一个Worker对象,并调用postMessage()方法将要涂抹的像素传递给它。当Worker线程将处理完的像素信息再传递回来后,代码将它们复制回<canvas>元素中,再作为data://URL提取它们,然后将该URL设置成最初<img>元素的src属性值。
例22-6:创建一个Web Worker线程处理图片
//异步地将图片内容替换成动态模糊版本
//以这种方式使用:<img src="testimage.jpg"onclick="smear(this)"/>
function smear(img){//创建一个和图片尺寸相同的屏幕外<canvas>
var canvas=document.createElement("canvas");
canvas.width=img.width;
canvas.height=img.height;//将图片复制到画布中,随后提取其像素
var context=canvas.getContext("2d");
context.drawImage(img,0,0);
var pixels=context.getImageData(0,0,img.width,img.height)//将像素信息传递给Worker线程
var worker=new Worker("SmearWorker.js");//创建Worker线程
worker.postMessage(pixels);//复制和传递像素信息
//注册事件处理程序来获取Worker的响应
worker.onmessage=function(e){
var smeared_pixels=e.data;//从Worker获取的像素信息
context.putImageData(smeared_pixels,0,0);//将它们复制到画布中
img.src=canvas.toDataURL();//然后,添加到img中
worker.terminate();//关闭Worker线程
canvas.width=canvas.height=0;//将周围像素清空
}
}
例22-7所示的代码是给例22-6中创建的Worker线程使用的。该例是一个图片处理函数:基于例21-10修改的。要注意的是,该例使用一行代码就建立了一套消息传递机制:onmessage事件处理程序只将传递给它的图片进行涂抹,随后传递回去。
例22-7:在Web Worker中进行图片处理
//从主线程中获取ImageData对象,对其进行处理并将它传递回去
onmessage=function(e){postMessage(smear(e.data));}//将ImageData中的像素信息向右涂抹,产生动态模糊效果
//对于大图片,此方法会进行大量的计算,
//如果它用在主线程中的话,很有可能导致无法响应UI操作的问题
function smear(pixels){
var data=pixels.data,width=pixels.width,height=pixels.height;
var n=10,m=n-1;//设置n倍大,用于更多的涂抹
for(var row=0;row<height;row++){//每一行
var i=rowwidth4+4;//第二个像素偏移
for(var col=1;col<width;col++,i+=4){//每一列
data[i]=(data[i]+data[i-4]*m)/n;//红色像素分量
data[i+1]=(data[i+1]+data[i-3]*m)/n;//绿色
data[i+2]=(data[i+2]+data[i-2]*m)/n;//蓝色
data[i+3]=(data[i+3]+data[i-1]*m)/n;//Alpha分量
}
}
return pixels;
}
要注意的是,例22-7中的代码可以用于处理任意数量的图片。然而,为了简单起见,例22-6为它要处理的每一幅图片创建了一个新的Worker对象。同时,为了确保没有线程闲置,它会对于已经完成操作的线程调用terminate()方法将其终止掉。
调试Worker线程
在WorkerGlobalScope中,有一个API是不可用的(至少截至撰写本书时是不可用的):控制台API以及它非常有用的console.log()函数。Worker线程不能输出日志,也不能和文档进行交互,因此要想调试,就要采用更加巧妙的方法。如果Worker抛出错误,那么主线程在Worker对象上会接收到一个error事件。但是,通常情况下,需要一种方式能够让Worker将调试消息输出到浏览器的Web控制台中。其中,最直接的方式就是通过修改和Worker间的消息传递协议,来让Worker将调试消息传递出来。比如,在例22-6中,可以将如下代码添加到onmessage事件处理程序的最开始:
if(typeof e.data==="string"){
console.log("Worker:"+e.data);
return;
}
有了新增的这部分代码,Worker线程只要简单地将字符串传递给postMessage()方法就能够实现展示调试消息了。
下面的例子展示了Web Worker如何允许书写同步代码并在客户端JavaScript中放心地使用它。18.1.2节介绍过如果使用XMLHttpRequest实现同步的HTTP请求,但是也警告过,在主浏览器线程中这样使用是个很不好的实践。然而,在Worker线程中进行同步请求是再理想不过的了,例22-8正是展示的是与之相关的例子。其中的onmessage事件处理程序接受一个待获取的URL数组。它通过同步XMLHttpRequest API来进行获取,然后,将获取到的文本内容以字符串的形式,组成一个数组,传递回主线程。或者,如果在HTTP请求过程中失败了,则会抛出错误,并会将其传递给Worker对象的onerror处理程序。
例22-8:在Web Worker中发起同步XMLHttpRequest
//此文件会通过一个新的Worker()来载入,因此,它是运行在独立的线程中的,
//可以放心地使用同步XMLHttpRequest API
//消息是URL数组的形式。以字符串形式同步获取每个URL指定的内容,
//并将这些字符串数组传递回去。
onmessage=function(e){
var urls=e.data;//输入:要获取的URL
var contents=[];//输出:URL指定的内容
for(var i=0;i<urls.length;i++){
var url=urls[i];//每个URL
var xhr=new XMLHttpRequest();//开始一个HTTP请求
xhr.open("GET",url,false);//false则表示进行同步请求
xhr.send();//阻塞住,一直到响应完成
if(xhr.status!==200)//如果请求失败则抛出错误
throw Error(xhr.status+""+xhr.statusText+":"+url);
contents.push(xhr.responseText);//否则,存储通过URL获取得到的内容
}
//最后,将这些URL内容以数组的形式传递回主线程
postMessage(contents);
}
22.5 类型化数组和ArrayBuffer
正如第7章介绍的那样,JavaScript中的数组是包含多个数值属性和一个特殊的length属性的通用对象。数组元素可以是JavaScript中任意的值。数组可以动态地增长和收缩,也可以是稀疏数组。JavaScript的实现中对数组做了很多的优化,使得典型的数组操作可以变得很快。类型化数组就是类数组对象(参见7.11节),它和常规的数组有如下重要的区别:
·类型化数组中的元素都是数字。使用构造函数在创建类型化数组的时候决定了数组中数字(有符号或者无符号整数或者浮点数)的类型和大小(以位为单位)。
·类型化数组有固定的长度。
·在创建类型化数组的时候,数组中的元素总是默认初始化为0。
一共有8种类型化数组,每一种的元素类型都不同。可以使用如下所示的构造函数来创建这8种类型化数组:

类型化数组、<canvas>和核心JavaScript
类型化数组是用于<canvas>元素的WebGL 3D图形化API中重要的一部分,浏览器已经将它们实现成为WebGL的一部分。本书不会对WebGL做介绍,但是类型化数组通常有用,因此在这里做相应的介绍。回忆一下,在第21章中介绍过,画布API定义了一个getImageDate()方法,该方法返回一个ImageData对象。ImageData对象的data属性就是一个字节数组。在HTML标准中把这叫做CanvasPixelArray,但是,它基本上和这里描述的Uint8Array是一样的,除了它可以处理超过0~255范围的值之外。
要注意的是,这些类型不是核心语言的一部分。JavaScript语言未来的版本可能会引入对这些类型化数组的支持,但是,截至撰写本书时,都尚未清楚,是否JavaScript语言本身会采用这里描述的这些API还是创建新的API。
在创建一个类型化数组的时候,可以传递数组大小给构造函数,或者传递一个数组或者类型化数组来用于初始化数组元素。一旦创建了类型化数组,就可以像操作其他类数组对象那样,通过常规的中括号表示法来对数组元素进行读/写操作:
var bytes=new Uint8Array(1024);//1KB字节
for(var i=0;i<bytes.length;i++)//循环数组的每个元素
bytes[i]=i&0xFF;//设置为索引的低8位值
var copy=new Uint8Array(bytes);//创建数组的副本
var ints=new Int32Array([0,1,2,3]);//包含这4个int值的类型化数组
现代JavaScript语言实现对数组进行了优化,使得数组操作已经非常高效。不过,类型化数组在执行时间和内存使用上都要更加高效。下面的函数用于计算出比指定数值小的最大素数。它使用了埃拉托色尼筛选算法,该算法要求使用一个大数组来存储哪些数字是素数,哪些是合数。由于每个数组元素只要使用一位信息,因此这里使用Int8Array要比使用常规的JavaScript数组更加高效:
//使用埃拉托色尼筛选算法,返回一个小于n的最大素数
function sieve(n){
var a=new Int8Array(n+1);//如果x是合数,则a[x]为1
var max=Math.floor(Math.sqrt(n));//因数不能比它大
var p=2;//2是第一个素数
while(p<=max){//对于小于max的素数
for(var i=2*p;i<=n;i+=p)//将p的倍数都标记为合数
a[i]=1;
while(a[++p])/empty/;//下一个未标记的索引值是素数
}
while(a[n])n—;//反向循环找到最大的素数
return n;//将它返回
}
如果将其中的Int8Array()构造函数替换成传统的Array()构造函数,sieve()函数依然可用,但是,处理过程中可能需要2~3倍的时间,而且需要更多的内存来存储大的参数n的值。当处理图形相关的数字或者数学相关的数字的时候,类型化数组也很有用:
var matrix=new Float64Array(9);//一个3×3的矩阵
var 3dPoint=new Int16Array(3);//3D空间中的一点
var rgba=new Uint8Array(4);//一个4字节的RGBA像素值
var sudoku=new Uint8Array(81);//一个9×9的数独板
使用JavaScript的中括号表示法可以获取和设置类型化数组的单个元素。然而,类型化数组自己还定义了一些用于设置和获取整个数组内容的方法。其中set()方法用于将一个常规或者类型化数组复制到一个类型化数组中:
var bytes=new Uint8Array(1024)//1KB缓冲区
var pattern=new Uint8Array([0,1,2,3]);//一个4个字节的数组
bytes.set(pattern);//将它们复制到另一个数组的开始
bytes.set(pattern,4);//在另一个偏移量处再次复制它们
bytes.set([0,1,2,3],8);//或直接从一个常规数组复制值
类型化数组还有一个subarray()方法,调用该方法返回部分数组内容:
var ints=new Int16Array([0,1,2,3,4,5,6,7,8,9]);//10个短整数
var last3=ints.subaarray(ints.length-3,ints.length);//最后三个
last3[0]//=>7:等效于ints[7]
要注意的是,subarray()方法不会创建数据的副本。它只是直接返回原数组的其中一部分内容:
ints[9]=-1;//改变原数组中的元素值,然后……
last3[2]//=>-1:同时也改变子数组中的元素值
subarray()方法返回当前数组的一个新视图,这一事实,说明了类型化数组中某些重要的概念:它们都是基本字节块的视图,称为一个ArrayBuffer。每个类型化数组都有与基本缓冲区相关的三个属性:
last3.buffer//=>返回一个ArrayBuffer对象
last3.buffer==ints.buffer//=>true:两者都是同一缓冲区上的视图
last3.byteOffset//=>14:此视图从基本缓冲区的第14个字节开始
last.bytelength//=>6:该视图是6字节(3个16位整数)长
ArrayBuffer对象自身只有一个返回它长度的属性:
last3.byteLength//=>6:此视图6个字节长
last3.buffer.byteLength//=>20:但是基本缓冲区长度有20个字节长
ArrayBuffer只是不透明的字节块。可以通过类型化数组获取这些字节,但是ArrayBuffer自己并不是一个类型化数组。然而,要注意的是:可以像对任意JavaScript对象那样,使用数字数组索引来操作ArrayBuffer。但是,这样做并不能赋予访问缓冲区中字节的权限:
var bytes=new Uint8Array(8);//分配8个字节
bytes[0]=1;//把第一个字节设置为1
bytes.buffer[0]//=>undefined:缓冲区没有索引值0
bytes.buffer[1]=255;//试着错误地设置缓冲区中的字节
bytes.buffer[1]//=>255:这只设置一个常规的JS属性
bytes[1]//=>0:上面这行代码并没有设置字节
可以直接使用ArrayBuffer()构造函数来创建一个ArrayBuffer,有了ArrayBuffer对象后,可以在该缓冲区上创建任意数量的类型化数组视图:
var buf=new ArrayBuffer(1024*1024);//1MB
var asbytes=new Uint8Array(buf);//视为字节
var asints=new Int32Array(buf);//视为32位有符号整数
var lastK=new Uint8Array(buf,1023*1024);//视最后1KB为字节
var ints2=new Int32Array(buf,1024,256);//视第二个1KB为256个整数
类型化数组允许将同样的字节序列看成8位、16位、32位或者64位的数据块。这里提到了“字节顺序”:字节组织成更长的字的顺序。为了高效,类型化数组采用底层硬件的原生顺序。在低位优先(little-endian)系统中,ArrayBuffer中数字的字节是按照从低位到高位的顺序排列的。在高位优先(big-endian)系统中,字节是按照从高位到低位的顺序排列的。可以使用如下代码来检测系统的字节顺序:
//如果整数0x00000001在内存中表示成:01 00 00 00,
//则说明当前系统是低位优先系统
//相反,在高位优先系统中,它会表示成:00 00 00 01
var little_endian=new Int8Array(new Int32Array([1]).buffer)[0]===1;
如今,大多数CPU架构都采用低位优先。然而,很多的网络协议以及有些二进制文件格式,是采用高位优先的字节顺序的。22.6节将会介绍如何使用ArrayBuffer来存储从文件中读取到的或者是从网络中下载下来的字节。当这么做的时候,要考虑平台的字节顺序。通常,处理外部数据的时候,可以使用Int8Array和Uint8Array将数据视为一个单字节数组,但是,不应该使用其他的多字节字长的类型化数组。取而代之的是可以使用DataView类,该类定义了采用显式指定的字节顺序从ArrayBuffer中读/写其值的方法:
var data;//假设这是一个来自网络的ArrayBuffer
var view=DataView(data);//创建一个视图
var int=view.getInt32(0);//从字节0开始的,高位优先顺序的32位有符号int整数
int=view.getInt32(4,false);//接下来的32位int整数也是高位优先顺序的
int=view.getInt32(8,true)//接下来的4个字节视为低位优先顺序的有符号int整数
view.setInt32(8,int,false);//以高位优先顺序格式将数字写回去
DateView为8种不同的类型化数组分别定义了8个get方法。名字诸如:getInt16()、getUint32()以及getFloat64()。这些方法的第一个参数指定了ArrayBuffer中的字节偏移量,表示从哪个值开始获取。除了getInt8()方法和getUint8()方法之外,其他所有getter方法都接受第二个可选的布尔类型的参数。如果忽略该参数或者将该参数设置为false,则表示采用高位优先字节顺序;反之,则采用低位优先字节顺序。
DateView同时也定义了8个对应的set方法,用于将值写入到那个基本缓存区ArrayBuffer中。这些方法的第一个参数指定偏移量,表示从哪个值开始写。第二个参数指定要写入的值。除了setInt8()方法和setUint8()方法之外,其他每个方法都接受第三个可选的参数。如果忽略该参数或者将该参数设置为false,则将值以高位优先字节顺序写入;反之,则采用低位优先字节顺序写入。
22.6 Blob
Blob是对大数据块的不透明引用或者句柄。名字来源于SQL数据库,表示“二进制大对象”(Binary Large Object)。在JavaScript中,Blob通常表示二进制数据,不过它们不一定非得是大量数据:Blob也可以表示一个小型文本文件的内容。Blob是不透明的:能对它们进行直接操作的就只有获取它们的大小(以字节为单位)、MIME类型以及将它们分割成更小的Blob:
var blob=…//后面会介绍如何获取一个Blob
blob.size//Blob大小(以字节为单位)
blob.type//Blob的MIME类型,如果未知的话,则是""
var subblob=blob.slice(0,1024,"text/plain");//Blob中前1KB视为文本
var last=blob.slice(blob.size-1024,1024);//Blob中最后1KB视为无类型
Web浏览器可以将Blob存储到内存中或者磁盘上,Blob可以表示非常大的数据块(比如视频文件),如果事先不用slice()方法将它们分割成为小数据块的话,无法存储在主内存中。正是因为Blob可以表示非常大的数据块,并且它可能需要磁盘的访问权限,所以使用它们的API是异步的(在Worker线程中有提供相应的同步版本)。
Blob本身并没有多大意思,但是它们为用于二进制数据的大量JavaScript API提供重要的数据交换机制。图22-2展示了如何从Web、本地文件系统、本地数据库或者其他的窗口和Worker中对Blob进行读写。不仅如此,图22-2还展示了如何以文本、类型化数组或者URL的形式读取Blob内容。
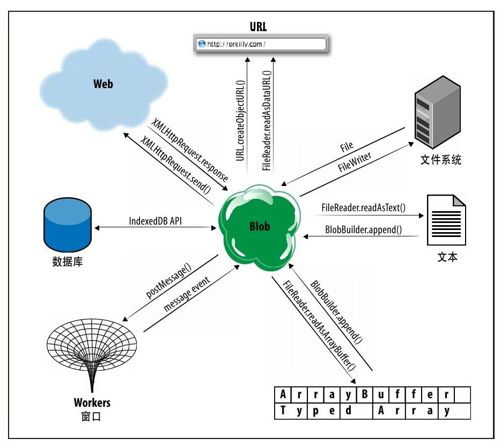
图 22-2 Blob以及使用Blob的API
在使用Blob之前,首先必须要获取Blob。获取Blob有很多方法,其中有些方法中涉及的API之前已经介绍过了,而有些API则会在本章后续部分做相应的介绍:
·Blob支持结构性复制算法(参见22.2节的“结构性复制”),这就意味着,可以通过message事件从其他窗口或者线程中获取Blob。参见22.3节和22.4节。
·可以从客户端数据库中获取Blob,这部分会在22.8节进行相应介绍。
·可以使用XHR2标准中的尖端特性,通过脚本化HTTP从Web中下载Blob。这部分内容会在22.6.2节进行相应介绍。
·可以使用BlobBuilder对象来从字符串、ArrayBuffer对象(参见22.5节)以及其他Blob来创建自己的Blob。BlobBuilder对象将在22.6.3节进行相应介绍。
·最后也是最重要的就是,客户端JavaScript的File对象是Blob的子类:File对象其实就是有名字和修改日期的Blob数据。通过<input type="file">元素以及拖放API可以获取File对象,这部分将在22.6.1节进行相应介绍。在22.7节中会介绍,File对象还可以使用文件系统API来获取。
一旦获取了Blob,就可以对其进行很多的操作,其中包括上述提到的一些操作:
·可以使用postMessage()方法向其他窗口或者Worker发送一个Blob。参见22.3节和22.4节。
·可以将Blob存储到客户端数据库中。参见22.8节。
·可以通过将Blob传递给一个XMLHttpRequest对象的send()方法,来将该Blob上传到服务器。例18-9介绍了相关的文件上传的例子(要记住,File对象就是特殊的类型的Blob)。
·可以使用createObjectURL()函数获取一个特殊的blob://URL,该URL代表一个Blob的内容,然后,将其和DOM或者CSS结合使用。22.6.4节会对其进行相应介绍。
·可以使用FileReader对象来异步地(或者在Worker线程中同步地)将一个Blob内容抽取成一个字符串或者ArrayBuffer。22.6.5节将展示该基本的技术。
·可以使用将在22.7节中介绍的文件系统API和FileWriter对象,来实现将一个Blob写入到一个本地文件中。
下面几节将介绍如何简单地获取和使用Blob。涉及本地文件系统和客户端数据库的更为复杂的技术将在它们各自的章节中做相应介绍。
22.6.1 文件作为Blob
<input type="file">元素最初是用于在HTML表单中实现文件上传的。浏览器总是很小心地实现该元素,目的是为了只允许上传用户显式选择的文件。脚本是无法将该元素的value属性设置成一个文件名的,这样它们就无法实现将用户电脑上任意的文件进行上传。最近,浏览器提供商已经对该元素进行了扩展,允许客户端可以访问用户选择的文件了。要注意的是,允许客户端脚本读取选择的文件内容不会引发安全问题,它和允许这些文件上传到服务器的安全级别是一样的。
在支持本地文件访问的浏览器中,<input type="file">元素上的files属性则是一个FileList对象。该对象是一个类数组对象,其元素要么是0,要么是用户选择的多个File对象。一个File对象就是一个Blob,除此之外,还多了name和lastModifiedDate属性:
<script>//输出选中的文件列表相关的信息
function fileinfo(files){
for(var i=0;i<files.length;i++){//files是一个类数组对象
var f=files[i];
console.log(f.name,//只是名字:没有路径
f.size,f.type,//size和type是Blob的属性
f.lastModifiedDate);//另外一个File对象的属性
}
}
</script>
<!—允许选择多个图片文件并将它们传递给fileinfo()方法—>
<input type="file"accept="image/*"multiple onchange="fileinfo(this.files)"/>
能够显示选中文件的名字、类型和大小并没有多大意义。22.6.4节和22.6.5节将会介绍如何真正操作文件内容。
除了通过<input>元素来选择文件之外,用户还可以通过将本地文件放到浏览器中来给予脚本访问它们的权限。当应用接收到一个drop事件,事件对象的dataTransfer.files属性就会和放入的FileList进行关联(如果有的话)。拖放API在17.7节中介绍过,例22-10会展示如何在文件中使用该API。
22.6.2 下载Blob
第18章介绍了使用XMLHttpRequest对象脚本化HTTP,同时还介绍了XMLHttpRequest Level 2(XHR2)标准草案中定义的一些新特性。截至撰写本书时,XHR2定义了一种将URL指定的内容以Blob的形式下载下来,但是浏览器还不支持它。由于代码还无法测试(浏览器不支持),因此,本节只简单地介绍操作Blob的XHR2 API。
例18-2介绍过如何将URL指定的内容以纯文本的形式下载下来,与之不同的是,例22-9展示了从Web下载一个Blob的基本技术:
例22-9:使用XMLHttpRequest下载Blob
//以Blob的形式获取URL指定的内容,并将其传递给指定的回调函数
//这里的代码没有测试过:因为截至撰写本书时,没有一个浏览器支持该API
function getBlob(url,callback){
var xhr=new XMLHttpRequest();//创建一个新的XHR对象
xhr.open("GET",url);//指定要获取内容的URL
xhr.responseType="blob"//以Blob的形式
xhr.onload=function(){//onload比onreadystatechange更容易
callback(xhr.response);//将Blob传递给回调函数
}
//注意,这里是.response,不是.responseText
xhr.send(null);//发送请求
}
如果要下载的数据量很大,想要在下载过程中显示一个进度条,那么可以使用onprogress事件处理程序,这部分将在22.6.5节中进行相应介绍。
22.6.3 构造Blob
Blob通常表示来自诸如本地文件、URL以及数据库外部资源的大数据块。然而,有的时候,Web应用想要创建的Blob,并将其上传到Web上或者存储到一个文件或者数据库中或者传递给另一个线程。要从自己的数据来创建Blob,可以使用BlobBuilder:
//创建一个新的BlobBuilder
var bb=new BlobBuilder();//把一个字符串追加到Blob中,并以一个NUL字符标记为字符串结束
bb.append("This blob contains this text and 10 big-endian 32-bit signed ints.");
bb.append("\0");//NUL结束符表示字符串的结束
//将数据存储到ArrayBuffer中
var ab=new ArrayBuffer(4*10);
var dv=new DataView(ab);
for(var i=0;i<10;i++)dv.setInt32(i*4,i);//将ArrayBuffer添加到Blob中
bb.append(ab);//现在从builder中获取Blob,并指定MIME类型
var blob=bb.getBlob("x-optional/mime-type-here");
在本节一开始介绍过Blob有一个slice()方法,用于将Blob拆分成多个片段。通过将多个Blob传递给BlobBuilder的append()方法可以实现将多个Blob合并在一起。
22.6.4 Blob URL
前面章节介绍过如何获取或者创建Blob。现在来介绍如何对获取的或者创建的Blob进行操作。其中最简单的就是可以创建一个URL来指向该Blob。随后,可以以一般的URL形式在任何地方使用该URL:在DOM中,在样式表中,甚至可以作为XMLHttpRequest的目标。
使用createObjectURL()函数可以创建一个Blob URL。截至撰写本书时,标准草案和Firefox 4都是将该函数放在全局对象中,命名为URL,Chrome和Webkit浏览器则在URL前加上了前缀,命名为webkitURL。早期标准(以及早期浏览器的实现)直接将该函数放在Window对象上。可以使用如下代码,实现跨浏览器创建Blob URL:
var getBlobURL=(window.URL&&URL.createObjectURL.bind(URL))||
(window.webkitURL&&webkitURL.createObjectURL.bind(webkitURL))||
window.createObjectURL;
Web Workers也允许使用该API和访问同样的URL(或者webkitURL)对象上同样的函数。
传递一个Blob给createObjectURL()方法会返回一个URL(以普通字符串形式)。该URL以blob://开始,紧跟着是一小串文本字符串,该字符串用不透明的唯一标识符来标识Blob。要注意的是,这和data://URL是不同的,data://URL会对内容进行编码。Blob URL只是对浏览器存储在内存中或者磁盘上的Blob的一个简单引用。blob://URL和file://URL也是不同的,file://URL直接指向本地文件系统中的一个文件,仅暴露了文件的路径、浏览目录的许可等,除此之外任何内容都会带来安全问题的。
例22-10展示了两种重要的技术。首先,它实现了一个和文件相关的用于监听拖放事件的“拖放目标区域”。然后,当用户将一个或多个文件拖放到该目标区域中时,它会使用createObjectURL()方法来为每个文件获取一个URL,然后创建<img>元素来展示URL引用图片的缩略图。
例22-10:用Blob URL来显示一个拖放的图片文件
<!DOCTYPE html><html><head><script>//截至撰写本书时,Firefox和Webkit在//createObjectURL()函数的命名上意见不统一var getBlobURL=(window.URL&&URL.createObjectURL.bind(URL))||(window.webkitURL&&webkitURL.createObjectURL.bind(webkitURL))||window.createObjectURL;var revokeBlobURL=(window.URL&&URL.revokeObjectURL.bind(URL))||(window.webkitURL&&webkitURL.revokeObjectURL.bind(webkitURL))||window.revokeObjectURL;//在文档载入后,在droptarget元素上添加事件处理程序//以便它可以处理文件的拖放window.onload=function(){//查询要向其中添加处理程序的元素var droptarget=document.getElementById("droptarget");//当用户开始拖放文件经过droptarget元素的时候,将其高亮显示droptarget.ondragenter=function(e){//如果拖的不是文件,则忽略它//在实现的时候,使用HTML5的dropzone属性会更加简单var types=e.dataTransfer.types;if(!types||(types.contains&&types.contains("Files"))||(types.indexOf&&types.indexOf("Files")!=-1)){droptarget.classList.add("active");//高亮显示droptargetreturn false;//阻止默认事件处理}};//如果用户移出该区域,则取消高亮显示拖放区域droptarget.ondragleave=function(){droptarget.classList.remove("active");};//此处理程序只是通知浏览器继续发送提醒droptarget.ondragover=function(e){return false;};//当用户放下文件时,就获取它们的URL,并显示对应的缩略图droptarget.ondrop=function(e){var files=e.dataTransfer.files;//放下的文件for(var i=0;i<files.length;i++){//循环每个文件var type=files[i].type;if(type.substring(0,6)!=="image/")//不是图片则忽略continue;var img=document.createElement("img");//创建<img>元素img.src=getBlobURL(files[i]);//在<img>元素上使用Blob URLimg.onload=function(){//图片载入的时候this.width=100;//调整图片大小并document.body.appendChild(this);//将它添加到文档中revokeBlobURL(this.src);//但是要避免内存泄漏}}droptarget.classList.remove("active");//取消高亮显示droptarget区域return false;//处理完毕}};</script><style>/*给文件拖放目标区域定义简单的样式*/#droptarget{border:solid black 2px;width:200px;height:200px;}#droptarget.active{border:solid red 4px;}</style></head><body><!--文档只定义文件拖放目标区域--><div id="droptarget">Drop Image Files Here</div></body></html>
Blob URL和创建它们的脚本拥有同样的源(参见13.6.2节)。这使得它们比file://URL更加灵活,由于file://URL是非同源的,因此要在Web应用中使用它们相对比较麻烦。Blob URL只有在同源的文档中才是有效的。比如,如果将一个Blob URL通过postMessage()传递给一个非同源窗口,则该URL对于该窗口来说是没有任何意义的。
Blob URL并不是永久有效的。一旦用户关闭了或者离开了包含创建Blob URL脚本的文档,该Blob URL就失效了。比如,将Blob URL保存到本地存储器中,然后当用户开始一个新的Web应用会话的时再使用它,这是不可能的。
可以通过调用URL.revokeObjectURL()方法(或者webkitURL.revokeObjectURL()方法),来手动让Blob URL失效,这在例22-10中已经使用到了。之所以提供这样的方式,是因为这和内存管理问题有关。一旦展示了图片的缩略图之后,Blob就不再需要了,应当回收它。但是,如果Web浏览器正维护创建的Blob和Blob URL之间的映射关系,那么即使该Blob已经不用了,也不会被回收。JavaScript解释器无法跟踪字符串的使用情况,如果URL仍然是有效的,那么它只能认为该URL可能还在用。这就意味着,在手动撤销该URL之前,是不会将其回收的。例22-10使用的是都是本地文件,不需要对其进行清除,但是,不难想象,如果通过BlobBuilder创建的Blob都是存储在内存中,或者通过XMLHttpRequest下载的Blob是存储在一个临时文件中的话,那么一定会有严重的内存管理问题。
blob://URL模式被显式地设计成像一个简化的http://URL那样工作,并且,当请求一个blob://URL的时候,要求浏览器像迷你的HTTP服务器那样做出响应。如果请求的Blob URL已经失效,浏览器必须返回一个404无法找到的状态码。如果请求的Blob URL来自另外的源,那么浏览器必须返回403禁止访问的状态码。Blob URL只允许通过GET请求获取,并且一旦获取成功,浏览器必须返回一个HTTP 200 OK的状态码,同时返回一个使用Blob type属性的Content-Type头部信息。由于Blob URL的工作方式和简单的HTTP URL一致,因此可以通过XMLHttpRequest将它们指定的内容“下载”下来。(然而,下一节会介绍如何使用FileReader对象更直接地读取Blob的内容。)
22.6.5 读取Blob
到目前为止,介绍了Blob是不透明的大数据块,只允许通过Blob URL来间接地访问它们的内容。FileReader对象允许访问Blob中的字符或者字节,可以将它视为是BlobBuilder对应的一个对象。(其实这个名字叫BlobReader会更好,因为它只适用于Blob而不是文件。)由于Blob可能会是存储在文件系统中的大对象,因此读取它们的API是异步的,和XMLHttpRequest API很像。尽管Worker线程也可以使用异步的API,但在Worker线程中有对应的同步版本的API,叫FileReaderSync。
要使用FileReader,首先要通过FileReader()构造函数创建一个实例。然后,定义一个事件处理程序。通常会给load事件、error事件以及可能会给progress事件定义处理程序。可以使用onload、onerror和onprogress或者使用标准的addEventListener()方法来定义处理程序。FileReader对象还会触发loadstart事件、loadend事件以及abort事件,这些事件和同名的XMLHttpRequest事件一样:参见18.1.4节。
创建了FileReader对象并注册了对应的事件处理程序之后,必须要将要读取的Blob传递给下面这4个方法其中之一:readAsText()、readAsArrayBuffer()、readAsDataURL()以及readAsBinaryString()。(当然了,也可以先调用其中的方法,然后再注册事件处理程序——22.4节介绍过JavaScript天生就是单线程的,这意味着除非等到调用的函数返回以及浏览器回到事件循环阶段,否则永远不会调用事件处理程序。)这些方法中前两个方法是非常重要的,这里会对它们做相应介绍。这里每个方法都接受Blob作为第一个参数。readAsText()方法还接受第二个可选的参数,该参数指定文本的编码方式。如果不传递该参数,则自动会采用ASCII和UTF-8文本(也可以通过标记字节顺序的UTF-16文本或者BOM)处理。
在FileReader读取指定的Blob的时候,它会更新它的readyState属性。该属性值开始是0,表示还未读取任何信息。当读取到一些数据的时候,它会变成1,而当数据完全读取完毕后,该值会变成2。它的result属性包含部分或者完整的结果(字符串或者ArrayBuffer形式)。一般不会直接轮询state和result属性,而是在onprogre ss或者onload事件处理程序中使用它们。
例22-11展示了如何使用readAsText()方法读取用户选择的本地文本文件。
例22-11:使用FileReader读取文本文件
<script>//读取指定文本文件并将内容显示在下面的<pre>元素中
function readfile(f){
var reader=new FileReader();//创建一个FileReader对象
reader.readAsText(f);//读取该文件
reader.onload=function(){//定义一个事件处理程序
var text=reader.result;//这是文件内容
var out=document.getElementById("output");//查询output元素
out.innerHTML="";//清除该元素内容
out.appendChild(document.createTextNode(text));//显示文件内容
}
reader.onerror=function(e){//如果发生了错误
console.log("Error",e);//将错误以日志形式输出
};
}
</script>
Select the file to display:
<input type="file"onchange="readfile(this.files[0])"></input>
<pre id="output"></pre>
readAsArrayBuffer()方法和readAsText()方法类似,不同的是,它额外多做了一些处理将结果以ArrayBuffer形式返回,而不是字符串形式。例22-12展示了如何使用readAsArrayBuffer()方法,以高位优先字节顺序读取文件的前4个字节。
例22-12:读取文件的前4个字节
<script>//检测指定的blob的前4个字节
//如果这个幻数标识文件的类型,那么就将其异步地设置成Blob的属性
function typefile(file){
var slice=file.slice(0,4);//只读取文件起始部分
var reader=new FileReader();//创建一个异步的FileReader对象
reader.readAsArrayBuffer(slice);//读取文件片段
reader.onload=function(e){
var buffer=reader.result;//ArrayBuffer形式的结果
var view=new DataView(buffer);//访问结果中的字节内容
var magic=view.getUint32(0,false);//以高位优先字节顺序,读取4个字节
switch(magic){//从中检测文件类型
case 0x89504E47:file.verified_type="image/png";break;
case 0x47494638:file.verified_type="image/gif";break;
case 0x25504446:file.verified_type="application/pdf";break;
case 0x504b0304:file.verified_type="application/zip";break;
}
console.log(file.name,file.verified_type);
};
}
</script>
<input type="file"onchange="typefile(this.files[0])"></input>
在Worker线程中,可以使用FileReaderSync取代FileReader。同步版本的API同样定义了readAsText()方法和readAsArrayBuffer()方法,它们和异步版本的方法接收同样的参数。不同的地方是同步方法会阻塞住,一直到操作完成并以字符串或者ArrayBuffer形式返回结果,并且不需要使用事件处理程序。下面的例22-14就使用FileReaderSync。
22.7 文件系统API
22.6.5 节介绍过使用FileReader类来读取用户选择的文件或者任意Blob的内容。其中文件的类型和Blob类型是在一份名为文件API的标准草案中定义的,另外还有一份比文件API更新的标准草案,它允许Web应用对一个私有的文件系统“沙箱”进行写文件、读文件、创建目录、列出目录等一些操作。截至撰写本书时,只有Google的Chrome浏览器实现了此文件系统API,尽管此API相比于本章介绍的其他API,甚至都还不够稳定,但是它依然是非常强大的,并且对本地存储器是尤为重要的,因此这里将会它进行介绍。本节会介绍基本的文件系统操作,但是不会对API所有的特性都一一做介绍。由于此API很新还未趋于稳定,因此在第三部分也不做介绍。
操作本地文件系统中的文件分为以下几步:首先,必须要获取一个表示本地文件系统的对象。在Worker线程中可以使用一个同步API来获取该对象,相应地在主线程中也有对应的异步API:
//同步地获取一个文件系统。传递文件系统的有效期和大小参数
//返回一个文件系统对象或者抛出错误
var fs=requestFileSystemSync(PERSISTENT,1024*1024);//异步版本的API需要使用回调函数来处理成功和失败的情况
requestFileSystem(TEMPORARY,//有效期
5010241024,//大小:50MB
function(fs){//fs就是该文件系统对象
//这里使用fs进行一些操作
},
function(e){//这里e是一个错误对象
console.log(e);//或者以其他方式处理它
});
不论是同步版本的API还是异步版本的API,都可以指定文件系统的有效期和大小。一个永久的(PERSISTENT)的文件系统适用于想要永久存储用户数据的Web应用。除非用户显式要求删除这些数据,否则浏览器永远都不会删除这些数据。一个临时的(TEMPORARY)文件系统适用于想要缓存数据,在浏览器删除该文件系统任然可以操作这些数据的Web应用。文件系统的大小是以字节为单位指定的,并且其大小应该是一个保证足够存储所需数据的合理上限[5]。浏览器可能会强制限额。
使用这些方法获取的文件系统依赖于包含它的文档源。所有同源(主机、端口和协议)的文档或者Web应用共享一个文件系统。两个非同源的文档或者Web应用拥有完全独立的文件系统。同时,文件系统和用户硬盘上其他的文件也是相互隔离的:Web应用是无法拥有整个硬盘的root权限的,或者说无法访问任意的文件。
要注意的是,这些函数名字中都有"request"。第一次调用的时候,浏览器在创建一个文件系统并授权[6]前,可能会询问用户是否允许。一旦用户允许了,接下来调用这些函数的时候,就只会返回一个表示已有本地文件系统的对象。
通过上述方法获取到的文件系统对象有一个root属性,该属性指向文件系统的根目录。这是一个DirectoryEntry对象,并且它可能还有嵌套的目录,这些嵌套的目录也用DirectoryEntry对象表示。文件系统的每个目录中包含的文件都用FileEntry对象表示。DirectoryEntry对象定义一些通过路径名(pathname)(如果指定的名字不存在,它们会根据指定的情况来创建新的目录或者文件)获取DirectoryEntry对象和FileEntry对象的方法。DirectoryEntry对象还定义了一个createReader()工厂方法,用于返回一个列出目录内容列表的DirectoryReader对象。
FileEntry类定义一个获取表示文件内容的File对象(一个Blob)的方法。然后,可以使用FileReader对象(22.6.5节介绍过)读取该文件。除此之外,FileEntry还定义一个方法,该方法返回一个FileWriter对象,用该对象可以将内容写入到文件中。
通过该API读取或者写入文件分为如下几步:首先要获得文件系统对象。然后通过该对象的根目录来查找(也可以创建)需要的文件的FileEntry对象。然后使用FileEntry对象获取File或者FileWriter对象来进行读/写操作。如果在使用异步API的情况下,这几步过程会更加复杂:
//读取文本文件"hello.txt",并将其内容以日志的形式输出
//由于使用了异步API,因此出现了4层函数嵌套
//此例子不包括任何错误回调处理
requestFileSystem(PERSISTENT,1010241024,function(fs){//获取文件系统
fs.root.getFile("hello.txt",{},function(entry){//获取FileEntry对象
entry.file(function(file){//获取File对象
var reader=new FileReader();
reader.readAsText(file);
reader.onload=function(){//获取文件内容
console.log(reader.result);
};
});
});
});
例22-13是一个更加完整的例子,涵盖了很多内容。它展示了如何使用异步API读文件、写文件、删除文件、创建目录以及列出目录。
例22-13:使用异步文件系统API
/*
*这些函数在Google Chrome10.0开发版中都测试过了
*启动Chrome的时候需要开启这些选项:
*—unlimited-quota-for-files:启用文件系统访问
*—allow-file-access-from-files:允许通过file://URL进行测试
*/
//这里使用的大部分异步函数都接受一个可选的错误回调参数
//这里的回调函数只是简单地将错误输出
function logerr(e){console.log(e);}//requestFileSystem()方法创建了一个在沙箱环境中的本地文件系统,
//并且只有同源的应用才可以访问
//可以在该文件系统中进行文件读/写,但是只能限定在该沙箱中
//不能访问其他的文件系统
var filesystem;//假设在调用下面的函数之前,已经初始化完毕
requestFileSystem(PERSISTENT,//或者采用用于缓存文件的临时(TEMPORARY)文件系统
1010241024,//10MB
function(fs){//完成后,调用此方法
filesystem=fs;//将文件系统保存到一个全局变量中
},
logerr);//如果发生错误则调用此方法
//以文本形式读取指定文件的内容,并将它们传递给回调函数
function readTextFile(path,callback){//根据指定的文件名,调用getFile()获取相应的FileEntry对象
filesystem.root.getFile(path,{},function(entry){//使用FileEntry调用此方法来获得文件
//现在调用FileEntry.file()方法获取File对象
entry.file(function(file){//file就表示File对象
var reader=new FileReader();//创建一个FileReader对象
reader.readAsText(file);//读取文件
reader.onload=function(){//当读取成功时
callback(reader.result);//将其内容传递给回调函数
}
reader.onerror=logerr;//记录调用readAsText()时发生的错误
},logerr);//记录调用file()方法时发生的错误
},
logerr);//记录调用getFile()时发生的错误
}
//将指定的内容添加到指定路径的文件中,
//如果指定路径的文件不存在,则使用该文件名创建一个新的文件
//完成之后,调用回调函数
function appendToFile(path,contents,callback){//filesystem.root指根目录
filesystem.root.getFile(//获取FileEntry对象
path,//想要获取的文件的名字和路径
{create:true},//如果不存在则创建一个
function(entry){//完成之后调用此函数
entry.createWriter(//为该文件创建一个FileWriter对象
function(writer){//创建完成之后调用此函数
//默认情况下,从文件最开始开始写入
//这里指定从文件最后开始写
writer.seek(writer.length);//移动到文件最后
//将文件内容转换成Blob
//contents参数可以是字符串、Blob或者ArrayBuffer
var bb=new BlobBuilder()
bb.append(contents);
var blob=bb.getBlob();//现在将该Blob写入到文件中
writer.write(blob);
writer.onerror=logerr;//记录调用writer()方法时发生的错误
if(callback)//如果有回调函数
writer.onwrite=callback;//则成功的时候调用
},
logerr);//记录调用createWriter()方法时发生的错误
},
logerr);//记录调用getFile()方法时发生的错误
}
//删除指定的文件,完成后调用指定的回调函数
function deleteFile(name,callback){
filesystem.root.getFile(name,{},//根据指定的名字获取相应的FileEntry对象
function(entry){//entry就是该FileEntry对象
entry.remove(callback,//删除FileEntry对象
logerr);//或者记录调用remove()方法时发生
//的错误
},
logerr);//记录调用getFile()方法时发生的错误
}
//根据指定的名字创建一个新的目录
function makeDirectory(name,callback){
filesystem.root.getDirectory(name,//要创建的目录的名字
{//选项
create:true,//如果不存在,则创建
exclusive:true//如果存在,则报错
},
callback,//完成后调用此方法
logerr);//记录错误
}
//读取指定目录的内容,并以字符串数组的形式将内容传递给指定的回调函数
function listFiles(path,callback){//如果指定的内容不存在,则列出根目录
//否则,根据名字查找目录并将目录内容列出来(或者如果发生错误就记录错误)
if(!path)getFiles(filesystem.root);
else filesystem.root.getDirectory(path,{},getFiles,logerr);
function getFiles(dir){//此方法在之前也使用过
var reader=dir.createReader();//一个DirectoryReader对象
var list=[];//用来存储文件名
reader.readEntries(handleEntries,//将每项都传递给下面的函数
logerr);//或者记录错误
//读取目录可以分成很多步
//必须一直调用readEntries()方法直到获取到空数组为止
//完成之后可以将整个列表传递给回调函数
function handleEntries(entries){
if(entries.length==0)callback(list);//完成
else{//否则,将这些项添加到列表中,并继续读取
//此类数组对象包含FileEntry对象
//这里需要挨个获取它们的名字
for(var i=0;i<entries.length;i++){
var name=entries[i].name;//获取名字
if(entries[i].isDirectory)name+="/";//标记目录
list.push(name);//添加到列表中
}
//获取下一批项
reader.readEntries(handleEntries,logerr);
}
}
}
}
在Worker线程中操作文件和文件系统会更加容易些,由于Worker线程中都是阻塞调用,因此可以使用同步的API。例22-14定义了与例22-13同样的文件系统工具函数,不同的是它使用同步的API,代码也更加精简。
例22-14:同步文件系统API
//在Worker线程中使用同步API实现的文件系统工具函数
var filesystem=requestFileSystemSync(PERSISTENT,1010241024);
function readTextFile(name){//从根DirectoryEntry中获取FileEntry对象,再从FileEntry中获取File
var file=filesystem.root.getFile(name).file();//使用同步FileReaderAPI读取
return new FileReaderSync().readAsText(file);
}
function appendToFile(name,contents){//从根DirectoryEntry中获取FileEntry对象,再从FileEntry中获取FileWriter
var writer=filesystem.root.getFile(name,{create:true}).createWriter();
writer.seek(writer.length);//从文件最后开始
var bb=new BlobBuilder()//将文件内容构造进Blob中
bb.append(contents);
writer.write(bb.getBlob());//将Blob写入文件中
}
function deleteFile(name){
filesystem.root.getFile(name).remove();
}
function makeDirectory(name){
filesystem.root.getDirectory(name,{create:true,exclusive:true});
}
function listFiles(path){
var dir=filesystem.root;
if(path)dir=dir.getDirectory(path);
var lister=dir.createReader();
var list=[];
do{
var entries=lister.readEntries();
for(var i=0;i<entries.length;i++){
var name=entries[i].name;
if(entries[i].isDirectory)name+="/";
list.push(name);
}
}while(entries.length>0);
return list;
}
//允许主线程通过发送消息来使用这些工具函数
onmessage=function(e){//消息是如下形式的对象
//{function:"appendToFile",args:["test","testing,testing"]}
//根据指定的args调用指定的函数
//再将结果消息发送回去
var f=self[e.data.function];
var result=f.apply(null,e.data.args);
postMessage(result);
};
22.8 客户端数据库
传统的Web应用架构是客户端包含HTML、CSS和JavaScript,服务器端包含一个数据库。而通过强大的HTML5 API可以实现客户端数据库。这些不是通过网络访问服务器端数据库的客户端API,而是真正存储在用户电脑上的客户端数据库,通过浏览器中的JavaScript代码可以直接访问的。
20.1 节介绍过的Web存储API可以认为是一种简单的数据库,用于将简单的键/值对形式的数据持久化下来。但是,除此之外,还有两个真正的客户端数据库API。其中一个叫Web SQL数据库,它是支持基本SQL查询的简单关系数据库。Chrome、Safari和Opera已经实现了该API,但是Firefox和IE还没有,并且看起来也不打算实现了。官方标准中关于此API的工作已经停止了,此功能齐全的SQL数据库或许永远也不会成为官方标准,哪怕是作为Web平台非官方的交互特性恐怕也不大可能。
目前官方标准已经将注意力转移到了另一种数据库API,叫做:IndexedDB。介绍关于此API的详细细节还为时过早(本书第四部分没有对其做相应介绍),但是Firefox 4和Chrome 11已经实现了此API,同时,本节也包含了一些例子,展示了IndexedDB API中一些最重要的特性。
IndexedDB是一个对象数据库,而不是关系数据库,它比支持SQL查询的数据库简单多了。但是,它要比Web存储API支持的键/值对存储更强大、更高效、更健壮。与Web存储和文件系统API一样,IndexedDB数据库的作用域也是限制在包含它们的文档源中:两个同源的Web页面互相之间可以访问对方的数据,但是非同源的页面则不行。
每个源可以有任意数目的IndexedDB数据库。但是每个数据库的名字在该源下必须是唯一的。在IndexedDB API中,一个数据库其实就是一个命名对象存储区(object store)的集合。顾名思义,对象存储区自然存储的是对象(也可以存储任意可以复制的值——参见22.2节的“结构性复制”)。每个对象都必须有一个键(key),通过该键实现在存储区中进行该对象的存储和获取。键必须是唯一的——同一个存储区中的两个对象不能有同样的键——并且它们必须是按照自然顺序存储,以便于查询。JavaScript中的字符串、数字和日期对象都可以作为该键。当把一个对象存储到IndexedDB数据库中时,IndexedDB数据库可以为该对象自动生成一个唯一的键。不过,通常情况下,存储一个对象的时候,该对象就已经包含一个属性,该属性适合用做键。这种情况下,在创建一个对象存储的时候,可以为该属性指定一条“键路径”。从概念上来说,键路径其实就是一个值,用于告诉数据库如何从一个对象中抽取出该对象的键。
除了通过键值从一个对象存储区中获取对象以外,可能还想要能够基于该对象中的其他属性值进行查询。要实现该功能,可以通过在对象存储区上定义索引。(之所以叫"IndexedDB"就是因为可以在对象存储区上创建索引)。每一个索引就等于是为存储的对象定义了次键。这些索引通常都不是唯一的,多个对象也可能匹配一个键值。因此,当通过索引在对象存储区中进行查询的时候,通常需要使用游标(cursor),它定义一个用于一次一个地获取流查询结果的API。在当需要在对象存储区(或者索引中)查询一定范围的键的时候还可以使用游标,IndexedDB API包含一个用于描述键值范围(上限和/或下限,开区间或者闭区间)的对象。
Indexed DB提供原子性的保证:对数据库的查询和更新都是包含在一个事务(transaction)中,以此来确保这些操作要么是一起成功,要么是一起失败,并且永远不会让数据库出现更新到一半的情况。IndexedDB中的事务要比很多数据库API中的事务简单得多:后面会再次介绍它们。
从概念上来说,IndexedDB API非常简单。要查询或者更新数据库,首先打开该数据库(通过指定名字)。然后,创建一个事务对象,并使用该对象在数据库中通过指定名字查询对象存储区。最后,调用对象存储区的get()方法来查询对象或者调用put()方法来存储新的对象。(或者如果要避免覆盖已存在对象的情况,可以调用add()方法)。如果想要查询表示键值范围的对象,通过创建一个IDBRange对象,并将其传递给对象存储区的openCursor()方法。或者,如果想要使用次键进行查询的话,通过查询对象存储区中的命名索引,然后调用索引对象上的get()方法或者openCursor()方法。
然而,这种概念简易性还是比较复杂的,IndexedDB API必须要是异步的,这样能够实现让Web应用使用这些API的同时又不阻塞浏览器的UI主线程。(IndexedDB标准定义了一个给Worker线程使用的同步版本的API,不过,截至撰写本书时,浏览器都没有实现该API,因此这里不做介绍。)创建事务以及查询对象存储区和索引是比较简单的同步操作。但是,打开数据库、通过put()方法更新对象存储区、通过get()方法或openCursor()查询对象存储区或者索引,这些操作都是异步的。这些异步方法都会立即返回一个request对象。当请求成功或者失败的时候,浏览器会在该request对象上出触发对应的success事件或者error事件,与此同时,还可以通过onsuccess属性和onerror属性来定义事件处理程序。在onsuccess处理程序中,可以通过request对象的result属性来获取操作的结果。
异步API中一个比较方便的特性就是它简化了事务管理。使用IndexedDB API的时候,通常是先打开数据库。这是一个异步的操作,因此它会触发onsucccess事件处理程序。在该处理程序中,创建一个事务对象,然后使用该事务对象来查询对象存储区或者使用的存储区。之后,调用该对象存储区上的get()方法和put()方法。所有这些操作都是异步的,因此不会立马有结果,但是,通过调用get()方法和put()方法生成的请求会自动和事务对象关联。如果需要的话,可以通过调用事务对象的abort()方法来撤销事务中所有挂起的操作(也可以撤销已经完成的操作)。在许多其他的数据库API中,事务对象都需要调用commit()方法来完成事务。然而,在IndexedDB中,在创建该事务对象的原始onsuccess事件处理程序退出,并且浏览器返回到事件循环中以及事务中所有挂起的操作都完成之后,就会提交事务(不需要在它们的回调函数中开始新的操作)。这听起来貌似很复杂,事实上,实践起来非常容易。尽管,在查询对象存储区的时候,IndexedDB API强制要求创建事务对象,但是,通常情况下,不必考虑太多事务问题。
最后,还有一种特殊的事务,它是IndexedDB API中很重要的一部分。通过IndexedDB API创建一个新的数据库是很容易的:只需要选个名字然后要求打开该数据库。不过,新的数据库是完全空的,除非将一个或多个对象存储区(索引也可以)添加到该数据库中,否则该数据库只是摆设,毫无用处。创建对象存储区和索引只能在request对象的onsuccess事件处理程序中完成,request对象是调用数据库对象的setVersion()方法返回的。setVersion()方法用于指定数据库的版本号——通常都是这么用的,每次更改数据库结构的时候就更新该版本号。但是,更重要的是,调用setVersion()方法会隐式地开始一类特殊的事务,在该事务中,允许调用数据库对象的createObjectStore()方法和对象数据区的createIndex()方法。
对IndexedDB有了一定认识,现在应该能够看懂例22-15了。该例使用IndexedDB来创建和查询一个数据库,该数据库包含美国邮政编码和城市的映射信息。它展示大部分(但非全部)IndexDB基础特性。截至撰写本书时,该例在Firefox 4和Chrome 11中都工作正常,但是,由于IndexedDB的标准也未稳定,相应的实现也都是初步的,因此,很有可能当你阅读本书的时候,它就已经无法工作了。但是,不管怎么说,该例总体的结构还是很有用的。例22-15代码很长,为了能够有助于理解,添加了很多的注释。
例22-15:存储美国邮政编码的IndexedDB数据库
<!DOCTYPE html>
<html>
<head>
<title>Zipcode Database</title>
<script>//IndexedDB的实现仍然使用API前缀
var indexedDB=window.indexedDB||//使用标准的DB API
window.mozIndexedDB||//或者Firefox早期版本的IndexedDB
window.webkitIndexedDB;//或者Chrome的早期版本
//这两个API,Firefox没有前缀
var IDBTransaction=window.IDBTransaction||window.webkitIDBTransaction;
var IDBKeyRange=window.IDBKeyRange||window.webkitIDBKeyRange;//使用此函数,以日志的形式记录发生的数据库错误
function logerr(e){
console.log("IndexedDB error"+e.code+":"+e.message);
}
//此函数异步地获取数据库对象(需要的时候,用于创建和初始化数据库),
//然后将其传递给f()函数
function withDB(f){
var request=indexedDB.open("zipcodes");//获取存储邮政编码的数据库
request.onerror=logerr;//以日志的方式记录发生的错误
request.onsuccess=function(){//或者完成的时候调用此回调函数
var db=request.result;//request对象的result值就表示该数据库
//即便该数据库不存在,也总能够打开它
//通过检查版本号来确定数据库是否已经创建或者初始化
//如果还没有,就做相应的创建或者初始化的工作
//如果db已经存在了,那么只需要将它传递给回调函数f()就可以了
if(db.version==="1")f(db);//如果db已经初始化了,就直接将它传递给f()函数
else initdb(db,f);//否则,先初始化db
}
}
//给定一个邮政编码,查询该邮政编码属于哪个城市,
//并将该城市名异步传递给指定的回调函数
function lookupCity(zip,callback){
withDB(function(db){//为本次查询创建一个事务对象
var transaction=db.transaction(["zipcodes"],//所需的对象存储区
IDBTransaction.READ_ONLY,//没有更新
0);//没有超时
//从事务中获取对象存储区
var objects=transaction.objectStore("zipcodes");//查询和指定的邮政编码的键匹配的对象
//上述代码是同步的,但是这里的是异步的
var request=objects.get(zip);
request.onerror=logerr;//以日志形式记录发生的错误
request.onsuccess=function(){//将结果传递给此函数
//result对象可以通过request.result属性获取
var object=request.result;
if(object)//如果查询到了,就将城市和州名传递给回调函数
callback(object.city+","+object.state);
else//否则,告诉回调函数,失败了
callback("Unknown zip code");
}
});
}
//给定城市名(区分大小写),来查询对应的邮政编码
//然后挨个将结果异步地传递给指定的回调函数
function lookupZipcodes(city,callback){
withDB(function(db){//和上述的情况一致,创建一个事务并获取对象存储区
var transaction=db.transaction(["zipcodes"],IDBTransaction.READ_ONLY,0);
var store=transaction.objectStore("zipcodes");//这次,从对象存储区中获取城市索引
var index=store.index("cities");//此次查询可能会返回很多结果,因此,必须使用游标对象来获取它们
//要创建一个游标,需要一个表示键值范围的range对象
var range=new IDBKeyRange.only(city);//传递一个单键给only()方法获取一个range对象
//上述所有的操作都是同步的
//现在,请求一个游标,它会以异步的方式返回
var request=index.openCursor(range);//获取该游标
request.onerror=logerr;//记录错误
request.onsuccess=function(){//将游标传递给此函数
//此事件处理程序会调用多次,
//每次有匹配查询的记录会调用一次,
//然后当标识操作结束的null游标出现的时候,也会调用一次
var cursor=request.result//通过request.result获取游标
if(!cursor)return;//如果没有游标就说明没有结果了
var object=cursor.value//获取匹配的数据项
callback(object);//将其传递给回调函数
cursor.continue();//继续请求下一个匹配的数据项
};
});
}
//下面展示的,document中的onchange回调函数会用到此方法
//此方法查询数据库并展示查询到的结果
function displayCity(zip){
lookupCity(zip,function(s){document.getElementById('city').value=s;});
}
//这是下面的文档中使用的另一个onchange回调函数
//它查询数据库并展示查询到的结果
function displayZipcodes(city){
var output=document.getElementById("zipcodes");
output.innerHTML="Matching zipcodes:";
lookupZipcodes(city,function(o){
var div=document.createElement("div");
var text=o.zipcode+":"+o.city+","+o.state;
div.appendChild(document.createTextNode(text));
output.appendChild(div);
});
}
//建立数据库的结构,并用相应的数据填充它,
//然后将该数据库传递给f()函数
//如果数据库还未初始化,withDB()函数会调用此函数
//这也是此程序中最巧妙的部分
function initdb(db,f){//第一次运行此应用的时候,
//下载邮政编码数据并将它们存储到数据库中,需要花一些时间
//因此在下载过程中,有必要给出提示
var statusline=document.createElement("div");
statusline.style.cssText=
"position:fixed;left:0px;top:0px;width:100%;"+
"color:white;background-color:black;font:bold 18pt sans-serif;"+
"padding:10px;";
document.body.appendChild(statusline);
function status(msg){statusline.innerHTML=msg.toString();};
status("Initializing zipcode database");//只有在setVersion请求的onsuccess处理程序中才能定义或者修改IndexedDB数据库的结构
var request=db.setVersion("1");//试着更新数据库的版本号
request.onerror=status;//失败的话,显示状态
request.onsuccess=function(){//否则,调用此函数
//这里邮政编码数据库只包含一个对象存储区
//该存储区包含如下形式的对象:{
//zipcode:"02134",
//发送到Zoom
//city:"Allston",
//state:"MA",
//latitude:"42.355147",
//longitude:"-71.13164"
//}
//
//使用对象的"zipcode"属性作为数据库的键
//同时,使用城市名来创建索引
//创建一个对象存储区,并为该存储区指定一个名字
//同时也为包含指定该存储区中键字段属性名的键路径的一个可选对象指定名字
//(如果省略键路径,IndexedDB会定义它自己的唯一的整型键)
var store=db.createObjectStore("zipcodes",//存储区名字
{keyPath:"zipcode"});//通过城市名以及邮政编码来索引对象存储区
//使用此方法,表示键路径的字符串要直接传递过去,
//并且是作为必需的参数而不是可选对象的一部分
store.createIndex("cities","city");//现在,需要下载邮政编码数据,将它们解析成对象,
//并将这些对象存储到之前创建的对象存储区中
//
//包含原始数据的文件内容格式如下:
//
//02130,Jamaica Plain,MA,42.309998,-71.11171
//02131,Roslindale,MA,42.284678,-71.13052
//02132,West Roxbury,MA,42.279432,-71.1598
//02133,Boston,MA,42.338947,-70.919635
//02134,Allston,MA,42.355147,-71.13164
//
//令人吃惊的是,美国邮政服务居然没有将这些数据开放
//因此,这里使用了统计出来的过期的邮政编码数据
//这些数据均来自
//http://mappinghacks.com/2008/04/28/civicspace-zip-code-database/
//使用XMLHttpRequest下载这些数据
//但在获取到数据后,使用新的XHR2 onload事件和onprogress事件来处理
var xhr=new XMLHttpRequest();//下载数据所需的XHR对象
xhr.open("GET","zipcodes.csv");//利用HTTP GET方法获取此URL指定的内容
xhr.send();//直接获取
xhr.onerror=status;//显示错误状态
var lastChar=0,numlines=0;//已经处理的数量
//获取数据后,批量处理数据库文件
xhr.onprogress=xhr.onload=function(e){//一个函数同时作为两个事件处理程序
//在接收数据的lastChar和lastNewline之间处理数据块(需要查询newlines,
//因此不需要处理部分记录项)
var lastNewline=xhr.responseText.lastIndexOf("\n");
if(lastNewline>lastChar){
var chunk=xhr.responseText.substring(lastChar,lastNewline)
lastChar=lastNewline+1;//记录下次从哪里开始
//将新的数据块分割成单独的行
var lines=chunk.split("\n");
numlines+=lines.length;//为了将邮政编码数据库存储到数据库中,
//这里需要事务对象
//在该此函数返回,
//浏览器返回事件循环时,向数据库提交所有使用该对象进行的所有数据库插入操作
//要创建事务对象,需要指定要使用的对象存储区
//并且告诉该对象存储区,
//需要对数据库进行写操作而不只是读操作:
var transaction=db.transaction(["zipcodes"],//对象存储区
IDBTransaction.READ_WRITE);//从事务中获取对象存储区
var store=transaction.objectStore("zipcodes");//现在,循环邮政编码文件中的每行数据
//为它们创建相应的对象,并将对象添加到对象存储区中
for(var i=0;i<lines.length;i++){
var fields=lines[i].split(",");//以逗号分割的值
var record={//要存储的对象
zipcode:fields[0],//所有属性都是字符串
city:fields[1],
state:fields[2],
latitude:fields[3],
longitude:fields[4]
};//IndexedDB API最好的部分就是对象存储区真的非常简单
//下面就是在数据库中添加一条记录的方式:
store.put(record);//或者使用add()方法避免覆盖
}
status("Initializing zipcode database:loaded"
+numlines+"records.");
}
if(e.type=="load"){//如果这是最后的载入事件,
//就将所有的邮政编码数据发送给数据库
//但是,由于刚刚处理了4万条数据,可能它还在处理中
//因此这里做个简单的查询
//当此查询成功时,就能够得知数据库已经就绪了
//然后就可以将状态条移除,
//最后调用此前传递给withDB()函数的f()函数
lookupCity("02134",function(s){//奥尔斯顿,马萨诸塞州
document.body.removeChild(statusline);
withDB(f);
});
}
}
}
}
</script>
</head>
<body>
<p>Enter a zip code to find its city:</p>
Zipcode:<input onchange="displayCity(this.value)"></input>
City:<output id="city"></output>
</div>
<div>
<p>Enter a city name(case sensitive,without state)to find cities and their zipcodes:</p>
City:<input onchange="displayZipcodes(this.value)"></input>
<div id="zipcodes"></div>
</div>
<p><i>This example is only known to work in Firefox 4 and Chrome 11.</i></p>
<p><i>Your first query may take a very long time to complete.</i></p>
<p><i>You may need to start Chrome with—unlimited-quota-for-indexeddb</i></p>
</body>
</html>
22.9 Web套接字
第18章介绍过客户端JavaScript代码如何通过网络进行通信。该章中的例子都使用HTTP协议,这也意味着它们受限于HTTP协议的特性:它是一种无状态的协议,由客户端请求和服务端响应组成。HTTP实际上是相对比较特殊的网络协议。大多数基于因特网(或者局域网)的网络连接通常都包含长连接和基于TCP套接字的双向消息交换。让不信任的客户端脚本访问底层的TCP套接字是不安全的,但是WebSocket API定义了一种安全方案:它允许客户端代码在客户端和支持WebSocket协议的服务器端创建双向的套接字类型的连接。这让某些网络操作会变得更加简单。
WebSocket协议
要通过JavaScript使用WebSocket,只须了解这里要介绍的WebSocket API。其中并没有用于书写一个WebSocket服务器的服务端API,但是本节会有一个简单服务器例子,该例子使用Node(见12.2节)和第三方WebSocket服务器库来实现。客户端和服务器端的通信是通过TCP套接字长连接实现的,其遵循WebSocket协议定义的规则。关于WebSocket协议的细节这里不做详细介绍,但是,值得注意的是,WebScoket是经过精心设计的协议,实现让Web服务器能够很容易地同时处理同一端口上的HTTP连接和WebSocket连接。
很多浏览器提供商都实现了WebSocket。但是,由于发现早期草案版本的WebSocket协议有重要的安全漏洞,因此,一直到撰写本书时,有些浏览器在安全版本的协议未标准化之前,都将它们支持的WebSocket功能关闭了。比如,在Firefox 4中,要启用WebSocket功能,需要访问about:config页面,然后将配置变量"network.websocket.override-security-block"设置为true。
WebSocket API的使用非常简单。首先,通过WebSocket()构造函数创建一个套接字:
var socket=new WebSocket("ws://ws.example.com:1234/resource");
WebSocket()构造函数的参数是一个URL,该URL使用ws://协议(或者类似于https://用于安全链接的wss://协议)。该URL指定要连接的主机,还有可能指定端口(WebSocket使用和HTTP以及HTTPS一样的默认端口)和路径或者资源。
创建了套接字之后,通常需要在上面注册一个事件处理程序:
socket.onopen=function(e){/套接字已经连接/};
socket.onclose=function(e){/套接字已经关闭./};
socket.onerror=function(e){/出错了/};
socket.onmessage=function(e){
var message=e.data;/服务器发送一条消息/
};
为了通过套接字发送数据给服务器,可以调用套接字的send()方法:
socket.send("Hello,server!");
当前版本的WebSocket API仅支持文本消息,并且必须以UTF-8编码形式的字符串传递给该消息。然而,当前WebSocket协议还包含对二进制消息的支持,未来版本的API可能会允许在客户端和WebSocket服务器端进行二进制数据的交换。
当完成和服务器的通信之后,可以通过调用close()方法来关闭WebSocket。
WebSocket完全是双向的,并且一旦建立了WebSocket连接,客户端和服务器端都可以在任何时候互相传送消息,与此同时,这种通信机制采用的不是请求和响应的形式。每个基于WebSocket的服务都要定义自己的“子协议”,用于在客户端和服务器端传输数据。慢慢的,这些“子协议”也可能发生演变,可能最终要求客户端和服务器端需要支持多个版本的子协议。幸运的是,WebSocket协议包含一种协商机制,用于选择客户端和服务器端都能“理解”的子协议。可以传递一个字符串数组给WebSocket()构造函数。服务器端会将该数组作为客户端能够理解的子协议列表。然后,它会选择其中一个使用,并将它传递给客户端。一旦连接建立之后,客户端就能够通过套接字的protocol属性检测当前在使用的是哪种子协议。
18.3 节介绍了EventSource API,并通过一个在线聊天的客户端和服务器展示了这些API如何使用。有了WebSocket,写这类应用就变得更加容易了。例22-16就是一个简单的聊天客户端:它和例18-5很像,不同的是它采用了WebSocket来实现双向通信,而没有使用EventSource来获取消息以及XMLHttpRequest来发送消息。
例22-16:基于WebSocket的聊天客户端
<script>
window.onload=function(){//关心一些UI细节
var nick=prompt("Enter your nickname");//获取用户昵称
var input=document.getElementById("input");//查找input字段
input.focus();//设置光标
//打开一个WebSocket,用于发送和接收聊天消息
//假设下载的HTTP服务器作为WebSocket服务器运作,并且使用同样的主机名和端口
//只是协议由htttp://变成ws://
var socket=new WebSocket("ws://"+location.host+"/");//下面展示了如何通过WebSocket从服务器获取消息
socket.onmessage=function(event){//当收到一条新消息
var msg=event.data;//从事件对象中获取消息内容
var node=document.createTextNode(msg);//将它标记为一个文本节点
var div=document.createElement("div");//创建一个<div>
div.appendChild(node);//将文本节点添加到该div中
document.body.insertBefore(div,input);//在input前添加该div
input.scrollIntoView();//确保输入框可见
}
//下面展示了如何通过WebSocket发送消息给服务器端
input.onchange=function(){//当用户敲击回车键
var msg=nick+":"+input.value;//用户昵称加上用户的输入
socket.send(msg);//通过套接字传递该内容
input.value="";//等待更多内容的输入
}
};
</script>
<!—聊天窗口UI很简单,一个宽的文本输入域—>
<!—新的聊天消息会插入在该元素中—>
<input id="input"style="width:100%"/>
例22-17是一个基于WebSocket的聊天服务器,运行在Node中(见12.2节)。通过将该例和例18-17作比较,可以发现,WebSocket将聊天应用的服务端简化成和客户端一样。
例22-17:使用WebSocket和Node的聊天服务器
/*
*这是运行在NodeJS上的服务器端JavaScript
*在HTTP服务器之上,它运行一个WebSocket服务器,该服务器使用来自
*https://github.com/miksago/node-websocket-server/的第三方WebSocket库实现
*如果得到"/"的一个HTTP请求,则返回聊天客户端的HTML文件
*除此之外任何HTTP请求都返回404
*通过WebSocket协议接收到的消息都仅广播给所有激活状态的连接
*/
var http=require('http');//使用Node的HTTP服务器API
var ws=require('websocket-server');//使用第三方WebSocket库
//启动阶段,读取聊天客户端的资源文件
var clientui=require('fs').readFileSync("wschatclient.html");//创建一个HTTP服务器
var httpserver=new http.Server();//当HTTP服务器获得一个新请求时,运行此函数
httpserver.on("request",function(request,response){//如果请求"/",则返回客户端聊天UI
if(request.url==="/"){//请求聊天UI
response.writeHead(200,{"Content-Type":"text/html"});
response.write(clientui);
response.end();
}
else{//对任何其他的请求返回404"无法找到"编码
response.writeHead(404);
response.end();
}
});//在HTTP服务器上包装一个WebSocket服务器
var wsserver=ws.createServer({server:httpserver});//当接收到一个新的连接请求的时候,调用此函数
wsserver.on("connection",function(socket){
socket.send("Welcome to the chat room.");//向新客户端打招呼
socket.on("message",function(msg){//监听来自客户端的消息
wsserver.broadcast(msg);//并将它们广播给每个人
});
});//在8000端口运行服务器。启动WebSocket服务器的时候也会启动HTTP服务器
//连接到http://localhost:8000/,并开始使用它
wsserver.listen(8000);
[1]指的是独立线程运行的代码。
[2]表示一直等下去。
[3]下面统一称为容器。
[4]Web Workers起初是作为HTML5标准的一部分,但是后来独立成一份相近的标准。截至撰写本书时,这份标准的草案可以通过http://dev.w3.org/html5/workers/和http://whatwg.org/ww进行访问。
[5]如果指定过大就是一种浪费。
[6]截至撰写本书时,Chrome不要求权限,但是它要求启动的时候,在命令行中带上—unlimited-quota-for-files标志。
