- 第9章 文件与文件系统的压缩与打包
- 这个 -c 的参数比较有趣。它会将压缩过程的数据输出到屏幕上,而不是写入成为
- *.Z 的压缩文件。所以,我们可以通过数据流重定向的方法将数据输出成为另一个文件名。
- 关于数据流重定向,我们会在第11章 bash中详细谈论的。
- 由于 man.config 这个原本的文件是文本文件,因此我们可以尝试使用 zcat 去读取。
- 此时屏幕上会显示 man.config.gz 解压缩之后的文件内容。
- 不要使用gunzip这个命令,使用gzip-d 来进行解压缩。
- 与gzip相反,gzip -d 会将原本的 .gz 删除,产生原本的 man.config 文件。
- 此时 man.config 会变成 man.config.bz2
- 此时屏幕上会显示 man.config.bz2 解压缩之后的文件内容。
- 由于加上 -v 这个参数,因此正在作用中的文件名就会显示在屏幕上。
- 如果你可以翻到第一页,会发现出现上面的错误信息,下面会讲解。
- 至于 -p的参数,重点在于保留原本文件的权限与属性之意。
- 显示的消息会跟上面一模一样。
- 为什么建议你使用 -j 这个参数?从上面的数值你可以知道了吧?
- 这次查阅文件名不含 -v 参数,所以仅有文件名而已,没有详细属性/权限等参数。
- 1. 先找到我们要的文件名,假设解开 shadow 文件好了:
- 先找出重要的文件名。其中那个grep是“选取”关键字的功能。我们会在第三篇说明。
- 这里你先有个概念即可,那个坚线 | 配合grep可以选取关键字的意思。
- 2. 将该文件解开。语法与实际方法如下:
- 此时只会解开一个文件而已。不过,重点是那个文件名。你要找到正确的文件名。
- 在本例中,你不能写成 /etc/shadow ,因为它是记录在 etc.tar.bz2 内的文件名。
- 1. 先由 find 找出比 /etc/passwd 还要新的文件
- 此时会显示出比 /etc/passwd 这个文件的 mtime 还要新的文件名,
- 这个结果在每台主机都不相同。你先自行查阅自己的主机即可,不会跟鸟哥一样。
- 2. 好了,那么使用tar来进行打包,日期为上面看到的 2008/09/29
- 最后一行显示的是“没有被备份的”,也即 not dumped 的意思。
- 3. 显示出文件即可
- 通过这个命令可以调出 tar.bz2 内的结尾非 / 的文件名。
- 将 /etc 整个目录一边打包一边在 /tmp中解开
- 这个操作有点像是cp -r /etc /tmp依旧是有其有用途的。
- 要注意的地方在于输出文件变成 - 而输入文件也变成 - ,又有一个 | 存在。
- 这分别代表 standard output, standard input 与管道命令。
- 简单的想法中,你可以将 - 想成是在内存中的一个设备(缓冲区)。
- 更详细的数据流与管道命令,请翻到 bash 章节。
- 1. 先处理要放置备份数据的目录与权限:
- 2. 假设今天是 2009/11/30 ,则新建备份的方式如下:
- 1. 先找出系统中最小的那个文件系统,如下所示:
- 2. 先测试一下如果要备份此文件系统需多少容量
- 3. 将完整备份的文件名记录成为 /root/boot.dump,同时更新记录文件:
- 在命令的执行方面,dump后面接 /boot 或 /dev/hdc1都可以的。
- 而执行 dump的过程中会出现如上的一些信息,你可以自行仔细查看。
- 由于加上 -u 的选项,因此 /etc/dumpdates文件的内容会被更新。注意,
- 这个文件仅有在 dump完整的文件系统时才有支持自动更新的功能。
- 4. 查看一下系统自动新建的记录文件:
- 1. 看一下有没有任何文件系统被 dump过的数据
- 如上面的结果,该结果会找出 /etc/fstab 里面第五字段设置有需要 dump的
- 分区,然后与 /etc/dumpdateS进行比对,可以得到上面的结果。
- 尤其是第三行,可以显示我们曾经对 /dev/hdc1进行过 dump的备份操作。
- 2. 先恶搞一下,新建一个大约 10 MB 的文件在 /boot 内:
- 3. 开始新建差异备份文件,此时我们使用 level 1吧:
- 看看文件大小,岂不是就是刚才我们所新建的那个大文件的大小吗?
- 4. 最后再看一下是否有记录 level 1备份的时间点呢?
- 让我们将 /etc 整个目录通过 dump进行备份,且含压缩功能
- 上面特殊字体的部分显示:原本有 124680KB 的容量,被压缩成为 18752KB,
- 整个压缩比为 6.649:1,还可以。
- 1. 先尝试更改文件系统的内容:
- 2. 看看查询文件系统与备份文件之间的差异。
- 看到上面的特殊字体了吧。那就是有差异的部分。总共有一个文件被更改。
- 我们刚才确实有改动过该文件。
- 3. 将文件系统改回来。
- 1. 先新建一个新的分区来使用,假设我们需要的是 150MB 的容量
- 这样就能够新建一个 /dev/hdc8 的分区,然后继续格式化。
- 2. 开始进行还原的操作。请你务必回到新文件系统的挂载点下面。
- 此时你就已经进入 restore 的互动模式解密中。要注意的是:
- 你目前已经在 etc.dump这个文件内了。所有的操作都是在 etc.dump内。
- 上面三个命令是重点。各命令的功能为:
- add file :将 file 加入等一下要解压缩的文件列表中
- delete file :将 file解压缩的列表中删除,并非删除 etc.dump内的文件。
- extract :开始将刚才选择的文件列表解压缩。
- 看吧。一堆数据都放置在一起。包括有的没有的目录与文件等等。
- 上面的命令会新建一个大文件,其中 -graft-point 后面接的就是我们要备份的数据。
- 必须要注意的是那个等号的两边,等号左边是在镜像文件内的目录,右侧则是实际的数据。
- 数据是分门别类地放在各个目录中,最后将数据卸载一下:
- 1. 先抹除光盘的原始内容(非可重复读写则可略过此步骤):
- 中间会显示出一堆信息告诉你抹除的进度,而且会有 10 秒钟的时间等待你的取消。
- 可以避免“手滑”的情况。
- 2. 开始刻录:
- 上面会显示进度,还有 10.5x 代表目前的刻录速度。
- 3. 刻录完毕后,测试挂载一下,检验内容:
- 1. 同样,先来抹除一下原本的内容:
- 2. 开始写入 DVD,请注意,有些参数与CD 并不相同了。
- 3. 同样,来给他测试测试。
- 仔细看一下,我的 /etc/passwd 文件大小为 1945bytes,因为我没有设置 bs,
- 所以默认是 512bytes为一个单位,因此,上面那个 3+1表示有 3 个完整的
- 512bytes,以及未满 512bytes的另一个 block 的意思。
- 事实上,感觉好像是cp这个命令。
- 第一个扇区内含有 MBR 与分区表,通过这个操作,
- 我们可以一口气将这个磁盘的 MBR 与分区表进行备份。
- 等于是将整个 /dev/hdc1通通备份下来的意思,如果要还原呢?就反向回去。
- ddif=/tmp/boot.whole.disk of=/dev/hdc1即可。非常简单。
- 简单地说,如果想要整个硬盘备份的话,就类似 Norton 的ghost 软件一般,
- 由 disk 到 disk,利用dd就可以了。
- 1. 先进行分区的操作
- 上面鸟哥仅获取重要的数据而已。我们可以看到 /dev/hdc1仅有 13 个磁柱
- 为什么要使用 2366 呢?因为 /dev/hdc1使用 13 个磁柱,因此新的分区
- 我们也给它 13 个磁柱,因此 2354 + 13 -1= 2366。
- 2. 不需要格式化,直接进行扇区表面的复制。
- 这两个磁盘大小会“一模一样”。
- 通过这个 find 我们可以找到 /boot 下面应该要存在的文件名,包括文件与目录
- 你可以自行比较一下 /root/boot 与 /boot 的内容是否一模一样。
- 1. 我们先来看看该文件是属于什么文件格式,然后再加以处理:
- 看起来似乎是使用gzip进行压缩过,那如何处理呢?
- 2. 通过更名,将该文件增加扩展名,然后予以解压缩看看:
- 确实是cpio 的文件。
- 3. 开始使用cpio 解开此文件:
- 这样就将这个文件解开了。
第9章 文件与文件系统的压缩与打包
在Linux下面有相当多的压缩指令命令可以运行操作。喔!这些压缩指令命令可以让我们更方便地从网络上面下载大型的文件呢!此外,我们知道在Linux下面的扩展名是没有什么很特殊的意义的,不过,针对这些压缩指令命令所做出来的压缩文件,为了方便记忆,还是会有一些特殊的命名方式啦!
9.1 压缩文件的用途与技术
你是否有过文件太大,导致无法以一张软盘存储?你是否有过发现一个软件里面有好多文件,这些文件要将它复制与携带都很不方便的问题?还有,你是否有过要备份某些重要数据,偏偏这些数据量太大了,耗掉了你很多的磁盘空间呢?这个时候,那个好用的“文件压缩”技术可就派得上用场了。
因为这些比较大型的文件通过所谓的文件压缩技术之后,可以将它的磁盘使用量降低,可以达到减低文件大小的效果,此外,有的压缩程序还可以进行大小限制,使一个大型文件可以分成为数个小型文件,以方便软盘携带。
那么什么是“文件压缩”呢?我们来稍微谈一谈它的原理好了。目前我们使用的计算机系统中都是使用所谓的 byte 单位来计量的。不过,事实上,计算机最小的计量单位应该是 bit 才对,此外,我们也知道 1byte = 8bit。但是如果今天我们只是记忆一个数字,也即是 1 这个数字呢?它会如何记录?假设一个byte可以看成下面的模样:
□□□□□□□□
由于1byte = 8bit,所以每个byte当中会有8个空格,而每个空格可以是0, 1,这里仅是作为一个简略的介绍,更多的详细资料数据请参考第零第0章的计算器计算机概论。
由于我们记录数字是 1,考虑计算机所谓的二进制,如此一来,1 会在最右边占据 1 个 bit ,而其他的7个bit将会自动被填上0。其实在这样的例子中,那7个bit应该是“空的”。不过,为了要满足目前我们的操作系统数据的访问,所以就会将该数据转为byte的形态来记录了。而一些聪明的计算机工程师就利用一些复杂的计算方式,将这些没有使用到的空间“丢”出来,以让文件占用的空间变小,这就是压缩的技术。
另外一种压缩技术也很有趣,它是将重复的数据进行统计记录的。举例来说,如果你的数据为“111….”,共有100个1时,那么压缩技术会记录为“100个1”而不是真的有100个1的位存在。这样也能够精简文件记录的容量。
简单地说,你可以将它想成,其实文件里面有相当多的“空间”存在,并不是完全填满的,而“压缩”的技术就是将这些“空间”填满,以让整个文件占用的容量下降。不过,这些压缩过的文件并无法直接被我们的操作系统所使用的,因此,若要使用这些被压缩过的文件数据,则必须将它“还原”成未压缩前的模样,那就是所谓的“解压缩”。而至于压缩前与压缩后的文件所占用的磁盘空间大小,就可以被称为是“压缩比”。更多的技术文件或许你可以参考一下:
RFC 1 952 文件:http://www.ietf.org/rfc/rfc1 952.txt
鸟 哥站上 的备 份: http://linux.vbird.org/linux_basic/0 240tarcompress/0 240tarcompress_gzip.php
这个“压缩”与“解压缩”的操作有什么好处呢?最大的好处就是压缩过的文件变小了,所以你的硬盘无形之中就可以容纳更多的数据。此外,在一些网络数据的传输中,也会由于数据量的降低,好让网络带宽可以用来做更多的工作。而不是老是卡在一些大型的文件传输上面呢。目前很多的 WWW 网站也是利用文件压缩的技术来进行数据的传送,好让网站带宽的可利用率上升。
上述的WWW网站压缩技术蛮有趣的!它让你网站上面“看得到的数据”在经过网络传输时,使用的是“压缩过的数据”,等到这些压缩过的数据到达你的计算机主机时,再进行解压缩,由于目前的计算机指令命令周期相当快速,因此其实在网页浏览的时候,时间都是花在数据的传输上面,而不是 CPU 的运算啦!如此一来,由于压缩过的数据量降低了,自然传送的速度就会加快不少!
若你是一位软件工程师,那么相信你也会喜欢将你自己的软件压缩之后提供大家下载来使用,毕竟没有人喜欢自己的网站天天都是带宽满载的吧?举个例子来说,Linux 2.6.27.4 完整的内核大小有300MB左右,而由于内核主要多是ASCII码的纯文本文件,这种文件的“多余空间”最多了。而一个提供下载的压缩过的 2.6.27.4内核大约仅有60MB左右,差了几倍呢?你可以自己算一算。
9.2 Linux系统常见的压缩命令
在Linux的环境中,压缩文件案的扩展名大多是.tar,.tar.gz,.tgz,.gz,.Z,.bz2,为什么会有这样的扩展名呢?不是说Linux的扩展名没有什么作用吗?
这是因为Linux支持的压缩命令非常多,且不同的命令所用的压缩技术并不相同,当然彼此之间可能就无法相互压缩/解压缩文件。所以,当你下载到某个压缩文件时,自然就需要知道该文件是由哪种压缩命令所制作出来的,好用来对照着解压缩。也就是说,虽然Linux文件的属性基本上是与文件名没有绝对关系的,但是为了帮助我们人类小小的大脑,所以适当的扩展名还是必要的。下面我们就列出几个常见的压缩文件案扩展名:
*.Z compress程序压缩的文件;
*.gz gzip程序压缩的文件;
*.bz2 bzip2程序压缩的文件;
*.tar tar程序打包的数据,并没有压缩过;
*.tar.gz tar程序打包的文件,其中经过gzip的压缩;
*.tar.bz2 tar程序打包的文件,其中经过bzip2的压缩。
Linux上常见的压缩命令就是gzip与bzip2,至于compress已经不再流行了。gzip是由GNU计划所开发出来的压缩命令,该命令已经替换了compress。后来GNU又开发出bzip2这个压缩比更好的压缩命令。不过,这些命令通常仅能针对一个文件来压缩与解压缩,如此一来,每次压缩与解压缩都要一大堆文件,岂不烦人?此时,那个所谓的打包软件tar就显得很重要了。
这个tar可以将很多文件“打包”成为一个文件。甚至是目录也可以这么玩。不过,单纯的tar功能仅是“打包”而已,即是将很多文件集结成为一个文件,事实上,它并没有提供压缩的功能,后来, GNU计划中,将整个tar与压缩的功能结合在一起,如此一来提供使用者更方便并且更强大的压缩与打包功能。下面我们就来谈一谈这些在Linux下面基本的压缩命令吧。
9.2.1 Compress
compress这个压缩命令是非常老旧的一款,大概只有在非常旧的UNIX机器上面还会找到这个软件。我们的CentOS默认并没有安装这个软件到系统当中,所以想要了解这个软件的使用时,请先安装 ncompress 这个软件。不过,由于 gzip 已经可以解开使用 compress 压缩的文件,因此,compress可以不用学习了。但是,如果你所在的环境还是有老旧的系统,那么还是得要学习一下。如果你有网络的话,那么安装其实很简单。
[root@www ~]# yum installncompress
base 100% |=========================| 1.1kB 00:00
updateS 100% |=========================| 951B 00:00
addonS 100% |=========================| 951B 00:00
extraS 100% |=========================| 1.1kB 00:00
Setting upInstall Process
Parsing package install arguments
Resolving DependencieS <==开始分析依赖性
—> Running transactionCheck
—-> Package ncompress.i386 0:4.2.4-47 set to be updated
—> Finished Dependency Resolution
DependencieSResolved
=======================================================
Package Arch Version Repository Size
=======================================================
Installing:
ncompress i386 4.2.4-47 base 23 k
Transaction Summary
=======================================================
Install 1Package(s) <==最后分析所要安装的软件数
Update 0Package(s)
Remove 0Package(s)
Total download size: 23 k
ISthiSok [y/N]: y <==这里请按下 y 来确认安装
Downloading Packages:
(1/1): ncompress-4.2.4-47 100% |=========================| 23 kB 00:00
warning: rpmts_HdrFromFdno: Header V3 DSA signature: NOKEY, key ID e8562897
ImportinggPG key 0xE8562897 "CentOS-5 Key (CentOS5 Official Signing Key)
<centos-5-key@centos.org>" from http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-5
ISthiSok [y/N]: y <==这里则是与数字签名有关
Running rpm_check_debug
Running Transaction Test
Finished Transaction Test
Transaction Test Succeeded
Running Transaction
Installing: ncompresS ######################### [1/1]
Installed: ncompress.i386 0:4.2.4-47
Complete!
关于 yum 更详细的用法我们会在后续的章节介绍,这里仅是提供一个大概的用法而已。等你安装好这个软件后,接下来让我们看看如何使用compress。
[root@www ~]#compress[-rcv] 文件或目录 <==这里是压缩
[root@www ~]#uncompress文件.Z <==这里是解压缩
选项与参数:
-r :可以连同目录下的文件也同时给予压缩;
-c :将压缩数据输出成为 standard output (输出到屏幕);
-v :可以显示出压缩后的文件信息以及压缩过程中的一些文件名变化。
范例一:将 /etc/man.config 复制到 /tmp,并加以压缩
[root@www ~]#cd /tmp
[root@www tmp]#cp/etc/man.config .
[root@www tmp]#compress-v man.config
man.config: — replaced with man.config.ZCompression: 41.86%
[root@www tmp]# ls-l /etc/man.config /tmp/man*
-rw-r—r—1root root 4617 Jan 6 2007 /etc/man.config <==原有文件
-rw-r—r—1root root 2684 Nov 10 17:14 /tmp/man.config.Z <==经过压缩的文件
不知道你有没有发现,复制到/tmp的man.config不见了,因为被压缩成为man.config.Z。也就是说,在默认的情况中,被compress压缩的源文件会不见,而压缩文件会被创建起来,而且扩展名会是 *.Z。仔细看一下,文件由原本的 4617bytes 降低到 2684bytes左右,确实有减少一点。那么如何解压缩呢?
范例二:将刚才的压缩文件解开
[root@www tmp]# uncompress man.config.Z
[root@www tmp]# ll man*
-rw-r—r—1root root 4617 Nov 10 17:14 man.config
解压缩直接用uncompress即可。解压缩完毕后该文件就自动变回来了。不过,那个压缩文件却又不存在。这样可以理解用法了吗?那如果我想要保留原文件且又要新建压缩文件呢?可以使用-c的语法。
范例三:将 man.config 压缩成另外一个文件来备份
[root@www tmp]#compress-c man.config > man.config.back.Z
[root@www tmp]# ll man*
-rw-r—r—1root root 4617 Nov 10 17:14 man.config
-rw-r—r—1root root 2684 Nov 10 17:24 man.config.back.Z
这个 -c 的参数比较有趣。它会将压缩过程的数据输出到屏幕上,而不是写入成为
*.Z 的压缩文件。所以,我们可以通过数据流重定向的方法将数据输出成为另一个文件名。
关于数据流重定向,我们会在第11章 bash中详细谈论的。
再次强调,compress已经很少人在使用了,因为这个程序无法解开.gz的文件,而gzip则可以解开.Z的文件,所以,如果你的distribution上面没有compress的话,那就不要进行上面的练习了。
9.2.2 gzip,zcat
gzip可以说是应用最广的压缩命令了。目前gzip可以解开compress、zip与gzip等软件所压缩的文件。至于gzip所新建的压缩文件为*.gz的文件名。让我们来看看这个命令的语法吧:
[root@www~]#gzip [-cdtv#] 文件名
[root@www ~]# zcat 文件名.gz
参数:
-c :将压缩的数据输出到屏幕上,可通过数据流重定向来处理;
-d :解压缩的参数;
-t :可以用来检验一个压缩文件的一致性,看看文件有无错误;
-v :可以显示出原文件/压缩文件的压缩比等信息;
-# :压缩等级,-1最快,但是压缩比最差,-9 最慢,但是压缩比最好默认是 –6。
范例一:将 /etc/man.config 复制到 /tmp中,并且以gzip压缩
[root@www ~]#cd /tmp
[root@www tmp]#cp/ etc/man.config .
[root@www tmp]#gzip -v man.config
man.config: 56.1% — replaced with man.config.gz
[root@www tmp]# ll /etc/man.config /tmp/man*
-rw-r—r—1root root 4617 Jan 6 2007 /etc/man.config
-rw-r—r—1root root 2684 Nov 10 17:24 /tmp/man.config.back.Z
-rw-r—r—1root root 2057 Nov 10 17:14 /tmp/man.config.gz <==gzip压缩比较佳
与compress类似,当你使用gzip进行压缩时,在默认的状态下原本的文件会被压缩成为.gz的文件名,原文件就不再存在了。你也可以发现,由于gzip的压缩比要比compress好得多,所以当然建议使用gzip。此外,使用gzip压缩的文件在Windows系统中,竟然可以被WinRAR这个软件解压缩。至于其他的用法如下:
范例二:由于man.config 是文本文件,请将范例一的压缩文件的内容读出来。
[root@www tmp]# zcat man.config.gz
由于 man.config 这个原本的文件是文本文件,因此我们可以尝试使用 zcat 去读取。
此时屏幕上会显示 man.config.gz 解压缩之后的文件内容。
范例三:将范例一的文件解压缩
[root@www tmp]#gzip -d man.config.gz
不要使用gunzip这个命令,使用gzip-d 来进行解压缩。
与gzip相反,gzip -d 会将原本的 .gz 删除,产生原本的 man.config 文件。
范例四:将范例三解开的 man.config 用最佳的压缩比压缩,并保留原来的文件
[root@www tmp]#gzip -9 -c man.config > man.config.gz
其实gzip的压缩已经优化过了,所以虽然gzip提供1~9的压缩等级,不过使用默认的6就非常好用了。因此上述的范例四可以不要加入那个-9的参数。范例四的重点在那个-c与>的使用。
cat可以读取纯文本文件,那个zcat则可以读取纯文本被压缩后的压缩文件。由于gzip这个压缩命令主要想要用来替代 compress 的,所以不但 compress 的压缩文件可以使用 gzip 来解开,同时zcat这个命令可以同时读取compress与gzip的压缩文件。
9.2.3 bzip2,bzcat
若说gzip是为了替代compress并提供更好的压缩比而成立的,那么bzip2则是为了取代gzip并提供更佳的压缩比而来的。bzip2真是很不错的东西,这玩意的压缩比竟然比gzip还要好。至于bzip2的用法几乎与gzip相同,用下面的用法介绍。
[root@www ~]#bzip2[-cdkzv#] 文件名
[root@www ~]# bzcat 文件名.bz2
参数:
-c :将压缩过程中产生的数据输出到屏幕上;
-d :解压缩的参数;
-k :保留原文件,而不会删除原始的文件;
-z :压缩的参数;
-v :可以显示出原文件/压缩文件的压缩比等信息;
-# :与gzip同样的,都是在计算压缩比的参数,-9 最佳,-1最快。
范例一:将刚才的 /tmp/man.config 以bzip2压缩
[root@www tmp]#bzip2-z man.config
此时 man.config 会变成 man.config.bz2
范例二:将范例一的文件内容读出来
[root@www tmp]# bzcat man.config.bz2
此时屏幕上会显示 man.config.bz2 解压缩之后的文件内容。
范例三:将范例一的文件解压缩
[root@www tmp]#bzip2 -d man.config.bz2
范例四:将范例三解开的 man.config 用最佳的压缩比压缩,并保留原本的文件
[root@www tmp]#bzip2 -9 -c man.config > man.config.bz2
使用 compress 扩展名自动创建为 .Z,使用 gzip 扩展名自动创建为.gz。这里的 bzip2 则是自动将扩展名构建为.bz2。所以当我们使用具有压缩功能的 bzip2 -z 时,那么刚才的 man.config 就会自动变成了man.config.bz2这个文件名。
好了,那么如果我想要读取这个文件的内容呢?是否一定要解压缩?当然不需要。使用简便的bzcat 这个命令来读取内容即可。例如上面的例子中,我们可以使用 bzcat man.config.bz2 来读取数据而不需要解压缩。此外,当你要解开一个压缩文件时,这个文件的名称为.bz,.bz2,.tbz,.tbz2等,那么就可以尝试使用 bzip2 来解压缩。当然,也可以使用 bunzip2 这个命令来替代 bzip2 -d。
9.3 打包命令:tar
前一小节谈到的命令大多仅能针对单一文件来进行压缩,虽然gzip与bzip2也能够针对目录来进行压缩,不过,这两个命令对目录的压缩指的是将目录内的所有文件“分别”进行压缩的操作。而不像在Windows的系统,可以使用类似WinRAR这一类的压缩软件来将好多数据“包成一个文件”的样式。
这种将多个文件或目录包成一个大文件的命令功能,我们可以称呼它是一种“打包命令”。那Linux有没有这种打包命令呢?那就是鼎鼎大名的tar。tar可以将多个目录或文件打包成一个大文件,同时还可以通过 gzip/bzip2 的支持,将该文件同时进行压缩。更有趣的是,由于 tar的使用太广泛了,目前Windows的WinRAR也支持.tar.gz文件名的解压缩。所以下面我们就来介绍一下。
9.3.1 tar
tar 的参数非常多。我们只讲几个常用的参数,更多参数你可以自行 man tar 查询。
[root@www ~]#tar [-j|-z] [cv] [-f 新建的文件名] filename… <==打包与压缩
[root@www ~]#tar [-j|-z] [tv] [-f新建的文件名] <==查看文件名
[root@www ~]#tar [-j|-z] [xv] [-f 新建的文件名] [-C 目录] <==解压缩
参数:
-c :新建打包文件,可搭配 -v 来查看过程中被打包的文件名(filename)。
-t :查看打包文件的内容含有哪些文件名,重点在查看文件名。
-x :解打包或解压缩的功能,可以搭配 -C (大写) 在特定目录解开。
特别留意的是,-c, -t, -x 不可同时出现在一串命令行中。
-j :通过bzip2的支持进行压缩/解压缩,此时文件名最好为 *.tar.bz2。
-z :通过gzip的支持进行压缩/解压缩,此时文件名最好为 *.tar.gz。
-v :在压缩/解压缩的过程中,将正在处理的文件名显示出来。
-f filename:-f 后面要接被处理的文件名。建议 -f 单独写一个参数。
-C 目录 :这个参数用在解压缩时,若要在特定目录解压缩,可以使用这个参数。
其他后续练习会使用到的参数介绍:
-p :保留备份数据的原本权限与属性,常用于备份(-c)重要的配置文件。
-P :保留绝对路径,即允许备份数据中含有根目录存在之意。
—exclude=FILE:在压缩的过程中,不要将 FILE 打包。
其实最简单的使用tar就只要记忆下面的方式即可:
压 缩:tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称
查 询:tar -jtv -f filename.tar.bz2
解压缩:tar -jxv -f filename.tar.bz2 -C 欲解压缩的目录
那个filename.tar.bz2是我们自己取的文件名,tar并不会主动产生创建的文件名。我们要自定义。所以扩展名就显得很重要了。如果不加[-j|-z]的话,文件名最好取为.tar即可。如果是-j参数,代表有bzip2的支持,因此文件名最好就取为.tar.bz2,因为bzip2会产生.bz2的扩展名。至于如果是加上了-z的gzip的支持,那文件名最好取为*.tar.gz。
另外,由于“-f filename”是紧接在一起的,过去很多文章常会写成“-jcvf filename”,这样是对的,但由于参数的顺序理论上是可以变换的,所以很多读者会误认为“-jvfc filename”,也可以,事实上这样会导致产生的文件名变成 C,因为-fc。所以建议你在学习 tar 时,将“-f filename”与其他参数独立出来,会比较不容易发生问题。
闲话少说,让我们来测试几个常用的tar方法。
使用tar加入-j或-z的参数备份/etc/目录。
有事没事备份一下/etc这个目录是件好习惯。备份/etc最简单的方法就是使用tar。让我们来试验一下:
[root@www ~]#tar -zpcv -f /root/etc.tar.gz /etc
tar: Removing leading `/' from member names <==注意这个警告消息
/etc/
….中间省略….
/etc/esd.conf
/etc/crontab
由于加上 -v 这个参数,因此正在作用中的文件名就会显示在屏幕上。
如果你可以翻到第一页,会发现出现上面的错误信息,下面会讲解。
至于 -p的参数,重点在于保留原本文件的权限与属性之意。
[root@www ~]#tar -jpcv -f /root/etc.tar.bz2 /etc
显示的消息会跟上面一模一样。
[root@www ~]# ll /root/etc*
-rw-r—r—1root root 8740252 Nov 15 23:07 /root/etc.tar.bz2
-rw-r—r—1root root 13010999 Nov 15 23:01/root/etc.tar.gz
[root@www ~]# du -sm /etc
118 /etc
为什么建议你使用 -j 这个参数?从上面的数值你可以知道了吧?
由上述的练习,我们知道使用 bzip2 也即-j 这个参数来制作备份时,能够得到比较好的压缩比。如上所示,由原本的/etc/(118M B)下降到 8.7MB 左右。至于加上“-p”这个参数的原因是为了保存原本文件的权限与属性。我们曾在第7章的Cp命令介绍时谈到权限与文件类型(例如连接文件)对复制的不同影响。同样,在备份重要的系统数据时,这些原本文件的权限需要做完整的备份比较好。此时-p 这个参数就派上用场了。接下来让我们看看打包文件内有什么数据存在。
查阅tar文件的数据内容(可查看文件名),与备份文件名有否根目录的意义
要查看文件名非常简单,可以这样做:
[root@www ~]#tar -jtv -f /root/etc.tar.bz2
….前面省略….
-rw-r—r— root/root 1016 2008-05-25 14:06:20 etc/dbus-1/session.conf
-rw-r—r— root/root 153 2007-01-07 19:20:54 etc/esd.conf
-rw-r—r— root/root 255 2007-01-06 21:13:33 etc/crontab
如果加上-v 这个参数时,详细的文件权限/属性都会被列出来。如果只是想要知道文件名而已,那么就将-v去掉即可。从上面的数据我们可以发现一件很有趣的事情,那就是每个文件名都没了根目录了。这也是上一个练习中出现的那个警告信息“tar:Removing leading /' from member names(删除了文件名开头的/')”所告知的情况。
那为什么要去掉根目录呢?主要是为了安全,我们使用tar备份的数据可能会需要解压缩回来使用,在 tar 所记录的文件名(就是我们刚才使用 tar -jtvf 所查看到的文件名)那就是解压缩后的实际文件名。如果去掉了根目录,假设你将备份数据在/tmp 中解开,那么解压缩的文件名就会变成“/tmp/etc/xxx”。但如果没有去掉根目录,解压缩后的文件名就会是绝对路径,即解压缩后的数据一定会被放置到/etc/xxx去。如此一来,你的原本的/etc/下面的数据就会被备份数据所覆盖过去了。
你会说:“既然是备份数据,那么还原回来也没有什么问题吧?”想象一个状况,你备份的数据是一年前的旧版CentOS 4.x,你只是想要了解一下过去的备份内容究竟有哪些数据而已,结果一解开该文件,却发现你目前新版的CentOS 5.x 下面的 /etc 被旧版的备份数据覆盖了。此时你该如何是好?所以当然是去掉根目录比较安全一些的。
如果你确定你就是需要备份根目录到tar的文件中,那可以使用-P(大写)这个参数,请看下面的例子分析:
范例:将文件名中的(根)目录也备份下来,并查看一下备份文件的内容文件名
[root@www ~]#tar -jpPcv -f /root/etc.and.root.tar.bz2 /etc
….中间过程省略….
[root@www ~]#tar -jtf /root/etc.and.root.tar.bz2
/etc/dbus-1/session.conf
/etc/esd.conf
/etc/crontab
这次查阅文件名不含 -v 参数,所以仅有文件名而已,没有详细属性/权限等参数。
有发现不同点了吧?如果加上-P 参数,那么文件名内的根目录就会存在。不过,鸟哥个人建议,还是不要加上-P 这个参数来备份。毕竟很多时候,我们备份是为了要未来追踪问题用的,倒不一定需要还原回原本的系统中。所以拿去根目录后,备份数据的应用会比较有弹性,也比较安全。
将备份的数据解压缩,并考虑特定目录的解压缩操作(-C参数的应用)
那如果想要解打包呢?很简单的操作就是直接进行解打包。
[root@www ~]#tar-jxv -f /root/etc.tar.bz2
[root@www ~]# ll
….(前面省略)….
drwxr-xr-x 105 root root 12288 Nov 1104:02 etc
….(后面省略)….
此时该打包文件会在本目录下进行解压缩的操作。所以,你等一下就会在主文件夹下面发现一个名为 etc 的目录。所以如果你想要将该文件在/tmp 下面解开,可以执行 cd /tmp 后,再执行上述的命令即可。不过,这样好像很麻烦,有没有更简单的方法可以指定欲解开的目录呢?有的,可以使用-C这个参数。举例来说:
[root@www ~]#tar -jxv -f /root/etc.tar.bz2 -C /tmp
[root@www ~]# ll /tmp
….(前面省略)….
drwxr-xr-x 105 root root 12288 Nov 1104:02 etc
….(后面省略)….
这样一来,你就能够将该文件在不同的目录解开。鸟哥个人认为,这个-C的参数务必要记一下。处理完毕后,请记得将这两个目录删除一下。
[root@www~]#rm -rf/root/etc /tmp/etc
再次强调,这个“rm -rf ”是很危险的命令。执行时请务必要确认一下后面接的文件名。我们要删除的是/root/etc与/tmp/etc,你可不要将/etc/删除掉了,否则系统会死掉。
仅解开单一文件的方法
刚才我们解压缩都是将整个打包文件的内容全部解开。想象一个情况,如果我只想要解开打包文件内的其中一个文件而已,那该如何做呢?你只要使用-jtv 找到你要的文件名,然后将该文件名解开即可。我们用下面的例子来说明一下:
1. 先找到我们要的文件名,假设解开 shadow 文件好了:
[root@www ~]#tar -jtv -f /root/etc.tar.bz2 |grep'shadow'
-r———— root/root 1230 2008-09-29 02:21:20 etc/shadow-
-r———— root/root 622 2008-09-29 02:21:20 etc/gshadow-
-r———— root/root 636 2008-09-29 02:21:25 etc/gshadow
-r———— root/root 1257 2008-09-29 02:21:25 etc/shadow <==这是我们要的。
先找出重要的文件名。其中那个grep是“选取”关键字的功能。我们会在第三篇说明。
这里你先有个概念即可,那个坚线 | 配合grep可以选取关键字的意思。
2. 将该文件解开。语法与实际方法如下:
[root@www ~]#tar -jxv -f 打包文件.tar.bz2 待解开文件名
[root@www ~]#tar -jxv -f /root/etc.tar.bz2 etc/shadow
etc/shadow
[root@www ~]# ll etc
total 8
-r————1root root 1257 Sep29 02:21shadow <==只有一个文件啦。
此时只会解开一个文件而已。不过,重点是那个文件名。你要找到正确的文件名。
在本例中,你不能写成 /etc/shadow ,因为它是记录在 etc.tar.bz2 内的文件名。
打包某目录,但不含该目录下的某些文件的做法
假设我们想要打包/etc//root这几个重要的目录,但却不想要打包/root/etc*开头的文件,因为该文件都是刚才我们才创建的备份文件。而且假设这个新的打包文件要放置成为/root/system.tar.bz2,当然这个文件自己不要打包自己(因为这个文件放置在/root下面),此时我们可以通过—exclude 的帮忙。那个exclude就是不包含的意思。所以你可以这样做:
[root@www ~]#tar -jcv -f /root/system.tar.bz2 —exclude=/root/etc* \
> —exclude=/root/system.tar.bz2 /etc /root
上面的命令是一整行的,其实你可以打成“tar -jcv -f /root/system.tar.bz2 —exclude=/ root/etc* —exclude=/root/system.tar.bz2 /etc/root”,如果想要两行输入时,最后面加上反斜杠(\)并立刻按下[Enter],就能够到第二行继续输入了。通过这个—exclude="file"的操作,我们可以将几个特殊的文件或目录删除在打包之列,让打包的操作变得更简便。
另外,在新版的 tar 命令中,鸟哥发现原本的“—excludefile”似乎无法实际操作。使用 man tar明明有看到这个参数的说明,但使用 info tar 才发现,参数功能已经变成了“—exclude=file”的模式。这个地方得要特别留意。
仅备份比某个时刻还要新的文件
某些情况下你会想要备份新的文件而已,并不想要备份旧文件。此时—newer-mtime 这个参数就很重要。其实有两个参数,一个是“—newer”,另一个就是“—newer-mtime”,这两个参数有何不同呢?我们在第7章的touch介绍中谈到过三种不同的时间参数,当使用—newer时,表示后续的日期包含“mtime与ctime”,而—newer-mtime则仅是mtime而已。那就让我们来尝试处理一下。
1. 先由 find 找出比 /etc/passwd 还要新的文件
[root@www ~]# find /etc -newer /etc/passwd
….(过程省略)….
此时会显示出比 /etc/passwd 这个文件的 mtime 还要新的文件名,
这个结果在每台主机都不相同。你先自行查阅自己的主机即可,不会跟鸟哥一样。
[root@www ~]# ll /etc/passwd
-rw-r—r—1root root 1945 Sep29 02:21/etc/passwd
2. 好了,那么使用tar来进行打包,日期为上面看到的 2008/09/29
[root@www ~]#tar-jcv -f /root/etc.newer.then.passwd.tar.bz2 \
> —newer-mtime="2008/09/29" /etc/*
….(中间省略)….
/etc/smartd.conf <==真的有备份的文件
….(中间省略)….
/etc/yum.repos.d/ <==目录都会被记录下来
tar: /etc/yum.repos.d/CentOS-Base.repo: file iSunchanged; not dumped
最后一行显示的是“没有被备份的”,也即 not dumped 的意思。
3. 显示出文件即可
[root@www ~]#tar -jtv -f /root/etc.newer.then.passwd.tar.bz2 | \
>grep-v '/$'
通过这个命令可以调出 tar.bz2 内的结尾非 / 的文件名。
现在你知道这个命令的好用了吧?它甚至可以进行差异文件的记录与备份呢,这样子的备份就会显得更容易。你可以这样想象,如果我在一个月前才进行过一次完整的数据备份,那么这个月想要备份时,当然可以仅备份上个月进行备份的那个时间点之后的更新的文件即可。为什么呢?因为原本的文件已经有备份了。干嘛还要进行一次?只要备份新数据即可。这样可以降低备份的容量。
基本名称: tarfile, tarball?
值得一提的是,tar 打包出来的文件有没有进行压缩所得到的文件称谓不同。如果仅是打包而已,就是“tar –cv –f file.tar ”而已,这个文件我们称呼为 tarfile。如果还有进行压缩的支持,例如“tar -jcv -f file.tar.bz2 ”时,我们就称呼为tarball(tar 球)。这只是一个基本的称谓而已,不过很多书籍与网络都会使用到这个tarball的名称。所以得要跟你介绍一下。
此外,tar 除了可以将数据打包成为文件之外,还能够将文件打包到某些特别的设备去,举例来说,磁带机(tape)就是一个常见的例子。磁带机由于是一次性读取/写入的设备,因此我们不能够使用类似 cp 等命令来复制的。那如果想要将/home, /root, /etc 备份到磁带机(/dev/st0)时,就可以使用“tar -cv -f /dev/st0 /home /root /etc”,很简单容易吧?磁带机用在备份 (尤其是企业应用)是很常见的工作。
特殊应用:利用管道命令与数据流
在 tar 的使用中,有一种方式最特殊,那就是通过标准输入输出的数据流重定向( standard input/standard output),以及管道命令(pipe)的方式,将待处理的文件一边打包一边解压缩到目标目录去。关于数据流重定向与管道命令更详细的数据我们会在第11章bash中再跟大家介绍,下面先来看一个例子。
将 /etc 整个目录一边打包一边在 /tmp中解开
[root@www ~]#cd /tmp
[root@www ~]#tar -cvf - /etc |tar-xvf -
这个操作有点像是cp -r /etc /tmp依旧是有其有用途的。
要注意的地方在于输出文件变成 - 而输入文件也变成 - ,又有一个 | 存在。
这分别代表 standard output, standard input 与管道命令。
简单的想法中,你可以将 - 想成是在内存中的一个设备(缓冲区)。
更详细的数据流与管道命令,请翻到 bash 章节。
在上面的例子中,我们想要将/etc下面的数据直接复制到目前所在的路径,也就是/tmp下面,但是又觉得使用 cp -r 有点麻烦,那么就直接以这个打包的方式来打包,其中,命令里面的-就是表示那个被打包的文件。由于我们不想要让中间文件存在,所以就以这一个方式来进行复制的行为。
例题:系统备份范例
系统上有非常多的重要目录需要进行备份,而且其实我们也不建议你将备份数据放置到/root目录下。假设目前你已经知道重要的目录有下面这几个:
/etc/ (配置文件)
/home/(用户的主文件夹)
/var/spool/mail/(系统中,所有账号的邮件信箱)
/var/spool/cron/(所有账号的工作调度配置文件)
/root(系统管理员的主文件夹)
然后我们也知道,由于第8章曾经做过的练习的关系,/home/loop*不需要备份,而且/root下面的压缩文件也不需要备份,另外假设你要将备份的数据放置到/backups,并且该目录仅有 root 有权限进入。此外,每次备份的文件名都希望不相同,例如使用backup-system-20091130.tar.bz2 之类的文件名来处理。那你该如何处理这个备份数据呢?(请先动手操作试试,再来查看一下下面的参考解答。)
1. 先处理要放置备份数据的目录与权限:
[root@www ~]# mkdir /backups
[root@www ~]#Chmod 700 /backups
[root@www ~]# ll -d /backups
drwx——— 2 root root 4096 Nov 30 16:35 /backups
2. 假设今天是 2009/11/30 ,则新建备份的方式如下:
[root@www ~]#tar -jcv -f /backups/backup-system-20091130.tar.bz2 \
> —exclude=/root/.bz2 —exclude=/root/.gz —exclude=/home/loop* \
> /etc /home /var/spool/mail /var/spool/cron /root
….(过程省略)….
[root@www ~]# ll -h /backups/
-rw-r—r—1root root 8.4M Nov 30 16:43 backup-system-20091130.tar.bz2
9.4 完整备份工具:dump
某些时刻你想要针对文件系统进行备份或者是存储的功能时,不能不谈到这个dump命令。这玩意儿我们曾在前一章的/etc/fstab里面稍微谈过。其实这个命令除了能够针对整个文件系统备份之外,也能够仅针对目录来备份。下面就让我们来谈一谈这个命令的用法。
9.4.1 dump
其实dump的功能很强,它除了可以备份整个文件系统之外,还可以制定等级。什么意思啊?假设你的/home是独立的一个文件系统,那你第一次进行过dump后,再进行第二次dump时,你可以指定不同的备份等级,假如指定等级为1时,此时新备份的数据只会记录与第一次备份所有差异的文件而已。我们用一张简图9-1来说明。
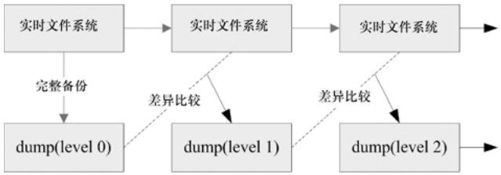
图9-1 dump 运行的等级(level)
如图9-1所示,上方的“实时文件系统”是一直随着时间而变化的数据,例如在/home里面的文件数据会一直变化一样。而下面的方块则是 dump 备份起来的数据,第一次备份时使用的是 level 0,这个等级也是完整的备份。等到第二次备份时,实时文件系统内的数据已经与 level 0 不一样了,而level1 仅只是比较目前的文件系统与 level 0 之间的差异后,备份有变化过的文件而已。至于 level 2则是与 level 1 进行比较。
虽然dump支持整个文件系统或者是单一目录,但是对于目录的支持是比较不足的,这也是dump的限制所在。简单地说,如果想要备份的数据如下时,则有不同的限制情况:
当待备份的数据为单一文件系统
如果是单一文件系统,那么该文件系统可以使用完整的dump功能,包括利用0~9的数个level来备份,同时,备份时可以使用挂载点或者是设备文件名(例如/dev/sda5 之类的设备文件名)来进行备份。
待备份的数据只是目录,并非单一文件系统
例如你仅想要备份/home/someone/,但是该目录并非独立的文件系统时。此时备份就有限制。包括:
所有的备份数据都必须要在该目录(本例为/home/someone/)下面;
且仅能使用 level 0,即仅支持完整备份而已;
不支持-u参数,即无法创建/etc/dumpdates这个level备份的时间记录文件。
dump 的参数虽然非常繁杂,不过如果只是想要简单的操作时,你只要记得下面的几个参数就很够用了。
[root@www ~]# dump [-Suvj] [-level] [-f 备份文件] 待备份数据
[root@www ~]# dump -W
参数:
-S :仅列出后面的待备份数据需要多少磁盘空间才能够备份完毕;
-u :将这次 dump的时间记录到 /etc/dumpdateS文件中;
-v :将 dump的文件过程显示出来;
-j :加入bzip2的支持,将数据进行压缩,默认bzip2压缩等级为 2;
-level:就是我们谈到的等级,从 -0 ~ -9 共10个等级;
-f :有点类似tar,后面接产生的文件,可接例如 /dev/st0 设备文件名等;
-W :列出在 /etc/fstab 里面的具有 dump设置的分区是否有备份过。
用dump备份完整的文件系统
现在就让我们来做几个范例。假如你要将系统的最小的文件系统找出来进行备份,那该如何进行呢?
1. 先找出系统中最小的那个文件系统,如下所示:
[root@www ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/hdc2 9.5G 3.7G 5.3G 42% /
/dev/hdc3 4.8G 651M 3.9G 15% /home
/dev/hdc1 99M 11M 83M 12% /boot <==看起来最小的就是它。
tmpfS 363M 0 363M 0% /dev/shm
2. 先测试一下如果要备份此文件系统需多少容量
[root@www ~]# dump -S/dev/hdc1
5630976 <==注意一下,这个单位是 byte,所以差不多是 5.6MB。
3. 将完整备份的文件名记录成为 /root/boot.dump,同时更新记录文件:
[root@www ~]# dump -0u -f /root/boot.dump/boot
DUMP: Date of thiSlevel0dump: Tue Dec 2 02:53:45 2008<==记录等级与备份时间
DUMP: Dumping /dev/hdc1(/boot)to /root/boot.dump <==dump的源与目标
DUMP: Label: /boot <==文件系统的 label
DUMP: Writing 10 Kilobyte records
DUMP: mapping (PasSI)[regular files] <==开始进行文件对应
DUMP: mapping (PasSII)[directories]
DUMP: estimated 5499 blocks. <==评估整体block数量
DUMP: Volume1started with block1at: Tue Dec 2 02:53:46 2008
DUMP: dumping (PasSIII)[directories] <==开始 dump工作
DUMP: dumping (PasSIV)[regular files]
DUMP:Closing /root/boot.dump <==结束写入备份文件
DUMP: Volume1completed at: Tue Dec 2 02:53:47 2008
DUMP: Volume15550 blockS(5.42MB) <==最终备份数据容量
DUMP: Volume1took 0:00:01
DUMP: Volume1transfer rate: 5550 kB/s
DUMP: 5550 blockS(5.42MB)on1volume(s)
DUMP: finished in1seconds, throughput 5550 kBytes/sec
DUMP: Date of thiSlevel0dump: Tue Dec 2 02:53:45 2008
DUMP: Date thiSdumpCompleted: Tue Dec 2 02:53:47 2008
DUMP: Average transfer rate: 5550 kB/s
DUMP: DUMPISDONE
在命令的执行方面,dump后面接 /boot 或 /dev/hdc1都可以的。
而执行 dump的过程中会出现如上的一些信息,你可以自行仔细查看。
[root@www ~]# ll /root/boot.dump/etc/dumpdates
-rw-rw-r—1root disk 43 Dec 2 02:53 /etc/dumpdates
-rw-r—r—1root root 5683200 Dec 2 02:53 /root/boot.dump
由于加上 -u 的选项,因此 /etc/dumpdates文件的内容会被更新。注意,
这个文件仅有在 dump完整的文件系统时才有支持自动更新的功能。
4. 查看一下系统自动新建的记录文件:
[root@www ~]#cat /etc/dumpdates
/dev/hdc1 0 Tue Dec 2 02:53:47 2008 +0800
[文件系统] [等级] [ Ctime 的时间 ]
这样很简单地就新建了/root/boot.dump 文件,该文件将整个/boot/文件系统都备份下来了。并且将备份的时间写入/etc/dumpdates文件中,准备让下次备份时可以作为一个参考依据。现在让我们来进行一个测试,检查看看能否真的新建 level 1 的备份呢。
1. 看一下有没有任何文件系统被 dump过的数据
[root@www ~]# dump -W
Last dump(s)done (Dump'>' file systems):
> /dev/hdc2 ( /)Last dump: never
> /dev/hdc3 ( /home)Last dump: never
/dev/hdc1 ( /boot)Last dump: Level 0, Date Tue Dec 2 02:53:47 2008
如上面的结果,该结果会找出 /etc/fstab 里面第五字段设置有需要 dump的
分区,然后与 /etc/dumpdateS进行比对,可以得到上面的结果。
尤其是第三行,可以显示我们曾经对 /dev/hdc1进行过 dump的备份操作。
2. 先恶搞一下,新建一个大约 10 MB 的文件在 /boot 内:
[root@www ~]#dd if=/dev/zero of=/boot/testing.img bs=1MCount=10
10+0 recordSin
10+0 recordSout
10485760 byteS(10 MB)Copied, 0.166128 seconds, 63.1MB/s
3. 开始新建差异备份文件,此时我们使用 level 1吧:
[root@www ~]# dump -1u -f /root/boot.dump.1/boot
….(中间省略)….
[root@www ~]# ll /root/boot*
-rw-r—r—1root root 5683200 Dec 2 02:53 /root/boot.dump
-rw-r—r—1root root 10547200 Dec 2 02:56 /root/boot.dump.1
看看文件大小,岂不是就是刚才我们所新建的那个大文件的大小吗?
4. 最后再看一下是否有记录 level 1备份的时间点呢?
[root@www ~]# dump -W
Last dump(s)done (Dump'>' file systems):
> /dev/hdc2 ( /)Last dump: never
> /dev/hdc3 ( /home)Last dump: never
> /dev/hdc1 ( /boot)Last dump: Level 1, Date Tue Dec 2 02:56:33 2008
….(中间省略)….
通过这个简单的方式,我们就能够仅备份差异文件的部分了。下面再来看看针对单一目录的dump用途。
用dump备份非文件系统,即单一目录的方法
现在让我们来处理一下/etc的dump备份。因为/etc并非单一文件系统,它只是个目录而已。所以依据限制的说明,-u evel 1~9 都是不适用的。我们只能够使用 level 0 的完整备份将/etcdump 下来,因此就变得很简单了。
让我们将 /etc 整个目录通过 dump进行备份,且含压缩功能
[root@www ~]# dump -0j -f /root/etc.dump.bz2 /etc
DUMP: Date of thiSlevel0dump: Tue Dec 2 12:08:22 2008
DUMP: Dumping /dev/hdc2 (/ (dir etc))to /root/etc.dump.bz2
DUMP: Label: /1
DUMP: Writing 10 Kilobyte records
DUMP:Compressing output atCompression level 2 (bzlib)
DUMP: mapping (PasSI)[regular files]
DUMP: mapping (PasSII)[directories]
DUMP: estimated 115343 blocks.
DUMP: Volume1started with block1at: Tue Dec 2 12:08:23 2008
DUMP: dumping (PasSIII)[directories]
DUMP: dumping (PasSIV)[regular files]
DUMP:Closing /root/etc.dump.bz2
DUMP: Volume1completed at: Tue Dec 2 12:09:49 2008
DUMP: Volume1took 0:01:26
DUMP: Volume1transfer rate: 218 kB/s
DUMP: Volume1124680kB uncompressed, 18752kBCompressed, 6.649:1
DUMP: 124680 blockS(121.76MB)on1volume(s)
DUMP: finished in 86 seconds, throughput 1449 kBytes/sec
DUMP: Date of thiSlevel0dump: Tue Dec 2 12:08:22 2008
DUMP: Date thiSdumpCompleted: Tue Dec 2 12:09:49 2008
DUMP: Average transfer rate: 218 kB/s
DUMP: Wrote 124680kB uncompressed, 18752kBCompressed, 6.649:1
DUMP: DUMPISDONE
上面特殊字体的部分显示:原本有 124680KB 的容量,被压缩成为 18752KB,
整个压缩比为 6.649:1,还可以。
一般来说dump不会使用包含压缩的功能,不过如果你想要将备份的空间降低的话,那个-j的参数是可以使用的。加上-j之后你的dump结果会使用较少的硬盘空间。如上述的情况来看,文件大小由原本的128MB左右下滑到18MB左右,当然可以节省备份空间。
9.4.2 restore
备份文件就是在急用时可以恢复系统的重要数据,所以有备份当然就得要学学如何恢复了。dump的恢复使用的是 restore 这个命令。这个命令的参数也非常多,你可以自行 man restore。鸟哥在这里仅作个简单的介绍。
[root@www ~]# restore -t [-f dumpfile] [-h] <==用来查看 dump文件
[root@www ~]# restore -C [-f dumpfile] [-D挂载点] <==比较dump与实际文件
[root@www ~]# restore -i [-f dumpfile] <==进入互动模式
[root@www ~]# restore -r [-f dumpfile] <==还原整个文件系统
参数:
相关的各种模式,各种模式无法混用。例如不可以写 -tC 。
-t :此模式用在查看 dump起来的备份文件中含有什么重要数据。类似tar-t 功能。
-C :此模式可以将 dump内的数据拿出来跟实际的文件系统做比较,
最终会列出“在 dump文件内有记录的,且目前文件系统不一样”的文件。
-i :进入互动模式,可以仅还原部分文件,用在 dump目录时的还原。
-r :将整个文件系统还原的一种模式,用在还原针对文件系统的 dump备份。
其他较常用到的参数功能:
-h :查看完整备份数据中的 inode 与文件系统 label 等信息。
-f :后面就接你要处理的那个 dump文件。
-D :与 -C 进行搭配,可以查出后面接的挂载点与 dump内有不同的文件。
用restore查看dump后的备份数据内容
要找出dump的内容就使用restore -t来查阅。例如我们将boot.dump的文件内容显示出来看看。
[root@www ~]# restore -t -f /root/boot.dump
Dump date: Tue Dec 2 02:53:45 2008 <==说明备份的日期
Dumped from: the epoch
Level0dumpof /boot on www.vbird.tsai:/dev/hdc1 <==说明 level 状态
Label: /boot <==说明该文件系统的表头。
2 .
11 ./lost+found
2009 ./grub
2011 ./grub/grub.conf
….下面省略….
[root@www ~]# restore -t -f /root/etc.dump
Dumptape isCompressed. <==加注说明数据有压缩
Dump date: Tue Dec 2 12:08:22 2008
Dumped from: the epoch
Level0dumpof / (dir etc)on www.vbird.tsai:/dev/hdc2 <==是目录。
Label: /1
2 .
1912545 ./etc
1912549 ./etc/rpm
1912550 ./etc/rpm/platform
….下面省略….
这个查阅的数据其实显示出的是文件名与原文件的inode状态,所以我们可以说,dump会参考inode的记录。通过这个查询我们也能知道dump的内容为何。再来查一查如何还原。
比较差异并且还原整个文件系统
为什么 dump 可以进行累积备份呢?就是因为它具有可以查询文件系统与备份文件之间的差异,并且将分析到的差异数据进行备份的缘故。所以我们先来看看,如何查询有变动过的信息呢?你可以使用如下的方法检验:
1. 先尝试更改文件系统的内容:
[root@www ~]#cd /boot
[root@www boot]# mvConfig-2.6.18-128.el5Config-2.6.18-128.el5-back
2. 看看查询文件系统与备份文件之间的差异。
[root@www boot]# restore -C -f /root/boot.dump
Dump date: Tue Dec 2 02:53:45 2008
Dumped from: the epoch
Level0dumpof /boot on www.vbird.tsai:/dev/hdc1
Label: /boot
filesys= /boot
restore: unable to stat ./config-2.6.18-128.el5: No such file or directory Some fileSwere modified!
1compare errors
看到上面的特殊字体了吧。那就是有差异的部分。总共有一个文件被更改。
我们刚才确实有改动过该文件。
3. 将文件系统改回来。
[root@www boot]# mv config-2.6.18-128.el5-back config-2.6.18-128.el5
[root@www boot]#cd /root
如同上面的操作,通过曾经备份过的信息,也可以找到与目前实际文件系统中有差异的数据呢。如果你不想要进行累积备份,但也能通过这个操作找出最近这一阵子有变动过的文件。那如何还原呢?由于dump是记录整个文件系统的,因此还原时你也应该要给予一个全新的文件系统才行。因此下面我们先新建一个文件系统,然后再来还原。
1. 先新建一个新的分区来使用,假设我们需要的是 150MB 的容量
[root@www ~]# fdisk /dev/hdc
Command (m for help): n
FirstCylinder (2335-5005, default 2335): <==这里按[Enter]
Using default value 2335
LastCylinder or +size or +sizeM or +sizeK (2335-5005, default 5005): +150M
Command (m for help): p
….中间省略….
/dev/hdc8 2335 2353 152586 83 Linux
Command (m for help): w
[root@www ~]# partprobe <==很重要的操作。别忘记。
这样就能够新建一个 /dev/hdc8 的分区,然后继续格式化。
[root@www ~]# mkfS -t ext3 /dev/hdc8
[root@www ~]# mount /dev/hdc8 /mnt
2. 开始进行还原的操作。请你务必回到新文件系统的挂载点下面。
[root@www ~]#cd /mnt
[root@www mnt]# restore -r -f /root/boot.dump
restore: ./lost+found: File exists
由于我们是备份整个文件系统,因此你也可以构建一个全新的文件系统来进行还原的操作。整个还原的操作也不难,如上面最后一个命令,就是将备份文件中的数据还原到本目录下。你必须要更改目录到挂载点所在的那个目录才行。这样还原的文件才不会跑错地方。如果你还想要将 level 1的/root/boot.dump.1那个文件的内容也还原的话,那就继续使用“restore –r –f /root/ boot.dump.1”去还原。
仅还原部分文件的restore互动模式
某些时候你只是要将备份文件的某个内容找出来而已,并不想要全部解开,那该如何是好?此时你可以进入 restore 的互动模式(interactive mode)。在下面我们使用 etc.dump 来进行范例说明。假如你要将 etc.dump 内的 passwd 与 shadow 找出来而已,该如何进行呢?
[root@www ~]# cd /mnt
[root@www mnt]# restore -i -f /root/etc.dump
restore >
此时你就已经进入 restore 的互动模式解密中。要注意的是:
你目前已经在 etc.dump这个文件内了。所有的操作都是在 etc.dump内。
restore > help
AvailableCommandSare:
lS[arg] - list directory <==列出 etc.dump内的文件或目录
Cd arg -Change directory <==在 etc.dump内更改目录
pwd - printCurrent directory <==列出 etc.dump内的路径文件名
add [arg] - add `arg' to list of fileSto be extracted
delete [arg] - delete `arg' from list of fileSto be extracted
extract - extract requested files
上面三个命令是重点。各命令的功能为:
add file :将 file 加入等一下要解压缩的文件列表中
delete file :将 file解压缩的列表中删除,并非删除 etc.dump内的文件。
extract :开始将刚才选择的文件列表解压缩。
setmodeS- set modeSof requested directories
quit - immediately exit program
what - list dumpheader information
verbose - toggle verbose flag (useful with ``ls'')
prompt - toggle the prompt display
helpor `?' - print thiSlist
restore > ls
.:
etc/ <==会显示出在 etc.dump内主要的目录,因为我们备份 /etc ,所以文件名为此。
restore >cd etc <==在 etc.dump内变换路径到 etc 目录下
restore > pwd <==列出本目录的文件名为?
/etc
restore > lSpasswd shadowgroup <==看看,真的有这三个文件。
passwd
shadow
group
restore > add passwd shadowgroup<==加入解压缩列表
restore > delete group <==加错了。将group从解压缩列表中删除
restore > ls passwd shadowgroup
passwd <==有要被解压缩的,文件名之前会出现 的符号。
*shadow
group
restore > extract <==开始进行解压缩。
You have not read any volumeSyet. <==这里会询问你需要的volume
UnlesSyou know which volume your file(s)are on you should start
with the last volume and work towardSthe first.
Specify next volume # (none if no more volumes):1<==只有一个 volume
set owner/mode for '.'? [yn] n <==不需要修改权限
restore > quit <==离开 restore 的功能
[root@www ~]# ll -d etc
drwxr-xr-x 2 root root 1024 Dec 15 17:49 etc <==解压缩后所新建出来的目录。
[root@www ~]# ll etc
total 6
-rw-r—r—1root root 1945 Sep29 02:21passwd
-r————1root root 1257 Sep29 02:21shadow
通过交互式的 restore 功能,可以让你将备份的数据取出一部份,而不必全部都得解压缩才能够取得你想要的文件数据。而restore内的add除了可以增加文件外,也能够增加整个备份的目录。
9.5 光盘写入工具
某些时刻你可能会希望将系统上最重要的数据备份出来,虽然目前U盘已经够便宜,你可以使用U 盘来备份。不过某些重要的、需要重复备份的数据(可能具有时间特性),你可能会需要使用类似DVD之类的存储媒体来备份出来。举例来说,你的系统配置文件或者是讨论区的数据库文件(变动性非常频繁)。虽然Linux图形解密已经有不少的刻录软件可用,但有时如果你希望系统自动在某些时刻帮你主动进行刻录时,那么命令行界面的刻录行为就有帮助了。
那么命令行模式的刻录行为要怎么处理呢?通常的做法是这样的:
先将所需要备份的数据构建成为一个镜像文件(iso),利用mkisofs命令来处理;
将该镜像文件刻录至光盘或DVD当中,利用cdrecord命令来处理。
下面我们就分别来谈谈这两个命令的用法。
9.5.1 mkisofs:新建镜像文件
我们从FTP站下载下来的Linux镜像文件(不管是CD还是DVD)都得要继续刻录成为光盘/DVD后,才能够进一步的使用,包括安装或更新你的 Linux。同样的道理,你想要利用刻录机将你的数据刻录到DVD时,也得要先将你的数据包成一个镜像文件,这样才能够写入DVD片中。而将你的数据包成一个镜像文件的方式就通过mkisofs这个命令。mkisofs的使用方式如下:
[root@www ~]# mkisofs [-o镜像文件] [-rv] [-m file] 待备份文件.. [-V vol] \
> -graft-point isodir=systemdir …
参数:
-o :后面接你想要产生的那个镜像文件名。
-r :通过 Rock Ridge 产生支持 UNIX/Linux 的文件数据,可记录较多的信息。
-v :显示构建 ISO 文件的过程。
-m file :-m 为排除文件 (exclude)的意思,后面的文件不备份到镜像文件中。
-V vol :新建 Volume。
-graft-point:graft有转嫁或移植的意思,相关数据在下面文章内说明。
其实mkisofs有非常多好用的参数可以选择,不过如果我们只是想要制作数据光盘时,上述的参数也就够用了。光盘的格式一般称为 ISO9660,这种格式一般仅支持旧版的 DOS 文件名,即文件名只能以8.3(文件名8个字符,扩展名3个字符)的方式存在。如果加上-r的参数之后,那么文件信息能够被记录得比较完整,可包括UID/GID与权限等。所以,记得加这个-r的参数。
此外,一般默认的情况下,所有要被加到镜像文件中的文件都会被放置到镜像文件中的根目录,如此一来可能会造成刻录后的文件分类不易的情况。所以,你可以使用-graft-point 这个参数,当你使用这个参数之后,可以利用如下的方法来定义位于镜像文件中的目录,例如:
镜像文件中的目录所在=实际Linux文件系统的目录所在
/movies/=/srv/movies/(在Linux的/srv/movies内的文件,加至镜像文件中的/movies/目录)
/linux/etc=/etc(将Linux中的/etc/内的所有数据备份到镜像文件中的/linux/etc/目录中)
我们通过一个简单的范例来说明一下。如果你想要将/root,/home,/etc等目录内的数据全部刻录起来的话,先得要处理一下镜像文件,我们先不使用-graft-point参数来处理这个镜像文件试看看:
[root@www ~]# mkisofS -r -v -o /tmp/system.img /root /home /etc
INFO: ISO-8859-1character encoding detected by locale settings.
Assuming ISO-8859-1encoded filenameSon source filesystem,
use -input-charset to override.
mkisofS2.01(cpu-pc-linux-gnu)
Scanning /root
Scanning /root/test4
….中间省略….
97.01% done, estimate finish Tue Dec 16 17:07:14 2008 <==显示百分比
98.69% done, estimate finish Tue Dec 16 17:07:15 2008
Total translation table size: 0
Total rockridge attributes bytes: 9840 <==额外记录属性所占用的空间
Total directory bytes: 55296 <==目录占用空间
Path table size(bytes): 406
Done with: The File(s) Block(s) 298728
Writing: Ending Padblock Start Block 298782
Done with: Ending Padblock Block(s) 150
Max brk space used 0
298932 extents written(583 MB)
[root@www ~]# ll -h /tmp/system.img
-rw-r—r—1root root 584M Dec 16 17:07 /tmp/system.img
[root@www ~]# mount -o loop/tmp/system.img /mnt
[root@www ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/tmp/system.img 584M 584M 0100% /mnt <==就是这玩意。
[root@www ~]# ls /mnt
alex Crontab2 etc.tar.gz system.tar.bz2
anaconda-ks.cfg etc install.log test1
arod etc.and.root.tar.bz2 install.log.syslog test2
boot.dump etc.dump loopdev test3
看吧。一堆数据都放置在一起。包括有的没有的目录与文件等等。
[root@www ~]# umount /mnt
由上面的范例我们可以看到,三个目录(/root, /home, /etc)的数据全部放置到了镜像文件的最顶层目录中。真是不方便,尤其由于/root/etc 的存在,导致那个/etc 的数据似乎没有被包含进来。真不合理,而且还有lost+found的目录存在。此时我们可以使用-graft-point来处理。
[root@www ~]# mkisofS -r -V 'linux_file' -o /tmp/system.img \
> -m /home/lost+found -graft-point /root=/root /home=/home /etc=/etc
[root@www ~]# ll -h /tmp/system.img
-rw-r—r—1root root 689M Dec 17 11:41/tmp/system.img
上面的命令会新建一个大文件,其中 -graft-point 后面接的就是我们要备份的数据。
必须要注意的是那个等号的两边,等号左边是在镜像文件内的目录,右侧则是实际的数据。
[root@www ~]# mount -o loop/tmp/system.img /mnt
[root@www ~]# ll /mnt
dr-xr-xr-x 105 root root 32768 Dec 17 11:40 etc
dr-xr-xr-x 5 root root 2048 Dec 17 11:40 home
dr-xr-xr-x 7root root 4096 Dec 17 11:40 root
数据是分门别类地放在各个目录中,最后将数据卸载一下:
[root@www ~]# umount /mnt
其实鸟哥一直觉得很奇怪,怎么我的数据会这么大(600多MB)?原来是/home里面在第8章的时候,练习时多了一个/home/loopdev的大文件。所以重新制作一次iso文件,并多加一个“-m/home/loopdev”来排除该文件的备份,最终的文件则仅有176MB。接下来让我们处理刻录的操作了。
9.5.2 cdrecord:光盘刻录工具
我们是通过cdrecord这个命令来进行命令行界面的刻录,这个命令常见的参数有下面几个。
[root@www ~]#cdrecord -scanbuSdev=ATA <==查询刻录机位置
[root@www ~]#cdrecord -v dev=ATA:x,y,z blank=[fast|all] <==抹除重复读写片
[root@www ~]#cdrecord -v dev=ATA:x,y,z -format <==格式化DVD+RW
[root@www ~]#cdrecord -v dev=ATA:x,y,z [可用参数功能] file.iso
参数:
-scanbuS :用在扫描磁盘总线并找出可用的刻录机,后续的设备为 ATA 接口
-v :在cdrecord运行的过程中,显示过程而已。
dev=ATA:x,y,z :后续的 x, y, z 为你系统上刻录机所在的位置,非常重要。
blank=[fast|all]:blank 为抹除可重复写入的CD/DVD-RW,使用fast较快,all较完整。
-format :仅针对 DVD+RW 这种格式的DVD而已。
[可用参数功能] 主要是写入CD/DVD 时可使用的参数,常见的参数包括:
-data :指定后面的文件以数据格式写入,不是以CD 音轨(-audio)方式写入。
speed=X :指定刻录速度,例如CD可用 speed=40 为40倍数,DVD则可用 speed=4 之类。
-eject :指定刻录完毕后自动退出光盘。
fs=Ym :指定多少缓冲存储器,可用在将镜像文件先暂存至暂存区。默认为 4M,
一般建议可增加到 8M,不过,还是得视你的刻录机而定。
针对DVD的参数功能:
driveropts=burnfree :打开 Buffer Underrun Free 模式的写入功能
-sao :支持 DVD-RW 的格式
检测你的刻录机所在位置
命令行模式的刻录确实是比较麻烦,因为没有所见即所得的环境。要刻录首先就得要找到刻录机才行。而由于早期的刻录机都是使用SCSI接口,因此查询刻录机的方法就得要配合着SCSI接口的认定来处理了。查询刻录机的方式为:
[root@www ~]#cdrecord –scanbus dev=ATA
Cdrecord-Clone 2.01(cpu-pc-linux-gnu)Copyright (C)1995-2004 J?rg Schilling
….中间省略….
scsibus1:
1,0,0 100)*
1,1,0 101)'ASUS ' 'DRW-2014S1 ' '1.01' Removable CD-ROM
1,2,0 102)*
1,3,0 103)*
1,4,0 104)*
1,5,0 105)*
1,6,0 106)*
1,7,0 107)*
利用 cdrecord -scanbus 就能够找到正确的刻录机。由于目前个人计算机上最常使用的磁盘驱动器接口为IDE与SATA,这两种接口都能够使用dev=ATA这种模式来查询,因此上述的命令得要背一下。另外,在查询的结果当中可以发现有一台刻录机,其中也显示出这台刻录机的型号,而最重要的就是上面有底线的那三个数字。那三个数字就是代表这台刻录机的位置。以上的例子中,这台刻录机的位置在“ATA:1,1,0”这个地方。
那么现在要如何将/tmp/system.img刻录到CD/DVD里面去呢?鸟哥这里先以CD为例,鸟哥用的是CD-RW(可重复读写)的光盘,虽然CD-RW或DVD-RW比较贵一点,不过至少可以重复利用,对环境的冲击比较小。建议大家使用可重复读写的光盘。由于CD-RW可能要先进行抹除的工作(将原本里面的数据删除)然后才能写入,因此,下面我们先来看看如何抹除一片CD/DVD的方法,然后直接写入光盘。
由于CD/DVD 都是使用cdrecord这个命令,因此不论是CD还是DVD,下达执行命令的方法都差不多!不过,DVD 的写入需要额外的driveropts=burnfree 或 -dao等选项的辅助才行。另外,CD有CD-R((一次写入))与CD-RW((重复写入)),至于DVD则主要有两种格式,分别是DVD-R及DVD+R两种格式。如果是可重复读写的则为DVD-RW和DVD+RW。除了DVD+RW的抹除方法可能不太一样之外,其他写入的方式则是一样的。
进行CD的刻录操作
1. 先抹除光盘的原始内容(非可重复读写则可略过此步骤):
[root@www ~]#cdrecord -v dev=ATA:1,1,0 blank=fast
中间会显示出一堆信息告诉你抹除的进度,而且会有 10 秒钟的时间等待你的取消。
可以避免“手滑”的情况。
2. 开始刻录:
[root@www ~]#cdrecord -v dev=ATA:1,1,0 fs=8m -dummy -data \
> /tmp/system.img
….中间省略….
Track 01: 168 of 176 MB written (fifo 100%)[buf 100%] 10.5x. <==显示百分比
上面会显示进度,还有 10.5x 代表目前的刻录速度。
cdrecord: fifo had 2919 putSand 2919gets.
cdrecord: fifo was0timeSempty and 2776 timeSfull, min fill waS97%.
3. 刻录完毕后,测试挂载一下,检验内容:
[root@www ~]# mount -t iso9660 /dev/cdrom /mnt
[root@www ~]# df -h /mnt
Filesystem Size Used Avail Use% Mounted on
/dev/hdd 177M 177M 0100% /mnt <==确实是光盘内容。
[root@www ~]# ll /mnt
dr-xr-xr-x 105 root root 32768 Dec 17 11:54 etc
dr-xr-xr-x 5 root root 2048 Dec 17 11:54 home
dr-xr-xr-x 7root root 4096 Dec 17 11:54 root
[root@www ~]# umount /mnt <==不要忘了卸载
事实上如果你忘记抹除可写入光盘时,其实 cdrecord 很聪明,会主动帮你抹除。因此上面的信息你只要记得刻录的功能即可。特别注意-data 那个参数。因为如果没有加上-data 的参数时,默认数据会以音轨格式写入光盘中,所以最好能够加上-data 这个参数。上述的功能是针对 CD,下面我们使用一张可重复读写的DVD-RW来测试一下写入的功能。
进行DVD-RW的刻录操作
1. 同样,先来抹除一下原本的内容:
[root@www ~]#cdrecord -v dev=ATA:1,1,0 blank=fast
2. 开始写入 DVD,请注意,有些参数与CD 并不相同了。
[root@www ~]#cdrecord -v dev=ATA:1,1,0 fs=8m -data -sao \
> driveropts=burnfree /tmp/system.img
3. 同样,来给他测试测试。
[root@www ~]# mount /dev/cdrom /mnt
[root@www ~]# df -h /mnt
Filesystem Size Used Avail Use% Mounted on
/dev/hdd 177M 177M 0100% /mnt
[root@www ~]# umount /mnt
整体命令没有很大的区别。只是CD-RW会自动抹除,但DVD-RW似乎得要自己手动抹除才行,并不会主动进入自动抹除的功能,害得鸟哥重新测试过好几次。现在你就知道如何将你的数据刻录出来了。
如果你的Linux是用来作为服务器之用的话,那么无时无刻去想如何备份重要数据是相当重要的。关于备份我们会在第五篇再仔细谈一谈,这里你要会使用这些工具即可。
9.6 其他常见的压缩与备份工具
还有一些很好用的工具得要跟大家介绍,尤其是dd这个命令。
9.6.1 dd
我们在第8章当中的特殊loop设备挂载时使用过dd这个命令对吧?不过,这个命令可不只是制作一个文件而已。这个dd命令最大的功效,鸟哥认为,应该是在于“备份”。因为dd可以读取磁盘设备的内容(几乎是直接读取扇区),然后将整个设备备份成一个文件呢。真的是相当好用,dd的用途有很多,但是我们仅讲一些比较重要的参数,如下:
[root@www ~]#dd if="input_file" of="output_file" bs="block_size" \
>count="number"
参数:
if :就是 input file ,也可以是设备。
of :就是 output file ,也可以是设备。
bs :规划的一个 block 的大小,若未指定则默认是 512bytes(一个扇区的大小)。
count:多少个 bs的意思。
范例一:将 /etc/passwd 备份到 /tmp/passwd.back 当中
[root@www ~]#dd if=/etc/passwd of=/tmp/passwd.back
3+1recordSin
3+1recordSout
1945 byteS(1.9 kB)Copied, 0.000332893 seconds, 5.8 MB/s
[root@www ~]# ll /etc/passwd /tmp/passwd.back
-rw-r—r—1root root 1945 Sep29 02:21/etc/passwd
-rw-r—r—1root root 1945 Dec 17 18:09 /tmp/passwd.back
仔细看一下,我的 /etc/passwd 文件大小为 1945bytes,因为我没有设置 bs,
所以默认是 512bytes为一个单位,因此,上面那个 3+1表示有 3 个完整的
512bytes,以及未满 512bytes的另一个 block 的意思。
事实上,感觉好像是cp这个命令。
范例二:将自己的磁盘第一个扇区备份下来
[root@www ~]#dd if=/dev/hdc of=/tmp/mbr.back bs=512Count=1
1+0 recordSin
1+0 recordSout
512 byteS(512 B)Copied, 0.0104586 seconds, 49.0 kB/s
第一个扇区内含有 MBR 与分区表,通过这个操作,
我们可以一口气将这个磁盘的 MBR 与分区表进行备份。
范例三:找出你系统最小的那个分区,并且将它备份下来:
[root@www ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/hdc2 9.5G 3.9G 5.1G 44% /
/dev/hdc3 4.8G 651M 3.9G 15% /home
/dev/hdc1 99M 21M 73M 23% /boot <==就备份它好了。
[root@www ~]#dd if=/dev/hdc1of=/tmp/boot.whole.disk
208782+0 recordSin
208782+0 recordSout
106896384 byteS(107 MB)Copied, 6.24721seconds, 17.1MB/s
[root@www ~]# ll -h /tmp/boot.whole.disk
-rw-r—r—1root root 102M Dec 17 18:14 /tmp/boot.whole.disk
等于是将整个 /dev/hdc1通通备份下来的意思,如果要还原呢?就反向回去。
ddif=/tmp/boot.whole.disk of=/dev/hdc1即可。非常简单。
简单地说,如果想要整个硬盘备份的话,就类似 Norton 的ghost 软件一般,
由 disk 到 disk,利用dd就可以了。
你可以说,tar可以用来备份关键数据,而 dd则可以用来备份整块分区或整块磁盘,如果要将数据填回到文件系统当中,可能需要考虑到原本的文件系统才能成功。让我们来完成下面的例题试看看。

你想要将你的/dev/hdc1 完整地复制到另一个分区上,请使用你的系统上面未分区完毕的空间再新建一个与/dev/hdc1差不多大小的分区(只能比/dev/hdc1大,不能比它小),然后将之进行完整的复制(包括需要复制启动扇区的区块)。
答:由于需要复制启动扇区的区块,所以使用cp或者是tar这种指令命令是无法达成完成需求的。此时那个dd就派上用场了。你可以这样做:
1. 先进行分区的操作
[root@www ~]# fdisk -l /dev/hdc
Device Boot Start End Blocks Id System
/dev/hdc1 * 1 13 104391 83 Linux
上面鸟哥仅获取重要的数据而已。我们可以看到 /dev/hdc1仅有 13 个磁柱
[root@www ~]# fdisk /dev/hdc
Command (m for help): n
FirstCylinder (2354-5005, default 2354):这里按 enter
Using default value 2354
LastCylinder or +size or +sizeM or +sizeK (2354-5005, default 5005): 2366
Command (m for help): p
Device Boot Start End BlockS Id System
/dev/hdc9 2354 2366 104391 83 Linux
Command (m for help): w
为什么要使用 2366 呢?因为 /dev/hdc1使用 13 个磁柱,因此新的分区
我们也给它 13 个磁柱,因此 2354 + 13 -1= 2366。
[root@www ~]# partprobe
2. 不需要格式化,直接进行扇区表面的复制。
[root@www ~]# dd if=/dev/hdc1of=/dev/hdc9
208782+0 recordSin
208782+0 recordSout
106896384 byteS(107 MB)Copied, 16.8797 seconds, 6.3 MB/s
[root@www ~]# mount /dev/hdc9 /mnt
[root@www ~]# df
Filesystem 1K-blockS Used Available Use% Mounted on
/dev/hdc1 101086 21408 74459 23% /boot
/dev/hdc9 101086 21408 74459 23% /mnt
这两个磁盘大小会“一模一样”。
[root@www ~]# umount /mnt
非常有趣的范例吧?新分区出来的分区不需要经过格式化,因为 dd 可以将原本旧的分区中扇区表面的数据整个复制过来。当然连同 superblock, boot sector, meta data 等全部也会复制过来。是否很有趣呢?未来你想要构建两块一模一样的磁盘时,只要执行“dd if=/dev/sda of=/dev/sdb”,就能够让两块磁盘一模一样,甚至/dev/sdb不需要分区与格式化,因为该命令可以将/dev/sda内的所有数据,包括MBR与分区表也复制到/dev/sdb中。
9.6.2 cpio
这个命令挺有趣的,因为cpio可以备份任何东西,包括设备设备文件。不过cpio有个大问题,那就是cpio不会主动去找文件来备份。cpio得要配合类似find等可以找到文件名的命令来告知cpio该被备份的数据在哪里。因为牵涉到我们在第三篇才会谈到的数据流重定向,所以这里你就先背一下语法,等到第三篇讲完你就知道如何使用cpio。
[root@www ~]#cpio -ovcB > [file|device] <==备份
[root@www ~]#cpio -ivcdu < [file|device] <==还原
[root@www ~]#cpio -ivct < [file|device] <==查看
备份会使用到的参数:
-o :将数据Copy 输出到文件或设备上。
-B :让默认的 Blocks可以增加至 5120 bytes,默认是 512 bytes。
这样的好处是可以让大文件的存储速度加快(请参考 i-nodes的观念。)
还原会使用到的参数:
-i :将数据自文件或设备复制到系统当中。
-d :自动新建目录。使用cpio 所备份的数据内容不见得会在同一层目录中,因此我们
必须要让cpio 在还原时可以新建新目录,此时就得要 -d 参数的帮助。
-u :自动将较新的文件覆盖较旧的文件。
-t :需配合 -i 参数,可用在查看以cpio 新建的文件或设备的内容。
一些可共享的参数:
-v :让存储的过程中文件名可以在屏幕上显示。
-c :一种较新的 portable format 方式存储。
你应该会发现一件事情,就是上述的参数与命令中怎么会没有指定需要备份的数据呢?还有那个大于(>)与小于(<)符号是怎么回事?因为 cpio 会将数据整个显示到屏幕上,因此我们可以通过将这些屏幕的数据重新导向(>)一个新的文件。至于还原呢?就是将备份文件读进来cpio(<)进行处理之意。我们来进行几个案例你就知道了。
范例:找出/boot 下面的所有文件,然后将它备份到 /tmp/boot.cpio 去。
[root@www ~]# find /boot -print
/boot
/boot/message
/boot/initrd-2.6.18-128.el5.img
….以下省略….
通过这个 find 我们可以找到 /boot 下面应该要存在的文件名,包括文件与目录
[root@www ~]# find /boot |Cpio -ocvB > /tmp/boot.cpio
[root@www ~]# ll -h /tmp/boot.cpio
-rw-r—r—1root root 16M Dec 17 23:30 /tmp/boot.cpio
我们使用 find/boot 可以找出文件名,然后通过“|”(即键盘上的 shift+\的组合),就能将文件名传给cpio来进行处理,最终会得到/tmp/boot.cpio那个文件。接下来让我们来进行解压缩看看。
范例:将刚才的文件在 /root/ 目录下解开
[root@www ~]# cpio -idvc < /tmp/boot.cpio
[root@www ~]# ll /root/boot
你可以自行比较一下 /root/boot 与 /boot 的内容是否一模一样。
事实上 cpio 可以将系统的数据完整地备份到磁带机上头去(如果你有磁带机的话)。
备份:find/|cpio-ocvB>/dev/st0
还原:cpio-idvc</dev/st0
这个cpio好像不怎么好用。但是,它可是备份的时候的一项利器。因为它可以备份任何的文件,包括/dev 下面的任何设备文件。所以它可是相当重要的呢。而由于 cpio 必须要配合其他的程序,例如find来新建文件名,所以cpio与管道命令及数据流重定向的相关性就相当重要了。
其实系统里面已经含有一个使用 cpio 新建的文件。那就是/boot/initrd-xxx 这个文件。现在让我们来将这个文件解压缩看看,看你能不能发现该文件的内容为何。
1. 我们先来看看该文件是属于什么文件格式,然后再加以处理:
[root@www ~]# file /boot/initrd-2.6.18-128.el5.img
/boot/initrd-2.6.18-128.el5.img:gzip Compressed data, …
看起来似乎是使用gzip进行压缩过,那如何处理呢?
2. 通过更名,将该文件增加扩展名,然后予以解压缩看看:
[root@www ~]# mkdir initrd
[root@www ~]#cd initrd
[root@www initrd]#cp/boot/initrd-2.6.18-128.el5.img initrd.img.gz
[root@www initrd]#gzip -d initrd.img.gz
[root@www initrd]# ll
-rw———-1root root 5408768 Dec 17 23:53 initrd.img
[root@www initrd]# file initrd.img
initrd.img: ASCIICpio archive (SVR4 with noCRC)
确实是cpio 的文件。
3. 开始使用cpio 解开此文件:
[root@www initrd]#Cpio -iduvc < initrd.img
sbin
init
sysroot
….以下省略….
这样就将这个文件解开了。
9.7 重点回顾
压缩命令为通过一些运算方法去将原本的文件进行压缩,以减少文件所占用的磁盘空间。压缩前与压缩后的文件所占用的磁盘空间比值,就可以称为“压缩比”。
压缩的好处是可以减少磁盘空间的浪费,在WWW网站也可以利用文件压缩的技术来进行数据的传送,好让网站带宽的可利用率上升。
压缩文件的扩展名大多是.tar,.tar.gz,.tgz,.gz,.Z,*.bz2。
常见的压缩命令有gzip与bzip2,其中bzip2压缩比gzip还要更好,建议使用bzip2。
tar可以用来进行文件打包,并可支持gzip或bzip2的压缩。
压 缩:tar -jcv –f filename.tar.bz2 被压缩的文件或目录名称。
查 询:tar -jtv -f filename.tar.bz2。
解压缩:tar –jxv -f filename.tar.bz2-C 欲解压缩的目录。
dump命令可备份文件系统或单一目录。
dump 的备份若针对文件系统时,可进行 0~9 的 level 差异备份。其中 level 0 为完整备份。
restore命令可还原被dump构建的备份文件。
要新建光盘刻录数据时,可通过mkisofs命令来构建。
可通过cdrecord来写入CD或DVD刻录机。
dd可备份完整的分区或磁盘,因为dd可读取磁盘的扇区表面数据。
cpio为相当优秀的备份命令,不过必须要搭配类似find命令来读入欲备份的文件名数据,才可进行备份操作。
9.8 本章习题
情境模拟题一
你想要让系统恢复到第8章情境模拟后的结果,即仅剩下/dev/hdc6以前的分区,本章练习产生的分区都需要恢复原状。因此/dev/hdc8,/dev/hdc9(在本章练习过程中产生的)请将它删除。删除的方法同第8章的情境模拟题一所示。
情境模拟题二
你想要逐时备份/srv/myproject 这个目录内的数据,又担心每次备份的信息太多,因此想要使用dump的方式来逐一备份数据到/backups这个目录下。该如何处理?
目标:了解到dump以及各个不同level的作用;
前提:被备份的数据为单一分区,即本例中的/srv/myproject;
需求:/srv/myproject为单一文件系统,且在/etc/fstab内此挂载点的dump字段为1。
实际处理的方法其实还挺简单的。我们可以这样做看看:
1.先替该目录制作一些数据,即复制一些东西过去。
cp -a/etc/boot/srv/myproject
2.开始进行 dump,记得,一开始是使用 level 0 的完整备份。
mkdir /backups
dump -0u –j –f /backups/myproject.dump/srv/myproject
上面多了个-j的参数,目的是为了要进行压缩,减少备份的数据量。
3.尝试将/srv/myproject这个文件系统加大,将/var/log/的数据复制进去。
cp –a /var/log//srv/myproject
此时原本的/srv/myproject已经被改变了。继续进行备份。
4.将/srv/myproject 以 level 1 来进行备份:
dump -1u –j –f /backups/myproject.dump.1/srv/myproject
ls -l/backups
你应该就会看到两个文件,其中第二个文件(myproject.dump.1)会小得多。这样就搞定了备份数据。
情境模拟三
假设过了一段时间后,你的 /srv/myproject 变得怪怪的,你想要将该文件系统以刚才的备份数据还原,此时该如何处理呢?你可以这样做的:
1.先将/srv/myproject卸载,并且将该分区重新格式化。
umount /dev/hdc6
mkfs –t ext 3/dev/hdc6
2.重新挂载原本的分区,此时该目录内容应该是空的。
mount –a
你可以自行使用 df 以及 ls -l/srv/myproject 查阅一下该目录的内容,是空的。
3.将完整备份的 level 0 的文件/backups/myproject.dump 还原回来:
cd /srv/myproject
restore –r –f /backups/myproject.dump
此时该目录的内容为第一次备份的状态,还需要进行后续的处理才行。
4.将后续的 level 1 的备份也还原回来:
cd /srv/myproject
restore –r –f /backups/myproject.dump.1
此时才是恢复到最后一次备份的阶段。如果还有 level 2,level 3 时,就得要一个一个依序还原才行。
9.9 参考数据与扩展阅读
台湾学术网络管理文件:BackupToolSin UNIX(Linux):
http://nmc.nchu.edu.tw/tanet/backup_tools_in_UNIX.htm
Linux How to 文件计划 (繁体):
http://www.linux.org.tw/CLDP/HOWTO/hardware/CD-Writing-HOWTO/CD-Writing-HOWTO-3.html
熊宝贝工作记录之Linux刻录实作:
http://csc.ocean-pioneer.com/docum/linux_burn.html
PHP5 网管实验室(繁体): http://www.php5.idv.tw/html.php?mod=article&do=show&shid=26
CentOS 5.x 之 man dump
CentOS 5.x 之 man restore
注 释
[2].参考维基百科所得数据,链接网址如下:条目:Ext2介绍http://en.wikipedia.org/wiki/Ext2
[3].PAVE为一套绘图软件,常应用于数值模式的输出文件再处理:PAVE使用手册:http://www.ie.unc.edu/cempd/EDSS/pave_doc/index.shtml
[8].NTFS 文件系统官网:Linux-NTFS Project: http://www.linux-ntfs.org/
[9].Linux内核所支持的硬件的设备代号(Major,Minor)查询:http://www.kernel.org/pub/linux/docs/device-list/devices.txt
