- 第12章 正则表达式与文件格式化处理
- dmesg 可列出内核产生的信息。通过 grep 来选取网卡相关信息 (eth) ,
- 就可发现如上信息。不过没有行号与特殊颜色显示。请看下个范例。
- 你会发现除了 eth 会有特殊颜色来表示之外,最前面还有行号。
- 如上所示,你会发现关键字 247 所在的前两行及 248 后三行也都被显示出来!
- 这样可以让你将关键字前后数据捕获出来进行分析。
- I am Vbird
- 那个 [:lower:] 代表的就是 a-z 的意思!请参考前两小节的说明
- 命令也可以是: grep -n '^[^[:alpha:]]' regular_express.txt
- 在 CentOS 中,结果可以发现有 33 行的输出,很多空白行与 # 开头
- 结果仅有 10 行,其中第一个“ -v '^$' ”代表不要空白行,
- 第二个“ -v '^#' ”代表不要开头是 # 的那行喔!
- 因为我们还没有讲到 IP ,这里你先有个概念即可啊。我们的重点在第二行,
- 也就是 192.168.1.100 那一行而已!先利用关键字找出那一行!
- 当场仅剩下一行!接下来,我们要将开始到 addr: 通通删除,就是像下面这样:
- inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
- 上面的删除关键在于“ ^.*inet addr: ”,正则表达式出现。
- 仔细与上个步骤比较一下,前面的部分不见了!接下来则是删除后续的部分,即:
- 192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
- 此时所需的正则表达式为“ Bcast.*$ ”
- when MANPATH contains an empty substring), to find out where the cat
- MANBIN pathname
- MANPATH manpath_element [corresponding_catdir]
- MANPATH_MAP path_element manpath_element
- MANBIN /usr/local/bin/man
- Every automatically generated MANPATH includes these fields
- 从上面可以看出来,原本批注的数据都变成空白行。所以,接下来要删除掉空白行
- 上头的 -i 参数可以让你的 sed 直接去修改后面接的文件内容而不是由屏幕输出。
- 这个范例是用在替换!请你自行 cat 该文件去查阅结果。
- 由于 $ 代表的是最后一行,而 a 的操作是新增,因此该文件最后新增。
- 这东西也很好玩。它可以将数值转换成为字符,如果你会写 script 的话,
- 可以自行测试一下,20~80 之间的数值代表的字符是什么。
- 注意喔!在 awk 内的 NR, NF 等变量要用大写,且不需要 $ 啦!
- 注意一下,sed 后面如果要接超过两个以上的动作时,每个动作前面得加 -e 才行!
- 通过这个动作,在 /tmp/test 里面便有新旧的 passwd 文件存在了!
- 用 diff 就把我们刚才的处理给比对完毕了!
- 文件就这样恢复成为旧版本
- Generated automatically from man.conf.in by the
- configure script.
第12章 正则表达式与文件格式化处理
正则表达式(Regular Expression)是通过一些特殊字符的排列,用以查找、替换、删除一行或多行文字字符串,简单地说,正则表达式就是用在字符串的处理上面的一项“表示式”。正则表达式并不是一个工具程序,而是一种字符串处理的标准依据,如果你想要以正则表达式的方式处理字符串,就得要使用支持正则表达式的工具程序才行,这类的工具程序很多,例如vi,sed,awk等。
正则表达式对于系统管理员来说实在是很重要,因为系统会产生很多的信息,这些信息有的重要,有的仅是告知,此时管理员可以通过正则表达式的功能来将重要信息选取出来,并产生便于查阅的报表来简化管理流程。此外很多的软件也都支持正则表达式的分析,例如邮件服务器的过滤机制(过滤垃圾信件)就是很重要的一个例子。所以你最好要了解正则表达式的相关技能,在将来管理主机时,才能够更精简处理你的日常事务!
注:本章用户需要多加练习,因为目前很多的套件都是使用正则表达式来达成其过滤、分析的目的,为了未来主机管理的便利性,用户至少要能看得懂正则表达式的意义。
12.1 前言:什么是正则表达式
简要了解了 Linux 的基本命令(BASH)并且熟悉了 vim 之后,相信你对于敲击键盘的打字与命令执行不陌生了吧?接下来下面要开始介绍一个很重要的概念,那就是所谓的“正则表达式”(Regular Expression, RE)。
12.1.1 什么是正则表达式
任何一个有经验的系统管理员,都会告诉你:正则表达式真是挺重要的!为什么很重要呢?因为日常生活就使用得到。举个例子来说,在你日常使用vim做文字处理或编写程序时使用到的查找、替嗌换等功能,这些举动要做得漂亮,就得要配合正则表达式来处理 !
简单地说,正则表达式就是处理字符串的方法,它是以行为单位来进行字符串的处理行为,正则表达式通过一些特殊符号的辅助,可以让用户轻易达到查找、删除、替换某特定字符串的处理程序。
举例来说,我只想找到VBird(前面两个大写字符)或Vbird(仅有一个大写字符)这个字样,但是不要其他的字符串(例如 VBIRD, vbird 等不需要),该如何处理?如果在没有正则表达式的环境中(例如 MS Word),你或许就得要使用忽略大小写的办法,或者是分别以 VBird 及 Vbird 查找两遍。但是忽略大小写可能会找到VBIRD/vbird/VbIrD等不需要的字符串而造成困扰。
再举个系统常见的例子好了,假设你发现系统在开机的时候,经常会出现一个关于mail程序的错误,而开机过程的相关程序都是在/etc/init.d/下面,也就是说,在该目录下面的某个文件内具有 mail这个关键字,你想要将该文件选出来进行查询修改的操作。此时你怎么找出来含有这个关键字的文件?你当然可以一个文件一个文件打开,然后去查找 mail 这个关键字,只是该目录下面的文件可能不止100个。如果了解正则表达式的相关技巧,那么只要一行命令就找出来啦:grep'mail'/etc/init.d/*,那个grep就是支持正则表达式的工具程序之一。如何?很简单吧!
谈到这里就得要进一步说明了,正则表达式基本上是一种“表示法”,只要工具程序支持这种表示法,那么该工具程序就可以用来作为正则表达式的字符串处理之用。例如 vi, grep, awk ,sed 等工具,因为它们有支持正则表达式,所以这些工具就可以使用正则表达式的特殊字符来进行字符串的处理。但例如cp,ls等命令并未支持正则表达式,所以就只能使用bash自身的通配符而已。
12.1.2 正则表达式对于系统管理员的用途
那么为何我需要学习正则表达式呢?对于一般用户来说,由于使用到正则表达式的机会可能不怎么多,因此感受不到它的魅力,不过对于身为系统管理员的你来说,正则表达式则是一个“不可不学的好东西”!怎么说呢?由于系统如果在繁忙的情况之下,每天产生的信息会多到你无法想象的地步,而我们也都知道,系统的“错误信息登录文件”(见第19章)的内容记载了系统产生的所有信息,当然,这包含你的系统是否被“入侵”的记录数据。
但是系统的数据量太大了,要身为系统管理员的你每天去看这么多的信息数据,从千百行的数据里面找出一行有问题的信息,光是用肉眼去看,想不疯掉都很难!在这个时候,我们就可以通过正则表达式的功能,将这些登录的信息进行处理,仅取出“有问题”的信息来进行分析,如此一来,你的系统管理工作将会更加方便。当然,正则表达式的优点还不止于此,等你有一定程度的了解之后,你会喜欢上它的喔!
12.1.3 正则表达式的广泛用途
正则表达式除了可以让系统管理员管理主机更方便之外,事实上,由于正则表达式强大的字符串处理能力,目前一堆软件都支持正则表达式。最常见的就是“邮件服务器”了。
如果你留意因特网上的消息,那么应该不能发现,目前造成网络大塞车的主原因之一就是“垃圾/广告邮件”了,而如果我们可以在服务器端就将这些问题邮件剔除的话,客户端就会减少很多不必要的带宽耗损了。那么如何过滤广告信件呢?由于广告信件几乎都有一定的标题或者是内容,因此,只要每次有来信时,都先将来信的标题与内容进行特殊字符串的对比,发现有不良邮件就给以过滤。这个工作怎么完成啊?那就得使用正则表达式了。目前两大邮件服务器软件sendmail与postfix以及支持邮件服务器的相关分析软件都支持正则表达式的比对功能。
当然还不止于此啦,很多的服务器软件都支持正则表达式呢!当然,虽然各家软件都支持它,不过,这些“字符串”的对比还是需要系统管理员来加入对比规则的,所以身为系统管理员的你,为了自身的工作以及客户端的需求,正则表达式实在是很需要也很值得学习的一项工具。
12.1.4 正则表达式与Shell 在Linux 当中的角色定位
说实在地,我们在学数学的时候,一个很重要但是很难的东西是一定要“背”的,那就是九九乘法表,成功背下来之后,在将来在数学应用的路途上,真是一帆风顺啊!这个九九乘法表我们在小学的时候几乎背了一整年才背下来,并不是这么好背的。但它却是基础当中的基础!你现在一定受惠相当多。
而我们谈到的这个正则表达式与前一章的BASH就有点像是数学的九九乘法表一样,是Linux基础当中的基础,虽然也是最难的部分,不过,如果学成了之后,一定对你大有帮助。这就好像是金庸小说里面的学武难关—任督二脉,打通任督二脉之后,武功立刻成倍成长!所以不论是对于系统的认识与系统的管理部分,它都有很有用的辅助。请好好学习这个基础吧!
12.1.5 扩展的正则表达式
正则表达式还可组分喔?没错!正则表达式的字符串表示方式依照不同的严谨度而分为基础正则表达式与扩展正则表达式。扩展型正则表达式除了简单的一组字符串处理之外,还可以做组的字符串处理,例如进行查找VBird或netman或lman的查找,注意,是或(or)而不是和(and)的处理,此时就需要扩展正则表达式的帮助了。通过特殊的“(”与“|”等字符的协助,就能够完成这样的目的。不过,我们在这里主要仅是介绍最基础的基础正则表达式而已。
有一点要向大家报告的,那就是正则表达式与通配符是完全不一样的东西!这很重要,因为通想符(wtilcard)代表的是bash操接口的一个功能,但正则表达式则是一种字符串处理的表示方式!这两者要分得很清楚才行,所以,学习本章,请将前一章bash的通配符意义先忘掉吧!
老实说,鸟哥以前刚接触正则表达式时,老想着要将这两者归纳在一起,结果就是错误认知一大堆,所以才会建议你学习本章先忘记通配符再来学习。
12.2 基础正则表达式
既然正则表达式是处理字符串的一种表示方式,那么对字符排序有影响的语系数据就会对正则表达式的结果有影响!此外,正则表达式也需要支持工具程序来辅助才行!所以,我们这里就先介绍一个最简单的字符串选取功能的工具程序,那就是grep。前一章已经介绍过grep的相关参数,本章着重介绍高级的grep参数说明。介绍完grep的功能之后,就进入正则表达式的特殊字符的处理能力了。
12.2.1 语系对正则表达式的影响
为什么语系的数据会影响到正则表达式的输出结果呢?我们在第0章计算机概论的文字编码系统里面谈到,文件其实记录的仅有0与1,我们看到的字符文字与数字都是通过编码表转换来的。由于不同语系的编码数据并不相同,所以就会造成数据选取结果的区别了。举例来说,在英文大小写的编码顺序中,zh_CN.big5及C这两种语系的输出结果分别如下:
LANG=C 时:0 1 2 3 4 … A B C D … Z a b c d …z
LANG=zh_CN 时:0 1 2 3 4 … a A b B c C d D … z Z
上面的顺序是编码的顺序,我们可以很清楚地发现这两种语系明显就是不一样!如果你想要选取大写字符而使用[A-Z]时,会发现 LANG=C 确实可以仅找到大写字符(因为是连续的),但是如果使用LANG=zh_CN.gb2312时,就会发现到,连同小写的b-z也会被选取出来,因为就编码的顺序来看,gb2312 语系可以选取到“A b B c C … z Z”这一堆字符哩!所以,使用正则表达式时,需要特别留意当时环境的语系为何,否则可能会发现与别人不相同的选取结果。
由于一般我们在练习正则表达式时,使用的是兼容于POSIX的标准,因此就使用“C”这个语系 [6]!因此,下面的很多练习都是使用“LANG=C”这个语系数据来进行的。另外,为了要避免这样编码所造成的英文与数字的选取问题,因此有些特殊的符号我们得要了解一下。这些符号主要有下面这些,意义如表12-1所示。
表12-1
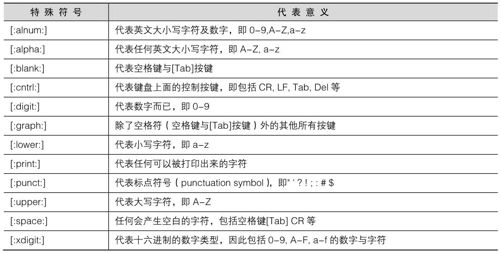
尤其上表中的[:alnum:]、[:alpha:]、[:upper:]、[:lower:]、[:digit:]这几个一定要知道代表什么意思,因为它要比a-z或A-Z的用途更确定。好了,下面就让我们开始来练习高级版的grep吧!
12.2.2 grep的一些高级参数
我们在第11章BASH里面的grep谈论过一些基础用法,但其实grep还有不少的高级用法喔!下面我们仅列出较高级的grep参数给大家参考,基础的grep用法请参考前一章的说明。
[root@www ~]# grep [-A] [-B] [—color=auto] '搜寻字符串' filename
参数:
-A :后面可加数字,为 after 的意思,除了列出该行外,后续的 n 行也列出来;
-B :后面可加数字,为 befer 的意思,除了列出该行外,前面的 n 行也列出来;
—color=auto 可将正确的那个选取数据列出颜色。
范例一:用 dmesg 列出内核信息,再以 grep 找出内含 eth 的那行
[root@www ~]# dmesg | grep 'eth'
eth0: RealTek RTL8139 at 0xee846000, 00:90:cc:a6:34:84, IRQ 10
eth0: Identified 8139 chip type 'RTL-8139C'
eth0: link up, 100Mbps, full-duplex, lpa 0xC5E1
eth0: no IPv6 routers present
dmesg 可列出内核产生的信息。通过 grep 来选取网卡相关信息 (eth) ,
就可发现如上信息。不过没有行号与特殊颜色显示。请看下个范例。
范例二:承上,要将找到的关键字显色,且加上行号来表示
[root@www ~]# dmesg | grep -n —color=auto 'eth'
247:eth0: RealTek RTL8139 at 0xee846000, 00:90:cc:a6:34:84, IRQ 10
248:eth0: Identified 8139 chip type 'RTL-8139C'
294:eth0: link up, 100Mbps, full-duplex, lpa 0xC5E1
305:eth0: no IPv6 routers present
你会发现除了 eth 会有特殊颜色来表示之外,最前面还有行号。
范例三:承上,在关键字所在行的前两行与后三行也一起找出来显示
[root@www ~]# dmesg | grep -n -A3 -B2 —color=auto 'eth'
245-PCI: setting IRQ 10 as level-triggered
246-ACPI: PCI Interrupt 0000:00:0e.0[A] -> Link [LNKB] …
247:eth0: RealTek RTL8139 at 0xee846000, 00:90:cc:a6:34:84, IRQ 10
248:eth0: Identified 8139 chip type 'RTL-8139C'
249-input: PC Speaker as /class/input/input2
250-ACPI: PCI Interrupt 0000:00:01.4[B] -> Link [LNKB] …
251-hdb: ATAPI 48X DVD-ROM DVD-R-RAM CD-R/RW drive, 2048kB Cache, UDMA(66)
如上所示,你会发现关键字 247 所在的前两行及 248 后三行也都被显示出来!
这样可以让你将关键字前后数据捕获出来进行分析。
grep是一个很常见也很常用的命令,它最重要的功能就是进行字符串数据的对比,然后将符合用户需求的字符串打印出来。需要说明的是grep在数据中查找一个字符串时,是以整行为单位来进行数据的选取的!也就是说,假如一个文件内有 10 行,其中有两行具有你所查找的字符串,则将那两行显示在屏幕上,其他的就丢弃了。
在关键字的显示方面,grep 可以使用—color=auto 来将关键字部分使用颜色显示。这可是个很不错的功能啊!但是如果每次使用grep都得要自行加上—color=auto又显得很麻烦,此时那个好用的 alias 就得来处理一下。你可以在~/.bashrc 内加上这行:alias grep='grep —color=auto',再以“ source~/.bashrc”来立即生效即可。这样每次执行 grep 它都会自动帮你加上颜色显示。
12.2.3 基础正则表达式练习
要了解正则表达式最简单的方法就是由实际练习去感受。所以在归纳正则表达式特殊符号前,我们先以下面这个文件的内容来进行正则表达式的理解。先说明一下,下面的练习大前提是:
语系已经使用“export LANG=C”的设置值;
grep 已经使用alias 设置成为“grep —color=auto”。
至于本章的练习用文件请由下面的链接来下载。需要特别注意的是,下面这个文件是鸟哥在Windows系统下编辑的,并且已经特殊处理过,因此,它虽然是纯文本文件,但是内含一些Windows系统下的软件常常自行加入的一些特殊字符,例如断行字符(^M)就是一例。所以,你可以直接将下面的文字以vi存储成regular_express.txt这个文件,不过,还是比较建议直接点下面的链接:
http://linux.vbird.org/linux_basic/0330regularex/regular_express.txt
如果你的Linux可以直接连上Internet的话,那么使用如下的命令来获取即可:
wget http://linux.vbird.org/linux_basic/0330regularex/regular_express.txt
至于这个文件的内容如下:
[root@www ~]# vi regular_express.txt
"Open Source" is a good mechanism to develop programs.
apple is my favorite food.
Football game is not use feet only.
this dress doesn't fit me.
However, this dress is about $ 3183 dollars.^M
GNU is free air not free beer.^M
Her hair is very beauty.^M
I can't finish the test.^M
Oh! The soup taste good.^M
motorcycle is cheap than car.
This window is clear.
the symbol '*' is represented as start.
Oh! My god!
The gd software is a library for drafting programs.^M
You are the best is mean you are the no. 1.
The world <Happy> is the same with "glad".
I like dog.
google is the best tools for search keyword.
goooooogle yes!
go! go! Let's go.
I am Vbird
这文件共有22行,最下面一行为空白行!现在开始我们一个案例一个案例来介绍。
例题一:查找特定字符串
查找特定字符串很简单吧?假设我们要从刚才的文件当中取得the这个特定字符串,最简单的方式就是这样:
[root@www ~]# grep -n 'the' regular_express.txt
8:I can't finish the test.
12:the symbol '*' is represented as start.
15:You are the best is mean you are the no. 1.
16:The world <Happy> is the same with "glad".
18:google is the best tools for search keyword.
那如果想要反向选择呢?也就是说,当该行没有'the'这个字符串时才显示在屏幕上,那就直接使用:
[root@www ~]# grep -vn 'the' regular_express.txt
你会发现,屏幕上出现的行是除了 8,12,15,16,18 五行之外的其他行。接下来,如果你想要取得不论大小写的'the'这个字符串,则:
[root@www ~]# grep -in 'the' regular_express.txt
8:I can't finish the test.
9:Oh! The soup taste good.
12:the symbol '*' is represented as start.
14:The gd software is a library for drafting programs.
15:You are the best is mean you are the no. 1.
16:The world <Happy> is the same with "glad".
18:google is the best tools for search keyword.
除了多两行(9, 14 行)之外,第 16 行也多了一个 The 的关键字被选取到。
例题二:利用中括号[]来查找集合字符
如果我想要查找test或taste这两个单词时,可以发现到,其实它们有共同的't?st'存在。这个时候,我可以这样来查找:
[root@www ~]# grep -n 't[ae]st' regular_express.txt
8:I can't finish the test.
9:Oh! The soup taste good.
了解了吧?其实[]里面不论有几个字符,它都只代表某“一个”字符,所以,上面的例子说明了,我需要的字符串是“tast”或“test”两个字符串而已!而如果想要查找到有oo的字符时,则使用:
[root@www ~]# grep -n 'oo' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.t
3:Football game is not use feet only.
9:Oh! The soup taste good.
18:google is the best tools for search keyword.
19:goooooogle yes!
但是,如果我不想要oo前面有g的话呢?此时,可以利用在集合字符的反向选择[^]来完成:
[root@www ~]# grep -n '[^g]oo' regular_express.txt
2:apple is my favorite food.
3:Football game is not use feet only.
18:google is the best tools for search keyword.
19:goooooogle yes!
意思就是说,我需要的是oo,但是oo前面不能是g就是了。仔细比较上面两个代码,你会发现,第1,9行不见了,因为oo前面出现了g所致。第2,3行没有疑问,因为foo与Foo均可被接受,但是第18行明明有google的goo啊!别忘记了,因为该行后面出现了tool的too。所以该行也被列出来。也就是说,18行里面虽然出现了我们所不要的项目(goo),但是由于有需要的项目(too),因此,是符合字符串查找的。
至于第19行,同样,因为goooooogle里面的oo前面可能是o,例如:go(ooo)oogle,所以,这一行也是符合需求的!
再来,假设我oo前面不想要有小写字符,所以,我可以这样写[^abcd….z]oo,但是这样似乎不怎么方便,由于小写字符的 ASCII 上编码的顺序是连续的,因此,我们可以将之简化为下面这样:
[root@www ~]# grep -n '[^a-z]oo' regular_express.txt
3:Football game is not use feet only.
也就是说,当我们在一组集合字符中,如果该字符组是连续的,例如大写英文/小写英文/数字等,就可以使用[a-z],[A-Z],[0-9]等方式来书写,那么如果我们的要求字符串是数字与英文呢?就将它全部写在一起,变成[a-zA-Z0-9]。例如,我们要取得有数字的那一行,就这样:
[root@www ~]# grep -n '[0-9]' regular_express.txt
5:However, this dress is about $ 3183 dollars.
15:You are the best is mean you are the no. 1.
但由于考虑到语系对于编码顺序的影响,因此除了连续编码使用减号“-”之外,你也可以使用如下的方法来取得前面两个测试的结果:
[root@www ~]# grep -n '[^[:lower:]]oo' regular_express.txt
那个 [:lower:] 代表的就是 a-z 的意思!请参考前两小节的说明
[root@www ~]# grep -n '[[:digit:]]' regular_express.txt
这样对于[]以及[^]以及[]当中的-,还有关于前面提到的特殊关键字了解了吗?
例题三:行首与行尾字符^$
我们在例题一当中,可以查询到一行字符串里面有the的,那如果我想要让the只在行首列出呢?这个时候就得要使用制表符了!我们可以这样做:
[root@www ~]# grep -n '^the' regular_express.txt
12:the symbol '*' is represented as start.
此时,就只剩下第12行,因为只有第12行的行首是the开头。此外,如果我想要开头是小写字符的那一行就列出呢?可以这样:
[root@www ~]# grep -n '^[a-z]' regular_express.txt
2:apple is my favorite food.
4:this dress doesn't fit me.
10:motorcycle is cheap than car.
12:the symbol '*' is represented as start.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
你可以发现我们可以找到第一个字符都不是大写的!只不过 grep 列出的关键字部分不只有第一个字符,grep是列出一整个字(word)的!同样,上面的命令也可以用如下的方式来替换:
[root@www ~]# grep -n '^[[:lower:]]' regular_express.txt
那如果我不想要开头是英文字母,则可以是这样:
[root@www ~]# grep -n '^[^a-zA-Z]' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
21:# I am VBird
命令也可以是: grep -n '^[^[:alpha:]]' regular_express.txt
注意到了吧?那个^符号在字符集合符号(中括号[])之内与之外是不同的!在[]内代表“反向选择”,在[]之外则代表定位在行首的意义,要分清楚。反过来思考,那如果我想要找出行尾结束为小数点(.)的那一行,该如何处理?
[root@www ~]# grep -n '.$' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
4:this dress doesn't fit me.
10:motorcycle is cheap than car.
11:This window is clear.
12:the symbol '*' is represented as start.
15:You are the best is mean you are the no. 1.
16:The world <Happy> is the same with "glad".
17:I like dog.
18:google is the best tools for search keyword.
20:go! go! Let's go.
特别注意到,因为小数点具有其他意义(下面会介绍),所以必须要使用转义字符(\)来加以解除其特殊意义。不过,你或许会觉得奇怪,但是第 5~9 行最后面也是.。怎么无法打印出来?这里就牵涉到Windows平台的软件对于断行字符的判断问题了!我们使用cat -A将第五行拿出来看,你会发现:
[root@www ~]# cat -An regular_express.txt | head -n 10 | tail -n 6
5 However, this dress is about $ 3183 dollars.^M$
6 GNU is free air not free beer.^M$
7 Her hair is very beauty.^M$
8 I can't finish the test.^M$
9 Oh! The soup taste good.^M$
10 motorcycle is cheap than car.$
我们在第10章内谈到过断行字符在Linux与Windows上的区别,在上文中我们可以发现5~9行为Windows的断行字符(^M$),而正常的Linux应该仅有第10行显示的那样($)。所以,那个.自然就不是紧接在$之前了,也就找不到 5~9 行了!这样可以了解^与$的意义吗?好了,先不要看下面的解答,自己想一想,那么如果我想要找出哪一行是“空白行”,也就是说,该行并没有输入任何数据,该如何查找?
[root@www ~]# grep -n '^$' regular_express.txt
22:
因为只有行首跟行尾(^$),所以,这样就可以找出空白行。再来,假设你已经知道在一个程序脚本(shell script)或者是配置文件当中,空白行与开头为#的那一行是批注,因此如果你要将数据列出给别人参考时,可以将这些数据省略掉以节省保贵的纸张,那么你可以怎么做呢?我们以/etc/syslog.conf这个文件来作范例,你可以自行参考一下输出的结果:
[root@www ~]# cat -n /etc/syslog.conf
在 CentOS 中,结果可以发现有 33 行的输出,很多空白行与 # 开头
[root@www ~]# grep -v '^$' /etc/syslog.conf | grep -v '^#'
结果仅有 10 行,其中第一个“ -v '^$' ”代表不要空白行,
第二个“ -v '^#' ”代表不要开头是 # 的那行喔!
是否节省很多版面啊?
例题四:任意一个字符.与重复字符*
在第11章bash当中,我们知道通配符*可以用来代表任意(0或多个)字符,但是正则表达式并不是通配符,两者之间是不相同的。至于正则表达式当中的“.”则代表绝对有一个任意字符的意思!这两个符号在正则表达式的意义如下:
.(小数点):代表一定有一个任意字符的意思;
*(星号):代表重复前一个0到无穷多次的意思,为组合形态。
这样讲不好理解,我们直接做个练习吧!假设我需要找出g??d的字符串,即共有四个字符,开头是g而结束是d,我可以这样做:
[root@www ~]# grep -n 'g..d' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
9:Oh! The soup taste good.
16:The world <Happy> is the same with "glad".
因为强调g与d之间一定要存在两个字符,因此,第13行的god与第14行的gd就不会被列出来了。再来,如果我想要列出有 oo, ooo, oooo 等的数据,也就是说,至少要有两个(含) o 以上,该如何是好?是o还是oo还是 ooo*呢?虽然你可以试看看结果,不过结果太占版面了,所以,我这里就直接说明。
因为代表的是重复 0 个或多个前面的 RE 字符的意义,因此,“o”代表的是具有空字符或一个o以上的字符,特别注意,因为允许空字符(就是有没有字符都可以的意思),因此,“grep -n 'o*' regular_express.txt ”将会把所有的数据都打印出来屏幕上!
那如果是“oo*”呢?则第一个o肯定必须要存在,第二个o则是可有可无的多个o,所以,凡是含有 o, oo, ooo, oooo 等,都可以被列出来。
同理,当我们需要至少两个o以上的字符串时,就需要ooo*,即:
[root@www ~]# grep -n 'ooo*' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
9:Oh! The soup taste good.
18:google is the best tools for search keyword.
19:goooooogle yes!
这样理解*的意义了吗?好了,现在出个练习,如果我想要字符串开头与结尾都是 g,但是两个 g 之间仅能存在至少一个 o,即是 gog, goog, gooog 等,那该如何?
[root@www ~]# grep -n 'goo*g' regular_express.txt
18:google is the best tools for search keyword.
19:goooooogle yes!
如此了解了吗?再来一题,如果我想要找出g开头与g结尾的字符串,当中的字符可有可无,那该如何是好?是“g*g”吗?
[root@www ~]# grep -n 'g*g' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
3:Football game is not use feet only.
9:Oh! The soup taste good.
13:Oh! My god!
14:The gd software is a library for drafting programs.
16:The world <Happy> is the same with "glad".
17:I like dog.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
但测试的结果竟然出现这么多行?太诡异了吧?其实一点也不诡异,因为gg里面的g代表空字符或一个以上的 g 再加上后面的 g,因此,整个正则表达式的内容就是 g, gg, ggg, gggg,因此,只要该行当中拥有一个以上的g就符合所需了!
那该如何得到我们的g….g的需求呢?我们可以利用任意一个字符“.”啊!即“g.g”的做法,因为可以是0或多个重复前面的字符,而.是任意字符,所以“.*”就代表零个或多个任意字符的意思。
[root@www ~]# grep -n 'g.*g' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
14:The gd software is a library for drafting programs.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
因为是代表 g 开头与 g 结尾,中间任意字符均可接受,所以,第 1, 14, 20 行是可接受的。这个.*的 RE 表示任意字符是很常见的,希望大家能够理解并且熟悉!再出一题,如果我想要找出“任意数字”的行列呢?因为仅有数字,所以就成为:
[root@www ~]# grep -n '[0-9][0-9]*' regular_express.txt
5:However, this dress is about $ 3183 dollars.
15:You are the best is mean you are the no. 1.
虽然使用 grep -n '[0-9]' regular_express.txt 也可以得到相同的结果,但鸟哥希望大家能够理解上面命令当中RE表示法的意义才好!
例题五:限定连续RE字符范围{}
在上个例题当中,我们可以利用.与RE字符及*来设置0个到无限多个重复字符,那如果我想要限制一个范围区间内的重复字符数呢?举例来说,我想要找出2~5个o的连续字符串,该如何做?这时候就得要使用到限定范围的字符{}了。但因为{与}的符号在shell是有特殊意义的,因此,我们必须要使用转义字符\来让它失去特殊意义才行。至于{}的语法是这样的,假设我要找到两个o的字符串,可以是:
[root@www ~]# grep -n 'o{2}' regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
9:Oh! The soup taste good.
18:google is the best tools for search keyword.
19:goooooogle yes!
这样看似乎与ooo*的字符没有什么区别啊?因为第19行有多个o也出现了!好,那么换个查找的字符串,假设我们要找出g后面接2到5个o,然后再接一个g的字符串,它会是这样:
[root@www ~]# grep -n 'go{2,5}g' regular_express.txt
18:google is the best tools for search keyword.
第19行终于没有被选用了(因为19行有6个o)。那么,如果我想要的是2个o以上的goooo…g呢?除了可以是gooo*g,也可以是:
[root@www ~]# grep -n 'go{2,}g' regular_express.txt
18:google is the best tools for search keyword.
19:goooooogle yes!
就可以找出来啦!
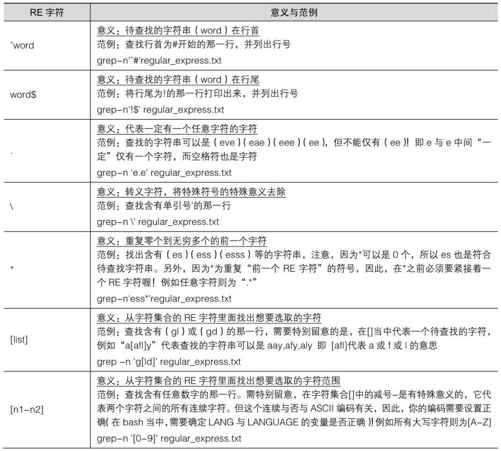
12.2.4 基础正则表达式字符(characters)
经过了上面的几个简单的范例,我们可以将基础的正则表达式特殊字符归纳成表12-2所示。
表12-2
罉裄
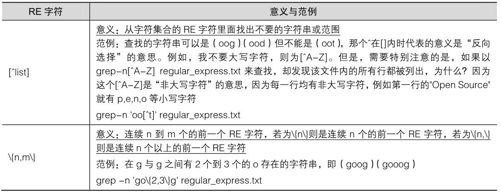
再次强调:正则表达式的特殊字符与一般在命令行输入命令的“通配符”并不相同,例如,在通配符当中的代表的是零到无限多个字符的意思,但是在正则表达式当中,则是重复 0 到无穷多个的前一个RE字符的意思,使用的意义并不相同,不要搞混了!
举例来说,在不支持正则表达式的 ls 这个工具中,若我们使用“ls -l”代表的是任意文件名的文件,而“ls -la”代表的是以 a 为开头的任何文件名的文件,但在正则表达式中,我们要找到含有以a为开头的文件,则必须要这样(需搭配支持正则表达式的工具):
ls | grep -n '^a.*'

以 ls -l 配合 grep 找出/etc/下面文件类型为连接文件属性的文件名。
答:由于 ls -l 列出连接文件时标头会是“lrwxrwxrwx”,因此使用如下的命令即可找出结果:ls -l /etc | grep '^l'
若仅想要列出几个文件,再以“|wc -l”来累加处理即可。
12.2.5 sed工具
在了解了一些正则表达式的基础应用之后,有两个命令可以练习一下,那就是sed与下面会介绍的awk了!这两个工具可是相当有用的。举例来说,鸟哥写的logfile.sh分析登录文件的小程序(第19章会谈到),绝大部分分析关键字的使用、统计等,就是用这两个工具来帮我完成的。
我们先来谈一谈 sed 好了,sed 本身也是一个管道命令,可以分析 standard input 的,而且 sed还可以将数据进行替换、删除、新增、选取特定行等的功能呢!我们先来了解一下sed的用法,再来聊它的用途好了!
[root@www ~]# sed [-nefr] [动作]
参数:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN
的数据一般都会被列出到屏幕上。但如果加上 -n 参数后,则只有经过
sed 特殊处理的那一行(或者操作)才会被列出来。
-e :直接在命令行模式上进行 sed 的动作编辑。
-f :直接将 sed 的动作写在一个文件内,-f filename 则可以执行 filename 内的
sed 动作。
-r :sed 的动作支持的是扩展型正则表达式的语法(默认是基础正则表达式语法)。
-i :直接修改读取的文件内容,而不是由屏幕输出。
动作说明: [n1[,n2]]function
n1, n2 :不见得会存在,一般代表选择进行动作的行数,举例来说,如果我的动作
是需要在10到20行之间进行的,则“ 10,20[动作行为] ”
function 有下面这些参数:
a :新增,a 的后面可以接字符串,而这些字符串会在新的一行出现(目前的下一行);
c :替换,c 的后面可以接字符串,这些字符串可以替换 n1,n2 之间的行!
d :删除,因为是删除,所以 d 后面通常不接任何参数;
i :插入,i 的后面可以接字符串,而这些字符串会在新的一行出现(目前的上一行);
p :打印,也就是将某个选择的数据打印出来。通常 p 会与参数 sed -n 一起运行。
s :替换,可以直接进行替换的工作。通常这个 s 的动作可以搭配
正则表达式!例如 1,20s/old/new/g 就是。
以行为单位的新增/删除功能
sed光是用看的是看不懂的。所以要来练习一下了。先来练习删除与新增的功能吧!
范例一:将 /etc/passwd 的内容列出并且打印行号,同时,请将第 2~5 行删除!
[root@www ~]# nl /etc/passwd | sed '2,5d'
1 root:x:0:0:root:/root:/bin/bash
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
…..(后面省略)…..
看到了吧?sed的动作为'2,5d',那个d就是删除。因为2~5行给它删除了,所以显示的数据就没有 2~5 行。另外,注意一下,原本应该是要执行 sed -e 才对,没有-e 也行。同时也要注意的是,sed后面接的动作,请务必以''两个单引号括住。
如果题型变化一下,举例来说,如果只要删除第 2 行,可以使用“nl /etc/passwd | sed '2d' ”来完成,至于若是要删除第 3 到最后一行,则是“nl /etc/passwd | sed '3,$d'”的,那个“ $ ”代表最后一行!
范例二:承上例,在第二行后(即是加在第三行)加上“drink tea?”字样!
[root@www ~]# nl /etc/passwd | sed '2a drink tea'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
drink tea
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
…..(后面省略)…..
在 a 后面加上的字符串就已将出现在第二行后面。那如果是要在第二行前呢?“nl /etc/passwd | sed '2i drink tea' ”就对了。就是将“a”变成“i”即可。增加一行很简单,那如果是要增加两行以上呢?
范例三:在第二行后面加入两行字,例如“Drink tea or …..”与“drink beer?”
[root@www ~]# nl /etc/passwd | sed '2a Drink tea or ……\
> drink beer ?'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
Drink tea or ……
drink beer ?
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
…..(后面省略)…..
这个范例的重点是我们可以新增不只一行,可以新增好几行,但是每一行之间都必须要以反斜杠“\”来进行新行的增加。所以,上面的例子中,我们可以发现在第一行的最后面就有\存在,那是一定要的。
以行为单位的替换与显示功能
刚才是介绍如何新增与删除,那么如果要整行替换呢?看看下面的范例吧:
范例四:我想将第2~5行的内容替换成为“No 2-5 number”
[root@www ~]# nl /etc/passwd | sed '2,5c No 2-5 number'
1 root:x:0:0:root:/root:/bin/bash
No 2-5 number
6 sync:x:5:0:sync:/sbin:/bin/sync
…..(后面省略)…..
通过这个方法我们就能够将数据整行替换了。非常容易吧!sed还有更好用的工具。我们以前想要列出第 11~20 行,得要通过“head -n 20 | tail -n 10”之类的方法来处理,很麻烦。sed则可以简单直接取出你想要的那几行!是通过行号来找的。先看看下面的范例:
范例五:仅列出 /etc/passwd 文件内的第 5-7 行
[root@www ~]# nl /etc/passwd | sed -n '5,7p'
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
上述的命令中有个重要的参数“-n”,按照说明文件,这个-n代表的是“安静模式”!那么为什么要使用安静模式呢?你可以自行执行 sed '5,7p'就知道了(5~7 行会重复输出)。有没有加上-n的参数时,输出的数据可是差很多的。你可以通过这个sed的以行为单位的显示功能,就能够将某一个文件内的某些行号找出来查阅。很不错的功能!不是吗?
部分数据的查找并替换的功能
除了整行的处理模式之外,sed还可以用行为单位进行部分数据的查找并替换的功能。基本上sed的查找与替换的与vi相当类似,它有点像这样:
sed 's/要被替换的字符串/新的字符串/g'
上表中特殊字体的部分为关键字,请记下来!至于三个斜线分成两栏就是新旧字符串的替换。我们使用下面这个取得IP数据的范例,一段一段来处理给你瞧瞧,让你了解一下什么是所谓的查找并替换吧!
步骤一:先查看源信息,利用 /sbin/ifconfig 查询 IP
[root@www ~]# /sbin/ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:90:CC:A6:34:84
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::290:ccff:fea6:3484/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
…..(以下省略)…..
因为我们还没有讲到 IP ,这里你先有个概念即可啊。我们的重点在第二行,
也就是 192.168.1.100 那一行而已!先利用关键字找出那一行!
步骤二:利用关键字配合 grep 选取出关键的一行数据
[root@www ~]# /sbin/ifconfig eth0 | grep 'inet addr'
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
当场仅剩下一行!接下来,我们要将开始到 addr: 通通删除,就是像下面这样:
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
上面的删除关键在于“ ^.*inet addr: ”,正则表达式出现。
步骤三:将 IP 前面的部分予以删除
[root@www ~]# /sbin/ifconfig eth0 | grep 'inet addr' | \
> sed 's/^.*addr://g'
192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
仔细与上个步骤比较一下,前面的部分不见了!接下来则是删除后续的部分,即:
192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
此时所需的正则表达式为“ Bcast.*$ ”
步骤四:将 IP 后面的部分予以删除
[root@www ~]# /sbin/ifconfig eth0 | grep 'inet addr' | \
> sed 's/^.addr://g' | sed 's/Bcast.$//g'
192.168.1.100
通过这个范例的练习也建议你依据此步骤来研究你的命令。就是先查看,然后再一步一步试做,如果有做不对的地方,就先予以修改,改完之后测试,成功后再往下继续测试。鸟哥上面的介绍中,那一大串命令就做了四个步骤。
让我们再来继续研究sed与正则表达式的配合练习!假设我只要存在MAN字样的那几行数据,但是含有#在内的批注我不想要,而且空白行我也不要。此时该如何处理呢?可以通过这几个步骤来实践看看:
步骤一:先使用 grep 将关键字 MAN 所在行取出来
[root@www ~]# cat /etc/man.config | grep 'MAN'
when MANPATH contains an empty substring), to find out where the cat
MANBIN pathname
MANPATH manpath_element [corresponding_catdir]
MANPATH_MAP path_element manpath_element
MANBIN /usr/local/bin/man
Every automatically generated MANPATH includes these fields
MANPATH /usr/man
….(后面省略)….
步骤二:删除掉批注之后的数据!
[root@www ~]# cat /etc/man.config | grep 'MAN'| sed 's/#.*$//g'
MANPATH /usr/man
….(后面省略)….
从上面可以看出来,原本批注的数据都变成空白行。所以,接下来要删除掉空白行
[root@www ~]# cat /etc/man.config | grep 'MAN'| sed 's/#.*$//g' | \
> sed '/^$/d'
MANPATH /usr/man
MANPATH /usr/share/man
MANPATH /usr/local/man
….(后面省略)….
直接修改文件内容(危险操作)
你以为sed只有这样的能耐吗?那可不!sed甚至可以直接修改文件的内容呢!而不必使用管道命令或数据流重定向。不过,由于这个操作会直接修改文件,所以请你千万不要随便拿系统配置文件来测试。我们还是使用你下载的regular_express.txt文件来测试看看吧!
范例六:利用 sed 将 regular_express.txt 内每一行结尾为“.”的换成“!”
[root@www ~]# sed -i 's/.$/!/g' regular_express.txt
上头的 -i 参数可以让你的 sed 直接去修改后面接的文件内容而不是由屏幕输出。
这个范例是用在替换!请你自行 cat 该文件去查阅结果。
范例七:利用 sed 直接在 regular_express.txt 最后一行加入“# This is a test”
[root@www ~]# sed -i '$a # This is a test' regular_express.txt
由于 $ 代表的是最后一行,而 a 的操作是新增,因此该文件最后新增。
sed的“-i”参数可以直接修改文件内容,这功能非常有帮助。举例来说,如果你有一个100万行的文件,你要在第100行加某些文字,此时使用vim可能会疯掉!因为文件太大了!那怎么办?就利用sed。通过sed直接修改/替换的功能,你甚至不需要使用vim去修改。
总之,这个 sed 不错。而且很多的 shell script 都会使用到这个命令的功能。sed 可以帮助系统管理员管理好日常的工作。所以要仔细学习呢!
12.3 扩展正则表达式
事实上,一般读者只要了解基础型的正则表达式大概就已经相当足够了,不过,某些时刻为了要简化整个命令操作,了解一下使用范围更广的扩展型正则表达式的表示式会更方便呢!举个简单的例子好了,在上节的例题三的最后一个例子中,我们要去除空白行与行首为#的行列,使用的是
grep -v '^$' regular_express.txt | grep -v '^#'
需要使用到管道命令来查找两次!那么如果使用扩展型的正则表达式,我们可以简化为:
egrep -v '^$|^#' regular_express.txt
扩展型正则表达式可以通过组功能“|”来进行一次查找!那个在单引号内的管道意义为“或or”!是否变得更简单呢?此外,grep默认仅支持基础正则表达式,如果要使用扩展型正则表达式,你可以使用grep-E,不过更建议直接使用egrep。直接区分命令比较好记忆。其实egrep与grep-E是类似命令别名的关系了。
熟悉了正则表达式之后,到这个扩展型的正则表达式,你应该也会想到,不就是多几个重要的特殊符号吗?所以,我们就直接来说明一下扩展型正则表达式有哪几个特殊符号。由于下面的范例还是有使用到 regular_express.txt,不巧的是刚才我们可能将该文件修改过了,所以,请重新下载该文件来练习。
表12-3
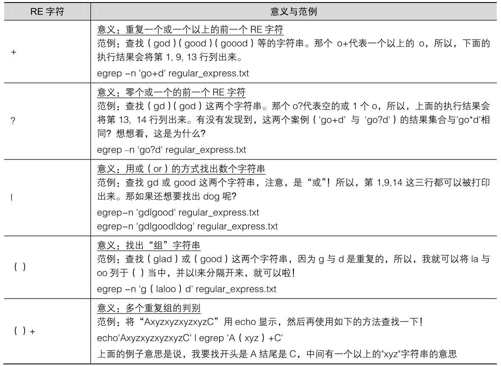
表12-3所示就是扩展型的正则表达式的特殊字符。另外,要特别强调的是,那个!在正则表达式当中并不是特殊字符,所以,如果你想要查出来文件中含有!与>的字行时,可以这样:
grep -n '[!>]' regular_express.txt
这样可以了解了吗?常常看到有陷阱的题目写:“'[!a-z]'反向选择对否?”是错的。要'[^a-z]才是对的!至于更多关于正则表达式的高级文章,请参考文末的参考数据 [7]。
12.4 文件的格式化与相关处理
接下来让我们来将文件进行一些简单的编排吧!下面这些操作可以将你的信息进行排版的操作,不需要重新以vim去编辑,通过数据流重定向配合下面介绍的printf功能,以及awk命令,就可以让你的信息以你想要的模样来输出了!试看看吧!
12.4.1 格式化打印:printf
在很多时候,我们可能需要将自己的数据给它格式化输出的!举例来说,考试分数的输出,姓名与科目及分数之间总是可以稍微做个比较漂亮的版面吧?例如我想要输出下面的样式:
Name Chinese English Math Average
DmTsai 80 60 92 77.33
VBird 75 55 80 70.00
Ken 60 90 70 73.33
上表的数据主要分成五个字段,各个字段之间可使用[tab]或空格键进行分隔。请将上面的数据转存成为printf.txt文件名,等一下我们会利用这个文件来进行几个小练习的。因为每个字段的原始数据长度其实并非是如此固定的(Chinese 长度就是比 Name 要多),而我就是想要如此表示出这些数据,此时,就得需要打印格式化命令printf的帮忙了!printf可以帮我们将数据输出的结果格式化,而且而支持一些特殊的字符。下面我们就来看看!
[root@www ~]# printf '打印格式'实际内容
参数:
关于格式方面的几个特殊样式:
\a 警告声音输出
\b 退格键(backspace)
\f 清除屏幕 (form feed)
\n 输出新的一行
\r 亦即 Enter 按键
\t 水平的 [tab] 按键
\v 垂直的 [tab] 按键
\xNN NN 为两位数的数字,可以转换数字成为字符。
关于 C 程序语言内,常见的变量格式
%ns 那个 n 是数字,s 代表 string ,即多少个字符;
%ni 那个 n 是数字,i 代表 integer ,即多少整数字数;
%N.nf 那个 n 与 N 都是数字,f 代表 floating (浮点),如果有小数字数,
假设我共要十个位数,但小数点有两位,即为 %10.2f 。
接下来我们来进行几个常见的练习。假设所有的数据都是一般文字(这也是最常见的状态),因此最常用来分隔数据的符号就是[Tab]。因为[Tab]按键可以将数据做个整齐的排列,那么如何利用printf呢?参考下面这个范例:
范例一:将刚才上头数据的文件 (printf.txt) 内容仅列出姓名与成绩(用 [tab] 分隔)
[root@www ~]# printf '%s\t %s\t %s\t %s\t %s\t \n' $(cat printf.txt)
Name Chinese English Math Average
DmTsai 80 60 92 77.33
VBird 75 55 80 70.00
Ken 60 90 70 73.33
由于 printf 并不是管道命令,因此我们得要通过类似上面的功能,将文件内容先提出来给 printf作为后续的数据才行。如上所示,我们将每个数据都以[tab]作为分隔,但是由于Chinese长度太长,导致English中间多了一个[tab]来将数据排列整齐,结果就看到数据对齐结果的区别了!
另外,在printf后续的那一段格式中,%s代表一个不固定长度的字符串,而字符串与字符串之间就以\t这个[tab]分隔符来处理!你要记得的是,由于\t与%s中间还有空格,因此每个字符串间会有一个[tab]与一个空格键的分隔。
既然每个字段的长度不固定会造成上述的困扰,那我将每个字段固定就好。没错!这样想非常好!所以我们就将数据进行固定字段长度的设计吧!
范例二:将上述数据关于第二行以后,分别以字符串、整数、小数点来显示
[root@www ~]# printf '%10s %5i %5i %5i %8.2f \n' $(cat printf.txt |\
> grep -v Name)
DmTsai 80 60 92 77.33
VBird 75 55 80 70.00
Ken 60 90 70 73.33
上面这一串格式想必你看得很辛苦,没关系!一个一个来解释。上面的格式共分为五个字段,%10s代表的是一个长度为 10 个字符的字符串字段,%5i 代表的是长度为 5 个字符的数字字段,至于那个%8.2f则代表长度为8个字符的具有小数点的字段,其中小数点有两个字符宽度。我们可以使用下面的说明来介绍%8.2f的意义:
字符宽度:12345678
%8.2f意义:00000.00
如上所述,全部的宽度仅有8个字符,整数部分占有5个字符,小数点本身(.)占一位,小数点下的位数则有两位。这种格式经常使用于数值程序的设计中。自己试看看如果要将小数点位数变成 1位又该如何处理?
printf除了可以格式化处理之外,它还可以依据ASCII的数字与图形对应来显示数据 [8]。举例来说十六进制的45可以得到什么ASCII的显示图(其实是字符)?
范例三:列出十六进制数值 45 代表的字符
[root@www ~]# printf '\x45\n'
E
这东西也很好玩。它可以将数值转换成为字符,如果你会写 script 的话,
可以自行测试一下,20~80 之间的数值代表的字符是什么。
printf的使用相当广泛,包括等一下后面会提到的awk以及在C程序语言当中使用的屏幕输出,都是利用printf。鸟哥这里也只是列出一些可能会用到的格式而已,有兴趣的话,可以自行做一些测试与练习。
打印格式化这个printf命令,乍看之下好像也没有什么很重要的。不过,如果你需要自行编写一些软件,需要将一些数据在屏幕上头漂漂亮亮地输出的话,那么printf可也是一个很不错的工具。
12.4.2 awk:好用的数据处理工具
awk也是一个非常棒的数据处理工具。相比于sed常常作用于一整行的处理,awk则比较倾向于将一行分成数个“字段”来处理。因此,awk相当适合处理小型的数据数据处理呢!awk通常运行的模式是这样的:
[root@www ~]# awk '条件类型1{动作1} 条件类型2{动作2} …' filename
awk 后面接两个单引号并加上大括号{}来设置想要对数据进行的处理动作。awk 可以处理后续接的文件,也可以读取来自前个命令的standardoutput。但如前面说的,awk主要是处理每一行的字段内的数据,而默认的字段的分隔符为空格键或[tab]键。举例来说,我们用last可以将登录者的数据取出来,结果如下所示:
[root@www ~]# last -n 5 <==仅取出前五行
root pts/1 192.168.1.100 Tue Feb 10 11:21 still logged in
root pts/1 192.168.1.100 Tue Feb 10 00:46 - 02:28 (01:41)
root pts/1 192.168.1.100 Mon Feb 9 11:41 - 18:30 (06:48)
dmtsai pts/1 192.168.1.100 Mon Feb 9 11:41 - 11:41 (00:00)
root tty1 Fri Sep 5 14:09 - 14:10 (00:01)
若我想要取出账号与登录者的IP,且账号与IP之间以[tab]隔开,则会变成这样:
[root@www ~]# last -n 5 | awk '{print $1 "\t" $3}'
root 192.168.1.100
root 192.168.1.100
root 192.168.1.100
dmtsai 192.168.1.100
root Fri
上面是awk最常使用的动作。通过print的功能将字段数据列出来!字段的分隔则以空格键或[tab]按键来隔开。因为不论哪一行我都要处理,因此,就不需要有条件类型的限制!我所想要的是第一列以及第三列,但是,第五行的内容很奇怪。这是因为数据格式的问题。所以使用awk的时候,请先确认一下你的数据,如果是连续性的数据,请不要有空格或[tab]在内,否则,就会像这个例子这样,会发生误判。
另外,由上面这个例子你也会知道,在每一行的每个字段都是有变量名称的,那就是$1, $2等变量名称。以上面的例子来说,root是$1,因为它是第一列嘛!至于192.168.1.100是第三列,所以它就是$3,后面以此类推。还有个变量,那就是$0 ,$0代表一整行数据的意思。以上面的例子来说,第一行的$0代表的就是“root….”那一行。由此可知,刚才上面五行当中,整个awk的处理流程是:
1.读入第一行,并将第一行的数据填入$0, $1, $2 等变量当中;
2.依据条件类型的限制,判断是否需要进行后面的动作;
3.做完所有的动作与条件类型;
4.若还有后续的“行”的数据,则重复上面1~3的步骤,直到所有的数据都读完为止。
经过这样的步骤,你会晓得,awk是以行为一次处理的单位,而以字段为最小的处理单位。好了,那么awk怎么知道我到底这个数据有几行和几列呢?这就需要awk的内置变量的帮忙了,如表12-4所示 。
表12-4

我们继续以上面 last –n 5 的例子来做说明,如果我想要:
列出每一行的账号(就是$1)
列出目前处理的行数(就是awk内的NR变量)
并且说明,该行有多少字段(就是awk内的NF变量)
则可以这样:
要注意喔,awk后续的所有动作是以单引号“'”括住的,由于单引号与双引号都必须是成对的,所以,awk的格式内容如查想要以print打印时,记得非变量的文字部分,包含一小节printf提到的格式中,都需要使用双引号来定义出来,因为单引号已是awk的命令固定用法了
[root@www ~]# last -n 5| awk '{print $1 "\t lines: " NR "\t columes: " NF}'
root lines: 1 columes: 10
root lines: 2 columes: 10
root lines: 3 columes: 10
dmtsai lines: 4 columes: 10
root lines: 5 columes: 9
注意喔!在 awk 内的 NR, NF 等变量要用大写,且不需要 $ 啦!
这样可以了解NR与NF的差别了吧?好了,下面来谈一谈所谓的条件类型了吧!
awk的逻辑运算符
既然有需要用到条件的类别,自然就需要一些逻辑运算。例如下面这些,如表12-5所示。
表12-5
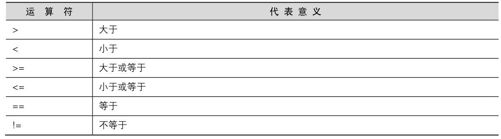
值得注意的是那个“==”的符号,因为:
逻辑运算上面也就是所谓的大于、小于、等于等判断式上面,习惯上是以“==”来表示;
如果是直接给予一个值,例如变量设置时,就直接使用=而已。
好了,我们实际来运用一下逻辑判断吧!举例来说,在/etc/passwd当中是以冒号":"来作为字段的分隔,该文件中第一字段为账号,第三字段则是UID。那假设我要查阅,第三列小于10以下的数据,并且仅列出账号与第三列,那么可以这样做:
[root@www ~]# cat /etc/passwd | \
> awk '{FS=":"} $3 < 10 {print $1 "\t " $3}'
root:x:0:0:root:/root:/bin/bash
bin 1
daemon 2
….(以下省略)….
有趣吧!不过,怎么第一行没有正确显示出来呢?这是因为我们读入第一行的时候,那些变量$1,$2…默认还是以空格键为分隔的,所以虽然我们定义了FS=":"了,但是却仅能在第二行后才开始生效。那么怎么办呢?我们可以预先设置awk的变量啊!利用BEGIN这个关键字,这样做:
[root@www ~]# cat /etc/passwd | \
> awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}'
root 0
bin 1
daemon 2
……(以下省略)……
很有趣吧!而除了BEGIN之外,我们还有END呢!另外,如果要用awk来进行“计算功能”呢?以下面的例子来看,假设我有一个薪资数据表文件名为pay.txt,内容是这样的:
Name 1st 2nd 3th
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000
如何帮我计算每个人的总额呢?而且我还想要格式化输出喔!我们可以这样考虑:
第一行只是说明,所以第一行不要进行加总(NR==1时处理);
第二行以后就会有加总的情况出现(NR>=2以后处理)。
[root@www ~]# cat pay.txt | \
> awk 'NR==1{printf "%10s %10s %10s %10s %10s\n",$1,$2,$3,$4,"Total" }
NR>=2{total = $2 + $3 + $4
printf "%10s %10d %10d %10d %10.2f\n", $1, $2, $3, $4, total}'
Name1st 2nd 3th Total
VBird23000 24000 25000 72000.00
DMTsai21000 20000 23000 64000.00
Bird243000 42000 41000 126000.00
上面的例子有几个重要事项应该要先说明的:
所有awk的动作,即在{}内的动作,如果有需要多个命令辅助时,可利用分号“;”间隔,或者直接以[Enter]按键来隔开每个命令,例如上面的范例中,鸟哥共按了三次[Enter]。
逻辑运算当中,如果是“等于”的情况,则务必使用两个等号“==”!
格式化输出时,在printf的格式设置当中,务必加上\n,才能进行分行!
与bash、shell的变量不同,在awk当中,变量可以直接使用,不需加上$符号。
利用awk这个工具,就可以帮我们处理很多日常工作了呢!真是好用得很。此外,awk的输出格式当中,常常会以printf来辅助,所以,最好你对 printf也稍微熟悉一下比较好。另外,awk的动作内{}也是支持if(条件)的。举例来说,上面的命令可以修改成为这样:
[root@www ~]# cat pay.txt | \
> awk '{if(NR==1) printf "%10s %10s %10s %10s %10s\n",$1,$2,$3,$4,"Total"}
NR>=2{total = $2 + $3 + $4
printf "%10s %10d %10d %10d %10.2f\n", $1, $2, $3, $4, total}'
你可以仔细比较一下上面两个输入有什么不同,从中去了解两种语法吧!我个人是比较倾向于使用第一种语法,因为会比较有统一性啊!
除此之外,awk还可以帮我们进行循环计算喔!真是相当好用!不过,那属于比较高级的课程了,我们这里就不再多加介绍。如果你有兴趣的话,请务必参考扩展阅读中的相关链接 [9]。
12.4.3 文件比较工具
什么时候会用到文件的比较啊?通常是同一个软件的不同版本之间,比较配置文件与源文件的区别。很多时候所谓的文件比较,通常是用在ASCII纯文本文件的比较上。那么比较文件的命令有哪些?最常见的就是diff。另外,除了diff比较之外,我们还可以通过cmp来比较非纯文本文件。同时,也能够通过diff创建的分析文件,以处理补丁(patch)功能的文件呢!就来练习先!
diff
diff就是用在比较两个文件之间的区别的,并且是以行为单位来比较的!一般是用在ASCII纯文本文件的比较上。由于是以行为比较的单位,因此diff通常是用在同一的文件(或软件)的新旧版本区别上!举例来说,假如我们要将/etc/passwd处理成为一个新的版本,处理方式为:将第四行删除,第六行则替换成为“no six line”,新的文件放置到/tmp/test 里面,那么应该怎么做?
[root@www ~]# mkdir -p /tmp/test <==先新建测试用的目录
[root@www ~]# cd /tmp/test
[root@www test]# cp /etc/passwd passwd.old
[root@www test]# cat /etc/passwd | \
> sed -e '4d' -e '6c no six line' > passwd.new
注意一下,sed 后面如果要接超过两个以上的动作时,每个动作前面得加 -e 才行!
通过这个动作,在 /tmp/test 里面便有新旧的 passwd 文件存在了!
接下来讨论一下diff的用法。
[root@www ~]# diff [-bBi] from-file to-file
参数:
from-file :一个文件名,作为欲比较文件的文件名;
to-file :一个文件名,作为目的比较文件的文件名。
注意,from-file 或 to-file 可以 - 替换,那个 - 代表“Standard input”之意。
-b :忽略一行当中仅有多个空白的区别(例如 "about me" 与 "about me" 视为相同)
-B :忽略空白行的区别。
-i :忽略大小写的不同。
范例一:比较 passwd.old 与 passwd.new
[root@www test]# diff passwd.old passwd.new
4d3 <==左边第四行被删除 (d) 掉了,基准是右边的第三行
< adm:x:3:4:adm:/var/adm:/sbin/nologin <==这边列出左边(<)文件被删除的那一行内容
6c5 <==左边文件的第六行被替换 (c) 成右边文件的第五行
< sync:x:5:0:sync:/sbin:/bin/sync <==左边(<)文件第六行内容
> no six line <==右边(>)文件第五行内容
用 diff 就把我们刚才的处理给比对完毕了!
用diff比较文件真的是很简单。不过,你不要用diff去比较两个完全不相干的文件,因为比不出个结果来!另外,diff 也可以比较整个目录下的区别。举例来说,我们想要了解一下不同的开机执行等级(runlevel)内容有什么不同,假设你已经知道执行等级3与5的启动脚本分别放置到/etc/rc3.d及/etc/rc5.d,则我们可以将两个目录比较一下:
[root@www ~]# diff /etc/rc3.d/ /etc/rc5.d/
Only in /etc/rc3.d/: K99readahead_later
Only in /etc/rc5.d/: S96readahead_later
我们的diff很聪明吧?还可以比较不同目录下的相同文件名的内容,这样真的很方便。
cmp
相对于diff的广泛用途,cmp似乎就用得没有这么多了。cmp主要也是在比较两个文件,它主要利用“字节”单位去比较,因此,当然也可以比较二进制文件。(还是要再提醒,diff主要是以“行”为单位比较,cmp则是以“字节”为单位去比较,这并不相同!)
[root@www ~]# cmp [-s] file1 file2
参数:
-s :将所有的不同点的字节处都列出来。因为 cmp 默认仅会输出第一个发现的不同点。
范例一:用 cmp 比较一下 passwd.old 及 passwd.new
[root@www test]# cmp passwd.old passwd.new
passwd.old passwd.new differ: byte 106, line 4
看到了吗?第一个发现的不同点在第四行,而且字节数是在第106 个字节处!这个 cmp也可以用来比较二进制文件。
patch
patch这个命令与diff可是有密不可分的关系啊!我们前面提到,diff可以用来分辨两个版本之间的区别,举例来说,刚才我们所新建的passwd.old及passwd.new之间就是两个不同版本的文件。那么,如果要“升级”呢?就是将旧的文件升级成为新的文件时,应该要怎么做呢?其实也不难啦!就是先比较新旧版本的区别,并将区别文件制作成为补丁文件,再由补丁文件更新旧文件即可。举例来说,我们可以这样做测试:
范例一:以 /tmp/test 内的 passwd.old 与 passwd.new 制作补丁文件
[root@www test]# diff -Naur passwd.old passwd.new > passwd.patch
[root@www test]# cat passwd.patch
—- passwd.old 2009-02-10 14:29:09.000000000 +0800 <==新旧文件的信息
+++ passwd.new 2009-02-10 14:29:18.000000000 +0800
@@ -1,9 +1,8 @@ <==新旧文件要修改数据的界定范围,旧文件在1~9行,新文件在1~8行
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
-adm:x:3:4:adm:/var/adm:/sbin/nologin <==左侧文件删除
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
-sync:x:5:0:sync:/sbin:/bin/sync <==左侧文件删除
+no six line <==右侧新文件加入
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
一般来说,使用 diff 制作出来的比较文件通常使用扩展名为.patch。至于内容就如同上面介绍的样子。基本上就是以行为单位,看看哪边有一样与不一样的,找到一样的地方,然后将不一样的地方替换掉!以上面内容为例,新文件看到-会删除,看到+会加入!好了,那么如何将旧的文件更新成为新的内容呢?就是将passwd.old改成与passwd.new相同!可以这样做:
[root@www ~]# patch -pN < patch_file <==更新
[root@www ~]# patch -R -pN < patch_file <==还原
参数:
-p :后面的N表示取消几层目录的意思。
-R :代表还原,将新的文件还原成原来旧的版本。
范例二:将刚才制作出来的 patch file 用来更新旧版数据
[root@www test]# patch -p0 < passwd.patch
patching file passwd.old
[root@www test]# ll passwd*
-rw-r—r— 1 root root 1929 Feb 10 14:29 passwd.new
-rw-r—r— 1 root root 1929 Feb 10 15:12 passwd.old <==文件一模一样!
范例三:恢复旧文件的内容
[root@www test]# patch -R -p0 < passwd.patch
[root@www test]# ll passwd*
-rw-r—r— 1 root root 1929 Feb 10 14:29 passwd.new
-rw-r—r— 1 root root 1986 Feb 10 15:18 passwd.old
文件就这样恢复成为旧版本
为什么这里会使用-p0呢?因为我们在比较新旧版的数据时是在同一个目录下,因此不需要减去目录啦!如果是使用整体目录比较(diff 新旧目录)时,就得要依据新建 patch 文件所在目录来进行目录的删减。
更详细的 patch 用法我们会在后续的第五部分的原码编译(第22 章)再跟大家介绍,这里仅是介绍给你,我们可以利用 diff 来比较两个文件,更可进一步利用这个功能来制作补丁文件(patch file),让大家更容易进行比较与升级。
12.4.4 文件打印准备:pr
如果你曾经使用过一些图形界面的文字处理软件的话,那么很容易发现,当我们在打印的时候,可以同时选择与设置每一页打印时的标题,也可以设置页码呢!那么,如果我是在Linux下面打印纯文本文件呢?可不可以具有标题啊?可不可以加入页码啊?当然可以。使用 pr 就能够达到这个功能了。不过,pr的参数实在太多了,鸟哥也说不完,一般来说,鸟哥都仅使用最简单的方式来处理而已。举例来说,如果想要打印/etc/man.config呢?
[root@www ~]# pr /etc/man.config
2007-01-06 18:24 /etc/man.config Page 1
#
Generated automatically from man.conf.in by the
configure script.
…..以下省略……
上面特殊字体那一行呢,其实就是使用pr处理后所造成的标题。标题中会有“文件时间”、“文件名”及“页码”三大项目。更多的pr使用,请参考pr的说明。
12.5 重点回顾
正则表达式就是处理字符串的方法,它是以行为单位来进行字符串的处理行为。
正则表达式通过一些特殊符号的辅助,可以让用户轻易达到查找、删除、替换某特定字符串的处理程序。
只要工具程序支持正则表达式,那么该工具程序就可以用来作为正则表达式的字符串处理之用。
正则表达式与通配符是完全不一样的。通配符(wildcard)代表的是bash操作接口的一个功能,但正则表达式则是一种字符串处理的表示方式!
使用grep或其他工具进行正则表达式的字符串比较时,因为编码的问题会有不同的状态,因此,你最好将LANG等变量设置为C或者是en等英文语系!
grep与egrep在正则表达式里面是很常见的两个程序,其中,egrep支持更严谨的正则表达式的语法。
由于编码系统的不同,不同的语系(LANG)会造成正则表达式选取数据的区别,因此可利用特殊符号如[:upper:]来替代编码范围较佳。
由于严谨度的不同,正则表达式之上还有更严谨的扩展正则表达式。
基础正则表达式的特殊字符有*, ?, [], [-], [^], ^,$等!
常见的正则表达式工具有 grep , sed, vim 等。
printf可以通过一些特殊符号来将数据进行格式化输出。
awk可以使用“字段”为依据,进行数据的重新整理与输出。
文件的比较中,可利用diff及cmp进行比较,其中diff主要用在纯文本文件方面的新旧版本比较。
patch命令可以将旧版数据更新到新版(主要由diff创建patch的补丁来源文件)。
12.6 本章习题
情境模拟题一
通过grep查找特殊字符串,并配合数据流重定向来处理大量的文件查找问题。
目标:正确使用正则表达式;
前提:需要了解数据流重定向,以及通过子命令$(command)来处理文件名的查找。
我们简单的以查找星号(*)来处理下面的任务:
1.利用正则表达式找出系统中含有某些特殊关键字的文件,举例来说,找出在/etc下面含有星号(*)的文件与内容:
解决的方法必须要搭配通配符,但是星号本身就是正则表达式的字符,因此需要如此进行:
[root@www ~]# grep '*' /etc/*
你必须要注意的是,在单引号内的星号是正则表达式的字符,但我们要找的是星号,因此需要加上转义字符(\)。但是在/etc/的那个则是bash的通配符!代表的是文件的文件名。不过由上述的这个结果中,我们仅能找到/etc 下面第一层子目录的数据,无法找到此目录的数据,如果想要连同完整的/etc目录数据,就得要这样做:
[root@www ~]# grep '*' $(find /etc -type f)
2.但如果文件数量太多呢?如同上述的案例,如果要找的是全系统(/)呢?你可以这样做:
[root@www ~]# grep '*' $(find / -type f)
-bash: /bin/grep: Argument list too long
真要命!由于命令列的内容长度是有限制的,因此当查找的对象是整个系统时,上述的命令会发生错误。那该如何是好?此时我们可以通过管道命令以及 xargs 来处理。举例来说,让 grep 每次仅能处理10个文件名,此时你可以这样想:
(1)先用find去找出文件;
(2)用xargs将这些文件每次丢10个给grep来作为参数处理;
(3)grep实际开始查找文件内容。
所以整个做法就会变成这样:
[root@www ~]# find / -type f | xargs -n 10 grep '*'
从输出的结果来看,数据量实在非常庞大!那如果我只是想要知道文件名而已呢?你可以通过grep的功能来找到如下的参数!
[root@www ~]# find / -type f | xargs -n 10 grep -l '*'
情境模拟题二
使用管道命令配合正则表达式新建新命令与新变量。我想要创建一个新的命令名为myip,这个命令能够将我系统的IP找出来显示。而我想要有个新变量,变量名为MYIP,这个变量可以记录我的IP。
处理的方式很简单,我们可以这样试看看:
1.首先,我们依据本章内的ifconfig、sed与awk来取得我们的IP,命令为:
[root@www ~]# ifconfig eth0 | grep 'inet addr' | \
> sed 's/^.*inet addr://g'| cut -d ' ' -f1
2.再来,我们可以将此命令利用alias指定为myip,如下所示:
[root@www ~]# alias myip="ifconfig eth0 | grep 'inet addr' | \
> sed 's/^.*inet addr://g'| cut -d ' ' -f1 "
3.最终,我们可以通过变量设置来处理MYIP。
[root@www ~]# MYIP=$( myip )
4.如果每次登录都要生效,可以将alias与MYIP的设置那两行写入你的~/.bashrc即可!
简答题部分
我想要知道,在/etc下面,只要含有XYZ三个字符的任何一个字符的那一行就列出来,要怎样进行?
将/etc/termcap内容取出后,去除开头为#的行、去除空白行、取出开头为英文字母的那几行以及最终统计总行数该如何进行?
