- 第15章 磁盘配额(Quota)与高级文件系统管理
- 制作账号环境时,由于有五个账号,因此鸟哥使用 script 来新建环境!
- !/bin/bash
- 使用script来新建实验quota所需的环境
- 重点就在于 usrquota和grpquota ,注意写法!
- 其他选项鸟哥并没有列出来,重点在于第四字段,于 default 后面加上两个参数。
- 针对整个系统含有 usrquota、grpquota 参数的文件系统进行 quotacheck 扫描
- 若执行这个命令却出现如下的错误信息,表示你没有任何文件系统有启动 quota 支持!
- quotacheck: Can't find filesystem to check or filesystem not mounted with
- quota option.
- 在鸟哥的案例中,/home 独立的文件系统,因此查询结果会将两个配置文件放在
- /home下面。这两个文件就是Quota最重要的信息了!
- 如果因为特殊需求需要强制扫描已挂载的文件系统时
- 数据要简洁很多,因为有配置文件存在。所以警告信息不会出现!
- 由于我们要启动 user/group 的 quota ,所以使用下面的语法即可
- 特殊用法,假如你的启动 /var 的 quota 支持,那么仅启动 user quota 时
- 将 myquota1 的限制值复制给其他四个账号
- 记得,单位为 KB 。
- 宽限时间原本为 7 天,将它改成 14 天吧!
- 原本是 7days ,我们将它给改为 14days 。
- 直接使用 quota 去显示出 myquota1 与 myquota2 的限额
- 这个命令显示出来的数据跟 edquota 几乎是一模一样的。只是多了个 grace 选项。
- 你会发现 grace 下面没有任何数据,这是因为我们的使用量 (80) 尚未超过 soft
- 显示出 myquotagrp 的用户组限额
- 查询本案例中所有用户的 quota 限制情况:
- 测试一:利用 myquota1 的身份,创建一个 270MB 的大文件,并查看 quota 结果!
- 注意看,我是使用 myquota1 的账号去进行 dd 命令。
- 然后你可以发现出现一个 warning 的信息。接下来看看报表。
- 这个命令则是利用 root 去查看的!
- 你可以发现 myquota1 的 grace 出现!并且开始倒数了。
- 测试二:再创建另外一个大文件,让总容量超过 300MB !
- 倒数整个归零,所以 grace 的部分就会变成 none 。不继续倒数
- 完全不会出现任何信息!没有信息就是“好信息”。
- 先找到下面这几行的设置值:
- 可以将它改成如下的模样啊!
- 在 MESSAGE 内的 | 代表断行的意思,反斜杠则代表连接下一行;
- 你没有看错,只要这一行,且将执行文件以绝对路径的方式写入即可。
- 查看原始的 myquota5 限值,并给予 soft/hard 分别为 100000/200000
- 看吧!真的有改变过来,这就是quota的简单脚本设置语法。
- 15.2 软件磁盘阵列(Software RAID)
- 从上面可以发现,我的 /dev/hda6~/dev/hda9 没有用到。将它删除看看!
- 这个操作很重要。还记得吧?将内核的 partition table 更新!
- 上述的动作请做五次!
- 上面的 6~10 号,就是我们需要的分区。
- 详细的参数说明请回去前面看看。这里我通过 {} 将重复的项目简化!
- 最后五行就是这五个设备目前的情况,包括四个 active sync 一个 spare !
- 至于 RaidDevice 指的则是此 RAID 内的磁盘顺序
- 有趣吧!是 /dev/md0 作为设备被格式化呢!
- 看吧!多了一个 /dev/md0 的设备,而且真的可以让你使用呢!
- 1. 先复制一些东西到 /mnt/raid 去,假设这个 RAID 已经在使用了
- 2. 假设 /dev/hda8 这个设备出错了!实际模拟的方式:
- 这个操作要快速操作才会看到! /dev/hda10 启动了而 /dev/hda8 死掉了
- 3. 已经通过 spare disk 重建完毕的 RAID 5 情况
- 4. 新建新的分区
- 此时系统会多一个 /dev/hda11 的分区。
- 5. 加入新的拔除有问题的磁盘
- 后面那一串数据就是这个设备向系统注册的 UUID 标识符!
- 开始设置 mdadm.conf
- RAID设备 标识符内容
- 开始设置开机自动挂载并测试
- 你得确定可以顺利挂载,并且没有发生任何错误!
- 1. 先卸载且删除配置文件内与这个 /dev/md0 有关的设置:
- 将这一行删除掉,或者是批注掉也可以。
- 2. 直接关闭 /dev/md0 的方法。
- 一样,删除它或是批注它!
- 1. 检查有无 PV 在系统上,然后将 /dev/hda6~/dev/hda9 新建成为 PV 格式
- 这个命令可以一口气新建四个分区成为 PV 。注意大括号的用途
- 这就分别显示每个 PV 的信息与系统所有 PV 的信息。尤其最后一行,显示的是:
- 整体 PV 的量 / 已经被使用到 VG 的 PV 量 / 剩余的 PV 量
- 2. 更详细列出系统上面每个 PV 的信息:
- 由于 PE 是在新建 VG 时才给予的参数,因此在这里看到的 PV 里面的 PE 都会是0
- 而且也没有多余的PE可供分配(allocatable)。
- 1. 将 /dev/hda6-8 新建成为一个 VG,且指定 PE 为 16MB。
- 确实存在这个 vbirdvg 的 VG 啦!
- 发现没?有三个 PV 被用掉,剩下一个 /dev/hda9 的 PV 没被用掉!
- 最后那三行指的就是 PE 能够使用的情况!由于尚未切出 LV,因此所有的 PE
- 均可自由使用。
- 2. 将剩余的 PV (/dev/hda9) 丢给 vbirdvg 吧!
- 基本上,不难吧?这样就可以抽换整个 VG 的大小。
- 1. 将整个 vbirdvg 全部分配给 vbirdlv,要注意,PE 共有 356 个。
- 由于本案例中每个 PE 为 16MB ,因此上述的命令也可以使用如下的方式来新建:
- lvcreate -L 5.56G -n vbirdlv vbirdvg
- open 0
- 1. 格式化、挂载与查看我们的 LV 吧!
- 1. 处理出一个 3GB 的新的分区,在鸟哥的系统中应该是 /dev/hda10
- 这个就是我们要的新的分区。
- 2. 新建新的 PV:
- 可以看到 /dev/hda10 是新加入并且尚未被使用的。
- 3. 加大 VG ,利用 vgextend 功能!
- 不但整体 VG 变大了!而且剩余的 PE 共有 179 个,容量则为 2.80G
- 4. 放大 LV 吧!利用 lvresize 的功能来增加!
- 这样就增加了 LV 了。lvresize 的语法很简单,基本上同样通过 -l 或 -L 来增加!
- 若要增加则使用 + ,若要减少则使用 - !详细的参数请参考 man lvresize 。
- open 1
- 5.1 先看一下原本的文件系统内的 superblock 记录情况吧!
- 5.2 resize2fs 的语法
- 5.3 完整地将 LV 的容量扩充到整个文件系统。
- 可怕吧!这一版的 lvm 竟然还可以在线进行 resize 的功能。
- 刚才复制进去的数据可还是存在的,并没有消失不见!
- 1. 先找出 /dev/hda6 的容量大小,并尝试计算文件系统需缩小到多少
- 从这里可以看出 /dev/hda6 有多大,而且含有 89 个 PE 的量。
- 那如果要使用 resize2fs 时,则总量减去 1.40GB 就对了!
- 从上面可以发现如果扣除 /dev/hda6 则剩余容量有:1.39×3+2.8=6.97
- 2. 直接降低文件系统的容量。
- 容量好像不能够写小数点位数,因此 6.9GB 是错误的,鸟哥就使用 6900MB 了。
- 此外,放大可以在线直接进行,缩小文件系统似乎无法支持。所以要这样做:
- 它要我们先进行磁盘检查,那就直接进行吧!
- 再来 resize2fs 一次就能够成功了,如上所示。
- 3. 降低 LV 的容量,同时我们知道 /dev/hda6 有 89 个 PE
- 会有警告信息。但是我们的实际数据量还是比 6.97GB 小,所以就按y吧!
- open 1
- 4.1 先确认 /dev/hda6 是否将 PE 都删除了!
- 搞了老半天,没有被使用的 PE 竟然在 /dev/hda10 。此时得要转移 PE 。
- pvmove 来源PV 目标PV ,可以将 /dev/hda6 内的 PE全部移动到 /dev/hda10
- 尚未被使用的 PE 去 (Free PE)。
- 4.2 将 /dev/hda6 移出 vbirdvg 中!
- 1. 先查看 VG 还剩下多少剩余容量
- 2. 将刚才删除的 /dev/hda6 加入这个 VG 。
- 3. 利用 lvcreate 新建系统快照区,我们取名为 vbirdss,且给予 60 个 PE
- 上述的命令中最重要的是那个 -s 的参数。代表是 snapshot 快照功能之意!
- -n 后面接快照区的设备名称,/dev/…. 则是要被快照的 LV 完整文件名。
- -l 后面则是接使用多少个 PE 来作为这个快照区使用。
- open 0
- 有没有看到!竟然是一模一样。我们根本没有动过
- /dev/vbirdvg/vbirdss 对吧?不过这里面会主动记录原 vbirdlv 的内容!
- 最后将它卸载。我们准备来玩玩有趣的东西!
- 1. 先将原本的/dev/vbirdvg/vbirdlv 内容作些更改,增减一些目录吧!
- 看起来数据已经不一样了!
- 从这里也看得出来,快照区已经被使用了 12.22% ,因为原始的文件系统有改动过。
- 2. 利用快照区将原本的文件系统备份
- 看吧!两者确实不一样了!开始将快照区内容复制出来吧!
- 此时你就会有一个备份资料,也即是 /backups/lvm.tar.bz2 了!
- 3. 将 vbirdss 卸除并删除 (因为里面的内容已经备份起来了)
- 是否与最初的内容相同啊?这就是通过快照来还原的一个简单的方法。
- 1. 新建一个大一些的快照区,让我们将 /dev/hda6 的 PE 全部给快照区!
- open 0
- 如何?这个快照区不小吧!
- 2. 隐藏 vbirdlv 挂载 vbirdss
- 3. 开始恶搞!
- 不论你在快照区恶搞什么,原本的 vbirdlv 里面的数据安好如初。
- 假设你将 vbirdss 搞烂了,里面的数据不再需要。那该如何是好?
- 4. 还原原本快照区的数据,回到与原文件系统相同的信息
- 数据这样就复原了!
- 15.4 重点回顾
- 15.5 本章习题
- open 0
第15章 磁盘配额(Quota)与高级文件系统管理
如果你的Linux服务器有多个用户经常访问数据时,为了维护所有用户对硬盘空间的公平使用,磁盘配额(Quota)就是一项非常有用的工具。另外,如果你的用户经常抱怨磁盘空间不够用,那么更高级的文件系统就得要学习了。本章我们会介绍磁盘阵列(RAID)及逻辑卷文件系统(LVM),这些工具都可以帮助你管理与维护用户可用的磁盘空间。
15.1 磁盘配额(Quota)的应用与实践
Quota就字面上的意思来看,就是有多少“限额”的意思。如果是用在零用钱上面,就是类似“有多少零用钱一个月”的意思。如果是在计算机主机的磁盘使用量上呢?以Linux来说,就是有多少容量限制的意思。我们可以使用quota来让磁盘的容量使用较为公平,下面我们会介绍什么是quota,然后以一个完整的范例来介绍quota。
15.1.1 什么是 Quota
在Linux系统中,由于是多用户、多任务的环境,所以会有多用户共同使用一个硬盘空间的情况发生,如果其中有少数几个用户大量占掉了硬盘空间的话,那肯定影响其他用户的使用权限。因此管理员应该适当限制硬盘的空间给用户,以妥善分配系统资源。
举例来说,我们用户的默认主文件夹都是在/home 下面,如果/home 是个独立的分区,假设这个分区有10G好了,而/home下面共有30个账号,也就是说,每个用户平均应该会有333MB的空间才对。偏偏有个用户在他的主文件夹下面塞了好多电影,占掉了8GB的空间,想想看,是否造成其他正常用户的不便呢?如果想要让磁盘的容量公平分配,这个时候就得要靠 quota的帮忙。
Quota的一般用途
quota比较常使用的几个情况是:
针对WWW server,例如:每个人的网页空间的容量限制!
针对mail server,例如:每个人的邮件空间限制。
针对file server,例如:每个人最大的可用网络硬盘空间(教学环境中最常见。)
上面讲的是针对网络服务的设计,如果是针对Linux系统主机上面的设置,用途有下面这些:限制某一用户组所能使用的最大磁盘配额(使用用户组限制)
你可以将你的主机上的用户分门别类,有点像是目前很流行的收费与免费会员制的情况,你比较喜好的那一群的使用配额就可以分配高一些。
限制某一用户的最大磁盘配额(使用用户限制)
在限制了用户组之后,你也可以再继续针对个人来进行限制,使得同一用户组之下还可以有更公平的分配。
以Link的方式来使邮件可以作为限制的配额(更改/var/spool/mail这个路径)
如果是分为收费与免费会员的“邮件主机系统”,是否需要重新再规划一个硬盘呢?也不需要。直接使用Link的方式指向/home(或者其他已经做好的quota磁盘)就可以。这通常是用于原本磁盘分区的规划不好但是却又不想要更改原有主机架构时。
大概有这些实际的用途。
Quota的使用限制
虽然quota很好用,但是使用上还是有些限制要先了解的:
仅能针对整个文件系统
quota实际在运行的时候,是针对整个文件系统进行限制的,例如:如果你的/dev/sda5是挂载在/home下面,那么在/home下面的所有目录都会受到限制。
内核必须支持quota
Linux 内核必须有支持 quota 这个功能才行:如果你是使用 CentOS 5.x 的默认内核,那恭喜你了,你的系统已经默认有支持 quota 这个功能。如果你是自行编译内核的,那么请特别留意你是否已经“真的”打开了quota这个功能?否则下面的工夫将全部都白做了。
Quota的日志文件
目前新版的 Linuxdistributions 使用的是 Kernel 2.6.xx 的内核版本,这个内核版本支持新的quota 模块,使用的默认文件( aquota.user,aquota.group )将不同于旧版本的quota.user,quota.group(多了一个a),而由旧版本的quota可以通过convertquota这个程序来转换呢!
只对一般身份用户有效
这就有趣了,并不是所有在 Linux 上面的账号都可以设置 quota 呢,例如 root 就不能设置quota,因为整个系统所有的数据几乎都是它的。
所以,你不能针对某个目录来进行 Quota 的设计,但你可以针对某个文件系统来设置。如果不明白目录与挂载点还有文件系统的关系,请回到第8章去看看再回来!
Quota的规范设置选项
quota针对整个文件系统的限制项目主要分为下面几个部分:
容量限制或文件数量限制(block或inode)
我们在第8 章谈到文件系统中,说到文件系统主要规划为存放属性的 inode 与实际文件数据的block块,Quota既然是管理文件系统,所以当然也可以管理inode或block。这两个管理的功能为:
限制inode用量:管理用户可以新建的“文件数量”;
限制block用量:管理用户磁盘容量的限制,较常见的为这种方式。
soft/hard
既然是规范,当然就有限制值。不管是inode/block,限制值都有两个,分别是soft与hard。通常hard限制值要比soft还要高。举例来说,若限制项目为block,可以限制hard为500MB而soft为400MB。这两个限值的意义为:
hard:表示用户的用量绝对不会超过这个限制值,以上面的设置为例,用户所能使用的磁盘容量绝对不会超过500MB,若超过这个值则系统会锁住该用户的磁盘使用权;
soft:表示用户在低于soft限值时(此例中为400MB),可以正常使用磁盘,但若超过soft且低于hard的限值(介于400~500MB之间时),每次用户登录系统时,系统会主动发出磁盘即将爆满的警告信息,且会给予一个宽限时间(gracetime)。不过,若用户在宽限时间倒数期间就将容量再次降低于 soft 限值之下,则宽限时间会停止。
会倒计时的宽限时间 (grace time)
刚才上面就谈到宽限时间了,这个宽限时间只有在用户的磁盘用量介于soft到hard之间时,才会出现且会倒数的一个时间。由于达到hard限值时,用户的磁盘使用权可能会被锁住。为了担心用户没有注意到这个磁盘配额的问题,因此设计了soft。当你的磁盘用量即将到达hard且超过 soft 时,系统会给予警告,但也会给一段时间让用户自行管理磁盘。一般默认的宽限时间为7天,如果7天内你都不进行任何磁盘管理,那么soft限制值会即刻替代hard限值来作为quota的限制。
以上面设置的例子来说,假设你的容量高达 450MB 了,那 7 天的宽限时间就会开始倒数,若7天内你都不进行任何删除文件的操作来为你的磁盘瘦身,那么7天后你的磁盘最大用量将变成400MB(那个soft的限制值),此时你的磁盘使用权就会被锁住而无法新增文件了。
整个 soft,hard,grace time 的相关性我们可以用图 15-1 来说明。
图中的直方图为用户的磁盘容量,soft/hard分别是限制值。只要小于400MB就一切OK,若高于soft就出现gracetime并倒数且等待用户自行处理,若到达hard的限制值,那我们就搬张小板凳等着看好戏了。这样图示有清楚一点了吗?
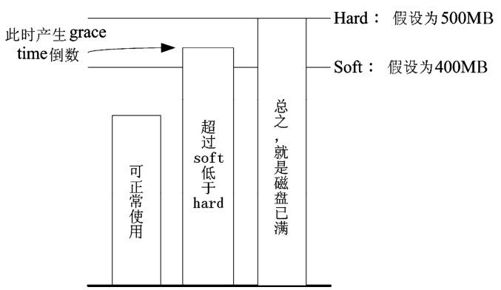
图15-1 soft,hard,grace time 的相关性
15.1.2 一个Quota范例
坐而言不如起而行,所以这里我们使用一个范例来设计一下如何处理Quota的设置流程。
目的与账号:现在我想要让我的专题设为五个为一组,这五个人的账号分别是 myquot a1,myquota2,myquota3,myquota4,myquota5,这五个用户的密码都是 password,且这五个用户所属的初始用户组都是myquotagrp。其他的账号属性则使用默认值。
账号的磁盘容量限制值:我想让这五个用户都能够取得300MB的磁盘使用量(hard),文件数量则不予限制。此外,只要容量使用率超过250MB,就予以警告(soft)。
用户组的限额:由于我的系统里面还有其他用户存在,因此我仅承认myquotagrp这个用户组最多仅能使用1GB的容量。这也就是说,如果myquota1,myquota2,myquota3都用了280MB的容量了,那么其他两人最多只能使用(1000MB-280MBx3=160MB)的磁盘容量。这就是用户与用户组同时设置时会产生的后果。
宽限时间的限制:最后,我希望每个用户在超过soft限制值之后,都还能够有14天的宽限时间。
好了,那你怎么规范账号以及相关的Quota设置呢?首先,在这个小节我们先来将账号相关的属性与参数搞定再说吧!
制作账号环境时,由于有五个账号,因此鸟哥使用 script 来新建环境!
[root@www ~]# viaddaccount.sh
!/bin/bash
使用script来新建实验quota所需的环境
groupadd myquotagrp
for username in myquota1 myquota2 myquota3 myquota4 myquota5
do
useradd -g myquotagrp $username
echo "password" | passwd —stdin $username
done
[root@www ~]# sh addaccount.sh
接下来,就让我们来实践Quota的练习。
15.1.3 实践Quota流程 1:文件系统支持
前面我们就谈到,要使用 Quota 必须要内核与文件系统支持才行。假设你已经使用了默认支持Quota的内核,那么接下来就是要启动文件系统的支持。不过,由于Quota仅针对整个文件系统来进行规划,所以我们得先查一下/home是否是个独立的文件系统。
[root@www ~]# df -h /home
Filesystem Size Used Avail Use% Mounted on
/dev/hda3 4.8G 740M 3.8G 17% /home <==鸟哥主机的 /home 确实是独立的!
[root@www ~]# mount | grep home
/dev/hda3 on /home type ext3 (rw)
从上面的数据来看,鸟哥这部主机的/home 确实是独立的文件系统,因此可以直接限制 /dev/hda3 。如果你的系统的/home 并非独立的文件系统,那么可能就得要针对根目录(/)来规范了!不过,不太建议在根目录设置 Quota。此外,由于 VFAT 文件系统并不支持 Linux Quota 功能,所以我们得要使用mount查询一下/home的文件系统,看起来是Linux传统的ext2/ext3,这种文件系统肯定有支持Quota。没问题!
如果只是想要在这次开机中实验Quota,那么可以使用如下的方式来手动加入quota的支持:
[root@www ~]# mount -o remount,usrquota,grpquota /home
[root@www ~]# mount | grep home
/dev/hda3 on /home type ext3 (rw,usrquota,grpquota)
重点就在于 usrquota和grpquota ,注意写法!
事实上,当你重新挂载时,系统会同步更新/etc/mtab 这个文件,所以你必须要确定 /etc/mtab 已经加入usrquota、grpquota的支持到你所想要设置的文件系统中。另外也要特别强调,用户与用户组的 quota 文件系统支持参数分别是 usrquota 和 grpquota,千万不要写错了,这点非常多初次接触Quota的朋友经常搞错。
不过手动挂载的数据在下次重新挂载就会消失,因此最好写入配置文件中。在鸟哥这台主机的案例中,我可以直接修改/etc/fstab成为下面这个样子:
[root@www ~]# vi /etc/fstab
LABEL=/home /home ext3 defaults,usrquota,grpquota 1 2
其他选项鸟哥并没有列出来,重点在于第四字段,于 default 后面加上两个参数。
[root@www ~]# umount /home
[root@www ~]# mount -a
[root@www ~]# mount | grep home
/dev/hda3 on /home type ext3(rw,usrquota,grpquota)
还是要再次强调,修改完/etc/fstab后,务必要测试一下。若有发生错误得要赶紧处理。因为这个文件如果修改错误,是会造成无法开机完全的情况。切记切记!最好使用vim来修改,因为会有语法的检验,就不会让你写错字了。启动文件系统的支持后,接下来让我们新建起quota的日志文件吧!
15.1.4 实践Quota流程 2:新建 Quota 配置文件
其实Quota是通过分析整个文件系统中每个用户(用户组)拥有的文件总数与总容量,再将这些数据记录在该文件系统的最顶层目录,然后在该配置文件中再使用每个账号(或用户组)的限制值去规定磁盘使用量的。所以,构建这个 Quota 配置文件就显得非常重要。扫描有支持 Quota 参数(usrquota,grpquota)的文件系统,就使用quotacheck这个命令。这个命令的语法如下:
quotacheck:扫描文件系统并新建Quota的配置文件
[root@www ~]# quotacheck [-avugfM] [/mount_point]
参数:
-a :扫描所有在 /etc/mtab 内,含有 quota 支持的文件系统,加上此参数后,
/mount_point 可不必写,因为扫描所有的文件系统了。
-u :针对用户扫描文件与目录的使用情况,会新建 aquota.user。
-g :针对用户组扫描文件与目录的使用情况,会新建 aquota.group。
-v :显示扫描过程的信息。
-f :强制扫描文件系统,并写入新的 quota 配置文件 (危险)。
-M :强制以读写的方式扫描文件系统,只有在特殊情况下才会使用。
quotacheck的参数你只要记得“-avug”一起执行即可。那个-f与-M是在文件系统可能已经启动 quota 了,但是你还想要重新扫描文件系统时,系统会要求你加入那两个参数(担心有其他人已经使用quota中)。平时没必要不要加上那两个选项。好了,那就让我们来处理我们的任务吧!
针对整个系统含有 usrquota、grpquota 参数的文件系统进行 quotacheck 扫描
[root@www ~]# quotacheck -avug
quotacheck: Scanning /dev/hda3 [/home] quotacheck: Cannot stat old user quota
file: No such file or directory <==有找到文件系统,但尚未制作配置文件。
quotacheck: Cannot stat old group quota file: No such file or directory
quotacheck: Cannot stat old user quota file: No such file or directory
quotacheck: Cannot stat old group quota file: No such file or directory
done <==上面三个错误只是说明配置文件尚未创建而已,可以忽略不理!
quotacheck: Checked 130 directories and 107 files <==实际查询结果
quotacheck: Old file not found.
quotacheck: Old file not found.
若执行这个命令却出现如下的错误信息,表示你没有任何文件系统有启动 quota 支持!
quotacheck: Can't find filesystem to check or filesystem not mounted with
quota option.
[root@www ~]# ll -d /home/a*
-rw———- 1 root root 8192 Mar 6 11:58 /home/aquota.group
-rw———- 1 root root 9216 Mar 6 11:58 /home/aquota.user
在鸟哥的案例中,/home 独立的文件系统,因此查询结果会将两个配置文件放在
/home下面。这两个文件就是Quota最重要的信息了!
这个命令只要进行到这里就够了,不要反复进行,因为等一下我们会启动 quota 功能,若启动后你还要进行quotacheck,系统会担心破坏原有的配置文件,所以会产生一些错误信息警告你。如果你确定没有任何人在使用quota时,可以强制重新进行quotacheck的操作。强制执行的情况可以使用如下的参数功能:
如果因为特殊需求需要强制扫描已挂载的文件系统时
[root@www ~]# quotacheck -avug -mf
quotacheck: Scanning /dev/hda3 [/home] done
quotacheck: Checked 130 directories and 109 files
数据要简洁很多,因为有配置文件存在。所以警告信息不会出现!
这样配置文件就创建起来了!你不用手动去编辑那两个文件,因为那两个文件是 quota 自己的数据文件,并不是纯文本文件,且该文件会一直变动,这是因为当你对/home 这个文件系统进行操作时,你操作的结果会影响磁盘,所以当然会同步记载到那两个文件中。因此要新建aquota.user,aquota.group,记得使用的是quotacheck命令。不是手动编辑。
15.1.5 实践Quota流程 3:Quota 启动、关闭与限制值设置
制作好Quota配置文件之后,接下来就是要启动quota了。启动的方式很简单。使用quotaon,至于关闭就用quotaoff即可。
quotaon:启动quota的服务
[root@www~]#quotaon[-avug]
[root@www~]#quotaon[-vug][/mount_point]
参数:
-u :针对用户启动 quota (aquota.user)。
-g :针对用户组启动 quota (aquota.group)。
-v :显示启动过程的相关信息。
-a :根据 /etc/mtab 内的文件系统设置启动有关的 quota ,若不加 -a 的话,
则后面就需要加上特定的那个文件系统。
由于我们要启动 user/group 的 quota ,所以使用下面的语法即可
[root@www ~]# quotaon -auvg
/dev/hda3 [/home]: group quotas turned on
/dev/hda3 [/home]: user quotas turned on
特殊用法,假如你的启动 /var 的 quota 支持,那么仅启动 user quota 时
[root@www ~]# quotaon -uv /var
这个“quotaon -auvg”的命令几乎只在第一次启动 quota 时才需要进行,因为下次等你重新启动系统时,系统的/etc/rc.d/rc.sysinit 这个初始化脚本就会自动的执行这个命令了。因此你只要在这次实例中进行一次即可,将来都不需要自行启动 quota,因为 CentOS 5.x 系统会自动帮你搞定它!
quotaoff:关闭quota的服务
[root@www ~]# quotaoff [-a]
[root@www ~]# quotaoff [-ug] [/mount_point]
参数:
-a :全部的文件系统的 quota 都关闭 (根据 /etc/mtab)
-u :仅针对后面接的那个 /mount_point 关闭 user quota
-g :仅针对后面接的那个 /mount_point 关闭 group quota
这个命令就是关闭了quota的支持。我们这里需要练习quota,所以这里请不要关闭它。接下来让我们开始来设置用户与用户组的quota限额。
edquota:编辑账号/用户组的限值与宽限时间
edquota是editquota的缩写,所以就是用来编辑用户或者是用户组限额的命令。我们先来看看edquota的语法,看完后再来实际操作一下。
[root@www ~]# edquota [-u username] [-g groupname]
[root@www ~]# edquota -t <==修改宽限时间
[root@www ~]# edquota -p 范本账号 -u 新账号
参数:
-u :后面接账号名称。可以进入 quota 的编辑界面(vi) 去设置 username 的限制值。
-g :后面接组名。可以进入 quota 的编辑界面 (vi) 去设置 groupname 的限制值。
-t :可以修改宽限时间。
-p :复制范本。那个“模板账号”为已经存在并且已设置好 quota 的用户,
意义为将“范本账号”这个人的 quota 限制值复制给新账号!
好了,先让我们来看看当进入myquota1的限额设置时会出现什么界面:
范例一:设置dmtsai这个用户的quota限制值
[root@www~]#edquota-umyquota1
Disk quotas for user myquota1 (uid 710):
Filesystem blocks soft hard inodes soft hard
/dev/hda3 80 0 0 10 0 0
上面第一行说明针对哪个账号(myquota1)进行quota的限额设置,第二行则是标题行,里面共分为七个字段,七个字段分别的意义为:
1.文件系统(filesystem):说明该限制值是针对哪个文件系统(或partition);
2.磁盘容量(blocks):这个数值是quota自己算出来的,单位为KB,请不要修改它;
3.soft:磁盘容量(block)的soft限制值,单位为KB;
4.hard:block 的hard 限制值,单位 KB;
5.文件数量(inodes):这是quota自己算出来的,单位为个数,请不要改动它;
6.soft:inode的soft限制值;
7.hard:inode的hard限制值。
当soft/hard为0时,表示没有限制的意思。好,依据我们的范例说明,我们需要设置的是blocks的soft/hard,至于inode则不要去更动它!因此上述的界面我们将它改成如下的模样:
在 edquota 的界面中,每一行只要保持七个字段就可以了,并不需要排列整齐的!
Disk quotas for user myquota1 (uid 710):
Filesystem blocks soft hard inodes soft hard
/dev/hda3 80 250000 300000 10 0 0
鸟哥使用1000去近似1024的倍数,比较好算。然后就可以保存后离开。
设置完成之后,我们还有其他 5 个用户要设置,由于设置值都一样,此时可以使用 quota复制。
将 myquota1 的限制值复制给其他四个账号
[root@www ~]# edquota -p myquota1 -u myquota2
[root@www ~]# edquota -p myquota1 -u myquota3
[root@www ~]# edquota -p myquota1 -u myquota4
[root@www ~]# edquota -p myquota1 -u myquota5
这样就方便多了。然后,赶紧更改一下用户组的quota限额吧!
[root@www ~]# edquota -g myquotagrp
Disk quotas for group myquotagrp (gid 713):
Filesystem blocks soft hard inodes soft hard
/dev/hda3 400 900000 1000000 50 0 0
记得,单位为 KB 。
最后,将宽限时间改成14天吧!
宽限时间原本为 7 天,将它改成 14 天吧!
[root@www ~]# edquota -t
Grace period before enforcing soft limits for users:
Time units may be: days, hours, minutes, or seconds
Filesystem Block grace period Inode grace period
/dev/hda3 14days 7days
原本是 7days ,我们将它给改为 14days 。
通过这个简单的小步骤,我们已经将用户/用户组/宽限时间都设置妥当!接下来就是查看到底设置有没有生效。
15.1.6 实践 Quota 流程 4:Quota 限制值的报表
quota 的报表主要有两种模式,一种是针对每个个人或用户组的 quota 命令,一个是针对整个文件系统的repquota命令。我们先从较简单的quota来介绍。你也可以顺道看看你的设置对不对。
quota:单一用户的quota报表
[root@www ~]# quota [-uvs] [username]
[root@www ~]# quota [-gvs] [groupname]
参数:
-u :后面可以接 username ,表示显示出该用户的 quota 限制值。若不接 username
,表示显示出执行者的 quota 限制值。
-g :后面可接 groupname ,表示显示出该用户组的 quota 限制值。
-v :显示每个用户在文件系统中的 quota 值。
-s :使用 1024 为倍数来指定单位,会显示如 M 之类的单位。
直接使用 quota 去显示出 myquota1 与 myquota2 的限额
[root@www ~]# quota -uvs myquota1 myquota2
Disk quotas for user myquota1 (uid 710):
Filesystem blocks quota limit grace files quota limit grace
/dev/hda3 80 245M 293M 10 0 0
Disk quotas for user myquota2 (uid 711):
Filesystem blocks quota limit grace files quota limit grace
/dev/hda3 80 245M 293M 10 0 0
这个命令显示出来的数据跟 edquota 几乎是一模一样的。只是多了个 grace 选项。
你会发现 grace 下面没有任何数据,这是因为我们的使用量 (80) 尚未超过 soft
显示出 myquotagrp 的用户组限额
[root@www ~]# quota -gvs myquotagrp
Disk quotas for group myquotagrp (gid 713):
Filesystem blocks quota limit grace files quota limit grace
/dev/hda3 400 879M 977M 50 0 0
由于使用常见的K,M,G等单位比较好算,因此上面我们使用了“-s”的参数,就能够以M为单位显示了。不过由于我们使用edquota设置限额时,使用的是近似值(1000)而不是实际的1024倍数,所以看起来会有点不太一样。由于quota仅能针对某些用户显示报表,如果要针对整个文件系统列出报表时,那repquota就派上用场啦!
repquota:针对文件系统的限额做报表
[root@www ~]# repquota -a [-vugs]
参数:
-a :直接到 /etc/mtab 查询具有 quota 标志的文件系统,并报告 quota 的结果。
-v :输出的数据将含有文件系统相关的详细信息。
-u :显示出用户的 quota 限值 (这是默认值)。
-g :显示出个别用户组的 quota 限值。
-s :使用 M, G 为单位显示结果
查询本案例中所有用户的 quota 限制情况:
[root@www ~]# repquota -auvs
* Report for user quotas on device /dev/hda3 <==针对 /dev/hda3
Block grace time: 14days; Inode grace time: 7days <==block 宽限时间为 14 天
Block limits File limits
User used soft hard grace used soft hard grace
root — 651M 0 0 5 0 0
myquota1 — 80 245M 293M 10 0 0
myquota2 — 80 245M 293M 10 0 0
myquota3 — 80 245M 293M 10 0 0
myquota4 — 80 245M 293M 10 0 0
myquota5 — 80 245M 293M 10 0 0
Statistics: <==这是所谓的系统相关信息,用 -v 才会显示
Total blocks: 9
Data blocks: 2
Entries: 22
Used average: 11.000000
根据这些信息,你就可以知道目前的限制情况。怎样,Quota 很简单吧?你可以赶紧针对你的系统设置一下磁盘使用的规则,让你的用户不会抱怨磁盘怎么老是被耗光!
15.1.7 实践Quota流程 5:测试与管理
Quota到底有没有效果?测试看看不就知道了?让我们使用myquota1去测试看看,如果创建一个大文件时,整个系统会便怎样呢?
测试一:利用 myquota1 的身份,创建一个 270MB 的大文件,并查看 quota 结果!
[myquota1@www ~]# dd if=/dev/zero of=bigfile bs=1M count=270
hda3: warning, user block quota exceeded.
270+0 records in
270+0 records out
283115520 bytes (283 MB) copied, 3.20282 seconds, 88.4 MB/s
注意看,我是使用 myquota1 的账号去进行 dd 命令。
然后你可以发现出现一个 warning 的信息。接下来看看报表。
[root@www ~]# repquota -auv
* Report for user quotas on device /dev/hda3
Block grace time: 14days; Inode grace time: 7days
Block limits File limits
User used soft hard grace used soft hard grace
myquota1 +- 276840 250000 300000 13days 11 0 0
这个命令则是利用 root 去查看的!
你可以发现 myquota1 的 grace 出现!并且开始倒数了。
测试二:再创建另外一个大文件,让总容量超过 300MB !
[myquota1@www ~]# dd if=/dev/zero of=bigfile2 bs=1M count=300
hda3: write failed, user block limit reached.
dd: writing `bigfile2': Disk quota exceeded <==看,错误信息不一样了!
23+0 records in <==没办法写入了,所以只记录 23 条
22+0 records out
23683072 bytes (24 MB) copied, 0.260081 seconds, 91.1 MB/s
[myquota1@www ~]# du -sk
300000 . <==果然是到极限了。
此时myquota1可以开始处理它的文件系统了。如果不处理的话,最后宽限时间会归零,然后出现如下的界面:
[root@www ~]# repquota -au
* Report for user quotas on device /dev/hda3
Block grace time: 00:01; Inode grace time: 7days
Block limits File limits
User used soft hard grace used soft hard grace
myquota1 +- 300000 250000 300000 none 11 0 0
倒数整个归零,所以 grace 的部分就会变成 none 。不继续倒数
其实倒数归零也不会有什么特殊的意外。别担心!只是如果你的磁盘使用量介于soft与hard 之间时,当倒数归零那么soft的值会变成严格限制,此时你就没有多余的空间可以使用了。如何解决?就登录到系统去删除文件即可。问题是,用户通常分不清楚到底系统出了什么问题,所以我们可能需要寄送一些警告信(email)给用户比较妥当。那么如何处理呢?通过warnquota来处置即可。
warnquota:对超过限额者发出警告信
warnquota 字面上的意义就是 quota 的警告(warn)。那么这东西有什么用呢?它可以依据/etc/warnquota.conf的设置,然后找出目前系统上面quota用量超过soft(就是有gracetime出现的那些家伙)的账号,通过 Email 的功能将警告信件发送到用户的电子邮件信箱。warnquota并不会自动执行,所以我们需要手动去执行它。单纯执行“warnquota”之后,它会发送两封信出去,一封给myquota1,一封给root!
[root@www ~]# warnquota
完全不会出现任何信息!没有信息就是“好信息”。
[root@www ~]# mail
N329 root@www.vbird.tsai Fri Mar 6 16:10 27/1007 "NOTE: ….
& 329 <==因为新信件在第 329 封的原因
From root@www.vbird.tsai Fri Mar 6 16:10:18 2009
Date: Fri, 6 Mar 2009 16:10:17 +0800
From: root <root@www.vbird.tsai>
Reply-To: root@myhost.com
Subject: NOTE: You are exceeding your allocated disk space limits
To: myquota1@www.vbird.tsai
Cc: root@www.vbird.tsai <==注意这三行,分别是标题、收件人与副本 (CC)。
Your disk usage has exceeded the agreed limits on this server <==问题说明
Please delete any unnecessary files on following filesystems:
/dev/hda3 <==下面这几行为发生磁盘“爆满”的信息。
Block limits File limits
Filesystem used soft hard grace used soft hard grace
/dev/hda3 +- 300000 250000 300000 13days 12 0 0
root@localhost <==这个是警告信息发送者的“签名数据”。
& exit <==离开 mail 程序!
执行warnquota可能也不会产生任何信息以及信件,因为只有当用户的quota有超过soft 时, warnquota 才会发送警告信。那么以上内容中,包括标题、信息内容说明、签名文件等数据放在哪里呢?刚才不是讲过吗?/etc/warnquota啦!因为上述的数据是英文,不好理解吗?没关系,你可以自己转成中文。所以你可以这样处理:
[root@www ~]# vi /etc/warnquota.conf
先找到下面这几行的设置值:
SUBJECT = NOTE: You are exceeding your allocated disk space limits <==第10行
CC_TO = "root@localhost" <==第11行
MESSAGE = Your disk usage has exceeded the agreed limits\ <==第21行
on this server|Please delete any unnecessary files on following filesystems:|
SIGNATURE = root@localhost <==第25行
可以将它改成如下的模样啊!
SUBJECT = 注意:你在本系统上拥有的文件容量已经超过最大容许限额
CC_TO = "root@localhost" <==除非你要寄给其他人,否则这个项目可以不改
MESSAGE = 你的磁盘容量已经超过本机的容许限额,|\
请在如下的文件系统中,删除不必要的文件:|
SIGNATURE = 你的系统管理员 (root@localhost)
在 MESSAGE 内的 | 代表断行的意思,反斜杠则代表连接下一行;
如果你重复执行warnquota,那么myquota1就会收到类似如下的信件内容:
Subject: 注意:你在本系统上拥有的文件容量已经超过最大容许限额
To: myquota1@www.vbird.tsai
Cc: root@www.vbird.tsai
你的磁盘容量已经超过本机的容许限额,
请在如下的文件系统中,删除不必要的文件:
/dev/hda3
Filesystem used soft hard grace used soft hard grace
/dev/hda3 +- 300000 250000 300000 none 11 0 0
你的系统管理员 (root@localhost)
不过这个方法并不适用在/var/spool/mail也爆满的quota控管中,因为如果用户在这个文件系统的容量已经达到限额了,那么新的信件当然就收不下来啦!此时就只能等待用户自己发现并跑来这里删除数据,或者是请求 root 帮忙处理。知道了这玩意儿这么好用,那么我们怎么让系统自动执行warnquota呢?你可以这样做:
[root@www ~]# vi /etc/cron.daily/warnquota
/usr/sbin/warnquota
你没有看错,只要这一行,且将执行文件以绝对路径的方式写入即可。
[root@www ~]# chmod 755 /etc/cron.daily/warnquota
那么将来每天早上4:02am时,这个文件就会主动被执行,那么系统就能够主动通知磁盘配额达到极限的用户。至于为何要写入上述的文件呢?留待下一章工作排程时我们再来加强介绍。
setquota:直接于命令中设置quota限额
如果你想要使用script的方法来新建大量的账号,并且所有的账号都在新建时就给予quota,那该如何是好?其实有两个方法可以考虑:
先新建一个原始quota账号,再以“edquota-pold-unew”写入script中;
直接以setquota新建用户的quota设置值。
不同于edquota是调用vi来进行设置,setquota直接由命令输入所必须要的各项限制值。它的语法有点像这样:
[root@www ~]# setquota [-u|-g] 名称 block(soft) block(hard) \
> inode(soft) inode(hard) 文件系统
查看原始的 myquota5 限值,并给予 soft/hard 分别为 100000/200000
[root@www ~]# quota -uv myquota5
Disk quotas for user myquota5 (uid 714):
Filesystem blocks quota limit grace files quota limit grace
/dev/hda3 80 250000 300000 10 0 0
[root@www ~]# setquota -u myquota5 100000 200000 0 0 /home
[root@www ~]# quota -uv myquota5
Disk quotas for user myquota5 (uid 714):
Filesystem blocks quota limit grace files quota limit grace
/dev/hda3 80 100000 200000 10 0 0
看吧!真的有改变过来,这就是quota的简单脚本设置语法。
15.1.8 不改动既有系统的Quota实例
想一想,如果你的主机原先没有想到要设置成为邮件主机,所以并没有规划将邮件信箱所在的/var/spool/mail/目录独立成为一个分区,然后目前你的主机已经没有办法新增或分出任何新的分区了。那我们知道quota是针对整个文件系统进行设计的,因此,你是否就无法针对mail的使用量给予quota的限制呢?
此外,如果你想要让用户的邮件信箱与主文件夹的总体磁盘使用量为固定,那又该如何是好?由于/home 及/var/spool/mail 根本不可能是同一个文件系统(除非是都不分区,使用根目录,才有可能整合在一起),所以,该如何进行这样的quota限制呢?
其实没有那么难,既然quota是针对整个文件系统来进行限制,假设你又已经有/home这个独立的分区了,那么你只要:
1.将/var/spool/mail这个目录完整地移动到/home下面;
2.利用 ln -s/home/mail/var/spool/mail 来新建连接数据;
3.将/home进行quota限额设置。
嗌只要这样的一个小步骤,你家主机的邮件就有一定的限额 !当然,你也可以依据不同的用户与用户组来设置quota然后同样以上面的方式来进行link的操作,就有不同的限额针对不同的用户提出,很方便吧!
朋友们需要注意的是,由于目前新的 distributions 大多有使用 SELinux 的机制,因此你要进行如同上面的目录转移时,在许多情况下可能会有使用上的限制。或许你得要先暂时关闭 SELinux 才能测试,也或许你得要自行修改 SELinux 的规则才行。
15.2 软件磁盘阵列(Software RAID)
在过去鸟哥还年轻的时代,我们能使用的硬盘容量都不大,几十GB的容量就是大硬盘了。但是某些情况下,我们需要很大容量的存储空间,例如鸟哥在跑的空气质量模式所输出的数据文件一个案例通常需要好几GB,连续跑个几个案例,磁盘容量就不够用了。此时我该如何是好?其实可以通过一种存储机制,称为磁盘阵列(RAID)的就是了。这种机制的功能是什么?它有哪些等级?什么是硬件、软件磁盘阵列?Linux支持什么样的软件磁盘阵列?下面就让我们来介绍。
15.2.1 什么是 RAID
磁盘阵列的英文全名是 RedundantArrays of Inexpensive Disks(RAID),即容错廉价磁盘阵列。RAID 可以通过一些技术(软件或硬件)将多个较小的磁盘整合成为一个较大的磁盘设备;而这个较大的磁盘功能可不止是存储而已,它还具有数据保护的功能。整个RAID由于选择的等级(level)不同,而使得整合后的磁盘具有不同的功能,基本常见的等级有这几种 [6]。
RAID-0(等量模式,stripe):性能最佳
这种模式如果使用相同型号与容量的磁盘来组成时,效果较佳。这种模式的RAID会将磁盘先切出等量的区块(举例来说,4KB),然后当一个文件要写入 RAID 时,该文件会依据块的大小切割好,之后再依序放到各个磁盘里面去。由于每个磁盘会交错存放数据,因此当你的数据要写入 RAID 时,数据会被等量放置在各个磁盘上面。举例来说,你有两块磁盘组成RAID-0,当你有100MB的数据要写入时,每个磁盘会各被分配到 50MB 的存储量。RAID-0的示意图如图15-2所示。
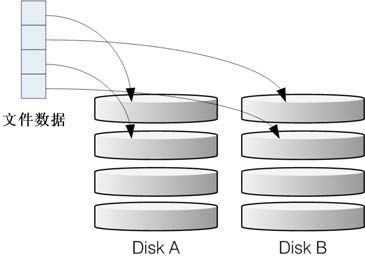
图15-2 RAID-0 的磁盘写入示意图
上图的意思是,在组成RAID-0时,每块磁盘(Disk A 与 Disk B)都会先被分隔成为小区块(chunk)。当有数据要写入RAID时,数据会先被分成符合小区块的大小,然后再依序一个一个放置到不同的磁盘去。由于数据已经先被分并且依序放置到不同的磁盘上面,因此每块磁盘所负责的数据量都降低了。照这样的情况来看,越多块磁盘组成的 RAID-0 性能会越好,因为每块负责的数据量就更低了,这表示我的数据可以分散让多块磁盘来存储,当然性能会变得更好。此外,磁盘总容量也变大了!因为每块磁盘的容量最终会加总成为RAID-0的总容量。
使用此等级你必须要自行负担数据损毁的风险,由上图我们知道文件是被切割成为适合每块磁盘分区区块的大小,然后再依序放置到各个磁盘中。想一想,如果某一块磁盘损毁了,那么文件数据将缺一块,此时这个文件就损毁了。由于每个文件都是这样存放的,因此RAID-0只要有任何一块磁盘损毁,在RAID上面的所有数据都会丢失而无法读取。
另外,如果使用不同容量的磁盘来组成 RAID-0 时,由于数据是一直等量依序放置到不同磁盘中,当小容量磁盘的区块被用完了,那么所有的数据都将被写入到最大的那块磁盘去。举例来说,我用200GB与500GB组成RAID-0,那么最初的400GB数据可同时写入两块磁盘(各消耗200GB的容量),后来再加入的数据就只能写入500GB的那块磁盘中了。此时的性能就变差了,因为只剩下一块可以存放数据。
RAID-1(映像模式,mirror):完整备份
这种模式也是需要相同的磁盘容量的,最好是一模一样的磁盘。如果是不同容量的磁盘组成RAID-1时,那么总容量将以最小的那一块磁盘为主!这种模式主要是让同一份数据完整保存在两块磁盘上面。举例来说,如果我有一个100MB的文件,且我仅有两块磁盘组成RAID-1时,那么这两块磁盘将会同步写入100MB到它们的存储空间去。因此,整体 RAID 的容量几乎少了50%。由于两块硬盘内容一模一样,好像镜子映照出来一样,所以我们也称它为mirror(镜像)模式。
如图 15-3 所示,一份数据传送到 RAID-1之后会被分为两股,并分别写入到各个磁盘里面去。由于同一份数据会被分别写入到其他不同磁盘,因此如果要写入100MB时,数据传送到I/O总线后会被复制多份到各个磁盘,结果就是数据量感觉变大了。因此在大量写入 RAID-1 的情况下,写入的性能可能会变得非常差(因为我们只有一个南桥芯片)。好在如果你使用的是硬件 RAID(磁盘阵列卡)时,磁盘阵列卡会主动复制一份而不使用系统的I/O总线,性能方面则还可以。如果使用软件磁盘阵列,可能性能就不好了。
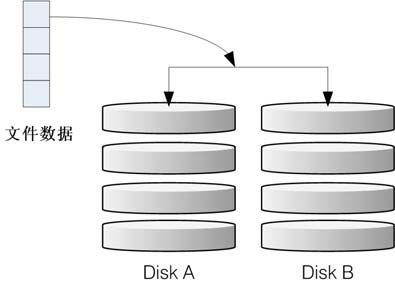
图15-3 RAID-1 的磁盘写入示意图
由于两块磁盘内的数据一模一样,所以任何一块硬盘损毁时,你的数据还是可以完整保留下来。所以我们可以说,RAID-1最大的优点大概就在于数据的备份。不过由于磁盘容量有一半用在备份,因此总容量会是全部磁盘容量的一半而已。虽然 RAID-1 的写入性能不佳,不过读取的性能则还可以。这是因为数据有两份在不同的磁盘上面,如果多个进程在读取同一条数据时,RAID会自行取得最佳的读取平衡。
RAID 0 + 1,RAID 1 + 0
RAID-0 的性能佳但是数据不安全,RAID - 1 的数据安全但是性能不佳,那么能不能将这两者整合起来设置 RAID 呢?可以啊!那就是 RAID 0 + 1 或 RAID 1 + 0。所谓的 RAID 0 + 1 就是先让两块磁盘组成 RAID 0,并且这样的设置共有两组;然后将这两组 RAID 0再组成一组 RAID 1。这就是 RAID 0 + 1。反过来说,RAID 1 + 0 就是先组成 RAID-1 再组成RAID-0的意思。
如图 15-4 所示,Disk A + Disk B 组成第一组 RAID 0,Disk C + Disk D 组成第二组 RAID 0,然后这两组再整合成为一组 RAID 1。如果我有 100MB 的数据要写入,则由于 RAID 1 的关系,两组 RAID 0 都会写入 100MB,但由于 RAID 0 的关系,因此每块磁盘仅会写入 50MB 而已。如此一来不论哪一组RAID 0的磁盘损毁,只要另外一组RAID 0还存在,那么就能够通过RAID1的机制来回复数据。
由于具有 RAID 0 的优点,所以性能得以提升,由于具有 RAID 1 的优点,所以数据得以备份。但是也由于 RAID 1 的缺点,所以总容量会少一半用来作为备份。
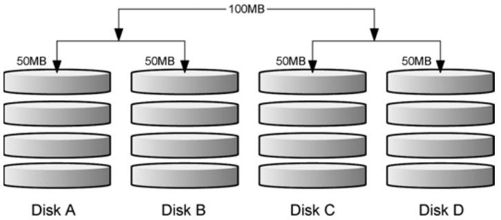
图15-4 RAID-0 + 1 的磁盘写入示意图
RAID 5:性能与数据备份的均衡考虑
RAID-5至少需要三块以上的磁盘才能够组成这种类型的磁盘阵列。这种磁盘阵列的数据写入有点类似 RAID-0 ,不过每个循环的写入过程中,在每块磁盘还加入一个同位检查数据(Parity),这个数据会记录其他磁盘的备份数据,用于当有磁盘损毁时的救援。RAID-5 读写的情况如图15-5所示。
图中,每个循环写入时,都会有部分的同位检查码(parity)被记录起来,并且记录的同位检查码每次都记录在不同的磁盘,因此,任何一个磁盘损毁时都能够通过其他磁盘的检查码来重建原本磁盘内的数据。不过需要注意的是,由于有同位检查码,因此RAID 5 的总容量会是整体磁盘数量减一块。以上图为例,原本的 3 块磁盘只会剩下(3-1)=2 块磁盘的容量,而且当损毁的磁盘数量大于等于两块时,这整组RAID 5 的数据就损毁了。因为RAID 5 默认仅能支持一块磁盘的损毁情况。
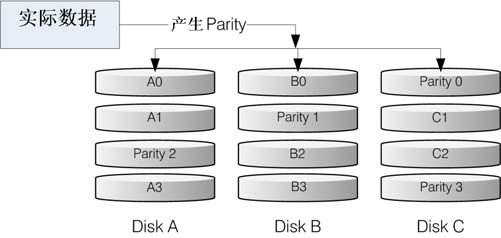
图15-5 RAID-5 的磁盘写入示意图
在读写性能的比较上,读取的性能还不赖。与 RAID-0 有得比,不过写的性能就不见得能够增加很多。这是因为要写入 RAID 5 的数据还得要经过计算同位检查码(parity)的关系。由于加上这个计算的操作,所以写入的性能与系统的硬件关系较大。尤其当使用软件磁盘阵列时,同位检查码是通过CPU去计算而非专门的磁盘阵列卡,因此性能方面还需要评估。
另外,由于RAID 5仅能支持一块磁盘的损毁,因此近来还有发展出另外一种等级,就是RAID 6,这个RAID 6则使用两块磁盘的容量作为parity的存储,因此整体的磁盘容量就会少两块,但是允许出错的磁盘数量就可以达到两块了!也就是在RAID 6的情况下,同时两块磁盘损毁时,数据还是可以救回来。
Spare Disk:预备磁盘的功能
当磁盘阵列的磁盘损毁时,就得要将坏掉的磁盘拔除,然后换一块新的磁盘。换成新磁盘并且顺利启动磁盘阵列后,磁盘阵列就会开始主动重建(rebuild)原本坏掉的那块磁盘数据到新的磁盘上,然后你磁盘阵列上面的数据就复原了。这就是磁盘阵列的优点。不过,我们还是得要动手拔插硬盘,此时通常得要关机才能这么做。
为了让系统可以实时地在坏掉硬盘时主动重建,因此就需要预备磁盘(spare disk)的辅助。所谓的 spare disk 就是一块或多块没有包含在原本磁盘阵列等级中的磁盘,这块磁盘平时并不会被磁盘阵列所使用,当磁盘阵列有任何磁盘损毁时,则这块 spare disk 会被主动拉进磁盘阵列中,并将坏掉的那块硬盘移出磁盘阵列,然后立即重建数据系统。如此你的系统则可以永保安康。若你的磁盘阵列有支持热拔插那就更完美了,直接将坏掉的那块磁盘拔除换一块新的,再将那块新的设置成为 spare disk,就完成了!
举例来说,鸟哥之前所在的研究室有一个磁盘阵列可允许16块磁盘的数量,不过我们只安装了 10 块磁盘作为 RAID 5。每块磁盘的容量为 250GB,我们用了一块磁盘作为 spare disk,并将其他的9块设置为一个RAID 5,因此这个磁盘阵列的总容量为(9-1)×250GB=2000GB。运行了一两年后真的有一块磁盘坏掉了,我们后来看灯号才发现!不过对系统没有影响。因为 spare disk 主动加入支持,将坏掉的那块拔掉换块新的,并重新设置成为 spare 后,系统内的数据还是完整无缺的。
磁盘阵列的优点
说得口沫横飞,重点在哪里呢?其实你的系统如果需要磁盘阵列的话,其实重点在于:
数据安全与可靠性:指的并非信息安全,而是当硬件(指磁盘)损毁时,数据是否还能够安全救援或使用之意;
读写性能:例如RAID 0 可以加强读写性能,让你的系统I/O 部分得以改善;
容量:可以让多块磁盘组合起来,故单一文件系统可以有相当大的容量。
尤其数据的可靠性与完整性更是使用RAID的考虑重点。毕竟硬件坏掉换掉就好了,软件数据损毁那可不是闹着玩的。所以企业界为何需要大量的RAID来作为文件系统的硬件基准,现在你有点了解了吧?
15.2.2 software,hardware RAID
为何磁盘阵列又分为硬件与软件呢?所谓的硬件磁盘阵列(hardware RAID)是通过磁盘阵列卡来完成数组的目的。磁盘阵列卡上面有一块专门的芯片在处理 RAID 的任务,因此在性能方面会比较好。在很多任务时(例如 RAID 5 的同位检查码计算)磁盘阵列并不会重复消耗原本系统的 I/O 总线,理论上性能会较佳。此外目前一般的中高级磁盘阵列卡都支持热拔插,即在不关机的情况下抽换损坏的磁盘,对于系统的复原与数据的可靠性方面非常好用。
不过一块好的磁盘阵列卡动不动就上万元,便宜的在主板上面“附赠”的磁盘阵列功能可能又不支持某些高级功能,例如低级主板若有磁盘阵列芯片,通常仅支持到 RAID 0 与 RAID1,鸟哥喜欢的RAID 5 并没有支持。此外,操作系统也必须要具有磁盘阵列卡的驱动程序,才能够正确识别磁盘阵列所产生的磁盘驱动器。
由于磁盘阵列有很多优秀的功能,然而硬件磁盘阵列卡偏偏又贵得很,因此就有发展出利用软件来仿真磁盘阵列的功能,这就是所谓的软件磁盘阵列(software RAID)。软件磁盘阵列主要是通过软件来仿真数组的任务,因此会损耗较多的系统资源,比如说CPU的运算与I/O总线的资源等。不过目前我们的个人计算机实在已经非常快速了,因此以前的速度限制现在已经不存在!所以我们可以来玩一玩软件磁盘阵列。
我们的CentOS提供的软件磁盘阵列为mdadm这套软件,这套软件会以分区或磁盘为单位,也就是说,你不需要两块以上的磁盘,只要有两个以上的分区就能够设计你的磁盘阵列了。此外,mdadm支持刚才我们前面提到的 RAID0/RAID1/RAID5/spare disk 等,而且提供的管理机制还可以达到类似热拔插的功能,可以在线(文件系统正常使用)进行分区的抽换,使用上也非常方便呢!
另外你必须要知道的是,硬件磁盘阵列在Linux下面看起来就是一块实际的大磁盘,因此硬件磁盘阵列的设备文件名为/dev/sd[a-p],因为使用到SCSI的模块之故。至于软件磁盘阵列则是系统仿真的,因此使用的设备文件名是系统的设备文件,文件名为/dev/md0,/dev/md1,两者的设备文件名并不相同。不要搞混了喔!因为很多朋友经常觉得奇怪:怎么它的RAID文件名跟我们这里测试的软件RAID文件名不同?所以这里特别强调说明。
15.2.3 软件磁盘阵列的设置
软件磁盘阵列的设置很简单呢!因为你只要使用一个命令即可,那就是mdadm这个命令。这个命令在新建RAID的语法时有点像这样:
[root@www ~]# mdadm —detail /dev/md0
[root@www ~]# mdadm —create —auto=yes /dev/md[0-9] —raid-devices=N \
> —level=[015] —spare-devices=N /dev/sdx /dev/hdx…
参数:
—create :为新建 RAID 的参数。
—auto=yes :决定新建后面接的软件磁盘阵列设备,即 /dev/md0, /dev/md1等。
—raid-devices=N :使用几个磁盘作为磁盘阵列的设备。
—spare-devices=N :使用几个磁盘作为备用 (spare) 设备。
—level=[015] :设置这组磁盘阵列的等级。支持很多,不过建议只要用0,1,5即可。
—detail:后面所接的那个磁盘阵列设备的详细信息。
上面的语法中,最后面会接许多的设备文件名,这些设备文件名可以是整块磁盘,例如/dev/sdb,也可以是分区,例如/dev/sdb1 之类。不过,这些设备文件名的总数必须要等于—raid-devices 与—spare-devices的个数总和才行。鸟哥利用我的测试机来构建一个RAID5的软件磁盘阵列。首先,将系统里面过去练习过而目前用不到的分区全部删除掉:
[root@www ~]# fdisk -l
Disk /dev/hda: 41.1 GB, 41174138880 bytes
255 heads, 63 sectors/track, 5005 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 13 104391 83 Linux
/dev/hda2 14 1288 10241437+ 83 Linux
/dev/hda3 1289 1925 5116702+ 83 Linux
/dev/hda4 1926 5005 24740100 5 Extended
/dev/hda5 1926 2052 1020096 82 Linux swap / Solaris
/dev/hda6 2053 2302 2008093+ 83 Linux
/dev/hda7 2303 2334 257008+ 82 Linux swap / Solaris
/dev/hda8 2335 2353 152586 83 Linux
/dev/hda9 2354 2366 104391 83 Linux
[root@www ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda2 9920624 3858800 5549756 42% /
/dev/hda1 101086 21408 74459 23% /boot
tmpfs 371332 0 371332 0% /dev/shm
/dev/hda3 4956316 1056996 3643488 23% /home
从上面可以发现,我的 /dev/hda6~/dev/hda9 没有用到。将它删除看看!
[root@www ~]# fdisk /dev/hda
Command (m for help): d
Partition number (1-9): 9
Command (m for help): d
Partition number (1-8): 8
Command (m for help): d
Partition number (1-7): 7
Command (m for help): d
Partition number (1-6): 6
Command (m for help): p
Disk /dev/hda: 41.1 GB, 41174138880 bytes
255 heads, 63 sectors/track, 5005 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 13 104391 83 Linux
/dev/hda2 14 1288 10241437+ 83 Linux
/dev/hda3 1289 1925 5116702+ 83 Linux
/dev/hda4 1926 5005 24740100 5 Extended
/dev/hda5 1926 2052 1020096 82 Linux swap / Solaris
Command (m for help): w
[root@www ~]# partprobe
这个操作很重要。还记得吧?将内核的 partition table 更新!
下面是鸟哥希望做成的 RAID 5 环境:
利用4个分区组成RAID5;
每个分区约为1GB大小,需确定每个分区一样大较佳;
利用1个分区设置为sparedisk;
这个 spare disk 的大小与其他 RAID 所需分区一样大!
将此RAID5设备挂载到/mnt/raid目录下。
最终我需要5个1GB的分区。由于鸟哥的系统仅有一块磁盘,这块磁盘剩余容量约20GB是够用的,分区代号仅使用到5号,所以要制作成RAID5应该是不成问题。接下来就是连续的构建流程。
构建所需的磁盘设备
如前所述,我需要5个1GB的分区,请利用fdisk来构建吧!
[root@www ~]# fdisk /dev/hda
Command (m for help): n
First cylinder (2053-5005, default 2053): <==直接按下 [enter]
Using default value 2053
Last cylinder or +size or +sizeM or +sizeK (2053-5005, default 5005): +1000M
上述的动作请做五次!
Command (m for help): p
Disk /dev/hda: 41.1 GB, 41174138880 bytes
255 heads, 63 sectors/track, 5005 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 13 104391 83 Linux
/dev/hda2 14 1288 10241437+ 83 Linux
/dev/hda3 1289 1925 5116702+ 83 Linux
/dev/hda4 1926 5005 24740100 5 Extended
/dev/hda5 1926 2052 1020096 82 Linux swap / Solaris
/dev/hda6 2053 2175 987966 83 Linux
/dev/hda7 2176 2298 987966 83 Linux
/dev/hda8 2299 2421 987966 83 Linux
/dev/hda9 2422 2544 987966 83 Linux
/dev/hda10 2545 2667 987966 83 Linux
上面的 6~10 号,就是我们需要的分区。
Command (m for help): w
[root@www ~]# partprobe
以mdadm创建RAID
接下来就简单啦!通过mdadm来创建磁盘阵列先!
[root@www ~]# mdadm —create —auto=yes /dev/md0 —level=5 \
> —raid-devices=4 —spare-devices=1 /dev/hda{6,7,8,9,10}
详细的参数说明请回去前面看看。这里我通过 {} 将重复的项目简化!
[root@www ~]# mdadm —detail /dev/md0
/dev/md0: <==RAID 设备文件名
Version : 00.90.03
Creation Time : Tue Mar 10 17:47:51 2009 <==RAID 被创建的时间
Raid Level : raid5 <==RAID 等级为 RAID 5
Array Size : 2963520 (2.83 GiB 3.03 GB) <==此 RAID 的可用磁盘容量
Used Dev Size : 987840 (964.85 MiB 1011.55 MB) <==每个设备的可用容量
Raid Devices : 4 <==用作 RAID 的设备数量
Total Devices : 5 <==全部的设备数量
Preferred Minor : 0
Persistence : Superblock is persistent
Update Time : Tue Mar 10 17:52:23 2009
State : clean
Active Devices : 4 <==启动的(active)设备数量
Working Devices : 5 <==可动作的设备数量
Failed Devices : 0 <==出现错误的设备数量
Spare Devices : 1 <==预备磁盘的数量
Layout : left-symmetric
Chunk Size : 64K
UUID : 7c60c049:57d60814:bd9a77f1:57e49c5b <==此设备(RAID)标识符
Events : 0.2
Number Major Minor RaidDevice State
0 3 6 0 active sync /dev/hda6
1 3 7 1 active sync /dev/hda7
2 3 8 2 active sync /dev/hda8
3 3 9 3 active sync /dev/hda9
4 3 10 - spare /dev/hda10
最后五行就是这五个设备目前的情况,包括四个 active sync 一个 spare !
至于 RaidDevice 指的则是此 RAID 内的磁盘顺序
由于磁盘阵列的构建需要一些时间,所以最好等待数分钟后再使用“mdadm —detail /dev/md0”去查阅你的磁盘阵列详细信息,否则有可能看到某些磁盘正在“spare rebuilding”之类的构建字样。通过上面的命令,你就能够新建一个 RAID5 且含有一块 spare disk 的磁盘阵列。非常简单吧!除了命令之外,你也可以查阅如下的文件来看看系统软件磁盘阵列的情况:
[root@www ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 hda9[3] hda10[4](S) hda8[2] hda7[1] hda6[0] <==第一行
2963520 blocks level 5, 64k chunk, algorithm 2 [4/4] [UUUU] <==第二行
unused devices: <none>
上述的数据比较重要的在特别指出的第一行与第二行 [7]:
第一行:指出 md0 为 raid 5,且使用了 hda9,hda8,hda7,hda6 四块磁盘设备。每个设备后面的中括号[]内的数字为此磁盘在RAID中的顺序(RaidDevice);至于hda10后面的[S]则代表hda10为spare之意。
第二行:此磁盘阵列拥有2963520个block(每个block单位为1KB),所以总容量约为3GB,使用 RAID 5 等级,写入磁盘的小区块(chunk)大小为 64KB,使用 algorithm 2 磁盘阵列算法。[m/n]代表此数组需要m个设备,且n个设备正常运行。因此本md0需要4个设备且这4个设备均正常运行。后面的[UUUU]代表的是四个所需的设备(就是[m/n]里面的m)的启动情况,U代表正常运作,若为_则代表不正常。
这两种方法都可以知道目前的磁盘阵列状态。
格式化与挂载使用RAID
接下来就是开始使用格式化工具。这部分就更简单了。
[root@www ~]# mkfs -t ext3 /dev/md0
有趣吧!是 /dev/md0 作为设备被格式化呢!
[root@www ~]# mkdir /mnt/raid
[root@www ~]# mount /dev/md0 /mnt/raid
[root@www ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda2 9920624 3858820 5549736 42% /
/dev/hda1 101086 21408 74459 23% /boot
tmpfs 371332 0 371332 0% /dev/shm
/dev/hda3 4956316 1056996 3643488 23% /home
/dev/md0 2916920 69952 2698792 3% /mnt/raid
看吧!多了一个 /dev/md0 的设备,而且真的可以让你使用呢!
15.2.4 仿真 RAID错误的救援模式
俗话说:天有不测风云、人有旦夕祸福!谁也不知道你的磁盘阵列内的设备啥时会出差错,因此,了解一下软件磁盘阵列的救援还是必需的。下面我们就来玩一玩救援的机制吧!首先来了解一下mdadm这方面的语法:
[root@www~]#mdadm —manage /dev/md[0-9] [—add 设备] [—remove 设备] \
> [—fail 设备]
参数:
—add :会将后面的设备加入到这个 md 中!
—remove :会将后面的设备从这个 md 中删除。
—fail :会将后面的设备设置成为出错的状态。
设置磁盘为错误 (fault)
首先,我们来处理一下,该如何让一个磁盘变成错误,然后让sparedisk自动开始重建系统呢?
1. 先复制一些东西到 /mnt/raid 去,假设这个 RAID 已经在使用了
[root@www ~]# cp -a /etc /var/log /mnt/raid
[root@www ~]# df /mnt/raid ; du -sm /mnt/raid/*
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/md0 2916920 188464 2580280 7% /mnt/raid
118 /mnt/raid/etc <==看吧!确实有数据在里面。
8 /mnt/raid/log
1 /mnt/raid/lost+found
2. 假设 /dev/hda8 这个设备出错了!实际模拟的方式:
[root@www ~]# mdadm —manage /dev/md0 —fail /dev/hda8
mdadm: set /dev/hda8 faulty in /dev/md0
[root@www ~]# mdadm —detail /dev/md0
….(前面省略)….
State : clean, degraded, recovering
Active Devices : 3
Working Devices : 4
Failed Devices : 1 <==出错的磁盘有一个!
Spare Devices : 1
….(中间省略)….
Number Major Minor RaidDevice State
0 3 6 0 active sync /dev/hda6
1 3 7 1 active sync /dev/hda7
4 3 10 2 spare rebuilding /dev/hda10
3 3 9 3 active sync /dev/hda9
5 3 8 - faulty spare /dev/hda8
这个操作要快速操作才会看到! /dev/hda10 启动了而 /dev/hda8 死掉了
[root@www ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 hda9[3] hda10[4] hda8[5](F) hda7[1] hda6[0]
2963520 blocks level 5, 64k chunk, algorithm 2 [4/3] [UU_U]
[>…….] recovery = 0.8% (9088/987840) finish=14.3min speed=1136K/sec
上面的界面你得要快速连续输入那些 mdadm 的命令才看得到。因为你的 RAID 5 正在重建系统。若你等待一段时间再输入后面的查看命令,则会看到如下的界面了:
3. 已经通过 spare disk 重建完毕的 RAID 5 情况
[root@www ~]# mdadm —detail /dev/md0
….(前面省略)….
Number Major Minor RaidDevice State
0 3 6 0 active sync /dev/hda6
1 3 7 1 active sync /dev/hda7
2 3 10 2 active sync /dev/hda10
3 3 9 3 active sync /dev/hda9
4 3 8 - faulty spare /dev/hda8
[root@www ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 hda9[3] hda10[2] hda8[4](F) hda7[1] hda6[0]
2963520 blocks level 5, 64k chunk, algorithm 2 [4/4] [UUUU]
看吧!又恢复正常了!我们的/mnt/raid文件系统是完整的,并不需要卸除。
将出错的磁盘删除并加入新磁盘
首先,我们再新建一个新的分区,这个分区要与其他分区一样大才好!然后再利用 mdadm 删除错误的并加入新的!
4. 新建新的分区
[root@www ~]# fdisk /dev/hda
Command (m for help): n
First cylinder (2668-5005, default 2668): <==这里按 [enter]
Using default value 2668
Last cylinder or +size or +sizeM or +sizeK (2668-5005, default 5005): +1000M
Command (m for help): w
[root@www ~]# partprobe
此时系统会多一个 /dev/hda11 的分区。
5. 加入新的拔除有问题的磁盘
[root@www ~]# mdadm —manage /dev/md0 —add /dev/hda11 —remove /dev/hda8
mdadm: added /dev/hda11
mdadm: hot removed /dev/hda8
[root@www ~]# mdadm —detail /dev/md0
….(前面省略)….
0 3 6 0 active sync /dev/hda6
1 3 7 1 active sync /dev/hda7
2 3 10 2 active sync /dev/hda10
3 3 9 3 active sync /dev/hda9
4 3 11 - spare /dev/hda11
你的磁盘阵列内的数据不但一直存在,而且你可以一直顺利运行/mnt/raid 内的数据,即使/dev/hda8损毁了!然后通过管理的功能就能够加入新磁盘且拔除坏掉的磁盘。注意,这一切都是在上线(on-line)的情况下进行。
15.2.5 开机自动启动 RAID 并自动挂载
新的distribution大多会自己查询/dev/md[0-9],然后在开机的时候给予设置好所需要的功能。不过鸟哥还是建议你修改一下配置文件。software RAID 也是有配置文件的,这个配置文件在/etc/mdadm.conf中。这个配置文件内容很简单,你只要知道/dev/md0的UUID就能够设置这个文件了。这里鸟哥仅介绍它最简单的语法:
[root@www ~]# mdadm —detail /dev/md0 | grep -i uuid
UUID : 7c60c049:57d60814:bd9a77f1:57e49c5b
后面那一串数据就是这个设备向系统注册的 UUID 标识符!
开始设置 mdadm.conf
[root@www ~]# vi /etc/mdadm.conf
ARRAY /dev/md0 UUID=7c60c049:57d60814:bd9a77f1:57e49c5b
RAID设备 标识符内容
开始设置开机自动挂载并测试
[root@www ~]# vi /etc/fstab
/dev/md0 /mnt/raid ext3 defaults 1 2
[root@www ~]# umount /dev/md0; mount -a
[root@www ~]# df /mnt/raid
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/md0 2916920 188464 2580280 7% /mnt/raid
你得确定可以顺利挂载,并且没有发生任何错误!
如果到这里都没有出现任何问题,接下来就请reboot你的系统并等待看看能否顺利启动。
15.2.6 关闭软件 RAID(重要!)
除非你将来就是要使用这块 softwareRAID(/dev/md0),否则你势必要跟鸟哥一样,将这个/dev/md0 关闭!因为它毕竟是我们在这个测试机上面的练习设备。为什么要关掉它呢?因为这个/dev/md0 其实还是使用到我们系统的磁盘分区,在鸟哥的例子里面就是/dev/hda{6,7,8,9,10,11},如果你只是将/dev/md0卸载,然后忘记将RAID关闭,结果就是将来你在重新分区/dev/hdaX时可能会出现一些莫名的错误状况,所以才需要关闭softwareRAID的步骤。那如何关闭呢?也很简单。(请注意,确认你的/dev/md0确实不要用且要关闭了才进行下面的操作。)
1. 先卸载且删除配置文件内与这个 /dev/md0 有关的设置:
[root@www ~]# umount /dev/md0
[root@www ~]# vi /etc/fstab
/dev/md0 /mnt/raid ext3 defaults 1 2
将这一行删除掉,或者是批注掉也可以。
2. 直接关闭 /dev/md0 的方法。
[root@www ~]# mdadm —stop /dev/md0
mdadm: stopped /dev/md0 <==这样就关闭了!
[root@www ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
unused devices: <none> <==看,确实不存在任何数组设备!
[root@www ~]# vi /etc/mdadm.conf
ARRAY /dev/md0 UUID=7c60c049:57d60814:bd9a77f1:57e49c5b
一样,删除它或是批注它!
在这个练习中,鸟哥使用同一块磁盘进行软件 RAID 的实验。不过朋友们要注意的是,如果真的要实作软件磁盘阵列,最好是由多块不同的磁盘来组成较佳!因为这样才能够使用到不同磁盘的读写,性能才会好。 而数据分配在不同的磁盘,当某块磁盘损毁时数据才能够通过其他磁盘挽救回来,这点得特别留意呢!
15.3 逻辑卷管理器 (Logical Volume Manager)
想象一个情况,你在当初规划主机的时候将/home只给他50GB,等到用户众多之后导致这个文件系统不够大,此时你能怎么做?多数的朋友都是这样:再加一块新硬盘,然后重新分区、格式化,将/home的数据完整复制过来,然后将原本的分区卸除重新挂载新的分区。若是第二次分区分配的空间太多,导致很多磁盘空间被浪费了,你想要将这个分区缩小时,又该如何做?将上述的流程再做一遍!尤其花费时间,有没有更简单的方法呢?有的,那就是我们这个小节要介绍的LVM。
LVM的重点在于可以弹性调整文件系统的容量!而并非在于性能与数据保全上面。需要文件的读写性能或者是数据的可靠性,请参考前面的RAID小节。LVM可以整合多个物理分区在一起,让这些分区看起来就像是一个磁盘一样,而且,还可以在将来其他的物理分区或将其从这个LVM管理的磁盘当中删除。如此一来,整个磁盘空间的使用上,实在是相当具有弹性。既然LVM这么好用,那就让我们来瞧瞧这玩意吧!
15.3.1 什么是 LVM:PV,PE,VG,LV 的意义
LVM 的全名是 Logical Volume Manager,中文可以翻译作逻辑卷管理器。之所以称为“卷”可能是因为可以将文件系统像卷一样伸长或缩短之故吧!LVM的作法是将几个物理的分区(或磁盘)通过软件组合成为一块看起来是独立的大磁盘(VG),然后将这块大磁盘再经过分成为可使用分区(LV),最终就能够挂载使用了。但是为什么这样的系统可以进行文件系统的扩充或缩小呢?其实与一个称为PE的选项有关,下面我们就得要针对这几个选项来好好聊聊。
PhysicalVolume,PV,物理卷
我们实际的分区需要调整系统标识符(system ID)成为 8e(LVM 的标识符),然后再经过pvcreate的命令将它转成LVM最底层的物理卷(PV),之后才能够将这些PV加以利用,调整 system ID 的方是就是通过 fdisk。
Volume Group,VG,卷用户组
所谓的LVM大磁盘就是将许多PV整合成这个VG,所以VG就是LVM组合起来的大磁盘。那么这个大磁盘最大可以达到多少容量呢?这与下面要说明的PE有关,因为每个VG最多仅能包含65534个PE而已。如果使用LVM默认的参数,则一个VG最大可达256GB的容量(参考下面的PE说明)。
Physical Extend,PE,物理扩展块
LVM默认使用4MB的PE块,而LVM的VG最多仅能含有65534个PE,因此默认的LVMVG会有4M×65534/(1024M/G)=256G。这个PE很有趣。它是整个LVM最小的存储块,也就是说,其实我们的文件数据都是由写入PE来处理的。简单地说,这个PE就有点像文件系统里面的block大小。这样说应该就比较好理解了吧?所以调整PE会影响到VG的最大容量。
Logical Volume,LV,逻辑卷
最终的VG还会被切成LV,这个LV就是最后可以被格式化使用的类似分区。那么LV是否可以随意指定大小呢?当然不可以。既然PE是整个LVM的最小存储单位,那么LV的大小就与在此LV内的PE总数有关。为了方便用户利用LVM来管理其系统,因此LV的设备文件名通常指定为“/dev/vgname/lvname”的样式!
此外,我们刚才有谈到LVM可弹性更改文件系统的容量,那是如何办到的?其实它就是通过交换PE来进行数据转换,将原本LV内的PE移转到其他设备中以降低LV容量,或将其他设备的PE加到此LV中以加大容量。VG、LV与PE的关系如图15-6所示。
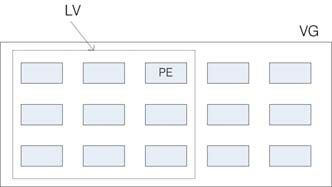
图15-6 PE 与 VG 的相关性图示
如上图所示,VG内的PE会分给虚线部分的LV,如果将来这个VG要扩充的话,加上其他的PV即可。而最重要的LV如果要扩充的话,也是通过加入VG内没有使用到的PE来扩充的!
实现流程
通过PV,VG,LV的规划之后,再利用mkfs就可以将你的LV格式化成为可以利用的文件系统了,而且这个文件系统的容量在将来还能够进行扩充或减少,里面的数据还不会被影响。实在是很有“福气”啦!那实现方面要如何进行呢?很简单,整个流程由基础到最终的结果可以这样,如图15-7所示。
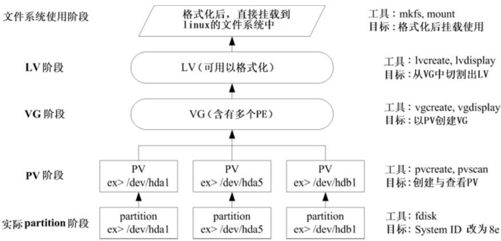
图15-7 LVM 各组件的实现流程图示
如此一来,我们就可以利用LV来进行系统的挂载了。不过,你应该要觉得奇怪的是,那么我的数据写入这个LV时,到底它是怎么写入硬盘当中的?其实,依据写入机制的不同,而有两种方式:
线性模式(linear):假如我将/dev/hda1,/dev/hdb1这两个分区加入到VG当中,并且整个VG只有一个LV时,那么所谓的线性模式就是当/dev/hda1的容量用完之后,/dev/hdb1的硬盘才会被使用到,这也是我们所建议的模式。
交错模式(triped):那什么是交错模式?很简单,就是我将一条数据拆成两部分,分别写入/dev/hda1 与/dev/hdb1 的意思,感觉上有点像 RAID 0。如此一来,一份数据用两块硬盘来写入,理论上,读写的性能会比较好。
基本上,LVM 最主要的用处是在实现一个可以弹性调整容量的文件系统上,而不是在新建一个性能为主的磁盘上,所以,我们应该利用的是LVM可以弹性管理整个分区大小的用途上,而不是着眼在性能上的。因此,LVM默认的读写模式是线性模式。如果你使用triped模式,要注意,当任何一个分区“归天”时,所有的数据都会“损坏”。所以,不是很适合使用这种模式。如果要强调性能与备份,那么就直接使用RAID即可,不需要用到LVM。
15.3.2 LVM 实作流程
LVM必须要有内核支持且需要安装lvm2这个软件,好在的是,CentOS与其他较新的distributions已经默认将LVM的支持与软件都安装妥当了,所以你不需要担心这方面的问题。
鸟哥使用的测试机又要出动了,刚才我们才练习过 RAID,必须要将一堆目前没有用到的分区先删除,然后再重建新的分区,并且由于鸟哥仅有一个40GB的磁盘,所以下面的练习都仅针对同一块磁盘来做的。我的要求有点像这样:
先分出4个分区,每个分区的容量均为1.5GB左右,且systemID需要为8e;
全部的分区整合成为一个VG,VG名称设置为vbirdvg;且PE的大小为16MB;
全部的VG容量都丢给LV,LV的名称设置为vbirdlv;
最终这个LV格式化为ext3的文件系统,且挂载在/mnt/lvm中。
鸟哥就不仔细介绍物理分区了,请你自行参考第8章的fdisk来达成下面的范例。(注意:修改系统标识符请使用t这个fdisk内的命令来处理即可。)
[root@www ~]# fdisk /dev/hda <==其他流程请自行参考第8章处理
[root@www ~]# partprobe <==别忘记这个操作了,很重要!
[root@www ~]# fdisk -l
Disk /dev/hda: 41.1 GB, 41174138880 bytes
255 heads, 63 sectors/track, 5005 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/hda1 * 1 13 104391 83 Linux
/dev/hda2 14 1288 10241437+ 83 Linux
/dev/hda3 1289 1925 5116702+ 83 Linux
/dev/hda4 1926 5005 24740100 5 Extended
/dev/hda5 1926 2052 1020096 82 Linux swap / Solaris
/dev/hda6 2053 2235 1469916 8e Linux LVM
/dev/hda7 2236 2418 1469916 8e Linux LVM
/dev/hda8 2419 2601 1469916 8e Linux LVM
/dev/hda9 2602 2784 1469916 8e Linux LVM
上面的 /dev/hda{6,7,8,9} 这四个分区就是我们的物理分区。也就是下面会实际用到的信息。注意看,那个 8e 的出现会导致 system 变成“Linux LVM”。其实没有设置成为 8e 也没关系,不过某些LVM的检测命令可能会检测不到该分区。接下来,就一个一个处理各流程吧!
PV阶段
要新建PV其实很简单,只要直接使用pvcreate即可。我们来谈一谈与PV有关的命令。
pvcreate:将物理分区新建成为PV;
pvscan:查询目前系统里面任何具有PV的磁盘;
pvdisplay:显示出目前系统上面的PV状态;
pvremove:将PV属性删除,让该分区不具有PV属性。
那就直接来瞧一瞧吧!
1. 检查有无 PV 在系统上,然后将 /dev/hda6~/dev/hda9 新建成为 PV 格式
[root@www ~]# pvscan
No matching physical volumes found <==找不到任何的 PV 存在。
[root@www ~]# pvcreate /dev/hda{6,7,8,9}
Physical volume "/dev/hda6" successfully created
Physical volume "/dev/hda7" successfully created
Physical volume "/dev/hda8" successfully created
Physical volume "/dev/hda9" successfully created
这个命令可以一口气新建四个分区成为 PV 。注意大括号的用途
[root@www ~]# pvscan
PV /dev/hda6 lvm2 [1.40 GB]
PV /dev/hda7 lvm2 [1.40 GB]
PV /dev/hda8 lvm2 [1.40 GB]
PV /dev/hda9 lvm2 [1.40 GB]
Total: 4 [5.61 GB] / in use: 0 [0 ] / in no VG: 4 [5.61 GB]
这就分别显示每个 PV 的信息与系统所有 PV 的信息。尤其最后一行,显示的是:
整体 PV 的量 / 已经被使用到 VG 的 PV 量 / 剩余的 PV 量
2. 更详细列出系统上面每个 PV 的信息:
[root@www ~]# pvdisplay
"/dev/hda6" is a new physical volume of "1.40 GB"
—- NEW Physical volume —-
PV Name /dev/hda6 <==实际的分区设备名称
VG Name <==因为尚未分配出去,所以空白!
PV Size 1.40 GB <==就是容量说明
Allocatable NO <==是否已被分配,结果是 NO
PE Size (KByte) 0 <==在此 PV 内的 PE 大小
Total PE 0 <==共分出几个 PE
Free PE 0 <==没被 LV 用掉的 PE
Allocated PE 0 <==尚可分配出去的 PE 数量
PV UUID Z13Jk5-RCls-UJ8B-HzDa-Gesn-atku-rf2biN
….(下面省略)….
由于 PE 是在新建 VG 时才给予的参数,因此在这里看到的 PV 里面的 PE 都会是0
而且也没有多余的PE可供分配(allocatable)。
讲是很难,做却很简单。这样就将PV新建了两个。
VG阶段
新建VG及VG相关的命令也不少,我们来看看:
vgcreate:就是主要新建VG的命令,它的参数比较多,等一下介绍。
vgscan:查找系统上面是否有VG存在;
vgdisplay:显示目前系统上面的VG状态;
vgextend:在VG内增加额外的PV;
vgreduce:在VG内删除PV;
vgchange:设置VG是否启动(active);
vgremove:删除一个VG。
与PV不同的是,VG的名称是自定义的!我们知道PV的名称其实就是分区的设备文件名,但是这个VG名称则可以随便你自己取。在下面的例子当中,我将VG名称取名为vbirdvg。新建这个VG的流程是这样的:
[root@www~]# vgcreate [-s N[mgt]] VG名称 PV名称
参数:
-s :后面接 PE 的大小 (size) ,单位可以是 m, g, t (大小写均可)
1. 将 /dev/hda6-8 新建成为一个 VG,且指定 PE 为 16MB。
[root@www ~]# vgcreate -s 16M vbirdvg /dev/hda{6,7,8}
Volume group "vbirdvg" successfully created
[root@www ~]# vgscan
Reading all physical volumes. This may take a while…
Found volume group "vbirdvg" using metadata type lvm2
确实存在这个 vbirdvg 的 VG 啦!
[root@www ~]# pvscan
PV /dev/hda6 VG vbirdvg lvm2 [1.39 GB / 1.39 GB free]
PV /dev/hda7 VG vbirdvg lvm2 [1.39 GB / 1.39 GB free]
PV /dev/hda8 VG vbirdvg lvm2 [1.39 GB / 1.39 GB free]
PV /dev/hda9 lvm2 [1.40 GB]
Total: 4 [5.57 GB] / in use: 3 [4.17 GB] / in no VG: 1 [1.40 GB]
发现没?有三个 PV 被用掉,剩下一个 /dev/hda9 的 PV 没被用掉!
[root@www ~]# vgdisplay
—- Volume group —-
VG Name vbirdvg
System ID
Format lvm2
Metadata Areas 3
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 3
Act PV 3
VG Size 4.17 GB <==整体的 VG 容量有这么大
PE Size 16.00 MB <==内部每个 PE 的大小
Total PE 267 <==总共的 PE 数量共有这么多!
Alloc PE / Size 0 / 0
Free PE / Size 267 / 4.17 GB
VG UUID 4VU5Jr-gwOq-jkga-sUPx-vWPu-PmYm-dZH9EO
最后那三行指的就是 PE 能够使用的情况!由于尚未切出 LV,因此所有的 PE
均可自由使用。
这样就新建一个VG了,假设我们要增加这个VG的容量,因为我们还有/dev/hda9。此时你可以这样做:
2. 将剩余的 PV (/dev/hda9) 丢给 vbirdvg 吧!
[root@www ~]# vgextend vbirdvg /dev/hda9
Volume group "vbirdvg" successfully extended
[root@www ~]# vgdisplay
….(前面省略)….
VG Size 5.56 GB
PE Size 16.00 MB
Total PE 356
Alloc PE / Size 0 / 0
Free PE / Size 356 / 5.56 GB
VG UUID 4VU5Jr-gwOq-jkga-sUPx-vWPu-PmYm-dZH9EO
基本上,不难吧?这样就可以抽换整个 VG 的大小。
我们多了一个设备。接下来为这个vbirdvg进行分区。通过LV功能来处理!
LV阶段
创造出VG这个大磁盘之后,再来就是要新建分区。这个分区就是所谓的LV。假设我要将刚才那个vbirdvg磁盘分成为vbirdlv,整个VG的容量都被分配到vbirdlv里面去。先来看看能使用的命令后,就直接工作了先!
lvcreate:新建LV;
lvscan:查询系统上面的LV;
lvdisplay:显示系统上面的LV状态;
lvextend:在LV里面增加容量;
lvreduce:在LV里面减少容量;
lvremove:删除一个LV;
lvresize:对LV进行容量大小的调整。
[root@www~]# lvcreate [-L N[mgt]] [-n LV名称] VG名称
[root@www ~]# lvcreate [-l N] [-n LV名称] VG名称
参数:
-L :后面接容量,容量的单位可以是 M,G,T 等,要注意的是,最小单位为 PE,
因此这个数量必须要是 PE 的倍数,若不相符,系统会自行计算最相近的容量。
-l :后面可以接 PE 的“个数”,而不是数量。若要这么做,得要自行计算 PE 数。
-n :后面接的就是 LV 的名称。
更多的说明应该可以自行查阅man lvcreate吧!
1. 将整个 vbirdvg 全部分配给 vbirdlv,要注意,PE 共有 356 个。
[root@www ~]# lvcreate -l 356 -n vbirdlv vbirdvg
Logical volume "vbirdlv" created
由于本案例中每个 PE 为 16MB ,因此上述的命令也可以使用如下的方式来新建:
lvcreate -L 5.56G -n vbirdlv vbirdvg
[root@www ~]# ll /dev/vbirdvg/vbirdlv
lrwxrwxrwx 1 root root 27 Mar 11 16:49 /dev/vbirdvg/vbirdlv ->
/dev/mapper/vbirdvg-vbirdlv
[root@www ~]# lvdisplay
—- Logical volume —-
LV Name /dev/vbirdvg/vbirdlv <==这个才是 LV 的全名!
VG Name vbirdvg
LV UUID 8vFOPG-Jrw0-Runh-ug24-t2j7-i3nA-rPEyq0
LV Write Access read/write
LV Status available
open 0
LV Size 5.56 GB <==这个 LV 的容量这么大!
Current LE 356
Segments 4
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:0
如此一来,整个分区也准备好了。接下来,就是针对这个 LV 来处理。要特别注意的是,VG的名称为vbirdvg,但是LV的名称必须使用全名!即是/dev/vbirdvg/vbirdlv才对。后续的处理都是这样的!这点初次接触LVM的朋友很容易搞错!
文件系统阶段
这个部分鸟哥我就不再多加解释了,直接来操作吧!
1. 格式化、挂载与查看我们的 LV 吧!
[root@www ~]# mkfs -t ext3 /dev/vbirdvg/vbirdlv <==注意 LV 全名!
[root@www ~]# mkdir /mnt/lvm
[root@www ~]# mount /dev/vbirdvg/vbirdlv /mnt/lvm
[root@www ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda2 9920624 3858984 5549572 42% /
/dev/hda3 4956316 1056996 3643488 23% /home
/dev/hda1 101086 21408 74459 23% /boot
tmpfs 371332 0 371332 0% /dev/shm
/dev/mapper/vbirdvg-vbirdlv
5741020 142592 5306796 3% /mnt/lvm
[root@www ~]# cp -a /etc /var/log /mnt/lvm
其实LV的名称构建成为/dev/vbirdvg/vbirdlv是为了让用户直观地找到我们所需要的数据,实际上LVM使用的设备是放置到/dev/mapper/目录下的!所以你才会看到上面的特殊字体部分。通过这样的功能,我们现在已经构建好一个LV了。你可以自由应用/mnt/lvm内的所有资源!
15.3.3 放大LV 容量
我们不是说 LVM 最大的特色就是弹性调整磁盘容量吗?好!那我们就来处理一下,如果要放大LV的容量时,该如何进行完整的步骤呢?其实一点都不难。你只要这样做即可:
1.用fdisk 设置新的具有8e systemID 的分区;
2.利用pvcreate构建PV;
3.利用vgextend将PV加入我们的vbirdvg;
4.利用lvresize将新加入的PV内的PE加入vbirdlv中;
5.通过resize2fs将文件系统的容量确实增加!
其中最后一个步骤最重要,我们在第8章当中知道,整个文件系统在最初格式化的时候就新建了inode/block/superblock 等信息,要改变这些信息是很难的。不过因为文件系统格式化的时候新建的是多个 block group,因此我们可以通过在文件系统当中增加 block group 的方式来增减文件系统的量,而增减 block group 就是利用 resize2fs。所以最后一步是针对文件系统来处理的,前面几步则是针对LVM的实际容量大小!
1. 处理出一个 3GB 的新的分区,在鸟哥的系统中应该是 /dev/hda10
[root@www ~]# fdisk /dev/hda <==其他的操作请自行处理
[root@www ~]# partprobe
[root@www ~]# fdisk -l
Device Boot Start End Blocks Id System
….(中间省略)….
/dev/hda10 2785 3150 2939863+ 8e Linux LVM
这个就是我们要的新的分区。
2. 新建新的 PV:
[root@www ~]# pvcreate /dev/hda10
Physical volume "/dev/hda10" successfully created
[root@www ~]# pvscan
PV /dev/hda6 VG vbirdvg lvm2 [1.39 GB / 0 free]
PV /dev/hda7 VG vbirdvg lvm2 [1.39 GB / 0 free]
PV /dev/hda8 VG vbirdvg lvm2 [1.39 GB / 0 free]
PV /dev/hda9 VG vbirdvg lvm2 [1.39 GB / 0 free]
PV /dev/hda10 lvm2 [2.80 GB]
Total: 5 [8.37 GB] / in use: 4 [5.56 GB] / in no VG: 1 [2.80 GB]
可以看到 /dev/hda10 是新加入并且尚未被使用的。
3. 加大 VG ,利用 vgextend 功能!
[root@www ~]# vgextend vbirdvg /dev/hda10
Volume group "vbirdvg" successfully extended
[root@www ~]# vgdisplay
—- Volume group —-
VG Name vbirdvg
System ID
Format lvm2
Metadata Areas 5
Metadata Sequence No 4
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 1
Max PV 0
Cur PV 5
Act PV 5
VG Size 8.36 GB
PE Size 16.00 MB
Total PE 535
Alloc PE / Size 356 / 5.56 GB
Free PE / Size 179 / 2.80 GB
VG UUID 4VU5Jr-gwOq-jkga-sUPx-vWPu-PmYm-dZH9EO
不但整体 VG 变大了!而且剩余的 PE 共有 179 个,容量则为 2.80G
4. 放大 LV 吧!利用 lvresize 的功能来增加!
[root@www ~]# lvresize -l +179 /dev/vbirdvg/vbirdlv
Extending logical volume vbirdlv to 8.36 GB
Logical volume vbirdlv successfully resized
这样就增加了 LV 了。lvresize 的语法很简单,基本上同样通过 -l 或 -L 来增加!
若要增加则使用 + ,若要减少则使用 - !详细的参数请参考 man lvresize 。
[root@www ~]# lvdisplay
—- Logical volume —-
LV Name /dev/vbirdvg/vbirdlv
VG Name vbirdvg
LV UUID 8vFOPG-Jrw0-Runh-ug24-t2j7-i3nA-rPEyq0
LV Write Access read/write
LV Status available
open 1
LV Size 8.36 GB
Current LE 535
Segments 5
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:0
[root@www ~]# df /mnt/lvm
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/vbirdvg-vbirdlv
5741020 261212 5188176 5% /mnt/lvm
看到了吧?最终的结果中LV真的有放大到8.36GB,但是文件系统却没有相对增加。而且,我们的LVM可以在线直接处理,并不需要特别给它umount。真是人性化,但是还是得要处理一下文件系统的容量。开始查看一下文件系统,然后使用resize2fs来处理一下吧!
5.1 先看一下原本的文件系统内的 superblock 记录情况吧!
[root@www ~]# dumpe2fs /dev/vbirdvg/vbirdlv
dumpe2fs 1.39 (29-May-2006)
….(中间省略)….
Block count: 1458176 <==这个文件系统的 block 总数
….(中间省略)….
Blocks per group: 32768 <==多少个 block 设置成为一个 block group
Group 0: (Blocks 0-32767) <==括号内为 block 的号码
….(中间省略)….
Group 44: (Blocks 1441792-1458175) <==这是本系统中最后一个 group
….(后面省略)….
5.2 resize2fs 的语法
[root@www ~]# resize2fs [-f] [device] [size]
参数:
-f :强制进行 resize 的操作。
[device]:设备的文件名。
[size] :可以加也可以不加。如果加上 size 的话,那么就必须要给予一个单位,
譬如 M, G 等。如果没有 size 的话,那么默认使用整个分区
的容量来处理!
5.3 完整地将 LV 的容量扩充到整个文件系统。
[root@www ~]# resize2fs /dev/vbirdvg/vbirdlv
resize2fs 1.39 (29-May-2006)
Filesystem at /dev/vbirdvg/vbirdlv is mounted on /mnt/lvm; on-line resizing
Performing an on-line resize of /dev/vbirdvg/vbirdlv to 2191360 (4k) blocks.
The filesystem on /dev/vbirdvg/vbirdlv is now 2191360 blocks long.
可怕吧!这一版的 lvm 竟然还可以在线进行 resize 的功能。
[root@www ~]# df /mnt/lvm
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/vbirdvg-vbirdlv
8628956 262632 7931368 4% /mnt/lvm
[root@www ~]# ll /mnt/lvm
drwxr-xr-x 105 root root 12288 Mar 11 16:59 etc
drwxr-xr-x 17 root root 4096 Mar 11 14:17 log
drwx——— 2 root root 16384 Mar 11 16:59 lost+found
刚才复制进去的数据可还是存在的,并没有消失不见!
真的放大了吧!而且如果你已经有填数据在LVM扇区当中的话,这个数据是不会死掉的。还是继续存在原本的扇区当中啦!整个操作竟然这么简单就完成了,原本的数据还是一直存在而不会消失。你说LVM好不好用啊?
此外,如果你再以dumpe2fs来检查/dev/vbirdvg/vbirdlv时,就会发现后续的group增加了。如果还是搞不清楚什么是blockgroup时,请回到第8章看一下该章内图8-3的介绍。
15.3.4 缩小LV 容量
上一小节我们谈到的是放大容量,现在来谈到的是缩小容量。假设我们想将/dev/hda6抽离出来。那该如何处理啊?就让上一小节的流程倒转过来即可,我们就直接来玩吧!
1. 先找出 /dev/hda6 的容量大小,并尝试计算文件系统需缩小到多少
[root@www ~]# pvdisplay
—- Physical volume —-
PV Name /dev/hda6
VG Name vbirdvg
PV Size 1.40 GB / not usable 11.46 MB
Allocatable yes (but full)
PE Size (KByte) 16384
Total PE 89
Free PE 0
Allocated PE 89
PV UUID Z13Jk5-RCls-UJ8B-HzDa-Gesn-atku-rf2biN
从这里可以看出 /dev/hda6 有多大,而且含有 89 个 PE 的量。
那如果要使用 resize2fs 时,则总量减去 1.40GB 就对了!
[root@www ~]# pvscan
PV /dev/hda6 VG vbirdvg lvm2 [1.39 GB / 0 free]
PV /dev/hda7 VG vbirdvg lvm2 [1.39 GB / 0 free]
PV /dev/hda8 VG vbirdvg lvm2 [1.39 GB / 0 free]
PV /dev/hda9 VG vbirdvg lvm2 [1.39 GB / 0 free]
PV /dev/hda10 VG vbirdvg lvm2 [2.80 GB / 0 free]
Total: 5 [8.36 GB] / in use: 5 [8.36 GB] / in no VG: 0 [0 ]
从上面可以发现如果扣除 /dev/hda6 则剩余容量有:1.39×3+2.8=6.97
2. 直接降低文件系统的容量。
[root@www ~]# resize2fs /dev/vbirdvg/vbirdlv 6900M
resize2fs 1.39 (29-May-2006)
Filesystem at /dev/vbirdvg/vbirdlv is mounted on /mnt/lvm; on-line resizing
On-line shrinking from 2191360 to 1766400 not supported.
容量好像不能够写小数点位数,因此 6.9GB 是错误的,鸟哥就使用 6900MB 了。
此外,放大可以在线直接进行,缩小文件系统似乎无法支持。所以要这样做:
[root@www ~]# umount /mnt/lvm
[root@www ~]# resize2fs /dev/vbirdvg/vbirdlv 6900M
resize2fs 1.39 (29-May-2006)
Please run 'e2fsck -f /dev/vbirdvg/vbirdlv' first.
它要我们先进行磁盘检查,那就直接进行吧!
[root@www ~]# e2fsck -f /dev/vbirdvg/vbirdlv
e2fsck 1.39 (29-May-2006)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/vbirdvg/vbirdlv: 2438/1087008 files (0.1% non-contiguous),
[root@www ~]# resize2fs /dev/vbirdvg/vbirdlv 6900M
resize2fs 1.39 (29-May-2006)
Resizing the filesystem on /dev/vbirdvg/vbirdlv to 1766400 (4k) blocks.
The filesystem on /dev/vbirdvg/vbirdlv is now 1766400 blocks long.
再来 resize2fs 一次就能够成功了,如上所示。
[root@www ~]# mount /dev/vbirdvg/vbirdlv /mnt/lvm
[root@www ~]# df /mnt/lvm
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/vbirdvg-vbirdlv
6955584 262632 6410328 4% /mnt/lvm
然后就是将LV的容量降低。要注意的是,我们想要抽离的是/dev/hda6,这个PV有89个PE(上面的pvdisplay查询到的结果)。所以要这样进行:
3. 降低 LV 的容量,同时我们知道 /dev/hda6 有 89 个 PE
[root@www ~]# lvresize -l -89 /dev/vbirdvg/vbirdlv
WARNING: Reducing active and open logical volume to 6.97 GB
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce vbirdlv? [y/n]: y
Reducing logical volume vbirdlv to 6.97 GB
Logical volume vbirdlv successfully resized
会有警告信息。但是我们的实际数据量还是比 6.97GB 小,所以就按y吧!
[root@www ~]# lvdisplay
—- Logical volume —-
LV Name /dev/vbirdvg/vbirdlv
VG Name vbirdvg
LV UUID 8vFOPG-Jrw0-Runh-ug24-t2j7-i3nA-rPEyq0
LV Write Access read/write
LV Status available
open 1
LV Size 6.97 GB
Current LE 446
Segments 5
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:0
很简单,这样就将LV缩小了。接下来就要将/dev/hda6移出vbirdvg这个VG之外。我们得要先确定/dev/hda6里面的PE完全不被使用后才能够将/dev/hda6抽离。所以得要这样进行:
4.1 先确认 /dev/hda6 是否将 PE 都删除了!
[root@www ~]# pvdisplay
—- Physical volume —-
PV Name /dev/hda6
VG Name vbirdvg
PV Size 1.40 GB / not usable 11.46 MB
Allocatable yes (but full)
PE Size (KByte) 16384
Total PE 89
Free PE 0
Allocated PE 89
PV UUID Z13Jk5-RCls-UJ8B-HzDa-Gesn-atku-rf2biN
….(中间省略)….
—- Physical volume —-
PV Name /dev/hda10
VG Name vbirdvg
PV Size 2.80 GB / not usable 6.96 MB
Allocatable yes
PE Size (KByte) 16384
Total PE 179
Free PE 89
Allocated PE 90
PV UUID 7MfcG7-y9or-0Jmb-H7RO-5Pa5-D3qB-G426Vq
搞了老半天,没有被使用的 PE 竟然在 /dev/hda10 。此时得要转移 PE 。
[root@www ~]# pvmove /dev/hda6 /dev/hda10
pvmove 来源PV 目标PV ,可以将 /dev/hda6 内的 PE全部移动到 /dev/hda10
尚未被使用的 PE 去 (Free PE)。
4.2 将 /dev/hda6 移出 vbirdvg 中!
[root@www ~]# vgreduce vbirdvg /dev/hda6
Removed "/dev/hda6" from volume group "vbirdvg"
[root@www ~]# pvscan
PV /dev/hda7 VG vbirdvg lvm2 [1.39 GB / 0 free]
PV /dev/hda8 VG vbirdvg lvm2 [1.39 GB / 0 free]
PV /dev/hda9 VG vbirdvg lvm2 [1.39 GB / 0 free]
PV /dev/hda10 VG vbirdvg lvm2 [2.80 GB / 0 free]
PV /dev/hda6 lvm2 [1.40 GB]
Total: 5 [8.37 GB] / in use: 4 [6.97 GB] / in no VG: 1 [1.40 GB]
[root@www ~]# pvremove /dev/hda6
Labels on physical volume "/dev/hda6" successfully wiped
很有趣吧!这样你的文件系统以及实际的LV与VG全部变小了,而且那个/dev/hda6还真的可以拿出来,可以进行其他的用途,非常简单吧!
15.3.5 LVM 的系统快照
现在你知道LVM的好处了,将来如果你有想要增加某个LVM的容量时,就可以通过这个放大、缩小的功能来处理。那么LVM除了这些功能之外,还有什么能力呢?其实它还有一个重要的功能,那就是系统快照(snapshot)。什么是系统快照啊?快照就是将当时的系统信息记录下来,就好像照相记录一般。将来若有任何数据改动了,则原始数据会被移到快照区,没有被改动的区域则由快照区与文件系统共享。讲解好像很难懂,我们用图15-8说明一下好了。
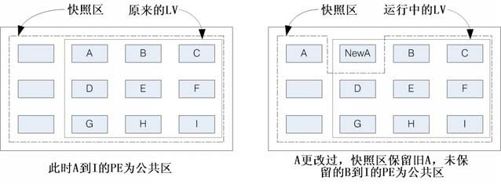
图15-8 LVM 系统快照区域的备份示意图(虚线为文件系统,长虚线为快照区)
左图为最初建立系统快照区的状况,LVM会预留一个区域(左图的左端三个PE区块)作为数据存放处。此时快照区内并没有任何数据,而快照区与系统区共享所有的 PE 数据,因此你会看到快照区的内容与文件系统是一模一样的。等到系统运行一阵子后,假设A区域的数据被改动了(上面右图所示),则改动前系统会将该区域的数据移动到快照区,所以在右图的快照区被占用了一块PE成为A,而其他B到I的区块则还是与文件系统共享!
照这样的情况来看,LVM的系统快照是非常棒的备份工具,因为它只有备份有被改动的数据,文件系统内没有被更改的数据依旧保持在原本的区块内,但是 LVM 快照功能会知道那些数据放置在哪里,因此“快照”当时的文件系统就得以“备份”下来,且快照所占用的容量又非常小。所以你说,这不是很棒的工具又是什么?
那么快照区要如何创建与使用呢?首先,由于快照区与原本的LV共享很多PE区块,因此快照区与被快照的LV必须要在同一个VG上面。但是我们刚才将/dev/hda6删除vbirdvg了,目前vbirdvg剩下的容量为0。因此,在这个小节里面我们得要再加入/dev/hda6到我们的VG后,才能继续新建快照区。如下面的练习来说明。
快照区的新建
下面的操作主要增加需要的 VG 容量,然后再通过 lvcreate -s 的功能新建快照区。
1. 先查看 VG 还剩下多少剩余容量
[root@www ~]# vgdisplay
—- Volume group —-
VG Name vbirdvg
….(其他省略)….
VG Size 6.97 GB
PE Size 16.00 MB
Total PE 446
Alloc PE / Size 446 / 6.97 GB
Free PE / Size 0 / 0 <==没有多余的 PE 可用!
2. 将刚才删除的 /dev/hda6 加入这个 VG 。
[root@www ~]# pvcreate /dev/hda6
Physical volume "/dev/hda6" successfully created
[root@www ~]# vgextend vbirdvg /dev/hda6
Volume group "vbirdvg" successfully extended
[root@www ~]# vgdisplay
—- Volume group —-
VG Name vbirdvg
….(其他省略)….
VG Size 8.36 GB
PE Size 16.00 MB
Total PE 535
Alloc PE / Size 446 / 6.97 GB
Free PE / Size 89 / 1.39 GB <==多出了 89 个 PE 嗌可用 !
3. 利用 lvcreate 新建系统快照区,我们取名为 vbirdss,且给予 60 个 PE
[root@www ~]# lvcreate -l 60 -s -n vbirdss /dev/vbirdvg/vbirdlv
Logical volume "vbirdss" created
上述的命令中最重要的是那个 -s 的参数。代表是 snapshot 快照功能之意!
-n 后面接快照区的设备名称,/dev/…. 则是要被快照的 LV 完整文件名。
-l 后面则是接使用多少个 PE 来作为这个快照区使用。
[root@www ~]# lvdisplay
—- Logical volume —-
LV Name /dev/vbirdvg/vbirdss
VG Name vbirdvg
LV UUID K2tJ5E-e9mI-89Gw-hKFd-4tRU-tRKF-oeB03a
LV Write Access read/write
LV snapshot status active destination for /dev/vbirdvg/vbirdlv
LV Status available
open 0
LV Size 6.97 GB <==被快照的原 LV 磁盘容量
Current LE 446
COW-table size 960.00 MB <==快照区的实际容量
COW-table LE 60 <==快照区占用的 PE 数量
Allocated to snapshot 0.00%
Snapshot chunk size 4.00 KB
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:1
你看看,这个/dev/vbirdvg/vbirdss 快照区就被新建起来了,而且它的 VG 量竟然与原本的/dev/vbirdvg/vbirdlv 相同。也就是说,如果你真的挂载这个设备时,看到的数据会跟原本的vbirdlv相同。我们就来测试看看:
[root@www ~]# mkdir /mnt/snapshot
[root@www ~]# mount /dev/vbirdvg/vbirdss /mnt/snapshot
[root@www ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda2 9920624 3859032 5549524 42% /
/dev/hda3 4956316 1056996 3643488 23% /home
/dev/hda1 101086 21408 74459 23% /boot
tmpfs 371332 0 371332 0% /dev/shm
/dev/mapper/vbirdvg-vbirdlv
6955584 262632 6410328 4% /mnt/lvm
/dev/mapper/vbirdvg-vbirdss
6955584 262632 6410328 4% /mnt/snapshot
有没有看到!竟然是一模一样。我们根本没有动过
/dev/vbirdvg/vbirdss 对吧?不过这里面会主动记录原 vbirdlv 的内容!
[root@www ~]# umount /mnt/snapshot
最后将它卸载。我们准备来玩玩有趣的东西!
利用快照区复原系统
首先,我们来看一下如何利用快照区复原系统吧!不过你要注意的是,你要复原的数据量不能够高于快照区所能负载的实际容量。由于原始数据会被移到快照区,如果你的快照区不够大,若原始数据被改动的实际数据量比快照区大,那么快照区当然容纳不了,这时候快照功能会失效。所以上面的案例中鸟哥才给予60个PE(共900MB)作为快照区存放数据用。
我们的/mnt/lvm已经有/mnt/lvm/etc,/mnt/lvm/log等目录了,接下来我们将这个文件系统的内容作个更改,然后再以快照区数据还原看看:
1. 先将原本的/dev/vbirdvg/vbirdlv 内容作些更改,增减一些目录吧!
[root@www ~]# df /mnt/lvm
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/vbirdvg-vbirdlv
6955584 262632 6410328 4% /mnt/lvm
[root@www ~]# ll /mnt/lvm
drwxr-xr-x 105 root root 12288 Mar 11 16:59 etc
drwxr-xr-x 17 root root 4096 Mar 11 14:17 log
drwx——— 2 root root 16384 Mar 11 16:59 lost+found
[root@www ~]# rm -r /mnt/lvm/log
[root@www ~]# cp -a /boot /lib /sbin /mnt/lvm
[root@www ~]# ll /mnt/lvm
drwxr-xr-x 4 root root 4096 Dec 15 16:28 boot
drwxr-xr-x 105 root root 12288 Mar 11 16:59 etc
drwxr-xr-x 14 root root 4096 Sep 5 2008 lib
drwx——— 2 root root 16384 Mar 11 16:59 lost+found
drwxr-xr-x 2 root root 12288 Sep 5 2008 sbin
看起来数据已经不一样了!
[root@www ~]# lvdisplay /dev/vbirdvg/vbirdss
—- [8]gical volume —-
LV Name /dev/vbirdvg/vbirdss
VG Name vbirdvg
….(中间省略)….
Allocated to snapshot 12.22%
….(下面省略)….
从这里也看得出来,快照区已经被使用了 12.22% ,因为原始的文件系统有改动过。
2. 利用快照区将原本的文件系统备份
[root@www ~]# mount /dev/vbirdvg/vbirdss /mnt/snapshot
[root@www ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/vbirdvg-vbirdlv
6955584 370472 6302488 6% /mnt/lvm
/dev/mapper/vbirdvg-vbirdss
6955584 262632 6410328 4% /mnt/snapshot
看吧!两者确实不一样了!开始将快照区内容复制出来吧!
[root@www ~]# mkdir -p /backups <==确认真的有这个目录!
[root@www ~]# cd /mnt/snapshot
[root@www snapshot]# tar -jcv -f /backups/lvm.tar.bz2 *
此时你就会有一个备份资料,也即是 /backups/lvm.tar.bz2 了!
为什么要备份呢?为什么不可以直接格式化/dev/vbirdvg/vbirdlv,然后将/dev/vbirdvg/vbirdss直接复制给vbirdlv呢?要知道vbirdss其实是vbirdlv的快照,因此如果你格式化整个vbirdlv时,原本的文件系统所有数据都会被移到vbirdss。那如果vbirdss的容量不够大(通常也真的不够大),那么部分数据将无法复制到vbirdss内,数据当然无法全部还原。所以才要在上面表格中制作出一个备份文件。
而快照还有另外一个功能,就是你可以比较/mnt/lvm与/mnt/snapshot的内容,就能够发现到最近你到底改了什么。接下来让我们准备还原vbirdlv的内容吧!
3. 将 vbirdss 卸除并删除 (因为里面的内容已经备份起来了)
[root@www ~]# umount /mnt/snapshot
[root@www ~]# lvremove /dev/vbirdvg/vbirdss
Do you really want to remove active logical volume "vbirdss"? [y/n]: y
Logical volume "vbirdss" successfully removed
[root@www ~]# umount /mnt/lvm
[root@www ~]# mkfs -t ext3 /dev/vbirdvg/vbirdlv
[root@www ~]# mount /dev/vbirdvg/vbirdlv /mnt/lvm
[root@www ~]# tar -jxv -f /backups/lvm.tar.bz2 -C /mnt/lvm
[root@www ~]# ll /mnt/lvm
drwxr-xr-x 105 root root 12288 Mar 11 16:59 etc
drwxr-xr-x 17 root root 4096 Mar 11 14:17 log
drwx——— 2 root root 16384 Mar 11 16:59 lost+found
是否与最初的内容相同啊?这就是通过快照来还原的一个简单的方法。
利用快照区进行各项练习与测试的任务,再以原系统还原快照
换个角度来想想,我们将原本的vbirdlv当作备份数据,然后将vbirdss当作实际运行中的数据,任何测试的操作都在vbirdss这个快照区当中测试,那么当测试完毕要将测试的数据删除时,只要将快照区删去即可。而要复制一个vbirdlv的系统,再制作另外一个快照区即可。这样是否非常方便啊?这对于教学环境中每年都要帮学生制作一个练习环境主机的测试非常有帮助呢!
以前鸟哥老是觉得使用 LVM 的快照来进行备份不太合理,因为还要制作一个备份文件。后来仔细研究并参考徐秉义老师的教材后,才发现 LVM 的快照实在是一个很棒的工具。尤其是在虚拟机当中构建多份给同学使用的测试环境,你只要有一个基础的环境并维护好,其他的环境使用快照来提供即可。就算同学将系统搞烂了,你只要将快照区删除,再重建一个快照区,这样环境就恢复了。实在是太棒了!
1. 新建一个大一些的快照区,让我们将 /dev/hda6 的 PE 全部给快照区!
[root@www ~]# lvcreate -s -l 89 -n vbirdss /dev/vbirdvg/vbirdlv
Logical volume "vbirdss" created
[root@www ~]# lvdisplay /dev/vbirdvg/vbirdss
—- Logical volume —-
LV Name /dev/vbirdvg/vbirdss
VG Name vbirdvg
LV UUID as0ocQ-KjRS-Bu7y-fYoD-1CHC-0V3Y-JYsjj1
LV Write Access read/write
LV snapshot status active destination for /dev/vbirdvg/vbirdlv
LV Status available
open 0
LV Size 6.97 GB
Current LE 446
COW-table size 1.39 GB
COW-table LE 89
Allocated to snapshot 0.00%
Snapshot chunk size 4.00 KB
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:1
如何?这个快照区不小吧!
2. 隐藏 vbirdlv 挂载 vbirdss
[root@www ~]# umount /mnt/lvm
[root@www ~]# mount /dev/vbirdvg/vbirdss /mnt/snapshot
[root@www ~]# df /mnt/snapshot
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/vbirdvg-vbirdss
7192504 265804 6561340 4% /mnt/snapshot
3. 开始恶搞!
[root@www ~]# rm -r /mnt/snapshot/etc /mnt/snapshot/log
[root@www ~]# cp -a /boot /lib /sbin /mnt/snapshot/
[root@www ~]# ll /mnt/snapshot
drwxr-xr-x 4 root root 4096 Dec 15 16:28 boot
drwxr-xr-x 14 root root 4096 Sep 5 2008 lib
drwx——— 2 root root 16384 Mar 11 16:59 lost+found
drwxr-xr-x 2 root root 12288 Sep 5 2008 sbin <==与原本数据有差异了
[root@www ~]# mount /dev/vbirdvg/vbirdlv /mnt/lvm
[root@www ~]# ll /mnt/lvm
drwxr-xr-x 105 root root 12288 Mar 11 16:59 etc
drwxr-xr-x 17 root root 4096 Mar 11 14:17 log
drwx——— 2 root root 16384 Mar 11 16:59 lost+found
不论你在快照区恶搞什么,原本的 vbirdlv 里面的数据安好如初。
假设你将 vbirdss 搞烂了,里面的数据不再需要。那该如何是好?
4. 还原原本快照区的数据,回到与原文件系统相同的信息
[root@www ~]# umount /mnt/snapshot
[root@www ~]# lvremove /dev/vbirdvg/vbirdss
Do you really want to remove active logical volume "vbirdss"? [y/n]: y
Logical volume "vbirdss" successfully removed
[root@www ~]# lvcreate -s -l 89 -n vbirdss /dev/vbirdvg/vbirdlv
[root@www ~]# mount /dev/vbirdvg/vbirdss /mnt/snapshot
[root@www ~]# ll /mnt/snapshot
drwxr-xr-x 105 root root 12288 Mar 11 16:59 etc
drwxr-xr-x 17 root root 4096 Mar 11 14:17 log
drwx——— 2 root root 16384 Mar 11 16:59 lost+found
数据这样就复原了!
老实说,上面的测试有点无厘头,因为快照区损毁了就删除再建一个就好啦!何必还要测试呢?不过,为了让你了解到快照区也能够这样使用,上面的测试还是需要存在的。将来如果你有接触到虚拟机,再回到这里来温习一下肯定会有收获的!
15.3.6 LVM 相关命令汇整与LVM 的关闭
好了,我们将上述用过的一些命令汇整一下,如表15-1所示,提供给你参考。
表15-1

至于文件系统阶段(文件系统的格式化处理)部分,还需要以resize2fs来修改文件系统实际的大小才行。至于虽然LVM可以弹性管理你的磁盘容量,但是要注意,如果你想要使用LVM管理你的硬盘时,那么在安装的时候就得要做好LVM的规划了,否则将来还是需要先以传统的磁盘增加方式来增加后,移动数据后,才能够进行LVM的使用。
会玩LVM还不行,你必须要会删除系统内的LVM。因为你的物理分区已经被使用到LVM去,如果你还没有将LVM关闭就直接将那些分区删除或转为其他用途的话,系统是会发生很大的问题。所以,你必须要知道如何将LVM的设备关闭并删除才行,会不会很难呢?其实不会啦!依据以下的流程来处理即可:
1.先卸载系统上面的LVM文件系统(包括快照与所有LV);
2.使用lvremove删除LV;
3.使用vgchange -an VGname 让VGname 这个VG 不具有Active 的标志;
4.使用vgremove删除VG:
5.使用pvremove删除PV;
6.最后,使用fdisk将ID修改回来。
那就实际将我们之前新建的所有LVM数据给删除吧!
[root@www ~]# umount /mnt/lvm
[root@www ~]# umount /mnt/snapshot
[root@www ~]# lvremove /dev/vbirdvg/vbirdss <==先处理快照
Do you really want to remove active logical volume "vbirdss"? [y/n]: y
Logical volume "vbirdss" successfully removed
[root@www ~]# lvremove /dev/vbirdvg/vbirdlv <==再处理原系统
Do you really want to remove active logical volume "vbirdlv"? [y/n]: y
Logical volume "vbirdlv" successfully removed
[root@www ~]# vgchange -a n vbirdvg
0 logical volume(s) in volume group "vbirdvg" now active
[root@www ~]# vgremove vbirdvg
Volume group "vbirdvg" successfully removed
[root@www ~]# pvremove /dev/hda{6,7,8,9,10}
Labels on physical volume "/dev/hda6" successfully wiped
Labels on physical volume "/dev/hda7" successfully wiped
Labels on physical volume "/dev/hda8" successfully wiped
Labels on physical volume "/dev/hda9" successfully wiped
Labels on physical volume "/dev/hda10" successfully wiped
最后再用fdisk将磁盘的ID改为82就好。整个过程就这样。
15.4 重点回顾
Quota可公平分配系统上面的磁盘空间给用户;分配的资源可以是磁盘容量(block)或可新建文件数量(inode)。
Quota的限制可以有soft、hard、gracetime等重要选项。
Quota仅能针对整个文件系统进行限制,不是针对目录。
Quota的使用必须要内核与文件系统均支持。文件系统的参数必须含有usrquota,grpquota。
Quota实践的命令有quotacheck,quotaon,edquota,repquota等。
磁盘阵列(RAID)有硬件与软件之分,Linux操作系统可支持软件磁盘阵列,通过mdadm套件来实现。
磁盘阵列构建的考虑依据为“容量”、“性能”、“数据可靠性”等。
磁盘阵列所建置的等级常见有的 RAID-0,RAID-1,RAID-0 + 1,RAID-5 及 RAID-6。
硬件磁盘阵列的设备文件名与 SCSI 相同,至于 software RAID 则为/dev/md[0-9]。
软件磁盘阵列的状态可通过/proc/mdstat文件来了解。
LVM强调的是弹性的变化文件系统的容量。
与LVM有关的组件有PV/VG/PE/LV等,可以被格式化为LV。
LVM 拥有快照功能,快照可以记录LV的数据内容,并与原有的LV 共享未更动的数据,备份与还原就变的很简单。
Ext3通过resize2fs命令可以弹性调整文件系统的大小。
15.5 本章习题
情境模拟题一
由于LVM可以弹性调整文件系统的大小,但是缺点是可能没有加速与硬件备份(与快照不同)的功能。而磁盘阵列则具有性能与备份的功能,但是无法提供类似LVM的优点。在此情境中,我们想利用在RAID上面构建LVM的功能,以达到两者兼顾的能力。
目标:测试在RAID磁盘上面架构LVM系统;
需求:需要具有磁盘管理的能力,包括RAID与LVM;
前提:将本章与之前章节练习所制作的分区全部删除,剩下默认的分区即可。
那要如何处理呢?如下的流程一个步骤一个步骤实施看看吧!
1.还原系统时,你必须要:
利用umount先卸载之前挂载的文件系统;
修改/etc/fstab里面的数据,让开机不会自动挂载;
利用fdisk将该分区删除。
最终你的系统应该会只剩下如下的模样:
[root@www ~]# fdisk -l
Device Boot Start End Blocks Id System
/dev/hda1 * 1 13 104391 83 Linux
/dev/hda2 14 1288 10241437+ 83 Linux
/dev/hda3 1289 1925 5116702+ 83 Linux
/dev/hda4 1926 9382 59898352+ 5 Extended
/dev/hda5 1926 2052 1020096 82 Linux swap / Solaris
2.新建 RAID,假设我们利用五个 1GB 的分区创建 RAID-5,且具有一个 spare disk,那么你应该要如何进行?首先,请自行使用fdisk创建好如下的分区状态:
[root@www ~]# fdisk -l
….(前面省略)….
/dev/hda6 2053 2175 987966 83 Linux
/dev/hda7 2176 2298 987966 83 Linux
/dev/hda8 2299 2421 987966 83 Linux
/dev/hda9 2422 2544 987966 83 Linux
/dev/hda10 2545 2667 987966 83 Linux
接下来开始新建RAID吧!新建的方法可以如下简单处理即可:
[root@www ~]# mdadm —create —auto=yes /dev/md0 —level=5 \
> —raid-devices=4 —spare-devices=1 /dev/hda{6,7,8,9,10}
若无出现任何错误信息,此时你已经具有 /dev/md0 这个磁盘阵列设备了。接下来让我们处理LVM。
3.开始处理LVM,现在我们假设所有的参数都使用默认值,包括PE,然后VG名为raidvg,LV名为raidlv,下面为基本的流程:
[root@www ~]# pvcreate /dev/md0 <==新建 PV
[root@www ~]# vgcreate raidvg /dev/md0 <==新建 VG
[root@www ~]# lvcreate -L 2.82G -n raidlv raidvg <==新建 LM
[root@www ~]# lvdisplay
—- Logical volume —-
LV Name /dev/raidvg/raidlv
VG Name raidvg
LV UUID zQsKqW-8Bt2-kpJF-8rCI-Cql1-XQYT-jw1mfH
LV Write Access read/write
LV Status available
open 0
LV Size 2.82 GB
Current LE 722
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:0
这样就搞定了LVM了,而且这个LVM是架构在/dev/md0上面的。然后就是文件系统的新建与挂载了!
4.尝试新建成为Ext3文件系统,且挂载到/mnt/raidlvm目录下:
[root@www ~]# mkfs -t ext3 /dev/raidvg/raidlv
[root@www ~]# mkdir /mnt/raidlvm
[root@www ~]# mount /dev/raidvg/raidlv /mnt/raidlvm
5.上述就是LVM架构在RAID上面的技巧,之后的操作都能够使用本章的其他管理方式来管理,包括RAID热拔插机制、LVM放大缩小机制等。测试完毕之后请务必要关闭本题所新建的各项信息。
[root@www ~]# umount /mnt/raidlvm <==卸载文件系统
[root@www ~]# lvremove /dev/raidvg/raidlv <==删除 LV
[root@www ~]# vgchange -a n raidvg <==让 VG 不活动
[root@www ~]# vgremove raidvg <==删除 VG
[root@www ~]# pvremove /dev/md0 <==删除 PV
[root@www ~]# mdadm —stop /dev/md0 <==关闭 /dev/md0 RAID
[root@www ~]# fdisk /dev/hda <==还原原本的分区
简答题部分
在前一章的第一个大量新增账号范例中,如果我想要让每个用户均具有soft、hard各为40MB、50MB的容量时,应该如何修改这个script?
如果我想要让 RAID 具有保护数据的功能,防止因为硬件损毁而导致数据的丢失,那我应该要选择的RAID等级可能有哪些(请以本章谈到的等级来思考即可)?
在默认的LVM设置中,请问LVM能否具有“备份”的功能?
LVM内的LV据说仅能达到256GB的容量,请问如何克服此容量问题?
如果你的计算机主机有提供 RAID 0 的功能,你将你的三块硬盘全部在 BIOS 阶段使用 RAID 芯片整合成为一块大磁盘,则此磁盘在Linux系统当中的文件名为何?
15.6 参考数据与扩展阅读
注3:徐秉义老师在网管人杂志(http://www.babyface.idv.tw/NetAdmin/)的投稿文章:磁盘管理:SoftRAID与LVM综合实做应用(上) http://www.babyface.idv.tw/NetAdmin/16200705SoftRAIDLVM01/ 磁盘管理:SoftRAID与LVM综合实做应用(下) http://www.babyface.idv.tw/NetAdmin/18200707SoftRAIDLVM02/
