- 第17章 程序管理与SELinux初探
- 在中括号内的号码为工作号码 (job number),该号码与 bash 的控制有关。
- 后续的 8400 则是这个工作在系统中的 PID。至于后续出现的数据是 tar 执行的数据流,
- 由于我们没有加上数据流重定向,所以会影响界面,不过不会影响前台的操作。
- 在 vi 的一般模式下,按下 [ctrl]-z 这两个按键
- 此时屏幕会非常忙碌!因为屏幕上会显示所有的文件名。请按下 [ctrl]-z 暂停
- 此时,请立刻按下 [ctrl]-z 暂停!
- 再过几秒你再执行 jobs 一次,就会发现 2 号工作不见了!因为被删除了!
- -SIGTERM 与 -15 是一样的!你可以使用 kill -l 来查阅!
- 1. 先编辑一个会“睡着 500 秒”的程序:
- !/bin/bash
- 2. 丢到后台中去执行,并且立刻注销系统:
- 你会发现每个字段与 ps -l 的输出情况相同,但显示的进程则包括系统所有的进程。
- 所以号码是 4286 及 4661 这两个,就是这样找的啦!
- 这样一来,嘿嘿!就可以将top的信息存到/tmp/top.txt文件中了。
- 在范例三的 top 界面当中直接按下 r 之后,会出现如下的图样!
- 注意一下,为了节省版面,所以鸟哥已经删去很多进程了!
- 在括号 () 内的即是 PID 以及该进程的 owner 。不过,由于我是使用
- root 的身份执行此一命令,所以属于 root 的进程就不会显示出来啦!
- 如果用 ps aux 仔细看一下,syslogd 才是完整的命令名称。但若包含整个参数,
- 则 syslogd -m 0 才是完整的呢!
- 具有互动的功能!可以询问你是否要删除 bash 这个进程。要注意,若没有 -i 的参数,
- 所有的 bash 都会被这个 root 给杀掉!包括 root 自己的 bash 。
- 原本的 bash PRI 为 75 ,所以 vi 默认应为 75。不过由于给予 nice 为 -5 ,
- 因此 vi 的 PRI 降低了!但并非降低到 70 ,因为内核还会动态调整!
- top 这个命令已经谈过相关信息,不再聊!
- 除了可以列出监听网络的端口与状态之外,最后一个字段还能够显示此服务的
- PID 号码以及进程的命令名称。例如最后一行的 4586 就是该 PID
第17章 程序管理与SELinux初探
一个程序被加载到内存当中运行,那么在内存内的那个数据就被称为进程(process)。进程是操作系统上非常重要的概念,所有系统上面跑的数据都会以进程的类型存在。那么系统的进程有哪些状态?不同的状态会如何影响系统的运行?进程之间是否可以互相控管等这些都是我们所必须要知道的项目。另外与进程有关的还有SELinux这个加强文件访问安全性的东东,也必须有个了解。
17.1 什么是进程(process)
由前面一连几个章节的数据看来,我们一直强调在Linux下面所有的命令与你能够进行的操作都与权限有关,而系统如何判定你的权限呢?当然就是第14章账号管理当中提到的UID/GID的相关概念,以及文件的属性相关性。再进一步来解释,你现在大概知道,在Linux系统当中:触发任何一个事件时,系统都会将它定义成为一个进程,并且给予这个进程一个ID,称为PID,同时依据触发这个进程的用户与相关属性关系,给予这个PID一组有效的权限设置。从此以后,这个PID能够在系统上面进行的操作,就与这个PID的权限有关了!
看这个定义似乎没有什么很奇怪的地方,不过,你必须了解什么叫做“触发事件”才行。我们在什么情况下会触发一个事件?而同一个事件可否被触发多次?先来介绍。
17.1.1 进程与程序(process & program)
我们如何产生一个进程呢?其实很简单,就是“执行一个程序或命令”就可以触发一个事件而取得一个 PID。我们说过,系统应该是仅认识二进制文件的,那么当我们要让系统工作的时候,当然就是需要启动一个二进制文件,那个二进制文件就是程序(program)。
那我们知道,每个进程都有三组人的权限,每组人都具有 r/w/x 的权限,所以:不同的用户身份执行这个程序时,系统给予的权限也都不相同!举例来说,我们可以利用touch来创建一个空的文件,当root 执行这个 touch 命令时,他取得的是 UID/GID = 0/0 的权限,而当 dmtsai(UID/GID = 501/501)执行这个touch时,他的权限就跟root不同。我们将这个概念绘制成图17-1所示。
如图 17-1 所示,程序一般是放置在磁盘中,然后通过用户的执行来触发。触发后会加载到内存中成为一个个体,那就是进程。为了操作系统可管理这个进程,因此进程有给予执行者的权限/属性等参数,并包括进程所需要的脚本与数据或文件数据等,最后再给予一个 PID。系统就是通过这个 PID来判断该process是否具有权限进行工作的,它是很重要的。
举个常见的例子,我们要操作系统的时候,通常是利用连接进程或者直接在主机前面登录,然后取得我们的shell,那么,我们的shell是bash对吧,这个bash在/bin/bash对吧,那么同时间的每个人登录都是执行/bin/bash。不过,每个人取得的权限就是不同,也就是说,我们可以这样看:
也就是说,当我们登录并执行bash时,系统已经给我们一个PID了,这个PID就是根据登录者的UID/GID(/etc/passwd)来的。以上面的图17-2配合图17-1来做说明的话,我们知道/bin/bash是一个程序(program),当 dmtsai 登录后,它取得一个 PID 号码为 2234 的进程,这个进程的User/Group都是dmtsai,而当这个进程进行其他工作时,例如上面提到的touch这个命令时,那么由这个进程衍生出来的其他进程在一般状态下,也会沿用这个进程的相关权限。
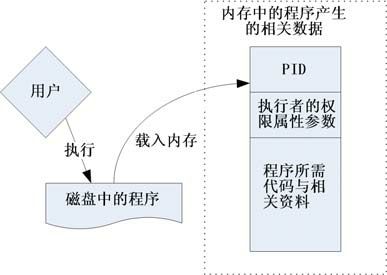
图17-1 程序被加载成为进程以及相关数据的示意图
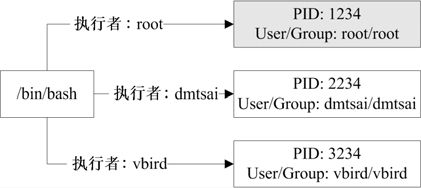
图17-2 程序与进程之间的区别
让我们将程序与进程作个总结:
程序(program):通常为二进制程序放置在存储媒介中(如硬盘、光盘、软盘、磁带等),以物理文件的形式存在;
进程(process):程序被触发后,执行者的权限与属性、程序的程序代码与所需数据等都会被加载到内存中,操作系统并给予这个内存内的单元一个标识符(PID),可以说,进程就是一个正在运行中的程序。
子进程与父进程
在上面的说明里面,我们有提到所谓的“衍生出来的进程”,那是什么?这样说好了,当我们登录系统后,会取得一个bash的shell,然后,我们用这个bash提供的接口去执行另一个命令,例如/usr/bin/passwd或者是touch等,那些另外执行的命令也会被触发成为PID,那个后来执行命令才产生的PID就是“子进程”,而在我们原本的bash环境下,就称为“父进程”了!借用我们在第11章Bash谈到的export所用的图17-3好了。
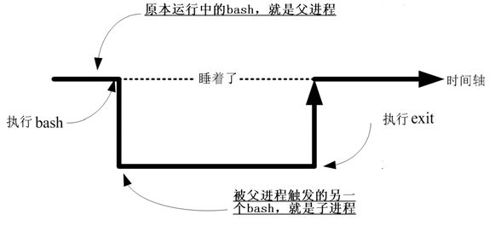
图17-3 进程相关系之示意图
所以你必须要知道,进程彼此之间是有相关性的。以上面的图示来看,连续执行两个bash后,第二个bash的父进程就是前一个bash。因为每个进程都有一个PID,那某个进程的父进程该如何判断?就通过 Parent PID(PPID)来判断即可。此外,由第 11 章的 export内容我们也探讨过环境变量的继承问题,子进程可以取得父进程的环境变量。让我们来进行下面的练习,以了解什么是子进程/父进程。

请在目前的 bash 环境下,再触发一次 bash,并以“ps -l”这个命令查看进程相关的输出信息。 答:直接执行 bash,会进入到子进程的环境中,然后输入 ps -l 后,出现:
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 8074 8072 2 76 0 - 1287 wait pts/1 00:00:00 bash
0 S 0 8102 8074 4 76 0 - 1287 wait pts/1 00:00:00 bash
4 R 0 8118 8102 0 78 0 - 1101 - pts/1 00:00:00 ps
有看到那个 PID 与 PPID 吗?第一个 bash 的 PID 与第二个 bash 的 PPID 都是 8 074,因为第二个 bash 是来自于第一个所产生的。另外,每台主机的进程启动状态都不一样,所以在你的系统上面看到的PID与我这里的显示一定不同,那是正常的!详细的ps命令我们会在本章稍后介绍,这里你只要知道 ps -l 可以查阅到相关的进程信息即可。
很多朋友经常会发现:“咦!明明我将有问题的进程关闭了,怎么过一阵子它又自动产生?而且新产生的那个进程的 PID 与原先的还不一样,这是怎么回事呢?”不要怀疑,如果不是crontab工作调度的影响,肯定有一个父进程存在,所以你杀掉子进程后,父进程就会主动再生一个。那怎么办?正所谓“擒贼先擒王”,找出那个父进程,然后将它删除就对啦!
fork and exec:过程调用的流程
其实子进程与父进程之间的关系还挺复杂的,最大的复杂点在于进程互相之间的调用,在Linux的过程调用中通常称为fork-and-exec的流程(注1)!进程都会通过父进程以复制(fork)的方式产生一个一模一样的子进程,然后被复制出来的子进程再以exec的方式来执行实际要进行的进程,最终就成为一个子进程的存在。整个流程有点像下面这张图17-4所示。
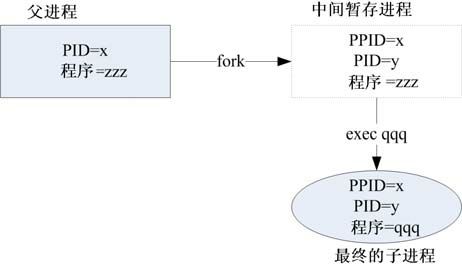
图17-4 程序使用fork and exec 调用的情况示意图
系统先以 fork 的方式复制一个与父进程相同的暂存进程,这个进程与父进程唯一的区别就是PID 不同!但是这个暂存进程还会多一个 PPID 的参数,PPID 如前所述,就是父进程的进程标识符。然后暂存进程开始以exec的方式加载实际要执行的程序,以上述图示来讲,新的进程名称为qqq,最终子进程的程序代码就会变成qqq了。
系统或网络服务:常驻在内存的进程
如果就我们之前学到的一些命令数据来看,其实我们执行的命令都很简单,包括用 ls 显示文件、用touch新建文件、rm/mkdir/cp/mv等命令管理文件、chmod/chown/passwd等的命令来管理权限等,不过,这些命令都是执行完就结束了。也就是说,该项命令被触发后所产生的PID很快就会终止。那有没有一直在执行的进程啊?当然有啊!而且多的是呢!
举个简单的例子来说好了,我们知道系统每分钟都会去扫描/etc/crontab 以及相关的配置文件,来进行工作调度。那么那个工作调度是谁负责的?当然不是鸟哥。是 crond 这个进程所管理的,它启动后在后台当中一直持续不断运行,套句以前DOS年代经常说的一句话,那就是常驻在内存当中的进程。
常驻在内存当中的进程通常都是负责一些系统所提供的功能以服务用户各项任务,因此这些常驻进程就会被我们称为服务(daemon)。系统的服务非常多,不过大致分成系统本身所需要的服务,例如刚才提到的 crond 及 atd,还有 syslog 等。还有一些则是负责网络联机的服务,例如Apache,named,postfix,vsftpd等。这些网络服务比较有趣的地方,在于这些程序被执行后,它会启动一个可以负责网络监听的端口(port),以提供外部客户端(client)的连接请求。
17.1.2 Linux 的多用户、多任务环境
我们现在知道了,其实在Linux下面执行一个命令时,系统会将相关的权限、属性、程序代码与数据等均加载到内存,并给予这个单元一个进程标识符(PID),最终该命令可以进行的任务则与这个PID 的权限有关。根据这个说明,我们就可以简单了解,为什么 Linux 这么多用户,但是却每个人都可以拥有自己的环境了。下面我们来谈谈Linux多用户、多任务环境的特色:
多用户环境
Linux最棒的地方就在于它的多用户、多任务环境了。那么什么是“多用户、多任务”?在Linux系统上面具有多种不同的账号,每种账号都有都有其特殊的权限,只有一个人具有至高无上的权利,那就是root(系统管理员)。除了root之外,其他人都必须要受一些限制的。而每个人进入Linux的环境设置都可以随着每个人的喜好来设置(还记得我们在第11章BASH提过的~/.bashrc吧?)。现在知道为什么了吧?因为每个人登录后取得的shell的PID不同。
多任务行为
我们在第0章谈到CPU的速度,目前的CPU速度可高达几个GHz。这代表CPU每秒钟可以运作109这么多次命令。我们的Linux可以让CPU在各个工作间进行切换,也就是说,其实每个工作都仅占去CPU的几个命令次数,所以CPU每秒就能够在各个进程之间进行切换。谁叫CPU可以在一秒钟进行这么多次的命令运行。
CPU切换进程的工作与这些工作进入到CPU运行的调度(CPU调度,非crontab调度)会影响到系统的整体性能。目前Linux使用的多任务切换行为是非常棒的一个机制,几乎可以将PC的性能整个压榨出来!由于性能非常好,因此当多人同时登录系统时,其实会感受到整台主机好像就为了你存在一般。这就是多用户、多任务的环境啦(注2)!
多重登录环境的七个基本终端窗口
在 Linux 当中,默认提供了 6 个命令行界面登录窗口,以及一个图形界面,你可以使用[Alt]+[F1]~[F7]来切换不同的终端机接口,而且每个终端机接口的登录者还可以是不同的人!很炫吧!这个东西可就很有用啦!尤其是在某个进程死掉的时候!
其实,这也是多任务环境下所产生的一个情况。我们的Linux默认会启动6个终端机登录环境的进程,所以我们就会有6个终端机接口。你也可以减少啊!就是减少启动的终端机进程就好了。详细的资料可以先查阅/etc/inittab这个文件,将来我们在开机管理流程(第20章)会再仔细介绍的!
特殊的进程管理行为
以前的鸟哥笨笨的,总是以为使用 Windows 98 就可以啦!后来,因为工作的关系,需要使用Unix系统,想说我只要在工作机前面就好,才不要跑来跑去地到Unix工作站前面去呢!所以就使用Windows联到我的Unix工作站工作。我一个程序跑下来要2~3天,偏偏经常到了第2.5 天的时候,Windows 98 就死机了!当初真的是怕死了,
后来因为换了新计算机,用了 Windows 2000,这东西真不错(指对单用户而言),在死机的时候,它可以仅将错误的进程踢掉,而不干扰其他的进程进行,从此以后,就不用担心会死机了。不过,2000毕竟还不够好,因为有的时候还是会死机。
那么Linux会有这样的问题吗?老实说,Linux几乎可以说绝对不会死机的。因为它可以在任何时候,将某个被困住的进程杀掉,然后再重新执行该进程而不用重新启动。那么如果我在 Linux 下以命令行界面登录,在屏幕当中显示错误信息后就挂了,动都不能动,该如何是好?这个时候那默认的7个窗口就帮上忙啦!你可以随意再按[Alt]+[F1]~[F7]来切换到其他的终端机接口,然后以ps -aux找出刚才的错误进程,然后杀一下,回到刚才的终端机接口。又恢复正常了!
为什么可以这样做呢?我们刚才不是提过吗?每个进程之间可能是独立的,也可能有相依性,只要到独立的进程当中,删除有问题的那个进程,它就可以被系统删除掉啦!
bash 环境下的工作管理(job control)
我们在上一个小节有提到所谓的“父进程、子进程”的关系,那我们登录bash之后,就是取得一个名为bash的PID了,而在这个环境下面所执行的其他命令,就几乎都是所谓的子进程。那么,在这个单一的bash接口下,我可不可以进行多个工作啊?当然可以啦!可以“同时”进行。举例来说,我可以这样做:
[root@www ~]# cp file1 file2 &
在这一串命令中,重点在那个&的功能,它表示将 file1 这个文件复制为 file2,且放置于后台中执行,也就是说执行这一个命令之后,在这一个终端仍然可以做其他的工作。而当这一个命令(cp file1 file2)执行完毕之后,系统将会在你的终端显示完成的消息,很方便。
多用户、多任务的系统资源分配问题考虑
多用户、多任务确实有很多的好处,但其实也有管理上的困扰,因为用户越来越多,将导致你管理上的困扰。另外,由于用户多,当用户达到一定的人数后,通常你的机器便需要升级了,因为CPU的运算与RAM的大小可能就会不够使用!
举例来说,鸟哥之前的网站管理得不太好,因为使用了一个很复杂的人数统计程序,这个程序会一直去访问MySQL数据库的数据,偏偏因为流量大,造成MySQL很忙碌。在这样的情况下,当鸟哥要登录去写网页数据,或者要去使用讨论区的资源时,慢得很!实在是太慢了。后来终于将这个程序停止不用了,以自己写的一个小程序来替代,这才让 CPU 的负载(loading)整个降下来,用起来顺畅多了。
17.2 工作管理(job control)
这个工作管理(job control)是用在 bash 环境下的,也就是说:当我们登录系统取得 bash shell之后,在单一终端机下同时进行多个工作的行为管理。举例来说,我们在登录 bash 后,想要一边复制文件一边进行数据查找,一边进行编译,还可以一边进行vi程序编写。当然我们可以重复登录那6个命令行界面的终端机环境中,不过,能不能在一个bash内实现?当然可以,就是使用job control。
17.2.1 什么是工作管理
从上面的说明当中,你应该要了解的是:在进行工作管理的行为中,其实每个工作都是目前bash的子进程,即彼此之间是有相关性的。我们无法以job control的方式由tty1的环境去管理tty2的bash。这个概念请你先建立起来,待后续的范例介绍之后,你就会清楚了。
或许你会觉得很奇怪,既然我可以在6个终端接口登录,那何必使用job control呢?不要忘记了呢,我们可以在/etc/security/limits.conf(第14 章)里面设置用户同时可以登录的连接数,在这样的情况下,某些用户可能仅能以一个连接来工作呢!所以,你就得要了解一下这种工作管理的模式了!此外,这个章节内容也会牵涉到很多的数据流重定向,所以,如果忘记的话,务必回到第11章BASH Shell看一看。
由于假设我们只有一个终端,因此在可以出现提示符让你操作的环境就称为前台(foreground),至于其他工作就可以让你放入后台(background)去暂停或运行。要注意的是,放入后台的工作想要运行时,它必须不能够与用户互动。举例来说,vim 绝对不可能在后台里面执行(running)。因为你没有输入数据它就不会跑。而且放入后台的工作是不可以使用[ctrl]+c来终止的!
总之,要进行bash 的job control 必须要注意到的限制是:
这些工作所触发的进程必须来自于你shell的子进程(只管理自己的bash);
前台:你可以控制与执行命令的这个环境称为前台(foreground)的工作;
后台:可以自行运行的工作,你无法使用[ctrl]+c终止它,可使用bg/fg调用该工作;
后台中“执行”的进程不能等待terminal/shell的输入(input)。
接下来让我们实际来管理这些工作吧!
17.2.2 job control 的管理
如前所述,bash只能够管理自己的工作而不能管理其他bash的工作,所以即使你是root也不能够将别人的bash下面的job给他拿过来执行。此外,又分前台与后台,然后在后台里面的工作状态又可以分为“暂停”(stop)与“运行中”(running)。那实际进行job控制的命令有哪些?下面就来谈谈。
直接将命令丢到后台中“执行”的 &
如同前面提到的,我们在只有一个bash的环境下,如果想要同时进行多个工作,那么可以将某些工作直接丢到后台环境当中,让我们可以继续操作前台的工作。那么如何将工作丢到后台中?最简单的方法就是利用“&”。举个简单的例子,我们要将/etc/整个备份成为/tmp/etc.tar.gz且不想要等待,那么可以这样做:
[root@www ~]# tar -zpcf /tmp/etc.tar.gz /etc &
[1] 8400 <== [job number] PID
[root@www ~]# tar: Removing leading `/' from member names
在中括号内的号码为工作号码 (job number),该号码与 bash 的控制有关。
后续的 8400 则是这个工作在系统中的 PID。至于后续出现的数据是 tar 执行的数据流,
由于我们没有加上数据流重定向,所以会影响界面,不过不会影响前台的操作。
仔细瞧一瞧,我在输入一个命令后,在该命令的最后面加上一个“&”代表将该命令丢到后台中,此时 bash 会给予这个命令一个“工作号码”(job number),就是那个[1]。至于后面那个8400则是该命令所触发的“PID”了!而且,有趣的是,我们可以继续操作bash。很不赖吧!不过,那么丢到后台中的工作什么时候完成?完成的时候会显示什么?如果你输入几个命令后,突然出现这个数据:
[1]+ Done tar -zpcf /tmp/etc.tar.gz /etc
就代表[1]这个工作已经完成(Done),该工作的命令则是接在后面那一串命令行。这样了解了吧!另外,这个&代表“将工作丢到后台中去执行”。注意到那个“执行”的字。这样的情况最大的好处是不怕被[ctrl]+c 中断的。此外,将工作丢到后台当中要特别注意数据的流向,包括上面的信息就有出现错误信息,导致我的前台被影响。虽然只要按下[enter]就会出现提示符,但如果我将刚才那个命令改成:
[root@www ~]# tar -zpcvf /tmp/etc.tar.gz /etc &
情况会怎样?在后台当中执行的命令,如果有stdout及stderr时,它的数据依旧是输出到屏幕上面的,所以,我们会无法看到提示符,当然也就无法完好地掌握前台工作。同时由于是后台工作的tar,此时你怎么按下[ctrl]+c也无法停止屏幕被搞得花花绿绿的!所以,最佳的状况就是利用数据流重定向,将输出数据传送至某个文件中。举例来说,我可以这样做:
[root@www ~]# tar -zpcvf /tmp/etc.tar.gz /etc > /tmp/log.txt 2>&1 &
[1] 8429
[root@www ~]#
如此一来,输出的信息都传送到/tmp/log.txt 当中,当然就不会影响到我们前台的工作了。这样说,你应该可以更清楚数据流重定向的重要性了吧?
工作号码(job number) 只与您这个 bash 环境有关,但是它既然是个命令触发的,所以当然一定是一个进程,因此您会查看到有 job number 也搭配一个 PID !
将目前的工作丢到后台中“暂停”:[ctrl]-z
想个情况:如果我正在使用vi,却发现我有个文件不知道放在哪里,需要到bash环境下进行查找,此时是否要结束vi呢?当然不需要。只要暂时将vi给他丢到后台当中等待即可。例如以下的案例:
[root@www ~]# vi ~/.bashrc
在 vi 的一般模式下,按下 [ctrl]-z 这两个按键
[1]+ Stopped vim ~/.bashrc
[root@www ~]# <==顺利取得了前台的操控权!
[root@www ~]# find / -print
….(输出省略)….
此时屏幕会非常忙碌!因为屏幕上会显示所有的文件名。请按下 [ctrl]-z 暂停
[2]+ Stopped find / -print
在vi的一般模式下,按下[ctrl]及z这两个按键,屏幕上会出现[1],表示这是第一个工作,而那个+代表最近一个被丢进后台的工作,且目前在后台下默认会被取用的那个工作(与fg这个命令有关)。而那个Stopped则代表目前这个工作的状态。在默认的情况下,使用[ctrl]-z丢到后台当中的工作都是“暂停”的状态。
查看目前的后台工作状态:jobs
[root@www ~]# jobs [-lrs]
参数:
-l :除了列出job number与命令串之外,同时列出PID的号码;
-r :仅列出正在后台run的工作;
-s :仅列出正在后台当中暂停(stop)的工作。
范例一:查看目前的bash 当中,所有的工作,与对应的 PID
[root@www ~]# jobs -l
[1]- 10314 Stopped vim ~/bashrc
[2]+ 10833 Stopped find /-print
如果想要知道目前有多少的工作在后台当中,就用jobs这个命令吧!一般来说,直接执行 jobs即可。不过,如果你还想要知道该job number的PID号码,可以加上-l这个参数。在输出的信息当中,例如上文,仔细看到那个+-号。那个+代表默认的取用工作。所以说,如果目前我有两个工作在后台当中,两个工作都是暂停的,而如果我仅输入fg时,那么那个[2]所代表的工作会被拿到前台当中来处理”。
其实+代表最近被放到后台的工作号码,-代表最近最后第二个被放置到后台中的工作号码。而超过最后第三个以后的工作,就不会有+/-符号存在了!
将后台工作拿到前台来处理:fg
刚才提到的都是将工作丢到后台当中去执行的,那么有没有可以将后台工作拿到前台来处理的?有啊!就是那个fg(foreground)。举例来说,我们想要将上头范例当中的工作拿出来处理时:
[root@www ~]# fg %jobnumber
参数:
%jobnumber :jobnumber 为工作号码(数字)。注意,那个 % 是可有可无的!
范例一:先以 jobs 查看工作,再将工作取出:
[root@www ~]# jobs
[1]- 10314 Stopped vim ~/.bashrc
[2]+ 10833 Stopped find / -print
[root@www ~]# fg <==默认取出那个 + 的工作,即 [2]。立即按下[ctrl]-z
[root@www ~]# fg %1 <==直接规定取出的那个工作号码!再按下[ctrl]-z
[root@www ~]# jobs
[1]+ Stopped vim ~/.bashrca
[2]- Stopped find / -print
经过fg命令就能够将后台工作拿到前台来处理。不过比较有趣的是最后一个显示的结果,我们会发现+出现在第一个工作后!怎么会这样啊?这是因为你刚才利用 fg %1 将第一号工作放到前台后又放回后台,此时最后一个被放入后台的将变成vi那个命令操作,所以当然[1]后面就会出现+了。另外,如果输入“fg-”则代表将-号的那个工作号码拿出来,上面就是[2]-那个工作号码。
让工作在后台下的状态变成运行中:bg
我们刚才提到,那个[ctrl]-z 可以将目前的工作丢到后台下面去“暂停”,那么如何让一个工作在后台下面“Run”呢?我们可以在下面这个案例当中来测试。注意,下面的测试要进行得快一点!
范例一:一执行 find / -perm +7000 > /tmp/text.txt 后,立刻丢到后台去暂停!
[root@www ~]# find / -perm +7000 > /tmp/text.txt
此时,请立刻按下 [ctrl]-z 暂停!
[3]+ Stopped find / -perm +7000 > /tmp/text.txt
范例二:让该工作在后台下进行,并且查看它!!
[root@www ~]# jobs ; bg %3 ; jobs
[1]- Stopped vim ~/.bashrc
[2] Stopped find / -print
[3]+ Stopped find / -perm +7000 > /tmp/text.txt
[3]+ find / -perm +7000 > /tmp/text.txt & <==用 bg%3 的情况!
[1]+ Stopped vim ~/.bashrc
[2] Stopped find / -print
[3]- Running find / -perm +7000 > /tmp/text.txt &
看到哪里有区别吗?没错!就是那个状态栏,已经由Stopping变成了Running。看到区别没?命令行最后方多了一个&的符号。代表该工作被启动在后台当中了啦!
管理后台当中的工作:kill
刚才我们可以让一个已经在后台当中的工作继续工作,也可以让该工作以fg拿到前台来,那么,如果想要将该工作直接删除呢?或者是将该工作重新启动呢?这个时候就得需要给予该工作一个信号(signal),让它知道该怎么做才好啊!此时,kill这个命令就派上用场啦!
[root@www ~]# kill -signal %jobnumber
[root@www ~]# kill -l
参数:
-l :这个是 L 的小写,列出目前 kill 能够使用的信号(signal) 有哪些
signal :代表给予后面接的那个工作什么样的指示。用 man 7 signal 可知:
-1 :重新读取一次参数的配置文件 (类似 reload);
-2 :代表与由键盘输入 [ctrl]-c 同样的操作;
-9 :立刻强制删除一个工作;
-15:以正常的程序方式终止一项工作。与 -9 是不一样的。
范例一:找出目前的 bash 环境下的后台工作,并将该工作“强制删除”。
[root@www ~]# jobs
[1]+ Stopped vim ~/.bashrc
[2] Stopped find / -print
[root@www ~]# kill -9 %2; jobs
[1]+ Stopped vim ~/.bashrc
[2] Killed find / -print
再过几秒你再执行 jobs 一次,就会发现 2 号工作不见了!因为被删除了!
范例:找出目前的 bash 环境下的后台工作,并将该工作“正常终止”掉。
[root@www ~]# jobs
[1]+ Stopped vim ~/.bashrc
[root@www ~]# kill -SIGTERM %1
-SIGTERM 与 -15 是一样的!你可以使用 kill -l 来查阅!
特别留意一下,-9通常是在强制删除一个不正常的工作时所使用的,-15则是以正常步骤结束一项工作(15 也是默认值),两者之间并不相同呦!举上面的例子来说,我用 vi 的时候,不是会产生一个.filename.swp的文件吗?那么,当使用-15时,vi会尝试以正常的步骤来结束掉该vi的工作,所以.filename.swp会主动被删除。但若是使用-9时,由于该vi工作会被强制删除掉,因此,filename.swp 就会继续存在文件系统当中。这样你应该可以稍微分辨一下了吧?
其实,kill 命令的妙用是很无穷的。它搭配 signal 所详列的信息(用 man 7 signal 去查阅相关资料)可以让你有效地管理工作与进程(Process),此外,那个killall也是同样的用法。至于常用的signal你至少需要了解1,9,15这三个signal的意义才好。此外,signal除了以数值来表示之外,也可以使用信号名称。举例来说,上面的范例二就是一个例子。至于signalnumber与名称的对应,使用 kill -l 就知道啦(L 的小写)!
另外,kill后面接的数字默认会是PID,如果想要管理bash的工作控制,就得要加上%数字了,这点也得特别留意才行。
17.2.3 脱机管理问题
要注意的是,我们在工作管理当中提到的“后台”指的是在终端机模式下可以避免[crtl]-c中断的一个情境,并不是放到系统的后台去。所以,工作管理的后台依旧与终端机有关。在这样的情况下,如果你是以远程连接方式连接到你的Linux主机,并且将工作以&的方式放到后台去,请问,在工作尚未结束的情况下你脱机了,该工作还会继续进行吗?答案是“否”,不会继续进行,而是会被中断掉。
那怎么办?如果我的工作需要进行一大段时间,我又不能放置在后台下面,那该如何处理呢?首先,你可以参考前一章的at来处理即可!因为at是将工作放置到系统后台,而与终端机无关。如果不想要使用at的话,那你也可以尝试使用nohup这个命令来处理。这个nohup可以让你在脱机或注销系统后,还能够让工作继续进行。它的语法有点像这样:
[root@www ~]# nohup [命令与参数] <==在终端机前台中工作
[root@www ~]# nohup [命令与参数] & <==在终端机后台中工作
好简单的命令吧?上述命令需要注意的是,nohup 并不支持 bash 内置的命令,因此你的命令必须要是外部命令才行。我们来尝试玩一下下面的任务吧!
1. 先编辑一个会“睡着 500 秒”的程序:
[root@www ~]# vim sleep500.sh
!/bin/bash
/bin/sleep 500s
/bin/echo "I have slept 500 seconds."
2. 丢到后台中去执行,并且立刻注销系统:
[root@www ~]# chmod a+x sleep500.sh
[root@www ~]# nohup ./sleep500.sh &
[1] 5074
[root@www ~]# nohup: appending output to ‘nohup.out’ <==会告知这个信息!
[root@www ~]#exit
如果你再次登录的话,再使用 ps -l 去查看你的进程,会发现 sleep500.sh 还在执行中,并不会被中断掉,这样了解意思了吗?由于我们的进程最后会输出一个信息,但是nohup与终端机其实无关了,因此这个信息的输出就会被定向“~/nohup.out”,所以你才会看到上述命令中,当你输入nohup后,会出现那个提示信息。
如果你想要让在后台的工作在你注销后还能够继续执行,那么使用nohup搭配&是不错的运行情境,可以参考看看!
17.3 进程管理
本章一开始就提到所谓的“进程”的概念,包括进程的触发、子进程与父进程的相关性等,此外,还有那个“进程的相依性”以及所谓的“僵尸进程”等需要说明的呢!为什么进程管理这么重要呢?这是因为:
首先,本章一开始就谈到的,我们在操作系统时的各项工作其实都是经过某个PID来达成的(包括你的bash环境),因此,能不能进行某项工作就与该进程的权限有关了。
再来,如果你的Linux系统是个很忙碌的系统,那么当整个系统资源快要被使用光时,你是否能够找出最耗系统的那个进程,然后删除该进程,让系统恢复正常呢?
此外,如果由于某个程序写得不好,导致产生一个有问题的进程在内存当中,你又该如何找出它,然后将它删除呢?
如果同时有五六项工作在你的系统当中运行,但其中有一项工作才是最重要的,该如何让那一项重要的工作被最优先执行呢?
所以,一个称职的系统管理员,必须要熟悉进程的管理流程才行,否则当系统发生问题时,还真是很难解决问题呢!下面我们会先介绍如何查看程序与程序的状态,然后再加以过程控制。
17.3.1 进程的查看
既然进程这么重要,那么我们如何查阅系统上面正在运行当中的进程呢?很简单啊!利用静态的ps或者是动态的top,还能以pstree来查阅程序树之间的关系。
ps:将某个时间点的进程运行情况选取下来
[root@www ~]# ps aux <==查看系统所有的进程数据
[root@www ~]# ps -lA <==也是能够查看所有系统的数据
[root@www ~]# ps axjf <==连同部分进程树状态
参数:
-A :所有的进程均显示出来,与 -e 具有同样的作用;
-a :不与 terminal 有关的所有进程;
-u :有效用户(effective user)相关的进程;
x :通常与 a 这个参数一起使用,可列出较完整信息。
输出格式规划:
l :较长、较详细地将该 PID 的的信息列出;
j :工作的格式 (jobs format);
-f :做一个更为完整的输出。
鸟哥个人认为 ps 这个命令的 man page 不是很好查阅,因为很多不同的 Unix 都使用这个 ps来查阅进程状态,为了要符合不同版本的需求,所以这个 man page 写得非常庞大。因此,通常鸟哥都会建议你,直接背两个比较不同的参数,一个是只能查阅自己bash 程序的“ps -l”一个则是可以查看所有系统运行的程序“ps aux!注意,你没看错,是“ps aux”,没有那个减号(-)!先来看看关于自己bash进程状态的查看。
仅查看自己的bash相关进程:ps-l
范例一:将目前属于你自己这次登录的 PID 与相关信息列出来(只与自己的 bash 有关)
[root@www ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 13639 13637 0 75 0 - 1287 wait pts/1 00:00:00 bash
4 R 0 13700 13639 0 77 0 - 1101 - pts/1 00:00:00 ps
系统整体的进程运行是非常多的,但如果使用 ps -l 则仅列出与你的操作环境(bash)有关的进程而已,即最上层的父进程会是你自己的 bash 而没有扩展到 init 这个进程去,那么 ps -l显示出来的数据有哪些呢?我们就来查看一下:
F:代表这个进程标志(process flags),说明这个进程的权限,常见号码有:
¬ 若为 4 表示此进程的权限为 root;
¬ 若为 1 则表示此子进程仅可进行复制(fork)而无法实际执行(exec)。
S:代表这个进程的状态(STAT),主要的状态有:
¬ R(Running):该进程正在运行中;
¬ S(Sleep):该进程目前正在睡眠状态(idle),但可以被唤醒(signal);
¬ D:不可被唤醒的睡眠状态,通常这个进程可能在等待 I/O 的情况(ex>打印);
¬ T:停止状态(stop),可能是在工作控制(后台暂停)或除错(traced)状态;
¬ Z(Zombie):“僵尸”状态,进程已经终止但却无法被删除至内存外。
UID/PID/PPID:代表此进程被该UID所拥有/进程的PID号码/此进程的父进程PID号码。
C:代表CPU使用率,单位为百分比。
PRI/NI:Priority/Nice的缩写,代表此进程被CPU所执行的优先级,数值越小代表该进程越快被CPU执行。详细的PRI与NI将在下一小节说明。
ADDR/SZ/WCHAN:都与内存有关,ADDR 是 kernel function,指出该进程在内存的哪个部分,如果是个running的进程,一般就会显示“-”。SZ代表此进程用掉多少内存/WCHAN表示目前进程是否运行中,同样,若为-表示正在运行中。
TTY:登录者的终端机位置,若为远程登录则使用动态终端接口(pts/n)。
TIME:使用掉的CPU时间,注意,是此进程实际花费CPU运行的时间,而不是系统时间。
CMD:就是command的缩写,造成此程序的触发进程的命令为何。
所以你看到的 ps -l 输出信息中,它说明的是 bash 的程序属于 UID 为 0 的用户,状态为睡眠(sleep),之所以为睡眠因为它触发了ps(状态为run)之故。此进程的PID为13639,优先执行顺序为75,执行bash所取得的终端接口为pts/1,运行状态为等待(wait)。这样已经够清楚了吧?你自己尝试解析一下ps那一行代表的意义为何?
接下来让我们使用ps来查看一下系统内所有的进程状态吧!
查看系统所有进程:psaux
范例二:列出目前所有的正在内存当中的进程:
[root@www ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 2064 616 ? Ss Mar11 0:01 init [5]
root 2 0.0 0.0 0 0 ? S< Mar11 0:00 [migration/0]
root 3 0.0 0.0 0 0 ? SN Mar11 0:00 [ksoftirqd/0]
…(中间省略)…
root 13639 0.0 0.2 5148 1508 pts/1 Ss 11:44 0:00 -bash
root 14232 0.0 0.1 4452 876 pts/1 R+ 15:52 0:00 ps aux
root 18593 0.0 0.0 2240 476 ? Ss Mar14 0:00 /usr/sbin/atd
你会发现 ps -l 与 ps aux 显示的项目并不相同!在 ps aux 显示的项目中,各字段的意义为:
USER:该进程属于那个用户账号的;
PID:该进程的进程标识符;
%CPU:该进程使用掉的CPU资源百分比;
%MEM:该进程所占用的物理内存百分比;
VSZ:该进程使用掉的虚拟内存量(KB);
RSS:该进程占用的固定的内存量(KB);
TTY:该进程是在那个终端机上面运行,若与终端机无关则显示?另外,tty1~tty6 是本机上面的登录者程序,若为pts/0等的,则表示为由网络连接进主机的进程;
STAT:该进程目前的状态,状态显示与 ps -l 的 S 标识相同(R/S/T/Z);
START:该进程被触发启动的时间;
TIME:该进程实际使用CPU运行的时间;
COMMAND:该进程的实际命令。
一般来说,ps aux 会依照 PID 的顺序来排序显示,我们还是以 13639那个 PID 那行来说明!该行的意义为root执行的bashPID为13639,占用了0.2%的内存容量百分比,状态为休眠(S),该程序启动的时间为 11:44,且取得的终端机环境为 pts/1。它与 ps aux 看到的其实是同一个进程。这样可以理解吗?让我们继续使用ps来查看一下其他的信息吧!
范例三:以范例一的显示内容,显示出所有的进程:
[root@www ~]# ps -lA
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 1 0 0 76 0 - 435 - ? 00:00:01 init
1 S 0 2 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd/0
1 S 0 3 1 0 70 -5 - 0 worker ? 00:00:00 events/0
…(以下省略)…
你会发现每个字段与 ps -l 的输出情况相同,但显示的进程则包括系统所有的进程。
范例四:列出类似进程树的程序显示:
[root@www ~]# ps axjf
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
0 1 1 1 ? -1 Ss 0 0:01 init [5]
…(中间省略)…
1 4586 4586 4586 ? -1 Ss 0 0:00 /usr/sbin/sshd
4586 13637 13637 13637 ? -1 Ss 0 0:00 _ sshd: root@pts/1
13637 13639 13639 13639 pts/1 14266 Ss 0 0:00 _ -bash
13639 14266 14266 13639 pts/1 14266 R+ 0 0:00 _ ps axjf
…(后面省略)…
看出来了吧?其实鸟哥在进行一些测试时,都是以一些联机的主机来测试的,所以,你会发现其实进程之间是有相关性的。不过,其实还可以使用pstree来达成这个进程树。以上面的例子来看,鸟哥是通过sshd提供的网络服务取得一个进程,该进程提供bash给我使用,而我通过 bash 再去执行 ps axjf!这样可以看得懂了吗?其他各字段的意义请 man ps(虽然真的很难找出来!)。
范例五:找出与 cron 与 syslog 这两个服务有关的 PID 号码
[root@www ~]# ps aux | egrep '(cron|syslog)'
root 4286 0.0 0.0 1720 572 ? Ss Mar11 0:00 syslogd -m 0
root 4661 0.0 0.1 5500 1192 ? Ss Mar11 0:00 crond
root 14286 0.0 0.0 4116 592 pts/1 R+ 16:15 0:00 egrep (cron|syslog)
所以号码是 4286 及 4661 这两个,就是这样找的啦!
除此之外,我们必须要知道的是“僵尸”(zombie)进程是什么?通常,造成僵尸进程的成因是因为该进程应该已经执行完毕,或者是因故应该要终止了,但是该进程的父进程却无法完整将该进程结束掉,而造成那个进程一直存在内存当中。如果你发现在某个进程的 CMD 后面还接上<defunct>时,就代表该进程是僵尸进程,例如:
apache 8683 0.0 0.9 83384 9992 ? Z 14:33 0:00 /usr/sbin/httpd <defunct>
当系统不稳定的时候就容易造成所谓的僵尸进程,可能是因为程序写得不好啦,或者是用户的操作习惯不良等所造成。如果你发现系统中很多僵尸进程时,记得啊!要找出该进程的父进程,然后好好做个跟踪,好好进行主机的环境优化。看看有什么地方需要改善的,不要只是直接将它杀掉而已呢!不然的话,万一它一直产生,那可就麻烦了!
事实上,通常僵尸进程都已经无法控管,而直接是交给init这个程序来负责了,偏偏init是系统第一个执行的程序,它是所有进程的父进程!我们无法杀掉该进程(杀掉它,系统就死掉了),所以,如果产生僵尸进程,而系统过一阵子还没有办法通过内核非经常性的特殊处理来将该进程删除时,那你只好通过reboot的方式来将该进程抹去了!
top:动态查看进程的变化
相对于ps是选取一个时间点的进程状态,top则可以持续检测进程运行的状态。使用方式如下:
[root@www ~]# top [-d 数字] | top [-bnp]
参数:
-d :后面可以接秒数,就是整个进程界面更新的秒数。默认是 5 秒。
-b :以批次的方式执行 top,还有更多的参数可以使用。
通常会搭配数据流重定向来将批处理的结果输出成为文件。
-n :与 -b 搭配,意义是,需要进行几次 top 的输出结果。
-p :指定某些个 PID 来进行查看监测而已。
在 top 执行过程当中可以使用的按键命令:
? :显示在 top 当中可以输入的按键命令;
P :以 CPU 的使用资源排序显示;
M :以内存的使用资源排序显示;
N :以 PID 来排序;
T :由该进程使用的 CPU 时间累积 (TIME+)排序;
k :给予某个 PID 一个信号 (signal);
r :给予某个 PID 重新制定一个 nice 值;
q :离开 top 软件的按键。
其实top的功能非常多,可以用的按键也非常多。可以参考man top的内部说明文件。鸟哥这里仅是列出一些鸟哥自己常用的参数而已。接下来让我们实际查看一下如何使用top 与top的界面。
范例一:每两秒钟更新一次 top ,查看整体信息:
[root@www ~]# top -d 2
top - 17:03:09 up 7 days, 16:16, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 80 total, 1 running, 79 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.5%us, 0.5%sy, 0.0%ni, 99.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 742664k total, 681672k used, 60992k free, 125336k buffers
Swap: 1020088k total, 28k used, 1020060k free, 311156k cached
<==如果加入 k 或 r 时,就会有相关的字样出现在这里喔!
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
14398 root 15 0 2188 1012 816 R 0.5 0.1 0:00.05 top
1 root 15 0 2064 616 528 S 0.0 0.1 0:01.38 init
2 root RT -5 0 0 0 S 0.0 0.0 0:00.00 migration/0
3 root 34 19 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0
top 也是个挺不错的程序查看工具!但不同于 ps 是静态的结果输出,top 这个程序可以持续监测整个系统的进程工作状态。在默认的情况下,每次更新进程资源的时间为 5 秒,不过,可以使用-d 来进行修改。top 主要分为两个界面,上面的界面为整个系统的资源使用状态,基本上总共有六行,显示的内容依序是:
第一行(top…):这一行显示的信息分别为:
目前的时间,即是17:03:09那个选项;
开机到目前为止所经过的时间,即是up7days,16:16那个选项;
已经登录系统的用户人数,亦即是1user选项;
系统在1,5,15分钟的平均工作负载。我们在第16章谈到的batch工作方式为负载小于0.8就是这个负载。代表的是1,5,15分钟,系统平均要负责运行几个进程(工作)的意思。越小代表系统越闲置,若高于1得要注意你的系统压力是否太过繁复了!
第二行( Tasks… ):显示的是目前进程的总量与个别进程在什么状态( running,sleeping,stopped,zombie)。比较需要注意的是最后的zombie那个数值,如果不是0,好好看看到底是哪个process变成僵尸了吧!
第三行(Cpus…):显示的是CPU的整体负载,每个选项可使用?查阅。需要特别注意的是%wa,那个选项代表的是I/Owait,通常你的系统会变慢都是I/O产生的问题比较大!因此这里得要注意这个选项耗用 CPU 的资源。另外,如果是多内核的设备,可以按下数字键“1”来切换成不同CPU的负载率。
第四行与第五行:表示目前的物理内存与虚拟内存(Mem/Swap)的使用情况。再次重申,要注意的是swap的使用量要尽量少!如果swap被大量使用,表示系统的物理内存实在不足!
第六行:这个是当在top进程当中输入命令时显示状态的地方。
至于top下半部分的界面,则是每个进程使用的资源情况。比较需要注意的是:
PID:每个进程的ID;
USER:该进程所属的用户;
PR:Priority的简写,进程的优先执行顺序,越小越早被执行;
NI:Nice的简写,与Priority有关,也是越小越早被执行;
%CPU:CPU的使用率;
%MEM:内存的使用率;
TIME+:CPU使用时间的累加。
top默认使用CPU使用率(%CPU)作为排序的重点,如果你想要使用内存使用率排序,则可以按下“M”,若要恢复则按下“P”即可。如果想要离开top则按下“q”吧!如果你想要将top的结果输出成为文件时,可以这样做:
范例二:将 top 的信息进行 2 次,然后将结果输出到 /tmp/top.txt
[root@www ~]# top -b -n 2 > /tmp/top.txt
这样一来,嘿嘿!就可以将top的信息存到/tmp/top.txt文件中了。
这玩意儿很有趣!可以帮助你将某个时段top查看到的结果存成文件,可以用在你想要在系统后台下面执行。由于是后台下面执行,与终端机的屏幕大小无关,因此可以得到全部的进程界面。那如果你想要查看的进程CPU与内存使用率都很低,结果老是无法在第一行显示时,该怎办?我们可以仅查看单一进程。如下所示:
范例三:我们自己的 bash PID 可由 $$ 变量取得,请使用 top 持续查看该 PID
[root@www ~]# echo $$
13639 <==就是这个数字!它是我们 bash 的 PID
[root@www ~]# top -d 2 -p 13639
top - 17:31:56 up 7 days, 16:45, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 742664k total, 682540k used, 60124k free, 126548k buffers
Swap: 1020088k total, 28k used, 1020060k free, 311276k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
13639 root 15 0 5148 1508 1220 S 0.0 0.2 0:00.18 bash
看到没?就只会有一个进程给你看,很容易查看吧!好,那么如果我想要在top下面进行一些操作呢?例如,修改NI这个数值呢?可以这样做:
范例四:承上题,上面的 NI 值是 0 ,想要改成10的话呢?
在范例三的 top 界面当中直接按下 r 之后,会出现如下的图样!
top - 17:34:24 up 7 days, 16:47, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni, 99.5%id, 0.0%wa, 0.0%hi, 0.5%si, 0.0%st
Mem: 742664k total, 682540k used, 60124k free, 126636k buffers
Swap: 1020088k total, 28k used, 1020060k free, 311276k cached
PID to renice: 13639 <==按下 r 然后输入这个 PID 号码
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
13639 root 15 0 5148 1508 1220 S 0.0 0.2 0:00.18 bash
在你完成上面的操作后,在状态栏会出现如下的信息:
Renice PID 13639 to value: 10 <==这是 nice 值
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
接下来你就会看到如下的显示界面!
top - 17:38:58 up 7 days, 16:52, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 742664k total, 682540k used, 60124k free, 126648k buffers
Swap: 1020088k total, 28k used, 1020060k free, 311276k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
13639 root 26 10 5148 1508 1220 S 0.0 0.2 0:00.18 bash
看到不同处了吧?底线的地方就是修改了之后所产生的效果。一般来说,如果鸟哥想要找出最损耗CPU资源的那个进程时,大多使用的就是top这个程序,然后强制以CPU使用资源来排序(在top当中按下P即可),就可以很快知道。
pstree
[root@www ~]# pstree [-A|U] [-up]
参数:
-A :各进程树之间的连接以 ASCII 字符来连接;
-U :各进程树之间的连接以utf8码的字符来连接,在某些终端接口下可能会有错误;
-p :同时列出每个进程的PID;
-u :同时列出每个进程的所属账号名称。
范例一:列出目前系统上面所有的进程树的相关性:
[root@www ~]# pstree -A
init-+-acpid
|-atd
|-auditd-+-audispd—-{audispd} <==这行与下面一行为 auditd 分出来的子进程
| `-{auditd}
|-automount—-4*[{automount}] <==默认情况下,相似的进程会以数字显示
…(中间省略)…
|-sshd—-sshd—-bash—-pstree <==就是我们命令执行的那个相依性!
…(下面省略)…
注意一下,为了节省版面,所以鸟哥已经删去很多进程了!
范例二:承上题,同时显示出 PID 与 users
[root@www ~]# pstree -Aup
init(1)-+-acpid(4555)
|-atd(18593)
|-auditd(4256)-+-audispd(4258)—-{audispd}(4261)
| `-{auditd}(4257)
|-automount(4536)-+-{automount}(4537) <==进程相似但 PID 不同!
| |-{automount}(4538)
| |-{automount}(4541)
| `-{automount}(4544)
…(中间省略)…
|-sshd(4586)—-sshd(16903)—-bash(16905)—-pstree(16967)
…(中间省略)…
|-xfs(4692,xfs) <==因为此进程所有者并非执行 pstree 者,所以列出账号
…(下面省略)…
在括号 () 内的即是 PID 以及该进程的 owner 。不过,由于我是使用
root 的身份执行此一命令,所以属于 root 的进程就不会显示出来啦!
如果要找进程之间的相关性,这个pstree真是好用。直接输入pstree可以查到进程相关性,如上所示,还会使用线段将相关性进程连接起来。一般连接符号可以使用 ASCII 码即可,但有时因为语系问题会主动以Unicode的符号来链接,但因为可能终端机无法支持该编码,或许会造成乱码问题。因此可以加上-A参数来克服此类线段乱码问题。
由pstree的输出我们也可以很清楚地知道,所有的进程都是依附在init这个进程下面的。仔细看一下,这个进程的PID是1号喔!因为它是由Linux内核所主动调用的第一个进程!所以PID就是1号了。这也是我们刚才提到僵尸进程时有提到,为什么发生僵尸进程需要重新启动,因为init要重新启动,而重新启动init就是reboot。
如果还想要知道PID与所属用户,加上-u及-p两个参数即可。我们前面不是一直提到,如果子进程挂点或者是老是杀不掉子进程时,该如何找到父进程吗?用这个pstree就对了!
17.3.2 进程的管理
进程之间是可以互相控制的!举例来说,你可以关闭、重新启动服务器软件,服务器软件本身是个程序,你既然可以让它关闭或启动,当然就是可以控制该程序啦!那么程序是如何互相管理的呢?其实是通过给予该进程一个信号(signal)去告知该进程你想要让它做什么!因此这个信号就很重要啦!
我们也在本章之前的bash工作管理当中提到过,要给予某个已经存在后台中的工作某些操作时,是直接给予一个信号给该工作号码即可。那么到底有多少 signal 呢?你可以使用 kill -l(小写的 L)或者是 man7 signal 都可以查询到!主要的信号代号与名称对应及内容如表 17-1 所示。
表17-1
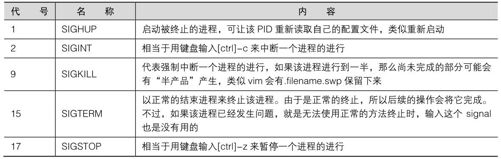
上面仅是常见的 signal 而已,更多的信号信息请自行 man7 signal 吧!一般来说,你只要记得“1,9,15”这三个号码的意义即可。那么我们如何传送一个信号给某个进程呢?就通过kill或killall。下面分别来看看:
kill -signal PID
kill 可以帮我们将这个 signal 传送给某个工作(%jobnumber)或者是某个 PID(直接输入数字)。要再次强调的是:kill后面直接加数字与加上%number的情况是不同的!这个很重要。因为工作控制中有 1 号工作,但是 PID 1 号则是专指“init”这个进程。你怎么可以将 init 关闭呢?关闭 init,你的系统就死掉了啊!所以记得那个%是专门用在工作控制的。我们就活用一下kill与刚才上面提到的ps来做个简单的练习吧!

以ps找出syslog这个进程的PID后,再使用kill传送信息,使得syslog可以重新读取配置文件。
答:由于需要重新读取配置文件,因此signal是1号。至于找出syslog的PID可以是这样做:
ps aux | grep 'syslog' | grep -v 'grep'| awk '{print $2}'
接下来则是实际使用 kill -1PID,因此,整串命令会是这样:
kill -SIGHUP $(ps aux|grep 'syslog'|grep -v 'grep'|awk '{print $2}')
如果要确认有没有重新启动syslog,可以参考日志文件的内容,使用如下命令查阅:
tail -5 /var/log/messages
如果你有看到类似“Mar19 15:08:20 www syslogd 1.4.1: restart”之类的字样,就是表示 syslogd在3/19有重新启动(restart)过了!
了解了这个用法以后,如果将来你想要将某个莫名其妙的登录者的连接删除的话,就可以通过使用 pstree -p 找到相关进程,然后再以 kill -9 将该进程删除,该连接就会被踢掉了!这样很简单吧!
killall -signal 命令名称
由于 kill 后面必须要加上 PID(或者是 job number),所以,通常 kill 都会配合 ps,pstree 等命令,因为我们必须要找到相对应的那个进程的 ID。但是,如此一来,很麻烦,有没有可以利用“执行命令的名称”来给予信号的?举例来说,能不能直接将 syslog 这个进程给予一个SIGHUP 的信号呢?可以的!用 kill all 吧!
[root@www ~]# killall [-iIe] [command name]
参数:
-i :interactive 的意思,交互式的,若需要删除时,会出现提示符给用户;
-e :exact 的意思,表示后面接的 command name 要一致,但整个完整的命令
不能超过 15 个字符。
-I :命令名称(可能含参数)忽略大小写。
范例一:给予 syslogd 这个命令启动的 PID 一个 SIGHUP 的信号
[root@www ~]# killall -1 syslogd
如果用 ps aux 仔细看一下,syslogd 才是完整的命令名称。但若包含整个参数,
则 syslogd -m 0 才是完整的呢!
范例二:强制终止所有以 httpd 启动的进程
[root@www ~]# killall -9 httpd
范例三:依次询问每个 bash 进程是否需要被终止运行!
[root@www ~]# killall -i -9 bash
Kill bash(16905) ? (y/N) n <==这个不杀!
Kill bash(17351) ? (y/N) y <==这个杀掉!
具有互动的功能!可以询问你是否要删除 bash 这个进程。要注意,若没有 -i 的参数,
所有的 bash 都会被这个 root 给杀掉!包括 root 自己的 bash 。
总之,要删除某个进程,我们可以使用PID或者是启动该进程的命令名称,而如果要删除某个服务呢?最简单的方法就是利用killall,因为它可以将系统当中所有以某个命令名称启动的进程全部删除。举例来说,上面的范例二当中,系统内所有以httpd启动的进程,就会全部被删除。
17.3.3 关于进程的执行顺序
我们知道Linux是多用户、多任务的环境,由top的输出结果我们也发现,系统同时间有非常多的进程在运行中,只是绝大部分的进程都在休眠(sleeping)状态而已。想一想,如果所有的进程同时被唤醒,那么CPU应该要先处理哪个进程呢?也就是说,哪个进程被执行的优先序比较高?这就得要考虑到程序的优先执行序(Priority)与CPU调度。
CPU 调度与前一章的例行性工作调度并不一样。 CPU 调度指的是每个程序被 CPU运行的演算规则,而例行性工作调度则是将某个程序安排在某个时间再交由系统执行。CPU 调度与操作系统较具有相关性!
Priority与Nice值
我们知道CPU一秒钟可以运行多达数G的微命令次数,通过内核的CPU调度可以让各进程被CPU所切换运行,因此每个进程在一秒钟内或多或少都会被CPU执行部分的脚本。如果进程都是集中在一个队列中等待CPU的运行,而不具有优先级之分,也就是像我们去游乐场玩热门游戏需要排队一样,每个人都是照顺序来,你玩过一遍后还想再玩(没有执行完毕),请到后面继续排队等待。情况有点像下面这样:
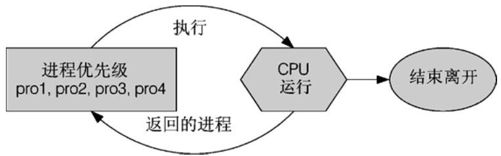
图17-5 并没有优先级的进程队列示意图
图17-5中假设pro1,pro2是紧急的进程,pro3,pro4是一般的进程,在这样的环境中,由于不具有优先级,pro1,pro2还是得要继续等待而没有优先权呢!如果pro3,pro4的工作“又臭又长”,那么紧急的pro1,pro2就得要等待老半天才能够完成。所以,我们想要将进程分优先级啦!如果优先序较高则运行次数可以较多次,而不需要与较慢优先的进程抢位置!我们可以将进程的优先级与CPU调度进行如图17-6所示的解释。
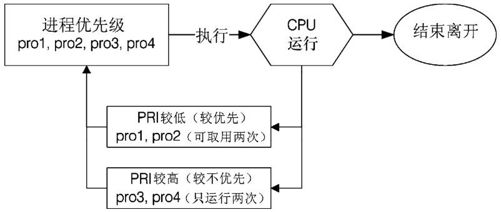
图17-6 具有优先级的进程队列示意图
如上图所示,具高优先级的pro1,pro2可以被取用两次,而较不重要的pro3,pro4则运行次数较少。如此一来pro1,pro2就可以较快被完成。要注意,上图仅是示意图,并非较优先者一定会被运行两次。为了要达到上述的功能,我们 Linux 给予进程一个所谓的“优先执行序”(priority,PRI),这个PRI值越低代表越优先的意思。不过这个PRI值是由内核动态调整的,用户无法直接调整PRI值的。先来瞧瞧PRI曾在哪里出现!
[root@www ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 18625 18623 2 75 0 - 1514 wait pts/1 00:00:00 bash
4 R 0 18653 18625 0 77 0 - 1102 - pts/1 00:00:00 ps
由于PRI是内核动态调整的,我们用户也无权去干涉PRI。那如果你想要调整进程的优先执行序时,就得要通过Nice值了!Nice值就是上面的NI。一般来说,PRI与NI的相关性如下:
PRI(new) = PRI(old) + nice
不过你要特别留意到,如果原本的PRI是50,并不是我们给予一个nice=5,就会让PRI变成55。因为PRI是系统“动态”决定的,所以,虽然nice值是可以影响PRI,不过,最终的PRI仍是要经过系统分析后才会决定的。另外,nice值是有正负的,而既然PRI越小越早被执行,所以,当nice值为负值时,那么该程序就会降低PRI值,即会变得较优先被处理。此外,你必须要留意到:
nice值可调整的范围为-20~19;
root可随意调整自己或他人进程的Nice值,且范围为-20~19;
一般用户仅可调整自己进程的Nice值,且范围仅为0~19(避免一般用户抢占系统资源);
一般用户仅可将nice值越调越高,例如本来nice为5,则将来仅能调整到大于5;
这也就是说,要调整某个进程的优先执行序,就是调整该进程的nice值。那么如何给予某个进程nice值呢?有两种方式,分别是:
一开始执行程序就立即给予一个特定的nice值:用nice命令;
调整某个已经存在的PID的nice值:用renice命令。
nice:新执行的命令即给予新的nice值
[root@www ~]# nice [-n 数字] command
参数:
-n :后面接一个数值,数值的范围为-20 ~ 19。
范例一:用 root 给一个 nice 值为-5 ,用于执行 vi ,并查看该进程!
[root@www ~]# nice -n -5 vi &
[1] 18676
[root@www ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 18625 18623 0 75 0 - 1514 wait pts/1 00:00:00 bash
4 T 0 18676 18625 0 72 -5 - 1242 finish pts/1 00:00:00 vi
4 R 0 18678 18625 0 77 0 - 1101 - pts/1 00:00:00 ps
原本的 bash PRI 为 75 ,所以 vi 默认应为 75。不过由于给予 nice 为 -5 ,
因此 vi 的 PRI 降低了!但并非降低到 70 ,因为内核还会动态调整!
[root@www ~]# kill -9 %1 <==测试完毕将 vi关闭
就如同前面说的,nice 是用来调整进程的执行优先级!这里只是一个执行的范例罢了!通常什么时候要将nice值调大呢?举例来说,系统的后台工作中,某些比较不重要的进程在运行,例如备份工作,由于备份工作相当耗系统资源,这个时候就可以将备份的命令的nice值调大一些,可以使系统的资源分配得更为公平!
renice:已存在进程的nice重新调整
[root@www~]#renice[number]PID
参数:
PID:某个进程的ID啊!
范例一:找出自己的bashPID,并将该PID的nice调整到10
[root@www~]#ps-l
FS UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 18625 18623 0 75 0 - 1514 wait pts/1 00:00:00 bash
4 R 0 18712 18625 0 77 0 - 1102 - pts/1 00:00:00 ps
[root@www ~]# renice 10 18625
18625: old priority 0, new priority 10
[root@www ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 18625 18623 0 85 10 - 1514 wait pts/1 00:00:00 bash
4 R 0 18715 18625 0 87 10 - 1102 - pts/1 00:00:00 ps
如果要调整的是已经存在的某个进程的话,那么就得要使用renice了。使用的方法很简单, renice后面接上数值及PID即可。因为后面接的是PID,所以你务必要以ps或者其他进程查看的命令去找出PID才行啊!
由上面这个范例当中我们也看得出来,虽然修改的是 bash 那个进程,但是该进程所触发的ps命令当中的nice也会继承而为10。整个nice值是可以在父进程→子进程之间传递呢!另外,除了renice之外,其实那个top同样也是可以调整nice值的!
17.3.4 系统资源的查看
除了系统的进程之外,我们还必须就系统的一些资源进行检查。举例来说,我们使用top可以看到很多系统的资源对吧?么,还有没有其他的工具可以查阅的?当然有啊!下面这些工具命令可以玩一玩!
free:查看内存使用情况
[root@www ~]# free [-b|-k|-m|-g] [-t]
参数:
-b :直接输入 free 时,显示的单位是 KB我们可以使用 b(bytes), m(MB,
k(KB,, 及 g(GB,来显示单位。
-t :在输出的最终结果中显示物理内存与 swap 的总量。
范例一:显示目前系统的内存容量
[root@www ~]# free -m
total used free shared buffers cached
Mem: 725 666 59 0 132 287
-/+ buffers/cache: 245 479
Swap: 996 0 996
仔细看看,我的系统当中有725MB左右的物理内存,我的swap有1GB左右,那我使用free-m 以MB来显示时,就会出现上面的信息。Mem 那一行显示的是物理内存的量,Swap 则是虚拟内存的量,otal 是总量,used 是已被使用的量,free 则是剩余可用的量。后面的shared/buffers/cached则是在已被使用的量当中用来作为缓冲及快取的量。
仔细看范例一的输出,我们的Linux测试用主机是很平凡的,根本没有什么工作,但是,我的物理内存是几乎被用光光的情况呢!不过,至少有132MB用在缓冲记忆(buffers)工作,287MB则用在缓存(cached)工作,也就是说,系统是很有效率地所有的内存用光,目的是为了让系统的访问性能加速。
很多朋友都会问到这个问题:“我的系统明明很轻松,为何内存会被用光?”被用光是正常的!而需要注意的反而是swap的量。一般来说,swap最好不要被使用,尤其swap最好不要被使用超过20%以上,如果你发现swap的用量超过20%,那么,最好还是买物理内存吧!因为,Swap的性能跟物理内存实在差很多,而系统会使用到swap,绝对是因为物理内存不足了才会这样做的。
Linux 系统为了要加速系统性能,所以会将最常使用到的或者是最近使用到的文件数据缓存下来,这样将来系统要使用该文件时,就直接由内存中取出,而不需要重新读取硬盘,速度上面当然就加快了。因此,物理内存被用光是正常的。
uname:查看统与内核相关信息
[root@www ~]# uname [-asrmpi]
参数:
-a :所有系统相关的信息,包括下面的数据都会被列出来;
-s :系统内核名称;
-r :内核的版本;
-m :本系统的硬件名称,例如 i686 或 x86_64 等;
-p :CPU 的类型,与 -m 类似,只是显示的是 CPU 的类型;
-i :硬件的平台 (ix86)。
范例一:输出系统的基本信息
[root@www ~]# uname -a
Linux www.vbird.tsai 2.6.18-92.el5 #1 SMP Tue Jun 10 18:49:47 EDT 2008 i686
i686 i386 GNU/Linux
这个命令我们前面使用过很多次了。uname 可以列出目前系统的内核版本、主要硬件平台以及CPU类型等的信息。以上面范例一的状态来说,我的Linux主机使用的内核名称为Linux,而主机名为 www.vbird.tsai ,内核的版本为 2.6.18-92.el5 ,该内核版本创建的日期为2 008/6/10,适用的硬件平台为 i386 以上等级的硬件平台。
uptime:查看系统启动时间与工作负载
这个命令很单纯呢!就是显示出目前系统已经开机多久的时间,以及1,5,15分钟的平均负载就是了。还记得top吧?没错,这个uptime可以显示出top界面的最上面一行!
[root@www~]#uptime
15:39:13 up 8 days, 14:52, 1 user, load average: 0.00, 0.00, 0.00
top 这个命令已经谈过相关信息,不再聊!
netstat:跟踪网络
这个netstat也是挺好玩的,其实这个命令比较常被用在网络的监控方面,不过,在进程管理方面也是需要了解的。这个命令的执行如下所示。本上,netstat 的输出分为两大部分,分别是网络与系统自己的进程相关性部分。
[root@www ~]# netstat -[atunlp]
参数:
-a :将目前系统上所有的连接、监听、Socket 数据都列出来;
-t :列出 tcp 网络数据包的数据;
-u :列出 udp 网络数据包的数据;
-n :不列出进程的服务名称,以端口号 (port number) 来显示;
-l :列出目前正在网络监听 (listen) 的服务;
-p :列出该网络服务的进程 PID。
范例一:列出目前系统已经新建的网络连接与 unix socket 状态
[root@www ~]# netstat
Active Internet connections (w/o servers) <==与网络比较相关的部分
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 132 192.168.201.110:ssh 192.168.:vrtl-vmf-sa ESTABLISHED
Active UNIX domain sockets (w/o servers) <==与本机的进程自己的相关性(非网络)
Proto RefCnt Flags Type State I-Node Path
unix 20 [ ] DGRAM 9153 /dev/log
unix 3 [ ] STREAM CONNECTED 13317 /tmp/.X11-unix/X0
unix 3 [ ] STREAM CONNECTED 13233 /tmp/.X11-unix/X0
unix 3 [ ] STREAM CONNECTED 13208 /tmp/.font-unix/fs7100
….(中间省略)….
在上面的结果当中,显示了两个部分,分别是网络的连接以及 linux 上面的 socket 程序相关性部分。我们先来看看因特网连接情况的部分:
Proto:网络的数据包协议,主要分为TCP与UDP数据包,相关数据请参考服务器篇;
Recv-Q:非由用户进程连接到此socket的复制的总字节数;
Send-Q:非由远程主机传送过来的acknowledged总字节数;
LocalAddress:本地的IP端口情况;
ForeignAddress:远程主机的IP端口情况;
State:连接状态,主要有建立(ESTABLISED)及监听(LISTEN)。
我们看上面仅有一条连接的数据,它的意义是通过TCP数据包的连接,将远程的192.168.:vrtl..连接到本地的 192.168.201.110:ssh,这条连接状态是建立(ESTABLISHED)的状态!至于更多的网络环境说明,就得到鸟哥的另一本书(服务器篇)查阅。
除了网络上的连接之外,其实Linux系统上面的进程是可以接收不同进程所发送来的信息,那就是 Linux 上面的(socket file)。我们在第 6 章的文件种类有稍微提到 socket 文件,但当时未谈到进程的概念,所以没有深入谈论。socket file 可以沟通两个进程之间的信息,因此进程可以取得对方传送过来的数据。由于有 socket file,因此类似 X Window 这种需要通过网络连接的软件,目前新版的distributions就以socket来进行窗口界面的联机通信了。上面的socketfile的输出字段有:
Proto:一般就是unix;
RefCnt:连接到此socket的进程数量;
Flags:连接的标识;
Type:socket访问的类型。主要有确认连接的STREAM与不需确认的DGRAM两种;
State:若为CONNECTED表示多个进程之间已经连接建立;
Path:连接到此socket的相关程序的路径,或者是相关数据输出的路径。
以上面的输出为例,最后那三行在/tmp/.xx下面的数据,就是X Window窗口界面的相关程序啦!而PATH指向的就是这些进程要交换数据的socket文件。那么netstat可以帮我们进行什么任务呢?我们先来看看,利用netstat去看看我们的哪些进程有启动哪些网络的“后门”。
范例二:找出目前系统上已在监听的网络连接及其 PID
[root@www ~]# netstat -tlnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:2208 0.0.0.0:* LISTEN 4566/hpiod
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 4328/portmap
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 4597/cupsd
tcp 0 0 0.0.0.0:728 0.0.0.0:* LISTEN 4362/rpc.statd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 4629/sendmail:
tcp 0 0 127.0.0.1:2207 0.0.0.0:* LISTEN 4571/python
tcp 0 0 :::22 :::* LISTEN 4586/sshd
除了可以列出监听网络的端口与状态之外,最后一个字段还能够显示此服务的
PID 号码以及进程的命令名称。例如最后一行的 4586 就是该 PID
范例三:将上述的本地 127.0.0.1:631 那个网络服务关闭
[root@www ~]# kill -9 4597
[root@www ~]# killall -9 cupsd
很多朋友经常有疑问,那就是,我的主机目前到底开了几个端口(port)!其实,不论主机提供什么样的服务,一定必须要有相对应的进程在主机上面执行才行啊!举例来说,我们鸟园的Linux主机提供的就是WWW服务,那么我的主机当然有一个进程在提供WWW的服务。
那就是 Apache 这个软件所提供的啦。所以,当我执行了这个程序之后,我的系统自然就可以提供 WWW 的服务了。那如何关闭啊?就关掉该程序所触发的那个进程就好了!例如上面的范例三所提供的例子啊!
dmesg:分析内核产生的信息
系统在开机的时候,内核会去检测系统的硬件,你的某些硬件到底有没有被识别出来,那就与这个时候的检测有关。但是这些检测的过程要不是没有显示在屏幕上,就是很飞快地在屏幕上一闪而逝!能不能把内核检测的信息找出来瞧瞧?可以的,那就使用dmesg。
所有内核检测的信息,不管是开机时候还是系统运行过程中,反正只要是内核产生的信息都会被记录到内存中的某个保护区段。dmesg这个命令就能够将该区段的信息读出来的!因为信息实在太多了,所以执行时可以加入这个管道命令“|more”来使界面暂停!
范例一:输出所有的内核开机时的信息
[root@www ~]# dmesg | more
范例二:查找开机的时候硬盘的相关信息
[root@www ~]# dmesg | grep -i hd
ide0: BM-DMA at 0xd800-0xd807, BIOS settings: hda:DMA, hdb:DMA
ide1: BM-DMA at 0xd808-0xd80f, BIOS settings: hdc:pio, hdd:pio
hda: IC35L040AVER07-0, ATA DISK drive
hdb: ASUS DRW-2014S1, ATAPI CD/DVD-ROM drive
hda: max request size: 128KiB
….(下面省略)….
由范例二就知道我这台主机的硬盘的格式是什么了吧?还可以查看能不能找到网卡。网卡的代号是 eth,所以,直接输入 dmesg | grep -i eth 试看看呢!
vmstat:检测系统资源变化
如果你想要动态了解一下系统资源的运行,那么这个vmstat确实可以玩一玩!vmstat可以检测CPU/内存/磁盘输入输出状态等,如果你想要了解一部繁忙的系统到底是哪个环节最累人,可以使用vmstat分析看看。下面是常见的参数说明:
[root@www ~]# vmstat [-a] [延迟 [总计检测次数]] <==CPU/内存等信息
[root@www ~]# vmstat [-fs] <==内存相关
[root@www ~]# vmstat [-S单位] <==设置显示数据的单位
[root@www ~]# vmstat [-d] <==与磁盘有关
[root@www ~]# vmstat [-p分区] <==与磁盘有关
参数:
-a :使用 inactive/active(活跃与否) 替代 buffer/cache 的内存输出信息;
-f :开机到目前为止系统复制 (fork) 的进程数;
-s :将一些事件 (开机至目前为止) 导致的内存变化情况列表说明;
-S :后面可以接单位,让显示的数据有单位。例如 K/M 取代 bytes 的容量;
-d :列出磁盘的读写总量统计表
-p :后面列出分区,可显示该分区的读写总量统计表
范例一:统计目前主机 CPU 状态,每秒一次,共计三次!
[root@www ~]# vmstat 1 3
procs —————-memory————— —-swap— ——-io—— —system— ——-cpu———
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 28 61540 137000 291960 0 0 4 5 38 55 0 0 100 0 0
0 0 28 61540 137000 291960 0 0 0 0 1004 50 0 0 100 0 0
0 0 28 61540 137000 291964 0 0 0 0 1022 65 0 0 100 0 0
利用vmstat甚至可以进行跟踪!你可以使用类似“vmstat5”代表每五秒钟更新一次,且一直更新!直到你按下[ctrl]-c为止。如果你想要实时知道系统资源的运行状态,这个命令就不能不知道,那么上面的各项字段的意义是什么?基本说明如下:
内存字段(procs)的选项分别为:
r:等待运行中的进程数量;b:不可被唤醒的进程数量。这两个选项越多,代表系统越忙碌(因为系统太忙,所以很多进程就无法被执行或一直在等待而无法被唤醒)。
内存字段(memory)选项分别为:
swpd:虚拟内存被使用的容量;free:未被使用的内存容量;buff:用于缓冲存储器;cache:用于高速缓存。这部分则与free是相同的。
内存交换空间(swap)的选项分别为:
si:由磁盘中将程序取出的量;so:由于内存不足而将没用到的程序写入到磁盘的swap的容量。如果si/so的数值太大,表示内存内的数据经常得在磁盘与内存之间传来传去,系统性能会很差!
磁盘读写(io)的选项分别为:
bi:由磁盘写入的块数量;bo:写入到磁盘去的块数量。如果这部分的值越高,代表系统的I/O非常忙碌!
系统(system)的项目分别为:
in:每秒被中断的进程次数;cs:每秒钟进行的事件切换次数;这两个数值越大,代表系统与接口设备的通信非常频繁。这些接口设备当然包括磁盘、网卡、时钟等。
CPU的选项分别为:
us:非内核层的CPU使用状态;sy:内核层所使用的CPU状态;id:闲置的状态;wa:等待 I/O 所耗费的 CPU 状态;st:被虚拟机(virtual machine)所盗用的 CPU 使用状态(2.6.11内核以后才支持)。
由于鸟哥的机器是测试机,所以并没有什么I/O或者是CPU忙碌的情况。如果改天你的服务器非常忙碌时,记得使用vmstat去看看,到底是哪个部分的资源被使用得最为频繁。一般来说,如果I/O部分很忙碌的话,你的系统会变得非常慢!让我们再来看看,那么磁盘的部分该如何查看。
范例二:系统上面所有的磁盘的读写状态
[root@www ~]# vmstat -d
disk- ——————reads—————— ——————writes—————- ——-IO———
total merged sectors ms total merged sectors ms cur sec
ram0 0 0 0 0 0 0 0 0 0 0
….(中间省略)….
hda 144188 182874 6667154 7916979 151341 510244 8027088 15244705 0 848
hdb 0 0 0 0 0 0 0 0 0 0
