第2章 程序语言基础知识
程序设计语言是为了书写计算机程序而人为设计的符号语言,用于对计算过程进行描述、组织和推导。程序设计语言的广泛使用始于1957年出现的FORTRAN,程序语言的发展是一个不断演化的过程,其根本的推动力是更高的抽象机制以及对程序设计思想的更好支持。
2.1 程序语言概述
本节主要介绍程序设计语言的基本概念、基本成分和一些有代表性的程序语言。
2.1.1 程序语言的基本概念
1.低级语言和高级语言
计算机的硬件只能识别由0,1组成的机器指令序列,即机器指令程序,因此机器指令是最基本的计算机语言。由于机器指令是特定的计算机系统所固有的、面向机器的语言,所以用机器语言进行程序设计时,效率低、程序可读性很差、难以理解、难以修改和维护。因此,人们就用容易记忆的符号代替0,1序列来表示机器指令,例如,用ADD表示加法、SUB表示减法等。用符号表示的指令称为汇编指令,汇编指令的集合被称为汇编语言。汇编语言与机器语言十分接近,其书写格式在很大程度上取决于特定计算机的机器指令,因此它仍然是一种面向机器的语言,人们称机器语言和汇编语言为低级语言。在此基础上,人们开发了功能更强、抽象级别更高的语言以支持程序设计,于是就产生了面向各类应用的程序语言,称为高级语言。常见的有Java、C、C++、PHP和Python和Delphi等。这类语言与人们使用的自然语言比较接近,大大提高了程序设计的效率。
2.编译程序和解释程序
计算机只能理解由0,1序列构成的机器语言,因此高级程序语言需要翻译,担负这一任务的程序称为“语言处理程序”。语言之间的翻译形式有多种,基本方式为汇编、解释和编译。
用某种高级语言或汇编语言编写的程序称为源程序,源程序不能直接在计算机上执行。如果源程序是用汇编语言编写的,则需要一个汇编程序将其翻译成目标程序后才能执行。如果源程序是用某种高级语言编写的,则需要对应的解释程序或编译程序对其进行翻译,然后在机器上运行。
解释程序也称为解释器,它或者直接解释执行源程序,或者将源程序翻译成某种中间代码后再加以执行;而编译程序(编译器)则是将源程序翻译成目标语言程序,然后在计算机上运行目标程序。这两种语言处理程序的根本区别是:在编译方式下,机器上运行的是与源程序等价的目标程序,源程序和编译程序都不再参与目标程序的执行过程;而在解释方式下,解释程序和源程序(或其某种等价表示)要参与到程序的运行过程中,运行程序的控制权在解释程序。简单来说,在解释方式下,翻译源程序时不生成独立的目标程序,而编译器则将源程序翻译成独立保存的目标程序。
3.程序设计语言的定义
一般地,程序设计语言的定义都涉及语法、语义和语用等方面。
语法是指由程序语言的基本符号组成程序中的各个语法成分(包括程序)的一组规则,其中由基本字符构成的符号(单词)书写规则称为词法规则,由符号构成语法成分的规则称为语法规则。程序语言的语法可用形式语言进行描述。
语义是程序语言中按语法规则构成的各个语法成分的含义,可分为静态语义和动态语义。静态语义指编译时可以确定的语法成分的含义,而运行时刻才能确定的含义是动态语义。一个程序的执行效果说明了该程序的语义,它取决于构成程序的各个组成部分的语义。
语用表示了构成语言的各个记号和使用者的关系,涉及符号的来源、使用和影响。
语言的实现则有个语境问题。语境是指理解和实现程序设计语言的环境,包括编译环境和运行环境。
4.程序设计语言的分类
程序语言有交流算法和计算机实现的双重目的,现在的程序语言种类繁多,它们在应用上各有不同的侧重面。若一种程序语言不依赖于机器硬件,则称为高级语言;若程序语言能够应用于范围广泛的问题求解过程中,则称为通用的程序设计语言。
1)程序语言的发展概述
FORTRAN是第一个被广泛用来进行科学计算的高级语言。一个FORTRAN程序由一个主程序和若干个子程序组成。主程序及每一个子程序都是独立的程序单位,称为一个程序模块。在FORTRAN中,子程序是实现模块化的有效途径。
ALGOL60主导了20世纪60年代程序语言的发展。它有严格的文法规则,采用巴科斯范式BNF来描述语言的语法。ALGOL是一个分程序结构的语言。一般来说,一个ALGOL程序本身就是一个分程序,每个分程序由begin和end括起来,以说明分程序的范围和它所管辖的名字的作用域。分程序的结构可以是嵌套的,即分程序内可以包含别的分程序。过程也可以称为一个分程序。同一个名字在不同的分程序中可以代表完全不同的实体。如果一个名字在若干层嵌套分程序中多次被说明,则程序中该名字的使用由离使用点最近的内层说明决定,即“最近嵌套原则”。此外,ALGOL还提供了数组的动态说明和过程的递归调用。
COBOL(Common Business Oriented Language)是一种面向事务处理的高级语言,1961年由美国数据系统语言协会公布,经不断修改、丰富、完善和标准化,已发展了多种版本。COBOL语言的语法规则很严格,使用了300多个英语保留字,大量采用普通英语词汇和句型,主要应用于情报检索、商业数据处理等。
PASCAL是一种结构化程序设计语言,由瑞士苏黎世联邦工业大学的沃斯(N. Wirth)教授设计,于1971年正式发表。该语言是从ALGOL60衍生的,但功能更强且容易使用。PASCAL语言在高校计算机软件教学中一直处于主导地位。在PASCAL语言中,分程序和过程这两个概念合二为一,统一为过程。PASCAL过程可以嵌套和递归。
C语言是20世纪70年代初发展起来的一种通用程序设计语言,UNIX操作系统及其上的许多软件都是用C编写的。它兼顾了高级语言和汇编语言的特点,提供了一个丰富的运算符集合以及比较紧凑的语句格式。由于C提供了高效的执行语句并且允许程序员直接访问操作系统和底层硬件,因此在系统级应用和实时处理应用的开发中成为主要语言。
C++是在C语言的基础上于20世纪80年代发展起来的,与C兼容。在C++中,最主要的是增加了类机制,使其成为一种面向对象的程序设计语言。
Java产生于20世纪90年代,其初始用途是开发网络浏览器的小应用程序,但是作为一种通用的程序设计语言,Java也得到了广泛的应用。Java保留了C++的基本语法、类和继承等概念,删掉了C++中一些不好的特征,因此与C++相比,Java更简单,其语法和语义更合理。
PHP(Hypertext Preprocessor)是一种在服务器端执行的、嵌入HTML文档的脚本语言,其语言风格类似于C语言,由网站编程人员广泛运用。PHP可以快速地执行动态网页,其语法混合了C、Java、Perl以及PHP自创的语法。由于在服务器端执行,PHP能充分利用服务器的性能。另外,PHP支持几乎所有流行的数据库以及操作系统。
Paython是一种面向对象的解释型程序设计语言,可以用于编写独立程序、快速脚本和复杂应用的原型。Python也是一种脚本语言,它支持对操作系统的底层访问,也可以将Python源程序翻译成字节码在Python虚拟机上运行。虽然Python的内核很小,但它提供了丰富的基本构建块,还可以用C、C++和Java等进行扩展,因此可以用它开发任何类型的程序。
Delphi是Borland公司研制的可视化开发工具,在Windows环境下使用,其在Linux上的对应产品是Kylix。它采用面向对象的编程语言Object Pascal和基于构件的开发结构框架。其主要特性为基于窗体和面向对象的方法、高速的编译器、强大的数据库支持、与Windows编程紧密结合以及成熟的组件技术。
各种程序语言都在不断地发展之中,也出现了许多新的语言,开发工具在组件化和可视化方面进展迅速。
2)程序语言的分类
程序语言的分类没有统一的标准,这里根据设计程序的方法将程序语言大致分为命令式程序设计语言(结构化程序设计语言)、面向对象的程序设计语言、函数式程序设计语言和逻辑型程序设计语言等范型。
(1)命令式程序设计语言。命令式语言是基于动作的语言,在这种语言中,计算被看成是动作的序列。命令式语言族开始于FORTRAN,PASCAL和C语言体现了命令式程序设计的关键思想。
通常所称的结构化程序设计语言属于命令式语言类,其结构特性主要反映在以下几个方面:一是用自顶向下逐步精化的方法编程,二是按模块组装的方法编程,三是程序只包含顺序、判定(分支)及循环构造,而且每种构造只允许单入口和单出口。结构化程序的结构简单清晰、模块化强,描述方式接近人们习惯的推理式思维方式,因此可读性强,在软件重用性、软件维护等方面都有所进步,在大型软件开发中曾发挥过重要的作用。目前仍有许多应用程序的开发采用结构化程序设计技术和方法。C、PASCAL等都是典型的结构化程序设计语言。
(2)面向对象的程序设计语言。程序设计语言的演化从最开始的机器语言到汇编语言到各种结构化高级语言,最后到支持面向对象技术的面向对象语言,反映的就是一条抽象机制不断提高的演化道路。
面向对象的程序设计在很大程度上应归功于从模拟领域发展起来的Simula,Simula提出了对象和类的概念。C++、Java和smaltalk是面向对象程序设计语言的代表,它们都必须支持新的程序设计技术,如数据隐藏、数据抽象、用户定义类型、继和多态等。
(3)函数式程序设计语言。函数式语言是一类以λ-演算为基础的语言,其基本概念来自于LISP,这是一个在1958年为了人工智能应用而设计的语言。函数是一种对应规则(映射),它使定义域中每个元素和值域中唯一的元素相对应。
函数定义1:Square[x]:=x*x
函数定义2:Plustwo[x]:=Plusone[Plusone[x]]
函数定义3:fact[n]:=if n=0 then 1 else n*fact[n-1]
在函数定义2中,使用了函数复合,即将一个函数调用嵌套在另一个函数定义中。在函数定义3中,函数被递归定义。由此可见,函数可以看成是一种程序,其输入就是定义中左边括号中的量。它也可将输入组合起来产生一个规则,组合过程中可以使用其他函数或该函数本身。这种用函数和表达式建立程序的方法就是函数式程序设计。函数型程序设计语言的优点之一就是对表达式中出现的任何函数都可以用其他函数来代替,只要这些函数调用产生相同的值。
函数式语言的代表LISP在许多方面与其他语言不同,其中最为显著的是LISP的程序和数据的形式是等价的,这样数据结构就可以作为程序执行,程序也可以作为数据修改。在LISP中,大量地使用递归。
(4)逻辑型程序设计语言。逻辑型语言是一类以形式逻辑为基础的语言,其代表是建立在关系理论和一阶谓词理论基础上的PROLOG。PROLOG代表Programming in Logic。PROLOG程序是一系列事实、数据对象或事实间的具体关系和规则的集合。通过查询操作把事实和规则输入数据库。用户通过输入查询来执行程序。在PROLOG中,关键操作是模式匹配,通过匹配一组变量与一个预先定义的模式并将该组变量赋给该模式来完成操作。以值集合S和T上的二元关系R为例,R实现后,可以询问:
①已知a和b,确定R(a,b)是否成立。
②已知a,求所有使R(a,y)成立的y。
③已知b,求所有使R(x,b)成立的x。
④求所有使R(x,y)成立的x和y。
逻辑型程序设计具有与传统的命令型程序设计完全不同的风格。PROLOG数据库中的事实和规则是形式为P:-P1,P2,…,Pn的Hore子句,其中n≥0,Pi(1≤i≤n)为形如Ri(…)的断言,Ri是关系名。该子句表示规则:若P1,P2,…,Pn均为真(成立),则P为真。当n=0时,Hore子句变成P.,这样的子句称为事实。
一旦有了事实与规则后,就可以提出询问。测试用户询问A是否成立时,采用归结方法。
①如果程序中包含事实P,且P和A匹配,则A成立。
②如果程序中包含Hore子句P:-P1,P2,…,Pn.,且P和A匹配,则PROLOG转而测试P1,P2,…,Pn。只有当P1,P2,…,Pn都成立时才能断言P成立。当求解某个Pi失败时,则返回到前面的某个成功点并尝试另一种选择,也就是进行回溯。
③只有当所有可能情况都已穷尽时,才能推导出P失败。
PROLOG有很强的推理功能,适用于书写自动定理证明、专家系统和自然语言理解等问题的程序。
2.1.2 程序语言的基本成分
程序语言的基本成分包括数据、运算、控制和传输等。
1.程序语言的数据成分
程序语言的数据成分指的是一种程序语言的数据类型。数据对象总是对应着应用系统中某些有意义的东西,数据表示则指示了程序中值的组织形式。数据类型用于代表数据对象,还用于在基础机器中完成对值的布局,同时还可用于检查表达式中对运算的应用是否正确。
数据是程序操作的对象,具有存储类别、类型、名称、作用域和生存期等属性,使用时要为它分配内存空间。数据名称由用户通过标识符命名,标识符是由字母、数字和下划线“_”组成的标记;类型说明数据占用内存的大小和存放形式;存储类别说明数据在内存中的位置和生存期;作用域则说明可以使用数据的代码范围;生存期说明数据占用内存的时间范围。从不同角度可将数据进行不同的划分。
1)常量和变量
按照程序运行时数据的值能否改变,将数据分为常量和变量。程序中的数据对象可以具有左值和(或)右值,左值指存储单元(或地址、容器),右值是值(或内容)。变量具有左值和右值,在程序运行过程中其右值可以改变;常量只有右值,在程序运行过程中其右值不能改变。
2)全局量和局部量
按数据的作用域范围,可分为全局量和局部量。系统为全局变量分配的存储空间在程序运行的过程中一般是不改变的,而为局部变量分配的存储单元是动态改变的。
3)数据类型
按照数据组织形式的不同可将数据分为基本类型、用户定义类型、构造类型及其他类型。C(C++)的数据类型如下。
(1)基本类型:整型(int)、字符型(char)、实型(float、double)和布尔类型(bool)。
(2)特殊类型:空类型(void)。
(3)用户定义类型:枚举类型(enum)。
(4)构造类型:数组、结构、联合。
(5)指针类型:type*。
(6)抽象数据类型:类类型。
其中,布尔类型和类类型由C++语言提供。
2.程序语言的运算成分
程序语言的运算成分指明允许使用的运算符号及运算规则。大多数高级程序语言的基本运算可以分成算术运算、关系运算和逻辑运算,有些语言如C(C++)还提供位运算。运算符号的使用与数据类型密切相关。为了明确运算结果,运算符号要规定优先级和结合性,必要时还要使用圆括号。
3.程序语言的控制成分
控制成分指明语言允许表述的控制结构,程序员使用控制成分来构造程序中的控制逻辑。理论上已经证明,可计算问题的程序都可以用顺序、选择和循环这三种控制结构来描述。
1)顺序结构
顺序结构用来表示一个计算操作序列。计算过程从所描述的第一个操作开始,按顺序依次执行后续的操作,直到序列的最后一个操作,如图2-1所示。顺序结构内也可以包含其他控制结构。
2)选择结构
选择结构提供了在两种或多种分支中选择其中一个的逻辑。基本的选择结构是指定一个条件P,然后根据条件的成立与否决定控制流走计算A还是走计算B,从两个分支中选择一个执行。如图2-2(a)所示。选择结构中的计算A或计算B还可以包含顺序、选择和重复结构。程序语言中通常还提供简化了的选择结构,也就是没有计算B的分支结构,如图2-2(b)所示。
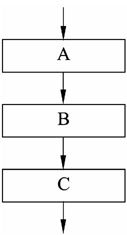
图2-1 顺序结构示意图
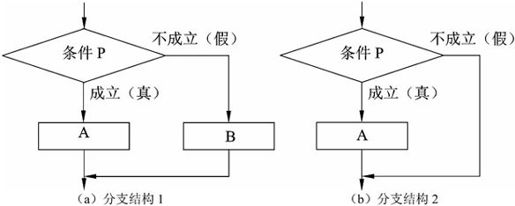
图2-2 选择结构示意图
3)循环结构
循环结构描述了重复计算的过程,通常由三部分组成:初始化、循环体和循环条件,其中初始化部分有时在控制的逻辑结构中不进行显式的表示。循环结构主要有两种形式:while型重复结构和do-while型重复结构。while型结构的逻辑含义是先判断条件P,若成立,则执行循环体A,然后再去判断重复条件;否则控制流就退出重复结构,如图2-3(a)所示。do-while型结构的逻辑含义是先执行循环体A,然后再判断条件P,若成立则继续执行A的过程并判断条件;否则控制流就退出循环结构,如图2-3(b)所示。
4)C(C++)语言提供的控制语句
(1)复合语句。复合语句用于描述顺序控制结构。复合语句是一系列用“{”和“}”括起来的声明和语句,其主要作用是将多条语句组成一个可执行单元。语法上能出现语句的地方都可以使用复合语句。复合语句是一个整体,要么全部执行,要么一条语句也不执行。
(2)if语句和switch语句。
①if语句实现的是双分支的选择结构,其一般形式为:
if(表达式)语句1;else语句2;
其中,语句1和语句2可以是任何合法的C(C++)语句,当语句2为空语句时,可以简化为:
if(表达式)语句1;
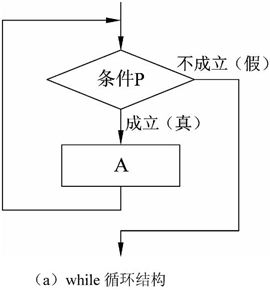
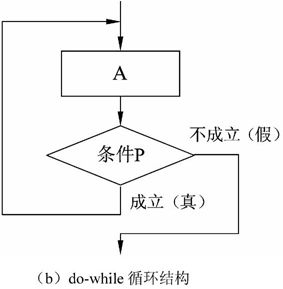
图2-3 循环结构示意图
使用if语句时,需要注意的是if和else的匹配关系。C语言规定,else总是与离它最近的尚没有else的if相匹配。
②switch语句描述了多分支的选择结构,其一般形式为:

执行switch语句时,首先计算表达式的值,然后用所得的值与列举的常量表达式值依次比较,若任一常量表达式都不能与所得的值相匹配,则执行default的“语句序列n+1”,然后结束switch语句。若此值与常量表达式i(i=1,2,…,n)的值相同,则执行“语句序列i”,当case i的语句序列i中无break语句时,则执行随后的语句序列i+1,语句序列i+2,……直到执行完语句序列n+1后,才退出switch语句;或者遇到break时跳出switch语句。要使得程序在执行“语句序列i”后结束整个switch语句,则语句序列i中应包含控制流能够到达的break语句。
表达式可以是任何类型的,常用的是字符型或整型表达式。多个常量表达式可以共用一个语句组。语句组可以包括任何可执行语句,且无须用“{”和“}”括起来。
(3)循环语句。C(C++)语言提供了三种形式的循环语句用于描述循环计算的控制结构。
①while语句。while语句描述了先判断条件再执行循环体的控制结构,其一般形式是:
while(条件表达式)循环体语句;
其中,循环体语句是内嵌的语句,当循环体语句多于一条时,应使用“{”和“}”括起来。执行while语句时,先计算条件表达式的值,当值为非0时,就执行循环体语句,然后重新计算条件表达式的值后再进行判断,否则就结束while语句的执行过程。
②do-while语句。do-while语句描述了先执行循环体再判断条件的控制结构,其一般格式是:
do
循环体语句;
while(条件表达式)
执行do-while语句时,先执行内嵌的循环体语句,然后再计算条件表达式的值,若值为非0,则再一次地执行循环体语句和计算条件表达式并进行判断,直到条件表达式的值为0时,才结束do-while语句的执行过程。
③for语句。for语句的基本格式是:
for(表达式1;表达式2;表达式3)循环体语句;
可用while语句等价地表示为:
表达式1;

for语句的使用是很灵活的,其内部的三个表达式都可以省略,但用于分隔三个表达式的分号“;”不能遗漏。
C语言中还提供了实现控制流跳转的goto语句,由于它会破坏程序的逻辑结构,因此不提倡使用。
程序语言的传输成分指明语言允许的数据传输方式,如赋值处理、数据的输入和输出等。
4.函数
C程序由一个或多个函数组成,每个函数都有一个名字,其中有且仅有一个名字为main的函数,作为程序运行时的起点。函数是程序模块的主要成分,它是一段具有独立功能的程序。函数的使用涉及三个概念:函数定义、函数声明和函数调用。
1)函数定义
函数的定义包括两部分:函数首部和函数体。函数的定义描述了函数做什么和怎么做。函数定义的一般格式是:
返回值的类型 函数名(形式参数表) //函数首部

函数首部说明了函数返回值的数据类型、函数的名字和函数运行时所需的参数及类型。函数所实现的功能在函数体部分进行描述。
C(C++)程序中所有函数的定义都是独立的。在一个函数的定义中不允许定义另外一个函数,也就是不允许函数的嵌套定义。
2)函数声明
函数应该先声明后引用。如果程序中对一个函数的调用在该函数的定义之前进行,则应该在调用前对被调用函数进行声明。函数原型用于声明函数。函数声明的一般形式为:
返回值类型 函数名(参数类型表);
使用函数原型的目的在于告诉编译器传递给函数的参数个数、类型以及函数返回值的类型,参数表中仅需要依次列出函数定义时参数的类型。函数原型可以使编译器更彻底地检查源程序中对函数的调用是否正确。
3)函数调用
当在一个函数(称为主调函数)中需要使用另一个函数(称为被调函数)实现的功能时,便以名字进行调用,称为函数调用。在使用一个函数时,只要知道如何调用就可以了,并不需要关心被调用函数的内部实现。因此,主调函数需要知道被调函数的名字、返回值和需要向被调函数传递的参数(个数、类型、顺序)等信息。
函数调用的一般形式为:
函数名(实参表);
在C程序的执行过程中,通过函数调用实现了函数定义时描述的功能。函数体中若调用自己,则称为递归调用。
C和C++通过传值方式将实参传递给形参。调用函数和被调用函数之间交换信息的方法主要有两种:一种是由被调用函数把返回值返回给主调函数,另一种是通过参数带回信息。函数调用时实参与形参间交换信息的方法有值调用和引用调用两种。
(1)值调用(Call by value)。若实现函数调用时实参向形式参数传递相应类型的值(副本),则称为是传值调用。这种方式下形式参数不能向实际参数传递信息。
在C语言中,要实现被调用函数对实际参数的修改,必须用指针作形参。即调用时需要先对实参进行取地址运算,然后将实参的地址传递给指针形参。本质上仍属于值调用。这种方式实现了间接内存访问。
(2)引用调用(Call by Reference)。引用是C++中增加的数据类型,当形式参数为引用类型时,形参名实际上是实参的别名,函数中对形参的访问和修改实际上就是针对相应实际参数所作的访问和改变。例如:
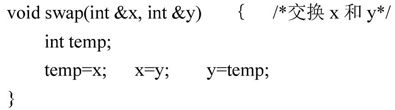
函数调用:swap(a,b);。
在实现调用swap(a,b)时,x、y就是a、b的别名,因此,函数调用完成后,交换了a和b的值。
2.2 语言处理程序基础
语言处理程序是一类系统软件的总称,其主要作用是将高级语言或汇编语言编写的程序翻译成某种机器语言程序,使程序可在计算机上运行。语言处理程序主要分为汇编程序、编译程序和解释程序三种基本类型。
2.2.1 汇编程序基本原理
1.汇编语言
汇编语言是为特定的计算机或计算机系统设计的面向机器的符号化的程序设计语言。用汇编语言编写的程序称为汇编语言源程序。因为计算机不能直接识别和运行符号语言程序,所以要用专门的翻译程序——汇编程序进行翻译。用汇编语言编写程序要遵循所用语言的规范和约定。
汇编语言源程序由若干条语句组成,一个程序中可以有三类语句:指令语句、伪指令语句和宏指令语句。
(1)指令语句。指令语句又称为机器指令语句,将其汇编后能产生相应的机器代码,这些代码能被CPU直接识别并执行相应的操作。基本的指令如ADD、SUB和AND等,书写指令语句时必须遵循指令的格式要求。
指令语句可分为传送指令、算术运算指令、逻辑运算指令、移位指令、转移指令和处理机控制指令等类型。
(2)伪指令语句。伪指令语句指示汇编程序在汇编源程序时完成某些工作,例如给变量分配存储单元地址,给某个符号赋一个值等。伪指令语句与指令语句的区别是:伪指令语句经汇编后不产生机器代码。而指令语句经汇编后要产生相应的机器代码。另外,伪指令语句所指示的操作是在源程序被汇编时完成的,而指令语句的操作必须在程序运行时完成。
(3)宏指令语句。在汇编语言中,还允许用户将多次重复使用的程序段定义为宏。宏的定义必须按照相应的规定进行,每个宏都有相应的宏名。在程序的任意位置,若需要使用这段程序,只要在相应的位置使用宏名,即相当于使用了这段程序。因此,宏指令语句就是宏的引用。
2.汇编程序
汇编程序的功能是将汇编语言所编写的源程序翻译成机器指令程序。汇编程序的基本工作包括将每一条可执行汇编语句转换成对应的机器指令;处理源程序中出现的伪指令。由于汇编指令中形成操作数地址的部分可能出现后面才会有定义的符号,所以汇编程序一般需要两次扫描源程序才能完成翻译过程。
第一次扫描的主要工作是定义符号的值并创建一个符号表ST,ST记录了汇编时所遇到的符号的值。另外,有一个固定的机器指令表MOT1,其中记录了每条机器指令的记忆码和指令的长度。在汇编程序翻译源程序的过程中,为了计算各汇编语句标号的地址,需要设立一个位置计数器或单元地址计数器LC(Location Counter),其初值一般为0。在扫描源程序时,每处理完一条机器指令或与存储分配有关的伪指令(如定义常数语句、定义储存语句),LC的值就增加相应的长度。这样,在汇编过程中,LC的内容就是下一条被汇编的指令的偏移地址。若正在汇编的语句是有标号的,则该标号的值就取LC的当前值。
此外,在第一次扫描中,还需要对与定义符号值有关的伪指令进行处理。为了叙述方便,不妨设立伪指令表POT1。POT1表的每一个元素只有两个域:伪指令助记符和相应的子程序入口。下面的步骤(1)~(5)描述了汇编程序第一次扫描源程序的过程。
(1)单元计数器LC置初值0。
(2)打开源程序文件。
(3)从源程序中读入第一条语句。
(4)while(若当前语句不是END语句) {
if(当前语句有标号)则将标号和单元计数器LC的当前值填入符号表ST;
if(当前语句是可执行的汇编指令语句)则查找MOT1表获得当前指令的长度K,并令LC=LC+K;
if(当前指令是伪指令)则查找POT1表并调用相应的子程序;
if(当前指令的操作码是非法记忆码)则调用出错处理子程序。
从源程序中读入下一条语句;
}
(5)关闭源程序文件。
第二次扫描的任务是产生目标程序。除了使用前一次扫描所生成的符号表ST外,还要使用机器指令表MOT2,该表中的元素有机器指令助记符、机器指令的二进制操作码(binary-code)、格式(type)和长度(length)。此外,还要设立一个伪指令表POT2,供第二次扫描时使用。POT2的每一元素仍有两个域:伪指令记忆码和相应的子程序入口。与第一次扫描的不同之处是:在第二次扫描中,伪指令有着完全不同的处理。
在第二次扫描中,可执行汇编语句应被翻译成对应的二进制代码机器指令。这一过程涉及两个方面的工作:一是把机器指令助记符转换成二进制机器指令操作码,这可通过查找MOT2表来实现;二是求出操作数区各操作数的值(用二进制表示)。在此基础上,就可以装配出用二进制代码表示的机器指令。从求值的角度看,第二部分工作并不复杂。由于形成操作数地址的各个部分都以表达式的形式出现,只要定义一个过程eval-expr(index,value),其功能是通过index给定一个表达式在汇编语句缓冲区S的开始位置,该过程就用value返回此表达式的值。例如,虚拟计算机COMET的机器指令可归属于X型指令,其汇编语句为:
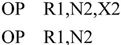
可以写出下面处理X型指令的程序段(假定index已指向操作数在缓冲区S的首地址):

类似地,可以写出其他类型指令处理操作数的程序段。设当前可执行汇编语句的操作助记符在MOT2表的索引值为i,则整个可执行汇编语句的处理可以描述如下:

将形成的指令送往输出区;
在第二次扫描中,根据伪指令助记符,调用POT2表相应元素所规定的子程序。DS伪指令的主要目的是预留存储空间。不妨设一个工作单元K(初值为0),用于累计以字节为单位的存储空间大小。从DS伪指令的操作数区求出K的大小后,就向输出区送K个空格以达到保留所规定存储单元的目的。DC伪指令处理的结果是向输出区送出转换得到的常量。开始伪指令工作是输出目标程序开始的标准信息,而结束伪指令则是输出目标程序结束的标准信息,这些信息都是为装配程序提供的。
2.2.2 编译程序基本原理
1.编译过程概述
编译程序的功能是把某高级语言书写的源程序翻译成与之等价的目标程序(汇编语言或机器语言)。编译程序的工作过程可以分为6个阶段,如图2-4所示,实际的编译器中可能会将其中的某些阶段结合在一起进行处理。
下面简要介绍各阶段实现的主要功能。
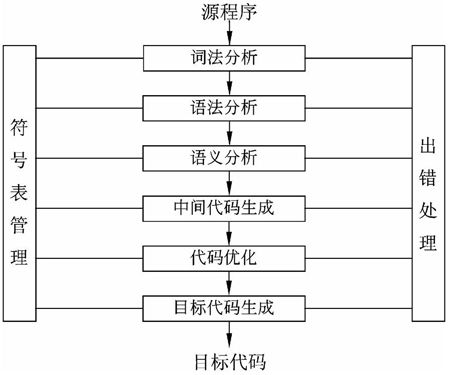
图2-4 编译器的工作阶段示意图
1)词法分析
源程序可以简单地被看成是一个多行的字符串。词法分析阶段是编译过程的第一阶段,这个阶段的任务是对源程序从前到后(从左到右)逐个字符地扫描,从中识别出一个个“单词”符号。“单词”符号是程序设计语言的基本语法单位,如关键字(或称保留字)、标识符、常数、运算符和分隔符(如标点符号、左右括号)等。词法分析程序输出的“单词”常以二元组的方式输出,即单词种别和单词自身的值。
词法分析过程依据的是语言的词法规则,即描述“单词”结构的规则。例如,对于某PASCAL源程序中的一条声明语句和赋值语句:
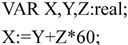
词法分析阶段将构成这条语句的字符串分割成如下的单词序列。

对于标识符X、Y、Z,其单词种别都是id(用户标识符),字符串″X″、″Y″和″Z″都是单词的值;而对于单词60,整常数是该单词的种类,60是该单词的值。这里用id1、id2和id3分别代表X、Y和Z,强调标识符的内部标识由于组成该标识符的字符串不同而有所区别。经过词法分析后,声明语句VAR X,Y,Z:real;表示为VAR id1,id2,id3:real,赋值语句X:=Y+Z60;表示为id1:=id2+id360;。
2)语法分析
语法分析的任务是在词法分析的基础上,根据语言的语法规则将单词符号序列分解成各类语法单位,如“表达式”、“语句”和“程序”等。语法规则就是各类语法单位的构成规则。通过语法分析确定整个输入串是否构成一个语法上正确的程序。如果源程序中没有语法错误,语法分析后就能正确地构造出其语法树;否则就指出语法错误,并给出相应的诊断信息。对id1:=id2+id1*60进行语法分析后形成的语法树如图2-5所示。
词法分析和语法分析本质上都是对源程序的结构进行分析。
3)语义分析
语义分析阶段主要检查源程序是否包含静态语义错误,并收集类型信息供后面的代码生成阶段使用。只有语法和语义都正确的源程序才能被翻译成正确的目标代码。
语义分析的一个主要工作是进行类型分析和检查。程序语言中的一个数据类型一般包含两个方面的内容:类型的载体及其上的运算。例如,整除取余运算符只能对整型数据进行运算,若其运算对象中有浮点数就认为是类型不匹配的错误。
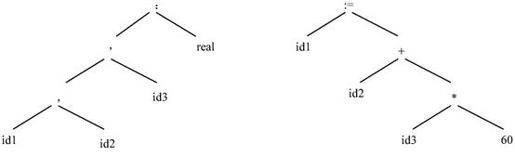
图2-5 语法树示意图
在确认源程序的语法和语义之后,就可对其进行翻译并给出源程序的内部表示。对于声明语句,需要记录所遇到的符号的信息,所以应进行符号表的填查工作。在图2-6所示的符号表中,每一行存放一个符号的信息。第一行存放标识符X的信息,其类型为real,为它分配的地址是0;第二行存放y的信息,其类型是real,为它分配的地址是4。因此,在这种语言中,为一个real型数据分配的存储空间是4个存储单元。对于可执行语句,则检查结构合理的表达式是否有意义。对id1:=id2+id1*60进行语义分析后的语法树如图2-6所示,其中增加了一个语义处理节点inttoreal,该运算用于将一个整型数转换为浮点数。
符号表部分内容
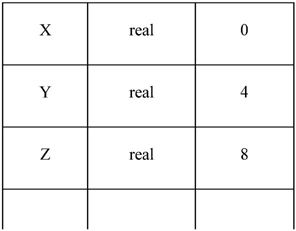
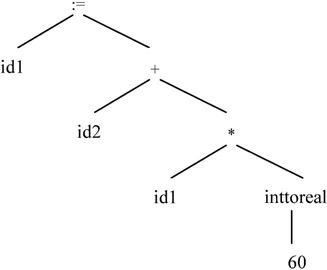
图2-6 语义分析后的符号表和语法树示意图
4)中间代码生成
中间代码生成阶段的工作是根据语义分析的输出生成中间代码。“中间代码”是一种简单且含义明确的记号系统,可以有若干种形式,它们的共同特征是与具体的机器无关。最常用的一种中间代码是与汇编语言的指令非常相似的三地址码,其实现方式常采用四元式。四元式的形式为:
(运算符,运算对象1,运算对象2,运算结果)
例如,对语句X:=Y+Z*60,可生成以下四元式序列:

其中,t1、t2、t3是编译程序生成的临时变量,用于存放临时的运算结果。
语义分析和中间代码生成所依据的是语言的语义规则。
5)代码优化
优化是一个编译器的重要组成部分,由于编译器将源程序翻译成中间代码的工作是机械的、按固定模式进行的,因此,生成的中间代码往往在时间上和空间上有较大的浪费。当需要生成高效的目标代码时,就必须进行优化。优化过程可以在中间代码生成阶段进行,也可以在目标代码生成阶段进行。由于中间代码不依赖于具体机器,此时所作的优化一般建立在对程序的控制流和数据流分析的基础之上,与具体的机器无关。优化所依据的原则是程序的等价变换规则。例如,在生成X:=Y+Z*60的四元式后,60是编译时已知的常数,把它转换为60.0的工作可以在编译时完成,没有必要生成一个四元式,同时t3仅仅用来将其值传递给id1,也可以被化简掉,因此上述的中间代码可转优化成下面的等价代码:
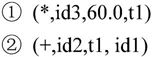
这只是优化工作中的一个简单示例,真正的优化工作还要涉及公共子表达式的提取、循环优化等更多的内容和技术。
6)目标代码生成
目标代码生成是编译器工作的最后一个阶段。这一阶段的任务是把中间代码变换成特定机器上的绝对指令代码、可重定位的指令代码或汇编指令代码,这个阶段的工作与具体的机器密切相关。例如,使用两个寄存器R1和R2,可对上述的四元式生成下面的目标代码:

这里用#表明60.0为常数。
7)符号表管理
符号表的作用是记录源程序中各个符号的必要信息,以辅助语义的正确性检查和代码生成,在编译过程中需要对符号表进行快速有效地查找、插入、修改和删除等操作。符号表的建立可以始于词法分析阶段,也可以放到语法分析和语义分析阶段,但符号表的使用有时会延续到目标代码的运行阶段。
8)出错处理
用户编写的源程序不可避免地会有一些错误,这些错误大致可分为静态错误和动态错误。动态错误也称动态语义错误,它们发生在程序运行时,例如变量取零时作除数、引用数组元素下标错误等。静态错误是指编译阶段发现的程序错误,可分为语法错误和静态语义错误,如单词拼写错误、标点符号错、表达式中缺少操作数、括号不匹配等有关语言结构上的错误称为语法错误,而语义分析时发现的运算符与运算对象类型不合法等错误属于静态语义错误。
在编译时发现程序中的错误后,编译程序应采用适当的策略修复它们,使得分析过程能够继续下去,以便在一次编译过程中尽可能多地找出程序中的错误。
对于编译器的各个阶段,在逻辑上可以把它们划分为前端和后端两部分。前端包括从词法分析到中间代码生成各阶段的工作,后端包括中间代码优化和目标代码的生成、优化等阶段。这样,以中间代码为分水岭,把编译器分成了与机器有关的部分和与机器无关的部分。如此一来,对于同一种程序语言的编译器,开发出一个前端之后,就可以针对不同的机器开发相应的后端,前后端有机结合后就形成了该语言的一个编译器。当语言有改动时,只会涉及前端部分的维护。对于不同的程序语言,分别设计出相应的前端,然后将各个语言的前端与同一个后端相结合,就可得到各个语言在某种机器上的编译器。
2.文法和语言的形式描述
1)字母表、字符串、字符串集合及运算
· 字母表∑和字符:字母表是字符的非空有穷集合,字符是字母表∑中的一个元素。例如∑={a,b},a或b是字符。
· 字符串:∑中的字符组成的有穷序列。例如a,ab,aaa都是∑上的字符串。
· 字符串的长度:指字符串中的字符个数。如|aba|=3。
· 空串ε:由零个字符组成的序列,|ε|=0。
· 连接:字符串S和T的连接是指将串T接续在串S之后,表示为S·T,连接符号·可省略。显然,对于字母表∑上的任意字符串S,S·ε=ε·S=S。
· ∑:是指包括空串ε在内的∑上所有字符串的集合。例如,设∑={a,b},∑={ε,a,b,aa,bb,ab,ba,aaa,……}。
· 字符串的方幂:把字符串α自身连接n次得到的串,称为字符串α的n次方幂,记为αn。α0=ε,αn=ααn-1=αn-1α(n>0)。
· 字符串集合的运算:设A,B代表字母表∑上的两个字符串集合。
◇ 或(合并):A∪B={α|α∈A或α∈B}。
◇ 积(连接):AB={αβ|α∈A且β∈B}。
◇ 幂:An=A·An-1=An-1·A(n>0),并规定A0={ε}。
◇ 正则闭包+:A+=A1∪A2∪A3∪…∪An∪…。
◇ 闭包:A=A0∪A+。显然,∑*=∑0∪∑1∪∑2∪…∪∑n∪…。
2)文法和语言的形式描述
语言L是有限字母表∑上有限长度字符串的集合,这个集合中的每个符号串都是按照一定的规则生成的。下面从产生语言的角度出发,给出文法和语言的形式定义。所谓产生语言,是指制定出有限个规则,借助它们就能产生此语言的全部句子。
(1)文法的定义。描述语言语法结构的形式规则称为文法。文法G是一个四元组,可表示为G=(VN,VT,P,S),其中VT是一个非空有限集,其每个元素称为一个终结符;VN是一个非空有限集,其每个元素称为非终结符。VN∩VT=Ф,即VN和VT不含公共元素。令V=VN∪VT,称V为文法G的词汇表,V中的符号称为文法符号,包括终结符和非终结符。S∈VN,称为开始符号,它至少要在一条产生式中作为左部出现。P是产生式的有限集合,每个产生式是形如“α→β”的规则,其中,α称为产生式的左部,α∈V+且α中至少含有一个非终结符;β称为产生式的右部,且β∈V*。若干个产生式α→β1,α→β2,…,α→βn的左部相同时,可简写为α→β1|β2|…|βn,称βi(1≤i≤n)为α的一个候选式。
(2)文法的分类。乔姆斯基(Chomsky)把文法分成4种类型,即0型、1型、2型和3型。这4类文法之间的差别在于对产生式要施加不同的限制。若文法G=(VN,VT,P,S)的每个产生式α→β,均有α∈(VN∪VT),α至少含有一个非终结符,且β∈(VN∪VT),则称G为0型文法。对0型文法的每条产生式分别施加以下限制,则可得以下文法。
· 1型文法:G的任何产生式α→β(S→ε除外)均满足|α|≤|β|(|x|表示x中文法符号的个数)。
· 2型文法:G的任何产生式形如A→β,其中A∈VN,β∈(VN∪VT)*。
· 3型文法:G的任何产生式形如A→a或A→aB(或者A→Ba),其中A,B∈VN,a∈VT。
0型文法也称为短语文法,其能力相当于图灵机,任何0型语言都是递归可枚举的;反之,递归可枚举集也必定是一个0型语言。1型文法也称为上下文有关文法,这种文法意味着对非终结符的替换必须考虑上下文,并且一般不允许替换成ε串。例如,若αAB→αγβ是1型文法的产生式,α和β不全为空,则非终结符A只有在左边是α,右边是β的上下文中才能替换成γ。2型文法就是上下文无关文法,非终结符的替换无需考虑上下文。3型文法等价于正规式,因此也被称为正规文法或线性文法。
(3)句子和语言。设有文法G=(VN,VT,P,S)
· 推导与直接推导:推导就是从文法的开始符号S出发,反复使用产生式,将产生式左部的非终结符替换为右部的文法符号序列(展开产生式用⇒表示),直到产生一个终结符的序列时为止。若有产生式α→β∈P,γ,δ∈V*,则γαδ⇒γβδ称为文法G中的一个直接推导,并称γαδ可直接推导出γβδ。显然,对P中的每一个产生式α→β都有α⇒β。若在文法中存在一个直接推导序列,即α0⇒α1⇒α2⇒…⇒αn(n>0),则称α0可推导出αn,αn是α0的一个推导,并记为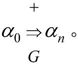 用记号
用记号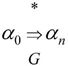 表示α0=αn或者
表示α0=αn或者
· 直接归约和归约(推导的逆过程):若文法G中有一个直接推导α⇒β则称β可直接归约成α,或α是β的一个直接归约。若文法G中有一个推导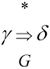 则称δ可归约成γ,或γ是δ的一个归约。
则称δ可归约成γ,或γ是δ的一个归约。
· 句型和句子:若文法G的开始符号为S,那么,从开始符号S能推导出的符号串称为文法的一个句型,即α是文法G的一个句型,当且仅当有如下推导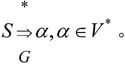 若X是文法G的一个句型,且
若X是文法G的一个句型,且 则称X是文法G的一个句子,即仅含终结符的句型是一个句子。
则称X是文法G的一个句子,即仅含终结符的句型是一个句子。
· 语言:从文法G的开始符号出发,能推导出的句子的全体称为文法G产生的语言,记为L(G)。
(4)文法的等价。若文法G1与文法G2产生的语言相同,即L(G1)=L(G2),则称这两个文法是等价的。
3.词法分析
语言中具有独立含义的最小语法单位是符号(单词),如标识符、无符号常数与界限符等。词法分析的任务是把构成源程序的字符串转换成单词符号序列。词法规则可用3型文法(正规文法)或正规表达式描述,它产生的集合是语言基本字符集∑(字母表)上的字符串的一个子集,称为正规集。
1)正规表达式和正规集
对于字母表∑,其上的正规式及其表示的正规集可以递归定义如下。
(1)ε是一个正规式,它表示集合L(ε)={ε}。
(2)若a是∑上的字符,则a是一个正规式,它所表示的正规集为{a}。
(3)若正规式r和s分别表示正规集L(r)和L(s),则:
①r|s是正规式,表示集合L(r)∪L(s)。
②r·s是正规式,表示集合L(r)L(s)。
③r是正规式,表示集合(L(r))。
④(r)是正规式,表示集合L(r)。
仅由有限次地使用上述三个步骤定义的表达式才是∑上的正规式,其中运算符“|”、“·”、“”分别称为“或”、“连接”和“闭包”。在正规式的书写中,连接运算符“·”可省略。运算符的优先级从高到低顺序排列为“”、“·”、“|”。
设∑={a,b},表2-1列出了∑上的一些正规式和相应的正规集。
表2-1 正规式与正规集示例
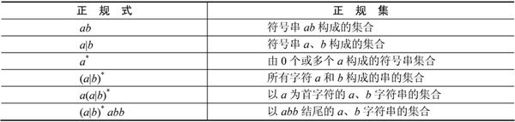
若两个正规式表示的正规集相同,则认为二者等价。两个等价的正规式U和V记为U=V。例如,b(ab)=(ba)b,(a|b)=(ab)。设U、V和W均为正规式,正规式的代数性质如表2-2所示。
表2-2 正规式的代数性质

2)有限自动机
有限自动机是一种识别装置的抽象概念,它能准确地识别正规集。有限自动机分为两类:确定的有限自动机和不确定的有限自动机。
(1)确定的有限自动机(Deterministic Finite Automata, DFA)。一个确定的有限自动机是个五元组(S,∑,f,s0,Z),其中:
· S是一个有限集,其每个元素称为一个状态。
· ∑是一个有穷字母表,其每个元素称为一个输入字符。
· f是S×∑→S上的单值部分映像。f(A,a)=Q表示当前状态为A、输入为a时,将转换到下一状态Q。称Q为A的一个后继状态。
· s0∈S,是唯一的一个开始状态。
· Z是非空的终止状态集合,Z⊆S。
一个DFA可以用两种直观的方式表示:状态转换图和状态转换矩阵。状态转换图简称为转换图,是一个有向图。DFA中的每个状态对应转换图中的一个节点,DFA中的每个转换函数对应图中的一条有向弧,若转换函数为f(A,a)=Q,则该有向弧从节点A出发,进入节点Q,字符a是弧上的标记。
【例2.1】 已知有DFA M1=({s0,s1,s2,s3},{a,b},f,S,{s3}),其中f为:
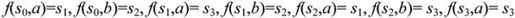
与DFA M1对应的状态图如图2-7(a)所示,其中,双圈表示的节点是终态节点。状态转换矩阵可以用一个二维数组M表示,矩阵元素M[A,a]的行下标表示状态,列下标表示输入字符,M[A,a]的值是当前状态为A、输入为a时,应转换到的下一状态。与DFA M1对应的状态转换矩阵如图2-7(b)所示。在转换矩阵中,一般以第一行的行下标所对应的状态作为初态,而终态则需要特别指明。

图2-7 DFA的状态转换图和转换矩阵
对于∑中的任何字符串ω,若存在一条从初态节点到某一终止状态节点的路径,且这条路径上所有弧的标记符连接成的字符串等于ω,则称ω可由DFA M识别(接受或读出)。若一个DFA M的初态节点同时又是终态节点,则空字ε可由该DFA识别(或接受)。DFA M所能识别的语言L(M)={ω|ω是从M的初态到终态的路径上的弧上标记所形成的串}。
∑上的一个字符串集合V是正规的,当且仅当存在∑上的一个DFA M,且V=L(M)。
(2)不确定的有限自动机(Nondeterministic Finite Automata, NFA)。一个不确定的有限自动机也是一个五元组,它与确定有限自动机的区别如下。
①f是S×∑→2S上的映像。对于S中的一个给定状态及输入符号,返回一个状态的集合。即当前状态的后继状态不一定是唯一确定的。
②有向弧上的标记可以是ε。
【例2.2】 已知有NFA N=({s0,s1,s2,s3},{a,b},f,S,{s3}),其中f为:
f(s0,a)=s0,f(s0,a)=s1,f(s0,b)=s0,f(s1,b)=s2,f(s2,b)=s3
与NFA M2对应的状态转换图和状态转换矩阵如图2-8所示。
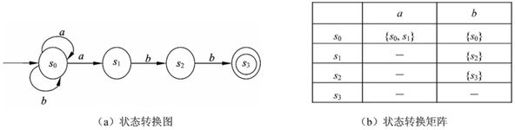
图2-8 NFA的状态转换图和转换矩阵
显然,DFA是NFA的特例。实际上,对于每个NFA M,都存在一个DFA N,且L(M)=L(N)。
对于任何两个有限自动机M1和M2,如果L(M1)=L(M2),则称M1和M2是等价的。
3)NFA到DFA的转换
任何一个NFA都可以转换为DFA,下面先定义转换过程中需要的计算。
(1)若I是NFA N的状态集合的一个子集,定义ε_CLOSURE(I)如下。
· 状态集I的ε_CLOSURE(I)是一个状态集。
· 状态集I的所有状态属于ε_CLOSURE(I)。
· 若s∈I,那么从s出发经过任意条ε弧到达的状态s′都属于ε_CLOSURE(I)。
状态集εCLOSURE(I)称为I的ε闭包。
由以上的定义可知,I的ε闭包就是从状态集I的状态出发,经ε所能到达的状态的全体。
假定I是NFA N的状态集的一个子集,a是∑中的一个字符,定义:
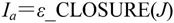
其中,J是所有那些可从I中的某一状态节点出发经过一条a弧而到达的状态节点的全体。
在定义了ε_CLOSURE后,就可以用子集法将一个NFA转换为一个DFA。
(2)NFA转换为DFA。设NFAN=(S,∑,f,s0,Z),与之等价的DFA M=(S′,∑,f',q0,Z′),用子集法将非确定的有限自动机确定化的算法步骤如下。
①求出DFA M的初态q0,即令q0=ε_CLOSURE({s0}),此时S′仅含初态q0,并且没有标记。
②对于S′中尚未标记的状态qi={si1,si2,…,sim},sij∈S(j=1,…,m)进行以下处理。
· 标记qi,以说明该状态已经计算过。
· 对于每个a∈∑,令T=f({si1,si2,…,sim},a),qj=ε_CLOSURE(T)。
· 若qj尚不在S′中,则将qj作为一个未加标记的新状态添加到S′,并把状态转换函数f′(qi,a)=qj添加到DFA M中。
③重复进行步骤②,直到S′中不再有未标记的状态时为止。
④令Z′={q|q∈S′且q∩Z≠φ}。
【例2.3】 已知一个识别正规式ab*a的非确定有限自动机,其状态转换图如图2-9所示,用子集法将其转换为DFA M。
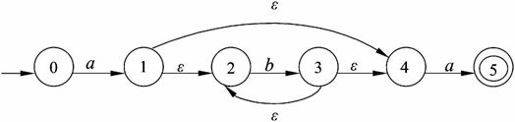
图2-9 ab*a的NFA状态转换图
根据ε_CLOSURE的定义,可以求出ε_CLOSURE({0})={0},将{0}记为DFA的初态q0。然后根据题中所给的状态转换图以及算法步骤②求解DFA M的各个状态的过程如下。
ε_CLOSURE(q0,a)={1,2,4},将{1,2,4}记为q1;ε_CLOSURE(q0,b)={},标记q0。
ε_CLOSURE(q1,a)={5},将{5}记为q2(终态)。
ε_CLOSURE(q1,b)={2,3,4},将{2,3,4}记为q3,标记q1。
ε_CLOSURE(q2,a)={},ε_CLOSURE(q2,b)={},标记q2。
ε_CLOSURE(q3,a)={5},即q2。
ε_CLOSURE(q3,b)={2,3,4},即q3,标记q3。
当S′中不再有未标记的状态时,算法即可终止,所得的DFA M如图2-10所示。
4)DFA的最小化
从NFA转换得到的DFA不一定是最简化的,可以通过等价变换将DFA进行最小化处理。
对于有限自动机中的任何两个状态t和s,若从其中一个状态出发接受输入字符串ω,而从另一状态出发不接受ω,或者从t和s出发到达不同的接受状态,则称ω对状态s和t是可区分的。若状态s和t不可区分,则称其为可以合并的等价状态。
对图2-10所示的自动机进行化简所得的DFA如图2-11所示。
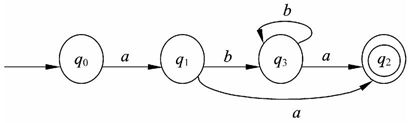
图2-10 识别ab*a的DFA示意图
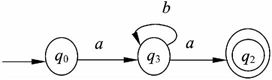
图2-11 识别ab*a的最小化DFA示意图
4.正规式与有限自动机之间的转换
1)有限自动机转换为正规式
对于∑上的NFA M,可以构造一个∑上的正规式R,使得L(R)=L(M)。
拓广状态转换图的概念,令每条弧可用一个正规式作标记。为∑上的NFA M构造相应的正规式R,分为如下两步。
(1)在M的状态转换图中加两个节点,一个x节点,一个y节点。从x节点到NFA M的初始状态节点引一条弧并用ε标记,从NFA M的所有终态节点到y节点引一条弧并用ε标记。形成一个与M等价的M′,M′只有一个初态x和一个终态y。
(2)按下面的方法逐步消去M′中除x和y的所有节点。在消除节点的过程中,用正规式来标记弧,最后节点x和y之间弧上的标记就是所求的正规式。消除节点的规则如图2-12所示。
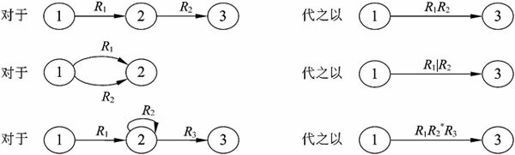
图2-12 有限自动机到正规式的转换规则示意图
2)正规式转换为有限自动机
同样地,对于∑上的每个正规式R,可以构造一个∑上的NFA M,使得L(M)=L(R)。
(1)对于正规式R,可用图2-13所示的拓广状态图表示。
(2)通过对正规式R进行分裂并加入新的节点,逐步把图转变成每条弧上的标记是∑上的一个字符或ε,转换规则如图2-14所示。
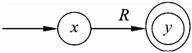
图2-13 拓广状态图

图2-14 正规式到有限自动机的转换规则示意图
最后所得的图即为一个NFA M,x为初态节点,y为终态节点。显然,L(M)=L(R)。
5.词法分析器的构造
有了正规式和有限自动机的理论基础后,就可以构造出编译程序的词法分析模块。构造词法分析器的一般步骤如下。
(1)用正规式描述语言中的单词构成规则。
(2)为每个正规式构造一个NFA,它识别正规式所表示的正规集。
(3)将构造出的NFA转换成等价的DFA。
(4)对DFA进行最小化处理,使其最简。
(5)从DFA构造词法分析器。
6.语法分析
语法分析的任务是根据语言的语法规则,分析单词串是否构成短语和句子,即表达式、语句和程序等基本语言结构,同时检查和处理程序中的语法错误。程序设计语言的绝大多数语法规则可以采用上下文无关文法进行描述。语法分析方法有多种,根据产生语法树的方向,可分为自底向上和自顶向下两类。
1)上下文无关文法
上下文无关文法属于乔姆斯基定义的2型文法,被广泛地用于表示各种程序设计语言的语法规则。对于上下文无关文法G[S]=(VN,VT,P,S),其产生式的形式都是A→β,其中A∈VN,β∈(VN∪VT)*。
若不加特别说明,下面用大写英文字母A、B、C等表示非终结符,小写英文字母a、b、c等表示终结符号,u,v,w等表示终结符号串,小写希腊字母α、β、γ、δ等表示终结符和非终结符混合的文法符号串。由于一个上下文无关文法的核心部分是其产生式集合,所以文法可以简写为其产生式集合的描述形式。
(1)规范推导(最右推导)。如果在推导的任何一步α⇒β(其中α、β是句型),都是对α中的最右(最左)非终结符进行替换,则称这种推导为最右(最左)推导。最右推导常称为规范推导。
(2)短语、直接短语和句柄。设αδβ是文法G的一个句型,即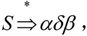 且满足
且满足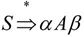 和
和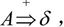 则称δ是句型αδβ相对于非终结符A的短语。特别地,如果有A⇒δ,则称δ是句型αδβ相对于产生式A→δ的直接短语。一个句型的最左直接短语称为该句型的句柄。
则称δ是句型αδβ相对于非终结符A的短语。特别地,如果有A⇒δ,则称δ是句型αδβ相对于产生式A→δ的直接短语。一个句型的最左直接短语称为该句型的句柄。
【例2.4】 对于简单算术表达式,可以用下面的文法G[E]进行描述。
G[E]=({E,T,F},{+,*,(,),id},P,E)
P={E→T|E+T,T→F|T*F,F→(E)|id}
可以证明,id+id*id是该文法的句子。下面用最右推导的方式从文法的开始符号出发推导出该句子。为了表示推导过程中相同符号的不同出现,给符号加一个下标。
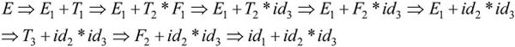
该推导过程可以用树型结构进行描述,如图2-15所示。
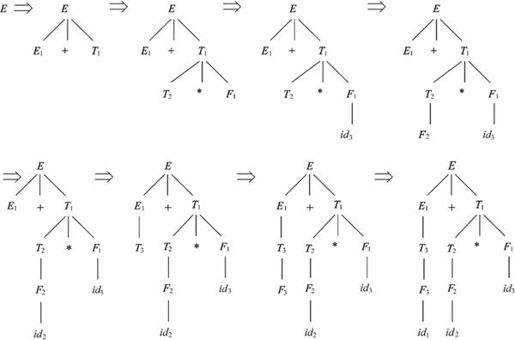
图2-15 推导过程示意图
由于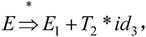 且
且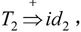 所以id2是句型
所以id2是句型 的相对于非终结符T的短语。
的相对于非终结符T的短语。
由于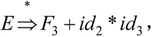 且F3⇒id1,所以id1是句型
且F3⇒id1,所以id1是句型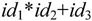 相对于非终结符F的短语,也是相对于产生式F→id的直接短语。
相对于非终结符F的短语,也是相对于产生式F→id的直接短语。
由于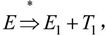 且
且 所以
所以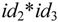 是句型
是句型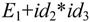 的相对于非终结符T的短语。
的相对于非终结符T的短语。
由于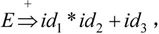 所以
所以 是句型
是句型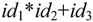 的相对于非终结符E的短语。
的相对于非终结符E的短语。
实际上id1,id2,id3,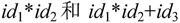 都是句型
都是句型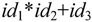 的短语,而且id1、id2、id3均是直接短语,其中id1是最左直接短语,即句柄。
的短语,而且id1、id2、id3均是直接短语,其中id1是最左直接短语,即句柄。
2)自顶向下语法分析方法
自顶向下分析法的基本思想是:对于给定的输入串ω,从文法的开始符号S出发进行最左推导,直到得到一个合法的句子或者发现一个非法结构。在推导的过程中试图用一切可能的方法,自上而下、从左到右地为输入串ω建立语法树。整个分析过程是一个试探的过程,是反复使用不同产生式谋求与输入序列匹配的过程。若输入串是给定文法的句子,则必能成功,反之必然出错。
文法中存在下述产生式时,自顶向下分析过程中会出现下面的问题。
(1)若文法中存在形如A→αβ|αδ的产生式,即A产生式中有多于一个候选项的前缀相同(称为公共左因子,简称左因子),则可能导致分析过程中的回溯处理。
(2)若文法中存在形如A→Aα的产生式,由于采取了最左推导,可能会造成分析过程陷入死循环的情况,产生式的这种形式被称为左递归。
因此,需要对文法进行改造,消除其中的左递归,以避免分析陷入死循环;提取左因子,以避免回溯。
(1)消除文法的左递归。
①消除直接左递归。一般而言,假定非终结符号A的产生式为A→Aα|β,其中,α不等于ε,β不以A开头,那么就对A的产生式进行如下的改造:
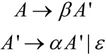
由于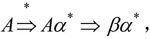 可知改造前后关于A的产生式是等价的。将上述结果推广到更一般的情况:先将非终结符A的产生式整理为如下形式。
可知改造前后关于A的产生式是等价的。将上述结果推广到更一般的情况:先将非终结符A的产生式整理为如下形式。
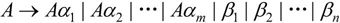
其中,αi(1≤i≤m)都不等于ε,βj(1≤j≤n)都不以A开头,然后用“A→β1A′|β2A′|…|βnA′和A′→α1A′|α2A′|…|αmA′|ε”代替A产生式。
②消除文法中一切左递归。消除文法中所有左递归的方法是:对产生式的右部进行代换,将所有的非直接左递归产生式改造为直接的左递归产生式,然后消除文法中的直接左递归产生式。
【例2.5】 对于文法G[E]=({E,T,F},{+,*,(,),id},P,E)
P={E→T|E+T,T→F|T*F,F→(E)|id},消除左递归后的文法为:
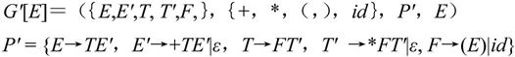
(2)提取公共左因子。假定关于A的产生式为A→αβ1|αβ2|…|αβn,那么称α为A的候选式的公共左因子(简称左因子)。如果A的产生式有左因子,推导过程中会出现无法确定用A产生式的哪个候选式替换A的情况,这时可以重写A产生式来推迟这种决定,直到看见足够的输入,能正确做出选择时为止,因此可将A的产生式改为A→αA′和A′→β|β2|…|βn。
经反复提取,就能使每个非终结符(包括新引进的)的任意两个候选式不含有公共前缀。
(3)LL(1)文法。一个文法G是LL(1)的,当且仅当G的任何两个产生式A→α|β满足下面的条件。
①对任何终结符a,α和β不能同时推导出以a开始的文法符号序列。
②α和β最多有一个可以推导出ε。
③若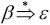 ,则α不能推导出以FOLLOW(A)中的终结符开始的任何文法符号序列。
,则α不能推导出以FOLLOW(A)中的终结符开始的任何文法符号序列。
下面说明FIRST(α)和FOLLOW(A)的含义。非形式地讲,文法符号序列α的FIRST集合,就是从α出发可以推导出的所有以终结符号开头的序列中的开头终结符号。而一个非终结符的FOLLOW集合,就是从文法开始符号可以推导出的所有含A句型中紧跟在A之后的终结符号。
①文法符号序列α的FIRST集合定义如下:
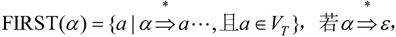 约定ε∈FIRST(α)。
约定ε∈FIRST(α)。
求解一个文法符号的FIRST集合时,先将每一个文法符号X(X∈VN∪VT)的IRST(X)置空,然后应用以下规则。
· 若X∈VT,则将FIRST(X)={X}。
· 若X∈VN,则考查其产生式。
· 若有X→ε,则将ε加入FIRST(X)。
· 若有X→a…,且a∈VT,则将a加入FIRST(X)。
· 若有X→Y1Y2…Yk,且Y1∈VN,则将FIRST(Y1)中除ε之外的所有元素加入FIRST(X);
若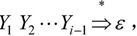 则将FIRST(Yi)中除ε之外的所有元素加入FIRST(X);特别地,若ε∈FIRST(Yj),j=1,2,…,k,则将ε加入FIRST(X)。
则将FIRST(Yi)中除ε之外的所有元素加入FIRST(X);特别地,若ε∈FIRST(Yj),j=1,2,…,k,则将ε加入FIRST(X)。
· 反复执行以上两步,直到每个文法符号的FIRST集合不再扩大时为止。
②非终结符A的FOLLOW集合定义如下:
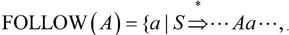 且a∈VT},若A是某个句型的最右符号,则约定#属于FOLLOW(A)。
且a∈VT},若A是某个句型的最右符号,则约定#属于FOLLOW(A)。
求解一个文法中非终结符A的FOLLOW集合时,先将FOLLOW(A)置空,然后应用以下规则。
· 若A是文法的开始符号,则将#加入FOLLOW(A),#是输入结束标记。
· 若有产生式A→αBβ,则将FIRST(β)中除ε之外的所有元素加入FOLLOW(B)中。
· 若有产生式A→αB,或A→αBβ且ε∈FIRST(β),则将FOLLOW(A)中的全体元素加入FOLLOW(B)中。
【例2.6】 对文法G[E]=({E,E′,T,T′,F,},{+,*,(,),id},P,E)
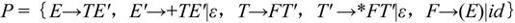
对于终结符号a,显然FIRST(a)={a},所以下面只列出文法中非终结符号的FIRST和FOLLOW集合的计算结果。
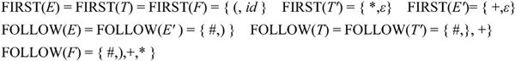
(4)递归下降分析法。递归下降分析法要求文法是LL(1)文法,它直接以程序的方式模拟产生式产生语言的过程,其基本思想是:为每一个非终结符构造一个子程序,每个子程序的过程体按该产生式候选项分情况展开,遇到终结符即进行匹配,而遇到非终结符则调用相应的子程序。该分析法从调用文法开始符号的子程序开始,直到所有非终结符都展开为终结符并得到匹配为止。若分析过程可以达到这一步,则表明分析成功,否则表明输入串中有语法错误。递归下降分析法的优点是简单且易于构造,缺点是程序与文法直接相关,对文法的任何改变都需要在程序中进行相应的修改。
(5)预测分析法。预测分析法是另一种自顶向下的分析方法,其基本模型如图2-16所示。
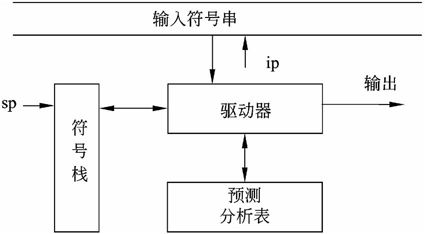
图2-16 预测分析模型示意图
一个LL(1)文法的预测分析表可以用一个二维数组M表示,其元素M[A,a](A∈VN,a∈VT∪#)存放关于A的产生式,表明当遇到输入符号为a且用A进行推导时,所应采用的产生式;若M[A,a]为error,则表明推导时遇到了不该出现的符号,应进行出错处理。构造一个文法的预测分析表的过程如下。
①对文法的每个产生式A→α,执行②和③。
②对FIRST(α)的每个终结符a,加入A→α到M[A,a]。
③若ε∈FIRST(α),则对FOLLOW(A)的每个非终结符b(包括#),加入A→α到M[A,b]中。
④M中其他没有定义的条目置为error。
预测分析法的工作过程是:初始时,将“#”和文法的开始符号依次压入栈中;在分析过程中,根据输入串中的当前输入符号a和当前的栈顶符号X进行处理。
若X=a=′#′,则分析成功;若X=′#′且a≠′#′,则出错。
若X∈VT且X=a,则X退栈,并读入下一个符号a;若X∈VT且X≠a,则出错。
若X∈VN且M[X,a]=′A→α′,则X退栈,α中的符号从右到左依次进栈(ε无须进栈);若M[X,a]=′error′,则调用出错程序进行处理。
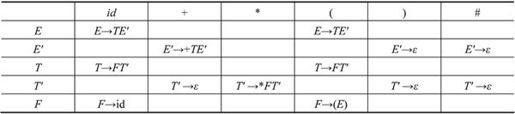
根据文法G[E]={E→TE′,E′→+TE′|ε,T→FT′,T′→*FT′|ε,F→(E)|id}构造的预测分析表为:
3)自底向上语法分析方法
自底向上分析方法也称移进—归约分析法,工作模型如图2-17所示。其基本思想是对输入序列ω自左向右进行扫描,并将输入符号逐个移进一个栈中,边移进边分析,一旦栈顶符号串形成某个句型的可归约串时,就用某个产生式的左部非终结符来替代,这称为一步归约。重复这一过程,直至栈中只剩下文法的开始符号且输入串也被扫描完时为止,确认输入串ω是文法的句子,表明分析成功;否则,进行出错处理。
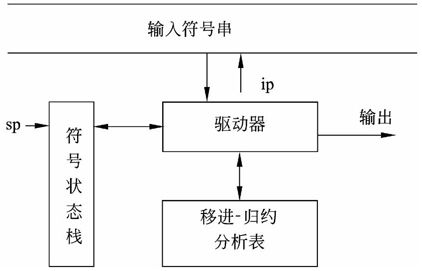
图2-17 移进-归约分析模型
移进-归约分析法的数学模型是下推自动机。若模型中采用算符优先分析表,用“最左素短语”来刻画“可归约串”,则相应的分析器称为算符优先分析器;若采用LR分析表,用“句柄”来刻画“可归约串”,则相应的分析器称为LR分析器。
LR分析法是一种规范归约分析法。规范归约是规范推导(最右推导)的逆过程,下面举例说明规范归约的过程。
【例2.7】 设文法G[S]={S→aAcBe,A→b,A→Ab,B→d},下面对输入串#abbcde#(#为开始和结束标志符号)进行分析。先设一个符号栈,并把句子左括号“#”放入栈底,其分析过程如下。
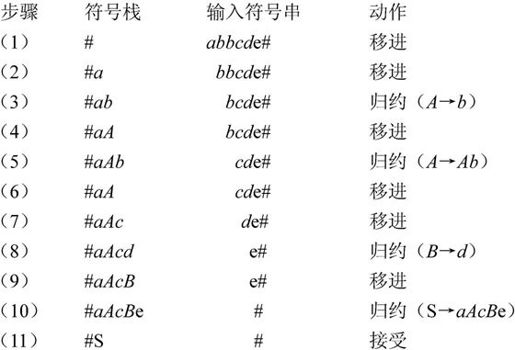
说明:在第(3)步中栈顶符号串b是句型abbcde的句柄,用产生式A→b进行归约;第(5)步中Ab是句型aAbcde的句柄,用相应产生式A→Ab进行归约;第(8)步和第(10)步是同样的道理。上述分析过程也可看成是自底向上构造语法树的过程。
LR分析法根据当前分析栈中的符号串(通常以状态表示)和向右顺序查看输入串的k个(k≥0)符号,就可唯一确定分析器的动作是移进还是归约,以及用哪条产生式进行归约,因而也就能唯一地确定句柄。当k=1时,已能满足当前绝大多数高级语言编译程序的需求。常用的LR分析器有LR(0)、SLR(1)、LALR(1)和LR(1)。
一个LR分析器由如下三个部分组成。
(1)驱动器。或称驱动程序。对所有LR分析器,驱动程序都是相同的。
(2)分析表。不同的文法具有不同的分析表。同一文法采用不同的LR分析器时,分析表也不同。分析表又可分为动作表(ACTION)和状态转换表(GOTO)两个部分,它们都可用二维数组表示。
(3)分析栈。包括文法符号栈和相应的状态栈。
分析器的动作由栈顶状态和当前输入符号决定(LR(0)分析器不需向前查看输入符号),LR分析器的模型如图2-18所示。
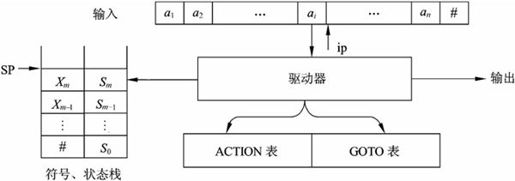
图2-18 LR分析器模型示意图
其中SP为栈顶指针,Si为状态,Xi为文法符号。ACTION[Si,a]=Sj规定了栈顶状态为Si且遇到输入符号a时应执行的动作。状态转换表GOTO[Si,X]=Sj表示当状态栈顶为Si且文法符号栈顶为X时应转向状态Sj。
LR分析器的工作过程以格局的变化来反映。格局的形式为:(栈,剩余输入,动作)。分析是从某个初始格局开始的,经过一系列的格局变化,最终达到接受格局,表明分析成功;或者达到出错格局,表明发现一个语法错误。因此,开始格局的剩余输入应该是全部的输入序列,而接受格局中的剩余输入应该为空,任何其他格局或者出错格局中的剩余输入应该是全部输入序列的一个后缀。
在LR分析过程中,改变格局的动作有以下4种。
(1)移进(shift)。当ACTION[Si,a]=Sj时,把a移进文法符号栈并转向状态Sj。
(2)归约(reduce)。当在文法符号栈顶形成句柄β时,把β归约为相应产生式A→β的非终结符A。若β的长度为r(即|β|=r),则弹出文法符号栈顶的r个符号,然后将A压入文法符号栈中。
(3)接受(accept)。当文法符号栈中只剩下文法的开始符号S,并且输入符号串已经结束时(当前输入符是“#”),分析成功。
(4)报错(error)。当输入串中出现不该有的文法符号时,就报错。
LR分析器的核心部分是分析表的构造,这里不再详述。
7.语法制导翻译和中间代码生成
程序语言的语义分为静态语义和动态语义。描述程序语义的形式化方法主要有属性文法、公理语义、操作语义和指称语义等,其中属性文法是对上下文无关文法的扩充。目前应用最广的静态语义分析方法是语法制导翻译,其基本思想是将语言结构的语义以属性的形式赋予代表此结构的文法符号,而属性的计算以语义规则的形式赋予文法的产生式。在语法分析的推导或归约的步骤中,通过语义规则实现对属性的计算,以达到对语义的处理。
1)中间代码
从原理上讲,对源程序进行语义分析之后就可以直接生成目标代码,但由于源程序与目标代码的逻辑结构往往差别很大,特别是考虑到具体机器指令系统的特点,要使翻译一次到位很困难,而且用语法制导方式机械生成的目标代码往往是繁琐和低效的,因此有必要设计一种中间代码,将源程序首先翻译成中间代码表示形式,以利于进行与机器无关的优化处理。由于中间代码实际上也起着编译器前端和后端分水岭的作用,所以使用中间代码也有助于提高编译程序的可移植性。常用的中间代码有后缀式、三元式、四元式和树等形式。
(1)后缀式(逆波兰式)。逆波兰式是波兰逻辑学家卢卡西维奇(Lukasiewicz)发明的一种表示表达式的方法。这种表示方式把运算符写在运算对象的后面,例如,把a+b写成ab+,所以也称为后缀式。这种表示法的优点是根据运算对象和算符的出现次序进行计算,不需要使用括号,也便于用栈实现求值。对于表达式x:=(a+b)(c+d),其后缀式为xab+cd+:=。
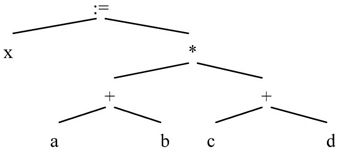
(2)树形表示。例如,表达式x:=(a+b)*(c+d)的树形表示为:
(3)三元式表示。三元式是由运算符OP、第一运算对象ARG1和第二运算对象ARG2组成的。例如,表达式x:=(a+b)*(c+d)的三元式表示为:

(4)四元式表示。四元式是一种普遍采用的中间代码形式,其组成成分为运算符OP、第一运算对象ARG1、第二运算对象ARG2和运算结果RESULT。其中,运算对象和运算结果有时指用户自定义的变量,有时指编译程序引入的临时变量,RESULT总是一个新引进的临时变量,用来存放运算结果。例如,表达式x:=(a+b)*(c+d)的四元式表示为:
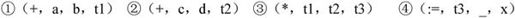
2)常见语法单位的翻译
常见的语法单位主要有算术表达式、布尔表达式、赋值语句和控制语句(if、while)等。不同结构需要不同的处理方法,但翻译程序的构造原理是相似的。
对于各种语法单位的语法制导翻译,一般是在相应的语法规则中加入适当的语义处理,下面先说明一些翻译过程中要使用的语义变量和语义过程。
· Entry(id):在符号表中查找标识符id以获取它在表中的位置(入口)。
· S.code:语句S被翻译后形成的代码序列。
· E.place:与非终结符E相联系的语义变量,表示存放E值的变量名在符号表的入口或整数码(若此变量是临时变量)。
· E.tc:当表达式E的值为真时控制流转向的语句标号(四元式的地址编号)。
· E.fc:当表达式E的值为假时控制流转向的语句标号(四元式的地址编号)。
· GEN(OP,ARG1,ARG2,RESULT):产生四元式(OP,ARG1,ARG2,RESULT)填进四元式表中。
· NXQ:表示下一个将要形成但尚未形成的四元式地址(编号)。NXQ的初值为1,每执行一次GEN(),NXQ就自动累增1。
· Merg(P1,P2):把以P1和P2为链首的两条链合并为一条链,并返回合并后的链首指针。
· Backpatch(p,t):把p所链接的每条四元式的第4项都以t作为值进行填充。
· Newtemp:生成一个新的临时存储单元。
拉链与回填的基本思想是当一个四元式中存在尚不确定的转向地址时,将所有转向同一地址的四元式链接成一个链表,一旦转向地址被确定,则沿此链向所有的四元式回填该地址。
下面简单说明程序语言中常见结构的语法制导翻译方法。
(1)赋值语句及简单算术表达式的翻译。下面的产生式描述了由简单变量,算术加、乘、取负运算和圆括号构成的简单算术表达式,以及将一个算术表达式赋值给一个简单变量的赋值语句的形式规则。
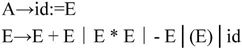
为该文法编写的语义规则如下:

(2)布尔表达式的翻译。布尔表达式常用于表示控制结构中的条件,其计算过程可采用直接计算和短路计算两种形式。直接计算是指布尔表达式中的每个因子都进行运算,而短路计算是指只要表达式的值能够确定下来,就停止计算。下面介绍布尔表达式作为控制条件时的翻译方法(采用短路计算方式)。
布尔表达式的形式定义(文法)为:
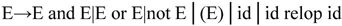
其中,relop代表关系运算符(<、>、≤、≥、=、≠),运算符的优先级和结合律遵照通常的习惯。E→E(1) and E(2),E→E(1) or E(2)的代码结构如图2-19(a)和图2-19(b)所示。
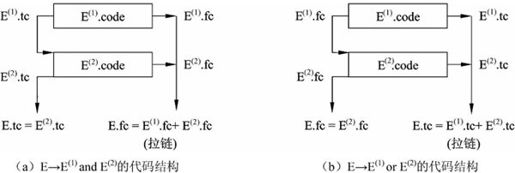
图2-19 and与or的代码结构示意图
改写文法并编写语义子程序如下。
对于E→E(1) and E(2),为记住E(2)的第一条四元式的地址,需改写为:
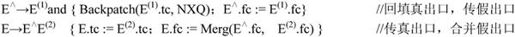
对于E→E(1) or E(2),为记住E(2)的第一条四元式的地址,需改写为:
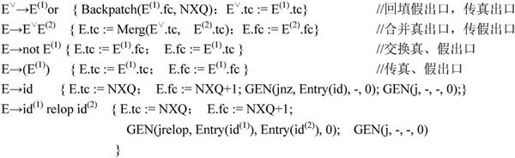
(3)常见语句的翻译。下面简单说明if语句和while语句的翻译方法,其形式定义为:
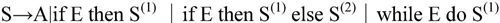
用语义变量S.chain记录语句结束后的转向地址。回填工作将在处理S的外层环境的某个时刻完成。If语句的代码结构如图2-20所示,while循环语句的代码结构如图2-21所示。
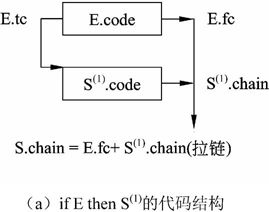
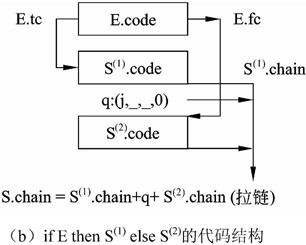
图2-20 if语句的代码结构
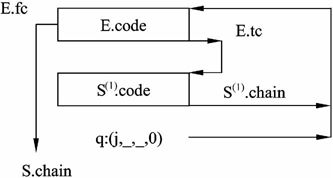
图2-21 while E do S(1)的代码结构

【例2.8】 设NXQ的初值为1,每产生一条四元式,NXQ的值就增1,将语句if a<b then while a<b do a:=a+b翻译成四元式的主要步骤如下。
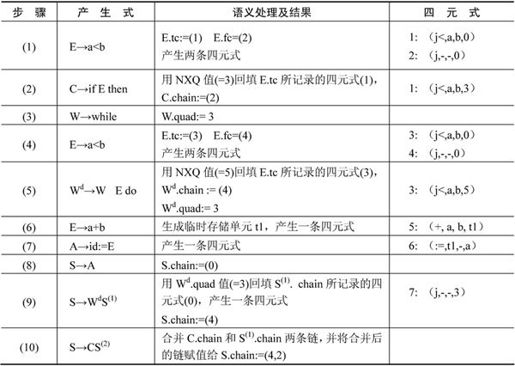
最后产生的四元式序列如下所示,其中2,4两条四元式有待于回填。
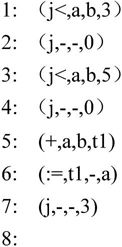
4)动态存储分配和过程调用的翻译
过程(函数)说明和过程(函数)调用是程序中一种常见的语法结构,绝大多数语言都含有这方面的内容。过程说明和调用语句的翻译,有赖于形式参数与实际参数结合的方式以及数据空间的分配方式。
由于各种语言的不同特点,在目标程序运行时,对存储空间的分配和组织有不同的要求,在编译阶段应产生相应的目标来满足不同的要求。需要分配存储空间的对象有基本数据类型(如整型、实型和布尔型等)、结构化数据类型(如数组和记录等)和连接数据(如返回地址、参数等)。分配的依据是名字的作用域和生存期的定义规则。分配的策略有静态存储分配和动态存储分配两大类。
如果在编译时就能确定目标程序运行时所需的全部数据空间的大小,则在编译时就安排好目标程序运行时的全部数据空间,并确定每个数据对象的存储位置。这种分配策略称为静态存储分配。FORTRAN语言的早期版本可以完全采用静态存储分配策略。
如果一个程序语言允许递归过程和可变数据结构,那么就需采用动态存储分配技术。动态存储分配策略的实现有栈分配方式和堆分配方式两种。在栈式动态存储分配中,将程序的数据空间设计为一个栈,每当调用一个过程时,它所需的数据空间就分配在栈顶;每当过程执行结束时,就释放这部分空间。若空间的使用未必服从“先申请后释放”的原则,那么栈式的动态存储分配方式就不适用了,这种情况下通常使用堆分配技术。下面仅就一个简单的栈式分配为例,说明过程调用和过程说明的翻译。
考虑一种简单的程序语言结构:没有分程序结构,过程定义不嵌套,但允许过程递归调用。
称过程(函数)的一次运行为一个活动。活动是一个动态的概念,除了设计为永不停机的过程(如操作系统等),或者是因为设计错误而出现死循环的情况外,任何过程的活动均有有限的生存期。每个活动在运行时的环境就称为它的活动记录。一般情况下,一个活动记录的内容如图2-22(a)所示,活动记录内容的一种安排方式如图2-22(b)所示。其中,SP指向当前活动记录在控制栈中的起始位置,TOP指向栈顶位置。


图2-22 过程的活动记录
设SP总是指向现行过程活动记录的起点,TOP始终指向栈顶单元,则过程调用语句call P(T1,T2,…,Tn)的四元式序列是:

(1)在运行时,para和call应产生传递参数和进行调用的代码。

(2)转入过程P后,就进入过程说明的代码。

(3)过程说明中数组说明的代码,调整TOP的代码。
(4)过程体内执行语句的代码(用SP变址方式访问数据对象)。
(5)退出过程语句时,return(E)的代码序列为。

8.中间代码优化和目标代码生成
优化就是对程序进行等价变换,使得从变换后的程序能生成更有效的目标代码。所谓等价,是指不改变程序的运行结果;所谓有效,是指目标代码运行时间较短,占用的存储空间较少。优化可在编译的各个阶段进行。最主要的优化是在目标代码生成以前对中间代码进行的,这类优化不依赖于具体的计算机。
目标代码的生成由代码生成器实现。代码生成器以经过语义分析或优化后的中间代码为输入,以特定的机器语言或汇编代码为输出。代码生成所需考虑的主要问题如下所述。
(1)中间代码形式。中间代码有多种形式,其中树与后缀表示形式适用于解释器,而编译器多采用与机器指令格式较接近的四元式形式。
(2)目标代码形式。目标代码可以分为两大类:汇编语言形式和机器指令形式。机器指令形式的目标代码又可以根据需求的不同分为绝对机器指令代码和可再定位机器代码。绝对机器代码的优点是可以立即执行,一般应用于一类称为load-and-go形式的编译模式,即编译后立即执行,不形成存在外存上的目标代码文件。可再定位机器代码的优点是目标代码可以被任意链接并装入内存的任意位置,是编译器采用较多的代码形式。汇编语言作为一种中间输出形式,便于进行分析和测试。
(3)寄存器的分配。由于存取寄存器的速度远快于存取内存单元的速度,所以总是希望尽可能多地使用寄存器存储数据,而寄存器的个数是有限的,因此,如何分配及使用寄存器,是目标代码生成时需要着重考虑的。
(4)计算次序的选择。代码执行的效率会随计算次序的不同有较大的差别。在生成正确目标代码的前提下,适当地安排计算次序并优化代码序列,也是生成目标代码时要考虑的重要因素之一。
2.2.3 解释程序基本原理
解释程序是另一种语言处理程序,在词法、语法和语义分析方面与编译程序的工作原理基本相同,但是在运行用户程序时,它直接执行源程序或源程序的内部形式。因此,解释程序不产生源程序的目标程序,这是它和编译程序的主要区别。图2-23显示了解释程序实现高级语言的三种方式。
源程序被直接解释执行的处理方式如图2-23中的标记A所示。这种解释程序对源程序进行逐个字符的检查,然后执行程序语句规定的动作。例如,如果扫描到符号序列:
解释程序就开始搜索源程序中标号L的定义位置(即L后面紧跟冒号“:”的语句位置)。这类解释程序通过反复扫描源程序来实现程序的运行,运行效率很低。
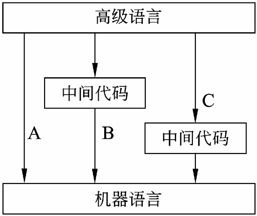
图2-23 解释器类型示意图
解释程序也可以先将源程序翻译成某种中间代码形式,然后对中间代码进行解释来实现用户程序的运行,这种翻译方式如图2-23中的标记B和C所示。通常,在中间代码和高级语言的语句间存在一一对应的关系。APL和SNOBOL4的很多实现就采用这种方法。解释方式B和C的不同之处在于中间代码的级别,在方式C下,解释程序采用的中间代码更接近于机器语言。在这种实现方案中,高级语言和低级中间代码间存在着1-n的对应关系。PASCAL-P解释系统是这类解释程序的一个实例,它在词法分析、语法分析和语义基础上,先将源程序翻译成P-代码,再由一个非常简单的解释程序来解释执行这种p-代码。这类系统具有比较好的可移植性。
1.解释程序的基本结构
解释程序通常可以分成两部分:第一部分是分析部分,包括通常的词法分析、语法分析和语义分析程序,经语义分析后把源程序翻译成中间代码,中间代码常采用逆波兰表示形式。第二部分是解释部分,用来对第一部分产生的中间代码进行解释执行。下面简要介绍第二部分的工作原理。
设用数组MEM模拟计算机的内存,源程序的中间代码和解释部分的各个子程序都存放在数组MEM中。全局变量PC是一个程序计数器,它记录了当前正在执行的中间代码的位置。这种解释部分的常见结构可以由下面两部分组成。
(1)PC:=PC+1。
(2)执行位于opcode-table[MEM[PC]]的子程序(解释子程序执行后返回到前面)。
下面用一个简单例子来说明其工作原理。设两个实型变量A和B进行相加的中间代码是:

其中,中间代码Ipush和Iaddreal实际上都是opcode-table表的索引值(即位移),而该表的单元中存放的值就是对应的解释子程序的起始地址,A和B都是MEM中的索引值。解释部分开始执行时,PC的值为start-1。

解释部分可表示如下:

其中,stackreal()表示把相应值压入栈中,而popreal()表示取得栈顶元素值并弹出栈顶元素。上面的代码基于栈实现了将两个数值相加并将结果存入栈中的处理。
2.高级语言编译与解释方式的比较
对于高级语言的编译和解释工作方式,可以从以下几个方面进行比较。
(1)效率。编译比解释方式可能取得更高的效率。
一般情况下,在解释方式下运行程序时,解释程序可能需要反复扫描源程序。例如,每一次引用变量都要进行类型检查,甚至需要重新进行存储分配,从而降低了程序的运行速度。在空间上,以解释方式运行程序需要更多的内存,因为系统不但需要为用户程序分配运行空间,而且要为解释程序及其支撑系统分配空间。
在编译方式下,编译程序除了对源程序进行语法和语义分析外,还要生成源程序的目标代码并进行优化,所以这个过程比解释方式需要更多的时间。虽然与仔细写出的机器程序相比,一般由编译程序创建的目标程序运行的时间更长,需要占用的存储空间更多,但源程序只需要被编译程序翻译一次,就可以多次运行。因此总体来讲,编译方式比解释方式可能取得更高的效率。
(2)灵活性。由于解释程序需要反复检查源程序,这也使得解释方式能够比编译方式更灵活。当解释器直接运行源程序时,“在运行中”修改程序就成为可能,例如增加语句或者修改错误等。另外,当解释器直接在源程序上工作时,它可以对错误进行更精确地定位。
(3)可移植性。解释器一般也是用某种程序设计语言编写的,因此只要对解释器进行重新编译,就可以使解释器运行在不同的环境中。
由于编译和解释的方法各有特点,因此现有的一些编译系统既提供编译的方式,也提供解释的方式,甚至将两种方式进行结合。例如,在Java虚拟机上发展的一种compiling-just-in-time新技术,就是在代码第一次运行时进行编译,在其后的运行中就不再进行编译了。
