第7章 数据库技术基础
数据库技术是研究数据库的结构、存储、设计、管理和应用的一门软件学科。数据库系统本质上是一个用计算机存储信息的系统。数据库管理系统是位于用户与操作系统之间的一层数据管理软件,其基本目标是提供一个可以方便、有效地存取数据库信息的环境。数据库就是信息的集合,它是收集计算机数据的仓库或容器,系统用户可以对这些数据执行一系列操作。设计数据库系统的目的是为了管理大量信息,给用户提供数据的抽象视图,即系统隐藏有关数据存储和维护的某些细节。对数据的管理涉及到信息存储结构的定义,信息操作机制的提供,安全性保证,以及多用户对数据的共享问题。
本章主要介绍一些背景知识和基本概念,使读者了解数据库的基本内容,形成数据库系统的总体框架,了解数据库系统在计算机系统中的地位以及数据库系统的功能。
7.1 基本概念
7.1.1 数据库与数据库管理系统
数据是描述事物的符号记录,它具有多种表现形式,可以是文字、图形、图像、声音和语言等。信息是现实世界事物的存在方式或状态的反映。信息具有可感知、可存储、可加工、可传递和可再生等自然属性,信息已是社会各行各业不可缺少的资源,这也是信息的社会属性。数据是信息的符号表示,而信息是具有特定释义和意义的数据。
数据库系统(DataBase System, DBS)是一个采用了数据库技术,有组织地、动态地存储大量相关联数据,方便多用户访问的计算机系统。广义上讲,DBS是由数据库、硬件、软件和人员组成。
(1)数据库(DataBase, DB)。是统一管理的、长期储存在计算机内的,有组织的相关数据的集合。其特点是数据间联系密切、冗余度小、独立性较高、易扩展,并且可为各类用户共享。
(2)硬件。构成计算机系统的各种物理设备,包括存储数据所需的外部设备。硬件的配置应满足整个数据库系统的需要。
(3)软件。其中包括操作系统、数据库管理系统及应用程序。数据库管理系统(DataBase Management System, DBMS)是数据库系统的核心软件,要在操作系统的支持下工作,解决如何科学地组织和储存数据,如何高效地获取和维护数据的系统软件。其主要功能包括数据定义功能、数据操纵功能、数据库的运行管理和数据库的建立与维护。
(4)人员。人员主要有4类。第一类为系统分析员和数据库设计人员,系统分析员负责应用系统的需求分析和规范说明,他们和用户及数据库管理员一起确定系统的硬件配置,并参与数据库系统的概要设计;数据库设计人员负责数据库中数据的确定、数据库各级模式的设计。第二类为应用程序员,负责编写使用数据库的应用程序,这些应用程序可对数据进行检索,建立,删除或修改。第三类为最终用户,他们应用系统的接口或利用查询语言访问数据库。第四类用户是数据库管理员(Data Base Administrator, DBA),负责数据库的总体信息控制。DBA的具体职责包括决定数据库中的信息内容和结构;决定数据库的存储结构和存取策略;定义数据库的安全性要求和完整性约束条件;监控数据库的使用和运行;数据库的性能改进、数据库的重组和重构,以提高系统的性能。
7.1.2 DBMS的功能
DBMS主要是实现对共享数据有效地组织、管理和存取,因此DBMS应具有如下几个方面的功能。
1.数据定义
DBMS提供数据定义语言(Data Definition Language, DDL),用户可以对数据库的结构描述,包括外模式、模式和内模式的定义;数据库的完整性定义;安全保密定义,如口令、级别和存取权限等。这些定义存储在数据字典中,是DBMS运行的基本依据。
2.数据库操作
DBMS向用户提供数据操纵语言(Data Manipulation Language, DML),实现对数据库中数据的基本操作,如检索、插入、修改和删除。DML分为两类:宿主型和自含型。所谓宿主型,是指将DML语句嵌入某种主语言(如C、COBOL等)中使用;自含型是指可以单独使用DML语句,供用户交互使用。
3.数据库运行管理
数据库在运行期间多用户环境下的并发控制、安全性检查和存取控制、完整性检查和执行、运行日志的组织管理、事务管理和自动恢复等是DBMS的重要组成部分。这些功能可以保证数据库系统的正常运行。
4.数据组织、存储和管理
DBMS分类组织、存储和管理各种数据,包括数据字典、用户数据和存取路径等。要确定以何种文件结构和存取方式在存储级上组织这些数据,以提高存取效率。实现数据间的联系、数据组织和存储的基本目标是提高存储空间的利用率。
5.数据库的建立和维护
数据库的建立和维护包括数据库的初始建立、数据的转换、数据库的转储和恢复、数据库的重组和重构、性能监测和分析等。
6.其他功能
如DBMS与网络中其他软件系统的通信功能,一个DBMS与另一个DBMAS或文件系统的数据转换功能等。
7.1.3 DBMS的特征及分类
1.DBMS的特征
通过DBMS来管理数据具有如下特点。
(1)数据结构化且统一管理。数据库中的数据由DBMS统一管理。由于数据库系统采用复杂的数据模型表示数据结构,数据模型不仅描述数据本身的特点,还描述数据之间的联系。数据不再面向某个应用,而是面向整个应用系统。数据易维护、易扩展,数据冗余明显减少,真正实现了数据的共享。
(2)有较高的数据独立性。数据的独立性是指数据与程序独立,将数据的定义从程序中分离出去,由DBMS负责数据的存储,应用程序关心的只是数据的逻辑结构,无须了解数据在磁盘上的数据库中的存储形式,从而简化应用程序,大大减少应用程序编制的工作量。数据的独立性包括数据的物理独立性和数据的逻辑独立性。
(3)数据控制功能。DBMS提供了数据控制功能,以适应共享数据的环境。数据控制功能包括对数据库中数据的安全性、完整性、并发和恢复的控制。
① 数据库的安全性保护。数据库的安全性(security)是指保护数据库以防止不合法的使用所造成的数据泄漏、更改或破坏。这样,用户只能按规定对数据进行处理,例如,划分了不同的权限,有的用户只能有读数据的权限,有的用户有修改数据的权限,用户只能在规定的权限范围内操纵数据库。
② 数据的完整性。数据库的完整性是指数据库正确性和相容性,是防止合法用户使用数据库时向数据库加入不符合语义的数据。保证数据库中数据是正确的,避免非法的更新。
③ 并发控制。在多用户共享的系统中,许多用户可能同时对同一数据进行操作。DBMS的并发控制子系统负责协调并发事务的执行,保证数据库的完整性不受破坏,避免用户得到不正确的数据。
④ 故障恢复。数据库中的4类故障是事务内部故障、系统故障、介质故障及计算机病毒。故障恢复主要是指恢复数据库本身,即在故障引起数据库当前状态不一致后,将数据库恢复到某个正确状态或一致状态。恢复的原理非常简单,就是要建立冗余(redundancy)数据。换句话说,确定数据库是否可恢复的方法就是其包含的每一条信息是否都可以利用冗余地存储在别处的信息重构。冗余是物理级的,通常认为逻辑级是没有冗余的。
2.DBMS分类
DBMS通常可分为如下三类。
(1)关系数据库系统(Relation DataBase Systems, RDBS)。是支持关系模型的数据库系统。在关系模型中,实体以及实体间的联系都是用关系来表示。在一个给定的现实世界领域中,相应于所有实体及实体之间联系的关系的集合构成一个关系数据库,也有型和值之分。关系数据库的型也称为关系数据库模式,是对关系数据库的描述,是关系模式的集合。关系数据库的值也称为关系数据库,是关系的集合。关系数据库模式与关系数据库通常统称为关系数据库。在计算机方式下常见的FOXPRO和ACCESS等DBMS,严格地讲不能算是真正的关系型数据库,对许多关系类型的概念并不支持,但它却因为简单实用、价格低廉,目前拥有很大的用户市场。
(2)面向对象的数据库系统(Object-Oriented DataBase System, OODBS)。是支持以对象形式对数据建模的数据库管理系统,这包括对对象的类、类属性的继承、子类的支持。面向对象数据库系统主要有两个特点:一是面向对象数据模型能完整描述现实世界的数据结构,能表达数据间的嵌套、递归的联系;二是具有面向对象技术的封装性和继承性,提高了软件的可重用性。
(3)对象关系数据库系统(Object-Oriented Relation DataBase System, ORDBS)。是在传统的关系数据模型基础上,提供元组、数组、集合一类更为丰富的数据类型以及处理新的数据类型操作的能力,这样形成的数据模型被称为“对象关系数据模型”,基于对象关系数据模型的DBS称为对象关系数据库系统。
7.1.4 数据库系统的体系结构
数据库系统是数据密集型应用的核心,其体系结构受数据库运行所在的计算机系统的影响很大,尤其是受计算机体系结构中的联网、并行和分布的影响。站在不同的角度或不同层次上看,数据库系统体系结构也不同。站在最终用户的角度看,数据库系统体系结构分为集中式、分布式、C/S(客户端/服务器)和并行结构。站在数据库管理系统的角度看,数据库系统体系结构一般采用三级模式结构。
1.集中式数据库系统
分时系统环境下的集中式数据库系统结构诞生于20世纪60年代中期。当时的硬件和操作系统决定了分时系统环境下的集中式数据库系统结构成为早期数据库技术的首选结构。在这种系统中,不但数据是集中的,数据的管理也是集中的,数据库系统的所有功能,从形式的用户接口到DBMS核心都集中在DBMS所在的计算机上,如图7-1所示。目前大多数关系DBMS的产品也是从这种系统结构开始发展的,目前这种系统还在使用。
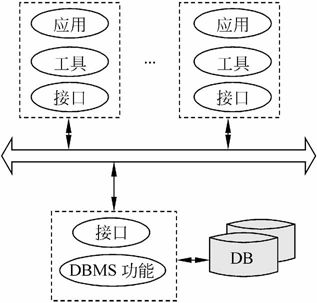
图7-1 集中式服务器结构
2.客户端/服务器体系结构
随着网络技术的迅猛发展,很多现代软件都采用客户端/服务器体系结构,在这种结构中,一个处理机(客户端)的请求被送到另一个处理机(服务器)上执行。其主要特点是客户端与服务器CPU之间的职责明确,客户端主要负责数据表示服务,而服务器主要负责数据库服务。
采用客户端/服务器结构后,数据库系统功能分为前端和后端。前端主要包括图形用户界面、表格生成和报表处理等工具;后端负责存取结构、查询计算和优化、并发控制以及故障恢复等。前端与后端通过SQL或应用程序来接口。ODBC(开放式数据库互连)和JDBC(Java程序数据库连接)标准定义了应用程序和数据库服务器通信的方法,也即定义了应用程序接口,应用程序用它来打开与数据库的连接、发送查询和更新以及获取返回结果等。
数据库服务器一般可分为事务服务器和数据服务器。
(1)事务服务器。事务服务器也称查询服务器。它提供一个接口,使得客户端可以发出执行一个动作的请求,服务器响应客户端请求,并将执行结果返回给客户端。用户端可以用SQL,也可以通过应用程序或使用远程过程调用机制来表达请求。一个典型的事务服务器系统包括多个在共享内存中访问数据的进程,包括服务器进程、锁管理进程、写进程、监视进程和检查点进程。
(2)数据服务器。数据服务器系统使得客户端可以与服务器交互,以文件或页面为单位对数据进行读取或更新。数据服务器与文件服务器相比提供更强的功能,所支持的数据单位可比文件还要小,如页、元组或对象;提供数据的索引机制和事务机制,使得客户端或进程发生故障时数据也不会处于不一致状态。
3.并行数据库系统
并行体系结构的数据库系统是多个物理上连在一起的CPU,而分布式系统是多个地理上分开的CPU。并行体系结构的数据库类型分为共享内存式多处理器和无共享式并行体系结构。
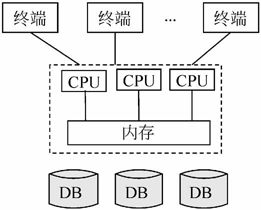
图7-2 共享式多处理器体系结构
1)共享内存式多处理器
共享内存式多处理器是指一台计算机上同时有多个活动的CPU,它们共享单个内存和一个公共磁盘接口,如图7-2所示。这种并行体系结构最接近于传统的单CPU处理器结构,其设计的主要挑战是用N个CPU来得到N倍单CPU的性能。但是,因为不同的CPU对公共内存的访问是平等的,这样可能会导致一个CPU被访问的数据被另一个CPU修改,所以必须要有特殊的处理。然而,由于内存访问采用的是一种高速机制,这种机制很难保证进行内存划分时不损失效率,所以这些共享内存访问问题会随着CPU个数的增加而变得难以解决。
2)无共享式并行体系结构
无共享式并行体系结构是指一台计算机上同时有多个活动的CPU,并且它们都有自己的内存和磁盘,如图7-3所示,图中粗线表示高速网络。在不产生混淆的情况下,也称为并行数据库系统。各个承担数据库服务责任的CPU划分它们自身的数据,通过划分的任务以及通过每秒兆位级的高速网络通信完成事务查询。
4.分布式数据库系统
分布式DBMS包括物理上分布、逻辑上集中的分布式结构和物理上分布、逻辑上分布的分布式数据库结构两种。前者的指导思想是把单位的数据模式(称为全局数据模式)按数据来源和用途,合理分布在系统的多个节点上,使大部分数据可以就地或就近存取。数据在物理上分布后,由系统统一管理,使用户不感到数据的分布。后者一般由两部分组成:一是本节点的数据模式,二是本节点共享的其他节点上有关的数据模式。节点间的数据共享由双方协商确定。这种数据库结构有利于数据库的集成、扩展和重新配置。
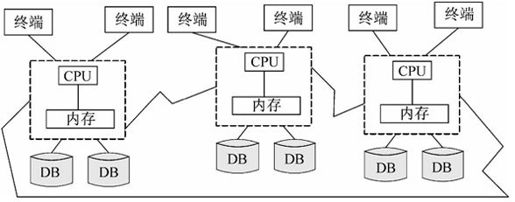
图7-3 无共享式并行体系结构
7.1.5 数据库的三级模式结构
实际上,数据库的产品很多,它们支持不同的数据模型,使用不同的数据库语言,建立在不同的操作系统上。数据的存储结构也各不相同,但体系结构基本上都具有相同的特征,采用“三级模式和两级映像”。如图7-4所示。
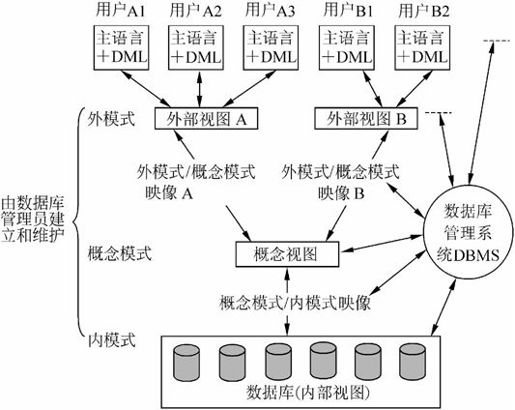
图7-4 数据库系统体系结构
数据库系统采用三级模式结构,这是数据库管理系统内部的系统结构。数据库有“型”和“值”的概念,“型”是指对某一数据的结构和属性的说明,“值”是型的一个具体赋值。
数据库系统设计员可在视图层、逻辑层和物理层对数据抽象,通过外模式、概念模式和内模式来描述不同层次上的数据特性。
1.概念模式
概念模式也称模式,是数据库中全部数据的逻辑结构和特征的描述,它由若干个概念记录类型组成,只涉及到型的描述,不涉及到具体的值。概念模式的一个具体值称为模式的一个实例,同一个模式可以有很多实例。
概念模式反映的是数据库的结构及其联系,所以是相对稳定的;而实例反映的是数据库某一时刻的状态,所以是相对变动的。
需要说明的是,概念模式不仅要描述概念记录类型,还要描述记录间的联系、操作、数据的完整性和安全性等要求。但是,概念模式不涉及到存储结构、访问技术等细节。只有这样,概念模式才算做到了“物理数据独立性”。
描述概念模式的数据定义语言称为“模式DDL(Schema Data Definition Language)”。
2.外模式
外模式也称用户模式或子模式,是用户与数据库系统的接口,是用户用到的那部分数据的描述。它由若干个外部记录类型组成。用户使用数据操纵语言对数据库进行操作,实际上是对外模式的外部记录进行操作。
描述外模式的数据定义语言称为“外模式DDL”。有了外模式后,程序员不必关心概念模式,只与外模式发生联系,按外模式的结构存储和操纵数据。
3.内模式
内模式也称存储模式,是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。定义所有的内部记录类型、索引和文件的组织方式,以及数据控制方面的细节。
例如,记录的存储方式是顺序存储,按照B树结构存储,还是Hash方法存储;索引按照什么方式组织;数据是否压缩存储,是否加密;数据的存储记录结构有何规定。
需要说明的是,内部记录并不涉及到物理记录,也不涉及到设备的约束。比内模式更接近于物理存储和访问的那些软件机制是操作系统的一部分(即文件系统)。例如,从磁盘上读、写数据。
描述内模式的数据定义语言称为“内模式DDL”。
总之,数据按外模式的描述提供给用户,按内模式的描述存储在磁盘上,而概念模式提供了连接这两极模式的相对稳定的中间观点,并使得两级的任意一级的改变都不受另一级的牵制。
4.两级映像
数据库系统在三级模式之间提供了两级映像:模式/内模式映像、外模式/模式映像。正因为这两级映像保证了数据库中的数据具有较高的逻辑独立性和物理独立性。
(1)模式/内模式的映像。存在于概念级和内部级之间,实现了概念模式到内模式之间的相互转换。
(2)外模式/模式的映像。存在于外部级和概念级之间,实现了外模式到概念模式之间的相互转换。
数据的独立性是指数据与程序独立,将数据的定义从程序中分离出去,由DBMS负责数据的存储,从而简化应用程序,大大减少应用程序编制的工作量。数据的独立性是由DBMS的二级映像功能来保证的。数据的独立性包括数据的物理独立性和数据的逻辑独立性。
(1)数据的物理独立性。是指当数据库的内模式发生改变时,数据的逻辑结构不变。由于应用程序处理的只是数据的逻辑结构,这样物理独立性可以保证,当数据的物理结构改变了,应用程序不用改变。但是,为了保证应用程序能够正确执行,需要修改概念模式/内模式之间的映像。
(2)数据的逻辑独立性。是指用户的应用程序与数据库的逻辑结构是相互独立的。数据的逻辑结构发生变化后,用户程序也可以不修改。但是,为了保证应用程序能够正确执行,需要修改外模式/概念模式之间的映像。
7.2 数据模型
7.2.1 数据模型的基本概念
模型就是对现实世界特征的模拟和抽象,数据模型是对现实世界数据特征的抽象。对于具体的模型人们并不陌生,如航模飞机、地图和建筑设计沙盘等都是具体的模型。最常用的数据模型分为概念数据模型和基本数据模型。
(1)概念数据模型。也称信息模型,是按用户的观点对数据和信息建模,是现实世界到信息世界的第一层抽象,强调其语义表达功能,易于用户理解,是用户和数据库设计人员交流的语言,主要用于数据库设计。这类模型中最著名的是实体联系模型,简称E-R模型。
(2)基本数据模型。它是按计算机系统的观点对数据建模,是现实世界数据特征的抽象,用于DBMS的实现。基本的数据模型有层次模型、网状模型、关系模型和面向对象模型(Object Oriented Model)。
7.2.2 数据模型的三要素
数据库结构的基础是数据模型,是用来描述数据的一组概念和定义。数据模型的三要素是数据结构、数据操作和数据的约束条件。
(1)数据结构。是所研究的对象类型的集合,是对系统静态特性的描述。
(2)数据操作。对数据库中各种对象(型)的实例(值)允许执行的操作的集合,包括操作及操作规则。如操作有检索、插入、删除和修改,操作规则有优先级别等。数据操作是对系统动态特性的描述。
(3)数据的约束条件。是一组完整性规则的集合。也就是说,对于具体的应用数据必须遵循特定的语义约束条件,以保证数据的正确、有效和相容。例如,某单位人事管理中,要求在职的“男”职工的年龄必须大于18岁小于60,工程师的基本工资不能低于1500元,每个职工可担任一个工种,这些要求可以通过建立数据的约束条件来实现。
7.2.3 E-R模型
概念模型是对信息世界建模,所以概念模型能够方便、准确地表示信息世界中的常用概念。概念模型有很多种表示方法,其中最为常用的是P. P. S. Chen于1976年提出的实体-联系方法(Entity Relationship Approach)。该方法用E-R图来描述现实世界的概念模型,称为实体-联系模型(Entity-Relationship Model,E-R模型)。
E-R模型是软件工程设计中的一个重要方法,因为它接近于人的思维方式,容易理解并且与计算机无关,所以用户容易接受,是用户和数据库设计人员交流的语言。但是,E-R模型只能说明实体间的语义联系,还不能进一步地详细说明数据结构。在解决实际应用问题时,通常应该先设计一个E-R模型,然后再把其转换成计算机能接受的数据模型。
1.实体
在E-R模型中,实体用矩形表示,通常矩形框内写明实体名。实体是现实世界中可以区别于其他对象的“事件”或“物体”。例如,企业中的每个人都是一个实体。每个实体由一组特性(属性)来表示,其中的某一部分属性可以唯一标识实体,如职工号。实体集是具有相同属性的实体集合,例如,学校所有教师具有相同的属性,因此教师的集合可以定义为一个实体集;学生具有相同的属性,因此学生的集合可以定义为另一个实体集。
2.联系
在E-R模型中,联系用菱形表示,通常菱形框内写明联系名,并用无向边分别与有关实体连接起来,同时在无向边旁标注上联系的类型(1∶1、1∶n或m∶n)。实体的联系分为实体内部的联系和实体与实体之间的联系。实体内部的联系反映数据在同一记录内部各字段间的联系。
1)两个不同实体之间的联系
两个不同实体集之间存在如下三种联系类型。
● 一对一(1∶1)。指实体集E1中的一个实体最多只与实体集E2中的一个实体相联系。
● 一对多(1∶n)。表示实体集E1中的一个实体可与实体集E2中的多个实体相联系。
● 多对多(m∶n)。表示实体集E1中的多个实体可与实体集E2中的多个实体相联系。
例如,图7-5表示两个不同实体集之间的联系。其中:
(1)电影院里一个座位只能坐一个观众,因此观众与座位之间是一个1∶1的联系,联系名为V_S,用E-R图表示如图7-5(a)所示。
(2)部门DEPT和职工EMP实体集,若一个职工只能属于一个部门,那么这两个实体集之间应是一个1∶n的联系,联系名为D_E,用E-R图表示如图7-5(b)所示。
(3)工程项目PROJ和职工EMP实体集,若一个职工可以参加多个项目,一个项目可以有多个职工参加,那么这两个实体集之间应是一个m∶n的联系,联系名为PR_E,用E-R图表示如图7-5(c)所示。
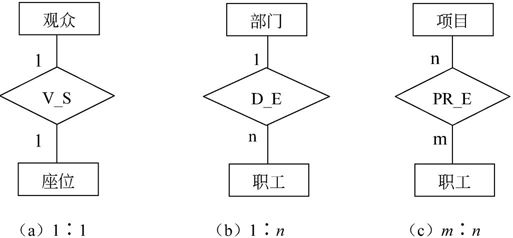
图7-5 两个不同实体集之间的联系
2)两个以上不同实体集之间的联系
两个以上不同实体集之间存在1∶1∶1、1∶1∶n、1∶m∶n和r∶m∶n的联系。例如,图7-6表示了三个不同实体集之间的联系。其中:
(1)图7-6(a)表示供应商Supp、项目Proj和零件Part之间多对多对多(r∶n∶m)的联系,联系名为SP_P。表示供应商为多个项目供应多种零件,每个项目可用多个供应商供应的零件,每种零件可由不同的供应商供应的语义。
(2)图7-6(b)表示病房、病人和医生之间一对多对多(1∶n∶m)的联系,联系名为P_D。表示一个特护病房有多个病人和多个医生,一个医生只负责一个病房,一个病人只属于一个病房的语义。
注意,三个实体集之间的多对多联系和三个实体集两两之间的多对多联系的语义是不同的。例如,供应商和项目实体集之间的“合同”联系,表示供应商为哪几个工程签了合同。供应商与零件两个实体集之间的“库存”联系,表示供应商库存零件的数量。项目与零件两个实体集之间的“组成”联系,表示一个项目由哪几种零件组成。
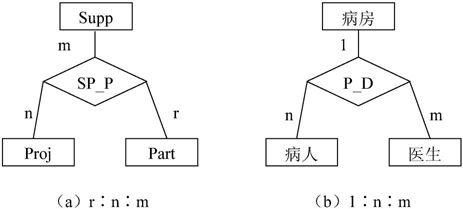
图7-6 三个不同实体集之间的联系
3)同一实体集内的二元联系
同一实体集内的各实体之间也存在1∶1、1∶n和m∶n的联系,如图7-7所示。
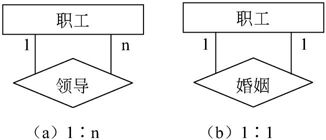
图7-7 同一实体集之间的1∶n和1∶1联系
从图中可见,职工实体集中的领导与被领导联系是1∶n的。但是,职工实体集中的婚姻联系是1∶1的。
3.属性
属性是实体某方面的特性。例如,职工实体集具有职工号、姓名、年龄、参加工作时间和通信地址等属性。每个属性都有其取值范围,如职工号为0001~9999的4位整型数,姓名为10位的字符串,年龄的取值范围为18~60等。在同一实体集中,每个实体的属性及其域是相同的,但可能取不同的值。E-R模型中的属性有如下分类。
(1)简单属性和复合属性。简单属性是原子的、不可再分的,复合属性可以细分为更小的部分(即划分为别的属性)。有时用户希望访问整个属性,有时希望访问属性的某个成分,那么在模式设计时可采用复合属性。例如,职工实体集的通信地址可以进一步分为邮编、省、市、街道。若不特别声明,通常指的是简单属性。
(2)单值属性和多值属性。前面所举的例子中,定义的属性对于一个特定的实体都只有单独的一个值。例如,对于一个特定的职工,只对应一个职工号、职工姓名,这样的属性叫做单值属性。但是,在某些特定情况下,一个属性可能对应一组值。例如,职工可能有0个、1个或多个亲属,那么职工的亲属的姓名可能有多个数目,这样的属性称为多值属性。
(3)NULL属性。当实体在某个属性上没有值或属性值未知时,使用NULL值。表示无意义或不知道。
(4)派生属性。派生属性可以从其他属性得来。例如,职工实体集中有“参加工作时间”和“工作年限”属性,那么“工作年限”的值可以由当前时间和参加工作时间得到。这里,“工作年限”就是一个派生属性。
4.E-R方法
概念模型中最常用的方法为实体-联系方法,简称E-R方法。该方法直接从现实世界中抽象出实体和实体间的联系,然后用非常直观的E-R图来表示数据模型。在E-R图中有表7-1所示的几个主要构件。
表7-1 E-R图中的主要构件
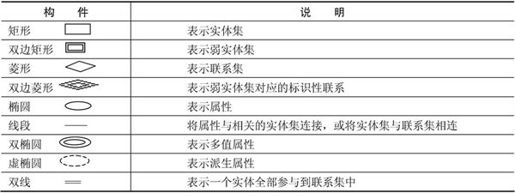
说明1:在E-R图中,实体集中作为主码的一部分属性以下划线标明。另外,在实体集与联系的线段上标上联系的类型。
说明2:在本书中,若不引起误解,实体集有时简称实体,联系集有时简称联系。
【例7.1】学校有若干个系,每个系有若干名教师和学生;每个教师可以担任若干门课程,并参加多项项目;每个学生可以同时选修多门课程。请设计该学校教学管理的E-R模型,要求给出每个实体、联系的属性。
解:该学校教学管理的E-R模型应该有5个实体:系、教师、学生、项目和课程。
(1)设计各实体属性如下:
系(系号,系名,主任名)
教师(教师号,教师名,职称)
学生(学号,姓名,年龄,性别)
项目(项目号,名称,负责人)
课程(课程号,课程名,学分)
(2)各实体之间的联系如下:
教师担任课程的1∶n“任课”联系;教师参加项目的n∶m“参加”联系;学生选修课程的n∶m“选修”联系;教师、学生与系之间所属关系的1∶n∶m“领导”联系。其中“参加”联系有一个排名属性,“选修”联系有一个成绩属性。
通过上述分析,该学校教学管理的E-R模型如图7-8所示。
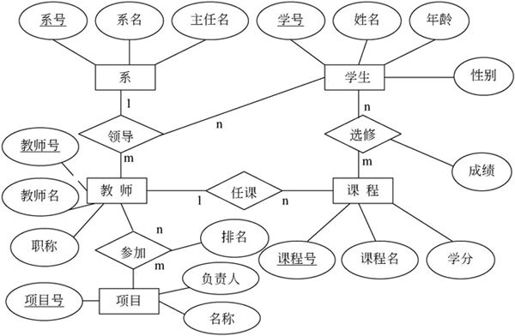
图7-8 学校教学管理的E-R模型
特别需要指出的是,E-R模型强调的是语义,与现实世界的问题密切相关。这句话的意思是,尽管都是学校教学管理,但由于不同的学校教学管理的方法可能会有不同的语义,因此会得到不同的E-R模型。
5.扩充的E-R模型
尽管基本的E-R模型足对大多数数据库特征建模,但数据库某些情况下的特殊语义,仅用基本E-R模型无法表达清楚。在这一节中,将讨论扩充的E-R模型,包括弱实体、特殊化、概括和聚集等概念。
1)弱实体
在现实世界中有一种特殊的联系,这种联系代表实体间的所有(ownership)关系,例如职工与家属的联系,家属总是属于某职工的。这种实体对于另一些实体具有很强的依赖关系,即一个实体的存在必须以另一个实体为前提,将这类实体称为弱实体。
在扩展的E-R图中,弱实体用双线矩形框表示。图7-9为职工与家属的E-R图。
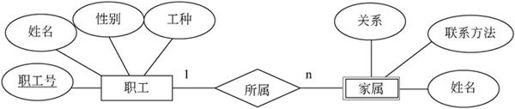
图7-9 弱实体与依赖联系
2)特殊化
前面已经介绍了,实体集是具有相同属性的实体集合。但在现实世界中,某些实体一方面具有一些共性,另一方面还具有各自的特殊性。这样,一个实体集可以按照某些特征区分为几个子实体。例如,学生实体集可以分为研究生、本科生和大专生等子集。将这种普遍到特殊的过程叫做“特殊化”。
将几个具有共同特性的实体集概括成一个更普遍的实体集的过程叫做“普遍化”。例如,可以将大专生、本科生和研究生概括为学生;还可以将学生、教师和职工概括为人。这就是从特殊到一般的过程。
设有实体集E,如果S是E的某些真子集的集合,记为S={Si|Si⊂E,i=1,2,…,n},则称S是E的一个特殊化,E是S1、S2、…、Sn的超类,S1、S2、…、Sn称为E的子类。
如果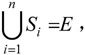 则称S是E的全特殊化,否则是E的部分特殊化。
则称S是E的全特殊化,否则是E的部分特殊化。
如果Si∩Sj=Φ,i≠j,则S是不相交特殊化,否则是重叠特殊化。
教职工实体集中的某个职工既是在职生又是教师或工人,那么在职生、教师和工人应该是重叠特殊化;而在职生、教师和工人的集合等于教职工,所以是全部特殊化。
在扩充的E-R模型中,子类继承超类的所有属性和联系,但是,子类还有自己特殊的属性和联系。例如,研究生除了学习外,还要参加科研项目。那么,研究生不仅要继承学生的所有属性,还要增加学位类型、导师的属性,并且需要增加与项目的联系。
在扩充的E-R图中,超类-子类关系模型使用特殊化圆圈和连线的一般方式来表示。超类到圆圈有一条连线,连线为双线表示全特殊化,连线为单线表示部分特殊化;双竖边矩形框表示子类;有符号“∪”的线表示特殊化;圆圈中的d表示不相交特殊化;圆圈中的o表示重叠特殊化;超类与圆圈用单线相连,则表示部分特殊化。图7-10给出了一个特殊化应用实例。
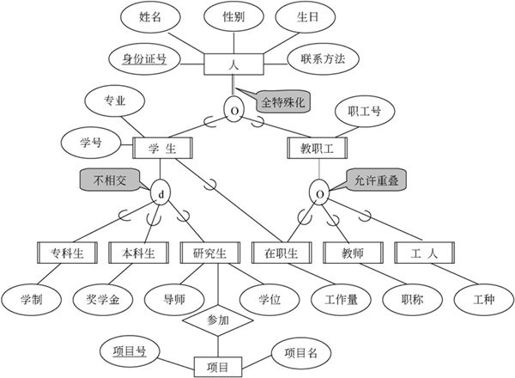
图7-10 特殊化应用实例
7.2.4 层次模型
层次模型(Hierarchical Model)采用树型结构表示数据与数据间的联系。在层次模型中,每一个节点表示一个记录类型(实体),记录之间的联系用节点之间的连线表示,并且根节点以外的其他节点有且仅有一个双亲节点。
【例7.2】某商场的部门、员工和商品三个实体的PEP模型如图7-11所示。在该模型中,每个部门有若干个员工,每个部门负责销售的商品有若干种,即该模型还表示部门到员工之间的一对多(1∶n)联系,部门到商品之间的一对多(1∶n)联系。

图7-11 层次模型
图7-11给出的只是PEP模型的“型”,而不是“值”。在数据库中,所谓“型”就是数据库模式,而“值”就是数据库实例。模式是数据库的逻辑设计,而数据库实例是给定时刻数据库中数据的一个快照。图7-12表示销售部的一个实例。该实例表示在某一时刻销售部是由李军负责,销售部下属有4个员工,负责销售的商品有5种。
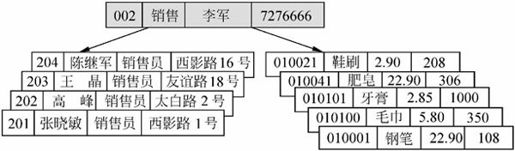
图7-12 层次模型实例
层次模型不能直接表示多对多的联系。若要表示多对多的联系,可采用如下两种方法。
(1)冗余节点法。两个实体的多对多联系转换为两个一对多联系。
该方法的优点是节点清晰,允许节点改变存储位置。缺点是需要额外的存储空间,有潜在的数据不一致性。
(2)虚拟节点分解法。将冗余节点转换为虚拟节点。虚拟节点是一个指引元,指向所代替的节点。该方法的优点是减少对存储空间的浪费,避免数据不一致性。缺点是改变存储位置可能引起虚拟节点中指针的修改。
层次模型的特点是记录之间的联系通过指针实现,比较简单,查询效率高。
层次模型的缺点是只能表示1∶n的联系,尽管有许多辅助手段实现m∶n的联系,但较复杂不易掌握;由于层次顺序严格和复杂,插入删除操作的限制比较多,导致应用程序编制比较复杂。1968年,美国IBM公司推出的IMS系统(信息管理系统)是典型的层次模型系统,20世纪70年代在商业上得到了广泛的应用。
【例7.3】员工与商品,员工可以销售多种商品,一种商品可以由多个员工销售,所以员工与商品之间是一个多对多的联系,如图7-13(a)所示。采用冗余节点法将其转换为两个一对多的联系,如图7-13(b)所示。采用虚拟节点分解法,将冗余节点转换为虚拟节点,如图7-13(c)所示。

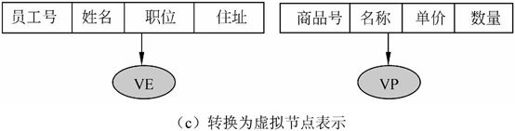
图7-13 员工与商品的多对多联系
7.2.5 网状模型
采用网络结构表示数据与数据间联系的数据模型称为网状模型(Network Model)。在网状模型中,允许一个以上的节点无双亲,一个节点可以有多于一个的双亲。
网状模型(也称DBTG模型)是一个比层次模型更具有普遍性的数据结构,是层次模型的一个特例。网状模型可以直接地描述现实世界,因为去掉了层次模型的两个限制,允许两个节点之间有多种联系(称之为复合联系)。
网状模型中的每个节点表示一个记录类型(实体),每个记录类型可以包含若干个字段(实体的属性),节点间的连线表示记录类型之间一对多的联系。层次模型和网状模型的主要区别如下。
(1)网状模型中子女节点与双亲节点的联系不唯一,因此需要为每个联系命名。
(2)网状模型允许复合链,即两个节点之间有两种以上的联系,如图7-14所示。
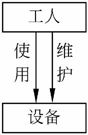
图7-14 网状模型举例
需要说明的是,网状模型不能表示记录之间的多对多联系,需要引入联结记录来表示多对多联系。
【例7.4】学生、课程以及他们之间的多对多联系不能直接用网状模型表示。因为一个学生可以选若干门课,而一门课可以被多个学生选。为此,引入选课联结记录,如图7-15(a)所示。这样,学生与选课之间的S-SC是一对多联系,课程与选课之间的C-SC也是一对多联系。图7-15(a)中,Sno、Sname、SD、Sage、Cno、Cname、Pcno和Grade分别表示学号、姓名、系、年龄、课程号、课程名、先修课程号和成绩。学生选课网状数据库的存储示意图如图7-15(b)所示。
通常,网状数据模型没有层次模型那样严格的完整性约束条件,但DBTG在模式DDL中提供了定义DBTG数据库完整性的若干概念和语句,主要有:
(1)支持记录码的概念。码能唯一标识记录的数据项的集合。
(2)保证一个联系中双亲记录和子女记录之间是一对多联系。
(3)以支持双亲记录和子女记录之间的某些约束条件。例如,当插入一条选课记录“010014,100,98”时,只有学生实体中存在学号为“010014”的学生记录,课程实体存在课程号,系统才认为是合法的操作。
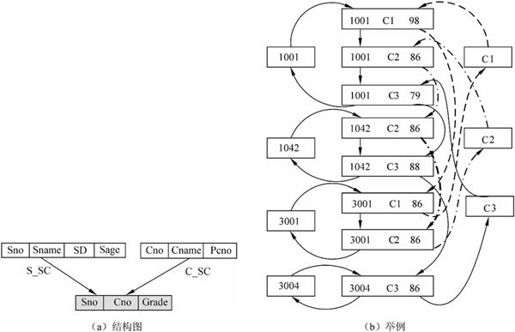
图7-1 学生选课网状数据库的存储示意图
网状模型的主要优点是能更为直接地描述现实世界,具有良好的性能,存取效率高。
网状模型的主要缺点是结构复杂。例如,当应用环境不断扩大时,数据库结构就变得很复杂,不利于最终用户掌握。编制应用程序难度比较大。DBTG模型的DDL、DML语言复杂,记录之间的联系是通过存取路径来实现的,因此程序员必须了解系统结构的细节,增加了编写应用程序的负担。
7.2.6 关系模型
关系模型(Relation Model)是目前最常用的数据模型之一。关系数据库系统采用关系模型作为数据的组织方式,在关系模型中用表格结构表达实体集以及实体集之间的联系,其最大特色是描述的一致性。关系模型是由若干个关系模式组成的集合。一个关系模式相当于一个记录型,对应于程序设计语言中类型定义的概念。关系是一个实例,也是一张表,对应于程序设计语言中变量的概念。给定变量的值随时间可能发生变化,类似地,当关系被更新时,关系实例的内容也随时间发生了变化。
【例7.5】教学数据库的4个关系模式如下:

关系模式中有下划线的属性是主码属性。图7-16是教学模型的一个具体实例
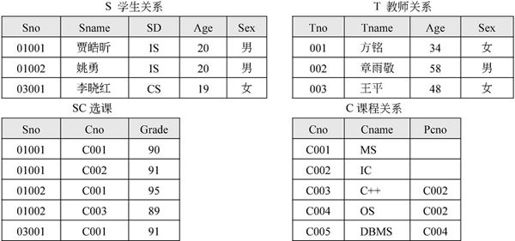
图7-16 关系模型的实例
由于关系模型比网状、层次模型更为简单灵活,因此,数据处理领域中,关系数据库的使用已相当普遍。但是,现实世界存在着许多含有更复杂数据结构的实际应用领域,例如CAD数据、图形数据和人工智能研究等,需要有一种数据模型来表达这类信息,这种数据模型就是面向对象的数据模型。
7.2.7 面向对象模型
面向对象数据模型(Object Oriented Model)的核心概念如下。
(1)对象和对象标识(OID)。对象是现实世界中实体的模型化,与记录、元组的概念相似,但远比它们复杂。每一个对象都有一个唯一的标识,称为对象标识。对象标识不等于关系模式中的记录标识,OID是独立于值的,全系统唯一的。
(2)封装(encapsulate)。每一个对象是状态(state)和行为(behavior)的封装。对象的状态是该对象属性的集合,对象的行为是在该对象状态上操作的方法(程序代码)的集合。被封装的状态和行为在对象外部是看不见的,只能通过显式定义的消息传递来访问。
(3)对象的属性(object attribute)。对象的属性描述对象的状态、组成和特性,对象的某个属性可以是单值或值的集合。对象的一个属性值本身在该属性看来也是一个对象。
(4)类和类层次(class and class hierarchy)。
① 类。所有具有相同属性和方法集的对象构成了一个对象类。任何一个对象都是某个对象类的一个实例(instance)。对象类中属性的定义域可以是任何类,包括基本类,如整型、实型和字串等;一般类,包含自身属性和方法类本身。
② 类层次。所有的类组成了一个有根有向无环图,称为类层次(结构)。一个类可以从直接/间接祖先(超类)中继承(inherit)所有的属性和方法,该类称为子类。
(5)继承(inherit)。子类可以从其超类中继承所有属性和方法。类继承可分为单继承(即一个类只能有一个超类)和多重继承(即一个类可以有多个超类)。
【例7.6】对于学生、教师和课程的E-R图如图7-17所示。可以设计成图7-18所示的面向对象模型。
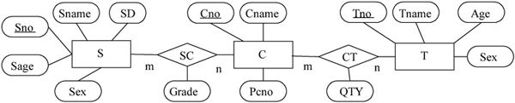
图7-17 学生、教师和课程的E-R图
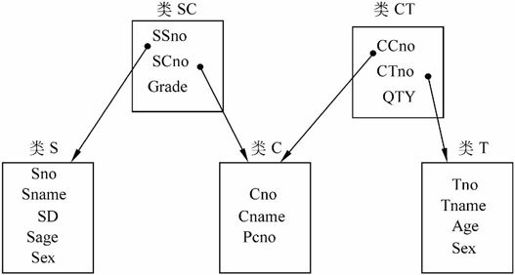
图7-18 学生、教师和课程的对象模型
这个面向对象模型中有5个类,分别是SC、CT、S、C和T,其中类SC的属性SSno取值为类S中的对象,属性SCno取值为类C中的对象,类CS中的属性CCno取值也为类C的对象,属性CTno值为类T的对象,这就充分表达了图中E-R图的全部语义。
面向对象数据模型比网络、层次、关系数据模型具有更加丰富的表达能力。但正因为面向对象模型的丰富表达能力,模型相对复杂、实现起来较困难。
7.3 关系代数
7.3.1 关系数据库的基本概念
1.属性和域
在现实世界中,要描述一个事物常常取若干特征来表示,这些特征称为属性(attribute)。例如,用学生学号、姓名、性别、系别、年龄和籍贯等属性来描述。每个属性的取值范围所对应一个值的集合,称为该属性的域(domain)。例如,学号的域是6位整型数;姓名的域是10位字符;性别的域为{男,女}等。
一般在关系数据模型中,对域还加了一个限制,所有的域都应是原子数据(atomic data)。例如,整数、字符串是原子数据,而集合、记录、数组是非原子数据。关系数据模型的这种限制称为第一范式(first normal form, 1NF)条件。但也有些关系数据模型突破了1NF的限制,称为非1NF的。
2.笛卡儿积与关系
【定义7.1】 设D1,D2,D3,…,Dn为任意集合,定义D1,D2,D3,…,Dn的笛卡儿积为
D1×D2×D3…×Dn={(d1,d2,d3,…,dn)|di∈Di,i=1,2,3,…,n}
其中,每一个元素(d1,d2,d3,…,dn)叫做一个n元组(n-tuple属性的个数),元组的每一个值di叫做元组一个分量,若Di(i=1,2,3,…,n)为有限集,其基数(Cardinal number元组的个数)为mi(i=1,2,3,…,n),则D1×D2×D3…×Dn的基数M为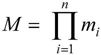 笛卡儿积可以用二维表来表示。
笛卡儿积可以用二维表来表示。
【例7.7】 若D1={0,1},D2={a,b},D3={c,d},求D1×D2×D3。
解:根据定义,笛卡儿积中的每一个元素应该是一个三元组,每个分量来自不同的域,因此结果为
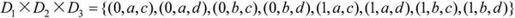
用二维表表示如图7-19所示。
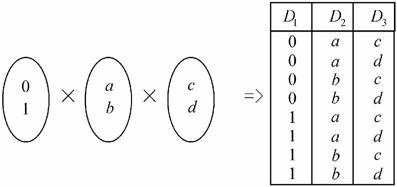
图7-19 D1×D2×D3笛卡儿积的二维表表示
【定义7.2】 D1×D2×D3…×Dn的子集叫做在域D1,D2,D3,…,Dn上的关系,记为R(D1,D2,D3,…,Dn),称关系R为n元关系。
定义7.2可以得出一个关系也可以用二维表来表示。关系中属性的个数称为“元数”,元组的个数称为“基数”。关系模型中的术语与一般术语的对应情况可以通过图7-20中的学生关系说明。图中学生关系模式可表示为:学生(S_no,Sname,SD,Sex)。该学生关系的主码为S_no,属性分别为S_no、Sname、SD和Sex,对属性Sex的域为男、女,等等。而该学生关系的元数为4,基数为6。
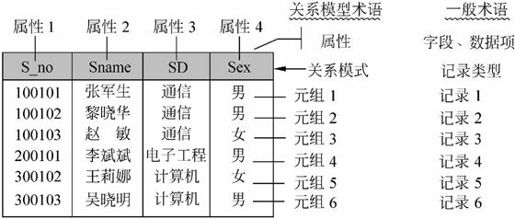
图7-20 学生关系与术语的对应情况
3.关系的相关名词
(1)目或度(Degree)。这里的R表示关系的名字,n是关系的目或度。
(2)候选码(Candidate Key)。若关系中的某一属性或属性组的值能唯一地标识一个元组,则称该属性或属性组为候选码。
(3)主码(Primary Key)。若一个关系有多个候选码,则选定其中一个为主码。
(4)主属性(Non-Key attribute)。包含在任何候选码中的诸属性称为主属性。不包含在任何候选码中的属性称为非码属性。
(5)外码(Foreign key)。如果关系模式R中的属性或属性组非该关系的码,但它是其他关系的码,那么该属性集对关系模式R而言是外码。
例如,客户与贷款之间的借贷联系c-1(c-id,loan-no),属性c-id是客户关系中的码,所以c-id是外码;属性loan-no是贷款关系中的码,所以loan-no也是外码。
(6)全码(All-key)。关系模型的所有属性组是这个关系模式的候选码,称为全码。
例如,关系模式R(T,C,S),属性T表示教师,属性C表示课程,属性S表示学生。假设一个教师可以讲授多门课程,某门课程可以由多个教师讲授,学生可以听不同教师讲授的不同课程,那么,要想区分关系中的每一个元组,这个关系模式R的码应为全属性T、C和S,即All-key。
4.关系的三种类型
(1)基本关系(通常又称为基本表或基表)。是实际存在的表,它是实际存储数据的逻辑表示。
(2)查询表。查询结果对应的表
(3)视图表。是由基本表或其他视图表导出的表。由于它本身不独立存储在数据库中,数据库中只存放它的定义,所以常称为虚表。
5.关系数据库模式
在数据库中要区分型和值。关系数据库中的型也称为关系数据库模式,是关系数据库结构的描述。它包括若干域的定义以及在这些域上定义的若干关系模式。实际上,关系的概念对应于程序设计语言中变量的概念,而关系模式对应于程序设计语言中类型定义的概念。关系数据库的值是这些关系模式在某一时刻对应的关系的集合,通常称之为关系数据库。
【定义7.3】关系的描述称为关系模式(Relation Schema)。可以形式化地表示为:
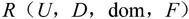
其中,R表示关系名;U是组成该关系的属性名集合;D是属性的域;dom是属性向域的映像集合;F为属性间数据的依赖关系集合。
通常将关系模式简记为:
R(U)或R(A1,A2,A3,…,An)
其中,R为关系名,A1,A2,A3,…,An为属性名或域名,属性向域的映像常常直接说明属性的类型、长度。通常在关系模式主属性上加下划线表示该属性为主码属性。
例如:学生关系S有学号Sno、学生姓名Same、系名SD、年龄SA属性;课程关系C有课程号Cno、课程名Cname、先修课程号PCno属性;学生选课关系SC有学号Sno、课程号Cno、成绩Grade属性。定义关系模式及主码如下(本题未考虑F属性间数据的依赖,该问题在后续内容讨论)。
(1)学生关系模式S(Sno,Sname,SD,SA)。
(2)课程关系模式C(Cno,Cname,PCno)Dom(PCno)=Cno。这里,Pcno是先行课程号,来自Cno域,但由于Pcno属性名不等于Cno值域名,所以要用Dom来定义。但是,不能将Pcno直接改为Cno,因为在关系模型中,各列属性必须取相异的名字。
(3)学生选课关系模式SC(Sno,Cno,Grade)。SC关系中的Sno、Cno又分别为外码。因为它们分别是S、C关系中的主码。
6.完整性约束
完整性规则提供了一种手段来保证当授权用户对数据库作修改时不会破坏数据的一致性。因此,完整性规则防止的是对数据的意外破坏。关系模型的完整性规则是对关系的某种约束条件。关系的完整性共分为三类:实体完整性、参照完整性(也称引用完整性)和用户定义完整性。
(1)实体完整性(Entity Integrity)。规定基本关系R的主属性A不能取空值。
(2)参照完整性(Referential Integrity)。现实世界中的实体之间往往存在某种联系,在关系模型中实体及实体间的联系是用关系来描述的,这样自然就存在着关系与关系间的引用。
例如,员工和部门关系模式表示如下,其中在关系模式主属性上加下划线表示该属性为主码属性。
员工(员工号,姓名,性别,参加工作时间,部门号)
部门(部门号,名称,电话,负责人)
这两个关系存在着属性的引用,即员工关系中的“部门号”值必须是确实存在的部门的部门号,即部门关系中有该部门的记录。也就是说,员工关系中的“部门号”属性取值要参照部门关系的“部门号”属性取值。
参照完整性规定,若F是基本关系R的外码,它与基本关系S的主码Ks相对应(基本关系R和S不一定是不同的关系),则对于R中每个元组在F上的值或者取空值(F的每个属性值均为空值),或者等于S中某个元组的主码值。
(3)用户定义完整性(User defined Integrity)。就是针对某一具体的关系数据库的约束条件,反映某一具体应用所涉及的数据必须满足的语义要求,由应用的环境决定。例如,银行的用户账户规定必须大于等于100000,小于999999。
7.关系运算
关系操作的特点是操作对象和操作结果都是集合,而非关系数据模型的数据操作方式则为一次一个记录的方式。关系数据语言分为三类:关系代数语言、关系演算语言和具有关系代数和关系演算双重特点的语言(如SQL)。关系演算语言包含元组关系演算语言(如Aplha、Quel)和域关系演算语言(如QBE)。
关系代数语言、元组关系演算和域关系演算是抽象查询语言,它与具体的DBMS中实现的实际语言并不一样,但是可以用它评估实际系统中的查询语言能力的标准。
关系代数运算符有4类:集合运算符,专门的关系运算符,算术比较符和逻辑运算符。根据运算符的不同,关系代数运算可分为传统的集合运算和专门的关系运算。传统的集合运算是从关系的水平方向进行的,包括并、交、差及广义笛卡儿积。专门的关系运算既可以从关系的水平方向进行运算,又可以向关系的垂直方向运算,包括选择、投影、连接以及除法,如表7-2所示。表7-2中,并、差、笛卡儿积、投影和选择是5种基本的运算,因为其他运算可以通过基本的运算导出。
表7-2 关系代数运算符
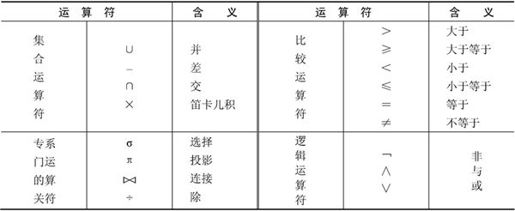
7.3.2 五种基本的关系代数运算
五种基本的关系代数运算包括并、差、笛卡儿积、投影和选择,其他运算可以通过基本的关系运算导出。
1.并(Union)
关系R与S具有相同的关系模式,即R与S的元数相同(结构相同)。关系R与S并由属于R或属于S的元组构成的集合组成,记作R∪S,其形式定义如下:
R∪S={t|t∈R∨t∈S}
式中t为元组变量。
2.差(Difference)
关系R与S具有相同的关系模式,关系R与S的差是由属于R但不属于S的元组构成的集合,记作R-S,其形式定义如下:
R-S={t|t∈R∧t∉S}
3.广义笛卡儿积(Extended Cartesian Product)
两个元数分别为n目和m目的关系R和S的广义笛卡儿积是一个(n+m)列的元组的集合。元组的前n列是关系R的一个元组,后m列是关系S的一个元组,记作R×S,其形式定义如下:
R×S={t|t=<tn,tm>∧tn∈R∧tm∈S}
如果R和S中有相同的属性名,可在属性名前加关系名作为限定,以示区别。若R有K1个元组,S有K2个元组,则R和S的广义笛卡儿积有K1×K2个元组。
注意:本教材中的<tn,tm>意为元组tn和tm拼接成的一个元组。
4.投影(Projection)
投影运算是从关系的垂直方向进行运算,在关系R中选择出若干属性列A组成新的关系,记作πA(R),其形式定义如下:
πA(R)={t[A]|t∈R}
5.选择(Selection)
选择运算是从关系的水平方向进行运算,是从关系R中选择满足给定条件的诸元组,记作σF(R),其形式定义如下:
σF(R)={t|t∈R∧F(t)=True}
其中,F中的运算对象是属性名(或列的序号)或常数,运算符、算术比较符(<、≤、>、≥、≠)和逻辑运算符(∧、∨、﹁)。例如,σ1≥6(R)表示选取R关系中第1个属性值大于等于第6个属性值的元组;σ1>′6′(R)表示选取R关系中第1个属性值大于等于6的元组。
【例7.8】设有关系R、S如图7-21所示,请求出R∪S,R-S,R×S,πA,C(R),σA>B(R)和σ3<4(R×S)。
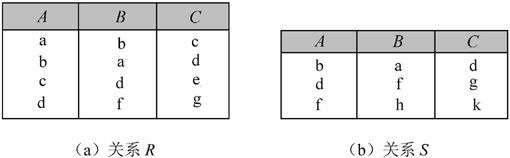
图7-21 关系R、S
解:R∪S,R-S,R×S,πA,C(R),σA>B(R)和σ3<4(R×S)的结果如图7-22所示。其中,R×S生成的关系属性名有重复,按照关系“属性不能重名”的性质,通常采用“关系名.属性名”的格式。对于σ3<4(R×S)的含义是R×S后“选取第3个属性值小于第4个属性值”的元组。由于R×S的第3个属性为R.C,第4个属性是S.A,因此σ3<4(R×S)的含义也是R×S后“选取R.C值小于S.A值”的元组。
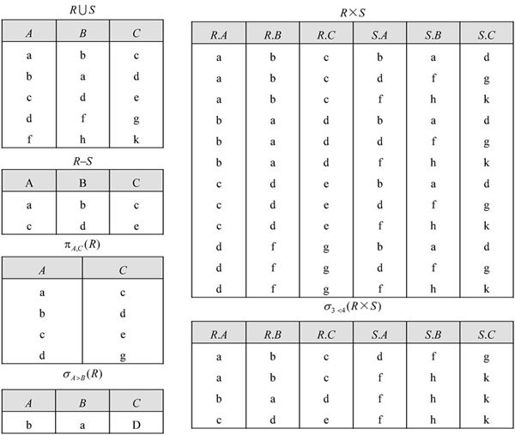
图7-22 运算结果
7.3.3 扩展的关系代数运算
扩展的关系代数运算可以从基本的关系运算中导出,主要包括选择、投影、连接、除法、广义笛卡儿积和外连接。
1.交(Intersection)
关系R与S具有相同的关系模式,关系R与S的交是由属于R同时又属于S的元组构成的集合,记作R∩S,其形式定义如下:
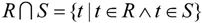
显然,R∩S=R-(R-S),或者R∩S=S-(S-R)。
2.连接(Join)
连接分为θ连接、等值连接及自然连接三种。连接运算是从两个关系R和S的笛卡儿积中选取满足条件的元组。因此,可以认为笛卡儿积是无条件连接,其他的连接操作认为是有条件连接。下面分述如下。
(1)θ连接。从R与S的笛卡儿积中选取属性间满足一定条件的元组。记作:
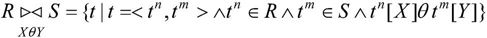
其中,XθY为连接的条件,θ是比较运算符,X和Y分别为R和S上度数相等,且可比的属性组。tn[X]表示R中tn元组的相应于属性X的一个分量。tm[Y]表示S中tm元组的相应于属性Y的一个分量。有如下说明。
① θ连接也可以表示为:
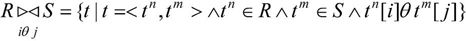
其中,i=1,2,3,…,n,j=1,2,3,…,m,iθj的含义为从两个关系R和S中选取R的第i列和S的第j列之间满足θ运算的元组进行连接。
② θ连接可以由基本的关系运算笛卡尔积和选取运算导出。因此,θ连接可表示为:
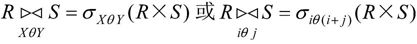
【例7.9】设有关系R、S如图7-19所示,求
解:本题连接的条件为R.A<S.B,意为将R关系中属性A的值小于S关系中属性B的值的元组取出来作为结果集的元组。结果集为R×S后选出满足条件的元组,并且结果集的属性为R.A,R.B,R.C,S.A,S.B,S.C。结果如图7-23所示。
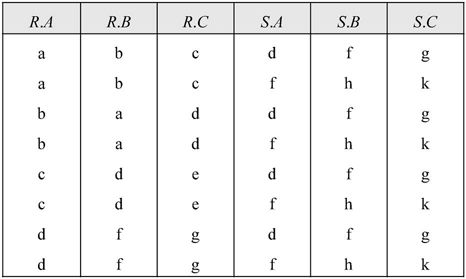
图 7-23 
(2)等值连接。当θ为“=”时,称之为等值连接,记为 其形式定义如下:
其形式定义如下:
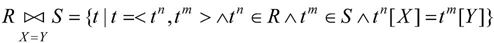
(3)自然连接。是一种特殊的等值连接,它要求两个关系中进行比较的分量必须是相同的属性组,并且在结果集中将重复属性列去掉。若tn表示R关系的元组变量,tm表示S关系的元组变量;R和S具有相同的属性组B,且B=(B1,B2,…,BK);并假定R关系的属性为A1,A2,…,An-k,B1,B2,…,BK,S关系的属性为B1,B2,…,BK,BK+1,BK+2,…,Bm;为S的元组变量tm去掉重复属性B所组成的新的元组变量为tm。自然连接可以记为R S,其形式定义如下:
S,其形式定义如下:
RS={t|t=<tn,tm>∧tn∈R∧tm∈S∧R.B1=S.B1∧R.B2=S.B2∧…∧R.Bn=S.Bn}
自然连接可以由基本的关系运算笛卡尔积和选取运算导出,因此自然连接可表示为:
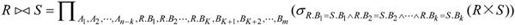
特别需要说明的是,一般连接是从关系的水平方向运算,而自然连接不仅要从关系的水平方向,而且要从关系的垂直方向运算。因为自然连接要去掉重复属性,如果没有重复属性,那么自然连接就转化为笛卡儿积。
【例7.10】设有关系R、S如图7-24所示,求RS。

图7-24 关系R、S
解:本题要求R与S关系的自然连接,自然连接是一种特殊的等值连接,它要求两个关系中进行比较的分量必须是相同的属性组,并且在结果中将重复属性列去掉。本题R与S关系中相同的属性组为AC,因此,结果集中的属性列应为ABCD。其结果如图7-25所示。
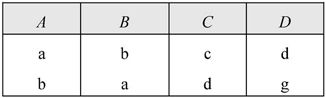
图7-25 RS
3.除(Division)
除运算是同时从关系的水平方向和垂直方向进行运算。给定关系R(X,Y)和S(Y,Z),X、Y、Z为属性组。R÷S应当满足元组在X上的分量值x的象集Yx包含关系S在属性组Y上投影的集合。其形式定义如下:
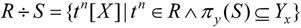
其中,Yx为x在R中的象集,x=tn[X]。且R÷S的结果集的属性组为X。
【例7.11】设有关系R、S如图7-26所示,求R÷S。
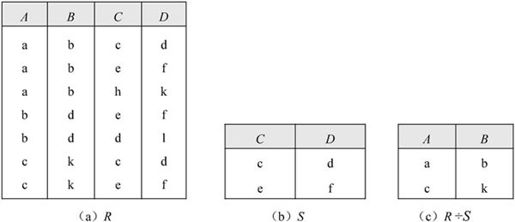
图7-26 R÷S
解:根据除法定义,此题的X为属性AB,Y为属性CD。R÷S应当满足元组在属性AB上的分量值x的象集Yx包含关系S在CD上投影的集合。
关系S在Y上的投影为πCD(S)={(c,d),(e,f)}。对于关系R,属性组X(即AB)可以取三个值{(a,b),(b,d),(c,k)},它们的象集分别为:
象集CD(a,b)={(c,d),(e,f),(h,k)}
象集CD(b,d)={(e,f),(d,l)}
象集CD(c,k)={(c,d),(e,f)}
由于上述象集包含πCD(S)有(a,b)和(c,k),因此R÷S={(a,b),(c,k)},结果如图7-26(c)所示。
【例7.12】设学生课程数据库中有学生S、课程C和学生选课SC三个关系,如图7-27所示。请用关系代数表达式表达如下检索问题。
(1)检索选修课程名为“数学”的学生号和学生姓名。
(2)检索至少选修了课程号为1和3的学生号。
(3)检索选修了“操作系统”或“数据库”课程的学号和成绩。
(4)检索年龄在18~20之间(含18和20)的女生的学号、姓名及年龄。
(5)检索选修了“对平”老师所讲课程的学生的学号、姓名及成绩。
(6)检索选修全部课程的学生姓名。
(7)检索选修课程包括1042学生所学课程的学生学号。
(8)检索不选修2课程的学生姓名和所在系。

图7-27 S、C、SC关系
解:(1)检索选修课程名为“数学”的学生号和学生姓名的关系代数表达式如下:
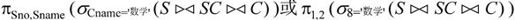
对于上述表达式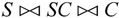 自然连接后重复的属性列为学号Sno和课程号Cno,去掉重复属性列的结果如图7-28所示。从图中可见,满足课程名为“数学”的只有三个元组,对Sno和Sname投影的结果如图7-29所示。由于Sno、Cno和Cname分别对应第1,2和8列属性,所以上述表达式还可以写为
自然连接后重复的属性列为学号Sno和课程号Cno,去掉重复属性列的结果如图7-28所示。从图中可见,满足课程名为“数学”的只有三个元组,对Sno和Sname投影的结果如图7-29所示。由于Sno、Cno和Cname分别对应第1,2和8列属性,所以上述表达式还可以写为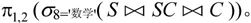
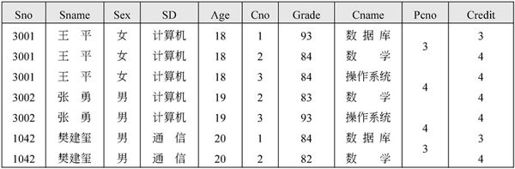
图7-28 SSCC
(2)检索至少选修了课程号为1和3的学生号可有如下两种解题思路。
① 关系代数表达式为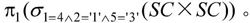 若设SC×SC中的第一个SC关系为S1,与第二个SC关系为S2,那么,该关系表达式的含义为先从SC×SC中选取满足条件S1.Sno=S2.Sno、S1.Cno=′1′、S2.Sno=′3′的元组,最后投影第一个属性列Sno即为所求结果集。
若设SC×SC中的第一个SC关系为S1,与第二个SC关系为S2,那么,该关系表达式的含义为先从SC×SC中选取满足条件S1.Sno=S2.Sno、S1.Cno=′1′、S2.Sno=′3′的元组,最后投影第一个属性列Sno即为所求结果集。
② 关系代数表达式为 分析如下。
分析如下。
表达式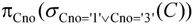 就是构造一个临时关系K,其属性为Cno,结果如下:
就是构造一个临时关系K,其属性为Cno,结果如下:
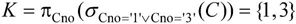
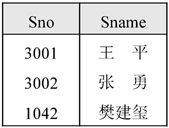
图7-29 例7.12的投影结果
查询表达式 的结果集的学生号所选的课程号应包括K。
的结果集的学生号所选的课程号应包括K。
求解的过程就是对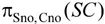 的每一个元组逐一求某一学生的象集。因为所求的Sno,所以X为Sno,Y为Cno,所以象集为
的每一个元组逐一求某一学生的象集。因为所求的Sno,所以X为Sno,Y为Cno,所以象集为 将Sno的值逐一代入求象集:
将Sno的值逐一代入求象集:
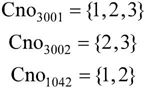
可以看出,只有3001包含了K在Cno的投影,所以,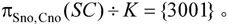
(3)检索选修了“操作系统”或“数据库”课程的学号和姓名的关系代数表达式为:
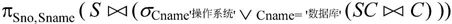
(4)检索年龄在18~20之间(含18和20)的女生的学号、姓名及年龄的关系代数表达式为:
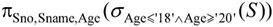
(5)检索选修了“数据库”课程的学生的学号、姓名及成绩的关系代数表达式为:
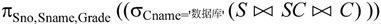
(6)检索选修全部课程的学生姓名及所在系的关系代数表达式为:
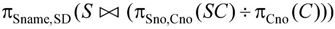
对于本题给出的具体关系,求解过程分析如下。
① 表示全部课程的临时关系K=πCno(C)={1,2,3,4,5,6,7}。
② 查询选修了所有课程的学生号为πsno,Cno(SC)÷K={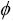 },因为学生所选课程分别为Cno3001={1,2,3},Cno3002={2,3}和Cno1042={1,2},所以3001,3002和1042都没有包含K,故结果集为空。
},因为学生所选课程分别为Cno3001={1,2,3},Cno3002={2,3}和Cno1042={1,2},所以3001,3002和1042都没有包含K,故结果集为空。
③ 与S关系进行自然连接在对学生姓名Sname和学号SD投影的结果也为空。
(7)检索选修课程包含1042学生所学课程的学生学号的关系表达式如下:
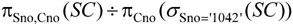
(8)检索不选修2课程的学生姓名和所在系的关系代数表达式为:
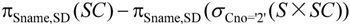
对于上式也可以用属性列号替换属性名,将上式写成如下等价的关系代数表达式:
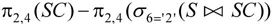
4.广义投影(generalized projection)
广义投影运算允许在投影列表中使用算术运算,实现了对投影运算的扩充。
若有关系R,条件F1,F2,…,Fn中的每一个都是涉及R中常量和属性的算术表达式,那么广义投影运算的形式定义如下:

【例7.13】信贷额度关系模式credit-in(C_name,limit,Credit_balance),属性分别表示用户姓名、信贷额度和到目前为止的花费。图7-30(a)表示了关系credit-in的一个具体。若要查询给出每个用户还能花费多少,可以用关系代数表达式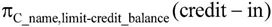 来表示,查询结果如图7-30(b)所示。
来表示,查询结果如图7-30(b)所示。
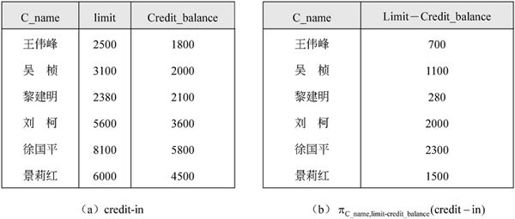
图7-30 信贷额度关系
5.外连接(outer jion)
外连接运算是连接运算的扩展,可以处理由于连接运算而缺失的信息。对于图7-27的S和SC关系,当对其进行自然连接SSC时,其结果如图7-31所示。
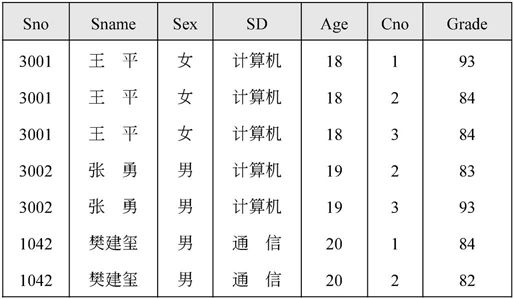
图7-31 SC
从图7-31可以看出,S与SC的自然连接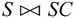 的结果丢失了黎明、对明远、赵国庆的相关信息。可是,使用外连接可以避免这样的信息丢失。外连接运算有三种:左外连接、右外连接和全外连接。
的结果丢失了黎明、对明远、赵国庆的相关信息。可是,使用外连接可以避免这样的信息丢失。外连接运算有三种:左外连接、右外连接和全外连接。
(1)左外连接 取出左侧关系中所有与右侧关系中任一元组都不匹配的元组,用空值null充填所有来自右侧关系的属性,构成新的元组,将其加入自然连接的结果中。对于图7-27的S和SC关系,当对其进行左外连接
取出左侧关系中所有与右侧关系中任一元组都不匹配的元组,用空值null充填所有来自右侧关系的属性,构成新的元组,将其加入自然连接的结果中。对于图7-27的S和SC关系,当对其进行左外连接 时,其结果如图7-32所示。
时,其结果如图7-32所示。
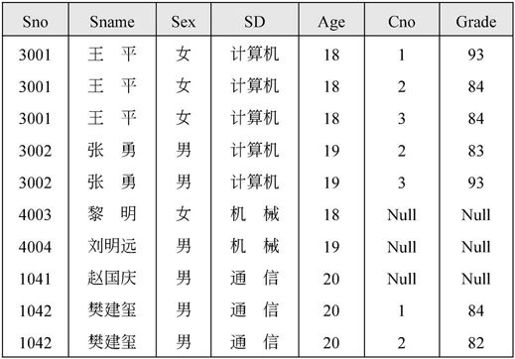
图7-32 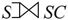
(2)右外连接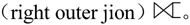 取出右侧关系中所有与左侧关系中任一元组都不匹配的元组,用空值null填充所有来自左侧关系的属性,构成新的元组,将其加入自然连接的结果中。对于图7-27的S和SC关系,当对其进行右外连接
取出右侧关系中所有与左侧关系中任一元组都不匹配的元组,用空值null填充所有来自左侧关系的属性,构成新的元组,将其加入自然连接的结果中。对于图7-27的S和SC关系,当对其进行右外连接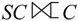 时,其结果如图7-33所示。
时,其结果如图7-33所示。
图7-33 
(3)全外连接 完成左外连接和右外连接的操作。即填充左侧关系中所有与右侧关系中任一元组都不匹配的元组,又填充右侧关系中所有与左侧关系中任一元组都不匹配的元组,将产生的新元组加入自然连接的结果中。
完成左外连接和右外连接的操作。即填充左侧关系中所有与右侧关系中任一元组都不匹配的元组,又填充右侧关系中所有与左侧关系中任一元组都不匹配的元组,将产生的新元组加入自然连接的结果中。
【例7.14】设有关系R、S如图7-34所示,求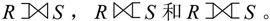
图7-34 关系R、S
对于图7-34的R、S关系,当对其进行左外连接 右外连接
右外连接 全外联接
全外联接 时,其结果分别如图7-35(a)、图7-35(b)和图7-35(c)所示。
时,其结果分别如图7-35(a)、图7-35(b)和图7-35(c)所示。
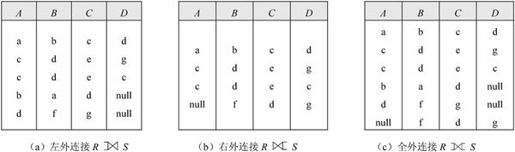
图7-35 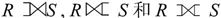
7.4 关系数据库SQL语言简介
SQL(Structured Query Language)早已确立起自己作为关系数据库标准语言的地位,已被众多商用DBMS产品如DB2、ORACLE、INGRES、SYSBASE、SQL Server和VFP等所采用,使得它已成为关系数据库领域中一个主流语言。SQL是1974年由Boyce和Chamberlin提出的,是在关系数据库中最普遍使用的语言,包括数据查询(query)、数据操纵(manipulation)、数据定义(definition)和数据控制(control)功能,是一种通用的、功能强大的关系数据库的标准语言。
7.4.1 SQL数据库体系结构
SQL主要有三个标准:ANSI(美国国家标准机构)SQL;对ANSI SQL进行修改后在1992年采用的标准SQL-92或SQL2;最近的SQL-99标准,也称为SQL3标准。SQL-99从SQL-92扩充而来,并增加了对象关系特征和许多其他新的功能。
1.SQL的特点
(1)综合统一。非关系模型的数据语言分为模式定义语言和数据操纵语言,其缺点是当要修改模式时,必须停止现有数据库的运行,转储数据,修改模式编译后再重装数据库。SQL是集数据定义、数据操纵和数据控制功能于一体,语言风格统一,可独立完成数据库生命周期的所有活动。
(2)高度非过程化。非关系数据模型的数据操纵语言是面向过程的,若要完成某项请求时,必须指定存储路径;而SQL语言是高度非过程化语言,当进行数据操作时,只要指出“做什么”,无须指出“怎么做”,存储路径对用户来说是透明的,提高了数据的独立性。
(3)面向集合的操作方式。非关系数据模型采用的是面向记录的操作方式,操作对象是一条记录。而SQL语言采用面向集合的操作方式,其操作对象、查找结果可以是元组的集合。
(4)两种使用方式。第一种方式,用户可以在终端键盘上输入SQL命令,对数据库进行操作,故称之为自含式语言;第二种方式,将SQL语言嵌入到高级语言程序中,所以又称为嵌入式语言。
(5)语言简洁、易学易用。SQL语言功能极强,完成核心功能只用了9个动词,包括如下4类。
● 数据查询:SELECT。
● 数据定义:CREATE、DROP、ALTER。
● 数据操纵:INSERT、UODATE、DELETE。
● 数据控制:GRANT、REVORK。
2.SQL支持三级模式结构
SQL语言支持关系数据库的三级模式结构,其中,视图对应外模式、基本表对应模式、存储文件对应内模式。具体结构如图7-36所示。
7.4.2 SQL的基本组成
SQL由以下几个部分组成。
(1)数据定义语言。SQL DDL提供定义关系模式和视图、删除关系和视图、修改关系模式的命令。
(2)交互式数据操纵语言。SQL DML提供查询、插入、删除和修改的命令。
(3)事务控制(transaction control)。SQL提供定义事务开始和结束的命令。
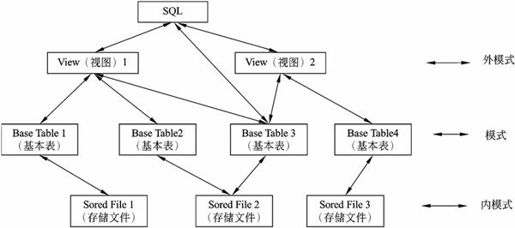
图7-36 关系数据库的三级模式结构
(4)嵌入式SQL和动态SQL(Embeded SQL and Dynamic SQL)。用于嵌入到某种通用的高级语言(C、C++、Java、PL/I、COBOL和VB等)中混合编程。其中,SQL负责操纵数据库,高级语言负责控制程序流程。
(5)完整性(integrity)。SQL DDL包括定义数据库中的数据必须满足的完整性约束条件的命令,对于破坏完整性约束条件的更新将被禁止。
(6)权限管理(authorization)。SQL DDL中包括说明对关系和视图的访问权限。
7.4.3 SQL数据定义
基本表和视图都是表,所不同的是基本表是实际存储在数据库中的表,视图是虚表,是从基本表或其他视图中导出的表。数据库中只存放视图的定义,而不存放视图的数据。用户可用SQL语句对基本表和视图进行查询等操作,在用户看来,基本表和视图一样,都是关系(即表)。一个基本表可以存储在一个或多个存储文件中,一个存储文件也可存储一个或多个基本表。一个表可以带若干索引,索引也存储在存储文件中。每个存储文件就是外部存储器上一个物理文件,存储文件的逻辑结构组成了关系数据库的内模式。
SQL的数据定义包括对表、视图、索引的创建和删除。
1.创建表(CREATE TABLE)
语句格式:CREATE TABLE<表名>(<列名><数据类型>[列级完整性约束条件]
[,<列名><数据类型>[列级完整性约束条件]]…
[,<表级完整性约束条件>]);
列级完整性约束条件有NULL(空)和UNIQUE(取值唯一),如NOT NULL UNIQUE表示取值唯一,不能取空值。
【例7.15】建立一个供应商、零件数据库。其中“供应商”表S(Sno,Sname,Status,City)分别表示供应商代码、供应商名、供应商状态和供应商所在城市。“零件”表P(Pno,Pname,Color,Weight,City)表示零件号、零件名、颜色、重量及产地。其中,数据库要满足如下要求。
(1)供应商代码不能为空,且值是唯一的,供应商的名也是唯一的。
(2)零件号不能为空,且值是唯一的;零件名不能为空。
(3)一个供应商可以供应多个零件,而一个零件可以由多个供应商供应。
分析:根据题意,供应商和零件分别要建立一个关系模式。供应商和零件之间是一个多对多的联系,在关系数据库中,多对多联系必须生成一个关系模式,而该模式的码是该联系两端实体的码加上联系的属性构成的,若该联系名为SP,那么关系模式为SP(Sno,Pno,Qty),其中,Qty表示零件的数量。
根据上述分析,用SQL建立一个供应商、零件数据库如下:

从上述定义可以看出,Sno CHAR(5)NOT NULL UNIQUE语句定义了Sno的列级完整性约束条件,取值唯一,不能取空值。
需要说明如下。
(1)PRIMARY KEY (Sno) 已经定义了Sno为主码,所以Sno CHAR(5) NOT NULL UNIQUE语句中的NOT NULL UNIQUE可以省略。
(2)FOREIGN KEY (Sno) REFERENCESS (Sno)定义了在SP关系中Sno为外码,其取值必须来自S关系的Sno域。同理,在SP关系中Pno也定义为外码。
2.修改和删除表
1)修改表(ALTER TABLE)
语句格式:ALTER TABLE<表名>[ADD<新列名><数据类型>[完整性约束条件]]
[DROP<完整性约束名>]
[MODIFY<列名><数据类型>];
例如,向“供应商”表S增加Zap“邮政编码”可用如下语句:
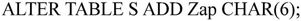
注意,不论基本表中原来是否已有数据,新增加的列一律为空。
又如,将Status字段改为整型可用如下信息:
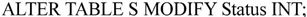
2)删除表(DROP TABLE)
语句格式:DROP TABLE<表名>
例如,执行DROP TABLE Student,此后关系Student不再是数据库模式的一部分,关系中的元组也无法访问。
3.索引建立与删除
数据库中的索引与书籍中的索引类似,在一本书中,利用索引可以快速查找所需信息,无须阅读整本书。在数据库中,索引使数据库程序无须对整个表进行扫描,就可以在其中找到所需数据。书中的索引是一个词语列表,其中注明了包含各个词的页码。而数据库中的索引是某个表中一列或者若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用如下。
(1)通过创建唯一索引,可以保证数据记录的唯一性。
(2)可以大大加快数据检索速度。
(3)可以加速表与表之间的连接,这一点在实现数据的参照完整性方面有特别的意义。
(4)在使用ORDER BY和GROUP BY子句中进行检索数据时,可以显著减少查询中分组和排序的时间。
(5)使用索引可以在检索数据的过程中使用优化隐藏器,提高系统性能。
索引分为聚集索引和非聚集索引。聚集索引是指索引表中索引项的顺序与表中记录的物理顺序一致的索引。
1)建立索引
语句格式:CREATE[UNIQUE][CLUSTER]INDEX<索引名>
ON<表名>(<列名>[<次序>][,<列名>[<次序>]]…);
参数说明如下。
● 次序:可选ASC(升序)或DSC(降序),默认值为ASC。
● UNIQUE:表明此索引的每一个索引值只对应唯一的数据记录。
● CLUSTER:表明要建立的索引是聚簇索引,意为索引项的顺序是与表中记录的物理顺序一致的索引组织。
【例7.16】假设供应销售数据库中有供应商S、零件P、工程项目J、供销情况SPJ关系,希望建立4个索引。其中,供应商S中Sno按升序建立索引;零件P中Pno按升序建立索引;工程项目J中Jno按升序建立索引;供销情况SPJ中Sno按升序,Pno按降序,Jno按升序建立索引。
解:根据题意建立的索引如下。

2)删除索引
语句格式:DROP INDEX<索引名>
例如,执行DROP INDEX StudentIndex,此后索引StudentIndex不再是数据库模式的一部分。
4.视图创建与删除
视图是从一个或者多个基本表或视图中导出的表,其结构和数据是建立在对表的查询基础上的。和真实的表一样,视图也包括几个被定义的数据列和多个数据行,但从本质上讲,这些数据列和数据行来源于其所引用的表。因此,视图不是真实存在的基本表,而是一个虚拟表,视图所对应的数据并不实际地以视图结构存储在数据库中,而是存储在视图所引用的表中。使用视图的优点和作用如下。
(1)可以使视图集中数据、简化和定制不同用户对数据库的不同数据要求。
(2)使用视图可以屏蔽数据的复杂性,用户不必了解数据库的结构,就可以方便地使用和管理数据,简化数据权限管理和重新组织数据以便输出到其他应用程序中。
(3)视图可以使用户只关心他感兴趣的某些特定数据和他们所负责的特定任务,而那些不需要的或者无用的数据则不在视图中显示。
(4)视图大大地简化了用户对数据的操作。
(5)视图可以让不同的用户以不同的方式看到不同或者相同的数据集。
(6)在某些情况下,由于表中数据量太大,因此在表的设计时常将表进行水平或者垂直分割,但表的结构的变化对应用程序产生不良的影响。
(7)视图提供了一个简单而有效的安全机制。
1)视图的创建
语句格式:CREATE VIEW 视图名(列表名)
AS SELECT 查询子句
[WITH CHECK OPTION];
注意:视图的创建中,必须遵循如下规定。
(1)子查询可以是任意复杂的SELECT语句,但通常不允许含有order by子句和DISTINCT短语。
(2)WITH CHECK OPTION表示对UPDATE,INSTER,DELETE操作时保证更新、插入或删除的行满足视图定义中的谓词条件(即子查询中的条件表达式)。
(3)组成视图的属性列名或者全部省略或者全部指定。如果省略属性列名,则隐含该视图由SELECT子查询目标列的主属性组成。
【例7.17】若学生关系模式为Student(Sno,Sname,Sage,Sex,SD,Email,Tel),建立“计算机系”(CS表示计算机系)学生的视图,并要求进行修改、插入操作时保证该视图只有计算机系的学生。

由于CS-STUDENT视图使用了WITH CHECK OPTION子句,因此,对该视图进行修改、插入操作时DBMS会自动加上SD=′CS′的条件,保证该视图只有计算机系的学生。
2)视图的删除
语句格式:DROP VIEW视图名
例如,DROP VIEW CS-STUDENT将删除视图CS-STUDENT。
7.4.4 SQL数据查询
SQL的数据操纵功能包括SELECT(查询)、INSERT(插入)、DELETE(删除)和UPDATE(修改)这4条语句。SQL语言对数据库的操作十分灵活方便,原因在于SELECT语句中成分丰富多样的元组,有许多可选形式,尤其是目标列和条件表达式。
本小节数据查询以图7-27所示学生选课数据库为例。
1.Select基本结构
数据库查询是数据库的核心操作,SQL语言提供了SELECT语句进行数据库的查询。
语句格式:SELECT[ALL|DISTINCT]<目标列表达式>[,<目标列表达式>]…

SQL查询中的子句顺序为SELECT、FROM、WHERE、GROUP BY、HAVING和ORDER BY。其中,SELECT、FROM是必须的,HAVING条件子句只能与GROUP BY搭配起来使用。
(1)SELECT子句对应的是关系代数中的投影运算,用来列出查询结果中的属性。其输出可以是列名、表达式、集函数(AVG、COUNT、MAX、MIN、SUM),DISTINCT选项可以保证查询的结果集中不存在重复元组。
(2)FROM子句对应的是关系代数中的笛卡儿积,它列出的是表达式求值过程中需扫描的关系,即在FROM子句中出现多个基本表或视图时,系统首先执行笛卡儿积操作。
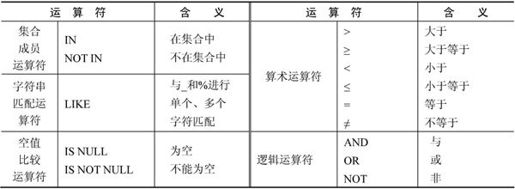
(3)WHERE子句对应的是关系代数中的选择谓词。WHERE子句的条件表达式中可以使用的运算符如表7-3所示。
一个典型的SQL查询具有如下形式:
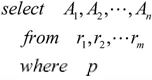
对应关系代数表达式为∏A1,A2,…,An(σp(r1×r2×…×rm))。
表7-3 WHERE子句的条件表达式中可以使用的运算符
2.简单查询
SQL最简单的查询是找出关系中满足特定条件的元组,这些查询与关系代数中的选择操作类似。简单查询只需要使用三个保留字SELECT、FROM和WHERE。
【例7.18】查询学生-课程数据库中计算机系CS学生的学号、姓名及年龄。

注意,通常为了便于理解查询语句的结构,在写SQL语句时要将保留字如FORM或WHERE作为每一行的开头。但是,如果一个查询或子查询非常短的时候,可以直接将它们写在一行上,这种风格使得查询语句很紧凑,也具有很好的可读性。如上例也可写成如下形式:

【例7.19】查询学生的出生年份。

3.连接查询
若查询涉及两个以上的表,则称为连接查询。
【例7.20】检索选修了课程号为“C1”的学生号和学生姓名,可用连接查询和嵌套查询实现,实现方法如下:

【例7.21】检索选修课程名为“MS”的学生号和学生姓名,可用连接查询和嵌套查询实现,实现方法如下:
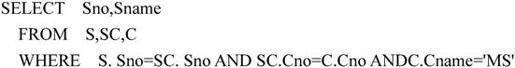
【例7.22】检索至少选修了课程号为“C1”和“C3”的学生号,实现方法如下:

4.子查询与聚集函数
1)子查询
子查询也称嵌套查询。嵌套查询是指一个SELECT-FROM-WHERE查询块可以嵌入另一个查询块之中。在SQL中允许多重嵌套。
【例7.23】例7-21可以采用嵌套查询来实现。

2)聚集函数
聚集函数是一个值的集合为输入,返回单个值的函数。SQL提供了5个预定义集函数:平均值avg、最小值min、最大值max、求和sum以及计数count。如表7-4所示。
使用ANY和ALL谓词必须同时使用比较运算符,其含义及等价的转换关系如表7-5所示。用集函数实现子查询通常比直接用ALL或ANY查询效率要高。
表7-4 集函数的功能
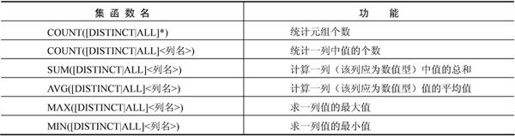
表7-5 ANY、ALL谓词含义及等价的转换关系

【例7.24】查询课程C1的最高分和最低分以及高低分之间的差距。
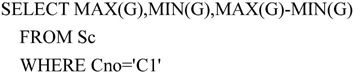
【例7.25】查询其他系比计算机系CS所有学生年龄都要小的学生姓名及年龄。
方法1:(用ALL谓词)

方法2:(用MIN集函数)从等价的转换关系表7-4中可见,<ALL可用<MIN代换。

说明:方法2实际上是找出计算机系年龄最小的学生的年龄,只要其他系的学生年龄比这个年龄小,那么就应在结果集中。
【例7.26】查询其他系比计算机系某一学生年龄小的学生姓名及年龄。
方法1:(用ANY谓词)

方法2:(用MAX集函数)从等价的转换关系表7-5中可见,<ANY可用<MAX代换。

说明:方法2实际上是找出计算机系年龄最大的学生的年龄,只要其他系的学生年龄比这个年龄大,那么就应在结果集中。
5.分组查询
1)GROUP BY子句
在WHERE子句后面加上GROUP BY子句可以对元组进行分组,保留字GROUP BY后面跟着一个分组属性列表。最简单的情况是FROM子句后面只有一个关系,根据分组属性对它的元组进行分组。SELECT子句中使用的聚集操作符仅用在每个分组上。
【例7.27】学生数据库中的SC关系,查询每个学生的平均成绩。
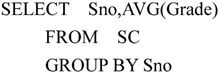
该语句是将SC关系的元组重新组织,并进行分组使得不同学号的元组分别被组织在一起,求出各个学生的平均值输出。
2)HAVING子句
假如元组在分组前按照某种方式加上限制,使得不需要的分组为空,可以在GROUP BY子句后面跟一个HAVING子句即可。
注意:当元组含有空值时,应该记住以下两点。
(1)空值在任何聚集操作中被忽视。它对求和、求平均值和计数都没有影响。它也不能是某列的最大值或最小值。例如,COUNT(*)是某个关系中所有元组数目之和,但COUNT(A)却是A属性非空的元组个数之和。
(2)NULL值又可以在分组属性中看作是一个一般的值。例如,SELECT A, AVG(B)FORM R中,当A的属性值为空时,就会统计A=NULL的所有元组中B的均值。
【例7.28】供应商数据库中的S、P、J、SPJ关系,查询某工程至少用了三家供应商(包含三家)供应的零件的平均数量,并按工程号的降序排列。

根据题意“某工程至少用了三家供应商(包含三家)供应的零件”,应该按照工程号分组,而且应该加上条件供应商的数目。但是需要注意的是,一个工程项目可能用了同一个供应商的多种零件,因此,在统计供应商数的时候需要加上DISTINCT,以避免重复统计导致错误的结果。例如,按工程号Jno='J1'分组,其结果如表7-6所示。如果不加DISTINCT,统计的结果数为7;而加了DISTINCT,统计的结果数为5。
表7-6 按工程号Jno='J1'分组

6.更名运算
SQL提供可为关系和属性重新命名的机制,这是通过使用具有如下形式的as子句来实现的:
As子句即可出现在select子句,也可出现在from子句中。
【例7.29】查询计算机系学生的Sname和Age,但Sname用“姓名”表示,Age用“年龄”表示。其语句如下:

SQL中的元组变量必须和特定的关系相联系。元组变量是通过from子句中使用As子句来定义的。通过例7.29来说明。
【例7.30】查询计算机系选修了C1课程的学生姓名Sname和成绩Grade。其语句如下:
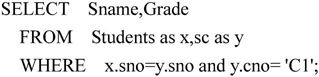
元组变量在比较同一关系的两个元组时非常有用。
7.字符串操作
对于字符串进行的最通常的操作是使用操作符like的模式匹配。使用两个特殊的字符来描述模式:“%”匹配任意字符串;“_”匹配任意一个字符。模式是大小写敏感的。例如:
Marry%匹配任何以Marry开头的字符串;%idge%匹配任何包含idge的字符串,例如Marryidge、Rock Ridge、Mianus Bridge和Ridgeway。
“_”匹配只含两个字符的字符串;“_%”匹配至少包含两个字符的字符串。
【例7.31】学生关系模式为(Sno,Sname,Sex,SD,Age,Add),其中,Sno为学号,Sname为姓名,Sex为性别,SD为所在系,Age为年龄,Add为家庭住址。请查询:
(1)家庭住址包含“科技路”的学生姓名。
(2)名字为“晓军”的学生姓名、年龄和所在系。
解:(1)家庭住址包含“科技路”的学生姓名的SQL语句如下:

(2)名字为“晓军”的学生姓名、年龄和所在系的SQL语句如下:
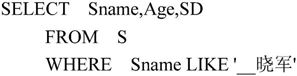
为了使模式中包含特殊模式字符(即%和_),在SQL中允许使用escape关键词来定义转义符。转义字符紧靠着特殊字符,并放在它的前面,表示该特殊字符被当成普通字符。例如,在like比较中使用escape关键词来定义转义符,例如使用反斜杠“\”作为转义符。
Like'ab\%cd%'escape'\',匹配所有以ab%cd开头的字符串。
Like'ab\cd%'escape'\',匹配所有以ab\cd开头的字符串。
8.视图的查询
【例7.32】建立“计算机系”(CS表示计算机系)学生的视图如下,并要求进行修改、插入操作时保证该视图只有计算机系的学生。

此时要查询计算机系年龄小于20岁的学生的学号及年龄的SQL语句如下:
SELECT Sno, Age FORM CS-STUDENT WHERE SD='CS' AND Age<20;
系统执行该语句时,通常先将其转换成等价的对基本表的查询,然后执行查询语句。即当查询视图表时,系统先从数据字典中取出该视图的定义,然后将定义中的查询语句和对该视图的查询语句结合起来,形成一个修正的查询语句。对上例修正之后的查询语句为:
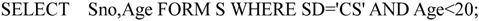
7.4.5 SQL数据更新
1.插入
要在关系数据库中插入数据,可以指定被插入的元组,或者用查询语句选出一批待插入的元组。插入语句的基本格式如下:

【例7.33】将学号为3002、课程号为C4、成绩为98的元组插入SC关系中。其语句如下:

【例7.34】若创建了一个新的视图v_employees,该视图基于表employees创建。

通过执行以下语句使用v_employees视图向表employees中添加一条新的数据记录。
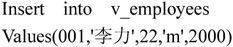
2.删除

【例7.35】删除表employees中姓名为张然的记录。
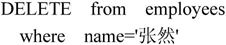
3.修改

【例7.36】将教师的工资增加5%。
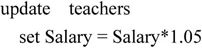
【例7.37】将教师的工资小于1000的增加5%工资。

使用视图可以更新数据记录,但应该注意的是,更新的只是数据库中的基表。
【例7.38】创建了一个基于表employees的视图v_employees,然后通过该视图修改表employees中的记录。其语句如下:

7.4.6 SQL访问控制
数据控制的是控制用户对数据的存储权力,是由DBA来决定的。但是,某个用户对某类数据具有何种权利,是个政策问题而不是技术问题。DBMS的功能就是保证这些决定的执行。因此,DBMS数据控制应具有如下功能。
(1)通过GRANT和REVOKE将授权通知系统,并存入数据字典。
(2)当用户提出请求时,根据授权情况检查是否执行操作请求。
SQL标准包括delete、insert、select和update权限。select权限对应于read权限,SQL还包括了references权限,用来限制用户在创建关系时定义外码的能力。
1.授权的语句格式
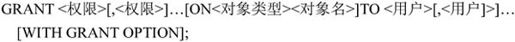
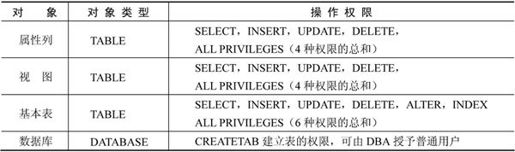
注意:不同类型的操作对象有不同的操作权限,常见的操作权限如表7-7所示。
表7-7 常见的操作权限
说明如下。
● PUBLIC:接受权限的用户可以是单个或多个具体的用户,PUBLIC参数可将权限赋给全体用户。
● WITH GRANT OPTION:若指定了此子句,那么获得了权限的用户还可以将权限赋给其他用户。
【例7.39】如果用户要求把数据库SPJ中供应商S、零件P、项目J表赋予各种权限。
(1)将对供应商S、零件P、项目J的所有操作权限赋给用户User1及User2,其授权语句如下:
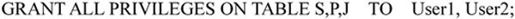
(2)将对供应商S的插入权限赋给用户User1,并允许将此权限赋给其他用户,其授权语句如下:
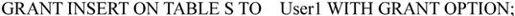
(3)DBA把数据库SPJ中建立表的权限赋给用户User1,其授权语句如下:
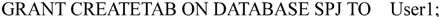
2.收回权限语句格式
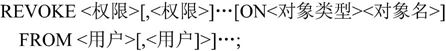
【例7.40】要求回收用户对数据库SPJ中供应商S、零件P、项目J表的操作权限。
(1)将用户User1及User2对供应商S、零件P、项目J的所有操作权限收回。
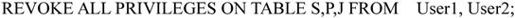
(2)将所有用户对供应商S的所有查询权限收回。
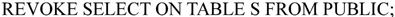
(3)将User1用户对供应商S的供应商编号Sno的修改权限收回。
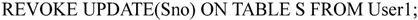
7.4.7 嵌入式SQL
SQL提供了将SQL语句嵌入到某种高级语言中的使用方式,通常采用预编译的方法识别嵌入在高级语言中的SQL语句。该方法的关键问题是必须区分主语言中嵌入的SQL语句,以及主语言和SQL间的通信问题。为了区分主语言与SQL语言,需要在所有的SQL语句前加前缀EXEC SQL,而SQL的结束标志随主语言的不同而不同。
例如,PL/I和C语言的引用格式为:
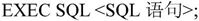
又如,COBOL语言的引用格式为:
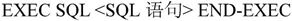
嵌入式SQL与主语言之间的通信通常有如下三种方式。
(1)SQL通信区(SQL Communication Area,SQLCA)向主语言传递SQL语句执行的状态信息,使主语言能够根据此信息控制程序流程。
(2)主变量也称共享变量。主语言向SQL语句提供参数主要通过主变量,主变量由主语言的程序定义,并用SQL的DECLARE语句说明。引用时,为了与SQL属性名相区别,需在主变量前加“:”。
【例7.41】根据共享变量givensno的值,查询学生关系students中学生的姓名、年龄和性别。
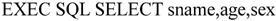

(3)游标SQL语言是面向集合的,一条SQL语句可产生或处理多条记录。而主语言是面向记录的,一组主变量一次只能放一条记录,所以,引入游标,通过移动游标指针来决定获取哪一条记录。
7.5 关系数据库规范化
在关系模型中,一个数据库模式是关系模式的集合。关系数据理论是指导数据库设计的基础,关系数据库设计是数据库语义学的问题。要保证构造的关系既能准确地反应现实世界,又有利于应用和具体的操作。关系数据库设计理论的核心是数据间的函数依赖,衡量的标准是关系规范化的程度及分解的无损连接和保持函数依赖性。关系数据库设计的目标是生成一组合适的、性能良好的关系模式,以减少系统中信息存储的冗余度,但又可方便地获取信息。
7.5.1 函数依赖
数据依赖是通过一个关系中属性间值的相等与否体现出来的数据间的相互关系,是现实世界属性间联系和约束的抽象,是数据内在的性质,是语义的体现。函数依赖则是一种最重要、最基本的数据依赖。
(1)函数依赖。设R(U)是属性集U上的关系模式,X、Y是U的子集。若对R(U)的任何一个可能的关系r,r中不可能存在两个元组在X上的属性值相等,而在Y上的属性值不等,则称X函数决定Y或Y函数依赖于X,记作X→Y。
(2)非平凡的函数依赖。如果X→Y,但Y⊈X,则称X→Y是非平凡的函数依赖。一般情况下,总是讨论非平凡的函数依赖。
(3)平凡的函数依赖。如果X→Y,但Y⊆X,则称X→Y是平凡的函数依赖。
(4)完全函数依赖。在R(U)中,如果X→Y,并且对于X的任何一个真子集X′,都有X′不能决定Y,则称Y对X完全函数依赖,记作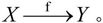
例如,给定一个学生选课关系SC(Sno,Cno,G),可以得到F={(Sno,Cno)→G},对(Sno,Cno)中的任何一个真子集Sno或Cno都不能决定G,所以,G完全依赖于Sno,Cno。
(5)部分函数依赖。如果X→Y,但Y不完全函数依赖于X,则称Y对X部分函数依赖,记作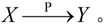 部分函数依赖也称为局部函数依赖。
部分函数依赖也称为局部函数依赖。
(6)传递依赖。在R(U,F)中,如果X→Y,Y⊈X,Y⊈X,Y→Z,则称Z对X传递依赖。
(7)码。设K为R(U,F)中属性的组合,若K→U,且对于K的任何一个真子集K′,都有K′不能决定U,则K为R的候选码。若有多个候选码,则选一个作为主码。候选码通常也称为候选关键字。
(8)主属性和非主属性。包含在任何一个候选码中的属性叫做主属性,否则叫做非主属性。
(9)外码。若R(U)中的属性或属性组X非R的码,但X是另一个关系的码,则称X为外码。
(10)函数依赖的公理系统(Armstrong公理系统)。设关系模式R(U,F),其中U为属性集,F是U上的一组函数依赖,那么有如下推理规则。
A1自反律:若Y⊆X⊆U,则X→Y为F所蕴涵。
A2增广律:若X→Y为F所蕴涵,且Z⊆U,则XZ→YZ为F所蕴涵。
A3传递律:若X→Y,Y→Z为F所蕴涵,则X→Z为F所蕴涵。
根据上述三条推理规则又可推出下述三条推理规则。
合并规则:若X→Y,X→Z,则X→YZ为F所蕴涵。
伪传递率:若X→Y,WY→Z,则XW→Z为F所蕴涵。
分解规则:若X→Y,Z⊆Y,则X→Z为F所蕴涵。
7.5.2 规范化
关系数据库设计的方法之一就是设计满足适当范式的模式,通常可以通过判断分解后的模式达到几范式来评价模式规范化的程度。范式有1NF、2NF、3NF、BCNF、4NF和5NF,其中1NF级别最低。这几种范式之间5NF⊂4NF⊂BCNF⊂3NF⊂2NF⊂1NF成立。通过分解,可以将一个低一级范式的关系模式转换成若干个高一级范式的关系模式,这种过程叫做规范化。下面给出1NF、2NF和3NF的定义。
1.1NF(第一范式)
定义:若关系模式R的每一个分量是不可再分的数据项,则关系模式R属于第一范式。
例如,供应者和它所提供的零件信息,关系模式FIRST和函数依赖集F如下:

若具体的关系如表7-8所示。从表7-8可以看出,每一个分量都是不可再分的数据项,所以是1NF的。但是,1NF存在如下4个问题。
(1)冗余度大。例如,每个供应者的Sno,Sname,Status,City要与其供应的零件的种类一样多。
(2)引起修改操作的不一致性。例如,供应者S1从“天津”搬到“上海”,若稍不注意,就会使一些数据被修改,另一些数据没有被修改,导致数据修改的不一致性。
表7-8 FIRST
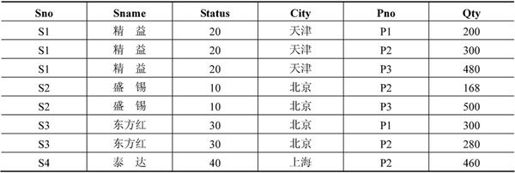
(3)插入异常。关系模式FRIST的主码为Sno、Pno,按照关系模式实体完整性规定,主码不能取空值或部分取空值。这样,当某个供应者的某些信息未提供时(如Pno),则不能进行插入操作,这就是所谓的插入异常。
(4)删除异常。若供应商S4的P2零件销售完了,并且以后不再销售P2零件,那么应删除该元组。这样,在基本关系FIRST找不到S4,可S4又是客观存在的。
正因为上述4个原因,所以要对模式进行分解,并引入了2NF。
2.2NF(第二范式)
定义:若关系模式R∈1NF,且每一个非主属性完全依赖于码,则关系模式R∈2NF。
换句话说,当1NF消除了非主属性对码的部分函数依赖,则称为2NF。
例如,FIRST关系中的码是Sno、Pno,而Sno→Status,因此非主属性Status部分函数依赖于码,故非2NF的。
若此时将FIRST关系分解为FIRST1(Sno,Sname,Status,City)和FIRST2(Sno,Pno,Qty)。其中,FIRST1∈2NF,FIRST2∈2NF。因为分解后的关系模式FIRST1的码为Sno,非主属性Sname、Status、City完全依赖于码Sno,所以属于2NF;关系模式FIRST2的码为Sno、Pno,非主属性Qty完全依赖于码,所以也属于2NF。
3.3NF(第三范式)
定义:若关系模式R(U,F)中若不存在这样的码X,属性组Y及非主属性Z(Z⊈Y)使得X→Y(Y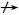 X),Y→Z成立,则关系模式R∈3NF。
X),Y→Z成立,则关系模式R∈3NF。
即当2NF消除了非主属性对码的传递函数依赖,则称为3NF。
例如,FIRST1∉3NF,因为在分解后的关系模式FIRST1中有Sno→Status,Status→City,存在着非主属性City传递依赖于码Sno。若此时将FIRST1继续分解为:
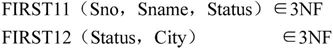
通过上述分解,数据库模式FIRST转换为FIRST11(Sno,Sname,Status),FIRST12(Status,City)和FIRST2(Sno,Pno,Qty)三个子模式。由于这三个子模式都达到了3NF,因此称分解后的数据库模式达到了3NF。
可以证明,3NF的模式必是2NF的模式。产生冗余和异常的两个重要原因是部分依赖和传递依赖。因为3NF模式中不存在非主属性对码的部分函数依赖和传递函数依赖,所以具有较好的性能。对于非3NF的1NF、2NF,其性能弱,一般不宜作为数据库模式,通常要将它们变换成为3NF或更高级别的范式,这种变换过程称为“关系模式的规范化处理”。
7.5.3 模式分解及分解应具有的特性
1.分解
定义:(分解)关系模式R(U,F)的一个分解是指ρ={R1(U1,F1),R2(U2,F2),…,Rn(Un,Fn)},其中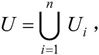 并且没有Ui⊆Uj,1≤i,j≤n;Fi是F在Ui上的投影,Fi={X→Y|X→Y∈F+∧XY⊆Ui}。
并且没有Ui⊆Uj,1≤i,j≤n;Fi是F在Ui上的投影,Fi={X→Y|X→Y∈F+∧XY⊆Ui}。
对一个给定的模式进行分解,使得分解后的模式是否与原来的模式等价有三种情况。
(1)分解具有无损连接性。
(2)分解要保持函数依赖。
(3)分解既要无损连接性,又要保持函数依赖。
2.无损连接
定义:(无损连接)ρ={R1(U1,F1),R2(U2,F2),…,Rk(Uk,Fk)}是关系模式R(U,F)的一个分解,若对R(U,F)的任何一个关系r均有r=mρ(r)成立,则分解ρ具有无损连接性(简称无损分解),其中,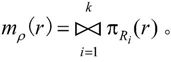
定理:关系模式R(U,F)的一个分解ρ={R1(U1,F1),R2(U2,F2)}具有无损连接的充分必要的条件是U1⋂U2→U1-U2∈F+或U1⋂U2→U2-U1∈F+证明略。
3.保持函数依赖
定义:设关系模式R(U,F)的一个分解ρ={R1(U1,F1),R2(U2,F2)…,Rk(Uk,Fk)},如果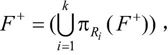 则称分解ρ保持函数依赖。
则称分解ρ保持函数依赖。
7.6 数据库的控制功能
7.6.1 事务管理
事务是一个操作序列,这些操作“要么都做,要么都不做”,是数据库环境中不可分割的逻辑工作单位。事务和程序是两个不同的概念,一般一个程序可包含多个事务。在SQL语言中,事务定义的语句有如下三条。
(1)BEGIN TRANSACTION:事务开始。
(2)COMMIT:事务提交。该操作表示事务成功地结束,它将通知事务管理器该事务的所有更新操作现在可以被提交或永久地保留。
(3)ROLLBACK:事务回滚。该操作表示事务非成功地结束,它将通知事务管理器出故障了,数据库可能处于不一致状态,该事务的所有更新操作必须回滚或撤销。
事务具有原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)。这4个特性也称事务的ACID性质。
(1)原子性。事务是原子的,要么都做,要么都不做。
(2)一致性。事务执行的结果必须保证数据库从一个一致性状态变到另一个一致性状态。因此,当数据库只包含成功事务提交的结果时,称数据库处于一致性状态。
(3)隔离性。事务相互隔离。当多个事务并发执行时,任一事务的更新操作直到其成功提交的整个过程,对其他事务都是不可见的。
(4)持久性。一旦事务成功提交,即使数据库崩溃,其对数据库的更新操作也将永久有效。
7.6.2 数据库的备份与恢复
在数据库的运行过程中,难免会出现计算机系统的软、硬件故障,这些故障会影响数据库中数据的正确性,甚至破坏数据库,使数据库中全部或部分数据丢失。因此,数据库的关键技术在于建立冗余数据,即备份数据。如何在系统出现故障后能够及时使数据库恢复到故障前的正确状态,就是数据库恢复技术。
1.故障类型
在数据库中的4类故障是事务内部故障、系统故障、介质故障及计算机病毒。
(1)事务内部故障。事务内部的故障有的可以通过事务程序本身发现。例如,银行转账事务,将账户A的金额转X到账户B,此时应该将账户A的余额-X,将账户B的余额+X。如果账户A的余额不足,那么,两个事务都不做,否则都做。但有些是非预期的,不能由事务程序处理,如运算溢出、并发事务发生死锁等。
(2)系统故障。通常称为软故障,是指造成系统停止运行的任何事件,使得系统要重新启动,如CPU故障、操作系统故障和突然停电等。
(3)介质故障。通常称为硬故障,如磁盘损坏、磁头碰撞和瞬时强磁干扰。此类故障发生几率小,但破坏性最大。
(4)计算机病毒。是一种人为的故障和破坏,是在计算机程序中插入的破坏,计算机功能或者数据,可以繁殖和传播的一组计算机指令或程序代码。
2.备份方法
恢复的基本原理是“建立数据冗余”(重复存储)。建立冗余数据的方法是进行数据转储和登记日志文件。数据的转储分为静态转储和动态转储、海量转储和增量转储。
(1)静态转储和动态转储。静态转储是指在转储期间不允许对数据库进行任何存取、修改操作;动态转储是在转储期间允许对数据库进行存取、修改操作,因此,转储和用户事务可并发执行。
(2)海量转储和增量转储。海量转储是指每次转储全部数据;增量转储是指每次只转储上次转储后更新过的数据。
(3)日志文件。在事务处理的过程中,DBMS把事务开始、事务结束以及对数据库的插入、删除和修改的每一次操作写入日志文件。一旦发生故障,DBMS的恢复子系统利用日志文件撤销事务对数据库的改变,回退到事务的初始状态。因此,DBMS利用日志文件来进行事务故障恢复和系统故障恢复,并可协助后备副本进行介质故障恢复。
3.恢复
事务恢复有如下三个步骤。
(1)反向扫描文件日志(即从最后向前扫描日志文件),查找该事务的更新操作。
(2)对事务的更新操作执行逆操作。
(3)继续反向扫描日志文件,查找该事务的其他更新操作,并做同样的处理,直到事务的开始标志。
4.数据库镜像
为了避免磁盘介质出现故障影响数据库的可用性,许多DBMS提供数据库镜像功能用于数据库恢复。需要说明的是,数据库镜像是通过复制数据实现的,但频繁地复制数据会降低系统的运行效果。因此,实际应用中往往对关键的数据和日志文件镜像。
7.6.3 并发控制
所谓并发操作,是指在多用户共享的系统中,许多用户可能同时对同一数据进行操作。并发操作带来的问题是数据的不一致性,主要有三类:丢失更新、不可重复读和读脏数据。其主要原因是事务的并发操作破坏了事务的隔离性。DBMS的并发控制子系统负责协调并发事务的执行,保证数据库的完整性不受破坏,避免用户得到不正确的数据。
1.并发操作带来的问题
并发操作带来的数据不一致性有三类:丢失修改、不可重复读和读脏数据,如图7-37所示。

图7-37 三种数据不一致性
(1)丢失修改。如图7-37(a)所示,事务T1、T2都是对数据A做减1操作。事务T1在时刻t6把A修改后的值15写入数据库,但事务T2在时刻t7再把它对A减1后的值15写入。两个事务都是对A的值进行减1操作并且都执行成功,但A中的值却只减了1。例如火车售票系统,T1与T2各售出了一张票,但数据库里的存票却只减了一张,造成数据的不一致。原因在于T1事务对数据库的修改被T2事务覆盖而丢失了,破坏了事务的隔离性。
(2)不可重复读。如图7-37(b)所示,事务T1读取A、B的值后进行运算,事务T2在t6时刻对B的值做了修改以后,事务T1又重新读取A、B的值再运算,同一事务内对同一组数据的相同运算结果不同,显然与事实不相符。同样是事务T2干扰了事务T1的独立性。
(3)读脏数据。如图7-37(c)所示,事务T1对数据C修改之后,在t4时刻事务T2读取修改后的C值做处理,之后事务T1回滚,数据C恢复了原来的值,事务T2对C所做的处理是无效的,它读的是被丢掉的垃圾值。
通过以上三个例子,在事务并行处理的过程中对相同数据进行访问,导致了数据的不一致性。解决问题的方法可以从保证事务的隔离性入手。
2.并发控制技术
并发控制的主要技术是封锁。基本封锁的类型有排它锁(简称X锁或写锁)和共享锁(简称S锁或读锁)。
1)封锁
(1)排它锁。若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他事务都不能再对A加任何类型的锁,直到T释放A上的锁。
(2)共享锁。若事务T对数据对象A加上S锁,则只允许T读取A,但不能修改A,其他事务只能再对A加S锁,直到T释放A上的S锁。这就保证了其他事务可以读A,但在T释放A上的S锁之前不能对A进行任何修改。
2)三级封锁协议
(1)一级封锁协议。事务在修改数据R之前必须先对其加X锁,直到事务结束才释放。事务结束包括正常结束(COMMIT)和非正常结束(ROLLBACK)。一级封锁协议可以解决丢失更新问题。
(2)二级封锁协议。在一级封锁协议的基础上,加上事务T在读数据R之前必须先对其加S锁,读完后即可释放S锁。二级封锁协议可以解决读脏数据的问题。但是,由于二级封锁协议读完了数据后即可释放S锁,所以不能保证可重复读。
(3)三级封锁协议。在一级封锁协议的基础上,加上事务T在读数据R之前必须先对其加S锁,直到事务结束时释放S锁。三级封锁协议除了防止丢失修改和不读“脏”数据外,还进一步防上了不可重复读。
3.活锁与死锁
所谓活锁,是指当事务T1封锁了数据R,事务T2请求封锁数据R,于是T2等待,当T1释放了R上的封锁后,系统首先批准了T3请求,于是T2仍等待,当T3释放了R上的封锁后,又批准了T4请求,依此类推,使得T2可能永远等待的现象。
所谓死锁,是指两个以上的事务分别请求封锁对方已经封锁的数据,导致长期等待而无法继续运行下去的现象。
4.并发调度的可串行性
多个事务的并发执行是正确的,当且仅当其结果与某一次序串行地执行它们时的结果相同,称这种调度策略是可串行化的调度。
可串行性是并发事务正确性的准则,按这个准则规定,一个给定的并发调度,当且仅当它是可串行化的才认为是正确调度。
5.两段封锁协议
所谓两段封锁协议,是指所有事务必须分两个阶段对数据项加锁和解锁。即事务分两个阶段,第一阶段是获得封锁,事务可以获得任何数据项上的任何类型的锁,但不能释放;第二阶段是释放封锁,事务可以释放任何数据项上的任何类型的锁,但不能申请。
6.封锁的粒度
封锁对象的大小称为封锁的粒度。封锁的对象可以是逻辑单元(如属性、元组、关系、索引项、整个索引直至整个数据库),也可以是物理单元(如数据页或索引页)。
