分布式开发样板——Linux内核开发过程

作者/ Wolfgang Mauerer
Wolfgang Mauerer资深Linux专家,有数十年Linux开发经验。从1997年最初发表关于内核的系列文章开始,他就醉心于解释Linux核心的内部机制、编写相关的文档。此外,他还著有LaTeX排版方面的图书,其撰写的大量文章已经被翻译成7种语言。
显然,算法、数据结构、代码构成了Linux开发的最核心部分,内核就是这些内容。但Linux还有另一个侧面,不应该被忽视:开发了内核的社区、其工作方式、人与人之间交互的方式。这个方面是很有趣的,因为内核是现存最大、最复杂的开源项目之一,它对于大规模的分布式分散开发来说,是一个样板。本文将对内核开发涉及的技术和社会方面提供一个概述。
简介
内核源代码(在主要的README文件中)将开发社区描述为一个“在网络上松散组织的黑客团队”,尽管从开始到现在,内核开发涉及的人数及其职业来源一直在发生变化,但所述说法一直是真实的。这导致的一个直接结果就是开放性:开发者之间大多数的通信都发生在邮件列表上,任何对操作系统演变方式感兴趣的人都可以阅读这些。一个要点在于,来自许多在各方面激烈竞争(请注意,是公司,不是开发者)的公司的开发者在内核开发中密切协作。而非技术人员,通常只能惊讶地站在一边。实际上,这是一项非凡的壮举!
现在,已经不需要多说Linux内核开发的基本原理了。尽管仅仅在15年前创建一个可以实际使用的开源操作系统似乎还是一个妄想,但大多数技术人员已经习以为常。Linux内核开发与经典的开发模型相比,一个本质区别是,前者没有什么固定的形式化规则来规范开发过程如何运作。确实有惯例存在,但很少以文档方式形式化。没有开发路线图,也没有中央代码存储库。但确实有重要的代码存储库和重要的开发者。与固定的刚性结构相比,这在许多情况下可能都是优点,因为开发过程变得更为动态和灵活。但如果对领域不熟悉,工作也会变得更困难。
内核代码树和开发的结构
Linux内核是一个非常动态的软件,最令人惊讶之处在于,其开发根本没有开发版本!至少没有由Linus Torvalds管理的显式、长期的开发版本。
此前的情况有所不同。传统上,内核开发分为两个不同的分支。一个分支包含稳定的内核版本,应该用于生产系统,其次版本号为偶数。内核分支2.0、2.2、2.4都是稳定分支(2.0.x、2.2.x、2.4.x是发布的各系列版本),而2.1、2.3、2.5是开发版本,诸如2.5.x等。这种方法的基本思想在于,使新的特性和试验性的补丁经历大量的测试和改进,一旦添加了足够数量的新特性,而且代码在实际上以可察觉的方式稳定下来时,就打开一个新的稳定的源代码树。理想情况下,发布商可以从稳定的版本分支取得内核,将其集成到发行版中。
遗憾的是,这种方式运作得不十分好。在打开新的稳定版本之前,一个开发周期可能需要数年,在IT界这是一个非常长的时间了。在新硬件出现时,买家通常不会花几年的时间等待内核的支持(至少是大多数人使用的稳定版本的内核)。不仅对设备驱动程序是这样,对大多数新特性来说,都是如此。因而,发布商确实从开发版内核向稳定分支移植了一些新特性。而且由于每个发行版的“口味”不同,后向移植所选择的特性也不同,这导致了发行版内核之间的分歧越来越大。
从内核版本2.6系列以来,采用了一种新的开发策略。只有一个内核系列,不再划分稳定代码树和开发代码树。而采用了若干比较试验性的内核代码树来测试新的特性,在经过稳定和测试期之后,新特性将直接合并到内核的主系列中。2.6版本的内核代码树由Linus Torvalds管理,读者可能听说过,他是Linux最初的创造者和发起者。来自该代码树的内核通常称之为vanilla内核,以区别发行版根据具体需要修改而来的内核,或各种试验性的代码树。该内核系列通常称之为主线内核。
主线内核代码树之外的代码树,通常在版本号之后增加一个后缀进行标识。主线内核之外,最重要的代码树是2.6-mm,由Andrew Morton管理,大多数补丁在被主线2.6内核接受之前,都会先经过该代码树。还存在许多其他子系统相关的代码树,它们通常关注内核的某个特定方面:2.6-net关注网络,而2.6-rt包含了与实时问题和交互性问题相关的工作,这只是其中两个例子。还有一个-stable版本,用于在正式的内核版本发布后,将重要的bug修复集成进来。内核代码树的变动可能因种种原因而发生:开发者可能失去维护代码的兴趣,如果代码树涉及的问题已经以某种方法解决,那么代码树本身可能也会消失。
命令链
内核的所有活动组件都有一个维护者,他会关注相关的特定领域的开发。许多维护者(特别是大组件的维护者)都被各个Linux厂商雇佣,但有一些仍然是在空闲时间工作。维护者的职责变动范围很大,可能只是控制单个设备驱动程序,也可能涉及一项基础设施(如内核对象机制),更大的范围可能涉及整个子系统(如所有的网络代码、块层或特定体系结构在arch/下的所有代码)。维护者在内核代码树顶层的MAINTAINERS文件中列出,其中包括几项信息,读者在这里可以看到:
MAINTAINERS
IA64 (Itanium) PLATFORM
P: Tony Luck
M: tony.luck@intel.com
L: linux-ia64@vger.kernel.org
W: http://www.ia64-linux.org/
T: git kernel.org:/pub/scm/linux/kernel/git/aegl/linux-2.6.git
S: Maintained
除了维护者的名字及其电子邮件联络方式,该文件提供了一个邮件列表,供讨论相应领域的开发使用。通常,与直接联系维护者相比,在邮件列表上提出和讨论问题更受欢迎。如果代码通过一个公众可访问的版本控制存储库进行管理,那么文件中会指定存储库的位置,在上面的例子中是一个git存储库,这是许多内核开发者的首选源代码管理系统(git在附录B中讨论过)。最后,还可以指定一个Web页面,其中包含了有关该子系统及其维护状态的信息。原则上,每个信息项都可以用状态Supported和Maintained来区分维护者是否受雇于Linux厂商,但这通常是一个哲学问题。更重要的区别是,受到活跃维护的部分、没有维护者的部分(Orphan)、旧的代码和废弃的代码(Obsolete)、很少被关注但并非完全没有维护的部分(Odd Fixes)。
对内核的各个部分设置维护者,从很小的部分(如驱动程序)到比较大的部分(如整个子系统),这在开发者之间建立了一个松散的层次结构。但没有一个形式上的权威机构来确定这个层次结构,它完全取决于贡献代码的人及其彼此间的信任程度。在代码进入内核时,通常(但并非唯一)的方式是自下而上遍历该层次结构。对代码的修正或新特性通常首先进入到特定于设备或子系统的邮件列表或到达相应的维护者,接下来向较高层的维护者前进,这些维护者将其传递到Andrew Morton的-mm代码树,1由此最终可能合并到vanilla内核代码树中。该过程通常称之为上溯合并(merging upstream)。但这只是一种可能性,规则决非是固定的。
1为减少因为新代码彼此不兼容而造成的-mm代码树中合并冲突的数目,在新代码进入-mm树之前,应该用另一个开发系列的代码树-next将此类问题整理出来。
开发周期
放弃明确的开发版内核系列,最重要的理由之一就是希望加速新特性应用到产品版本内核的速度,而不必由发行版厂商来后向移植。该目标显然已经达到:2.6系列中,内核版本发布的间隔大约是70~110天,这意味着每两三个月,就有一个新内核出现。开发工作的许多方面已经由Linux基金会出版的一项研究阐明([KHCM]),对该研究的更新不时出现在www.lwn.net上。该研究的一个特别有趣的预测是,vanilla内核树的进展是以一种猝发形式进行的,这是故意的。该代码树会等待一些特性就位后,突然向前跨出一步。参见图F-1,该图说明了对内核的修改随时间的变化。
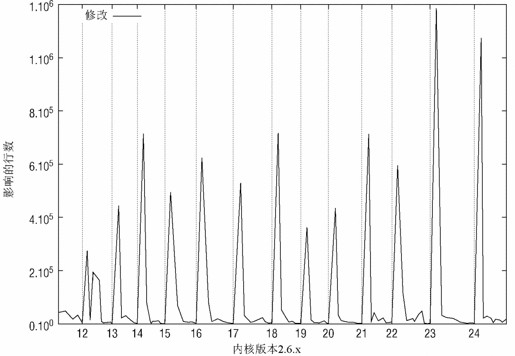
图1 vanilla内核树的的变化率。每当打开合并窗口,都会出现一次猝发的大量变更,而后是一段稳定时期,只有相对少的修改
在一个新的内核版本发布后,Linus Torvalds都会打开一个合并窗口(merge window),在比较短的一段时间内保持开放,大约两个星期。新代码通常只能在这段时间内进入。尽管该规则有例外情况,但该策略的实施是相当严格的。在此期间,代码的变化率是相当大的。在合并窗口关闭时,这段活动时间就结束了,而候选的发布版内核也准备好了。候选发布版提供了一个机会,可以测试各项修改之间的交互,以及识别并修复bug。这段时间的变化率会飞速下降,因为修复通常是非常短的补丁,其重要性等同于初始的特性提交。在一切都稳定以后,一个新的内核版本就发布了。这种行为模式的细节如图2所示,其中给出了内核版本2.6.21到2.6.24的开发进展情况。请注意,y坐标轴采用的是对数坐标。虽然第一个候选发布版包含了1 000 000个修改,但下一个发布版这个数字就下降到大约10 000个,后续就降低的更多,直至最后正式发布。
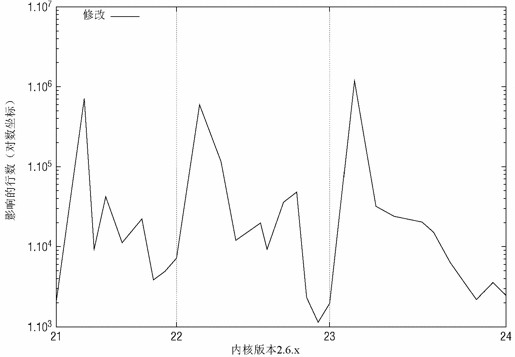
图2 对内核版本2.6.22到2.6.24之间代码变化率的详细分析。请注意,y轴采用的是对数坐标
图3的视角稍有不同,该图通过对各个内核版本及候选发布版累积作出的修改来考察代码树稳定的过程。从斜率的剧烈变化可以很清楚地看到合并窗口,而后是比较平坦的曲线,表明这是代码树的稳定期。2
2这种呈现数据的方式,是受Jonathan Corbet的Kernel Report演讲的鼓舞,在许多Linux相关的会议和类似的场合,都可以看到他的演讲。一些会议的网站(如linux.conf.au)提供了其演讲的视频。
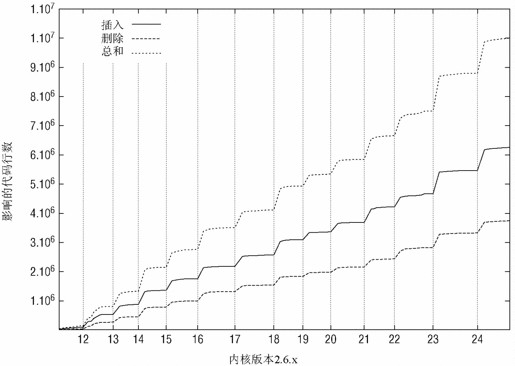
图3 在Linux开发过程中累积的修改。合并窗口和稳定期的效应看上去非常明显
注意,如果用纯粹的数字来度量软件项目的生产率,总是很困难,特别是这些数字只是基于代码行的增删时。例如,先引进大量代码,然后再删除,合并的效果是没什么意义的,当然按上述方法测量时,将导致很高的变化率。不过呢,这里介绍的这种相对简单的方法可以使读者对开发过程的组织方式获得一个很好的直观理解。也应注意,这样的结果可以非常容易地得到,因为在git存储库中可以获得完整的内核开发历史,读者用类似的方法来自行分析内核源代码中感兴趣的领域,也应该并不困难。
新特性不会突然从天上掉下来,在被主线内核接受之前,它们通常有一段很长的开发历史。开发在这一阶段如何进行,很大程度上取决于特定的子系统和相关的维护者。在代码被主线内核接受之前,可能已经讨论了多年,这并非罕见。例如,Reiser文件系统就花费了很长时间来解决许多开发者对其提出的问题。有时候需要花费大量时间才能将代码推进到vanilla内核中,但有时候进展会快速得多。
例如,Ext4文件系统的开发过程是与vanilla内核密切集成的,其代码从最初开始开发到最终接受广泛测试的整个过程中,一直都处于主线内核中。实际上,其代码库是从Ext3的一个副本开始,然后不断地修改以集成许多新的思想和改进。
在线资源
有大量网站致力于Linux内核开发,它们提供了很多有用信息。因为Web的结构快速变化,在这里进行综述没有实际的意义,因为大多数链接可能都会很快过期。但是,只依赖于所喜爱的搜索引擎来抓取有关内核开发的有用链接,并不是到达成功的最容易路径,特别是需要判断结果的相关性和质量时。因而,下述列表根据作者个人的偏好,提供了一部分较好的链接。
当前的内核源代码以及许多基本的用户空间工具都可以从网站www.kernel.org获得。在git.kernel.org上列出了大量的git源代码存储库。
www.lwn.net是内核开发过程方面的首要信息源,该网站每周定期报道这方面的更新情况。这些更新不仅仅只是内核方面的。该网站收集了Linux开发所有方面的有趣新闻以及IT社区中的相关事件,而优秀的研究文章对各个项目的发展现状给出了深刻的见解。内核在发表一星期之后即免费提供,但大多数最新的信息只对订阅者开放。由于费用较低,我推荐读者尽快订阅!3
内核的全部修改日志很容易达到若干兆字节。尽管它们细致地记录了到最终版本的每一次提交,但实际上不可能根据日志记录来从一个比较宽泛的角度概览内核开放过程中发生的情况。谢天谢地,www.linuxnewbies.net提供了不那么细致的修改日志,更多地强调全景而不是细节。
Linux基金会提供了一个“天气预报”服务,试图预测哪些补丁和特性将被未来的内核版本接纳。这项服务是最接近于Linux内核路线图的,它对开发的方向提供了有价值的信息。其URL是www.linux-foundation.org/en/Linux_Weather_Forecast。
3当然,我与LWN没有商业利益,也没有任何关系。但这个网站确实令人敬畏。
补丁的结构
内核开发者预期好的补丁应该满足某些固定的条件。尽管这对补丁的准备工作提出了更多要求,但它使得维护者、审阅者、测试者的工作更为容易。因为如果补丁都遵循同样的惯例,就可以减少理解各项修改所需的时间。内核对如何准备补丁包含了详细的指令,可以在Documentation/SubmittingPatches中找到。本节将综述要点,但读者在向任何维护者或邮件列表发送代码之前,都务请阅读整个SubmittingPatches文档。更多的建议在Andrew Morton的The Perfect Patch文档中给出,可以在www.zip.com.au/~akpm/linux/patches/stuff/tpp.txt上获得,也可以在linux.yyz.us/patch-format.html上得到。
首要地,必须将大的修改分解为单项修改,与在单个补丁中修改跨越50 000个子目录的1 000万个文件相比,单项修改易于提取要点。一个补丁应该对源代码进行一项逻辑上的修改,即使这意味着需要一个补丁系列,其中有多个补丁会修改同一个文件,也是如此。理想地,补丁应该是可叠加的,即补丁应该是可以独立应用的。但由于修改的性质所致,这不见得总是可能的,在不可能的情况下,应该对应用补丁的正确顺序给出文档。
原则上,补丁序列可以用附录B所述的diff和patch手工创建。时间稍长,这可能就变得相当乏味,但http://savannah.nongnu.org/projects/quilt的quilt工具箱可以使管理补丁栈的大部分工作自动化,从而在一定程度上减轻了工作。
技术问题
就补丁格式的技术方面来说,请注意,一个统一的(unified)补丁要求包含所修改的C函数相关的信息。这样的补丁可使用diff -up生成。如果补丁添加了新文件或关注多个子目录下的文件,那么必须使用diff -uprN来解决。附录B讨论了形成的补丁的外观,及其包含的内容。
- 编码风格
内核有一些编码风格要求,定义在Documentation/CodingStyle。尽管并非所有开发者都同意该文件中每一个要求,但许多开发者对违反编码风格的做法比较敏感。有一个共同的编码风格是件好事情。内核包含了大量代码,如果补丁/文件使用大量不同的规范,那是真正的麻烦。谢天谢地,Linux内核在编码风格方面不像其他项目那样狂热,但对不受欢迎的风格有着明确的意见,读者可以在下述文档片段中看到:
Documentation/CodingStyle
首先,我建议打印一份GNU编码标准,但不要阅读。烧掉它们,这是一种姿态。
内核开发者预期何种风格呢?要点如下所示。
- 不同缩进层次总是以一个tab分隔,一个tab总是等于8个空格。这对于看过很多用户层代码的程序员来说,可能太大了,但内核是不同的。很自然,代码在几次缩进之后,会向屏幕右侧快速移动,但这可用作一个报警信号:需要太多缩进层次的代码通常应该替换为更干净的代码,或划分为函数,接下来问题自动地解决了。
比较大的缩进通常会导致字符串和过程参数超过一行80个字符的边界,因而必须明智地分解为块。
除了前述原因之外,许多内核开发者的工作方式有很不寻常的倾向,长时间地专注于代码并非罕见的情况。在连续三天在一行中编写了大量代码之后,视觉可能会变得模糊,大的缩进肯定对这种情况有所帮助(以及大量咖啡饮料)。
- 开始的花括号放在行的结尾,而结束的花括号放在行的开头。在接下来是控制语句时(例如else分支,或do循环中的while条件),接下来的语句不再占用新行,而是接着结束的花括号开始。如果一个块语句中只包含一个语句,那么额外的花括号是不必要的。实际上,不鼓励增加额外的花括号(想一想,从长期来看,这可以为你节省多少次输入)。
函数的惯例不同:开始和结束的花括号都需要独立的一行。
下列代码给出了上述规则的示例:
kernel/sched.c
static void __update_rq_clock(struct rq rq)
{
u64 prev_raw = rq->prev_clock_raw;
u64 now = sched_clock();
…
if (unlikely(delta < 0)) {
clock++;
rq->clock_warps++;
} else {
/
Catch too large forward jumps too:
/
if (unlikely(clock + delta > rq->tick_timestamp + TICK_NSEC)) {
if (clock < rq->tick_timestamp + TICK_NSEC)
clock = rq->tick_timestamp + TICK_NSEC;
else
clock++;
rq->clock_overflows++;
} else {
if (unlikely(delta > rq->clock_max_delta))
rq->clock_max_delta = delta;
clock += delta;
}
}
rq->prev_clock_raw = now;
rq->clock = clock;
}
括号内部不应该使用环绕空格,因此if(condition)是反对的,而if(condition)将受到普遍欢迎。关键字(如if)后应接一个空格,而函数定义和函数调用则不需要。前述代码片段也包含了这些规则的示例。
常数应该由宏或enum枚举中的成员表示,其名称应该都是大写字母。
函数通常不应该长于一个屏幕(即24行)。更长的代码应该分解为多个函数,即使形成的辅助函数只有一个调用者,也是如此。
局部变量名称应该简短,不要试图像写小说那样讲故事,比如OnceUponATimeThereWasA-CounterWhichMustBeIntializedWithZero。也可以使用tmp这样的名称,这样也减少了输入次数(同时保护了你的手指)。
全局标识符应该提供更多有关其自身的信息,因为它们在所有上下文都是可见的。prio_tree_remove是一个全局函数的好名字,而cur和ret则只适用于局部变量名称。由多个表达式注册的名称,应该使用下划线来分隔其组成部分,而不能混用大小写字母。
- typedef被认为是邪恶的化身,因为它们隐藏了一个对象的实际定义,因此通常不应该采用。它可能为补丁的创建者节省一些输入,但将给所有其他开发者的阅读增加困难。
但有时候必须隐藏某个数据类型的定义,例如在需要根据底层体系结构而对一个量提供不同实现的时候,但通用代码不应该注意到这一点。例如,用于原子计数器的atomic_t类型,或页表的各种成员类型(如pte_t、pud_t等)。它们都不能直接访问和修改,只能通过专用的辅助函数,因此其定义对通用代码是不可见的。
所有这些规则(还有更多)都在编码风格文档Documentation/CodingStyle中进行了讨论,连同其后的基本原理(包括最重要的规则,编号为17:不要重新发明轮子!)。因此,在这里重复该文档中的信息是没有意义的,每一份内核副本都带有该文档,直接去看就可以了!此外,在通读内核源代码时,读者会很快熟悉所要求的风格。
下列两个实用程序,有助于遵守所要求的编码风格:
Lindent,位于内核的scripts/目录下,它向GNU indent提供命令行选项,以便根据内核首选的缩进选项,来对一个文件重新缩进。
checkpatch.pl,同样位于内核源代码树的scripts/目录下,它可以扫描补丁文件,以查找违反编码风格之处,并提供适当的诊断。
- 可移植性
内核可以在大量体系结构上运行,这些体系结构有很多不同之处,对C代码也具有各种不同的限制。新代码的先决条件之一,就是在原则上可能的情况下,该代码应该能够移植到所有支持的体系结构并运行。这里将提醒读者一些重要的、在为内核编写代码时必须考虑的问题。
使用适当的锁机制,确保你的代码能够在多处理器环境下安全运行。由于可抢占内核的缘故,这在单处理器系统上同样重要。
总是应该编写字节序中立的代码。对小端序和大端序机器,你的代码都应该能够工作。
不要假定页长度为4 KiB,而应该使用PAGE_SIZE。
不要对任何数据类型假定位宽度。在需要固定数目的比特位时,总是使用具有显式位宽的类型(如u16、s64等)。但读者总是可以假定sizeof(long) == sizeof(void *)。
不要使用浮点计算。
要记住,栈长度是固定的,有上限。
- 为代码编写文档
除了为提交的补丁编写文档之外,同样重要的是为代码编写文档,特别是可能从其他子系统或驱动程序调用的函数。内核为此使用了下列特殊形式的C注释:
fs/char_dev.c
/*
register_chrdev() - Register a major number for character devices.
@major: major device number or 0 for dynamic allocation
@name: name of this range of devices
@fops: file operations associated with this devices
If @major == 0 this functions will dynamically allocate a major and return
its number.
If @major > 0 this function will attempt to reserve a device with the given
major number and will return zero on success.
Returns a -ve errno on failure.
The name of this device has nothing to do with the name of the device in
/dev. It only helps to keep track of the different owners of devices. If
your module name has only one type of devices it’s ok to use, for example, the name
of the module here.
This function registers a range of 256 minor numbers. The first minor number
is 0.
/
int register_chrdev(unsigned int major, const char name,
const struct file_operations fops)
…
请注意,注释行以两个星号开始,表明该注释是一个kerneldoc注释。以此类注释开头的函数将包含在API参考手册中,参考手册可以用make htmldocs或类似的命令创建。参数名必须以@符号为前缀开始,在生成的输出中将包含对应参数的注释。注释应该包括以下内容:
对参数的描述,指定该函数做什么(而不是如何做);
可能的返回代码及其语义;
对函数的限制,有效参数的范围,和/或任何必须考虑的特殊问题。
提交和审阅
本节讲述内核开发中两个重要的社会性部分:将补丁提交到邮件列表,以及后续的审阅过程。
- 为邮件列表准备补丁
大多数补丁在被考虑包含到任何内核代码树之前,都首先发送到对应子系统的邮件列表,除非你是一个第一流的内核贡献者,能够直接向Linus或Andrew提交补丁。还有一些需要遵守的惯例,如下所述。
标题行以[PATCH]开始,标题的其余部分应该对补丁所做的事情作一个简明的描述。一个好的标题是非常重要的,因为它不仅仅用于邮件列表上,在被接受的情况下,它还会出现在git的修改日志中。
如果一个补丁不应该直接应用,或需要更多讨论,它可以用一个其他的标识符进行标记,如[RFC]。
较大的改动应该分解为多个补丁,每个补丁完成逻辑上的修改。类似地,每个电子邮件只应该发送一个补丁。每个补丁应该以[PATCH m/N]的形式进行编号,其中m是一个计数器,而N则是补丁的总数。[PATCH 0/N]应该包含有关后续补丁的一个概述。
对每个补丁自身的更详细描述应该包含在电子邮件的内容部分。同样,在补丁集成后,该说明文本也不会丢失,它也会进入到git存储库中,用作此次修改的文档。
代码本身应该直接呈现在电子邮件中,而不能使用任何形式的base64编码、压缩或其他技巧。附件也不特别受欢迎,首选的方式是直接将代码包含在邮件中。任何应该包含在描述中,而不应该进入到git存储库的文本,都应该从补丁分隔开来,可通过一行上的连续三个破折号表示。
很自然,电子邮件客户端不应该进行自动换行操作。有谣言声称,编译器很难接受随机换行的代码。还有,HTML格式的电子邮件是不合适的,纯属多余。
接下来,给出了一个试验性补丁的标题行。它们遵守了此前讨论的惯例:
[PATCH 0/4] [RFC] Verification and debugging of memory initialisation Mel Gorman (Wed Apr 16 2008 - 09:51:19 EST)
[PATCH 1/4] Add a basic debugging framework for memory initialisation Mel Gorman (Wed Apr 16 2008 - 09:51:32 EST)
[PATCH 2/4] Verify the page links and memory model Mel Gorman (Wed Apr 16 2008 - 09:51:53 EST)
[PATCH 3/4] Print out the zonelists on request for manual verification Mel Gorman (Wed Apr 16 2008 - 09:52:22 EST)
[PATCH 4/4] Make defencive checks around PFN values registered for memory usage Mel Gorman (Wed Apr 16 2008 - 09:52:37 EST)
请注意,4个包含实际代码的邮件是作为对第一个介绍性邮件的回复发表的。这使得许多邮件客户端可以将发表的邮件归类,更容易将这些补丁识别为一个实体。
看一下第一个邮件的内容:
This patch creates a new file mm/mm_init.c which memory initialisation should
be moved to over time to avoid further polluting page_alloc.c. This patch
introduces a simple mminit_debug_printk() function and an (undocumented)
mminit_debug_level command-line parameter for setting the level of tracing
and verification that should be done.
Signed-off-by: Mel Gorman <mel@xxxxxxxxx>
—-
mm/Makefile | 2 +-
mm/internal.h | 9 +++++++++
mm/mm_init.c | 40 ++++++++++++++++++++++++++++++++++++++++
mm/page_alloc.c | 16 ++++++++++———
4 files changed, 60 insertions(+), 7 deletions(-)
(PATCH)
在概述代码之后,附加了由diffstat产生的diff统计信息。这些信息可以快速确定一个补丁引入的修改数目,这是以添加和删除的代码行来衡量的,还包括了这些修改发生的位置。这些统计信息对讨论代码是有用的,但没有必要保存到长期的修改日志(毕竟,该信息可以从补丁生成),因此放置在三个破折号之后。接下来是由diff生成的补丁,但这就与我们的讨论不相关了,因此不转载其具体内容。
- 补丁的来源
描述还包含了一个signed-off4行,标识了补丁的开发者,并用作法律上有效的声明,表明开发者有权利以开源形式发表该代码,通常由GNU General Public License(GPL)版本2涵盖。
4signed-off是未经签署而同意,即非正式同意的意思。——译者注
多个人可以sign off同一个补丁,即使他们并非该代码的直接作者。这表示签字人已经审阅了该补丁,对该代码非常熟悉,并根据其学识判断,该代码能够像声称的那样工作,不会导致数据破坏,不会使笔记本电脑着火,也不会做其他险恶之事。它还跟踪了补丁最终到达vanilla内核树之前,其穿过开发者层次结构的路径。维护者会大量参与sign off活动,因为他们必须审阅大量并非自己编写、但要加入到相应子系统的代码。
在signed-off行上只接受真名,笔名和假名是不能使用的。形式上,补丁的sign off意味着签字人可以证明以下事实:
Documentation/SubmittingPatches
Developer's Certificate of Origin 1.1
By making a contribution to this project, I certify that:
(a) The contribution was created in whole or in part by me and I have the right to submit it under the open source license indicated in the file; or
(b) The contribution is based upon previous work that, to the best of my knowledge, is covered under an appropriate open source license and I have the right under that license to submit that work with modifications, whether created in whole or in part by me, under the same open source license (unless I am permitted to submit under a different license), as indicated in the file; or
(c) The contribution was provided directly to me by some other person who certified (a), (b) or (c) and I have not modified it.
(d) I understand and agree that this project and the contribution are public and that a record of the contribution (including all personal information I submit with it, including my sign-off) is maintained indefinitely and may be redistributed consistent with this project or the open source license(s) involved.
补丁的sign off在很晚才引入到内核开发中,“三字母公司”(SCO)声称因种种原因他们将拥有所有内核代码,因而所有Linux用户应该把钱都交给该公司,sign off在本质上是对该公司的说法的一种反应。很自然,一些开发者对该公司的这种说法很是不以为然,包括Linus Torvalds本人:5
5顺便说及,在Linux内核邮件列表上指责别人是可卡因瘾君子,并不是非常罕见的事情,邮件列表上的对话有时候还是比较粗鲁的。
Some of you may have heard of this crazy company called SCO (aka "Smoking
Crack Organization") who seem to have a hard time believing that open
source works better than their five engineers do. They've apparently made
a couple of outlandish claims about where our source code comes from,
including claiming to own code that was clearly written by me over a
decade ago.
实际上,这个案子现在已经几乎成为历史了,而人们(SCO公司的CEO可能是个例外)普遍确信,即使你可能拥有一个简单的最先适配分配器的版权,这绝不意味着一个完整的UNIX内核。不过,由于Signed-off-by标记,现在我们可以确切地标识补丁的开发者。
在标记补丁时,还有两种较弱的形式。
- Acked-by意味着一个开发者没有直接涉入该补丁,但在经过一些审阅之后认为它是正确的。
这并不一定意味着Acked-by的开发者已经通读了补丁,只是表明他接触到的部分达到了水准。
举例来说,如果一个体系结构开发者确认(Acked-by)称一个补丁对arch/xyz目录下执行的修改看起来都没有问题,但是该补丁还包含了fs/下的代码,会破坏以M开头的文件中包含奇数个字符的字符串,这种情况下是不能指责进行确认的开发者的。
当然,上述情况的可能性很小,因为体系结构维护者都非常专业,将根据该文件的“气味”6来检测到补丁的破坏性问题,上例只是用来说明概念。
- CC用于表示,一个人至少已经知道该补丁,因此他在理论上意识到该补丁的存在,并有机会发表反对意见。
6有经验的开发者有时候能够凭借一些表面迹象判断出质量着的源代码,这种迹象被称为“bad smell”。——译者注
在内核版本2.6.25的开发期间,发生了一次讨论,主题是关于代码审阅的价值,以及如何对审阅者评定信用,讨论者就一个解决方案达成一致,引入了所谓的Reviewed-by补丁标记。该标记声称:
Documentation/SubmittingPatches
Reviewer's statement of oversight
By offering my Reviewed-by: tag, I state that:
(a) I have carried out a technical review of this patch to evaluate its appropriateness and readiness for inclusion into the mainline kernel.
(b) Any problems, concerns, or questions relating to the patch have been communicated back to the submitter. I am satisfied with the submitter's response to my comments.
(c) While there may be things that could be improved with this submission, I believe that it is, at this time, (1) a worthwhile modification to the kernel, and (2) free of known issues which would argue against its inclusion.
(d) While I have reviewed the patch and believe it to be sound, I do not (unless explicitly stated elsewhere) make any warranties or guarantees that it will achieve its stated purpose or function properly in any given situation.
由于这个原因引入的另一个新标记是Tested-by,读者可以猜测到,它声称补丁已经由签字人测试过,而且在所处计算机上进行的测试是足够的,可以向该补丁增加一个Tested-by标记。
小结
作为实际上最大的开源项目之一,Linux内核之所以有趣,不仅仅是从技术角度来看,而且它也是将开发工作分布到整个世界上和相互竞争的公司的一种新颖而独特的方式。本文讲述了其开发过程是如何组织的,以及对贡献代码有什么要求。在本文中,读者知道了这两者交互的方式,二者之间的不同主要起因于不同的“文化”,以及如何能够最好地弥合二者之间的分歧。

众所周知,Linux操作系统的源代码复杂、文档少,对程序员的要求高,要想看懂这些代码并不是一件容易事。《深入Linux内核架构》结合内核版本2.6.24源代码中最关键的部分,深入讨论Linux内核的概念、结构和实现。具体包括进程管理和调度、虚拟内存、进程间通信、设备驱动程序、虚拟文件系统、网络、时间管理、数据同步等方面的内容。本书引导你阅读内核源代码,熟悉Linux所有的内在工作机理,充分展现Linux系统的魅力。本文选自《深入Linux内核架构》。
