3.5.3 数据源组件的实现细节
在数据源的使用中,有一个很重要的类android.content.ContentResolver。ContentResolver相当于数据源组件的DNS和本地代理,它负责将各个URI定位到具体的数据源组件,并经由它对数据源进行增、删、改、查等操作。
ContentResolver提供的数据操作接口,与ContentProvider中的函数一一对应,只是在参数中附加了一个定位数据源组件的URI对象。ContentResolver对数据的操作,其实是分两个步骤完成的。首先是定位,根据URI找到对应的数据源组件,然后,通过对应的数据源组件执行所请求的操作。
如图3-16所示,当ContentResolver收到数据操作请求时,会先根据URI的信息去查找对应的数据源组件。ContentResovler对象中,有一个数据源组件的缓存对象ProviderMap,它是一个哈希表,存储各个URI对应到数据源组件对象。如果ContentResolver在缓存中未能查到对应的数据源组件,则会将查找请求发送给组件管理服务,该服务会负责查找到对应数据源组件的信息,并在ContentResolver中构造对象缓存。
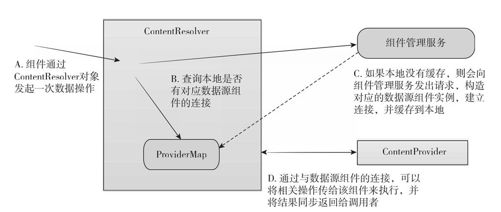
图 3-16 ContentResolver的实现机理
ContentResolver缓存的数据源组件对象,其实是对应数据源组件的代理。当ContentResolver调用其接口进行操作时,相关指令会打包成消息,并通过Android进程间通信机制传到远端的数据源组件中,而数据源组件执行完成后再将结果序列化传回,整个流程是个同步的操作。
在这样的模型下,所有对数据源组件对象中数据的操作都是在消息队列中串行执行的,也就是说所有数据操作都不会并发执行。这就降低了数据源组件开发的难度,开发者不需要在数据源组件中处理复杂的并发情形。
同时,在默认情况下,每个数据源组件都只有一个实例,来自不同进程的请求都会通过进程间通信机制与其交互。如果频繁地进行交互则开销较大,存在性能隐患。开发者可以将配置文件中<provider>的参数mutiprocess设置为true,来改变这种进程模型。当mutiprocess为true时,数据源组件会在每个调用它的应用进程中构造一个组件对象,避免进程间通信的开销,从而提高操作和数据传输的效率。
毫无疑问,多个实例并存会带来并发性的问题。首先,在数据源组件对象中,就不能再存放与全局相关的数据,因为不同对象间的数据无法同步。其次,多个数据源实例对底层数据的读写操作可能是并发执行的,开发者要通过一些并发控制手段来确保操作的正确性。这些并发控制手段(比如加锁)不但增加了开发的复杂性,还会带来额外的时间开销,从整体上降低了执行效率。
因此,开发者需要综合考虑数据源组件的实现特征和使用场景,进而决定使用何种进程模型来构造数据源组件。
既然存在进程间的数据传输,一个不得不讨论的问题就是大数据的传输问题。对数据源组件的一次查询,可能会有几千、几万甚至更多匹配的数据项—这些数据需要从数据源组件所在的进程中拷贝到调用者所在的进程中。
一次性拷贝全部数据不仅消耗时间,也会浪费内存;而每次拷贝一条数据则会增加进程间通信的成本。因此,Android采用了数据窗口的模式。在数据指针对象android.database.Cursor中,包含一个android.database.CursorWindow对象,它会在调用者一端缓存部分数据,缓存数据的内容包括当前指针指向位置相关的若干条数据。CursorWindow类的底层实现是基于C++的,以此来提高执行效率。
