4.3 内嵌式DSL:类型化抽象模式
迄今为止,我们对于模式的探讨全都离不开精简DSL代码结构这个主题,而且从使用和实现两个方向进行了反复的讨论。
本节暂时把动态语言放到一边,我们试试看能否利用类型系统的威力激发DSL的表现力。本节的示例全部使用Scala语言(以Scala 2.8为准)。我们重点说明类型怎样(甚至在程序运行之前)给DSL的一致性增加一层额外保障。此外,类型在使DSL语言精练方面的能力不输于我们先前讨论的一些动态语言。多看看图4-2,本章讨论的所有模式都在那个大纲里面。
4.3.1 运用高阶函数使抽象泛化
一直以来凡是涉及领域的讨论,我们总是拿金融中介系统里的操作来举例,如维护客户账户、处理交易和成交、代客户下单等。本节我们来看一份客户文件,上面记录了中介在工作日内进行的所有交易活动。交易组织会为某些客户生成这样一份账户每日交易活动报表,然后发送到客户的邮件地址。
1. 生成一份分组报表
图4-7是一份账户活动报表,里面记录了交易的票据品种、数量、时间、金额。
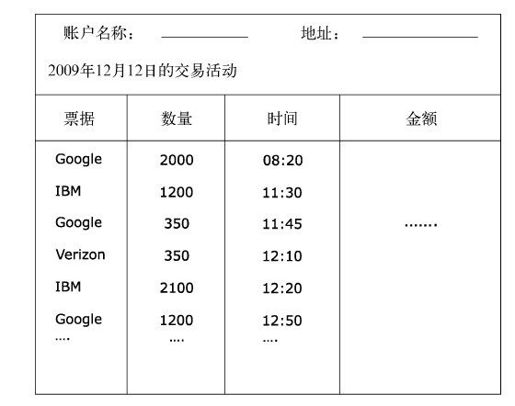
图4-7 经过简化的账户活动明细报表
很多组织会为客户提供灵活的每日交易情况查看方式。客户可以要求交易情况按某一项表格元素排序或者分组。比如,我会希望一天内所有的交易按照票据品种排序并且分组显示,如图4-8所示。
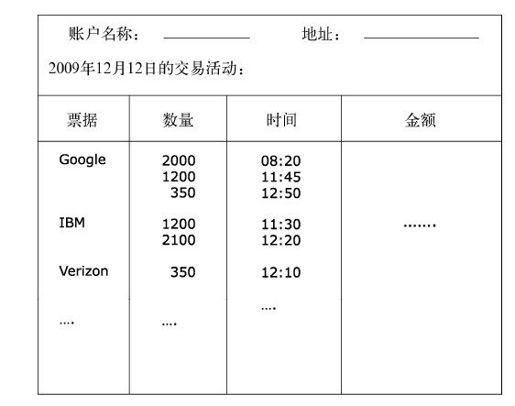
图4-8 一份账户活动报表,按照票据品种进行了排序和分组。注意票据栏的排序方式,数量栏将同一种票据的记录排在了一起
我也可以要求把所有的交易按照交易数量来分组,如图4-9所示。
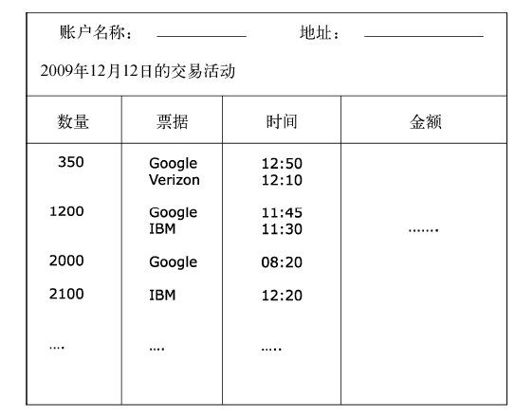
图4-9 一份账户交易报表,按照当日的交易数量进行了排序和分组
现实中的账户活动报表还会有其他很多内容,不过图中的信息已经足够满足下面的实现和讨论需要了。我们现在要构建一种DSL来实现自定义的分组函数,让客户按需要调整交易活动报表的样式。一开始,我们可以这样设计DSL:每种分组操作分别用一个函数来实现。然后,我们考虑设计一个泛化的groupBy组合子——即一个以分组条件为参数的高阶函数——来改善DSL的精炼度。
定义 组合子是以其他函数作为输入的高阶函数。组合子可以被组织起来构成DSL的语言结构,本节以及第6章都有这方面的例子。附录A也详细讨论了组合子。
Scala类型系统可以保证操作的静态类型安全,又有着处理高阶函数的能力,你阅读完本节的例子,必定会对Scala的这些特点深有体会。那么,我们就直接来看代码示例吧。
Scala知识点
case类定义不可变的值对象。case类是一种简洁的抽象设计手段,可以用于自动获得编译器提供的许多额外便利。
针对已有的抽象,隐式类型转换提供了一种完全非侵入的扩展方式。
For-comprehensions特性针对集合上的迭代子提供了一种函数式抽象。
运用高阶函数,你可以设计和组织起能力强悍的函数式抽象。
2. 建立基本抽象
我们来试一下从后往前推的方法,先设想一下DSL最后的样子,再尝试用Scala实现出来。用户将会这样使用我们的DSL:
activityReport groupBy(_.instrument)activityReport groupBy(_.quantity)
第一行DSL代码生成一份按票据品种分组的活动报表,第二行代码生成的报表则按交易数量分组。下面的代码片段实现了账户活动报表的基本抽象,我们来仔细看看它具备的一些特性。
type Instrument = String ➊ 具体类型定义case class TradedQuantity(instrument: Instrument, quantity: Int) ➋ 值对象implicit def tuple2ToLineItem(t: (Instrument, Int)) =TradedQuantity(t._1, t._2) ➌ Tuple2到LineItem的隐式类型转换case class ActivityReport(account: String,quantities: List[TradedQuantity]) { ➍ 主体抽象//...}
本书不是一本Scala专著,但为了帮助读者理解本书,我将重点说明这段代码展现出来的一些语言特性。这样一来,你可以把它和等价的Java代码相比较,从而对它的表现力水平有一些直观的认识。
实现DSL随时都要注意对表现力的要求。代码开头用一则类型定义来对领域制品建模➊,避免直接套用意义含糊的原生数据类型,让代码直接说明自身的含义。这样不但利于领域用户的理解,还给Instrument类型留下了日后修改的余地。
TradedQuantity➋是个case类,它建模了一个值对象。值对象一般被认为是不可变的,选用Scala的case类作为表达手段正是用其所长。case类的特点是数据成员自动具备不可变性质,拥有特别简便的内建构造器语法,而且默认实现了equals、hashCode和toString方法。(Scala语言的case类特别适合用于建模值对象。详细介绍请参阅4.7节文献[4]。)
Scala语言通过隐式声明➌提供数据类型之间的自动转换。Scala的隐式特性是一种限定了词法作用域的语言结构,也就是说,只有当一个模块明确导入了隐式定义,类型转换才在该模块范围内生效。在本例中,按照声明,二元组(Instrument, Int)可被这种声明隐式转换成一个TradedQuantity对象。Scala允许用(Instrument, Int)这种字面写法来表示二元组,它的完整写法是Tuple2[Instrument, Int]。(前面3.2.2节讨论过Scala语言implicits特性的工作原理,如有需要可以翻回去温习一下。)
最后说到账户活动报表的主体抽象。ActivityReport➍包含账户信息和当日所有交易活动的一个列表,列表元素是交易数量和交易品种组成的二元组。
接下来我们就要展开一系列迭代式的建模过程,实现分组函数,满足客户自定义每日交易报表显示方式的需要。我们打算用迭代式的过程逐步改进模型,见表4-3。
表4-3 对DSL的迭代式改进
| 步骤 | 说明 |
|---|---|
创造一种DSL供用户查看交易活动报表,该语言有按照Instrument和Quantity进行分组的功能 | 每种分组条件各实现一个专门的分组函数,即groupByInstrument和groupByQuantity
实现泛型分组函数groupBy[T ,以减少重复性的固定代码 |
那么,我们先来实现几个groupBy函数。
3. 第一步:专用实现
如果我们在ActivityReport抽象内按分组条件提供专用的groupBy函数,DSL用户得到的API表现力会很好。不过我们还要从实现的角度去考虑,使用方面的表现力并非判定DSL完善程度的唯一标准。代码清单4-9给出了按照Instrument和Quantity分组的专用实现。注意每种分组条件都需要单独定义一个专用函数。
代码清单4-9 活动报表,
groupBy函数采取专用实现
type Instrument = Stringcase class TradedQuantity(instrument: Instrument, quantity: Int)implicit def tuple2ToLineItem(t: (Instrument, Int)) =TradedQuantity(t._1, t._2)case class ActivityReport(account: String,quantities: List[TradedQuantity]) {import scala.collection.mutable._def groupByInstrument = {val m =new HashMap[Instrument, Set[TradedQuantity]]with MultiMap[Instrument, TradedQuantity] ➊ 用mixin方式定义MultiMapfor(q <- quantities)m addBinding (q.instrument, q) ➋ for comprehensionm.keys.toList.sortWith(_ < _).map(m.andThen(_.toList)) ➌ 按票据品种分组}def groupByQuantity = {val m =new HashMap[Int, Set[TradedQuantity]]with MultiMap[Int, TradedQuantity]for(q <- quantities)m addBinding (q.quantity, q)m.keys.toList.sortWith(_ < _).map(m.andThen(_.toList))}}
你能看出这种实现方案的缺点吗?让我们先简单看下代码中用到的一些Scala惯用法,然后再作进一步的分析。
在代码清单4-9的ActivityReport实现里面,quantities可以含有对应同一个Instrument对象的多个条目,所以我们定义一个MultiMap容器➊来归置从quantities取出的条目,定义MultiMap容器用到Scala的mixin语法。在HashMap对象上我们混入trait MultiMap,就得到MultiMap的具体实例。关于Scala语言中trait和mixin特性的详细解释,请参阅4.7节文献[4]。
在遍历quantities并填充HashMap的时候,我们运用了Scala语言的for comprehension特性➋。它和命令式语言中的for循环有明显区别(6.9节谈及Scala语言的Monad化结构的时候,我们再详细讨论for comprehension特性)。然后,我们对MultiMap的键进行排序并建立一个按Instrument分组的List➌。该List的每个元素都是一个Set容器,里面存放了某票据品种对应的全部交易数量条目。代码中下划线的语法含义与3.2.2节介绍的相同。
代码清单4-9中实现的主要缺点是代码重复部分较多。groupByInstrument和groupByQuantity函数在结构上完全相同,只有作为分组依据的属性不一样。你应该马上就警觉到,这种情形违反了优秀抽象的设计原则。万一你还没有认识到其中的缺点,请翻阅附录A,那里介绍了如何对抽象进行精炼以摒除非本质复杂性。总之,专用实现会助长重复性代码,这就是问题的症结。而且,如果日后向ActivityReport类增加更多分组条件,那些刻板代码只会一再重复出现。怎样才能纠正当前实现的缺点呢?我们需要更一般化的实现方案。
4. 一般化的实现
我们现在就把实现推广到更一般化的情况,将原来分立的一系列专用方法概括成一个通用的方法。
代码清单4-10 泛型
groupBy实现
type Instrument = Stringcase class TradedQuantity(instrument: Instrument, quantity: Int)implicit def tuple2ToLineItem(t: (Instrument, Int)) =TradedQuantity(t._1, t._2)case class ActivityReport(account: String,quantities: List[TradedQuantity]) {import scala.collection.mutable._def groupBy[T <% Ordered[T]](f: TradedQuantity => T) = { ➊ 把分组条件参数化val m =new HashMap[T, Set[TradedQuantity]]with MultiMap[T, TradedQuantity]for(q <- quantities)m addBinding (f(q), q)m.keys.toList.sort(_ < _).map(m.andThen(_.toList))}}
新的实现明显更简短。你有没有发现,泛型groupBy➊方法产生了更有力的抽象,同时代码的紧致度也在同步上升。表4-4简要总结如何实现泛型groupBy方法。
表4-4 实现泛型groupBy方法
| 步骤 | 说明 |
|---|---|
实现泛型groupBy方法 | 将groupBy方法参数化,带上对活动报表分组所依据的类型
groupBy方法接受f函数作为输入参数,f对分组条件建模。这里体现了Scala对高阶函数的支持。函数可以像其他数据类型一样被当做参数和返回类型传来传去。对分组条件进行抽象的时候可以利用这个特点,代替代码清单4-9中的专用实现
图4-10可以帮助你理解泛型groupBy函数的执行过程和原理 |
下面我们来观察DSL用户调用groupBy的过程,把实现步骤从头到尾过一遍。这样的练习可以帮助你理解Scala的类型系统是怎样在背后发挥作用,默默塑造出富于表现力的DSL语言结构的。
探究现象背后的来龙去脉是DSL设计工作的重要一环,DSL的实现者尤其应该全面、细致地掌握相关知识。读者有必要反复阅读本节,直到完全理解Scala语言如何进行方法分发。代码清单4-10中短短15行的实现代码里面隐藏了相当数量的惯用法,值得你好好学习。当你能够看清各种惯用法之间互相联系的脉络,知道怎样将它们契合在一起满足API的契约,这些惯用法就会成为你手中的“工具”。
val activityReport =ActivityReport("john doe",List(("IBM", 1200), ("GOOGLE ", 2000), ("GOOGLE", 350),("VERIZON", 350), ("IBM", 2100), ("GOOGLE", 1200)))println(activityReport groupBy(_.instrument))println(activityReport groupBy(_.quantity))
与其用文字说明上面的代码,我们不如用图4-10来解释activityReport groupBy(_.instrument)调用前后发生的一系列动作。
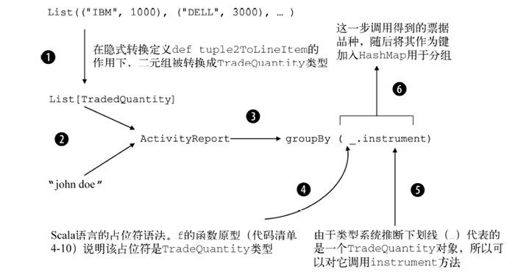
图4-10 按票据品种分组的活动报表(groupBy(_.instrument))的产生过程。顺序观察图中所有步骤,将图解与代码清单4-10的DSL实现,以及上文运用DSL为客户john doe生成ActivityReport的代码片段相对照
高阶函数的应用场合远不止本节所介绍的类型化抽象模式。所有现代语言,无论是否静态类型的语言,全都支持高阶函数和闭包。本节讨论的模式实现可以套用到不同的情形和语言中去。实践者要留心使用模式的上下文环境,善用实现语言的特点把事情做好。
我们的目标是跨越实现语言的界限,探索JVM平台上所有的内部DSL实现模式。无论你选择静态类型还是动态类型的实现语言,总之应该根据DSL建模所需的能力去挑选合适的工具。
下一节将讨论怎样运用显式类型约束来表达领域逻辑和行为。这种表达手段不适用于动态类型语言。不过只要类型系统表现力充沛,显式类型约束可以成为得力的建模工具。它对于使DSL语言简洁有着惊人的效果。
4.3.2 运用显式类型约束建模领域逻辑
设计领域模型的时候,抽象必须遵照领域所施予的规则和约束去实现其行为。Ruby、Groovy等动态类型语言将领域规则表达为运行时的约束。4.2节已经演示过Ruby和Groovy语言的反射式元编程手法,讲解过怎样实现一些DSL语言结构来建立领域规则的模型。本节将首先用Ruby语言实现一个运行时验证示例,然后演示如何借助Scala语言的静态类型系统更简洁地表达类似约束。
1. Ruby语言的运行时验证
我们继续沿用代码清单4-6中的Trade抽象这个例子,先前已经用Ruby语言建立一个简单的领域模型。Trade对象需要对应一个Account对象,即客户的交易账户。代码清单4-6把账户对象表示为类方法attr_accessor。交易系统的领域概念里存在很多不同类型的账户(参见3.2.2节的补充内容“金融中介系统:客户账户”)。对于Trade抽象来说,这个账户被限定为交易账户,结算账户不可以用在这个地方。那么,我们每次建立Trade对象并为它设置Account对象的时候,都必须验证这条领域规则。用Ruby语言应该怎么写呢?你可以像下面的代码片段一样插入常用的检查语句:
class Tradeattr_accessor :ref_no, :account, :instrument, :principaldef initialize(ref, acc, ins, prin)@ref_no = refraise ArgumentError.new("必须为交易账户")unless trading?(acc)@account = acc## ...
凡是领域模型中要求接受交易账户的地方,你都要在运行时反复执行同样的验证。(我们可以采取类似Rails的做法,把验证操作写成类方法,实现声明式的验证,但验证操作终究还是在运行时进行的。)而且每一处验证都必须明确地进行单元测试,确认当输入非交易账户的时候领域行为如同预期的一样中止执行。以上重重防范必然要增加代码量,但如果语言允许显式规定类型化的约束条件,我们就可以节省这部分代码。
在静态类型语言里,我们可以把约束条件用类型的方式规定出来,让它们在编译时接受编译器的检查。如果一个程序能正确编译,那就说明模型中领域行为的一致性至少有了一重保证。
2. Scala语言的显式类型约束
我们尝试用Scala语言建模Trade对象,对其中的账户和票据加上一些具有领域含义的约束条件。经过本例的练习,你将认识到在显式类型约束的作用下,DSL抽象无需实际运行就已经得到了一层额外的一致性保证,而这是动态类型语言所不具备的。假如你选择静态类型语言作为实现语言,那么显式类型约束绝对是不可或缺的一样工具。
Scala知识点
基于类型的编程方法。以类型为手段,在DSL中表达领域约束。泛型类型参数和抽象类型都是你的好帮手。
抽象的
val成员可使抽象在进入最后的实例化阶段之前保持开放。
每个Trade对象都对应一个Trading账户。我们用Scala语言对这条规则进行建模。代码清单4-11只展示了Trade对象中与本段讨论相关的一个侧面。
代码清单4-11 带上类型化约束的
Trade对象,Scala语言
trait Accounttrait Trading extends Accounttrait Settlement extends Account ➊ 两种Account类型trait Trade {type A <: Trading ➋ Trading子类型的账户val account: A ➌ Account实例def valueOf: Unit}
从这个示例中我们可看出类型如何隐式落实业务规则。这段代码用了Scala语言的trait特性建模Account和Trade对象(参见4.7节文献[4])。我们为Trading账户和Settlement账户各安排了一种类型➊。程序员不可以向要求Trading账户的方法传递Settlement账户。编译器会捍卫这条规则,要求Trading账户的相关业务规则不需要特别去检测账户类型是否符合要求。
有一些业务规则是在代码中明确规定的。我们在Trade的定义里对抽象类型A设置了约束(<: Trading)➋,因此不能使用Trading之外的任何账户类型来实例化Trade对象➌。用户不需要另外增加验证账户类型的代码,这条规则的检验工作同样由编译器代劳。
“交易”是指参与票据买卖双方之间订立的合约。如果想复习交易的一些性质,请回头翻阅1.4节的补充内容。根据交易的票据种类的不同,交易的行为、周期过程和计算方法都有差异。股权交易(equity trade)涉及股票与现金的交换。而当被交换的票据属于固定收益类型,我们称之为固定收益交易(fixed income trade)。关于股权、固定收益等票据类型的详情,请阅读本节的补充内容。
金融中介系统:票据类型
票据的类型可说是五花八门,而它们都是为了迎合投资者和发行者的需要而设计的。类型不同,票据的交易、结算过程的生命周期也不同。
票据主要分为股权(equity)和固定收益(fixed income)两大类。
股权类票据又可进一步分为普通股、优先股、累积股、权证、存托凭证。固定收益类证券(又称债券)包括直接债券、零息债券、浮动利率债券。就我们的讨论而言,并无必要全面了解这方面的详细内容,我们只要记住当交易的票据类型不同,对应的
Trade抽象也不一样即可。
下面的代码将Trade抽象的定义进一步具化,建立EquityTrade和FixedIncomeTrade的模型。
代码清单4-12
EquityTrade和FixedIncomeTrade模型
trait Instrumenttrait Stock extends Instrumenttrait FixedIncome extends Instrumenttrait EquityTrade extends Trade {type S <: Stock ➊ EquityTrade作用于Stockval equity: S ➋ 票据类型def valueOf {//... ➌ 交易计值的具体实现}}trait FixedIncomeTrade extends Trade {type FI <: FixedIncome ➍ FixedIncomeTrade作用于FixedIncomeval fi: FI ➎ 票据类型def valueOf {//... ➏ 交易计值的具体实现}}
代码中对所交易票据的类型进行了约束,类似于代码清单4-11中对Account所做的显式约束。此业务规则照旧由编译器隐式地强制实施。
我们分别规定了EquityTrade类型➊和FixedIncomeTrade类型➍。程序员不可以把FixedIncomeTrade对象传递给要求EquityTrade对象的方法。编译器会捍卫此规则,对具体的Trade类型有所要求的业务规则不需要特别去检测交易类型是否符合要求。
EquityTrade负责处理Stock交易➊,FixedIncomeTrade负责FixedIncome交易➍。我们据此分别对抽象val(equity➋和fi➎)进行了约束。以上基本业务规则完全在编译器层面得到保证,程序员无需编写一行验证代码。
valueOf方法是多态的、类型化的。不同的Account和Instrument类型对应着不同的Trade抽象,也分别对应着不同的valueOf方法实现(➌ 和 ➏)。
我们运用类型化抽象手段,并且对值和类型施加显式约束,在没有写一行过程式逻辑的情况下成功描述了相当数量的领域行为。不仅代码规模缩小了,单元测试的数量也减少了,直接降低了编写和维护的负担。当你维护代码的时候,如果类型标注能描述性地说明模型背后的领域含义,那么维护工作不是会顺利得多吗?
对比之前关于用动态语言实现DSL的讨论,本节讨论中体现出来的实现思路很不一样。现在我们总结一下什么是静态类型思维,看它和Ruby或Groovy的思维方式有何区别。
4.3.3 经验总结:类型思维
经过本节的学习,你已经知道对于设计表现力丰富的领域抽象,类型可以起到很重要的作用。由于拥有静态类型检查这张安全网,静态类型的实现天生就具备一层正确性保障,这就是它与前面的Groovy和Ruby示例的主要区别。类型化的代码只要能通过编译,就足矣证明它满足了相当数量的领域约束。在第6章用Scala设计更多DSL的时候,我们会继续讨论这个议题。图4-11总结了本节介绍过的几种内部DSL模式。
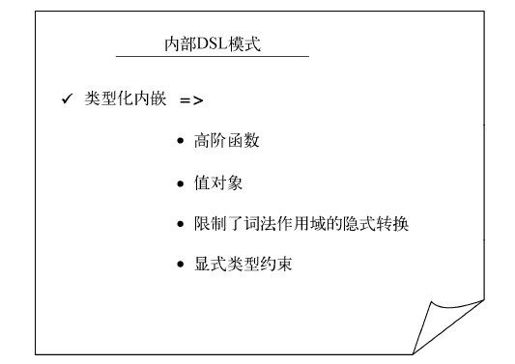
图4-11 类型化内嵌方式下用于内部DSL的程序结构。你可以从这些模式中学会运用类型思维去驾驭编程语言
我们讨论了运用静态类型语言实现内部DSL的过程中常会使用的若干重要模式。虽然静态类型语言没有动态语言那样的元编程绝技,但类型化抽象同样是非常简洁有力的DSL开发手段。
本节要点
本节的主要目的是引导你用类型思考。对于领域模型中的每个抽象,你应该把它类型化,然后围绕类型组织相关的业务规则。很多业务规则会自动被编译器强制实施,因此你不需要专门为之编写代码。如果实现语言拥有合适的类型系统,那么DSL的简洁程度不会亚于动态语言的实现。
到目前为止,我们介绍了不少内部DSL实现模式,有利用类型系统抽象出领域规则的,也有利用宿主语言的元编程能力做反射的。下一节将要介绍的模式能让语言运行时帮你编写代码。你要用生成的代码来创作简洁的DSL。
