7.3 语法分析器的分类
当语法分析器成功识别传递给它的输入流,就会为DSL脚本产生一棵完整的分析树。分析器依据分析树节点的构造顺序,分为不同类别。有的分析器从根节点开始构造分析树,称为自顶向下(top-down)分析器。有的分析器则相反,一开始先构造叶子节点,然后逐层构造根节点。这类分析器称为自底向上(bottom-up)分析器。自顶向下和自底向上这两类分析器的实现复杂度不同,它们所能识别的语法结构类型也不相同。DSL设计者至少应该大致了解每一类分析器的相关概念。图7-8分别展示了这两类分析器构造分析树的过程。
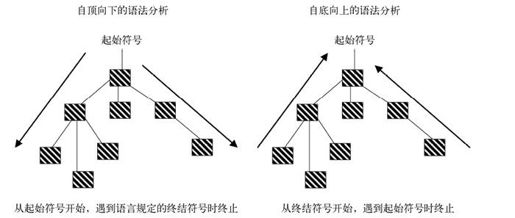
图7-8 自顶向下分析器和自底向上分析器构造分析树的过程
本节主要围绕分析树的构造方式,以及从产生式规则推导语言的方式,来讨论语法分析器的分类。在自顶向下和自底向上两大类别之下,存在着多种多样的变体,分别适合识别不同类型的语言结构,同时实现复杂度也有着相应的变化。这里假设读者已经基本了解语言处理方面的概念,掌握语法分析技术、前瞻处理(look-ahead processing)、分析树等基础知识。如果需要了解这方面的背景知识,请参阅7.6节文献[3]。
首先介绍自顶向下分析器,学习其中一些常见的实现变体。
7.3.1 简单的自顶向下语法分析器
自顶向下分析器从根节点开始构造分析树,向输入流的最左推导(leftmost derivation)进行。也就是说,分析器处理输入的顺序是从左边的符号到右边的符号。
最常见的自顶向下分析器是RD(recursive descent,递归下降)分析器。递归下降这个名字应该如何理解呢?递归,说明分析器是通过一系列递归函数调用实现的(参见7.6节文献[1])。下降指的是分析树的构造从树的顶部开始,与“自顶向下”的含义相同。
我们的学习过程将从最简单的RD分析器开始,然后逐步深入到其他功能更强大也更复杂的分析器,通过高效率的实现识别出更多的语言类。首先讨论LL(1)和LL(k) RD分析器。它们是自顶向下分析器中最简单的两种实现,涵盖了设计外部DSL所需的大部分功能。
1. LL(1)递归下降分析器
LL(1) RD分析器依靠一个前瞻词法单元完成对语法结构的分析。LL(1)这个名字应该怎样理解?第一个L表示分析器从左到右扫描输入字符串。第二个L表示当分析器自根至叶构造分析树时,产生子节点的次序是从左到右。最后括号内的1从分析器的定义就能猜到,它代表每步向前看一个符号。由于仅有唯一的前瞻符号,分析器将根据这个符号选择与其匹配的下一条产生式规则。
要是分析器找不到一条正好与前瞻符号完全匹配的产生式规则,会怎么样呢?这种情况有可能出现,语法里可能有多条产生式规则开头都是同一个符号。偏偏LL(1)分析器向前看的符号个数仅为一个。要想解决这种同一前瞻符号匹配多条规则的语法二义性问题,我们可以改用k>1的LL(k)分析器,也可以通过对语法定义提取左因子的方式,使之满足LL(1) RD分析器的要求(详见7.6节文献[1])。
自顶向下分析器有时需要处理左递归的情况。例如语法中出现形如“A : A a | b”的规则,就会令自顶向下分析器陷入无限循环。前面提过,RD分析器通过一系列递归调用来实现。产生式规则中的左递归将使分析器永远递归下去。语法规则中的左递归可以通过规则变换来消除。7.6节文献[3]详细介绍了这方面的技术。
2. LL(k)递归下降分析器
LL(k)分析器与LL(1)分析器相似,但允许有更多的前瞻符号,因此功能更强大。它同样依靠其前瞻集来判断适用于输入符号的产生式规则。虽然更大的前瞻集意味着更复杂的分析器结构,但权衡之下,比起提高分析器能力的好处,增加一点复杂度还是值得的。
LL(k)分析器到底能比LL(1)强多少?增大前瞻集,使LL(k)分析器能解析更多的计算机语言。但在消除语法规则的二义性方面,它仍然只能应付k个符号以下的情况。这时可以为LL(k)分析器增加另外一些巧妙的特性。回溯即为其中之一,具备回溯能力的分析器可以识别具有任意前瞻集的语言。7.3.2节将讨论回溯分析器。
ANTLR可生成能处理任意前瞻集的LL(k)分析器,最适合在实际应用中实现DSL。Google App Engine、Yahoo Query Language(YQL)、IntelliJ IDEA等许多大型软件应用都采用了ANTLR来分析、解释其自定义语言。
掌握了分析器的基本形式,下面开始讨论一些比较高级的自顶向下分析器。这些分析器的使用频率可能不高,但还是值得我们了解其实现,学习它们为提高效率而采取的技术手段。何况第8章讨论通过Scala分析器组合子设计外部DSL时,将要用到其中一种技术。
7.3.2 高级的自顶向下语法分析器
高级的语法分析技术可以赋予分析器更强大的功能,代价是增加实现上的复杂性。不过一般我们通过分析器生成器、分析器组合子等抽象手段来间接实现分析器,其实现复杂性已经被封装在抽象内部。开发者使用的只是抽象对外公开的接口而已。
1. 递归下降回溯分析器
这种分析器在LL(k) RD分析器的基础上增加了回溯机制,因此能够处理任意大小的前瞻集。在回溯机制的帮助下,分析器可以根据需要向前试探。如果找不到匹配项,分析器则回滚其输入,换成别的规则重新进行尝试。与LL(k)分析器相比,这种试探机制使回溯分析器的分析能力有了极大提升。
分析器在回溯并选择另一条规则时,有没有选择的优先次序呢?以ANTLR为例,我们可以通过语法谓词(syntactic predicate)的形式,向分析器提示规则的优先次序(见7.6节文献[2])。分析器根据我们指定的顺序,选择最恰当的规则用于输入流。
这类分析器支持一种表达能力更强的语法形式,称为PEG(parsing expression grammar,解析表达语法)。PEG对ANTLR的回溯和语法谓词进行了扩展,提高了表现力。它加入了&、!等运算符用于文法规则的定义,可对回溯和分析器的行为进行更细致的控制。文法描述本身读起来也好理解得多。运用中间结果记忆(memoizing)等技术,我们可以开发出线性时间的PEG分析器。
2. 带中间结果记忆的分析器
回溯RD分析器在执行回溯,尝试其他规则时,常常要重复计算一些分析结果。带记忆的分析器通过缓存分析的部分中间结果,提高了分析的效率。
提高效率很好,不过加入记忆机制,意味着需要更多的内存空间来放置前面的计算结果。传统回溯分析器实现的效率大为提高,增加一套机制所带来的麻烦还是值得的。况且,我们的老朋友ANTLR支持记忆功能,并不需要我们亲自动手。
记忆分析器需要占用更大内存空间的弱点,可以通过一种叫做Packrat分析器的实现方案来规避。这种分析器除了它奇特的名字,更为引人注目的是其函数式特征(详见7.6节文献[6])。Haskell等函数式语言具备的惰性特性可以很自然地应用在Packrat分析器的实现当中。8.2.3节谈及各种Scala分析器时,会再次详细探讨Packrat分析器。
3. 语义谓词分析器
有时,RD分析器无法仅凭语法本身判断应该应用的规则。我们可以在分析器上标注一些Boolean表达式,以帮助它做出决定。只有当Boolean表达式求值为真时,候选规则才算匹配成功。
语义谓词分析器的典型用途是,用单个分析器来处理一种语言的多个版本。分析器的基干承担核心语言的识别工作,而语言的扩展和其他版本,则由附加的语义谓词去解决。对语义谓词分析器的详细解说请参阅第7.6节文献[1]。
自顶向下分析器非常简单,类似于7.3.1节的LL(1)。但对于复杂的语言分析,我们需要准备能力与之相称的分析器,例如本节介绍的回溯分析器、记忆分析器、语义谓词分析器。这些高级分析技术适应的语言结构范围更广,其实现的时间复杂度和空间复杂度有所降低。下一小节将介绍另一类分析器,它们可以识别任意的确定性上下文无关语法,从这个意义上说,他们比自顶向下分析器适用性更强。
7.3.3 自底向上语法分析器
自底向上分析器从叶子开始构造分析树,逐步移向根节点。分析器从左向右扫描输入流,通过对文法规则的后续规约构造最右推导,朝语法的起始符号方向处理。方向与自顶向下分析器正好相反。
自底向上分析器最为常用的实现技法称为移进-归约(shift-reduce)分析。分析器扫描输入并遇到一个符号时,它有两种选择。
- 将当前符号移进到一旁(通常推入某种符号栈)供后续归约。
- 匹配当前句柄(handle)(即输入串中,与一条产生式规则右部相匹配的子串),并以产生式规则左部的非终结符号替换该句柄。这个步骤一般称为“归约”。
我们将介绍两种最为常用的移进-归约式自底向上分析器,一种是算符优先(operator precedence)分析器,另一种是LR分析器。算符优先分析器功能有限,但手工实现起来极为简单。相对来说,LR分析器在各种生成器中得到了非常广泛的应用。
1. 算符优先分析器
这种自底向上分析器只能识别数量有限的语言类型。它基于分配给各终结符号的一组静态优先关系规则。
算符优先分析器很容易手工实现,但由于它既处理不了同一符号的多重优先关系,又不不能识别存在并列的非终结符号的文法,因而适用范围受到限制。例如下面的片段就不符合算符优先文法的要求,因为规则expr operator expr中含有多个相邻的非终结符号。
expr : expr operator exproperator : + | - | * | /
接下来我们要介绍一种应用最为广泛的自底向上分析器,它能实现非常多的语言类型,也为YACC和Bison等流行的分析器生成器所采用。
2. LR(k)分析器
LR(k)分析器是效率最高的自底向上分析器,它可以识别一大类上下文无关文法。LR(k)名字中的L指分析器从左向右扫描输入串。R指其分析过程是构造最右推导的逆过程。最后的k显然还是指前瞻符号的数目,分析器依据k个前瞻符号来决定适用的产生式规则。
LR分析器由分析表驱动。生成器将分析器识别出输入符号时应该执行的操作,存储在一张分析表中。这里所谓的操作其实就是移进或者归约。整个输入串识别完毕,我们说成分析器“归约到了文法的起始符号”。
这种类型的分析器很难手工实现,但YACC、Bison等生成器对LR分析器的支持十分完善。
3. LR分析器的变体
LR分析器有三种变体:简单LR(SLR)、前瞻LR(LALR)、规范LR(canonical LR)。SLR分析器使用简单的逻辑来判断前瞻集合,分析过程容易产生大量的冲突状态。LALR分析器较SLA复杂,对前瞻的处理更周详,冲突也更少。规范LR分析器比LALR能识别更多类型的语言。
4. 我们真正会用的方法
分析器是外部DSL的核心所在。我们需要基本了解分析器与被识别的语言类型之间的关系。本节介绍了很多这方面的专门知识,应该能帮助选择正确类型的分析器去实现DSL。不过在现实中,除非要实现的语言实在太过简单,否则我们绝对不会手工实现分析器。使用分析器生成器才是正确选择。
使用生成器,我们可以在更高级的抽象上思考。定好文法规则(也就是语言的语法),然后生成器帮助构建实际的分析器实现。不过别忘了,生成的实现中只包含语言的识别机制和一棵简单的AST树。我们还要进一步将AST转换为语义模型,才能满足DSL处理的实际需求。建立语义模型的方法是在文法规则中嵌入自定义的操作代码。
下一节要在DSL开发过程里导入丰富的工具支持,从而在更高级的抽象上使用生成器进行DSL开发。
