8.2 Scala的分析器组合子库
Scala在其核心语言之上实现了分析器组合子库。这个库随Scala语言一起发布,包的位置在scala.util.parsing。以库的形式实现分析器组合子,便于在不影响核心语言的前提下进行扩展。本节将通过各种DSL片段来学习Scala库的使用技巧和惯用法。API方面的细节可以参考8.6节文献[1]和文献[2],或者直接查阅Scala的源代码。(不幸的是,目前还没有详细介绍Scala分析器组合子的出版物,源代码是眼下最好的参考资料。)
8.2.1 分析器组合子库中的基本抽象
通过上一节的讨论,我们知道分析器是一个将输入流变换为分析结果的函数。Scala库根据这个概念建立了如图8-5所示的模型。

图8-5 Scala库将分析器建模为一个函数
ParseResult是对分析器产生的结果的抽象,结果可以是成功也可以是失败。此外ParseResult还跟踪着尚未被当前分析器处理的下一输入。Scala库建模的ParseResult是一个泛型抽象类,Success和Failure是它的两个特化实现。下面的代码清单给出了Scala对ParseResult[T]类型的定义,以及该类型的特化实现Success和Failure。
代码清单8-1 Scala对分析结果的建模
trait Parsers {sealed abstract class ParseResult[+T] {//..val next: Input ➊ ParseResult跟踪着下一输入}case class Success[+T](result: T, override val next: Input)extends ParseResult[T] { ➋ 分析成功//.. implementation}sealed abstract class NoSuccess(val msg: String, override val next: Input)extends ParseResult[Nothing] { ➌ 针对分析不成功情况的基类//..}case class Failure(override val msg: String, override val next: Input)extends NoSuccess(msg, next) { ➍ 失败 => 回溯并重试//..}case class Error(override val msg: String, override val next: Input)extends NoSuccess(msg, next) { ➎ 不可恢复的错误,不回溯//..}//..}
ParseResult对分析器产生的结果的数据类型做了泛型化处理。当结果为Success➋时,我们得到类型为T的结果。当结果为Failure➌时,我们得到一条失败消息。Failure分为可恢复错误(nonfatal)和不可恢复错误(fatal)。对于可恢复的Failure ➍,我们可以回溯并尝试其他备选的分析器。对于不可恢复的Error ➎,不存在任何回溯,分析过程终止。不管发生哪种情况(Success 或Failure),结果都会说明当前分析过程处理了多少输入,分析器链条中的下一个分析器应该从输入流的哪个位置开始接手➊。
本章后续的外部DSL例子会继续演示替代和回溯的具体做法。如何处理分析中出现的不成功的情况,这是我们设计DSL时必须仔细考虑的一个要点。例如有时候替代安排得太多,可能导致性能衰退,而且有时候客观条件不允许我们设计带回溯的分析器。
你想知道分析器组合子库里的这些类都在DSL实现中扮演什么角色吗?
我们建模时每一段DSL都要有一个配套的分析器,由它负责检查语法的有效性。只有当用户提供的脚本语法正确时,DSL处理过程才会继续下去。如果语法是有效的,分析器返回
Success;否则返回Error或Failure。对于Failure的情况,分析器可以进行回溯,尝试用别的替代规则来分析。
现在我们知道了分析器和ParseResult的各种实现,但那么多分析器是怎么串联在一起,完成整个 DSL的分析工作的呢?这正是组合子的作用。所以,接下来我们要介绍Scala提供的一些组合子,学习怎样高效率地利用这些组合子把我们设计的分析器一个个连接起来。
8.2.2 把分析器连接起来的组合子
Scala分析器组合子库含有一整套用来连接各种分析器的组合子。我们在第7章用ANTLR和Xtext来设计外部DSL的时候,利用分析器生成器技术同样可以写出近似EBNF形式的文法。组合子技术与之相比,不需要借助宿主语言以外的任何外部环境。我们在Scala语言范围内,利用其高阶函数特性即可定义出类似EBNF的文法。假如把DSL语法看作是众多小片段的集合,那么组合子的作用就是把每个片段对应的分析器拼接到一起,构成一个大的、针对DSL整体的分析器。
学习Scala组合子的最佳方式自然是通过真实的例子。我们继续沿用前面章节用过的领域示例,设计一种外部DSL来处理用户通过一系列输入提供的客户交易指令。我们需要生成的抽象如图8-6所示。
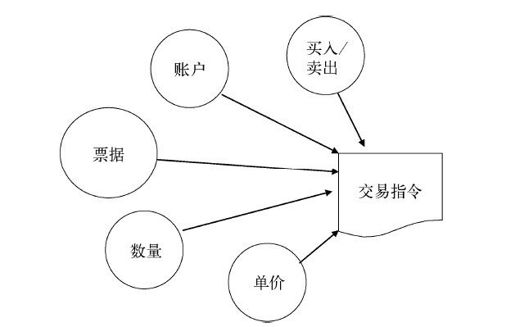
图8-6 以各种输入项目作为属性来生成交易指令
大致掌握分析器组合子的能力之后,我们现在多了一种可行的选择。排除了通过外部分析器生成器(如ANTLR)的实现方式,我们还可以考虑用Scala提供的组合子把一系列较小的分析器连接起来,实现对DSL的语法分析。
分析链条中的每一个小分析器只负责分析一小块固定的DSL结构,然后在组合子的协调下,将输入流转交给下一个分析器。经过与客户的反复商讨和迭代开发,我们确定了客户希望的语法,最后得到下面代码清单中的文法定义。这段代码使用了我们刚刚介绍过的Scala分析器组合子来表达DSL语法。
代码清单8-2 用Scala分析器组合子设计外部DSL的示例
package trading.dslimport scala.util.parsing.combinator.syntactical._object OrderDsl extends StandardTokenParsers {lexical.reserved +=("to", "buy", "sell", "min", "max", "for", "account", "shares", "at")lexical.delimiters += ("(", ")", ",") ➊ 词法分隔符和保留字lazy val order =items ~ account_spec ➋ 顺序组合子(~)lazy val items ="(" ~> rep1sep(line_item, ",") <~ ")" ➌ 重复组合子,带分隔符lazy val line_item =security_spec ~ buy_sell ~ price_speclazy val buy_sell ="to" ~> ("buy" | "sell") ➍ 替代组合子(|)lazy val security_spec =numericLit ~ (ident <~ "shares")lazy val price_spec ="at" ~> (min_max?) ~ numericLitlazy val min_max ="min" | "max"lazy val account_spec ="for" ~> "account" ~> stringLit}
用上面的文法定义可以成功分析下面的 DSL片段:
(100 IBM shares to buy at max 45, 40 Sun shares to sellat min 24, 25 CISCO shares to buy at max 56)for trading account "A1234"
鼓鼓掌吧!刚刚我们用分析器组合子库设计了第一个DSL。稍后我们会对它进行一些再加工,让它输出反映领域抽象的语义模型。
现在我们知道了文法写出来是什么样子,也知道了它能处理什么样的语言,下面可以着手探究每一条文法规则的具体分析过程了。
正式开始之前,我们需要提一提出现于文法规则开头的那组词法分隔符(lexical delimiter)➊,这个列表里的字符在输入流中起划分词法单元的作用。另外我们还定义了一组准备用在语言里的保留字,即代码清单8-2中的lexical.reserved列表。本节余下的部分会对Scala库中提供的组合子予以透彻的解说,教会你用它们来搭建自己的语言。如果要查阅Scala组合子的细节信息,Scala发行包中的源代码是最完整的资料来源。
1.每一条文法规则都是一个函数
文法规则对领域概念进行建模。规则要有合适的命名,这样才能正确传达其模型代表的领域概念。规则的主体部分采用EBNF形式记述,我们先前在ANTLR中定义上下文无关文法时,用的也是相同的EBNF形式。
每一条规则返回一个Parser,代表函数体的返回值。如果函数体是由通过组合子连接起来的多个分析器构成的,那么依次使用所有的组合子之后得到的最终结果,才是规则最后返回的Parser。目前我们假定所有的规则都返回一个Parser [Any],等到第8.3.4小节我们再介绍怎样在规则体中通过定制函数返回具体类型的分析器。
我们编写文法规则,务必记住一条DSL设计的黄金守则:正确地命名文法规则,让名字反映规则建模的领域概念。在用分析器组合子设计外部DSL的过程中,文法规则起着规划蓝图的作用,是我们和领域专家一起审议的凭据。它们叙述简练、含义丰富,而且能够恰当地向领域人员传递易于理解的信息。
2.顺序组合子
Scala语言用“~”符号表示顺序组合子。我们可以在代码清单8-2的位置➋找到它。简便起见,用符号“~”来命名,但它其实只是Parsers[T]类中定义的一个普通方法。
Scala允许中缀运算符的书写形式,因此a ~ b其实等同于a.~(b)。顺序组合子写成中缀形式时,语句看上去如同按EBNF形式书写的样式。另外,Scala语言的类型推断特性使得语句显得更直观。
我们再从代码清单8-2中挑选一处细节来说明顺序组合子的工作原理。在位置➋,items接收到传给分析器组合体的原始输入,于是它尝试调用以items命名的规则体(或方法)来分析输入➌。如果分析成功,即产生一个ParseResult,假设叫做r1。然后序列中的下一个分析器account_spec,开始处理items余下的输入。如果也分析成功并产生ParseResult r2,那么这时“~”组合子将返回一个结果类型为(r1, r2)的Parser。
3.替代组合子
Scala库用“|”符号表示替代组合子。替代组合子以回溯方式查找备选规则。只有当前一个分析器发生可恢复失败,并且允许进行回溯的时候,替代组合子才生效。
请看代码清单8-2的位置➍。输入首先进入第一条备选规则"to" ~> "buy"。定义在Parsers 特征里面的一个隐式转换把String转换为Parsers[String]。如果分析成功,则不用理会后面的任何替代规则,分析结果直接作为buy_sell的结果返回。如果分析不成功,则尝试下一条备选规则"to" ~> "sell"。如果这次的分析成功了,就返回其结果。分析器总是按照备选规则的书写顺序决定选择的先后次序。
4.选择性顺序组合子
这种组合子在“~>”和“<~”方法中实现,分别选择性地保留右边的结果和左边的结果。选择性顺序组合子常用于剔除那些不属于语义模型构成部分的信息。也就是说,虽然我们需要识别整个序列,但只有其中一个分析器的结果是我们感兴趣的。
再看代码清单8-2。我们以位置➌的代码来说明选择性顺序组合子的原理。~>的用法类似于~,只不过它仅保留运算符右侧分析器的结果。例中的"("在后续处理中是不需要的,因此不在结果中保留。<~方法同样与~用法相似,但仅保留运算符左侧分析器的结果。例中的")"在后续处理中也是不需要的,因此也从结果中去除。
5.重复组合子
重复组合子用来实现重复性的结构。表8-2给出了重复组合子的各种变体。
表8-2 不同变体形式的重复组合子
| 变体形式 | 解释 |
|---|---|
(rep(p), p*) | 重复p零次或更多次 |
(repsep(p, sep), p*(sep)) | 重复p零次或更多次,中间有分隔符 |
(rep1(p), p+) | 重复p一次或更多次 |
(rep1sep(p, sep), p+(sep)) | 重复p一次或更多次,中间有分隔符 |
(repN(n, p)) | 重复p正好n次 |
代码清单8-2在位置➌处使用了重复组合子。items由一个或多个line_item组成,以“,”作为分隔符。
6.知识点间的联系
许多开发者都有一个共同的顾虑,担心这些组合子可能难以实现。的确,我们必须先做好大量的铺垫工作,才能确保组合分析器的效果。通过抽象之间的轻松组合构造更大的抽象,始终是我们对优秀的抽象设计的最高追求。在本章中,我们将看到,分析器组合子能够以较小的代码编写负担,建立一种具有分析器绑定能力的抽象。
这种抽象就是在第6章曾经出现的Scala的Monad。那时学到的知识现在正好派上用场,Monad化的操作将使组合子的实现大大简化。
8.2.3 用Monad组合DSL分析器
分析器组合子是一种运用函数式编程的原则来组合分析器的抽象,将简单基本的分析器组合成更大更复杂、语言识别能力更强的分析器。图8-7形象地表现了组合子的作用。
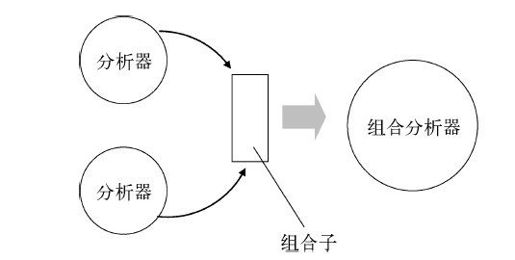
图8-7 组合子将较小的分析器组合起来,形成更大的分析器
我们从上一节得知,顺序组合子和替代组合子能把交给它们的输入串联起来。那么这种串联具体是怎么实施的呢?
1.实现顺序组合子的笨办法
我们先来考虑Scala顺序组合子的实现方案。代码清单8-3是其中一种做法:
代码清单8-3 实现 Scala的顺序组合子
def ~ [U](p: => Parser[U]): Parser[~[T, U]] =new Parser[~[T, U]] {def apply(in: Input) =Parser.this(in) match { ➊ 调用当前分析器来分析输入case Success(r1, next1) => p(next1) match { ➋ 成功!把余下的输入传下去case Success(r2, next2) => Success((r1, r2), next2) ➌ 最后成功!case Failure(msg, next) => Failure(msg, next)}case Failure(msg, next) => Failure(msg, next)}}
这个实现是正确的,组合子的行为完全符合要求。当前分析器处理原始输入流并进行分析➊。如果成功,则分析结果连同余下的输入一起被传递给参数中指定的下一个分析器进行分析➋。如果也成功了,最后的分析结果连同余下的输入一起,作为最后的分析器~[T, U]返回。Parsers trait里为~[T, U]定义了一个类。
那这个实现挺不错的,对吧?呃,好像哪里不对劲。你看出来问题在哪里了吗?
那些担任串场角色的代码占据了舞台的中心,这段程序的观众很难在一片喧闹的掩盖下发现表达顺序组合语义的核心逻辑。这种含义不清的错误应该时时引起我们的警觉。错误的根源出在代码清单8-3的抽象层次上,我们用了非常低层次的抽象来编程,因此导致实现细节被暴露在用户面前。
2.用Monad消灭串场代码
观察现在的组合子实现,那些需要被遮掩起来的细节,都是一些负责连接组合各抽象的串场代码。而我们从第6章就知道,Monad特别擅长解决这类问题。Monad化的绑定操作可以帮助我们无缝地连接各抽象,它在Scala语言里的对应实现是flatMap组合子。因此我们可以在组合子的设计里纳入Monad的概念,依靠各种Monad化的抽象来组合分析器。为了防止低层次的具体实现细节干扰组合子的设计,Scala组合子库把ParseResult和Parser都设计成Monad化的抽象。也就是说,我们不需要自行添加任何串场用的逻辑,就可以直接把多个Parser和ParseResult抽象连接在一起。改造之后,我们的顺序组合子实现变成了一行简单的for-comprehension语句:
def ~ [U](p: => Parser[U]): Parser[~[T, U]] =(for(a <- this; b <- p) yield new ~(a,b)).named("~")
这就对了!一个看着漂亮、用着简洁的抽象就这么呈现在我们面前。
Monad跟我们的DSL实现有什么关系呢?
作为DSL设计者,我们除了使用一个库,还需要对其内部的实现技术有所了解。Scala用库的形式来提供分析器组合子,其实是在告诉我们,这些组合子本来就是准备要被扩展的。我们在现实中必定会遇到需要自行实现组合子的情况。到那个时候,通过各种Monad化的抽象设计来连接分析器的知识就会派上用场。
美好的结果总是由各种琐碎而关键的细节支撑起来的,这些知识需要你到Scala组合子库的源代码中去发掘。
编写DSL分析器的时候,可以用Monad来改善组合子的设计,这个话题我们就说到这里。接下来,话题将转到Scala组合子库的另一项特性,它也是实现复杂DSL结构必不可少的强力工具。
8.2.4 左递归DSL语法的packrat分析
到目前为止,我们研习过的若干自顶向下递归下降分析器(参阅第7章)都只能处理固定数量的前瞻符号集,这因此限制了它们所能识别的语言种类。我们的DSL很有可能含有一些超出常规自顶向下分析器能力范围的语法,这些语法或者无法被正确识别,或者识别的效率太低。LL(1)分析器(见第7.3.1小节)只用一个前瞻符号来搜寻适用的文法规则,而且LL(k)的前瞻符号集合的大小也是有限的,最多能够匹配k个符号。这类分析器称为预测分析器(predictive parsers),因为它们通过预先查看输入流的内容来推测适用的规则。
还有另一类自顶向下递归下降分析器,叫做回溯分析器(backtracking parsers)。它们通过回退并逐条尝试备选规则的方式来推断下一条适用规则。我们从上文对Scala组合子库的介绍中得知,替代组合子就有这样的能力,它会回溯并尝试我们提供的其他备选文法规则。
预测分析器速度很快,使用线性时间解析,而回溯分析器实现会轻易地退化为指数时间。请考虑下面这段用Scala分析器组合子写成的简单的文法规则,它的工作是对表达式求值:
lazy val exp = exp ~ ("+" ~> term) |exp ~ ("-" ~> term) |term
按照这个exp分析器的定义,如果第一行备选规则开头的exp成功了,但随后的输入不是“+”,那么分析器将回滚输入,改为尝试第二行备选规则。这时分析器又把第二行开头的exp重新分析一遍。在分析器找到一条完全匹配的备选之前,会反复出现重新分析的情形。这种重复性的分析过程将导致指数级的时间复杂度。
packrat分析器(见第8.6节文献[3])通过中间结果记忆(memoization)技术来解决重复计算的问题。packrat分析器会缓存它执行过的所有计算,因此当分析器再次遇到相同的计算时,就不必再算一遍,而是直接从缓存中取出结果,其时间复杂度为常数。packtrat分析器通过回溯的方式,可以处理不限数量的前瞻符号。另外,这种分析器分析算法的时间复杂度是线性的。我们将在以下几个小节说明packrat分析器的优势。
定义 “记忆”(memoization)是一种实现技术,通过缓存前面的计算结果来达到避免重新计算的目的。
1.记忆特性提高packrat分析器的执行效率
我们应该怎样实现packrat分析器的中间结果记忆特性呢?这取决于用什么语言来实现packrat分析器。如果使用像Haskell那样默认采取缓求值(lazy-by-default)的语言,那么完全不需要为实现记忆特性做任何工作。Haskell本身就是按需求调用(call-by-need)语义来实现的,它一方面延迟求值,另一方面记忆已求值的结果,以备后续使用。Haskell通过纯函数式的、带记忆特性的回溯分析器提供最完美的实现。
Scala不是一种默认采取缓求值的语言。分析器组合子通过使用一个特殊的、带有缓存能力的Reader来显式实现记忆特性。从下面的片段可以看出,Scala的packrat分析器扩展了Parsers trait,并在其中嵌入一个实现了记忆特性的特殊Reader(PackratReader):
trait PackratParsers extends Parsers {class PackratReader[+T](underlying: Reader[T])extends Reader[T] {//..}//..}
如果用Scala提供的PackratParsers实现来执行刚才举例的exp分析器,效率将大为提高。虽然分析器匹配第一行备选时失败了,但对该行开头的exp识别是成功的,这个识别的结果将被记忆起来。于是当分析器遇到第二行备选开头的exp时,就不必再执行一遍识别过程,而是直接从缓存中取出分析结果。由于重用了执行过的运算,packrat分析可以在线性时间内完成。
2.packrat分析器支持左递归
即使带有记忆特性,最初的packrat分析器设计照样处理不了左递归的文法规则。实际上,任何自顶向下递归下降分析器都处理不了左递归。我们可以继续用刚才的表达式求值分析器来进行说明:
lazy val exp = exp ~ ("+" ~> term) |exp ~ ("-" ~> term) |term
如果把“100 – 20 – 45”这样的表达式输入分析器会出现什么情况呢?exp分析器首先会查找记忆表,确定是否有自身的求值结果。由于这是首次尝试进行分析,记忆表是空的,表示为Nil。于是exp分析器尝试对规则体进行求值,而不幸的是规则体又以exp开头。所以exp分析器就这样陷入了无限递归的死循环。
任何左递归的规则都可以通过一个变换过程,转为等价的非左递归文法。有些packrat分析器实现可以对直接左递归的规则进行变换。但变换后的规则会较为晦涩而难以阅读,并且令AST的生成过程更为复杂。
现在的packrat分析器通过一种新的记忆技术实现了对(直接和间接)左递归的支持,该技术最先由Warth等人实现(参见第8.6节文献[4])。
Scala组合子库里的PackratParsers实现了这种形式的记忆特性,可支持文法规则中的直接及间接左递归。我们会在第8.3节看到用Scala分析器处理左递归文法的例子。关于该特性实现技术的详情,请在Scala源代码中查阅与packrat分析器相关的部分。除了能在线性时间内完成不限前瞻符号数量的回溯分析外,parsers分析器还有更多适合用于外部DSL实现的特性。
3.packrat分析器提供无扫描器的语法分析
典型的分析器会单独设立一个扫描器,用于输入流词法单元的划分。Packrat分析器不需要单独的扫描器,其表达词法和表达上下文无关文法的形式体系是统一的。
你可能想知道无扫描器的语法分析有什么优点。首先分析器不需要安排一个单独的词法分析器抽象,因为只有一套统一的语法需要处理。由于采用packrat分析的文法在一个抽象里囊括了整个分析阶段,所以文法间的组合会较为容易。如果我们需要组合多种外部DSL,这样的设计能提高组合能力。
当然,无扫描器的语法分析也是有缺点的。为了区分保留字和标识符,我们需要为文法补充一些作为消除歧义用途的额外信息。此外,语言中的分隔符也需要额外的消除歧义处理才能被正确识别。
4.支持语义谓词
除了packrat分析器本身具有的语法匹配能力外,我们还可以在文法规则中添加语义谓词。这些语义谓词可以根据其他语法实体的语义来判断分析是否成功。
5.依序选择
Packrat分析器不同于其他使用上下文无关文法的分析器,其替代组合子只支持依序选择。因此如果组合子的几个备选项开头部分有重合,应该把匹配长度较长的备选项排在前面。
packrat分析器用依序选择的规定来消除LR分析器下可能出现的“移进/归约”冲突和“归约/归约”冲突。
现在,我们理解了什么是分析器组合子,也知道用packrat分析器可以得到高效率的分析设计。第8.4节时,我们会再回到packrat分析器这个话题,并且用它来设计一个DSL。
是否有必要把一个DSL实现内所有的分析器都设计成packrat分析器?
通常DSL只在某些局部才需要处理复杂的左递归文法规则。我们可以在这些地方使用packrat分析器,而其他地方还是用一般的递归下降分析器,Scala分析器组合子库允许我们自由地混用普通分析器和packrat分析器。
到目前为止,本章介绍了分析器组合子的基础知识,说明了怎样在函数式语言里使用这些组合子来设计外部DSL,还对一个用Scala提供的组合子库实现的交易指令处理DSL文法样例(代码清单8-2)进行了详细的分析。经过以上学习,你肯定已经意识到,用分析器组合子这样的函数式手段来设计DSL,所要求的思维方式是不同的。我们决定实现策略的前提,是掌握了各种技术的相关能力和优缺点。下一节,我们将融汇全书关于DSL设计的全部讨论内容。其中的重点是辨析内部DSL、使用分析器生成器的外部DSL、使用分析器组合子的外部DSL三者之间的差异。
