7.2 语法分析器在外部DSL设计中的作用
待执行的DSL脚本被送入词法分析器,经过词法分析器的处理,输入流被划分为语法分析器能理解的的可识别单元。当语法分析器顺利处理完全部输入流,到达一个成功的终结状态,我们就说该语法分析器识别了输入的语言。图7-6是这个过程的图解。
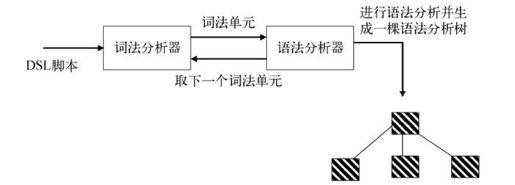
图7-6 语法分析过程。DSL脚本被送入词法分析器去划分词法单元,结果送入语法分析器
一提起词法分析器和语法分析器,我们总是不由自主地想得很复杂,实际上并非如此。它们的复杂度取决于你所设计的语言。前面提到,假如DSL足够简单,我们甚至不必区分词法分析阶段和语法分析阶段。一个通过正则表达式来操作调整输入脚本的字符串处理器,就足以承担全部的解析工作。简单的语言可以靠手工编写分析器,与之相对,更复杂一些的语言需要借助一些专业的开发设施。下面就介绍如何使用生成语法解析器的基础设施,来构建面向复杂DSL的语法解析器。
7.2.1 语法分析器、语法分析器生成器
我们所设计的语法分析器,实质是对语言语法的一种抽象。如果我们打算手工编写整个分析器,那么需要做这两件事情:
- 定义语言的BNF语法;
- 编写与该语法对应的语法分析器。
然而手工编写有一个弊病,这样写出来的全部语法都嵌入到了代码中。对语法的任何修改,都意味着也要对相应的实现代码进行大幅修改。这种情况是实施编程的抽象层次过低的典型表现(附录A有详细解释)。
对于较复杂的语法分析器,利用语法分析器生成器要比直接手写更好一些。语法分析器生成器可以提高我们实施编程的抽象层次。我们只需要定义这两样东西:
- 按Extended Backus Naur Form(EBNF)语法格式书写的语法规则;
- 当语法规则识别成功时,希望执行的自定义操作。
在运用生成器的情况下,实现自定义语法分析器的基础代码完全封装在生成器内部。错误处理、生成分析树等一般事务成为内建在生成器内部的标准例程,无论我们创建什么样子的语法分析器,这些部分都相同。
语法分析器生成器作为一种提高抽象层次的技术,其优点首先是减少代码量,减轻编写、管理、维护的负担。另外,很多生成器能够生成多种目标语言下的语法分析器,这也是重要的优点。表7-1汇总了目前常用的几种生成器。
表7-1 当前存在的语法分析器生成器
| 语法分析器生成器 | 相应的词法分析器 | 详情 |
|---|---|---|
| YACC | LEX | 属于UNIX发布版的一部分(最早开发于1975年),生成C语言编写的语法分析器 |
| Bison | Flex | 属于GNU发布版的一部分,功能几乎与YACC和LEX相同,但能生成C++语言编写的语法分析器 |
| ANTLR(见http://antlr.org) | 已包含在ANTLR内 | 由Terrance Parr开发。能生成多种语言编写的语法解析器,包括Java、C、C++、Python、Ruby等语言 |
| Coco/R | 自动生成词法扫描器(scanner) | Coco/R是一种编译器生成器,将一种源语言的属性语法(attributed grammar)输入给它,它会生成该语言的词法扫描器(scanner)和语法分析器 |
除了表7-1列出来的这几种生成器,还有原Sun Microsystems公司开发的Java Compiler Compiler(JavaCC,见https://javacc.dev.java.net/)和IBM公司开发的Jikes Parser Generator(见http://www10.software.ibm.com/developerworks/opensource/jikes/project/)。Jike和JavaCC生成的都是Java代码的语法分析器,其功能也都类似于YACC和Bison。
无论产生语法分析器的途径是手工编写,还是由生成器产生,指导语法分析器行为的始终是你所用语言的语法。当分析器成功识别了语言,它会产生一棵语法分析树,将整个识别过程封装到这个递归的数据结构里面。如果我们在语法规则上附加了自定义动作,那么最后生成的分析树也会增加这些额外信息,形成语义模型。接下来我们用ANTLR做一次示范,看看生成器怎样把自定义语法翻译成领域语义模型。
7.2.2 语法制导翻译
外部DSL实现在处理一段脚本时,首先要识别脚本中的语法,然后经过解析和翻译,产生语义模型。语义模型充当领域操作的仓库,供给后续的程序使用。那么如何识别语法呢?表7-2说明,要想成功识别,我们需要准备两套材料。
表7-2 识别DSL语法
| 材料 | 作用 |
|---|---|
| 一套上下文无关语法。它的意义是决定哪些产生式是有效的 | 语法规定了撰写DSL的结构形式。只有按照文法规则定义写成的DSL脚本才是有效的 注意:本节的所有例子都用ANTLR生成器来定义语法 |
| 一套语义规则,作用对象是语法识别的符号的属性。这些规则在生成语义模型时发挥作用 | 在每一条语法规则里,我们可以进一步定义一些操作,当语法规则被识别时执行。操作可以是生成语法分析树,也可以是生成其他任意的触发行为,只要与被识别的规则相关即可。这些操作很容易定义。任何一种语法分析器生成器都允许在DSL语法的定义中嵌入其他语言的代码。例如ANTLR可以嵌入Java代码,YACC可以内嵌C代码 |
图7-7展示了语法规则及其附带的自定义操作如何经过语法分析器生成器的处理,最后变成语义模型。
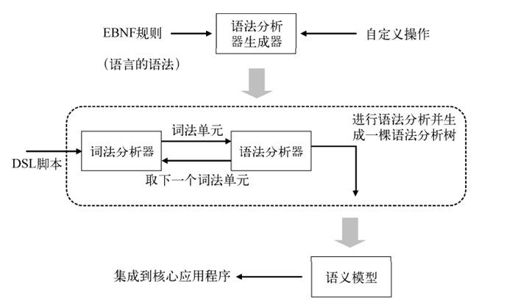
图7-7 语法分析器生成器的输入是语法规则及其附带的自定义。生成器随后生成词法分析器和语法分析器。DSL脚本经过词法和语法分析器的处理,形成语义模型。语义模型成为核心应用的一部分
那么,我们就拿不起眼的“交易指令处理DSL”做一次实习,用ANTLR生成器来实现其语言解析。练习中将定义词法分析器和语法,并且在语法定义里加入若干自定义操作,生成交易指令处理DSL的语义模型。
1. 预备ANTLR示例
我们要定义的语言类似于第2章用Groovy开发的交易指令处理DSL,而且还要更简单一些。这个例子的目的是演示通过语法分析器生成器开发外部DSL的步骤。我们的工作除了制定DSL的语法,还要建立语义模型,然后由语义模型来生成一个代表全部交易指令的自定义抽象。
假设用户向交易机构发出了一串交易指令,看上去是这个样子:
buy IBM @ 100 for NOMURAsell GOOGLE @ limitprice = 70 for CHASE
整组指令由格式相同的若干行构成。我们首先要用ANTLR设计一个能处理这段脚本的外部DSL,然后生成适当的数据结构作为语义模型。简单起见,我们规定每一行代表一条交易指令,用户下达的全部指令构成一个指令列表集合。第一步从设计词法分析器开始。词法分析器的作用是对输入脚本进行预处理,使它成为一组可被语法识别的符号。
2. 设计词法分析器
词法分析器读入输入流,比照预设的词法单元定义,将输入流中的字符组合转换成一个个词法单元。利用ANTLR,可以在文法定义中直接内联词法规则,也可以将词法规则单独写到另外的文件。我们的例子单独用一个文件保存全部词法单元定义,文件名为OrderLexer.g。ANTLR用.g扩展名来表示文法定义文件(g是grammar的首字母)。请注意,代码清单7-1在书写词法单元定义时也用了一种DSL,其可读性和表现力都很优秀。
代码清单7-1 OrderLexer.g:用ANTLR编写的DSL词法分析器
lexer grammar OrderLexer;EQ : '=';BUY : 'buy';SELL : 'sell';AT : '@';FOR : 'for';LPRICE : 'limitprice';ID : ('a'..'z'|'A'..'Z')+;INT : '0'..'9'+;NEWLINE : '\r'? '\n';WS : (' '|'\t')+ {skip();}; 跳过空格
词法规则按“贪婪”方式匹配。分析器在对输入流进行匹配时,会选取匹配程度最高的规则。假如遇到分不出高低的情况,那么分析器会按照规则在定义文件中的出现次序,选取最先出现的规则。
接下来我们转到另一个尚待实现的方面——语言的语法。语法由我们设计的语法规则来决定。
3. 设计语法规则
你希望DSL有什么样的语法,就定义什么样的语法规则。由于我们的DSL特别简单,而且只是用来演示,所以尽量省略错误处理方面的功能,着重突出语法规则的架构方面。读者可以从7.6节文献[2]了解ANTLR在语法规则定义上的详细做法,以及它为用户提供的各种灵活选项。
代码清单7-2定义的语法规则放在一个单独的文件OrderParser.g里面。文件中描述语法所用的标记方法,对于语言设计者来说,是表达能力极为出色的EBNF语法标记。当将词法分析器和语法分析器与驱动语法分析器的处理程序代码整合在一起时,你就会发现ANTLR如何通过这些EBNF描述,生成真正的语法分析器代码。生成语法分析器涉及的所有繁重事务都由ANTLR生成器代劳。开发者只需要专心定义好语言的语法即可。
代码清单7-2 OrderParser.g:用ANTLR编写的DSL文法规则
parser grammar OrderParser;options {tokenVocab = OrderLexer; ➊ 词法分析器的引用}orders : order+ EOF; ➋ 全部交易指令order : line NEWLINE; ➌ 每条交易指令独占一行line : (BUY | SELL) security price account;security : ID;limitprice : LPRICE EQ INT;price : AT (INT | limitprice);account : FOR ID;
熟悉EBNF语法记号的读者会觉得这些文法规则很好理解。我们希望建立一个交易指令的集合➋。每则指令占一行,说明下达的指令详情➌。语法定义文件的开头部分有一个指向词法分析器类的引用,放在options块内➊。
ANTLR带有一个图形界面的语言解释环境(ANTLRWorks,见http://www.antlr.org/works),允许用户通过规定的语法交互地运行示例DSL脚本。该环境会帮我们建立分析树。如果文法规则的解析出现异常,我们还可以在该环境内进行调试。
代码清单7-2指定的语法并没有包含任何语法制导翻译方面的自定义操作。这是故意为之,目的是让你领略一下ANTLR语法定义提供的DSL语法多么轻巧灵便。只要准备好语法规则,就可以成功识别一段有效的DSL脚本,并不需要其他任何东西!下一小节将学习怎样在语法规则中嵌入Java代码来执行自定义操作。
4. 嵌入其他语言的代码作为自定义操作
像代码清单7-2那样的文法规则,ANTLR通过它生成的分析器,可以构建一棵默认的分析树。如果希望在分析树上增加其他信息,或者希望经通过分析DSL脚本生成另一个语义模型,那么可以采用内嵌其他语言代码的方式,于模型内添加自定义操作。下面就在代码清单7-2定义的语法规则基础上,添加自定义操作代码,让DSL脚本在解析后生成一个自定义的Java对象集合。
内嵌代码首先需要定义Order对象,这是一个简单的Java对象(POJO)。解析脚本后,它会生成由一个Order对象列表构成的语义模型。代码清单7-3展示了嵌入语法规则中的最终操作。
代码清单7-3 OrderParser.g:语法规则中内嵌了执行自定义操作的代码
parser grammar OrderParser;options {tokenVocab = OrderLexer;}@header { 设定内嵌代码需要的导入声明和包声明import java.util.List;import java.util.ArrayList;}@members { 分析器类共享的代码private List<Order> orders = new ArrayList<Order>();public List<Order> getOrders() {return orders;}}orders : order+ EOF;order : line NEWLINE {orders.add($line.value);}; ➊ 构造Order对象的集合line returns [Order value] ➋ 规则有返回值: (e=BUY | e=SELL) security price account{$value = new Order($e.text, $security.value,$price.value, $account.value);};security returns [String value]: ID {$value = $ID.text;};limitprice returns [int value]: LPRICE EQ INT {$value = Integer.parseInt($INT.text);};price returns [int value] : AT(INT {$value = Integer.parseInt($INT.text);}|limitprice {$value = $limitprice.value;});account returns [String value] : FOR ID {$value = $ID.text;};
如果读者不熟悉EBNF风格的语法规则描述方式,或者不清楚在规则中嵌入操作代码的写法,可以参阅7.6节文献[2]。注意,我们可以对规则定义返回值➋,返回值会跟着语法分析的进展向上传播。嵌套的运算一层层向上递进,最后形成一个Order对象的集合➊。
Order类的抽象如代码清单7-4所示,其代码出于演示目的已经尽量简化。
代码清单7-4 Order.java:
Order抽象
public class Order {private String buySell;private String security;private int price;private String account;public Order(String bs, String sec, int p, String acc) {buySell = bs;security = sec;price = p;account = acc;}public String toString() {return new StringBuilder().append("Order is ").append(buySell).append("/").append(security).append("/").append(price).append("/").append(account).toString();}}
下一小节要编写语言处理程序的主模块,由ANTLR生成的词法分析器、语法分析器,以及其他任何自定义的Java代码,都要在这里整合到一起。下面就来看看DSL脚本是怎样被解析并产生输出的。
5. 构建语法分析器模块
我们现在就可以用ANTLR构建分析器,与驱动代码进行集成。不过在此之前,还要先准备好驱动代码。驱动代码的任务是从输入中取得字符流,传递给词法分析器从而生成词法单元,再传递给语法分析器对DSL脚本进行识别。代码清单7-5中的Processor类就是这样的一段驱动代码。
代码清单7-5 Processor.java:分析器模块的驱动代码
import java.io.*;import java.util.List;import org.antlr.runtime.*;import org.antlr.runtime.tree.*;public class Processor {public static void main(String[] args) 驱动入口throws IOException, RecognitionException {List<Order> os =new Processor().processFile(args[0]);for(Order o : os) { 输出指令列表System.out.println(o);}}private List<Order> processFile(String filePath) 从文件中读入DSL脚本throws IOException, RecognitionException {OrderParser p =new OrderParser(getTokenStream(new FileReader(filePath))); ➊ 语法分析器读入词法单元流p.orders();return p.getOrders();}private CommonTokenStream getTokenStream(Reader reader)throws IOException {OrderLexer lexer =new OrderLexer(new ANTLRReaderStream(reader));return new CommonTokenStream(lexer); 词法分析器生成的词法单元流}}
划分词法单元和读取输入流都利用了ANTLR的内建类。这段代码在构造语法分析器➊之后,随即在起始符号上调用了orders()方法,这个方法是ANTLR生成的。代码中引用的所有类(如OrderLexer、CommonTokenStream和OrderParser),要么是ANTLR根据语法规则生成的,要么来自ANTLR运行时。这段代码假设待执行的DSL脚本存放在一个文件里面,其路径作为命令行调用的第一个参数提供。
代码清单7-5还稍微演示了一下语义模型的用途,它输出语法分析过程中生成的Order对象列表。如果在真实的应用当中,我们可以将这些对象提供给系统中的其他模块,这样一来,DSL就与应用的核心集成在一起了。
这一节做了不少工作,现在不妨简要回顾一下。
6. 目前的成果
ANTLR提供了org.antlr.Tool等工具类,负责根据语法定义文件生成Java代码。然后所有的Java类,包括作为自定义代码一部分的Java类,都按照一般的构建过程那样编译就可以了。至此,处理外部DSL的基础设施就搭建完毕了,表7-3对我们已完成的工作做了一个小结。
表7-3 使用ANTLR语法分析器生成器构建外部DSL的步骤
| 步骤 | 说明 |
|---|---|
| (1)确定词法要素,为ANTLR准备词法分析器 | 代码清单7-1建立了词法分析器OrderLexer.g。词法单元定义沿用了之前的交易指令处理DSL 注意:词法分析器的定义文件应该与语法分析器的定义分开。单独存储的词法定义可以跨语法分析器重用 |
| (2)用EBNF标记编写文法规则 | 代码清单7-2定义了DSL的语法,定义文件OrderParser.g按照ANTLR的语法写成 文法规则的作用是识别有效的DSL语法,并在出现无效语法时给出异常 |
| (3)生成语义模型 | 代码清单7-3充实了语法规则的定义,通过插入自定义的Java代码,向语法分析过程中注入了语义操作。插入的一个个代码片段,实际上是搭建语义模型的部件 |
| (4)收尾 | 代码清单7-4的自定义Java代码完成对Order抽象的建模。代码清单7-5的驱动代码利用ANTLR的基础设施,将我们的DSL脚本送入前面建好的语法分析过程 |
经历了上面这些工作,我们应该对通过语法分析器生成器来构建和处理外部DSL的完整开发过程有了基本了解。利用生成器来实现外部DSL是非常常见的做法。如果你希望构建基于自定义基础设施的语言来设计外部DSL,那么使用生成器是最适合的。
ANTLR是一款十分优秀的的语法分析器生成器,广泛用于构建各式分析器和DSL。我们现在的成果只发挥了ANTLR的一小部分能力。ANTLR能处理许多种类的语法,而我们甚至连文法的分类都没介绍。理论上,如果对生成的分析器没有效率上的要求,我们其实可以分析任意语言。但实际上我们需要作出让步。开发DSL时,我们希望分析器能以最高效率处理我们的语言。一款能处理许多种语言的通用分析器虽然不坏,但假如它处理起我们的语言效率低下,那对于我们就没什么用处。ANTLR只是分析器生成工具中的一种,它所生成的分析器只能识别一部分特定类型的语言。
DSL的设计者需要清楚语法分析器的一般分类,每一种分析器的实现难点,还有每一种分析器能处理的语言类型。所以下一节将全面介绍语法分析器的分类及其实现复杂度。
