- define 预处理指令最基本的用法就是替换功能,#define NAME stuff 指令会在预处理阶段,把源码中出现的NAME 替换成stuff。请注意,这里只是简单地替换,不做任何的语法和语义方面的检查。
- !/bin/bash
- include <stdio.h>
- include <stdio.h>
- include< stdio.h>
- include <stdio.h>
- include "a.h"
- inlcude "b.h"
- include "a.h"
- ifndef _A_H
- define _A_H
- endif
- include "a.h"
- ifdef __cplusplus
- endif
- ifdef __cplusplus
- endif
C 语言支持预处理指令。预处理指令由预处理器来处理。预处理器会在编译源代码之前,首先处理预处理指令,根据预处理指令来完成替换、条件编译等功能。最常见的预处理指令主要有三种,分别为文件包含、条件编译和宏替换,下面分别进行介绍。
文件包含功能通过预处理指令#include "a.h" 来完成。它是一种最为常见的预处理,主要就是一个简单的替换功能,把#include "a.h"这一语句替换成整个a.h 头文件的内容。另外一种头文件的写法为#include <a.h>,不同的是不用双引号括起文件名,而是用大于小于号。大于小于号表示预处理器要从标准库路径开始搜索这个头文件。而对于双引号括起的头文件,如#include "a.h",预处理器从用户的工作路径开始搜索。所以对于标准的头文件,我们一般用大于小于号,如#include <stdio.h>;而对于自己的头文件,我们一般用双引号,如#include "zhaoyan.h"。
头文件内容的后面一定要加个分号,这也是很多人经常犯错误的一个地方。这种错误有时会造成编译器错误地理解你的程序。这种错误比较隐蔽,不太容易查出来,所以必须非常小心。这种错误具体解释起来比较复杂,我可以通过一个简单的例子来说明,那就是标点符号有的时候会改变一句话的含义。记得以前看过一个相关的故事,主人把“下雨天,留客天,天留我不留”的纸条给客人看,客人看后加了一个标点,变成了“下雨天,留客天,天留我不,留”你看,含义彻底改变了。
下面把这个故事引申到我们的头文件中,如果第一个头文件中的内容为“白天;”,另外一个头文件的内容是“鹅在游;”。我们说过,头文件就是一个简单地替换,当我们包含这两个头文件后,我们就得到“白天;鹅在游;”这句话;但是如果在第一个头文件中我们忘记了分号,那么最后就得到“白天鹅在游;”这句话,可以看出,与原来的含义是完全不同的。这回你明白加上必要的分号对编译器正确理解你的程序是多么重要了吧。
条件编译语句如#if、#ifndef、#ifdef、#endif、#undef 等,它们也是比较常见的预处理指令,主要作用是编译时根据条件选择某些语句进行编译,或者忽略掉某些语句。
有这种需求的场景很多。例如,用于调试的语句在最终发布产品的时候是不应该存在的,但是我们还不想把它从源代码中删除掉,因为一旦产品有问题了,这些语句可以帮助我们定位错误,这个时候就可以使用条件编译指令,如程序7-1 中第1~3行所示。如果想编译这个调试语句,只要使用#define DEBUG 就可以了。另外一个应用就是使得程序支持跨平台编译。有的头文件在不同的平台,可能所在的路径是不一样的。为了支持跨平台编译,我们可以使用条件编译指令,使程序在不需要修改源代码的前提下,在所有的平台上都能够顺利地编译,如程序7-1 中第4~8 行所示。
程序7-1 预处理指令条件编译语句
1 #ifdef DEBUG
2 printf("debug information");
3 #endif
4 #ifdef linux
5 # include <ext/hash_map>
6 #else
7 # include <hash_map>
8 #endif
条件编译语句还有一个常用的作用,那就是防止对头文件的重复包含,这个我们在7.8 节还会详细介绍。
define 预处理指令最基本的用法就是替换功能,#define NAME stuff 指令会在预处理阶段,把源码中出现的NAME 替换成stuff。请注意,这里只是简单地替换,不做任何的语法和语义方面的检查。
有两种类型的宏替换,一种为object-like①,另外一种为function-like。object-like不接受参数(parameter),而function-like接受参数。这两种宏替换的语法分别如程序7-2 第2 行和第4 行所示。
注释:① 我并没有给出这个翻译,因为我实在不知道该如何翻译 object-like。
程序7-2 第4 行后面有一个反斜杠,当#define 语句很长的时候,你可以把它断成多行,不过除了最后一行外,其他每行的末尾都需要一个反斜杠‘\’,表示与上一行是接续的关系。
程序7-2 第5 行和第6 行则分别给出了object-like 和function-like 的两个具体实例。一个定义了常数PI,另外一个定义了类似函数的宏,给定圆的半径r,这个宏会计算圆的周长。
程序7-2 预处理指令跨平台编译
1 /object-like macro /
2 #define <identifier> <replacement token list>
3 /function-like macro/
4 #define <identifier>(<parameter list>) \
<replacement token list>
5 #define PI 3.14159
6 #define PERIMETER(r) (2PI(r))
有两点需要注意,3.14159 后面不能跟分号,同时,function-like 的宏必须加很多的括号。这个问题在《C Programming FAQs》[3]中的Question 10.1 中已经说得非常非常到位了,你可以参考本书网站中“扩展内容”网页中的“《C Programming FAQs》网络版”。
无论你多喜欢用宏替换,你都必须明白它所带来的各种副作用。C++语言中提倡大家尽量避免使用#define,详细的解释可以参考《Effective C++中文版》[15]的条款1。坦白地说,在C 语言中,你也应该非常认真地考虑并采用这个建议。
所有的C 语言程序都包含一个main()函数,main 函数里面应该包含你的程序想要完成的功能。在C 语言中,main 函数是必须存在的。当然,你也可以写出一个空的main 函数main(){}。其实,你一不小心,就写出了这个世界上最完美的程序,因为它绝对没有错误。这和人类社会一样,你只要干点事请,总会出错,如果什么也不干,出错的机会为零。
为什么需要main 函数?这是因为你的程序是运行在操作系统里面的,操作系统才是真正的Boss,而你的程序只是小弟。当你想运行你的程序时,操作系统需要把电脑的部分控制权转交给你的程序;当你的程序运行完毕后,操作系统也需要回收这部分控制权。那么一个现实的问题就是,把控制权交给你程序中的哪个函数呢?为了方便,C 语言标准中规定,操作系统的控制权交给程序中的main 函数,当运行完程序,从main 函数中返回给操作系统控制权。这种契约一旦达成,操作系统只会在你的程序中找main 函数,如果找不到,操作系统将不会向你的程序转交控制权,也就是说,你的程序根本没有办法被运行。
很多同学对main 函数的传入参数和返回值不理解,这也不完全怪他们,他们已经是被Windows 捆绑的一代。Windows 就像是一个金碧辉煌的大坑,一旦跳进去,你就再也出不来或者不愿意出来。在Windows 下,运行任何程序只要鼠标双击程序图标就行了。如果换作我,也不能理解为什么还需要传入参数和返回值。但是如果你使用Linux,经常使用Linux 下的各种命令并进行Linux 下的脚本编程,你就会明白,程序的传入参数和返回值都是那么天经地义和顺其自然。
在 Linux 中,你的程序就是一个命令。有的命令在完成一定功能的时候需要搭配特定的命令行参数。例如,在Linux 下如果需要删除两个文件,你可以通过以下命令rm file1 file2 来完成。如果rm 是你的程序,那么file1 和file2 就是命令行参数。命令行参数就需要通过main 函数中的传入参数传递进去。
有的时候,在脚本编程中需要利用你程序的返回值。例如,如果在删除file1 和file2的时候发生了错误,rm 将会返回一个大于零的值,因为你的程序只是脚本中的一个命令,脚本中的后续命令需要根据程序的返回值来决定下面的流程。例如程序7-3 是Linux 下的一个脚本,演示了如何利用rm 命令的返回值。
程序7-3 bash 脚本示例
!/bin/bash
if rm file1 file2 -gt 0; then
exit 1
fi
综上所述,main 函数的返回值就显得很重要了。所以,正确的main 函数是应该具有返回值的,至于返回什么没有官方的定义,取决于你的具体应用。你可以把返回 1 定位为正常,也可以把返回0 定义为正常。一般情况下,都把返回0 定义为正常。把其它的整数定义为不同的错误状态。借用一句谚语来说就是:“幸福的家庭总是相似的,不幸的家庭却各有各的不幸。”值得注意的是,返回值一旦定义了,你就不要轻易改动。因为你的程序可能已经被很多人使用了,任意改动接口的设置将会给别人使用你的程序带来很大的麻烦。
其实在 Windows 下也有类似的脚本概念,只不过叫作批处理。由于Windows 是基于图形界面的操作系统,批处理的使用远没有Linux 下脚本使用得那么广泛。
一般的,main 函数被定义为三种格式。如果你的程序只是打印一个“hello world”,那么完全可以不要传入参数,这个时候我推荐程序7-4 中第2 行的写法,这种写法移植性更好一些,几乎可以通吃所有的编译器。
main 函数的返回值都被声明为int。这是一个必须遵守的习惯,即使你的程序不需要任何返回值。这样程序会有更好的移植性。有些事情深究起来没必要,记住就行了,例如,不要用舌头舔冰,如果你偏要深究或者尝试一下,可以试试看。
程序7-4 main 函数的三种定义方式
int main() / 无传入参数 /
int main(void) / 无传入参数 /
int main(int argc, char argv[]) / 有传入参数 */
值得注意的是,程序7-4 中第3 行中的argc 和argv 可以换成别的名字,不过我劝你还是遵守一些已经形成的程序员内部的规范。argc 代表的是传入参数的个数,argv 为一个指针数组,其中每一个指针指向了传入参数的具体的值。argc[0]指向的是你可执行程序的名字。
另外一种常见的写法为int argc, char **argv,这个比较有趣,这个有趣的话题将在10.6.2 节中展开来说,这里先卖个关子,按下不表。
你还需要知道的是,从main 函数中返回可以用return 语句,另外一个候选就是exit 函数。比起return 语句,exit 函数会做一些额外的数据清理工作,具体的细节可以参考8.6 节。
命令行解析用起来挺容易,让我们先从Linux 下的一个经典命令说起,这个命令为less,用处是查看文本文件的具体内容。这个命令支持一些选项,例如选项-N 可以给每一行加上行号;选项-x 后接一个数字后,可以指定显示中tab 的距离,例如-x 18 可以指定每一个tab 键占据18 个字符的宽度。
注意,为了与后面的文件名相区别,所有的选项都是以一个短横杠“-”开头的。在你具体使用这个命令的时候,你可以用less -Nx 18 file,也可以用less -N -x 18 file,还可以用less -x 18 -N file。这三个命令是完全等价的。不仅如此,N 和x 还只是其中两个选项,事实上,这个命令支持非常多的选项,不信你可以在Linux 操作系统下查询一下这个命令的参考文档。选项的字母几乎覆盖了英文的26 个字母。而且还分大小写呢!
现在的问题是,当你尝试用传入参数int argc, char *argv[]来处理这上面这三种不同的写法的时候,你会发现这其实是一个挺难的任务。为此,Linux 下提供了getopt 函数,用于对命令行中的参数进行灵活地解析,有了这个函数,对命令行的解析变得简单了很多。
不过遗憾的是,Windows 下几乎所有的程序都是用双击来运行的,根本也不需要输入什么命令行参数,所以,Windows 平台下的C 语言编译器编译器对getopt 函数不支持。为此,程序7-5 给出了一个相对简单的解决方法,这段程序可以支持上面介绍的二种命令行选项写法,大家可以参考一下。
程序7-5 的一个缺点就是不支持less -Nx18 file 这种写法,但是getopt 函数对less -Nx18 file 这种写法也是支持的,这回你知道getopt 函数有多强大了吧。
程序7-5 windows 平台下命令行解析
main(int argc, char *argv[]){
int argi; int Nflag = 0;
char *xval = NULL;
for(argi = 1; argi < argc && argv[argi][0]
== '-'; argi++) {
char *p;
for(p = &argv[argi][1]; *p != '\0'; p++) {
switch(*p) {
case 'N':
Nflag = 1;
printf("-N seen\n");
break;
case 'x':
xval = argv[++argi];
printf("-x seen (\"%s\")\n", xval);
break;
default:
fprintf(stderr,
"unknown option -%c\n", *p);
}
}
}
}
一只小象,每天的任务就是跟在妈妈的大屁股后面。这个时候,它会非常反感它的长鼻子,因为有的时候就会踩到,然后被绊个大跟头;等到长成了大象,它就会明白,长鼻子是上帝给它的最好的礼物。同样的,如果你是一个新手或者是菜鸟,你每天的任务就是跟在项目经理的大屁股后面,这个时候,你也会感到,C 语言为什么有那么多的特性?等到你当上项目经理,你就会明白,C 语言的每个特性都对应着每一个特定的应用场景。就像我们下面要介绍的static 和const 关键字一样。
作为作者,我非常想把这本书写得系统而全面,介绍static 的时候,当然需要介绍const,因为它们都可以修饰变量、函数等。const 关键字当与指针变量配合使用的时候,最让人产生混淆和疑惑,例如,const char p; 和char const p;之间的区别。《Effective C++中文版》[15]的条款21 给出了一个非常简单的区分方法。你可以画一条垂直线穿过上述指针声明中的星号()位置,如果const 出现在线的左边,指针指向的数据为常量;如果const 出现在线的右边,指针本身为常量;所以const char p;中指针p 指向的数据为常量,而char* const p;中,指针p 本身为常量,不能改变指针p 的指向。
const 更细致的用法已经在《Effective C++中文版》的条款21 中介绍得很详细了。如果你只有C 语言的基础,对条款21 中有的概念可能看不太懂,但是没关系,我告诉你一个以后处理类似情况的办法,那就是能看懂多少算多少!相信我,看懂的那一部分,就可以让你受益匪浅了。我真的希望你在阅读本书的时候,手头还有《Effective C++中文版》以及《C 陷阱与缺陷》等我参考文献中列出的那些书,哪怕是电子版也行,如果再有一个能上网的电脑,那几乎就完美了!相信我,这些书会让你少走很多弯路。当然,“这些书”里也包括本书。
static 的用法在很多的教科书中都有介绍,那就是声明一个静态变量,这也是static 这个英文单词原来代表的含义。静态变量和全局变量都存储在一块叫作静态存储区的内存区内。关于程序的内存映像,可以参考10.7 节。静态存储区与栈不同,不会伴随着函数的退出而消失。事实上,静态存储区内的变量会和整个程序的寿命一样长。static 类型的变量,如果你不初始化的话,那么它的值为零,而不是像某些自动变量那样是一个随机数。就算你把它定义在一个函数内,它也不会伴随着函数的退出而消失。所以经典的用法就是用来统计这个函数被调用了多少次,如程序7-6 所示。
程序7-6 static 用法范例
int f(int i)
{
static int f_called_num;
……
f_called_num++;
printf("function has been called %d",f_called_num);
}
在程序7-6 中,我们通过全局变量也可以达到同样的目的,但是,这样做不优雅。全局变量的一个特点就是所有的函数都能访问它。如果你的程序中全局变量f_called_num突然变成了-1,你都不知道是谁改变了它。
在程序7-6 中,我们希望f_called_num 是静态的,不伴随着函数结束而消失。同时,我们还希望f_called_num 只能被函数f 访问。如果f_called_num 突然变成了-1,很快就能定位出肇事者。这个时候,我们就需要用到static 的第二个特性了。
static 的第二个特性,并没有通过static 这个词的英文含义表达出来,那就是信息隐藏。信息隐藏就是:static 变量只在定义它的范围内可见,在其他范围内不可见。如果你把一个static 变量定义在一个函数内,那么只有这个函数可以读写它,其他函数对它不可见。如果你把它定义在一个.c 文件中,那么只有这个.c 文件中的函数可以读写它,其他的.c 文件中对这个变量不可见。这点类似于C++中class 中的private 类型变量。这也是static 变量与全局变量的区别,虽然它们被保存在同一块内存区域——静态存储区。
如果 static 用来修饰函数,这个函数只在当前的.c 文件中可见,这样我们就可以在不同的.c 文件中定义同名的函数,而不会引起冲突,只要其中的一个函数用static 来修饰。其实,命名冲突的问题,不仅在C 语言中常见,在我们的现实生活中也是如此。如果你有了自己的孩子,并且想给自己的孩子起个独一无二的响亮的名字,你就会知道这个任务真的很难。
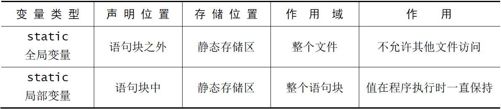
最后总结一下 static 的含义和用法,如表7-1 所示。它有两个含义,分别是静态和隐藏。基本的用法是:用static 定义的函数和变量只在此模块(文件)中有效。
如果要定义一个允许被其它.c 文件使用的全局变量,你可以在任意一个.c 文件中定义出这个全局变量,定义的时候不能加static 修饰符。在其它.c 文件中使用这个全局变量前,你需要使用extern 修饰符对这个变量进行声明。extern 修饰符会告诉编译器,这个全局变量已经在某个.c 文件中被定义了。
表7-1 static 用法总结
无论利用什么编译器编译自己的程序,Visual Studio 或是GCC,C 语言都要经过编译和链接两个步骤才能变成一个可执行的程序。集成开发环境(IDE)把编译和链接的整体细节都隐藏了起来。例如,在Visual Studio 中,你只需要按下Ctrl+F5,可执行.exe 程序就已经被生成,并自动地运行了。
生成可执行.exe 程序的整个过程中,你也许并不需要与编译和链接直接打交道,但是如果你能理解编译和链接的一些知识,对理解C 语言中的某些现象,如为什么要有头文件、头文件中应该包含什么、什么是头文件的重复包含等,就会有更多的帮助。
本书不会对编译器做深入的技术上的介绍,原因很简单,因为我也不会。我本科并不是学计算机的,而且连极限和求导到底是什么都没搞清楚,就稀里糊涂地毕业了。这里我暴露自己的出身,只是希望帮助你鼓起学习计算机的勇气。我的这等出身,最后居然写了一本C 语言的书,如果你好好学,你也行!
详细的编译器介绍可以参考两本书,分别为《编译原理技术与工具》[16]和《Modern Compiler Implementation in C》[17],它们的封面上分别印着一个龙和一个虎,所以它们被并称为编译原理的“龙虎”书。提醒大家,千万别把名字记错了,是“龙虎”书,不是“龙虎豹”书。否则你要是上书店,对卖书的MM 说要买龙虎豹,你马上就亮了,切记!切记!
编译器的基本任务只是理解程序,然后把理解的结果翻译成对应的机器码,并不需要生成可执行文件。既然是理解程序,编译器只要确认每个标识符的类型,做到能认识它就可以了。而链接器的功能是在内存中定位这个标识符,链接器要唯一地找到它。以上课点名为例,有两位老师共同完成这个任务,编译器老师只是低头点名,听到有人喊“到”就ok 了;编译器老师点完名后,链接器老师说:“所有喊过到的同学站起来,我要准确定位你的位置。”呵呵,怎么样,滥竽充数的同学这下死定了。
大家可以看出,程序7-7 并不是一个完整的程序,因为它并没有给出函数foo 的定义。但是编译器只需要知道foo 是个函数,它传入一个int,返回一个int,对编译器来说,这些信息就足够了。所以,程序7-7 会顺利完成编译。
编译生成的机器码中,函数foo 只是一个引用,在链接的过程中,会把foo 的引用链接到真实的foo 的实现上。由于我们并没有给出foo 具体的实现,虽然编译成功,但是当链接的时候,会收到一个连接错误:“error LNK2019:无法解析的外部符号_foo,该符号在函数_main 中被引用”,当然,也不会生成最后的可执行程序。
程序7-7 可以通过编译的程序
include <stdio.h>
int foo(int i);
void main(void){
foo(5);
}
编译器的另外一个特点就是单元编译。也就是说,编译器每次只编译一个.c 文件,而且当编译这个.c 文件的时候,对其它的.c 文件一无所知,其实也不需要知道。知道了编译器的这两个特点,对我们了解C 语言中的很多语言特性有很大的好处。
一般的,如果一个学生学习到了函数,那么他对C 语言的了解已经比较深入了。同时,对某些概念也有了一个固定的认识,哪怕这个认识是错误的。例如,当你在一个.c 文件中写下了int i;,这个时候,你会很自然地说,我声明了一个变量i。无论是老师,还是你的同学,都会认可你这种说法,但是,你的说法不够准确。你应该说,我定义了一个变量i。关于函数和变量的声明和定义,可以参考程序7-8。
程序7-8 声明和定义
include <stdio.h>
int foo(int i); / 声明一个函数 /
extern int k; / 声明一个变量 /
void main(void){
int i = 5; / 定义一个变量 /
foo(k); / 调用一个函数 /
}
int foo(int i){ / 定义一个函数 /
return i+1;
}
为了说明声明和定义的区别,我们需要把自己想象成一个编译器。编译器对声明的态度就是:“我知道了”。对声明的变量或者函数,编译器并不申请内存,只是保留一个引用;当执行链接的时候,把正确的内存地址连接到那个引用上。但是对定义来说,编译器要做实际的事,无论是变量还是函数,定义的时候都要分配一段内存,以便把定义的变量和函数装入内存中去。
声明一个函数只要定义出函数的返回值、函数名、函数参数列表就可以了,别忘了在函数声明的后面要加上一个分号“;”。声明一个变量需要用extern 关键字,编译器遇到这个关键字后,不会为它后面的变量申请内存,因为编译器知道,这个变量在其他的.c 文件中已经定义。注意,extern 关键字只用于声明数据类型,不用于声明函数。
事实上,你也可以用extern int f();声明一个函数,但是这种声明与int f();完全等价,所以能省还是省省吧!令人沮丧的是,除了我,几乎所有的书都是混用“声明”和“定义”这两个词的,包括《C Programming Language》。一旦你认定声明和定义是两个不同的概念,你再去阅读其他的书籍时会非常的“拧巴”和困难。所以我不得不向权贵低头,含泪委屈地说,声明和定义是一样的。有的时候就是这样,你必须要尊重传统。据我所知,现代键盘上这么混乱的字母布局设计,当初并不是为了让打字更快,而是让打字更慢。但是传统就是传统,你要是不服,可以发明一个全新布局的键盘,问题是你猜会不会有人买?
我原来想发明一个新词,把extern int i;叫作“说明”一个新变量,但是我感觉这样更别扭,所以我最终决定两件事。
第一,承认声明和定义代表一回事。本书中也继续混用两个词。
第二,你要知道,有两种声明,一种伴随着分配内存,另外一种不伴随着分配内存,至于到底是哪种声明,你自己根据源码判别。
把这个球踢给你以后,我是轻松多了。但是你也不用紧张,判别两种声明非常简单。对变量来说,带extern 的就是不申请内存的声明;对函数来说,只给出函数的接口定义,后面跟一个分号,就是不申请内存的声明。怎么样,这么说够简单了吧!
说明了两种声明以后,你还要知道,无论是变量还是函数,不分配内存的声明,可以声明很多次,可以放到头文件中,也可以放到.c 文件中;但是分配内存的声明,你只能声明一次,而且一定要放到.c 文件中。
假设程序7-8 被写在了a.c 文件中,我们在main 函数的前面声明了一个变量k和函数foo,这样在main 中,我们就可以使用这个函数foo 和变量k 了。这个时候,a.c 文件完全可以编译过去。现在有一个问题,假设我们还有一个b.c 文件,其中要用到foo 函数,那么我们还需不需要在b.c 中的开头重新声明一下函数?有些读者会问,不是在a.c 中声明了吗?编译器已经编译过a.c 了,就应该知道foo 是个什么东西了。不对!别忘了编译器的第二个特点,它每次只处理一个.c 文件,并且在处理这个.c 文件的时候,对其它的.c 文件一无所知。也就是说,编译器具有失忆症,就算它编译过a.c 文件,也不会把任何声明的知识带到编译b.c 文件的过程中。在编译b.c 文件的时候,它会从零开始。所以,在b.c 文件的开头,我们必须也写上int foo(int i);。如果还有c.c 和d.c 呢?现在,我们的程序中到处都充斥了函数的声明int foo(int i);,这样不仅效率低下,而且如果有一天函数foo 发生了改动,我们需要修改散布在很多.c 文件中的声明,那时真是手足无措,而且也会带来潜在的错误。
更好的办法就是将函数foo 的声明放到头文件foo.h 中,在需要使用foo 函数的时候,在开头的地方包含foo.h 就可以了。这也是C 语言常用的一个方法。还记得我们使用time 函数的时候,一定要#include <time.h>,就是这样一个道理。当调用任何C 库函数的时候,我们都要有这样一个意识,看看需要包含哪些对应的头文件。没有对应的头文件,编译器在编译的时候就会报错或给出警告。程序7-9 由于缺乏包含#include<stdio.h>,在有的编译器上会报错,有的编译器会给出警告。
程序7-9 缺乏头文件
void main(void){
printf("hello world");
}
更讨厌的事是有的时候如果你忘了包含头文件,会发生逻辑错误。程序7-10 在VS2010 上编译的时候,会出现一个警告,提示你没有包含math.h。但是一般的程序员,包括我,往往忽略掉警告。这段程序编译并运行的时候,没有任何错误的提示,只是打印出来的结果不对,这种逻辑错误修改起来很简单,就是加一个头文件,但是定位这个错误,确实非常非常难。
程序7-10 缺乏头文件的危害
include< stdio.h>
/ 缺失 #include< math.h> /
void main(void){
double f;
f = log10(10);
printf("%f",f);
}
这段程序教给我们两件事:
• 调用任何一个库函数前,一定要包含对应的头文件。至于对应的头文件是什么,参看库函数的参考文档。
• 不要忽视编译器给出的任何信息,包括警告。
在介绍怎么避免头文件重复包含之前,我们先来说明头文件重复包含如何引起的?头文件重复包含有什么坏处?一般情况下,我们不会连续写两个#include <stdio.h>语句,所以,头文件的重复包含都是隐式发生的。为了模拟出头文件重复包含的场景,我构造了三个文件,分别为main.c、a.h 和b.h,如程序7-11、程序7-12、程序7-13 所示。
程序7-11 main.c 文件内容
include <stdio.h>
include "a.h"
inlcude "b.h"
void main(void){
printf("%d %d",a,b);
foo();
}
程序7-12 a.h 头文件内容
int a = 10;
程序7-13 b.h 头文件内容
include "a.h"
int b=5;
void bf(){
printf("%d",a);
}
事实上我并不是故意构造出这么多文件。一个大一新生的C 语言作业可能只包含一个.c 文件,但是任何一个实用点的C 语言项目中,通常都会包含若干个.h 和.c 文件。有的甚至包含成百上千个文件。以至于每次编译整个项目需要花费很长时间。“我的项目正编译呢”,这句话成了无数C 程序员最理直气壮地偷懒借口,如图7-1所示。

图7-1 我的项目正在编辑呢
在 main.c 中,我想访问变量a 和b,它们被分别定义在a.h 和b.h 两个文件中,所以在main.c 中我必须要同时包含a.h 和b.h 两个文件;同时,b.h 中因为要用到a 这个变量,所以,也必须要包含a.h。这样main.c 包含b.h,b.h 又包含a.h,相当于main.c 包含了a.h 两次,所以int a 这个变量就被定义了两次。在这种情况下,当编译main.c 文件的时候,就会收到一个重复定义的错误。
为了避免这个错误,我们可以把头文件的内容放到一个宏判断指令#ifndef 当中,这个可以说是标准的做法了,如程序7-14 所示。
程序7-14 a.h 头文件的修改
ifndef _A_H
define _A_H
int a = 10;
endif
当我们再次编译这个程序的时候,编译通过!你长吁了一口气,又学到了一招,避免头文件的重复包含,就可以避免变量的重复定义。
且慢,你错了,而且错得很离谱。这也是初学者最容易犯的一个错误,Stackoverflow.com 论坛上关于这种问题的讨论铺天盖地。为了证明你错了,我现在在项目中加入另外一个foo.c 文件,如程序7-15 所示。
程序7-15 foo.c 文件内容
include "a.h"
void foo(){
printf("%d",a);
}
当再一次编译这个项目的时候,我们会收到一个链接错误,说变量a 在main.obj 和foo.obj 中同时定义了,链接器不知道该链接哪一个。别忘了,C 语言编译一个.c 文件的时候,对其他的.c 文件一无所知,所以,编译器在编译foo.c 时,它不知道变量a 已经在main.c 文件中被定义了。最终的结果就是,变量又被定义了两次。
其实,我们在开始的时候就错了,我们不应该把任何定义变量或函数的语句放到头文件中。头文件中只应该包含那些不申请内存的声明语句,这是一条基本的原则。我们在b.h 文件中不仅定义了变量b,还定义了函数bf,真是错上加错!如果不能在头文件中定义变量或函数,那么应该在哪里呢?答案就是应该在任何一个.c 文件中,任何一个.c 文件都可以,只要你别定义两次就行。
如果头文件中只是包含声明语句,那么重复包含头文件也不会引发任何编译和链接错误,那么为什么我们还要避免重复包含头文件呢?避免重复包含只是为了提高编译的效率。因为针对一个大的项目,头文件都比较庞大,如果头文件被重复包含了,就算.c 文件中只有一行,经过预处理指令#include 后,编译器面临的也可能是一个上万行的怪兽。
最后把本节的内容归结为一句话:不要在头文件中定义申请内存的变量和函数,避免重复包含以提高编译器的效率。这句话才是我们应该记住并严格执行的。
模块化编程的一个基本思想就是分治,把不同的功能分解到不同的模块中。模块可以是不同的.c 文件,也可以是不同的库。模块中不同的功能再分解到不同的函数中。把所有的功能都塞到一个函数里是很愚蠢的。同样,把所有的函数都塞到一个.c 文件中也是不优雅的。一般情况下,哪怕是一个中小规模的任务,构建多个.c 文件,并把对应的功能分配到对应的.c 文件中也是正常并且正确的,如图7-2 所示。
图7-2 多文件项目
在一个多文件项目中,通常会包含若干的.c 文件和.h 文件。作为一个基本的原则,你应该把不分配内存的声明语句放到头文件中,它们包括:
• 用于避免重复包含的#ifndef…#endif 语句
• 宏定义
• struct、union、enum 等类型的typedef 类型定义
• 全局变量及函数的不申请内存的声明(变量前面带extern,函数不给出具体定义)
程序 7-16 给出了一个头文件的例子,大家可以参考程序中的注释理解一下。值得注意的是,在一个项目中,最好把所有的声明放到一个统一的global.h 文件中,哪个.c 文件用到对应的函数、结构体、全局变量时就包含这个global.h 文件。不要把这些声明重复地放到不同的.c 文件中,否则一旦发生改动,将非常的麻烦。
源文件(.c)中包含一系列函数、全局变量、静态变量的分配内存的定义。如果只想在a.c 文件中读取一个变量k,那么我们可以把它定义为static int k;,且定义在所有函数的外面。这样,a.c 中的所有函数都可以访问变量k,但是其他的.c 文件就不能读取k 变量了。如果想让一个变量foo 被所有的.c 文件读取,那么我们可以在任何一个.c 文件中定义变量foo,然后把这个变量的声明放到程序7-16 所定义的头文件中,具体可以参考第12 行,然后在任何想访问这个foo 变量的.c 文件中包含这个头文件就可以了。
程序7-16 头文件范例
1 #ifndef GLOBAL_H
2 #define GLOBAL_H
3 #include "others.h" /其他头文件/
4 typedef long WORD ; /类型定义/
5 typedef struct student
6 {
7 int num;
8 char name[20];
9 int age;
10 } STUD; /类型typedef,但是并没有定义一个变量/
11 int f(int i); /函数的声明/
12 extern int foo; /全局变量声明/
13 #endif 第7章函数、模块和宏定义
目前主流的程序语言以C++为主,大部分的应用程序都是基于C++程序开发,但是有的时候,你还想使用某些过去的、用C 语言实现的某些功能。C 语言文件主要保存在.c 文件中,而C++文件主要保存在.cpp 文件中。当编译器编译.cpp 文件的时候,它按照C++标准编译文件,当编译器处理编译.c 文件的时候,它按照C 标准编译文件。
按照 C++标准编译文件的时候,为了支持函数重载,编译器执行一项name mangle 的过程。name mangle 编译的时候,会改变函数的名字,这样在链接的时候,就会出现错误。整个过程如图7-3 所示。
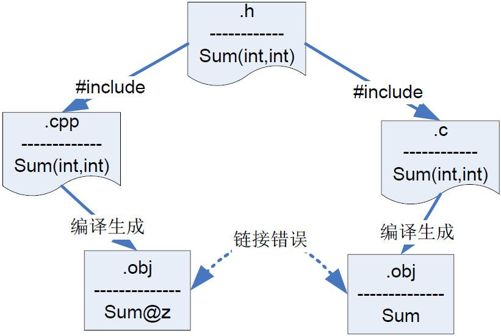
图7-3 name mangle 造成链接错误
例如,编译.cpp 文件的时候,函数sum 在.obj 文件中编译成sum@z;而编译.c 文件的时候,函数sum 在.obj 文件中并没有改变名字。这个时候,当链接器工作的时候,它就不能把sum@z 和sum 链接到一起了。
为了支持.c 和.cpp 混合编程,你需要使用extern “C”关键字。这个关键字主要是告诉编译器不要进行name mangle。这里你需要注意一个问题,C 语言中并不支持extern “C”。如果你把extern “C”放到.h 文件中,如果.c 文件又包含了这个文件,那么就会出现编译错误。所以我们一般把头文件写成程序7-17 的形式,这样的头文件既可以被C 文件包含,又可以被C++文件包含了。
程序7-17 应用于.c 和.cpp 文件的通用的头文件格式
ifdef __cplusplus
extern "C" {
endif
Sum(int,int);
ifdef __cplusplus
}
endif
使用 extern “C”说起来比较复杂,有很多种不同的应用场景和上下文。但是具体应用的时候,你只需要遵守2 个基本的原则就可以了。
1)在C 语言的源文件.c 中不使用extern “C”关键字。在C++语言的.cpp 文件中也没必要使用extern “C”关键字。
2)在C 语言和C++语言混合编程的一个项目中,无论是C++语言中要使用C 语言中定义的函数Sum,还是C 语言中要使用C++语言中定义的函数Sum,都使用程序7-17 所描述的头文件对函数Sum 进行声明。
extern “C”只对函数有作用,对C++中的类没有任何作用。你可以从更笨的角度想一下,就算你通过extern “C”来避免C++对类的名字进行name mangle,C++中的类在C 语言中也用不了,C 语言不是面向对象的语言,它根本不认识class 这个东西。
学习完本章,你应该知道常用的预处理指令,哪怕你记不住它们准确的名字,你也应该记住它们通常都以#开头,这点要求不过分吧?预处理指令中用于文件包含的命令最常见,任何一个C 语言程序都会用到,那就是#include<stdio.h>,其次是条件编译用法,也比较常用。#define 命令尽量少用。
main 函数部分你需要了解命令行参数的具体含义,以及如何灵活地解析命令行参数。不过这部分内容有点学术,毕竟,Linux 下才会频繁用到命令行参数的解析,不过人家有getopt 函数这个利器啊。
编译和链接过程中,你要明白编译器的两个特点:编译器只需要认识某个变量或函数,而且编译器执行健忘的“单元编译”。明白这两个特点,才能更好的理解C 语言中的很多语法现象。
本章最核心的一个概念就是如何区分声明一个不分配内存的变量(函数)和定义一个分配内存的变量(函数)。明白了这种区别,你才能明白为什么只能在头文件中声明一个不分配内存的变量(函数)。这是因为,如果你在头文件中定义了变量,就分配了一块内存,当头文件再次被包含的时候,变量被再次定义,并分配了另一块内存。这个时候你让人家链接器就有点抓狂了,我该链接哪块内存呢?
不是说可以通过条件编译避免重复包含头文件吗?避免重复包含头文件的本意并不是为了避免重复定义,而只是为了提高编译器的效率。避免重复包含头文件只在编译一个.c 文件的时候有效。编译器执行单元编译,所以在编译下一个.c 文件的时候,不能避免重复包含上一个.c 文件中包含过的头文件,因此你最好乖乖地、只把不分配内存的声明语句放到头文件中,这样做才是最保险的。
