关于指针,有一些传统的错误认识,其中之一就是大家都认为指针很难,而且这种认识被一直传承下来。老师吓师兄,师兄吓师弟,师弟吓师妹。师妹早就不怕、不怕了!因为师妹根本就没打算学。
其实,指针的基本概念非常简单,它只是一个保存地址的变量而已!概念虽然不难,但是它的用法很繁琐。尤其是指针和数组的关系,更是需要一点细心。通常,C 语言的精神崇尚一个问题只有一种解决方法。但是指针这部分明显违背了这一方针,这一点在指针和数组部分表现得特别明显。另外,几乎所有的数据结构中都有指针的影子,一些很精巧、高效的算法中也能看到指针。这都会让人误认为指针很难。其实,指针本身并不难,如果能够抛开现象而看到本质,那么就会发现复杂用法的下面,指针的本质非常简单。
指针很灵活,这一点有点像双节棍,使用得好可以威力无比,使用得不好就会伤及自身。李小龙大家都很熟悉。他玩双节棍的时候,总是会发出尖叫,就是因为在开始练的时候,经常会一棍拍到自己的脸上,然后就是尖叫一声。后来虽然使用双节棍很熟练了,但是这种尖叫的习惯已经改不过来了。
同样,指针具有很大的能力,这种能力来源于:指针可以指向内存中任意一个地址,并且可以通过指针解引用修改那个地址上的值。这一点类似于大力水手手中的菠菜。能力大是好事,你可以搬起更大的石头,但是如果那块更大的石头砸在自己的脚上,你就会抱怨这种能力。为了避免把石头砸在自己的脚上,下面我会介绍一些使用指针的常见错误以及避免这些错误的基本方法。好了,朋友们,准备好了吗?下面让我们开始神奇的指针之旅吧!
为了介绍指针,我们需要介绍一点基本的知识,那就是硬盘和内存。我们大家都知道,硬盘保存数据是基于物理的磁性,访问靠机械运动,所以速度比较慢。
内存保存数据是基于电信号,速度比较快,但是所有数据不能长久保存,掉电即失。有的时候你会听到某位同学一声惨叫,响彻环宇,可能就是工作了一天的文件忘记保存在硬盘上,恰好这个时候,电脑断电或者是Windows 蓝屏了。当然,也不排除被双节棍拍脸上的可能。所以一定要保证经常按Ctrl+s,以便把内存中的数据保存到硬盘上。我个人觉得,这应该是你使用电脑时最常用的一个快捷键。
在几乎所有的C 语言书中,指针的介绍都是以内存和地址开始的,本书也遵循这一惯例。内存的基本单位是字节(byte),每一个字节都有一个独一无二的地址。目前,主流的电脑应该是32 位居多,所以地址位数通常也为32 位。有的教材为了说明简单,内存地址都表示成相对数值较小的10 进制数。但是当我们在电脑上查看内存的时候,内存中的地址都被表示成8 位16 进制数。例如0x0041fa60,就是我电脑上一个合法的内存地址。要形成内存地址都是用16 进制数表示的这样一种惯例,本书后面都使用这一惯例来描述一个内存地址。
为了保存内存中的一个地址值,C 语言需要一种特殊的变量类型,这种变量类型就是指针变量类型。整型变量保存一个整数,字符变量保存一个字符,指针变量保存一个地址。OK,指针讲完了,收工!
怎么样,指针不难吧!基本概念很简单,但是……,唉,果真凡事都怕“但是”两字,但是指针用起来却是非常的灵活。就拿最简单的声明一个指针变量为例,就有一些值得注意的地方。下面我们通过程序10-1 来逐项说明。
首先,指针的定义通常有两种风格,如程序10-1 中第2 行和第3 行所示。那么哪一种风格更好一些呢?我通常采用风格1 的方式。char 是一个基本类型,而p 说明这个一个指针。char 不仅让人感到有点奇怪,有的时候还会造成一种视觉上的误差,如第4 行所示,貌似定义两个指针,但真实的情况确是定义了一个指针p1,外加一个是char 型变量p2。这个时候写成char *p1,p2;的话,更符合实际定义的情况,所以我推荐使用风格1 的方式。
其次需要注意的是,有的同学定义了一个指针以后,就误认为p 保存的是一个内存地址,如程序10-1 中第5 行所示。其实单独的p 表示的是指针指向的数据的值,p 中的是取值(解引用)运算符,与取址运算符&对应。要想表示一个指针变量,直接用p 就可以了。所以第5 行正确的写法应该是p=&a;
程序10-1 指针声明
1 char a = 'a';
2 char p; /style 1*/
3 char p; /style 2*/
4 char p1, p2; /- error */
5 p = &a; / p = &a is right */
6 i*p; /- what is this?*/
7 p**p; /- and then? */
8 p/p; /-My God!/
最后就是要注意星号“”在C 语言中还代表乘法的意思,所以在程序10-1中的第6~8 行,你需要正确地理解每一个星号“”,尤其是最后一行的含义,你可能会猜错答案的。不信你就亲自把这行代码敲进电脑,看一看最终是什么结果。
如果你以为理解了程序10-1 中的第7~8 行,就已经完全理解了指针表达式,那你就错了。《C 和指针》[13]一书中第6 章的“指针表达式”一节,详细地列举出了很多关于指针的表达式,这些表达式有些很常用,有些很学术,有些就是为了找一乐儿。无论如何,理解这些表达式,对你正确地理解和使用指针,都有很大的帮助。例如,你会理解为什么对于指针变量p,p++='c'是合法的,但是(p)++='c'却编译出错。
《C 和指针》第6 章不仅包含指针的表达式的内容,还包含关于内存和地址、值和类型、间接访问或解引用指针等知识的更详细的介绍。同时书中还包含了很多图,可以帮你更形象化地理解指针和指针指向内容之间的关系。我承认,这里我有点偷懒了。关于基础知识的介绍就说这么多,如果还不明白,就去看看《C 和指针》的第6 章。如果要彻底学好指针,除了本书以外,你还需要《C 和指针》这本书。
之所以认为指针很难,我个人觉得有一部分原因是中文的问题。所以在本书中,我先试图把道理阐述清楚,然后在此基础上,介绍这种道理的多种对应的中文描述。本书的原则就是:把自己的道理搞清楚,让别人说去吧!
首先,10.1 节我们介绍过,内存中每个字节(byte)都对应着一个地址(你也可以把地址理解成编号)。在32 位计算机上,地址从0x00000000 到0xFFFFFFFF。所以,如果你的计算机是32 位机,那么它最多支持232 字节内存,也就是4G 内存。某个字节的编号其实就是这个字节的地址,所以地址就是32 位的。如果要保存这个地址,就需要保存一个32 位的二进制数,所以一个地址值就需要占据4 字节的空间。
指针类型变量就是保存地址的。让我们看一个简单的指针类型变量的定义:short ptr。这个定义包含两部分,数据类型short 和星号“”。星号“*”说明ptr 是一指针类型的变量,所以ptr 变量里面只能保存一个地址。只要是地址,就占据4 字节的空间。所以,32 位计算机上,所有的指针类型的变量都占据4 字节空间。
别忘了,指针只是保存地址,有了地址,并不能保证在解析指针的时候正确。下面我们把自己想象成编译器,现在你知道ptr 变量占4 个字节,并且这4 个字节中保存的是一个地址,例如是0x4235FFAC。当我们针对指针ptr 进行取值(解引用)操作时,我们不知道从0x4235FFAC 开始,多少个字节内的数据是有效的,并且该用什么数据类型去理解这些数据。
定义中的short 就是回答编译器这些问题的,它说明指针指向的是一个short 类型。每一个指针在定义的时候,都要规定它指向的数据类型。上面的例子中,有了指向的数据类型short,我们就知道从0x4235FFAC 开始,需要从后取两个字节,并且把这两个字节的数据按照short 类型来翻译,不要按照float 类型或其它字符类型来翻译。所以,指针指向的数据类型在定义指针的时候,也是必不可少的。
综上所述,任何指针类型变量都有两个属性:本身保存的地址和指向变量的类型。指针本身只存储地址,编译器根据指针指向的变量的类型从指针保存的地址向后寻址,指针指向的变量类型不同则寻址范围也不同。比如,int 从指定地址向后寻找4 字节作为变量的存储单元,double 从指定地址向后寻找8 字节作为变量的存储单元。对指针进行算术运算也遵循这一规律,例如,针对short ptr;这个定义,ptr++语句把ptr 的保存的地址值加2;如果对int ptr;这个定义,ptr++语句把ptr 保存的地址值加4。
short *ptr;这个定义,已经在大声地对我们说:“ptr 是一个指向short 类型的指针类型,我是一个指针类型,所以我用4 个字节保存一个地址,我指向一个短整型(short)类型,所以请用short 变量的地址为我赋值”。这么说很啰嗦,一般情况下,我们会说ptr 是一个short 类型指针,或者说ptr 是一个指向short 的指针。当然我们不应该局限于short 类型,为了应对后面我要介绍的更复杂的情况,现在就引入一种更抽象的数据类型——xx 型。
对一个指针变量完整的描述应该是xx 型指针或者是指向xx 型的指针。
在数学上,当我们用字母代替某个具体的数字的时候,一门全新的学科就诞生了,那就是代数。同样,当我们把short 类型换成xx 类型时,我们在指针的认知道路上也迈进了一大步,这一点当以后介绍指针型指针,数组型指针,甚至是函数型指针时,你的体会会更加的明显。
当定义一个指针的时候,如果不对它进行初始化,那么它指向的就是一个不确定的地址。这种情况下,当我们访问这个指针指向的变量的时候,程序可能就会发生问题,如程序10-2 所示。
程序10-2 野指针
1 short p; / 定义一个指针变量 */
2 printf ("%p \n",p);
3 printf("%d",*p) ;
4 *p=5;
运行程序10-2 会产生一个运行时错误,原因是程序试图访问一个非法的内存地址。解决野指针的办法很简单,那就是定义一个指针变量的时候强制带等号。也就是当我们定义一个指针类型的变量的时候,顺手就在后面写上一个等号。但是这样做,如果暂时不知道指针该指向何处,该怎么办呢?很简单,那就让它指向NULL,如short* ptr = NULL;。
就像图10-1 所示,如果你不知道把枪(指针)指向哪里,那就指向地(NULL)。指向其他的地方,样子虽然很酷,但是一看就是新手。

图10-1 新手和老手的区别
指针有一条最简单的真理,那就是:一个xx 型的指针指向一个xx 型的地址。或者你可以说:一个xx 型的指针保存一个xx 型的地址。这是一条放之四海皆准的真理,它非常精简,但是非常有用,真可谓:大道至简,重剑无锋。请大家一定要记住这句话,本书后面会反反复复地重复这句话,为了避免占据过多的篇幅,我把这句话简称为指针真理。
掌握了这个道理,你就可以保证对指针赋予正确的值。
如何取得xx 型的地址呢?最直接的方法就是对xx 型变量使用取地址运算符&来得到地址。除了这个方法,下面列表中还给出了几种其它的方法,可以用来对一个xx 型的指针进行赋值。
• xx 型的地址
o 地址符号o 其他xx 型指针o xx 型数组
• 强制转换成xx 型的地址
o malloc 函数申请的内存o 任何void 类型指针
• 空指针
o NULL
大家可能认为xx 型太抽象,为了说明清楚,程序10-3 中给出一个实例,并把xx 型换成int 型。当然,你可以把xx 型换成任何类型,包括你自定义的struct 类型。
程序10-3 指针赋值
1 int p1,p2;
2 int a = 10;
3 int array[]={1,2,3};
4 p2 = &array[0];
5 p1=&a; / 取地址运算符 /
6 p1=p2+1; / 其他指针 /
7 p1=array; / 数组 /
8 p1=(int )malloc(sizeof(int)); / 强制转换malloc申请的内存 */
9 p1=NULL; / 空指针 /
void 一般用在两种情况下。第一种情况是,如果函数没有返回值或参数,那么应声明为void,不同的编译器会对省略的定义有不同的解释,这种显式的定义明显可以提高程序的平台移植性。例如下面就定义了一个没有传入参数、没有返回值的一个函数void func(void)。如果返回值的类型不用void 指定,有的编译器会默认返回的是一个int 类型,这样就会造成一些潜在的移植错误。
第二种使用void 的情况是声明一个void 类型的指针:void* vp。对于void 类型指针,它只保存一个地址,不包含指向变量的类型信息,所以任何类型的指针都可以直接赋值给它,无需进行强制类型转换,如程序10-4 中第4 行所示。
任何指针内部其实都包含一个地址信息和一个类型(长度)信息。由于void 类型指针只包含地址信息,不包含长度信息,将任何类型的指针赋值给void 类型指针时,类型(长度)长度信息就丢失了。现在你就可以理解为什么对void 类型指针进行算术运算和进行取值操作都是不允许的,如程序10-4 中第5、6 行所示。
程序10-4 void 指针
1 void *vp;
2 int *ip = &i;
3 int k;
4 vp = ip;
5 vp++; / error /
6 k = vp; / error */
7 ip =(int *)vp;
8 ip++; / ok /
9 k = ip; / ok */
与此相反,如果将void 类型指针赋给其他类型的指针,则需要进行强制类型转换,使其包含类型(长度)信息,如程序10-4 中第7 行所示。
void 类型指针一般用在函数的参数和返回值中,以达到泛型的目的,目的就是使一个函数能够处理更多的类型。如程序10-5 所示,malloc 返回的就是一个void 类型指针,同理,memcpy 和memset 两个函数也使用void 类型指针来达到泛型的目的。这样,任何类型的指针都可以传入memcpy 和memset 中,这也真实地体现了内存操作函数的意义,因为它操作的对象仅仅是一片内存,并不关心这片内存中保存的是什么类型。
程序10-5 内存操作函数
void * malloc ( size_t size );
void memcpy(void dest, const void *src, size_t len);
void memset ( void buffer, int c, size_t num );
void 类型指针虽然可以用来达到泛型的目的,但是它也包含一些风险,这种风险主要是丢失了类型的信息。如果有类型信息,编译器可以帮助我们进行类型匹配的检查,如程序10-6 中第一段程序所示。因为你想把一个int 型的指针赋值给一个float 类型,类型并不匹配,所以编译器会编译失败。
而在第二段程序中,当你把int 型地址复制给void 类型指针时,类型信息丢失了。在函数foo2 内部,当你把void 类型强制转换成float 类型的指针时,编译器并不进行任何类型匹配的检查,所以你的程序顺利地经过了编译。
很显然,如果你运行第二段程序,使用pf 指针的时候,它指向的地址并不包含你期望的一个浮点数,所以就会产生一些非常奇怪的错误。这种运行时的错误也是非常难以查找和排除的。
程序10-6 void 类型指针的潜在风险
/第一段程序/
void foo1(int* pi){
float pf = pi /编译出错*/
}
int i = 5;
foo1(&i);
/第二段程序/
void foo2(void* pi){
float pf = (float)pi /编译通过/
}
int i= 5;
foo2(&i)
虽然翻译成中文都是“空”的意思,但是与void 类型指针不同,NULL 不是指针的类型,而是用来描述指针的值。一般情况下,NULL 被定义为0。如果定义int *p=NULL;的话,就意味着p 没有指向任何地址。也就是说,它根本就没指向一个具体可用的地址。让p 没有指向任何地址是安全的。NULL 对暂时不用的指针变量赋初值,以避免产生野指针的问题。关于野指针的问题我们已经介绍过了。NULL 有时也用在返回指针的一些函数中,如果返回的是NULL,那么就代表函数调用并没有成功,如fopen 函数以及fgets 函数等。
为了说明这个比较难缠的问题,我参考了本书中所列参考文献中的所有C 语言的书籍,所以本节中可能会有一些英文,我并没有对这些英文进行翻译,一是因为这些英文已经很简单了,如果你的第一外语是英文,你一定能看明白。第二个原因就是,我怕我的翻译不够准确,没有把原文当中的意思非常清楚地表达出来。翻译讲究“信,达,雅”,以前我一直不理解什么是“雅”,直到有一天,当我看到“Open books, not legs”被翻译成了“白驹过隙早开卷,莫解罗裳床帐间”时才算明白了“雅”的真谛。从此以后,我就再也不敢轻易翻译别人的东西了。
本节讨论的两个主角,一个是指针,刚刚介绍过;一个是数组,第9 章介绍过。两位主角都已经到齐,现在我们正式开戏。可能大家对数组有点忘记了,所以首先复习一下数组。语句int a[5]定义了一个数组,然后我们可以通过下标来访问其中的一个元素,如a[1]。数组变量a 本身代表的是什么呢?代表的是整个数组吗?不对!其实数组变量a 代表的是一个地址,也就是数组中第1 个元素的地址,等价于&a[0]。为此,我们再引入一个真理:xx 型数组变量代表一个xx 型地址,我们把这个真理叫做数组真理。大家也要记住数组真理的内容,因为后面也要反复地提到。
好了,现在已经有了两个真理了,分别为指针真理和数组真理,我们已经有了两把厉斧,下面就来综合利用这两把厉斧开山劈路。
分析一下为什么一个int型的指针int* p 能指向一个int 型的数组int a[2]。首先,根据数组真理,int 型的数组int a[2]中,数组变量a 就是一个int 型地址;再根据指针真理,int 型指针p 可以指向一个int 型地址,综上,指针p 可以指向数组变量a,即p = a;。
你可能觉得我有点啰嗦,有点小题大做,不过你要养成使用这两个真理分析问题的好习惯。我们在10.6 节中会遇到比较复杂的情况,那时这两个真理的威力会更好地发挥出来,让我们拭目以待。
如果指针P 指向了数组变量a,那么通过数组的下标访问数组中的元素,和通过指针加偏移量来访问数组中的元素是等价的,他们之间完全可以进行互换。如程序10-7 中从第3~4 行所示,这四种方法访问的是数组中同一个元素,而且访问方式都是完全合法的。另外,在函数定义的时候,函数的形参可以定位为一个指针func(int p),或者定义为一个数组类型func(int a[]),这两者也是等价的。当调用func(int p)函数的时候,传给函数的实参却可以是一个数组。如程序10-7 的第9行所示。从上面的例子中可以看出,xx 型指针和xx 型数组在一定的上下文条件下是等价的。
程序10-7 指针和数组的相同之处
1 int a[5];
2 int *p = a;
3 a[1]==(a+1); / 返回逻辑真 */
4 (p+1)==p[1]; / 返回逻辑真 */
5 func(int p) / 函数定义*/
6 {
7 p[1] = 10;
8 }
9 func(a); / 函数调用 /
以上这些等价的写法造成了一个关于指针和数组关系的经典错误认识,那就是“指针和数组是一样的”。其实就算你对C 语言一无所知,也会马上知道这句话是错误的。如果它们真的是一样的,C 语言中没必要同时保留数组和指针这两个东西。根据奥卡姆剃刀原理,这个世界上没有用的东西,早被这把锋利的剃刀剃掉了。如果没有剃掉,那么这个东西一定是有用的。哲学是一切科学的根源,不服不行啊!
如果指针和数组是不同的,为什么它们有如此等价的写法呢?这到底是怎么一回事?这是因为《C Programming Language》section 5.3 中说:“In short, an array-and-index expression is equivalent to one written as a pointer and offset. In evaluating a[i], C converts it to *(a+i) immediately”。
也就是说,当a[i]用在一个表达式中的时候,编译器自动地将其转换为指针加偏移量*(a+i)的形式。所以a[i]这种书写方式,只是为了给程序员书写源代码的时候准备的。经过编译以后,是不存在a[i]这种下标访问这种方式的。编译器会自动地把下标操作转换成指针(地址)加偏移量操作。
当处理指针算数运算的时候,其实也是地址加偏移量这种操作。所以说程序10-7 中从第3~4 行的四种写法,经过编译器处理后,其实产生的是相同的机器代码。至于你选择那四种写法,只是你的编程风格而已,这回你明白了吧!同理,当数组类型被用于声明函数形参的时候,如函数声明func(int a[]),编译器自动将其转换为func(int a)。也就是说, 函数的形参就是一个指针,func(int a[])这种写法只是为新手准备的,新手一般不敢把一个数组传递给函数func(int a),一定要传给函数func(int a[])心里才踏实些:)。
一个有趣的事实是在C 语言中,数组变量和下标可以互换,如a[3]和3[a]都会成功经过编译,最终运行的结果也是一致的。上一段我们说过数组下标被编译器转换成地址加偏移量,所以a[3]被转化为(a+3)。根据加法交换律,只要一个是指针,另一个是整型就行,而无关顺序。所以(a+3)可以写成(3+a),而(3+a)最终与3[a]一致。有了上面这些知识,下面试一个更变态的,猜猜5["abcdef"]等于几?这种语句就是为了玩玩而已,千万不要在实际的代码中写出这么怪异的语句哦。
既然数组下标能写成地址加偏移量,那么哪种写法更好一些呢?我的建议如下。
如果你定义的是一个数组变量int a[5];,那么就用下标方式a[1]访问。如果你定义了一个指针并指向了数组的首地址int pa = a;,那么就用指针方式(pa+1)访问。有些同学会说,不是会统一编译成地址加偏移量的方式吗,那么还不如直接写成*(a+1),这样不是能更快吗?你忘了,无论你怎么写,生成的都是一样的机器码,所以答案是一样快,你唯一收获的就是,你的代码对于其它的程序员来说,有点晦涩了。
在优化和清晰之间,我会更倾向于后者,尤其是自以为是的优化,关于优化的问题,可以参考本书的第14 章。至于func(int a)和func(int a[])哪种好,上段我已经给出答案了,func(int a[])是给新手准备的。如果你不信,可以去看看字符串处理函数的官方定义,例如,求字符串长度的函数定义为strlen(const char str),并没有定义为strlen(const char str[])!这为将来我们学习提供了一个很好的线索,当你日后有相关的疑问的时候,先查阅一下标准库,看它是怎么做的。
请注意,千万不要因为存在上面的转换,就把数组和指针看作是相同的。事实上,编译器并不是一看到数组变量int a[5]就将其转化为指针常量。例如,当sizeof 或者取地址运算符&作用于数组变量a 的时候,a 并不转化为指针常量。这也是sizeof(a)会返回整个数组的长度、而不是一个指针的长度的原因。
另外,程序10-8 中还演示了一些指针和数组的不同之处,主要有以下几点:
• 你不能改变数组a 的地址,所以a++;这个语句是不允许的。但是pa++;却没有问题。因为指针可以改变指向,如程序10-8 中第4 行所示。
• 当指针pa 指向一个单独的变量b 的时候,指针的行为就和数组a 没有一点相似的地方了。例如,你再也不应该写出pa[1]这样的语句,否则就会去访问紧挨着变量b 的一块内存,谁也不能确定那块内存的内容和意义,所以这种行为是非常危险的。
• 如果你在一个文件中定义了int a[5];,在另外的文件中却声明为extern 第10 章 指针
int *a;,这样也是不对的。
程序10-8 指针和数组的不同之处
1 int a[5];
2 int b = 10;
3 int *pa = a;
4 pa++; / 正确 /
5 pa = &b; / 指针可以改变指向 /
6 a++; / 错误 /
7 extern int a; / 另外一个文件中定义 */
关于字符指针和字符数组的不同,更是复杂并且微妙,我们放到10.10 节中再详细介绍。
总之,这里你只要清楚,数组和指针是完全不同的,就可以了!最后让我们用一句话总结吧。《C Programming FAQs》Question 6.3 中说:“pointer arithmetic and array indexing are equivalent in C, pointers and arrays are different”。
现在我们有了两个关键词,分别为指针和数组,下面把这两个关键词放到一张二维表里,如表10-1 所示。
表10-1 指针和数组二维表

表中通过“指针”和“数组”两个关键词的排列组合,产生了4 个不同的概念,它们分别是“指针指针”、“指针数组”、“数组指针”以及“数组数组”。有趣的是,这四个概念在C 语言中都真实存在,其中“指针指针”在C 语言中通常叫作指向指针的指针,而数组数组通常叫作二维数组。
首先以最简单的类型int 来说明这四个概念如何在C 语言中定义。int *pp 定义了一个指向指针的指针(指针指针),int pa[5]定义了一个指针数组,int (*ap)[5]定义了一个数组指针,int aa[2][3]定义了一个数组数组,也就是一个二维数组,如表10-2 所示。
表10-2 四个概念在C 语言中的真实定义

怎么样,是不是有点头晕了?先别晕菜,这四个概念还有一定的联系呢!下面我们就说说它们之间存在的联系。
我刚开始学习C 语言的时候,一直固执地认为,既然指针可以指向一维数组,那么指向指针的指针就可以指向二维数组,这个错误伴随着我很长时间。如果我犯了这个错误,我猜你也会犯。下面我们根据指针真理和数组真理,分析一下我到底错在哪里。首先,让我们重新复习一下这两个真理。
• 指针真理:一个xx 型指针应该指向一个xx 型地址。
• 数组真理:xx 型数组变量就是一个xx 型地址。
指向指针的指针就是指针型指针。二维数组int array[2][3]其实就是一维数组,一维数组中每一个元素本身又是一个一维int 数组型变量,本例中,我们暂时把一维int 数组型定义为int[3]。这个时候,变量array 不再是一个int 型的地址,而是一个数组型地址。那么根据指针真理,一个指针型指针是不能指向一个数组型地址的。
如果我们要遵守指针真理,可以把上面那一句错误的话变为两句正确的话。
1)一个指针型指针指向一个指针型地址。
2)一个数组型指针指向一个数组型地址。
让我们继续使用数组真理:xx 型数组变量就是一个xx 型地址。把xx 替换一下,可以得到两句话。
1)指针型数组变量就是一个指针型地址。
2)数组型数组(二维数组)变量就是一个数组型地址。
综合应用上面的这四句话,我们就可以得到下面的结论:
一个指针型指针可以指向一个指针型数组变量(指针数组),也就是说,在表10-2中的第1 行,pp=pa 成立;一个数组型指针可以指向一个数组型数组(二维数组)。也就是说,在表10-2 中的第2 行,ap=aa 成立;
有点绕口是吗?没关系,帮人帮到底,送佛送到西,我再画一个表,来把这个问题说清楚。
表10-3 指针变量可以指向对应数组变量

根据在表10-3 中的位置所对应的行标题和列标题,char p 可以被表述成char 类型指针变量,char a[5] 可以被表述成char 类型数组变量,由于它们都是char 类型,所以我们可以将a 赋值给p,即p= a;,第一行分析完毕。现在分析第二行,int **pp 可以被表述成指针类型指针变量,int pa[5]可以被表述成指针类型数组变量,由于它们都是指针类型,所以可以pp = pa;;以此类推,可以ap=aa;。
有些同学可能对int *pp 和int (ap)[5]这两个变量还不太明白,没关系,下面我们再详细介绍一下这个两个概念,看看一般情况下,它们有什么具体的用处。
首先分析一下,什么叫指向指针的指针?也就是指针型的指针。指针里面不就是保存的地址吗?没错,但是别忘了,每个变量,无论它保存的是什么,它本身也都有地址,如图10-2 所示。
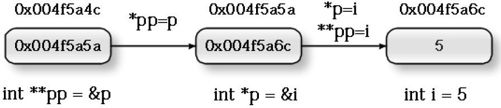
图10-2 指向指针的指针
图10-2 中,指针变量p 保存的是变量i 的地址0x004f5a6c,但是p 本身的地址是0x004f5a5a。指针变量pp 中保存的是指针变量p 的地址0x004f5a5a。为了保存指针型变量p 的地址,我们必须定义一个指针型指针,那就是int **pp;。
对于一个指针数组,数组中保存的都是指针,数组名就是指针型地址。为了保存这种指针型地址,根据指针真理,我们自然应该用指针型指针了,如程序10-9所示。
程序10-9 指针型指针和指针数组
char *a[]={"zhao","yan","is","a","good","teacher",NULL};
char **p;
for(p=a;*p!=NULL;p++)
{
printf("%s\n",*p);
}
程序10-9 也演示了指针型指针和指针数组之间紧密的联系。很显然,本程序不是来源于实际项目,而是我创造的,不过其中还是反映了指针数组常用的场景,那就是用来模拟一个锯齿形状的二维数组。保存多个长度不相等的字符串正是这种锯齿形状二维数组的典型应用。通常,把数组中最后一个指针设为NULL 可以标记数组的末尾状态。
另外一个说明两者关系的例子来源于main 函数,事实上,不同的教材有两种不同的main 函数接口定义,如程序10-10 所示。你现在应该明白它们其实是一样的。
程序10-10 main 函数接口定义
int main(int argc, char *argv[]);
int main(int argc, char **argv);
使用指针数组的一个优点就在于对多个字符串的排序,排序的过程并不需要移动真实的字符串,而只需要改变指针的指向,这是一种非常高效的办法,无论字符串有多长,这都是一个常数时间。代码片段如程序10-11 所示,排序后的结果如图10-3所示。
程序10-11 字符串排序指针数组实现
char *temp = NULL;
char *ptr[N] = {"Pascal", "Basic","Fortran", "Java", "Visual C"};
if(strcmp(ptr[j],ptr[i])<0){
temp = ptr[i];
ptr[i] = ptr[j];
ptr[j] = ptr[i];
}
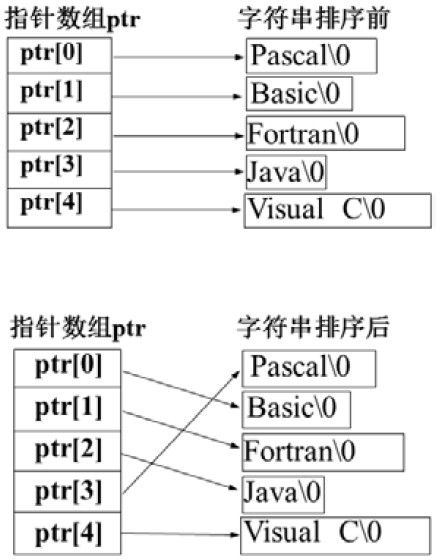
图10-3 字符串排序指针数组实现的结果
如果换成二维数组的方式来实现一个字符串的排序,效率明显要低很多,因为这里涉及到利用strcpy 函数来复制和移动整个字符串。它执行的时间不再是常数时间,而是和字符串的长度成正比,如果字符串很长,这种方法的效率更低。代码片段如程序10-12 所示,排序后的结果如图10-4 所示。
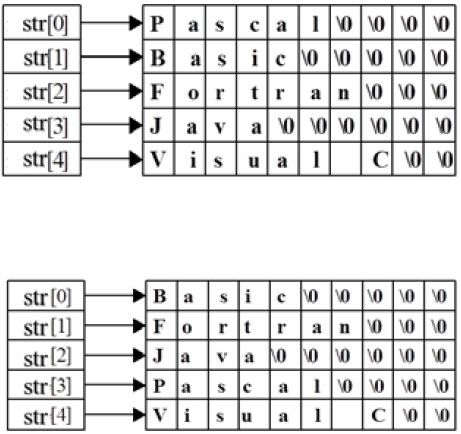
图10-4 字符串排序二维数组实现的结果
程序10-12 字符串排序的二维数组实现
char temp[10];
char str[][10] = {"Pascal", "Basic","Fortran", "Java", "Visual C"};
if(strcmp(str[j],str[i])<0)
{
strcpy(temp ,str[i]);
strcpy(str[i],str[j]);
strcpy(str[j] ,str[i]);
}
上面我们已经说过,必须用一个数组型的指针指向一个二维数组。道理已经很清楚了,但是还有一个问题,如何定义一个数组型的指针?这个写法就有点讲究了。以int 类型为例,我们不能写成int p[3],这是因为“[]”的优先级比“”号高,所以int p[3]会被编译器解释为int (p[3])。这是一个数组,数组中每一个元素是一个指针,这其实就是上面介绍过的指针数组,而不是我们要定义的数组指针。为了解决这个问题,我们用括号改变它的优先级,写成int (p)[3]。这时(p) 是一个指针,指针指向的类型为int[3],这是一个一维数组型变量,符合我们的定义。
表10-4 中给出了一维数组和二维数组中,数组变量和指针变量的关系的一个对照。通过对照可以帮助我们更好的理解数组指针这个概念。表中int a[2]和int array[2][3]分别为一维数组和二维数组。
表10-4 数组指针的实例

有了int (*p)[3]=array[2][3]的写法,我们对二维数组也可以利用指针来进行访问了,如下面所示。
• p 即 &array[0]
o 代表二维数组的首地址,第0 行的地址o 一维int 数组型变量int[]的地址
• p+i 即 &array[i]
o 代表第i 行的地址o 一维int 数组型变量int[]的地址
• *(p+i) 即 array[i]
o 代表第i 行第0 列的地址o 一维int 数组型int[]变量,等价于int 类型的地址
• *(p+i)+j 即 &(array[i][j])
o 代表第i 行第j 列的地址o int 类型的地址
• ((p+i)+j ) 即 array[i][j]
o 代表第i 行第j 列的元素o int 类型的值
看到这里,如果你感觉有点抽象,可以参考《C 和指针》这本书,其中数组一章也有与此类似的内容,不过它对应的每种写法都有一个具体的图来帮助你加深理解。这里我就不把这些图复制过来了。坦白地说,这一章的理论味道要远远大于它的工程应用,它可以很好地帮你理解指针。如果你理解了这部分内容,你理解指向函数的指针int (*p)()就会完全没有问题。
但在实际的项目中,我自己都很少使用指针的形式访问二维数组,还是a[i][j]的方式更符合人的习惯,虽然计算机内部使用的还是指针的形式。如果你能看懂,最好!如果你实在看不懂,也不要着急,再多读几遍,自己编个程序验证一下。实话对你说,我也不是一上来就懂的。不过,现在你们比我幸运。那时候,没有人告诉我,理解这个问题的关键就在于一个xx 型的指针指向一个xx 型地址这么一句看似简单的话上。而现在,你们已经知道了关键点所在。产生问题,并被问题困扰是非常有价值的,只有这样,经过自己一段时间的思考和理解,那堵墙才会在你面前轰然倒下。
一个利用C 语言编写的程序,当它开始运行之前,需要装入内存。它在内存中的映像如图10-5 所示,主要分为:堆,栈,静态存储区,常量存储区,以及代码段。
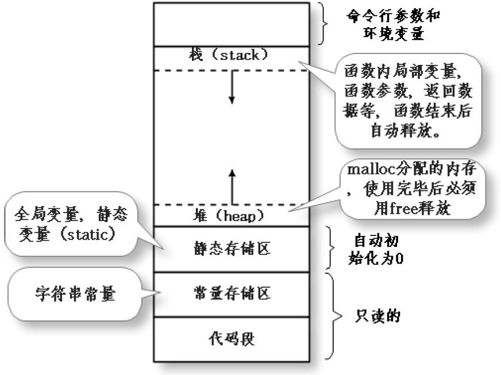
图10-5 可执行程序内存映像
从图10-5 中可以看出,C 语言的内存映像中与变量有关的主要有三种内存区域,分别为静态存储区,栈和堆。静态存储区在程序编译的时候就已经分配好,在程序的整个运行期间都存在,全局变量、static 变量都保存在这里。
在执行函数时,函数内部非静态局部变量、函数的参数和返回值等在栈上创建,函数执行结束时自动释放这些存储单元,其操作方式类似于数据结构中的栈(后进先出LIFO)。
堆是用来进行动态内存分配的。程序在运行的时候用malloc 从堆上申请一块内存,使用完毕后用free 释放这块内存。动态内存的生存期由我们决定,使用非常灵活,但往往问题也最多。“内存是C 程序员永远的痛”,这一句话说得完全没有错。10.8节我们会介绍动态内存分配的相关问题。
从图10-5 中还可以看出,栈和堆是对向增长的,它们的容量并不是无限的,而是一定的。当使用递归函数的时候,如果调用的层数太深,栈会不断地增长,最后就会造成栈溢出(stack overflow)的错误。一个最简单的栈溢出错误可以通过程序10-13 来产生。这段程序在我的电脑上运行不超过一分钟,就会产生一个“栈溢出”的异常而最终终止。
程序10-13 最简单的递归函数
int main (){
main();
}
程序中的变量,根据不同的定义位置,被分配到不同的内存区域中,具体的例子可以参考程序10-14。值得注意的是,你要区分指针变量本身和指针变量指向的内存之间的区别。如果一个指针变量定义在一个函数内部,那么这个指针变量本身保存在栈上。但是指针变量指向的内存却可以分布在不同的区域, 如char p =(char)malloc(1)中,p 指向的内存在堆上,而char pstr = “hello”中,pstr 指向的内存在常量存储区。
程序10-14 程序的具体内存印象
int a = 4 / 全局变量,保存在静态存储区 /
static float f = 2.0f; / 静态变量,保存在静态存储区 /
int foo(int i){
int m; / 局部变量m,保存在栈上 /
i++; / 函数实参i,保存在栈上 /
}
int main(){
int p,k = 5; / 局部变量k和p,保存在栈上 */
/ hello字符串保存在常量存储区,pstr保存在栈上 /
char* pstr="hello";
/ hello字符串以及变量astr,保存在栈上 /
char astr[10]="hello";
/ 变量p,保存在栈上, malloc申请到的内存在堆上。 /
char p=(char*) malloc(1);
/ 释放在堆上申请的内存 /
free(p);
}
为什么需要从堆上申请动态的内存?这个问题可以通过复制字符串的程序10-15说起。
程序10-15 拷贝字符串
/ 方法一 /
char *t;
strcpy(t, s); / 错误 /
/ 方法二 /
char t[100];
strcpy(t, s); / 可能错误 /
/ 方法三 /
char t = (char)malloc(strlen(s)+1);
strcpy(t, s);
假设我们有一个字符串s,我们想把它复制给t。这个时候,方法一绝对是错误的,因为指针t 根本没有指向一块区域以容纳拷贝过来的字符串。第二种方法也有风险,如果字符串s 很短,就造成了内存的浪费;如果字符串很长,那么就会数组越界,造成“住到邻居家”这种结果的发生。第三种方法是最好的,不仅正确,而且没有浪费一个字节。这就是动态分配内存的一个典型例子。使用动态分配的原因就在于字符串s 的长度,我们只能在运行的时候才确切地知道。
这只是一个简单的例子。事实上,动态内存分配用得非常广泛,包括各种数据结构,如链表、树、图以及后面我们要介绍的动态数组等等。
C 语言中有两个函数可以从堆中申请内存,分别为malloc 和calloc。这两个函数有两点区别,第一点就是函数的参数不一样,分别如程序10-16 的第1 行和第2行所示。
程序10-16 malloc 和calloc 的区别
1 void *malloc(size_t size);
2 void *calloc(size_t numElements,size_t sizeOfElement);
3 p = malloc(m * n);
4 memset(p, 0, m * n);
5 int p = (int) malloc(sizeof(int)*10);
单从这两个函数的定义上看,有些同学会有一种错误的认识,那就是malloc 用于申请一个单独的内存,而calloc 用于申请一块连续的内存。其实这个认识有点肤浅。我们可以用malloc(sizeof(int)*10)来申请10 个连续的int 内存单元,也可以用calloc(sizeof(int),1)来申请一个独立的int 内存单元。所以说参数的不同并不是这两个函数的主要区别。经过简单地换算,这两个参数完全是通用的。
这两个函数真正的不同在于它们申请完内存后的动作。函数calloc 会将所分配的内存空间中的每一位都初始化为零,也就是说,如果你是为字符类型或整数类型的元素分配内存,那么这些元素将保证会被初始化为0;如果你是为指针类型的元素分配内存,那么这些元素通常会被初始化为空指针NULL;如果你为实型数据分配内存,则这些元素会被初始化为浮点型的零。从这个意义来说,calloc(m,n)等价于程序10-16 中的第3~4 行。
这里需要注意一下的就是,无论是malloc 函数,还是calloc 函数,分配的时候都没有数据类型的概念,分配的基本单位就是字节。如果你想分配10 个int 类型的数,不能写成malloc(10),而应该写成malloc(sizeof(int)*10)。
从程序10-16 中,我们可以看到两个函数都返回一个void 类型的指针,void 类型明显有泛型的概念,用户需要把void 类型强制转换成需要的类型,如程序10-16 第5 行所示。
很显然,如果分配相同规模的内存,那么malloc 要比calloc 快些,因为它不需要把所分配的内存都填充上零。同时,使用calloc 比调用malloc 外加memset 要快。具体的问题和解释可以参考stackoverflow 论坛。最终使用哪个函数来分配内存,需要根据你的问题来灵活地决定。不要过分信任和依赖calloc 函数的填充零来完成初始化,对变量的手工初始化也许有些麻烦,但是可以避免很多移植性的问题。
说到现在,我相信大家一定有点烦了,倒不是我唧唧歪歪,而是内存分配函数的用法确实有点琐碎。最后允许我说一句,在使用malloc 和calloc 函数前,一定要包含头文件<stdlib.h>。如果不包含<stdlib.h>,有些编译器会默认认为malloc 函数返回一个int 类型的值,这不会引起编译错误,但会引起后续的运行错误,这种错误非常难以发现而且危害极大。
在读这一节之前,你应该先到网上去看看realloc 函数的说明文档,为了节省本文的篇幅,我不想把很多内容直接复制到这里。如果看完了,我们接着说。
首先,realloc 函数的原型为void realloc ( void ptr, size_t size);,在它的说明文档,你会发现其中有这样一句话,如果ptr 为NULL,那么它的作用与malloc 的用处一样,分配size 这么大的内存,然后把这块内存的首地址通过指针返回,那么接下来的问题就是,为什么要这么定义呢?
一般情况下,realloc 通常用在动态递增的内存分配上,如程序10-17 所示。程序演示了如何从文件中读入一行,而这一行在理论上可以是任意长度。当申请的内存长度容纳不下的时候,程序会利用realloc 这个函数再次申请一个长度为原始内存长度2 倍的一块内存,以容纳这一行中没有被读入的部分。在程序10-17 第2 行,我们看到了oldbuf 初始值为NULL,这样我们就可以在while 循环中统一地使用realloc 这个函数了,这就为我们的编程带来了很大的便利。
程序10-17 realloc 函数演示
1 char getline(FILE fp){
2 char newbuf, oldbuf = NULL;
3 size_t nchread = 0, nchmax = 100;
4 int c;
5 while((c = getc(fp)) != EOF) {
6 if(nchread >= nchmax) {
7 nchmax *=2;
8 newbuf = realloc(oldbuf, nchmax + 1);
9 if(newbuf == NULL) {
10 free(oldbuf);
11 return NULL;
12 }
13 oldbuf = newbuf;
14 }
15 if(c == '\n')
16 break;
17 oldbuf[nchread++] = c;
18 }
19 return oldbuf;
20 }
程序10-17 中,值得我们关注的还有以下几点。
• realloc 第一个参数所指向的指针,或者是NULL,或者是malloc、calloc 或者是realloc 三个函数返回的指针,而不是任何一个指针都行的。这是因为,函数realloc 中的re 代表的是重复,如果没有第一次,哪来的重复呢?你说对不?
• realloc 的返回值一般都用一个临时指针变量来保存,不推荐使用oldbuf =realloc(oldbuf,…)。这是因为一旦realloc 调用失败, 将返回一个NULL 给oldbuf,这个时候原始oldbuf 指向的内存并没有被free,但是因为oldbuf 已经变成了NULL,所以原始oldbuf 指向的内存丢失了,这样就发生了内存泄漏。所以一个更好的办法就是先使用一个临时指针变量,如果realloc 失败,调用程序10-17 第9~12 行free 掉oldbuf 指向的内存;如果realloc 成功,那么就oldbuf = newbuf;,如程序10-17 的第13 行所表示。
• 程序的第8 行,调用realloc 以后,newbuf 也许和oldbuf 相等,也许不相等。这取决于oldbuf 指向的内存后面是否还有足够的空闲内存来容纳nchmax + 1 这么多字节。如果有足够的地方,很简单,直接把oldbuf 指向的那块内存进行扩展,原始的值不变,扩展部分的值是随机的。这个时候,返回的newbuf 和oldbuf 指向同一地址。如果没有足够的地方,那么realloc 会找到一个能容纳nchmax + 1 字节的内存块,并把oldbuf 指向的内容复制到newbuf 中,同时把oldbuf 那块内存free 掉。这个时候,返回的newbuf 和oldbuf 是不相等的。
即使在函数内部,用malloc 申请的内存,也不会伴随着函数的退出而释放,必须用free 来显式地释放,否则会在程序运行期间一直在堆中存在。如果你运行程序10-18,由于内存被逐步地占用而不释放,你会发现你的电脑会越来越慢,直到最后死机。
程序10-18 内存泄漏演示
include<stdio.h>
int main(){
while(1){
malloc(sizeof(int));
}
}
所以你一定要养成一个好习惯,在写malloc 或者calloc 函数的时候,同时就写一个配对的free 函数,就像写一个左大括号“{”的同时就加上一个右大括号“}”一样。剩下的问题就是把free 函数放到哪里的问题了。
关于free 函数,有一些地方需要注意:
• free 后的内存并不返还给操作系统,而是对同一程序中未来的malloc 函数的调用可用。
• free 函数中的指针必须是malloc 或者calloc、realloc 函数返回的指针。
• C 语言中函数遵循的单向值传递特性使得free 函数并不能改变传入的指针的值。
我再重复一遍,free 函数并不能修改传入的指针的值,所以在程序10-19 的第3行,就算调用free(p);函数以后,p 的值依然没有改变,它依然保存着同样的一个地址值。这样就存在p 被再次使用或者再次free 的可能。使用被释放的内存或者重复释放内存都会引发令人讨厌的运行错误。
一个更好的使用free 函数的方法如程序10-19 第4 到第7 行所示。当free 一块内存后,同时就把这个指针指向了NULL,这样就没有被使用或者重复释放的可能了。
程序10-19 free 函数的使用
1 char p = (char ) malloc(10);
2 ……
3 free(p);
4 if(p!=NULL){ / 更好的与free配套调用的代码片段 /
5 free(p);
6 p = NULL;
7 }
除了内存分配和释放函数以外,还有一些内存操作函数,主要包括内存拷贝函数memcpy,内存移动函数memmove,内存设置函数memset,内存比较函数memcmp 和内存查找函数memchr。这些函数从名字上基本上就能猜出是什么功能了,所以我也不详细地解释了。具体使用前,你可以查阅每个函数的参考文档。
值得一提的是memcpy 和memmove 两个函数,它们的定义如程序10-20 第1 行和第2 行所示,可以看出它们有相同的参数。这两个函数都是从src 所指向的地址中复制count 个字符到dest 指向的地址中去。它们之间一个最大的区别在于,memmove 函数可以用在源内存区和目标内存区有重叠的情况。重叠是指如果dest 指向了src 字符串的内容,这个时候就存在dest 指向的空间与src 指向的空间发生重叠的问题,如图10-6 所示。
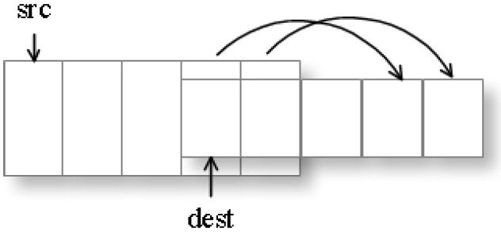
图10-6 memmove 的移动策略
发生重叠时memmove 依然可以正确地复制到dest 中去,而memcpy 则执行非法操作。其实这个你轻易都能想得出来,复制要求同时保留源数据,如果源数据块和目标数据块有重叠,怎么保证源数据块不被改变呢?
memmove 是如何解决重叠问题的呢?程序10-20 中给出了一个具体的实现。memmove 函数处理这种重叠的技巧非常简单,当dest 指向了src 字符串的内容后,从src 指向的数组的尾巴开始复制每个字符,而不是从头开始复制。这样就可以有效处理两个字符串重叠的问题了。
程序10-20 memcpy 和memmove 函数的区别
void memcpy(void dest,void* src, size_t count);
void memmove(void dest,void* src, size_t count);
void memmove(void dest, void const *src, size_t n){
register char *dp = dest;
register char const *sp = src;
if(dp < sp) {
while(n— > 0)
dp++ = sp++;
} else {
dp += n;
sp += n;
while(n— > 0)
—dp = —sp;
}
return dest;
}
这种从尾到头遍历的方法有点违背我们日常处理数据的习惯,但是在处理实际问题的时候还是很常用的,比如,如果你要向一个数组的某个位置中插入一个元素,就必须把插入位置后的元素依次后移,想想怎么办?这种在数组中插入元素的方法在插入排序中就用得到。
malloc 函数的具体实现非常的复杂,并且与系统相关,远远超过了本书的范围。这里只要知道一点,反复地调用malloc 和free 函数,堆将变得很“碎”。在一个很“碎”的堆上调用malloc 函数效率很低,这是因为它需要花费很长的一段时间来找到一块合适的地方。
如果你的应用程序需要频繁使用多个较少的内存空间,更好的办法是预先分配一块大内存,在需要新的小的内存时就从预先分配的大内存中获取,等全部使用完毕后再一次性释放这块大内存,避免频繁地分配和释放小块内存,同时减少内存碎片。这种策略下建立的大块内存通常叫作“内存池”。
数组的长度是编译时需要的一个常量,也就是说,数组定义的时候必须给定长度,如果采用一个变量来定义数组的长度,会产生一个编译错误。不过有的时候我们需要一个动态的数组,这时该怎么办?最简单的办法就是利用C++中STL 模板类库中的vector。关于vector 的使用技巧可以参考《Effective STL》。
第9 章介绍过,C 语言中的数组在内存中是连续分布的。我们可以利用这一特点在C 语言中构建一个动态数组。首先利用calloc 或者是malloc 函数来申请一块用来容纳动态数组的连续的内存,然后利用指针和数组之间的等价关系,来模拟出一个动态数组,如程序10-21 所示。
注意,因为指针p 指向100 个连续的int 类型数据,所以p[50]是合法的,等价于*(p+50)这种写法。因为是为了模拟数组,所以p[50]不仅合法,还能提醒我们正在操作一个“数组”,这种写法更值得推荐。与正规的数组不同,千万别忘了在使用完这个动态数组以后,使用free 函数来释放malloc 函数分配的内存,否则会造成前面介绍过的内存泄漏。
程序10-21 动态一维数组
include< stdio.h>
include<stdlib.h>
void main(void){
int n = 100;
int p=(int )calloc(n,sizeof(int));
printf("%d\n",p[50]);
free(p);
}
模拟出一个动态二维数组的方法比较多,如果知道列的宽度,例如列的宽度为3,那么我们可以利用指向数组的指针来模拟出一个动态的二维数组,如程序10-22所示。
程序10-22 动态二维数组的数组指针实现
include< stdio.h>
include<stdlib.h>
void main(void){
int n = 100
int (p)[3] =(int ()[3])calloc( n*3,sizeof(int));
p[50][0] = 1;
printf("%d\n",p[50][0]);
/释放申请到的内存/
free(p);
/ 函数的定义 /
void f(int (*a)[3], int nrows, int ncolumns);
/ 函数的调用 /
f(p,100,3);
}
这种方法使用起来最为自然,但是你需要理解int (*p)[3]这个东东。
除了这一种方法,还有很多其他的方法可以实现。例如,当不知道二维数组的列的宽度时,我们可以使用指向指针的指针来模拟一个指针数组,然后再使指针数组中的每一个指针指向二维数组中的每一行,整个结构如图10-7 所示。
根据这种思想,我们可以写出程序10-23,数组的行数nrows 和列数ncolumns 都是运行时指定的。这种方法的一个好处就是可以处理每行长度并不一致的锯齿形状的二维数组。程序中另外一个值得注意的地方是free 函数的使用。当利用free 函数来释放malloc 分配的内存时,我们与malloc 的调用顺序正好是逆序的,也就是说,需要首先释放“子结构内存块”。然后再释放“父结构内存块”。
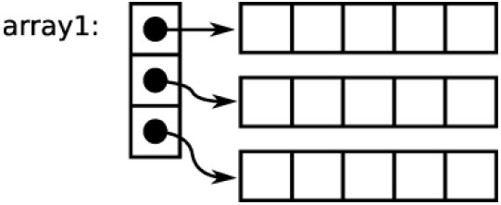
图10-7 利用指针数组模拟二维数组
程序10-23 动态二维数组的指针数组实现
/ 动态建立二维数组 /
int *array1 = malloc(nrows sizeof(int *));
for(i = 0; i < nrows; i++)
array1[i] = malloc(ncolumns * sizeof(int));
/ 释放申请到的内存/
for(i = 0; i < nrows; i++)
free((void *)array1[i]);
free((void *)array1);
/ 使用二维数组 /
void f3(int **pp, int nrows, int ncolumns);
在本书网站“扩展内容”网页中“动态二维数组”链接中,你可以发现程序10-23的代码,网页中一共介绍了三种二维数组的模拟方法,大家可以去看看。
一般的教材中都把字符串的概念放到数组里面讲解,这是有一定道理的。与其他语言不同,C 语言中没有字符串这种数据类型。C 语言中利用字符数组来模拟一个字符串。
同时,我们也可以使用char* pstr="hello";来定义一个字符串。看来字符串不仅和数组有关系,和指针也有一定的关系。所以我决定在讲解完数组和指针以后,一起来讲解字符串的概念。
关于字符串的基础知识,大家都已经了解了,它以一个“\0”为截止符。零在C 语言中占有非常重要的地位。数组下标从零开始,NULL 也是零,字符串截止符也是零,逻辑假也是零。所以如果你想申请一个数组char str[n];,请注意,它只能保存n-1个字符,因为最后后面还要保存一个截止符“\0”。
程序10-24 中,有4 个“hello”字符串。为了讲解清楚,我们必须要复习10.7 节介绍过的内存映像图,4 个“hello”字符串在内存中分配的地方并不完全相同。下面我们逐步进行分析。
程序10-24 字符串的不同存储位置
1 char gp= "hello"; /hello1保存在常量存储区*/
2 char ga[] = "hello"; /hello2保存在静态存储区/
3 char* foo(){
4 char p= "hello"; /hello3保存在常量存储区*/
5 char a[] = "hello"; /hello4保存在栈上/
6 p[0]='z' /运行时错/
7 gp[0]='z'; /运行时错/
8 gp=a;
9 gp[0] = 'z' /允许/
10 return a;
11 }
12 int main(void){
13 char *str = f();
14 str[0]='z'; /运行时错/
15 ga[0]='z'; /允许/
16 }
程序10-24 中第1 行的字符串“hello”被保存在常量存储区,而指针gp 变量被保存在静态存储区。第2 行的数组ga 以及数组内容“hello”被保存到静态存储区,第4 行的字符串“hello”被保存在常量存储区,而指针变量p 被保存在栈上。第5 行的数组a 以及数组内容“hello”也在栈上保存。
一旦明白了它们的存储位置,你就会明白对这些字符串内容和变量,你可以采取什么操作,不可以采取什么操作。首先,第6 行和第7 行试图改变保存在常量存储区字符串的操作都是不合法的,因为gp 和p 指向的“hello”和“hello”保存在常量存储区。这个区域内的东东你是不能改的,用阿Q 的话说,叫做“许看不许摸”。如果你很好奇的话,你可以分别输出gp 和p 的值,你会发现它们都指向同一个地方,也就是说gp 和p 指向的是常量存储区中同一个“hello”。这样你也就理解了为什么不能改变这个东东,如果真的允许改变,你通过p[0]='z'修改了字符串,但是当打印gp 的时候,却发现输出的是“zello”,这个就有点令人抓狂了。
其次,数组ga 和a 的内容,或者保存在静态存储区,或者保存在栈上,它们都是独立的,有自己的存储空间,所以允许对数组的内容进行修改。但是,数组char a[]在栈上生成,当函数foo 结束的时候,所有的局部变量都从栈中弹出而消失,所以数组char a[]和其内容都不再存在。这个时候,即使在第13 行你用str 得到了数组的地址,也是指向一个不存在的数组。所以str[0]='z';也是不允许的。
最后。指针gp 和p 所指向的内容不可修改,但是并不意味着指针本身的值、也就是指针的指向不可修改。我们完全可以写出gp=a 的语句,这个时候,gp 指向数组a,这样,gp[0]='z'就是合法的了。看来,指针只是指向一个存储地点,不同的存储地点有不同的行为,所以,指针也就有了对应的特性,这些特性并不是指针带来的,而是由字符串处在不同的存储地点带来的。
程序10-24 几乎集成了C 语言字符串所有的问题。你需要理解字符串内容“hello”被保存在什么地方,数组变量ga,a 被保存在什么地方,指针gp 指向哪里,并配合10.7 节介绍的内存映像知识,综合地去理解这些问题。
我强烈建议你把程序10-24 自己运行一遍,这样才能把我上面讲解的内容理解充分。这个世界上,没有一个耳朵会被嘴巴说明白。一般人都是经过实践、错误、思考、总结,最后伴随着“souga!”、“妈的!”、“shit!”之类的感叹词,才能进入哲学上所说的必然世界。一旦进入了这个世界,相关的问题将终生不再困扰你。
利用函数中的指针形参,可以改变传入函数的实参的值。这个理念一直被当成指针的经典应用之一。还记得我们前面介绍过的scanf 函数,这回你明白为什么需要传入变量的地址、而不是直接传入变量了吧。
很多教科书都以编写一个交换两个数的程序为例,说明单向值传递的局限性,以及如何使用指针参数来解决这个问题。这种方法可以更改指针指向的内容的值,却不能改变指针本身的值。下面让我们看程序10-25。我写这段程序的本意如图10-8所示。
程序10-25 传递一个指针
include<stdio.h>
include<stdlib.h>
int f(int *ptr){
ptr= (int*)malloc(sizeof(int));
*ptr=999;
}
int main(){
int *p,k = 5;
p = &k;
f(p);
printf("%d",*p);
}
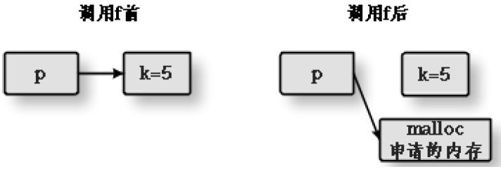
图10-8 传入指针参数的目的
既然通过指针传递可以改变传入函数的实参,原来指针p 指向变量k,我想调用完f 后,指针p 指向函数f 内部通过malloc 函数申请来的一块内存。所以,我希望我的这段程序最后会输出999。
但是这段程序真实的输出却是5。它内部真实的流程如图10-9 所示。因为函数调用遵循单向值传递,所以,进入函数时,p 把自身保存的地址传递给ptr,它们同时指向k。当程序运行到第4 行的时候,ptr 指向了malloc 申请的一块内存。当程序退出后,ptr 因为是局部变量,在栈上定义,所以伴随着函数出栈而消失。这里带来了两个问题,第一,指针p 的指向并没有被改变;第二,malloc 申请的内存由于没有任何指针指向,所以不能利用free 来释放,造成了内存的泄露。
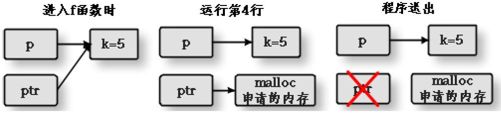
图10-9 指向指针的指针
为了解决这两个问题,我们可以采用两种方法。第一种方法是利用函数返回值的方法,如程序10-26 所示。
程序10-26 返回一个指针
int* f(){
int ptr= (int)malloc(sizeof(int));
*ptr=999;
return ptr;
}
int main(){
int *p = f();
printf("%d", *p);
free(p); / 避免内存泄漏 /
}
第二种方法就是利用指向指针类型的指针,如程序10-27 所示。注意,传入函数的是一个指针变量的地址,在函数f 要区分ptr 和*ptr 之间的区别。
程序10-27 指向指针的指针
void f(int **ptr){
ptr= (int)malloc(sizeof(int));
**ptr=999;
}
int main(){
int *p = NULL;
f(&p);
printf("%d", *p);
free(p); / 避免内存泄漏 /
}
函数可以返回任何类型,那么函数返回指针类型也是天经地义,貌似没什么可说的。所以我们先避开这个话题,一起完成一个函数。这个函数把一个整数变为字符串,就是把整数123 变为字符串“123”,函数的名字就叫作IntToString。这里我们先不考虑内部是如何实现的,只考虑这个函数接口的定义。最自然的一个接口定义如程序10-28 所示,我们传入一个整数,返回一个指针来指向结果字符串的首地址。
程序10-28 IntToString 接口定义1
char* IntToString(int i){
char str[100];
/ 具体实现 /
return str;
}
程序10-28 有一个很严重的bug。函数中数组str 定义在栈上,所以str 会随着函数的结束而消失,虽然通过函数返回了一个指针,但是指向一个消失变量的指针还有什么意义呢?
程序10-29 是改进后的程序。其中,利用malloc 函数从堆申请出一片内存,这块内存不会伴随着函数的退出而消失。所以使用完这个函数后,我们必须调用第8 行的free 函数来释放内存。
程序10-29 IntToString 接口定义2
1 char* IntToString(int i){
2 char str = (char) malloc(100);
3 / 具体实现 /
4 return str;
5 }
6 char* p =IntToString(5)
7 printf("%s", p);
8 free(p);
对使用IntToString 函数的用户来说,这种附加的、强制的要求可以被认为是一种霸王条款,就像我在一个饭店吃了一碗面条,店主要求我一定把碗刷干净才能走一样。所以,这种函数接口的设计以及实现也并不完美。事实上,查遍标准库的函数,你也不会发现有任何一个函数要求使用完这个函数后,还要采取额外的free 来清理内存。
更好的一个接口定义如程序10-30 所示,这回我们允许函数传入一个地址。当使用这个函数时,你可以通过指针p 传入一个数组,或者传入一个malloc 函数分配的内存。如果你使用malloc 函数分配的内存,你应该有责任使用free 来释放这片内存;如果你忘了,对不起!与我IntToString 函数无关。另外,这个函数还把传入的地址返回,这样这个函数就可以直接用在表达式中,如程序10-30 的最后一行所示,这才是一个良好的函数接口定义!
程序10-30 IntToString 实现3
char IntToString(int i,char p){
/ 具体实现 /
return p;
}
char a[100]; /`或者char a = malloc(n);`*/
printf("%s",IntToString(5,a));
事实上,标准库中已经有了完成这个功能的函数,那就是itoa,你现在就去看看这个函数的定义,是不是和我的一样:),事实上应该说,我的定义和标准库的一样。
讨论完指针和函数的关系,我们再说说指向函数的指针。有点绕口令的感觉吧?注意一下,千万别把本节的标题和10.11 节的标题搞混淆了,10.11 节是“函数和指针”,说的是函数和指针的关系。而本节是“函数指针”,说的就是一个东西,这个东西是一个指针,这个指针有点特别,因为它指向一个函数。
坦白地说,函数指针并不是经常会用到。但是你不能说它没用,毕竟“天生我才必有用”。函数指针最常见的一个用处就是“回调函数”。在介绍这个杀手应用之前,我们先简单介绍一下函数指针的基本知识。
函数指针的声明和数组指针有点类似,例如int (p)[3]指向的是一个数组,而int (pf)()指向的就是一个函数,这个函数返回一个整数。至于这个函数接受什么参数,在声明函数指针的时候并不重要,可以忽略不写。如果能忽略最好就忽略,多一事不如少一事。声明一个函数指针后,通过取地址运算符pf=&f 来让函数指针pf 指向一个特定的函数f。最后就是如何使用函数指针了。你可以用pf()或者是(pf)()来调用f 这个函数。整个的过程如程序10-31 所示。
程序10-31 函数指针的用法
int f(int i,int j){
return i+j;
}
int main ()
{
int (*fp)() = &f;
printf("%d",(*fp)(2,3));
}
这一节只是简单地介绍了函数指针的基本概念和用法。事实上,我们很少像程序10-31 中那样使用函数指针,任何人都可以看得出来,直接使用函数f 更方便和简洁。一般情况下,函数指针经常用在需要使用回调函数的场景中。
回调函数(callback function)从字面上很难理解,所以下面我先给出一个实际的例子。这个实际的例子实现了一个简单的冒泡排序算法,冒泡排序通过两两比较相邻元素来完成整个数组的排序。整个算法不难实现,你可以很快写出一个整型数的冒泡排序程序,但是这个函数只能处理整型数。当我们想对一个浮点数进行排序的时候,我们还需要重新写一个新的函数,新的函数和旧的函数主题基本都相同,唯一不同的就是处理的数据类型。
现在,能不能写一个冒泡排序函数,可以支持所有常见的数据类型呢?在C 语言中这是可以的,这里我们就需要一个泛型的概念,具体的代码如程序10-32 所示。
程序10-32 回调函数实例
void sort(void data, int n, int type_size,int (ptr)(const void , const void ))
{
int i, j;
void *temp = malloc(type_size);
void addr_1, addr_2;
for(i = 0; i < n - 1; i++)
{
for(j = i + 1; j < n; j++)
{
addr_1 = data + i * type_size;
addr_2 = data + j * type_size;
if(ptr(addr_1, addr_2) > 0)
{
memcpy(temp, addr_1, type_size);
memcpy(addr_1, addr_2, type_size);
memcpy(addr_2, temp, type_size);
}
}
}
free(temp);
}
}
程序中的sort 函数的第一个参数为要排序的数组,第二个参数是数组内的数量,第三个参数是数组中的元素类型所占的空间字节大小,第四个参数为一个函数指针,这个函数指针指向一个比较函数,比较函数实现了相邻数据的比较大小。函数sort 中并不直接比较两个相邻元素的大小,比较元素大小是通过调用函数指针指向的比较函数来实现的。
程序中,memcpy 函数采用了内存复制的方式来交换两个变量,不管内存中是什么类型的数据,只要交换二进制表示即可实现两个数据的交换。当要排序的数组中保存的是double 类型数据时,定义的比较函数如程序10-33 所示。
程序10-33 浮点数比较程序
int comp_double(const void a, const void b)
{
if((double)a - (double)b > 0)
return 1;
else if((double)a - (double)b < 0.001)
return 0;
return -1;
}
sort(n, 9, sizeof(double), &comp_double); / 调用函数 /
如果我们想利用sort 函数来比较整型数组,只要完成comp_int 这个比较函数,并在调用sort 函数的时候传入comp_int 这个地址就可以了。我们并不需要修改sort 函数的实现。从这里可以看出,比较函数comp_double 是sort 函数通过函数指针“回调的”。至于调用哪个函数并没有固化在sort 函数中,而是在运行的时候,根据传入的函数指针动态地决定。函数指针可以达到“泛型”的一种概念。事实上,标准库中有qsort 函数,采用快速排序算法,比我的冒泡排序效率要高。qsort 函数采用的也是这种基于回调函数的方法。
如果你还对回调函数有疑问,我再通过图10-10 来解释一下“回调”的含义。在图10-10 中的左面,如果我们实现了只对整型数排序的sortint(int p, int size)函数,那么对于使用这个函数的用户来说,他只需要直接sortint(int p, int 第10 章 指针size)函数就可以了。在图10-10 的右面,如果调用sort(void p, int (fp)())这个函数,那么用户还需要提供一个comp_xxx 函数给*fp 这个指针,以便sort 函数“回调”到comp_xxx 这个函数。也就是说,用户调用sort 函数的时候,sort 函数“回调”用户提供的函数。这就是“回调”这个词的由来!
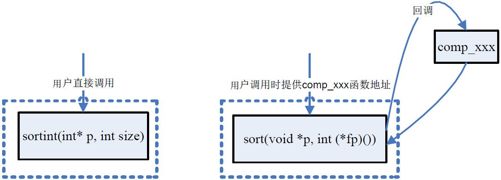
图10-10 “回调”函数图示
这种回调函数的方法用途很多,在Windows 操作系统中,利用回调函数来连接多个动作,如移动鼠标和点击按钮后,系统会回调用户程序中某个特定的函数。
在第10.12.1 节中,我们介绍了函数指针的基本概念。第10.12.2 节介绍了函数指针的一个具体应用,那就是回调函数。有些同学会想到一个问题,那就是10.12.1 节中我们直接通过函数名调用函数不是更好吗?为什么还要绕一大圈呢?而在10.12.2 节我们确实通过回调函数达到了sort 函数的泛型支持。如果用C++中的模板来达到泛型的目的,不是也行吗?没错,如果你能想到这些,你一定天赋秉异,是一个搞软件的奇才。程序10-31 利用函数指针来调用函数完全是池塘冒泡——多鱼(余)。用C++中的模板来达到泛型的目的是更好的选择,因为它是类型安全的,而10.12.2 节介绍的方法是类型不安全的。这主要归结于int (ptr)(const void , const void *)函数中的void 指针把类型信息给搞丢了。例如,当你想对一个整型数组排序的时候,你完全可以传进程序10-33 中的浮点数比较程序,编译器一声都不吭,只会默默等着看你运行程序时候的笑话。这一部分的知识,我们已经在10.4 节给大家介绍过了。既然如此,为什么还要有函数指针呢?
一般的教材写完10.12.1 节就不写了。厚一点、好一点的教材也许会把类似于10.12.2节的一些函数指针的应用写上,然后也结束了。这多少让我想起了上大学的时候学习微积分的过程。高数老师上来就开始介绍极限和求导,然后是一大堆求导的公式。这让我很快丧失了学习的兴趣,因为我根本就不知道微积分是用来干什么的。现在回头想想,如果我是一位教微积分的老师,我会首先留给同学们一个思考题,如何求取一个不规则形状的面积?等到同学们思考完了以后,我再开始教微积分,这样效果会好很多。所以在本书中,我也从一个问题开始,等你思考完这个问题,我再开始讲授函数指针的作用。在讲授的过程中我会涉及到一些非C 语言的技术,但是我不会涉及到过多的技术细节,所以请放心,你一定看得懂。我的问题从以前的一个故事说起。
我在读计算机专业研究生的时候,有一次和一位朋友去买电脑。那个时候,组装电脑比较便宜,所以我们就去一家店里去买组装电脑,选完主板,硬盘,显卡,内存等组件后,一个后腰别着螺丝刀的伙计就开始飞快地组装了起来。装的过程我们就开始聊天,他问我是学什么的?我说我是学电脑的,然后他说了一句让我终身难忘的话,“电脑有什么好学的?”我很理解这位老兄,在他眼里,电脑就是一堆硬件,用螺丝刀把它们装到一起,然后再安装一个盗版Windows,这也确实没有什么可学的。只要你腰里别着一个螺丝刀,你就是一个硬件工程师;就像你只要腰里别着一个死耗子,你就是一个打猎的。
我希望你们正确理解我的幽默感,我丝毫没有看不起这位老兄。事实上,把一个事情搞简单才是最高境界。这一点上,硬件领域做得很好。如果你想装一台电脑,你会发现一切都是现成的,都有现成的组件,不仅有,还可以根据你的要求进行选择和定制。这是一件多么舒服的事!如果我们软件行业能像装配硬件那样快速、方便地“装配”一个软件,那该多好啊!这简直就是软件行业的最高理想了。
软件开发的早期时代,软件都是铁板一块的程序,各种的功能和数据纠缠在一起,如果要用一个超级量词来形容,那就是“一坨”。这种程序只完成特定的功能。如果有新的需求,你需要再从头开始编写软件,因为以前的“一坨”软件是很难复用的。
现在我提出我的问题了,如何打碎这铁板一块的程序?
想到了吗?如果把功能封装到不同的模块中,就把程序打碎了。没错,这就是标准答案!很简单是不是,如图10-11 所示。
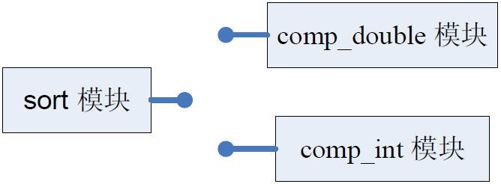
图10-11 功能封装到不同模块
在图10-11 中,我们可以看出,sort 就是一个模块,comp_double 也是一个模块,由于这两个模块是独立的,所以sort 模块就可以在其他的软件中复用。但是问题就是两个模块之间还需要合作,这个时候,好的方法就是定义出一个固定的接口规范,这个接口规范用图中sort 模块和comp_double 模块上面伸出来的一个圆头小杆来表示。如果你comp_double 模块符合我sort 的接口规范,那么我们就可以合作和通信。不仅如此,如果comp_int 也符合我的接口规范,我们也可以合作。这个接口规范在C 语言中其实就是用int (ptr)(const void , const void *)这样一个函数指针来定义的。这回你该明白了,其实,函数指针的战略目的就是要打碎铁板一块的程序,为了达到这个战略目的,它为不同的模块定义出了一个接口的规范。
在C++中,我们也想做同样的事情,达到同样的目的。这个时候,我们引入了一个更高级的概念,虚拟基类。例如我们定义了一个虚拟基类transportation,如程序10-34 所示。
程序10-34 transportation 虚拟基类
class transportation
{
virtual Move() = 0;
virtual Stop() = 0;
}
这个时候,你可以从transportation 派生出两个类car 和bus,如图10-12所示。
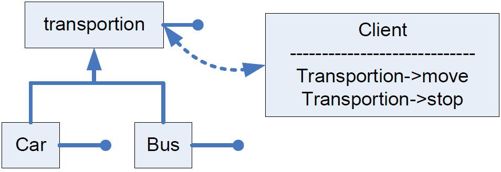
图10-12 C++中用虚拟基类描述接口规范
这个程序被打散成了三个模块,分别是client、car 和bus。client 用户通过transportation 接口规范来使用某一个交通工具,你可以把一个car 给用户用,也可以把一个bus 给用户用。你甚至可以从transportation 派生出一个goose (鹅)传给你的用户,毕竟goose 也可以move 和stop,也遵守transportation 定义的接口规范,只是move 和stop 的方式和car 不太一样罢了。
你不要认为这很可笑,姚期智在《科学家与科学之路》一文中提到过:“科学家有两种,第一种是看到已经发生的事情,问‘为什么会这样’。第二种是尝试一些从未发生的事情,然后追问‘为什么不能这样’。”OK,那为什么不能骑鹅呢?不管你信不信,我很小的时候,确确实实骑过鹅。而且那个时候,家里还没有电视,所以我也没看过《尼尔斯骑鹅旅行记》。
好了,现在让我们从童话和童年中走回来,重新研究一下虚基类的物理实现。你会发现虚基类维护一个vtbl 虚拟函数表,这个虚拟函数表里保存着类中所有对应虚函数的函数指针。所有的虚基类的派生类都维护(或者说遵守)这个vtbl 的规范。从这个意义上说,C 语言用一个函数指针来定义一个接口规范,而C++却用多个函数指针来定义一个接口规范,确实更高级了。
请注意,上面的整个思想有的书中叫作“后绑定”,与之对应的叫“前绑定”,这里的前后是相对编译阶段来说的。在程序的编译阶段,用户并没有办法确定自己要具体使用哪种交通工具,因为用户通过一个抽象的接口transportation 来使用交通工具;只有在程序运行的时候,才会确实知道自己要使用car、bus、还是goose。
可以看出,接口就是打散软件的那把大锤,正是因为有了统一的、规范的接口,各个组件才可以互相独立,同时还可以互相合作。基于这个基本的概念,微软提出了COM(Component Object Model)的标准和架构。在COM 中,无论是接口Interface 还是组件component 都不再是抽象的概念,而是具体的实体和关键字。它可以做到你在本地用C 语言编写的一个组件调用远程计算机上用C#或其他语言编写的另外一个组件的功能,真正做到软件行业的“组件”化。
不过,COM 也有自己的缺点。为了达到“组件”化这种效果,COM 本身变得很复杂。以至于微软公司不得不开发出专门的工具ATL 来降低开发一个组件的难度。即便如此,你也不要以为ATL 有多简单,不信你去读读《ATL internals》[17]试试看。
另外一个缺点是COM 本身的理想是做到跨语言和跨平台,但是实际上它并不是通行天下的。很多公司的操作系统和语言并不买微软的帐。虽然科学是没有国界的,但是钱却有国界。所以目前只有Windows 下支持COM。把自己的思想装到别人头脑中的是老师,把别人的钱装到自己口袋中的是老板,同时做到这两点的是我老婆。从这一点上说,微软要好好向我老婆学习学习。
介绍COM 的初级入门的一本很好的书籍是《COM 技术内幕》[19],看这本书前,你需要有一定的C++知识。本书毕竟是一本C 语言的书,所以就此打住了。
指针这一章已经很臃肿了,但是我不得不再加上这一节。本来声明一个变量在本书的开头就应该介绍了,但是这里描述的是一个复杂的声明,复杂的声明通常涉及到数组和指针,所以必须等到数组和指针介绍完毕后才能介绍,所以我不得不放到这里介绍。文章讲究虎头猪肚豹尾。虎头豹尾不敢说,但是猪肚现在做到了,行文如此,做人依然!
复杂的声明我们已经在10.6.3 节遇到过了,那就是定义一个数组指针int (p)[3]。下面我们来看一看一个更复杂的声明,如char const (next)();。在《C 专家编程》[20]的第3 章,你可以看到这个声明的最终解释,那就是“next 是一个指向函数的指针,该函数返回另一个指针,该指针指向一个只读的指向char 的指针”。针对这个比较变态的声明,你可能会产生两个疑问。第一,如何解释或定义这种复杂的声明?第二,这种复杂的声明有什么用?对于第一个问题,《C 专家编程》的第3 章给出了一种操作性很高的方法,这里我强烈推荐大家去阅读并了解。据说,掌握了这种办法,多么复杂的声明都能迎刃而解。
本书对这种方法做一个简单的总结,并加上了自己的一点体会,可以归结为以下五个步骤。
1)从左面找第一个标识符。
2)找标识符左面的“[”或者“(”符号。如果找到“[”,那么它就是在声明一个数组,表达式中剩下的部分都是在描述数组里面保存的是什么类型。如果找到“(”,那么它就是在声明一个函数,表达式剩余部分都是在描述这个函数的返回值。
3)如果左面没有“[”或者“(”符号,找右面的“”号。如果找到“”,那它就是在声明一个指针,表达式剩余部分都是在描述这个指针指向的是一个什么类型。
4)从上到下逐层分析。
5)从下到上利用typedef 逐层定义。
我看别人的书时,最喜欢看到的不是描述,而是实例。通过实例,可以很快而且很清楚地明白作者的意图。就像星球大战中尤达大师的一句名言“use source!”翻译成中文就是“别罗嗦了,直接上源代码吧!”
第一个例子是void ( ap[10])(void ()())。根据上面的步骤,我们首先从左面找到第一个标识符ap。第二步就是找左面的“[”,找到了,说明这个声明最上层的定义就是一个数组,表达式中剩下的部分都是在描述数组里面保存的是什么类型。我们继续分析,既然是一个数组,那么把数组的那一部分去掉,整个表达式变成了void ()(void ()())。这个时候,我们可以看出剩下的部分是一个函数指针,这个函数指针指向一个函数,这个函数返回一个void,并且接受另外一个函数指针作为函数的形参。最后作为函数形参的函数指针void ()()指向这样一个函数,函数返回void,并且没有函数形参。后面的分析有点麻烦,但是大家可以看出这并不难。最后,这个表达式的含义是:这是一个指针数组,数组里面保存的是函数指针,这个函数指针指向返回值为void、形参为void ()()的函数。可以看出,最关键的是理解这个复杂声明最上层是一个数组,这对彻底分析整个结构有提纲挈领的作用。
第二个例子是int ( frp(int))(char char)。根据上面的步骤,我们首先从左面找到第一个标识符frp。第二步就是找左面的“(”,找到了,说明这个声明最上层的定义就是一个函数,表达式剩余部分都是在描述这个函数的返回值。这个函数的返回值是什么呢?我们继续分析,既然是一个函数,那么把函数的那一部分去掉,整个表达式变成了int ()(char char)。这个时候,我们可以看出剩下的部分是一个函数指针,这个函数指针指向一个函数,这个函数返回一个返回值是int,并且接受两个字符指针char作为函数的形参。后面的分析有点麻烦,但是大家可以看出这并不难。最后,这个表达式的含义是:这是一个函数,这个函数本身接受一个int 形参,同时返回一个函数指针,这个函数指针指向一个函数,这个函数返回一个int,并且接受两个字符指针char作为函数的形参。最关键的是理解这个复杂声明最上层是一个函数,这对彻底分析整个结构有提纲挈领的作用。
第三个例子是void (fp)()。根据上面的步骤,我们首先从左面找到第一个标识符fp。第二步就是找左面的“(”和“[”,没有找到,然后找左面的“”号,找到了,就说明这个声明最上层的定义是一个指针,表达式剩余部分都是在描述这个指针指向的类型的。指向的类型是什么呢?我们继续分析。把指针的那一部分去掉,整个表达式变成了void ()()。这个时候,我们可以看出剩下的部分是一个函数,这个函数返回一个void,没有形参。最后,这个表达式的含义是:这是一个函数指针,函数指针指向一个函数,这个函数返回一个void,并且没有形参。最关键的是理解这个复杂声明最上层是一个指针,这对彻底分析整个结构有提纲挈领的作用。
这里我只是给出了三个简单的例子,比较详细的方法描述还应该参考《C 专家编程》的第3 章。不过我个人认为,这三个例子非常有代表性。再复杂的声明归根到底无非也就是数组、函数、指针三种。所以如果你明白了上面三种复杂的声明,就能应付很多工程方面的问题了。
10.13.1 节中提到了int ( frp(int))(char, char*),现在我们再进一步分析一下这个声明。它声明了一个函数,这个函数返回值是一个函数指针。它有两点值得说明。
第一,想让一个函数返回一个函数指针,你不能写成int ()(char char)fp(int);的样子,这符合人的理解,但是有两个完全并行的包含形参的括号,(charchar) 和(int) , 这会让编译器凌乱甚至抓狂, 所以必须写成int (frp(int))(char, char)这种形式。下面我再逐步地分析一下这个声明的组成步骤。
• frp 是一个标识符
• frp() 是一个函数
• frp(int) 函数接受一个整型形参
• *frp(int) 函数返回一个指针
• (*frp(int))() 这个指针指向一个函数
• (frp(int n))(char, char*) 指针指向的函数接受两个字符型指针
• int (frp(int n))(char, char*) 指针指向的函数返回一个int
第二,这种复杂的声明到底有什么用?下面我给出一个具体的例子,如程序10-35所示。这个例子实现了一个叫作“鹦鹉”的机器翻译系统。这个系统之所以叫作“鹦鹉”,因为它只会翻译一句话,那就是实现了“你好”的中英文互译,其他的一概不会翻译。说句实话,这还真不如一个鹦鹉的智商高。所以大家不要以机器翻译的角度去参考这个程序。这个程序真正值得关注的地方是使用了返回函数指针的函数frp,这个函数接受一个整型参数,如果输入是0,就返回CE 函数的地址,也就是说,把中文翻译成英文;如果输入是1,就返回EC 函数的地址,也就是说,把英文翻译成中文。
程序10-35 “鹦鹉”机器翻译系统
int CE(char c, char e){
if(strcmp(c, "你好")==0){
strcpy(e,"Hello\n");
return 1;
}
strcpy(e,"Sorry\n"); return 0;
}
int EC(char e, char c){
if(strcmp(e, "Hello")==0){
strcpy(c,"你好\n");
return 1;
}
strcpy(c,"对不起\n"); return 0;
}
int (frp(int i))(char, char *) {
if(i == 0)
return CE;
if(i == 1)
return EC;
}
void main()
{
char result[100];
frp(0)("你好",result);
printf("%s",result);
frp(1)("Hello",result);
printf("%s",result);
}
在main 函数中,你会发现frp(1)("Hello",result);这个语句。你会发现有两个括号。如果你只写成frp(1),那么只是调用了frp 函数,虽然返回了EC 函数的地址,但是EC 这个函数并没有被调用;如果写成了frp(1)("Hello",result),那么就等同于我们调用了EC 函数。也就是说,frp(1)("Hello",result)等价于EC("Hello",result)。
目前,我们已经掌握了复杂声明的解析能力,对void (ap[10]) (void ()()); 这种非常变态的声明也能读得懂。现在换一个角度,如果让我们从头开始定义这个声明,你办得到吗?
坦白地说,上面介绍的那些复杂的声明确实不像是一个正常人写出来的,反倒像是你在擦拭键盘时留下来的记录。这里有好多的括号,一不小心就会写错。写错了也许会编译错误,如果这样你真应该烧高香,因为有的时候虽然你写错了,也会编译通过,但是明显是不同的语义,使程序出现更加难以调试的逻辑错误。难道没有一种更好的办法来定义一种复杂的声明吗?
有!霹雳一声震天响,typedef 横空出世了。说起typedef,我们在后面的结构体部分还会提到。这里我们先用它解决复杂声明的定义问题。typedef 的主要功能就是帮助我们定义一个新的数据类型,并给这个新的数据类型一个别名,这样我们就可以利用这个别名去定义别的变量了。例如,我们可以使用typedef 分三步定义出void (ap[10]) (void ()() ),如程序10-36 所示。
程序10-36 typedef 定义一个复杂声明
void (ap[10]) (void ()() );
/ 利用typedef定义 /
typedef void (*pfv)();
typedef void (*pf_taking_pfv) (pfv);
pf_taking_pfv ap[10];
可以看出,使用typedef,整个定义的思路非常的清晰,这样就大大降低了出错的概率,同时也给我们解析这个声明带来了便利,现在任何人都可以第一眼看出ap 是一个数组。最后,定义出了void (pfv)()后,我们也可以把它复用在其他的场合。例如,利用pfv 的定义,如果我们想定义一个返回函数指针的函数void (f())();也可以像程序10-37 那样进行定义。我们可以看出,比起原始的定义,pfvf()这种定义要清晰得多!
程序10-37 复用typedef 定义的新类型
void (*f()) ();
/ 利用typedef定义 /
typedef void (*pfv)();
pfv f();
在复杂声明中利用typedef 进行定义真是一石三鸟。可以这么说,typedef 在定义复杂声明的时候,真是上帝给的一个神器,没有不用的道理。
最后介绍一下复杂声明的另外一个用处,那就是用于强制类型转换。还是借用尤达大师的名言,“别白话了,上源码”。《C 陷阱和缺陷》的2.1 节,讲述了一个具体的应用场景,那就是如何显式地调用地址为0 的一个程序,它的答案是((void()())0)();。你要知道,(0)()这种调用方法是不行的,因为(0)()中的“”必须作用于一个函数指针,而0 没有任何类型信息,所以第一步应该把0 转换成一个函数指针类型,这就涉及到了C 语言中的强制类型转换的知识。我们通过(void()())0 将0 转换成了一个函数指针,然后利用(*fp)()的方式去调用这个函数指针,可以看出,正确地理解上面的表达式需要我们具有解析复杂声明的能力。
明白了上面的这个例子后,另外一个更实际的例子来源于10.12.2 节的程序10-32,我们可以将程序10-32 改写成程序10-38 的样子。
请大家注意,以方便对比参照。我把程序10-32 中的部分代码也放到程序10-38中,程序10-38 上面那一段源码来源于程序10-32,而下面的那一段源码则使用了本节介绍的强制类型转换。
可以看出,利用强制类型转换技术,下面的com_double 函数要比上面的com_double 更简洁和更安全,因为它并没有使用void 类型指针。
程序10-38 比较函数的类型强制转换
int comp_double(const void a, const void b)
{
if((double)a - (double)b > 0)
return 1;
else if((double)a - (double)b < 0.001)
return 0;
return -1;
}
sort(n, 9, sizeof(double), &comp_double); / 旧的办法 /
int comp_double(const double a, const double b)
{
if(a - b > 0)
return 1;
else if(a - b < 0.001)
return 0;
return -1;
}
sort(n,9, sizeof(double), (int ()(const void, const void*))comp_double)
/ 指针转换的办法 /
指针有点像围棋,规则很简单,但是想用(下)好,却很难,全世界的围棋高手手不超过100 个。有点像开车,开车的理论知识也很简单,油门加速,刹车减速,方向盘控制方向,但是全世界的F1 车手不超过100 个。也有点像照相,快门、光圈、焦距,但是全世界的摄影大师也不超过100 个。
没错,指针本身只保存一个地址,但是它可以指向任何数据类型。指针可以指向一个字符,可以指向整型,可以指向一个浮点型,可以指向一个数组,可以指向一个字符串,可以指向一个结构,可以指向另外一个指针,甚至可以指向一个函数。正如“雅典的学院”这一幅名画,柏拉图右手指天,好像在说“天启万物之源”,亚里斯多德右手指地,好象在说“现实是真理之本”。指针也做到了上可指天,下可指地。
一旦指针指向了数组,数组的所有问题和特点就被附到了这个指针上,如数组的越界、如何申请一个动态数组、如何让指针指向一个二维数组等。一旦指针指向了字符串,内存映像的知识你就要了解,什么是静态变量、什么是常量存储区你要非常明白。一旦指针指向了结构体,就会带来一大堆数据结构的知识,什么是链表,哪个是二叉树。一旦指针指向了函数,操作系统的知识铺面而来,什么是回调函数,消息、事件和信号到底都是些什么东东。另外,内存的申请和释放,内存的泄漏,高效地使用内存等等,这些也都和指针密切相关。所以说,指针它不是一个人在战斗,这也是很多人认为指针很难的原因。
本书虽然共有14 章,但是用了将近1/5 的篇幅论述指针,可以这么说,如果只局限于指针本身的范围,那么指针相关的难点和特点也都介绍得比较全面了。全部理解了这一章的内容,我确保你不会用错指针,但是我还不敢保证你用好指针,你也别期望通过本书完全、彻底、一劳永逸地掌握指针,因为这涉及到很多指针以外的知识。
无论怎么样,还是要恭喜你!终于学完了最复杂的指针。最后让我们轻松一下,综合利用学到的知识,描述一下程序员的爱情观。爱情就是死循环,一旦执行就陷进去了;爱上一个人,就是内存泄漏——你永远释放不了;真正爱上一个人的时候,那就是const 限定,永远不会改变;女朋友就是static 变量,只有我这个文件才能调用;情人就是指针,用的时候一定要注意,要不然会带来巨大的灾难。
