C 语言中数组的定义有点丑陋。比如定义一个整型数组变量array,按照一般定义变量的顺序,应该是int[3] array 才对。后来的语言,例如Java 和C#,都支持int[] array 这种写法,希望下一版的C 标准也能支持这种写法,但是目前的标准还不行。定义数组的时候,你只能写成int array[3]这种形式。
对于 C 语言的数组,你需要知道几件事。数组变量array 就是此数组的首地址,它与&array[0]等价;同时array 的地址也不能改变。也就是说,你不能把数组变量array 放到等号的左边,也不能对其运行自增减运算符,如array++和—array 等。
数组的下标从零开始,这一点让初学者有点不适应,不过你只需记住一个口诀,那就是:数组下标从零开始,生活何尝不是如此呢!每当我遇到困难和挫折,我都会默念这个口诀,然后便会充满了正能量。
定义一个数组变量的时候,编译器会根据数组的长度声明一块连续的内存给数组。这块连续内存的外边是什么,谁也不知道。数组本身不会运行越界检查。还记得我们在第3.3.3 节提到的两个C 语言的风格吗?那就是:信任程序员,只要快。你要对得起这份信任,而不是滥用这种信任。记住数组下标从零开始,可以避免一半以上的数组越界错误,另一半就需要细心了。如果定义int array[n];,一个好的避免溢出的方法就是记住遍历这个数组时循环的区间是一个半闭半开的区间[0,n),最好写成for(i = 0;i<n;i++),不要写成for(i = 0;i<=n;i++),否则就会发生数组越界了。
数组定义的时候,必须指定它的长度。虽然C 语言中支持int array[]={1,2,3}这种写法,但是这种写法也隐含地指定了数组的长度。在指针一节,我们会介绍一种模拟动态长度数组的方法。
程序9-1 中第1 行,当我们通过int array[3];定义一个数组的时候,其中的元素是随机数。第2 行中,当我们指定第一个元素的值以后,后面的元素全部为零。当然,你也可以通过第3 行的方法,对数组中每一个元素都进行初始化。定义并同时初始化一个变量是一个好习惯,可以避免一些隐含的错误。对数组变量来说,这一原则也同样适用。
如果你想把一个数组的全部元素赋值为0,可以通过一个循环完成,如程序9-1 的第4~6 行所示。一个更简单的办法就是利用程序9-1 中第7 行的memset 函数来完成这个任务。当数组的元素比较多的时候,这种方法的效率明显高于使用循环的方法。
程序9-1 数组的初始化
1 int array[3]; / array中元素为随机值 /
2 int array1[3]={1};
3 int array1[3]={1,2,3};
4 for(int i = 0;i<3;i++){
5 array[i] = 0;
6 }
7 memset(array,0,sizeof(array));
在9.1 节介绍过,数组名不能放到等号左边。如果你想把数组b 赋值给数组a,程序9-2 中第3~5 行给出了正确的方法。既然能通过memset 函数来初始化一块内存,那么能不能直接复制一段内存呢?如果能,数组间的赋值就可以避免使用循环操作了。没错,C 库函数还提供一个函数memcpy,这个函数用于将一块内存拷贝到另一块内存。程序9-2 中的第6 行演示了这种用法。注意其中sizeof 的用法。
程序9-2 数组不支持直接赋值
1 int a[3] = {1,2,3},b[3];
2 b=a / 错误,不能把b放到左值 /
3 for(int i = 0;i<3;i++){ / 数组间赋值之循环方法 /
4 b[i] = a[i];
5 }
6 memcpy(b,a,sizeof(a)); / 数组间赋值之高效方法 /
函数的参数遵循单向值传递,这一点在传递数组时不成立,传递数组的时候,遵循的是引用传递。向一个函数传递一个数组,其实是把数组的首地址传入,这样函数内部对数组的任何修改,都会影响到传入的实参数组。同时,函数的形参只需要声明为int b_array[]就可以了,这样就已经代表b_array 是一个地址了,如程序9-3 所示。
程序9-3 向函数传递一个数组
int foo(int b_array[] ){
b_array[0] = 100;
}
void main(void){
int a_array[]={1,2,3};
foo(a_array);
}
为什么要这么做呢?其实非常简单,如果还是单向值传递,那么传递的效率实在是太低了。想象一下我们有包含一万个数据的数组,如果采用值传递,那么我们需要在栈上再构造一个数组,然后把一万个数据再复制到新数组中,这个很愚蠢!所以,我们采用引用传递,只是传递一个地址,这样,传递的效率会大大地提高。
当然这么做也是有风险的。在程序9-3 中,当调用完foo(a_array)这个函数后,a_array[0]就被修改为100 了。虽然效率提高了,但是,在函数foo 中对数组b_array 所做的任何更改其实都是对a_array 进行更改。如果我们不想让函数foo 改变a_array 的值,可以把函数的形参声明为const int b_array[],这个时候b_array[0] = 100; 语句就会编译出错,保证传入的数组a_array 不会被函数foo 意外地修改。
如果要从函数返回一个数组,也必须要遵循值传递。因为任何在函数内声明的数组都是自动变量,它们声明在栈上,会伴随着函数的结束而消失,所以返回它们的地址是没有意义的。如果是值传递且b_array 是一个数组,那么必须支持b_array=foo();这种写法。但是很遗憾,b_array 作为单独的数组变量名,不能放到等号的左边。所以,C 语言的函数不支持用return 返回一个数组。
还记得在5.7 节介绍的溢出攻击吗?它就是直接利用了数组的越界。为了让大家更加清楚数组越界的危害,下面我再给出一个实例,如程序9-4 所示。
程序9-4 数组越界的危害
int salary[3]={1000,1500,2000};
int age[3] ={28,30,33};
int *p = &age[0];
int index ;
scanf("%d",&index);
*(p+index) = 40;
printf("%d",salary[0]);
这段程序原本想改变一个人的年龄,由输入决定要修改第几个人,然后把他的年龄改成40 岁。输入1 的时候,age[1]中的30 被改成了40,没有问题;如果输入5,打印出的salary[0]却变为了40。编译没报错,执行没报错,就是结果不对。这个逻辑错误非常可怕,因为难以查到原因。你会把主要的精力都放到关于salary 的操作上,而不会关心age。但是你的问题,恰好就是age 数组越界造成的。由于一直围绕着salary 进行debug,你不会找到真正的原因。直到最后,你会怀疑是不是自己的人品出了问题。
另外,这段程序中使用了指针,如果你写下age[5]=40 的时候,多多少少还会有点溢出的担忧,那么当你写*(p+index) = 40 的时候,你的哪怕一点点担忧,都荡然无存。但是这两者却是完全等价的,这也是为什么指针更容易引起潜在错误的原因。
有些读者会对程序9.4 的代码产生疑问,如果数组的第一个元素下标为0,并且age 和salar 两个数组紧挨着,那么当我们输入3 的时候就会侵犯到salary[0],而在我们的实验中为什么是输入5 呢?我在前面已经说过,我使用的是VS2010 开发环境,VS 中每一个项目,你都可以分别建立release 版和debug 版。release 版本通常不进行边界检查,这是与debug 版之间的最大的区别之一。
在 debug 版下,当定义一块数组的时候,它会在数组的后面加上两个元素,如图9-1 所示。
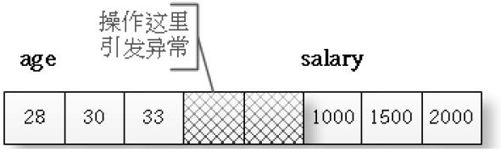
图9-1 debug 版下数组后面有两个元素
一旦由于发生越界而操作了数组后面加上的这两个元素,程序将会被终止,同时系统会弹出一个对话框,如图9-2 所示,来提示你发生了数组越界。这个特性可以帮助我们侦测到数组越界的问题,不过如果你直接越过这两个元素,直接侵入下面的,VS 就不会报警了。另外,在VC 6.0 下,如果侵入数组后面的两个元素,也没有这种警告提示。
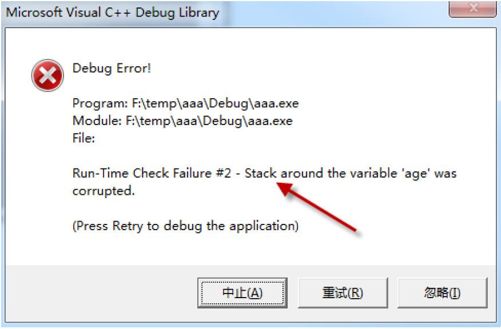
图9-2 debug 版下数组越界的提示
无论是报警还是不报警,都发生在debug 版下。release 版不会在数组的后面另外加上两个元素,所以如果在release 版下运行,那么输入3 就会更改salary[0]了。同时,release 版也不会对数组越界进行检查和报警,就算你侵犯到了salary[0]变量,程序还会“正常”地运行下去,不会给你任何提示,直到月底你的工资变成了40元钱,你可能才会知道出问题了。
C 语言中允许我们定义多维数组。但是实际的项目中,我们最常用的就是二维数组,所以下面以二位数组为例进行讲解,多维数组的原理和使用于此类似。
每个一维数组都是有数据类型的。例如,整型一维数组,那么数组中每一个元素都是整型;浮点型一维数组,那么数组中每一个元素都是浮点型;或者字符型一维数组,那么数组中每一个元素都是字符型。如果我们定义了自己的数据类型——xx 型,那么我们也可以定义一个xx 型一维数组。而xx 可以是任何东东。既然xx 可以是任何东东,魔法就在一瞬间产生了。如果xx 本身就是一维数组,那么我们就定义了一维数组型一维数组。这样,数组中每个元素都是一个一维数组。其实这个魔法有一个专业的名字,在计算机科学领域叫递归。
有点绕口啊!但是这对理解二维数组有很大的帮助,尤其是当我们讲解指针的时候。虽然C 语言中可以写int a[2][3],但那只是一种简写方式。事实上,C 语言只有一维数组,没有二维数组。二维数组在内部只是被当成一维数组型一维数组。
二维数组的初始化方法可以借鉴一维数组的方法,如程序9-5 第1 行所示。这种写法是可以的,但不是非常的醒目。更好的办法是用大括号来界定对应的行,如程序程序9-5 第2 行所示;或者如程序9-5 第3 行所示,省略行的维度,由初始化的数据决定。
程序9-5 二维数组的初始化
1 int a[2][3]={1,2,3,4,5,6};
2 int a[2][3]={{1,2,3},
{4,5,6}};
3 int a[][3]={{1,2,3},
{4,5,6}};
注意一点,初始化的时候,int a[][3]是可以的,但是int a[2][]却不行。这是因为当我们声明xx 型一维数组时,一维数组的长度可以通过初始化表达式来隐含地定义,但是xx 型的长度必须是确定的,以便编译器为每一个xx 型分配对应的内存。如果xx 型的长度不确定,编译器会报错。二维数组中,每个元素就是一个一维数组,其中的一维数组长度必须指定,也就是说,列的长度必须指定。另外,在后面,当介绍指向数组的指针和指向指针的针时,正确地理解二维数组也是非常必要的。
为了论述简单,还是统一称为二维数组吧,毕竟用二维数组比用一维数组型一维数组简单。二维数组int a[2][3]在逻辑上定义了一个2 行3 列的表格。但是你别忘了,二维数组其实就是一维数组,如果你还不承认这一点,看看9.6.1 节的解释。对一维数组,编译器会分配连续的内存给数组。所以,二维数组在内存中也是线性连续保存的,而不是被保存成行列结构。那只是一种逻辑结构,而不是物理结构,如图9-3 所示。
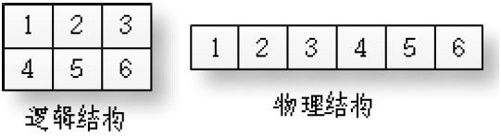
图9-3 二维数组的逻辑结构和物理结构
二维数组的寻址,例如定义数组:int a[M][N];,那么元素a[m][n]在数组a 中的位置是:m*N + n。所以,在程序9-6 中,a[0][4]和a[1][0]指向的是同一个元素,因为不检查越界,所以a[0][4]的写法也是正确的。如果不细心,这里又是一个可能会造成错误的隐患。千错万错,都是数组越界惹得祸。
程序9-6 二维数组的访问
char ch = (char)0xAA;
char a[6][4]={(char)0xFF};
a[0][0] = 0x00;
a[1][0] = 0x10;
a[0][4] = 0x04; / 修改了a[1][0] /
a[5][4] = 0x54; / 又越界了,唉! /
数组变量代表的是一个地址,同时你不能改变这个地址。
定义一个数组的时候,必须指定数组的长度,或者通过初始化每个元素的方法来隐含的指定长度。
利用数组的一个根本的问题就是越界,为了避免越界,就应该知道数组下标从零开始。利用循环操作数组的时候,推荐采用半开半闭的区间访问数组。
Visual studio 的debug 版下数组一般后接两个元素,一旦侵入了这两个元素会引发一个异常。所以我们最好在debug 版下开发程序,这有助于尽早定位数组越界的错误。
二维数组应该被理解为一维数组型一维数组。这么理解对于你后面学习指针和数组的关系的时候,有很多的好处;同时也有助于你理解二维数组在内存中物理结构的连续性。
实际操作二维数组的时候,推荐采用a[m][n]这种下标方式,不推荐a[m*N + n]使用这种方式。前者对程序员来说,语法更清晰。但是对编译器来说,这两种方式是完全等价的。无论是m 还是n,都要注意越界的问题。
