FILE 是C 语言中定义的一个结构类型,它定义在头文件stdio.h 中。当我们利用fopen 函数打开一个文件的时候,它返回的是一个FILE 指针变量。每个FILE 指针变量标识一个特定的磁盘文件(你也可以把指针理解为用来标识一个特定的流,参考5.1 节),FILE 结构内部的成员可以参考程序12-1。这里需要注意,用户绝对不应修改FILE *指针变量指向的结构类型内部的所有数据。
程序12-1 FILE 结构体细节
typedef struct
{
short level; / 缓冲区‘满’或‘空’的程度/
unsigned flags; /文件状态标志/
char fd; /文件描述符/
unsigned char hold; /如无缓冲区不读字符/
short bsize; /缓冲区的大小/
unsigned char buffer;/数据缓冲区的位置*/
unsigned char curp; /指针当前的指向*/
unsigned istemp; /临时文件指示器/
short token; /用于有效性检查/
}FILE;
为什么要返回一个指针呢?因为FILE 结构比较大,所以传回这个结构的首地址明显要比复制整个结构体并传回效率要高。我们还可以从另外一个名词来理解这个问题。有的书中把FILE *叫做“文件句柄”。“句柄”这个词来源于英文“handle”。把“handle”翻译成“句柄”是因为Windows 编程,但是我个人认为这是计算机英文翻译的第二烂的代表,第一烂是把“Object”翻译成“对象”。如果让我翻译,我更愿意把“handle”直接翻译成“柄”或“把手”。
那么我们为什么要翻译成“把手”呢?我们可以把FILE 结构想象成一口锅,当我想把这口锅传给你的时候,第一,我不会再复制一口锅,因为这样成本太高;第二,我也不会让你去抓锅沿,因为锅可能很烫。就像传递一把刀,礼貌的办法是把刀的把手递给对方,而不是把刀锋递给对方。当我把锅的把手交给你,而你接住锅的把手,这样就完成了锅的传递。这个时候,FILE *就是那个把手,也就是“柄”了,如图12-1 所示。

图12-1 文件句柄的演示
Windows 下用反斜杠“\”来分隔路径。我刚开始接触计算机的时候,总是分不清楚斜杠和反斜杠。直到有一天,我恍然大悟。斜杠“/”和地平线成一个锐角,而反斜杠“\”和地平线成一个钝角。因为UNIX 在辈分上是Windows 的舅老爷,所以UNIX 优先采用了斜杠。后来的Windows 想追求不同,只能用反斜杠了。我经常听有的人说,为什么Linux 用斜杠呢?其实这句话应该这样问,为什么Windows 用反斜杠呢?
Windows 用反斜杠来区分路径名的一个坏处就在于,反斜杠“\”在C 语言中也充当转义字符,所以如果要正确地表达出一个反斜杠,我们必须用“\”来表示。好在盖茨也感到这么做有点不厚道,所以在Windows 下用C 语言的时候,它也支持用斜杠分割目录名。我们编程的时候,最好统一用斜杠分割目录名,例如:路径名“/data/log.txt”在Windows 和Linux 两个系统中都支持。
fopen 函数支持以下的文件打开模式,"r"代表读,"w"代表写,"+"号代表读写。"r+"就是代表读写了,那么"w+"呢?不是也代表读写吗?它们的区别在于你要打开的文件是否存在。如果文件不存在,"r+"就失败,而"w+"会新建一个文件。如果文件存在,"r+"不清空文件,而"w+"会清空文件。所以,如果文件存在,一定要慎用"w+"。
使用文件打开模式的时候,一定要注意,输入的模式参数应该是字符串,而不是单个字符,哪怕只有一个字符。也就所说fopen("file",'r');是错的,应该用fopen("file","r");。
那么我们能否使用模式rw 呢?这多少让我想起了一个笑话。一个鹦鹉,如果拽他左腿,它会说:“你好”;如果你拽它右腿,它会说:“再见”。如果你两个腿一起拽呢?它会说:“你个傻冒!我还能站住了吗?”。如果你用rw,你可以看看编译器对你说什么:)
你真的去尝试使用"rw"模式了吗?如果是,我真的很欣赏你。你真是一个有好奇心的好学生。乔帮主(苹果的乔布斯,不是丐帮的乔峰)有句名言:“Keep hungry, Keep stupid”,其中的“Keep hungry”就是让大家有足够的求知欲和好奇心。
当我们利用“r+”或是“w+”打开一个文件的时候,我们是支持对一个文件同时进行读写的。例如,我们可以读入一块数据,修改以后,再写回到这个文件中,覆盖掉原来的数据。交替读写貌似很强大,但是也非常容易出问题,因为读写其实公用一个缓冲区。
首先,我强烈不推荐对一个文件同时进行读写。因为每次读写都隐含着文件位置指针的改变,所以结果就是你很容易写乱,破坏了原来的文件。如果恰好你还没有原文件的备份,那么我恭喜你!常见的做法是使用一个临时文件专门用来写,写完以后,经过核对检查确认没有问题,再用临时文件替换掉原来的文件。这样即使出错,原来的文件内容也不会被破坏。别忘了,Keep hungry 的同时,最好也Keep stupid。
如果在某个特定场景下,你必须要交替读写,需要遵守两个原则:
• 如果中间没有fflush、fseek、fsetpos 或rewind,则输出的后面不能直接跟随输入。
• 如果中间没有fseek、fsetpos 或rewind,或者一个输出操作没有到达文件尾端,则在输入操作之后不能直接跟随输出。
程序12-2 演示了如何将一个文本文件中的小写字母变成大写字母,使用了文件的交替读写功能。第6 行中的fseek 函数貌似没有用,因为它并没有移动文件位置指针,但是也不能缺少。因为输入和输出操作之间,必须要有一个fseek 来进行分割。
程序12-2 file 交替读写
1 do{
2 c = fgetc(fp);
3 if(islower(c) != 0){
4 fseek(fp, -1L, SEEK_CUR);
5 fputc(toupper(c), fp);
6 fseek(fp, 0L, SEEK_CUR); / 这一句不能少 /
7 }
8 }while (!feof(fp));
首先,为了准确定义出一行文本,我们必须引入一个断行标志符或行尾标志符的概念。在计算机还没有出现之前,有一种叫做电传打字机(Teletype Model 33,Linux/Unix 下的tty 概念也来源于此)的玩意,每秒钟可以打10 个字符。但是它有一个问题,就是打完一行,需要换行的时候,要用去0.2 秒,正好可以打两个字符。要是在这0.2 秒里面又有新的字符传过来,那么新传过来的字符就丢失了。于是,聪明的工程师们想了个办法解决这个问题,就是在每行后面加两个表示结束的字符,一个叫作“回车(return)”,告诉打字机把打印头定位在左边界;另一个叫作“换行(line feed)”,告诉打字机把纸向下移一行。这就是“回车”和“换行”的由来,它们代表的操作从它们的英语名字上也可以看出一二。
后来,计算机发明了,这两个概念也就被搬到了计算机上。早期,存储器很贵,一些程序员认为在每行结尾加两个字符表示文本行的末尾有点太浪费了,加一个就可以,于是,就出现了分歧。目前主流的个人电脑操作系统,主要集中在Windows、Linux 和Mac 三种上。这三种系统中,文本文件的行尾标志符定义各不相同。
• UNIX/Linux 下:用“换行”来表示。
• DOS/Windows 下:用“回车+换行”表示,与传统一致。
• Mac 下:用“回车”来表示。
这种不一致性带来的一个问题就是,UNIX和Mac 系统下的文本文件如果在Windows 里打开的话,所有文字都会变成一行;而Windows 里的文件在UNIX 和Mac 下打开的话,在每行的结尾可能会多出一个符号。
如果你的电脑中安装了UltraEdit 这个程序,你就可以验证上面的结论。这个程序支持各种不同平台的断行符之间的转换,转换结束后,你可以在它支持的二进制的模式下查看转换的结果。这里我给出了三种格式所对应的二进制结果。例子所用的文本文件只包含两行,第一行为数字1,第二行为数字2,这里主要考察它们不同的断行格式,结果如图12-2 表示。这里大家要知道,回车符在ASC 码中的十六进制表示为0x0D,换行符在ASC 码中的十六进制表示为0x0A。
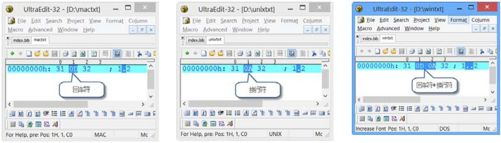
图12-2 Mac 格式(左)、UNIX 格式(中)和Windows 格式(右)
我相信,到目前大家都还清楚我在说什么。在不同的平台(操作系统)下,表示断行的标志符是不一样的。我们趁热打铁,下面说说C 语言中的情况。在C 语言中,“回车符”用'\r'来表示,而“换行符”用'\n'来表示。回车符'\r'依然代表定位在左边界这样一个物理意义,也就是说,回到本行行首。如果后面还有输出,那么后面的输出又从本行的行首处开始输入,结果就是本行以前的输出将被覆盖掉。如程序12-3 的第3 行所示,最后只会输出“you are handsome boy”这一行文本。
程序12-3 \r 代表的物理意义
1 int main()
2 {
3 printf("you are handsome boy\r");
4 printf("yan");
5 }
如果想在Windows 下输出多行文本,我们是不是就应该在每行的文本后面加上“\r\n”呢?在UNIX 下编写就在每行文本下面只加上“\r”呢?如果这样,那么C 12.3 断行标志符语言的跨平台移植性实在不值得恭维。事实上,我们完全没有必要这样做。其实C 语言的I/O 函数并不直接读写硬盘,而是通过调用操作系统的API 来完成的,如图12-3所示。
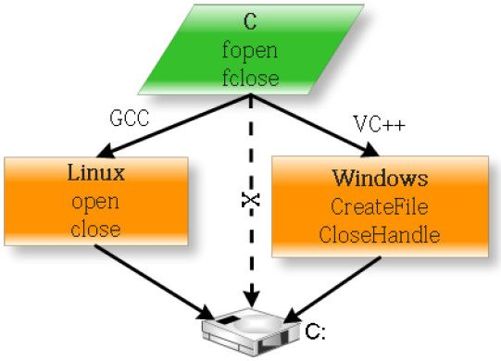
图12-3 C 语言函数不直接操作硬盘
所以,在C 语言中,不管外面的平台用什么表示断行符,C 语言内部统一用'\n'来表示断行。当C 语言的字符串中遇到'\n'时,在不同的平台上,C 语言会调用不同平台对应的I/O 函数,完成相应的转换,然后把正确的内容写到文件中。例如在Windows 平台上,'\n'被转化为0x0D 0x0A;在Mac 下,'\n'被转化为0x0D;在UNIX 或Linux 下,不做转换。不仅写出时做这种转换,读入的时候也做相反的转换。这样,我们的C 语言具有很好的跨平台性,整个过程如图12-4 所示。
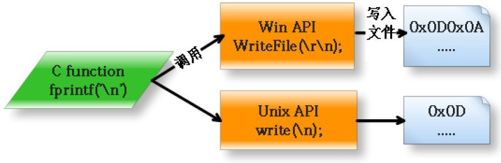
图12-4 C 语言中将\n 根据不同平台转化成与平台对应的断行符
明白以上的道理,我们就可以对程序12-3 进行修改。为了能够完整地输出两行,我们在程序12-3 中的第3 行中将“\r”改成“\n”就可以了。不用根据不同的平台写不同的代码。
有的时候,C 语言中“\n”也叫回车换行符,这主要针对Windows 平台。关于这一部分的内容,可以参考本书网站“扩展内容”网页中“小小换行符乱谈”链接,说得很到位、很细致,非常值得参考。
在12.1.3 节中,我们已经对打开文件时的读写模式做了一些介绍。C 语言中,文件的打开模式还支持二进制选项。fp = fopen("text.txt" "w+"); 就是以文本模式打开文件。如果在打开模式中增加字母“b”,如fp = fopen("file.bin""wb+");,就是以二进制模式打开文件。为什么有这两种模式呢?二者之间又有什么区别呢?
在我最开始学习C 语言的时候,我的第一反应是文本方式用来读写文本,而二进制方式用来读写数字。这种简单的字面理解是不对的。为什么有两种模式呢?其实,这都是12.3 节讲过的不同的系统有不同的断行符定义造成的。上面我们已经讲过,为了能够有更好的平台移植性,C 语言内部会对“\n”在写出和读入的时候做对应的转换。
下面给出一个例子,如程序12-4 所示。在Windows 操作系统下,程序12-4 默认情况下以文本模式打开文件,这里我们用fwrite 方式写入一个整数。
程序12-4 文本方式打开file
1 int i = 0x000a0000; / 整型数65530 /
2 fp = fopen("data", "w+");
3 fwrite(&i, sizeof(int),1,fp);
4 fclose(fp);
运行文件结束以后,利用UltraEdit 打开data 文件,然后转到二进制模式,发现data 文件包含5 个字节,内容为:0x00 0x0D 0x0A 0x00 0x00。可以看出,就算是你用fwrite 函数的时候,一旦在字节流中发现'\n'=0x0A,马上将其转换为'\r''\n'=0x0D 0x0A。这明显违背了我们保存一个整数(65530)的初衷。
再看程序12-5,在Windows 操作系统下,本程序以二进制模式打开文件,以fputs 方式写入两行文本。
程序12-5 二进制方式打开file
1 char *str = "the first line\n";
2 char * str1 = "the second line\n";
3 FILE *fp = fopen("text", "wb+");
4 fputs(str ,fp);
5 fputs(str1,fp);
6 fclose(fp);
运行文件结束以后,利用UltraEdit 打开text 文件,然后转到二进制模式,发现text 文件中'\n'被保存成0x0A,并没有像在文本模式下转换成0x0D 0x0A。这种格式在Linux 下是可以正常查看的。但是在Windows 下,如果用笔记本程序打开,因为没有正确的换行符,所以两行显示在同一行。
通过上面两个程序,我们可以得到结论,当以文本模式打开文件时,写'\n'到一个文件,或者从一个文件读取换行符,都会进行对应的转换;而以二进制模式b 打开的文件,不进行这种转换。上述两个例子的错误在于,不该转换的时候转换了,该转换的时候却没有转换。
无论文本模式还是二进制模式打开文件,都只在Windows 或Mac 操作系统上才有意义;在Linux 系统上,字符串中的'\n'写到文本中的时候,就是0x0A,不做任何转换。所以,在Linux 下,没有文本模式和二进制模式之间的区别。对了,我是不是很早就说过,Linux 比较适合程序员做开发工作呢?
C 语言中有不同的文件读写函数,可以按字符读写,如fputs、fgets、fputc,fgetc 等;也可以按数据块读写,如fread 和fwrite。正常情况下,按字符读写,我们应该以文本方式打开文件。如果按数据块读写,我们应该以二进制的方式打开文件。否则就会发生上面类似的错误。
好了,下面进行总结:
• 在Linux 下,没有文本模式和二进制模式之间的区别。
• 非Linux 下,如果你要使用fputs、fgets、fputc、fgetc、fprintf 等文本相关函数,务必用文本模式打开文件。
• 非Linux 下,如果你想用fread、fwrite、fseek、rewind、ftell 等数据块读写相关函数,务必用二进制模式打开文件。
我很早就遇到过函数feof 的一些问题。C 语言中,函数feof 非常具有迷惑性。从函数字面的解释就是如果文件位置指针指向文件的末尾,就应该返回真,否则返回假。真实的情况却是,有的时候,就算文件位置指针指向文件的末尾,它也返回假。例如:在程序12-6 中,文本文件test.txt 中只有一个字母“a”,并且字母“a”后面没有回车,所以test.txt 文本文件的大小为1 个字节。令人奇怪的是,运行这个程序后,会打印出“97 -1”,“-1”这个天外来客从何而来?
程序12-6 feof 的用法思考
1 int c;
2 FILE *fp = fopen("test.txt","r+");
3 / only 'a' in the file/
4 while(!feof(fp)){
5 c=fgetc(fp);
6 printf("%d ",c);
7 }
针对feof 的特性,我很早就有了对应的解决方法。但是我发现,自己会,和让别人会之间还是有很大距离的。就像一个厨师,你让他亲自炒菜没问题,如果让他写一本炒菜的书,那么保证你会看到“盐少许,油适量”这种毫无信息量的废话。我的处境和厨师一样,那就是如何把一个很难说清楚的函数feof 说清楚。你们看到的这一节,我已经重新写了三遍,不是修改,而是全部重写。所以如果你觉得这一节写的是本书最糟糕的,那么你错了,最糟糕的你还没有看到。
feof 的难度来源于它的定义,不查不知道,一查还真吓一跳。通过VS 自带的帮助文档,还有通过Linux 下的命令man feof,最后还有http://www.cplusplus.com 网站上的参考定义,我得到了三种不同的定义。
• VS 上:The feof routine (implemented both as a function and as a macro)determines whether the end of stream has been passed. When the end of file is passed, read operations return an end-of-file indicator until the stream is closed or until rewind, fsetpos, fseek, or clearerr is called against it.
• Linux 上:The function feof() tests the end-of-file indicator for the stream pointed to by stream.
• cplusplus.com 网络上:Checks whether the End-of-File indicator associated with stream is set, returning a value different from zero if it is. This indicator is generally set by a previous operation on the stream that reached the End-of-File.
我的这本书里基本上没有什么英文①。但是我决定把这三段英文保留下来,以便你们知道我所处的处境和苦衷。我该如何基于这三个不同的解释,把程序12-6 的问题浅显地给你们讲明白呢?
注释:① 不过,作为程序员,应该有良好的英文功底,同时也应该养成多阅读英文参考文献的习惯。
前两遍我试图基于上面的三种定义解释这个问题,直到给我自己都写得糊涂了。第三遍的时候,我决定改变这个思路。我要发明一种我自己的解释,这个解释要完全用我最流利的母语,而且完全能够合理、准确地解释所有feof 的现象。为了方便大家理解我的解释,我需要引出两个基本知识。
首先,大家要明白一件事,当我们从缓冲区读取一个文件内容的时候,缓冲区中文件的末尾处会添加一个EOF 标志。这个EOF 标志只会出现在缓冲区内,而不会出现在硬盘上的文件中。所以硬盘上的文件test.txt 的大小还是1 字节。但是如果把test.txt 放到缓冲区内,那么它的末尾会添加一个EOF 标志。
其次,feof 返回真,则文件位置指针一定指向末尾的EOF,但是反过来却不成立。如果借鉴我们高中的知识,那就是,文件位置指针指向末尾的EOF 是feof 返回真的充分非必要条件。feof 内部是通过判断一个标志位来返回真的,而这个标志位是上一个操作设置的。那么,什么时候上一个操作会设置这个标志位呢?
OK,我们已经具备了所有的基本知识。下面我要引出我的那句话,那就是:如果读操作,如fgetc、fgets、fscanf、fread 读取到了EOF 符的时候,会设置这个标志位。
为了详细解释这句话,下面我们开始分析程序12-6,整个过程如图12-5 所示。
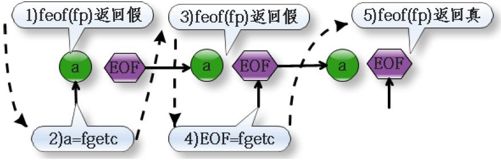
图12-5 feof 的解释
第2)步中运行fgetc 时,文件的位置指针指向a,当我们执行fgetc 函数后,我们读取了字符a,然后把文件的位置指针加1,位置指针指向了EOF。
这个时候,虽然位置指针指向了EOF,但是因为fgetc 没有读取到EOF,所以,当我们第3)步中再次执行feof 的时候,它依然返回假。这个就是最让初学者感到迷惑的地方了。
好了,让我们继续来,第4)步中执行fgetc,这回读取到了EOF,标志位被设置。
第5)步中运行feof 的时候,因为第4)步中fgetc 函数把标志位置位。所以feof 返回了真值,循环退出,整个过程如图12-5 中虚线箭头表示。
如果你理解了我在说什么,下面我们再看程序12-7。如果文件test.txt 只包含abc 三个字符,那么会打印出abc。如果文件test.txt 包含abc 和一个回车的话,本程序会打印出两行abc。
程序12-7 fgets 函数特点
1 FILE *fp = fopen("test.txt","r+");
2 char str[100];
3 while(!feof(fp)){
4 fgets(str,100,fp);
5 printf("%s",str);
6 }
为了明白这种现象是如何发生的,你需要知道关于fgets 的下面的两点知识。这些知识来源于fgets 的标准定义。在你使用每个函数前,仔细阅读函数的参考定义是非常必要的。
• Reads characters from stream and stores them as a C string into ch until 99(这里的99 和ch 都是为了配合程序12-7 而修改的,并不是官方的定义内容)characters have been read or either a newline or a the End-of-File is reached, whichever comes first.
• If the End-of-File is encountered and no characters have been read, the contents of ch remain unchanged,and a null pointer is returned.
有了fgets 的定义,再配合上面我们讲的基础知识,你就能正确地理解原因了。如果还不能的话,我再给你一点提示,如果abc 后面没有回车,那么fgets 会直接读取到EOF,feof 返回真;如果abc 后面有回车,fgets 会读取到回车。由于没有读取到EOF,feof 不会返回真;当fgets 第二遍读取的时候,读取到了EOF 并且没有其他字符被读入,所以str 中内容不变。
feof 这个名字给人的第一感觉就是用它来判断文件位置指针是否指向了末尾,但是经过上面的分析,我们现在知道这是不对的。鉴于feof 函数需要上一个读操作读取到EOF 时才返回真,所以一个更恰当的名字应该为freadeof 才对。
那么,feof 函数应该用在什么场景下呢?要说明这个函数的用处,我们有必要先看一看fgetc 函数的返回值,说明如下:
If the stream is at the end-of-file OR a read error occurs, the function returns EOF.
看到那个加黑的OR 的吗?现在我的问题就是,如果fgetc 返回EOF,那么到底是读到末尾了?还是读取出错了?要知道,这两种情况可以相差很大的,如果读到末尾,程序可以继续运行,如果是读取出错了,必须要终止程序的。这个时候,你就应该使用feof 这个函数了,如果是读到末尾了,根据上节的介绍,调用feof 会返回真,但是如果是出错了,调用ferror 函数会返回真。
不仅是fgetc 函数,几乎所有的读函数,例如fread()、fscanf()和fgetc(),当它们读取到末尾或者读取出错的时候,都会返回相同的值,所以这个时候,你必须分别使用feof 和ferror 函数,来判断到底是哪一种情况发生了。换句话说,无论是feof 函数还是ferror 函数,它们必须在一个读取函数如fgetc()的后面被调用。
明白了上面这些,你会发现程序12-6 中的feof 函数的用法是不正确的。这个程序中,如果fgetc 发生了读取错误,那么feof 永远返回false,整个程序会陷入死循环中。
那么该如何正确地判断是否一个读取操作已经读取到末尾,从而成功完成对整个文件的读取呢?程序12-8 给出了正确的程序。其中可以看出,feof 函数的调用发生在fgetc 函数的后面。同时,分别使用了feof 和ferror 来区分错误和到到末尾两种情况。
程序12-8 中以fgetc 为例进行了说明,事实上对fread()、fgets、fscanf()和fgetc()等读取函数,程序中的思路依然适用。
程序12-8 判断读取到文件末尾
int c:
while(c = fgetc(fp))
{
if(c == EOF){
if(feof(fp)!=0)
break;
if(ferror(fp)!=0)
error_handle;
}
else{
do_something
}
}
文件操作是事故多发区,会有各种各样的情况引起读写错误,如:
• 文件不存在
• 文件已存在
• 磁盘满
• 写一个只读文件
• 读一个只写文件
• 设备损坏
在事故发生时,程序必须能自如应对,这就需要错误处理技术。一般来说,我们有两种方法来判断是否出现了错误,第一是检查调用函数的返回值判断其是否出错;第二是调用一个文件函数后,立即检查ferror 函数的值。不过一般情况下,ferror 函数我们用的不多,因为从调用函数本身的返回值,我们就可以知道有没有错误发生。
常见的错误判断和处理策略可以参考《C 语言程序设计》[4]给出的如图12-6 所示的建议。
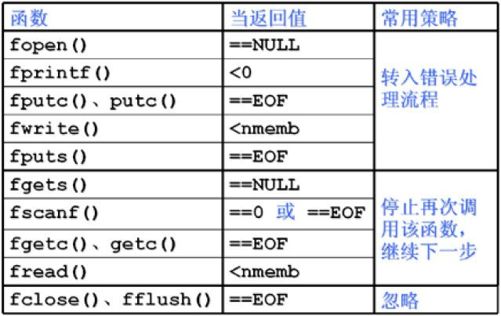
图12-6 常用的错误判断和处理策略
本章首先介绍了“句柄”的概念,并用我的东北家乡话把它翻译成了“把手”,希望你们喜欢我的这个翻译。另外用文件断行标志符的不同定义,引申出了文件打开方式中的“文本模式”和“二进制方式”的不同。这是本章的一个亮点。
本章的另外一个亮点就是对feof 函数的介绍。如果你实在看不明白也没关系,那就把程序12-8 中判断输入结束的方法牢牢记住,就算大功告成了。
