1.2 CVS——开启版本控制大爆发
CVS(Concurrent Versions System)[1]诞生于1985年,是由荷兰阿姆斯特丹VU大学的Dick Grune教授实现的。当时Dick Grune和两个学生共同开发一个项目,但是三个人的工作时间无法协调到一起,迫切需要一个记录和协同开发的工具软件。于是Dick Grune通过脚本语言对RCS(一个针对单独文件的版本管理工具)进行封装,设计出有史以来第一个被大规模使用的版本控制工具。Dick教授的网站上介绍了CVS的这段早期历史。[2]
“在1985年的一个糟糕的秋日里,我在校汽车站等车回家,脑海里一直纠结着一件事——如何处理RCS文件、用户文件(工作区)和Entries文件的复杂关系,有的文件可能会缺失、冲突、删除,等等。我的头有些晕了,于是决定画一个大表,将复杂的关联画在其中,看看出来的结果是什么样的……”
1986年Dick通过新闻组发布了CVS,1989年Brian Berliner用C语言将CVS进行了重写。
从CVS的历史可以看出,CVS不是设计出来的,而是被实际需要“逼”出来的,因此根据“实用为上”的原则,借用了已有的针对单一文件的版本管理工具RCS。CVS采用客户端/服务器架构设计,版本库位于服务器端,实际上就是一个RCS文件容器。每一个RCS文件以",v"作为文件名后缀,用于保存对应文件的每一次更改历史。RCS文件中只保留一个版本的完全拷贝,其他历次更改仅将差异存储其中,使得存储变得非常有效率。我在2008年设计了一个SVN管理后台pySvnManager[3],实际上也采用了RCS作为SVN授权文件的变更记录的“数据库”。
图1-1展示了CVS版本控制系统的工作原理,可以看到作为RCS文件容器的CVS版本库和工作区目录结构的一一对应关系。
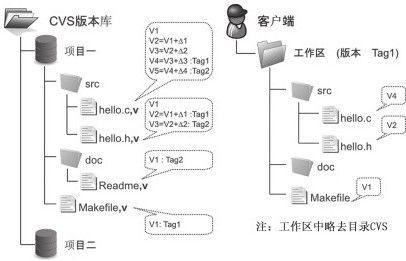
图 1-1 CVS版本控制系统示意图
CVS这种实现方式的最大好处就是简单。把版本库中任意一个目录拿出来就可以成为另外一个版本库。如果将版本库中的一个RCS文件重命名,工作区检出的文件名也会相应地改变。这种低成本的服务器管理模式成为很多CVS粉丝至今不愿离开CVS的原因。
CVS的出现让软件工程师认识到了原来还可以这样工作。CVS成功地为后来的版本控制系统确立了标准,像提交说明(commit log)、检入(checkin)、检出(checkout)、里程碑(tag)、分支(branch)等概念在CVS中早就已经确立。CVS的命令行格式也被后来的版本控制系统竞相模仿。
在2001年,我正为使用CVS激动不已的时候,公司领导要求采用和美国研发部门同样的版本控制解决方案。于是,我的项目组率先进行了从CVS到该商业版本控制工具的迁移[4]。虽然商业版本控制工具有更漂亮的界面及更好的产品整合性,但是就版本控制本身而言,商业版本控制工具存在着如下缺陷。
采用黑盒子式的版本库设计。让人捉摸不透的版本库设计,最主要的目的可能就是阻止用户再迁移到其他平台。
缺乏版本库整理工具。如果有一个文件(如记录核弹引爆密码的文件)检入到版本库中,就无法再彻底移除它。
商业版本控制工具很难为个人提供版本控制解决方案,除非个人愿意花费高昂的许可证费用。
商业版本控制工具注定是小众软件,新员工的培训成本不可忽视。
而上述商业版本控制系统的缺点恰恰是CVS及其他开源版本控制系统的优点。但在经历了最初的成功之后,CVS也尽显疲态:
服务器端松散的RCS文件导致在建立里程碑或分支时效率不高,服务器端文件越多,速度越慢。
分支和里程碑不可见,因为它们被分散地记录在服务器端的各个RCS文件中。
合并困难重重,因为缺乏对合并的追踪,从而导致重复合并,引发严重冲突。
缺乏对原子提交的支持,会导致客户端向服务器端提交不完整的数据。
不能优化存储内容相同但文件名不同的文件,因为在服务器端每个文件都是单独进行差异存储的。
不能对文件和目录的重命名进行版本控制,虽然直接在服务器端修改RCS文件名可以让改名后的文件保存历史,但是这样做实际上会破坏历史。
CVS的成功导致了版本控制系统的大爆发,各式各样的版本控制系统如雨后春笋般诞生了。新的版本控制系统或多或少地解决了CVS版本控制系统存在的问题。在这些版本控制系统中,最典型的就是Subversion(SVN)。
[2]http://dickgrune.com/Programs/CVS.orig/
