第20章 STL映射类
标准模板库(STL)向程序员提供了一些容器类,供需要进行频繁而快速搜索的应用程序使用。在本章中,您将学习:
• 如何使用STL map、multimap、unordered_map和 unordered_multimap;
• 插入、删除和查找元素;
• 提供自定义的排序谓词;
• 散列表工作原理简介。
20.1 STL映射类简介
map和multimap是键-值对容器,支持根据键进行查找,如图20.1所示。

图20.1 键-值对容器
map和multimap之间的区别在于,后者能够存储重复的键,而前者只能存储唯一的键。
为实现快速查找,STL map和multimap的内部结构看起来像棵二叉树。这意味着在map或multimap中插入元素时将进行排序;还意味着不像vector那样可以使用其他元素替换给定位置的元素,位于map中特定位置的元素不能替换为值不同的新元素,这是因为map将把新元素同二叉树中的其他元素进行比较,进而将它放在其他位置。
 要使用STL map或multimap类,需要包含头文件<map>:
要使用STL map或multimap类,需要包含头文件<map>:

20.2 std::map和std::multimap的基本操作
STL map和multimap都是模板类,要使用其成员函数,必须先实例化。
20.2.1 实例化std::map和std::multimap
要实例化将整数用作键、将字符串用作值的 map 或 multimap,必须具体化模板类 std::map 或std::multimap。实例化模板类map时,需要指定键和值的类型以及可选的谓词(它帮助map类对插入的元素进行排序)。因此,典型的map实例化语法如下:

第三个模板参数是可选的。如果您值指定了键和值的类型,而省略了第三个模板参数,std::map和std::multimap将把std::less<>用作排序标准。因此,将整数映射到字符串的map或multimap类似于下面这样:
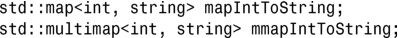
程序清单20.1更详细地说明了实例化方式。
程序清单20.1 实例化STL map和multimap(键类型为 int,值类型为 string)

分析:
首先,将重点放在第12~39行的main()函数上。第21和22行演示了实例化键类型为int、值类型为string的map和multimap的最简单方式;第25~29行演示了如何创建一个map或multimap,并使用另一个map或multimap中指定范围内的值对其进行初始化;第31~36行演示了在实例化map或multimap时如何自定义排序标准。请注意,默认使用排序标准std::less<T>,这将元素按升序排列。如果要改变这种行为,可提供一个谓词——一个实现了operator()的类或结构。第4~10行定义了一个这样的谓词——结构ReverseSort,第32和35行实例化map和multimap时使用了该谓词。
 cbegin()和cend()是否导致编译错误?
cbegin()和cend()是否导致编译错误?
如果要使用不遵循 C++11 的编译器编译该程序,请将 cbegin()和 cend()分别替换为 begin()和end()。cbegin()和cend()是C++11新增的,它们返回一个const迭代器,不能用于修改元素。
map和multimap的大多数函数的用法类似,它们接受类似的参数,返回类型也类似。例如,要在这两种容器中插入元素,都可使用成员函数insert:

鉴于这两种容器包含的元素都是键-值对,因此也可直接使用std::pair来指定要插入的键和值:
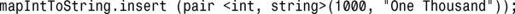
另外,还可使用类似于数组的语法进行插入。这种方式对用户不太友好,是由下标运算符([ ])支持的:
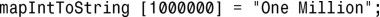
还可使用map来实例化multimap:

程序清单20.2演示了各种插入元素的方式。
程序清单20.2 使用 insert()以及数组语法(运算符[])在STL map或multimap中插入元素

输出:

分析:
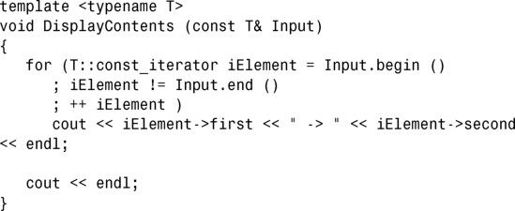
第7行和第8行给模板类map和multimap的实例指定了别名,这样可让代码看起来更简单(避免使用模板带来的混乱)。第10~19行是针对map和multimap改写后的DisplayContents(),它使用迭代器来访问表示键的first以及表示值的second。第26~32行演示了使用重载方法insert()将键-值对插入到map中的各种方式。第35行表明,可使用数组语法(运算符[])在map中插入元素。请注意,这些插入方式也适用于multimap,如第47行所示,这行代码在multimap中插入了一个重复的元素。有趣的是,第42和43行使用map的内容初始化multimap。输出表明,这两种容器都自动根据键升序排列输入的键-值对;输出还表明,multimap 可存储两个键相同(这里是 1000)的键-值对。第56 行使用了multimap::count(),这个函数指出有多少个元素包含指定的键。
 关键字auto是否导致编译错误?
关键字auto是否导致编译错误?
在程序清单20.2中,函数DisplayContents()使用了C++11关键字auto来指定迭代器类型,如第13所示。对于这个示例及后面的示例,要使用不遵循C++11的编译器对其进行编译,需要将auto替换为显式类型。
因此,如果您使用的是较旧的编译器,需要将DisplayContents()修改成下面这样:
诸如map和multimap等关联容器都提供了成员函数find(),它让您能够根据给定的键查找值。find()总是返回一个迭代器:
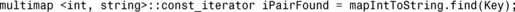
您应首先检查该迭代器,确保find()已成功,再使用它来访问找到的值:
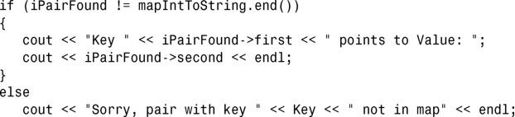
 如果您使用的编译器遵循C++11标准,可使用关键字auto来简化迭代器声明:
如果您使用的编译器遵循C++11标准,可使用关键字auto来简化迭代器声明:
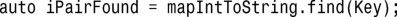
编译器将根据map::find()的返回类型自动推断出迭代器的类型。
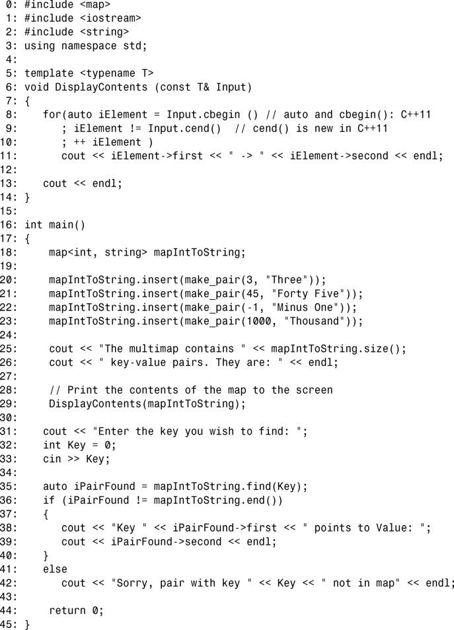
程序清单20.3演示了multimap::find的用法。
程序清单20.3 使用成员函数find在map中查找键-值对
输出:

再次运行的输出(这次find()没有找到匹配的元素):

分析:
在main()函数中,第20~23行使用几个键-值对填充一个map,每个键-值对都将整型键映射到字符串值。用户指定要用于在map中查找元素的键后,第35行使用函数find()根据指定的键在map中进行查找。map::find()总是返回一个迭代器,核实find()操作成功总是明智的,为此可将返回的迭代器与end()进行比较,如第36行所示。如果该迭代器有效,则通过成员second访问值,如第39行所示。第二次运行时,您指定的键2011不包含在map中,因此显示了一条错误消息。
 使用find()返回的迭代器之前,务必通过检查迭代器核实find()操作成功了。
使用find()返回的迭代器之前,务必通过检查迭代器核实find()操作成功了。
如果程序清单 20.3 使用的是 multimap,容器可能包含多个键相同的键-值对,因此需要找到与指定键对应的所有值。为此,可使用multimap::count()确定有多少个值与指定的键对应,再对迭代器递增,以访问这些相邻的值:
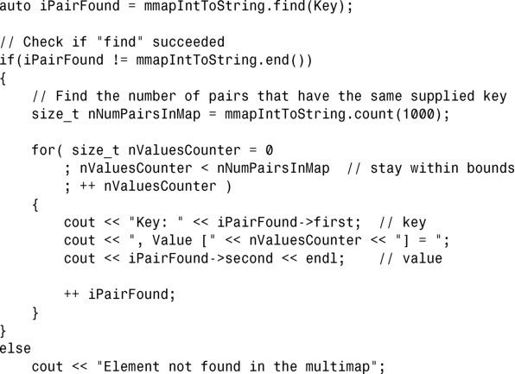
map和multimap提供了成员函数erase(),该函数删除容器中的元素。调用erase函数时将键作为参数,这将删除包含指定键的所有键-值对:
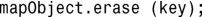
erase函数的另一种版本接受迭代器作为参数,并删除迭代器指向的元素:
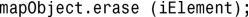
还可使用迭代器指定边界,从而将指定范围内的所有元素都从map或multimap中删除:

程序清单20.4演示了函数erase()的用法。
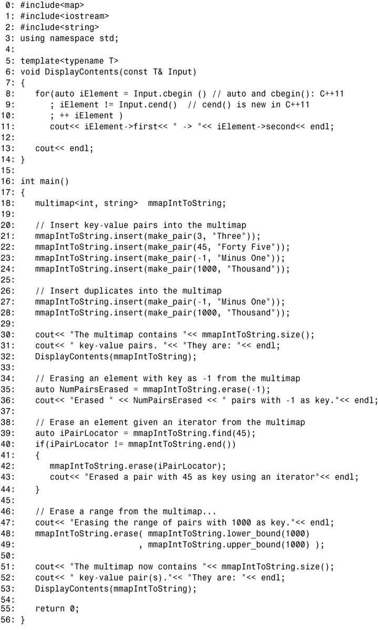
程序清单20.4 删除multimap中的元素
输出:

分析:
第21~28行将一些插入到 multimap中,有些是重复的(因为 multimap不同于 map,它允许插入重复的元素)。将键-值对插入到multimap后,第35行调用接受一个键作为参数的erase函数,将所有包含该键(-1)的键-值对都删除。multimap::erase(Key)的返回值为删除的元素数,这显示到了屏幕上。第39行使用find(45)返回的迭代器,将键为45的键-值对从multimap中删除。第48和49行表明,可使用lower_bound()和upper_bound()来指定范围,从而将包含特定键的所有键-值对都删除。
20.3 提供自定义的排序谓词
map和multimap的模板定义包含第3个参数,该参数是确保map能够正常工作的排序谓词。如果没有指定这个参数(如前面的示例所示),将使用 std::less <>提供的默认排序标准,该谓词使用<运算符来比较两个对象。
要提供不同的排序标准,可编写一个二元谓词——实现了operator()的类或结构:

对于键类型为std::string的map,默认排序谓词std::less<T>导致根据std::string类定义的<运算符进行排序,因此区分大小写。很多应用程序(如电话簿)要求执行插入和搜索操作时不区分大小写,为满足这种需求,一种解决方案是在实例化map时提供一个排序谓词,它根据不区分大小写的比较结果返回true或false,如下所示:
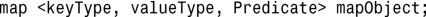
程序清单20.5对此做了更详细的解释。
程序清单20.5 提供自定义排序谓词——电话簿应用程序
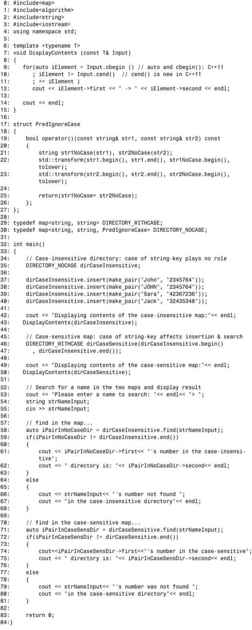
输出:

分析:
程序清单20.5实现了两个电话簿。其中一个在实例化时没有提供谓词,因此使用默认谓词std::less<T>,导致根据区分大小写的std::string::operator<进行排序和查找。实例化另一个电话簿时指定了谓词PreIgnoreCase,该谓词是在第17~27行定义的,它将两个字符串转换为小写后再进行比较。从输出可知,在这两个map中查找sara时,在不区分大小写的map中能够找到Sara,但在区分大小写的map中找不到该条目。
 在程序清单 20.5 中,也可将结构 PredIgnoreCase 声明为类。在这种情况下,需要给operator()加上关键字public。在C++编译器看来,结构类似于类,但成员默认为公有的,继承方式也默认为公有的。
在程序清单 20.5 中,也可将结构 PredIgnoreCase 声明为类。在这种情况下,需要给operator()加上关键字public。在C++编译器看来,结构类似于类,但成员默认为公有的,继承方式也默认为公有的。
这个示例演示了如何使用谓词来定制 map 的行为,它还表明键可以是任何类型的,而程序员可提供一个谓词以定义这种类型的map的行为。注意到这里使用的谓词是一个实现了运算符()的结构,但也可以是类。这种也可作为函数的对象被称为函数对象(或Functor),这将在第21章更详细地介绍。
 std::map 非常适合用于存储键-值对,让您能够根据指定的键查找值。在查找方面,map的性能确实比STL vector和 list高,但查找速度会随元素的增加而降低。map的复杂度为对数,即所需的时间与map包含的元素数的对数成正比。
std::map 非常适合用于存储键-值对,让您能够根据指定的键查找值。在查找方面,map的性能确实比STL vector和 list高,但查找速度会随元素的增加而降低。map的复杂度为对数,即所需的时间与map包含的元素数的对数成正比。
简单地说,对数复杂度意味着 std::map 和 std::set 等容器包含的元素数从 10000 减少到100时,速度将提高一倍。
vector 的元素未经排序,其查找复杂度为线性,这意味着当元素数从 10000 减少到 100时,速度将提高100倍。
虽然对数复杂度已相当不错,但别忘了,map、multimap、set和multiset等容器在插入时对元素进行排序,因此其插入速度更慢。因此,大家一直在寻找速度更快的容器,数学家和程序员找到了最优秀的容器,其插入和查找时间固定。散列表就是一种这样的容器,其插入时间是固定的,根据键查找元素的时间也几乎是固定的(大多数情况下如此),而不受容器大小的影响。
C++11
基于散列表的STL键-值对容器std::unordered_map
从C++11起,STL支持散列映射——std::unordered_map类。要使用这个模板类,需要包含头文件<unordered_map>:

unordered_map的平均插入和删除时间是固定的,查找元素的时间也是固定的。
这一直是博士论文探讨的主题,本书不打算详细讨论它,只简要地讨论散列表的工作原理。
可将散列表视为一个键-值对集合,根据给定的键,可找到相应的值。散列表与简单映射的区别在于,散列表将键-值对存储在桶中,每个桶都有索引,指出了它在散列表中的相对位置(类似于数组)。这种索引是使用散列函数根据键计算得到的:
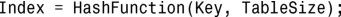
使用find()根据键查找元素时,将使用HashFunction()计算元素的位置,并返回该位置的值,就像数组返回其存储的元素那样。如果HashFunction()不佳,将导致多个元素的索引相同,进而存储在同一个桶中,即桶变成了元素列表。这种情形被称为冲突(collision),它会降低查找速度,使查找时间不再是固定的。
20.3.2 使用C++11散列表unordered_map和unordered_multimap
从使用的角度看,这两种容器与std::map和std::multimap差别不大,可以类似的方式执行实例化、插入和查找:
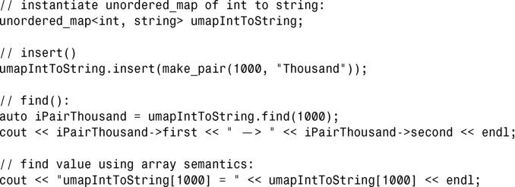
然而,一个重要的特点是,unordered_map包含一个散列函数,用于计算排列顺序:

要获悉键对应的索引,可调用该散列函数,并将键传递给它:

鉴于unordered_map将键-值对存储在桶中,在元素数达到或接近桶数时,它将自动执行负载均衡:

load_factor()指出了unordered_map桶的填满程度。因插入元素导致load_factor()超过max_load_factor()时,unordered_map将重新组织以增加桶数,并重建散列表,如程序清单20.6所示。
 std::unordered_map与unordered_map类似,只是可存储多个键相同的键-值对。
std::unordered_map与unordered_map类似,只是可存储多个键相同的键-值对。
std::unordered_multimap的用法与std::multimap很像,但包含一些散列表特有的函数,如程序清单20.6所示。
程序清单 20.6 实例化 STL 散列表实现 unordered_map,并使用 insert()、find()、size()、max_bucket_count()、load_factor()和max_load_factor()

输出:

分析:
从输出可知,该程序中的unordered_map最初8个键-值对和8个桶,但插入第9个元素时自动调整了大小,而桶数增加到 64个。注意到第 9~11行使用了方法 max_bucket_count()、load_factor()和max_load_factor()。除此之外,其他代码与使用std::map时差别不大,这包括使用find()的第42行。与用于std::map时一样,该函数返回一个迭代器,需要将其与end()进行比较,以确定操作成功。
 无论使用的键是什么,都不要编写依赖于 unordered_map 中元素排列顺序的代码。在unordered_map,元素相对顺序取决于众多因素,其中包括键、插入顺序、桶数等。
无论使用的键是什么,都不要编写依赖于 unordered_map 中元素排列顺序的代码。在unordered_map,元素相对顺序取决于众多因素,其中包括键、插入顺序、桶数等。
这些容器为提高查找性能进行了优化,遍历其中的元素时,不要依赖于元素的排列顺序。
 在不发生冲突的情况下,std::unordered_map的插入和查找时间几乎是固定的,不受包含的元素数的影响。然而,这并不意味着它优于在各种情形下复杂度都为对数的 std::map。在包含的元素不太多的情况下,固定时间可能长得多,导致 std::unordered_map 的速度比std::map慢。
在不发生冲突的情况下,std::unordered_map的插入和查找时间几乎是固定的,不受包含的元素数的影响。然而,这并不意味着它优于在各种情形下复杂度都为对数的 std::map。在包含的元素不太多的情况下,固定时间可能长得多,导致 std::unordered_map 的速度比std::map慢。
选择容器类型时,务必执行模拟实际情况的基准测试。

20.4 总结
本章介绍了STL map和multimap的用法及其重要的成员函数和特征,这些容器的复杂度为对数。STL还提供了散列表容器unordered_map和unordered_multimap,这些容器的insert()和find()性能不受容器大小的影响。您还学习了使用谓词定制排序标准的重要性,程序清单20.5的电话簿应用程序演示了这一点。
20.5 问与答
问:如何声明一个其元素按降序排列的整型set?
答:map <int>定义一个整型map,这种map使用默认排序谓词 std::less <T>将元素按升序排列,也可将其定义为map <int, less <int> >。要按降序排列,应将map定义为map <int, greater <int> >。
问:如果在一个字符串map中插入字符串Jack两次,将发生什么情况?
答:map不能存储重复的值,因此std::map类的实现不允许再次插入Jack。
问:在前一个例子中,如果需要两个Jack,该如何办?
答:map不能存储重复的值,应选择使用multimap。
问:multimap的哪一个成员函数返回容器中有多少个元素包含特定的值?
答:count (value)函数。
问:我使用函数find()在map中找到了一个元素,并有一个指向该元素的迭代器。能否使用这个迭代器来修改它指向的元素的值?
答:不能。有些STL实现可能允许用户通过迭代器(如函数find()返回的迭代器)修改元素的值,但不应这样做。应将指向map中元素的迭代器视为const迭代器,即使STL实现没有强制这样做。
问:我使用的编译器较老,不支持关键字auto。该如何声明一个变量,用于存储map::find()的返回值?
答:迭代器总是使用下述语法定义的:
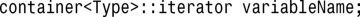
对于指向整型map中元素的迭代器,其声明如下:

20.6 作业
作业包括测验和练习,前者帮助读者加深对所学知识的理解,后者提供了使用新学知识的机会。请尽量先完成测验和练习题,然后再对照附录D的答案。在继续学习下一章前,请务必弄懂这些答案。
1.使用map <int>声明整型map时,排序标准将由哪个函数提供?
2.在multimap中,重复的值以什么方式出现?
3.map和multimap的哪个成员函数指出容器包含多少个元素?
4.在map中的什么地方可以找到重复的值?
1.编写一个应用程序来实现电话簿,它不要求人名是唯一的。应选择哪种容器?写出容器的定义。
2.下面是电话簿应用程序中一个map的定义:

其中wordProperty是一个结构:

请定义二元谓词fPredicate,用于帮助该map根据wordProperty键包含的string属性对元素进行排序。
3.map不接受重复元素,而multimap接受;请编写一个简单程序来演示这一点。
