第23章 STL算法
标准模板库(STL)中很重要的一部分是通用函数,这些函数位于头文件<algorithm>中,可帮助操作容器的内容。本章介绍如何使用各种STL算法以及如何根据应用程序的需求定制这些算法。
在本章中,您将学习:
• 如何使用STL算法简化模板代码;
• 帮助在STL容器中执行计数、搜索、查找、删除等操作的通用函数。
23.1 什么是STL算法
查找、搜索、删除和计数是一些通用算法,其应用范围很广。STL 通过通用的模板函数提供了这些算法以及其他的很多算法,可通过迭代器对容器进行操作。要使用STL算法,程序员必须包含头文件<algorithm>。
 虽然大多数算法都通过迭代器对容器进行操作,但并非所有算法都对容器进行操作,因此并非所有算法都需要迭代器。有些算法接受一对值,例如,swap()将这对值交换。同样,min()和max()也对值进行操作。
虽然大多数算法都通过迭代器对容器进行操作,但并非所有算法都对容器进行操作,因此并非所有算法都需要迭代器。有些算法接受一对值,例如,swap()将这对值交换。同样,min()和max()也对值进行操作。
23.2 STL算法的分类
STL算法分两大类:非变序算法与变序算法。
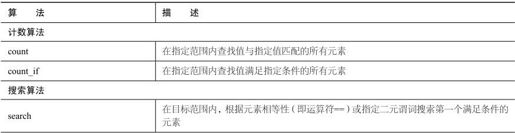
不改变容器中元素的顺序和内容的算法称为非变序算法。表23.1列出了一些主要的非变序算法。
表23.1 非变序算法
续表

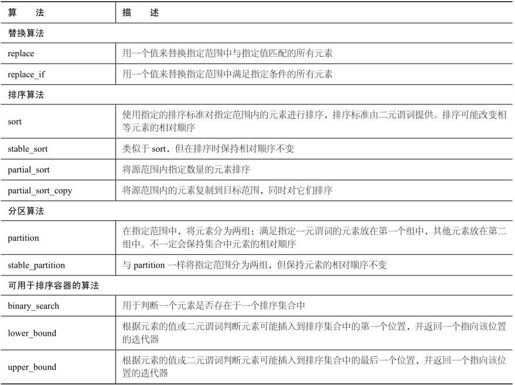
变序算法改变其操作的序列的元素顺序或内容,表23.2列出了STL提供的一些最有用的变序算法。
表23.2 变序算法

续表
23.3 使用STL算法
要学习表23.1和表23.2所示STL算法的用法,最佳的方法是亲自动手实践。为此,读者可通过下面的示例代码学习如何使用算法,并在自己的应用程序使用它们。
STL算法find()和find_if()用于在vector等容器中查找与值匹配或满足条件的元素。find()的用法如下:

find_if()的用法与此类似,但需要通过第三个参数提供一个一元谓词(返回 true 或 false 的一元函数):

这两个函数都返回一个迭代器,您需要将其同容器的end()或cend()进行比较,检查查找操作是否成功。如果成功,便可进一步使用该迭代器。程序清单23.1使用find()在vector中查找一个值,并使用find_if()找到第一个偶数。
程序清单23.1 使用find()在vector中查找一个整数,并使用find_if以及一个用lambda表达式表示的一元谓词查找第一个偶数

输出:

再次运行的输出:

分析:
在main()函数中,首先创建了一个整型vector,并将其初始化为−9~9。第17~19行使用find()查找用户输入的数字;第29~31行使用find_if()在指定范围内查找第一个偶数。第31行的一元谓词是以lambda表达式的方式提供的,该lambda表达式在element能被2整除时返回true。
 在程序清单23.1中,注意到总是将find()或find_if()返回的迭代器同cend()进行比较,以核实其有效性。这种检查绝不能省略,因为它表明 find()操作成功。不能想当然地认为find()操作成功。
在程序清单23.1中,注意到总是将find()或find_if()返回的迭代器同cend()进行比较,以核实其有效性。这种检查绝不能省略,因为它表明 find()操作成功。不能想当然地认为find()操作成功。
 在程序清单 17.5 的第 21 行,也演示了如何使用 std::distance 来确定找到的元素相对于vector开头的偏移量。
在程序清单 17.5 的第 21 行,也演示了如何使用 std::distance 来确定找到的元素相对于vector开头的偏移量。
算法std::count()和count_if()计算给定范围内的元素数。std::find()计算包含给定值(使用相当运算符==进行测试)的元素数:
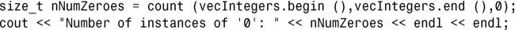
std::count_if()计算这样的元素数,即满足通过参数传递的一元谓词(可以是函数对象,也可以是lambda表达式):

程序清单23.2演示了这些函数的用法。
程序清单23.2 使用std::count()和count_if()分别计算有多少个元素包含指定值和满足指定条件

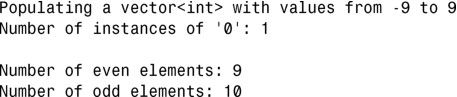
输出:
分析:
第 21行使用了 count()来计算 vector<int>包含多少个值为零的元素;同样,第 25行使用了count_if()来计算 vector包含多少个偶数元素。注意到第 3个参数是第 6~9行定义的一元谓词IsEven()。为计算 vector 包含多少个奇数元素,将 vector 包含的元素总数(由 size()返回)减去count_if()返回的值。
 程序清单23.2在count_if()中使用了谓词IsEven(),而在程序清单23.1中,在find_if()中使用了一个lambda表达式来完成IsEven()的工作。
程序清单23.2在count_if()中使用了谓词IsEven(),而在程序清单23.1中,在find_if()中使用了一个lambda表达式来完成IsEven()的工作。
使用lambda表达式可节省多行代码,但别忘了,如果将这两个示例合并成一个,则可将IsEven()用于find_if()和count_if()中,从而提高了代码的可重用性。
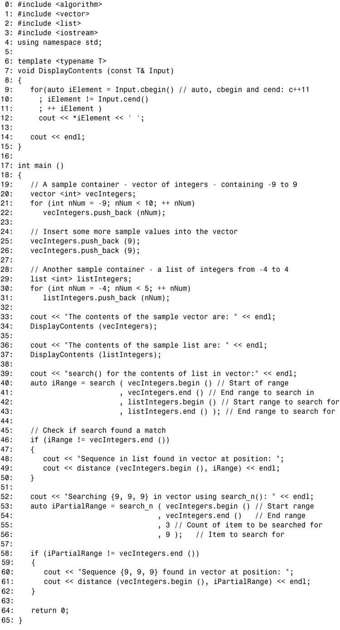
程序清单23.1演示了如何在容器中查找元素,但有时需要查找序列或模式。在这种情况下,应使用search()或search_n()。search()用于在一个序列中查找另一个序列:

search_n()用于在容器中查找n个相邻的指定值:

这两个函数都返回一个迭代器,它指向找到的第一个模式;使用该迭代器之前,务必将其与end()进行比较。程序清单23.3演示了search()和search_n()的用法。
程序清单23.3 使用search和search_n在集合中查找序列
输出:

分析:
在这个例子中,首先定义了两个容器:一个vector和一个list,并使用一些整型值填充它们。第40行使用search()在vector中查找list。由于要在整个vector中查找list的全部内容,因此使用了这两个容器类的成员方法 begin()和 end()返回的迭代器来指定范围。这表明迭代器在算法和容器之间搭建了桥梁;在算法看来,提供迭代器的容器的特征无关紧要,因为它只使用迭代器,因此能够在 vector 中无缝地查找list的全部内容。第53行使用search_n()搜索序列{9,9,9}在vector中首次出现的位置。
STL算法fill()和fill_n()用于将指定范围的内容设置为指定值。fill()将指定范围内的元素设置为指定值:

顾名思义,fill_n()将 n 个元素设置为指定的值,接受的参数包括起始位置、元素数以及要设置的值:
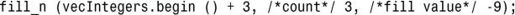
程序清单23.4表明,使用这些算法可轻松设置vector<int>中元素的值。
程序清单23.4 使用fill()和fill_n()设置容器中元素的初始值

输出:

分析:
程序清单23.4使用函数fill()和fill_n()将容器的内容初始化为两组不同的值,如第12行和第18行所示。请注意,在使用值填充范围前调用了函数 resize(),它实际上创建了随后要填充的元素。fill()算法对整个vector进行操作,而fill_n()可对vector的一部分进行操作。
23.3.5 使用std::generate()将元素设置为运行阶段生成的值
函数fill()和fill_n()将集合的元素设置为指定的值,而generate()和generate_n()等STL算法用于将集合的内容设置为一元函数返回的值。
可使用generate()将指定范围内的元素设置为生成器函数返回的值:
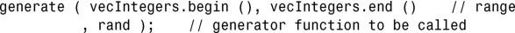
generate_n()与generate()类似,但您指定的是要设置的元素数,而不是闭区间:
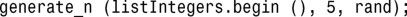
因此,可使用这两种算法将容器设置为文件的内容或随机值,如程序清单23.5所示。
程序清单23.5 使用generate()和generate_n()将集合设置为随机值

输出:

分析:
程序清单23.5使用函数generate()将vector的所有元素都设置为函数rand提供的随机值。注意到函数 generate()接受一个范围作为输入,并为该范围内的每个元素调用指定的函数对象 rand;而generate_n()接受起始位置,调用指定的函数对象 rand count次,以设置容器中 count个元素的值。容器中不在指定范围内的元素不受影响。
算法for_each()对指定范围内的每个元素应用了指定的一元函数对象,其用法如下:
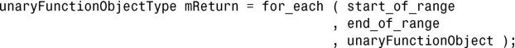
也可使用接受一个参数的lambda表达式代替一元函数对象。
返回值表明,for_each()返回用于对指定范围内的每个元素进行处理的函数对象(functor)。这意味着使用结构或类作为函数对象可存储状态信息,并在for_each()执行完毕后查询这些信息,如程序清单23.6所示。该程序清单使用函数对象显示指定范围内的元素,并使用它了确定显示了多少个元素。
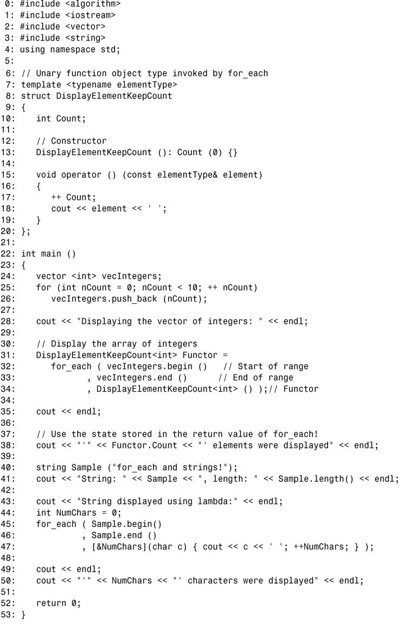
程序清单23.6 使用for_each()显示集合的内容
输出:

分析:
上述代码不仅演示了如何使用for_each(),还说明了它返回函数对象这一特点。返回的函数对象可存储信息,如被调用的次数。上述代码定义了两个范围,一个包含在整型 vector vecIntergers中,另一个是std::string对象Sample。第32行和第45行分别对这两个范围调用了for_each(),前者将一元谓词DisplayElementKeepCount 用作函数对象,而后者使用了一个 lambda 表达式。for_each()对指定范围内的每个元素调用operator(),而operator()将元素显示在屏幕上,并将内部计数加1。for_each()执行完毕后返回该函数对象,其成员 Count 指出了函数对象被调用的次数。在实际编程中,将信息(或状态)存储在算法返回的对象中很有帮助。第45行的for_each()执行的操作与第32行的for_each()相同,但操作的是一个std::string,且使用的是lambda表达式,而不是函数对象。
23.3.7 使用std::transform()对范围进行变换
std::for_each()和 std::transform()很像,都对源范围内的每个元素调用指定的函数对象。然而, std::transform()有两个版本,第一个版本一个接受一元函数,常用于将字符串转换为大写或小写(使用的一元函数分别是toupper()和tolower()):

第二个版本接受一个二元函数,让transform()能够处理一对来自两个不同范围的元素:

不像for_each()那样只处理一个范围,这两个版本的transform()都将指定变换函数的结果赋给指定的目标范围。程序清单23.7演示了std::transform()的用法。
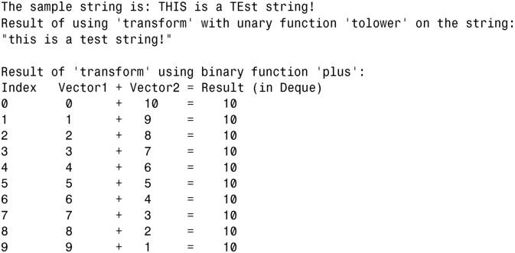
程序清单23.7 使用一元函数和二元函数的std::transform()

输出:
分析:
该示例演示了 std::transform()的两种版本的用法:一种版本使用一元函数 tolower 处理一个范围,如第 20行所示;另一个版本使用二元函数 plus处理两个范围,如第 40行所示。第一个版本修改字符串的大小写,将每个字符都改为小写。如果使用touppe而不是tolower,将把字符变为大写。std::transform()的另一个版本如第36~40行所示,它对来自两个输入范围(这里是两个vector)内的元素进行操作:使用一个二元谓词——STL函数plus()(由头文件<functional>提供)将两个元素相加。std::transform()每次处理一对元素,它将这对元素提供给二元函数 plus,然后将结果赋给目标范围中的元素——这里是std::deque中的元素。注意,这里使用另一种容器来存储结果只是出于演示目的。这个例子表明,通过使用迭代器,可将容器及其实现同 STL 算法分离:transform()是一种处理范围的算法,它无需知道实现这些范围的容器的细节。因此,虽然这里的输入范围为vector,而输出范围为deque,但该算法仍管用——只要指定范围的边界(提供给transform的输入参数)有效。
STL 提供了三个重要的复制函数:copy()、copy_if()和 copy_backward()。copy 沿向前的方向将源范围的内容赋给目标范围:

copy_if()仅在指定的一元谓词返回true时才复制元素:

 copy_if()是C++11新增的算法,包含在命名空间std中;如果您使用的编译器较旧(为遵循C++11),使用该算法可能导致问题。
copy_if()是C++11新增的算法,包含在命名空间std中;如果您使用的编译器较旧(为遵循C++11),使用该算法可能导致问题。
copy_backward()沿向后的方向将源范围的内容赋给目标范围:

remove()将容器中与指定值匹配的元素删除:

remove_if()使用一个一元谓词,并将容器中满足该谓词的元素删除:

程序清单23.8演示了这些复制和删除函数的用法。
程序清单23.8 一个演示copy()、copy_if()、copy_backward()、remove()和remove_if()的示例,它将list的内容复制到vector中,并删除包含零或偶数的元素

输出:

分析:
第 28 行使用了 copy(),它将 list 的内容复制到 vector 中。第 33 行使用了 copy_if(),它将listIntegers中的所有奇数都复制到vecIntegers中,并存储到从copy()返回的迭代器iLastPos开始的位置。第41行使用了remove(),它删除vecIntegers中所有值为零的元素。第45行使用remove_if()删除了所有奇数。
 程序清单23.8表明,remove()和remove_if()都返回一个指向容器末尾的迭代器,但容器vecIntegers一直未调整大小。删除算法删除元素时,其他元素将向前移,但size()返回的值没变,这意味着vector末尾还有其他值。要调整容器的大小(这很重要,否则末尾将包含不需要的值),需要调用erase(),并将remove()或remove_if()返回的迭代器传递给它,如第42和48行所示。
程序清单23.8表明,remove()和remove_if()都返回一个指向容器末尾的迭代器,但容器vecIntegers一直未调整大小。删除算法删除元素时,其他元素将向前移,但size()返回的值没变,这意味着vector末尾还有其他值。要调整容器的大小(这很重要,否则末尾将包含不需要的值),需要调用erase(),并将remove()或remove_if()返回的迭代器传递给它,如第42和48行所示。
STL算法replace()与replace_if()分别用于替换集合中等于指定值和满足给定条件的元素。replace()根据比较运算符==的返回值来替换元素:

replace_if()需要一个用户指定的一元谓词,对于要替换的每个值,该谓词都返回true:

程序清单23.9演示了这两个函数的用法。
程序清单23.9 使用replace()和replace_if()在指定范围内替换值

输出:

分析:
该示例给整型 vector vecIntegers填充值,然后使用STL算法 std::random_shuffle将这些值打乱,如第24行所示。第30行使用replace()将所有的5都替换为8。因此,第33行使用replace_if()将所有偶数都替换为-1后,集合包含6个元素,每个元素的值都为-1,如输出所示。
在实际的应用程序中,经常需要排序以及在有序范围内(出于性能考虑)进行搜索。经常需要对一组信息进行排序,为此可使用STL算法sort():

这个版本的sort()将std::less<>用作二元谓词,而该谓词使用vector存储的数据类型实现的运算符<。您可使用另一个重载版本,以指定谓词,从而修改排列顺序:

同样,在显示集合的内容前,需要删除重复的元素。要删除相邻的重复值,可使用unique():

要进行快速查找,可使用STL算法binary_search(),这种算法只能用于有序容器:

程序清单23.10使用STL算法std::sort()将一个范围排序,使用std::binary_search()在有序的范围内进行搜索,然后使用std::unique()删除相邻的重复元素(执行sort()后,重复的元素将彼此相邻)。
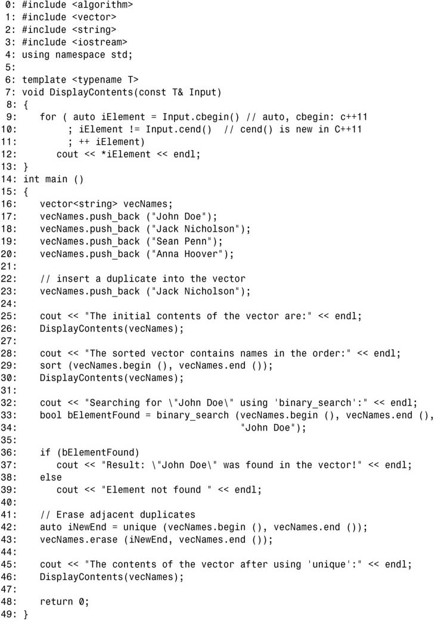
程序清单23.10 使用sort()、binary_search()和unique()
输出:

分析:
上述代码首先对 vector vecNames进行排序,如第 29行所示,再使用 binary_search在其中查找 John Doe,如第33行所示。同样,第42行使用std::unique()删除第二个相邻的重复元素。请注意,与remove()一样,unique()也不调整容器的大小。它将元素前移,但不会减少元素总数。为避免容器末尾包含不想要或未知的值,务必在调用unique()后调用vector::erase(),并将unique()返回的迭代器传递给它,如第42和43行所示。
 binary_search()算法只能用于经过排序的容器,如果将其用于未经排序的vector,结果可能出乎意料。
binary_search()算法只能用于经过排序的容器,如果将其用于未经排序的vector,结果可能出乎意料。
 stable_sort()的用法与sort()类似,这在前面介绍过。stable_sort()确保排序后元素的相对顺序保持不变。为确保相对顺序保持不变,将降低性能,这是一个需要考虑的因素,尤其在元素的相对顺序不重要时。
stable_sort()的用法与sort()类似,这在前面介绍过。stable_sort()确保排序后元素的相对顺序保持不变。为确保相对顺序保持不变,将降低性能,这是一个需要考虑的因素,尤其在元素的相对顺序不重要时。
std::partition()将输入范围分为两部分:一部分满足一元谓词;另一部分不满足。

然而,std::partition()不保证每个分区中元素的相对顺序不变。在相对顺序很重要,需要保持不变时,应使用std::stable_partition():
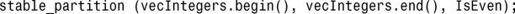
程序清单23.11演示了这些算法的用法。
程序清单23.11 使用partition()和stable_partition()将整型范围分为偶数值和奇数值
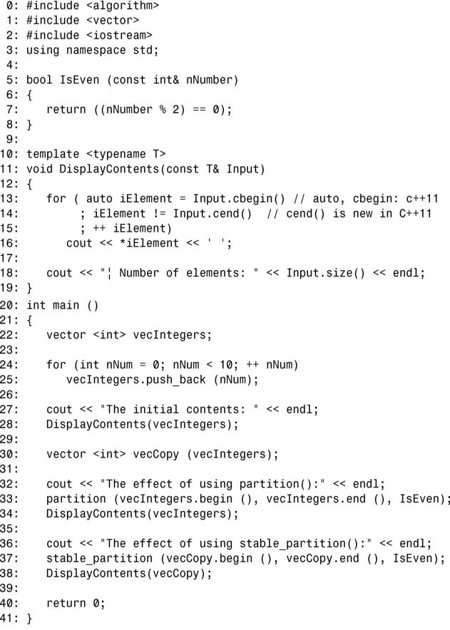
输出:
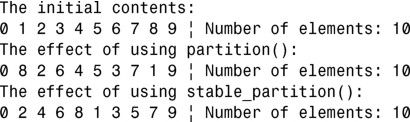
分析:
上述代码将包含在 vector vecIntegers中的整型范围分为偶数和奇数。第一次分区是在第 33行使用std::partition()完成的,第二次是在第 37 行使用 stable_partition()完成的。为便于比较,这里将范围vecIntegers复制到vecCopy中,并对前者使用std::partition(),对后者使用std::stable_partition()。与使用partition()相比,使用stable_partition()的效果很明显,如输出所示。stable_partition()保持每个分区中元素的相对顺序不变。注意,保持相对顺序不变是有代价的,这种代价可能很小(如在这个例子中),也可能很大,这取决于包含在范围中的对象类型。
 stable_partition()的速度比partition()慢,因此应只在容器中元素的相对顺序很重要时使用它。
stable_partition()的速度比partition()慢,因此应只在容器中元素的相对顺序很重要时使用它。
将元素插入到有序集合中时,将其插入到正确位置很重要。为满足这种需求, STL 提供了lower_bound()和upper_bound()等函数:

lower_bound()和upper_bound()都返回一个迭代器,分别指向在不破坏现有顺序的情况下,元素可插入到有序范围内的最前位置和最后位置。
程序清单23.12演示了如何使用lower_bound()将元素插入到在有序的人名list中的最前位置。
程序清单23.12 使用lower_bound()和upper_bound()在有序范围中插入元素
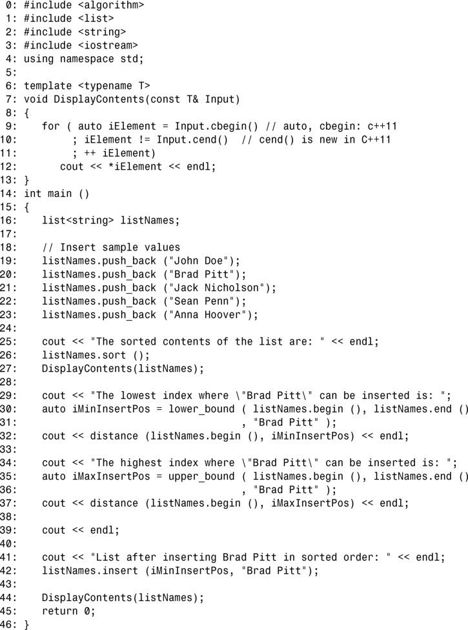
输出:

分析:
可将元素插入到有序集合中的两个位置:一个是 lower_bound()返回的最前位置(离集合开头最近),另一个是upper_bound()返回的迭代器,它是最后位置(离集合开头最远)。在程序清单23.12中,要插入到有序集合的字符串Brad Pitt已包含在集合中(这是在第 20行插入的),因此最前位置和最后位置不同(否则,两者将相同)。在第30行和第35行分别调用了这两个函数。如输出所示,第42行使用lower_bound()返回的迭代器将字符串插入list后,list仍处于有序状态。因此,这些算法可帮助确定不破坏集合有序状态的元素插入位置。使用upper_bound()返回的迭代器也如此。

23.4 总结
本章介绍了STL中最重要、功能最强大的方面:算法。在本章中,读者了解了各种类型的算法,并通过示例对其用法有更清晰的认识。
23.5 问与答
问:诸如std::transform()等变序算法能否用于关联容器(如std::set)?
答:即使可以,也不应这样做。应将关联容器的内容视为常量,这是因为关联容器在插入元素时进行排序,因此元素的相对位置不仅对find()等函数来说很重要,对容器的效率也很重要。因此,不应将诸如 std::transform()等变序算法用于STL set。
问:要将顺序容器的每个元素都设置为特定的值,可使用std::transform()吗?
答:虽然可以使用std::transform(),但使用fill()或fill_n()更合适。
问:copy_backward()是否会反转目标容器中元素的排列顺序?
答:不会。STL算法copy_backward()按相反的顺序复制元素,但不改变元素的排列顺序,即它从范围末尾开始复制到开头。如果要反转集合中元素的排列顺序,应使用std::reverse()。
问:是否应对list使用std::sort()?
答:std::sort()可用于 list,用法与用于其他顺序容器一样。然而,list 需要保持一个特殊特征:对list的操作不会导致现有迭代器失效,而 std::sort()不能保证该特征得以保持。因此,STL list通过成员函数list::sort()提供了sort算法。应使用该函数,因为它确保指向list中元素的迭代器不会失效,即使元素的相对位置发生了变化。
问:为什么在将元素插入到有序范围中时,使用lower_bound()或upper_bound()等函数很重要?
答:这两个函数分别提供有序集合中的第一个位置和最后一个位置,将元素插入这些位置时不会破坏集合的有序状态。
23.6 作业
作业包括测验和练习,前者帮助读者加深对所学知识的理解,后者提供了使用新学知识的机会。请尽量先完成测验和练习题,然后再对照附录D的答案。在继续学习下一章前,请务必弄懂这些答案。
1.要将list中满足特定条件的元素删除,应使用std::remove_if()还是list::remove_if()?
2.假设有一个包含ContactItem对象的list,在没有显式指定二元谓词时,函数list::sort()将如何对这些元素进行排序?
3.STL算法generate()将调用函数generator()多少次?
4.std::transform()与std::for_each()之间的区别何在?
1.编写一个二元谓词,它接受字符串作为输入参数,并根据不区分大小写的比较结果返回一个值。
2.演示STL算法(如copy)如何使用迭代器实现其功能——复制两个类型不同的容器存储的序列,而无需知道目标集合的特征。
3.您正在编写一个应用程序,它按星星在地平线上升起的顺序记录它们的特点。在天文学中,星球的大小很重要,其升起和落下的相对顺序亦如此。如果要根据星星的大小对这个集合进行排序,应使用std::sort()还是std::stable_sort()?
