附录D 答案
第1章
测验
1.解释器是一种对代码(或字节码)进行解释并执行相应操作的工具;编译器将代码作为输入,并生成目标文件。就 C++而言,编译和链接后,将得到一个可执行文件,处理器可直接执行它,而无需做进一步解释。
2.编译器将C++代码文件作为输入,并生成一个使用机器语言的目标文件。通常,您的代码依赖于库和其他代码文件中的函数。链接器负责建立这些链接,并生成一个可执行文件,它集成了您指定的所有直接或间接依存关系。
3.编写代码;通过编译创建目标文件;通过链接创建可执行文件;执行应用程序以便进行测试;调试;修复代码中的错误并重复这些步骤。
4.C++支持可移植的线程模型,让程序员能够使用标准C++线程函数创建多线程应用程序。通过在多个CPU核心中同时执行应用程序的不同线程,最大限度地发挥了多核处理器的潜力。
练习
1.显示x减y、x乘以y和x加y的结果。
2.输出应如下:
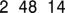
3.在第1行,包含iostream的预编译器指令应以#打头。
4.它显示如下内容:
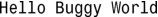
第2章
测验
1.C++代码区分大小写,在编译器看来,Int与表示整型的int不是一回事。
2.可以。

练习
1.因为C++编译器区分大小写,不知道std::Cout是什么以及它后面的字符串为何不以左引号打头。另外,声明main时,总是应该将其返回类型指定为int。
2.下面是修正后的程序:

3.下面的程序修改了程序清单2.4,以演示减法和乘法:

输出:

第3章
测验
1.有符号整型变量的最高有效位(MSB)用作符号位,指出了整数值是正还是负,而无符号整型变量只能存储正整数。
2.#define 是一个预处理器编译指令,让编译器对定义的值进行文本替换。然而,它不是类型安全的,是一种原始的常量定义方式,应避免使用。
3.确保变量包含非随机的确定值。
4.2。
5.这个变量名不具描述性,并重复地指出了变量的类型。这种代码虽然能够通过编译,但难以理解和维护,应避免。声明变量时,应使用能揭示其用途的名称,如:
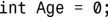
练习
1.方式有很多,下面是其中的两种:

2.参考程序清单3.4,并对其进行修改以获得这个问题的答案。
3.下面的程序要求用户输入圆的半径,并计算其面积和周长:

输出:

4.如果将计算得到的面积和周长存储到int变量中,将出现编译警告(而不是编译错误),且输出类似于下面这样:
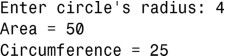
5.auto让编译器根据赋给变量的初始值自动确定其类型。这里的代码未初始化变量,无法通过编译。
第4章
测验
1.对于包含5个元素的数组,其第一个元素和最后一个元素的索引分别是0和4。
2.不应该,因为使用C风格字符串来存储用户输入很不安全,用户可能输入比数组长度更长的字符串。
3.一个终止空字符。
4.这取决于您如何使用它。如果将其用于cout语句,将不断读取字符,直到遇到终止空字符。这将跨越数组边界,可能导致应用程序崩溃。
5.只需将矢量声明中的int替换为char即可:
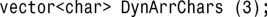
练习
1.下面是一种可能的解决方案,这里只初始化了包含“车”的棋盘方格,但足以让您明白其中的要点:

2.要设置第5个元素,应使用MyNumbers[4],因为索引从零开始。
3.这里使用了数组的第4个元素,但之前没有初始化,也没有赋值,因此输出是不确定的。务必初始化变量和数组,否则它将包含最后一次存储在相应内存单元中的值。
第5章
测验
1.用户可能想将两个浮点数相除,而int变量不能包含小数,因此应使用float。
2.编译器将操作数视为整数,因此结果为4。
3.由于分子为32.0而不是32,因此编译器将此视为为浮点数运算,结果为浮点数,大约为4.571。
4.sizeof为运算符,不能重载。
5.与预期不符,因为加法运算符的优先级高于移位运算符,因此将对number移6(1+5)位,而不是1位。
6.XOR的结果为false,如表5.5所示。
练习
1.下面是一种解决方案:
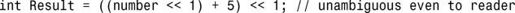
2.result包含将number向左移7位的结果,因为运算符+的优先级高于运算符<<。
3.下面的程序让用户输入两个布尔值,并显示对其执行各种按位运算的结果:

输出:

第6章
测验
1.缩进并非为方便编译器,而是为了方便其他需要阅读或理解代码的程序员。
2.通过避免使用goto,可防止代码不直观且难以维护。
3.参见练习1的解决方案,其中使用了递减运算符。
4.由于for语句中的条件不满足,该循环一次也不会执行,其中的cout语句也不会执行。
练习
1.您需要知道,数组的索引从零开始,而最后一个元素的索引为Length -1:

输出:
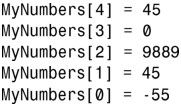
2.下面的嵌套循环类似于程序清单6.13,但以倒序方式将一个数组的每个元素都与另一个数组的每个元素相加:

输出:
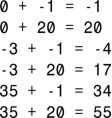
3.需要将值为5的int常量替换为下述让用户输入的代码:
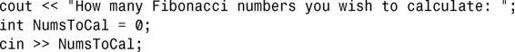
4.下面的switch-case结构使用枚举常量指出用户选择的颜色是否包含在彩虹中:

输出:

5.在for循环条件中,程序员不小心将10赋给了一个变量。
6.在 while 语句后面是一条空语句(;),因此无法实现预期的循环。另外,由于控制 while 的LoopCounter永远不会递增,因此while循环永远不会结束,它后面的语句不会执行。
7.遗漏了break。由于之前所有的case没有退出switch-case结构break,因此default部分总是会执行。
第7章
测验
1.这些变量的作用域为当前函数。
2.SomeNumber是指向调用函数中相应变量的引用,而不是其拷贝。
3.递归函数。
4.重载的函数。
5.栈顶!可将栈视为一叠盘子,可取出最上面的盘子,栈指针指向的就是这个地方。
练习
1.函数原型将类似于下面这样:
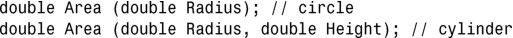
函数实现(定义)使用提供的公式计算体积,并将其作为返回值返回给调用者。
2.请参阅程序清单7.8。函数原型类似于下面这样:
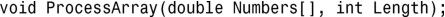
3.要让函数Area发挥作用,参数Result应为引用:
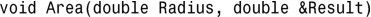
4.要么将有默认值的参数放在列表末尾,要么给所有参数都指定默认值。
5.该函数应通过引用将其输出数据返回给调用者。

第8章
测验
1.如果编译器允许这样做,将能轻松地突破const引用的限制:不能修改它指向的数据。
2.它们是运算符。
3.内存地址。
4.运算符*。
练习
1.40。
2.在第一个重载的函数中,实参将被复制给形参;在第二个函数中,不会复制,相反,形参是指向实参的引用,且函数可以修改它们;第三个使用的是指针,指针不同于引用,可能为NULL或无效,因此使用前必须核实它们是有效的。
3.使用关键字const:
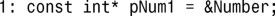
4.将整数直接赋给了指针,这将把指针包含的内存地址改为相应的整数值:

5.new返回给pNumber的内存地址被复制给了pNumberCopy,不能对该内存地址调用delete两次。删除其中一条delete语句。
6.30。
第9章
测验
1.在自由存储区中创建,与使用new给int变量分配内存时一样。
2.sizeof( )根据声明的数据成员计算类的大小。将 sizeof( )用于指针时,结果与指向的数据量无关,因此类包含指针成员时,将sizeof用于该类的结果也是固定的。
3.除该类的成员方法外,在其他地方都不能访问。
4.可以。
5.构造函数通常用于初始化数据成员和资源。
6.析构函数通常用于释放资源和内存。
练习
1.C++区分大小写。类声明应以class(而不是Class)打头,且以分号(;)结尾,如下所示:

2.由于Human::Age是私有成员(别忘了,不同于结构,类的成员默认为私有),且没有公有的存取函数,因此这个类的用户无法访问Age。
3.在下面的Human类中,构造函数包含一个初始化列表:

4.注意到按要求未将Pi向外暴露:
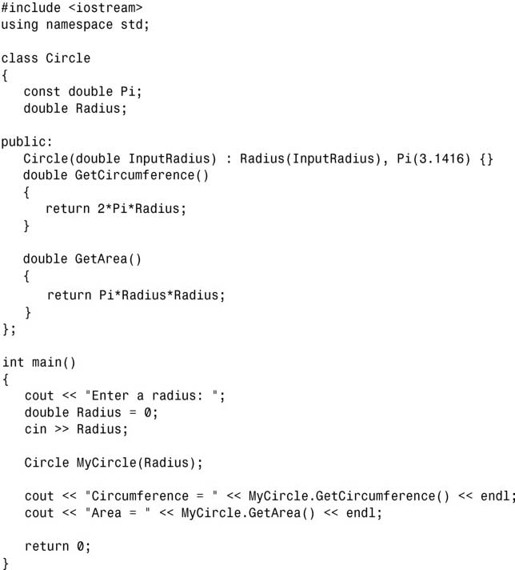
第10章
测验
1.通过使用访问限定符protected,可确保派生类能够访问基类的成员,但不能通过派生类实例进行访问。
2.派生类对象被切除,只按值传递对应于基类的部分。切除导致的行为无法预测。
3.使用组合,这样可提高设计的灵活性。
4.用于避免隐藏基类方法。
5.不能,因为Derived类与Base类是私有继承关系,这导致Base类对SubDerived类隐藏了其公有成员,即SubDerived不能访问它们。
练习
1.构造顺序与类声明中指定的顺序相同,即依次为Mammal、Bird、Reptile和Platypus;析构顺序则相反。下面的程序演示了这一点:

2.类似于下面这样:


3.要禁止D2类访问Base类的公有成员,D1类和Base类之间的继承关系应为私有的。
4.类的继承关系默认为私有。如果Derived是结构,继承关系将为公有。
5.SomeFunc按值接受一个类型为Base的参数。这意味着下面的函数调用将发生切除,导致不稳定和不可预测的结果:

第11章
测验
1.声明抽象基类Shape,并在其中将Area( )和Print( )声明为纯虚函数,从而要求Circle和Triangle必须实现这些函数。
2.编译器只为包含虚函数的类(包括派生类)创建VFT。
3.是抽象基类,因为它不能被实例化。只要类至少包含一个纯虚函数,它就是抽象基类,而不管它是否包含其他定义完整的函数和属性。
练习
1.继承层次结构如下,其中Shape是抽象基类,Circle和Triangle从Shape派生而来:

2.缺少虚析构函数。
3.实例化时,依次调用构造函数Car( )和Vehicle;由于没有虚析构函数,销毁时只调用~Car( )。
第12章
测验
1.不可以。C++不允许两个函数的名称相同,但返回类型不同。您可编写运算符[ ]的这样两种实现:它们的返回类型相同,但一个为const函数,另一个不是。在这种情况下,如果执行的是与赋值相关的操作,编译器将使用非const版本,否则使用const版本:
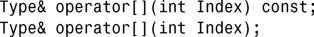
2.可以,但仅当您希望类不允许复制或赋值时才应这样做。
3.只有动态分配的资源才会导致复制构造函数和复制赋值运算符进行不必要的内存分配和释放,而 Date 类没有包含动态分配的资源,因此给它提供移动构造函数或移动赋值运算符没有意义。
练习
1.转换运算符 int( )如下所示:

2.移动构造函数和移动赋值运算符如下所示:

第13章
测验
1.dynamic_cast。
2.当然是修改函数。一般而言,除非万不得已,否则不要使用const_cast和类型转换运算符。
3.对。
4.对。
练习
1.总是应该检查动态转换的结果,看其是否有效:

2.由于知道指向的是Tuna对象,应使用static_cast。为证明这一点,对程序清单13.1进行修改,将main( )改成下面这样:

第14章
测验
1.这是一个预编译器结构,用于避免多次或递归包含头文件。
2.4。
4.结果为 10 + 10 / 5 = 10 + 2 =12。
5.加上括号:
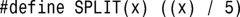
练习
1.如下所示:
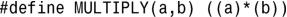
2.模板函数如下:

3.模板函数swap的定义如下:

4. 
5.该模板类的定义类似于下面这样:
第15章
测验
1.deque。只有deque允许在容器开头和末尾插入元素,且时间是固定的。
2.如果要存储的是键-值对,应选择std::set或std::map;如果有重复的元素,应选择std::multiset或std::multimap。
3.可能。实例化std::set模板时,可提供第二个模板参数,它是一个二元谓词,set类将它用作排序标准。可根据应用程序的需求定义该二元谓词,它必须能够对元素进行排序。
4.迭代器在算法和容器之间架设了桥梁,让算法能够在不知道容器类型的情况下对容器进行操作。
5.hash_set并非C++标准容器,因此不应在有移植性需求的应用程序中使用它。在这种情况下,应使用std::map。
第16章
测验
1.std::basic_string <T>。
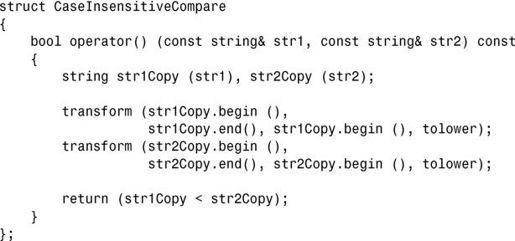
2.将两个字符串复制到两个副本对象中,再将每个复制的字符串都转换为小写或大写。然后对转换后的字符串进行比较,并返回比较结果。
3.否。C风格字符串实际上是类似于字符数组的原始指针,而STL string是一个类,实现了各种运算符和成员函数,使字符串操作和处理尽可能简单。
练习
1.该程序需要使用std::reverse:

2.使用std::find:

3.使用函数toupper:

4.可以这样编写程序:

第17章
测验
1.否。仅当在vector末尾插入元素时所需的时间才是固定的。
2.10个。插入第11个元素,将导致重新分配内存。
3.删除最后一个元素,即删除末尾的元素。
4.类型CMammal。
5.通过下标运算符([])或函数 at( )。
6.随机访问迭代器。
练习
1.下面是一种解决方案:

2.使用std::find算法:

3.修改练习1的解决方案,以接受用户输入并显示vector的内容。
第18章
测验
1.可将元素插入到list中间,可也将其插入到两端,插入位置不会影响性能。
2.list的独特之处在于,这些操作不会导致现有迭代器失效。
3.mList.clear ();或mList.erase (mList.begin(), mList.end());
4.可以。insert函数的一个重载版本可用于插入集合中特定范围内的元素。
练习
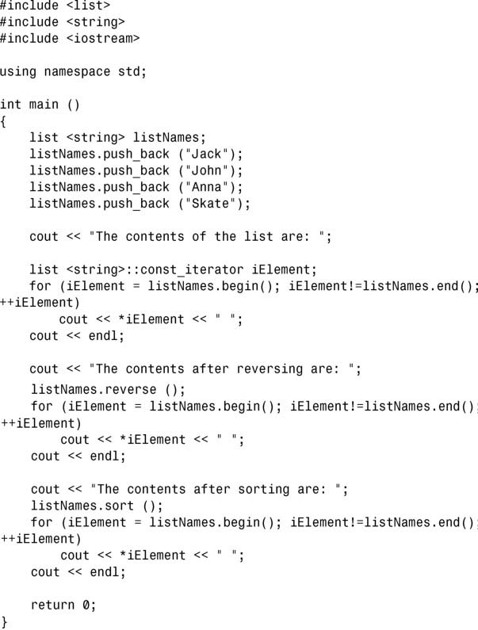
1.这类似于第17章中练习1的解决方案,唯一需要修改的地方是使用list的insert函数,如下所示:
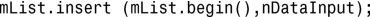
2.存储两个指向list元素的迭代器,使用list的insert函数在中间插入一个元素,然后使用这两个迭代器来演示在插入元素后它们仍指向以前的元素。
3.下面是一种可能的解决方案:
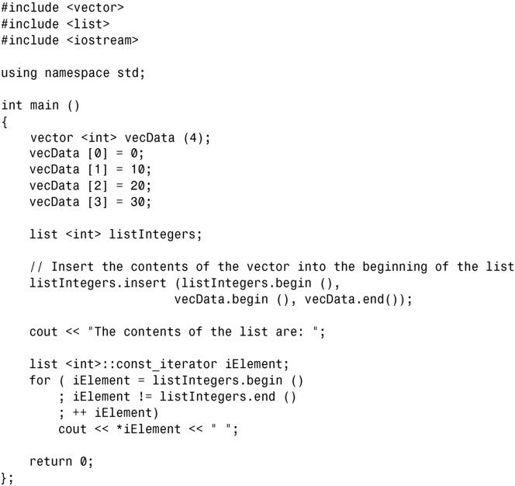
4.下面是一种可能的解决方案:
第19章
测验
1.默认排序标准由std::less<>指定,它使用运算符<来比较两个整数,并在第一个小于第二个时返回true。
2.重复的元素在一起,它们彼此相邻。
3.size(),所有STL容器都是。
练习
1.该二元谓词可以是这样的:

2.该结构和multiset的定义如下:

3.下面是一种解决方案:

第20章
测验
1.默认排序标准由std::less<>指定。
2.彼此相邻。
3.size ( )。
4.在map中找不到重复的元素!
练习
1.可包含重复元素的关联容器,如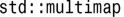 :
:
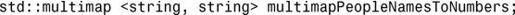
2.下面是一种解决方案:

3.参考第19章中练习3的解决方案。
第21章
测验
1.一元谓词。
2.它可以显示数据或计算元素个数。
3.在C++中,在应用程序运行阶段存在的所有实体都是对象,因此结构和类也可用作函数,这称为函数对象。注意,函数也可通过函数指针来调用,它们也是函数对象。
练习
1.下面是一种解决方案:

可以这样使用该一元谓词:

2.添加一个整型成员,每次调用operator()时都递增该成员:
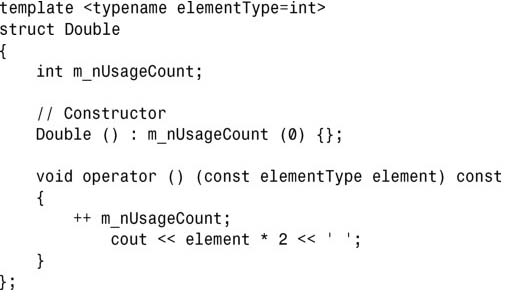
3.该二元谓词的定义如下:

可以这样使用该谓词:

第22章
测验
1.lambda表达式总是以[]打头。
2.通过捕获列表:[Var1, Var2, …] (Type& param){…;}。
3.像下面这样做:
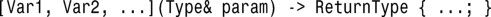
练习
1.该lambda表达式类似于下面这样:
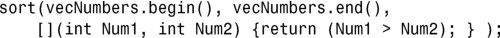
2.该lambda表达式类似于下面这样:
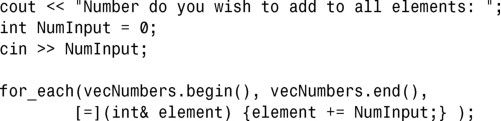
下面的示例演示了练习1和练习2的解决方案:
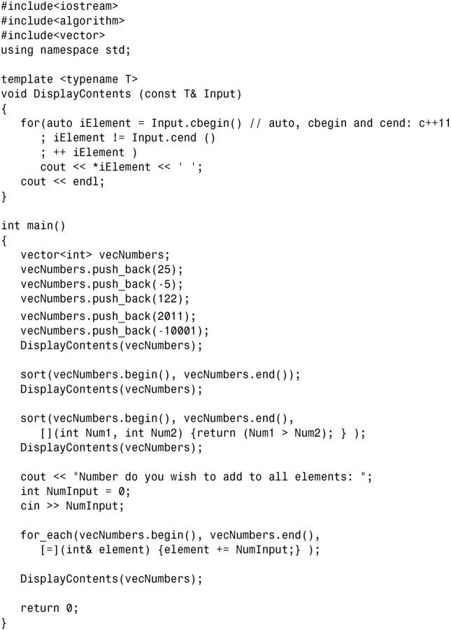
输出:

第23章
测验
1.使用函数 std::list::remove_if( ),因为它确保指向 list中(未被删除的)元素的现有迭代器仍有效。
2.如果没有显式指定谓词,list::sort( )(和 std::sort( ))将使用 std::less<>,这将使用运算符<对集合中的对象进行排序。
3.对指定范围内的每个元素调用一次。
4.for_each( )返回函数对象。
练习
1.下面是一种解决方案:
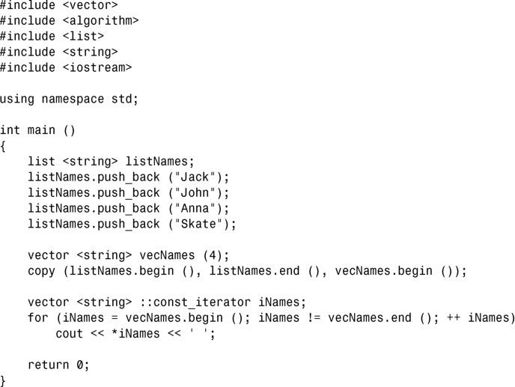
2.下面是一个演示程序。注意到 std::copy( )复制时无需知道集合的特征。它只使用迭代器类:
3.std::sort( )与 std::stable_sort( )之间的区别在于,后者在排序时保持对象的相对位置不变。由于该应用程序需要按生成顺序存储数据,因此应使用 stable_sort( ),以保持天体事件的相对顺序不变。
第24章
测验
1.可以,通过提供一个谓词。
2.运算符<。
3.不能,只能操作栈顶元素。因此,不能访问栈底的Coins对象。
练习
1.该二元谓词可以是运算符<:

2.只需将字符串依次插入到栈中。弹出数据时,字符串的排列顺序便反转了,因为栈是一种LIFO容器。
第25章
测验
1.不能。bitset可存储的位数在编译阶段就已确定。
2.因为它不能像其他容器那样动态地调整长度,它也不像容器那样支持迭代器。
3.不会。在这种情况下使用std::bitset最合适。
练习
1.std::bitset支持实例化、初始化、显示和相加,如下所示:

2.对前一个示例中的 bitset对象调用函数 flip( ):

第26章
测验
1.我会先看看www.boost.org,希望您也如此!
2.不会。一般而言,如果智能指针编写得好(且选择正确)的话是不会的。
3.如果是侵入式的,将由指针拥有的对象保存引用计数;否则,指针可将这种信息保存在自由存储区中的共享对象中。
4.需要双向遍历链表,因此必须是双向链表。
练习
1.语句 pObject->DoSomething ();有问题,因为指针在复制时失去了对对象的拥有权。这将导致程序崩溃(或发生令人非常不愉快的事情)。
2.代码类似于下面这样:

鉴于MakeFishSwim( )接受的参数为引用,不会导致复制,因此不会出现切除问题。另外,请注意变量myCarp的实例化语法。
3.unique_ptr的复制构造函数和复制赋值运算符都是私有的,因此不允许复制和赋值。
第27章
测验
1.在只需写入文件时,应使用ofstream。
2.使用 cin.getline( )。参见程序清单 27.7。
3.不应该,因为std::string包含的是文本信息。您可使用默认模式,即文本模式。
4.检查 open( )是否成功。
练习
1.您打开了一个文件,但在使用流并关闭它之前,没有使用 is_open( )检查 open( )是否成功。
2.您不能插入到ifstream。ifstream设计用于输入,而不是输出,因此不支持流插入运算符<<。
第28章
测验
1.这是一个类,类似于其他类,但创建它旨在用作其他异常类(如bad_alloc)的基类。
2.try块是一组可能导致异常的语句。
3.catch语句是一个例程,其参数指出了它能处理的异常类型。它位于try 块后面,用于捕获try块内可能引发的异常。
4.异常是一个对象,可包含在用户创建的类中能定义的任何信息。
练习
1.绝不要在析构函数中引发异常。
2.没有处理代码可能引发的异常,即缺少try…catch块:
3.绝不要在catch块中分配内存,更不用说为一百万个整数分配内存了。如果try块内的代码分配内存失败,将导致恶性循环。
第29章
测验
1.您的应用程序好像是在一个线程中执行所有的任务。因此,如果图像处理本身(调整对比度)是处理器密集型的,UI将没有响应。应该将这两种操作放在两个线程中,这样操作系统将在这两个线程之间切换,向UI线程和执行对比度调整的工作线程提供处理器时间。
2.可能没有妥善地同步线程。您的应用程序同时读写同一个对象,导致数据不一致。请使用一个二值信号量,在数据库表被访问时禁止对其进行修改。
