6.3.2 原子操作与C++11原子类型
所谓原子操作,就是多线程程序中“最小的且不可并行化的”的操作。通常对一个共享资源的操作是原子操作的话,意味着多个线程访问该资源时,有且仅有唯一一个线程在对这个资源进行操作。那么从线程(处理器)的角度看来,其他线程就不能够在本线程对资源访问期间对该资源进行操作,因此原子操作对于多个线程而言,就不会发生有别于单线程程序的意外状况。
通常情况下,原子操作都是通过“互斥”(mutual exclusive)的访问来保证的。实现互斥通常需要平台相关的特殊指令,这在C++11标准之前,这常常意味着需要在C/C++代码中嵌入内联汇编代码。对程序员来讲,就必须了解平台上与同步相关的汇编指令。当然,如果只是想实现粗粒度的互斥,借助POSIX标准的pthread库中的互斥锁(mutex)也可以做到。我们可以看看代码清单6-18所示的例子。
代码清单6-18
include <pthread.h>
include <iostream>
using namespace std;
static long long total=0;
pthread_mutex_t m=PTHREAD_MUTEX_INITIALIZER;
voidfunc(void){
long long i;
for(i=0;i<100000000LL;i++){
pthread_mutex_lock(&m);
total+=i;
pthread_mutex_unlock(&m);
}
}
int main(){
pthread_t thread1,thread2;
if(pthread_create(&thread1,NULL,&func,NULL)){
throw;
}
if(pthread_create(&thread2,NULL,&func,NULL)){
throw;
}
pthread_join(thread1,NULL);
pthread_join(thread2,NULL);
cout<<total<<endl;//9999999900000000
return 0;
}
//编译选项:g++6-3-1.cpp-lpthread
在代码清单6-18中,我们给出了一个在Linux上使用pthread进行原子操作的例子。这里,为了保证total+=i语句的原子性,我们创建了一个pthread_mutex_t类型的互斥锁m,并且在语句的前后使用加锁(pthread_mutex_lock)和解锁(pthread_mutex_unlock)两种操作来确保该语句只有单一线程可以访问。这里我们启动了两个线程thread1和thread2,并将它们加入(join)程序的执行。由于两个线程互斥地访问原子操作语句,从而得出total正确结果为9999999900000000。对于多线程的程序而言,进出临界区(即我们的原子操作语句total+=i)的加锁/解锁操作都是必须的。如果将加锁/解锁操作的代码都注释掉的话,在我们的实验机上,total的结果将由于线程间对数据的竞争(contention)而不再准确。因此,为了防止数据竞争问题,我们总是需要确保对total的操作是原子操作。
不过显而易见地,代码清单6-18中基于pthread的方法虽然可行,但代码编写却很麻烦。程序员需要为共享变量创建互斥锁,并在进入临界区前后进行加锁和解锁的操作。对于习惯了在单线程情况下编程的程序员而言,互斥锁的管理无疑是种负担。不过在C++11中,通过对并行编程更为良好的抽象,要实现同样的功能就简单了很多。我们可以看看代码清单6-19所示的例子。
代码清单6-19
include <atomic>
include <thread>
include <iostream>
using namespace std;
atomic_llong total{0};//原子数据类型
void func(int){
for(long long i=0;i<100000000LL;++i){
total+=i;
}
}
int main(){
thread t1(func,0);
thread t2(func,0);
t1.join();
t2.join();
cout<<total<<endl;//9999999900000000
return 0;
}
//编译选项:g++ -std=c++11 6-3-2.cpp-lpthread
在代码清单6-19中,我们将变量total定义为一个“原子数据类型”:atomic_llong,该类型长度等同于C++11中的内置类型long long。在C++11中,程序员不需要为原子数据类型显式地声明互斥锁或调用加锁、解锁的API,线程就能够对变量total互斥地进行访问。这里我们定义了C++11的线程std::thread变量t1及t2,它们都执行同样的函数func,并类似于pthread_t,调用了std::thread成员函数join加入程序的执行。可以看到,由于原子数据类型的原子性得到了可靠的保障,程序最后打印出的total的值依然为9999999900000000。
相比于基于C以及过程编程的pthread“原子操作API”而言,C++11对于“原子操作”概念的抽象遵从了面向对象的思想——C++11标准定义的都是所谓的“原子类型”。而传统意义上所谓的“原子操作”,则抽象为针对于这些原子类型的操作(事实上,是原子类型的成员函数,稍后解释)。直观地看,编译器可以保证原子类型在线程间被互斥地访问。这样设计,从并行编程的角度看,是由于需要同步的总是数据而不是代码,因此C++11对数据进行抽象,会有利于产生行为更为良好的并行代码。而进一步地,一些琐碎的概念,比如互斥锁、临界区则可以被C++11的抽象所掩盖,因而并行代码的编写也会变得更加简单。
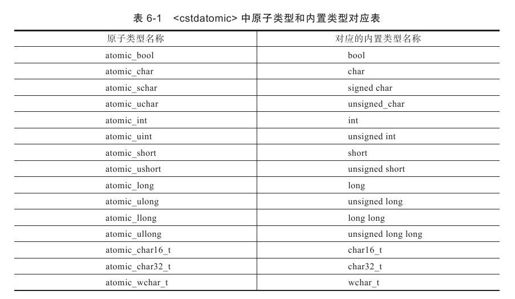
在C++11的并行程序中,使用原子类型是非常容易的。事实上,由于C++11与C11标准都支持原子类型,因此我们可以简单地通过#include<cstdatomic>头文件中来使用对应于内置类型的原子类型定义。<cstdatomic>中包含的原子类型定义如表6-1所示。
代码清单6-19就采用了这样的方式。不过更为普遍地,程序员可以使用atomic类模板。通过该类模板,程序员任意定义出需要的原子类型。比如下列语句:
std::atomic<T>t;
就声明了一个类型为T的原子类型变量t。编译器会保证产生并行情况下行为良好的代码,以避免线程间对数据t的竞争。而在C11中,要想定义原子的自定义类型,则需要使用C11的新关键字_Atomic来完成(不过在本书完成时,各个编译器对C11中原子操作的支持都非常有限)。
对于线程而言,原子类型通常属于“资源型”的数据,这意味着多个线程通常只能访问单个原子类型的拷贝。因此在C++11中,原子类型只能从其模板参数类型中进行构造,标准不允许原子类型进行拷贝构造、移动构造,以及使用operator=等,以防止发生意外。比如:
atomic<float> af{1.2f};
atomic<float> af1{af};//无法通过编译
其中,af1{af}的构造方式在C++11中是不允许的(事实上,atomic模板类的拷贝构造函数、移动构造函数、operator=等总是默认被删除的。我们会在第7章中介绍如何删除一些默认的函数)。
不过从atomic<T>类型的变量来构造其模板参数类型T的变量则是可以的。比如:
atomic<float> af{1.2f};
float f=af;
float f1{af};
这是由于atomic类模板总是定义了从atomic<T>到T的类型转换函数的缘故。在需要时,编译器会隐式地完成原子类型到其对应的类型的转换。
那么,使得原子类型能够在线程间保持原子性的缘由主要还是因为编译器能够保证针对原子类型的操作都是原子操作。如我们之前提到的,原子操作都是平台相关的,因此有必要为常见的原子操作进行抽象,定义出统一的接口,并根据编译选项(或环境)产生其平台相关的实现。在C++11中,标准将原子操作定义为atomic模板类的成员函数,这囊括了绝大多数典型的操作,如读、写、交换等。当然,对于内置类型而言,主要是通过重载一些全局操作符来完成的。以之前在代码清单6-19中看到的operator+=操作为例,在我们的实验机上使用g++进行编译的话,会产生一条特殊的lock前缀的x86指令,lock能够控制总线及实现x86平台上的原子性的加法。
表6-2显示了所有atomic类型及其相关的操作。
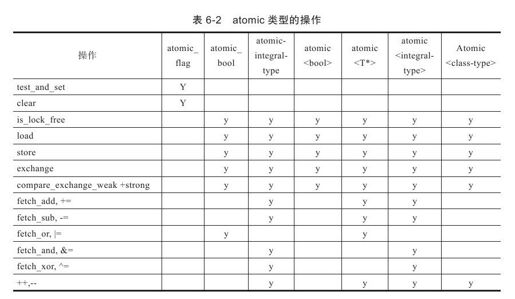
这里的atomic-integral-type和integral-type,指的都是表6-1中所有原子类型的整型,而class-type则是指自定义类型。可以看到,对于大多数的原子类型而言,都可以执行读(load)、写(store)、交换(exchange)、比较并交换(compare_exchange_weak/compare_exchange_stronge)等操作。通常情况下,这些原子操作已经足够使用了。比如在下列语句中:
atomic<int> a;
int b=a;
赋值语句b=a实际就等同于b=a.load()。而由于a.load是原子操作,因此可以避免线程间关于a的竞争,而下列语句:
atomic<int> a;
a=1;
其赋值语句a=1则等同于调用a.store(1)。同样的,由于a.store是原子操作,也可以避免线程间关于a的竞争。而exchange和compare_exchange_weak/compare_exchange_stronge则更为复杂一些。由于每个平台上对线程间实现交换、比较并交换等操作往往有着不同的方式,无法用一致的高级语言表达,因此这些接口封装了平台上最高性能的实现,使得程序员能够在不同平台上都能获得最佳的性能。
此外,对于整型和指针类型,我们还可以看到,标准为其定义了一些算术运算和逻辑运算的操作符,其意义都比较直观,就不赘述了。不过在表6-2中,我们还可以看到一个比较特殊的布尔型的atomic类型:atomic_flag(注意,atomic_flag跟atomic_bool是不同的),相比于其他的atomic类型,atomic_flag是无锁的(lock-free),即线程对其访问不需要加锁,因此对atomic_flag而言,也就不需要使用load、store等成员函数进行读写(或者重载操作符)。而典型地,通过atomic_flag的成员test_and_set以及clear,我们可以实现一个自旋锁(spin lock)。我们来看看代码清单6-20所示的例子。
代码清单6-20
include <thread>
include <atomic>
include <iostream>
include <unistd.h>
using namespace std;
std::atomic_flag lock=ATOMIC_FLAG_INIT;
void f(int n){
while(lock.test_and_set(std::memory_order_acquire))//尝试获得锁
cout<<"Waiting from thread"<<n<<endl;//自旋
cout<<"Thread"<<n<<"starts working"<<endl;
}
void g(int n){
cout<<"Thread"<<n<<"is going to start."<<endl;
lock.clear();
cout<<"Thread"<<n<<"starts working"<<endl;
}
int main(){
lock.test_and_set();
thread t1(f,1);
thread t2(g,2);
t1.join();
usleep(100);
t2.join();
}
//编译选项:g++ -std=c++11 6-3-3.cpp-lpthread
在代码清单6-20中,我们声明了一个全局的atomic_flag变量lock。最开始,将lock初始化为值ATOMIC_FLAG_INIT,即false的状态。而在线程t1中(执行函数f的代码),我们不停地通过lock的成员test_and_set来设置lock为true。这里的test_and_set()是一种原子操作,用于在一个内存空间原子地写入新值并且返回旧值。因此test_and_set会返回之前的lock的值。所以当线程t1执行join之后,由于在main函数中调用过test_and_set,因此f中的test_and_set将一直返回true,并不断打印信息,即自旋等待。而当线程t2加入运行的时候,由于其调用了lock的成员clear,将lock的值设为false,因此此时线程t1的自旋将终止,从而开始运行后面的代码。这样一来,我们实际上就通过自旋锁达到了让t1线程等待t2线程的效果。当然,还可以将lock封装为锁操作,比如:
void Lock(atomic_flag*lock){while(lock.test_and_set());}
void Unlock(atomic_flag*lock){lock.clear();}
这样一来,就可以通过Lock和UnLock操作,像“往常”一样互斥地访问临界区了。除此之外,很多时候,了解底层的程序员会考虑使用无锁编程,以最大限度地挖掘并行编程的性能,而C++11的无锁机制为这样的实现提供了高级语言的支持。
在上面的例子中,我们的原子操作都是比较直观的。事实上,在C++11中,原子操作还可以包含一个参数:memory_order。通常情况下,使用该参数将有利于编译器进一步释放并行的潜在的性能。不过在这之前,我们必须先了解一下什么是内存模型。
