8.3 Unicode支持
类别:所有人
8.3.1 字符集、编码和Unicode
在了解Unicode之前,我们先回顾一下计算机表示信息的方式。无论是存储器中的晶体管通断,还是磁盘中磁畴的极性,或者是光盘中的坑槽,计算机总是使用两种不同的状态来作为基本信息,即二进制信息。而要标识现实生活中更为复杂的实体,则需要通过多个这样的基本信息的组合来完成。在计算机中,首当其冲需要被标识的就是字符。为了使二进制组合标识字符的方法在不同设计的计算机间通用,就迫切需要统一的字符编码方法。于是在20世纪60年代的时候,现在使用最为广泛的ASCII字符编码就出现了。
在ANSI颁布的标准中,基本ASCII的字符使用了7个二进制位进行标识,这意味着总共可以标识128种不同的字符。这对英文字符(以及一些控制字符、标点符号等)来说绰绰有余,不过随着计算机在全世界的普及,非字符构成的语言(如中文)也需要得到支持,128个字符对于全世界众多语言而言就显得力不从心了。
到了20世纪90年代,ISO与Unicode两个组织共同发布了能够唯一地表示各种语言中的字符的标准。通常情况下,我们将一个标准中能够表示的所有字符的集合称为字符集。通常,我们称ISO/Unicode所定义的字符集为Unicode。在Unicode中,每个字符占据一个码位(Code point)。Unicode字符集总共定义了1 114 112个这样的码位,使用从0到10FFFF的十六进制数唯一地表示所有的字符。不过不得不提的是,虽然字符集中的码位唯一,但由于计算机存储数据通常是以字节为单位的,而且出于兼容之前的ASCII、大数小段数段、节省存储空间等诸多原因,通常情况下,我们需要一种具体的编码方式来对字符码位进行存储。比较常见的基于Unicode字符集的编码方式有UTF-8、UTF-16及UTF-32(一般人常常把UTF-16和Unicode混为一谈,在阅读各种资料的时候读者要注意区别)。
以UTF-8为例,其采用了1~6字节的变长编码方式编码Unicode,英文通常使用1字节表示,且与ASCII是兼容的,而中文常用3字节进行表示。UTF-8编码由于较为节约存储空间,因此使用得比较广泛。表8-1所示就是UTF-8的编码方式。
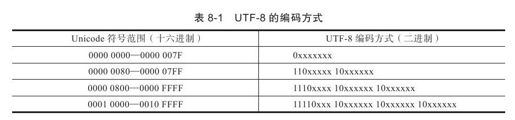
注意 事实上,现行桌面系统中,Windows内部采用了UTF-16的编码方式,而Mac OS、Linux等则采用了UTF-8编码方式。
除了基于Unicode字符集的UTF-8、UTF-16等编码外,在中文语言地区,我们还有一些常见的字符集及其编码方式,GB2312、Big5就是其中影响最大、使用最广泛的两种。
GB2312的出现先于Unicode。早在20世纪80年代,GB2312作为简体中文的国家标准被颁布使用。GB2312字符集收入6763个汉字和682个非汉字图形字符,而在编码上,是采用了基于区位码的一种编码方式,采用2字节表示一个中文字符。GB2312在中国大陆地区及新加坡都有广泛的使用。
而BIG5则常见于繁体中文,俗称“大五码”。BIG5是长期以来的繁体中文的业界标准,共收录了13 060个中文字,也采用了2字节的方式来表示繁体中文。BIG5在中国台湾、香港、澳门等地区有着广泛的使用。
扩展 关于内码和交换码
内码实际就是字符在计算机存储单元中的二进制表示,在早期中文字符编码混乱的时候,内码和交换码等概念就产生了。每一种二进制表示的中文的编码都被认为是一种内码,而在有多种内码的情况下,交换码被设计为协调不同的内码间数据交换的手段。依照这种认知方式,UTF-8等编码即是内码,也是交换码。随着时代的发展和各种标准的先后制定,内码和交换码的概念也在被逐渐淡化,因为通常情况下,两者总是一致的。
不同的编码方式对于相同的二进制字符串的解释是不同的。常见的,如果一个UTF-8编码的网页中的字符串按照GB2312编码进行显示,就会出现乱码。而BIG5和GB2312之间的乱码则在中文地区软件中有着“悠久”的历史。不过随着Unicode的使用和发展,以及软件系统对多种编码的支持,程序发生乱码的现象也越来越少。总的说来,Unicode还在其发展期,Unicode、GB2312以及BIG5等多种编码共存的状况可能在以后较长的时间内都会持续下去。
