- 6.3.3 内存模型,顺序一致性与memory_order
- include <thread>
- include <atomic>
- include <iostream>
- include <thread>
- include <atomic>
- include <iostream>
- include <thread>
- include <atomic>
- include <iostream>
- include <thread>
- include <atomic>
- include <iostream>
- include <thread>
- include <atomic>
- include <iostream>
- include <thread>
- include <atomic>
- include <cassert>
- include <string>
6.3.3 内存模型,顺序一致性与memory_order
如果只是简单地想在线程间进行数据的同步的话,原子类型已经为程序员已经提供了一些同步的保障。不过这样做的安全性却是建筑于一个假设之上,即所谓的顺序一致性(sequential consistent)的内存模型(memory model)。要了解顺序一致性以及内存模型,我们不妨看看代码清单6-21所示的例子。
代码清单6-21
include <thread>
include <atomic>
include <iostream>
using namespace std;
atomic<int> a{0};
atomic<int> b{0};
int ValueSet(int){
int t=1;
a=t;
b=2;
}
int Observer(int){
cout<<"("<<a<<","<<b<<")"<<endl;//可能有多种输出
}
int main(){
thread t1(ValueSet,0);
thread t2(Observer,0);
t1.join();
t2.join();
cout<<"Got("<<a<<","<<b<<")"<<endl;//Got(1,2)
}
//编译选项:g++ -std=c++11 6-3-4.cpp-lpthread
在代码清单6-21中,我们创建了两个线程t1和t2,分别执行ValueSet和Observer函数。在ValueSet中,为a和b分别赋值1和2。而在Observer中,只是打印出a和b的值。可以想象,由于Observer打印a和b的时间与ValueSet设置a和b的时间可能有多种组合方式,因此Obsever可能打印出(0,0),或者(1,2),甚至是(1,0)这样的结果。不过无论Observer打印了什么,在线程结束后再打印a和b的值,总会得到(1,2)这样的结果。如图6-4所示,展示了这样的多种可能性。
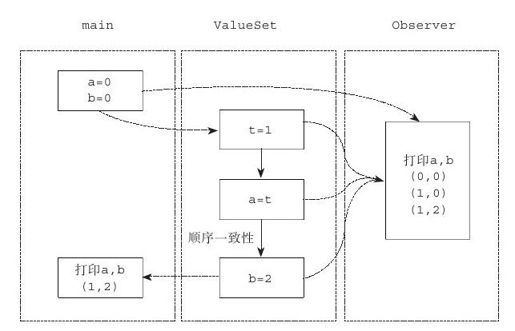
图 6-4 代码清单6-21所示例子的线程示意图
虽然Observer可能打印出a、b的3种组合,但这里如果Observer打印出(0,2)这样的值是否合理呢?按照通常的程序是顺序执行的理解,(0,2)应该不是合理的输出。这从图6-4中也可以直观地看到,a的赋值语句a=t总是先于b的赋值语句b=2执行的,这是一个合乎情理的假设,但对于本例却并不重要。Observer的编写者只是试图一窥线程ValueSet的执行状况,不过这种窥看相比于结果——线程结束后a和b的值总是(1,2)而言,并不是必须的。也就是说,在本例的假定下,a、b的赋值语句在ValueSet中谁先执行谁后执行并不会对程序的执行产生影响,因此说执行顺序是不重要的。
这一点假设虽然看似并不起眼,但对于编译器(甚至是处理器,下面我们会解释)来说非常重要。通常情况下,如果编译器认定a、b的赋值语句的执行先后顺序对输出结果有任何的影响的话,则可以依情况将指令重排序(reorder)以提高性能。而如果a、b赋值语句的执行顺序必须是a先b后,则编译器则不会执行这样的优化。如果我们假定,所有的原子类型的执行顺序都无关紧要,那么在多线程情况下就可能发生严重的错误。我们来看看代码清单6-22所示的例子。
代码清单6-22
include <thread>
include <atomic>
include <iostream>
using namespace std;
atomic<int> a;
atomic<int> b;
int Thread1(int){
int t=1;
a=t;
b=2;
}
int Thread2(int){
while(b!=2)
;//自旋等待
cout<<a<<endl;//总是期待a的值为1
}
int main(){
thread t1(Thread1,0);
thread t2(Thread2,0);
t1.join();
t2.join();
return 0;
}
//编译选项:g++ -std=c++11 6-3-5.cpp-lpthread
在代码清单6-22中,Thread2函数所在线程一开始总是在自旋等待,直到b的值被赋值为2,它才会继续执行打印a的指令。如果这里,我们假设Thread1中a的赋值语句的执行被重排序到b的赋值语句之后的话,那么Thread2则可能打印出a的值为0。这与程序员的看见的代码执行顺序完全背离,而一旦发生这样的情况,程序员也很难想象居然这是编译器(或者处理器)改变了代码的执行顺序而导致错误。因此为了避免这样的错误,在多线程情况下,非常有必要保证如同代码清单6-21及代码清单6-22中原子变量a的赋值语句先于原子变量b的赋值语句发生。
实际上默认情况下,在C++11中的原子类型的变量在线程中总是保持着顺序执行的特性(非原子类型则没有必要,因为不需要在线程间进行同步)。我们称这样的特性为“顺序一致”的,即代码在线程中运行的顺序与程序员看到的代码顺序一致,a的赋值语句永远发生于b的赋值语句之前。这样的“顺序一致”能够最大限度地保证程序的正确性。如同我们在代码清单6-22中看到的一样,a的赋值语句先于b的赋值语句发生,这样的“先于发生”(happens-before)关系必须得到遵守,否则可能导致严重的错误。不过偏偏在代码清单6-21中我们又看到了相反的例子,ValueSet中的a、b赋值语句的执行顺序并不重要。如果我们能够允许编译器(处理器)在单个线程中打乱指令的运行顺序,即不遵守先于发生的关系的话,则有可能进一步并行程序的性能。
那么有没有办法让一些代码遵守先于发生的关系,而另外一部分的代码不遵守呢?在C++11中,这是完全可能呢。不过语言的设计者的考量远远多过于这一点。更为确切地,他们对各种平台、处理器、编程方式都进行了考量,总结出了不同的“内存模型”。事实上,顺序一致只是属于C++11中多种内存模型中的一种。而在C++11中,并不是只支持顺序一致单个内存模型的原子变量,因为顺序一致往往意味着最低效的同步方式。要使用C++11中更为高效的原子类型变量的同步方式,我们先要了解一些处理器和编译器相关的知识。
通常情况下,内存模型通常是一个硬件上的概念,表示的是机器指令(或者读者将其视为汇编语言指令也可以)是以什么样的顺序被处理器执行的。现代的处理器并不是逐条处理机器指令的,我们可以看看下面这个段伪汇编码:

这里我们演示了“t=1;a=t;b=2;”这段C++语言代码的伪汇编表示。按照通常的理解,指令总是按照1->2->3->4->5这样顺序执行,如果处理器的执行顺序是这样的话,我们通常称这样的内存模型为强顺序的(strong ordered)。可以看到,在这种执行方式下,指令3的执行(a的赋值)总是先于指令5(b的赋值)发生。
不过这里我们看到,指令1、2、3和指令4、5运行顺序上毫无影响(使用了不同的寄存器,以及不同的内存地址),一些处理器就有可能将指令执行的顺序打乱,比如按照1->4->2->5->3这样顺序(通常这样的执行顺序都是超标量的流水线,即一个时钟周期里发射多条指令而产生的)。如果指令是按照这个顺序被处理器执行的话,我们通常称之为弱顺序的(weak ordered)。而在这种情况下,指令5(b的赋值)的执行可能就被提前到指令3(a的赋值)完成之前完成。
注意 事实上,一些弱内存模型的构架比如PowerPC,其写回操作是不能够被乱序的,这里只是一个帮助读者理解的示例,并非事实。
那么在多线程情况下,强顺序和弱顺序又意味着什么呢?我们知道,多线程的程序总是共享代码的,那么强顺序意味着:对于多个线程而言,其看到的指令执行顺序是一致的。具体地,对于共享内存的处理器而言,需要看到内存中的数据被改变的顺序与机器指令中的一致。反之,如果线程间看到的内存数据被改变的顺序与机器指令中声明的不一致的话,则是弱顺序的。比如在我们的伪汇编中,假设运行的平台遵从的是一个弱顺序的内存模型的话,那么可能线程A所在的处理器看到指令执行顺序是先3后5,而线程B以为指令执行的顺序依然是先5后3,那么反馈到代码清单6-22的源代码中,我们就有可能看Thread2打印出的a的值是0了。
在现实中,x86以及SPARC(TSO模式)都被看作是采用强顺序内存模型的平台。对于任何一个线程而言,其看到原子操作(这里都是指数据的读写)都是顺序的。而对于是采用弱顺序内存模型的平台,比如Alpha、PowerPC、Itanlium、ArmV7这样的平台而言,如果要保证指令执行的顺序,通常需要由在汇编指令中加入一条所谓的内存栅栏(memory barrier)指令。比如在PowerPC上,就有一条名为sync的内存栅栏指令。该指令迫使已经进入流水线中的指令都完成后处理器才执行sync以后指令(排空流水线)。这样一来,sync之前运行的指令总是先于sync之后的指令完成的。比如我们可以这样来保证我们伪汇编中的指令3的执行先于指令5:

sync指令对高度流水化的PowerPC处理器的性能影响很大,因此,如果可以不顺序提交语句的运行结果的话,则可以保证弱顺序内存模型的处理器保持较高的流水线吞吐率(throughput)和运行时性能。
注意 为什么会有弱顺序的内存模型?
简单地说,弱顺序的内存模型可以使得处理器进一步发掘指令中的并行性,使得指令执行的性能更高。
注意 为什么我们只关心读写操作的执行顺序问题?
这是由处理器的设计决定的,通常情况下,处理器总是从内存中读出数据进行运算,再将运行结果又返回内存,因此内存中的数据是一个“准绳”,相对的,寄存器中的内容则是“临时量”。所以在多核心处理器上,核心往往都有全套的寄存器来分别存储临时量,而数据交流总是以内存中的数据为准。这么一来,一些寄存器中的运算(比如伪汇编中的指令2)就不会被多处理器关注,处理器只关心读写等原子操作指令的顺序。
以上都是硬件上一些可能的内存模型的描述。而C++11中定义的内存模型和顺序一致性跟硬件的内存模型的强顺序、弱顺序之间有着什么样的联系呢?事实上,在高级语言和机器指令间还有一层隔离,这层隔离是由编译器来完成的。如我们之前描述的,编译器出于代码优化的考虑,会将指令前后移动,已获得最佳的机器指令的排列及产生最佳的运行时性能。那么对于C++11中的内存模型而言,要保证代码的顺序一致性,就必须同时做到以下几点:
❑编译器保证原子操作的指令间顺序不变,即保证产生的读写原子类型的变量的机器指令与代码编写者看到的是一致的。
❑处理器对原子操作的汇编指令的执行顺序不变。这对于x86这样的强顺序的体系结构而言,并没有任何的问题;而对于PowerPC这样的弱顺序的体系结构而言,则要求编译器在每次原子操作后加入内存栅栏。
如前文所述,在C++11中,原子类型的成员函数(原子操作)总是保证了顺序一致性。这对于x86这样的平台来说,禁止了编译器对原子类型变量间的重排序优化;而对于PowerPC这样的平台来说,则不仅禁止了编译器的优化,还插入了大量的内存栅栏。这对于意图是提高性能的多线程程序而言,无疑是一种性能伤害。具体而言,对于代码清单6-21中ValueSet这样的不需要遵守a、b赋值语句“先于发生”关系的程序而言,由于atomic默认的顺序一致性则会在对a、b的赋值语句间加入内存栅栏,并阻止编译器优化,这无疑会增加并行开销(内存栅栏尤其如此)。那么解除这样的性能约束也势在必行。
在C++11中,设计者给出的解决方式是让程序员为原子操作指定所谓的内存顺序:memory_order。比如在代码清单6-21中,就可以采用一种松散的内存模型(relaxed memory model)来放松对原子操作的执行顺序的要求。我们来看看代码清单6-23对代码清单6-21的所作的改进。
代码清单6-23
include <thread>
include <atomic>
include <iostream>
using namespace std;
atomic<int> a{0};
atomic<int> b{0};
int ValueSet(int){
int t=1;
a.store(t,memory_order_relaxed);
b.store(2,memory_order_relaxed);
}
int Observer(int){
cout<<"("<<a<<","<<b<<")"<<endl;//可能有多种输出
}
int main(){
thread t1(ValueSet,0);
thread t2(Observer,0);
t1.join();
t2.join();
cout<<"Got("<<a<<","<<b<<")"<<endl;//Got(1,2)
return 0;
}
//编译选项:g++ -std=c++11 6-3-6.cpp-lpthread
在代码清单6-23中,我们对ValueSet函数进行了改造。之前的对a、b进行赋值的语句我们改用了atomic类模板的store成员。store能够接受两个参数,一个是需要写入的值,一个是名为memory_order的枚举值。这里我们使用的值是memory_order_relaxed,表示使用松散的内存模型,该指令可以任由编译器重排序或者由处理器乱序执行。这样一来,a、b赋值语句的“先于发生”顺序得到了解除,我们也就可能得到最佳的运行性能。当然,相应的结果是,对于Observer来说,打印出(0,2)这样的结果也就是合理的了。
如我们在上节最后提到的,大多数atomic原子操作都可以使用memory_order作为一个参数,在C++11中,标准一共定义了7种memory_order的枚举值,如表6-3所示。

memory_order_seq_cst表示该原子操作必须是顺序一致的,这是C++11中所有atomic原子操作的默认值,不带memory_order参数的原子操作就是使用该值。而memorey_order_relaxed则表示该原子操作是松散的,可以被任意重排序的。其他几种我们会在后面解释。值得注意的是,并非每种memory_order都可以被atomic的成员使用。通常情况下,我们可以把atomic成员函数可使用的memory_order值分为以下3组:
❑原子存储操作(store)可以使用memorey_order_relaxed、memory_order_release、memory_order_seq_cst。
❑原子读取操作(load)可以使用memorey_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_seq_cst。
❑RMW操作(read-modify-write),即一些需要同时读写的操作,比如之前提过的atomic_flag类型的test_and_set()操作。又比如atomic类模板的atomic_compare_exchange()操作等都是需要同时读写的。RMW操作可以使用memorey_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_release、memory_order_acq_rel、memory_order_seq_cst。
一些形如“operator=”、“operator+=”的函数,事实上都是memory_order_seq_cst作为memory_order参数的原子操作的简单封装。也即是说,之前小节中的代码都是采用顺序一致性的内存模型。如果读者需要的正是顺序一致性的内存模型的话,那么这些操作符都是可以直接使用的。而如果读者是要指定内存顺序的话,则应该采用形如load、atomic_fetch_add这样的版本。
如之前提到的,memory_order_seq_cst这种memory_order对于atomic类型数据的内存顺序要求过高,容易阻碍系统发挥线程应有的性能。而memorey_order_relaxed对内存顺序毫无要求,这在代码清单6-21中满足了我们解除“先于发生”顺序的需求。但在另外一些情况下,则还是可能无法满足真正的需求。我们可以看看由代码清单6-22改造而来的代码清单6-24的例子。
代码清单6-24
include <thread>
include <atomic>
include <iostream>
using namespace std;
atomic<int> a;
atomic<int> b;
int Thread1(int){
int t=1;
a.store(t,memory_order_relaxed);
b.store(2,memory_order_relaxed);
}
int Thread2(int){
while(b.load(memory_order_relaxed)!=2);//自旋等待
cout<<a.load(memory_order_relaxed)<<endl;
}
int main(){
thread t1(Thread1,0);
thread t2(Thread2,0);
t1.join();
t2.join();
return 0;
}
//编译选项:g++ -std=c++11 6-3-7.cpp-lpthread
代码清单6-24与代码清单6-22的例子基本一致,只不过这里我们并不希望完全禁用关于原子类型的优化,而采用了memory_order_relaxed作为memory_order参数。在一些弱内存模型的机器上,这两条a、b赋值语句将有可能任意一条被先执行。那么对于Thread2函数而言,它先是自旋等待b的值被赋为2,随后将a的值输出。按照松散的内存顺序,我们输出的a的值则有可能为0,也有可能为1。这显然是不符合代码作者的期望的。
那么排除顺序一致和松散两种方式,我们能不能保证程序“既快又对”地运行呢?如果读者仔细地分析的话,我们所需要的只是a.store先于b.store发生,b.load先于a.load发生的顺序。这要这两个“先于发生”关系得到了遵守,对于整个程序而言来说,就不会发生线程间的错误。建立这种“先于发生”关系,即原子操作间的顺序则需要利用其他的memory_order枚举值。我们可以看看代码清单6-25中修改的代码。
代码清单6-25
include <thread>
include <atomic>
include <iostream>
using namespace std;
atomic<int> a;
atomic<int> b;
int Thread1(int){
int t=1;
a.store(t,memory_order_relaxed);
b.store(2,memory_order_release);//本原子操作前所有的写原子操作必须完成
}
int Thread2(int){
while(b.load(memory_order_acquire)!=2);//本原子操作必须完成才能执行之后所有的读原子操作
cout<<a.load(memory_order_relaxed)<<endl;//1
}
int main(){
thread t1(Thread1,0);
thread t2(Thread2,0);
t1.join();
t2.join();
return 0;
}
//编译选项:g++ -std=c++11 6-3-8.cpp-lpthread
这里代码清单6-25对代码清单6-24做了两处改动,一是b.store采用了memory_order_release内存顺序,这保证了本原子操作前所有的写原子操作必须完成,也即a.store操作必须发生于b.store之前。二是b.load采用了memory_order_acquire作为内存顺序,这保证了本原子操作必须完成才能执行之后所有的读原子操作。即b.load必须发生在a.load操作之前。这样一来,通过确立“先于发生”关系的,我们就完全保证了代码运行的正确性,即当b的值为2的时候,a的值也确定地为1。而打印语句也不会在自旋等待之前打印a的值。Thread1和Thread2的执行顺如图6-5所示。
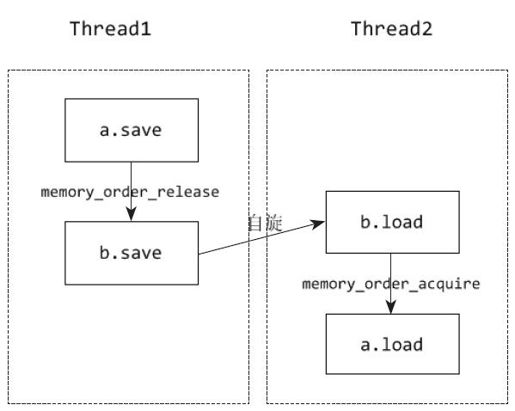
图 6-5 Thread1和Thread2的顺序
由于memory_order_release和memory_order_acquire常常结合使用,我们也称这种内存顺序为release-acquire内存顺序。
通常情况下,“先于发生”关系总是传递的,比如原子操作A发生于原子操作B之前,而原子操作B又发生于原子操作C之前的话,则A一定发生于C之前。有了这样的顺序,就可以指导编译器在重排序指令的时候在不破坏依赖规则(相当于多给了一些依赖关系)的情况下,仅在适当的位置插入内存栅栏,以保证执行指令时数据执行正确的同时获得最佳的运行性能。
在表6-3中,我们还看到了memory_order_consume这个memory_order的枚举值。该枚举值与memory_order_acquire相比,进一步放松了一些依赖关系。我们可以看看代码清单6-26所示的例子[1]。
代码清单6-26
include <thread>
include <atomic>
include <cassert>
include <string>
using namespace std;
atomic<string*>ptr;
atomic<int> data;
void Producer(){
string*p=new string("Hello");
data.store(42,memory_order_relaxed);
ptr.store(p,memory_order_release);
}
void Consumer(){
string*p2;
while(!(p2=ptr.load(memory_order_consume)))
;
assert(*p2=="Hello");//总是相等
assert(data.load(memory_order_relaxed)==42);//可能断言失败
}
int main(){
thread t1(Producer);
thread t2(Consumer);
t1.join();
t2.join();
}
//编译选项:g++ -std=c++11 6-3-9.cpp-lpthread
在代码清单6-26中,我们定义了两个线程t1和t2,分别运行Producer和Consumer函数。在Producer函数中,使用了memory_order_release来为原子类型atomic<string>变量ptr存储一个值;而在Consumer函数中,通过memory_order_consume的内存顺序来完成变量ptr的读取。这里我们可以看到,这样的内存顺序保证了ptr.load(memory_order_consume)必须发生在ptr这样的解引用操作(实际上涉及的是读指针ptr.load的操作)之前。不过与memory_order_acquire不同的是,该操作并不保证发生在data.load(memory_order_relaxed)之前,因为data和ptr是不同的原子类型数据,而memory_order_comsume只保证原子操作发生在与ptr有关的原子操作之前。所以实际上相比于memory_order_acquire,“先于发生”的关系又被弱化了。
形如其名,memory_order_release和memory_order_consume的配合会建立关于原子类型的“生产者-消费者”的同步顺序。同样的,我们可以称之为release-consume内存顺序。
顺序一致、松散、release-acquire和release-consume通常是最为典型的4种内存顺序。其他的如memory_order_acq_rel,则是常用于实现一种叫做CAS(compare and swap)的基本同步元语,对应到atomic的原子操作compare_exchange_strong成员函数上。我们也称之为acquire-release内存顺序。
事实上,由于并行编程在C++11中是非常新的一个话题,因此C++11中关于原子操作的设计还涉及大量的细节和众多特性。不过在本书编写时,还没有编译器正式支持所有并行的特性,为了避免理解上的偏差,因此除去语言中关于并行的比较核心的部分,本书也不再进一步地进行讲解了[2]。
而回到内存模型上来。虽然在C++11中,我们看到了大量的内存顺序相关的设计。不过这样的设计主要还是为了从各种繁杂不同的平台上抽象出独立于硬件平台的并行操作。如果读者不太愿意了解内存模型等相关概念,那么简单地使用C++11原子操作的顺序一致性就可以进行并行程序的编写了。而如果读者想让自己的程序在多线程情况下获得更好的性能的话,尤其当使用的是一些弱内存顺序的平台,比如PowerPC的话,建立原子操作间内存顺序则很有必要,因为这可会带来极大的性能提升(事实上,这也是弱一致性内存模型平台的优势)。
但对于并行编程来说,可能最根本的(这是本书没有涉及的话题)还是思考如何将大量计算的问题,按需分解成多个独立的、能够同时运行的部分,并找出真正需要在线程间共享的数据,实现为C++11的原子类型。虽然有了原子类型的良好设计,实现这些都可以非常的便捷,但并不是所有的问题或者计算都适合用并行计算来解决,对于不适用的问题,强行用并行计算来解决会收效甚微,甚至起到相反效果。因此在决定使用并行计算解决问题之前,程序员必须要有清晰的设计规划。而在实现了代码并行后,进一步使用一些性能调试工具来提高并行程序的性能也是非常必要的。
[1]本例来自于http://en.cppreference.com/w/cpp/atomic/memory_order。
[2]我们从svn上得到的gcc版本应该对应的是gcc-4.8,gcc-4.8可能会支持所有并行的语义。不过本书编写时,gcc-4.8还没有发布。
