9.1.4 数据包过滤的原理简介
CMU/Stanford数据包过滤器(CMU/Stanford Packet Filter,CSPF)是第一个数据包过滤器,也是目前很多过滤解决方案的源头。它显著的特点就是引入了过滤虚拟机的概念,其基于一个紧凑与高效指令集的虚拟CPU实现,一个过滤器被编译为一段小的程序在一个虚拟机上执行。但是,CSPF也存在下面的三个主要缺点:
❑过滤操作使用的栈会在内存中被模拟,维护栈指针需要使用若干的加、减等操作,而内存操作是现代计算机架构的主要瓶颈。
❑布尔表达式树造成了不需要的重复计算。
❑不能分析数据包的变长头部。
在该领域中最重要的进步是由McCanne与Van Jacobson在1993年发布的Berkeley数据包过滤器(Berkeley Packet Filter,BPF)。BPF从下面两个方面改进了CSPF:
❑限制数据包复制的次数。
❑定义一个新的虚拟CPU。该CPU更有效率,并带一个小而全的指令集(比如,基本的加载、存储、比较与跳转指令),该指令集基于寄存器实现。
源于BSD的操作系统仍然把BPF作为一个默认的捕获工具,其他的系统也具有兼容BPF的功能。
BPF的设计思想和当时计算机硬件的发展有很大联系,相对老式的CSPF过滤方式,它有下列两大特点:
❑它基于寄存器的过滤机制,而不是基于早期的内存堆栈过滤机制。
❑它直接使用独立的、非共享的内存缓冲区。
同时,BPF在过滤算法上也有很大的进步,它使用无环控制流图(Control Flow Graph,CFG),而不是老式的布尔表达式树。图9-2所示为这两种算法在处理过滤以太网中IP以及ARP协议时的情况。
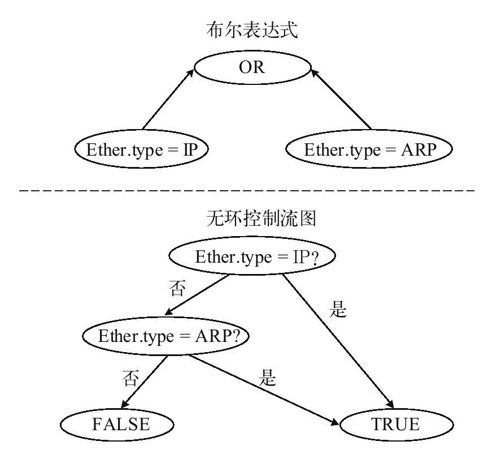
图 9-2 布尔表达式树及无环控制流图(过滤表达式为ip and arp)
由图9-2所示可以看出,布尔表达式树在理解上比较直观,它的每一个叶结点就是一个谓词判断,而非叶结点则为布尔操作。而无环控制流图算法是一种特殊的状态机,图中每一个非叶结点代表的是对数据包进行谓词判断操作,叶结点则是判断的结果。在无环控制流图中只存在两个叶结点,分别代表过滤通过(TRUE)和过滤未通过(FALSE)。
无环控制流图与布尔表达式树相比,具有以下优点:
❑布尔表达式树的编码实现很自然地采用了基于内存堆栈的方式,无环控制流图的实现则采用基于寄存器的方式。内存读取和内存堆栈操作会导致布尔表达式树效率低下。因此无环控制流图具有结构设计先进的优点。
❑布尔表达式树存在冗余计算。从图9-2所示中可以看出,两种过滤器在确定以太网数据类型为IP后,无环控制流图会立即返回过滤通过(TRUE),而布尔表达式树则需要对数据包再次进行是否为ARP的判断,之后还需要对两次判断结果进行"OR"操作。随着过滤条件更加复杂,布尔表达式树的效率也将迅速降低。直观地看,无环控制流图是一种“快速的、一直向前的”先进算法。
