第13章
数据结构基础
面试时间一般有两个小时,其中至少有20~30分钟时间是用来回答数据结构相关问题的。而由于链表是一种相对简单的数据结构,容易引起面试官多次反复发问。此外,数组的排序和逆置也是面试官必考的内容之一。事实上,单链表的复杂程度并不亚于树、图等复杂数据结构。面试官完全有可能构造出极富挑战性的试题。最后一个考点是堆栈,面试官会节合程序对你的思维能力进行考量。
13.1 单链表
面试例题1:编程实现一个单链表的建立/测长/打印。[日本某著名家电/通信/IT企业面试题]
答案:
完整代码如下:

面试例题2:编程实现单链表删除节点。[美国某著名分析软件公司面试题]
解析:如果删除的是头节点,如下图所示。
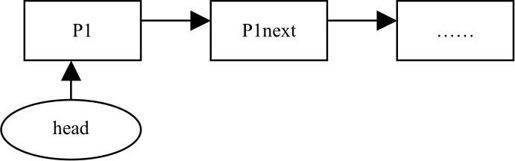
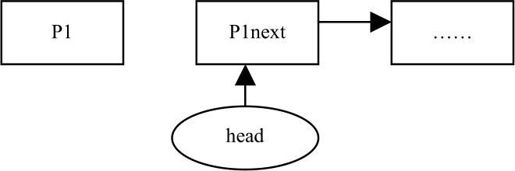
则把head指针指向头节点的下一个节点。同时free p1,如下图所示。
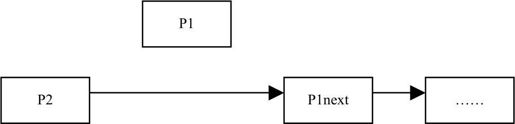
如果删除的是中间节点,如下图所示。

则用p2的next指向p1的next同时,free p1,如下图所示。
答案:
完整代码如下:

面试例题3:编写程序实现单链表的插入。[美国某著名计算机嵌入式公司2005年面试题]
解析:单链表的插入,如下图所示。
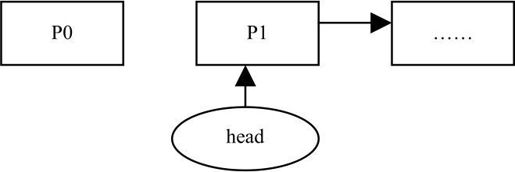
如果插入在头节点以前,则p0的next指向p1,头节点指向p0,如下图所示。
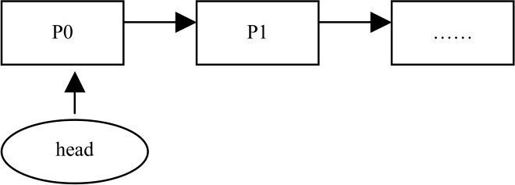
如果插入中间节点,如下图所示。

则先让p2的next指向p0,再让p0指向p1,如下图所示。
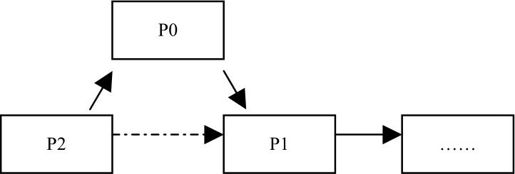
如果插入尾节点,如下图所示。

则先让p1的next指向p0,再让p0指向空,如下图所示。

答案:完整代码如下:

面试例题4:编程实现单链表的排序。
答案:
完整代码如下:

面试例题5:编程实现单链表的逆置。[美国某著名分析软件公司2005年面试题]
解析:
单链表模型如下图所示。

进行单链表逆置,首先要让p2的next指向p1,如下图所示。

再由p1指向p2,p2指向p3,如下图所示。

然后重复p2的next指向p1,p1指向p2,p2指向p3。
答案:完整代码如下:

面试例题6:有一个C语言用来删除单链表的头元素的函数,请找出其中的问题并加以纠正。[中国某著名综合软件公司2005年面试题]

解析:如果先做free(head)之后,就找不到head了,下一句head=head->next就不能正确链接了。
答案:正确程序如下:

面试例题7:给出一个单链表,不知道节点N的值,怎样只遍历一次就可以求出中间节点,写出算法。[中国著名通信企业H公司2007年11月面试题]

解析:设立两个指针,比如p和q。p每次移动两个位置,即p=p-> next-> next,q每次移动一个位置,即q=q-> next。
当p到达最后一个节点时,q就是中间节点了。
答案:
算法如下:

13.2 双链表
双链表的情况与单链表类似,只是增加了一个前置链而已。
面试例题1:编程实现双链表的建立。
答案:完整代码如下:
面试例题2:编程实现双链表删除/插入节点。
答案:
完整代码如下:

13.3 循环链表
面试例题:已知n个人(以编号1,2,3,…,n分别表示)围坐在一张圆桌周围。从编号为k的人开始报数,数到m的那个人出列;他的下一个人又从K开始报数,数到m的那个人又出列;依此规律重复下去,直到圆桌周围的人全部出列。试用C++编程实现。[中国著名门户网站W公司2008年面试题]
解析:本题就是约瑟夫环问题的实际场景。要通过输入n、m、k 3个正整数,求出列的序列。这个问题采用的是典型的循环链表的数据结构,就是将一个链表的尾元素指针指向队首元素:

解决问题的核心步骤如下:
(1)建立一个具有n个链节点、无头节点的循环链表。
(2)确定第1个报数人的位置。
(3)不断地从链表中删除链节点,直到链表为空。
答案:完整代码如下:

13.4 队列
面试例题1:If the frequent-used operation done to a link list to access a random selected item with specified index and insert or delete item from the rest, then which of the following is the most suitable structure to save time?(如果按index访问item并就地插入或删除数据,这种操作比较频繁,那使用什么节构最节省时间?)
A.Sequential list顺序表(数组)。
B.Double linked list(双向链表)。
C.Double linked list with header pointer(单独存储head指针的双向链表)。
D.Linked list(链表)。
答案:A
面试例题2:编程实现队列的入队/出队操作。[美国某著名计算机嵌入式公司2005年面试题]
答案:
完整代码如下:

13.5 栈
面试例题1:编程实现栈的入栈/出栈操作。[中国著名网络企业XL公司2007年12月面试题]
答案:完整代码如下:

面试例题2:如下C++程序:

请问刚进入func函数时,参数在栈中的形式可为以下哪种?(左侧为地址,右侧为数据。)[中国著名网络企业XL公司2007年11月面试题]
A.
| 0x0013FCF0 | 0x61616161 |
| 0x0013FCF4 | 0x22222222 |
| 0x0013FCF8 | 0x0013FCF8 |
B.
| 0x0013FCF0 | 0x22222222 |
| 0x0013FCF4 | 0x0013FCF8 |
| 0x0013FCF8 | 0x61616161 |
C.
| 0x0013FCF0 | 0x22222222 |
| 0x0013FCF4 | 0x61616161 |
| 0x0013FCF8 | 0x00000000 |
D.
| 0x0013FCF0 | 0x0013FCF8 |
| 0x0013FCF4 | 0x22222222 |
| 0x0013FCF8 | 0x61616161 |
解析:本题考查的是函数调用时的参数传递和栈帧节构。
调用函数时首先进行参数压栈,一般情况下压栈顺序为从右到左,先压sz再压i……最后压函数地址,但是压sz的时候不是直接压0x61616161而压的是szTest的地址。不过除了压栈顺序,还要考虑栈的生长方向。事实上,在Windows平台上,栈都是从上向下生长的。
如果依题意压sz压的是0x61616161,压栈顺序为从右到左的话,答案应该是D。
A:栈的生长方向应该是从上到下。
B:压栈顺序不对。
C:压栈顺序不对。
答案:D
面试例题3:编号为123456789的火车经过如下轨道从左边入口处移到右边出口处(每车都必须且只能进临时轨道M一次,且不能再回左边入口处)
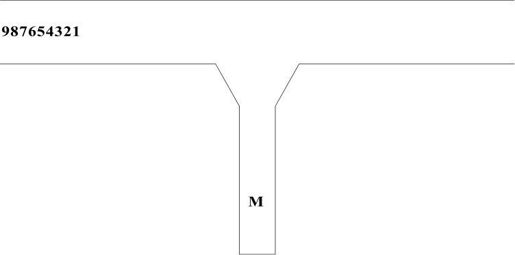
按照从左向右的顺序,下面的结果不可能的是哪项?[中国台湾某CPU硬件厂商2009年11月面试题]
A.123876549
B.321987654
C.321456798
D.987651234
解析:本题实际上考的是数据结构的栈。临时轨道M就是栈。
A是123挨个过去,45678入栈再出栈变成87654,9再过去。
B是123入栈再出栈变成321,456789入栈再出栈变成987654。
C是123入栈再出栈变成321,4567直接过去,89入栈再出栈变成98。
D是98765在前,则1234必须全部先进栈,98765过去后,剩下1234必须先回到左边,再通过才满足1234。但是题意要求不可再回到左边入口处,所以这个选项不可行。
答案:D
扩展知识:如果M只能容纳4列车。上面选项应该选哪个才可行?
面试例题4:用两个栈实现一个队列的功能,请用C++实现它。
解析:思路如下:
假设两个栈A和B,且都为空。
可以认为栈A提供入队列的功能,栈B提供出队列的功能。
入队列:入栈A。
出队列:
● 如果栈B不为空,直接弹出栈B的数据。
● 如果栈B为空,则依次弹出栈A的数据,放入栈B中,再弹出栈B的数据。
答案:
代码如下:

13.6 堆
面试例题1:请讲述heap与stack的差别。[美国著名数据库公司S 2006年、2008年面试题]
解析:本题2006年、2008年两次出现。
在进行C/C++编程时,需要程序员对内存的了解比较精准。经常需要操作的内存可分为以下几个类别。
● 栈区(stack):由编译器自动分配和释放,存放函数的参数值、局部变量的值等。其操作方式类似于数据结构中的栈。
● 堆区(heap):一般由程序员分配和释放,若程序员不释放,程序节束时可能由操作系统回收。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
● 全局区(静态区)(static):全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序节束后由系统释放。
● 文字常量区:常量字符串就是放在这里的。程序节束后由系统释放。
● 程序代码区:存放函数体的二进制代码。
以下是一段实际说明的程序代码:

堆和栈的理论知识如下。
1.申请方式
栈:由系统自动分配。例如,声明在函数中的一个局部变量int b,系统自动在栈中为b开辟空间。
堆:需要程序员自己申请,并指明大小,在C中用malloc函数。
如:

在C++中用new运算符,如:

但是注意p1、p2本身是在栈中的。
2.申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆节点,然后将该节点从空闲节点链表中删除,并将该节点的空间分配给程序。对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确地释放本内存空间。另外,由于找到的堆节点的大小不一定正好等于申请的大小,系统会自动地将多余的那部分重新放入空闲链表中。
3.申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在Windows下,栈的大小是2MB(也有的说是1MB,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表存储空闲内存地址的,自然是不连续的。而链表的遍历方向是由低地址向高地址,堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
4.申请效率的比较
栈:由系统自动分配,速度较快。但程序员无法控制。
堆:是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便。
另外,在Windows下,最好的方式是用VirtualAlloc分配内存。不是在堆,也不是在栈,而是直接在进程的地址空间中保留一块内存,虽然用起来最不方便,但是速度最快,也最灵活。
5.堆和栈中的存储内容
栈:在函数调用时,第一个进栈的是主函数中的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数。在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用节束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容由程序员安排。
6.存取效率的比较

aaaaaaaaaaa是在运行时刻赋值的,而bbbbbbbbbbb是在编译时就确定的。但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
比如:

对应的汇编代码如下:

第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把edx指中,再根据edx读取字符,显然慢了。
7.小节
堆和栈的区别可以用如下的比喻来描述。
使用栈就像我们去饭馆里吃饭,只管点菜(发出申请)、付钱和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作。好处是快捷,但是自由度小。使用堆就像是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
数据结构方面的堆和栈,这些都是不同的概念。这里的堆实际上指的就是(满足堆性质的)优先队列的一种数据结构,第一个元素有最高的优先权;栈实际上就是满足先进后出的性质的数学或数据结构。虽然“堆栈”的说法是连起来叫,但是它们还是有很大区别的。
答案:
heap是堆,stack是栈。
stack的空间由操作系统自动分配/释放,heap上的空间手动分配/释放。
stack空间有限,heap是很大的自由存储区。
C中的malloc函数分配的内存空间即在堆上,C++中对应的是new操作符。
程序在编译期对变量和函数分配内存都在栈上进行,且程序运行过程中函数调用时参数的传递也在栈上进行。
面试例题2:全部变量放在( );函数内部变量static int ncount放在( );函数内部变量char p="AAA",p的位置在( );指向空间的位置( );函数内变量char p=new char;,p的位置( );指向空间的位置( )。[中国某著名综合软件公司2005年面试题]
A.数据段
B.代码段
C.堆栈
D.堆
E.不一定,看情况
解析:堆栈是一种简单的数据结构,是一种只允许在其一端进行插入或删除的线性表。允许插入或删除操作的一端称为栈顶,另一端称为栈底。对堆栈的插入和删除操作称为入栈和出栈。有一组CPU指令可以实现对进程的内存实现堆栈访问。其中,POP指令实现出栈操作,PUSH指令实现入栈操作。CPU的ESP寄存器存放当前线程的栈顶指针,EBP寄存器中保存当前线程的栈底指针。CPU的EIP寄存器存放下一个CPU指令存放的内存地址。当CPU执行完当前的指令后,从EIP寄存器中读取下一条指令的内存地址,然后继续执行。
答案:A,A,C,A,C,D。
扩展知识(变量的内存分配情况)
接触过编程的人都知道,高级语言都能通过变量名访问内存中的数据。那么这些变量在内存中是如何存放的呢?程序又是如何使用这些变量的呢?
首先,来了解一下C语言的变量是如何在内存分布的。C语言有全局变量(Global)、本地变量(Local)、静态变量(Static)和寄存器变量(Register)。每种变量都有不同的分配方式。先来看下面这段代码:

编译后的执行结果是:

输出的结果就是变量的内存地址。其中v1、v2、v3是本地变量,g1、g2、g3是全局变量,s1、s2、s3是静态变量。你可以看到这些变量在内存中是连续分布的,但是本地变量和全局变量分配的内存地址差了十万八千里,而全局变量和静态变量分配的内存是连续的。这是因为本地变量和全局/静态变量是分配在不同类型的内存区域中的结果。对于一个进程的内存空间而言,可以在逻辑上分成3个部分:代码区、静态数据区和动态数据区。动态数据区一般就是“堆栈”。“栈(stack)”和“堆(heap)”是两种不同的动态数据区。栈是一种线性节构,堆是一种链式节构。进程的每个线程都有私有的“栈”,所以每个线程虽然代码一样,但本地变量的数据都是互不干扰的。
一个堆栈可以通过“基地址”和“栈顶”地址来描述。全局变量和静态变量分配在静态数据区,本地变量分配在动态数据区,即堆栈中。程序通过堆栈的基地址和偏移量来访问本地变量,如下图所示。

堆栈是一个先进后出的数据结构,栈顶地址总是小于等于栈的基地址。我们可以先了解一下函数调用的过程,以便对堆栈在程序中的作用有更深入的了解。不同的语言有不同的函数调用规定,这些因素有参数的压入规则和堆栈的平衡。Windows API的调用规则和ANSI C的函数调用规则是不一样的,前者由被调函数调整堆栈,后者由调用者调整堆栈。两者通过“_stdcall”和“_cdecl”前缀区分。先看下面这段代码:

编译后的执行结果是:

下面详细解释函数调用的过程中堆栈的分布:
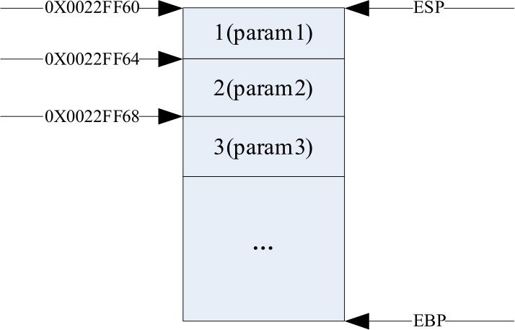
在堆栈中分布变量是从高地址向低地址分布,EBP指向栈底指针,ESP是指向栈顶的指针,根据__stdcall调用约定,参数从右向左入栈,所以首先,3个参数以从右到左的次序压入堆栈,先压“param3”,再压“param2”,最后压入“param1”。栈内分布如下图所示。
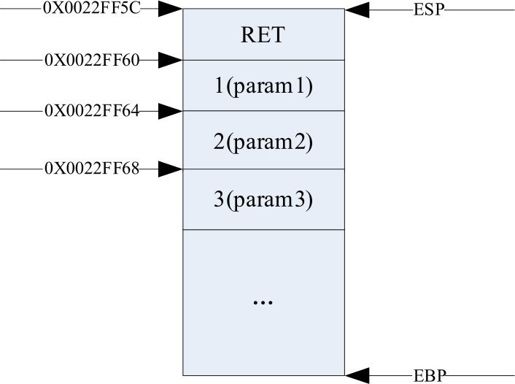
然后函数的返回地址入栈,栈内分布如下图所示。
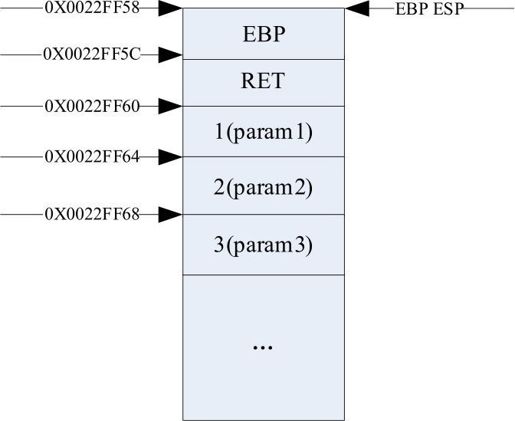
通过跳转指令进入函数。函数地址入栈后,EBP入栈,然后把当前的ESP的值给EBP,汇编下指令为:

此时栈底指针和栈顶指针指向同一位置,栈内分布为如下图所示。
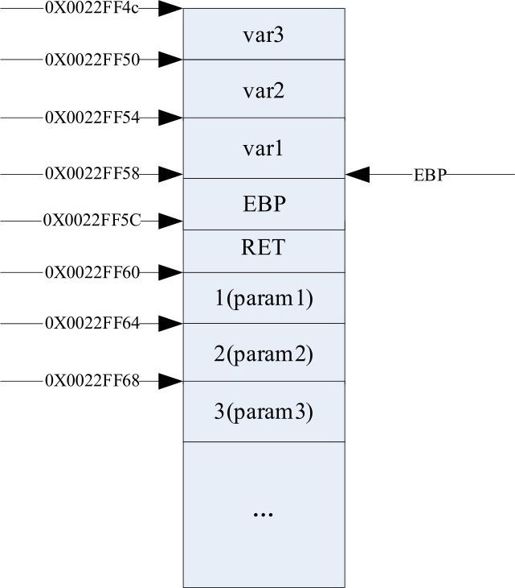
然后是int var1=param1;int var2=param2;int var3=param3;也就是变量var1,var2,var3的初始化(从左向右的顺序入栈),按声明顺序依次存储到EBP-4,EBP-8,EBP-12位置,栈内分布如下图所示。
Windows下的动态数据除了可存放在栈中,还可以存放在堆中。了解C++的朋友都知道,C++可以使用new关键字来动态分配内存。来看下面的C++代码:

程序执行结果为:

可以发现用new关键字分配的内存既不在栈中,也不在静态数据区。
面试例题3:以下两种情况:
(1)new一个10个整型的数组。
(2)分10次new一个整型的变量。
哪个占的空间更大些?
A.1
B.2
C.一样多
D.不确定
[美国著名操作系统、数据库软件公司W 2008年4月面试题]
解析:如果所谓“占用空间”不包含操作系统HeapAlloc时的额外损耗,则两者占用空间是一样多的。如果包括额外损耗,自然是第二个占用空间多。
有人觉得new一个10个整型的数组会包含数组长度,以便delete []时知道要释放多少空间,事实上,这种说法是不正确的。
在调用HeapAlloc的时候,操作系统已经记录了这块分配的内存的大小,因此HeapFree的时候直接给出指针就行,根本不必给出额外的大小信息。因此如果对于内建类型,完全不必另外开4字节去保存数组的长度,直接调用HeapFree就可以了。
可以编程做一个测试:

汇编代码如下:

但是到了带有析构函数的类就不行了,因为delete []p的时候需要知道调用析构函数的次数,此时便有额外的4字节被分配来记录数组大小。
如果上面的程序改成:

汇编代码如下:
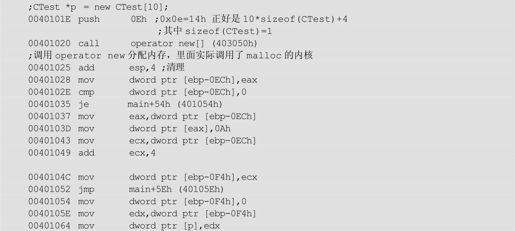
在后面delete []p的时候,正是根据那个额外的信息来确定调用析构函数的次数的。实际是调用了CTest::vector deleting destructor,这是为每个类默认生成的一个析构函数。
由题意来看,应该是考堆的分配的额外损耗的问题,所以笔者认为第二种做法占用空间多。
至于new是否会产生“内存碎片”的问题,因为内存碎片只是系统分给程序时会产生的:假如程序第一次分配了10KB,而系统内存分配粒度为32KB,剩余的22KB如果没有被程序用到则产生内存碎片。如果程序继续分配,则系统很可能优化,继续使用剩下的22KB。而本例中没有大于分配粒度,因此产生的碎片应该是一样的。
但对于操作系统来说:new一块内存,Windows不仅分配给你内存,还用4字节在那段内存后作为内存分配边界,如果从这个角度来说的话第二次就分配多了。
答案:B
面试例题4:If one compiled and ran following C Program in Windows , which of the statements below is correct about the program's run-time memory allocation?(下面程序描述正确的是)[美国著名硬件公司E2013年面试题]

A.Memory used by variable 'p' is allocated in a stack area.
B.Memory used by array variable 'b' is allocated in a stack area.
C.Memory used by variable 'c' is allocated in a heap area.
D.Memory to which is pointed by pointer 'p' is leaked. After the program termination, system loses control of that memory area.
解析:变量p、c分布在栈区。变量b分布在全局静态初始化区。所以B,C错误;A正确。
至于选项D:在Windows中,对于一般没有free的malloc,在进程正常结束时是可以回收的,不管用户程序怎么malloc,在进程结束的时候,其虚拟地址空间就会被直接销毁,操作系统只需要在进程结束的时候让内存管理模块。把分页文件中与此进程相关的记录全部删除,标记为“可用空间”,就可以使所有申请的内存都一次性地回收。
但是,这里有一个条件,就是在进程退出时。(也只有这个时候,内核会调用内存管理模块来执行清理),如果是一个服务器上长期运行的程序,不可能动不动就退出来清理一次。这种时候,不合理的内存分配导致的泄漏就会使程序运行出现问题。
答案:A
13.7 树、图、哈希表
面试例题1:If a pre-order traversal sequence of a binary tree is abcdefg, which one of the following is NOT possible in-order traversal sequence?(前序遍历二叉树值为abcdefg,下面哪个不可能是中序遍历)[美国著名软件公司M2013年11月笔试题]
A.abcdefg
B.gfedcba
C.bcdefga
D.bceadfg
解析:二叉树遍历原则如下:前序遍历是根左右,中序遍历是左根右,后序遍历是左右根。如果前序遍历二叉树值为abcdefg,那么a一定是根,这样我们再来看选项D,如果bceadfg是中序遍历,那么bce在左,a为根,dfg在右。根据前序遍历,bce就一定在dfg左边,所以前序遍历二叉树值不可能为abcdefg。
答案:D
面试例题2:There is binary search tree which is used to store characters 'A','B','C','D','E','F','G','H',which of the following is post-order tree walk result?(有一个二叉搜索树用来存储字符'A', 'B', 'C','D','E','F','G','H'下面哪个结果是后序树遍历结果)[美国著名软件公司M2009年11月笔试题]
A.ADBCEGFH
B.BCAGEHFD
C.BCAEFDHG
D.BDACEFHG
解析:二叉搜索树(Binary Search Tree),或者是一棵空树,或者是具有下列性质的二叉树:对于树中的每个节点X,它的左子树中所有关键字的值都小于X的关键字值,而它的右子树中的所有关键字值都大于X的关键字值。这意味着该树所有的元素都可以用某种统一的方式排序。
例如下面就是一棵合法的二叉搜索树:

它的左、右子树也分别为二叉搜索树。
二叉搜索树的查找过程和次优二叉树类似,通常采取二叉链表作为二叉搜索树的存储节构。中序遍历二叉搜索树可得到一个关键字的有序序列,一个无序序列可以通过构造一棵二叉搜索树变成一个有序序列,构造树的过程即为对无序序列进行排序的过程。每次插入的新的节点都是二叉搜索树上新的叶子节点,在进行插入操作时,不必移动其他节点,只需改动某个节点的指针,由空变为非空即可。搜索、插入、删除的复杂度等于树高,即O(log(n))。
二叉树的一个重要的应用是它们在查找中的使用。二叉搜索树的概念相当容易理解,二叉搜索树的性质决定了它在搜索方面有着非常出色的表现:要找到一棵树的最小节点,只需要从根节点开始,只要有左儿子就向左进行,终止节点就是最小的节点。找最大的节点则是往右进行。例如上面的例子中,最小的节点是1,在最左边;最大的节点是8,在最右边。
对于本题而言,二叉搜索树则必满足对树中任一非叶节点,其左子树都小于该节点值,右子树所有节点值都大于该节点值。节合二叉树后序遍历的特点,最后一个肯定是根节点
A.ADBCEGFH
->(H)左子树(ADBCEGF),右子树(空) (左子树必须都小于根H,右子树都大于根H)
—>(F)左子树(ADBCE),右子树(G)
—->(E)左子树(ADBC),右子树(空)
——>(C)剩下(ADB)不能区别左子树,右子树,所以选项A不成立;
B.BCAGEHFD
->(D, (BCA), (GEHF))
—>GEHF, F为根,剩下GEH不能根据F分成两个子段,所以B不成立;
C.BCAEFDHG
->(G, (BCAEFD), (H))
—>(G, (D, (BCA), (EF)), (H))
—->(G, (D, (A, (), (BC)), (F, (E), ())), (H))
——>(G, (D, (A, (), (C, (B), ())), (F, (E), ())), (H))

选项C成立;
D.BDACEFHG
->(G, (BDACEF), (H))
—>(G, (F, (BDACE), ()), (H))
—->(G, (F, (E, (BDAC), ()), ()), (H))
——>BDAC子树,C为根,据C不能将序列BDA划分为两个子序列,使得左子序列全小于C,右子序列全大于C
所以选项D不成立。
答案:C
面试例题3:Which of the following data sequence(s) should NOT produces a balanced binary search tree if the inserted from left to right?
A.8,-1,6,7,4,3,-2
B.20,10,16,4,30,24,31
C.7,12,3,-2,8,19,5,10
D.10,5,20,6,2,1,22,15,30
解析:平衡二叉树(Balanced Binary Tree)具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。按照这个原则衡量如下二叉搜索树,显然A选项不符合要求。
答案:A
面试例题4:如下数据结构:

请实现两棵树是否相等的比较,相等返回0否则返回其他值。并说明你的算法复杂度。[美国著名软件公司M2009年11月笔试题]
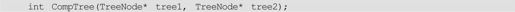
注:A、B两棵树相等当且仅当RootA-> c==RootB-> c,而且A和B的左右子树对应相等或者左右互换后相等。
答案:这道题涉及二叉树,用递归方法比较方便,具体代码如下:

面试例题5:A quad-tree, starting from the root node, could consist of many nodes: leaf-node and non-leaf node. Each non-leaf node may have 1 to 4 child nodes; each node has an internal value V, if not null, which would refer to any node in the same quad-tree. Hierarchically, depth of node describes the distance between a node in a tree and the tree's root node, the farther the distance is, the deeper the node is at in the tree. The goal is to find all the nodes in the quad-tree which fulfills the condition: the value of node A refers to a node B in the same tree, where the depth of node A is larger than the depth of node B. The input would be a data structure representing the quad-tree; the output would be a data structure representing the list of nodes fulfilling the conditions.(四叉树由许多个节点组成,其起点是根节点。节点有两种:有叶节点,无叶节点,其中每个无叶节点又可分出1到4个子节点。每一节点都包含其内在价值V。如果这个价值是有效值,则可以表示同一四叉树上任一节点的价值。从等级上划分,节点的深度表明节点与根节点之间的距离:距离越远,节点的深度越深。目的是找出四叉树上所有符合以下条件的节点:在同一树上,节点A的价值说明节点B的价值但其深度要大于节点B的深度。四叉树以数据输入的节构呈现,而符合各条件的节点列以数据输出的节构呈现。)
Question: Describe how you will solve the problem and explain why you pick the solution. The best answer should consider multiple solutions and choose the optimal one in terms of time and space complexity, and explain why you choose this one.(说明你如何解决这个问题并解释你为什么采取那种解决方式。最好的回答应是在多种解决方案中根据时空的复杂程度选择最佳的一种并解释你为什么选择该项。)[英国某图形软件公司2009年9月笔试题]
解析:用广度优先的方法遍历(先遍历离根近的节点),配合hash(将所有节点信息保存至hash表,同时记录节点同根节点的距离),当某节点包含引用值时,判断hash里面是否存在该节点,如果不存在,则说明当前节点的级别<=引用节点的级别,如果hash里面存在该节点信息,再判断当前节点的级别是否=引用节点的级别,!=说明引用节点的级别比当前节点高。复杂度为O(n)。
答案:建立该树时按照完全四叉树的位置给每个节点编号。编号为n节点,其4个子节点为4n,4n+1,4n+2,4n+3,根节点编0,编1都无所谓。要完成题目的工作,只需要把其引用编号(内涵值)与其编号一比就知道了。遍历一次即可,复杂度o(N)。
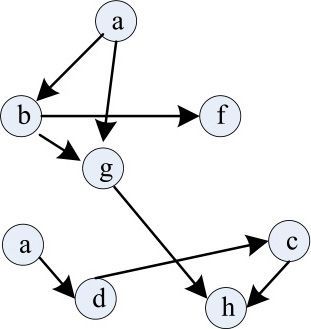
面试例题6:下面哪个序列不是下图的一个拓扑排序?
A.ebfgadch
B.aebdgfch
C.adchebfg
D.aedbfgch
解析:有向图拓朴排序算法的基本步骤如下:
1>从图中选择一个入度为0的顶点,输出该顶点;
2>从图中删除该顶点及其相关联的弧,调整被删弧的弧头结点的入度(入度-1);
3>重复执行1、2直到所有顶点均被输出。
选项C内容adch执行到h时候,h入度不为0,所以错误。
答案:C
面试例题7:下面是邻接表存储的图,以[0]点出发,求深度优先遍历和广度优先遍历结果。[美国某数据库公司2012年11月笔试题]

解析:深度优先遍历:
1>首先访问出发点v,并将其标记为已访问过;然后依次从v出发搜索v的每个邻接点w。
2>若w未曾访问过,则以w为新的出发点继续进行深度优先遍历,直至图中所有和源点v有路径相通的顶点(亦称为从源点可达的顶点)均已被访问为止。
3>若此时图中仍有未访问的顶点,则另选一个尚未访问的顶点作为新的源点重复上述过程,直至图中所有顶点均已被访问为止。
广度优先遍历:
1>从图中某个顶点V0出发,并访问此顶点。
2>从V0出发,访问V0的各个未曾访问的邻接点W1,W2,…,Wk;然后,依次从W1,W2,…,Wk出发访问各自未被访问的邻接点。
3>重复步骤2,直到全部顶点都被访问为止。
答案:DFS=0 1 2 3 4 5 8 6 7 End;BFS=0 1 5 6 2 4 8 7 3 End。
面试例题8:如何设计一个魔方(六面)的程序,说说方法。[中国某著名搜索引擎公司2010年6月笔试题]
答案:把魔方展开,得到6个正方形,定义6个节构体,内容为一个9个点和一个编号,每个点包括一个颜色标识;在魔方展开图中根据正方形的相邻关系编号,每个正方形都有4个函数:左翻、右翻、上翻、下翻。
根据相邻关系,每个操作会引起相邻面的相关操作;比如一个面的左翻会调用右边相邻面的左翻;也就意味着左相邻面的0、1、2三个元素与当前面互换;递归下去,直到所有面都交换完毕。
面试例题9:在百度或淘宝搜索时,每输入字符都会出现搜索建议,比如输入“北京”,搜索框下面会以北京为前缀,展示“北京爱情故事”、“北京公交”、“北京医院”等等搜索词。实现这类技术后台所采用的数据结构是什么?[中国某著名搜索引擎B公司2012年6月笔试题]
答案:Trie树,又称单词查找树、字典树,是一种树形结构,是一种哈希树的变种,是一种用于快速检索的多叉树结构。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。Trie树的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
对于搜索引擎,一般会保留一个单词查找树的前N个字(全球或最近热门使用的);对于每个用户,保持Trie树最近前N个字为该用户使用的结果。
如果用户点击任何搜索结果,Trie树可以非常迅速并异步获取完整的部分/模糊查找,然后预取数据,再用一个Web应用程序可以发送一个较小的一组结果的浏览器。
面试例题10:用二进制来编码字符串“abcdabaa”,需要能够根据编码,解码回原来的字符串,最少需要多长的二进制字符串?
A.12
B.14
C.18
D.24
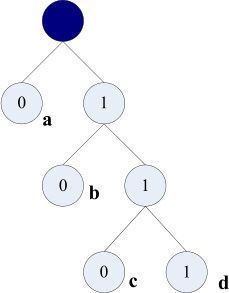
解析:哈夫曼编码问题:字符串“abcdabaa”有4个a、2个b、1个c、1个d。构造哈夫曼树如下图所示。a编码0(1位),b编码10(2位),c编码110(3位),d编码111(3位)。这个字符串的总长度为:14+22+31+31=14。
答案:B
面试例题11:一个包含n个结点的四叉树,每一个节点都有4个指向孩子节点的指针,这个四叉树有__个空指针。
答案:n个节点有n-1个非空指针,其余皆为空指针。4n-(n-1)=3n+1
面试例题12:有1千万条短信,有重复,以文本文件的形式保存,一行一条,有重复。请用5分钟时间,找出重复出现最多的前10条。[中国某著名互联网公司2010年5月笔试题]
解析:对于本题来说,某些面试者想用数据库的办法实现:首先将文本导入数据库,再利用select语句某些方法得出前10条短信。但是实际上用数据库是绝对满足不了5分钟解决这个条件的。这是因为1千万条短信即使1秒钟录入1万条(这已经算是很快的数据导入了)5分钟才3百万条。即便真的能在5分钟内录完1千万条,也必须先建索引,不然sql语句5分钟内肯定得不出结果。但对1千万条记录建索引即使在5分钟内都不能完成的。所以用数据库的办法不行。
这种类型的题之所以会出现,这是因为互联网公司无时无刻都在需要处理由用户产生的海量数据/日志,所以海量数据的题现在很热,基本上互联网公司都会考。重点考察的是你的数据结构设计与算法基本功。类似题目是如何根据关键词搜索访问最多的前10个网站。
答案:方法1:可以用哈希表的方法对1千万条分成若干组进行边扫描边建散列表。第一次扫描,取首字节,尾字节,中间随便两字节作为Hash Code,插入到hash table中。并记录其地址和信息长度和重复次数,1千万条信息,记录这几个信息还放得下。同hash code且等长就是疑似相同,比较一下。相同记录只加1次进hash table,但将重复次数加1。一次扫描以后,已经记录各自的重复次数,进行第二次hash table的处理。用线性时间选择可在O(n)的级别上完成前10条的寻找。分组后每份中的top 10必须保证各不相同,可hash来保证。也可直接按hash值的大小来分类。
方法2:可以采用从小到大排序的办法,根据经验,除非是群发的过节短信,否则字数越少的短信出现重复的几率越高。建议从字数少的短信开始找起,比如一开始搜一个字的短信,找出重复出现的top10并分别记录出现次数,然后搜两个字的,依次类推。对于对相同字数的比较长的短信的搜索,除了hash之类的算法外,可以选择只抽取头、中和尾等几个位置的字符进行粗判,因为此种判断方式是为了加快查找速度但未必能得到真正期望的top10,因此需要做标记;如此搜索一遍后,可以从各次top10结果中找到备选的top10,如果这top10中有刚才做过标记的,则对其对应字数的所有短信进行精确搜索以找到真正的top10并再次比较。
方法3:可以采用内存映射办法,首先,1千万条短信按现在的短信长度将不会超过1G空间,使用内存映射文件比较合适。可以一次映射(当然如果更大的数据量的话,可以采用分段映射),由于不需要频繁使用文件I/O和频繁分配小内存,这将大大提高数据的加载速度。其次,对每条短信的第i(i从0到70)个字母按ASCII码进行分组,其实也就是创建树。i是树的深度,也是短信第i个字母。
该问题主要是解决两方面的内容,一是内容加载,二是短信内容比较。采用文件内存映射技术可以解决内容加载的性能问题(不仅仅不需要调用文件I/O函数,而且也不需要每读出一条短信都分配一小块内存),而使用树技术可以有效减少比较的次数。代码如下:

扩展知识
有1亿个浮点数,请找出其中最大的10000个。提示:假设每个浮点数占4个字节,1亿个浮点数就要占到相当大的空间,因此不能一次将全部读入内存进行排序。
既然不可以一次读入内存,那可以使用如下方法:
方法1:读出100万个数据,找出最大的1万个,如果这100万数据选择够理想,那么最小的这1万个数据里面最小的为基准,可以过滤掉1亿数据里面99%的数据,最后就再一次在剩下的100万(1%)里面找出最大的1万个。
方法2:分块查找,比如100万一个块,找出最大1万个,一次下来就剩下100万数据需要找出1万个。
找出100万个数据里面最大的1万个,可以采用快速排序的方法,分2堆,如果大的那堆个数N大于1万个,继续对大堆快速排序一次分成2堆,如果大堆个数N小于1万,就在小的那堆里面快速排序一次,找第10000-N大的数字;递归以上过程,就可以找到相关结果。
13.8 排序
排序问题是各大IT公司必考的题目。
所谓排序,就是整理文件中的记录,使之按关键字递增(或递减)的顺序排列起来。其确切定义如下:
输入:n个记录R1、R2、…、Rn,其相应的关键字分别为K1、K2、…、Kn。
输出:Ril、Ri2、…、Rin,使得Ki1≤Ki2≤…≤Kin(或Ki1≥Ki2≥…≥Kin)。
1.被排序对象——文件
被排序的对象——文件由一组记录组成。
记录则由若干个数据项(或域)组成。其中有一项可用来标识一个记录,称为关键字项。该数据项的值称为关键字(Key)。
2.排序运算的依据——关键字
用来做排序运算依据的关键字,可以是数字类型,也可以是字符类型。
关键字的选取应根据问题的要求而定。
在高考成绩统计中将每个考生作为一个记录。每条记录包含准考证号、姓名、各科的分数和总分数等项内容。若要唯一地标识一个考生的记录,则必须用“准考证号”作为关键字。若要按照考生的总分数排名次,则需用“总分数”作为关键字。
3.排序的稳定性
当待排序记录的关键字均不相同时,排序结果是唯一的,否则排序结果不唯一。
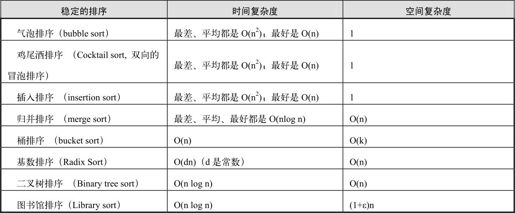
在待排序的文件中,若存在多个关键字相同的记录,经过排序后这些具有相同关键字的记录之间的相对次序保持不变,该排序方法是稳定的;若具有相同关键字的记录之间的相对次序发生变化,则称这种排序方法是不稳定的。排序算法的稳定性是针对所有输入实例而言的。即在所有可能的输入实例中,只要有一个实例使得算法不满足稳定性要求,则该排序算法就是不稳定的。稳定的排序如下表所示。
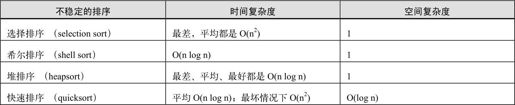
不稳定的排序如下表所示:
4.排序方法的分类
1)按是否涉及数据的内、外存交换分
在排序过程中,若整个文件都是放在内存中处理,排序时不涉及数据的内、外存交换,则称为内部排序(简称内排序)。反之,若排序过程中要进行数据的内、外存交换,则称为外部排序。
注意:
● 内排序适用于记录个数不很多的小文件。
● 外排序则适用于记录个数太多,不能一次将其全部记录放入内存的大文件。
2)按策略划分内部排序方法
可以分为5类:插入排序、选择排序、交换排序、归并排序和分配排序。
5.排序算法的基本操作
大多数排序算法都有两个基本的操作:
● 比较两个关键字的大小。
● 改变指向记录的指针或移动记录本身。
注意:第二种基本操作的实现依赖于待排序记录的存储方式。
6.待排文件的常用存储方式
1)以顺序表(或直接用向量)作为存储节构
排序过程:对记录本身进行物理重排,即通过关键字之间的比较判定,将记录移到合适的位置。
2)以链表作为存储节构
排序过程:无须移动记录,仅需修改指针。通常将这类排序称为链表(或链式)排序。
3)用顺序的方式存储待排序的记录,但同时建立一个辅助表(如包括关键字和指向记录位置的指针组成的索引表)
排序过程:只需对辅助表的表目进行物理重排(即只移动辅助表的表目,而不移动记录本身)。适用于难于在链表上实现,且仍需避免排序过程中移动记录的排序方法。
7.排序算法性能评价
1)评价排序算法好坏的标准
评价排序算法好坏的标准主要有两条:
● 执行时间和所需的辅助空间。
● 算法本身的复杂程度。
2)排序算法的空间复杂度
若排序算法所需的辅助空间并不依赖于问题的规模n,即辅助空间是O(1),则称为就地排序(In-PlaceSort)。
非就地排序一般要求的辅助空间为O(n)。
3)排序算法的时间开销
大多数排序算法的时间开销主要是关键字之间的比较和记录的移动。有的排序算法其执行时间不仅依赖于问题的规模,还取决于输入实例中数据的状态。
面试例题1:The following is an improved quick sort algorithm. Please fill in the blank.(下面的程序是一个快速排序问题,请填空。)[美国某著名计算机嵌入式公司2005年面试题]

解析:数据结构的快速排序问题。
答案:improveqsort(list,m,j-1);
improveqsort(list,i,n);
扩展知识(快速排序的算法思想)
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称为分治法(Divide-and- Conquer Method)。
1.分治法的基本思想
分治法的基本思想是将原问题分解为若干个规模更小但节构与原问题相似的子问题。递归地解决这些子问题,然后将这些子问题的解组合为原问题的解。
2.快速排序的基本思想
设当前待排序的无序区为R[low..high],利用分治法可将快速排序的基本思想描述为:
1)分解
在R[low..high]中任选一个记录作为基准(Pivot),以此基准将当前无序区划分为左、右两个较小的子区间R[low..pivotpos-1]和R[pivotpos+1..high],并使左边子区间中所有记录的关键字均小于等于基准记录(不妨记为pivot)的关键字pivot.key,右边的子区间中所有记录的关键字均大于等于pivot.key,而基准记录pivot则位于正确的位置(pivotpos)上,它无须参加后续的排序。
注意:
划分的关键是要求出基准记录所在的位置pivotpos 。划分的结果可以简单地表示为(注意pivot=R[pivotpos]):
R[low..pivotpos-1].keys≤R[pivotpos].key≤R[pivotpos+1.
.high].keys
其中low≤pivotpos≤high。
2)求解
通过递归调用快速排序对左、右子区间R[low..pivotpos-1]和R[pivotpos+1..high]快速排序。
3)组合
因为当“求解”步骤中的两个递归调用节束时,其左、右两个子区间已有序。对快速排序而言,“组合”步骤无须做什么,可看做是空操作。
3.快速排序算法QuickSort
代码如下:

注意:
为排序整个文件,只须调用QuickSort(R, 1, n)即可完成对R[l..n]的排序。
4.划分算法Partition
1)简单的划分方法
①具体做法
第1步:(初始化)设置两个指针i和j,它们的初值分别为区间的下界和上界,即i=low,i=high;选取无序区的第一个记录R[i](即R[low])作为基准记录,并将它保存在变量pivot中。
第2步:令j自high起向左扫描,直到找到第1个关键字小于pivot.key的记录R[j],将R[j])移至i所指的位置上,这相当于R[j]和基准R[i](即pivot)进行了交换,使关键字小于基准关键字pivot.key的记录移到了基准的左边,交换后R[j]中是pivot;然后,令i指针自i+1位置开始向右扫描,直至找到第1个关键字大于pivot.key的记录R[i],将R[i]移到i所指的位置上,这相当于交换了R[i]和基准R[j],使关键字大于基准关键字的记录移到了基准的右边,交换后R[i]中又相当于存放了pivot;接着令指针j自位置j-1开始向左扫描,如此交替改变扫描方向,从两端各自往中间靠拢,直至i=j时,i便是基准pivot最终的位置,将pivot放在此位置上就完成了一次划分。
②划分算法
代码如下:

5.快速排序执行过程
快速排序执行的全过程可用递归树来描述,如下图所示。

一次划分过程如下图所示。
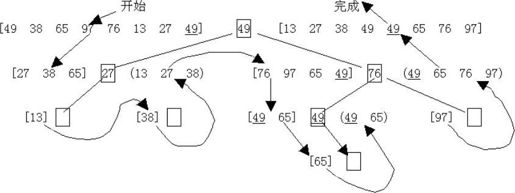
QuickSort执行时的递归树:

对递归树的每层上个无序区划分之后的状态。
6.时间复杂度
快速排序法是一种不稳定的排序方法,平均时间复杂度O(n×lgn/lg2),最差情况时间复杂度为O(n2)。
面试例题2:请用C或C++写出一个冒泡排序程序,要求输入10个整数,输出排序结果。[中国著名通信企业H公司面试题]
解析:交换排序中的冒泡排序问题。
答案:
程序如下:

扩展知识(交换排序的算法思想)
交换排序的基本思想是两两比较待排序记录的关键字,发现两个记录的次序相反时即进行交换,直到没有反序的记录为止。
应用交换排序基本思想的主要排序方法有冒泡排序和快速排序。
1.冒泡排序方法
将被排序的记录数组R[1..n]垂直排列,每个记录R[i]看做是重量为R[i].key的气泡。根据轻气泡不能在重气泡之下的原则,从下往上扫描数组R。凡扫描到违反本原则的轻气泡,就使其向上“飘浮”。如此反复进行,直到最后任何两个气泡都是轻者在上,重者在下为止。
1)初始
R[1..n]为无序区。
2)第一趟扫描
从无序区底部向上依次比较相邻的两个气泡的重量,若发现轻者在下、重者在上,则交换二者的位置。即依次比较(R[n], R[n-1])、(R[n-1], R[n-2])、…、(R[2], R[1]);对于每对气泡(R[j+1], R[j]),若R[j+1].key<R[j].key,则交换R[j+1]和R[j]的内容。
第一趟扫描完毕时,“最轻”的气泡就飘浮到该区间的顶部,即关键字最小的记录被放在最高位置R[1]上。
3)第二趟扫描
扫描R[2..n]。扫描完毕时,“次轻”的气泡飘浮到R[2]的位置上。
最后,经过n-1趟扫描可得到有序区R[1..n]。
注意:
第i趟扫描时,R[1..i-1]和R[i..n]分别为当前的有序区和无序区。扫描仍是从无序区底部向上直至该区顶部。扫描完毕时,该区中最轻气泡飘浮到顶部位置R[i]上,结果是R[1..i]变为新的有序区。
2.排序算法
1)分析
因为每一趟排序都使有序区增加了一个气泡,在经过n–1趟排序之后,有序区中就有n–1个气泡,而无序区中气泡的重量总是大于等于有序区中气泡的重量,所以整个冒泡排序过程至多需要进行n–1趟排序。
若在某一趟排序中未发现气泡位置的交换,则说明待排序的无序区中所有气泡均满足轻者在上、重者在下的原则,因此,冒泡排序过程可在此趟排序后终止。为此,在下面给出的算法中,引入一个布尔量exchange,在每趟排序开始前,先将其置为FALSE。若排序过程中发生了交换,则将其置为TRUE。各趟排序节束时检查exchange,若未曾发生过交换则终止算法,不再进行下一趟排序。
2)具体算法
代码如下:

3.算法分析
1)算法的最好时间复杂度
若文件的初始状态是正序的,一趟扫描即可完成排序。所需的关键字比较次数C和记录移动次数M均达到最小值:
Cmin=n–1
Mmin=0
冒泡排序最好的时间复杂度为O(n)。
(2)算法的最坏时间复杂度
若初始文件是反序的,需要进行n–1趟排序。每趟排序要进行n–i次关键字的比较(1≤i≤n–1),且每次比较都必须移动记录3次来交换记录位置。在这种情况下,比较和移动次数均达到最大值:
Cmax=n(n–1)/2=O(n2)
Mmax=3n(n–1)/2=O(n2)
冒泡排序的最坏时间复杂度为O(n2)。
3)算法的平均时间复杂度为O(n2)
虽然冒泡排序不一定要进行n–1趟,但由于它的记录移动次数较多,故平均时间性能比直接插入排序要差得多。
4)算法稳定性
冒泡排序是就地排序,且它是稳定的。
面试例题3:请用C或C++写出一个Shell排序程序,要求输入10个整数,输出排序结果。[中国某著名通信企业H公司面试题]
解析:希尔排序(Shell Sort)是插入排序的一种,因D.L.Shell于1959年提出而得名。
答案:
完整代码如下:

扩展知识(希尔(Shell)排序基本思想)
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为dl的倍数的记录放在同一个组中。先在各组内进行直接插入排序,然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
该方法实质上是一种分组插入方法。
给定实例的Shell排序的排序过程如下。
假设待排序文件有10个记录,其关键字分别是49,38,65,97,76,13,27,49,55,04。
增量序列的取值依次为5,3,2,1。排序过程如下图所示。
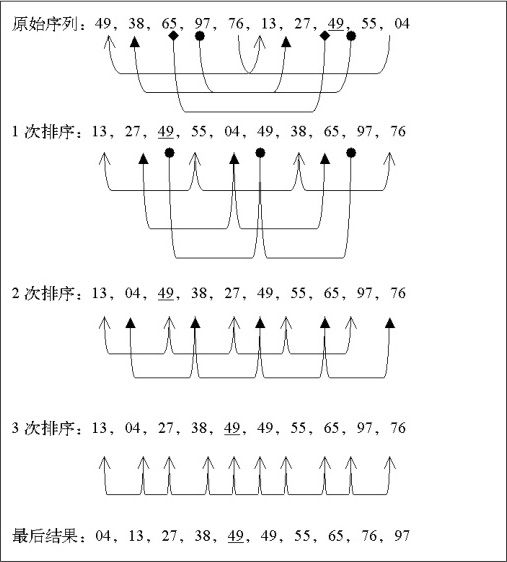
Shell排序的算法实现如下:

注意:当增量d=1时,ShellPass和InsertSort基本一致,只是由于没有哨兵而在内循环中增加了一个循环判定条件“j>0”,以防下标越界。
算法分析:
1)增量序列的选择
Shell排序的执行时间依赖于增量序列。
好的增量序列的共同特征如下:
● 最后一个增量必须为1。
● 应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况。
有人通过大量的实验,给出了目前较好的结果:当n较大时,比较和移动的次数约在n1.25~1.6n1.25之间。
2)Shell排序的时间性能优于直接插入排序
希尔排序的时间性能优于直接插入排序的原因如下:
● 当文件初态基本有序时,直接插入排序所需的比较和移动次数均较少。
● 当n值较小时,n和n2的差别也较小,即直接插入排序的最好时间复杂度O(n)和最坏时间复杂度O(n2)差别不大。
在希尔排序开始时增量较大,分组较多,每组的记录数目少,故各组内直接插入较快。后来增量di逐渐缩小,分组数逐渐减少,而各组的记录数目逐渐增多。但由于已经按di-1作为距离排过序,使文件较接近于有序状态,所以新的一趟排序过程也较快。
因此,希尔排序在效率上较直接插入排序有较大的改进。
3)稳定性
希尔排序是不稳定的。参见上述实例,该例中两个相同关键字49在排序前后的相对次序发生了变化。
面试例题4:以下哪种排序属于稳定排序?[美国某著名分析软件公司2005年面试题]
A.归并排序
B.快速排序
C.希尔排序
D.堆排序
解析:只有归并排序是稳定排序,其他3个都是不稳定的。
答案:D
扩展知识(各种排序方法比较)
按平均时间将排序分为以下4类。
● 平方阶(O(n2))排序:一般称为简单排序,例如直接插入、直接选择和冒泡排序。
● 线性对数阶(O(nlgn))排序:如快速、堆和归并排序。
● O(n1+£)阶排序:£是介于0和1之间的常数,即0<£<1,如希尔排序。
● 线性阶(O(n))排序:如桶、箱和基数排序。
简单排序中直接插入排序最好,快速排序最快。当文件为正序时,直接插入排序和冒泡排序均最佳。
1.影响排序效果的因素因为不同的排序方法适应不同的应用环境和要求,所以选择合适的排序方法应综合考虑下列因素:
● 待排序的记录数目n。
● 记录的大小(规模)。
● 关键字的节构及其初始状态。
● 对稳定性的要求。
● 语言工具的条件。
● 存储节构。
● 时间和辅助空间复杂度等。
2.不同条件下排序方法的选择
(1)若n较小(如n≤50),可采用直接插入或直接选择排序。
当记录规模较小时,直接插入排序较好。否则因为直接选择移动的记录数少于直接插入,应选直接选择排序为宜。
(2)若文件初始状态基本有序(指正序),则应选用直接插入排序、冒泡排序或随机的快速排序为宜。
(3)若n较大,则应采用时间复杂度为O(nlgn)的排序方法(快速排序、堆排序或归并排序)。
快速排序被认为是目前基于比较的内部排序中最好的方法。当待排序的关键字随机分布时,快速排序的平均时间最短。
堆排序所需的辅助空间少于快速排序,并且不会出现快速排序可能出现的最坏情况。这两种排序都是不稳定的。
若要求排序稳定,则可选用归并排序。但本章介绍的从单个记录起进行两两归并的排序算法并不值得提倡,通常可以将它和直接插入排序节合在一起使用。先利用直接插入排序求得较长的有序子文件,然后再两两归并之。因为直接插入排序是稳定的,所以改进后的归并排序仍是稳定的。
13.9 时间复杂度
面试例题1:定义了如下类和有序表关键字序列为b c d e f g q r s t,则在二分法查找关键字b的过程中,先后进行比较的关键字依次是多少?[中国某互联网公司2009年11月面试题]
A.f c b
B.f d b
C.g c b
D.g d b
解析:二分法查找是指已知有序队列中找出与给定关键字相同的数的具体位置。原理是分别定义三个指针low、high、mid,分别指向待查元素所在范围的下界和上界及区间的中间位置,即mid=(low+high)/2,让关键字与mid所指的数比较,若相等则查找成功并返回mid,若关键字小于mid所指的数则high=mid-1,否则low=mid+1,然后继续循环直到找到或找不到为止。下面代码是二分法的C++实现:

对于本题而言,要比较三个关键字,分别是f、e、b。具体情况如下图所示。
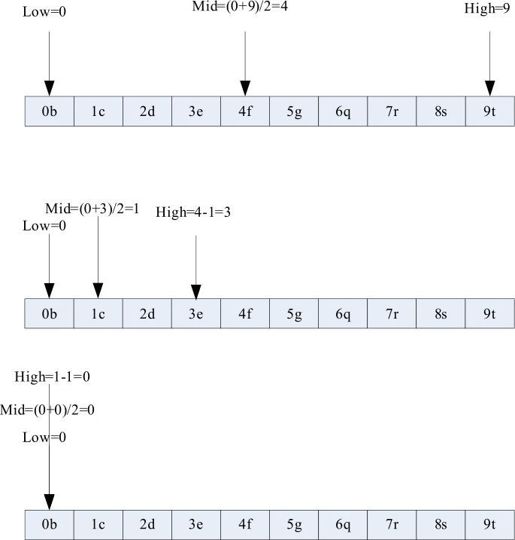
答案:A
面试例题2:Which of the choices below correctly describes the amount of time used by the following code?(下面哪个选项正确地描述了代码运行的调度次数?)[美国著名软件公司M2009年10月面试题]

A.Θ(n^3)
B.Θ(n2logn)
C.Θ(n(log n)*2)
D.Θ(n log n)
解析:本题考量面试者对时间复杂度的理解。本题涉及如下概念:
1)时间频度
一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
2)时间复杂度
在刚才提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n))为算法的渐进时间复杂度,简称时间复杂度。
在各种不同算法中,若算法中语句执行次数为一个常数,则时间复杂度为O(1),另外,在时间频度不相同时,时间复杂度有可能相同,如T(n)=n^2+3n+4与T(n)=4n^2+2n+1,它们的频度不同,但时间复杂度相同,都为O(n^2)。
按数量级递增排列,常见的时间复杂度有:

随着问题规模n的不断增大,上述时间复杂度不断增大,而算法的执行效率不断降低。
3)算法的时间复杂度
若要比较不同的算法的时间效率,受限要确定一个度量标准,最直接的办法就是将计算法转化为程序,在计算机上运行,通过计算机内部的计时功能获得精确的时间,然后进行比较。但该方法受计算机的硬件、软件等因素的影响,会掩盖算法本身的优劣,所以一般采用事先分析估算的算法,即撇开计算机软硬件等因素,只考虑问题的规模(一般用用自然数n表示),认为一个特定的算法的时间复杂度,只采取于问题的规模,或者说它是问题的规模的函数。
为了方便比较,通常的做法是,从算法选取一种对于所研究的问题(或算法模型)来说是基本运算的操作,以其重复执行的次数作为评价算法时间复杂度的标准。该基本操作多数情况下是由算法最深层环内的语句表示的,基本操作的执行次数实际上就是相应语句的执行次数。
一般说来:
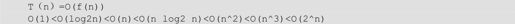
所以要选择时间复杂度量级低的算法。
至于本题,在这里观看代码可知,x=x+1,是循环最内侧代码,其时间复杂度最高,所以只求这句代码的复杂度即可。从内到外看,k循环从1==2^0开始每次变成原来的2倍,一直到大于n-1,所以应该是循环体运行次数是|log(n)|,时间复杂度为O(log(n))(计算机中log默认底数是2);j循环从1开始每次递增n/2,一直到n-1,第一次递增之后j变成(n+2)/2,第二次递增j则是n+1所以应该是循环了2次,但是时间复杂度还是O(1),因为常数次数的时间复杂度都是O(1)的,i循环从1开始,每次增1一直到n-1,所以循环体运行n-1次,时间复杂度为O(n)。最后相乘得到总的时间复杂度就是O(n1log(n))=O(n*log(n));这里要强调一下:时间复杂度都不带常数项或者常数系数的,所以不存在所谓O(2n)这样的时间复杂度。
答案:D
面试例题3:以下哪种节构,平均来讲获取任意一个指定值最快,为什么?[中国某互联网公司2009年11月面试题]
A.二叉排序树
B.哈希表
C.栈
D.队列
解析:一般来说,哪个需要的额外空间越多,哪个越快。
哈希表和哈希函数是大学数据结构中的课程,实际开发中我们经常用到Hashtable这种节构,当遇到键-值对存储,采用Hashtable比ArrayList查找的性能高。为什么呢?我们在享受高性能的同时,需要付出高额外空间的代价。那么使用Hashtable是否就是很好的选择呢?就此疑问,做分析如下:
1.于键-值查找性能高
数据结构描述线性表和树时,记录在节构中的相对位置是随机的,记录和关键字之间不存在明确的关系,因此在查找记录的时候,需要进行一系列的关键字比较,这种查找方式建立在比较的基础之上,在Java中(Array,ArrayList,List)这些集合节构采用了上面的存储方式。比如,现在我们有一个班同学的数据,包括姓名、性别、年龄、学号等。假如数据如下:

假如,我们按照姓名来查找,查找函数FindByName(string name):
(1)查找“张三”:
只需在第一行匹配一次。
(2)查找“王五”
在第一行匹配,失败;
在第二行匹配,失败;
在第三行匹配,成功。
上面两种情况,分析了最好的情况和最坏的情况,那么平均查找次数应该为(1+3)/2=2次,即平均查找次数为(记录总数+1)的1/2。尽管有一些优化的算法,可以使查找排序效率增高,但是复杂度会保持在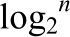 的范围之内。
的范围之内。
如何更更快的进行查找呢?我们所期望的效果是一下子就定位到要找记录的位置之上,这时候时间复杂度为1,查找最快。如果我们事先为每条记录编一个序号,然后让它们按号入位,我们又知道按照什么规则对这些记录进行编号的话,如果我们再次查找某个记录的时候,只需要先通过规则计算出该记录的编号,然后根据编号,在记录的线性队列中,就可以轻易地找到记录了。
注意,上述的描述包含了两个概念,一个是用于对学生进行编号的规则,在数据结构中,称之为哈希函数,另外一个是按照规则为学生排列的顺序节构,称之为哈希表。
仍以上面的学生为例,假设学号就是规则,老师手上有一个规则表,在排座位的时候也按照这个规则来排序,查找李四,首先该教师会根据规则判断出,李四的编号为2,就是在座位中的2号位置,直接走过去,就可以找到李四了。
流程如下:
从上面的图中,可以看出哈希表可以描述为两个表,一个表用来装记录的位置编号,另一个表用来装记录;此外存在一套规则,用来表述记录与编号之间的联系。这个规则通常是如何制定的呢?
1)直接定址法
对于整型的数据GetHashCode()函数返回的就是整型本身,其实就是基于直接定址的方法,比如有一组0~100的数据,用来表示人的年龄。那么,采用直接定址的方法构成的哈希表为:

这样的定址方式简单方便,适用于原数据能够用数字表述或者原数据具有鲜明顺序关系的情形。
2)数字分析法:
有这样一组数据,用于表述一些人的出生日期:

分析一下,年和月的第一位数字基本相同,造成冲突的几率非常大,而后面三位差别比较大,所以采用后三位:
3)平方取中法
取关键字平方后的中间几位作为哈希地址。
4)折叠法
将关键字分割成位数相同的几部分,最后一部分位数可以不相同,然后取这几部分的叠加和(取出进位)作为哈希地址,比如有这样的数据:

可以:

取出进位1,取0128为哈希地址。
5)取余法
取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址。H(key)=key MOD p (p<=m)。
6)随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key)=random(key),其中random为随机函数。通常关键字长度不等时采用此法。
总之,哈希函数的规则是通过某种转换关系,使关键字适度的分散到指定大小的的顺序节构中。越分散,则以后查找的时间复杂度越小,空间复杂度越高。
2.使用hash付出的代价
hash是一种典型以空间换时间的算法,比如原来一个长度为100的数组,对其查找,只需要遍历且匹配相应记录即可,从空间复杂度上来看,假如数组存储的是Byte类型数据,那么该数组占用100Byte空间。现在我们采用hash算法,我们前面说的hash必须有一个规则,约束键与存储位置的关系,那么就需要一个固定长度的hash表,此时,仍然是100Byte的数组,假设我们需要的100Byte用来记录键与位置的关系,那么总的空间为200Byte,而且用于记录规则的表大小会根据规则,大小可能是不定的。
hash表最突出的问题在于冲突,就是两个键值经过哈希函数计算出来的索引位置很可能相同。
答案:B
面试例题4:Which of the following operation performs NOT faster on an ordered data over a disordered data?(有序队列数据相对于无序队列数据,下列哪种操作并不快?)[中国某杀毒软件公司2009年11月面试题]
A.Find the minimum(找出最小值)
B.Calculate the average value(估算平均值)
C.Find the median(找出中间值)
D.Find the one with maximal occurrence(找出最大出现可能性)
解析:对于这4种情况分别分析如下:
● 对于寻找最小值:有序队列数据的时间复杂度是O(1),无序队列数据的时间复杂度是O(n)。
● 对于估算平均值:有序队列数据的时间复杂度是O(n),无序队列数据的时间复杂度是O(n)。
● 对于找出中间值:有序队列数据的时间复杂度是O(1),无序队列数据的时间复杂度是O(n)(O(n)的算法类似于快排)。
● 对于找出最大出现可能性:有序队列数据的时间复杂度是O(n),无序队列数据的时间复杂度是O(nlgn)(使用平衡查找节构而不是哈希表)。
答案:B
面试例题5:有20个数组,每个数组里面有500个数,升序排列,求出这10000个数字中最大的500个。求复杂度[中国某著名搜索引擎公司B2012年11月面试题]
解析:20个数组的最小元素全部进堆。每次取最小的一个的时候,从最小元素对应的数组里取下来一个放进堆里。堆里一直最多有20个数,充分利用20个数组的有序性。
答案:复杂度500*log(20)
面试例题6:辗转相除法的时间复杂度是多少?[美国某搜索引擎公司G2013年4月面试题]
答案:欧几里得算法,又称辗转相除法,用于求两个自然数的最大公约数.算法的思想很简单,基于下面的数论等式gcd(a, b)=gcd(b, a mod b),其时间复杂度为O(logn)。
