1.2 关于指针
1.2.1 恶名昭著的指针究竟是什么
关于“指针”一词,在 K&R 中有下面这样的说明(第 5 章“指针和数组”的开头部分):
指针是一种保存变量地址的变量,在 C 中频繁地使用。
其实在表达上,这样的说明是有很大问题的。总会让人感觉,一旦提起指针,就要把它当作变量的意思。实际上并非总是如此。
此外,在 C 语言标准中最初出现“指针”一词的部分,有这样一段话:
指针类型(pointer type)可由函数类型、对象类型或不完全的类型派生,派生指针类型的类型称为引用类型。指针类型描述一个对象,该类对象的值提供对该引用类型实体的引用。由引用类型 T 派生的指针类型有时称为“(指向)T 的指针”。从引用类型构造指针类型的过程称为“指针类型的派生”。这些构造派生类型的方法可以递归地应用。
这段话的内容也许会让你一头雾水*。那就让我们先关注第一句话吧,那里出现了“指针类型”一词。
* 既然是标准,那总要有点标准的范儿吧。
提到“类型”,立刻会让人想起“int 类型”、“double 类型”等。同样,在 C 语言中也存在“指针类型”这样的类型。
“指针类型”其实不是单独存在的,它是由其他类型派生而成的。以上对标准内容的引用中也提到“由引用类型 T 派生的指针类型有时称为‘(指向)T 的指针’”。
也就是说,实际上存在的类型是“指向 int 的指针类型”、“指向 double 的指针类型”。
因为“指针类型”是类型,所以它和 int 类型、double 类型一样,也存在“指针类型变量”和“指针类型的值”。糟糕的是,“指针类型”、“指针类型变量”和“指针类型的值”经常被简单地统称为“指针”,所以非常容易造成歧义,这一点需要提高警惕*。
* 至少本书还是尽力将这些说法进行区别的,但有时候,无论怎么写也做不到自然地表述想要表达的意思,最后只好投降……非常抱歉。
要 点
先有“指针类型”。
因为有了“指针类型”,所以有了“指针类型的变量”和“指针类型的值”。
比如,在 C 中,使用 int 类型表示整数。因为 int 是“类型”,所以存在用于保存 int 型的变量,当然也存在 int 型的值。
指针类型同样如此,既存在指针类型的变量,也存在指针类型的值。
因此,几乎所有的处理程序中,所谓的“指针类型的值”,实际是指内存的地址。
变量的内容是保存在内存的某个地方的,“某个地方”的说法总是会让人产生困惑,因此,就像使用“门牌号”确定“住址”一样,在内存中,我们也给变量分配“门牌号”。在 C 的内存世界里,“门牌号”被称为“地址”。
为了帮助理解这一点,还是写一个程序来验证一下。
1.2.2 和指针的第一次亲密接触
下面我们通过实际编程来尝试输出指针的值(参照代码清单 1-1)。
代码清单 1-1 pointer.c
1: #include <stdio.h>2:3: int main(void)4: {5: int hoge = 5;6: int piyo = 10;7: int *hoge_p;8:9: /*输出每个变量的地址*/10: printf("&hoge..%p\n", &hoge);11: printf("&piyo..%p\n", &piyo);12: printf("&hoge_p..%p\n", &hoge_p);13:14: /*将hoge 的地址赋予hoge_p*/15: hoge_p = &hoge;16: printf("hoge_p..%p\n", hoge_p);17:18: /*通过hoge_p 输出hoge 的内容*/19: printf("*hoge_p..%d\n", *hoge_p);20:21: /*通过hoge_p 修改hoge 的内容*/22: *hoge_p = 10;23: printf("hoge..%d\n", hoge);24:25: return 0;26: }
下面是我的环境(FreeBSD 3.2-RELEASE 和 gcc version 2.7.2.1)里输出的结果。
&hoge..0xbfbfd9e4&piyo..0xbfbfd9e0&hoge_p..0xbfbfd9dchoge_p..0xbfbfd9e4*hoge_p..5hoge..10
第 5~7 行声明了 int 类型变量 hoge、piyo 和“指向 int 的指针”类型的变量 hoge_p。如果理解 hoge_p 的声明有困难,不妨先单纯地将它理解成“指向 int 的指针”类型的变量(请参照本节的补充内容)。
int 类型的变量 hoge 和 piyo,在声明的同时分别被初始化为 5 和 10。
在第 10~12 行,使用地址运算符&,输出各变量的地址。在我的环境中,变量在内存中保存成下面这样(请参照图 1-1)。
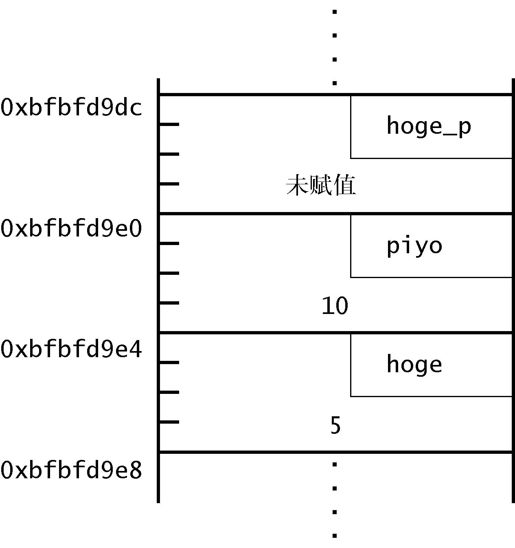
图 1-1 变量的保存状况
总觉得在我的环境中,变量是按照声明的逆向顺序保存在内存中的。可能会让人感觉有些奇妙,其实这是常见的现象,不要太在意。
要 点
变量不一定按照声明的顺序保存在内存中。
前面曾经提到,因为存在“指针类型”,所以存在“指针类型的变量”和“指针类型的值”。这里输出的“地址”,是指“指针类型的值”。
另外,以上的例子在使用 printf()输出指针的值时,使用了参数%p。很多人都使用过%x 这样的参数。遗憾的是,这种使用方式是错误的。关于这点的解释,请参照 1.2.3 节。
在第 15 行,将 hoge 的地址赋给指针变量 hoge_p。因为 hoge 的地址是 0xbfbfd94e4,这时内存变成图 1-2 所示的状态。
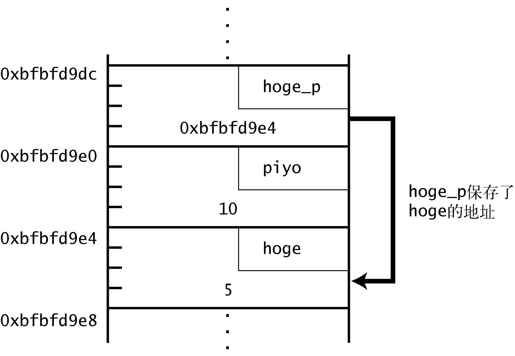
图 1-2 将指向 hoge 的指针的值赋给 hoge_p
像这样,指针变量 hoge_p 保存了另外一个变量 hoge 的地址,我们认为“hoge_p 指向 hoge”。
此外,对 hoge 变量实施&运算得到“hoge 的地址”。有时候也称“hoge 的地址”的值为“指向 hoge 的指针”(此时的“指针”指的是“指针类型的值”)。
在我的环境里,变量是按照声明的逆向顺序保存在内存中的。根据不同的环境,内存中变量位置的顺序可能有所不同,纠结于究竟 hoge、piyo 和 hoge_p 以什么样的顺序排列是没有意义的。图 1-2 也可以用图 1-3 的表现方式。
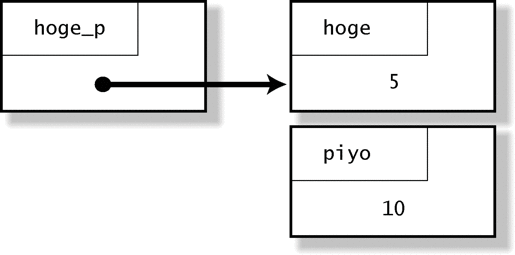
图 1-3 图 1-2 的另一种表现方式
上图更能直接地表现“hoge_p 指向 hoge”这个含义。
在第 19 行,使用解引用*,“顺藤摸瓜”输出 hoge 的值。
在指针前面加上*,可以表示指针指向的变量。因为 hoge_p 指向 hoge,所以*hoge_p 等同于 hoge。一旦要求输出*hoge_p,就会输出 hoge 中保存的值 5。
因为*hoge_p 和 hoge 表示同一个事物,通过*hoge_p 输出 hoge 的值之外,还可以赋值。在第 22 行,通过将 10 赋给*hoge_p,修改了 hoge 的值。在第 23 行输出 hoge 的值,运行结果为 10。
指针的基本知识就介绍到这里。以下是整理出的要点。
要 点
对变量使用&运算符,可以取得该变量的地址。这个地址称为指向该变量的指针。
指针变量
hoge_p保存了指向其他变量的地址的情况下,可以说“hoge_p指向hoge”。对指针变量运用运算符,就等同于它指向的变量。如果
hoge_p指向hoge,\hoge_p就等同于hoge。
补充 关于十六进制
在说明地址概念的时候,世上的 C 语言入门书籍中经常使用“门牌号 100”这样极其小的十进制值。
确实,对于初学者来说,可能这样更容易入门。但是本书偏执地使用了十六进制来说明。这是因为,如果想要了解地址的真正面目,把地址实际地表示出来才是最好的方式。本书例程中输出的所有地址,全部是通过我的环境实际运行程序后获得的。
对于那些对指针还是不太明白的读者来说,一定也要像我这样将例程实际地敲一遍,然后通过自己的环境确认一下究竟会输出什么东东。当然,通过你自己的环境输出的地址肯定和我的环境中输出的不同,但是其中的原理是一样。
哦?你说你不懂十六进制?——不好意思,你应该事先学习一下这方面的知识。
补充 混乱的声明——如何自然地理解声明?
通常,C 的声明像
- int hoge;
这样,使用“类型 变量名;”的形式进行书写。
可是,像“指向
int的指针”类型的变量,却要像下面这样进行声明:
- int hoge_p;
似乎这里声明了一个名为
\hoge_p的变量,而实际上,这里声明的变量是hoge_p,hoge_p的类型是“指向int的指针”。因为这种声明方式不太好理解,所以有人提出将
*靠近类型这一侧进行书写,如下:
- int hoge_p;
的确,这种书写方式符合“类型 变量名;”的形式。但是在同时声明多个变量的情况下就会出现破绽:
- /声明两个“指向int 的指针”?——其实不是/
- int hoge_p, piyo_p;
此外,数组也是 C 的一种类型,比如
- int hoge[10];
这样的写法,就不符合“类型 变量名;”的形式。
说一些题外话,Java 在声明“
int的数组”时,通常写成
- int[] hoge;
的形式,这样好像是符合“类型 变量名;”的形式。至少在这一点上,Java 的语法比起 C 显得更为合理。可是,Java 为了让 C 程序员更容易地将程序向 Java 移植,竟然也兼容
int hoge[]这样的写法。这种不伦不类的做法倒还真像 Java 的风格。Java 可以通过在使用
new进行实例化的时候定义数组元素的个数,所以这里没有元素个数的声明。我们换个角度考虑问题,对于
- int hoge_p;
这个声明,因为当
hoge_p指向hoge的时候,\hoge_p和hoge可以同等地使用,所以有人可能会产生下面的想法。你们看,一旦在
hoge_p之前追加*,就可以和int变量hoge同样使用呢。也就是说,这个声明意味着hoge_p之前追加上*后成为int类型了。这种思考方式,确实也有它一定的道理(比如数组也同样可以这么说),那么,如果写成
- int *&hoge;
这样,
hoge是可以作为int类型的变量来声明的吧?尝试一下就会明白,这里会发生一个语法错误。其次,在声明中出现
const的时候,这种观点也会出现破绽(表达式中是不可以出现const的),声明指向函数的指针时同样会出现问题。以我的经验来看,一切关于“如果这样考虑,是不是就可以很自然地解释 C 的声明了?”的尝试都是徒劳的。为什么这么说,因为 C 语言的语法本来就是不自然、奇怪而又变态的。
在第 3 章会详细地说明 C 的声明语法。姑且带着问题继续往下阅读吧。
补充 关于 int main(void)
在 C 语言标准中,关于
main()函数的使用只有如下两种方式:
- int main(int argc, char *argv[])
或者
- int main(void)
尽管如此,还是可以在一些入门书籍中遇到
- void main(void)
这样的写法,这是错误的。确实,就算是这么写,很多程序也能动起来。但是在有些环境下,编译器可能会报告一些警告信息。
main函数返回一个int类型的值,因此在处理的最后必须有return(现在的很多编译器都会提示没有return的警告)。本书所有例程的
main函数的末尾都写了return 0;。返回
0表示通知运行环境程序“正常结束”。
题外话 hoge 是什么?
本书的例程中,经常使用
hoge或piyo作为变量的名称。这是啥?很多人会有这样的疑问。在日本,
hoge这个名字使用非常广泛。在为变量和文件的取名感到苦恼的时候,大家经常使用hoge这个词。通常都会给变量取一个有意义的名字,但因为本书是单纯讲解 C 语法的书,所以很多地方使用了没有实际意义的单词。当然了,就算使用了“
a”、“b”这样的变量名称,编译器也不会抱怨什么,但是这种一个字母的变量名用在面向初学者的书中,似乎不太合适。为了也能明确地表示那些没有意义的变量,我们使用具有 4 个字母的
hoge。谁也不知道是哪个大侠最先使用
hoge这个单词的。目前最有力的说法是,在 20 世纪 80 年代前半期,hoge在日本各地被同时频繁地使用起来,详细的说明请参见:“关于
hoge的网页”http://kmaebashi.com/programmer/hoge.html
原始网页已经取消不能访问了。承蒙作者吉田先生的允诺,此网页的内容已转载入我的网页中。
在美国,和
hoge这个单词一样,foo和bar等单词经常被使用。偶尔可以在 OS 的操作手册等资料中看见它们的身影。
1.2.3 指针和地址之间的微妙关系
在本章 1.2.1 节中,有下面一句话:
几乎所有的处理程序中,所谓的“指针类型的值”,实际是指内存的地址。
对于这句话,有人也许会产生下面的疑问。
【常见疑问之 1】
归根结底,指针就是地址,地址就是内存中被分配的“门牌号”。所以,指针类型和
int类型应该是一回事吧。
实际上,从某种意义来看,这种认识也不无道理。
在 C 语言前身的 B 语言中,指针和整数是没有区别的。此外,虽然我们经常使用 printf()和%p 来表示指针,实际上包括我的运行环境在内,使用%x 也可以很好地表示地址。对不太擅长十六进制的人来说,通过使用%d,也能利用十进制的方式来确认地址的内容。
很可惜,这里说的运行环境并不具有普适性。其实在很多的运行环境中,int 类型和指针类型的长度并不相同,此外,由于 Intel 8086 的功能限制,在直到最近还被广泛使用的 MS-DOS 中,是通过将 16 位的值分成两组来表示 20 位的地址的1。
1 8086 是分段寻址的,具体来说是指一个物理地址由段地址(segment selector)与偏移量(offset)两部分组成,长度各是 16 位。其中段地址左移 4 位(即乘以 16)与偏移量相加即为物理地址。——译者注
还有——不,还是先回答下一个问题吧。
【常见疑问之 2】
指针就是地址吧。那么,指向
int的指针也好,指向double的指针也好,它们有什么不一样吗?有必要去区分它们吗?
在某种意义上,这种说法也有一定道理。
对于大部分的运行环境来说,当程序运行时,不管是指向 int 的指针,还是指向 double 的指针,都保持相同的表现形式(偶尔也会有一些运行环境,它们对于指向 char 的指针和指向 int 的指针有着不一样内部表示和位数)。
不仅如此,ANSI C 还为我们准备了“可以指向任何类型的指针类型”—— void*类型。
1: int hoge = 5;2: void *hoge_p;3:4: hoge_p = &hoge; ←这里不报错5: printf("%d\n", *hoge_p); /*打印输出hoge_p 指向的变量的值*/
以上代码中的第 4 行是不会报错的。
但是,像第 5 行这样在 hoge_p 前附加*……在我的环境里会出现下面的警告:
warning: dereferencing 'void *' pointerinvalid use of void expression
只需稍微考虑一下,就知道出现这样的错误是意料之中的。如果仅仅告之内存地址,却没有告之在那个地址上保存的数据类型,当然是不能取出值来的。
如果将上面的第 5 行修改成下面这样,不但可以顺利地通过编译,甚至可以正常地运行。
5: printf("%d\n", *(int*)hoge_p); /*将hoge_p 强制转换成int* */
这里通过将“所指类型不明的指针”hoge_p 强制转型成“指向 int 的指针”,来告之编译器类型信息,由此可以取出 int 类型的值。
但每次都这样写是比较繁琐的,不妨事先写成以下的声明:
int *hoge_p;
因为编译器可以记住“hoge_p 是指向 int 的指针”,所以只需要简单地在 hoge_p 前面添加*,就可以通过指针间接取值。
之前也提到,在大部分的运行环境里,不管是“指向 int 的指针”,还是“指向 double 的指针”,在运行时都是相同的事物。可是,通过在 int 类型的变量之前加上&来取得它的指针,随后利用指针间接取出来的值,不出意外肯定是 int 类型。为什么?因为 int 和 double 的内部表示完全不同。
因此,如今的运行环境,像下面这样取得指向 double 类型变量的指针,之后将其赋给指向 int 的指针变量,编译器必定会提示警告。
int *int_p;double double_variable;/*将指向double 变量的指针赋予指向int 的指针变量(恶搞!) */int_p = &double_variable;
顺便说一下,在我的环境里出现了下面的警告:
warning: assignment from incompatible pointer type
下面的“指针运算”这一小节,会进一步说明“编译器会帮我们记住指针指向什么样的类型”的重要意义。
1.2.4 指针运算
C 语言的指针运算功能是其他语言所没有的。
指针运算是针对指针进行整数加减运算,以及指针之间进行减法运算的功能。
我们先来看一看下面这个例程(参照代码清单 1-2)。
【注意 1】
严格地说,代码清单 1-2 的程序并不符合 C 语言标准。
对于指针加减运算,标准只允许指针指向数组内的元素,或者超过数组长度的下一个元素。指针运算的结果也只是允许指针指向数组内的元素,以及超过数组长度的下一个元素(关于这一点,请参照 4.3.2 节的补充内容“指针可以指向数组最后元素的下一个元素”)。标准没有对除此之外的情况做出任何定义。在下面的例程中,因为对不是指向数组的指针
hoge_p进行了加法运算,所以它在这一点上违反了 C 语言标准。标准写道:“一个指向非数组对象的指针,和指向只包含一个元素(类型和前者相同)的数组的第一个元素的指针,具有相同的意义”。因此,只要你不做加 2 以上(包括 2)的加法运算就不会出现错误。
在大多数的环境下,这个程序是可以运行的。为了有效地说明后面的问题,比起严格遵守标准,我还是选择了这个简单、直接的例程。
代码清单 1-2 pointer_calc.c
- 1: #include <stdio.h>
- 2:
- 3: int main(void)
- 4: {
- 5: int hoge;
- 6: int *hoge_p;
- 7:
- 8: /*将指向hoge 的指针赋予hoge_p */
- 9: hoge_p = &hoge;
- 10: /*输出hoge_p 的值*/
- 11: printf("hoge_p..%p\n", hoge_p);
- 12: /*给hoge_p 加1*/
- 13: hoge_p++;
- 14: /*输出hoge_p 的值*/
- 15: printf("hoge_p..%p\n", hoge_p);
- 16: /*输出hoge_p 加3 后的值*/
- 17: printf("hoge_p..%p\n", hoge_p + 3);
- 18:
- 19: return 0;
- 20: }
我的环境中的结果如下:
hoge_p..0xbfbfd9e4 ← 最初的值hoge_p..0xbfbfd9e8 ← 加1 后的值hoge_p..0xbfbfd9f4 ← 加1 之后再加3 的值
第 9 行,将指向 hoge 的指针赋予 hoge_p,第 11 行输出 hoge_p 的值。我的环境里,hoge 被保存在门牌号为 0xbfbfd9e4 的地址中。
在第 13 行,使用运算符++,给 hoge_p 加 1。
输出结果……0xbfbfd9e4 变成了 0xbfbfd9e8,为什么不是增加了 1,而是增加了 4 呢?
在第 17 行,给加 1 后的 hoge_p 再加上 3,输出的结果由 0xbfbfd9e8 变成了 0xbfbfd9f4,增加了 12。
这就是指针运算的特征。在 C 语言中,对指针进行加 1 运算,地址的值会增加当前指针所指向数据类型的长度。例程中的 hoge_p 是 “指向 int 的指针”,因为我的环境中 int 类型的长度为 4,所以给地址加 1,指针前进 4 个字节,给地址加 3,指针就前进 12 个字节。
要 点
对指针加 N,指针前进“当前指针指向的数据类型的长度×N”。
【常见疑问之 3】
指针就是地址吧,给指针加 1,指针难道不应该前进 1 个字节吗?
这是最常见的疑问了。理解这一点的前提,需要先弄清楚 C 语言中指针和数组之间有什么样的微妙关系,以及为什么 C 中会存在指针运算这样奇怪的功能。
关于这些问题,稍后会进行说明,目前还是让我们带着疑问往下走吧。
1.2.5 什么是空指针
空指针是一个特殊的指针值。
空指针是指可以确保没有指向任何一个对象的指针。通常使用宏定义 NULL 来表示空指针常量值。
空指针确保它和任何非空指针进行比较都不会相等,因此经常作为函数发生异常时的返回值使用。另外,对于第 5 章的链表来说,也经常在数据的末尾放上一个空指针来提示:“请注意,后面已经没有元素了哦。”
在如今的操作系统下,应用程序一旦试图通过空指针引用对象,就会马上招致一个异常并且当前应用程序会被操作系统强制终止*。因此,如果每次都使用 NULL 来初始化指针变量,在错误地使用了无效(未初始化)的指针时,我们就可以马上发现潜在的 bug。
* 并不是所有的操作系统都能对空指针引用进行错误处理的。像 DOS 这样没有内存保护功能的操作系统也就罢了,连 UNIX 居然也允许通过空指针引用对象。
通常,我们可以根据指针指向的数据类型来明确地区别指针的类型。如果将“指向 int 的指针”赋给“指向 double 的指针”,如今的编译器会报出前面提到的警告。但是,只有 NULL,无论对方指向什么类型的变量,都可以被赋值和比较。
偶尔会见到先将空指针强制转型,然后进行赋值、比较操作的程序,这不但是徒劳的,甚至还会让程序变得难以阅读。
补充 NULL、0 和'\0'
经常有一种错误的程序写法:使用
NULL来结束字符串。
- /
- 通常,C 的字符串使用'\0'结尾,可是因为strncpy()函数在 src 的长度大于len
- 的情况下没有使用'\0'来结束,所以一板一眼地写了一个整理成C 的字符串形式的
- 函数(企图)
- /
- void my_strncpy(char dest, char src, int len) {
- strncpy(dest, src, len);
- dest[len] = NULL; ←使用NULL 来结束字符串!!
- }
上面的代码,尽管在某些运行环境下能跑起来,但无论怎样它就是错误的。因为字符串是使用“空字符”来结束的,而不是用空指针来结束。
在 C 语言标准中,空字符的定义为“所有的位为 0 的字节称为空字符(null character)”(5.2.1)。也就是说,空字符是值为 0 的字符。
空字符在表现上通常使用
'\0'。因为'\0'是常量,所以实际上它等同于 0。也许有些吓到你了,'\0'呀'a'呀什么的,它们的数据类型其实并不是char,而是int。如果是C++,就不是这个结论了。
另外,在我的环境中,
NULL在 stdio.h 里的定义如下:
- #define NULL 0
看到这个,你可能会说:“说来说去,那还不都是 0 嘛。”确实在大部分的情况下是这样的,但背后的事情却异常复杂。
正如前面说的那样,写成
'\0'和写成常量的0其实是一样的。使用'\0'只不过是习惯使然。如果想让代码容易读,遵从习惯是非常重要的。将
0当作空指针来使用,除了极其例外的情况,通常是不会发生错误的。但是,如果在字符串的最后使用
NULL,就必然会发生错误。标准允许将
NULL定义成(void\)0,所以在NULL被定义成(void*)的时候,如果使用NULL来结束字符串,编译器必然会提示警告。看到刚才的关于
NULL的定义,可能有人会产生下面的推测:啥呀?所谓空指针,不就是为 0 的地址嘛。
在 C 中,为 0 的地址上应该是不能保存有效数据的吧?放什么都起不到任何作用,这没什么大不了的。
这种推测好像颇有道理,但也是有问题的。
确实在大多数的环境中,空指针就是为 0 的地址。但是,由于硬件状况等原因,世上也存在值不为 0 的空指针。
偶尔会有人在获得一个结构体之后,先使用
memset()将它的内存区域清零然后再使用。此外,虽然 C 语言提供了动态内存分配函数malloc()和calloc(),但是抱着“清零后比较好”的观点,偏爱 calloc()的人倒有很多。这样也许可以避免一些难以再现的 bug。使用
memset()和calloc()将内存区域清零,其实就是单纯地使用 0 来填充位。通过这种处理,当结构体的成员中包含指针的时候,这个指针能不能作为空指针来使用,最终是由运行环境来决定的。顺便说一下,对于浮点数,即使它的位模式为 0,值也不一定为 0。
整数类型还好,但是我还是感觉依赖环境编出来的代码是不干净的。
说到这里,
哦,原来这样啊,所以要使用宏定义的
NULL呢。对于空指针的值不为 0 的运行环境,NULL的值应该被#define成别的值吧。可能会有人产生以上的想法。实际上,这种想法也是有偏差的,这涉及问题的内部根源。
比如,尝试编译下面的代码:
- int p = 3;
在我的环境里,会出现以下警告:
- warning: initialization makes pointer from integer without a cast
因为 3 无论怎么说都是
int型,指针和int型是不一样的,所以编译器会提示警告。尽管在我的环境里指针和int的长度都是 4 个字节,但还是出现了警告。如今的编译器,几乎都是这样的。继续,让我们尝试编译下面的代码:
- int p = 0;
这一次没有警告。
如果说将
int型的值赋予指针就会得到一个警告,那么为什么值为 3 的时候出现警告,值为 0 的时候却没有警告呢?简直匪夷所思!这是因为在 C 语言中,“当常量 0 处于应该作为指针使用的上下文中时,它就作为空指针使用”。上面的例子中,因为接受赋值的对象为指针,编译器根据上下文判断出“0 应该作为指针使用”,所以将常数 0 作为空指针来读取。
无论如何,编译器都会针对性地对待“需要将 0 作为指针进行处理的上下文”,所以即便是空指针的值不为 0 的情况下,使用常量 0 来代替空指针也是合法的。
此外,如上所述,有的环境中像下面这样定义
NULL:
- #define NULL ((void)0)
ANSI C 中,根据“应该将 0 作为指针进行处理的上下文”的原则,将常量 0 作为指针来处理。因此,显式将 0 强制转型成
void\是没有意义的。但是在某些情况下,编译器也可能会理解不了“应该将 0 作为指针进行处理的上下文”。这些情况是:
没有原型声明的函数的参数
可变长参数函数中的可变部分的参数
ANSI C 中,因为引入了原型声明,只有在你确实做了原型声明的情况下,编译器才能知道你“想要传递指针”。
可是,对于以
printf()为代表的可变长参数函数,其可变部分的参数的类型编译器是不能理解的。另外糟糕的是,在可变长参数的函数中,还经常使用常量NULL来表示参数的结束(比如 UNIX 的系统调用execl()函数)。以上情况下,简单地传递常量 0,会降低程序的可移植性。
因此,通过使用宏定义
NULL来将 0 强制转型成void*,可以显式地告之编译器当前的 0 为指针。关于这个话题,在 C 语言 FAQ(http://www.catnet.ne.jp/kouno/c_faq/c_faq.htm)中,也花费了一章的笔墨进行 了讨论。
1.2.6 实践——swap函数
到这里为止,已经对指针进行了大致的介绍,但是关于指针的用处还没有解释。
在这里,我们使用经常用于展示指针使用方法的例程——招牌的 swap 函数来进行下面的说明。
下面这个函数试图交换两个 int 类型变量的值,虽然这个例子总让人觉得不太自然,但我们这里还是使用了这个例子。
void swap(int a, int b){int temp;temp = a;a = b;b = temp;}
让我们调用一下这个函数。
- int x, y;
- x = 5;
- y = 10;
- swap(x, y);
- printf("x..%d y..%d\n", x, y);
通过运行以上的调用,我们发现 x 和 y 的值并未交换。
调用 C 的函数,参数传递往往是传值,这种方式传递的是参数的副本。
可能会有人这样想:
啥?这本书也谈传值的问题?以前俺买的那些 C 语言入门书中也有这个内容呢。也罢,姑且先听你说说看,所谓的传值究竟是怎么回事?
为了这部分读者,我换个角度来说明一下。
这个例子中的 swap 函数,有两个 int 型的参数。所以,也一定可以通过下面的方式调用这个函数:
swap(3, 5);
那么,在 swap 这一边,我们先排除形参(这里是 a 和 b)在调用的时候被设定值的情况,将它们和通常的局部变量同样对待。当然,赋值也是可以的。
假设给 a 和 b 赋值会让调用方的变量给 x、y 带来影响,那么像 swap(3,5)这种方式的调用,究竟会发生什么呢?常量 3 变成 5,5 变成 3?绝不可能。
顺便提一下,有一些 C 语言之外的其他语言,给函数的形参赋值是会影响到调用方的实参的。在以前的 FORTRAN 中,所有的参数都是这样的。在将常量作为参数进行传递的时候,稀里糊涂地给形参赋了值——结果有可能惨不忍睹。在 Pascal 中,为了不给调用方的变量带来影响,在定义函数的时候,特别地指定参数为变量参数。如果试图给变量参数指定常量,编译器会报错。
C 语言里完全没有这样的现象。无论如何,函数的形参都和调用时被设定值的局部变量一样。如果不是这样的话,就会背负 FORTRAN 那样的危险,或者像 Pascal 那样在语法下做些文章。从 C 语言的发展过程来看,采取 Pascal 那样麻烦的方式是不可能的。
因此,在 C 里面想要改写调用方的变量,可采取传递指针的方式。
void swap(int *a, int *b){int temp;temp = *a;*a = *b;*b = temp;}
调用方式为:
swap(&x, &y);
在本例中,向函数传递指向 x 和 y 的指针(也就是地址)。尽管指针是通过传值的方式进行传递的,但由于在 swap 中使用了*运算符,所以通过指针可以间接访问到 x 和 y。向 swap 传递的是地址,x 和 y 自身并没有移动。
给大家举一个例子。有一位从不信任部下,甚至神经质得有点让人讨厌的上司,每当他向部下分配任务的时候,总是将复制后的文档交给部下。这些部下无论多么地努力,也不可能调换这位上司的文件柜中存在的“文档 A” 和“文档 B”的内容。除非上司这样吩咐他的部下:“给我将书柜某个地方的文档 A,以及书柜某个地方的文档 B 调换一下!”如果告知了文档的“地点”,这些部下就能调换文档内容了。就是这么一回事。
如果换个方式说明这一小节开头的那个例子,就好像冷不丁地向 swap 函数要求“帮我把 5 和 10 交换过来”。
换成其他的函数,
a = 5;func(a);
或
func(5);
你不认为它们是一样的吗?
后面的那个例子向 swap 函数提出了“请交换这里的变量和那里的变量”的要求。显然这个要求是可以满足的。
说个题外话,如果仅仅是需要交换整型变量的值,完全不使用临时变量也是可以的。比如使用下面的宏定义:
#define SWAP(a, b) (a += b, b = a - b, a -= b)
在这种方式(还可以使用异或运算符)下,在颠倒使用同一个变量时,这个程序是不能正常运行的。比如你写了 SWAP(a[i],a[j]),并且恰巧 i == j,那我只能恭喜你中招了。当然,如果你能担保这种情况永远不可能出现,使用这个宏也未尝不可。
如果到现在为止,对以上内容还是不太明白,请阅读第 2 章。第 2 章会具体讲解当提到形参是实参的副本时,实参究竟被复制到哪里,以及怎样实现复制。
补充 形参和实参
几乎所有的 C 语言的入门书籍中,都会讲解“形参”和“实参”的概念。但是它们还是经常被轻易混淆。
实参是调用函数时的参数。
- func(5); ←这里的5 是实参。
形参是接受实参的一方。
- void func(int hoge) ←这里的 hoge 是形参
- {
- ┊
- }
后面会经常出现“形参”、“实参”这样的词,请大家一定注意不要混淆它们。
