2.5 自动变量(栈)
2.5.1 内存区域的“重复使用”
通过代码清单 2-2 的实验,我们看到 func1()的自动变量 func1_variable 和 func2()的自动变量 func2_variable 存在于完全相同的地址上。
在声明自动变量的函数执行结束后,自动变量就不能被使用了。因此,func1()执行结束后,func2()重复使用相同的内存区域是完全没有问题的。
要 点
自动变量重复使用内存区域。
因此,自动变量的地址是不一定的。
2.5.2 函数调用究竟发生了什么
自动变量在内存中究竟是怎样被保存的?为了更加详细地了解这一点,还是让我们用下面这个测试程序做一下实验。
代码清单 2-3 auto.c
1: #include <stdio.h>2:3: void func(int a, int b)4: {5: int c, d;6:7: printf("func:&a..%p &b..%p\n", &a, &b);8: printf("func:&c..%p &d..%p\n", &c, &d);9: }10:11: int main(void)12: {13: int a, b;14:15: printf("main:&a..%p &b..%p\n", &a, &b);16: func(1, 2);17:18: return 0;19: }
在我的环境中运行结果如下:
main:&a..0xbfbfd9e4 &b..0xbfbfd9e0func:&a..0xbfbfd9d8 &b..0xbfbfd9dcfunc:&c..0xbfbfd9cc &d..0xbfbfd9c8
如果把运行结果用图来说明,应该是图 2-5 这样的。
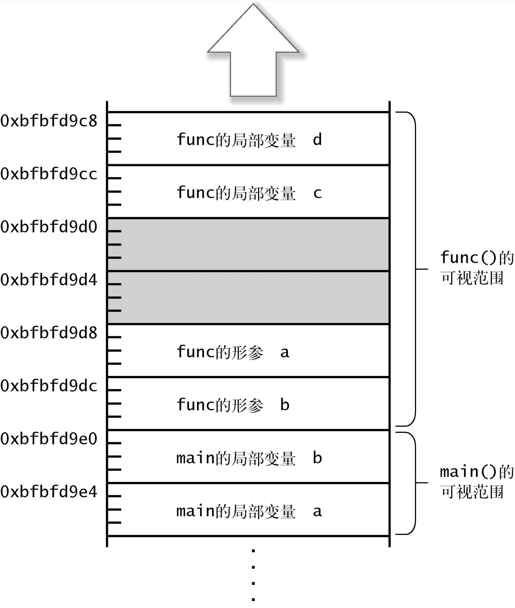
图 2-5 局部变量和参数的地址
如果将 main()的局部变量、func()的局部变量以及 func()的形参的地址进行比较,func()相关的地址看上去相对小一些。
C 语言中,在现有被分配的内存区域之上以“堆积”的方式,为新的函数调用分配内存区域*。在函数返回的时候,会释放这部分内存区域供下一次函数调用使用。图 2-6 粗略地表现了这个过程。
* 图 2-3 中,自动变量的区域上方有一片广大的区域。在这片区域中,栈不断地增长。
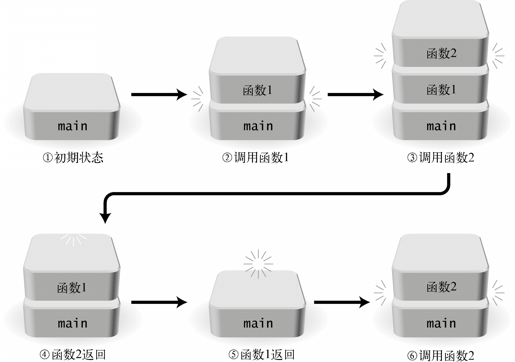
图 2-6 函数调用的概念图
对于像这样使用“堆积”方式的数据结构,我们一般称为栈。
程序员们有时候也使用数组等方式实现栈。但是,大部分的 CPU 中已经嵌入了栈的功能,C 语言通常直接使用。
要 点
C 语言中,通常将自动变量保存在栈中。
通过将自动变量分配在栈中,内存区域可以被重复利用,这样可以节约内存。
此外,将自动变量分配在栈中,对于递归调用(参照 2.5.4 节)也具有重要的意义。
下面归纳了最简约的 C 语言函数调用的实现*:
* 当然,最近的编译器做了各种优化,它们不一定完全以这里描述的方式动作。但是基本思想是一致的。
- 在调用方,参数从后往前按顺序被堆积在栈中*。
- 关于为什么参数是从后往前堆积的,请参照 2.5.3 节。
和函数调用关联的返回信息(返回地址等)也被堆积在栈中(对应于图 2-5 的灰色部分)。所谓的“返回地址”,是指函数处理完毕后应该返回的地址。正因为返回地址被堆积在栈中,所以无论函数从什么地方被调用,它都能返回到调用点的下一个处理。
跳转到作为被调用对象的函数地址。
栈为当前函数所使用的自动变量增长所需大小的内存区域。1到4所增长的栈的区域成为当前函数的可引用区域。
在函数的执行过程中,为了进行复杂的表达式运算,有时候会将计算过程中的值放在栈中。
一旦函数调用结束,局部变量占用的内存区域就被释放,并且使用返回信息返回到原来的地址。
从栈中除去调用方的参数。
图 2-7 展示了 func(1, 2)被调用时,栈的使用情况。它与图 2-5 相吻合。
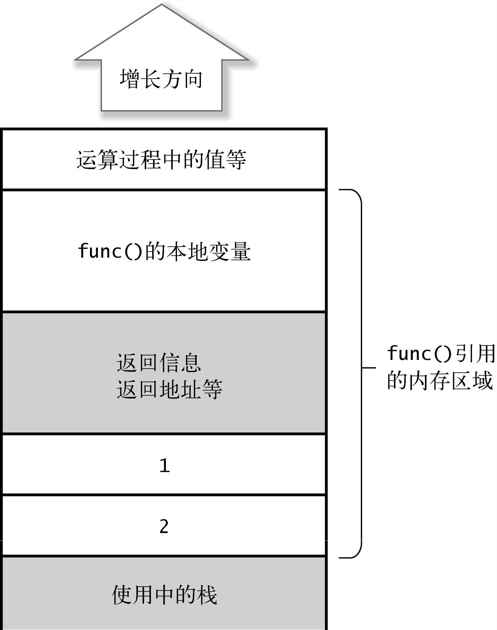
图 2-7 调用 func(1, 2)时栈的使用情况
此外,在调用函数时,请留意为形参分配新的内存区域。我们经常听说“C 的参数都是传值,向函数内部传递的是实参的副本”其中的复制动作,其实就是在这里发生的。
补充 一旦函数执行结束,自动变量的内存区域就会被释放!
初学者经常写出下面这样的程序。
- /将 int 变换成字符串的程序/
- char int_to_str(int int_value)
- {
- char buf[20];
- sprintf(buf, "%d", int_value);
- return buf;
- }
恐怕……这个程序不能正常地跑起来。
在某些环境下可能也能跑起来,但这只是偶然。
原因估计你也知道了:自动变量
buf的内存区域在函数执行结束后就会被释放。为了让这个程序先动起来,可以将
buf声明成下面这样:
- static char buf[20];
因为
buf的内存区域一直会被静态地保持,所以即使函数执行结束,buf的内存区域也不会被释放。在这种方式下,当你连续两次调用这个函数,第二次函数调用会“悄悄地”修改第一次函数调用得到的字符串。
- str1 = int_to_str(5);
- str2 = int_to_str(10);
- printf("str1..%s, str2..%s\n", str1, str2); ←这里究竟会输出什么样的结果呢?
程序员当然希望输出的是
str1..5, str2..10。可惜最终事与愿违。这样的函数引起了一个出乎意料的 bug。此外,在多线程编程的情况下,当前函数同样也是有问题的。
标准库中有一个函数
strtok(),此函数也存在类似的问题,招致了很多抱怨。借助于
malloc()动态地分配内存区域,可以解决上面的问题(参照 2.6 节),但是使用方需要同时使用free()。* 由于 Java 具有垃圾回收机制,所以不需要我们显式地调用
free()。其实,作为最终的解决方案,如果函数调用方事先知道数组的长度上限,可以在调用方声明一个数组,然后通过函数将结果输出到此数组中。 对于 C 语言来说,这是一个最实用的方案。
补充 一旦破坏了自动变量的内存区域
假设,通过自动变量声明下面的数组:
- int hoge[10];
如果没有做数组长度检查,将数据写入了超过数组内存区域的地方,究竟又会引发怎样的悲剧呢?
如果只是超过一点点,可能也就是破坏相邻的自动变量的内容。但是,一旦将前方的内存区域径直地破坏下去……
自动变量是保存在栈中的,如果是数组,表示如下图(参照图 2-8),
图 2-8 栈中的数组
在这里,如果大范围地超过数组内存区域写入数据,内存中直到存储函数的返回信息的区域都有可能被破坏。也就是说,这个函数不能返回了。
当我们在追踪一个 bug 的时候,发现函数处理已经走到了最后,可偏偏不能返回到调用方。此时,就应该质疑是不是已经不小心将数据写入了保存函数返回地址的内存领域。
这种情况下,就算是调试也经常不能定位程序发生错误的地方。因为调试也是使用堆积在栈中的信息,如果大量地破坏了栈的内存领域,是很难追踪到 bug 发生的具体地点的。
此外,由于越界向数组类型的自动变量写入数据,以至于返回信息(返回地址)被覆盖,甚至可能造成安全漏洞。
对于那些没有切实做好数组长度检查的程序,一些无良的骇客会故意地传递很大的数据,造成函数的返回地址被恶意的数据所改写。也就是说,骇客完全可以让你的程序去运行任意的机器语言代码。
请参照“‘黑客不是骇 客’协会”http://www-vacia.media.is.tohoku.zc.jp/~s-yamane/hackerML/。
标准库中有一个
gets()函数,它和fgets()同样都可以从标准输入读取一行输入,但与fgets()不同的是你不能向它传递缓冲的大小。因此,gets()是不可能做数组长度检查的。在 C 语言中,所谓将数组作为参数进行传递,只不过是传递指向数组初始元素的指针。作为被调用方,是完全不知道数组究竟有多长的。
gets()函数多用于将标准输入,也就是“从外部”来的输入保存在数组中。因此,在使用gets()的程序中,通过故意将包含尺寸很大的行的数据传递给gets(),就可以达到数组越界且改写返回地址的目的。1988 年名震互联网的“互联网蠕虫”,就是利用了
gets()的这个弱点。因为这些原因,
gets()已经被视为落后于时代的函数。我使用的编译器(gcc version 2.7.2.1)在编译和连接过程中,一旦发现当前代码使用了gets(),就会提示以下警告:
- warning: this program uses gets(), which is unsafe.
如果你一意孤行还是要运行这个程序,还会提示同样的警告。
不只是
gets(),还有比如对于scanf()这个函数,如果使用"%s"也会招致同样的结果。但是,你可以通过对scanf()指定"%10s"来限制字符串的最大长度。下面再给大家举一个有点恶搞的例子(参照代码清单 2-4)。
并不是所有的运行环境都是这样,但是至少在 Windows 98 和 FreeBSD (编译器是 gcc)下,
hello()会被调用(而且不止一次)。为什么会这样?——请读者自己思考。
另外,这个程序必然会以崩溃告终,所以请在具有内存保护的操作系统上运行。
代码清单 2-4 stackoverflow.c
- 1: #include <stdio.h>
- 2:
- 3: void hello(void)
- 4: {
- 5: fprintf(stderr, "hello!\n");
- 6: }
- 7:
8: void func(void)- 9: {
- 10: void *buf[10];
- 11: static int i;
- 12:
13: for (i = 0; i < 100; i++) { ←越界!- 14: buf[i] = hello;
- 15: }
- 16: }
- 17:
18: int main(void)- 19: {
- 20: int buf[1000];
- 21:
22: func();- 23:
24: return 0;- 25: }

2.5.3 可变长参数
大部分的 C 语言入门书籍往往在一开始就频繁地使用 printf()这个输出文字信息的函数,利用这个函数,可以将可变个数的参数填充到字符串中的指定位置。因为这个奇怪的特征,在教初学者 C 语言的时候,经常会有这样让人费解的说明:
快看,在 C 中的输入输出并不是语言的一部分,而是作为函数库被提供的。因此,
printf()这个函数和程序员平时写的函数没有什么不一样哦。
在这里姑且把这个问题先放一边。
正如 2.5.2 节中说明的那样,C 语言的参数是从后往前被堆积在栈中的。
另外,在 C 语言中,应该是由调用方将参数从栈中除去。
顺便提一下,Pascal 和 Java 是从前往后将参数堆积在栈中的。这种方式能够从前面开始对参数进行处理,所以对于程序员来说比较直观。此外,将参数从栈中除去是被调用方应该承担的工作。大部分情况下,这种方式的效率还是比较高的。
为什么 C 故意采取和 Pascal、Java 相反的处理方式呢?其实就是为了实现 可变长参数这个功能*。1
* Pascal 和 Java 中不能写带有可变长参数的函数。
1 Java 在 JDK1.5 之后的版本也开始支持可变长函数了。——译者注
比如,对于像
printf("%d, %s\n", 100, str);
这样的调用,栈的状态如图 2-9 所示。
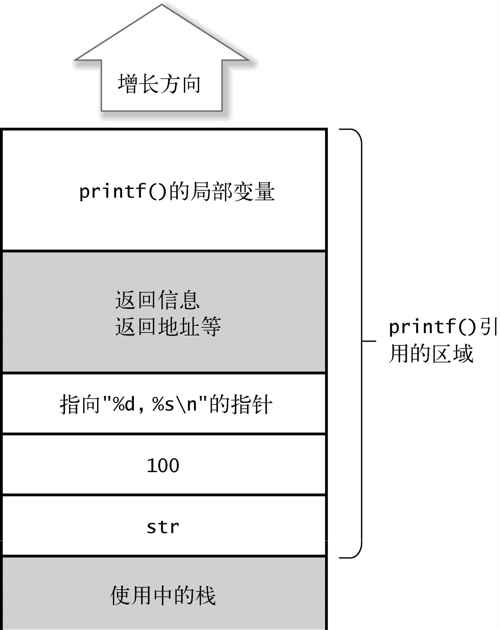
图 2-9 调用持有可变长参数的函数
重要的是,无论需要堆积多少个参数,总能找到第一个参数的地址。从图中我们可以看出,从 printf()的局部变量来看,第一个参数(指向"%d, %s\n"的指针)一定存在于距离固定的场所。如果从前往后堆积参数,就肯定不能找到第一个参数。
之后,在 printf()中,通过对找到的第一个参数"%d, %s\n"进行解析,就可以知道后面还有几个参数。
由于其余的参数是连续排列在第一个参数后面的,所以你可以顺序地将它们取出。
可是,现实中有一些部分是依赖运行环境的。ANSI C 为了提高可移植性,通过头文件 stdarg.h*提供了一组方便使用可变长参数的宏。
* ANSI C 以前的 C 使用 varargs.h 这个头文件,它和 stdarg.h 在使用上有很大的差异。
下面就让我们实际使用 stdarg.h 写一个具有可变长参数的函数。
我们考虑写一个山寨版的 printf(),取名为 tiny_printf()。
tiny_printf()的第一个参数指定后续的各参数的类型,第二个参数开始指定需要输出的值。
tiny_printf("sdd", "result..", 3, 5);
在这个例子中,通过第一个参数"sdd",指定后续的参数类型为“字符串,int,int”(和 printf()一样,s 表示字符串,d 表示数字)。从第二个参数开始,分别向函数传递字符串"result"和两个整数。
函数执行后的结果如下:
result.. 3 5
和 printf()不同,因为指定换行字符的输出比较繁琐,tiny_printf() 在默认情况下会主动进行换行。 代码如下(参照代码清单 2-5)。
代码清单 2-5 tiny_printf.c
1: #include <stdio.h>2: #include <stdarg.h>3: #include <assert.h>4:5: void tiny_printf(char *format, ...)6: {7: int i;8: va_list ap;9:10: va_start(ap, format);11: for (i = 0; format[i] != '\0'; i++) {12: switch (format[i]) {13: case 's':14: printf("%s ", va_arg(ap, char*));15: break;16: case 'd':17: printf("%d ", va_arg(ap, int));18: break;19: default:20: assert(0);21: }22: }23: va_end(ap);24: putchar('\n');25: }26:27: int main(void)28: {29: tiny_printf("sdd", "result..", 3, 5);30:31: return 0;32: }
从第 5 行开始函数的定义。对于形参声明中的…这种写法,可能大家会感到有些陌生,但原型声明也是写成这样的。如果原型声明的参数中出现…,对于这部分的参数是不会做类型检查的。
在第 8 行,声明 va_list 类型的变量 ap。stdarg.h 文件中定义了 va_list 类型,我的环境中是这样定义的,
typedef char *va_list;
也就是说,在我的环境中,va_list 被定义成“指向 char 的指针”。
在第 10 行,va_start(ap, format);意味着“使指针 ap 指向参数 format 的下一个位置”。
因此,我们得到了可变长部分的第一个参数。在后面的第 14 行和第 17 行,给宏 va_arg()指定 ap 和参数类型,就可以顺序地取出可变长部分的参数。
第 23 行的 va_end()只不过是个“摆设”,只不过因为在标准里指出了对于具有 va_start()的函数需要写 va_end()。
顺便说一下,在我的环境中,宏 va_end()是这样被定义的:
#define va_end(ap)
实际上,va_end()就是个空定义。
以上就是开发具有可变长参数的函数的方法。
这里必须要注意的是,因为无论怎样都是从函数内部顺序地读出各参数,所以要实现可变长参数的函数就必须知道参数的类型和个数。
printf()将输出内容整理得很利落,但是如果只是输出很少的内容,使用 printf()就显得有点小题大做。这种情况下,Pascal 的 writeln()和 BASIC 的 print 语句倒是比较简洁。
如
writeln("a..", 10, " b..", 5);
输出结果为:
a..10 b..5
但是 C 语言是无法提供这样的函数的。这是因为在 writeln()内部无法知道参数的类型和个数。
话说回来,一旦学会了可变长函数的开发方法,还是感觉自己挺了不起的,无论如何总是想找个机会秀一下。我就是这样的*。
* 以前年少无知,看到 XView 的函数使用方法,还觉得挺帅的。
可是,对于可变长参数的函数,是不能通过原型声明来校验参数的类型的。另外,函数的执行需要被调用方完全信任调用方传递的参数的正确性*。因此,对于使用了可变长参数的函数,调试会经常变得比较麻烦。一般只有在这种情况下,才推荐使用可变长参数的函数:如果不使用可变长参数得函数,程序写起来就会变得困难。
* 偶尔,对于 printf,编译器有时也会亲切地给出“格式定义符和实际参数的类型不一致”的警告。其实这只不过是编译器特别照顾了 printf()。毕竟 printf() 是一个被“超”频繁使用的函数。
要 点
在决定开发可变长参数的函数之前,有必要讨论是否真的需要这么做。
补充 assert()
代码清单 2-5 中,有
assert(0);这样的语句。
assert()是在 assert.h 中定义的宏,使用方式如下:
- assert(条件表达式);
若条件表达式的结果为真,什么也不会发生;若为假,则会输出相关信息并且强制终止程序。
我们经常会看到如下注释:
- /这里的str[i]必定为'\0' /
虽然这种方式可以提高程序的可读性,但也不是说你可以什么检查也不做。这种情况下,如果使用,
- assert(str[i] == '\0');
可以帮我们挑出 bug。
代码清单 2-5 的
assert(0)的参数为 0(假),因此只要程序执行经过这里就会被强制终止。如果程序自身没有 bug,程序是不会走到过程语句switch的default部分的,我认为这种编程方式是值得肯定的。对于使用“强制终止程序运行”的方式来进行异常处理,很多人是持有反对意见的。确实,对于用户的一些奇怪的操作,比如传入一个奇怪的文件等行为,突然草率地终止程序会让用户感到不知所措。
可是,如果不是由于这样的“外部因素”,只要程序自身没有 bug 就绝对不会发生异常的情况下,我想还是应该果断地终止程序。使用“通过返回值返回错误状态”等冗长的处理方式,一旦调用方偷懒没做检查,就会放过很多本来可以很容易就发现的 bug。
这个经常有。
像 C 这样可以导致内存区域破坏的语言,一旦发现很明显的 bug,就表明当前程序已经无法保证正常运行了。如果栈被破坏了,就算你想返回错误状态,也有可能无济于事,因为当前的函数可能连
return也完成不了。如果是 Java 这样能够保证内存区域不会破坏,并且具备完善的异常处理机制的语言,将例外返回反而是一个正确的做法。
让我们在那些潜在 bug 还没有给你带来更大的麻烦之前,麻利地把它们消灭吧!
如果是在编辑重要的数据,应该采取紧急安全措施。当然了,文件名称需要和普通情况下的不一样。

补充 尝试开发一个用于调试的函数吧
经常看到很多人为了调试方便,使用
printf()输出变量的值。“拜托你使用调试好吗?”我们经常会听到这样的声音。实际上由于这样那样的原因,我们不能完全否定“
printf()调试”这样的做法。但如果直接使用
printf()或者fprintf(),当调试结束后要删除它们可就麻烦了。
- #ifdef DEBUG
- printf(…);
- #endif / DEBUG /
在有的书籍中推荐了上面的写法,但如果代码中充斥了大量这样的东西,就会变得很难读懂。
我们可能更需要下面这样类似于
printf()的写法:
- debug_write("hoge..%d, piyo..%d\n", hoge, piyo);
可是,因为
printf()是持有可变长参数的函数,无法实现通过debug_write()函数重新调用printf()的功能。所以说,自己实现printf()还是有些难度的。啊,怎么办呢?这种情况下,标准库中提供了
vprintf()和vfprintf()这两个函数。
- void debug_write(char fmt, …)
- {
- va_list ap;
- va_start(ap, fmt);
- vfprintf(stderr, fmt, ap); ←参数中传递ap 的地方是指针
- va_end(ap);
- }
此外,如果在此函数中引用一个全局变量,就可以用来控制是否输出调试信息。但伴随着
debug_write()调用而导致的开销是无法避免的。如果是宏,在编译时是可以完全回避这部分系统开销的。但可惜的是,我们无法向 C 的宏传递可变长参数。
在下面,我们先定义一个宏:
- #ifdef DEBUG
- #define DEBUG_WRITE(arg) debug_write arg
- #else
- #define DEBUG_WRITE(arg)
- #endif
然后使用如下技巧:
- DEBUG_WRITE(("hoge..%d\n", hoge));
这里必须要加两重括号,这可是个难点哟。
C 语言的常见问题集《C 语言编程 FAQ》[6]中介绍了,在非调试模式时将
DEBUG_WRITE定义为(void)的技巧(p.151)。非常遗憾,《C 语言编程 FAQ》的日语版(英文版名为 Cprogramming FAQS),已经绝版了。(第 8 次印刷注:由新纪元出版社重新出版。ISBN:4775302507)
通过这个技巧,上面的语句会展开成
(void)( "hoge..%d\n", hoge)的形式,它意味着“将逗号运算符连接的表达式强制转型成void”。优秀的编译器会通过优化完全忽略这条语句。随便提一下,在 ISO C99 中的宏已经可以取得可变长参数。不过好像几乎都不是专门用于调试的。
或者,对于比较简单的输出,如果事先定义这样一个针对
int、double、char\的宏,可以使后面的开发变得简便一些。
- #define SNAP_INT(arg) fprintf(stderr, #arg "…%d\n", arg)
这个宏可以像下面这样使用(如果有兴趣知道原理,你可以调查一下预处理器手册):
- SNAP_INT(hoge);
输出结果为:
- hoge…5
此外还有一点需要补充。使用
printf()输出调试信息,由于输出被缓冲,所以在程序异常结束的时候会发生关键信息没有被输出的情况。通过fprintf()将调试信息输出到stderr或者文件时 ,建议事先使用setbuf()停止缓冲。依照标准,
stderr是 不进行缓冲的。
2.5.4 递归调用
C 语言通常在栈中分配自动变量的内存区域。这除了可以重复使用该区域来节省内存以外,还可以实现递归调用。
递归调用就是函数对自身的调用。
可是很多程序员对递归都感到比较纠结。
纠结的原因,除了递归调用本身的难度之外,也有“不明白究竟有什么作用”这一点。
世间的 C 语言入门书籍也经常用阶乘运算等作为递归调用的例题,我觉得这是有点不太合适的。为什么呢?阶乘什么的,用循环来写不是更简单易懂吗?
关于现实中递归调用的使用,就拿我来说,遍历树结构、图形结构中各元素的情况是占绝大多数的,但由于篇幅的限制,就不用这些应用作为例子了。
这里举一个“如果不用递归调用,程序就不太好写”的例子:快速排序。
所谓排序,就是将很多数据以一定的顺序(比如从小到大等)进行排列。作为排序的手法,冒泡算法、插入算法、堆排序等很多方法都为大家所知。顾名思义,快速排序是其中最快速的排序算法*。
* 实际上,利用像本书中举的这么简单的程序 来应对特殊的案例,似 乎显得过于幼稚。尽管 如此,几乎在所有的情况下,处理速度还是比 冒泡算法等要快很多。
快速排序的基本思路如下:
从需要排序的数据中,找到一个适当的基准值(
pivot)。将需要排序的数据按照小于
pivot和大于pivot进行分类。对分类后的两类数据各自再次进行上述的 1 和 2 的处理。
如果排列对象是数组,上面的第 2 个步骤就点麻烦。下面是在不使用大的临时内存区域的情况下,对数组进行分类的思路(假设是升序排序):
从左向右,检索比
pivot大的数据。从右向左,检索比
pivot小的数据。如果两个方向都能检索到数据,将找到的数据交换。
重复进行1~3的操作,直到从左开始检索的下标和从右开始检索的下标发生冲突为止。
可能有人会对这种算法的敏捷性表示怀疑,但是这种算法的确很高效。在我的运行环境中,测试对 5 万个随机整数进行排序,冒泡算法排序花了 117 秒,快速排序算法用了 65 毫秒就完成了工作(1 毫秒=千分之一秒)。
要 点
根据算法不同,程序的处理速度会有天壤之别。所以,选择合适的算法是非常重要的。
代码清单 2-6 是实现快速排序的源代码。
代码清单 2-6 快速排序的程序
- 1: #define SWAP(a, b) {int temp; temp = a; a = b; b = temp;}
- 2:
- 3: void quick_sort_sub(int *data, int left, int right)
- 4: {
- 5: int left_index = left;
- 6: int right_index = right;
- 7: int pivot = data[(left + right) / 2];
- 8:
- 9: while (left_index <= right_index) {
- 10: for ( ; data[left_index] < pivot; left_index++)
- 11: ;
- 12: for ( ; data[right_index] > pivot; right_index--)
- 13: ;
- 14:
- 15: if (left_index <= right_index) {
- 16: SWAP(data[left_index], data[right_index]);
- 17: left_index++;
- 18: right_index--;
- 19: }
- 20: }
- 21:
- 22: if (right_index > left) {
- 23: quick_sort_sub(data, left, right_index);
- 24: }
- 25: if (left_index < right) {
- 26: quick_sort_sub(data, left_index, right);
- 27: }
- 28: }
- 29:
- 30: void quick_sort(int *data, int data_size)
- 31: {
- 32: quick_sort_sub(data, 0, data_size - 1);
- 33: }
这个例程是对 int 的数组进行排序。
向函数 quick_sort()传递 int 型数组 data 和数组的长度,数组中的元素会被升序排序。
quick_sort_sub()将数组 data 的元素从 data[left]到 data[right] 的部分进行排序(包括 data[left]和 data[right])。
quick_sort_sub()首先决定 pivot 的值,然后把数组的元素分成大于 pivot 和小于 pivot 两个类别*。
* 尽管这里的算法占了整篇代码的一大半,但为了不跑题,笔者对算法不进行详细的说明,还是请读者自己去解读。
然后,对于分类后还存在两个以上元素的数组,递归地调用自身(第 23 行和第 26 行)。
因为程序优先对数组的左侧进行处理,所以数组将会被排序成图 2-10 中的样子。
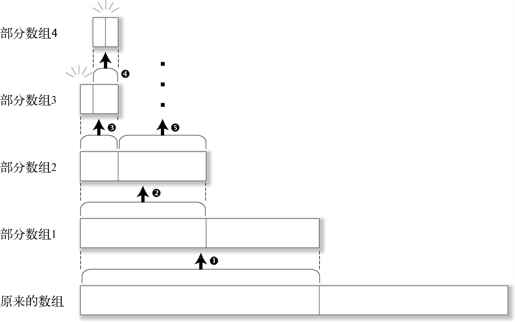
图 2-10 快速排序的概念图
首先,原始的数组被分类成大于 pivot 和小于 pivot 两个部分。对分类后的左侧(部分数组 1)递归调用自身再次进行分类(1)。然后对分类的结果的左侧再分类,再分类……就这样不断地递归下去,一直进行到左侧还剩下一个元素(4),再去处理右侧。就这样顺次地连续返回,对残留的部分进行处理(5)。
那么在这里,处理完数组某部分的左侧之后,之所以处理还能够转移到右侧,是因为 C 将自动变量分配在栈中。
这个程序将数组分成两部分之后,再进行递归调用。此时,在栈中分配了新的用于当前部分数组的内存区域。另外,当某部分数组的数据处理完毕,函数调用返回的时候,栈会收缩,调用前的状态恰好处于栈的最初位置。正因为如此,处理才这样不断地向右移动。
如果这个程序不写成递归,程序写起来会变得有点麻烦。
拒绝偏见,请大家慢慢习惯去运用递归。
补充 ANSI C 以前的 C,为什么不能初始化自动变量的聚合类型?
ANSI C 以前的 C,只有标量才能在声明的同时被初始化(参照 1.1.8 节)。
因此,在如今能这样写的代码:
- void func(void)
- {
- int array[] = {1, 2, 3, 4, 5};
- ┊
曾经只能写成下面这样:
- void func(void)
- {
- static int array[] = {1, 2, 3, 4, 5};
- ┊
就像现在看到的这样,局部变量的内存区域是在函数被调用时,也就是在执行中被分配的。在执行中,如果想要初始化数组等聚合类型,编译器必须在现场生成一些代码,编译器就被复杂化。你应该还记得前面提到过“原本 C 是只能使用标量的语言”吧。
对于这这种情况,如果加上
static作为静态变量分配内存区域,就可以在程序的执行前被完全初始化。从 ANSI C 开始,聚合类型的自动变量也可以在声明的时候进行初始化。可是,尽管这样还是会花费相应的成本,在可以使用静态数组的情况下,如果添加
static可以获得令人满意的运行效率。如果同时加上const,效率可能会更好。此外,就算是 ANSI C,在聚合类型的初始化运算符中也只能写常量。
比如,
- void func(double angle)
- {
- double hoge = sin(angle);
- ┊
这样写是没有问题的,但
- void func(double angle)
- {
- double hoge[] = {sin(angle), cos(angle)};
- ┊
这么写就违反语法规范了。
Rationale 的 3.5.7 中说明了理由。下面的代码似乎会引起理解上的混乱,
- int x[2] = { f(x[1]), g(x[0]) };
由于聚合类型的初始化运算符中只能写常量,所以编译器的处理会变得简单一些。因为只要事先在某个地方分配一个填充初始值的内存区域,然后在进入程序块的时候复制这个区域就可以了。
