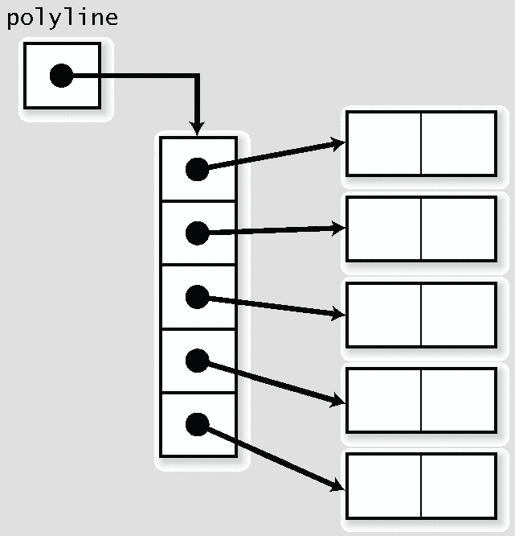
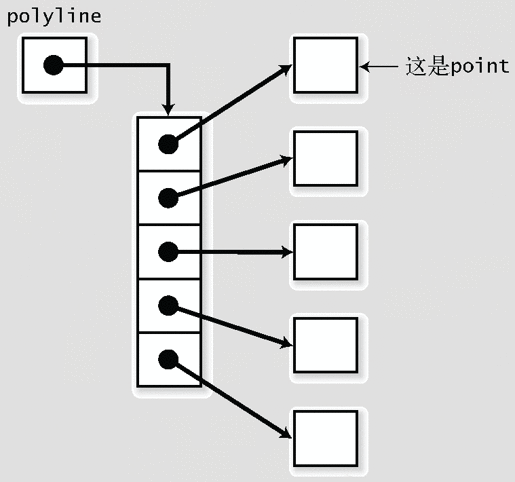
4.2 组合使用
4.2.1 可变长数组的数组
让我们考虑开发一个管理“今天的标语”的程序。
周一的标语是“日行一善”,周二的标语“常回家看看”,等等。哈哈,是不是太说教了?
一周有 7 天,这是不会变化的。但是,标语的字数是相互不同的。对于“勿以善小而不为”,中文1的一个汉字为 2 个字节,末尾加上'\0',就是 15 个字节;对于“常回家看看”,就是 11 个字节。此时,如果按照最长标语的字数声明一个二维数组,就避免不了浪费一些内存。
1 原文这里是“日语汉字”,日语汉字的一个字的长度也是 2 个字节。——译者注
此外,为了让用户可以自由地修改每天的标语,会考虑使用配置文件*,所以标语的最大长度我们是无法预测的。
* 一般也是这样的吧。
因为标语的长度是可变的,使用“char 的可变长数组”应该是一个很好的选择。也就是说,一周的标语可以放在“char 的可变长数组的数组(元素个数 7)”中(参照图 4-2)。
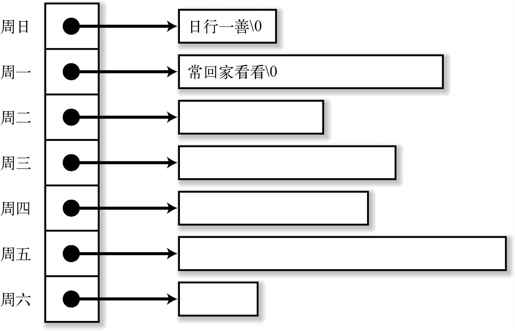
图 4-2 一周的标语
可以像下面这样进行声明:
char *slogan[7];
实现可变长数组的时候,一般需要开发者自己管理元素的个数。但是此时保存的是字符串,字符串必然是使用空字符结束的,所以不需要保持元素个数(在需要知道元素个数时,可以计算获得)。
如果从配置文件中读取一周的标语,程序应该就像代码清单 4-5 这样(这里省略了对 malloc()返回值的检查)。
代码清单 4-5 read_slogan.c
- 1: #include <stdio.h>
- 2: #include <stdlib.h>
- 3: #include <string.h>
- 4: void read_slogan(FILE *fp, char **slogan)
- 5: {
- 6: char buf[1024];
- 7: int i;
- 8:
- 9: for (i = 0; i < 7; i++) {
- 10: fgets(buf, 1024, fp);
- 11:
- 12: /*删除换行字符*/
- 13: buf[strlen(buf)-1] = '\0';
- 14:
- 15: /*分配保存一个标语的内存空间*/
- 16: slogan[i] = malloc(sizeof(char) * (strlen(buf) + 1));
- 17:
- 18: /*复制标语的内容*/
- 19: strcpy(slogan[i], buf);
- 20: }
- 21: }
- 22:
- 23: int main(void)
- 24: {
- 25: char *slogan[7];
- 26: int i;
- 27:
- 28: read_slogan(stdin, slogan);
- 29:
- 30: /*输出读取的标语*/
- 31: for (i = 0; i < 7; i++) {
- 32: printf("%s\n", slogan[i]);
- 33: }
- 34:
- 35: return 0;
- 36: }
代码清单 4-5 中,从标准输入读取一周的标语,之后再将其输出(第 31~33 行)。
在程序中,通过 slogan[i]可以取出指向每条标语的初始字符的指针,如果要取出标语第 n 个字符,就写成下面这样*:
* 汉字都是 2 个字符,所以通过“第 n 个字符”可能是取不出某个汉字的。这里姑且让我们先忽视掉这个问题吧  。请暂时把它们当成英语的标语。
。请暂时把它们当成英语的标语。
- slogan[i][n]
slogan 不是多维数组(数组的数组),其内存布局完全不同于多维数组。
对于下面的多维数组的声明,
int hoge[10][10];
hoge[i]的类型是“int 的数组(元素个数 10)”。因为在表达式中数组可以解读成指针,hoge[i]就成为“指向 int 的指针”,所以可以通过 hoge[i][j] 引用到数组的内容。
对于 slogan , slogan[i] 从一开始 就是指针,所以还是可以写成 slogan[i][n]这样。
此外,通过第 6 行的代码,我们能够发现标语的最大长度限制为 1024 个字节。
既然是“
char的可变长数组”,为什么不取消对标语长度的限制呢?如果无论如何都要添加限制,那么当初用多维数组就好了……
抱有上面想法的人请做一下下面的思考。对于多维数组,如果同样也加上“最大 1024 个字符”的限制,声明如下,
char slogan[7][1024];
此时,内存消耗为 7×1024 个字符。可是在代码清单 4-5 中,读取 1024 个字符时使用一个临时缓冲区就解决问题了。而且,由于这个数组是自动变量,所以,read_slogan()执行结束时这个缓冲区就会释放*。这种方式下,尽管有字符数的限制。但是这个限制是非常宽松的,从使用效果上来看,这个方式还是非常实用的。
* 也有一些处理环境中栈空间的大小是固定的,而且也非常小。这种情况下,如果使用自动变量声明特别大的数组,有时会发生栈溢出问题。
可是在某些情况下,这种对字符数做出的限制,还是会让人感觉不便*,此时,可以使用 malloc()动态分配读取字符用的临时缓冲区。如果空间不足,再考虑通过 realloc()进行内存区域扩展。
* 顺便介绍一下,GNU 的编程标准中,取消了对这种方式的限制(http://www.sra.co.jp/public/sra/product/wingnut/standards-j.html)。
代码清单 4-6 就是实现了可以读取任意长度的行的例程。
代码清单 4-6 read_line.c
- 1: #include <stdio.h>
- 2: #include <stdlib.h>
- 3: #include <assert.h>
- 4: #include <string.h>
- 5: #define ALLOC_SIZE (256)
- 6:
- 7: /*
- 8: *读取行的缓冲,必要时进行扩展。但是区域不会被缩小。
- 9: *调用free_buffer()释放。
- 10: */
- 11: static char *st_line_buffer = NULL;
- 12:
- 13: /*
- 14: *在st_line_buffer 前方被分配的内存区域的大小。
- 15: */
- 16: static int st_current_buffer_size = 0;
- 17:
- 18: /*
- 19: * st_line_buffer 中现在保存的字符的大小。
- 20: */
- 21: static int st_current_used_size = 0;
- 22:
- 23: /*
- 24: *如有必要,扩展st_line_buffer 前方的内存区域。
- 25: *在st_line_buffer 末尾追加一个字符。
- 26: */
- 27: static void
- 28: add_character(int ch)
- 29: {
- 30: /*
- 31: *此函数每次被调用,st_current_used_size 都必定会增加1,
- 32: *正常的情况下,下面的断言肯定不会出错。
- 33: */
- 34: assert(st_current_buffer_size >= st_current_used_size);
- 35:
- 36: /*
- 37: * st_current_used_size 达到st_current_buffer_size 的时候,
- 38: *扩展缓冲区的内存区域。
- 39: */
- 40: if (st_current_buffer_size == st_current_used_size) {
- 41: st_line_buffer = realloc(st_line_buffer,
- 42: (st_current_buffer_size + ALLOC_SIZE)
- 43: * sizeof(char));
- 44: st_current_buffer_size += ALLOC_SIZE;
- 45: }
- 46: /*在缓冲区末尾追加一个字符*/
- 47: st_line_buffer[st_current_used_size] = ch;
- 48: st_current_used_size++;
- 49: }
- 50:
- 51: /*
- 52: *从fp 读取一行字符,一旦读到文件末尾,就返回NULL。
- 53: */
- 54: char *read_line(FILE *fp)
- 55: {
- 56: int ch;
- 57: char *ret;
- 58:
- 59: st_current_used_size = 0;
- 60: while ((ch = getc(fp)) != EOF) {
- 61: if (ch == '\n') {
- 62: add_character('\0');
- 63: break;
- 64: }
- 65: add_character(ch);
- 66: }
- 67: if (ch == EOF) {
- 68: if (st_current_used_size > 0) {
- 69: /*如果最终行后面没有换行*/
- 70: add_character('\0');
- 71: } else {
- 72: return NULL;
- 73: }
- 74: }
- 75:
- 76: ret = malloc(sizeof(char) * st_current_used_size);
- 77: strcpy(ret, st_line_buffer);
- 78:
- 79: return ret;
- 80: }
- 81:
- 82: /*
- 83: *释放缓冲区内存。其实即使不调用这个函数也不会有什么问题,
- 84: *但对于那些抱有“程序结束时,最好使用free()释放掉malloc()分配的内存区域”这种想法的人,
- 85: *可以调用这个函数。
- 86: */
- 87: void free_buffer(void)
- 88: {
- 89: free(st_line_buffer);
- 90: st_line_buffer = NULL;
- 91: st_current_buffer_size = 0;
- 92: st_current_used_size = 0;
- 93: }
代码清单 4-7 read_line.h
1: #ifndef READ_LINE_H_INCLUDED2: #define READ_LINE_H_INCLUDED3:4: #include <stdio.h>5:6: char *read_line(FILE *fp);7: void free_buffer(void);8:9: #endif /* READ_LINE_H_INCLUDED */
read_line()将读取的一行字符作为返回值返回(删除了换行字符)。如果读到了文件末尾,返回 NULL。
在 read_line()中,指针 st_line_buffer*指向缓冲区的初始位置,该缓冲区用于存放临时读取的字符。当缓冲区空间不足时,缓冲区会被扩展 ALLOC_SIZE 大小的区域。其实使用这种方式,由于非常频繁地调用 realloc(),会降低程序运行效率,同时也带来内存碎片化的风险(参照 2.6.5 节)。
* 对于生命周期为“文件内”的 static 变量,我一般习惯加上前缀 st_。
一旦读到行末,该函数会跟据当前行的大小重新分配内存区域(第 76 行),然后将 st_line_buffer 的内容复制到此内存区域。因为下一次的调用还会使用缓冲区,所以此时无需释放 st_line_buffer*。
* 这种方法中使用了 static 变量,所以不是可重入的(reentrant)。多线程的情况下,也会出现问题。只要不在这些情况下,这种方式还是很有效的。
因为 st_line_buffer 只会伸长不会缩短,所以每次 st_line_buffer 只会消费至今为止读取的最长的行的大小(+α)。不管怎么说也就是这一个内存区域用于缓冲,所以不去管它也不会出什么问题。对于抱有“程序结束时,最好使用 free()释放掉 malloc()分配的内存区域”这种想法的人,可以在最后调用 free_buffer。
read_line()中,因为通过 malloc()分配了字符串所需要的内存区域,所以一旦使用结束必须在调用方使用 free()释放所分配的内存区域。
char *str;str = read_line(fp);/*一系列处理*/free(str); ←一旦终止使用就释放!
此外,我们在代码清单 4-6 中省略了对返回值的检查。其实对于可以通用的函数,应该切实做好返回值的检查工作。因此,在 4.2.4 节中提供了这方面的例程。
4.2.2 可变长数组的可变长数组
4.2.1 节中使用可变长数组来表现一个标语,但标语的个数固定为一周的天数(7 个)。
如果需要在内存中加载任意行数的文本文件,可以考虑使用“可变长数组的可变长数组”(参照图 4-3)。
“类型 T 的可变长数组”是通过“指向 T 的指针”来实现的(但是元素个数就需要自己来管理)。
因此,如果需要“T 的可变长数组的可变长数组”,可以使用“指向 T 的指针的指针”(参照图 4-3)。
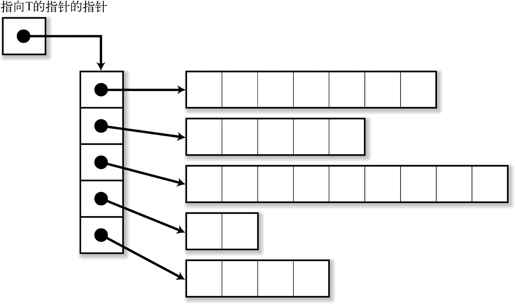
图 4-3 可变长数组的可变长数组
代码清单 4-8 中,从标准输入读取文本文件的内容,并且将其用于标准输出。为了读取任意长度的行,这里使用了代码清单 4-6 的函数 read_line()。
代码清单 4-8 read_file.c
- 1: #include <stdio.h>
- 2: #include <stdlib.h>
- 3: #include <assert.h>
- 4:
- 5: #define ALLOC_SIZE (256)
- 6:
- 7: #include "read_line.h"
- 8:
- 9:
- 10:
- 11: char **add_line(char **text_data, char *line,
- 12: int *line_alloc_num, int *line_num)
- 13: {
- 14: assert(*line_alloc_num >= *line_num);
- 15: if (*line_alloc_num == *line_num) {
- 16: text_data = realloc(text_data,
- 17: (*line_alloc_num + ALLOC_SIZE) * sizeof(char*));
- 18: *line_alloc_num += ALLOC_SIZE;
- 19: }
- 20: text_data[*line_num] = line;
- 21: (*line_num)++;
- 22:
- 23: return text_data;
- 24: }
- 25:
- 26: char **read_file(FILE *fp, int *line_num_p)
- 27: {
- 28: char **text_data = NULL;
- 29: int line_num = 0;
- 30: int line_alloc_num = 0;
- 31: char *line;
- 32:
- 33: while ((line = read_line(fp)) != NULL) {
- 34: text_data = add_line(text_data, line,
- 35: &line_alloc_num, &line_num);
- 36: }
- 37: /*将text_data 缩小到实际需要的大小 */
- 38: text_data = realloc(text_data, line_num * sizeof(char*));
- 39: *line_num_p = line_num;
- 40:
- 41: return text_data;
- 42: }
- 43:
- 44: int main(void)
- 45: {
- 46: char **text_data;
- 47: int line_num;
- 48: int i;
- 49:
- 50: text_data = read_file(stdin, &line_num);
- 51:
- 52: for (i = 0; i < line_num; i++) {
- 53: printf("%s\n", text_data[i]);
- 54: }
- 55:
- 56: return 0;
- 57: }
因为不读到文件的最后就无法知道总共的行数,所以在 read_file()中,对于指针数组也使用 realloc()顺序地将其占用的内存空间加长。
read_line()中,为了共享一些变量,使用了文件内的 static 变量。但这里使用了通过参数传递指针的方式。通过文件内的 static 变量和全局变量共享数据时,因为无法知道“值在什么地方被改写”,所以在很多情况下通过参数传递指针的方式显得很有效。
4.2.3 命令行参数
正如 1.2 节中说明的那样,对于 main 函数,标准中指出必须要写成下面两种形式的中的一种*。
* 很多 UNIX 环境将指向环境变量的指针作为第 3 个参数传递,其实这并不符合标准。
int main(void) ← ①
或者
int main(int argc, char *argv[]) ← ②
直到现在,我们还一直使用第①种形式,如果使用第②种形式,还可以取得命令行的参数。
比如,UNIX 中的 cat 命令——它用于输出文件的内容*。
* DOS 中使用 type 命令。但是,DOS 的 type 命令不具备文件的连接功能(可以使用 copy 命令)。
像下面这样:
cat hoge.txt
命令名后是想要输出的文件名。如果像下面这样将多个文件名作为参数排列起来:
cat hoge.txt piyo.txt
输出就是将 hoge.txt 和 piyo.txt 两个文件的内容连接后所得的结果*。
* cat 是 concatenate(连接)的简写。
其实,事先是无法知道 cat 有几个参数的。不仅如此,各参数(文件名)所对应文件的长度也无法预测。因此,这些参数可以使用“char 的可变长数组的可变长数组”、“指向指针的指针”来表现。
对于刚才的 main 函数的第②种形式,它其实和下面这种形式是完全一样的,
int main(int argc, char **argv)
你既然读到这了,我想应该能明白这是为什么*。
* 不理解的同学,请再次阅读 3.5.1 节。
argv 在内存中的结构,如图 4-4 所示。
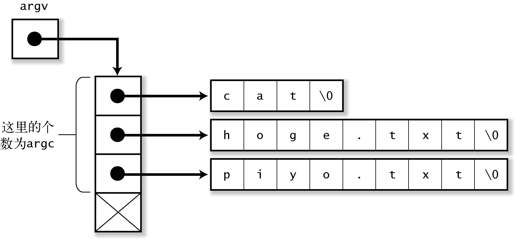
图 4-4 argv 的结构
argv[0]中保存了命令名自身。在程序输出错误提示信息时*,或者需要通过命令名称改变程序的行为时,会经常使用 argv[0]。
* UNIX 中,可以通过管道将命令连接起来执行处理,在错误信息中,为了在错误信息中提示某个命令自身的信息,需要给自己定义一个名称。
argc 中保存了参数的个数(包含了 argv[0])。实际上,从 ANSI C 之后,会保证 argv[argc]肯定为 NULL,所以完全可以没有 argc,但是目前仍然还有很多人习惯性地引用 argc。
代码清单 4-9 是 UNIX 的 cat 的简单实现。
代码清单 4-9 cat.c
- 1: #include <stdio.h>
- 2: #include <stdlib.h>
- 3:
- 4: void type_one_file(FILE *fp)
- 5: {
- 6: int ch;
- 7: while ((ch = getc(fp)) != EOF) {
- 8: putchar(ch);
- 9: }
- 10: }
- 11:
- 12: int main(int argc, char **argv)
- 13: {
- 14: if (argc == 1) {
- 15: type_one_file(stdin);
- 16: } else {
- 17: int i;
- 18: FILE *fp;
- 19:
- 20: for (i = 1; i < argc; i++) {
- 21: fp = fopen(argv[i], "rb");
- 22: if (fp == NULL) {
- 23: fprintf(stderr, "%s:%s can not open.\n",argv[0], argv[i]);
- 24: exit(1);
- 25: }
- 26: type_one_file(fp);
- 27: fclose(fp);
- 28: }
- 29: }
- 30:
- 31: return 0;
- 32: }
和 UNIX 的 cat 一样,如果不指定参数,则使用标准输入(第 14~15 行)。
第 20~27 行,在 for 循环中顺序地处理参数指定的文件名。
世间有很多人在此时,一直顽固地拒绝使用循环计数,他们宁愿一边对 argc 做减法运算,一边前移 argv。我还是习惯使用计数器,然后使用下标访问,因为这种方式很容易让人理解。
4.2.4 通过参数返回指针
4.2.1 节中使用函数 read_line()(参照代码清单 4-6),将读取的行作为返回值返回,如果到达文件的终点则返回 NULL。
可是,作为返回值的形式,read_line()返回的是通过 malloc()分配的内存区域。代码清单 4-6 中并没有对返回值做检查。如果真的想要让 read_line()成为通用的函数,就必须好好地对返回值做检查,并且能向调用方返回函数的处理状态。
对于 read_line()向调用方返回的处理状态,下面列出了几种可能状况:
正常地读取了 1 行。
读到了文件的末尾。
内存不足导致处理失败。
将这些状态用枚举类型来表示:
typedef enum {READ_LINE_SUCCESS, /*正常地读取了1 行*/READ_LINE_EOF, /*读到了文件的末尾*/READ_LINE_OUT_OF_MEMORY /*内存不足导致处理失败*/} ReadLineStatus;
作为向调用方返回处理状态的方式,考虑像下面这样通过参数返回:
char *read_line(FILE *fp, ReadLineStatus *status);
这种方案是非常正确的,但是也有不少软件项目选择坚持“应该通过返回值返回处理状态”的观点。
但是,如果将返回值用于表示处理状态,那么当前通过返回值返回的读取到的字符串,就必须通过参数返回。
如果使用参数返回类型 T,可以使用“指向 T 的指针”。目前我们想要返回类型“指向 char 的指针”,所以参数的类型就应该是“指向 char 的指针的指针”。
因此,函数的原型如下:
ReadLineStatus read_line(FILE *fp, char **line);
代码清单 4-10 为修订版的头文件,代码清单 4-11 是实现代码。
代码清单 4-10 read_line.h(修订版)
- 1: #ifndef READ_LINE_H_INCLUDED
- 2: #define READ_LINE_H_INCLUDED
- 3:
- 4: #include <stdio.h>
- 5:
- 6: typedef enum {
- 7: READ_LINE_SUCCESS, /*正常地读取了1 行*/
- 8: READ_LINE_EOF, /*读到了文件的末尾*/
- 9: READ_LINE_OUT_OF_MEMORY /*内存不足导致处理失败*/
- 10: } ReadLineStatus;
- 11:
- 12: ReadLineStatus read_line(FILE *fp, char **line);
- 13: void free_buffer(void);
- 14:
- 15: #endif /* READ_LINE_H_INCLUDED */
代码清单 4-11 read_line.c(修订版)
- 1: #include <stdio.h>
- 2: #include <stdlib.h>
- 3: #include <assert.h>
- 4: #include <string.h>
- 5: #include "read_line.h"
- 6: #define ALLOC_SIZE (256)
- 7:
- 8: /*
- 9: *读取行的缓冲,必要时进行扩展。但是区域不会被缩小
- 10: *调用free_buffer()释放。
- 11: */
- 12: static char *st_line_buffer = NULL;
- 13:
- 14: /*
- 15: *在st_line_buffer 前方分配的内存区域大小。
- 16: */
- 17: static int st_current_buffer_size = 0;
- 18:
- 19: /*
- 20: * st_line_buffer 中现在被保存的字符的大小。
- 21: */
- 22: static int st_current_used_size = 0;
- 23:
- 24: /*
- 25: *在st_line_buffer 末尾追加一个字符。
- 26: *如果有必要,扩展st_line_buffer 前方的内存区域。
- 27: */
- 28: static ReadLineStatus
- 29: add_character(int ch)
- 30: {
- 31: /*
- 32: *此函数每次被调用,st_current_used_size 都必定会增加1。
- 33: *正常的情况下,下面的断言肯定不会出错。
- 34: */
- 35: assert(st_current_buffer_size >= st_current_used_size);
- 36:
- 37: /*
- 38: *当st_current_used_size 达到st_current_buffer_size 的时候,
- 39: *扩展缓冲区的内存区域。
- 40: */
- 41: if (st_current_buffer_size == st_current_used_size) {
- 42: char *temp;
- 43: temp = realloc(st_line_buffer,
- 44: (st_current_buffer_size + ALLOC_SIZE)
- 45: * sizeof(char));
- 46: if (temp == NULL) {
- 47: return READ_LINE_OUT_OF_MEMORY;
- 48: }
- 49: st_line_buffer = temp;
- 50: st_current_buffer_size += ALLOC_SIZE;
- 51: }
- 52: /*在缓冲区末尾追加一个字符。*/
- 53: st_line_buffer[st_current_used_size] = ch;
- 54: st_current_used_size++;
- 55:
- 56: return READ_LINE_SUCCESS;
- 57: }
- 58:
- 59: /*
- 60: *释放缓冲区内存。其实即使不调用这个函数也不会有什么问题,
- 61: *但对于那些抱有“程序结束时,最好使用free()释放掉malloc()分配的内存区域”这种想法的人,
- 62: *可以调用这个函数。
- 63: */
- 64: void free_buffer(void)
- 65: {
- 66: free(st_line_buffer);
- 67: st_line_buffer = NULL;
- 68: st_current_buffer_size = 0;
- 69: st_current_used_size = 0;
- 70: }
- 71:
- 72: /*
- 73: *从fp 读取一行字符,一旦读到文件末尾,就返回NULL。
- 74: */
- 75: ReadLineStatus read_line(FILE *fp, char **line)
- 76: {
- 77: int ch;
- 78: ReadLineStatus status = READ_LINE_SUCCESS;
- 79:
- 80: st_current_used_size = 0;
- 81: while ((ch = getc(fp)) != EOF) {
- 82: if (ch == '\n') {
- 83: status = add_character('\0');
- 84: if (status != READ_LINE_SUCCESS)
- 85: goto FUNC_END;
- 86: break;
- 87: }
- 88: status = add_character(ch);
- 89: if (status != READ_LINE_SUCCESS)
- 90: goto FUNC_END;
- 91: }
- 92: if (ch == EOF) {
- 93: if (st_current_used_size > 0) {
- 94: /*如果最终行后面没有换行*/
- 95: status =add_character('\0');
- 96: if (status != READ_LINE_SUCCESS)
- 97: goto FUNC_END;
- 98: } else {
- 99: status = READ_LINE_EOF;
- 100: goto FUNC_END;
- 101: }
- 102: }
- 103:
- 104: *line = malloc(sizeof(char) * st_current_used_size);
- 105: if (*line == NULL) {
- 106: status = READ_LINE_OUT_OF_MEMORY;
- 107: goto FUNC_END;
- 108: }
- 109: strcpy(*line, st_line_buffer);
- 110:
- 111: FUNC_END:
- 112: if (status != READ_LINE_SUCCESS && status != READ_LINE_EOF) {
- 113: free_buffer();
- 114: }
- 115: return status;
- 116: }
在 read_line()中,一旦 malloc()返回 NULL,程序马上通过 goto 将处理转移到 FUNC_END。
在处理失败的情况下,FUNC_END 调用 free_buffer()来释放缓冲区占用的内存。一般在内存不足的时候 malloc()才会发生错误,所以释放掉这部分内存,多少能腾出一些空间来完成后面的处理(只是可能)。
世上有很多主张“禁用 goto”的教条主义者,但在这种异常处理中,如果不用 goto,反而会让程序变得更复杂*。
* 如果是 C++和 Java 这种具备异常处理机制的语言,当然可以不使用goto。在 C 中也有 setjmp()/longjmp(),使用它们也能达到相似的效果。
这里顺便插一段,曾经打响“goto 威胁论”第一枪的 Edsger W. Dijkstra 老师在事后说了这么一段话(《计算机程序设计艺术》[8] p.41),
对于我的禁用
goto的这个极端片面的想法,还是希望大家不要掉进迷信的圈套。通过代码写法上的某个技巧去解决程序设计上的问题,就和企图创造一个新兴宗教一样让人感到不快。
要 点
异常处理中使用 goto,反而可以让程序更加整洁。
4.2.5 将多维数组作为函数的参数传递
在 C 中,其实不存在多维数组,看上去貌似多维数组的其实是“数组的数组”。
将类型 T 的数组作为参数进行传递时,可以传递“指向 T 的指针”(参照 4.1.2 节)。因此,如果想要将“数组的数组”作为参数进行传递,可以考虑传递“指向数组的指针”。
在代码清单 4-12 中,将 3×4 的二维数组传递给函数 func(),然后在 func()中将其内容输出。
代码清单 4-12 pass_2d_array.c
- 1: #include <stdio.h>
- 2:
- 3: void func(int (*hoge)[3])
- 4: {
- 5: int i, j;
- 6:
- 7: for (i = 0; i < 4; i++) {
- 8: for (j = 0; j < 3; j++) {
- 9: printf("%d, ", hoge[i][j]);
- 10: }
- 11: putchar('\n');
- 12: }
- 13: }
- 14:
- 15: int main(void)
- 16: {
- 17: int hoge[][3] = {
- 18: {1, 2, 3},
- 19: {4, 5, 6},
- 20: {7, 8, 9},
- 21: {10, 11, 12},
- 22: };
- 23:
- 24: func(hoge);
- 25:
- 26: return 0;
- 27: }
4.2.6 数组的可变长数组
假设要开发一个支持多点折线(曲线)的画笔工具。
考虑使用可变长数组来表现多点折线中的“点”,并且使用“double 的数组(元素个数 2)”来记录一个“点”。
因此,多点折线就可以被定义成:
double 的数组(元素个数 2)的可变长数组
可以使用“指向类型 T 的指针”实现“类型 T 的可变长数组*,所以上面的定义可以变化成
* 但是,元素个数需要通过别的方式管理。
指向 double 的数组(元素个数 2)的指针
因此,分配多点折线的内存区域,可以写成下面这样:
double (*polyline)[2];← polyline 是指向double 数组(元素个数2)的指针/* npoints 是构成多点折线的坐标的个数*/polyline = malloc(sizeof(double[2]) * npoints);
如果感觉理解上有些困难,不妨通过下面的方式对“double 的数组(元素个数 2)”这部分进行类型定义:
typedef double Point[2];
此时,ployline 的声明和内存区域的申请可以写成下面这样:
Point *polyline; ← polyline 是指向 Point 的指针polyline = malloc(sizeof(Point) * npoints);
我想这样就容易理解了吧。
无论使用上面的哪种方式,第 i 个点的 X 坐标都写成
polyline[i][0]
Y 坐标都写成
polyline[i][1]
但是本书却不推荐大家使用本小节中介绍的方法,理由在下一小节给大家说明。
4.2.7 纠结于“可变”之前,不妨考虑使用结构体
在 4.2.6 节中,使用了“指向数组的指针”来表现多点折线。
假设有 5 条多点折线,应该通过什么样的方式来管理呢?
“多点折线”是“指向 double 的数组(元素个数 2)的指针”(需要自己管理元素个数)。因此,如果是“多点折线的数组(元素个数 5)”,就可以解释为“指向 double 数组(元素个数 2)的指针的数组(元素个数 5)”,声明如下:
double (*polylines[5])[2];
你既然读到这了,应该可以很轻松地读懂上面的声明吧。但客观地说,这个声明仍然比较复杂。
此外,因为有 5 根折线,所以对于每根折线对应的元素个数 npoint(每根折线上的坐标个数),就需要声明为以下数组:
int npoints[5];
如果不是 5 根,而是将任意数量的“折线”作为参数来接收的函数原型,应该大致是下面这样:
func(int polyline_num, double (**polylines)[2], int *npoints);
可以定义一个 Point 类型:
typedef double Point[2];
函数原型就可以变成下面这样:
func(int polyline_num, Point **polylines, int *npoints);
如果顺便再定义下面的类型,
typedef Point *Polyline;
上面的函数原型就变成了下面这样:
func(int polyline_num, Polyline *polylines, int *npoints);
尽管使用 typedef 可以简化声明,但还是不能让这个声明变得更加容易理解。
但要说最不尽如人意的地方,那还是“需要程序员自己管理数组的元素个数”这件事吧。
索性像下面这样使用结构体来定义 Point 吧:
typedef struct {double x;double y;} Point;
同样地,也可以用结构体定义 Polyline:
typedef struct {int npoints;Point *point;} Polyline;
将 npoints 和 point 进行统一管理,编程工作好像变得更简单,并且也不需要做“X 坐标为[0],Y 坐标为[1]”这样的暗喻。
在 CAD 这样的应用中,需要经常进行坐标的行列转换。对于 Point 这样的结构体,就要使用循环逻辑来回倒腾数据。此时不妨考虑使用下面的方式:
typedef struct {double coordinate[3];} Point;
其实,对于 2D 的画笔程序,具有 x,y 成员的结构体就已经够用了。
补充 什么是“宽度”可变的二维数组?
如图 4-5 所示,4.2.6 节中使用了“定长数组的可变长数组”。
图 4-5 定长数组的可变长数组
但有时我们希望在运行时确定数组两个维度的大小。
很遗憾,C 语言不支持这种使用数组的方式。正如已经说明过的那样,所谓 C 语言的二维数组,其实本质上是“数组的数组”。为了引用数组的元素,C 语言必须在编译时就确定数组元素的类型大小。
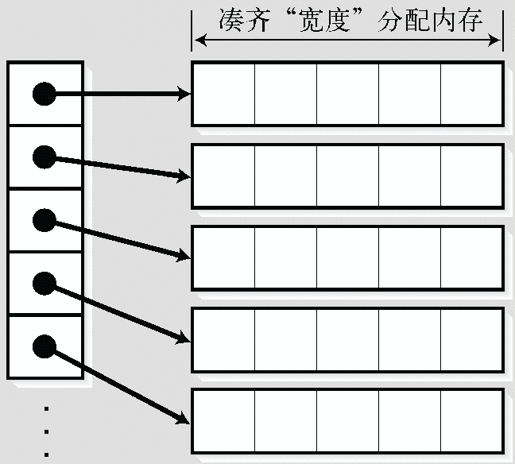
如果使用 4.2.2 节中介绍的方法,当然可以实现如图 4-6 这样的“宽度可变的二维数组”的替代品。
图 4-6 宽度可变的二维数组(替代品)实现 1
但由于这种方式需要多次调用
malloc(),所以在效率和速度上都不会令人满意。此外,过多的malloc()调用,也会让free()的调用变得很繁琐。针对这个问题,可以将
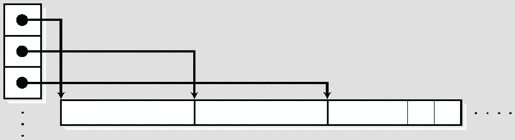
malloc()的调用限制在两次,如图 4-7 这样将指针进行伸展。
图 4-7 宽度可变的二维数组(替代品)实现 2
当然,无论是图 4-6 还是图 4-7,在引用数组的内容的时候都可以写成
array[i][j]这样的形式。其实,现实中除了拘泥于
array[i][j]这样的写法,也是可以简单地使用一维可变长数组,使用array[i * width + j]来引用数组的内容,这也许是最省事的方式了。

补充 Java 的多维数组
这部分可能有些离题,让我们来谈谈 Java。
4.1 节的补充内容“Java 的数组”中提到,Java 经常使用指针来操作数组。
此外,Java 和 C 一样不存在多维数组,也是使用数组的数组来实现多维数组(替代品)。但是,Java 和 C 不同的是,Java 的数组都是指针,所以所谓的“数组的数组”其实是“指向数组的指针的数组”。
在 Java 中,如果使用二维数组来表现“二维多点折线”,你可以写成下面这样:
- // nPoints 为坐标的个数
- double[][] polyline = new int[nPoints][2];
各元素在内存中的配置如图 4-8 所示。
图 4-8 Java 的多点折线二维数组
你可以将
polyline[1]赋给polyline[0],也可以将null赋给polyline[0]。顺便介绍一下,Java 中的类(相当于 C 中的结构体)也是保存在堆中,并且只能利用指针进行操作。因此,Java 中没有类似 C 中“结构体的数组”这样的对象。
在 4.2.7 节中,没有使用二维数组而是使用了结构体来表现多点折线。如果使用 Java 实现,其中各元素的内存布局如图 4-9 所示。
图 4-9 Java 的多点折线结构体(类)
可以使用下面的代码构造这样的结构:
- // nPoints 为坐标的个数
- Point[] polyline = new Point[nPoints];
- for (int i = 0; i < nPoints; i++) {
- polyline[i] = new Point();
- }
其实阻碍 Java 程序快速执行的最大原因就是 Java 过多地使用了堆操作。
关于 Java 过多地进行堆操作这一点,可以说是面向对象语言的必然特征。
C++的对象可以不通过指针,而是通过实体来操作。为了实现这个特性,C++使用了带参数的构造方法以及继承的概念,导致了 C++编程变得非常复杂。