4.3 违反标准的技巧
4.3.1 可变长结构体
在 4.2.7 节中,使用了下面的方式定义了多点折线。
typedef struct {int npoints;Point *point;} Polyline;
使用 malloc()动态地为 Polyline 分配内存的时候,需要调用两次 malloc()——两次在堆空间上分配内存(参照图 4-10)。

图 4-10 Polyline 的实现方法 1
从实现方法上来看,其实这样做也是非常正确的。但是,对于 malloc() 分配的每个内存区域,通常都需要一些额外的管理区域。除此以外,内存碎片化也是一个问题(请参照第 2 章相关内容)。此时,不妨以下面的方式声明 Polyline 类型:
typedef struct {int npoints;Point point[1];} Polyline;
并且使用下面的手法进行内存分配:
Polyline *polyline;polyline = malloc(sizeof(Polyline) + sizeof(Point) * (npoints-1));
在这种方式下,如果使用 polyline->point[3]进行引用,会发生越界引用,因为 Polyline 类型的 point 成员的元素个数是 1。好在大部分的 C 处理环境都不做数组范围检查,你可以使用 malloc()在 Polyline 后面追加分配必要的内存空间(参照图 4-11)。
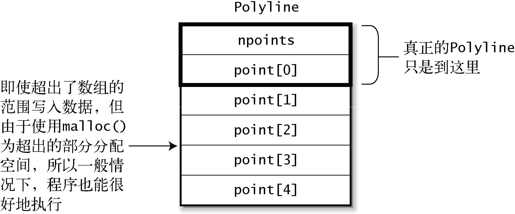
图 4-11 Polyline 的实现方法 2
通过这样的写法,结构体的最后成员不使用指针也可以直接保存可变长数组。这种(似乎)可以让结构体长度可变的技巧,称为“可变长结构体”(虽然不是标准称呼)。
此外,如果将 Polyline 类型的成员 point 声明成 point[0]这样,在 malloc()的时候就不需要做 npoints – 1 这样的调整。但是 ANSI C 规定了数组的元素个数必须大于 0。虽然也有处理环境(如 gcc 等)允许声明元素个数为 0 的数组,但不管怎么说,这只是个别实现。
可是,可变长结构体这样的技巧并不总是有效的。比如,想要增加 Polyline 的坐标个数的时候,对于 Point 数组,可以通过 realloc()扩展必要的内存区域。但对于可变长结构体 Polyline,就需要整体重新分配内存区域,Polyline 自身的地址发生变化的可能性很高。如果有很多持有指向 Polyline 的指针的指针变量,必须对它们进行全部更新。这事儿还是挺麻烦的!
其实,“可变长结构体”这样的技巧,如果用于将结构体整体保存到文件,或者通过进程间通信、网络等条件进行传输,应该会产生不错的效果。使用 fwrite()这样函数将内存中的结构输出的时候,指针类型的成员所指向的对象是输出不了的。但如果是可变长结构体,其内存区域自身是一个整体,因此可以简单地将所有数据输出。反过来,使用 fread()这样的函数,可以将数据整体再读取(还原)到内存。
* 当然,正如 2.8 节中说明的那样,将结构体整体保存在文件中,然后通过网络进行传输这样的操作,可能自身会存在一些问题。但如果是通过同一台机器上的临时文件进行数据交换,或者在同一台机器上的进程间进行通信的情况下,即使使用了这种方法,也是没有问题的。
* Windows 的 BMP 文件就是通过这样的方式从内存中输出的。对于类似于 BMP 文件这样经常被用于多种环境的数据文件,利用“将整体结构体从内存中输出”的这种方式,无论如何都只是 Windows 特有的做法:-P
但无论怎样,从所谓的 ANSI C(ISO-IEC 9899-1990)定义的语法标准来看,可变长结构体还是属于违反标准的技巧。因为规范中指出,对于超出范围对数组的访问,并不保证其有效性和正确性。
毕竟大部分的环境都支持“可变长结构体”的手法,既然事实上已经被广泛使用,所以我们也就没有必要去故意回避。虽然提出了“严守规范编程”(strictly confirming program)的忠告,但在实际开发中也不能过于教条。
顺便告诉大家,ISO C99(ISO/IEC 9899:1999)中,可变长结构体已经被正式承认,并且成为专用语法。
4.3.2 从 1 开始的数组
C 的数组下标是从 0 开始的。初学者经常对此产生困惑,但是大部分情况下,“从 0 开始”要比“从 1 开始”让人感觉更加合适(参照 1.3 节的补充内容)。
但是,在对 FORTRAN 开发的程序进行移植的时候,情况就不是这样的了。
这种情况下,可以通过下面的方法勉强地做出从 1 开始的数组:
/*需要一个1~10 的数组*/double hoge_buf[10];double *hoge = &hoge_buf[-1];此时,hoge[1]恰好就指向hoge_buf[0]。
如果是多维数组,就像下面这样:
/*需要4×4 的二维数组*/double a_buf[4][4];double (*a)[4] = &a_buf[-1][-1];
其实很早之前,上面的手法就为大家所知,将 FORTRAN 程序转换成 C 程序的工具 f2c 中,就用到了这种手法。但是,严格地说,它违反了 C 标准。
C 语言中,对指向超出数组范围以外的指针,除非它指向“最后元素的下 一个元素”,其他情形都属于未定义。
因此,对于下面的语句:
double *a = &a_buf[-1];
因为指针变量 a 指向了 a_buf[-1],仅凭这一点就违反了标准,这和有没有使用当前这个指针进行实际地读写无关。如此这般让指针指向一个没有被分配的内存区域,在不同的处理环境中,CPU 可能会抛出异常,或者地址最后被“晕头转向”地指到了一个莫名其妙的地方。
可是,C 标准却偏偏承认指向数组“最后元素的下一个元素”的指针是合法的,究竟为什么会存在这个不公平的潜规则?关于这个问题,请阅读下面的补充内容。
补充 指针可以指到数组的最后元素的下一个元素
C 标准只承认指向数组的“最后元素的下一个元素”的指针是合法的。如果指针指向“最后元素的下下个元素”(这和有没有发生读写无关),此行为就被认定为未定义。
作为理由,Rationale 里记载了下面这样的一个例子:
- SOMETYPE array[SPAN];
- / … /
- for (p = &array[0]; p < &array[SPAN]; p++)
这里没有使用循环计数器,而是使用指针遍历数组的各元素。
如此这般,当循环到达终点时,如果要问
p指向哪里,答案当然是&array[SPAN]了,也就是array的最后元素的下一个元素。只是为了照顾到以前写的代码,标准才允许指针可以指到数组的“最后元素的下一个元素”。
话说回来,本书还是推荐“不要使用指针运算,而是使用下标来访问数组”。
如果只是为了照顾到很久以前的事,倒是大可不必勉强接受这个奇怪的潜规则。
尽管在早期使用指针运算可以写出执行效率高的代码……
