1.3 关于数组
1.3.1 运用数组
数组是指将固定个数、相同类型的变量排列起来的对象。
还是先让我们来体验一把(参照代码清单 1-3)。
运行结果如下:
01234&array[0]... 0xbfbfd9d4&array[1]... 0xbfbfd9d8&array[2]... 0xbfbfd9dc&array[3]... 0xbfbfd9e0&array[4]... 0xbfbfd9e4
代码清单 1-3 array.c
1: #include <stdio.h>2:3: int main(void)4: {5: int array[5];6: int i;7:8: /*为数组array 的各元素设值*/9: for (i = 0; i < 5; i++) {10: array[i] = i;11: }12:13: /*输出数组各元素的值*/14: for (i = 0; i < 5; i++) {15: printf("%d\n", array[i]);16: }17:18: /*输出数组各元素的地址*/19: for (i = 0; i < 5; i++) {20: printf("&array[%d]... %p\n", i, &array[i]);21: }22:23: return 0;24: }
在第 5 行,声明数组类型变量 array。
在第 9~11 行,为 array 的各元素设定值。这里就是单纯地依次将 0 赋给 array[0],将 1 赋给 array[1] ……
在第 14~16 行,输出数组各元素的值,就是运行结果最前面的那 5 行。
在第 19~21 行,输出数组各元素的地址。观察输出的地址,可以发现这些地址的值与值之间都相差 4 个字节。
我的环境中,int 的长度正好是 4 个字节,内存中数组的布局如图 1-4 所示。

图 1-4 数组在内存中的布局
在本章 1.2.4 节中,曾经提到“对指针加 N,指针前进‘当前指针指向的数据类型的长度 × N’”的原则。在这里将会重新提起这个话题,更详细的说明请阅读下一节。
补充 C 的数组是从 0 开始的
使用 C 语言,声明一个数组变量:
- int hoge[10];
这里指定的 10 是数组元素的个数,因为在 C 中,数组的下标从 0 开始,通过上面这 个声明,你 可以使用
hoge[0]~hoge[9],但你不能使用hoge[10]。这个规则经常会让菜鸟们犯迷糊。
FORTRAN 的数组就是从 1 开始的,要是 C 跟 FORTRAN 一样那该多好……有读者会这么想吧?
这样真的好吗?我觉得你需要三思而行。
打个比方,我上班的公司位于名古屋的一座 5 层的写字楼里,假设某人每爬一层楼花费 10 秒钟,那么此人如果从地面爬上 5 楼,一共需要多少秒呢?50 秒?恭喜你,答错了,答案是 40 秒。
相信大家在中学里都学过“等差数列”,等差数列第 n 项等于“初项 + 公差 × (n-1)”。
“1900 年代”1不是 19 世纪,它的一大半属于 20 世纪。更让人纠结的是,2000 年不属于 21 世纪,而属于 20 世纪。
1 “××××年代”是日本的年代表达方式,“1900 年代”指 1900~1999 年。——译者注
对于这些现象,如果把
写字楼和地面相同高度的那层,计数为 0 层,
数列最初的项,计数为 0 项,
最初的世纪计数为 0 世纪,公历最初的年计数为 0 年,
就能够回避问题。
平时编程中,也经常发生“差 1 错误”问题。普遍的观点是使用 0 作为基准进行编号。
如果还是有人不太理解,可以再举一个和编程相关的例子。
C 语言中可以使用二维数组(准确地说应该是“数组的数组”),但必须在编译的时候知道二维数组的宽度。
假设我们执意要用一维数组去代替宽度可变的二维数组使用,
- / width 为行的宽度,引用第 line 行,第 col 列的元素/
- array[line width + col]
假设最初的行为第 1 行,最初的列为第 1 列,并且数组的下标是从 1 开始,就需要把上面的代码修改成下面这样,
- array[(line-1) width + col]
C 的数组下标从 0 开始,还有一个语法上的原因(后面会提到)。
如果你使用习惯了,从 0 开始的数组比起从 1 开始的数组,使用起来方便得多。
反正如今的内存已经很大了,还不如声明数组的时候多一个 元素的长度,下标就可以从 1 开始使用了。
比起这种敷衍了事的想法,我们还不如让自己习惯于从 0 开始使用数组,除非你正在做 FORTRAN 程序的移植工作。
1.3.2 数组和指针的微妙关系
正如之前说明的那样,给指针加 N,指针前进“当前指针指向的变量类型的长度 × N”。
因此,给指向数组的某个元素的指针加 N 后,指针会指向 N 个之后的元素。
代码清单 1-4 array2.c
1: #include <stdio.h>2:3: int main(void)4: {5: int array[5];6: int *p;7: int i;8:9: /*给数组array 的各元素设定值*/10: for (i = 0; i < 5; i++) {11: array[i] = i;12: }13:14: /*输出数组各元素的值(指针版)*/15: for (p = &array[0]; p != &array[5]; p++) {16: printf("%d\n", *p);17: }18:19: return 0;20: }
运行结果如下。可以发现运行结果和代码清单 1-3 的前半部分相同。
01234
从第 15 行开始一个 for 循环,最初指针 p 指向 array[0],通过 p++顺序地移动指针,引导指针指向 array[5](尽管它不存在)(请参照图 1-5)。
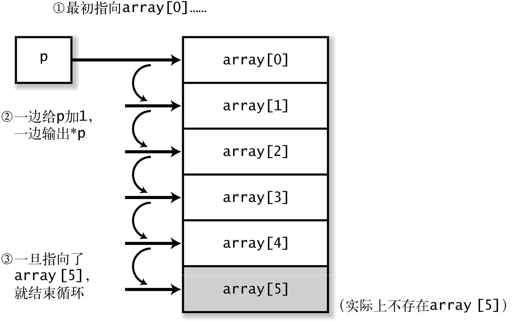
图 1-5 利用指针输出数组的值
使用++运算符给指针加 1,指针前进 sizeof(int)个字节。
此外,第 15~17 行的代码也可以换一种写法(我们可以称之为“改写版”)。
/*利用指针输出数组各元素的值——改写版*/p = &array[0];for (i = 0; i < 5; i++) {printf("%d\n", *(p + i));}
这种写法里,指针并没有一步步前进,而是固定的,只是在打印的时候加 i。
话说回来,你觉得这种写法容易阅读吗?
至少在我看来,无论写成 p++,还是*(p + i),都不容易阅读。还是最初的例子中 a[i]这样的方式更容易理解。
实际上,本书主张的是“因为利用指针运算的写法不容易阅读,所以让我们抛弃这种写法吧”。
先把写法好坏的问题放在一边。事实上,指针运算是 C 语言的一个“奇怪”的功能。到底有多“奇怪”,片刻之后就为你一一道来。
1.3.3 下标运算符[]和数组是没有关系的
在前一小节的“改写版”例程中,像下面这样将指针指向数组的初始元素。
p = &array[0];
其实也可以写成下面这样:
p = array;
对于这种写法,很多 C 语言的入门书籍是这样说明的:
在 C 中,如果在数组名后不加
[],单独地只写数组名,那么此名称就表示“指向数组初始元素的指针”。
在这里,我可以负责地告诉你,上面的说明是错误的*。
* 如果考虑给人留点面子,其实我应该这么说:“不能说这个说明总是对的。”可是考虑一下听到这个说明的人如何解释它,就感觉还不如痛痛快快地指出来“这个说明完全是错误的”。
又惊着你了吧?
在 C 的世界里,事到如今你再去否定“数组名后不加[],就代表指向初始元素的指针”这个“强大的”误解显得有点无奈。对于这种已经深入人心的观点,你突然放言它其实是个误解,可能很多人无法接受。下面让我们依法来证明。
将&array[0]改写成 array,“改写版”的程序甚至可以写成下面这样:
p = array; ←只是改写了这里,可是……for (i = 0; i < 5; i++) {printf("%d\n", *(p + i));}
另外,程序中*(p + i)也可以写成 p[i]。
p = array;for (i = 0; i < 5; i++) {printf("%d\n", p[i]);}
也就是说,
*(p + i)
和
p[i]
是同样的意思。可以认为后面的写法是前面的简便写法。
在这个例子中,最初通过 p = array;完成了向 p 的赋值,但之后 p 一直没有发生更改。所以,早知如此,何必当初偏要多声明一个 p,还不如一开始就写成 array 呢。
for (i = 0; i < 5; i++) {printf("%d\n", array[i]);}
呀,好像又回去了呢。
结论就是,
p[i]
这种写法只不过是
*(p + i)
这种写法的简便写法,除此之外,它毫无意义。array[i]和 p[i]有什么不一样吗?array[i]也可以像 p[i]一样,将 array 解读成“指向数组的初始元素的指针”。
也就是说,存在
int array[5];
这样的声明的时候,“一旦后面不追加[],只写 array”并不代表要使 array 具有指向数组第 1 个元素的指针的含义,无论加不加[],在表达式中,数组都可以被解读成指针。
顺便说一下,对于这个规则来说,有三个小的例外,我们会在第 3 章作详细说明。
你可以认为这是一个哗众取宠的异端邪说,但至少在语法上,数组下标运算符[]和数组无关。
这里也是 C 的数组下标从 0 开始的理由之一。
要 点
【非常重要!!】
表达式中,数组可以解读成“指向它的初始元素的指针”。尽管有三个小例外,但是这和在后面加不加[]没有关系。
要 点
p[i]是*(p + i)的简便写法。下标运算符
[]原本只有这种用法,它和数组无关。
需要强调的是,认为[]和数组没有关系,这里的[]是指在表达式中出现的下标运算符[]。
声明中的[],还是表达数组的意思。也就是说,声明中的[]和表达式中的[]意义完全不同。表达式中的*和声明中的*的意义也是完全不同的。这些现象使得 C 语言的声明在理解上变得更加扑朔迷离……对此,第 3 章将会进行详细的说明。
此外,如果将 a + b 改写成 b + a,表达式的意义没有发生改变,所以你可以将*(p + i)写成*(i + p)。其次,因为 p[i]是*(p + i)的简便写法,实际上它也可以写成 i[p]。
引用数组元素的时候,通常我们使用 array[5]这样的写法。其实,就算你写成 5[array],还是可以正确地引用到你想要的元素。可是,这种写法实在太另类了,它不能给我们带来任何好处。
要 点
p[i]可以写成i[p]。
要 点
【比上面这个要点更重要的要点】
但是别写成那样。
补充 语法糖
p[i]是*(p+i)的简单写法,实际上,至少对于编译器来说,[]这样的运算符完全可以不存在。可是,对于人类来说,
*(p + i)这种写法在解读上比较困难,写起来也麻烦(键入量大)。因此,C 语言引入了[]运算符。就像这样,这些仅仅是为了让人类容易理解而引入的功能,的确可以让我们感受到编程语言的甜蜜味道(容易着手),有时我们称这些功能为语法糖(syntax sugar 或者 syntactic sugar)。
1.3.4 为什么存在奇怪的指针运算
如果试图访问数组的内容,老老实实地使用下标就可以了。为什么存在指针运算这样奇怪的功能呢?
其中的一个原因就是受到了 C 的祖先 B 语言的影响。
在 1.1.2 节的补充内容中也提到了,B 是一种“没有类型”的语言。B 中可以使用的类型只有 word 型(也就是整型),指针也是作为整型来使用的(像浮点型这样高级的事物,你根本见不到)。B 是虚拟机上运行的解释器,这个虚拟机以 word 为单位分配内存地址(如今普通的计算机以字节为单位)。
由于 B 以 word 为单位,如果指针(仅仅是表现地址的简单的整数)加 1,指针就指向数组的下一个元素。为了继承这种特性,C 引入了“指针加 1,指针前进它所指向类型的长度”这个规则*。
* 关于这方面的论述在“ The Development of the C Language”[5]这篇论文(也可以认为是随笔吧)中有记载。你可以从 Dennis Ritchie 的网站上获取它。
B 语言中同样存在 p[i]是*(p + i)的语法糖这样的规则。可是,这里的(p + i)只不过是单纯的整数之间的加法运算*。
* 因此,在 B 中,将 p[i] 写成 i[p]是一件“理所当然”的事。但是这种规则居然被原封不动地搬到了 C 中(有点悲哀!)。
解引用*、地址运算符&,也以几乎和 C 相同的形态存在于 B 语言中。
另外还有一个理由就是,早先使用指针运算可以写出高效的程序。
通常情况下,我们总是使用循环语句来处理数组,一般都写成下面的}形式,
for (i = 0; i < LOOP_MAX; i++) {/**在这里,使用array[i]进行各种各样的处理。* array[i]会出现多次。*/}
array[i]在循环中会出现多次,每次都要进行相当于*(array + i)的加法运算,效率自然比较低。
因此,可以使用指针运算重写上面这段循环,
for (p = &array[0]; p != &array[LOOP_MAX]; p++) {/**在这里,使用*p 进行各种各样的处理。* *p 会出现多次。*/}
尽管*p 在循环内部会出现多次,但加法运算只有在循环结束的时候执行一次。
K&R p.119 中叙述了“一般情况下,使用指针的程序比较高效”。上面的说明应该可以作为这段叙述的根据吧。
可是,这些无论怎样都是老黄历了。
如今,编译器在不断地被优化,对于循环内部重复出现的表达式的集中处理,是编译器优化的基本内容。对于现在一般的 C 编译器,无论你使用数组还是指针,效率上都不会出现明显的差距。基本上都是输出完全相同的机器码。
总的来说,C 的指针运算功能的出现,源自于早期的 C 自身没有优化手段。这一点并不奇怪,请大家回想一下在前面介绍过的内容,C 本来只是为了解决开发现场的人们眼前的问题而出现的一种语言。Unix 之前的 OS 几乎都是使用汇编写的,即使晦涩难懂,人们也不会大惊小怪。对于当时的环境,追求什么编译器优化实在有点勉为其难。因此,当初开发 C 语言的时候,是完全有必要提供指针运算功能的。可是……
1.3.5 不要滥用指针运算
被称为 C 语言宝典的 K&R 指出:“一般情况下,使用指针的程序比较高效。”这完全是“那个时代的错误”。
可是,正如前面所说,对于如今的编译器,无论是使用指针运算还是下标运算,都生成几乎完全相同的执行代码。
事到如今……难道不应该放弃使用指针运算*,老老实实地使用下标访问吗?
* 下标运算符也是“指针运算 + 解引 用运算符”,这里提到的“指针运算”是指明确地对指针进行加减运算的程序写法。
虽然 K&R 被很多人奉为“神书”,可是对于我来说,它连作为菜鸟实习的资料也不够格。为什么这么说?因为在此书中,那些滥用指针的例程完全可以让你崩溃。
莫名其妙地使用像*++args[0]这样的语句,并且乐此不疲,实在让人心烦。
K&R 里面记载了下面这个作为 strcpy()实现的例子:
- /* strcpy: 将 t 复制到s;指针版 3 */
- void strcpy(char *s, char *t)
- {
- while (*s++ = *t++)
- ;
- }
- >
虽然乍一看不容易理解,但是这种写法其实是非常方便的。因为会在 C 程序中经常遇到,所以我们应该掌握这种惯用写法。
既然知道“乍一看不容易理解”,那就不应该这样写,难道不是吗?*
* 特别是,在这段代码中,当循环结束后,指针指向了空字符的下一个字符,之后如果继续复制其他字符串,会很容易诱发 bug。
满大街的 C 语言入门书都在教育我们,使用指针运算比使用下标会让程序
更有效率
更有 C 语言范儿
所谓的“更有效率”,只不过是臆想罢了。对于这种“微不足道的”优化工作,与其让人去小心翼翼地做,还不如交给编译器来干。
所谓“更有 C 语言范儿”好像是有些道理。如果只是为了要让程序“有范儿”,而让代码变得晦涩难懂,那么还是拜托你行行好,扔掉这种恶习吧。
在学校里,我们要完成一些课后作业。好不容易完成了一个使用下标的程序题,不料后面的那道题为“请使用指针将刚才那道题的程序重新完成一遍”。这种事常有吧。
老实说,这种事很无聊。也许你会很“威武”地依然使用下标原封不动地把程序又写了一遍,然后交给了老师。面对老师的指责,你义正辞严:
咦,下标运算符
[]只不过是指针运算的语法糖而已,在本质上这样的写法也是在使用指针啊。
尽管这样,这位可爱的老师可能还是不会放过你,于是你就急了:
行,不就是把像
p[i]这样使用下标的地方,机械地一个个替换成*(p+i)嘛。
话说回来,丢了学分,我可不负责哟。在 C 的世界里,使用指针运算要比使用下标的写法让人感觉更“帅一些”。
但是……与其在这些无聊的地方“耍酷”,倒不如多花点时间学一些有用的知识。你要知道,作为一个程序员,还有堆积如山的知识等着你去掌握呢。
当然,什么样的规则都有例外,比如,在“一个巨大的 char 数组中,参杂了各种类型的数据2,并且我们试图读取第多少字节的数据”这样的情况下,还是使用指针运算写的程序比较容易理解。
2 在网络通讯中,数据交换程序中经常会使用一个 char 数组保存各种数据类型的数据。我们通常将这种行为称为序列化。——译者注
此外,作为一个 C 程序员连指针运算的代码也读不懂,多少有点可悲。
尽管如此,让我们至少从现在开始尽量使用下标来写新的程序,这样做对自己,以及对以后有机会阅读你的程序的人,都有好处。
补充 修改参数,好吗?
刚才那个在 K&R 中记载的实现
strcpy()的例子中,使用++直接修改了形参s和t的值。确实,C 的形参可以和事先被设定值的局部变量同样使用,对值进行修改在语法上并没有任何问题。但我从来不这么做。
函数的参数是从调用方得到的非常重要的信息,如果一时疏忽错误地修改了参数,就再也恢复不了了。对于在后面追加新的逻辑,或者调试程序的情况下,因为原始的参数已经被修改,如果想要看一下参数的值,你会感觉非常棘手。
此外,参数都应该有一个有意义的名称(刚才的
strcpy()是个反面教材)。在修改参数的时候,违背最初参数名称的意义的“恶行”也屡见不鲜。这种恶行多发生在循环计数的逻辑中。
顺便说一下,
Ada和Eiffel不允许修改作为输入信息的函数参数。在内部,我认为应该是和 C 采用了大抵相同的参数传递方式。
1.3.6 试图将数组作为函数的参数进行传递
在这里,让我们首先来做一个具有实用价值的例子:从英文的文本文件中将单词一个一个取出来。
关于调用方式,模仿 fgets(),定义成下面的形式:
int get_word(char *buf, int buf_size, FILE *fp);
函数的返回值是单词的字母个数,当读到文件末尾的时候返回 EOF。
对于单词的定义,如果仔细考虑一下,好像还真不是件容易的事。这里我们选择使用 C 的 isalnum()这个宏(ctype.h)。如果返回真,就表示是连续的几个字符那就作为单词,否则就是空白字符。
单词长度大于 buf_size 的情况下,因为处理会变得比较麻烦,我们考虑使用 exit()果断地结束程序。
为了测试这个函数,在程序中添加 main()用来驱动测试过程(调用 get_word())(参照代码清单 1-5)。
main()中声明的数组 buf,在 get_word()中被填充值。
在 main()中,buf 作为函数的参数传递,因为这里是在表达式中,所以 buf 可以解读成“指向数组初始元素的指针”。因此,接受 buf 的 get_word() 才可以像
int get_word(char *buf, int buf_size, FILE *fp)
这样,合法地接受 char *。
其次,在 get_word()中,可以像 buf[len]这样操作 buf 的内容。那是因为 buf[len]是*(buf + len)的语法糖。
一旦在 get_word 中使用下标运算符访问 buf 的内容,倒还真的会让人感觉从 main()传递过来的是 buf 这样的数组。显然这是个错觉,无论如何,从 main()传递过来的是指向 buf 的初始元素的指针(请回忆一下我们曾经提到的“C 是本来只能使用标量的语言”这个观点,参照 1.1.8 节)。
代码清单 1-5 get_word.c
1: #include <stdio.h>2: #include <ctype.h>3: #include <stdlib.h>4:5: int get_word(char *buf, int buf_size, FILE *fp)6: {7: int len;8: int ch;9:10: /*跳过读取空白字符*/11: while ((ch = getc(fp)) != EOF && !isalnum(ch))12: ;13: if (ch == EOF)14: return EOF;15:16: /*此时,ch 中保存了单词的初始字符。*/17: len = 0;18: do {19: buf[len] = ch;20: len++;21: if (len >= buf_size) {22: /*由于单词太长,提示错误*/23: fprintf(stderr, "word too long.\n");24: exit(1);25: }26: } while ((ch = getc(fp)) != EOF && isalnum(ch));27: buf[len] = '\0';28:29: return len;30: }31:32: int main(void)33: {34: char buf[256];35:36: while (get_word(buf, 256, stdin) != EOF) {37: printf("<<%s>>\n", buf);38: }39:40: return 0;41: }
准确地说,在 C 中是不能将数组作为函数参数进行传递的。但是,你可以通过传递指向初始元素的指针来达到将数组作为参数进行传递的目的。
要 点
如果试图将数组作为函数参数进行传递,那就传递指向初始元素的指针。
可是,一般情况下将 int 等作为参数进行传递的时候,与在当前的例子中将数组作为参数进行传递的时候,它们的传递方式是完全不同的。
在 C 中,函数参数传递都是传值,向函数传递的都是参数的副本。当前的例子同样如此,向 get_word()传递的是指向 buf 初始元素的指针的副本。但是,main()和 get_word()引用的都是 buf 本身,而不是 buf 的副本。正因为如此,get_word()才能正确地向 buf 填充字符串的内容。
补充 如果对数组进行值传递
在迫不得已的情形下,如果你执意要将数组的副本作为参数进行传递,可以使用替代方法——将数组的所有元素整理成结构体的成员。
正如 1.1.8 节中说明的那样,C 本来就是只能使用标量的语言。但是这个问题在比较早的时期就得到了改善,我们现在已经可以对结构体进行赋值了。
可是,这种方法在效率上是有问题的,关于这一点你需要有心理准备。当在操作一个巨大的数组的时候,如果对所有元素一一复制,那可是非常耗时的。
我以前在模拟奥赛罗棋游戏3的行棋思路的时候,曾经通过这种方法来对表示盘面形势的二维数组进行值传递。在行棋思路中,通过对“如果这样下,形势就会这样”的巨大的树结构进行不断地递归探寻,来得到最优的出棋对策,因此,针对每一着棋都需要对记录盘面形势的二维数组进行复制。我感觉,也就是在这种需求下才会使用这种技术。
3 奥赛罗棋是一种双人棋盘游戏。在划分 64 格的棋盘上排列正反面为黑白色的圆形棋子,夹住对方棋子时可把它翻面换成己方的棋子的颜色,以此争胜负。——译者注
要 点
无论如何都要将数组进行值传递的时候,建议将数组整体整理成结构体成员。
1.3.7 声明函数形参的方法
本书的例程中,将 get_word()的参数像下面这样使用 char *进行声明,
- int get_word(char buf, int buf_size, FILE fp)
“咦?俺可是一直这么写的哦”
- int get_word(char buf[], int buf_size, FILE *fp)
应该有同学是这样想的吧。
只有在声明函数形参时,数组的声明才可以被解读成指针。
比如,对于
int func(int a[])
编译器可以针对性地解读成:
int func(int *a)
即使像下面这样定义了元素个数,编译器也是无视的,
int func(int a[10])
这也是语法糖之一。
必须要引起注意的是,int a[]和 int *a 具有相同意义,在 C 的语法中只有这么一种情况。关于这一点,在第 3 章中会有具体的说明。
要 点
在下面声明的形参,都具有相同的意义。
- int func(int a); /写法1/
- int func(int a[]); /写法2/
- int func(int a[10]); /写法3*/
写法 2 和写法 3 是写法 1 的语法糖。
补充 C 语言为什么不做数组下标越界检查?
通常,C 对数组的长度范围是不做检查的。“托它的福”,当向数组越界写入数据的时候,经常产生“内存被破坏”的问题。如果在较早的阶段,操作系统发现异常并且提示 Segmentation fault,或者“强制关闭异常的应用程序”这样的消息还算幸运。最不幸的是,相邻变量的值已经被破坏,程序却还在继续运行,并且你无法预知悲剧会在何时何地发生。
频繁地进行范围检查会影响效率,但至少应该让我们在编译的时候可以使用一个选项,以便要求编译器在调试模式下编译程序的时候,帮我们实施数组下标范围的检查。有这样的想法的人,不只是我一个吧。
但是,请稍微再想一想这个问题。
可以使用
int a[10];这样的方式声明数组,并且通过a[i]的方式引用数组元素的那些编程语言,可以比较容易地进行数组长度范围检查。但是对于 C,当数组出现在表达式中的时候,它会立刻被解读成指针。此外,使用其他的指针变量也可以指向数组的任意元素,并且这个指针可以随意进行加减运算。引用数组元素的时候,虽然你可以写成
a[i],但是它只不过是*(a + i)的语法糖。还有,当你向一个函数传递数组的时候,实际上你传递的是一个指向初始元素的指针。如果这个函数还存在于其他的代码文件中(另外一个编译单元),那么通过编译器是不可能追踪到数组的。
要求这样的语言在编译时生成检查数组长度的代码,是不是有些强人所难?
如果无论如何都需要进行数组长度检查,可以考虑将指针封装成结构体那样,运行时让指针自身持有可取值范围的信息。可是这么做对性能的影响很大,同时,也丧失了非调试模式下编译后的库和指针的兼容性。
总的来说,除了某些解释型的编程语言之外,目前几乎没有编译器可以为我们做数组的越界检查。
