2.7 内存布局对齐
稍微转换一下话题_……
假设有下面这样的一个结构体:
typedef struct {int int1;double double1;char char1;double double2;} Hoge;
在我的环境中,sizeof(int)的结果为 4,sizeof(double)的结果为 8,随便说一下,根据 C 标准,sizeof(char)的结果必定为 1*。敢问阁下,这个结构体的尺寸是多大?
* 比如,即使 char 为 9 bit 的处理环境(如果真的存在),sizeof(char)值也是 1。标准就是这么定义的。
4 + 8 + 1 + 8 = 21 个字节——几乎在所有的情况下,这个答案都是错误的。在我的处理环境中,答案是 24 个字节。
还是通过程序做个实验吧(参照代码清单 2-8)。
声明一个 Hoge 类型的变量,然后将各成员的地址输出*。
* 如果需要获得结构体成员距离初始位置的偏移量,一般使用 stddef.h 中定义的宏 offsetof()。使用这个宏,不需要声明哑变量(dummy )也可以获取偏移量。
代码清单 2-8 alignment.c
1: #include <stdio.h>2:3: typedef struct {4: int int1;5: double double1;6: char char1;7: double double2;8: } Hoge;9:10: int main(void)11: {12: Hoge hoge;13:14: printf("hoge size..%d\n", sizeof(Hoge));15:16: printf("hoge ..%p\n", &hoge);17: printf("int1 ..%p\n", &hoge.int1);18: printf("double1..%p\n", &hoge.double1);19: printf("char1 ..%p\n", &hoge.char1);20: printf("double2..%p\n", &hoge.double2);21:22: return 0;23: }
我的环境中的运行结果如下:
hoge size..24hoge ..0xbfbfd9d0int1 ..0xbfbfd9d0double1..0xbfbfd9d4char1 ..0xbfbfd9dcdouble2..0xbfbfd9e0
观察运行结果可以发现,char1 的后面空出来一块。
这是因为根据硬件(CPU)的特征,对于不同数据类型的可配置地址受到一定限制。或者,即使可以配置,某些 CPU 的效率也会降低。此时,编译器会适当地进行边界调整(布局对齐),在结构体内插入合适的填充物。
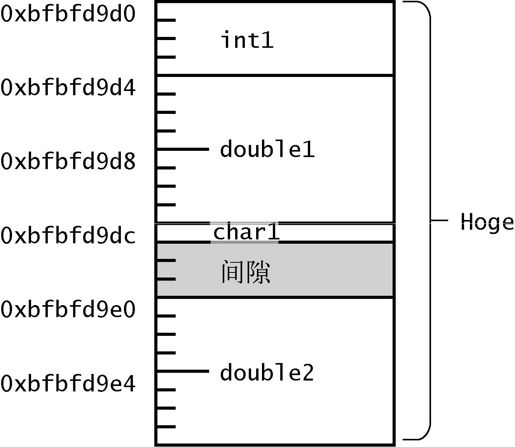
图 2-16 布局对齐
根据这个实验,在我的环境中,int 和 double 被配置在 4 的倍数的地址上。
布局对齐处理有时候也在结构体的末尾进行,这是由于有时候需要构造结构体数组的缘故。针对这样的结构使用 sizeof 运算符,会返回包含末尾对齐字节的结构体长度。将结果和元素个数相乘,就可以获得整个数组的大小。
此外,malloc()会充分考虑到各种类型的长度,返回调整后最优化的地址。局部变量等也会被配置到优化调整后的地址上。
布局对齐操作是根据 CPU 的情况进行的。因此,根据 CPU 的不同,布局对齐填充的方式也不同。在我的环境中,double 可以被配置在 4 的倍数的地址上,但在很多 CPU 上,double 只能被配置在 8 的倍数的地址上。
偶尔,也会有人比较讨厌布局对齐方式对硬件的依赖,通过手工调整边界来提高可移值性。
typedef struct {int int1;char pad1[4]; ←通过手工填充double double1;char char1;char pad2[7]; ←这里也是double double2;} Hoge;
可是,这么做究竟有什么作用呢?
即使不这么做,编译器也会根据 CPU 的情况帮我们进行适当的边界调整。如果只是引用成员名,就根本没有必要去理会布局对齐方式。
如果需要将结构体照原样(通过 fwrite())输出到文件中,由于 CPU 的不同,在其他机器上想要读取这个结构体的时候,对齐方式的不同可能导致问题。那么,通过手工方式调整边界,说不定某台机器上输出的数据,也能被其他机器读取。可是无论怎样,这只不过是偶尔才可以拿出来说的例子。
在上面的例子中,pad1 的尺寸为 4,pad2 的尺寸为 7。究竟这些数字是怎么冒出来呢?连标准也不能保证 sizeof(int)为 4,sizeof(double)为 8。将这些数字直接写在程序中,还说什么“为了提高可移植性”……
也就是说,手工插入填充物的方法,即使可以让不同机器的数据交换成为可能,也只不过是敷衍逃避。原型开发也许会允许使用这种方式,但是如果在现实中进行数据交换,将结构体按照原样写入到文件的方式本身就是个错误。
另外,即使是 sizeof(int)为 4 的处理环境,其内部表现也不一定相同。关于这一点,下一节会进行说明。
要 点
即使手工进行布局对齐,也不能提高可移植性。
