2.6 利用 malloc()来进行动态内存分配(堆)
2.6.1 malloc()的基础
C 语言中可以使用 malloc()进行动态内存分配。
malloc()根据参数指定的尺寸来分配内存块,它返回指向内存块初始位置的指针,经常被用于动态分配结构体的内存领域、分配执行前还不知道大小的数组的内存领域等。
p = malloc(size);
一旦内存分配失败(内存不足),malloc()将返回 NULL。利用 malloc()分配的内存被结束使用的时候,通过 free()来释放内存。
free(p); ←释放 p 指向的内存区域
以上是 malloc()的基本使用方式。
像这样能够动态地(运行时)进行内存分配,并且可以通过任意的顺序释放的记忆区域,称为堆(heap)*。
* 它不是 C 语言定义的术语。
英语中“heap”这个单词是指像山一样堆得高高的事物(比如干草等)。malloc()就好像从内存的山上分出一部分内存,为我们“从堆中取来所需的内存区域”。
malloc()主要有以下的使用范例:
- 动态分配结构体
藏书家可能会用计算机管理自己的藏书。刚从书店买回来一本书,却发现:“啊!原来这本书我已经有了!”特别是漫画书,经常会有重复购买的现象,有吧?(难道只有我是这样?)
因此,最好做一个“藏书管理程序”。
假设用下面这样的结构体管理一本书的数据:
typedef struct {char title[64]; /*书名*/int price; /*价格*/char isbn[32]; /*ISBN*/┊} BookData;
对于藏书家来说,他一定要管理堆积如山的 BookData。
在这种情况下,当然可以通过一个巨大的数组来管理大量的 BookData,但是在 C 中必须明确定义数组的长度,究竟需要定义多大的数组是一件让人头疼的事情。如果申请过大的数据空间浪费内存,但如果申请的大小刚刚好,随着书的增加,数组的空间又会变得不足。
通过下面的方式,就可以在运行时分配 BookData 的内存区域。
BookData *book_data_p;/*分配一个结构体BookData 的内存区域*/book_data_p = malloc(sizeof(BookData));
如果使用链表来管理,就可以保持任意个数的 BookData。当然,只要你内存足够。
关于链表的使用方法,在这里只是稍稍提一下,在第 5 章会详细说明。
首先让我们向结构体 BookData 中追加一个指向 BookData 类型的指针成员。
typedef struct BookData_tag {char title[64]; /*书名*/int price; /*价格*/char isbn[32]; /* ISBN */┊struct BookData_tag *next; ←追加这一行} BookData;
在这个例子中,利用 typedef 为 struct BookData_tag 定义同义词 BookData(不用一次次地写 struct 了)。尽管如此,由于成员 next 声明时 typedef 还没有结束,所以请注意这里必须要写成 struct BookData_tag。tag 不能省略。
通过 next 持有“指向下一个 BookData 的指针”,像图 2-11 这样形成串珠的数据结构,就能够保存大量的 BookData*。
- 以后,图中的•→表示 指针,
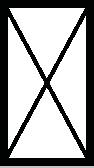 表示
表示 NULL。
图 2-11 链表
这种被称为“链表”的数据结构运用非常广泛。
- 分配可变长数组
在刚才的 BookData 类型中,书名的地方写成下面这样:
char title[64]; /*书名*/
可是有的情况下,书名也很变态,比如,
京都露天混浴澡堂蒸气谋杀事件——美女大学生 3 人组所见!
谜一样的旅馆女主人死亡和 10 年前的观光客失踪事件的背后所潜藏的真相是?
(这还是书名吗?)
此时,char title[64]就放不下这么长的书名了。可是,也不是所有的书都有这么长的书名,所以准备太长的数组也是浪费。
这里,将 title 的声明写成:
char *title; /*书名*/
然后,
BookData *book_data_p;┊/*这里 len 为标题字符数+1(空字符部分的长度) */book_data_p->title = malloc(sizeof(char) * len);
就能够只给标题字符串分配它必要的内存区域了。
此时,如果想要引用 title 中某个特定的字符,当然可以写成
book_data_p->title[i]
大家想必还记得 p[i]是*(p + i)的语法糖吧。
补充 malloc()的返回值的类型为 void
ANSI C 以前的 C,因为没有
void\这样的类型,所以malloc()返回值的类型就被简单地定义成char*。char*是不能被赋给指向其他类型的指针变量的,因此在使用malloc()的时候,必须要像下面这样将返回值进行强制转型:
- book_data_p = (BookData)malloc(sizeof(BookData));
ANSI C 中,
malloc()的返回值类型为void\,void*类型的指针可以不强制转型地赋给所有的指针类型变量。因此,像上面的强制转型现在已经不需要了。尽管如此,现在还有人时常在这里使用强制转型。我认为,不写多余的强制转型代码,对于顺畅地读懂代码是有利的。
此外,假设忘记了
#includestdlib.h,一旦笨拙地对返回值进行强制转型,编译器很可能不会输出警告。C 语言默认地将没有声明的函数的返回值解释成
int类型,那些运气好、目前还能跑起来的程序,如果被迁移到int和指针长度不同的处理环境中,就会突然跑不动了。如果可能,应该提高警告的级别,以便让警告可以输出。
因此,我们不要对
malloc()的返回值进行强制转型。因为 C 不是 C++。另外,C++中可以将任意的指针赋给
void*类型的变量,但不可以将void*类型的值赋给通常的指针变量。所以在 C++中,malloc()的返回值必须要进行强制转型。但是,如果是 C++,通常使用new来进行动态内存分配(也应该这样)。
2.6.2 malloc()是“系统调用”吗
这里有一点离题。
C 的函数库中为我们准备了很多的函数(printf()等)。另外,标准库的一部分函数最终会调用“系统调用”。所谓系统调用*,就是请求操作系统来帮我们做一些特殊的函数群。标准函数通过 ANSI C 进行了标准化,但是不同操作系统上的系统调用的行为却经常会有差别。
* 这原本是 UNIX的术语。
比如在 UNIX 操作系统中,printf()最终调用 write()这样的系统调用。不只是 printf(),putchar()和 puts()在最终也是调用 write()。
由于 write()只能输出指定的字节串,为了让应用开发人员更方便地使用和提高可移植性,C 语言给 write()披上了标准库的“皮”。
话说回来,malloc()是系统调用?还是标准库函数?
可能很多人会认为它是系统调用。恰恰相反,malloc()实际上属于标准库函数,它不是系统调用。
要 点
malloc()不是系统调用。
2.6.3 malloc()中发生了什么
malloc()大体的实现是,从操作系统一次性地取得比较大的内存,然后将这些内存“零售”给应用程序。
根据操作系统的不同,从操作系统取得内存的手段也是不一样的,在 UNIX 的情况下使用 brk()的系统调用。
* break 的略称。
* 在最近的实现中,有时也会使用 mmap()(后面会提到)。使用 malloc() 分配小区域的时候,还是使用 brk()。
请大家回想一下,在图 2-3 中,“利用 malloc 分配的内存区域”的下面,是一片范围很大的空间。系统调用 brk()就是通过设定这个内存区域的末尾地址,来伸缩内存空间的函数的。
调用函数的时候,栈会向地址较小的一方伸长。多次调用 malloc()时,会调用一次 brk(),内存区域会向地址较大的一方伸长。
图 2-12 内存区域的伸长
“啥?就算可以通过这种方式分配内存区域,但是做不到以任意的顺序释放内存吧?”
也许会有很多人存在以上的想法。实际上,这是有道理的。
如果这么说,大家自然会想问:“那么 free()又是什么?”那么下面来说说 malloc()和 free()的基本原理。
现实中的 malloc()的实现,在改善运行效率上下了很多工夫。这里我们只考虑最单纯的实现方式——通过链表实现。
顺便提一下,K&R 中也记载了通过链表实现 malloc()的例程。
最朴素的实现就是如图 2-13,在各个块之前加上一个管理区域,通过管理区域构建一个链表。
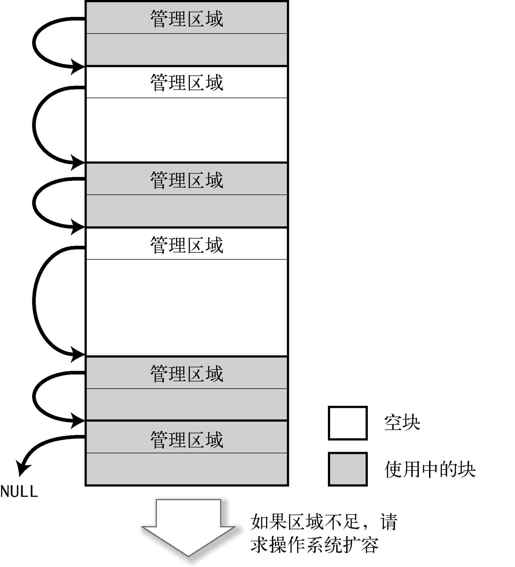
图 2-13 通过链表实现 malloc()的例子
malloc()遍历链表寻找空的块,如果发现尺寸大小能够满足使用的块,就分割出来将其变成使用中的块,并且向应用程序返回紧邻管理区域的后面区域的地址。free()将管理区域的标记改写成“空块”,顺便也将上下空的块合并成一个块。这样可以防止块的碎片化*。
* 这个操作被称为合并(coalescing)。也有不实现这个操作的,但这样会加剧碎片化(参照 2.6.5 节)。
如果不存在足够大的空块,就请求操作系统对空间进行扩容(UNIX 下使用 brk()系统调用)。
那么,在这种内存管理方式的运行环境中,一旦数组越界检查发生错误,越过 malloc()分配的内存区域写入了数据,又会发生什么呢?
此刻将会破坏下一个块的管理区域,所以从此以后的 malloc()和 free()调用中出现程序崩溃的几率会非常高。这种情况下,不能因为程序是从 malloc()中崩溃的就一口咬定“这是库的 bug!!!”这么做只会自取其辱。
现实中的处理环境,是不会这样单纯地实现 malloc()功能的。
比如,作为内存管理方法,除了这里说明的链表方式之外,还有一个被大家广泛熟知的“buddy block system”方法。这种将大的内存逐步对半分开的方式,虽然速度很快,但会造成内存的使用效率低下。
此外,让管理区域和传递给应用程序的区域相邻也是比较危险的,所以有的实现中会将它们分开存放。我的环境(FreeBSD3.2)就是这样的(现行的实现中也有很多是相邻存放的)。
不过,我在这里只是想说明“malloc()绝对不是一个魔法函数”。
随着 CPU 和操作系统的不断进化,也许有一天 malloc()会成为真正的魔法函数。但目前你肯定不能将 malloc()看成魔法函数。对于 malloc()的工作原理,如果不是非常了解,就很有可能陷入程序不能正常进行调试的窘境,或者常常写出非常低效的程序。
所以我建议大家先充分理解 malloc()后再去使用它,不然它只会给你带来危险。
要 点
malloc()绝对不是魔法函数。
2.6.4 free()之后,对应的内存区域会怎样
正如刚才所说,malloc()管理从操作系统一次性地被分配的内存,然后零售给应用程序,这是它大致的实现方式。
因此,一般来说调用 free()之后,对应的内存区域是不会立刻返还给操作系统的。让我们通过代码清单 2-7 来做个实验。
代码清单 2-7 free.c
1: #include <stdio.h>2: #include <stdlib.h>3:4: int main(void)5: {6: int *int_p;7:8: int_p = malloc(sizeof(int)); ←在利用malloc()分配的内存区域中……9:10: *int_p = 12345; ←写入11:12: free(int_p); ←调用free()之后13:14: printf("*int_p..%d\n", *int_p); ←输出对应的内容!15:16: return 0;17: }
在我的环境中执行这个程序,会输出 12345。之后随着某次 malloc()调用,恰好将这片区域重新进行分配后,才会发生这部分内容的改写。
但是,C 标准不能保证情况总是这样。因此,调用 free()之后,是不能引用对应的内存区域的。
这里之所以特地举出这个例子,是因为“调用 free()之后,对应的内存内容不会被马上破坏”。这样的特性给程序调试中的原因查明带来了困难。
如图 2-14,某内存区域被两个指针同时引用。使用指针 A 引用这个区域的程序员认为当前区域对他来说已经不需要了,于是稀里糊涂地调用了 free()。实际上,在远离当前这段代码的地方,指针 B 还在引用当前这片区域。此时,会发生什么呢*?
* 大型的程序常常会出现这种问题。
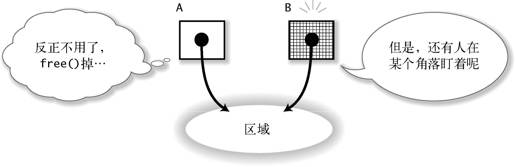
图 2-14 一个内存区域被两个指针引用……
仓促地调用 free()是有问题的,就算调用了 free(),指针 B 引用的内存区域也不会立刻被破坏,暂时还保持着以前的值。直到在某个地方执行 malloc(),随着当前内存区域被重新分配,内容才开始被破坏。这样的 bug,从原因产生到 bug 被发现之间周期比较长,因此给程序调试带来很大困难。
为了避免这个问题,如果是大型程序,可以做一个函数给 free()披一张皮,并且使程序员们只能调用这个函数,在区域被释放之前故意将区域破坏(可以胡乱地填充一个像 0xCC 这样的值)。可惜的是,我们无法知道当前指针指向的区域的大小*。如果偏要这么做,可以考虑也给 malloc()批上一张皮,每次分配内存的时候可以多留出一点空间,然后在最前面的部分设定区域的大小信息。
* 如果使用 malloc()分配内存,标准库肯定是知道此内存的大小的。遗憾的是,ANSI C 没有提供公开内存大小的函数。
当然,这种手法只能用于程序的调试版本。在去掉调试选项对程序进行编译的时候,这些代码就会消失。这样就不会影响发行版的程序的运行效率。
这么做虽然有点麻烦,但是对于大规模的程序来说,这种手法还是非常有效的。
2.6.5 碎片化
某些处理环境对 malloc()的实现,和 2.6.3 节中描述的没有大的差别,但是以随机的顺序分配、释放内存。此时,又会发生什么问题呢?
此时,内存被零零碎碎分割,会出现很多细碎的空块。并且,这些区域事实上是无法被利用的。 这种现象,我们称为碎片化(fragmentation)(参照图 2-15)。
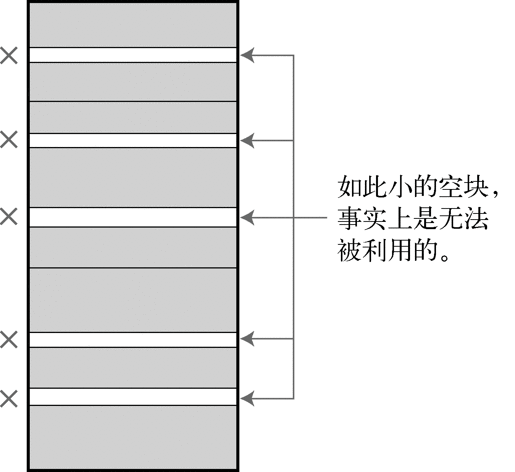
图 2-15 碎片化
将块向前方移动,缩小块之间的距离,倒是可以整合零碎的区域并将它们组合成较大的块*。可是 C 语言将虚拟地址直接交给了应用程序,库的一方是不能随意移动内存区域的。
* 这样的操作称为压缩(compaction)。
在 C 中,只要使用 malloc()的内存管理过程,就无法根本回避碎片化问题。但若利用 realloc()函数(在下一节说明),倒可以让问题得到一些改善。
2.6.6 malloc()以外的动态内存分配函数
本书介绍 malloc()以外的动态内存分配函数,首先介绍 calloc()函数。
#include <stdlib.h>void *calloc(size_t nmemb, size_t size)
calloc()使用和 malloc()相同的方式分配 nmemb × size 大小的内存区域,并且将该区域清零返回。也就是说,calloc()和下面的代码具有同等效果。
p = malloc(nmemb * size);memset(p, 0, nmemb * size);
老实说,我对 C 语言提供这个函数的意图完全无法理解。通过两个参数传递区域的尺寸,实际上只是在内部做乘法运算,这点就让人费解。将区域清零返回这一点也让人感觉别扭。因为就算通过 memset()清零,在浮点数和指针的情况下它们的值也不一定为 0(也许是空指针)*。
* 可是,在现行的大部分处理环境中,浮点数的值被初始化为浮点数 0,指针被初始化为空指针。这无疑是多此一举地将问题复杂化。
calloc()对于避免难以再现的 bug 是有效的。我一般是给 malloc()披一张皮,但不是清零,而是填充一个无意义的值 0xCC。对于在那些没有好好做初始化的程序中发现 bug,我的方式肯定更好一些。
此外,在 K&R 的第一版中有一个 cfree()函数*,看上去好像可以利用这个函数释放由 calloc()分配的内存。其实这个函数和 free()做的事完全一样。现在,为了维持向后的兼容性,在大部分的环境中仍然可以使用 cfree()。但是 ANSI C 的标准中是不存在这个函数的。就算你使用了 calloc(),在释放内存的时候也请使用 free()。
* 随便提一下,实际上在 K&R 的第 1 版中,只记载了 calloc() 和 cfree()的配对函数,并没有记载 malloc()。
要 点
不要使用
cfree()。
还有一个内存分配函数是 realloc()。
此函数用于改变已经通过 malloc()分配的内存的尺寸。
#include <stdlib.h>void *realloc(void *ptr, size_t size);
realloc()将 ptr 指定的区域的尺寸修改成 size,并且返回指向新的内存区域的指针。
话虽这么说,但正如前面说明的那样,malloc()不是一个魔法函数,realloc()同样如此。通常,我们使用 realloc()来扩展内存区域。如果通过 ptr 传递的区域后面有足够大小的空闲空间,就直接实施内存区域扩展。但是,如果后面的区域没有足够多的空闲空间,就分配其他新的空间,然后将内容复制过去。
我们经常需要对数组顺次追加元素,这种情况下,如果每追加一个元素都利用 realloc()进行内存区域扩展,将会发生什么呢?
如果手气不错,后面正好有足够大的空地儿,这样还好。如果不是这样,就需要频繁地复制区域中的内容,这样自然会影响运行效率。另外,不断地对内存进行分配、释放的操作,也会引起内存碎片化。此时不妨考虑一下这种手法:假设以 100 个元素为单位,一旦发现空间不足,就一次性进行内存扩展分配*。
* Java的java.util.Vector 类就是采用了这个手法。但是本质上,Java 并不背离堆的机制。
此外,一旦利用 realloc()扩展巨大的内存区域,除了在复制上花费很多时间之外,也会造成堆中大量的空间过分地活跃。如果想要动态地为大量的元素分配内存空间,最好不要使用连续的内存区域,而是应该积极使用链表。
要 点
请谨慎使用 realloc()。
另外,如果通过 ptr 向 realloc()传入 NULL,realloc()的行为就和 malloc()完全相同。偶尔会见到像下面这样的代码,
if (p == NULL) {p = malloc(size);} else {p = realloc(p, size);}
完全可以简洁地写成下面这样,
p = realloc(p, size);
(姑且先把返回 NULL 的问题放在一边*)。
* 对于这种写法,realloc()返回 NULL 的时候,p 会永远被丢失,这是一个问题。
随便说一下,如果通过 size 向 realloc()传入 0,realloc()的行为就和 free()完全相同。
补充 malloc()的返回值检查
内存分配一旦失败,
malloc()会返回NULL。大部分 C 的书籍都歇斯底里地提醒大家“如果你调用了
malloc(),就必须做返回值检查”,关于这一点,本书倒是要对此唱唱反调。不是吗?那么做太麻烦了。完美地对应内存不足的问题,
- p = malloc(size);
- if (p == NULL) {
- return OUT_OF_MEMORY_ERROR;
- }
并不是像上面这样机械地写一段代码那么单纯的。
当然我们在构造某些数据结构的时候,既需要确保数据结构自身没有任何矛盾,还要确保函数能够返回,随之而来的测试也会变得更加复杂。假设能够做到这些,却又因为分配已达上限字节数的内存区域而失败,此时我们又该怎么办呢?
通过对话框通知用户“内存不足”?此时,也许程序自身已经没有能力弹出对话框了……
为了不丢失写到一半的文档数据,姑且将文件保持打开状态……能做到吗?
安全起见,通过递归的方式遍历深层次的树结构……可以分配栈的空间吗?
还是先保护硬盘数据吧……对于 Windows 这样存放了交换文件的文件系统,如果此时恰恰只有一个分区,硬盘数据又会出现什么状况呢?
其实并不是只有显式的
malloc()调用才会导致内存不足,深度的递归调用也会引起栈内存不足。此外,根据不同情况,printf()内部有时也会调用malloc()。不光是malloc()调用,操作系统往内存中写入数据的时候也会进行内存区域分配,对于这种情况,调用malloc()时是无法发现内存不足的。开发通用性极高的库程序的时候,“切实地进行返回值检查”的确是必须的。但是如果是开发普通的应用程序,只需要给
malloc()披上一张皮,一旦发生内存不足,当场输出错误信息并且终止该程序,这种做法在很多时候也是可行的。主张“一旦调用
malloc(),绝对要对返回值进行检查,并且进行完善的处理。”的人,一般在使用 Java 时,一定会在合适的层次上使用
catch,当然他们也不会去使用 Perl 等等的 Shell 脚本……
补充 程序结束时必须调用 free()吗?
网上的新闻组 fj.comp.lang.c 曾经针对下面的主题发生过一次激烈的口水战。
程序结束之前,一定需要释放
malloc()分配的内存吗?这是一个让人头疼的问题。在现实中,如果是普通 PC 上使用的操作系统,在进程结束时,肯定会释放曾经分配给当前进程的内存空间。
其实 C 语言标准却并没有规定必须要这么做,只是正经的操作系统都主动提供这个功能。此外,在写推荐内存为 128MB 的程序时,你不会去考虑以后还要将它移植到电视机遥控器的嵌入式芯片上吧。也就是说,在程序结束之前,没有必要调用
free()。可是,对于进行“读取一个文件→处理→输出结果→结束”这样的处理,如果要扩展成可以连续处理多个文件,一旦原来的程序没有调用
free(),后面的人那可真的遭罪了。为了提前发现内存溢出(忘了调用
free())的漏洞,最近出现了一些工具,它可以报告那些没有在结束时被实施free()的内存区域的列表。此时,“故意不调用free()的区域”和“忘记调用free()区域”被混同在一起出现在报告中,让人难以区分。对于不能使用这些工具的开发环境,可以采用“将malloc()和free()披上一张皮,然后计算它们被调用的次数,并且确认程序结束时次数是否一致”这样简单可行的方法,并且这种方法对于检查内存泄漏非常有效。从这一点上来看,我认为“对于调用
malloc()分配的内存区域,在程序结束前一定要调用free()”这样的原则也是相当合理的。那么到底应该怎么做?答案是“具体问题具体分析”(我倒!跟没说一样)。
我倒是不太喜欢“必定
free()派”的观点,其实之所以“必定free()”,是因为他们认为:
使用
malloc()之后写上对应的free()是一种谨慎的编程风格程序员就应该留意将
malloc()和free()对应起来“调用了
exit(),就没有必要调用free()了”这种想法是不负责任并且恶劣的编程风格不管怎么说程序员也是人(瞧这话说的),对于人来说,恐怕会犯错的地方必定犯错。明明如此,你还去标榜什么“写程序要谨慎”,我觉得有点自讨没趣。
“谨慎地”编程有那么了不起吗?我认为那些能尽力让自己摆脱“麻烦事”的程序员才是优秀的。该脱手时就脱手,尽可能依赖工具去完成检查工作而不是总去目测。就算在那些无论如何也要依靠手动去应对的情况下,也暗自发誓“总有一天我把它做成自动化”。此类程序员才是人才!
