5.1 案例学习 1:计算单词的出现频率
5.1.1 案例的需求
直到第 4 章,本书主要对“声明的解读方法”和“数组和指针的微妙关系”进行了说明。
这些内容都属于 C 语言特有的话题,正因为如此,人们才普遍认为“C 的指针比较难”。
但是,指针同时也是构造链表或者树这样的“数据结构”必需的概念。因此,在比较成熟的、正统的编程语言中,必定存在指针*。本章给大家介绍在构造一般数据结构的过程中指针的使用方法。
* 对于链表这种程度的数据结构,如果有了集合类库,操作数据时就可以不用顾及指针的存在了。
下面是一个经常被使用的案例,非常对不起,这的确是一个没有新意、老掉牙的案例。
设计开发一个将文本文件作为输入,计算出其中各单词出现频率的程序。
这个程序的名称是 word_count*。
* 这里容易和 UNIX 的 wc 命令产生混淆,可以先不管它。
使用下面的命令行,
word_count 文件名
将英文文本文件的文件名作为参数传递给 word_count,程序执行的结果是:将英文单词按照字母顺序排序后输出,并且在各单词的后面显示当前单词的出现次数。
如果省略参数,就将标准输入的内容作为输入进行处理。
补充 各种语言中对指针的叫法
正如我反复强调的那样,如果没有指针,就无法构造正统的数据结构,因此,比较成熟的、正统的编程语言,必定会存在指针。
以前,FORTRAN、COBOL 和 BASIC 中都没有指针,但是在 fortran90、Visual Basic 等升级版中,正式引入了指针功能。
咦?我怎么听说 Java 就没有指针呢……
我可以负责任地告诉你,这是个谣言。
第 4 章的补充内容中也曾经提到,Java 只能通过指针来操作数组和对象,因此,Java 比 C 更离不开指针。
在早期的 Java 白皮书中,就有“Java 中没有指针”这样的说法。Java 中被称为“引用”的概念,在 C 和 Pascal 的程序员看来,怎么看都相当于指针。我认为在“Java 中没有指针”这个观点的背后,弥漫着下面这样“狡猾的”市场营销的气味,
请参照 http://java.sun.com/docs/overviews/java/java-overview-1.html。
因为对于 C 语言,大家都认为“指针比较难”,如果强调“没有指针”,编程新手也许更容易接受。
但是 Java 的引用又和 C 的指针有着很大的不同。Java 没有指针运算,因此不存在指针运算和数组之间的那种微妙关系,此外你也不能取得指向变量的指针。如果你认为这些差别能成为“Java 中没有指针”的理由,那么 Pascal 是不是也没有指针呢?
除 Java 之外,Lisp、Smalltalk 和 Perl(Ver.5 以后)中相当于指针的对象也被称为“引用”,但是也有人会使用“指针”这样的叫法。也就是说,这些语言并没有严格地将“引用”和“指针”分开。因为它们的本质相同,所以 Java 故意强调“没有指针”,反而让人觉得奇怪。
诞生在日本的面向对象的脚本语言 Ruby,作者在自己的著作中就断言“Ruby 中没有指针这样的概念”,其实 Ruby 中也有叫做“引用”的指针。
Ruby 中连字符串这样的基本类型也不是不可变的,像这样的语言“没有指针”,是不是很危险?
Pascal、Modula2/3 和 C 一样,都称之为指针。
Ada 中的名称为“Access 类型”。这种叫法有点人让人摸不着头脑。
悲哀的是,C++在语法上将“指针”和“引用”区别成两个不同的概念。
C++的“指针”和 C、Pascal 的“指针”,以及 Java 的“引用”同义。其次,C++中的“引用”是指本来应该被称为“别名”(
alias)的对象,正因为是别名,所以一旦确定“别名是什么”,就再也不能修改了。实际上,C++的术语“引用”也是通过指针实现的,所以它其实是一个重复的功能。很多熟练的 C++程序员往往不使用“引用”,而总是使用指针。但是,在某些运算符重载,以及复制构造函数的场景下,可能会不得不使用“引用”。对于 C++,有人说它太深奥,有人说使用它开发项目成本太高,甚至有人质疑“是否存在理解 C++全貌的人”……总之,C++也是一门让人纠结的开发语言。
5.1.2 设计
在开发大型应用程序的时候,非常有必要将程序按照单元功能(模块)分开。尽管这次的程序很小,但为了达到练习的目的,我们准备将这次的程序模块化。
将 word_count 程序分割成如图 5-1 的样子。
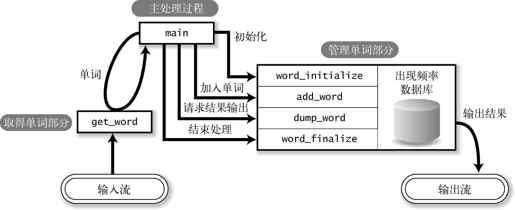
图 5-1 word_count 的模块结构
- 取得单词部分
从输入流(文件等)一个个地取得单词。
- 管理单词部分
管理单词。最终的结果输出功能也包含在这部分。
- 主处理过程
统一管理以上两个模块。
对于“取得单词部分”,我们完全可以直接使用 1.3.6 节中的实现*。
* 好像本书的章节安排都是有预谋的哦,哈哈!
get_word()中,对调用方输入的单词字符数做了限制,并且存在一些无论如何都不允许的情况*。对于这一点,其实不必过于纠结,解决方案是提供一个足够大的缓冲——1024 个字符的临时缓冲区。
* 此时,可以考虑使用 4.2.4 节中介绍的方法。
对于如何定义“英语单词”,如果严密地去考虑,那就没完没了了,不妨结合现成的 get_word()中的实现——将使用 C 的宏(ctype.h)isalnum()返回真的连续的字符视作单词。
作为公开给其他部分的接口,“取得单词部分”提供了 get_word.h(参照代码清单 5-1),在需要的时候,可以通过#include 引用这个头文件。
代码清单 5-1 get_word.h
1: #ifndef GET_WORD_H_INCLUDED2: #define GET_WORD_H_INCLUDED3: #include <stdio.h>4:5: int get_word(char *buf, int size, FILE *stream);6:7: #endif /* GET_WORD_H_INCLUDED */
这次的主题是“管理单词部分”。
“管理单词部分”提供了 4 个函数作为对外接口。
- 初始化
void word_initialize(void);
初始化“管理单词部分”。使用“管理单词部分”的一方,必须在一开始就要调用
word_initialize()。
- 单词的追加
void add_word(char *word);
向“管理单词部分”加入单词。
add_word()为传入的字符串动态地分配内存区域,并且将字符串保存在其中。
- 输出单词的出现频率
void dump_word(FILE *fp);
将利用
add_word()加入的单词按照字母顺序进行排序,并且向各单词追加它们各自出现的次数(调用add_word()的次数),最后输出fp指向的流。
- 结束处理
void word_finalize(void);
结束“单词管理部分”。一旦结束使用“单词管理部分”,需要调用
word_finalize()。调用
word_finalize()之后,再调用word_initialize(),管理单词部分就回到最初的状态(清空了过去加入的单词)。
将这些整理到头文件中,如代码清单 5-2 所示。
代码清单 5-2 word_manage.h
1: #ifndef WORD_MANAGE_H_INCLUDED2: #define WORD_MANAGE_H_INCLUDED3: #include <stdio.h>4:5: void word_initialize(void);6: void add_word(char *word);7: void dump_word(FILE *fp);8: void word_finalize(void);9:10: #endif /* WORD_MANAGE_H_INCLUDED */
在“主处理过程”中,使用 get_word()努力地从输入流读取单词,然后通过调用 add_word(),将每次读取到的单词,不断地加入到“单词管理部分”,最后再调用 dump_word()将最终结果输出(参照代码清单 5-3)。
代码清单 5-3 main.c
- 1: #include <stdio.h>
- 2: #include <stdlib.h>
- 3: #include "get_word.h"
- 4: #include "word_manage.h"
- 5:
- 6: #define WORD_LEN_MAX (1024)
- 7:
- 8: int main(int argc, char **argv)
- 9: {
- 10: char buf[WORD_LEN_MAX];
- 11: FILE *fp;
- 12:
- 13: if (argc == 1) {
- 14: fp = stdin;
- 15: } else {
- 16: fp = fopen(argv[1], "r");
- 17: if (fp == NULL) {
- 18: fprintf(stderr, "%s:%s can not open.\n",argv[0], argv[1]);
- 19: exit(1);
- 20: }
- 21: }
- 22:
- 23: /* 初始化“管理单词部分” */
- 24: word_initialize();
- 25:
- 26: /* 边读取文件,边加入单词 */
- 27: while (get_word(buf, WORD_LEN_MAX, fp) != EOF) {
- 28: add_word(buf);
- 29: }
- 30: /* 输出单词的出现频率 */
- 31: dump_word(stdout);
- 32:
- 33: /* “管理单词部分”的结束处理 */
- 34: word_finalize();
- 35:
- 36: return 0;
- 37: }
代码清单 5-3 中,特意将 WORD_LEN_MAX 的值设定得大一些,但是无论如何,这只是提供给临时缓冲的空间的大小。在 add_word()内部,只是分配需要的内存区域,并且将字符串复制进去,所以不会浪费太多的内存区域。
此外,考虑到例程的简洁,本章的程序省略了对所有的 malloc()返回值检查。
补充 头文件的写法
写头文件的时候,必须遵守下面两个原则,
所有的头文件中,必须要有防止
#include重复的保护。所有的头文件只
#include自己直接依赖的头文件。“防止重复
#include的保护”是指,假设对于 word_manage.h(参照代码清单 5-2)来说,
- #ifndef WORD_MANAGE_H_INCLUDED
- #define WORD_MANAGE_H_INCLUDED
- ┊
- #endif / WORD_MANAGE_H_INCLUDED /
如果像上面这么做,即使当前头文件被重复
#include,其中的内容也会被无视,因此,就不会出现重复定义的错误。下面来谈谈第 2 个规则。假设对于头文件 a.h,它依赖于头文件 b.h(使用了 b.h 定义的类型或者宏等),因此在 a.h 的开头
#include了 b.h。比如,word_manage.h 使用了结构体 FILE,所以 word_manage.h 中#include了 stdio.h。很多人讨厌将
#include嵌套来写,但在 a.h 依赖 b.h 的时候,如果不采用嵌套,就需要在所有使用 a.h 的地方都写成下面这样,作为 C 的编程风格的指导书,著名的《Indian Hill 编程风格手册》(参照 http://dennou-t.ms.u-tokyo.ac.jp/arch/com-ptech/cstyle/cstyle-ja.htm)中,也表达了“不要用
#include嵌套”这样的观点。可是,在附属于 C 处理环境的头文件中,以及广泛使用的开源软件中,随处可以看到嵌套的头文件。(第 8 次印刷注:上面的网页好像已经不存在了,但在 http://www.archive.org 中输入上面的 URL,应该可以看到以前的影子)
- #include "b.h"
- #include "a.h"
这样做是不是有点笨拙?不光每次写得很辛苦,而且将来某个时刻 a.h 不再依赖 b.h 后,上面的两行可能就永远地留在代码中了。另外,对于这种
#include方式,开发现场的“可爱的”程序员们不可避免地会有下面的举动,唉~究竟是谁依赖谁,真是完全搞不明白哦!嗯~,先把已经编译通过的.c 文件中开头的#include 部分完全复制过来吧,嘿嘿……
这样恶搞,肯定会在很多代码文件中留下大量无效的头文件引用。
啊?你问 Makefile 的依赖关系是怎么做的?这必然是通过工具自动生成的——这可是常识哦。
对于头文件,还有一个要点需要跟大家提前说明,那就是“应该把公有的和私有的分开”这个原则,具体的内容会在后面给大家介绍。
要 点
写头文件时必须遵守的原则:
所有的头文件中,必须要有防止重复#include 的保护。
所有的头文件只#include 自己直接依赖的头文件。
5.1.3 数组版
对于 word_count 的“管理单词部分”的数据结构,先让我们考虑使用数组来实现一下。
在使用数组管理单词的时候,可以考虑采取下面的方式:
将单词和其出现的次数整理到结构体中。
将这些结构体组织成数组,并且管理各单词的出现频率。
为了将单词的追加和结果输出变得更加简单,使用将数组的元素按照单词的字母顺序排序的方式进行管理。
据此写的头文件 word_manage_p.h 内容如下(参照代码清单 5-4):
代码清单 5-4 word_manage_p.h(数组版)
1: #ifndef WORD_MANAGE_P_H_INCLUDED2: #define WORD_MANAGE_P_H_INCLUDED3: #include "word_manage.h"4:5: typedef struct {6: char *name;7: int count;8: } Word;9:10: #define WORD_NUM_MAX (10000)11:12: extern Word word_array[];13: extern int num_of_word;14:15: #endif /* WORD_MANAGE_P_H_INCLUDED */
每当加入一个新的单词时,可以考虑对数组进行下面这样的操作:
从数组的初始元素开始遍历。如果发现同样的单词,将此单词的出现次数加 1。
如果没有发现相同的单词,就在行进到比当前单词“大的单词”(根据字母顺序,位置在后面的单词)的时刻,将当前单词插入到“大的单词”前面。
向数组中插入单词的方法如下(参照图 5-2):
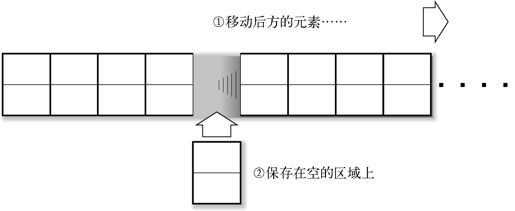
图 5-2 向数组插入元素
将插入点后方的元素顺次向后移动。
将新的元素保存在空出来的位置上。
此时出现的问题是:每次向数组插入元素的时候,必须要移动后方的元素。
一般地,在初始化数组时必须要确定元素个数。当然,你可以使用 4.1.3 节中说明的方法,动态地为数组分配内存空间,此后使用 realloc()“嗖嗖地”将数组伸长……其实,前面曾经给大家建议过,应该避免频繁地使用 realloc()扩展内存区域(参照 2.6.5 节)。
如果采用下节中介绍的“链表”,就可以规避以上的问题*。
* 其实数组也不是一无是处。排序后数组的检索速度非常快,这就是数组的一个优点,关于这一点可以参照 5.1.5 节。
数组版的管理单词的源代码为代码清单 5-5、代码清单 5-6、代码清单 5-7 和代码清单 5-8*。
* 本例中没有对数组越界情况做检查。
代码清单 5-5 initialize.c(数组版)
1: #include "word_manage_p.h"2:3: Word word_array[WORD_NUM_MAX];4: int num_of_word;5:6: /************************************************************7: * 初始化管理单词部分8: ************************************************************/9: void word_initialize(void)10: {11: num_of_word = 0;12: }
代码清单 5-6 add_word.c(数组版)
1: #include <stdio.h>2: #include <stdlib.h>3: #include <string.h>4: #include "word_manage_p.h"5:6: /*7: * 将 index 后面的元素(包括index)依次向后方移动8: */9: static void shift_array(int index)10: {11: int src; /* 被复制元素的索引 */12:13: for (src = num_of_word - 1; src >= index; src--) {14: word_array[src+1] = word_array[src];15: }16: num_of_word++;17: }18:19: /*20: * 复制字符串。21: * 尽管大多数处理环境都有strdup()这样的函数,22: * 但是ANSI C 规范中却没有定义这个函数,姑且先自己写一个。23: */24: static char *my_strdup(char *src)25: {26: char *dest;27:28: dest = malloc(sizeof(char) * (strlen(src) + 1));29: strcpy(dest, src);30:31: return dest;32: }33:34: /*********************************************************35: * 追加单词36: *********************************************************/37: void add_word(char *word)38: {39: int i;40: int result;41:42: for (i = 0; i < num_of_word; i++) {43: result = strcmp(word_array[i].name, word);44: if (result >= 0)45: break;46: }47: if (num_of_word != 0 && result == 0) {48: /* 发现相同的单词 */49: word_array[i].count++;50: } else {51: shift_array(i);52: word_array[i].name = my_strdup(word);53: word_array[i].count = 1;54: }55: }
代码清单 5-7 dump_word.c(数组版)
1: #include <stdio.h>2: #include "word_manage_p.h"3:4: void dump_word(FILE *fp)5: {6: int i;7:8: for (i = 0; i < num_of_word; i++) {9: fprintf(fp, "%-20s%5d\n",10: word_array[i].name, word_array[i].count);11: }12: }
代码清单 5-8 finalize.c(数组版)
1: #include <stdlib.h>2: #include "word_manage_p.h"3:4: /*********************************************************5: * 管理单词部分的结束处理6: *********************************************************/7: void word_finalize(void)8: {9: int i;10:11: /* 释放单词部分的内存区域 */12: for (i = 0; i < num_of_word; i++) {13: free(word_array[i].name);14: }15:16: num_of_word = 0;17: }
5.1.4 链表版
在前面一节中,我们指出了数组版中存在下面的问题:
- 中途向数组插入元素,后面的元素就必须依次向后方移动,导致效率低下*。
- 当然,在删除元素时,如果需要填充空出来的位置,也有必要去移动后面的元素。此时,可以使用“删除标记”这种手法,但这不能算是正当的做法,如果能不用还是不要用吧。
- 数组初始化时就需要决定元素个数。尽管可以使用
realloc()不断地进行空间扩展,但在数组占用了较大的内存区域的情况下,还是要尽量避免使用这种手法。
使用被称为链表的数据结构,可以避免这些问题。
链表是指将节点(node)对象通过指针连接成锁链状的数据结构(参照图 5-3)。

图 5-3 链表
为了通过链表来管理单词,在结构体 Word 中追加指向下一个元素的指针 next。
typedef struct Word_tag {char *name;int count;struct Word_tag *next;} Word;
这里的 next 就是指向下一个元素的指针。
代码清单 5-9 就是链表版的 word_manage_p.h。
代码清单 5-9 word_manage_p.h(链表版)
1: #ifndef WORD_MANAGE_P_H_INCLUDED2: #define WORD_MANAGE_P_H_INCLUDED3:4: #include "word_manage.h"5:6: typedef struct Word_tag {7: char *name;8: int count;9: struct Word_tag *next;10: } Word;11:12: extern Word *word_header;13:14: #endif /* WORD_MANAGE_P_H_INCLUDED */
链表通过将内存单元链接起来,持续地给 Word 分配内存区域。和对数组通过 realloc()进行内存扩展不同,链表方式不需要连续的内存区域,所以不会出现效率非常低下的情况。
此外,链表元素的插入、删除都是非常方便的。对于数组,插入元素时需要将插入点后的元素顺次向后移动,对于链表,只需简单地调整一下指针的指向就完成操作了。链表中的元素不需要在内存中连续排列。
以下是对链表的一些基本操作,
- 检索
通过对指针进行追踪,从链表中检索出目标元素*。
pos是 position 的简称。
/* header 是链表初始元素的地址 */for (pos = header; pos != NULL; pos = pos->next) {if (找到目标元素)break;}if (pos == NULL) {/* 没有找到目标元素后的处理 */} else {/* 找到目标元素后的处理 */}
- 插入
在已经获得指向某个元素的指针 pos 的情况下,在当前元素的后面插入新的元素 new_item,下面是具体操作(参照图 5-4),
new_item->next = pos->next;pos->next = new_item;
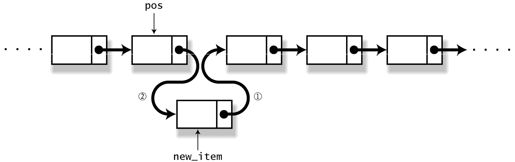
图 5-4 向链表追加元素
如果 pos 指向链表的最后一个元素,此时根据实际情况,只需要在链表的末尾追加新的元素就可以了。
这一次我们使用的是“单向链表”,因为从单向链表中的某个元素不能追溯到它前面的元素*,所以目前还不能将一个新的元素插入到已知元素的前面。
- 实际上,“将元素先追加在
pos的后面,然后交换元素内部的数据内容”这样的技巧,也可以在视觉上达到将元素追加在pos前面的效果。在 C 语言开发中,在数据元素自身中放入指针信息构造一个链表,是很普遍的做法,如果只是移动“元素内容”,那么在确定当前元素内容被哪 个指针所指向时,就比较麻烦,所以还是不要用这种方法。
- 删除
在已经获取指向某个元素的指针 pos 的情况下,如果需要删除这个元素的下一个元素,可以进行下面的操作(参照图 5-5),
temp = pos->next;pos->next = pos->next->next;free(temp);
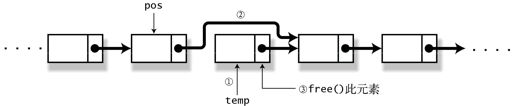
图 5-5 从链表删除元素
对于单向链表,即使是获取了某个元素的指针,也无法删除这个元素本身*。这还是因为不能追溯到它前面的元素的缘故。
- 这里也可以用“将
pos后面的元素内部的数据内容复制到pos,然后删除掉pos后面的元素”这样的技巧。但如果要删除最后一个元素,这种方法就无能为力了。
链表版的管理单词部分的源代码为代码清单 5-10、代码清单 5-11、代码 清单 5-12 和代码清单 5-13。
代码清单 5-10 initialize.c(链表版)
1: #include "word_manage_p.h"2:3: Word *word_header = NULL;4:5: /*********************************************************6: * 初始化单词管理部分7: *********************************************************/8: void word_initialize(void)9: {10: word_header = NULL;11: }
代码清单 5-11 add_word.c(链表版)
1: #include <stdio.h>2: #include <stdlib.h>3: #include <string.h>4: #include "word_manage_p.h"5:6: /*7: * 复制字符串8: * 尽管大多数处理环境都有strdup()这样的函数,9: * 但是ANSI C 规范中却没有定义这个函数,姑且先自己写一个。10: */11: static char *my_strdup(char *src)12: {13: char *dest;14:15: dest = malloc(sizeof(char) * (strlen(src) + 1));16: strcpy(dest, src);17:18: return dest;19: }20:21: /*22: * 生成新的Word 结构体23: */24: static Word *create_word(char *name)25: {26: Word *new_word;27:28: new_word = malloc(sizeof(Word));29:30: new_word->name = my_strdup(name);31: new_word->count = 1;32: new_word->next = NULL;33:34: return new_word;35: }36:37: /*********************************************************38: * 追加单词39: *********************************************************/40: void add_word(char *word)41: {42: Word *pos;43: Word *prev; /* 指向pos 前一个 Word 元素的指针 */44: Word *new_word;45: int result;46:47: prev = NULL;48: for (pos = word_header; pos != NULL; pos = pos->next) {49: result = strcmp(pos->name, word);50: if (result >= 0)51: break;52:53: prev = pos;54: }55: if (word_header != NULL && result == 0) {56: /* 发现相同的单词 */57: pos->count++;58: } else {59: new_word = create_word(word);60: if (prev == NULL) {61: /* 插入到初始位置 */62: new_word->next = word_header;63: word_header = new_word;64: } else {65: new_word->next = pos;66: prev->next = new_word;67: }68: }69: }
代码清单 5-12 dump_word.c(链表版)
1: #include <stdio.h>2: #include "word_manage_p.h"3:4: /*********************************************************5: * 将内存中的单词输出6: *********************************************************/7: void dump_word(FILE *fp)8: {9: Word *pos;10:11: for (pos = word_header; pos; pos = pos->next) {12: fprintf(fp, "%-20s%5d\n",13: pos->name, pos->count);14: }15: }
代码清单 5-13 finalize.c
1: #include <stdlib.h>2: #include "word_manage_p.h"3:4: /*********************************************************5: * 管理单词部分的结束处理6: *********************************************************/7: void word_finalize(void)8: {9: Word *temp;10:11: /* 将所有登录的单词free() */12: while (word_header != NULL) {13: temp = word_header;14: word_header = word_header->next;15:16: free(temp->name);17: free(temp);18: }19: }
这里的 add_word()和数组版一样,从头开始顺序地遍历链表。行进到比当前单词“大的单词”(按照字母顺序处在后面的单词)时,将当前单词插入到这个“大的单词”前面。但是对于单向链表,在发现了比当前单词“大的单词”的时候,无法在其前面插入当前单词。因此,在例程中,声明了一个称为 prev 的指针,它指向 pos 前面一个元素。
word_finalize()通过 free()释放链表中所有的元素。用一句话来表述就是:从链表的初始元素开始将元素一个个剥离,然后 free()掉。
此时,很多人也许会写出下面的代码,
Word *pos;/* 从链表的初始位置开始顺序地遍历,然后进行free()(意图上)*/for (pos = word_header; pos != NULL; pos = pos->next) {free(pos->name)free(pos);}
以上这段代码是错误的。将 pos 通过 free()释放掉之后,应该是不能引用 pos->next 了吧。但是这段程序在一般处理环境中还是能很好地执行。但在某些环境中也会给我们带来麻烦(参照 2.6.4 节)。
补充 头文件的公有和私有
本章在统计单词出现频率的应用中,对于“管理单词部分”,介绍了“数组版”和“链表版”两个版本的程序。
可是,“管理单词部分”向外部公开的头文件 word_manage.h 却没有发生任何改动。因此,即使将“管理单词部分”的实现方式从数组变成链表,对于使用它的一方(main.c)也没有必要做任何的修改,也不需要再重新编译(只需重新连接一次就可以了)。
“管理单词部分”向外部公开的的头文件 word_manage.h 和用于“管理单词部分”内部共享数据的头文件 word_manage_p.h,是完全分离的。因此,无论“管理单词部分”内部的实现怎样变化,都不会给“使用的一方”带来影响。
我一般将向外部公开的头文件称为“公共头文件”,将用于内部共享数据的头文件称为“私有头文件”。
私有头文件的内部大多都使用了公共头文件提供的类型、宏或者函数,所以私有头文件在大部分的情况下,都
#include了公共头文件。但是,无论是间接地还是直接地,公共头文件都不可能
#include私有头文件。这就好比对于一个公司来说,将向公司外部发布的宣传资料同时在公司内部公开,是没有问题的,但是公司内部的商业资料(内部机密)要是流传到公司外部,那就……!!如果遵守以上的规则,私有头文件中记述的内容就不会暴露给使用它的模块,因此,在大型程序的开发中,可以使用多团队来各自分担开发任务。
此外,在开发大型程序的工程,对于函数名、全局变量名,公共头文件中声明的类型名、宏名,会使用“命名规约”来防止名称冲突。但是这次的例程中,我们还没有做到这么规范。
对于 Java、Ada 或者 C++ 这样的自身有命名空间控制的语言,编程时是不需要依赖命名规约的。但是在现实中,
java.awt.List和java.util.List还是经常会发生冲突,让人感到困惑。现在,在 Swing 中,也在类名加上了“J”这样的前缀,这就说明命名规约还是必要的。
补充 怎样才能同时使用多份数据
在如今的应用程序中(MS-Word、MS-Excel 等),同时打开多个文件,并且分别在不同的窗口进行编辑,已经是很正常的事情了。
可是,在这次的“管理单词部分”,无论是数组版还是链表版,数据的“源头”都保存在全局变量中。因为全局变量“在同一时刻只存在一份”,所以无法同时使用多份数据。
如果要解决这个问题,不妨将保存数据的“源头”的部分定义成结构体,对于链表版,可以定义成下面这样,
- typedef struct {
- Word word_header;
- } WordManager;
然后,在
word_initialize()中,使用malloc()给WordManager分配新的内存区域,并且返回指向这片内存区域的指针。
- WordManager word_initialize(void);
另外,对于“管理单词部分”的其他函数,都将指向
WordManager的指针作为第 1 个参数进行传递。
- void add_word(WordManager word_manager, char word);
- void dump_word(WordManager word_manager, FILE fp);
- void word_finalize(WordManager word_manager);
通过这样的方式,使用“管理单词部分”的一方能够管理多个
WordManager,当然也就可以同时使用多份数据。此外,对于在公共头文件中声明的
WordManager类型中,Word类型也是必须的,因此,此时对使用方屏蔽了“使用了链表”这个实现上的细节。其实对于使用方来说,只有指向
WordManager的指针才是必须的,并没有必要知道内部的细节。这种情况下,只声明一个“不完全类型”倒是一种常用手法。
- typedef struct WordManager_tag WordManager;
然后在私有头文件中,将实体填充到
struct WordManager_tag中,
- struct WordManager_tag {
- Word word_header;
- };
5.1.5 追加检索功能
目前的 word_count 仅仅是读取文本文件,然后输出统计数据。既然好不容易统计出文本文件中各单词的出现频率,如果程序还能提供“这个单词出现了几次”这样的功能是不是更好?
因此,在“管理单词部分”中追加下面的接口,
int get_word_count(char *word);返回通过word 指定的单词的出现次数。
最简单的方法就是,对保存在数组或者链表中的单词,从头开始顺序地遍历,这样肯定能检索到目标单词。这种方法称为线性检索(linear search)。但是对于数组中的数据已被排序的情况,可是考虑使用效率更高的二分检索(binary search)。
以下是二分检索的过程,
定位到数组中央的元素。
如果此元素是
要检索的目标元素,结束检索。
比要检索的目标元素小,就对数组中此元素后面的元素进行相同操作。
比要检索的目标元素大,就对数组中此元素前面的元素进行相同操作。
其实我们在查字典的时候,也经常使用这个方法。
代码清单 5-14 是“数组版”的 get_word_count()的实现例程。
代码清单 5-14 get_word_count.c
1: #include <stdio.h>2: #include <string.h>3: #include "word_manage_p.h"4: /*********************************************************5: * 返回某单词出现的次数6: *********************************************************/7: int get_word_count(char *word)8: {9: int left = 0;10: int right = num_of_word - 1;11: int mid;12: int result;13:14: while (left <= right) {15: mid = (left + right) / 2;16: result = strcmp(word_array[mid].name, word);17: if (result < 0) {18: left = mid + 1;19: } else if (result > 0) {20: right = mid - 1;21: } else {22: return word_array[mid].count;23: }24: }25: return 0;26: }
这种方法只对数组有效。对于链表,因为很难(迅速地)找到“中央的元素”,所以不能使用二分检索。
任何一种数据结构都不是万能的,各自都有自己的优缺点,我们必须根据实际需要选择合适的数据结构。比如在元素的个体相对比较大的情况下,就推荐使用指针的可变长数组(参照图 5-6)。
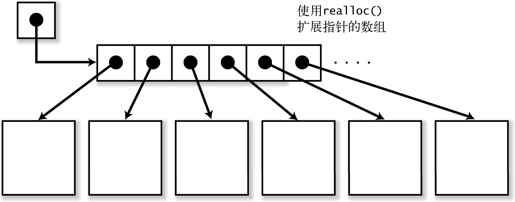
图 5-6 使用指向元素的指针的数组
如果是这种方式,即使每一个元素都比较大,指针的数组自身占用的内存区域也不会变得很大,因此也许可以使用 realloc()来不断地增加数组的内存空间*。这种情况下,可以使用二分法做检索操作。
* 确实,在元素个数很多的情况下,使用 realloc()来扩展数组的内存区域,有点……
题外话 倍倍游戏1
1 来自曾吕利新左卫门和丰臣秀吉之间的一段对话,曾吕利新左卫门对丰臣秀吉说:“作为奖赏,第 1 天给 1 粒米,次日给第 1 天的加倍的量,再次日给第 2 天加倍的量,如此这般。”——译者注
在数据量少的情况下,无论是使用线性检索还是二分检索,执行效率上并不会产生显著的差距。可是,随着数据量的增加,二分检索在执行效率上就会凸显出压倒性的优势。
对于上面的结论,也许有人会产生疑问:
真的吗?二分检索的逻辑复杂性肯定也会影响执行效率吧?是不是会和自身原本的优势相互抵消呢?结果就是,二分检索和线性检索的效率不会相差很大呢!
对于线性检索,随着数据量的增加,检索时间按比例延长。但是,使用二分检索的时候,数据每增加一倍,检索次数只会增加一次。因此,即使是数据量大到现实中无法想象的地步,也能够使用很短的时间将数据检索出来。
为了更感性地理解这一点,下面给大家打一个比方。
假设手头有一张报纸,它的厚度是 0.1mm,将它对折,厚度就变成了 0.2mm,再对折,就变成了 0.4mm 了吧。
那么,这样折了 100 次后,厚度变成了多少呢?
当然,也许我们折不了这么多次,此时切成两份再堆积起来,也能达到同样的目的。还是让我们单纯从数字上来回答:对折 100 次后的厚度是多少?
1 米左右?NO~NO~答案是,约 134 亿光年。如果你不信,你可以用手头的计算器算算(1 光年为 9 兆 4600 亿 KM)。
所以对于我来说,在机器猫的道具中,比起“地球毁灭炸弹”(参照瓢虫系列漫画第 7 卷),“加倍药水”(参照瓢虫系列漫画第 17 卷)更让我感到“坑爹”,哈哈。
也就是说,如果使用二分检索,对于“134 亿光年/0.1mm”条数据,仅仅 100 次循环就完成检索了。这么大的数据量,如果选择使用线性检索……嗯,恐怕在我有生之年是完成不了这个工作了。
5.1.6 其他的数据结构
这一节介绍一下其他的数据结构。
▲双向链表
之前为大家介绍过“单向链表”。
因为“单向链表”不能“回溯”,所以它有以下缺点,
在向链表中追加元素的时候,必须要知道追加点前面的元素。
从链表中删除元素的时候,必须要知道被删除元素前面的元素。
很难逆向遍历链表。
如果是双向链表(double linked list),就可以解决上面的问题。

图 5-7 双向链表
使用结构体定义链表,大概就像下面这样:
typedef struct Node_tag {/* Node 自身的数据 */struct Node_tag *prev; /* 指向前一个元素的指针 */struct Node_tag *next; /* 指向后一个元素的指针 */} Node;
可是,双向链表也有不足的地方,
因为每个元素都需要 2 个指针,所以会消耗多余的内存。
指针操作过于频繁,编程容易出现 bug。
▲树
UNIX 和 DOS 的“目录”,以及 Windows 和 Macintosh 的“文件夹”都是层次结构。这样的数据结构好似一棵倒置的树,所以我们称之为“树”(tree)结构。
树中的各元素称为节点(node)。最根部的节点称为根(root)。某节点 A 在节点 B 的直接下方的位置,A 就称为 B 的子(child)节点,B 就称为 A 的父(parent)节点。比如,在图 5-8 中,Node5 为 Node2 的子节点,Node2 为 Node5 的父节点。父节点和子节点之间的连接线称为枝(branch)。
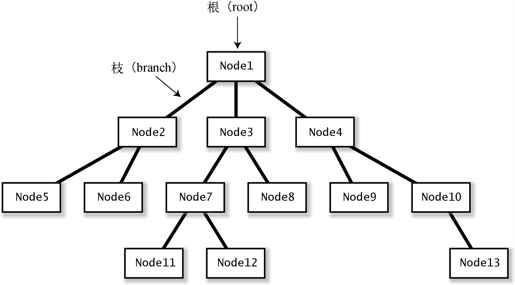
图 5-8 树
使用 C 语言表示树的时候,一般定义一个像下面这样的结构体(参照图 5-9),
typedef struct Node_tag {/* 节点自身的数据 */int nchildren; /* 子的个数 */struct Node_tag **child; /* 此指针指向的是通过malloc()分配的内存区域,其中包含指向子节点的指针的可变长数组*/} Node;
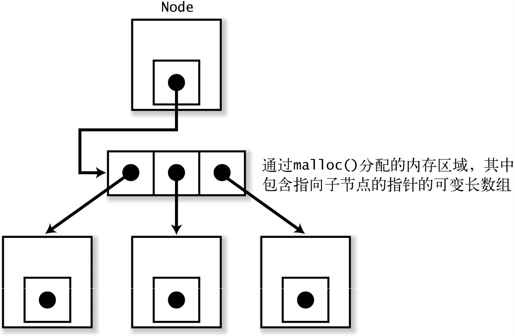
图 5-9 如果使用 C 来表示树……
如果树中的任意节点最多只有两个子节点,此时称这种树为二叉树(binary tree)*。
* 问题:最多只有一个子节点的树,怎么称呼?——是“链表”哦。
使用二叉树的二叉检索树(binary search tree)这样的数据结构,也适用于前面的
word_count这个案例。
二叉检索树是所有节点满足以下条件的二叉树(参照图 5-10),
节点
p左侧的子都小于p节点
p右侧的子都大于p
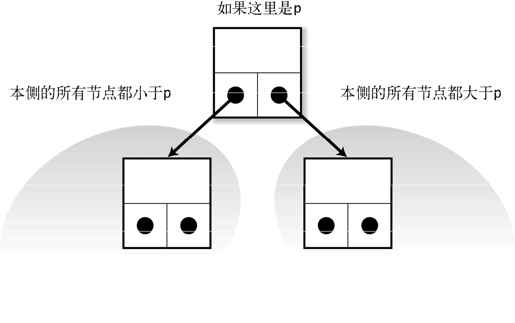
图 5-10 二叉检索树
对二叉树元素的追加和检索,按以下方式进行。
- 追加
从根开始顺序地追加,如果追加的元素小于当前节点,就向左移动,大于当前节点,就向右移动。如果遇到相等的节点或者 NULL,就将元素追加到当前位置。
- 检索
从根开始顺序地遍历,如果追加的元素小于当前节点,就向左移动,大于当前节点,就向右移动。一旦查找到目标节点,检索结束。如果遇到 NULL 的元素,就说明树中不存在目标元素。
如果二叉树的结构比较理想,追加和检索应该还是非常快速的。可是,最坏的情况下(比如,对 word_count 按照字母排序进行处理),二叉树只不过是个链表而已。
在不同情况下,单纯的二叉树在效率上的表现是参差不齐的,而且还容易引起 worst-case*,所以现实中,单纯的二叉树可能并不实用。有时候可以用 B 树、AVL 树等来代替单纯的二叉树。
* 输入的数据从一开始就有序的情况也很多见。
▲哈希
日常生活中,我们怎样管理大量的数据(假设它们记录在卡片上)呢?而且对这些数据的追加、删除和检索等操作还十分频繁。
干事严谨的人,会将记录数据的卡片排好顺序进行保存。此时,使用二分法检索应该是个不错的选择。可是,在需要保证数据有序的情况下,插入卡片是相当花费时间的(尤其当卡片保存在多个抽屉中时)。
懒散的人会把所有的卡片一齐扔到一个箱子中,想找一张卡片的时候,他也许会从头开始一张张地去寻找。这种方式对于追加操作很简单,但是检索过程却格外地花费时间。
如果是严谨而又不失灵活的人,会考虑将卡片放进几个分好类的箱子中进行管理。
所谓哈希(hash)就是基于上面第三种想法进行构造的。
典型的哈希结构“链式哈希*”就是通过在哈希表(hash table)中保存链表的方式,实现对元素的管理(参照图 5-11)。
* 除此之外,还有完全哈希、线性再哈希、非线性再哈希等种类的哈希结构。但是我很少见到它们用于现实中。
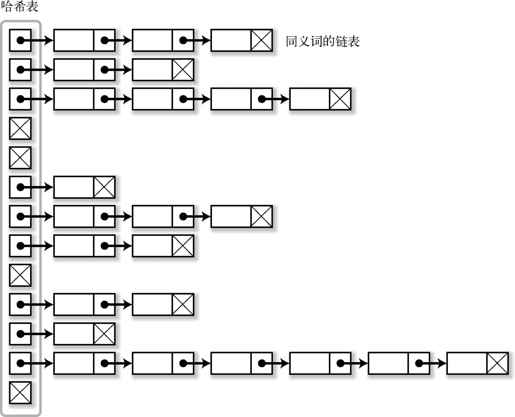
图 5-11 链式哈希
此时,通过哈希函数来决定保存某元素的哈希表的下标。哈希函数根据检索的 key(对于 word_count 的 get_word_count(),key 就是单词的字符串),会尽量返回一个无规律的值。在将字符串作为 key 的情况下,哈希函数通常会使用“将每个字符进行移位运算,然后进行加法运算,其结果除以哈希表的元素个数,最后得到余数”这样的算法。如果不走运,哈希函数对于不同的 key 也会返回相同的值,此时这些 key 被称为同义词(synonym)。
在检索的时候,以检索 key 求得哈希表的下标,从与此下标关联的链表中检索元素。如果哈希函数尽量返回均匀的值,和哈希表相连的链表就会变短,自然就会大幅地提高检索的速度。
在编译器的标识符管理和 AWK、Perl 等语言的哈希数组等实现中,经常会用到哈希表。
* 不光可以使用整数,还可以用字符串作为下标的数组。
* Perl 从 Ver.5 开始,将“哈希数组”称为“哈希”……虽说哈希数组可能是用哈希的方式实现的,但是有意地将内部“实现手段”体现在名称这些表面的东西上,对于我来说,有点难以理解。
